

এই কোডল্যাবে, আপনি শিখবেন কীভাবে একটি নিউরাল নেটওয়ার্ক তৈরি এবং প্রশিক্ষণ দেওয়া যায় যা হাতে লেখা অঙ্কগুলিকে চিনতে পারে। পাশাপাশি, আপনি 99% নির্ভুলতা অর্জনের জন্য আপনার নিউরাল নেটওয়ার্ককে উন্নত করার সাথে সাথে আপনি ট্রেডের সরঞ্জামগুলিও আবিষ্কার করবেন যা গভীর শিক্ষার পেশাদাররা তাদের মডেলগুলিকে দক্ষতার সাথে প্রশিক্ষণের জন্য ব্যবহার করে।
এই কোডল্যাবটি MNIST ডেটাসেট ব্যবহার করে, 60,000 লেবেলযুক্ত সংখ্যার একটি সংগ্রহ যা পিএইচডিদের প্রজন্মকে প্রায় দুই দশক ধরে ব্যস্ত রেখেছে। আপনি পাইথন/টেনসরফ্লো কোডের 100 টিরও কম লাইন দিয়ে সমস্যার সমাধান করবেন।
আপনি কি শিখবেন
- একটি নিউরাল নেটওয়ার্ক কি এবং কিভাবে এটি প্রশিক্ষণ
- কিভাবে tf.keras ব্যবহার করে একটি মৌলিক 1-স্তর নিউরাল নেটওয়ার্ক তৈরি করবেন
- কীভাবে আরও স্তর যুক্ত করবেন
- শেখার হারের সময়সূচী কীভাবে সেট আপ করবেন
- কীভাবে কনভোল্যুশনাল নিউরাল নেটওয়ার্ক তৈরি করবেন
- নিয়মিতকরণের কৌশলগুলি কীভাবে ব্যবহার করবেন: ড্রপআউট, ব্যাচ স্বাভাবিককরণ
- ওভারফিটিং কি
আপনি কি প্রয়োজন হবে
শুধু একটি ব্রাউজার। এই কর্মশালাটি সম্পূর্ণরূপে Google Colaboratory-এর মাধ্যমে চালানো যেতে পারে।
প্রতিক্রিয়া
আপনি যদি এই ল্যাবে কিছু ভুল দেখেন বা আপনি যদি মনে করেন এটি উন্নত করা উচিত তাহলে অনুগ্রহ করে আমাদের বলুন৷ আমরা গিটহাব সমস্যার মাধ্যমে প্রতিক্রিয়া পরিচালনা করি [ প্রতিক্রিয়া লিঙ্ক ]।
