
Cloud Vision API umożliwia zrozumienie treści obrazu dzięki wykorzystaniu zaawansowanych modeli uczenia maszynowego w prostym interfejsie REST API.
W tym module wyślemy obrazy do interfejsu Vision API i sprawdzimy, czy wykryje on obiekty, twarze i punkty orientacyjne.
Czego się nauczysz
- Tworzenie żądania do interfejsu Vision API i wywoływanie tego interfejsu za pomocą polecenia curl
- Korzystanie z metod wykrywania etykiet, stron internetowych, twarzy i punktów orientacyjnych interfejsu Vision API
Czego potrzebujesz
Jak zamierzasz wykorzystać ten samouczek?
Jak oceniasz korzystanie z Google Cloud Platform?
Samodzielne konfigurowanie środowiska
Jeśli nie masz jeszcze konta Google (Gmail lub Google Apps), musisz je utworzyć. Zaloguj się w konsoli Google Cloud Platform (console.cloud.google.com) i utwórz nowy projekt:



Zapamiętaj identyfikator projektu, czyli unikalną nazwę we wszystkich projektach Google Cloud (podana powyżej nazwa jest już zajęta i nie będzie działać w Twoim przypadku). W dalszej części tego laboratorium będzie on nazywany PROJECT_ID.
Następnie musisz włączyć płatności w konsoli Cloud, aby móc korzystać z zasobów Google Cloud.
Wykonanie tego samouczka nie powinno kosztować więcej niż kilka dolarów, ale może okazać się droższe, jeśli zdecydujesz się wykorzystać więcej zasobów lub pozostawisz je uruchomione (patrz sekcja „Czyszczenie” na końcu tego dokumentu).
Nowi użytkownicy Google Cloud Platform mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD.
Kliknij ikonę menu w lewym górnym rogu ekranu.

Wybierz Interfejsy API i usługi z menu i kliknij Panel.
Kliknij Włącz interfejsy API i usługi.
Następnie w polu wyszukiwania wpisz „wzrok”. Kliknij Google Cloud Vision API:

Aby włączyć interfejs Cloud Vision API, kliknij Włącz:

Odczekaj kilka sekund, aż się włączy. Gdy ta funkcja będzie włączona, zobaczysz:
Google Cloud Shell to środowisko wiersza poleceń działające w chmurze. Ta maszyna wirtualna oparta na Debianie zawiera wszystkie potrzebne narzędzia dla programistów (gcloud, bq, git i inne) i oferuje trwały katalog domowy o pojemności 5 GB. Do utworzenia żądania do Speech API użyjemy Cloud Shell.
Aby rozpocząć korzystanie z Cloud Shell, kliknij ikonę „Aktywuj Google Cloud Shell”  w prawym górnym rogu paska nagłówka.
w prawym górnym rogu paska nagłówka.

