
ক্লাউড ভিশন API আপনাকে একটি সাধারণ REST API এ শক্তিশালী মেশিন লার্নিং মডেলগুলিকে এনক্যাপসুলেট করে একটি চিত্রের বিষয়বস্তু বুঝতে দেয়৷
এই ল্যাবে, আমরা ভিশন API-এ ছবি পাঠাব এবং এটি বস্তু, মুখ এবং ল্যান্ডমার্ক সনাক্ত করতে দেখব।
আপনি কি শিখবেন
- একটি ভিশন API অনুরোধ তৈরি করা এবং কার্ল দিয়ে API কল করা
- দৃষ্টি API-এর লেবেল, ওয়েব, মুখ এবং ল্যান্ডমার্ক সনাক্তকরণ পদ্ধতি ব্যবহার করে
W কি আপনার প্রয়োজন হবে
- একটি Google ক্লাউড প্ল্যাটফর্ম প্রকল্প
- একটি ব্রাউজার, যেমন ক্রোম বা ফায়ারফক্স
আপনি কিভাবে এই টিউটোরিয়াল ব্যবহার করবেন?
Google ক্লাউড প্ল্যাটফর্মের সাথে আপনার অভিজ্ঞতাকে কীভাবে মূল্যায়ন করবে?
স্ব-গতিসম্পন্ন পরিবেশ সেটআপ
আপনার যদি ইতিমধ্যে একটি Google অ্যাকাউন্ট না থাকে (Gmail বা Google Apps), তাহলে আপনাকে অবশ্যই একটি তৈরি করতে হবে। Google ক্লাউড প্ল্যাটফর্ম কনসোলে সাইন-ইন করুন ( console.cloud.google.com ) এবং একটি নতুন প্রকল্প তৈরি করুন:



প্রজেক্ট আইডিটি মনে রাখবেন, সমস্ত Google ক্লাউড প্রকল্প জুড়ে একটি অনন্য নাম (উপরের নামটি ইতিমধ্যে নেওয়া হয়েছে এবং আপনার জন্য কাজ করবে না, দুঃখিত!)। এটি পরে এই কোডল্যাবে PROJECT_ID হিসাবে উল্লেখ করা হবে।
এর পরে, Google ক্লাউড সংস্থানগুলি ব্যবহার করার জন্য আপনাকে ক্লাউড কনসোলে বিলিং সক্ষম করতে হবে৷
এই কোডল্যাবের মাধ্যমে চালানোর জন্য আপনার কয়েক ডলারের বেশি খরচ করা উচিত নয়, তবে আপনি যদি আরও সংস্থান ব্যবহার করার সিদ্ধান্ত নেন বা আপনি যদি সেগুলিকে চলমান রেখে দেন তবে এটি আরও বেশি হতে পারে (এই নথির শেষে "পরিষ্কার" বিভাগটি দেখুন)।
