
Cloud Vision API מאפשר לכם להבין את התוכן של תמונה באמצעות מודלים עוצמתיים של למידת מכונה שמוצגים בממשק API פשוט ל-REST.
בשיעור ה-Lab הזה נשלח תמונות אל Vision API ונראה איך הוא מזהה אובייקטים, פנים וציוני דרך.
מה תלמדו
- יצירת בקשה ל-Vision API והפעלת ה-API באמצעות curl
- שימוש בשיטות label, web, face ו-landmark detection של Vision API
מה צריך לעשות
איך תשתמשו במדריך הזה?
איזה דירוג מגיע לדעתך לחוויית השימוש שלך ב-Google Cloud Platform?
הגדרת סביבה בקצב אישי
אם עדיין אין לכם חשבון Google (Gmail או Google Apps), אתם צריכים ליצור חשבון. נכנסים ל-Google Cloud Platform Console (console.cloud.google.com) ויוצרים פרויקט חדש:



חשוב לזכור את מזהה הפרויקט, שהוא שם ייחודי בכל הפרויקטים ב-Google Cloud (השם שמופיע למעלה כבר תפוס ולא יתאים לכם, מצטערים!). בהמשך ה-codelab הזה, נתייחס אליו כאל PROJECT_ID.
בשלב הבא, תצטרכו להפעיל את החיוב ב-Cloud Console כדי להשתמש במשאבים של Google Cloud.
העלות של התרגיל הזה לא אמורה להיות גבוהה, אבל היא יכולה להיות גבוהה יותר אם תחליטו להשתמש ביותר משאבים או אם תשאירו אותם פועלים (ראו את הקטע 'ניקוי' בסוף המסמך הזה).
משתמשים חדשים ב-Google Cloud Platform זכאים לתקופת ניסיון בחינם בשווי 300$.
לוחצים על סמל התפריט בפינה השמאלית העליונה.

ברשימה הנפתחת לוחצים על APIs & services ואז על Dashboard.
לוחצים על Enable APIs and services.
לאחר מכן, מחפשים את האפשרות 'ראייה' בתיבת החיפוש. לוחצים על Google Cloud Vision API:

לוחצים על הפעלה כדי להפעיל את Cloud Vision API:

מחכים כמה שניות עד שהאפשרות תופעל. אחרי ההפעלה, תראו את ההודעה הבאה:
Google Cloud Shell היא סביבת שורת פקודה שפועלת בענן. המכונה הווירטואלית הזו מבוססת על Debian, וטעונים בה כל הכלים הדרושים למפתחים (gcloud, bq, git וכלים אחרים), ועם ספריית בית בעלת אחסון מתמיד בגודל 5GB. נשתמש ב-Cloud Shell כדי ליצור את הבקשה שלנו ל-Speech API.
כדי להתחיל להשתמש ב-Cloud Shell, לוחצים על הסמל 'הפעלת Google Cloud Shell'  בפינה השמאלית העליונה של סרגל הכותרת.
בפינה השמאלית העליונה של סרגל הכותרת.

בחלק התחתון של המסוף ייפתח סשן של Cloud Shell בתוך מסגרת חדשה ותופיע הודעה של שורת הפקודה. ממתינים עד להופעת ההנחיה user@project:~$
אנחנו נשתמש ב-curl כדי לשלוח בקשה ל-Vision API, ולכן נצטרך ליצור מפתח API כדי להעביר אותו בכתובת ה-URL של הבקשה. כדי ליצור מפתח API, עוברים לקטע Credentials (פרטי כניסה) של APIs & services (ממשקי API ושירותים) במסוף Cloud:
בתפריט הנפתח, בוחרים באפשרות API key:
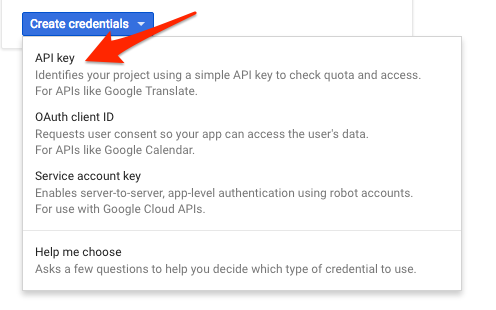
לאחר מכן, מעתיקים את המפתח שנוצר.