Sesja Cloud Shell otworzy się w nowej ramce u dołu konsoli, zostanie również wyświetlony monit wiersza poleceń. Poczekaj, aż pojawi się prompt user@project:~$
Ponieważ w celu wysłania żądania do interfejsu Vision API będziesz korzystać z narzędzia curl, musisz wygenerować klucz interfejsu API, aby przekazać go w URL żądania. Aby utworzyć klucz interfejsu API, w konsoli Cloud otwórz sekcję Dane logowania w sekcji Interfejsy API i usługi:
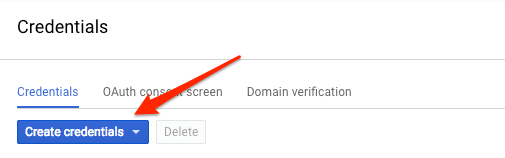
Z menu wybierz Klucz interfejsu API:
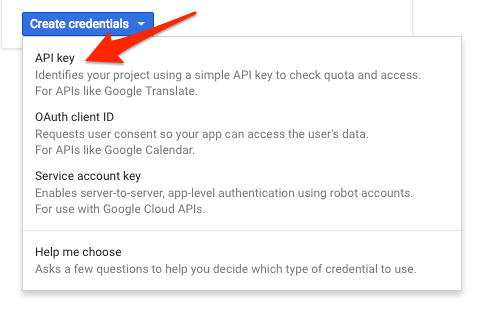
Następnie skopiuj wygenerowany klucz.
Po utworzeniu klucza interfejsu API należy zapisać go jako zmienną środowiskową, dzięki czemu unikniesz wprowadzania jego wartości przy każdym żądaniu. Możesz to zrobić w Cloud Shell. Pamiętaj, aby zastąpić <your_api_key> skopiowanym właśnie kluczem.
export API_KEY=<YOUR_API_KEY>Tworzenie zasobnika Cloud Storage
Obraz do interfejsu Vision API można wysłać na 2 sposoby: przekazując interfejsowi API ciąg znaków obrazu zakodowany w formacie base64 lub przekazując mu adres URL pliku przechowywanego w Google Cloud Storage. Użyjemy adresu URL Cloud Storage. Utworzymy zasobnik Google Cloud Storage, w którym będziemy przechowywać obrazy.
W konsoli Cloud otwórz przeglądarkę Storage w swoim projekcie:
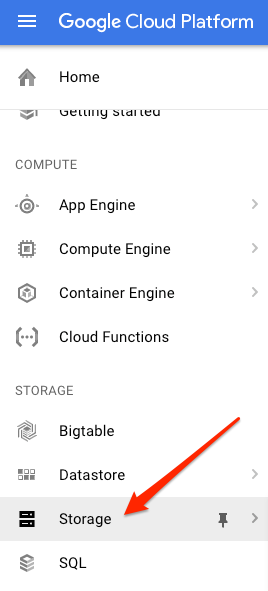
Następnie kliknij Utwórz zasobnik. Nadaj zasobnikowi unikalną nazwę (np. identyfikator projektu) i kliknij Utwórz.
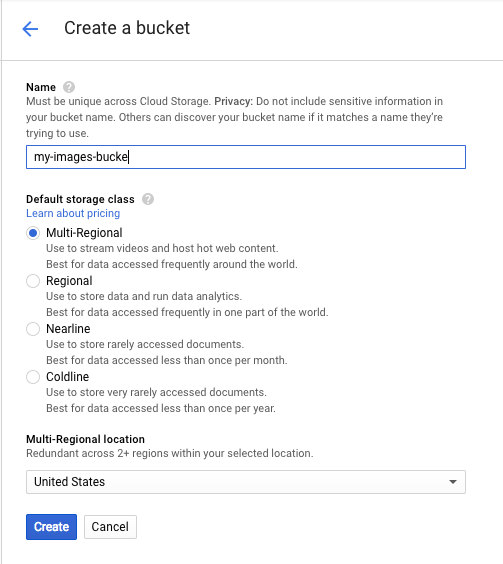
Przesyłanie obrazu do zasobnika
Kliknij prawym przyciskiem myszy poniższy obraz z pączkami, a następnie kliknij Zapisz obraz jako i zapisz go w folderze Pobrane pliki jako donuts.png.

W przeglądarce pamięci przejdź do utworzonego przed chwilą zasobnika i kliknij Prześlij pliki. Następnie kliknij donuts.png.
Plik powinien być widoczny w zasobniku:

Następnie zmień uprawnienia do obrazu.
Kliknij Dodaj element.
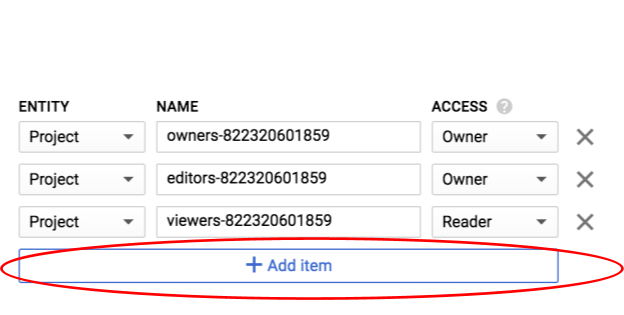
Dodaj nową encję typu Group i nazwę allUsers:
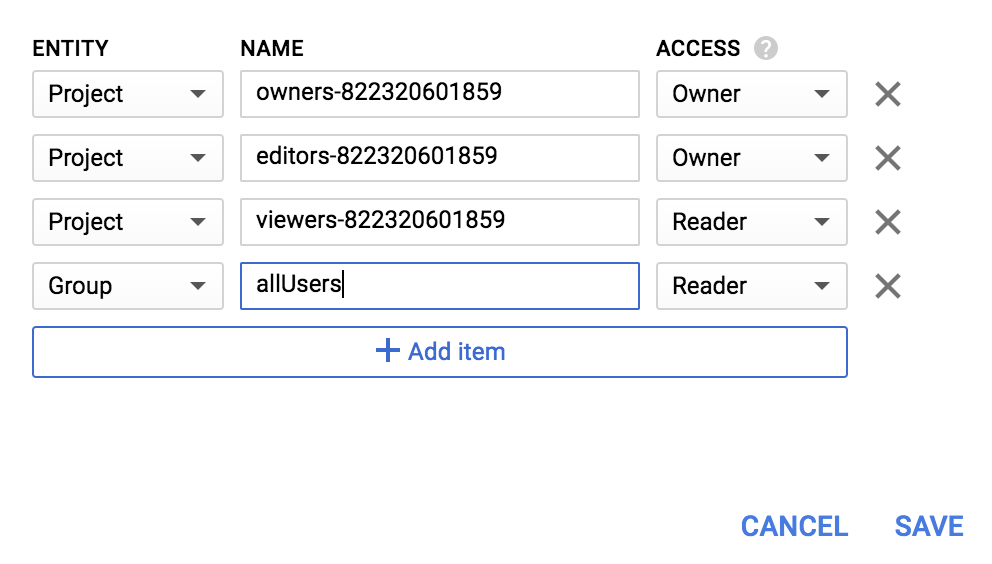
Kliknij Zapisz.
Teraz, gdy plik znajduje się w zasobniku, możesz utworzyć żądanie do interfejsu Vision API, przekazując mu adres URL tego zdjęcia pączków.
W środowisku Cloud Shell utwórz plik request.json z poniższym kodem, pamiętając o zastąpieniu my-bucket-name nazwą utworzonego zasobnika Cloud Storage. Możesz utworzyć plik za pomocą jednego z preferowanych edytorów wiersza poleceń (nano, vim, emacs) lub użyć wbudowanego edytora Orion w Cloud Shell:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "LABEL_DETECTION",
"maxResults": 10
}
]
}
]
}Pierwszą funkcją interfejsu Cloud Vision API, którą omówimy, jest wykrywanie etykiet. Ta metoda zwróci listę etykiet (słów) opisujących zawartość obrazu.
Teraz możemy wywołać interfejs Vision API za pomocą polecenia curl:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}Odpowiedź powinna wyglądać mniej więcej tak:
{
"responses": [
{
"labelAnnotations": [
{
"mid": "/m/01dk8s",
"description": "powdered sugar",
"score": 0.9436922
},
{
"mid": "/m/01wydv",
"description": "beignet",
"score": 0.7160288
},
{
"mid": "/m/06_dn",
"description": "snow",
"score": 0.71219236
},
{
"mid": "/m/02wvn_6",
"mid": "/m/0bp3f6m",
"description": "fried food",
"score": 0.7075312
},
{
"mid": "/m/02wvn_6",
"description": "ricciarelli",
"score": 0.5625
},
{
"mid": "/m/052lwg6",
"description": "baked goods",
"score": 0.53270763
}
]
}
]
}Interfejs API rozpoznał konkretny rodzaj tych pączków (beignets). Super! W przypadku każdej etykiety znalezionej przez interfejs Vision API zwraca on description z nazwą elementu. Zwraca też score, czyli liczbę z zakresu 0–100, która wskazuje, jak bardzo opis pasuje do obrazu. Wartość mid jest mapowana na identyfikator MID elementu w Grafie wiedzy Google. Podczas wywoływania interfejsu Knowledge Graph API możesz użyć znaku mid, aby uzyskać więcej informacji o elemencie.
Oprócz etykiet opisujących zawartość obrazu interfejs Vision API może też wyszukiwać w internecie dodatkowe informacje o obrazie. Za pomocą metody interfejsu API uzyskujemy wiele interesujących danych:webDetection
