
A API Cloud Vision faz o encapsulamento de modelos avançados de machine learning em uma API REST simples, o que permite entender o conteúdo de imagens.
Neste laboratório, enviaremos imagens à API Vision para que ela identifique objetos, rostos e pontos de referência.
O que você vai aprender
- Criar uma solicitação da API Vision e chamar a API com curl
- Como usar os métodos de detecção de rótulos, da Web, de rostos e de pontos de referência da API Vision
O que é necessário
Como você vai usar este tutorial?
Como você classificaria sua experiência com o Google Cloud Platform?
Configuração de ambiente autoguiada
Se você ainda não tem uma Conta do Google (Gmail ou Google Apps), crie uma. Faça login no Console do Google Cloud Platform (console.cloud.google.com) e crie um projeto:



Lembre-se do código do projeto, um nome exclusivo em todos os projetos do Google Cloud. O nome acima já foi escolhido e não servirá para você. Faremos referência a ele mais adiante neste codelab como PROJECT_ID.
Em seguida, ative o faturamento no console do Cloud para usar os recursos do Google Cloud.
A execução por meio deste codelab terá um custo baixo, mas poderá ser mais se você decidir usar mais recursos ou se deixá-los em execução. Consulte a seção "limpeza" no final deste documento.
Novos usuários do Google Cloud Platform têm direito a uma avaliação sem custo financeiro de US$300.
Clique no ícone de menu no canto superior esquerdo da tela.

Selecione APIs e serviços no menu suspenso e clique em Painel.
Clique em Ativar APIs e serviços.
Em seguida, digite "vision" na caixa de pesquisa. Clique em API Google Cloud Vision:

Clique em Ativar para ativar a API Cloud Vision:

Aguarde alguns segundos para que ele seja ativado. Quando ele estiver ativado, você verá isto:
O Google Cloud Shell é um ambiente de linha de comando executado na nuvem. Essa máquina virtual baseada em Debian contém todas as ferramentas de desenvolvimento necessárias (gcloud, bq, git e outras) e oferece um diretório principal permanente de 5 GB. Vamos usar o Cloud Shell para criar nossa solicitação à API Speech.
Para começar a usar o Cloud Shell, clique no ícone  "Ativar o Google Cloud Shell" no canto superior direito da barra de cabeçalho.
"Ativar o Google Cloud Shell" no canto superior direito da barra de cabeçalho.

Uma sessão do Cloud Shell é aberta em um novo frame na parte inferior do console e um prompt de linha de comando é exibido. Aguarde até que o prompt user@project:~$ apareça.
Como vamos usar curl para enviar uma solicitação à API Vision, será necessário gerar uma chave de API para transmitir nosso URL de solicitação. Para criar uma chave de API, navegue até a seção "Credenciais" de "APIs e serviços" no console do Cloud:
No menu suspenso, selecione Chave de API:
Em seguida, copie a chave que você acabou de gerar.
Agora salve a chave de API em uma variável de ambiente para não precisar inserir o valor dela em cada solicitação. É possível fazer isso no Cloud Shell. Lembre-se de substituir <your_api_key> pela chave que você copiou.
export API_KEY=<YOUR_API_KEY>Como criar um bucket do Cloud Storage
Há duas maneiras de enviar uma imagem à API Vision para detecção: enviando uma string de imagem codificada em base64 ou transmitindo o URL de um arquivo armazenado no Google Cloud Storage. Vamos usar um URL do Cloud Storage. Vamos criar um bucket do Google Cloud Storage para armazenar as imagens.
Acesse o navegador do Storage no console do Cloud para seu projeto:
Depois, clique em Criar bucket. Dê um nome exclusivo ao bucket, como o ID do projeto, e clique em Criar.
Fazer upload de uma imagem para o bucket
Clique com o botão direito do mouse na imagem de donuts, clique em Salvar imagem como e salve na pasta "Downloads" como donuts.png.

No navegador do Storage, acesse o bucket que você criou e clique em Fazer upload de arquivos. Em seguida, selecione donuts.png.
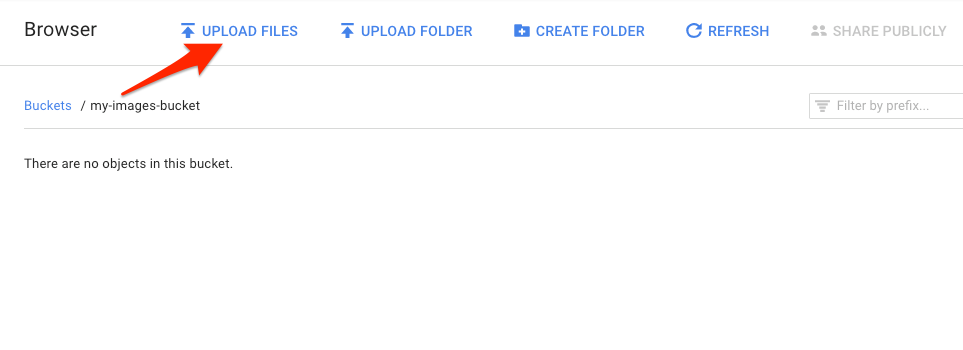
O arquivo vai aparecer no bucket:

Em seguida, edite a permissão da imagem.
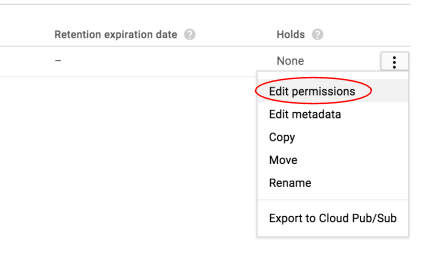
Clique em Adicionar item.
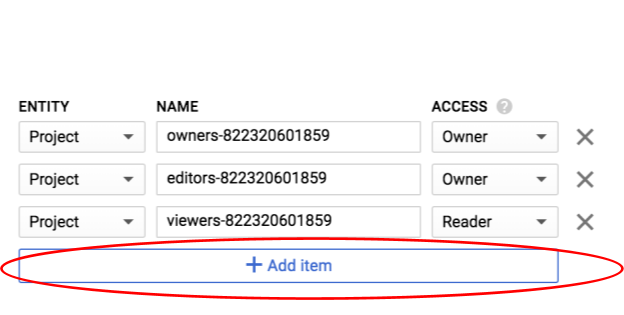
Adicione uma nova entidade de Group e um nome de allUsers:
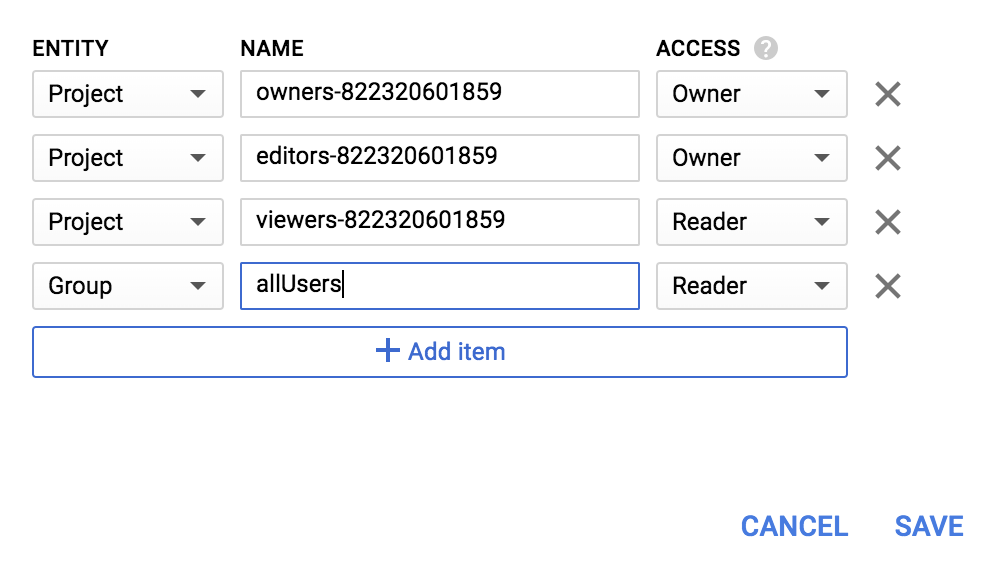
Clique em Salvar.
Agora que o arquivo já está no bucket, você pode criar uma solicitação na API Vision transmitindo o URL dessa imagem de donuts.
No seu ambiente do Cloud Shell, crie um arquivo request.json com o código abaixo. Não se esqueça de substituir my-bucket-name pelo nome do bucket do Cloud Storage que você criou. É possível criar o arquivo usando um dos editores de linha de comando que preferir (nano, vim, emacs) ou usar o editor Orion integrado no Cloud Shell:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "LABEL_DETECTION",
"maxResults": 10
}
]
}
]
}O primeiro recurso da API Cloud Vision que vamos conhecer é a detecção de rótulos. Esse método retornará uma lista de rótulos (palavras) que descrevem o conteúdo da imagem.
Agora podemos chamar a API Vision com curl:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}A resposta deverá ser semelhante a esta:
{
"responses": [
{
"labelAnnotations": [
{
"mid": "/m/01dk8s",
"description": "powdered sugar",
"score": 0.9436922
},
{
"mid": "/m/01wydv",
"description": "beignet",
"score": 0.7160288
},
{
"mid": "/m/06_dn",
"description": "snow",
"score": 0.71219236
},
{
"mid": "/m/02wvn_6",
"mid": "/m/0bp3f6m",
"description": "fried food",
"score": 0.7075312
},
{
"mid": "/m/02wvn_6",
"description": "ricciarelli",
"score": 0.5625
},
{
"mid": "/m/052lwg6",
"description": "baked goods",
"score": 0.53270763
}
]
}
]
}A API identificou o tipo específico de donuts (beignets). Legal! Para cada rótulo encontrado pela API Vision, ela retorna um description com o nome do item. Ele também retorna um score, um número de 0 a 100 que indica o nível de confiança na correspondência entre a descrição e o que está na imagem. O valor mid faz o mapeamento para o mid do item no Mapa de informações do Google. É possível usar o mid ao chamar a API Knowledge Graph para ter mais informações sobre o item.
Além de extrair os rótulos da imagem, a API Vision também é capaz de pesquisar mais detalhes sobre ela na Internet. Com o método webDetection da API, você recebe muitos dados interessantes:
- Uma lista das entidades encontradas na imagem, com base no conteúdo de páginas com imagens semelhantes
- URLs de imagens correspondentes (exatas e parciais) encontradas na Web, junto com os URLs dessas páginas
- URLs de imagens semelhantes, como na pesquisa reversa de imagens
Para testar a detecção na Web, vamos usar a mesma imagem dos beignets acima. Assim, só precisamos mudar uma linha no arquivo request.json. Se quiser tentar algo novo, use uma imagem completamente diferente. Na lista de recursos, mude o tipo de LABEL_DETECTION para WEB_DETECTION. Agora, request.json vai ficar assim:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "WEB_DETECTION",
"maxResults": 10
}
]
}
]
}Para enviá-lo à API Vision, use o mesmo comando curl de antes (basta pressionar a seta para cima no Cloud Shell):
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}Vamos analisar a resposta, começando com webEntities. Veja algumas entidades retornadas por essa imagem:
"webEntities": [
{
"entityId": "/m/01hyh_",
"score": 0.7155,
"description": "Machine learning"
},
{
"entityId": "/m/01wydv",
"score": 0.48758492,
"description": "Beignet"
},
{
"entityId": "/m/0105pbj4",
"score": 0.3976,
"description": "Google Cloud Platform"
},
{
"entityId": "/m/02y_9m3",
"score": 0.3782,
"description": "Cloud computing"
},
...
]
Essa imagem foi reutilizada em muitas apresentações sobre nossas APIs do Cloud ML. Por isso, a API encontrou as entidades "Machine learning", "Google Cloud Platform" e "Computação em nuvem".
Se inspecionarmos os URLs em fullMatchingImages, partialMatchingImages e pagesWithMatchingImages, vamos notar que muitos deles apontam para o site deste codelab (super meta!).
Digamos que você queira encontrar outras imagens de beignets, mas não exatamente as mesmas. É aí que entra a parte visuallySimilarImages da resposta da API. Veja algumas das imagens visualmente semelhantes encontradas por ela:
"visuallySimilarImages": [
{
"url": "https://igx.4sqi.net/img/general/558x200/21646809_fe8K-bZGnLLqWQeWruymGEhDGfyl-6HSouI2BFPGh8o.jpg"
},
{
"url": "https://spoilednyc.com//2016/02/16/beignetszzzzzz-852.jpg"
},
{
"url": "https://img-global.cpcdn.com/001_recipes/a66a9a6fc2696648/1200x630cq70/photo.jpg"
},
...
]É possível acessar esses URLs para ver imagens parecidas:




Legal! Depois de todas essas imagens, você deve ter ficado com vontade de comer um beignet com açúcar de confeiteiro. Esse processo é semelhante à pesquisa de uma imagem nas Imagens do Google:
Com o Cloud Vision, é possível acessar essa funcionalidade com uma API REST fácil de usar e integrá-la aos seus aplicativos.
Em seguida, vamos conhecer os métodos de detecção de rostos e pontos de referência da API Vision. O método de detecção de rosto retorna dados sobre os rostos encontrados, inclusive as emoções e o local da imagem. A detecção de pontos de referência consegue identificar lugares comuns (e desconhecidos também). Ela retorna o nome do ponto de referência, as coordenadas de latitude e longitude e o local onde esse ponto foi identificado na imagem.
Fazer upload de uma nova imagem
Para usar esses dois novos métodos, faça upload de uma nova imagem com rostos e pontos de referência para o bucket do Cloud Storage. Clique com o botão direito do mouse na imagem abaixo. Em seguida, clique em Salvar imagem como e salve-a na pasta "Downloads" como selfie.png.

Em seguida, faça upload para o bucket do Cloud Storage da mesma forma que na etapa anterior, marcando a caixa de seleção "Compartilhar publicamente".
Atualização da nossa solicitação
Em seguida, vamos atualizar o arquivo request.json para incluir o URL da nova imagem e usar a detecção de rostos e pontos de referência em vez de rótulos. Substitua my-bucket-name pelo nome do bucket do Cloud Storage:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/selfie.png"
}
},
"features": [
{
"type": "FACE_DETECTION"
},
{
"type": "LANDMARK_DETECTION"
}
]
}
]
}Como chamar a API Vision e analisar a resposta
Agora você pode chamar a API Vision usando o mesmo comando curl citado anteriormente:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}Vamos analisar o objeto faceAnnotations na nossa resposta primeiro. Veja que a API retorna um objeto para cada rosto encontrado na imagem (nesse caso são três). Esta é uma versão parcial da nossa resposta:
{
"faceAnnotations": [
{
"boundingPoly": {
"vertices": [
{
"x": 669,
"y": 324
},
...
]
},
"fdBoundingPoly": {
...
},
"landmarks": [
{
"type": "LEFT_EYE",
"position": {
"x": 692.05646,
"y": 372.95868,
"z": -0.00025268539
}
},
...
],
"rollAngle": 0.21619819,
"panAngle": -23.027969,
"tiltAngle": -1.5531756,
"detectionConfidence": 0.72354823,
"landmarkingConfidence": 0.20047489,
"joyLikelihood": "POSSIBLE",
"sorrowLikelihood": "VERY_UNLIKELY",
"angerLikelihood": "VERY_UNLIKELY",
"surpriseLikelihood": "VERY_UNLIKELY",
"underExposedLikelihood": "VERY_UNLIKELY",
"blurredLikelihood": "VERY_UNLIKELY",
"headwearLikelihood": "VERY_LIKELY"
}
...
}
}O boundingPoly informa as coordenadas X,Y ao redor do rosto na imagem. fdBoundingPoly é uma caixa menor do que boundingPoly e codifica a parte da pele do rosto. landmarks é uma matriz de objetos para cada recurso facial (alguns que talvez você não conheça). Ela informa o tipo de ponto de referência, junto com a posição 3D desse recurso (coordenadas X, Y, Z) onde a coordenada Z é a profundidade. Os demais valores dão mais detalhes sobre o rosto, incluindo a probabilidade das expressões de alegria, tristeza, raiva e surpresa. O objeto acima é da pessoa que está de pé mais ao fundo da imagem. É possível ver que há uma expressão brincalhona. Isso explica o joyLikelihood de POSSIBLE.
Agora, vamos analisar a parte landmarkAnnotations da nossa resposta:
"landmarkAnnotations": [
{
"mid": "/m/0c7zy",
"description": "Petra",
"score": 0.5403372,
"boundingPoly": {
"vertices": [
{
"x": 153,
"y": 64
},
...
]
},
"locations": [
{
"latLng": {
"latitude": 30.323975,
"longitude": 35.449361
}
}
]Aqui a API Vision conseguiu informar que esta foto foi tirada em Petra. Isso é impressionante, uma vez que as dicas visuais da imagem são mínimas. Os valores nessa resposta devem ser semelhantes à resposta labelAnnotations acima.
Recebemos o mid do ponto de referência, o nome dele (description) e uma confiança score. boundingPoly mostra a região na imagem onde o ponto de referência foi identificado. A chave locations informa as coordenadas de latitude e longitude deste ponto de referência.
Você acabou de aprender sobre os métodos de detecção de rótulos, rostos e pontos de referência da API Vision, mas há três outros que ainda não conhece. Consulte a documentação para saber mais:
- Detecção de logotipo: identifica logotipos comuns e os locais deles em uma imagem.
- Detecção de pesquisa segura: determina se uma imagem tem conteúdo explícito. É útil para aplicativos com conteúdo gerado pelo usuário. É possível filtrar imagens com base em quatro fatores: conteúdo adulto, médico, violento e falso.
- Detecção de texto: usa OCR para extrair texto de imagens. Esse método pode até mesmo identificar o idioma do texto presente em uma imagem.
Você aprendeu a analisar imagens com a API Vision. Neste exemplo, você transmitiu o URL do Google Cloud Storage da imagem para a API. Outra opção é enviar uma string codificada em base64 da imagem.
O que vimos
- Como chamar a API Vision com "curl" transmitindo o URL de uma imagem em um bucket do Cloud Storage
- Como usar os métodos de detecção de rótulos, Web, rostos e pontos de referência da API Vision
Próximas etapas
- Confira os tutoriais da API Vision na documentação.
- Encontre uma amostra da API Vision na sua linguagem favorita.
- Teste os codelabs da API Speech e da API Natural Language.