এই ল্যাবটি Google Colaboratory ব্যবহার করে এবং আপনার পক্ষ থেকে কোনো সেটআপের প্রয়োজন নেই৷ আপনি এটি একটি Chromebook থেকে চালাতে পারেন। অনুগ্রহ করে নীচের ফাইলটি খুলুন এবং Colab নোটবুকের সাথে নিজেকে পরিচিত করতে সেলগুলি চালান।

নীচের অতিরিক্ত নির্দেশাবলী:
একটি GPU ব্যাকএন্ড নির্বাচন করুন

Colab মেনুতে, রানটাইম > রানটাইম পরিবর্তন করুন এবং তারপর GPU নির্বাচন করুন। রানটাইমের সাথে সংযোগটি প্রথম সম্পাদনে স্বয়ংক্রিয়ভাবে ঘটবে, অথবা আপনি উপরের-ডান কোণে "সংযোগ" বোতামটি ব্যবহার করতে পারেন।
নোটবুক এক্সিকিউশন

একটি কক্ষে ক্লিক করে এবং Shift-ENTER ব্যবহার করে এক সময়ে সেলগুলি চালান৷ আপনি রানটাইম > সমস্ত চালান দিয়ে পুরো নোটবুক চালাতে পারেন
বিষয়বস্তুর সারণী

সমস্ত নোটবুকের বিষয়বস্তুর একটি টেবিল আছে। আপনি বাম দিকে কালো তীর ব্যবহার করে এটি খুলতে পারেন।
লুকানো কোষ

কিছু ঘর শুধুমাত্র তাদের শিরোনাম দেখাবে। এটি একটি Colab-নির্দিষ্ট নোটবুক বৈশিষ্ট্য। ভিতরে কোড দেখতে আপনি তাদের উপর ডাবল ক্লিক করতে পারেন কিন্তু এটি সাধারণত খুব আকর্ষণীয় হয় না। সাধারণত সমর্থন বা ভিজ্যুয়ালাইজেশন ফাংশন. ভিতরে ফাংশন সংজ্ঞায়িত করার জন্য আপনাকে এখনও এই ঘরগুলি চালাতে হবে।
