

이 Codelab에서는 필기 입력 숫자를 인식하는 신경망을 빌드하고 학습시키는 방법을 알아봅니다. 99% 의 정확도를 달성하기 위해 신경망을 개선하는 과정에서 딥 러닝 전문가가 모델을 효율적으로 학습시키는 데 사용하는 도구도 발견하게 됩니다.
이 Codelab에서는 MNIST 데이터 세트를 사용합니다. MNIST 데이터 세트는 20년 가까이 여러 세대의 박사 과정을 바쁘게 만든 60,000개의 라벨이 지정된 숫자로 구성되어 있습니다. 100줄 미만의 Python / TensorFlow 코드로 문제를 해결합니다.
학습할 내용
- 신경망이란 무엇이며 어떻게 학습시키나요?
- tf.keras를 사용하여 기본 1계층 신경망을 빌드하는 방법
- 레이어를 추가하는 방법
- 학습률 일정 설정 방법
- 컨볼루셔널 신경망을 빌드하는 방법
- 정규화 기법 사용 방법: 드롭아웃, 배치 정규화
- 과적합이란 무엇인가요?
필요한 항목
브라우저만 있으면 됩니다. 이 워크숍은 Google Colaboratory를 사용하여 완전히 실행할 수 있습니다.
의견
이 실습에서 잘못된 점이 있거나 개선해야 할 점이 있다면 알려주세요. GitHub 문제[의견 링크]를 통해 의견을 처리합니다.
이 실습에서는 Google Colaboratory를 사용하며 사용자가 설정할 필요가 없습니다. Chromebook에서 실행할 수 있습니다. 아래 파일을 열고 셀을 실행하여 Colab 노트북을 숙지하세요.

아래의 추가 안내를 참고하세요.
GPU 백엔드 선택

Colab 메뉴에서 런타임 > 런타임 유형 변경을 선택한 다음 GPU를 선택합니다. 런타임에 대한 연결은 첫 번째 실행 시 자동으로 이루어지며, 오른쪽 상단의 '연결' 버튼을 사용할 수도 있습니다.
노트북 실행

셀을 클릭하고 Shift-Enter를 사용하여 셀을 한 번에 하나씩 실행합니다. 런타임 > 모두 실행을 사용하여 전체 노트북을 실행할 수도 있습니다.
목차

모든 노트북에는 목차가 있습니다. 왼쪽의 검은색 화살표를 사용하여 열 수 있습니다.
숨겨진 셀

일부 셀에는 제목만 표시됩니다. Colab 전용 노트북 기능입니다. 더블클릭하면 내부 코드를 볼 수 있지만 일반적으로 그다지 흥미롭지는 않습니다. 일반적으로 지원 또는 시각화 기능입니다. 내부의 함수를 정의하려면 이러한 셀을 실행해야 합니다.
먼저 신경망이 학습하는 것을 살펴보겠습니다. 아래 노트북을 열고 모든 셀을 실행하세요. 아직 코드는 신경 쓰지 마세요. 나중에 설명해 드리겠습니다.
노트북을 실행할 때는 시각화에 집중하세요. 자세한 내용은 아래를 참고하세요.
학습 데이터
각 그림이 나타내는 것(0~9 사이의 숫자)을 알 수 있도록 라벨이 지정된 손으로 쓴 숫자 데이터 세트가 있습니다. 노트북에 다음과 같은 발췌문이 표시됩니다.
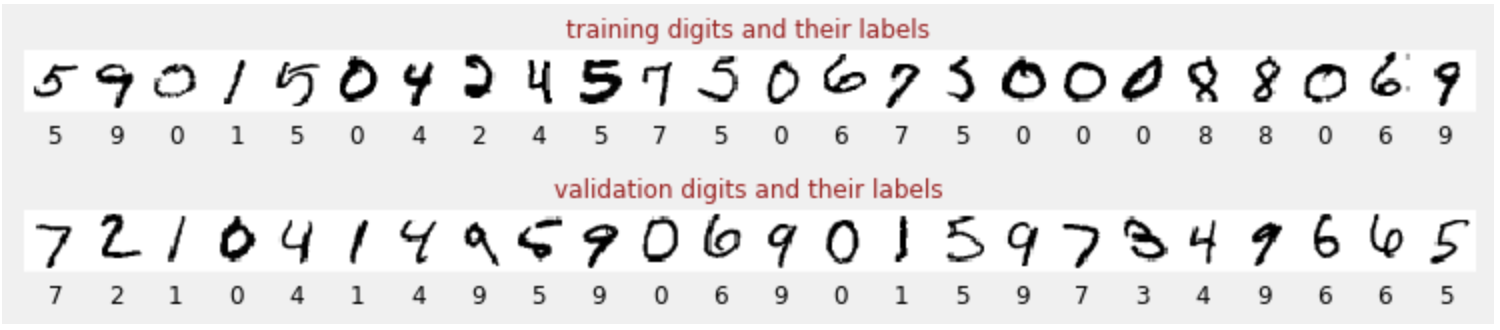
빌드할 신경망은 필기 입력 숫자를 10개의 클래스 (0~9)로 분류합니다. 분류가 제대로 작동하려면 올바른 값을 가져야 하는 내부 매개변수를 기반으로 합니다. 이 '정확한 값'은 이미지와 연결된 정답이 포함된 '라벨이 지정된 데이터 세트'가 필요한 학습 과정을 통해 학습됩니다.
학습된 신경망이 제대로 작동하는지 어떻게 알 수 있나요? 학습 데이터 세트를 사용하여 네트워크를 테스트하는 것은 부정행위입니다. 학습 중에 데이터 세트를 여러 번 확인했으므로 성능이 매우 우수할 것입니다. 네트워크의 '실제' 성능을 평가하려면 학습 중에 사용된 적이 없는 라벨이 지정된 데이터 세트가 하나 더 필요합니다. 이를 '검증 데이터 세트'라고 합니다.
교육
학습이 진행됨에 따라 한 번에 하나의 학습 데이터 배치씩 내부 모델 파라미터가 업데이트되고 모델이 손으로 쓴 숫자를 인식하는 능력이 점점 향상됩니다. 학습 그래프에서 확인할 수 있습니다.
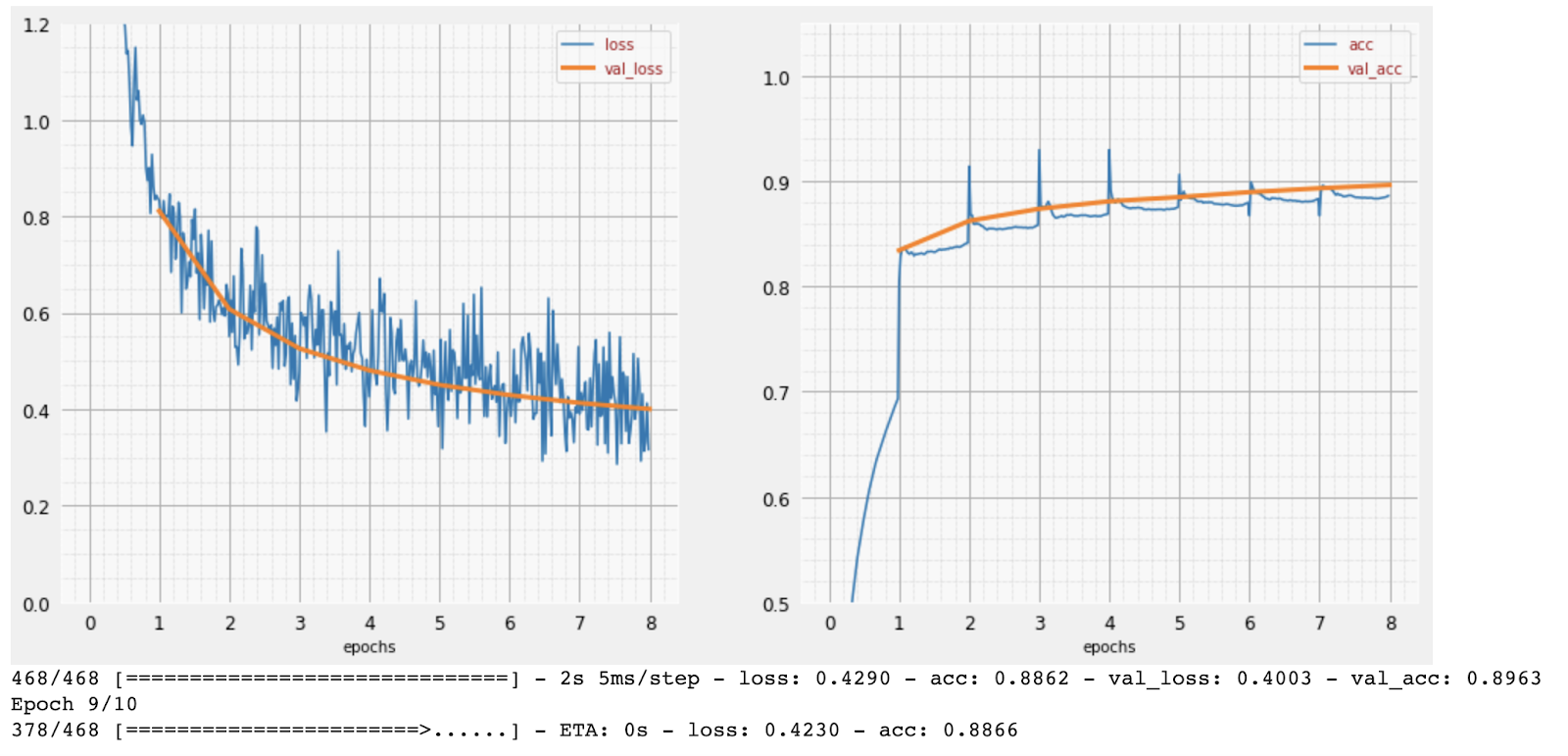
오른쪽의 '정확도'는 올바르게 인식된 숫자의 비율입니다. 학습이 진행될수록 증가하는 것이 좋습니다.
왼쪽에는 '손실'이 표시됩니다. 학습을 진행하기 위해 시스템이 숫자를 얼마나 잘못 인식하는지를 나타내는 '손실' 함수를 정의하고 이를 최소화하려고 합니다. 여기에서 학습이 진행됨에 따라 학습 데이터와 검증 데이터 모두에서 손실이 감소하는 것을 확인할 수 있습니다. 이는 좋은 현상입니다. 이는 신경망이 학습하고 있다는 의미입니다.
X축은 전체 데이터 세트를 통한 '에포크' 또는 반복 횟수를 나타냅니다.
예측
모델이 학습되면 이를 사용하여 손으로 쓴 숫자를 인식할 수 있습니다. 다음 시각화는 로컬 글꼴에서 렌더링된 몇 개의 숫자 (첫 번째 줄)와 검증 데이터 세트의 10,000개 숫자에 대한 성능을 보여줍니다. 예측된 클래스는 각 숫자 아래에 표시되며, 틀린 경우 빨간색으로 표시됩니다.

보시다시피 이 초기 모델은 그다지 좋지 않지만 일부 숫자는 올바르게 인식합니다. 최종 검증 정확도는 약 90% 로, 단순한 모델로 시작하는 것치고는 나쁘지 않지만 10,000개의 검증 숫자 중 1,000개를 놓친다는 의미이기도 합니다. 표시할 수 있는 것보다 훨씬 많기 때문에 모든 답변이 틀린 (빨간색) 것처럼 보입니다.
텐서
데이터는 행렬에 저장됩니다. 28x28 픽셀 그레이 스케일 이미지는 28x28 2차원 행렬에 적합합니다. 하지만 컬러 이미지의 경우 더 많은 차원이 필요합니다. 픽셀당 3개의 색상 값 (빨간색, 녹색, 파란색)이 있으므로 [28, 28, 3] 차원의 3차원 표가 필요합니다. 128개의 컬러 이미지 배치를 저장하려면 [128, 28, 28, 3] 차원의 4차원 표가 필요합니다.
이러한 다차원 표를 '텐서'라고 하며, 차원 목록을 '모양'이라고 합니다.
요약
다음 단락의 굵은 글씨로 표시된 모든 용어를 이미 알고 있다면 다음 연습으로 이동해도 됩니다. 딥 러닝을 처음 시작하는 경우 환영합니다. 계속 읽어 주세요.

