

در این نرم افزار کد، نحوه ساخت و آموزش یک شبکه عصبی که ارقام دست نویس را تشخیص می دهد، یاد خواهید گرفت. در طول مسیر، همانطور که شبکه عصبی خود را برای دستیابی به دقت 99 درصد تقویت می کنید، ابزارهای تجارتی را نیز کشف خواهید کرد که متخصصان یادگیری عمیق از آنها برای آموزش کارآمد مدل های خود استفاده می کنند.
این آزمایشگاه کد از مجموعه داده MNIST استفاده می کند، مجموعه ای از 60000 رقم برچسب گذاری شده که نسل های دکترا را برای تقریبا دو دهه مشغول نگه داشته است. با کمتر از 100 خط کد پایتون/تنسورفلو مشکل را حل خواهید کرد.
چیزی که یاد خواهید گرفت
- شبکه عصبی چیست و چگونه آن را آموزش دهیم
- نحوه ساخت یک شبکه عصبی پایه 1 لایه با استفاده از tf.keras
- نحوه اضافه کردن لایه های بیشتر
- نحوه تنظیم برنامه نرخ یادگیری
- نحوه ساخت شبکه های عصبی کانولوشنال
- نحوه استفاده از تکنیک های منظم سازی: ترک تحصیل، عادی سازی دسته ای
- چه چیزی بیش از حد مناسب است
آنچه شما نیاز دارید
فقط یک مرورگر این کارگاه به طور کامل با Google Colaboratory قابل اجرا است.
بازخورد
لطفاً اگر چیزی در این آزمایشگاه اشتباه می بینید یا فکر می کنید باید بهبود یابد، به ما بگویید. ما بازخورد را از طریق مشکلات GitHub [ لینک بازخورد ] مدیریت میکنیم.
این آزمایشگاه از Google Colaboratory استفاده می کند و نیازی به تنظیم از طرف شما ندارد. میتوانید آن را از Chromebook اجرا کنید. لطفاً فایل زیر را باز کنید و سلول ها را اجرا کنید تا با نوت بوک های Colab آشنا شوید.

دستورالعمل های اضافی در زیر:
یک باطن GPU را انتخاب کنید

در منوی Colab، Runtime > Change runtime type و سپس GPU را انتخاب کنید. اتصال به زمان اجرا به طور خودکار در اولین اجرا انجام می شود، یا می توانید از دکمه "اتصال" در گوشه سمت راست بالا استفاده کنید.
اجرای نوت بوک

با کلیک بر روی یک سلول و استفاده از Shift-ENTER سلول ها را یکی یکی اجرا کنید. همچنین می توانید کل نوت بوک را با Runtime > Run all اجرا کنید
فهرست مطالب

همه نوت بوک ها دارای فهرست مطالب هستند. می توانید آن را با استفاده از فلش سیاه سمت چپ باز کنید.
سلول های پنهان

برخی از سلول ها فقط عنوان خود را نشان می دهند. این یک ویژگی نوت بوک مخصوص Colab است. می توانید روی آنها دوبار کلیک کنید تا کد داخل آن را ببینید اما معمولاً چندان جالب نیست. به طور معمول توابع پشتیبانی یا تجسم. هنوز باید این سلول ها را اجرا کنید تا توابع داخل آن تعریف شوند.
ابتدا قطار شبکه عصبی را تماشا خواهیم کرد. لطفاً دفترچه یادداشت زیر را باز کرده و از تمام سلول ها عبور کنید. هنوز به کد توجه نکنید، بعداً توضیح خواهیم داد.
همانطور که نوت بوک را اجرا می کنید، روی تجسم ها تمرکز کنید. برای توضیحات زیر را ببینید.
داده های آموزشی
ما مجموعه داده ای از ارقام دست نویس داریم که برچسب گذاری شده اند تا بدانیم هر تصویر چه چیزی را نشان می دهد، یعنی عددی بین 0 تا 9. در دفترچه، گزیده ای را مشاهده خواهید کرد:

شبکه عصبی که ما خواهیم ساخت، ارقام دست نویس را در 10 کلاس آنها طبقه بندی می کند (0، ..، 9). این کار را بر اساس پارامترهای داخلی انجام می دهد که برای اینکه طبقه بندی به خوبی کار کند، باید مقدار صحیحی داشته باشد. این "مقدار صحیح" از طریق یک فرآیند آموزشی که به یک "داده داده برچسب دار" با تصاویر و پاسخ های صحیح مرتبط نیاز دارد، آموخته می شود.
چگونه بفهمیم که شبکه عصبی آموزش دیده عملکرد خوبی دارد یا خیر؟ استفاده از مجموعه داده آموزشی برای آزمایش شبکه تقلب خواهد بود. قبلاً این مجموعه داده چندین بار در طول آموزش دیده شده است و مطمئناً در آن بسیار کارآمد است. برای ارزیابی عملکرد «دنیای واقعی» شبکه به مجموعه داده برچسبدار دیگری نیاز داریم که هرگز در طول آموزش دیده نشده است. به آن مجموعه داده اعتبار سنجی می گویند
آموزش
با پیشرفت آموزش، یک دسته از داده های آموزشی در یک زمان، پارامترهای مدل داخلی به روز می شوند و مدل در تشخیص ارقام دست نویس بهتر و بهتر می شود. می توانید آن را در نمودار آموزشی مشاهده کنید:

در سمت راست، "دقت" به سادگی درصد ارقام به درستی تشخیص داده شده است. با پیشرفت تمرین بالا می رود که خوب است.
در سمت چپ، ما می توانیم "از دست دادن" را ببینیم. برای هدایت آموزش، یک تابع "از دست دادن" را تعریف می کنیم که نشان دهنده میزان بد تشخیص ارقام توسط سیستم است و سعی می کنیم آن را به حداقل برسانیم. آنچه در اینجا مشاهده می کنید این است که با پیشرفت آموزش، ضرر هم به داده های آموزشی و هم به داده های اعتبار سنجی کاهش می یابد: این خوب است. یعنی شبکه عصبی در حال یادگیری است.
محور X تعداد "دوران" یا تکرارها را در کل مجموعه داده نشان می دهد.
پیش بینی ها
هنگامی که مدل آموزش داده می شود، می توانیم از آن برای تشخیص ارقام دست نویس استفاده کنیم. تجسم بعدی نشان میدهد که چقدر در چند رقم ارائهشده از فونتهای محلی (خط اول) و سپس روی 10000 رقم مجموعه داده اعتبارسنجی عملکرد خوبی دارد. کلاس پیش بینی شده در زیر هر رقم، در صورتی که اشتباه بود، با رنگ قرمز ظاهر می شود.

همانطور که می بینید، این مدل اولیه خیلی خوب نیست اما هنوز برخی از ارقام را به درستی تشخیص می دهد. دقت اعتبار نهایی آن در حدود 90٪ است که برای مدل ساده ای که ما با آن شروع می کنیم چندان بد نیست، اما همچنان به این معنی است که 1000 رقم اعتبارسنجی از 10000 را از دست می دهد. این بسیار بیشتر است که می توان نمایش داد، به همین دلیل به نظر می رسد که همه پاسخ ها اشتباه هستند (قرمز).
تانسورها
داده ها در ماتریس ها ذخیره می شوند. یک تصویر 28x28 پیکسل در مقیاس خاکستری در یک ماتریس دو بعدی 28x28 قرار می گیرد. اما برای یک تصویر رنگی به ابعاد بیشتری نیاز داریم. 3 مقدار رنگ در هر پیکسل (قرمز، سبز، آبی) وجود دارد، بنابراین یک جدول سه بعدی با ابعاد مورد نیاز است [28، 28، 3]. و برای ذخیره یک دسته از 128 تصویر رنگی، یک جدول چهار بعدی با ابعاد [128، 28، 28، 3] مورد نیاز است.
این جداول چند بعدی «تانسور» نامیده میشوند و فهرست ابعاد آنها «شکل» آنها است.
به طور خلاصه
اگر تمام عبارات پررنگ در پاراگراف بعدی قبلاً برای شما شناخته شده است، می توانید به تمرین بعدی بروید. اگر تازه شروع به یادگیری عمیق کرده اید، خوش آمدید و لطفاً ادامه دهید.