আমরা প্রথমে একটি নিউরাল নেটওয়ার্ক ট্রেন দেখব। অনুগ্রহ করে নীচের নোটবুকটি খুলুন এবং সমস্ত কক্ষের মাধ্যমে চালান৷ কোডে এখনও মনোযোগ দেবেন না, আমরা পরে এটি ব্যাখ্যা করতে শুরু করব।
আপনি যখন নোটবুকটি চালান, ভিজ্যুয়ালাইজেশনগুলিতে ফোকাস করুন। ব্যাখ্যা জন্য নীচে দেখুন.
প্রশিক্ষণ তথ্য
আমাদের হাতে লেখা অঙ্কগুলির একটি ডেটাসেট আছে যা লেবেল করা হয়েছে যাতে আমরা জানতে পারি প্রতিটি ছবি কী প্রতিনিধিত্ব করে, যেমন 0 এবং 9 এর মধ্যে একটি সংখ্যা। নোটবুকে, আপনি একটি উদ্ধৃতি দেখতে পাবেন:
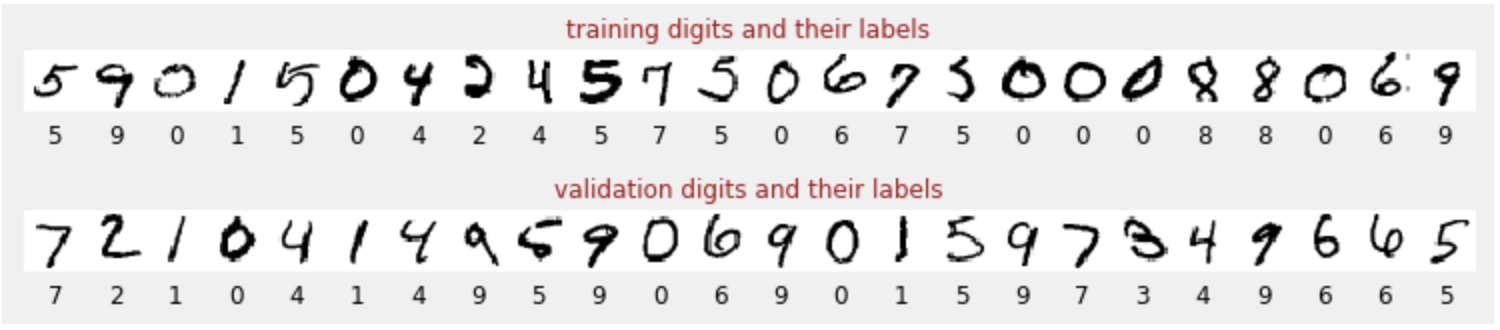
আমরা যে নিউরাল নেটওয়ার্ক তৈরি করব তা তাদের 10টি ক্লাসে (0, .., 9) হাতে লেখা অঙ্কগুলিকে শ্রেণীবদ্ধ করে। এটি অভ্যন্তরীণ পরামিতিগুলির উপর ভিত্তি করে এটি করে যা শ্রেণীবিভাগের জন্য ভালভাবে কাজ করার জন্য একটি সঠিক মান থাকা প্রয়োজন। এই "সঠিক মান" একটি প্রশিক্ষণ প্রক্রিয়ার মাধ্যমে শেখা হয় যার জন্য ছবি এবং সংশ্লিষ্ট সঠিক উত্তরগুলির সাথে একটি "লেবেলযুক্ত ডেটাসেট" প্রয়োজন।
আমরা কিভাবে জানি যে প্রশিক্ষিত নিউরাল নেটওয়ার্ক ভাল কাজ করে কি না? নেটওয়ার্ক পরীক্ষা করার জন্য প্রশিক্ষণ ডেটাসেট ব্যবহার করা প্রতারণা করা হবে। এটি ইতিমধ্যে প্রশিক্ষণের সময় একাধিকবার ডেটাসেট দেখেছে এবং এটি অবশ্যই খুব কার্যকর। নেটওয়ার্কের "বাস্তব-বিশ্ব" কর্মক্ষমতা মূল্যায়ন করার জন্য আমাদের আরেকটি লেবেলযুক্ত ডেটাসেট প্রয়োজন, যা প্রশিক্ষণের সময় কখনও দেখা যায় না। এটিকে " বৈধকরণ ডেটাসেট " বলা হয়