Google ক্লাউড প্ল্যাটফর্মের নতুন ব্যবহারকারীরা $300 বিনামূল্যের ট্রায়ালের জন্য যোগ্য৷
স্ক্রিনের উপরের বাম দিকে মেনু আইকনে ক্লিক করুন।

ড্রপ ডাউন থেকে APIs এবং পরিষেবাগুলি নির্বাচন করুন এবং ড্যাশবোর্ডে ক্লিক করুন
APIs এবং পরিষেবাগুলি সক্ষম করুন -এ ক্লিক করুন।
তারপরে, অনুসন্ধান বাক্সে "ভিশন" অনুসন্ধান করুন। গুগল ক্লাউড ভিশন API এ ক্লিক করুন:

ক্লাউড ভিশন API সক্ষম করতে সক্ষম করুন ক্লিক করুন:

এটি সক্ষম করার জন্য কয়েক সেকেন্ডের জন্য অপেক্ষা করুন। এটি সক্রিয় হয়ে গেলে আপনি এটি দেখতে পাবেন:
Google ক্লাউড শেল হল একটি কমান্ড লাইন পরিবেশ যা ক্লাউডে চলে । এই ডেবিয়ান-ভিত্তিক ভার্চুয়াল মেশিনটি আপনার প্রয়োজনীয় সমস্ত ডেভেলপমেন্ট টুলের সাথে লোড করা হয়েছে ( gcloud , bq , git এবং অন্যান্য) এবং একটি স্থায়ী 5GB হোম ডিরেক্টরি অফার করে। আমরা স্পিচ এপিআইতে আমাদের অনুরোধ তৈরি করতে ক্লাউড শেল ব্যবহার করব।
ক্লাউড শেল দিয়ে শুরু করতে, "Google ক্লাউড শেল সক্রিয় করুন" এ ক্লিক করুন  হেডার বারের উপরে ডানদিকের কোণায় আইকন
হেডার বারের উপরে ডানদিকের কোণায় আইকন

একটি ক্লাউড শেল সেশন কনসোলের নীচে একটি নতুন ফ্রেমের ভিতরে খোলে এবং একটি কমান্ড-লাইন প্রম্পট প্রদর্শন করে। user@project:~$ প্রম্পট প্রদর্শিত না হওয়া পর্যন্ত অপেক্ষা করুন
যেহেতু আমরা ভিশন API এ একটি অনুরোধ পাঠাতে কার্ল ব্যবহার করব, তাই আমাদের অনুরোধের URL পাস করার জন্য আমাদের একটি API কী তৈরি করতে হবে। একটি API কী তৈরি করতে, আপনার ক্লাউড কনসোলে API এবং পরিষেবাগুলির শংসাপত্র বিভাগে নেভিগেট করুন:
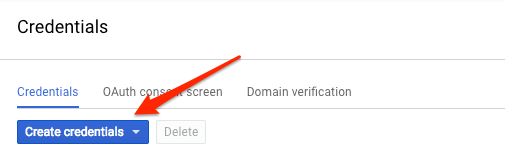
ড্রপ ডাউন মেনুতে, API কী নির্বাচন করুন:
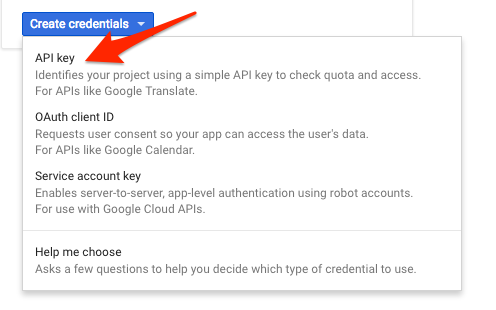