레이어 시퀀스로 빌드된 모델의 경우 Keras는 Sequential API를 제공합니다. 예를 들어 밀집층 3개를 사용하는 이미지 분류기는 Keras에서 다음과 같이 작성할 수 있습니다.
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[28, 28, 1]),
tf.keras.layers.Dense(200, activation="relu"),
tf.keras.layers.Dense(60, activation="relu"),
tf.keras.layers.Dense(10, activation='softmax') # classifying into 10 classes
])
# this configures the training of the model. Keras calls it "compiling" the model.
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy']) # % of correct answers
# train the model
model.fit(dataset, ... )
단일 밀집 레이어
MNIST 데이터 세트의 손으로 쓴 숫자는 28x28픽셀 그레이 스케일 이미지입니다. 이를 분류하는 가장 간단한 방법은 28x28=784픽셀을 1계층 신경망의 입력으로 사용하는 것입니다.
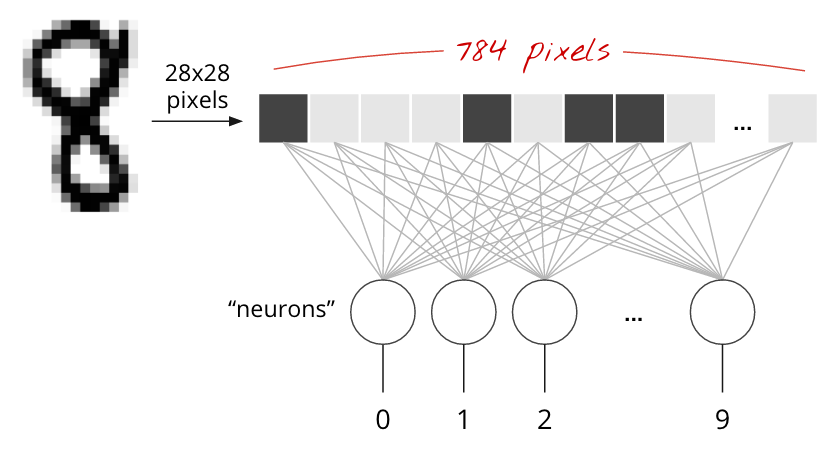
신경망의 각 '뉴런'은 모든 입력의 가중 합을 계산하고 '바이어스'라는 상수를 추가한 다음 일부 비선형 '활성화 함수'를 통해 결과를 공급합니다. '가중치'와 '편향'은 학습을 통해 결정되는 매개변수입니다. 처음에는 무작위 값으로 초기화됩니다.
위 그림은 숫자를 10개의 클래스 (0~9)로 분류하려는 10개의 출력 뉴런이 있는 1계층 신경망을 나타냅니다.
행렬 곱셈 사용
이미지 모음을 처리하는 신경망 레이어를 행렬 곱셈으로 나타내는 방법은 다음과 같습니다.
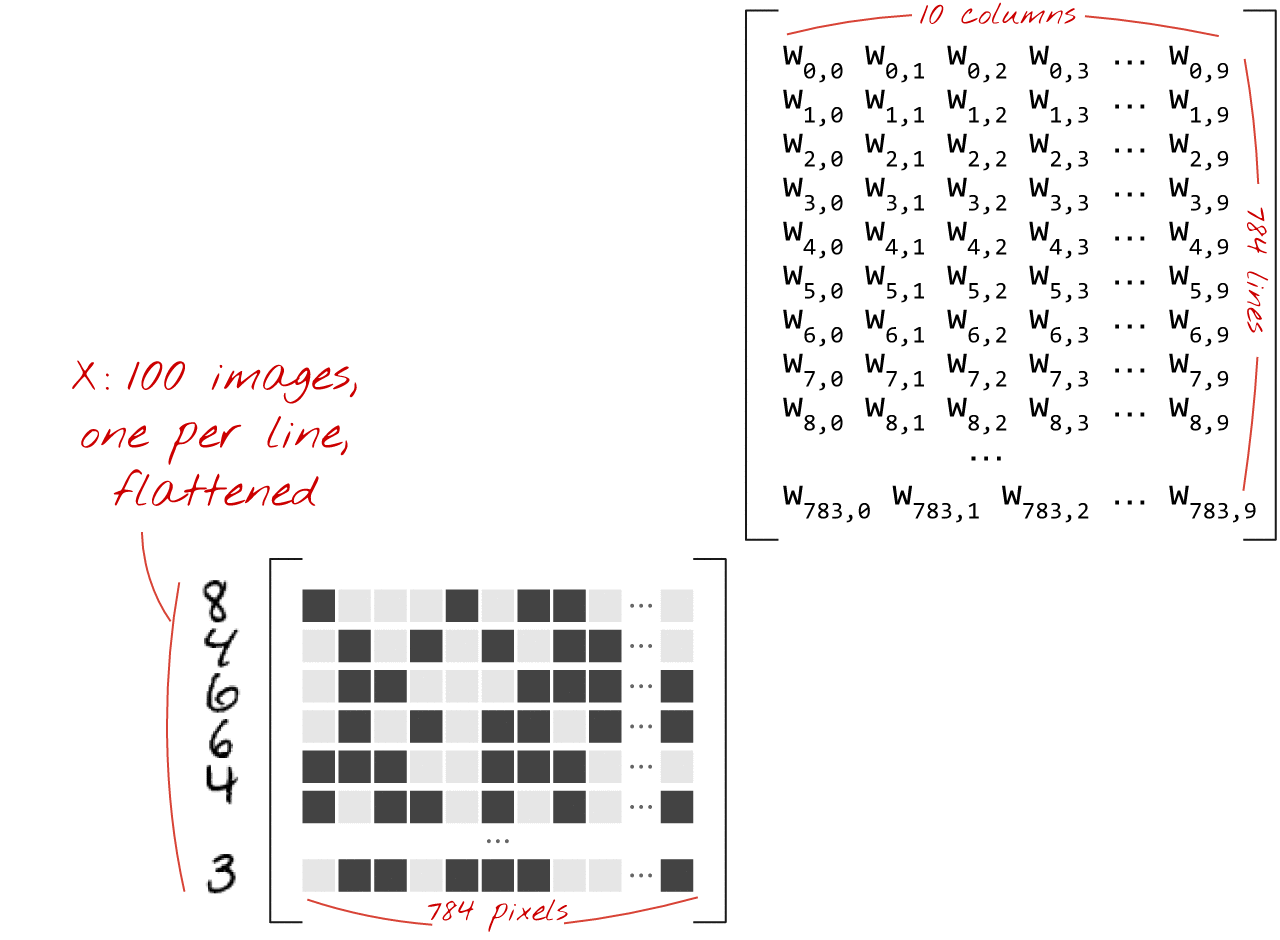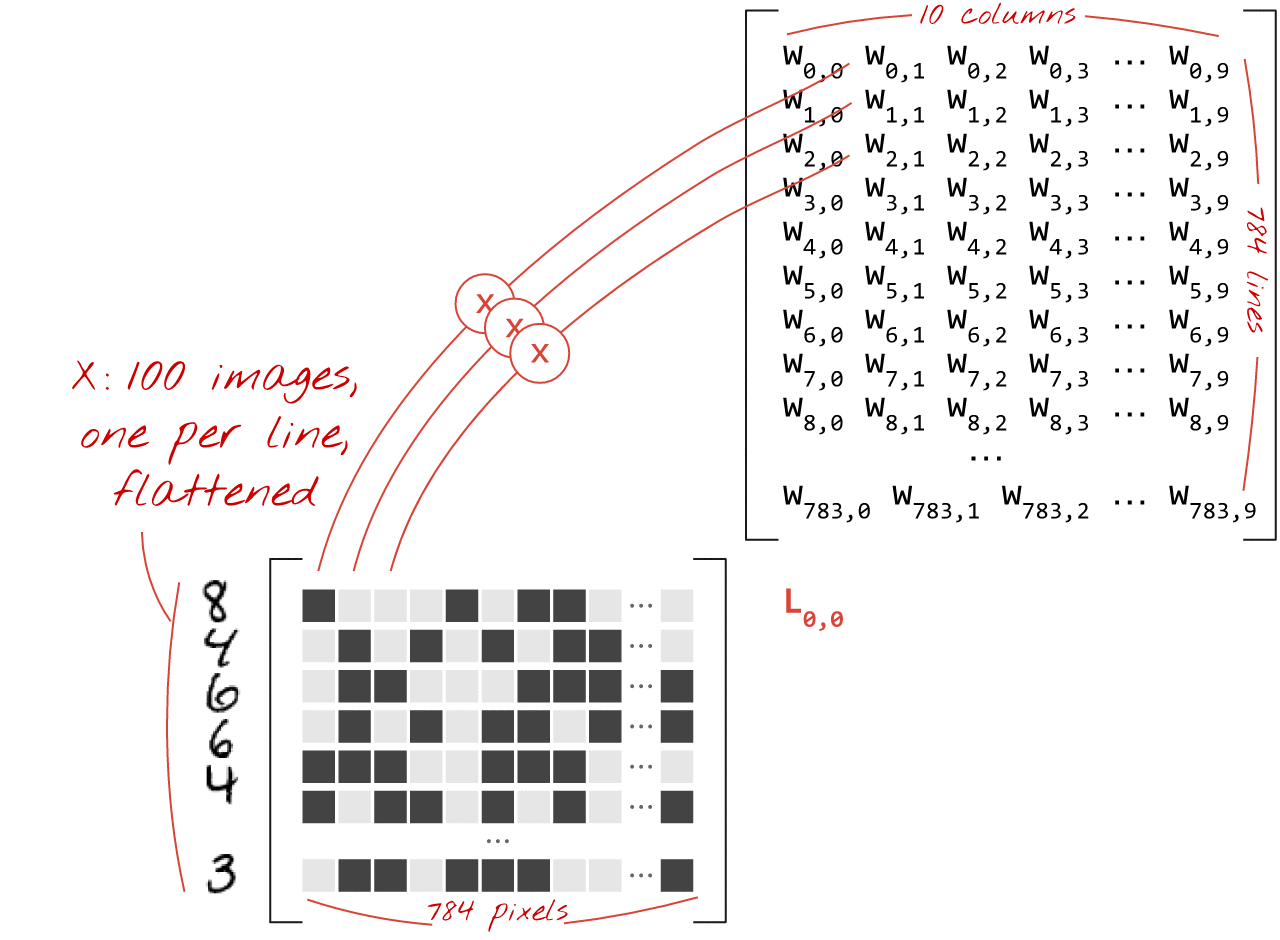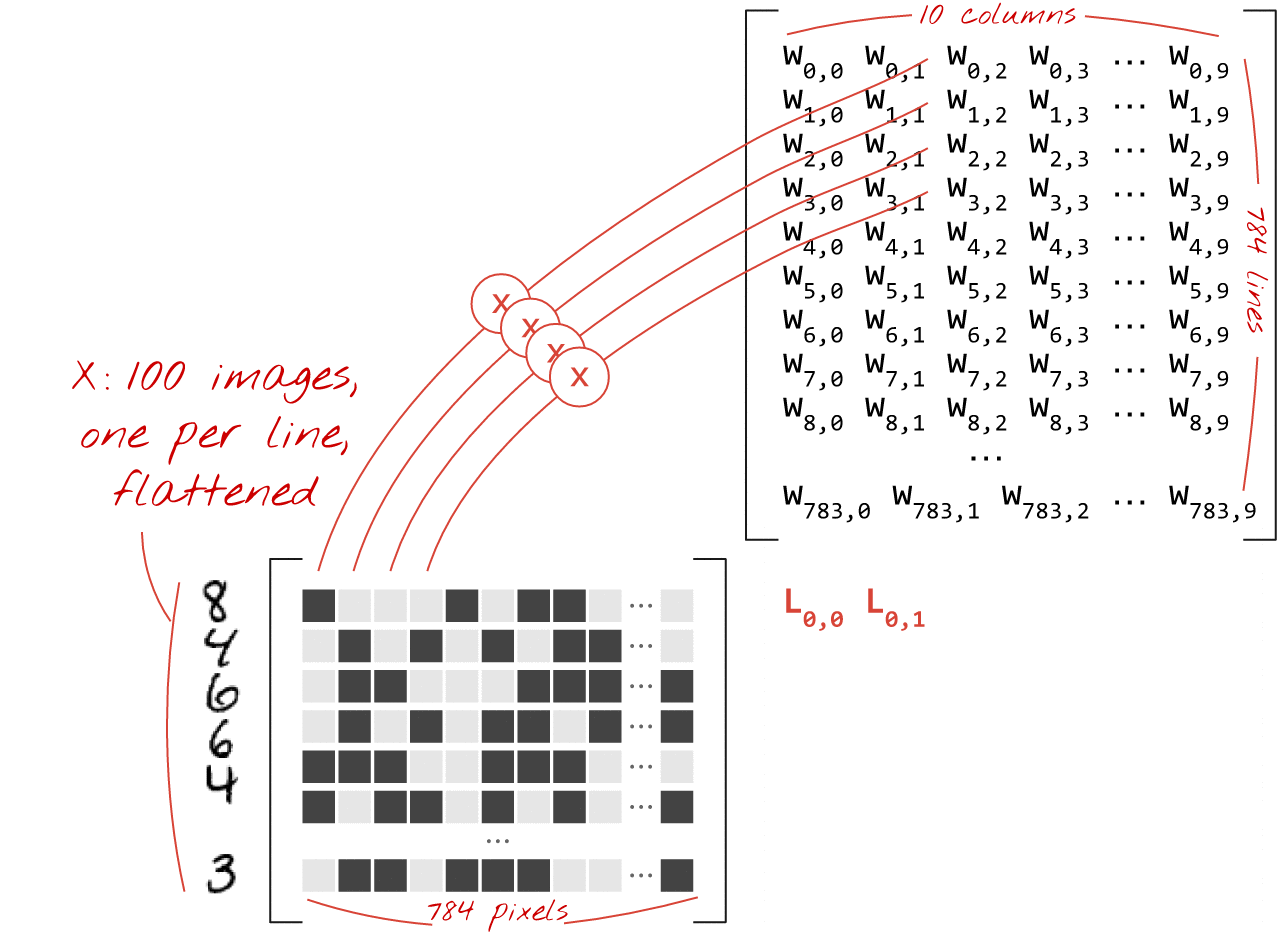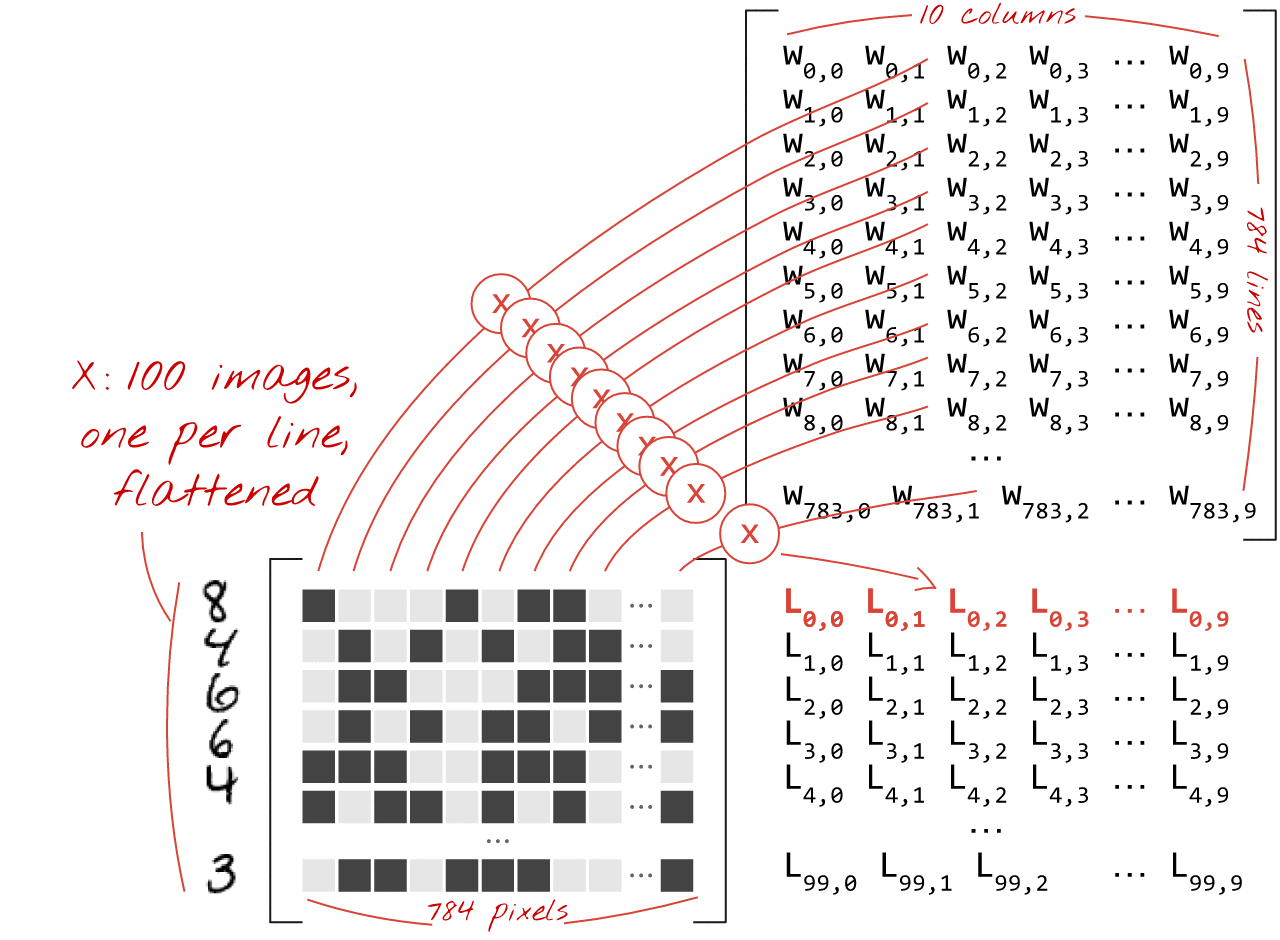
가중치 행렬 W의 첫 번째 가중치 열을 사용하여 첫 번째 이미지의 모든 픽셀의 가중치 합계를 계산합니다. 이 합계는 첫 번째 뉴런에 해당합니다. 두 번째 가중치 열을 사용하여 두 번째 뉴런에 대해 동일한 작업을 수행하고 10번째 뉴런까지 계속합니다. 그런 다음 나머지 99개 이미지에 대해 작업을 반복할 수 있습니다. 100개의 이미지가 포함된 행렬을 X라고 하면 100개의 이미지에서 계산된 10개의 뉴런의 모든 가중치 합은 단순히 행렬 곱셈인 X.W입니다.
이제 각 뉴런은 편향 (상수)을 추가해야 합니다. 뉴런이 10개이므로 편향 상수가 10개 있습니다. 이 10개 값의 벡터를 b라고 하겠습니다. 이 값은 이전에 계산된 행렬의 각 행에 추가되어야 합니다. '브로드캐스팅'이라는 마법을 사용하여 간단한 더하기 기호로 이를 작성합니다.
마지막으로 활성화 함수(예: 아래 설명된 'softmax')를 적용하고 100개의 이미지에 적용된 1계층 신경망을 설명하는 공식을 얻습니다.
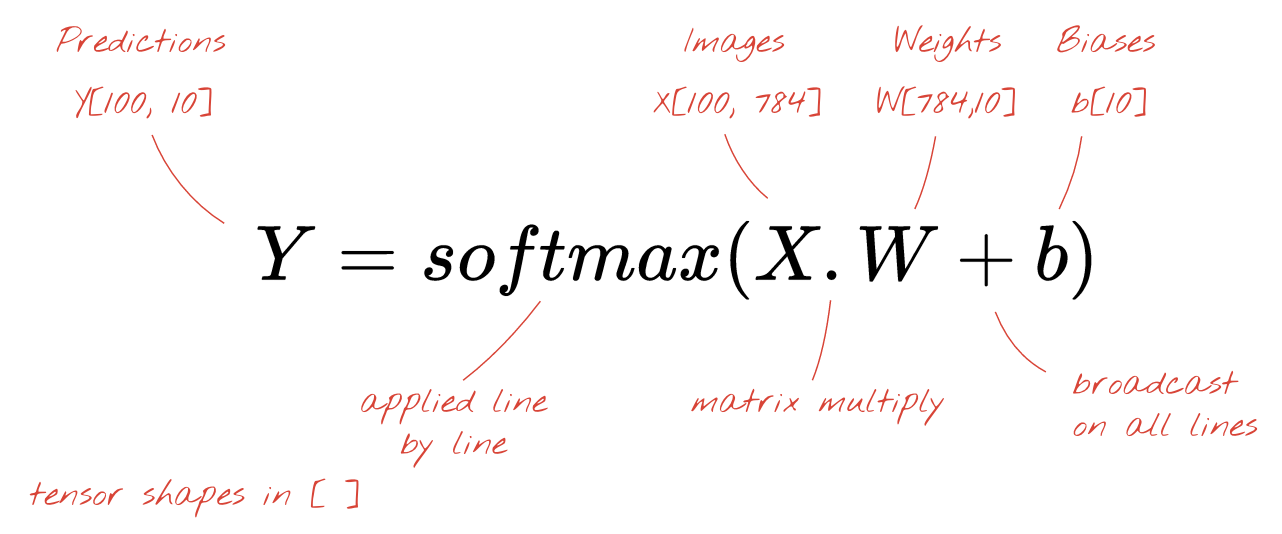
Keras에서
Keras와 같은 고급 신경망 라이브러리를 사용하면 이 공식을 구현할 필요가 없습니다. 하지만 신경망 레이어는 곱셈과 덧셈의 모음일 뿐이라는 점을 이해하는 것이 중요합니다. Keras에서 밀집층은 다음과 같이 작성됩니다.
tf.keras.layers.Dense(10, activation='softmax')자세히 알아보기
신경망 레이어를 연결하는 것은 간단합니다. 첫 번째 레이어는 픽셀의 가중치 합계를 계산합니다. 후속 레이어는 이전 레이어의 출력의 가중 합계를 계산합니다.
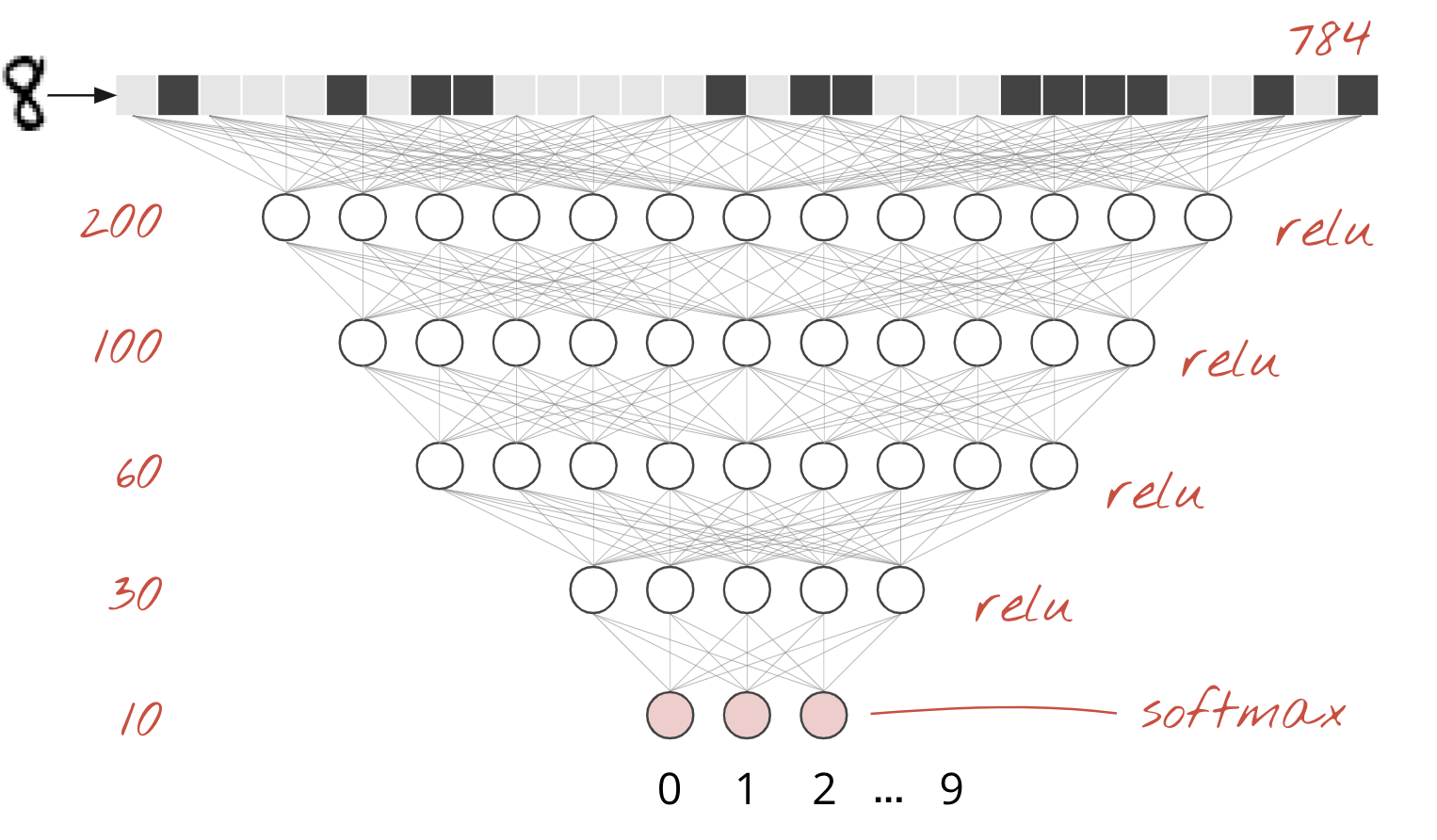
뉴런 수를 제외하고는 활성화 함수 선택만 다릅니다.
활성화 함수: relu, softmax, sigmoid
일반적으로 마지막 레이어를 제외한 모든 레이어에 'relu' 활성화 함수를 사용합니다. 분류기의 마지막 레이어는 '소프트맥스' 활성화를 사용합니다.
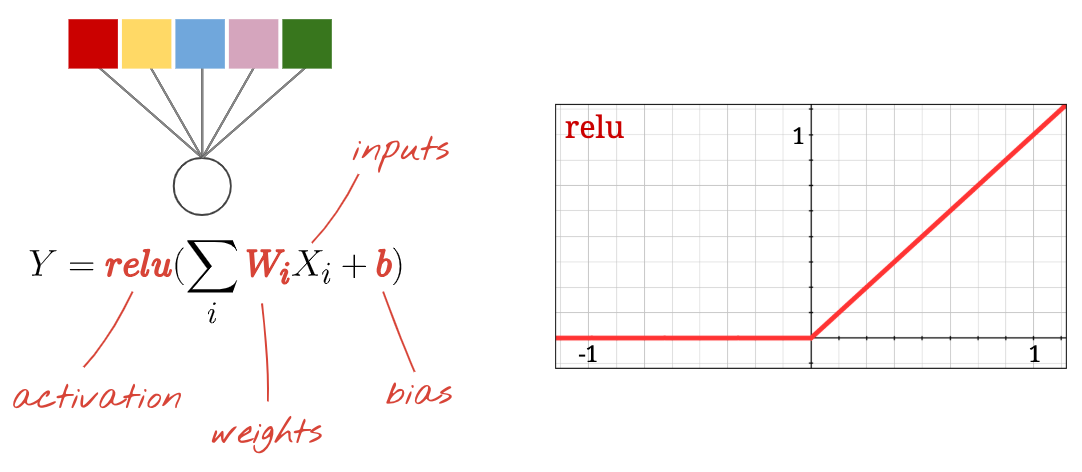
'뉴런'은 모든 입력의 가중 합을 계산하고 '바이어스'라는 값을 추가한 후 활성화 함수를 통해 결과를 제공합니다.
가장 인기 있는 활성화 함수는 정류 선형 유닛의 약자인 'ReLU'라고 합니다. 위 그래프에서 볼 수 있듯이 매우 간단한 함수입니다.
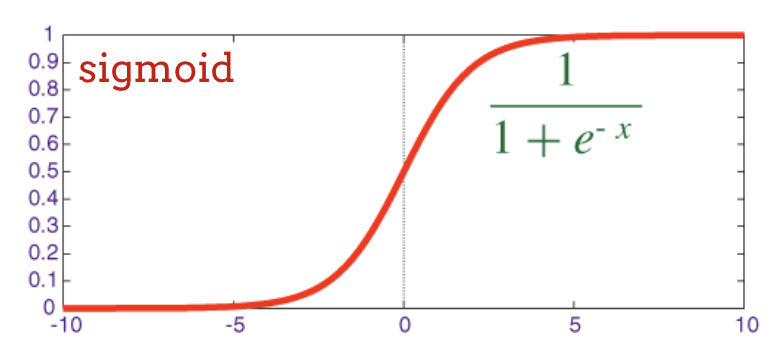
신경망의 기존 활성화 함수는 '시그모이드'였지만, 'relu'가 거의 모든 곳에서 더 나은 수렴 속성을 갖는 것으로 나타나 현재 선호됩니다.
분류를 위한 소프트맥스 활성화
손으로 쓴 숫자를 10개의 클래스 (0~9)로 분류하려고 하므로 신경망의 마지막 레이어에는 뉴런이 10개 있습니다. 이 숫자가 0, 1, 2 등일 확률을 나타내는 0과 1 사이의 숫자 10개를 출력해야 합니다. 이를 위해 마지막 레이어에서 '소프트맥스'라는 활성화 함수를 사용합니다.
벡터에 소프트맥스를 적용하려면 각 요소의 지수를 취한 다음 정규화된 값이 합산되어 1이 되고 확률로 해석될 수 있도록 일반적으로 'L1' norm (즉, 절대값의 합)으로 나누어 벡터를 정규화합니다.
활성화 전 마지막 레이어의 출력을 '로짓'이라고도 합니다. 이 벡터가 L = [L0, L1, L2, L3, L4, L5, L6, L7, L8, L9]인 경우 다음이 적용됩니다.
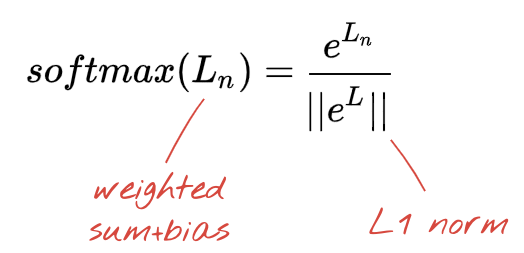
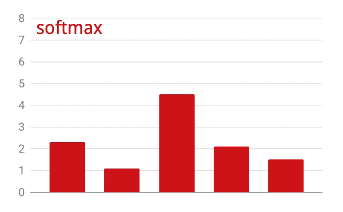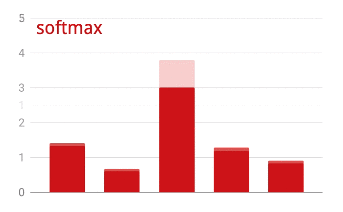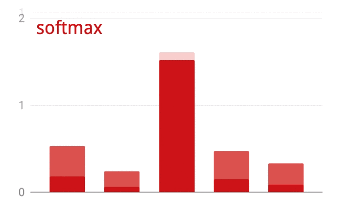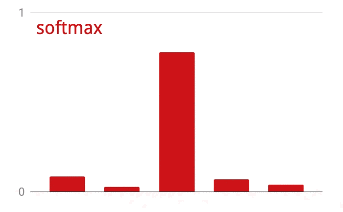
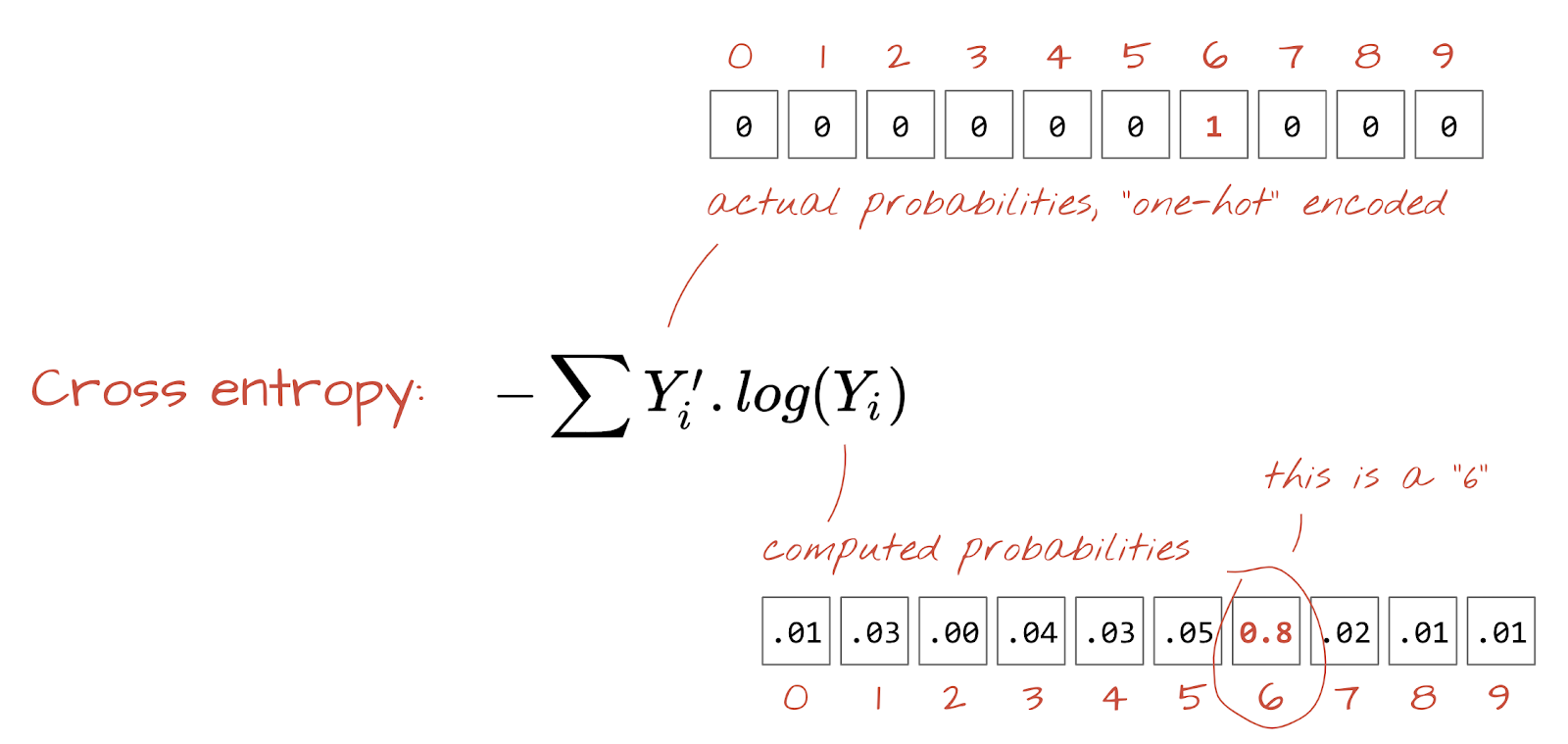
교차 엔트로피 손실
이제 신경망이 입력 이미지에서 예측을 생성하므로 예측의 정확도, 즉 신경망이 알려주는 값과 정답(일반적으로 '라벨'이라고 함) 간의 거리를 측정해야 합니다. 데이터 세트의 모든 이미지에 올바른 라벨이 지정되어 있습니다.
어떤 거리든 사용할 수 있지만 분류 문제의 경우 소위 '교차 엔트로피 거리'가 가장 효과적입니다. 이를 오류 또는 '손실' 함수라고 합니다.
경사하강법
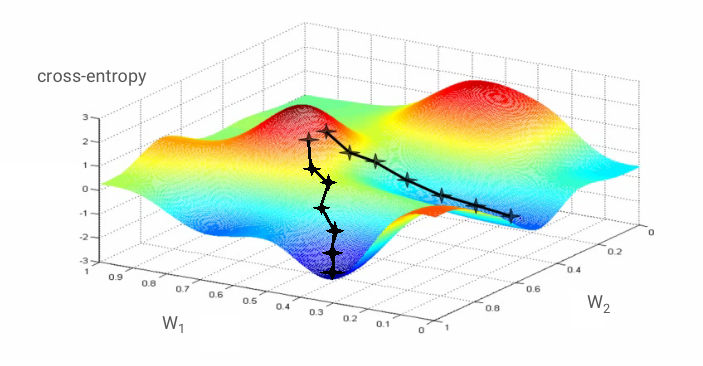
신경망을 '학습'한다는 것은 실제로 교차 엔트로피 손실 함수를 최소화하기 위해 학습 이미지와 라벨을 사용하여 가중치와 편향을 조정한다는 의미입니다. 작동 방식은 다음과 같습니다.
교차 엔트로피는 가중치, 편향, 학습 이미지의 픽셀, 알려진 클래스의 함수입니다.
모든 가중치와 모든 편향에 대한 교차 엔트로피의 편미분을 계산하면 주어진 이미지, 라벨, 현재 가중치 및 편향 값에 대해 계산된 '기울기'가 구해집니다. 가중치와 편향이 수백만 개 있을 수 있으므로 경사를 계산하는 것은 많은 작업이 필요합니다. 다행히 TensorFlow에서 이 작업을 처리해 줍니다. 그라데이션의 수학적 속성은 '위'를 가리킨다는 것입니다. 교차 엔트로피가 낮은 곳으로 이동해야 하므로 반대 방향으로 이동합니다. 경사의 일부를 사용하여 가중치와 편향을 업데이트합니다. 그런 다음 학습 루프에서 다음 학습 이미지 및 라벨 배치를 사용하여 동일한 작업을 반복합니다. 이 최소값이 고유하다는 보장은 없지만 크로스 엔트로피가 최소인 지점으로 수렴할 수 있습니다.
미니 배치 및 모멘텀
하나의 예시 이미지에서만 그라데이션을 계산하고 가중치와 편향을 즉시 업데이트할 수 있지만, 예를 들어 128개의 이미지 배치에서 이렇게 하면 다양한 예시 이미지에서 부과된 제약 조건을 더 잘 나타내는 그라데이션이 제공되므로 솔루션으로 더 빠르게 수렴될 수 있습니다. 미니 배치 크기는 조정 가능한 매개변수입니다.
'확률적 경사 하강법'이라고도 하는 이 기법에는 또 다른 실용적인 이점이 있습니다. 배치로 작업하면 더 큰 행렬로 작업하게 되며, 이러한 행렬은 일반적으로 GPU와 TPU에서 최적화하기가 더 쉽습니다.
하지만 수렴은 여전히 약간 혼란스러울 수 있으며, 경사 벡터가 모두 0이면 중지될 수도 있습니다. 이것이 최솟값을 찾았다는 의미인가요? 항상 그렇지는 않습니다. 그라데이션 구성요소는 최소 또는 최대에서 0일 수 있습니다. 요소가 수백만 개인 그라데이션 벡터에서 모든 요소가 0인 경우 모든 0이 최소값에 해당하고 최대값에 해당하는 요소가 없을 확률은 매우 작습니다. 다양한 차원으로 구성된 공간에서는 안장점이 흔하며, 안장점에서 멈추고 싶지 않습니다.
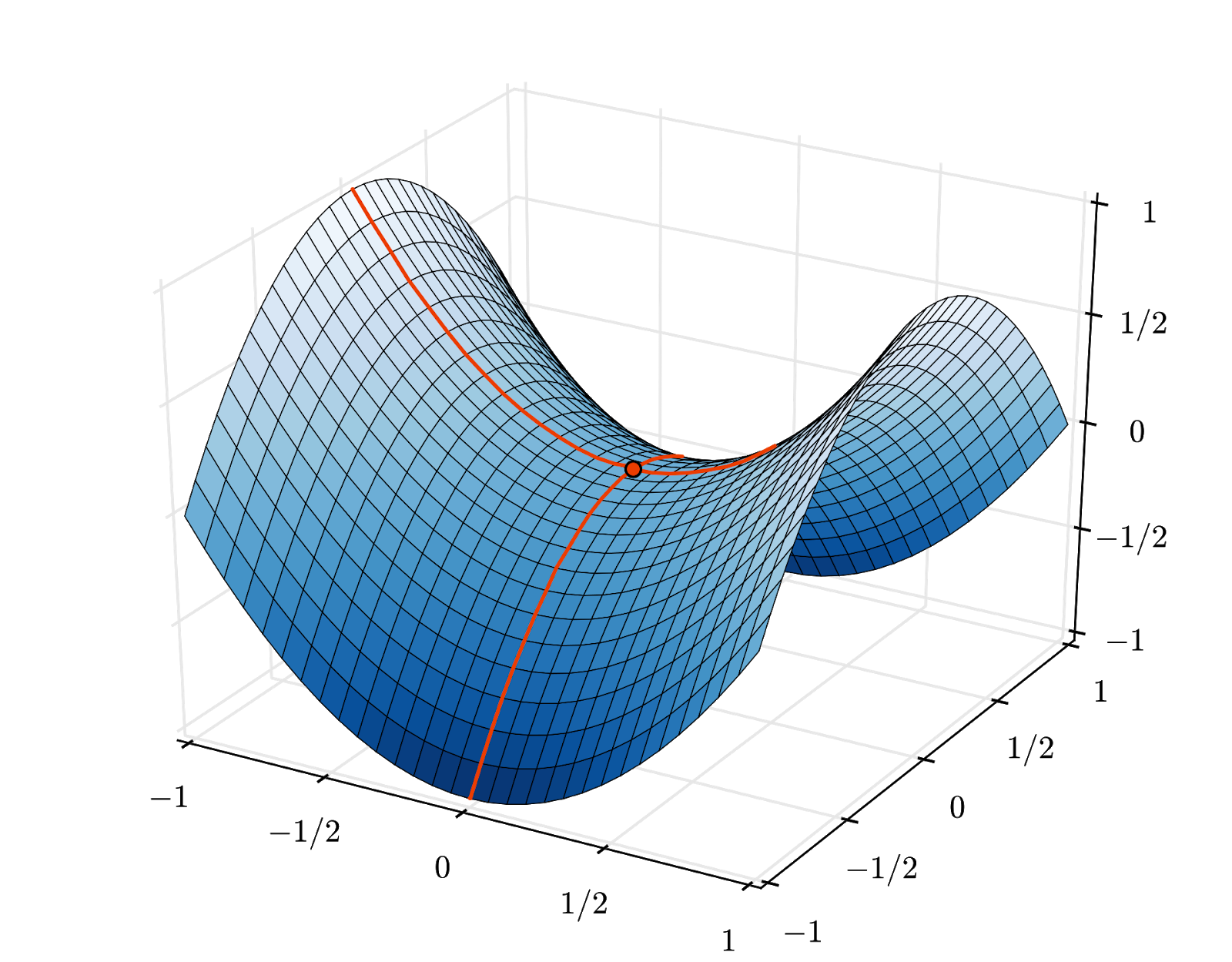
그림: 안장점 기울기는 0이지만 모든 방향에서 최소값은 아닙니다. (이미지 출처: Wikimedia: Nicoguaro 제작, CC BY 3.0)
해결책은 최적화 알고리즘에 모멘텀을 추가하여 안장점을 멈추지 않고 지나갈 수 있도록 하는 것입니다.
용어집
배치 또는 미니 배치: 학습은 항상 학습 데이터 및 라벨의 배치에서 실행됩니다. 이렇게 하면 알고리즘이 수렴하는 데 도움이 됩니다. '배치' 측정기준은 일반적으로 데이터 텐서의 첫 번째 측정기준입니다. 예를 들어 모양이 [100, 192, 192, 3] 인 텐서에는 픽셀당 값이 3개 (RGB)인 192x192 픽셀 이미지가 100개 포함되어 있습니다.