אחרי שיצרתם מפתח API, כדאי לשמור אותו במשתנה סביבה כדי שלא תצטרכו להוסיף את הערך של מפתח ה-API בכל בקשה. אפשר לעשות את זה ב-Cloud Shell. חשוב להחליף את <your_api_key> במפתח שהעתקתם.
export API_KEY=<YOUR_API_KEY>יצירת קטגוריה של Cloud Storage
יש שתי דרכים לשלוח תמונה ל-Vision API לצורך זיהוי תמונות: שליחת מחרוזת תמונה מקודדת ב-Base64 אל ה-API, או העברת כתובת ה-URL של קובץ שמאוחסן ב-Google Cloud Storage. נשתמש בכתובת URL של Cloud Storage. ניצור קטגוריה של Google Cloud Storage כדי לאחסן את התמונות.
נכנסים לדף Storage browser במסוף Cloud של הפרויקט:
אחר כך לוחצים על יצירת מאגר. נותנים לקטגוריה שם ייחודי (למשל מזהה הפרויקט) ולוחצים על Create.
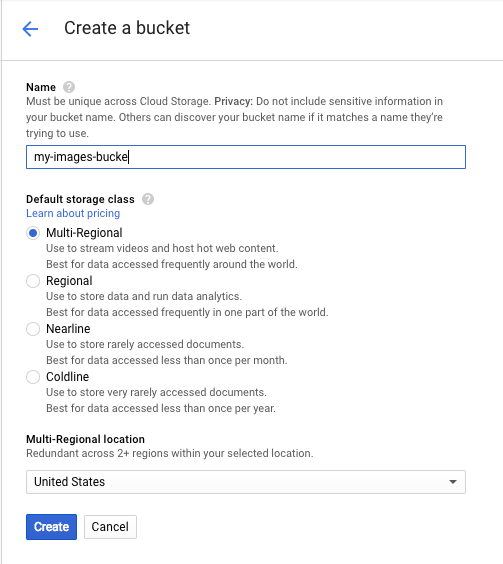
העלאת תמונה לקטגוריה
לוחצים לחיצה ימנית על התמונה הבאה של סופגניות, לוחצים על שמירת תמונה בשם ושומרים אותה בתיקייה 'הורדות' בשם donuts.png.

עוברים לקטגוריית האחסון שיצרתם בדפדפן האחסון ולוחצים על העלאת קבצים. אחר כך בוחרים באפשרות donuts.png.
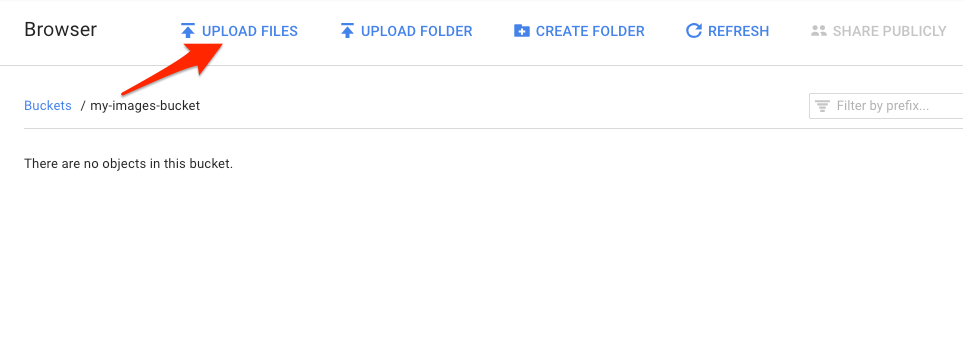
הקובץ אמור להופיע בדלי:

בשלב הבא, עורכים את ההרשאה של התמונה.