এরপরে, আপনি যে কী তৈরি করেছেন তা অনুলিপি করুন।
এখন আপনার কাছে একটি API কী আছে, প্রতিটি অনুরোধে আপনার API কীটির মান সন্নিবেশ করা এড়াতে এটিকে একটি পরিবেশ পরিবর্তনশীলে সংরক্ষণ করুন। আপনি Cloud Shell এ এটি করতে পারেন। আপনি এইমাত্র কপি করা কী দিয়ে <your_api_key> প্রতিস্থাপন করতে ভুলবেন না।
export API_KEY=<YOUR_API_KEY>একটি ক্লাউড স্টোরেজ বালতি তৈরি করা হচ্ছে
ছবি সনাক্তকরণের জন্য Vision API-এ একটি ছবি পাঠানোর দুটি উপায় রয়েছে: API-কে একটি base64 এনকোডেড ইমেজ স্ট্রিং পাঠিয়ে, অথবা Google ক্লাউড স্টোরেজে সঞ্চিত একটি ফাইলের URL দিয়ে। আমরা একটি ক্লাউড স্টোরেজ URL ব্যবহার করব৷ আমরা আমাদের ছবি সংরক্ষণ করার জন্য একটি Google ক্লাউড স্টোরেজ বালতি তৈরি করব।
আপনার প্রকল্পের জন্য ক্লাউড কনসোলে স্টোরেজ ব্রাউজারে নেভিগেট করুন:
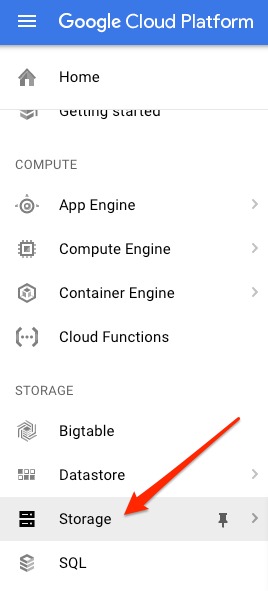
তারপর Create bucket এ ক্লিক করুন। আপনার বালতিটিকে একটি অনন্য নাম দিন (যেমন আপনার প্রকল্প আইডি) এবং তৈরি করুন ক্লিক করুন।
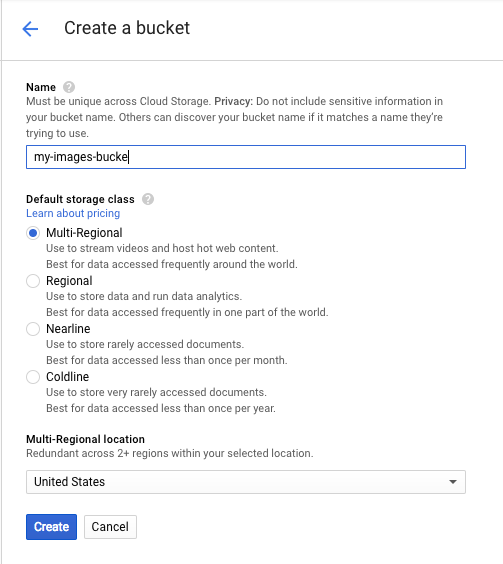
আপনার বালতি একটি ছবি আপলোড
ডোনাটস এর নিচের ছবিতে রাইট ক্লিক করুন, তারপর সেভ ইমেজ এ ক্লিক করুন এবং আপনার ডাউনলোড ফোল্ডারে donuts.png হিসাবে সেভ করুন।

স্টোরেজ ব্রাউজারে আপনি এইমাত্র তৈরি করা বালতিতে নেভিগেট করুন এবং ফাইল আপলোড করুন এ ক্লিক করুন। তারপর donuts.png নির্বাচন করুন।
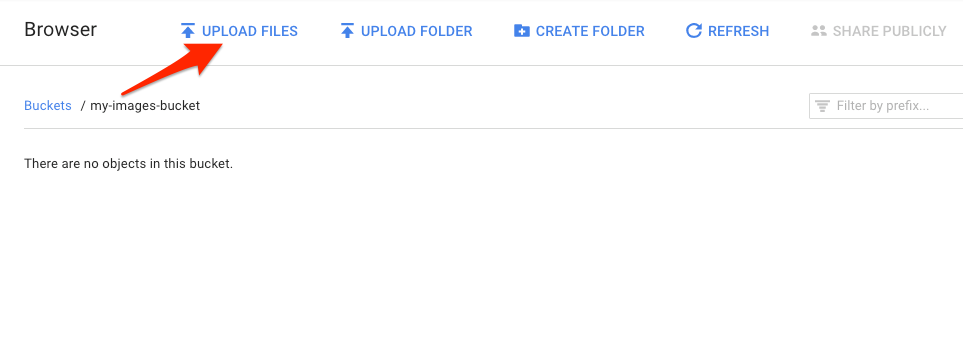
আপনার বালতিতে ফাইলটি দেখতে হবে:

এর পরে, ছবির অনুমতি সম্পাদনা করুন।
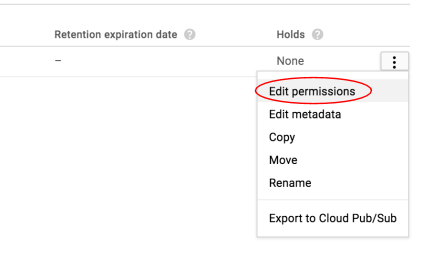
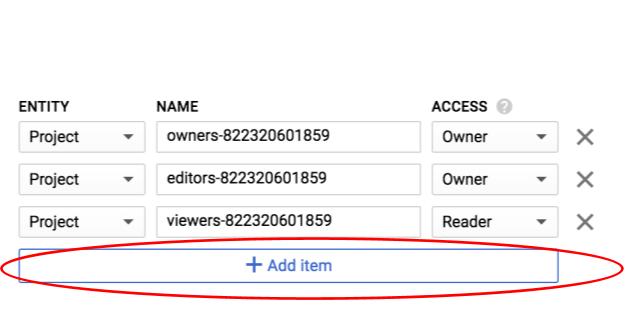
আইটেম যোগ করুন ক্লিক করুন.