교차 엔트로피 손실: 분류기에서 자주 사용되는 특수 손실 함수입니다.
밀집층: 각 뉴런이 이전 레이어의 모든 뉴런에 연결된 뉴런 레이어입니다.
특성: 신경망의 입력을 '특성'이라고도 합니다. 좋은 예측을 얻기 위해 데이터 세트의 어떤 부분 (또는 부분의 조합)을 신경망에 입력해야 하는지 파악하는 기술을 '특성 엔지니어링'이라고 합니다.
라벨: 지도 분류 문제에서 '클래스' 또는 정답의 또 다른 이름
학습률: 학습 루프의 각 반복에서 가중치와 편향이 업데이트되는 기울기의 비율입니다.
로짓: 활성화 함수가 적용되기 전의 뉴런 레이어의 출력을 '로짓'이라고 합니다. 이 용어는 가장 인기 있는 활성화 함수였던 '로지스틱 함수' 또는 '시그모이드 함수'에서 유래했습니다. '로지스틱 함수 전의 뉴런 출력'이 '로짓'으로 단축되었습니다.
손실: 신경망 출력을 정답과 비교하는 오류 함수
뉴런: 입력의 가중 합을 계산하고 편향을 추가하고 활성화 함수를 통해 결과를 제공합니다.
원-핫 인코딩: 5개 중 3번째 클래스는 3번째 요소를 제외한 모든 요소가 0인 5개 요소의 벡터로 인코딩됩니다.
relu: 정류 선형 유닛입니다. 뉴런에 널리 사용되는 활성화 함수입니다.
sigmoid: 한때 인기가 많았으며 특수한 경우에 여전히 유용한 또 다른 활성화 함수입니다.
softmax: 벡터에 작용하고 가장 큰 구성요소와 다른 모든 구성요소 간의 차이를 늘리며 확률 벡터로 해석될 수 있도록 벡터의 합이 1이 되도록 정규화하는 특수 활성화 함수입니다. 분류기의 마지막 단계로 사용됩니다.
텐서: '텐서'는 행렬과 비슷하지만 차원 수가 임의입니다. 1차원 텐서는 벡터입니다. 2차원 텐서는 행렬입니다. 그런 다음 3, 4, 5개 이상의 차원을 갖는 텐서를 사용할 수 있습니다.
연구 노트북으로 돌아가 이번에는 코드를 읽어 보겠습니다.
이 노트북의 모든 셀을 살펴보겠습니다.
'매개변수' 셀
여기에서 배치 크기, 학습 에포크 수, 데이터 파일 위치가 정의됩니다. 데이터 파일은 Google Cloud Storage (GCS) 버킷에서 호스팅되므로 주소가 gs://로 시작합니다.
'가져오기' 셀
여기에서는 TensorFlow와 시각화를 위한 matplotlib을 비롯한 필요한 모든 Python 라이브러리를 가져옵니다.
셀 '시각화 유틸리티 [실행]'
이 셀에는 흥미롭지 않은 시각화 코드가 포함되어 있습니다. 기본적으로 접혀 있지만 시간이 있을 때 더블클릭하여 열고 코드를 살펴볼 수 있습니다.
셀 'tf.data.Dataset: 파일 파싱 및 학습 및 검증 데이터 세트 준비'
이 셀은 tf.data.Dataset API를 사용하여 데이터 파일에서 MNIST 데이터 세트를 로드했습니다. 이 셀에 너무 많은 시간을 할애할 필요는 없습니다. tf.data.Dataset API에 관심이 있다면 TPU 속도의 데이터 파이프라인 튜토리얼을 참고하세요. 현재 기본 사항은 다음과 같습니다.
MNIST 데이터 세트의 이미지와 라벨 (정답)은 4개 파일의 고정 길이 레코드에 저장됩니다. 파일은 전용 고정 레코드 함수를 사용하여 로드할 수 있습니다.
imagedataset = tf.data.FixedLengthRecordDataset(image_filename, 28*28, header_bytes=16)이제 이미지 바이트 데이터 세트가 있습니다. 이미지로 디코딩해야 합니다. 이를 위한 함수를 정의합니다. 이미지는 압축되지 않으므로 함수가 아무것도 디코딩할 필요가 없습니다 (decode_raw는 기본적으로 아무것도 하지 않음). 그런 다음 이미지가 0과 1 사이의 부동 소수점 값으로 변환됩니다. 여기서 2D 이미지로 재구성할 수도 있지만 초기 밀도층에서 예상하는 것이므로 28*28 크기의 평면 픽셀 배열로 유지합니다.
def read_image(tf_bytestring):
image = tf.decode_raw(tf_bytestring, tf.uint8)
image = tf.cast(image, tf.float32)/256.0
image = tf.reshape(image, [28*28])
return image.map를 사용하여 이 함수를 데이터 세트에 적용하고 이미지 데이터 세트를 가져옵니다.
imagedataset = imagedataset.map(read_image, num_parallel_calls=16)라벨에 대해서도 동일한 종류의 읽기 및 디코딩을 실행하고 이미지와 라벨을 함께 .zip합니다.
dataset = tf.data.Dataset.zip((imagedataset, labelsdataset))이제 (이미지, 라벨) 쌍의 데이터 세트가 있습니다. 이는 모델에서 예상하는 것입니다. 아직 학습 함수에서 사용할 준비가 되지 않았습니다.
dataset = dataset.cache()
dataset = dataset.shuffle(5000, reshuffle_each_iteration=True)
dataset = dataset.repeat()
dataset = dataset.batch(batch_size)
dataset = dataset.prefetch(tf.data.experimental.AUTOTUNE)tf.data.Dataset API에는 데이터 세트를 준비하는 데 필요한 모든 유틸리티 함수가 있습니다.
.cache는 RAM에 데이터 세트를 캐시합니다. 이 데이터 세트는 매우 작으므로 작동합니다. .shuffle은 5,000개 요소의 버퍼로 이를 섞습니다. 학습 데이터가 잘 섞여 있어야 합니다. .repeat는 데이터 세트를 반복합니다. 이 데이터로 여러 번 (여러 에포크) 학습합니다. .batch는 여러 이미지와 라벨을 하나의 미니 배치로 가져옵니다. 마지막으로 .prefetch는 현재 배치에 GPU에서 학습이 진행되는 동안 CPU를 사용하여 다음 배치를 준비할 수 있습니다.
검증 데이터 세트도 비슷한 방식으로 준비됩니다. 이제 모델을 정의하고 이 데이터 세트를 사용하여 모델을 학습시킬 수 있습니다.
'Keras 모델' 셀
모든 모델은 레이어의 연속된 시퀀스이므로 tf.keras.Sequential 스타일을 사용하여 만들 수 있습니다. 여기에서는 처음에는 단일 밀집 레이어입니다. 필기 숫자를 10개의 클래스로 분류하므로 뉴런이 10개 있습니다. 분류기의 마지막 레이어이므로 '소프트맥스' 활성화를 사용합니다.
Keras 모델은 입력의 형태도 알아야 합니다. tf.keras.layers.Input을 사용하여 정의할 수 있습니다. 여기서 입력 벡터는 길이가 28*28인 픽셀 값의 플랫 벡터입니다.
model = tf.keras.Sequential(
[
tf.keras.layers.Input(shape=(28*28,)),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
# print model layers
model.summary()
# utility callback that displays training curves
plot_training = PlotTraining(sample_rate=10, zoom=1)모델 구성은 Keras에서 model.compile 함수를 사용하여 실행됩니다. 여기서는 기본 옵티마이저 'sgd' (확률적 경사하강법)를 사용합니다. 분류 모델에는 교차 엔트로피 손실 함수가 필요하며, Keras에서는 이를 'categorical_crossentropy'라고 합니다. 마지막으로 모델에 올바르게 분류된 이미지의 비율인 'accuracy' 측정항목을 계산하도록 요청합니다.
Keras는 생성한 모델의 세부정보를 출력하는 매우 유용한 model.summary() 유틸리티를 제공합니다. 친절한 강사님이 학습 중에 다양한 학습 곡선을 표시하는 PlotTraining 유틸리티('시각화 유틸리티' 셀에 정의됨)를 추가했습니다.
'모델 학습 및 검증' 셀
여기서 model.fit를 호출하고 학습 데이터 세트와 검증 데이터 세트를 모두 전달하여 학습이 이루어집니다. 기본적으로 Keras는 각 에포크가 끝날 때 검증 라운드를 실행합니다.
model.fit(training_dataset, steps_per_epoch=steps_per_epoch, epochs=EPOCHS,
validation_data=validation_dataset, validation_steps=1,
callbacks=[plot_training])Keras에서는 콜백을 사용하여 학습 중에 맞춤 동작을 추가할 수 있습니다. 이 워크숍에서는 동적으로 업데이트되는 학습 플롯이 이렇게 구현되었습니다.
'예측 시각화' 셀
모델이 학습되면 model.predict()를 호출하여 모델에서 예측을 가져올 수 있습니다.
probabilities = model.predict(font_digits, steps=1)
predicted_labels = np.argmax(probabilities, axis=1)여기에서는 테스트로 로컬 글꼴에서 렌더링된 인쇄된 숫자 집합을 준비했습니다. 신경망은 최종 '소프트맥스'에서 10개의 확률 벡터를 반환합니다. 라벨을 얻으려면 어떤 확률이 가장 높은지 알아야 합니다. numpy 라이브러리의 np.argmax가 이 작업을 실행합니다.
axis=1 매개변수가 필요한 이유를 이해하려면 128개의 이미지 배치를 처리했으므로 모델이 확률 벡터 128개를 반환한다는 점을 기억하세요. 출력 텐서의 모양은 [128, 10]입니다. 각 이미지에 대해 반환된 10개의 확률에서 argmax를 계산하므로 axis=1 (첫 번째 축이 0)입니다.
이 간단한 모델은 이미 숫자의 90% 를 인식합니다. 나쁘지 않지만 이제 크게 개선할 수 있습니다.
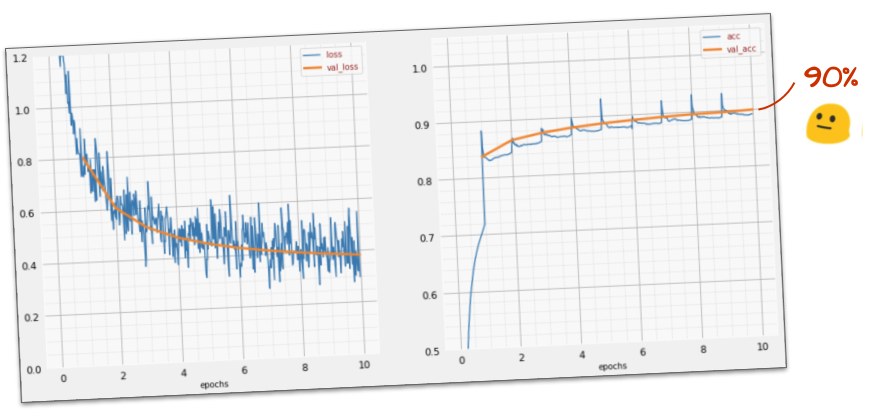