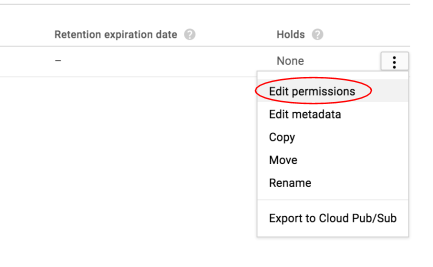
לוחצים על הוספת פריט.
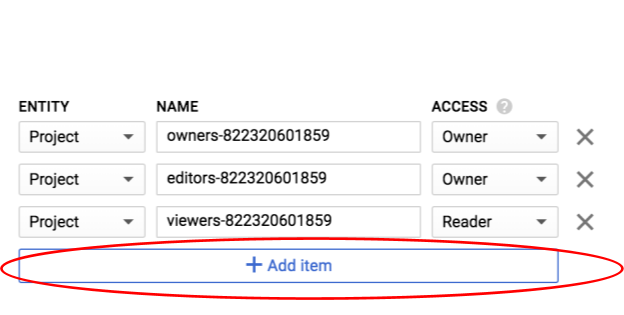
מוסיפים ישות חדשה מסוג Group ושם מסוג allUsers:
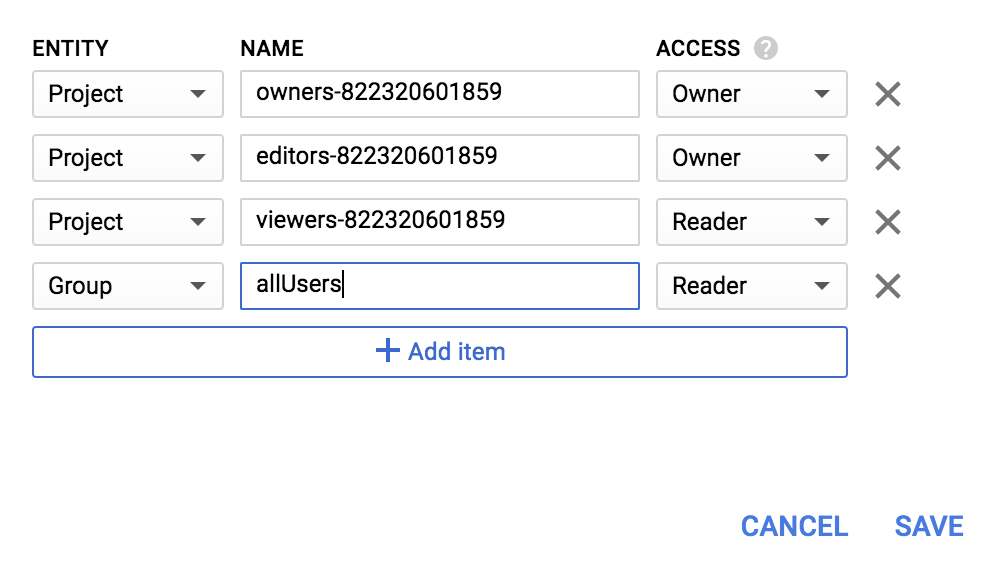
לוחצים על שמירה.
עכשיו, אחרי שהקובץ נמצא בדלי, אפשר ליצור בקשה ל-Vision API ולהעביר אליה את כתובת ה-URL של תמונת הסופגניות הזו.
בסביבת Cloud Shell, יוצרים קובץ request.json עם הקוד שבהמשך, ומקפידים להחליף את my-bucket-name בשם של קטגוריית Cloud Storage שיצרתם. אפשר ליצור את הקובץ באמצעות אחד מעורכי שורת הפקודה המועדפים (nano, vim, emacs) או להשתמש בעורך Orion המובנה ב-Cloud Shell:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "LABEL_DETECTION",
"maxResults": 10
}
]
}
]
}התכונה הראשונה של Cloud Vision API שנבדוק היא זיהוי תוויות. השיטה הזו תחזיר רשימה של תוויות (מילים) שמתארות את מה שרואים בתמונה.
