
API Cloud Vision позволяет понять содержание изображения, инкапсулируя мощные модели машинного обучения в простой API REST.
В этой лабораторной работе мы отправим изображения в Vision API и увидим, как он распознает объекты, лица и ориентиры.
Чему вы научитесь
- Создание запроса API Vision и вызов API с помощью curl
- Использование методов обнаружения меток, веб-страниц, лиц и ориентиров API машинного зрения
Что вам понадобится
Как вы будете использовать это руководство?
Как бы вы оценили свой опыт использования Google Cloud Platform?
Настройка среды для самостоятельного обучения
Если у вас ещё нет учётной записи Google (Gmail или Google Apps), необходимо её создать . Войдите в консоль Google Cloud Platform ( console.cloud.google.com ) и создайте новый проект:



Запомните идентификатор проекта — уникальное имя для всех проектов Google Cloud (имя, указанное выше, уже занято и не будет вам работать, извините!). Далее в этой практической работе он будет обозначаться как PROJECT_ID .
Далее вам необходимо включить биллинг в Cloud Console, чтобы использовать ресурсы Google Cloud.
Выполнение этой лабораторной работы не должно обойтись вам дороже нескольких долларов, но может обойтись дороже, если вы решите использовать больше ресурсов или оставите их запущенными (см. раздел «Очистка» в конце этого документа).
Новые пользователи Google Cloud Platform имеют право на бесплатную пробную версию стоимостью 300 долларов США .
Нажмите на значок меню в левом верхнем углу экрана.

Выберите API и службы из раскрывающегося списка и нажмите «Панель управления».
Нажмите «Включить API и службы» .
Затем введите «vision» в поле поиска. Нажмите на Google Cloud Vision API :

Нажмите «Включить» , чтобы включить API Cloud Vision:

Подождите несколько секунд, пока он включится. После включения вы увидите следующее:
Google Cloud Shell — это среда командной строки, работающая в облаке . Эта виртуальная машина на базе Debian оснащена всеми необходимыми инструментами разработки ( gcloud , bq , git и другими) и предлагает постоянный домашний каталог объёмом 5 ГБ. Мы будем использовать Cloud Shell для создания запроса к Speech API.
Чтобы начать работу с Cloud Shell, нажмите «Активировать Google Cloud Shell».  значок в правом верхнем углу панели заголовка
значок в правом верхнем углу панели заголовка

Сеанс Cloud Shell откроется в новом фрейме в нижней части консоли и отобразит приглашение командной строки. Дождитесь появления приглашения user@project:~$.
Поскольку мы будем использовать curl для отправки запроса к Vision API, нам потребуется сгенерировать API-ключ для передачи URL-адреса запроса. Чтобы создать API-ключ, перейдите в раздел «Учётные данные» в разделе API и сервисы в консоли Cloud:
В выпадающем меню выберите API-ключ :
Затем скопируйте только что сгенерированный вами ключ.
Теперь, когда у вас есть ключ API, сохраните его в переменной окружения, чтобы не вставлять значение ключа API в каждый запрос. Это можно сделать в Cloud Shell. Не забудьте заменить <your_api_key> на только что скопированный вами ключ.
export API_KEY=<YOUR_API_KEY>Создание контейнера облачного хранилища
Существует два способа передать изображение в Vision API для распознавания: отправив API строку изображения в кодировке Base64 или передав ему URL-адрес файла, хранящегося в Google Cloud Storage. Мы будем использовать URL-адрес Cloud Storage. Для хранения изображений мы создадим контейнер Google Cloud Storage.
Перейдите в браузер хранилища в облачной консоли для вашего проекта:
Затем нажмите «Создать контейнер» . Присвойте ему уникальное имя (например, идентификатор вашего проекта) и нажмите «Создать» .
Загрузите изображение в свой контейнер
Щелкните правой кнопкой мыши по следующему изображению пончиков, затем нажмите «Сохранить изображение как» и сохраните его в папке «Загрузки» как donuts.png .

Перейдите к только что созданному контейнеру в обозревателе хранилища и нажмите «Загрузить файлы» . Затем выберите donuts.png .
Вы должны увидеть файл в своем контейнере:

Далее отредактируйте разрешение изображения.
Нажмите «Добавить элемент» .
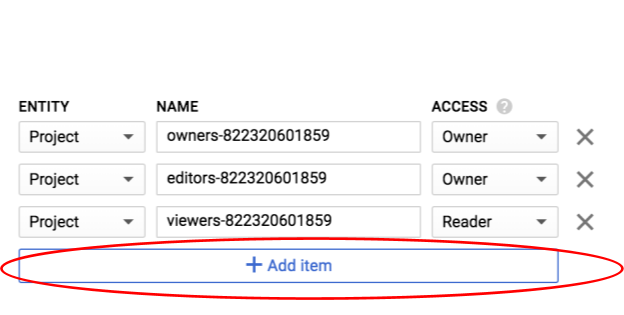
Добавьте новую сущность Group и имя allUsers :
Нажмите «Сохранить» .
Теперь, когда файл находится в вашем контейнере, вы готовы создать запрос Vision API, передав ему URL-адрес этой картинки пончика.
В вашей среде Cloud Shell создайте файл request.json с кодом ниже, заменив my-bucket-name именем созданного вами контейнера Cloud Storage. Вы можете создать файл в одном из предпочитаемых вами редакторов командной строки (nano, vim, emacs) или использовать встроенный редактор Orion в Cloud Shell:
запрос.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "LABEL_DETECTION",
"maxResults": 10
}
]
}
]
}Первая функция API Cloud Vision, которую мы рассмотрим, — это распознавание меток. Этот метод вернёт список меток (слов) того, что изображено на вашем изображении.
Теперь мы готовы вызвать Vision API с помощью curl:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}Ваш ответ должен выглядеть примерно так:
{
"responses": [
{
"labelAnnotations": [
{
"mid": "/m/01dk8s",
"description": "powdered sugar",
"score": 0.9436922
},
{
"mid": "/m/01wydv",
"description": "beignet",
"score": 0.7160288
},
{
"mid": "/m/06_dn",
"description": "snow",
"score": 0.71219236
},
{
"mid": "/m/02wvn_6",
"mid": "/m/0bp3f6m",
"description": "fried food",
"score": 0.7075312
},
{
"mid": "/m/02wvn_6",
"description": "ricciarelli",
"score": 0.5625
},
{
"mid": "/m/052lwg6",
"description": "baked goods",
"score": 0.53270763
}
]
}
]
} API смог определить конкретный тип пончиков (бенье), круто! Для каждой найденной метки Vision API возвращает description с названием товара. Он также возвращает score — число от 0 до 100, указывающее степень уверенности в том, что описание соответствует изображению. mid значение соответствует среднему значению товара в базе знаний Google Knowledge Graph . Вы можете использовать mid при вызове API Knowledge Graph , чтобы получить дополнительную информацию об этом товаре.
Помимо получения меток для объектов на изображении, Vision API также может искать в Интернете дополнительную информацию о нём. С помощью метода webDetection API мы получаем много интересных данных:
- Список сущностей, найденных на нашем изображении, на основе контента страниц с похожими изображениями.
- URL-адреса точных и частичных совпадающих изображений, найденных в Интернете, а также URL-адреса этих страниц
- URL-адреса похожих изображений, например, для обратного поиска изображений
Чтобы протестировать функцию веб-детектирования, мы используем то же изображение бенье, что и выше, поэтому нам нужно изменить всего одну строку в файле request.json (вы также можете рискнуть и использовать совершенно другое изображение). В списке функций просто измените тип с LABEL_DETECTION на WEB_DETECTION . Теперь request.json должен выглядеть так:
запрос.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "WEB_DETECTION",
"maxResults": 10
}
]
}
]
}Чтобы отправить его в Vision API, вы можете использовать ту же команду curl, что и раньше (просто нажмите стрелку вверх в Cloud Shell):
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY} Давайте разберёмся с ответом, начав с webEntities . Вот некоторые сущности, которые вернуло это изображение:
"webEntities": [
{
"entityId": "/m/01hyh_",
"score": 0.7155,
"description": "Machine learning"
},
{
"entityId": "/m/01wydv",
"score": 0.48758492,
"description": "Beignet"
},
{
"entityId": "/m/0105pbj4",
"score": 0.3976,
"description": "Google Cloud Platform"
},
{
"entityId": "/m/02y_9m3",
"score": 0.3782,
"description": "Cloud computing"
},
...
]
Это изображение было повторно использовано во многих презентациях наших API облачного машинного обучения, поэтому API обнаружил сущности «Машинное обучение», «Google Cloud Platform» и «Облачные вычисления».
Если мы проанализируем URL-адреса под fullMatchingImages , partialMatchingImages и pagesWithMatchingImages , мы заметим, что многие из URL-адресов указывают на этот сайт с кодовой лабораторией (супермета!).
Допустим, мы хотим найти другие изображения бенье, но не точно такие же. В этом случае пригодится часть ответа API visuallySimilarImages . Вот несколько визуально похожих изображений, которые были найдены:
"visuallySimilarImages": [
{
"url": "https://igx.4sqi.net/img/general/558x200/21646809_fe8K-bZGnLLqWQeWruymGEhDGfyl-6HSouI2BFPGh8o.jpg"
},
{
"url": "https://spoilednyc.com//2016/02/16/beignetszzzzzz-852.jpg"
},
{
"url": "https://img-global.cpcdn.com/001_recipes/a66a9a6fc2696648/1200x630cq70/photo.jpg"
},
...
]Мы можем перейти по этим URL-адресам, чтобы увидеть похожие изображения:




Круто! А теперь вам, наверное, очень хочется бенье (извините). Это похоже на поиск по картинке в Google Картинках :
Но с помощью Cloud Vision мы можем получить доступ к этой функциональности с помощью простого в использовании REST API и интегрировать ее в наши приложения.
Далее мы рассмотрим методы обнаружения лиц и ориентиров в Vision API. Метод обнаружения лиц возвращает данные о лицах на изображении, включая их эмоции и местоположение на изображении. Распознавание ориентиров позволяет идентифицировать распространённые (и малоизвестные) ориентиры: оно возвращает название ориентира, его координаты широты и долготы, а также местоположение, где ориентир был обнаружен на изображении.
Загрузить новое изображение
Чтобы использовать эти два новых метода, загрузим новое изображение с лицами и достопримечательностями в наше облачное хранилище. Щёлкните правой кнопкой мыши по следующему изображению, затем выберите «Сохранить изображение как» и сохраните его в папке «Загрузки» под именем selfie.png .