인식 정확도를 높이기 위해 신경망에 레이어를 더 추가합니다.

분류에 가장 적합한 활성화 함수이므로 마지막 레이어의 활성화 함수는 소프트맥스로 유지합니다. 하지만 중간 레이어에서는 가장 고전적인 활성화 함수인 시그모이드를 사용합니다.
예를 들어 모델은 다음과 같을 수 있습니다 (쉼표를 잊지 마세요. tf.keras.Sequential는 쉼표로 구분된 레이어 목록을 사용합니다).
model = tf.keras.Sequential(
[
tf.keras.layers.Input(shape=(28*28,)),
tf.keras.layers.Dense(200, activation='sigmoid'),
tf.keras.layers.Dense(60, activation='sigmoid'),
tf.keras.layers.Dense(10, activation='softmax')
])모델의 '요약'을 확인합니다. 이제 매개변수가 10배 이상 많아졌습니다. 10배 더 나은 환경을 제공해야 합니다. 하지만 어떤 이유로든
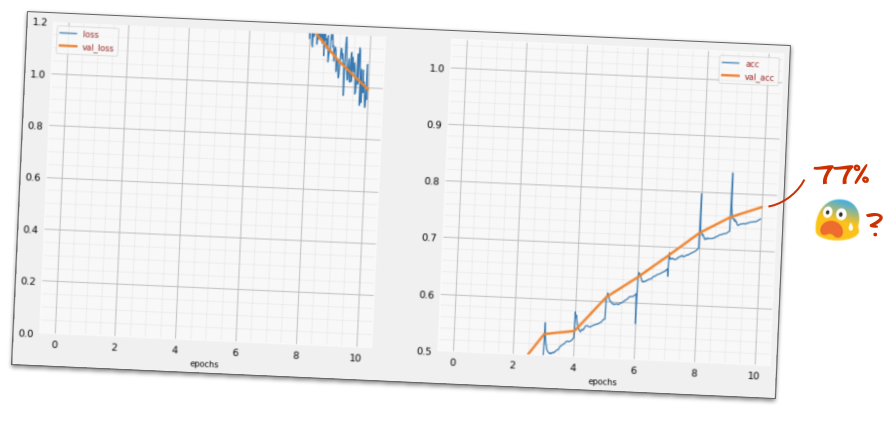
손실도 급증한 것 같습니다. 문제가 발생했습니다.
지금까지 1980년대와 1990년대에 사람들이 설계했던 신경망을 경험했습니다. 이러한 이유로 아이디어를 포기하고 소위 'AI 겨울'이 시작된 것은 당연합니다. 실제로 레이어를 추가하면 신경망이 수렴하기가 점점 더 어려워집니다.
레이어가 많은 심층 신경망 (오늘날에는 20, 50, 심지어 100개)은 수렴하도록 하는 몇 가지 수학적 속임수를 사용하면 매우 잘 작동할 수 있습니다. 이러한 간단한 트릭의 발견은 2010년대에 딥 러닝이 부흥한 이유 중 하나입니다.
RELU 활성화