Group একটি নতুন সত্তা এবং allUsers নাম যোগ করুন:
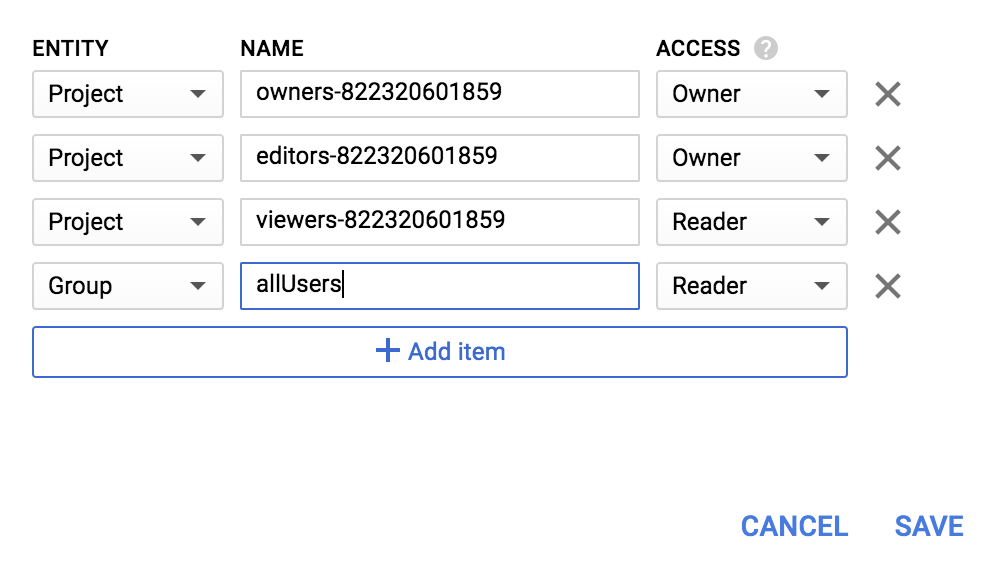
Save এ ক্লিক করুন।
এখন যেহেতু আপনার বালতিতে ফাইলটি আছে, আপনি একটি ভিশন API অনুরোধ তৈরি করতে প্রস্তুত, এটিকে এই ডোনাট ছবির URL দিয়ে দিন৷
আপনার ক্লাউড শেল পরিবেশে, নীচের কোড সহ একটি request.json ফাইল তৈরি করুন, আপনার তৈরি করা ক্লাউড স্টোরেজ বাকেটের নামের সাথে my-bucket-name প্রতিস্থাপন করা নিশ্চিত করুন৷ আপনি আপনার পছন্দের কমান্ড লাইন সম্পাদক (ন্যানো, ভিম, ইমাক্স) ব্যবহার করে ফাইলটি তৈরি করতে পারেন বা ক্লাউড শেল-এ অন্তর্নির্মিত ওরিয়ন সম্পাদক ব্যবহার করতে পারেন:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "LABEL_DETECTION",
"maxResults": 10
}
]
}
]
}প্রথম ক্লাউড ভিশন API বৈশিষ্ট্যটি আমরা অন্বেষণ করব তা হল লেবেল সনাক্তকরণ৷ এই পদ্ধতিটি আপনার ছবিতে যা আছে তার লেবেলের (শব্দ) একটি তালিকা ফিরিয়ে দেবে।
আমরা এখন কার্ল সহ ভিশন API কল করতে প্রস্তুত:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}আপনার প্রতিক্রিয়া নিম্নলিখিত মত কিছু দেখতে হবে:
{
"responses": [
{
"labelAnnotations": [
{
"mid": "/m/01dk8s",
"description": "powdered sugar",
"score": 0.9436922
},
{
"mid": "/m/01wydv",
"description": "beignet",
"score": 0.7160288
},
{
"mid": "/m/06_dn",
"description": "snow",
"score": 0.71219236
},
{
"mid": "/m/02wvn_6",
"mid": "/m/0bp3f6m",
"description": "fried food",
"score": 0.7075312
},
{
"mid": "/m/02wvn_6",
"description": "ricciarelli",
"score": 0.5625
},
{
"mid": "/m/052lwg6",
"description": "baked goods",
"score": 0.53270763
}
]
}
]
} এপিআই নির্দিষ্ট ধরণের ডোনাটগুলি সনাক্ত করতে সক্ষম হয়েছিল যেগুলি (বিগনেট), দুর্দান্ত! ভিশন API পাওয়া প্রতিটি লেবেলের জন্য, এটি আইটেমের নামের সাথে একটি description প্রদান করে। এটি একটি score প্রদান করে, 0 - 100 থেকে একটি সংখ্যা নির্দেশ করে যে এটি কতটা আত্মবিশ্বাসী যে বর্ণনাটি চিত্রটিতে যা আছে তার সাথে মেলে৷ Google-এর নলেজ গ্রাফে আইটেমের mid মান মানচিত্র। আইটেম সম্পর্কে আরও তথ্য পেতে নলেজ গ্রাফ এপিআই কল করার সময় আপনি mid ব্যবহার করতে পারেন।