עכשיו אפשר להפעיל את Vision API באמצעות curl:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}התגובה אמורה להיראות כך:
{
"responses": [
{
"labelAnnotations": [
{
"mid": "/m/01dk8s",
"description": "powdered sugar",
"score": 0.9436922
},
{
"mid": "/m/01wydv",
"description": "beignet",
"score": 0.7160288
},
{
"mid": "/m/06_dn",
"description": "snow",
"score": 0.71219236
},
{
"mid": "/m/02wvn_6",
"mid": "/m/0bp3f6m",
"description": "fried food",
"score": 0.7075312
},
{
"mid": "/m/02wvn_6",
"description": "ricciarelli",
"score": 0.5625
},
{
"mid": "/m/052lwg6",
"description": "baked goods",
"score": 0.53270763
}
]
}
]
}ה-API הצליח לזהות את הסוג הספציפי של הסופגניות האלה (בנייה), מגניב! לכל תווית ש-Vision API מצא, הוא מחזיר description עם שם הפריט. היא גם מחזירה score, מספר בין 0 ל-100 שמציין את רמת הביטחון שהתיאור תואם למה שמופיע בתמונה. הערך mid ממופה למזהה האמצעי של הפריט ב-Knowledge Graph של Google. אפשר להשתמש ב-mid כשמתקשרים אל Knowledge Graph API כדי לקבל מידע נוסף על הפריט.
בנוסף לקבלת תוויות לגבי מה שמופיע בתמונה, Vision API יכול גם לחפש באינטרנט פרטים נוספים על התמונה. דרך השיטה webDetection של ה-API, אנחנו מקבלים בחזרה הרבה נתונים מעניינים:
- רשימת ישויות שנמצאו בתמונה, על סמך תוכן מדפים עם תמונות דומות
- כתובות URL של תמונות עם התאמה מדויקת או חלקית שנמצאו באינטרנט, וגם כתובות ה-URL של הדפים שבהם הן מופיעות
- כתובות URL של תמונות דומות, כמו חיפוש באמצעות תמונות
כדי לנסות את זיהוי האינטרנט, נשתמש באותה תמונה של סופגניות שהשתמשנו בה למעלה, כך שכל מה שצריך לשנות הוא שורה אחת בקובץ request.json (אפשר גם לנסות משהו חדש ולהשתמש בתמונה אחרת לגמרי). מתחת לרשימת התכונות, פשוט משנים את הסוג מ-LABEL_DETECTION ל-WEB_DETECTION. הקוד request.json אמור להיראות עכשיו כך:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "WEB_DETECTION",
"maxResults": 10
}
]
}
]
}כדי לשלוח אותו אל Vision API, אפשר להשתמש באותה פקודת curl כמו קודם (פשוט לוחצים על החץ למעלה ב-Cloud Shell):
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}בואו נתעמק בתשובה, החל מ-webEntities. אלה חלק מהישויות שהתמונה הזו החזירה:
"webEntities": [
{
"entityId": "/m/01hyh_",
"score": 0.7155,
"description": "Machine learning"
},
{
"entityId": "/m/01wydv",
"score": 0.48758492,
"description": "Beignet"
},
{
"entityId": "/m/0105pbj4",
"score": 0.3976,
"description": "Google Cloud Platform"
},
{
"entityId": "/m/02y_9m3",
"score": 0.3782,
"description": "Cloud computing"
},
...
]
התמונה הזו שימשה שוב ושוב במצגות רבות על ממשקי ה-API של Cloud ML, ולכן ה-API זיהה את הישויות Machine learning (למידת מכונה), Google Cloud Platform (הפלטפורמה של Google Cloud) ו-Cloud computing (מחשוב ענן).
אם נבדוק את כתובות ה-URL בקטע fullMatchingImages, partialMatchingImages ו-pagesWithMatchingImages, נראה שרבות מכתובות ה-URL מפנות לאתר הזה של Codelab (סופר מטא!).