برای مدلهایی که بهعنوان دنبالهای از لایهها ساخته میشوند، Keras API متوالی را ارائه میکند. برای مثال، یک طبقهبندیکننده تصویر با استفاده از سه لایه متراکم میتواند در Keras به صورت زیر نوشته شود:
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[28, 28, 1]),
tf.keras.layers.Dense(200, activation="relu"),
tf.keras.layers.Dense(60, activation="relu"),
tf.keras.layers.Dense(10, activation='softmax') # classifying into 10 classes
])
# this configures the training of the model. Keras calls it "compiling" the model.
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy']) # % of correct answers
# train the model
model.fit(dataset, ... )
یک لایه متراکم
ارقام دست نویس در مجموعه داده MNIST تصاویر 28x28 پیکسلی در مقیاس خاکستری هستند. ساده ترین روش برای طبقه بندی آنها استفاده از 28x28=784 پیکسل به عنوان ورودی برای یک شبکه عصبی 1 لایه است.
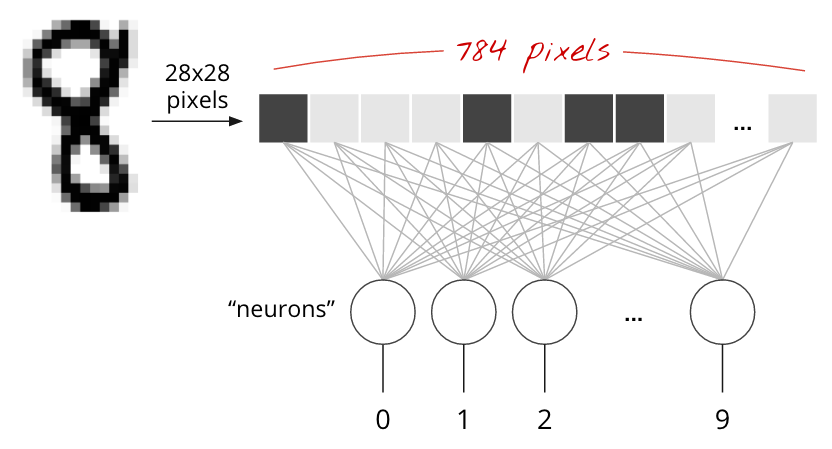
هر "نورون" در یک شبکه عصبی یک مجموع وزنی از تمام ورودی های خود را انجام می دهد، یک ثابت به نام "بایاس" را اضافه می کند و سپس نتیجه را از طریق "تابع فعال سازی" غیر خطی تغذیه می کند. "وزن" و "سوگیری" پارامترهایی هستند که از طریق آموزش مشخص می شوند. آنها در ابتدا با مقادیر تصادفی مقداردهی اولیه می شوند.
تصویر بالا نشان دهنده یک شبکه عصبی 1 لایه با 10 نورون خروجی است زیرا می خواهیم ارقام را به 10 کلاس (0 تا 9) طبقه بندی کنیم.
با ضرب ماتریس
در اینجا آمده است که چگونه یک لایه شبکه عصبی، پردازش مجموعه ای از تصاویر، را می توان با ضرب ماتریس نشان داد:
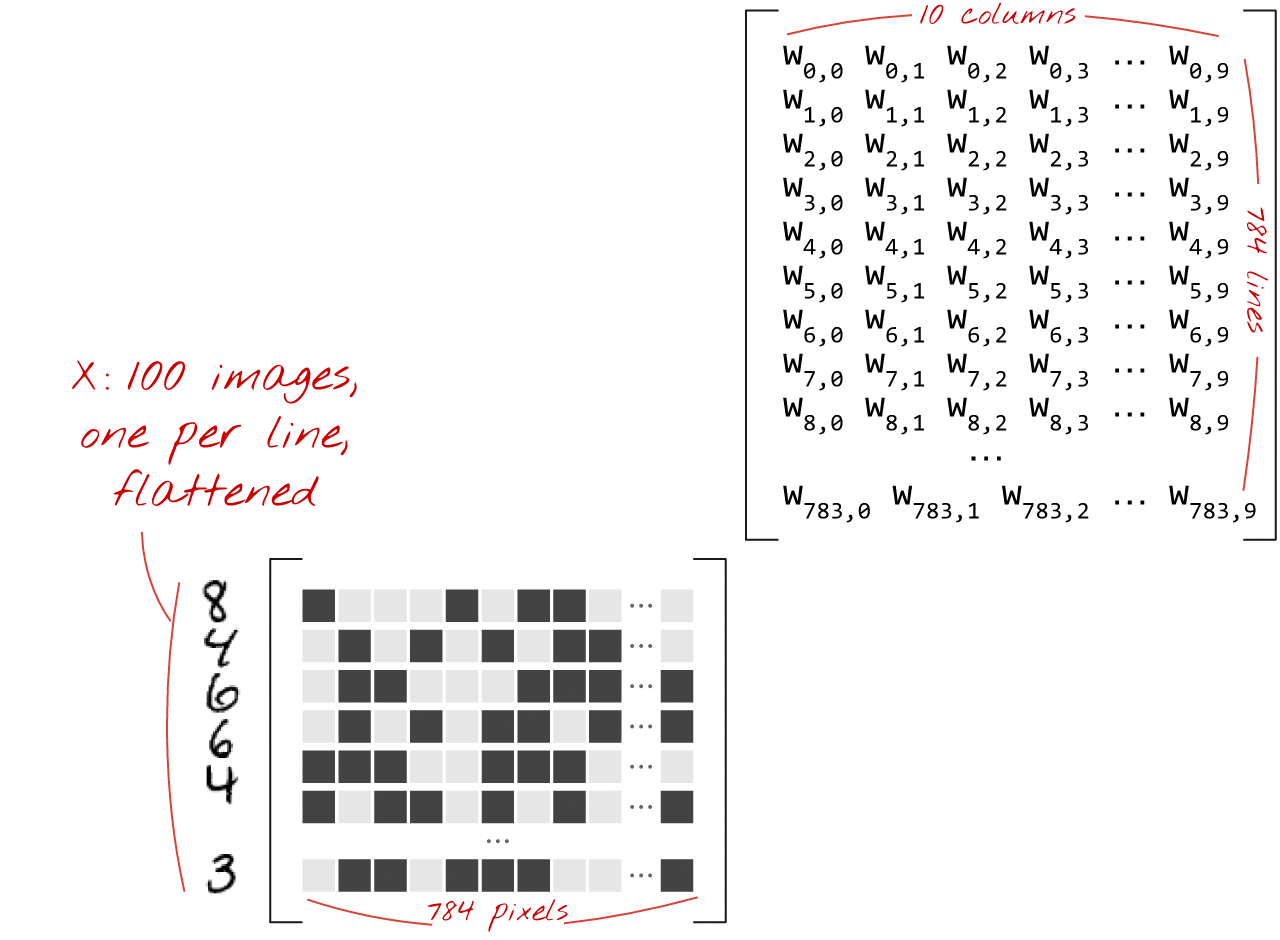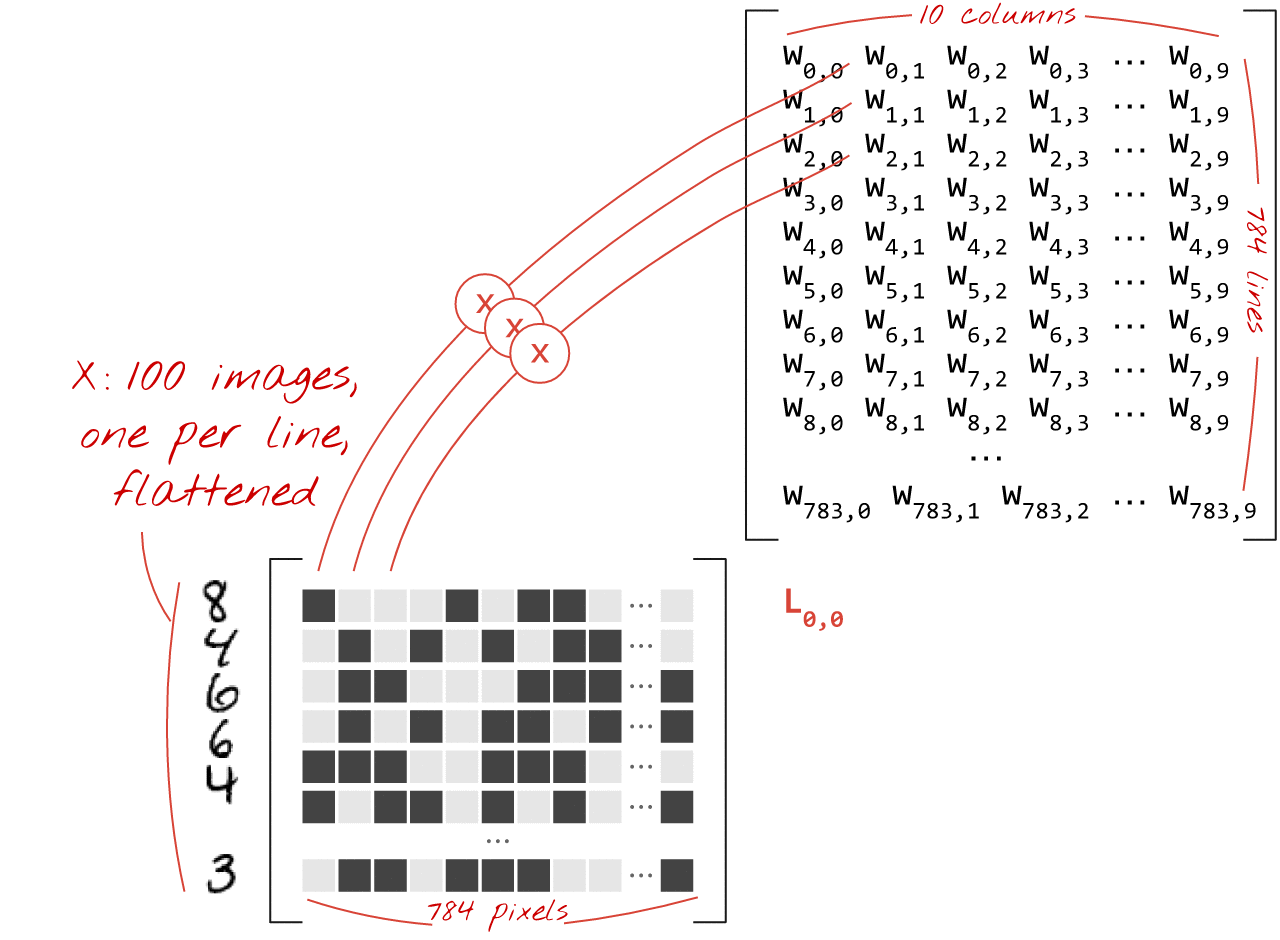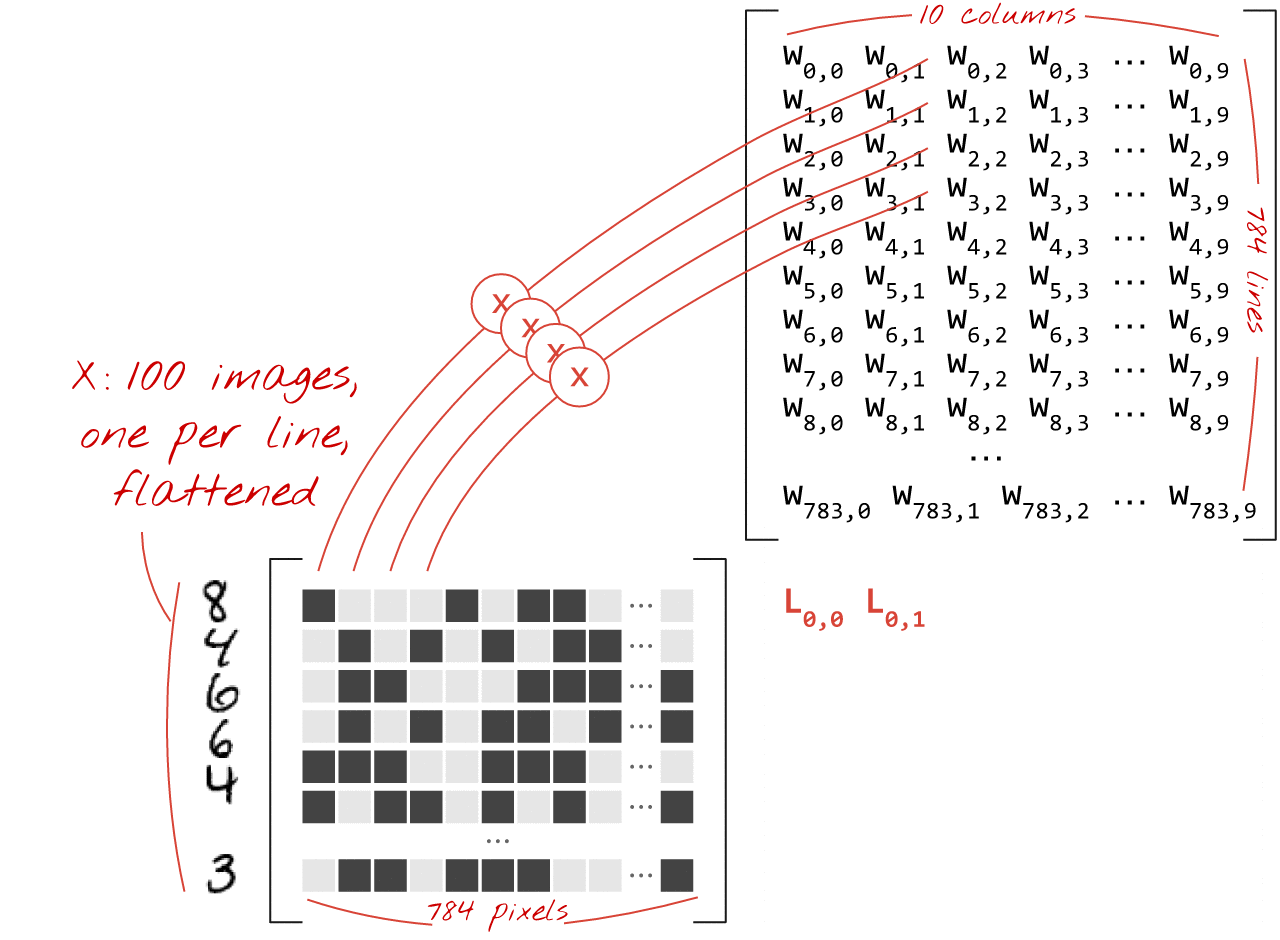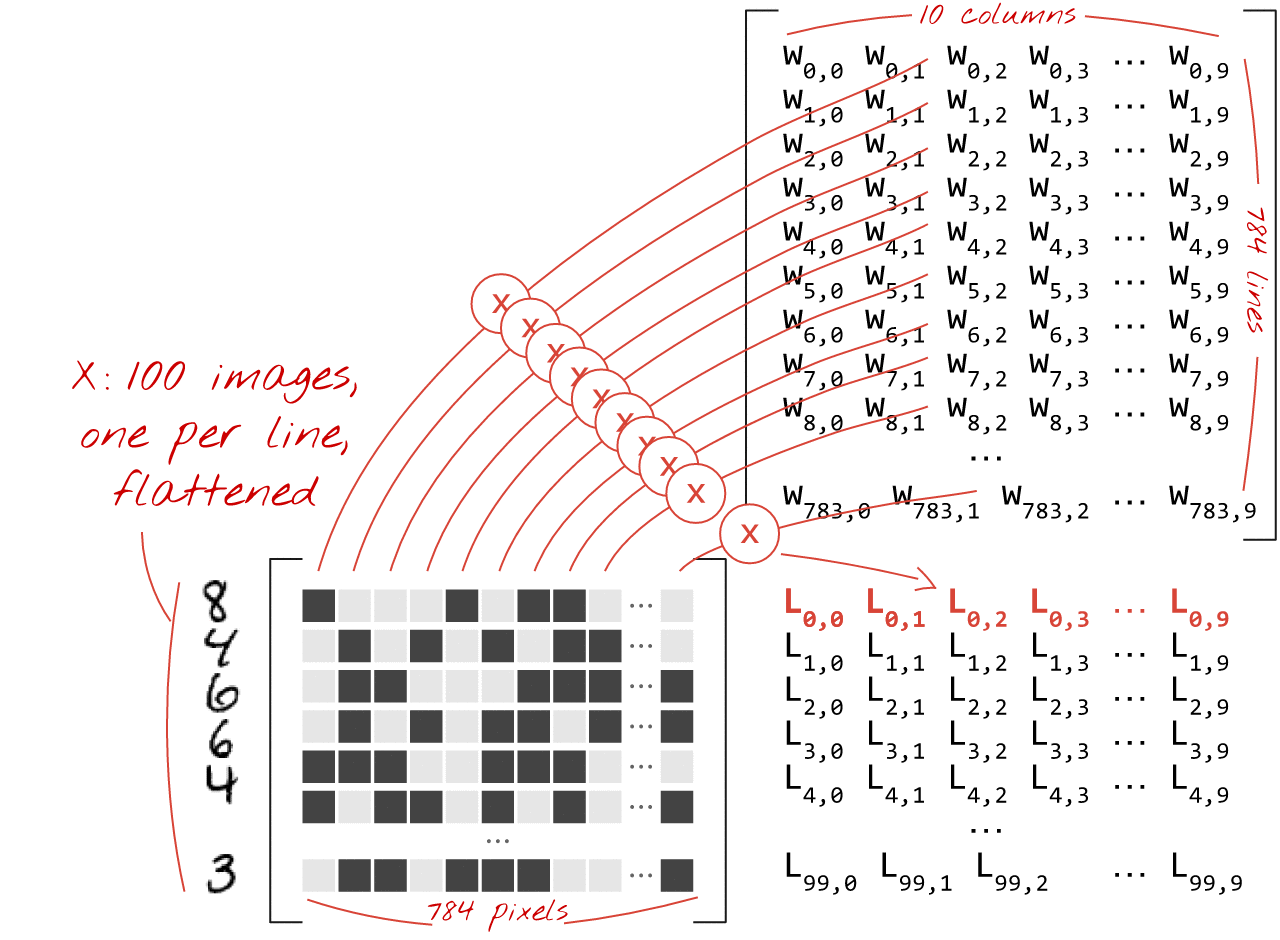
با استفاده از اولین ستون وزن ها در ماتریس وزن W، مجموع وزنی تمام پیکسل های تصویر اول را محاسبه می کنیم. این مجموع مربوط به اولین نورون است. با استفاده از ستون دوم وزن ها، همین کار را برای نورون دوم انجام می دهیم و تا نرون دهم به همین ترتیب ادامه می دهیم. سپس می توانیم این عملیات را برای 99 تصویر باقیمانده تکرار کنیم. اگر X را ماتریس حاوی 100 تصویر خود بنامیم، تمام مجموع وزنی 10 نورون ما که بر روی 100 تصویر محاسبه می شود، صرفاً XW است، یک ضرب ماتریس.
اکنون هر نورون باید بایاس خود (یک ثابت) را اضافه کند. از آنجایی که ما 10 نورون داریم، 10 ثابت بایاس داریم. این بردار 10 مقداری را b می نامیم. باید به هر خط از ماتریس محاسبه شده قبلی اضافه شود. با استفاده از کمی جادو به نام "پخش" این را با یک علامت مثبت ساده می نویسیم.
ما در نهایت یک تابع فعال سازی، به عنوان مثال "softmax" (که در زیر توضیح داده شده است) اعمال می کنیم و فرمولی را که یک شبکه عصبی 1 لایه ای را توصیف می کند، به دست می آوریم که برای 100 تصویر اعمال می شود:
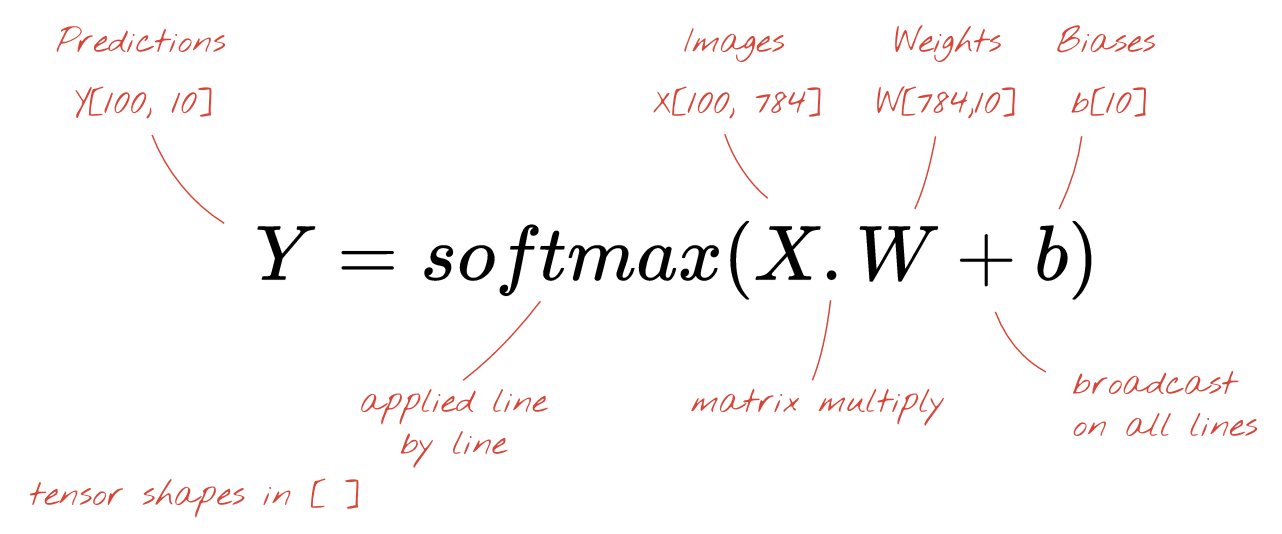
در کراس
با کتابخانه های شبکه عصبی سطح بالا مانند Keras، نیازی به پیاده سازی این فرمول نخواهیم داشت. با این حال، درک این نکته مهم است که یک لایه شبکه عصبی فقط یک دسته از ضرب و جمع است. در Keras، یک لایه متراکم به صورت زیر نوشته می شود:
tf.keras.layers.Dense(10, activation='softmax')به عمق برو
زنجیر کردن لایه های شبکه عصبی امری بی اهمیت است. لایه اول مجموع وزنی پیکسل ها را محاسبه می کند. لایه های بعدی مجموع وزنی خروجی های لایه های قبلی را محاسبه می کنند.