আমাদের ছবিতে যা আছে তার লেবেল পাওয়ার পাশাপাশি, ভিশন এপিআই আমাদের ছবির অতিরিক্ত বিবরণের জন্য ইন্টারনেটেও অনুসন্ধান করতে পারে। API এর webDetection পদ্ধতির মাধ্যমে, আমরা অনেক আকর্ষণীয় ডেটা ফিরে পাই:
- আমাদের ছবিতে পাওয়া সত্তাগুলির একটি তালিকা, অনুরূপ ছবি সহ পৃষ্ঠাগুলির সামগ্রীর উপর ভিত্তি করে৷
- সেই পৃষ্ঠাগুলির URLগুলির সাথে ওয়েব জুড়ে পাওয়া সঠিক এবং আংশিক মিলে যাওয়া চিত্রগুলির URLগুলি৷
- একই ধরনের ছবির URL, যেমন একটি বিপরীত চিত্র অনুসন্ধান করা
ওয়েব সনাক্তকরণ চেষ্টা করার জন্য, আমরা উপরে থেকে বিগনেটের একই চিত্র ব্যবহার করব তাই আমাদের request.json json ফাইলে একটি লাইন পরিবর্তন করতে হবে (আপনি অজানাতেও যেতে পারেন এবং সম্পূর্ণ ভিন্ন চিত্র ব্যবহার করতে পারেন)। বৈশিষ্ট্য তালিকার অধীনে, শুধু প্রকার পরিবর্তন করুন LABEL_DETECTION থেকে WEB_DETECTION । request.json এখন এই মত দেখতে হবে:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "WEB_DETECTION",
"maxResults": 10
}
]
}
]
}এটি ভিশন API এ পাঠাতে, আপনি আগের মতো একই কার্ল কমান্ড ব্যবহার করতে পারেন (শুধু ক্লাউড শেল-এ উপরের তীর টিপুন):
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY} আসুন webEntities দিয়ে শুরু করে প্রতিক্রিয়ার মধ্যে ডুব দেওয়া যাক। এই চিত্রটি ফিরে এসেছে এমন কিছু সত্তা এখানে রয়েছে:
"webEntities": [
{
"entityId": "/m/01hyh_",
"score": 0.7155,
"description": "Machine learning"
},
{
"entityId": "/m/01wydv",
"score": 0.48758492,
"description": "Beignet"
},
{
"entityId": "/m/0105pbj4",
"score": 0.3976,
"description": "Google Cloud Platform"
},
{
"entityId": "/m/02y_9m3",
"score": 0.3782,
"description": "Cloud computing"
},
...