시그모이드 활성화 함수는 실제로 심층 네트워크에서 상당히 문제가 됩니다. 0과 1 사이의 모든 값을 압축하며, 이를 반복하면 뉴런 출력과 그라데이션이 완전히 사라질 수 있습니다. 이는 역사적인 이유로 언급되었지만 최신 네트워크에서는 다음과 같은 RELU (정류 선형 유닛)를 사용합니다.
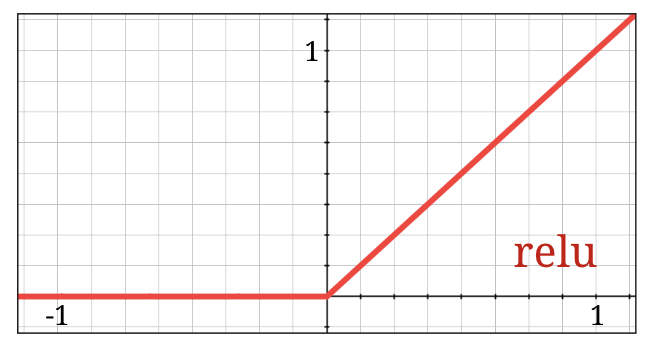
반면 relu는 적어도 오른쪽에서 도함수가 1입니다. ReLU 활성화를 사용하면 일부 뉴런에서 오는 경사가 0이더라도 항상 0이 아닌 명확한 경사를 제공하는 뉴런이 있으므로 적절한 속도로 학습을 계속할 수 있습니다.
더 나은 최적화 도구
여기처럼 매우 고차원 공간에서는 가중치와 편향이 10,000개 정도이므로 '안장점'이 자주 발생합니다. 이러한 점은 지역 최솟값이 아니지만 경사가 0이므로 경사하강법 최적화 프로그램이 멈춰 있는 곳입니다. TensorFlow에는 관성으로 작동하여 안장점을 안전하게 지나가는 옵티마이저를 비롯한 다양한 옵티마이저가 있습니다.
무작위 초기화
학습 전에 가중치 편향을 초기화하는 기술은 그 자체로 연구 분야이며 이 주제에 관한 논문이 많이 발표되었습니다. Keras에서 사용할 수 있는 모든 이니셜라이저는 여기에서 확인할 수 있습니다. 다행히 Keras는 기본적으로 올바른 작업을 수행하며 거의 모든 경우에 가장 적합한 'glorot_uniform' 초기화 프로그램을 사용합니다.
Keras가 이미 올바른 작업을 수행하므로 개발자가 취해야 할 조치는 없습니다.
NaN ???
교차 엔트로피 공식에는 로그가 포함되어 있으며 log(0)은 숫자가 아닙니다 (NaN, 원하는 경우 숫자 충돌). 교차 엔트로피의 입력이 0일 수 있나요? 입력은 기본적으로 지수 함수인 소프트맥스에서 가져오며 지수 함수는 0이 될 수 없습니다. 따라서 안전합니다.
정말요? 수학의 아름다운 세계에서는 안전하겠지만 컴퓨터 세계에서는 float32 형식으로 표현된 exp(-150)이 0에 가까워 교차 엔트로피가 비정상 종료됩니다.
다행히도 여기에서도 할 일은 없습니다. Keras가 이를 처리하고 숫자 안정성을 보장하고 무서운 NaN을 방지하기 위해 특히 신중한 방식으로 소프트맥스와 교차 엔트로피를 계산하기 때문입니다.
성공?
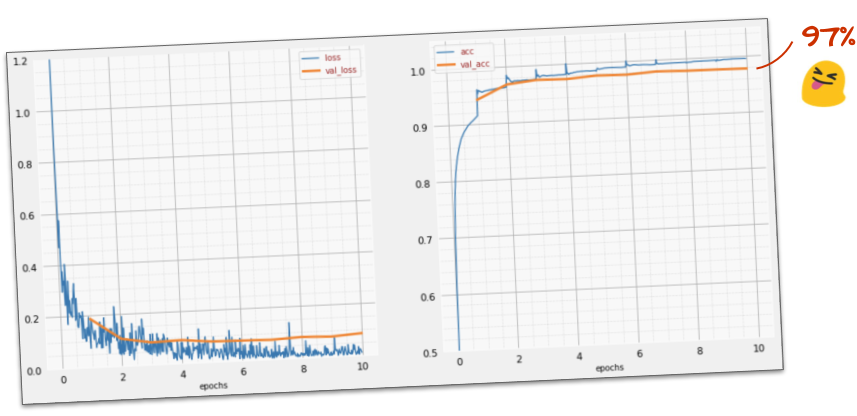
이제 정확도가 97% 에 도달해야 합니다. 이 워크숍의 목표는 99% 를 훨씬 넘는 것이므로 계속 진행하겠습니다.
진행이 막힌 경우 현재 해결 방법은 다음과 같습니다.
더 빠르게 학습해 볼까요? Adam 옵티마이저의 기본 학습률은 0.001입니다. 늘려 보겠습니다.
더 빨리 가도 별로 도움이 되지 않는 것 같고 이 소리는 뭐지?
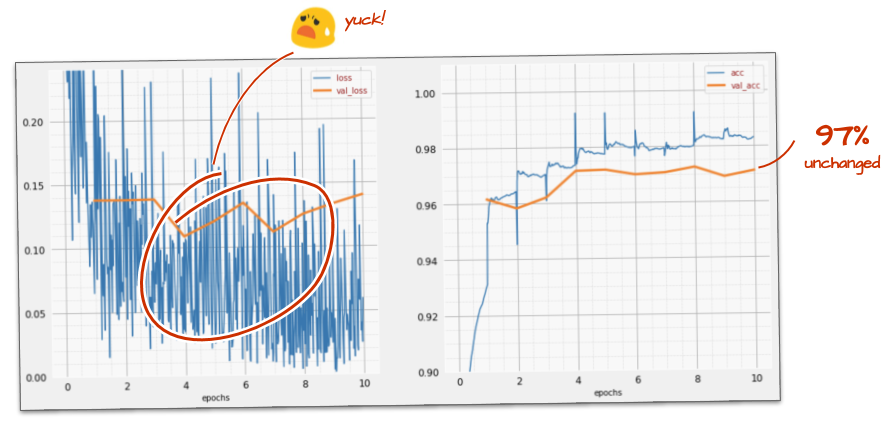
학습 곡선이 매우 노이즈가 많고 검증 곡선이 위아래로 움직입니다. 이는 너무 빠른 속도로 진행되고 있다는 의미입니다. 이전 속도로 돌아갈 수도 있지만 더 나은 방법이 있습니다.