تنها تفاوت، جدا از تعداد نورون ها، انتخاب تابع فعال سازی خواهد بود.
توابع فعال سازی: relu، softmax و sigmoid
شما معمولاً از تابع فعال سازی "relu" برای همه لایه ها به جز آخرین لایه استفاده می کنید. آخرین لایه، در یک طبقه بندی، از فعال سازی "softmax" استفاده می کند.

دوباره، یک "نورون" مجموع وزنی همه ورودی های خود را محاسبه می کند، مقداری به نام "bias" اضافه می کند و نتیجه را از طریق تابع فعال سازی تغذیه می کند.
محبوب ترین تابع فعال سازی "RELU" برای واحد خطی اصلاح شده نام دارد. این یک تابع بسیار ساده است همانطور که در نمودار بالا می بینید.
تابع فعالسازی سنتی در شبکههای عصبی «سیگموئید» بود، اما نشان داده شد که «relu» تقریباً در همه جا ویژگیهای همگرایی بهتری دارد و اکنون ترجیح داده میشود.

فعال سازی Softmax برای طبقه بندی
آخرین لایه شبکه عصبی ما دارای 10 نورون است زیرا می خواهیم ارقام دست نویس را به 10 کلاس (0،..9) طبقه بندی کنیم. باید 10 عدد بین 0 و 1 را خروجی دهد که نشان دهنده احتمال 0، 1، 2 و غیره بودن این رقم است. برای این کار، در آخرین لایه، از یک تابع فعال سازی به نام "softmax" استفاده می کنیم.
اعمال Softmax بر روی یک بردار با گرفتن نمایی هر عنصر و سپس عادی سازی بردار انجام می شود، معمولاً با تقسیم آن بر هنجار "L1" آن (یعنی مجموع مقادیر مطلق) به طوری که مقادیر نرمال شده تا 1 جمع می شوند و می توان آنها را به عنوان احتمال تفسیر کرد.
خروجی آخرین لایه، قبل از فعال سازی گاهی اوقات "logits" نامیده می شود. اگر این بردار L = [L0، L1، L2، L3، L4، L5، L6، L7، L8، L9] باشد، آنگاه:


از دست دادن آنتروپی متقابل
اکنون که شبکه عصبی ما پیشبینیهایی را از تصاویر ورودی تولید میکند، باید میزان خوب بودن آنها را اندازهگیری کنیم، یعنی فاصله بین آنچه که شبکه به ما میگوید و پاسخهای صحیح، که اغلب «برچسبها» نامیده میشوند. به یاد داشته باشید که ما برچسب های درستی برای تمام تصاویر موجود در مجموعه داده داریم.
هر فاصله ای کار می کند، اما برای مشکلات طبقه بندی، به اصطلاح "فاصله آنتروپی متقابل" موثرترین است. ما این را تابع خطا یا "از دست دادن" خود می نامیم:

نزول گرادیان
"آموزش" شبکه عصبی در واقع به معنای استفاده از تصاویر و برچسب های آموزشی برای تنظیم وزن ها و سوگیری ها به گونه ای است که تابع تلفات متقابل آنتروپی را به حداقل برساند. در اینجا نحوه کار آن است.
آنتروپی متقاطع تابعی از وزن ها، بایاس ها، پیکسل های تصویر تمرینی و کلاس شناخته شده آن است.
اگر مشتقات جزئی آنتروپی متقاطع را نسبت به همه وزنها و همه بایاسها محاسبه کنیم، یک "gradient" به دست میآوریم که برای تصویر، برچسب و ارزش فعلی وزنها و بایاسها محاسبه میشود. به یاد داشته باشید که ما میتوانیم میلیونها وزن و سوگیری داشته باشیم، بنابراین محاسبه گرادیان کار زیادی به نظر میرسد. خوشبختانه، TensorFlow این کار را برای ما انجام می دهد. ویژگی ریاضی یک گرادیان این است که به سمت بالا اشاره می کند. از آنجایی که می خواهیم به جایی برویم که آنتروپی متقاطع کم است، در جهت مخالف می رویم. وزن ها و سوگیری ها را با کسری از گرادیان به روز می کنیم. سپس همین کار را بارها و بارها با استفاده از دسته های بعدی تصاویر و برچسب های آموزشی در یک حلقه آموزشی انجام می دهیم. امیدواریم که این به جایی برسد که آنتروپی متقاطع حداقل باشد، اگرچه هیچ چیزی منحصر به فرد بودن این حداقل را تضمین نمی کند.
مینی بچینگ و تکانه
میتوانید گرادیان خود را فقط بر روی یک تصویر مثال محاسبه کنید و وزنها و بایاسها را فوراً بهروزرسانی کنید، اما انجام این کار روی دستهای از مثلاً 128 تصویر، گرادیانی به دست میدهد که محدودیتهای اعمالشده توسط تصاویر نمونههای مختلف را بهتر نشان میدهد و بنابراین احتمالاً سریعتر به سمت حل همگرا میشود. اندازه مینی بچ یک پارامتر قابل تنظیم است.
این تکنیک، که گاهی اوقات "نزول گرادیان تصادفی" نامیده میشود، یک مزیت عملیتر دیگر نیز دارد: کار با دستهها همچنین به معنای کار با ماتریسهای بزرگتر است و معمولاً بهینهسازی آنها روی GPU و TPU آسانتر است.
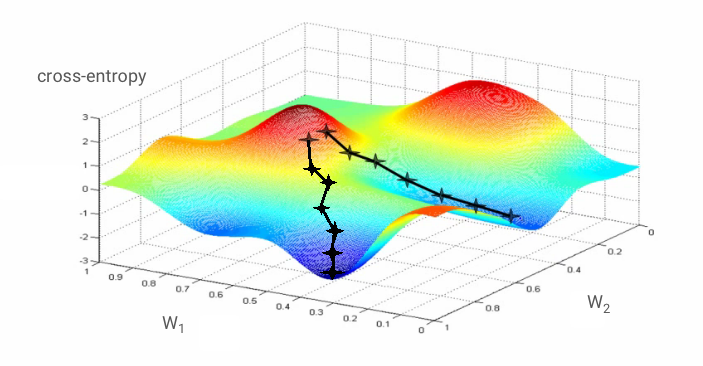
با این حال، همگرایی همچنان می تواند کمی آشفته باشد و حتی اگر بردار گرادیان صفر باشد، می تواند متوقف شود. آیا این بدان معناست که ما حداقلی را پیدا کرده ایم؟ نه همیشه. یک مولفه گرادیان می تواند بر روی حداقل یا حداکثر صفر باشد. با یک بردار گرادیان با میلیونها عنصر، اگر همه آنها صفر باشند، احتمال اینکه هر صفر با یک حداقل و هیچ یک از آنها به نقطه حداکثر مطابقت داشته باشد بسیار کم است. در فضایی با ابعاد مختلف، نقاط زین بسیار رایج هستند و ما نمی خواهیم در آنها توقف کنیم.

تصویر: یک نقطه زین. گرادیان 0 است اما در همه جهات حداقل نیست. (اشاره به تصویر ویکیمدیا: توسط Nicoguaro - Own Work, CC BY 3.0 )
راه حل این است که مقداری حرکت به الگوریتم بهینه سازی اضافه شود تا بتواند بدون توقف از نقاط زین عبور کند.
واژه نامه
دسته ای یا مینی دسته ای : آموزش همیشه بر روی دسته ای از داده ها و برچسب های آموزشی انجام می شود. انجام این کار به همگرایی الگوریتم کمک می کند. بعد "دسته ای" معمولاً اولین بعد تانسورهای داده است. برای مثال یک تانسور شکل [100، 192، 192، 3] حاوی 100 تصویر 192x192 پیکسل با سه مقدار در هر پیکسل (RGB) است.
از دست دادن آنتروپی متقابل : یک تابع تلفات ویژه که اغلب در طبقهبندیکنندهها استفاده میشود.
لایه متراکم : لایه ای از نورون ها که در آن هر نورون به تمام نورون های لایه قبلی متصل است.
ویژگی ها : ورودی های یک شبکه عصبی گاهی اوقات "ویژگی" نامیده می شود. هنر فهمیدن اینکه کدام بخش از یک مجموعه داده (یا ترکیبی از قطعات) باید به شبکه عصبی وارد شود تا پیشبینیهای خوبی داشته باشیم، «مهندسی ویژگی» نامیده میشود.
برچسب ها : نام دیگری برای "کلاس ها" یا پاسخ های صحیح در یک مشکل طبقه بندی نظارت شده
نرخ یادگیری : کسری از گرادیان که توسط آن وزنها و سوگیریها در هر تکرار از حلقه آموزشی بهروز میشوند.
logits : خروجی های لایه ای از نورون ها قبل از اعمال تابع فعال سازی "logits" نامیده می شوند. این اصطلاح از "عملکرد لجستیک" با نام "تابع سیگموئید" می آید که در گذشته محبوب ترین تابع فعال سازی بود. "خروجی های نورون قبل از عملکرد لجستیک" به "logits" کوتاه شد.
ضرر : تابع خطا در مقایسه خروجی های شبکه عصبی با پاسخ های صحیح
نورون : مجموع وزنی ورودی های خود را محاسبه می کند، بایاس اضافه می کند و نتیجه را از طریق یک تابع فعال سازی تغذیه می کند.
کدگذاری تک داغ : کلاس 3 از 5 به صورت بردار 5 عنصری کدگذاری می شود، همه صفرها به جز سومی که 1 است.
relu : واحد خطی اصلاح شده یک تابع فعال سازی محبوب برای نورون ها.
sigmoid : یکی دیگر از عملکردهای فعال سازی که قبلاً محبوب بود و هنوز هم در موارد خاص مفید است.
softmax : یک تابع فعالسازی ویژه که بر روی یک بردار عمل میکند، اختلاف بین بزرگترین مؤلفه و سایر مؤلفهها را افزایش میدهد، و همچنین بردار را با مجموع 1 نرمال میکند تا بتوان آن را به عنوان بردار احتمالات تفسیر کرد. به عنوان آخرین مرحله در طبقه بندی کننده ها استفاده می شود.
تانسور : یک "تانسور" مانند یک ماتریس است اما دارای تعداد دلخواه ابعاد است. تانسور یک بعدی یک بردار است. یک تانسور دو بعدی یک ماتریس است. و سپس می توانید تانسورهایی با ابعاد 3، 4، 5 یا بیشتر داشته باشید.
به دفترچه مطالعه برگردیم و این بار، کد را بخوانیم.
بیایید تمام سلول های این دفترچه را مرور کنیم.
سلول "پارامترها"
اندازه دسته ای، تعداد دوره های آموزشی و محل فایل های داده در اینجا تعریف شده است. فایلهای داده در یک سطل Google Cloud Storage (GCS) میزبانی میشوند، به همین دلیل آدرس آنها با gs:// شروع میشود.
سلول "واردات"
تمام کتابخانههای ضروری پایتون، از جمله TensorFlow و همچنین matplotlib برای تجسم، در اینجا وارد میشوند.
سلول " ابزارهای تصویرسازی [RUN ME] "
این سلول حاوی کد تجسم غیر جالب است. به طور پیشفرض جمعشده است، اما میتوانید آن را باز کنید و با دوبار کلیک کردن بر روی آن، زمانی که زمان دارید به کد نگاه کنید.
سلول " tf.data.Dataset: تجزیه فایل ها و آماده سازی مجموعه داده های آموزشی و اعتبار سنجی "
این سلول از tf.data.Dataset API برای بارگیری مجموعه داده های MNIST از فایل های داده استفاده می کند. نیازی به صرف زمان زیاد برای این سلول نیست. اگر به tf.data.Dataset API علاقه مند هستید، در اینجا آموزشی وجود دارد که آن را توضیح می دهد: خطوط لوله داده با سرعت TPU . در حال حاضر، اصول اولیه عبارتند از:
تصاویر و برچسب ها (پاسخ های صحیح) از مجموعه داده های MNIST در رکوردهای طول ثابت در 4 فایل ذخیره می شوند. فایل ها را می توان با تابع اختصاصی ضبط ثابت بارگذاری کرد:
imagedataset = tf.data.FixedLengthRecordDataset(image_filename, 28*28, header_bytes=16) اکنون مجموعه داده ای از بایت های تصویر داریم. آنها باید در تصاویر رمزگشایی شوند. برای این کار یک تابع تعریف می کنیم. تصویر فشرده نشده است، بنابراین تابع نیازی به رمزگشایی چیزی ندارد ( decode_raw اساساً هیچ کاری انجام نمی دهد). سپس تصویر به مقادیر ممیز شناور بین 0 و 1 تبدیل میشود. ما میتوانیم آن را در اینجا به عنوان یک تصویر دو بعدی تغییر شکل دهیم، اما در واقع آن را به عنوان یک آرایه مسطح از پیکسلهایی با اندازه 28*28 نگه میداریم زیرا این همان چیزی است که لایه متراکم اولیه ما انتظار دارد.
def read_image(tf_bytestring):
image = tf.decode_raw(tf_bytestring, tf.uint8)
image = tf.cast(image, tf.float32)/256.0
image = tf.reshape(image, [28*28])
return image این تابع را با استفاده از .map به مجموعه داده اعمال می کنیم و مجموعه داده ای از تصاویر را به دست می آوریم:
imagedataset = imagedataset.map(read_image, num_parallel_calls=16) ما همان نوع خواندن و رمزگشایی را برای برچسب ها انجام می دهیم و تصاویر و برچسب ها را با هم .zip می کنیم:
dataset = tf.data.Dataset.zip((imagedataset, labelsdataset))اکنون مجموعه داده ای از جفت ها (تصویر، برچسب) داریم. این چیزی است که مدل ما انتظار دارد. ما هنوز کاملاً آماده استفاده از آن در عملکرد آموزشی نیستیم:
dataset = dataset.cache()
dataset = dataset.shuffle(5000, reshuffle_each_iteration=True)
dataset = dataset.repeat()
dataset = dataset.batch(batch_size)
dataset = dataset.prefetch(tf.data.experimental.AUTOTUNE)tf.data.Dataset API تمام تابع کاربردی لازم برای تهیه مجموعه داده ها را دارد:
.cache مجموعه داده را در RAM ذخیره می کند. این یک مجموعه داده کوچک است بنابراین کار خواهد کرد. .shuffle آن را با یک بافر از 5000 عنصر به هم می زند. مهم است که داده های آموزشی به خوبی در هم ریخته شوند. .repeat مجموعه داده را حلقه می کند. ما چندین بار (دوره های متعدد) در مورد آن آموزش خواهیم داد. .batch چندین تصویر و برچسب را با هم در یک مینی نچ جمع می کند. در نهایت، .prefetch می تواند از CPU برای آماده سازی دسته بعدی در حالی که دسته فعلی در GPU در حال آموزش است استفاده کند.
مجموعه داده اعتبارسنجی به روشی مشابه تهیه شده است. اکنون آماده تعریف یک مدل و استفاده از این مجموعه داده برای آموزش آن هستیم.
سلول "مدل کراس"
همه مدلهای ما دنبالهای مستقیم از لایهها خواهند بود، بنابراین میتوانیم از سبک tf.keras.Sequential برای ایجاد آنها استفاده کنیم. در ابتدا در اینجا، این یک لایه متراکم است. این 10 نورون دارد زیرا ما ارقام دست نویس را به 10 کلاس طبقه بندی می کنیم. از فعال سازی "softmax" استفاده می کند زیرا آخرین لایه در یک طبقه بندی است.
یک مدل Keras همچنین باید شکل ورودی های خود را بداند. می توان tf.keras.layers.Input برای تعریف آن استفاده کرد. در اینجا، بردارهای ورودی، بردارهای مسطح با مقادیر پیکسل به طول 28*28 هستند.
model = tf.keras.Sequential(
[
tf.keras.layers.Input(shape=(28*28,)),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
# print model layers
model.summary()
# utility callback that displays training curves
plot_training = PlotTraining(sample_rate=10, zoom=1) پیکربندی مدل در Keras با استفاده از تابع model.compile انجام می شود. در اینجا ما از بهینه ساز اصلی 'sgd' (Stochastic Gradient Descent) استفاده می کنیم. یک مدل طبقه بندی به یک تابع از دست دادن آنتروپی متقابل نیاز دارد که در Keras 'categorical_crossentropy' نامیده می شود. در نهایت، از مدل میخواهیم متریک 'accuracy' را که درصد تصاویر طبقهبندی شده درست است، محاسبه کند.
Keras ابزار بسیار زیبا model.summary() را ارائه می دهد که جزئیات مدلی را که ایجاد کرده اید چاپ می کند. مربی مهربان شما ابزار PlotTraining را اضافه کرده است (تعریف شده در سلول "ابزارهای تجسم") که منحنی های آموزشی مختلف را در طول آموزش نمایش می دهد.
سلول "آموزش و اعتبارسنجی مدل"
این جایی است که آموزش با فراخوانی model.fit و پاس کردن در هر دو مجموعه داده آموزشی و اعتبارسنجی اتفاق میافتد. بهطور پیشفرض، Keras یک دور اعتبارسنجی را در پایان هر دوره اجرا میکند.
model.fit(training_dataset, steps_per_epoch=steps_per_epoch, epochs=EPOCHS,
validation_data=validation_dataset, validation_steps=1,
callbacks=[plot_training])در Keras امکان افزودن رفتارهای سفارشی در حین آموزش با استفاده از callback وجود دارد. به این ترتیب طرح آموزشی به روز رسانی پویا برای این کارگاه پیاده سازی شد.
سلول "تجسم پیش بینی ها"
هنگامی که مدل آموزش داده شد، میتوانیم با فراخوانی model.predict() پیشبینیهایی از آن دریافت کنیم:
probabilities = model.predict(font_digits, steps=1)
predicted_labels = np.argmax(probabilities, axis=1)در اینجا مجموعه ای از ارقام چاپ شده از فونت های محلی را به عنوان آزمایش آماده کرده ایم. به یاد داشته باشید که شبکه عصبی بردار 10 احتمال را از "softmax" نهایی خود برمی گرداند. برای بدست آوردن برچسب، باید دریابیم که کدام احتمال بالاترین است. np.argmax از کتابخانه numpy این کار را انجام می دهد.
برای درک اینکه چرا پارامتر axis=1 مورد نیاز است، لطفاً به یاد داشته باشید که ما دسته ای از 128 تصویر را پردازش کرده ایم و بنابراین مدل 128 بردار احتمال را برمی گرداند. شکل تانسور خروجی [128، 10] است. ما argmax را در 10 احتمال بازگشتی برای هر تصویر محاسبه می کنیم، بنابراین axis=1 (محور اول 0 است).
این مدل ساده از قبل 90 درصد ارقام را تشخیص می دهد. بد نیست، اما شما اکنون این را به میزان قابل توجهی بهبود خواهید داد.