]
এই চিত্রটি আমাদের ক্লাউড এমএল এপিআই-এর অনেক উপস্থাপনায় পুনঃব্যবহার করা হয়েছে, যে কারণে এপিআই "মেশিন লার্নিং," "গুগল ক্লাউড প্ল্যাটফর্ম," এবং "ক্লাউড কম্পিউটিং" সত্তা খুঁজে পেয়েছে।
আমরা যদি fullMatchingImages , partialMatchingImages , এবং pagesWithMatchingImages এর অধীনে ইউআরএলগুলিকে ইনসেকশন করি, তাহলে আমরা লক্ষ্য করব যে অনেকগুলি URL এই কোডল্যাব সাইটে নির্দেশ করে (সুপার মেটা!)।
ধরা যাক আমরা বিগনেটের অন্যান্য ছবি খুঁজে পেতে চাই, কিন্তু ঠিক একই ছবি নয়। এখানেই API প্রতিক্রিয়ার visuallySimilarImages অংশটি কাজে আসে। এখানে কিছু দৃশ্যত অনুরূপ চিত্র পাওয়া গেছে:
"visuallySimilarImages": [
{
"url": "https://igx.4sqi.net/img/general/558x200/21646809_fe8K-bZGnLLqWQeWruymGEhDGfyl-6HSouI2BFPGh8o.jpg"
},
{
"url": "https://spoilednyc.com//2016/02/16/beignetszzzzzz-852.jpg"
},
{
"url": "https://img-global.cpcdn.com/001_recipes/a66a9a6fc2696648/1200x630cq70/photo.jpg"
},
...
]অনুরূপ চিত্রগুলি দেখতে আমরা সেই URLগুলিতে নেভিগেট করতে পারি:




শান্ত! এবং এখন আপনি সম্ভবত সত্যিই একটি beignet চান (দুঃখিত)। এটি গুগল ইমেজে একটি চিত্র দ্বারা অনুসন্ধানের অনুরূপ:
কিন্তু ক্লাউড ভিশনের সাহায্যে, আমরা REST API ব্যবহারে সহজে এই কার্যকারিতাটি অ্যাক্সেস করতে পারি এবং এটিকে আমাদের অ্যাপ্লিকেশনগুলিতে সংহত করতে পারি।
এরপরে আমরা ভিশন API এর মুখ এবং ল্যান্ডমার্ক সনাক্তকরণ পদ্ধতিগুলি অন্বেষণ করব৷ মুখ সনাক্তকরণ পদ্ধতি একটি ছবিতে পাওয়া মুখের ডেটা প্রদান করে, যার মধ্যে মুখের আবেগ এবং ছবিতে তাদের অবস্থান। ল্যান্ডমার্ক সনাক্তকরণ সাধারণ (এবং অস্পষ্ট) ল্যান্ডমার্ক সনাক্ত করতে পারে - এটি ল্যান্ডমার্কের নাম, এর অক্ষাংশ দ্রাঘিমাংশের স্থানাঙ্ক এবং একটি ছবিতে যেখানে ল্যান্ডমার্ক চিহ্নিত করা হয়েছিল তার অবস্থান প্রদান করে।
একটি নতুন ছবি আপলোড করুন
এই দুটি নতুন পদ্ধতি ব্যবহার করতে, আসুন আমাদের ক্লাউড স্টোরেজ বালতিতে মুখ এবং ল্যান্ডমার্ক সহ একটি নতুন ছবি আপলোড করি। নিচের ছবিতে রাইট ক্লিক করুন, তারপর Save image as এ ক্লিক করুন এবং সেলফি.png হিসেবে আপনার ডাউনলোড ফোল্ডারে সেভ করুন।

তারপরে এটিকে আপনার ক্লাউড স্টোরেজ বালতিতে আপলোড করুন যেভাবে আপনি আগের ধাপে করেছিলেন, নিশ্চিত করুন যে "সর্বজনীনভাবে ভাগ করুন" চেকবক্সটি চেক করুন৷
আমাদের অনুরোধ আপডেট করা হচ্ছে