נניח שאנחנו רוצים למצוא תמונות אחרות של ביינייה, אבל לא את אותן תמונות בדיוק. כאן נכנס לתמונה החלק visuallySimilarImages בתגובת ה-API. הנה כמה מהתמונות הדומות מבחינה ויזואלית שהוא מצא:
"visuallySimilarImages": [
{
"url": "https://igx.4sqi.net/img/general/558x200/21646809_fe8K-bZGnLLqWQeWruymGEhDGfyl-6HSouI2BFPGh8o.jpg"
},
{
"url": "https://spoilednyc.com//2016/02/16/beignetszzzzzz-852.jpg"
},
{
"url": "https://img-global.cpcdn.com/001_recipes/a66a9a6fc2696648/1200x630cq70/photo.jpg"
},
...
]אנחנו יכולים לעבור לכתובות ה-URL האלה כדי לראות את התמונות הדומות:




מגניב! ועכשיו אתם בטח ממש רוצים בינייה (סליחה). הפעולה הזו דומה לחיפוש באמצעות תמונה ב-חיפוש תמונות ב-Google:
אבל עם Cloud Vision, אנחנו יכולים לגשת לפונקציונליות הזו באמצעות API ל-REST שקל לשימוש ולשלב אותו באפליקציות שלנו.
בשלב הבא נסקור את השיטות לזיהוי פנים ונקודות ציון ב-Vision API. שיטת זיהוי הפנים מחזירה נתונים על פנים שנמצאו בתמונה, כולל הרגשות של הפנים והמיקום שלהן בתמונה. זיהוי ציוני דרך יכול לזהות ציוני דרך נפוצים (וגם לא נפוצים) – הוא מחזיר את השם של ציון הדרך, את הקואורדינטות של קווי האורך והרוחב שלו ואת המיקום שבו ציון הדרך זוהה בתמונה.
העלאת תמונה חדשה
כדי להשתמש בשתי השיטות החדשות האלה, נצטרך להעלות תמונה חדשה עם פנים ונקודות ציון לקטגוריה שלנו ב-Cloud Storage. לוחצים לחיצה ימנית על התמונה הבאה, לוחצים על שמירת תמונה בשם ושומרים אותה בתיקיית ההורדות בשם selfie.png.

לאחר מכן מעלים אותו לקטגוריה של Cloud Storage באותה דרך שבה העליתם אותו בשלב הקודם, ומוודאים שתיבת הסימון 'שיתוף באופן ציבורי' מסומנת.
עדכון הבקשה
בשלב הבא, נעדכן את קובץ request.json כדי לכלול את כתובת ה-URL של התמונה החדשה, וכדי להשתמש בזיהוי פנים ונקודות ציון במקום בזיהוי תוויות. חשוב להחליף את my-bucket-name בשם של הקטגוריה של Cloud Storage:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/selfie.png"
}
},
"features": [
{
"type": "FACE_DETECTION"
},
{
"type": "LANDMARK_DETECTION"
}
]
}
]
}שליחת קריאה ל-Vision API וניתוח התגובה
עכשיו אפשר להפעיל את Vision API באמצעות אותה פקודת curl שבה השתמשתם למעלה:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}בואו נתחיל עם האובייקט faceAnnotations בתשובה שלנו. אפשר לראות שה-API מחזיר אובייקט לכל פנים שנמצאו בתמונה – במקרה הזה, שלושה. הנה גרסה מקוצרת של התשובה שלנו:
{
"faceAnnotations": [
{
"boundingPoly": {
"vertices": [
{
"x": 669,
"y": 324
},
...
]
},
"fdBoundingPoly": {
...
},
"landmarks": [
{
"type": "LEFT_EYE",
"position": {
"x": 692.05646,
"y": 372.95868,
"z": -0.00025268539
}
},
...