برای بهبود دقت تشخیص، لایههای بیشتری را به شبکه عصبی اضافه میکنیم.
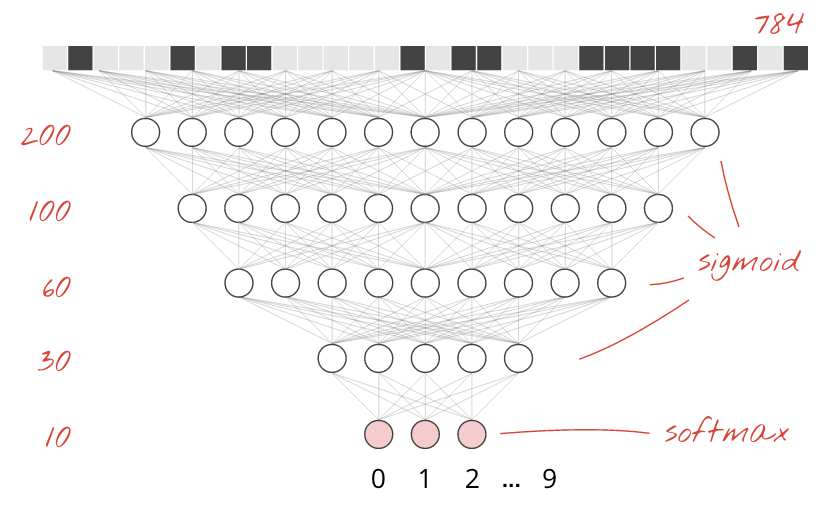
ما softmax را به عنوان تابع فعال سازی در آخرین لایه نگه می داریم زیرا این چیزی است که برای طبقه بندی بهترین کار را دارد. با این حال، در لایههای میانی از کلاسیکترین تابع فعالسازی استفاده خواهیم کرد: سیگموئید:
برای مثال، مدل شما میتواند به این شکل باشد (کاما را فراموش نکنید، tf.keras.Sequential یک لیست لایههای جدا شده با کاما را میگیرد):
model = tf.keras.Sequential(
[
tf.keras.layers.Input(shape=(28*28,)),
tf.keras.layers.Dense(200, activation='sigmoid'),
tf.keras.layers.Dense(60, activation='sigmoid'),
tf.keras.layers.Dense(10, activation='softmax')
])به "خلاصه" مدل خود نگاه کنید. اکنون حداقل 10 برابر پارامترهای بیشتری دارد. باید 10 برابر بهتر باشد! اما بنا به دلایلی اینطور نیست ...

به نظر می رسد باخت از پشت بام نیز عبور کرده است. چیزی کاملا درست نیست.
شما به تازگی شبکه های عصبی را تجربه کرده اید، همانطور که مردم در دهه 80 و 90 آنها را طراحی می کردند. جای تعجب نیست که آنها از این ایده دست کشیدند و به اصطلاح "زمستان هوش مصنوعی" را آغاز کردند. در واقع، با اضافه کردن لایهها، شبکههای عصبی مشکلات بیشتری برای همگرایی دارند.
به نظر می رسد که شبکه های عصبی عمیق با لایه های زیاد (20، 50، حتی 100 لایه امروزی) می توانند واقعاً خوب کار کنند، چند ترفند کثیف ریاضی برای همگرا کردن آنها. کشف این ترفندهای ساده یکی از دلایل تجدید حیات یادگیری عمیق در دهه 2010 است.
فعال سازی RELU

تابع فعال سازی سیگموئید در واقع در شبکه های عمیق کاملاً مشکل ساز است. تمام مقادیر بین 0 و 1 را له می کند و وقتی این کار را به طور مکرر انجام دهید، خروجی های نورون و گرادیان آنها می توانند به طور کامل ناپدید شوند. به دلایل تاریخی ذکر شد، اما شبکه های مدرن از RELU (واحد خطی اصلاح شده) استفاده می کنند که به شکل زیر است:

از طرف دیگر relu مشتق 1 دارد، حداقل در سمت راست آن. با فعالسازی RELU، حتی اگر شیبهایی که از برخی نورونها میآیند صفر باشد، همیشه دیگران شیب غیر صفر واضحی ارائه میدهند و آموزش میتواند با سرعت خوبی ادامه یابد.
بهینه ساز بهتر
در فضاهای با ابعاد بسیار بالا مانند اینجا - ما در مرتبه 10K وزن و بایاس داریم - "نقاط زین" مکرر است. اینها نقاطی هستند که مینیمم محلی نیستند، اما با این وجود، گرادیان صفر است و بهینه ساز نزول گرادیان در آنجا گیر می کند. TensorFlow دارای مجموعه ای کامل از بهینه سازهای موجود است، از جمله برخی که با مقداری اینرسی کار می کنند و با خیال راحت از نقاط زین عبور می کنند.
مقداردهی اولیه تصادفی
هنر اولیه سازی سوگیری های وزنه ها قبل از تمرین به خودی خود یک حوزه تحقیقاتی است و مقالات متعددی در این زمینه منتشر شده است. در اینجا می توانید نگاهی به تمام اولیه سازهای موجود در Keras داشته باشید. خوشبختانه Keras به طور پیش فرض کار درست را انجام می دهد و از مقداردهی اولیه 'glorot_uniform' استفاده می کند که تقریباً در همه موارد بهترین است.
هیچ کاری برای شما وجود ندارد، زیرا Keras قبلاً کار درست را انجام می دهد.
NaN ???
فرمول آنتروپی متقابل شامل یک لگاریتم است و log(0) عددی نیست (NaN، اگر ترجیح می دهید یک تصادف عددی است). آیا ورودی آنتروپی متقاطع می تواند 0 باشد؟ ورودی از softmax می آید که اساساً نمایی است و نمایی هرگز صفر نیست. پس ما در امانیم!
واقعا؟ در دنیای زیبای ریاضیات، ما ایمن خواهیم بود، اما در دنیای کامپیوتر، exp(-150)، که در قالب float32 نشان داده شده است، به اندازه صفر است و آنتروپی متقاطع خراب می شود.
خوشبختانه، شما در اینجا نیز کاری برای انجام دادن ندارید، زیرا Keras از این کار مراقبت می کند و softmax و سپس آنتروپی متقاطع را به روشی بسیار دقیق محاسبه می کند تا از ثبات عددی اطمینان حاصل کند و از NaN های مخوف جلوگیری کند.
موفقیت؟