좋은 해결책은 빠르게 시작하고 학습률을 지수적으로 감소시키는 것입니다. Keras에서는 tf.keras.callbacks.LearningRateScheduler 콜백을 사용하여 이를 수행할 수 있습니다.
복사하여 붙여넣을 수 있는 유용한 코드:
# lr decay function
def lr_decay(epoch):
return 0.01 * math.pow(0.6, epoch)
# lr schedule callback
lr_decay_callback = tf.keras.callbacks.LearningRateScheduler(lr_decay, verbose=True)
# important to see what you are doing
plot_learning_rate(lr_decay, EPOCHS)생성한 lr_decay_callback을 사용하는 것을 잊지 마세요. model.fit의 콜백 목록에 추가합니다.
model.fit(..., callbacks=[plot_training, lr_decay_callback])이 작은 변화의 영향은 놀랍습니다. 노이즈가 대부분 사라지고 테스트 정확도가 이제 지속적으로 98% 를 초과합니다.
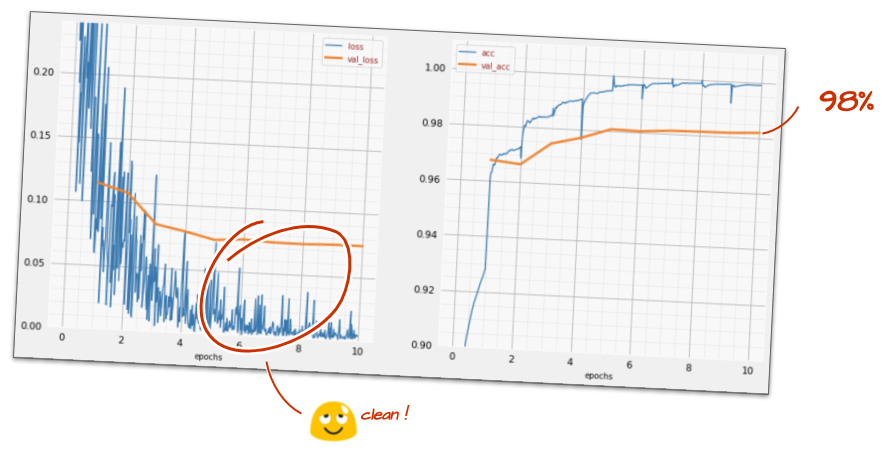
이제 모델이 잘 수렴되는 것 같습니다. 더 깊이 들어가 보겠습니다.
도움이 되었나요?
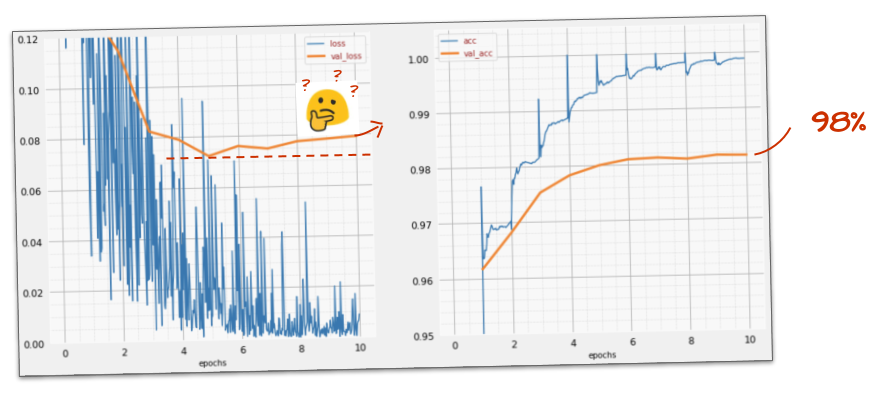
아니요. 정확도는 여전히 98% 에 머물러 있고 검증 손실을 살펴보세요. 올라가고 있습니다. 학습 알고리즘은 학습 데이터에서만 작동하며 이에 따라 학습 손실을 최적화합니다. 검증 데이터를 보지 못하므로 시간이 지나면 작업이 더 이상 검증 손실에 영향을 미치지 않아 검증 손실이 감소하지 않고 때로는 다시 반등하는 것은 놀라운 일이 아닙니다.
이는 모델의 실제 인식 기능에 즉시 영향을 주지는 않지만 여러 번 반복하는 것을 방지하며 일반적으로 학습이 더 이상 긍정적인 영향을 미치지 않는다는 신호입니다.

이러한 단절을 일반적으로 '과적합'이라고 하며, 이러한 현상이 나타나면 '드롭아웃'이라는 정규화 기법을 적용해 볼 수 있습니다. 드롭아웃 기법은 각 학습 반복에서 임의의 뉴런을 선택합니다.
결과
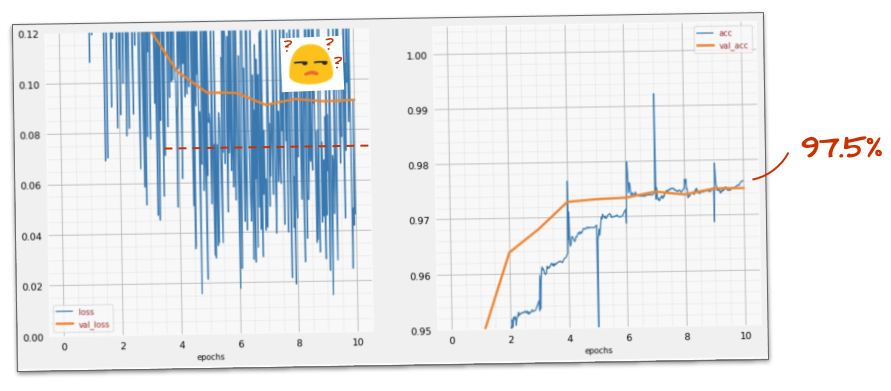
드롭아웃이 작동하는 방식을 고려하면 노이즈가 다시 표시되는 것은 당연합니다. 검증 손실이 더 이상 증가하지는 않지만 드롭아웃이 없는 경우보다 전반적으로 높습니다. 검증 정확도가 약간 낮아졌습니다. 다소 실망스러운 결과입니다.
드롭아웃이 올바른 해결책이 아니거나 '과적합'이 더 복잡한 개념이며 일부 원인은 '드롭아웃' 수정에 적합하지 않은 것 같습니다.
'과적합'이란 무엇인가요? 과적합은 신경망이 학습 예시에서는 작동하지만 실제 데이터에서는 잘 작동하지 않는 방식으로 '잘못' 학습하는 경우 발생합니다. 드롭아웃과 같은 정규화 기법을 사용하면 더 나은 방식으로 학습하도록 강제할 수 있지만 과적합에는 더 깊은 뿌리가 있습니다.