],
"rollAngle": 0.21619819,
"panAngle": -23.027969,
"tiltAngle": -1.5531756,
"detectionConfidence": 0.72354823,
"landmarkingConfidence": 0.20047489,
"joyLikelihood": "POSSIBLE",
"sorrowLikelihood": "VERY_UNLIKELY",
"angerLikelihood": "VERY_UNLIKELY",
"surpriseLikelihood": "VERY_UNLIKELY",
"underExposedLikelihood": "VERY_UNLIKELY",
"blurredLikelihood": "VERY_UNLIKELY",
"headwearLikelihood": "VERY_LIKELY"
}
...
}
}התג boundingPoly מספק לנו את הקואורדינטות x,y של הפנים בתמונה. fdBoundingPoly הוא תיבה קטנה יותר מ-boundingPoly, שמוצגת על חלק העור של הפנים. landmarks הוא מערך של אובייקטים לכל תכונת פנים (יכול להיות שלא ידעתם על חלק מהן!). המידע הזה מאפשר לנו לדעת את סוג נקודת הציון, וגם את המיקום התלת-ממדי שלה (קואורדינטות x,y,z), כאשר קואורדינטת z היא העומק. הערכים שנותרו מספקים לנו פרטים נוספים על הפנים, כולל הסבירות להבעות של שמחה, עצב, כעס והפתעה. האובייקט שלמעלה הוא האדם הכי רחוק בתמונה – אפשר לראות שהוא עושה פרצוף קצת טיפשי, וזה מסביר את joyLikelihood של POSSIBLE.
עכשיו נבדוק את החלק landmarkAnnotations בתשובה שלנו:
"landmarkAnnotations": [
{
"mid": "/m/0c7zy",
"description": "Petra",
"score": 0.5403372,
"boundingPoly": {
"vertices": [
{
"x": 153,
"y": 64
},
...
]
},
"locations": [
{
"latLng": {
"latitude": 30.323975,
"longitude": 35.449361
}
}
]במקרה הזה, Vision API הצליח לזהות שהתמונה צולמה בפטרה – זה די מרשים בהתחשב ברמזים החזותיים המינימליים בתמונה הזו. הערכים בתגובה הזו צריכים להיות דומים לתגובה labelAnnotations שמופיעה למעלה.
אנחנו מקבלים את mid של ציון הדרך, את השם שלו (description) ואת רמת הסמך score. boundingPoly מציג את האזור בתמונה שבו זוהה ציון הדרך. המפתח locations מציין את הקואורדינטות של קו הרוחב וקו האורך של נקודת הציון הזו.
בדקנו את שיטות הזיהוי של תוויות, פנים וציוני דרך ב-Vision API, אבל יש עוד שלוש שיטות שלא בדקנו. במאמרי העזרה אפשר לקרוא על שלושת הסוגים האחרים:
- זיהוי לוגו: זיהוי לוגו נפוץ והמיקום שלו בתמונה.
- זיהוי בחיפוש בטוח: קביעה אם תמונה מכילה תוכן בוטה. האפשרות הזו שימושית לכל אפליקציה עם תוכן שנוצר על ידי משתמשים. אפשר לסנן תמונות לפי ארבעה קריטריונים: תוכן למבוגרים בלבד, תוכן רפואי, תוכן אלים ותוכן שמציג הטעיה.
- זיהוי טקסט: הפעלת OCR כדי לחלץ טקסט מתמונות. השיטה הזו יכולה אפילו לזהות את השפה של הטקסט שמופיע בתמונה.
למדתם איך לנתח תמונות באמצעות Vision API. בדוגמה הזו, העברתם ל-API את כתובת ה-URL של התמונה ב-Google Cloud Storage. אפשר גם להעביר מחרוזת בקידוד base64 של התמונה.
מה למדנו
- שליחת קריאה ל-Vision API באמצעות curl על ידי העברת כתובת ה-URL של תמונה בקטגוריה של Cloud Storage
- שימוש בשיטות לזיהוי תוויות, אתרים, פנים וציוני דרך ב-Vision API
השלבים הבאים
- אפשר לעיין במדריכים של Vision API במסמכי התיעוד
- חיפוש דוגמה ל-Vision API בשפה המועדפת
- מומלץ לנסות את ה-codelabs של Speech API ושל Natural Language API.