اکنون باید به دقت 97 درصد رسیده باشید. هدف در این کارگاه این است که به طور قابل توجهی به بالای 99 درصد برسیم، پس بیایید ادامه دهیم.
اگر گیر کرده اید، در اینجا راه حل وجود دارد:
شاید بتوانیم سعی کنیم سریعتر تمرین کنیم؟ نرخ یادگیری پیش فرض در بهینه ساز Adam 0.001 است. بیایید سعی کنیم آن را افزایش دهیم.
به نظر می رسد سریعتر رفتن کمک زیادی نمی کند و این همه سروصدا چیست؟

منحنی های آموزشی واقعاً پر سر و صدا هستند و به هر دو منحنی اعتبار سنجی نگاه می کنند: آنها در حال بالا و پایین پریدن هستند. این به این معنی است که ما خیلی سریع پیش می رویم. ما می توانستیم به سرعت قبلی خود برگردیم، اما راه بهتری وجود دارد.

راه حل خوب این است که سریع شروع کنید و سرعت یادگیری را به صورت تصاعدی کاهش دهید. در Keras، میتوانید این کار را با tf.keras.callbacks.LearningRateScheduler انجام دهید.
کد مفید برای کپی پیست:
# lr decay function
def lr_decay(epoch):
return 0.01 * math.pow(0.6, epoch)
# lr schedule callback
lr_decay_callback = tf.keras.callbacks.LearningRateScheduler(lr_decay, verbose=True)
# important to see what you are doing
plot_learning_rate(lr_decay, EPOCHS)فراموش نکنید که از lr_decay_callback که ایجاد کرده اید استفاده کنید. آن را به لیست تماسهای برگشتی در model.fit اضافه کنید:
model.fit(..., callbacks=[plot_training, lr_decay_callback])تاثیر این تغییر کوچک دیدنی است. می بینید که بیشتر نویز از بین رفته است و دقت تست اکنون به صورت پایدار بالای 98٪ است.

اکنون به نظر می رسد که مدل به خوبی همگرا شده است. بیایید سعی کنیم حتی عمیق تر برویم.
آیا کمک می کند؟

نه واقعاً، دقت هنوز در 98٪ گیر کرده است و به ضرر اعتبارسنجی نگاه کنید. داره بالا میره! الگوریتم یادگیری فقط بر روی داده های آموزشی کار می کند و بر این اساس از دست دادن آموزش را بهینه می کند. هیچگاه دادههای اعتبارسنجی را نمیبیند، بنابراین جای تعجب نیست که پس از مدتی کار آن دیگر تأثیری بر از دست دادن اعتبارسنجی ندارد که متوقف میشود و گاهی اوقات حتی به عقب بازمیگردد.
این فوراً بر قابلیتهای تشخیص دنیای واقعی مدل شما تأثیر نمیگذارد، اما از اجرای بسیاری از تکرارها جلوگیری میکند و به طور کلی نشانه آن است که آموزش دیگر تأثیر مثبتی ندارد.

به این قطع ارتباط معمولاً «بیش از حد مناسب» می گویند و وقتی آن را می بینید، می توانید از یک تکنیک منظم سازی به نام «ترک کردن» استفاده کنید. تکنیک انصراف نورون های تصادفی را در هر تکرار تمرین شلیک می کند.
کار کرد؟

سر و صدا دوباره ظاهر می شود (با کمال تعجب با توجه به نحوه کار ترک تحصیل). به نظر نمی رسد که از دست دادن اعتبار دیگر در حال خزیدن باشد ، اما در کل بالاتر از بدون ترک تحصیل است. و دقت اعتبارسنجی کمی کاهش یافت. این یک نتیجه نسبتاً ناامیدکننده است.
به نظر می رسد که ترک تحصیل راه حل صحیح نبوده است ، یا شاید "بیش از حد" مفهومی پیچیده تر باشد و برخی از دلایل آن برای رفع "ترک" قابل تحمل نیست؟
"بیش از حد" چیست؟ بیش از حد هنگامی اتفاق می افتد که یک شبکه عصبی "بد" را بیاموزد ، به گونه ای که برای نمونه های آموزش کار می کند اما در مورد داده های دنیای واقعی چندان خوب نیست. تکنیک های منظم مانند ترک تحصیل وجود دارد که می تواند آن را وادار به یادگیری به روشی بهتر کند اما بیش از حد بیش از حد ریشه های عمیق تری دارد.