- Lista elementów znalezionych na obrazie na podstawie treści ze stron z podobnymi obrazami.
- Adresy URL obrazów znalezionych w internecie, które są dopasowane dokładnie lub częściowo, oraz adresy URL tych stron.
- adresy URL podobnych obrazów, np. w wyniku odwrotnego wyszukiwania grafiki;
Aby wypróbować wykrywanie w internecie, użyjemy tego samego obrazu beignetów co powyżej. Wystarczy, że zmienisz jeden wiersz w pliku request.json (możesz też zaryzykować i użyć zupełnie innego obrazu). Na liście funkcji zmień typ z LABEL_DETECTION na WEB_DETECTION. request.json powinien teraz wyglądać tak:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "WEB_DETECTION",
"maxResults": 10
}
]
}
]
}Aby wysłać go do interfejsu Vision API, możesz użyć tego samego polecenia curl co wcześniej (wystarczy nacisnąć strzałkę w górę w Cloud Shell):
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}Zacznijmy od webEntities. Oto niektóre z elementów, które zwróciło to zdjęcie:
"webEntities": [
{
"entityId": "/m/01hyh_",
"score": 0.7155,
"description": "Machine learning"
},
{
"entityId": "/m/01wydv",
"score": 0.48758492,
"description": "Beignet"
},
{
"entityId": "/m/0105pbj4",
"score": 0.3976,
"description": "Google Cloud Platform"
},
{
"entityId": "/m/02y_9m3",
"score": 0.3782,
"description": "Cloud computing"
},
...
]
Ten obraz był wielokrotnie używany w prezentacjach dotyczących naszych interfejsów Cloud ML API, dlatego interfejs API znalazł na nim elementy „uczenie maszynowe”, „Google Cloud Platform” i „przetwarzanie w chmurze”.
Jeśli sprawdzimy adresy URL w sekcjach fullMatchingImages, partialMatchingImages i pagesWithMatchingImages, zauważymy, że wiele z nich prowadzi do tej witryny z ćwiczeniami (super meta!).
Załóżmy, że chcemy znaleźć inne zdjęcia beignetów, ale nie te same. W takiej sytuacji przydaje się część visuallySimilarImages odpowiedzi interfejsu API. Oto kilka podobnych wizualnie obrazów, które znalazł:
"visuallySimilarImages": [
{
"url": "https://igx.4sqi.net/img/general/558x200/21646809_fe8K-bZGnLLqWQeWruymGEhDGfyl-6HSouI2BFPGh8o.jpg"
},
{
"url": "https://spoilednyc.com//2016/02/16/beignetszzzzzz-852.jpg"
},
{
"url": "https://img-global.cpcdn.com/001_recipes/a66a9a6fc2696648/1200x630cq70/photo.jpg"
},
...
]Możemy przejść do tych adresów URL, aby zobaczyć podobne obrazy:




Super! Pewnie masz teraz ochotę na beignet (przepraszam). Działa to podobnie jak wyszukiwanie obrazem w Grafice Google:
Dzięki Cloud Vision możemy jednak uzyskać dostęp do tej funkcji za pomocą łatwego w obsłudze interfejsu API REST i zintegrować ją z naszymi aplikacjami.
Następnie przyjrzymy się metodom wykrywania twarzy i punktów orientacyjnych w interfejsie Vision API. Metoda wykrywania twarzy zwraca dane o twarzach znalezionych na obrazie, w tym emocje i lokalizację twarzy na obrazie. Wykrywanie punktów orientacyjnych może identyfikować popularne (i mniej znane) punkty orientacyjne – zwraca nazwę punktu orientacyjnego, jego współrzędne geograficzne oraz lokalizację, w której został on zidentyfikowany na obrazie.
Przesyłanie nowego obrazu
Aby skorzystać z tych dwóch nowych metod, prześlijmy do zasobnika Cloud Storage nowy obraz z twarzami i punktami charakterystycznymi. Kliknij prawym przyciskiem myszy poniższy obraz, a potem kliknij Zapisz obraz jako i zapisz go w folderze Pobrane pliki jako selfie.png.

Następnie prześlij go do zasobnika Cloud Storage w taki sam sposób jak w poprzednim kroku, pamiętając o zaznaczeniu pola wyboru „Udostępnij publicznie”.
Aktualizowanie prośby
Następnie zaktualizujemy plik request.json, aby zawierał adres URL nowego obrazu i wykorzystywał wykrywanie twarzy i punktów orientacyjnych zamiast wykrywania etykiet. Pamiętaj, aby zastąpić my-bucket-name nazwą zasobnika Cloud Storage:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/selfie.png"
}
},
"features": [
{
"type": "FACE_DETECTION"
},
{
"type": "LANDMARK_DETECTION"
}
]
}
]
}Wywoływanie interfejsu Vision API i parsowanie odpowiedzi
Teraz możesz wywołać interfejs Vision API za pomocą tego samego polecenia curl, którego używasz powyżej:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}Przyjrzyjmy się najpierw obiektowi faceAnnotations w naszej odpowiedzi. Zwraca ona obiekt dla każdej twarzy znalezionej na obrazie – w tym przypadku 3. Oto skrócona wersja naszej odpowiedzi:
{
"faceAnnotations": [
{
"boundingPoly": {
"vertices": [
{
"x": 669,
"y": 324
},
...
]
},
"fdBoundingPoly": {
...
},
"landmarks": [
{
"type": "LEFT_EYE",
"position": {
"x": 692.05646,
"y": 372.95868,
"z": -0.00025268539
}
},
...
],
"rollAngle": 0.21619819,
"panAngle": -23.027969,
"tiltAngle": -1.5531756,
"detectionConfidence": 0.72354823,
"landmarkingConfidence": 0.20047489,
"joyLikelihood": "POSSIBLE",
"sorrowLikelihood": "VERY_UNLIKELY",
"angerLikelihood": "VERY_UNLIKELY",
"surpriseLikelihood": "VERY_UNLIKELY",
"underExposedLikelihood": "VERY_UNLIKELY",
"blurredLikelihood": "VERY_UNLIKELY",
"headwearLikelihood": "VERY_LIKELY"
}
...
}
}boundingPoly podaje współrzędne x,y wokół twarzy na obrazie. fdBoundingPoly to mniejszy obszar niż boundingPoly, obejmujący skórę twarzy. landmarks to tablica obiektów dla każdej cechy twarzy (o niektórych z nich możesz nawet nie wiedzieć!). Informuje nas o rodzaju punktu orientacyjnego oraz jego położeniu 3D (współrzędne x, y,z), gdzie współrzędna z określa głębokość. Pozostałe wartości dostarczają więcej szczegółów na temat twarzy, w tym prawdopodobieństwo radości, smutku, złości i zdziwienia. Obiekt powyżej dotyczy osoby znajdującej się najdalej z tyłu na zdjęciu – widać, że robi śmieszną minę, co wyjaśnia joyLikelihood POSSIBLE.
Przyjrzyjmy się teraz części landmarkAnnotations naszej odpowiedzi:
"landmarkAnnotations": [
{
"mid": "/m/0c7zy",
"description": "Petra",
"score": 0.5403372,
"boundingPoly": {
"vertices": [
{
"x": 153,
"y": 64
},
...
]
},
"locations": [
{
"latLng": {
"latitude": 30.323975,
"longitude": 35.449361
}
}
]Interfejs Vision API rozpoznał, że to zdjęcie zostało zrobione w Petrze. Jest to dość imponujące, biorąc pod uwagę, że wskazówki wizualne na tym obrazie są minimalne. Wartości w tej odpowiedzi powinny być podobne do wartości w odpowiedzi labelAnnotations powyżej.
Otrzymujemy mid punktu orientacyjnego, jego nazwę (description) oraz poziom ufności score. boundingPoly wskazuje region na obrazie, w którym zidentyfikowano punkt orientacyjny. Klucz locations zawiera współrzędne szerokości i długości geograficznej tego punktu orientacyjnego.
Przyjrzeliśmy się metodom wykrywania etykiet, twarzy i punktów orientacyjnych w interfejsie Vision API, ale są jeszcze 3 inne, których nie omówiliśmy. Więcej informacji o pozostałych 3 rodzajach znajdziesz w dokumentacji:
- Wykrywanie logo: rozpoznawanie popularnych logo i ich lokalizacji na obrazie.
- Wykrywanie SafeSearch: określanie, czy obraz zawiera treści dla pełnoletnich. Jest to przydatne w przypadku każdej aplikacji z treściami generowanymi przez użytkowników. Obrazy możesz filtrować na podstawie 4 czynników: treści dla dorosłych, treści medyczne, treści zawierające przemoc i treści parodiujące.
- Wykrywanie tekstu: uruchom OCR, aby wyodrębnić tekst z obrazów. Ta metoda może nawet rozpoznawać język tekstu znajdującego się na obrazie.
Wiesz już, jak analizować obrazy za pomocą interfejsu Vision API. W tym przykładzie przekazaliśmy do interfejsu API adres URL obrazu w Google Cloud Storage. Zamiast tego możesz przekazać obraz w formie tekstu zakodowanego w formacie base64.
Omówione zagadnienia
- Wywoływanie interfejsu Vision API za pomocą polecenia curl przez przekazanie mu adresu URL obrazu w zasobniku Cloud Storage
- Korzystanie z metod wykrywania etykiet, stron internetowych, twarzy i punktów orientacyjnych w interfejsie Vision API
Następne kroki
- Zapoznaj się z samouczkami na temat interfejsu Vision API w dokumentacji.
- Znajdź przykładowy kod Vision API w wybranym języku
- Wypróbuj codelaby Speech API i Natural Language API.