기본 과적합은 신경망에 당면한 문제에 비해 자유도가 너무 많은 경우 발생합니다. 네트워크에 뉴런이 너무 많아서 네트워크가 모든 학습 이미지를 저장한 다음 패턴 일치로 인식할 수 있다고 가정해 보겠습니다. 실제 데이터에서는 완전히 실패합니다. 신경망은 학습 중에 학습한 내용을 일반화하도록 강제되도록 어느 정도 제한되어야 합니다.
학습 데이터가 매우 적은 경우 작은 네트워크도 이를 암기할 수 있으며 '과적합'이 발생합니다. 일반적으로 신경망을 학습시키려면 항상 많은 데이터가 필요합니다.
마지막으로, 모든 것을 정석대로 수행하고, 자유도가 제한되도록 다양한 크기의 네트워크를 실험하고, 드롭아웃을 적용하고, 많은 데이터로 학습했는데도 성능 수준이 개선되지 않는 경우가 있을 수 있습니다. 즉, 현재 형태의 신경망은 여기의 경우와 같이 데이터에서 더 많은 정보를 추출할 수 없습니다.
단일 벡터로 평탄화된 이미지를 사용하는 방법을 기억하시나요? 정말 나쁜 생각이었어요. 손으로 쓴 숫자는 모양으로 구성되어 있으며 픽셀을 평탄화할 때 모양 정보를 삭제했습니다. 하지만 모양 정보를 활용할 수 있는 신경망 유형이 있습니다. 바로 컨볼루션 네트워크입니다. 한번 사용해 보겠습니다.
진행이 막힌 경우 현재 해결 방법은 다음과 같습니다.
요약
다음 단락의 굵은 글씨로 표시된 모든 용어를 이미 알고 있다면 다음 연습으로 이동해도 됩니다. 컨볼루셔널 신경망을 처음 시작하는 경우 계속 읽어 보세요.
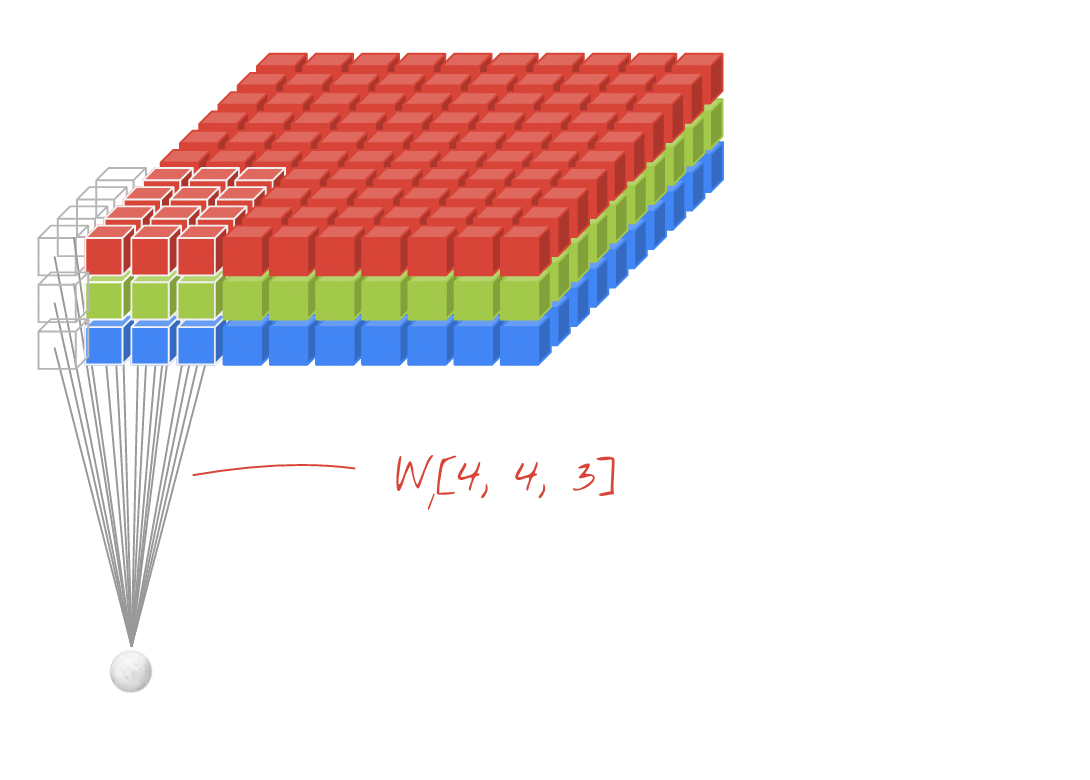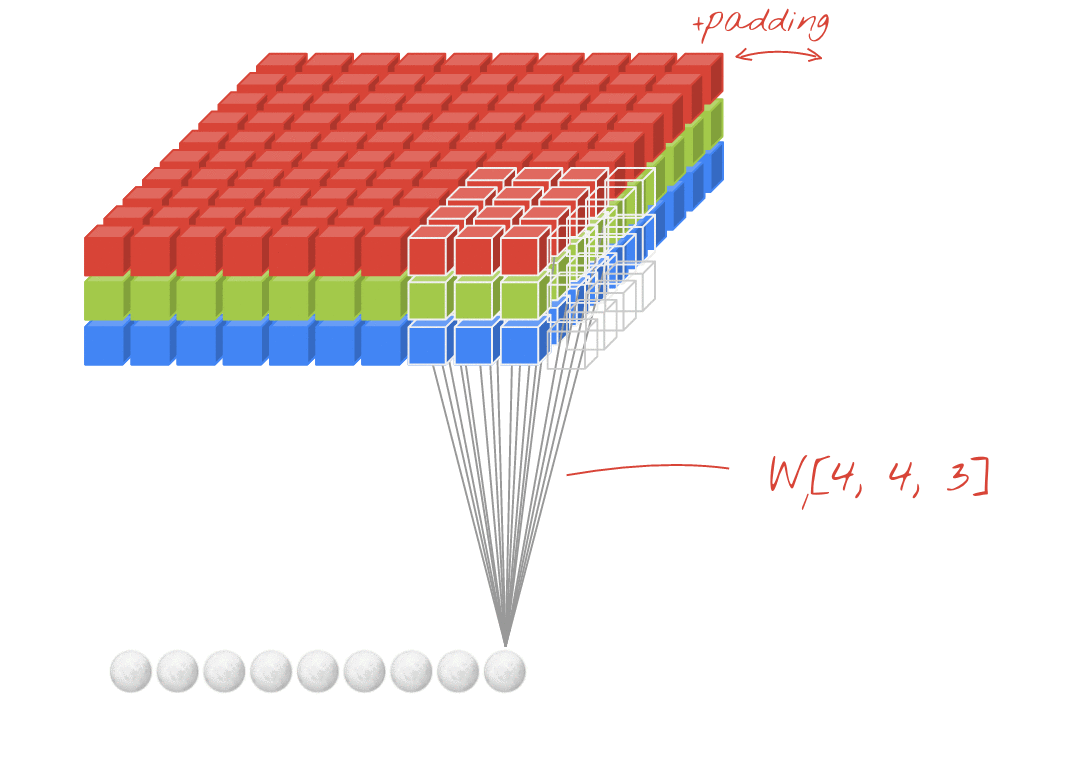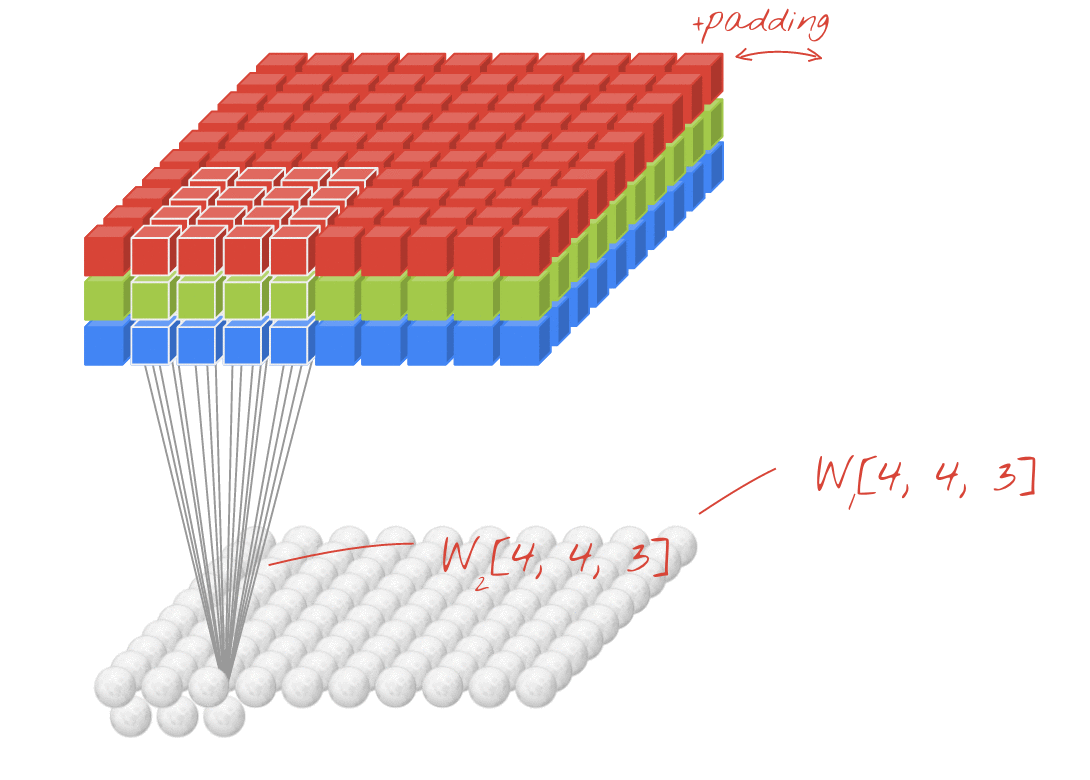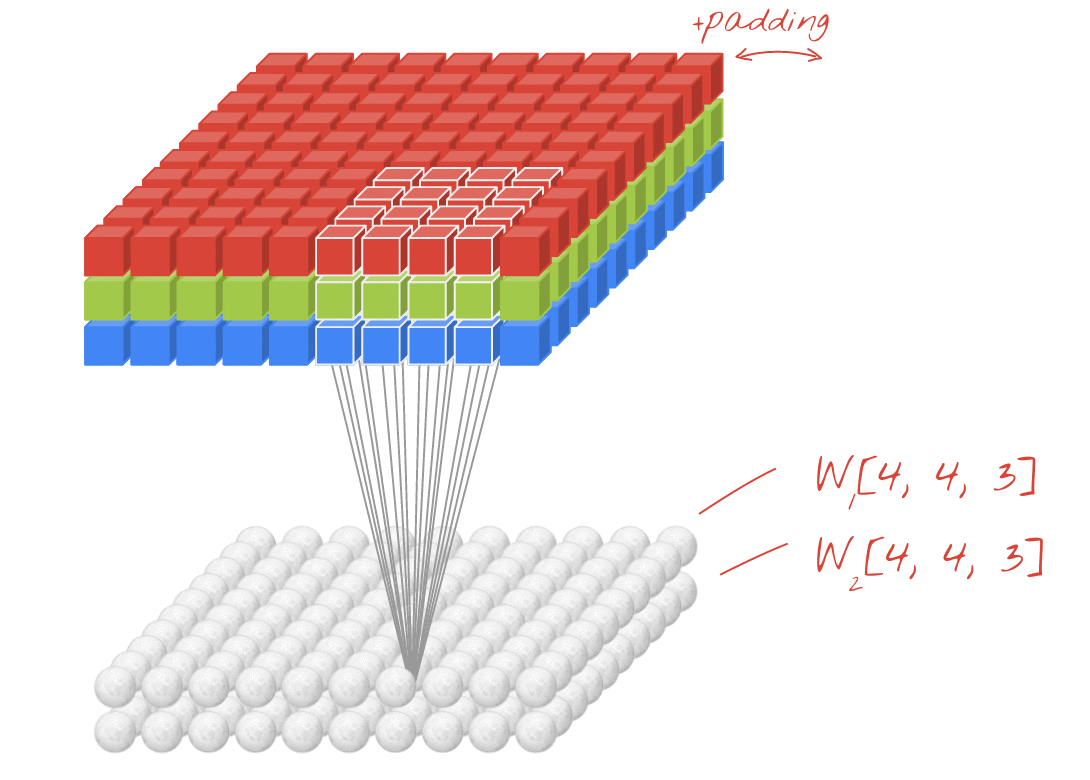
설명: 각각 학습 가능한 가중치가 4x4x3=48개인 연속된 두 필터로 이미지를 필터링합니다.
Keras에서 간단한 컨볼루셔널 신경망은 다음과 같이 표시됩니다.
model = tf.keras.Sequential([
tf.keras.layers.Reshape(input_shape=(28*28,), target_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(kernel_size=3, filters=12, activation='relu'),
tf.keras.layers.Conv2D(kernel_size=6, filters=24, strides=2, activation='relu'),
tf.keras.layers.Conv2D(kernel_size=6, filters=32, strides=2, activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10, activation='softmax')
])
컨볼루션 네트워크의 레이어에서 한 '뉴런'은 이미지의 작은 영역에서만 바로 위에 있는 픽셀의 가중치를 합산합니다. 일반 밀집 레이어의 뉴런과 마찬가지로 편향을 추가하고 활성화 함수를 통해 합계를 공급합니다. 그런 다음 동일한 가중치를 사용하여 전체 이미지에 걸쳐 이 작업이 반복됩니다. 밀집층에서는 각 뉴런에 자체 가중치가 있었습니다. 여기서 가중치의 단일 '패치'가 양방향으로 이미지 전체를 슬라이드합니다('컨볼루션'). 출력에는 이미지의 픽셀 수만큼 값이 있습니다 (가장자리에는 패딩이 필요함). 필터링 작업입니다. 위 그림에서는 4x4x3=48 가중치의 필터를 사용합니다.
하지만 48개의 가중치로는 충분하지 않습니다. 자유도를 더 추가하기 위해 새로운 가중치 집합으로 동일한 작업을 반복합니다. 그러면 새로운 필터 출력이 생성됩니다. 입력 이미지의 R,G,B 채널과 유사하게 출력의 '채널'이라고 부르겠습니다.
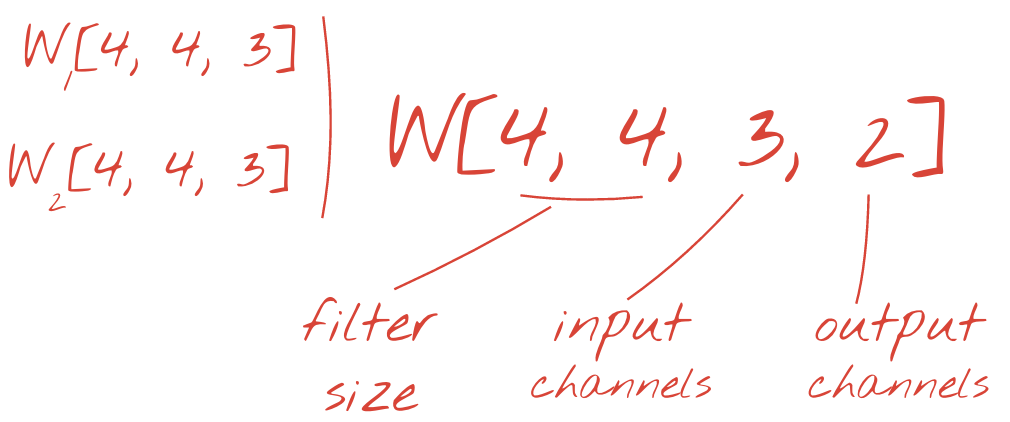
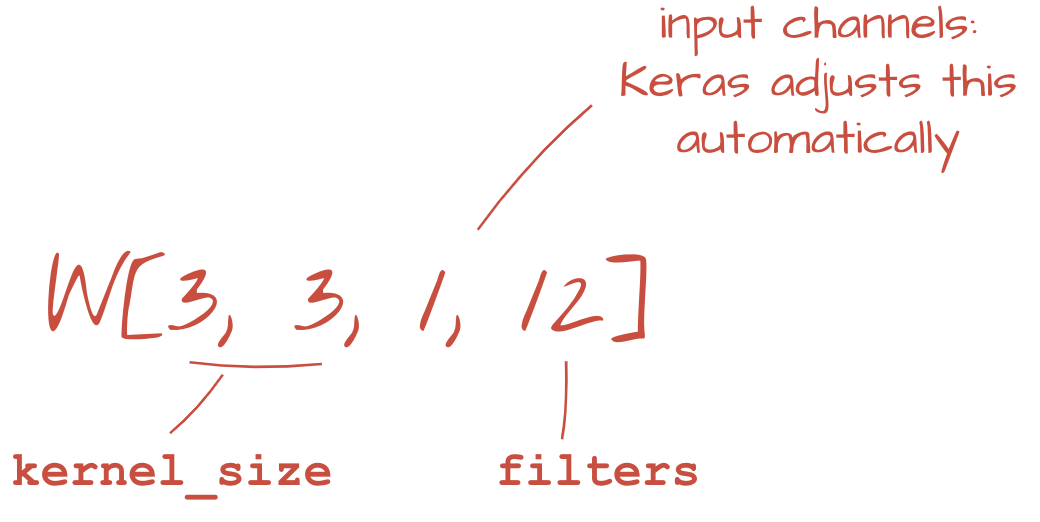
두 개 이상의 가중치 집합은 새 차원을 추가하여 하나의 텐서로 합산할 수 있습니다. 이렇게 하면 컨볼루션 레이어의 가중치 텐서의 일반적인 모양이 표시됩니다. 입력 및 출력 채널 수는 파라미터이므로 컨볼루션 레이어를 스태킹하고 연결할 수 있습니다.
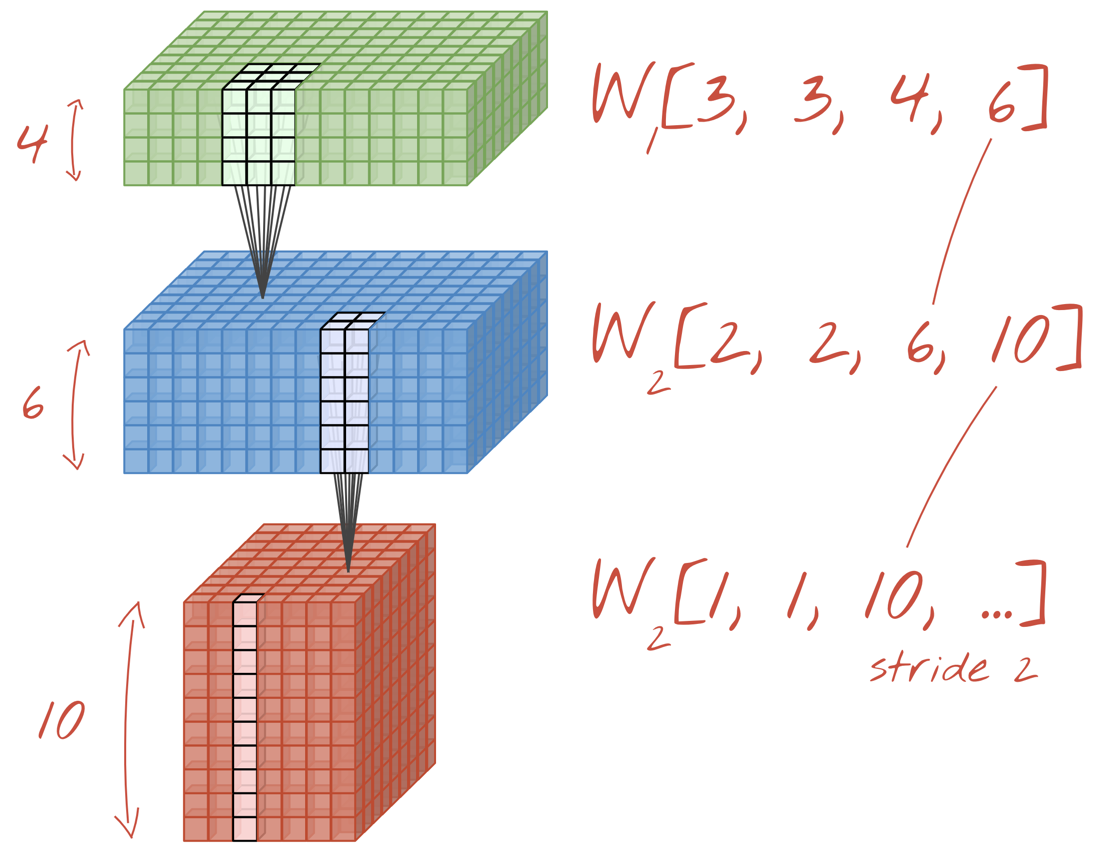
그림: 컨볼루셔널 신경망이 데이터 '큐브'를 다른 데이터 '큐브'로 변환합니다.
스트라이드 컨볼루션, 최대 풀링
보폭이 2 또는 3인 컨볼루션을 수행하면 결과 데이터 큐브를 가로 방향으로 축소할 수도 있습니다. 이 작업을 실행하는 두 가지 일반적인 방법은 다음과 같습니다.
- 스트라이드 컨볼루션: 위와 같이 슬라이딩 필터가 있지만 스트라이드가 1보다 큼
- 최대 풀링: MAX 작업을 적용하는 슬라이딩 윈도우 (일반적으로 2x2 패치에서 2픽셀마다 반복됨)