بیش از حد اساسی هنگامی اتفاق می افتد که یک شبکه عصبی دارای درجه آزادی زیادی برای مشکل مورد نظر باشد. تصور کنید که ما نورون های زیادی داریم که شبکه می تواند تمام تصاویر آموزشی ما را در آنها ذخیره کند و سپس آنها را با تطبیق الگوی تشخیص دهیم. این به طور کامل در داده های دنیای واقعی شکست خواهد خورد. یک شبکه عصبی باید تا حدودی محدود باشد تا مجبور شود آنچه را که در طول آموزش می آموزد تعمیم دهد.
اگر داده های آموزش بسیار کمی دارید ، حتی یک شبکه کوچک می تواند آن را از طریق قلب یاد بگیرد و "بیش از حد" را مشاهده خواهید کرد. به طور کلی ، شما همیشه برای آموزش شبکه های عصبی به داده های زیادی نیاز دارید.
سرانجام ، اگر همه کارها را با کتاب انجام داده اید ، با اندازه های مختلف شبکه آزمایش کرده اید تا اطمینان حاصل کنید که درجه آزادی آن محدود شده است ، ترکیبی کاربردی است و بر روی داده های زیادی آموزش دیده اید که هنوز هم ممکن است در سطح عملکردی گیر کنید که به نظر نمی رسد هیچ چیز قادر به بهبود آن نیست. این بدان معنی است که شبکه عصبی شما ، به شکل فعلی ، قادر به استخراج اطلاعات بیشتر از داده های شما نیست ، مانند مورد ما در اینجا.
به یاد داشته باشید که چگونه ما از تصاویر خود استفاده می کنیم ، که در یک بردار واحد صاف شده است؟ این یک ایده واقعاً بد بود. ارقام دستنویس از اشکال ساخته شده است و وقتی پیکسل ها را صاف کردیم ، اطلاعات شکل را دور ریختیم. با این حال ، نوعی از شبکه عصبی وجود دارد که می تواند از اطلاعات شکل استفاده کند: شبکه های حلقوی. بگذارید آنها را امتحان کنیم.
اگر گیر کرده اید ، در اینجا راه حل در این مرحله است:
به طور خلاصه
اگر تمام اصطلاحات جسورانه در پاراگراف بعدی برای شما شناخته شده باشد ، می توانید به تمرین بعدی بروید. اگر تازه با شبکه های عصبی Convolutional شروع کرده اید ، لطفاً در ادامه بخوانید.
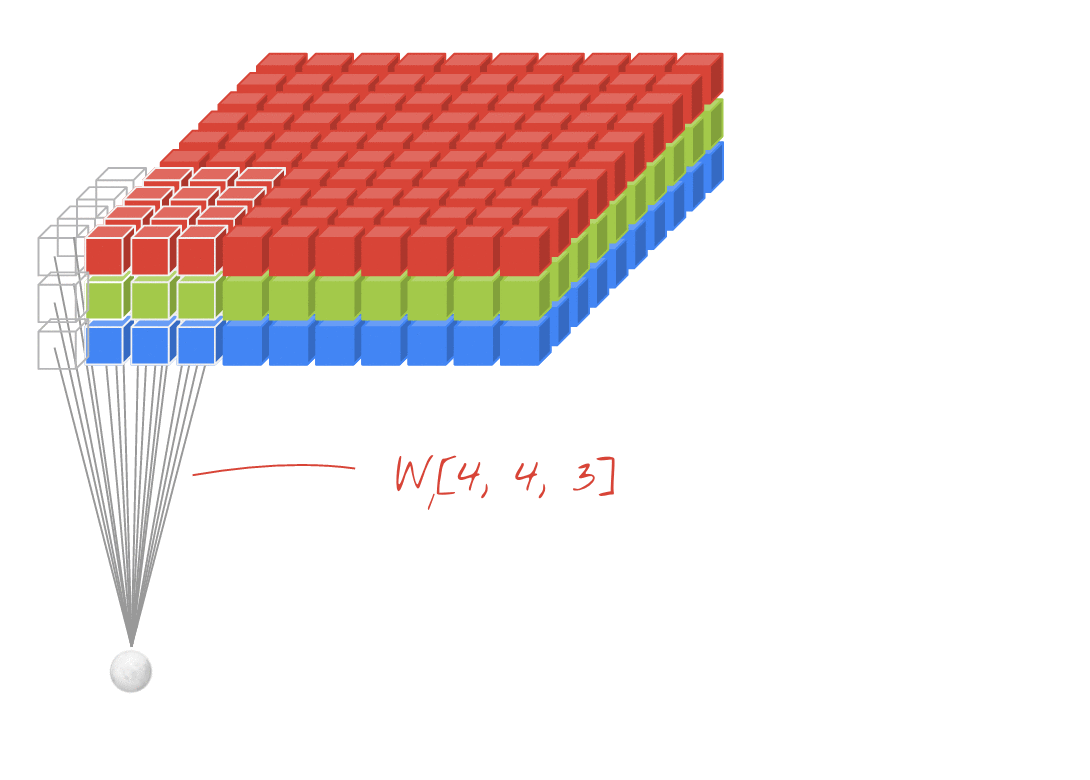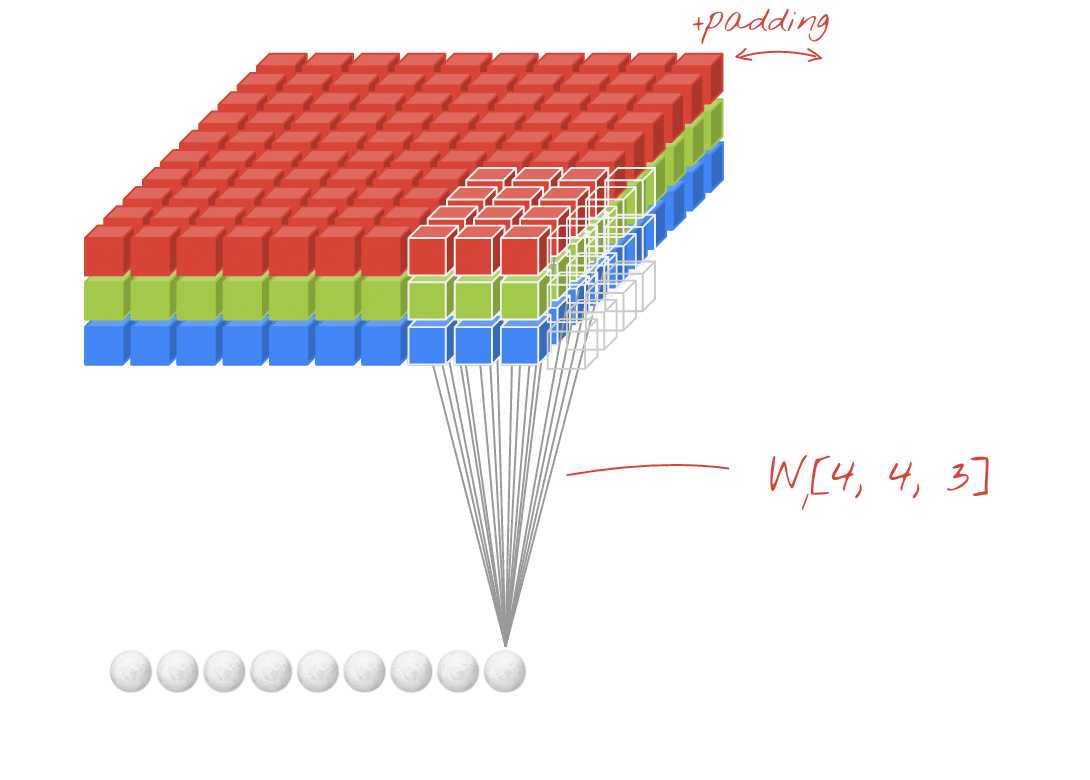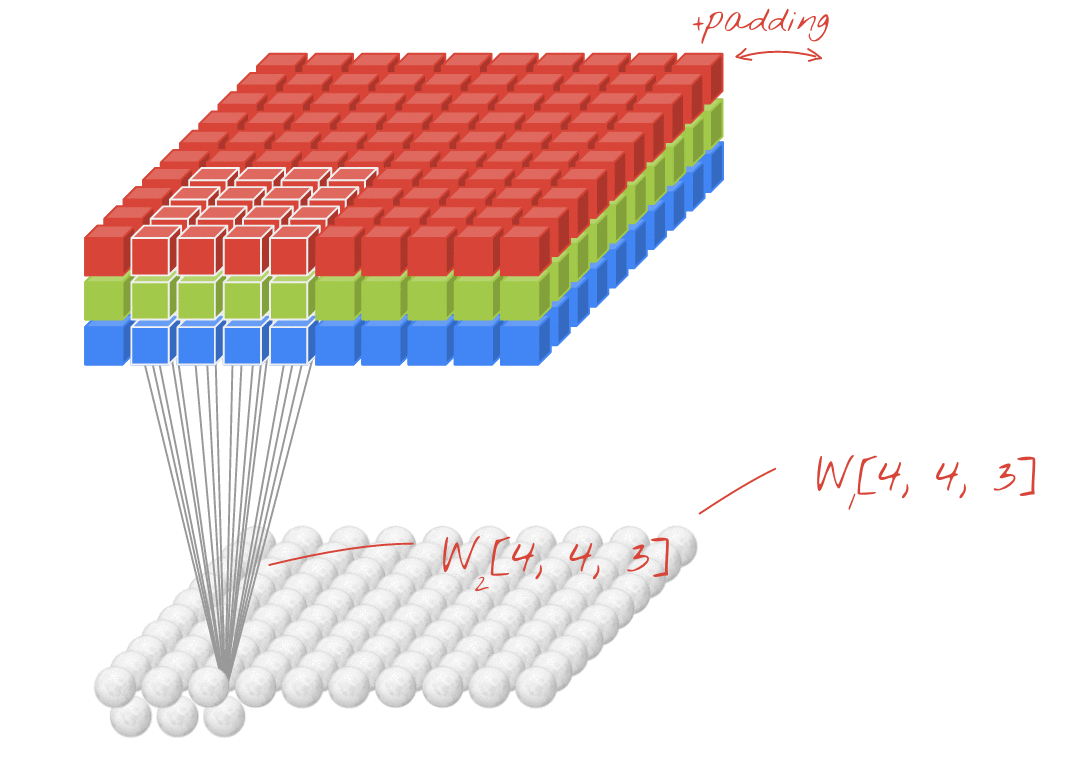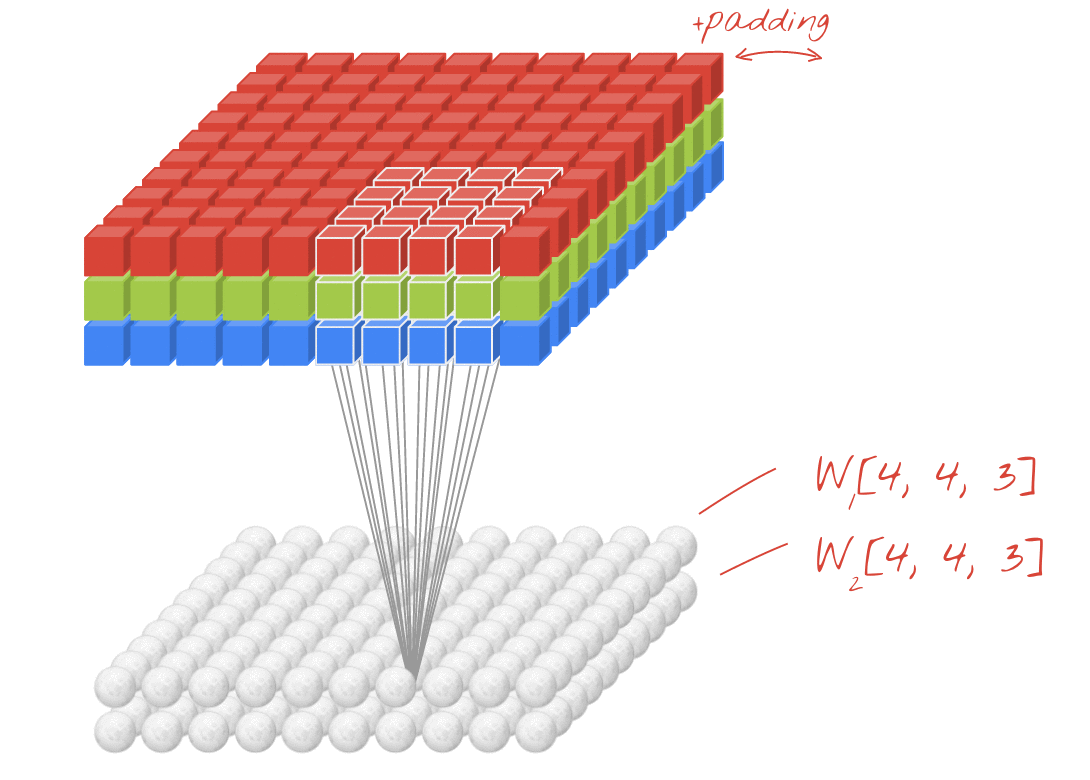
تصویر: فیلتر کردن یک تصویر با دو فیلتر پی در پی ساخته شده از 4x4x3 = 48 وزن قابل یادگیری هر کدام.
اینگونه است که یک شبکه عصبی ساده در کراس به نظر می رسد:
model = tf.keras.Sequential([
tf.keras.layers.Reshape(input_shape=(28*28,), target_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(kernel_size=3, filters=12, activation='relu'),
tf.keras.layers.Conv2D(kernel_size=6, filters=24, strides=2, activation='relu'),
tf.keras.layers.Conv2D(kernel_size=6, filters=32, strides=2, activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10, activation='softmax')
])
در یک لایه از یک شبکه حلقوی ، یک "نورون" مبلغ وزنی از پیکسل ها را دقیقاً بالای آن ، در یک منطقه کوچک از تصویر انجام می دهد. این یک تعصب را اضافه می کند و جمع را از طریق یک عملکرد فعال سازی تغذیه می کند ، دقیقاً همانطور که یک نورون در یک لایه متراکم معمولی انجام می شود. سپس این عمل در کل تصویر با استفاده از همان وزنه ها تکرار می شود. به یاد داشته باشید که در لایه های متراکم ، هر نورون وزن خود را داشت. در اینجا ، یک "پچ" از وزنه ها از هر دو جهت در تصویر می چرخد ("یک" حل "). خروجی به همان اندازه مقادیر زیادی دارد که پیکسل ها در تصویر وجود دارد (هرچند مقداری بالشتک در لبه ها لازم است). این یک عملیات فیلتر است. در تصویر بالا از فیلتر 4x4x3 = 48 وزن استفاده می کند.
با این حال ، 48 وزن کافی نخواهد بود. برای افزودن درجه های بیشتر آزادی ، ما همان عمل را با مجموعه جدیدی از وزنه ها تکرار می کنیم. این مجموعه جدیدی از خروجی های فیلتر را تولید می کند. بیایید آن را "کانال" از خروجی ها به قیاس با کانال های R ، G ، B در تصویر ورودی بنامیم.
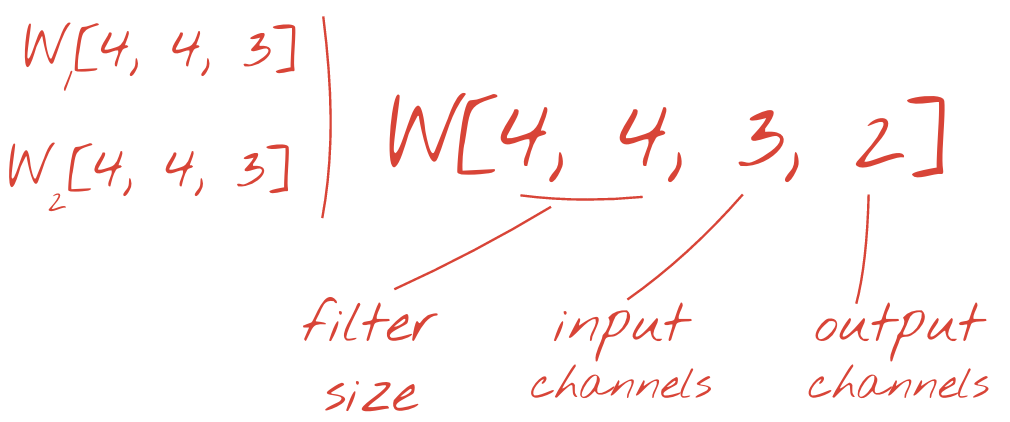
دو (یا بیشتر) وزن را می توان با اضافه کردن یک بعد جدید به عنوان یک تانسور خلاصه کرد. این به ما شکل عمومی تانسور وزنه ها را برای یک لایه حلقوی می بخشد. از آنجا که تعداد کانال های ورودی و خروجی پارامترهایی هستند ، می توانیم شروع به جمع آوری و زنجیر کردن لایه های حلزونی کنیم.