Затем загрузите его в облачное хранилище так же, как вы это делали на предыдущем шаге, обязательно отметив флажок «Поделиться публично».
Обновление нашего запроса
Далее мы обновим файл request.json , включив URL нового изображения и используя распознавание лиц и ориентиров вместо распознавания меток. Не забудьте заменить my-bucket-name на имя нашего контейнера Cloud Storage:
запрос.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/selfie.png"
}
},
"features": [
{
"type": "FACE_DETECTION"
},
{
"type": "LANDMARK_DETECTION"
}
]
}
]
}Вызов Vision API и анализ ответа
Теперь вы готовы вызвать Vision API с помощью той же команды curl, которую вы использовали выше:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}Давайте сначала посмотрим на объект faceAnnotations в нашем ответе. Вы заметите, что API возвращает объект для каждого лица, найденного на изображении — в данном случае три. Вот сокращённая версия нашего ответа:
{
"faceAnnotations": [
{
"boundingPoly": {
"vertices": [
{
"x": 669,
"y": 324
},
...
]
},
"fdBoundingPoly": {
...
},
"landmarks": [
{
"type": "LEFT_EYE",
"position": {
"x": 692.05646,
"y": 372.95868,
"z": -0.00025268539
}
},
...
],
"rollAngle": 0.21619819,
"panAngle": -23.027969,
"tiltAngle": -1.5531756,
"detectionConfidence": 0.72354823,
"landmarkingConfidence": 0.20047489,
"joyLikelihood": "POSSIBLE",
"sorrowLikelihood": "VERY_UNLIKELY",
"angerLikelihood": "VERY_UNLIKELY",
"surpriseLikelihood": "VERY_UNLIKELY",
"underExposedLikelihood": "VERY_UNLIKELY",
"blurredLikelihood": "VERY_UNLIKELY",
"headwearLikelihood": "VERY_LIKELY"
}
...
}
}boundingPoly даёт нам координаты x и y вокруг лица на изображении. fdBoundingPoly — это меньший по размеру блок, чем boundingPoly , кодирующий часть кожи лица. landmarks — это массив объектов для каждой черты лица (о некоторых вы, возможно, даже не знали!). Он сообщает нам тип ориентира, а также трёхмерное положение этой черты (координаты x, y и z), где координата z — это глубина. Остальные значения дают нам больше информации о лице, включая вероятность радости, печали, гнева и удивления. Объект выше относится к человеку, находящемуся дальше всего на изображении — вы можете видеть, что он корчит глупую гримасу, что объясняет joyLikelihood для POSSIBLE .
Далее давайте рассмотрим часть landmarkAnnotations нашего ответа:
"landmarkAnnotations": [
{
"mid": "/m/0c7zy",
"description": "Petra",
"score": 0.5403372,
"boundingPoly": {
"vertices": [
{
"x": 153,
"y": 64
},
...
]
},
"locations": [
{
"latLng": {
"latitude": 30.323975,
"longitude": 35.449361
}
}
]В данном случае Vision API смог определить, что фотография была сделана в Петре — это весьма впечатляет, учитывая, что визуальных подсказок на этом изображении минимум. Значения в этом ответе должны быть похожи на ответ labelAnnotations выше.
Мы получаем mid точку ориентира, его название ( description ) и score достоверности. boundingPoly показывает область на изображении, где был идентифицирован ориентир. Ключ locations указывает координаты широты и долготы этого ориентира .
Мы рассмотрели методы обнаружения меток, лиц и ориентиров в Vision API, но есть ещё три, которые мы не рассмотрели. Подробнее об остальных трёх методах читайте в документации :
- Распознавание логотипов : определение распространенных логотипов и их расположения на изображении.
- Обнаружение безопасного поиска : определяет, содержит ли изображение контент для взрослых. Это полезно для любых приложений с пользовательским контентом. Вы можете фильтровать изображения по четырём критериям: материалы для взрослых, медицинские, жестокие и пародийные.
- Распознавание текста : используйте OCR для извлечения текста из изображений. Этот метод позволяет даже определить язык текста, представленного на изображении.
Вы научились анализировать изображения с помощью Vision API. В этом примере вы передали API URL-адрес изображения в Google Cloud Storage. Вы также можете передать строку изображения в кодировке Base64.
Что мы рассмотрели
- Вызов API Vision с помощью curl путем передачи ему URL-адреса изображения в контейнере облачного хранилища
- Использование методов обнаружения меток, веб-страниц, лиц и ориентиров Vision API
Следующие шаги
- Ознакомьтесь с учебными пособиями по Vision API в документации.
- Найдите пример Vision API на вашем любимом языке
- Попробуйте практические занятия по Speech API и Natural Language API !