এর পরে, আমরা নতুন ছবির URL অন্তর্ভুক্ত করতে এবং লেবেল সনাক্তকরণের পরিবর্তে মুখ এবং ল্যান্ডমার্ক সনাক্তকরণ ব্যবহার করতে আমাদের request.json ফাইলটি আপডেট করব৷ আমাদের ক্লাউড স্টোরেজ বাকেটের নামের সাথে my-bucket-name প্রতিস্থাপন করতে ভুলবেন না:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/selfie.png"
}
},
"features": [
{
"type": "FACE_DETECTION"
},
{
"type": "LANDMARK_DETECTION"
}
]
}
]
}ভিশন API কল করা এবং প্রতিক্রিয়া পার্স করা
এখন আপনি উপরে ব্যবহার করা একই কার্ল কমান্ড ব্যবহার করে ভিশন API কল করতে প্রস্তুত:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}আসুন প্রথমে আমাদের প্রতিক্রিয়াতে faceAnnotations অবজেক্টটি দেখে নেওয়া যাক। আপনি লক্ষ্য করবেন যে এপিআই ছবিতে পাওয়া প্রতিটি মুখের জন্য একটি বস্তু ফেরত দেয় - এই ক্ষেত্রে, তিনটি। এখানে আমাদের প্রতিক্রিয়ার একটি ক্লিপড সংস্করণ রয়েছে:
{
"faceAnnotations": [
{
"boundingPoly": {
"vertices": [
{
"x": 669,
"y": 324
},
...
]
},
"fdBoundingPoly": {
...
},
"landmarks": [
{
"type": "LEFT_EYE",
"position": {
"x": 692.05646,
"y": 372.95868,
"z": -0.00025268539
}
},
...
],
"rollAngle": 0.21619819,
"panAngle": -23.027969,
"tiltAngle": -1.5531756,
"detectionConfidence": 0.72354823,
"landmarkingConfidence": 0.20047489,
"joyLikelihood": "POSSIBLE",
"sorrowLikelihood": "VERY_UNLIKELY",
"angerLikelihood": "VERY_UNLIKELY",
"surpriseLikelihood": "VERY_UNLIKELY",
"underExposedLikelihood": "VERY_UNLIKELY",
"blurredLikelihood": "VERY_UNLIKELY",
"headwearLikelihood": "VERY_LIKELY"
}
...
}
}boundingPoly আমাদের ছবিটিতে মুখের চারপাশে x,y স্থানাঙ্ক দেয়। fdBoundingPoly হল boundingPoly থেকে একটি ছোট বাক্স, মুখের ত্বকের অংশে এনকোডিং। landmarks হল প্রতিটি মুখের বৈশিষ্ট্যের জন্য বস্তুর একটি বিন্যাস (কিছু আপনি হয়তো জানেন না!) এটি সেই বৈশিষ্ট্যের 3D অবস্থানের সাথে (x,y,z স্থানাঙ্ক) যেখানে z স্থানাঙ্কের গভীরতা তা আমাদেরকে ল্যান্ডমার্কের ধরন বলে। অবশিষ্ট মানগুলি আমাদের মুখের উপর আরও বিশদ বিবরণ দেয়, যার মধ্যে আনন্দ, দুঃখ, রাগ এবং বিস্ময়ের সম্ভাবনা রয়েছে। উপরের বস্তুটি ছবিটির সবচেয়ে দূরে থাকা ব্যক্তির জন্য - আপনি দেখতে পাচ্ছেন যে তিনি একটি নির্বোধ মুখ তৈরি করছেন যা POSSIBLE joyLikelihood ব্যাখ্যা করে।
এর পরে আমাদের প্রতিক্রিয়ার landmarkAnnotations অংশটি দেখুন:
"landmarkAnnotations": [
{
"mid": "/m/0c7zy",
"description": "Petra",
"score": 0.5403372,
"boundingPoly": {
"vertices": [
{
"x": 153,
"y": 64
},
...