그림: 컴퓨팅 창을 3픽셀만큼 슬라이드하면 출력 값이 줄어듭니다. 스트라이드 컨볼루션 또는 최대 풀링 (스트라이드 2로 슬라이딩되는 2x2 창의 최대값)은 가로 방향으로 데이터 큐브를 축소하는 방법입니다.
최종 레이어
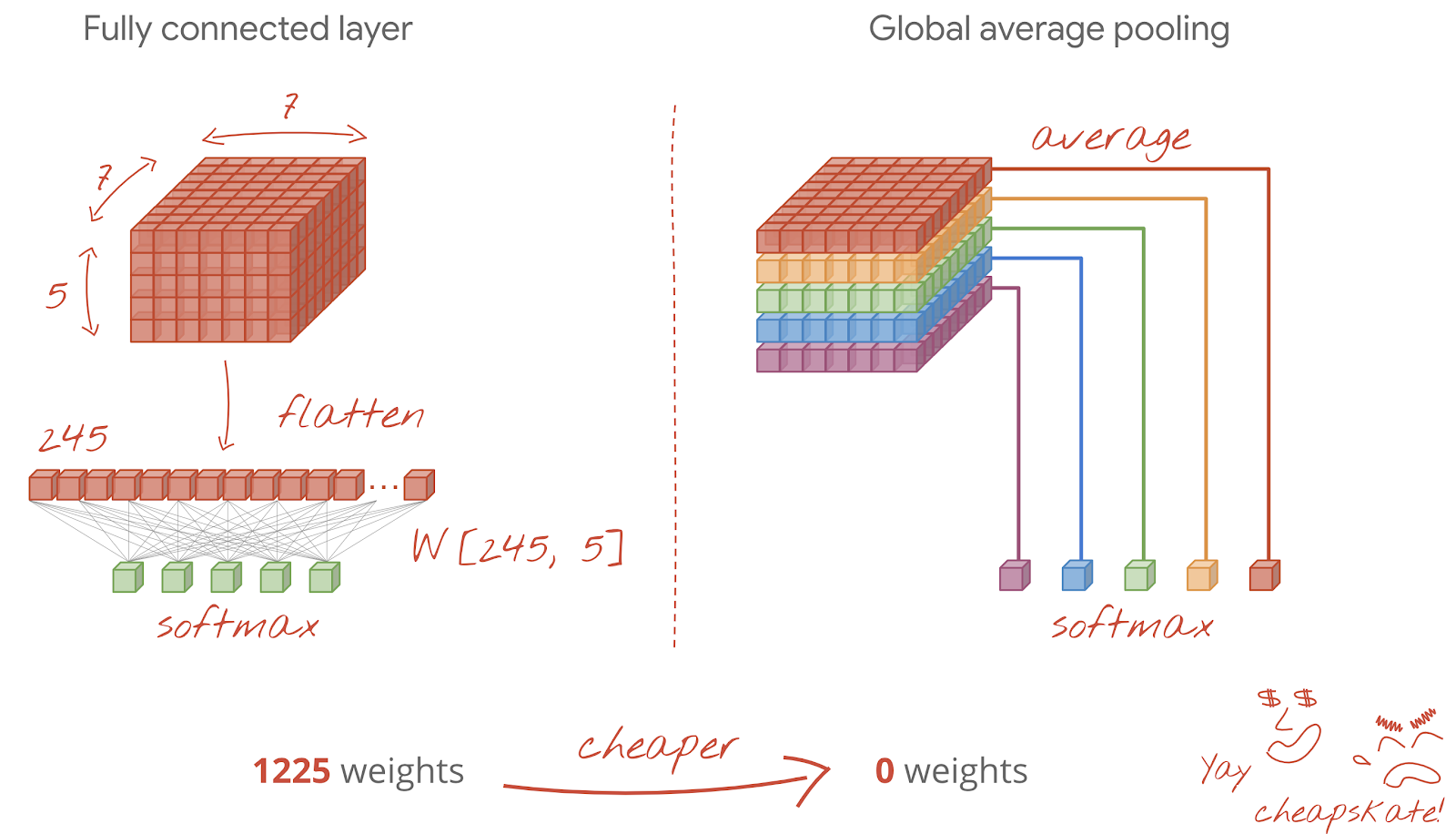
마지막 컨볼루션 레이어 후 데이터는 '큐브' 형태입니다. 최종 밀집 레이어를 통해 공급하는 방법에는 두 가지가 있습니다.
첫 번째 방법은 데이터 큐브를 벡터로 평탄화한 다음 소프트맥스 레이어에 공급하는 것입니다. 소프트맥스 레이어 앞에 밀도 높은 레이어를 추가할 수도 있습니다. 이는 가중치 수 측면에서 비용이 많이 드는 경향이 있습니다. 컨볼루션 네트워크 끝에 있는 밀집 레이어에는 전체 신경망의 가중치 절반 이상이 포함될 수 있습니다.
비용이 많이 드는 밀집층을 사용하는 대신 들어오는 데이터 '큐브'를 클래스 수만큼 여러 부분으로 분할하고 값을 평균화하여 소프트맥스 활성화 함수를 통해 공급할 수도 있습니다. 이러한 방식으로 분류 헤드를 빌드하면 가중치가 0입니다. Keras에는 이를 위한 레이어인 tf.keras.layers.GlobalAveragePooling2D()가 있습니다.
다음 섹션으로 이동하여 당면한 문제에 대한 컨볼루션 네트워크를 빌드합니다.
필기 숫자 인식을 위한 컨볼루션 네트워크를 빌드해 보겠습니다. 상단에 컨볼루션 레이어 3개를 사용하고 하단에 기존 소프트맥스 판독 레이어를 사용하며 완전 연결 레이어 하나로 연결합니다.
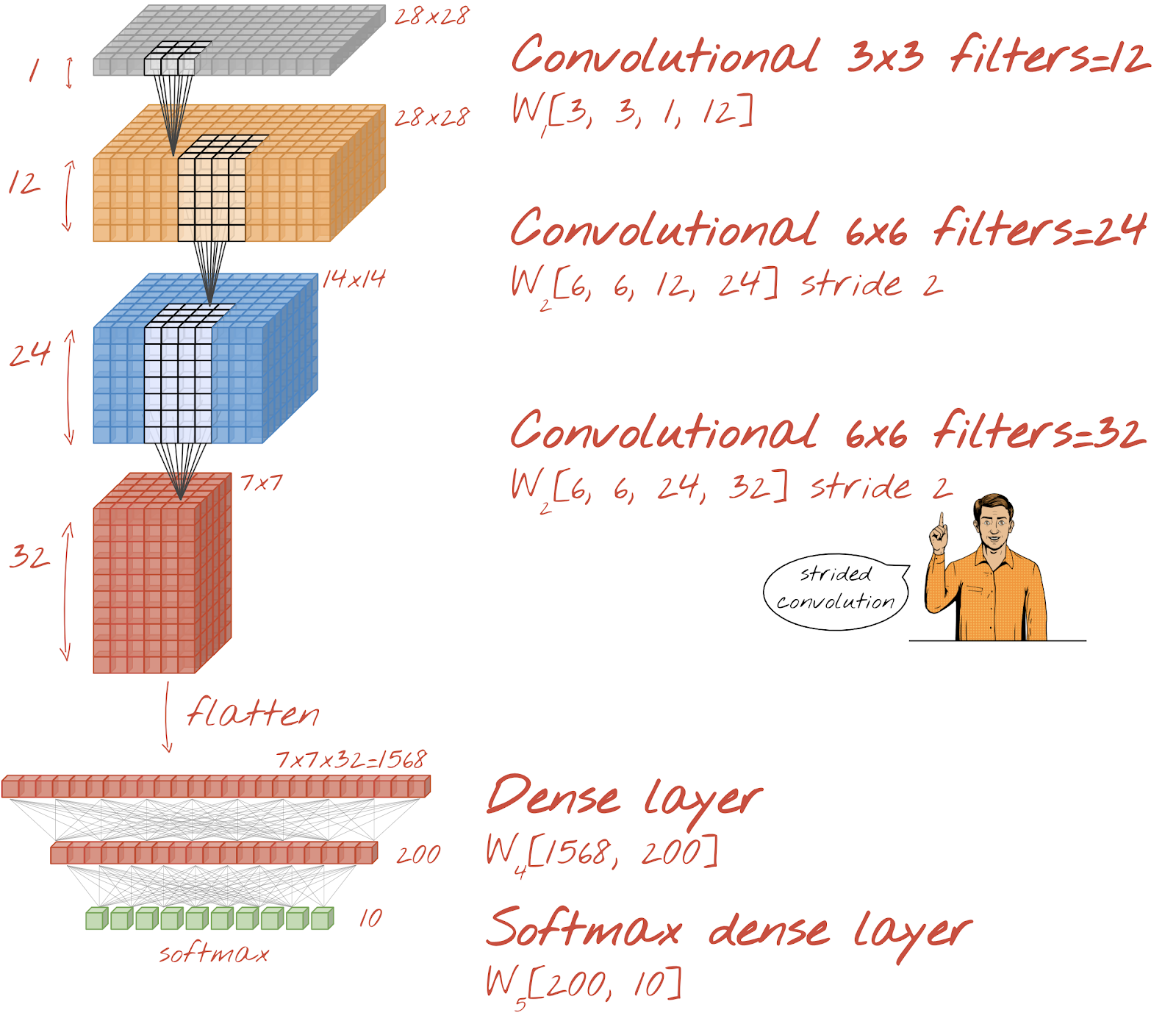
두 번째와 세 번째 컨볼루션 레이어의 스트라이드가 2이므로 출력 값의 수가 28x28에서 14x14로, 다시 7x7로 줄어듭니다.
Keras 코드를 작성해 보겠습니다.
첫 번째 컨볼루션 레이어 이전에는 특별한 주의가 필요합니다. 실제로 데이터의 3D '큐브'를 예상하지만 지금까지 데이터 세트는 밀도 높은 레이어용으로 설정되어 있으며 이미지의 모든 픽셀이 벡터로 평탄화되어 있습니다. 28x28x1 이미지 (그레이 스케일 이미지의 경우 1채널)로 다시 변환해야 합니다.
tf.keras.layers.Reshape(input_shape=(28*28,), target_shape=(28, 28, 1))지금까지 사용한 tf.keras.layers.Input 레이어 대신 이 줄을 사용할 수 있습니다.
Keras에서 'relu' 활성화 컨볼루션 레이어의 구문은 다음과 같습니다.
tf.keras.layers.Conv2D(kernel_size=3, filters=12, padding='same', activation='relu')스트라이드 컨볼루션의 경우 다음과 같이 작성합니다.
tf.keras.layers.Conv2D(kernel_size=6, filters=24, padding='same', activation='relu', strides=2)밀도 높은 레이어에서 사용할 수 있도록 데이터 큐브를 벡터로 평탄화하려면 다음을 실행하세요.
tf.keras.layers.Flatten()밀도 레이어의 경우 구문이 변경되지 않았습니다.
tf.keras.layers.Dense(200, activation='relu')모델이 99% 정확도 장벽을 넘었나요? 거의 다 왔습니다. 검증 손실 곡선을 살펴보세요. 이게 기억나시나요?
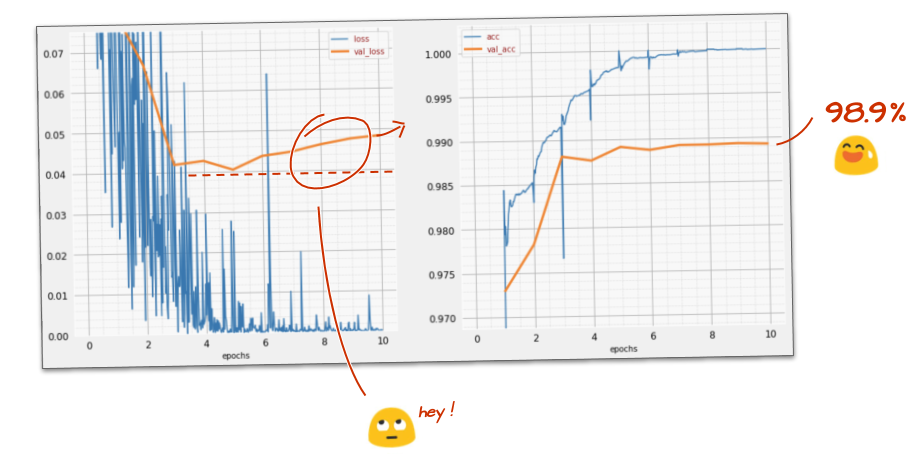
예측도 확인하세요. 이제 10,000개의 테스트 숫자가 대부분 올바르게 인식되는 것을 확인할 수 있습니다. 잘못 감지된 행은 약 4½개만 남았습니다 (10,000개 중 약 110개).

진행이 막힌 경우 현재 해결 방법은 다음과 같습니다.
이전 학습에서는 과적합의 명확한 징후가 나타나며 정확도가 99% 에 미치지 못합니다. 드롭아웃을 다시 시도해야 할까요?
이번에는 어땠나요?
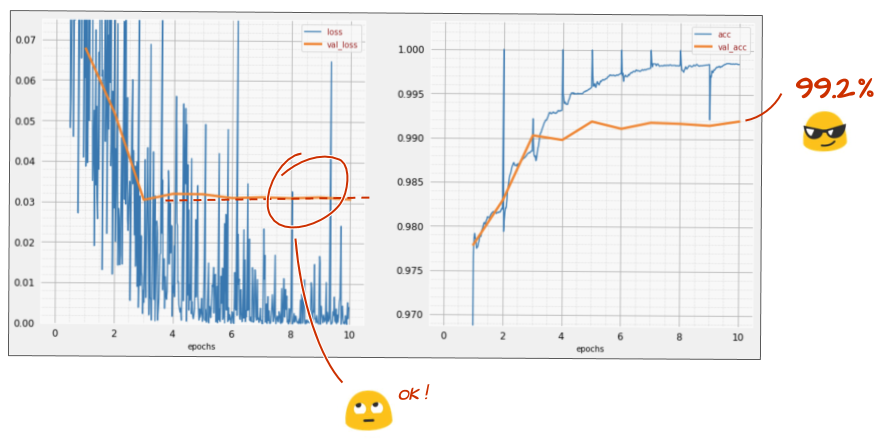
이번에는 드롭아웃이 작동한 것 같습니다. 검증 손실이 더 이상 증가하지 않으며 최종 정확도는 99%를 훨씬 넘어야 합니다. 축하합니다.
드롭아웃을 처음 적용했을 때 과적합 문제가 있다고 생각했지만 실제로는 신경망 아키텍처에 문제가 있었습니다. 컨볼루션 레이어가 없으면 더 나아갈 수 없으며 드롭아웃이 할 수 있는 일은 없습니다.
이번에는 과적합이 문제의 원인인 것 같고 드롭아웃이 실제로 도움이 되었습니다. 학습 손실 곡선과 검증 손실 곡선 사이에 불일치가 발생하여 검증 손실이 증가할 수 있는 요인이 많다는 점을 기억하세요. 과적합 (네트워크에서 잘못 사용되는 자유도가 너무 많음)은 그중 하나일 뿐입니다. 데이터 세트가 너무 작거나 신경망 아키텍처가 적절하지 않으면 손실 곡선에서 비슷한 동작이 나타날 수 있지만 드롭아웃은 도움이 되지 않습니다.

마지막으로 배치 정규화를 추가해 보겠습니다.
이론은 이렇지만 실제로는 다음 몇 가지 규칙만 기억하면 됩니다.
지금은 규칙을 따르고 마지막을 제외한 각 신경망 레이어에 배치 정규화 레이어를 추가해 보겠습니다. 마지막 'softmax' 레이어에는 추가하지 마세요. 이 경우 유용하지 않습니다.
# Modify each layer: remove the activation from the layer itself.
# Set use_bias=False since batch norm will play the role of biases.
tf.keras.layers.Conv2D(..., use_bias=False),
# Batch norm goes between the layer and its activation.
# The scale factor can be turned off for Relu activation.
tf.keras.layers.BatchNormalization(scale=False, center=True),
# Finish with the activation.
tf.keras.layers.Activation('relu'),이제 정확도가 어떤가요?
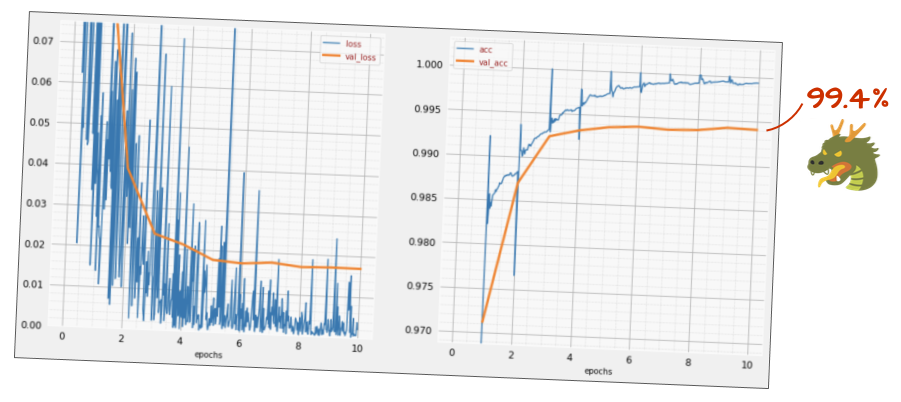
약간의 조정 (BATCH_SIZE=64, 학습률 감소 매개변수 0.666, 밀도층의 드롭아웃 비율 0.3)과 약간의 운이 있다면 99.5%에 도달할 수 있습니다. 학습률과 드롭아웃 조정은 배치 정규화 사용에 관한 '권장사항'에 따라 이루어졌습니다.
- 배치 정규화는 신경망이 수렴하는 데 도움이 되며 일반적으로 더 빠르게 학습할 수 있습니다.
- 배치 정규화는 정규화기입니다. 일반적으로 드롭아웃의 양을 줄이거나 드롭아웃을 전혀 사용하지 않을 수 있습니다.
솔루션 노트북의 학습 실행은 99.5% 입니다.

GitHub의 mlengine 폴더에서 클라우드 지원 버전의 코드를 확인할 수 있으며, Google Cloud AI Platform에서 코드를 실행하는 방법도 확인할 수 있습니다. 이 부분을 실행하려면 먼저 Google Cloud 계정을 만들고 결제를 사용 설정해야 합니다. 실습을 완료하는 데 필요한 리소스는 몇 달러 미만입니다 (GPU 하나에서 1시간 동안 학습한다고 가정). 계정을 준비하려면 다음 단계를 따르세요.
- Google Cloud Platform 프로젝트 (http://cloud.google.com/console)를 만듭니다.
- 결제를 사용 설정합니다.
- GCP 명령줄 도구 (여기에서 GCP SDK)를 설치합니다.
- Google Cloud Storage 버킷을 만듭니다 (
us-central1리전에 배치). 학습 코드를 스테이징하고 학습된 모델을 저장하는 데 사용됩니다. - 필요한 API를 사용 설정하고 필요한 할당량을 요청합니다 (학습 명령어를 한 번 실행하면 사용 설정해야 하는 항목을 알려주는 오류 메시지가 표시됨).
첫 번째 신경망을 빌드하고 99% 정확도까지 학습했습니다. 이 과정에서 배우는 기법은 MNIST 데이터 세트에만 적용되는 것이 아니라 신경망을 사용할 때 널리 사용됩니다. 마지막 선물로 실습의 '요약' 카드를 만화 버전으로 준비했습니다. 이 기능을 사용하면 학습한 내용을 기억할 수 있습니다.

다음 단계
- 완전 연결 네트워크와 컨볼루션 네트워크를 살펴본 후에는 순환 신경망을 살펴보세요.
- 분산 인프라에서 클라우드로 학습 또는 추론을 실행하려면 Google Cloud에서 AI Platform을 제공합니다.
- 마지막으로, 의견을 보내주세요. 이 실습에서 잘못된 점이 있거나 개선해야 할 점이 있다면 알려주세요. GitHub 문제[의견 링크]를 통해 의견을 처리합니다.

저자: 마틴 괴르너 트위터: @martin_gorner |
|


이 실습의 모든 만화 이미지 저작권: alexpokusay / 123RF 스톡 사진