تصویر: یک شبکه عصبی حلقوی "مکعب" داده ها را به "مکعب" های دیگر داده ها تبدیل می کند.
پیچش های قدم ، حداکثر استخر
با انجام پیچیدگی ها با قدم 2 یا 3 ، می توانیم مکعب داده حاصل را در ابعاد افقی آن کوچک کنیم. دو روش مشترک برای انجام این کار وجود دارد:
- Convolution Strided: یک فیلتر کشویی مانند بالا اما با یک قدم> 1
- حداکثر استخر: یک پنجره کشویی با استفاده از حداکثر عمل (به طور معمول در تکه های 2x2 ، هر 2 پیکسل تکرار می شود)

تصویر: کشویی پنجره محاسبات توسط 3 پیکسل منجر به مقادیر خروجی کمتری می شود. پیچش های قدم یا جمع آوری حداکثر (حداکثر در یک پنجره 2x2 که توسط 2 گام به حرکت در می آید) راهی برای کوچک کردن مکعب داده در ابعاد افقی است.
لایه نهایی
پس از آخرین لایه حلقوی ، داده ها به شکل "مکعب" است. دو روش تغذیه آن از طریق لایه متراکم نهایی وجود دارد.
مورد اول این است که مکعب داده ها را به یک بردار صاف کنید و سپس آن را به لایه SoftMax تغذیه کنید. بعضی اوقات ، حتی می توانید قبل از لایه SoftMax یک لایه متراکم اضافه کنید. این از نظر تعداد وزنه ها گران است. یک لایه متراکم در پایان یک شبکه حلقوی می تواند حاوی بیش از نیمی از وزن کل شبکه عصبی باشد.
به جای استفاده از یک لایه متراکم گران قیمت ، می توانیم داده های ورودی "مکعب" را به همان تعداد قسمت هایی که کلاس داریم ، تقسیم کنیم ، مقادیر آنها را متوسط و از طریق یک عملکرد فعال سازی SoftMax تغذیه می کنیم. این روش ساخت سر طبقه بندی 0 وزن دارد. در کروس ، لایه ای برای این کار وجود دارد: tf.keras.layers.GlobalAveragePooling2D() .

برای ایجاد یک شبکه حلقوی برای مشکل مورد نظر ، به بخش بعدی پرش کنید.
بگذارید یک شبکه حلقوی برای تشخیص رقم دست نویس بسازیم. ما از سه لایه حلقوی در بالا ، لایه سنتی SoftMax Readout ما در پایین استفاده خواهیم کرد و آنها را با یک لایه کاملاً متصل به هم وصل می کنیم:

توجه کنید که لایه های حلقوی دوم و سوم از دو گام برخوردار هستند که توضیح می دهد که چرا تعداد مقادیر خروجی را از 28x28 به 14x14 و سپس 7x7 پایین می آورند.
بیایید کد Keras را بنویسیم.
قبل از اولین لایه حلقوی مورد توجه ویژه قرار می گیرد. در واقع ، انتظار می رود یک مکعب سه بعدی از داده ها باشد اما مجموعه داده ما تاکنون برای لایه های متراکم تنظیم شده است و تمام پیکسل های تصاویر در یک بردار صاف شده اند. ما باید آنها را دوباره به تصاویر 28x28x1 تغییر دهیم (1 کانال برای تصاویر با مقیاس خاکستری):
tf.keras.layers.Reshape(input_shape=(28*28,), target_shape=(28, 28, 1))شما می توانید به جای لایه tf.keras.layers.Input که تاکنون داشته اید از این خط استفاده کنید.
در کروس ، نحو برای یک لایه حلقوی فعال شده "فعال شده است:

tf.keras.layers.Conv2D(kernel_size=3, filters=12, padding='same', activation='relu')برای یک حل و فصل قدم ، می نویسید:
tf.keras.layers.Conv2D(kernel_size=6, filters=24, padding='same', activation='relu', strides=2)برای صاف کردن یک مکعب از داده ها به یک بردار به طوری که می توان آن را با یک لایه متراکم مصرف کرد:
tf.keras.layers.Flatten()و برای لایه متراکم ، نحو تغییر نکرده است:
tf.keras.layers.Dense(200, activation='relu')آیا مدل شما سد دقت 99 ٪ را شکست؟ بسیار نزدیک ... اما به منحنی ضرر اعتبار سنجی نگاه کنید. آیا این زنگ زنگ می زند؟

همچنین به پیش بینی ها نگاه کنید. برای اولین بار ، باید ببینید که بیشتر 10،000 رقم آزمون اکنون به درستی شناخته شده است. فقط در حدود 4 ردیف نادرست (حدود 110 رقم از 10،000)

اگر گیر کرده اید ، در اینجا راه حل در این مرحله است:
آموزش قبلی علائم روشنی از بیش از حد را نشان می دهد (و هنوز هم از دقت 99 ٪ کم است). آیا باید دوباره ترک را امتحان کنیم؟
این بار چطور شد؟

به نظر می رسد که Dropout این بار کار کرده است. از دست دادن اعتبار دیگر در حال خزیدن نیست و دقت نهایی باید بالاتر از 99 ٪ باشد. تبریک می گویم!
اولین باری که سعی در استفاده از ترک داشتیم ، فکر کردیم که مشکل بیش از حد داریم ، وقتی که در واقع مشکل در معماری شبکه عصبی بود. ما نتوانستیم بدون لایه های حلقوی فراتر برویم و هیچ کاری نمی تواند در مورد آن انجام دهد.
این بار ، به نظر می رسد که بیش از حد علت مشکل بود و ترک تحصیل در واقع کمک کرد. به یاد داشته باشید ، موارد بسیاری وجود دارد که می تواند باعث قطع ارتباط بین منحنی های ضرر آموزش و اعتبار سنجی شود ، با از بین رفتن اعتبار سنجی. بیش از حد (بیش از حد درجات آزادی ، که توسط شبکه بد استفاده می شود) تنها یکی از آنهاست. اگر مجموعه داده شما خیلی کوچک است یا معماری شبکه عصبی شما کافی نیست ، ممکن است یک رفتار مشابه در منحنی های ضرر مشاهده کنید ، اما ترک تحصیل کمکی نخواهد کرد.

در آخر ، بیایید سعی کنیم عادی سازی دسته ای را اضافه کنیم.
این نظریه ، در عمل ، فقط چند قانون را به خاطر بسپارید:
بیایید فعلاً با این کتاب بازی کنیم و یک لایه هنجار دسته ای را در هر لایه شبکه عصبی اما آخرین مورد اضافه کنیم. آن را به آخرین لایه "softmax" اضافه نکنید. در آنجا مفید نخواهد بود.
# Modify each layer: remove the activation from the layer itself.
# Set use_bias=False since batch norm will play the role of biases.
tf.keras.layers.Conv2D(..., use_bias=False),
# Batch norm goes between the layer and its activation.
# The scale factor can be turned off for Relu activation.
tf.keras.layers.BatchNormalization(scale=False, center=True),
# Finish with the activation.
tf.keras.layers.Activation('relu'),اکنون دقت چگونه است؟

با کمی تند و تیز (batch_size = 64 ، پارامتر پوسیدگی نرخ یادگیری 0.666 ، نرخ ترک تحصیل در لایه متراکم 0.3) و کمی شانس ، می توانید به 99.5 ٪ برسید. نرخ یادگیری و تنظیمات ترک تحصیل به دنبال "بهترین شیوه ها" برای استفاده از هنجار دسته ای انجام شد:
- Batch Norm به شبکه های عصبی کمک می کند و معمولاً به شما امکان می دهد سریعتر تمرین کنید.
- Batch Norm یک تنظیم کننده است. معمولاً می توانید میزان ترک تحصیل را که استفاده می کنید کاهش دهید یا حتی به هیچ وجه از ترک تحصیل استفاده نکنید.
نوت بوک راه حل دارای یک تمرین 99.5 ٪ است:

شما می توانید یک نسخه آماده از کد را در پوشه Mlengine در GitHub ، به همراه دستورالعمل اجرای آن در پلت فرم Google Cloud AI پیدا کنید. قبل از اینکه بتوانید این قسمت را اجرا کنید ، باید یک حساب Google Cloud ایجاد کرده و صورتحساب را فعال کنید. منابع لازم برای تکمیل آزمایشگاه باید کمتر از چند دلار باشد (با فرض 1 ساعت زمان آموزش در یک GPU). برای تهیه حساب خود:
- یک پروژه Google Cloud Platform ایجاد کنید ( http://cloud.google.com/console ).
- صورتحساب را فعال کنید.
- ابزارهای خط فرمان GCP ( GCP SDK را در اینجا ) نصب کنید.
- یک سطل ذخیره سازی Google Cloud ایجاد کنید (در منطقه
us-central1قرار دهید). از این برنامه برای مرحله بندی کد آموزش و ذخیره مدل آموزش دیده شما استفاده می شود. - API های لازم را فعال کرده و سهمیه های لازم را درخواست کنید (یک بار دستور آموزش را اجرا کنید و باید پیام های خطایی دریافت کنید که به شما می گوید چه چیزی را فعال کنید).
شما اولین شبکه عصبی خود را ساخته اید و آن را به دقت 99 ٪ آموزش داده اید. تکنیک های آموخته شده در طول راه مختص مجموعه داده MNIST نیستند ، در واقع هنگام کار با شبکه های عصبی به طور گسترده ای مورد استفاده قرار می گیرند. به عنوان یک هدیه فراق ، در اینجا کارت "یادداشت های کلیف" برای آزمایشگاه ، در نسخه کارتونی قرار دارد. شما می توانید از آن استفاده کنید تا آنچه را که آموخته اید به خاطر بسپارید:

مراحل بعدی
- پس از شبکه های کاملاً متصل و حلقوی ، باید نگاهی به شبکه های عصبی مکرر داشته باشید.
- Google Cloud برای اجرای آموزش یا استنتاج خود در ابر در زیرساخت های توزیع شده ، پلت فرم هوش مصنوعی را ارائه می دهد.
- سرانجام ، ما عاشق بازخورد هستیم. لطفاً اگر چیزی را در این آزمایشگاه می بینید یا فکر می کنید باید بهبود یابد ، به ما بگویید. ما بازخورد را از طریق مسائل GitHub [ پیوند بازخورد ] انجام می دهیم.

نویسنده: مارتین گورنر توییتر: martin_gorner |
|


تمام تصاویر کارتونی در این آزمایشگاه کپی رایت: عکسهای سهام Alexpokusay / 123RF