]
},
"locations": [
{
"latLng": {
"latitude": 30.323975,
"longitude": 35.449361
}
}
]এখানে, ভিশন API বলতে সক্ষম হয়েছিল যে এই ছবিটি পেট্রাতে তোলা হয়েছিল - এই ছবিতে চাক্ষুষ সংকেতগুলি ন্যূনতম হওয়ায় এটি বেশ চিত্তাকর্ষক। এই প্রতিক্রিয়ার মানগুলি উপরের labelAnnotations প্রতিক্রিয়ার মতো দেখতে হবে৷
আমরা ল্যান্ডমার্কের mid , এটির নাম ( description ), একটি আত্মবিশ্বাসের score সহ। boundingPoly ছবিতে সেই অঞ্চল দেখায় যেখানে ল্যান্ডমার্ক চিহ্নিত করা হয়েছিল৷ locations কী আমাদের এই ল্যান্ডমার্কের অক্ষাংশ দ্রাঘিমাংশের স্থানাঙ্কগুলিকে বলে।
আমরা ভিশন API-এর লেবেল, মুখ এবং ল্যান্ডমার্ক সনাক্তকরণ পদ্ধতিগুলি দেখেছি, তবে আরও তিনটি আছে যা আমরা অন্বেষণ করিনি৷ অন্য তিনটি সম্পর্কে জানতে ডক্সে ডুব দিন:
- লোগো সনাক্তকরণ : একটি ছবিতে সাধারণ লোগো এবং তাদের অবস্থান সনাক্ত করুন।
- নিরাপদ অনুসন্ধান সনাক্তকরণ : একটি ছবিতে স্পষ্ট বিষয়বস্তু আছে কিনা তা নির্ধারণ করুন। এটি ব্যবহারকারী-উত্পাদিত সামগ্রী সহ যেকোনো অ্যাপ্লিকেশনের জন্য উপযোগী। আপনি চারটি বিষয়ের উপর ভিত্তি করে ছবি ফিল্টার করতে পারেন: প্রাপ্তবয়স্ক, চিকিৎসা, হিংসাত্মক এবং স্পুফ বিষয়বস্তু।
- পাঠ্য সনাক্তকরণ : চিত্রগুলি থেকে পাঠ্য বের করতে OCR চালান। এই পদ্ধতিটি এমনকি একটি ছবিতে উপস্থিত পাঠ্যের ভাষা সনাক্ত করতে পারে।
আপনি ভিশন API এর মাধ্যমে ছবি বিশ্লেষণ করতে শিখেছেন। এই উদাহরণে আপনি আপনার ছবির Google ক্লাউড স্টোরেজ URL API পাস করেছেন। বিকল্পভাবে, আপনি আপনার ছবির একটি base64 এনকোডেড স্ট্রিং পাস করতে পারেন।
আমরা কভার করেছি কি
- একটি ক্লাউড স্টোরেজ বালতিতে একটি চিত্রের URL পাস করে কার্ল সহ ভিশন API কল করা
- Vision API এর লেবেল, ওয়েব, ফেস এবং ল্যান্ডমার্ক সনাক্তকরণ পদ্ধতি ব্যবহার করে
পরবর্তী পদক্ষেপ
- ডকুমেন্টেশনে ভিশন API টিউটোরিয়াল দেখুন
- আপনার প্রিয় ভাষায় একটি ভিশন API নমুনা খুঁজুন
- স্পিচ এপিআই এবং ন্যাচারাল ল্যাঙ্গুয়েজ এপিআই কোডল্যাব ব্যবহার করে দেখুন!