প্রশিক্ষণ
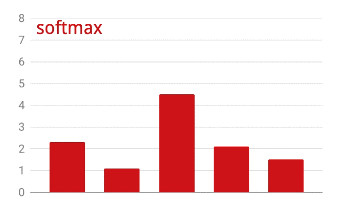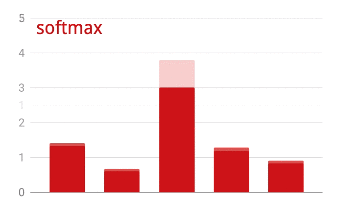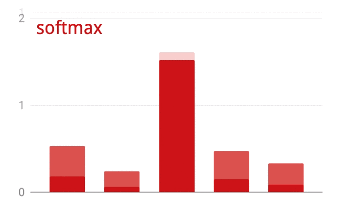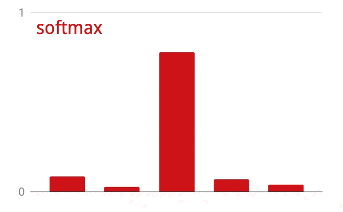
প্রশিক্ষণের অগ্রগতির সাথে সাথে, এক সময়ে প্রশিক্ষণের এক ব্যাচের ডেটা, অভ্যন্তরীণ মডেল প্যারামিটারগুলি আপডেট হয় এবং মডেলটি হস্তলিখিত অঙ্কগুলিকে চিনতে আরও ভাল হয়। আপনি এটি প্রশিক্ষণ গ্রাফে দেখতে পারেন:
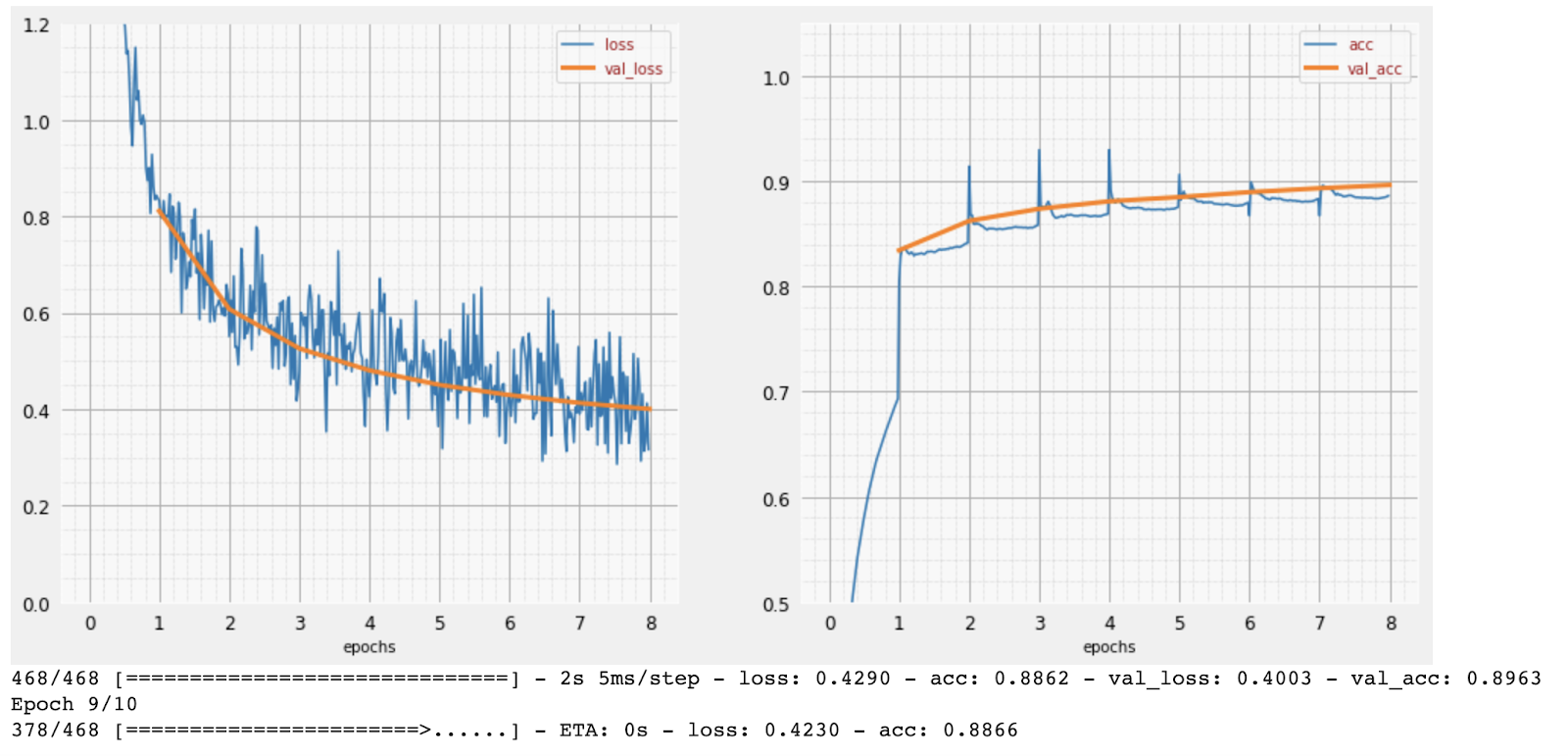
ডানদিকে, "নির্ভুলতা" হল সঠিকভাবে স্বীকৃত সংখ্যার শতাংশ। প্রশিক্ষণের অগ্রগতির সাথে সাথে এটি বেড়ে যায়, যা ভাল।
বাম দিকে, আমরা "ক্ষতি" দেখতে পাচ্ছি। প্রশিক্ষণ চালানোর জন্য, আমরা একটি "ক্ষতি" ফাংশন সংজ্ঞায়িত করব, যা প্রতিনিধিত্ব করে যে সিস্টেমটি সংখ্যাগুলিকে কতটা খারাপভাবে চিনতে পারে এবং এটি ছোট করার চেষ্টা করে। আপনি এখানে যা দেখতে পাচ্ছেন তা হল প্রশিক্ষণ এবং যাচাইকরণ ডেটা উভয়েরই ক্ষতি কমে যায় যখন প্রশিক্ষণের অগ্রগতি হয়: এটি ভাল। এর মানে নিউরাল নেটওয়ার্ক শিখছে।
X-অক্ষ সমগ্র ডেটাসেটের মাধ্যমে "যুগ" বা পুনরাবৃত্তির সংখ্যা উপস্থাপন করে।
ভবিষ্যদ্বাণী
যখন মডেলটি প্রশিক্ষিত হয়, তখন আমরা হাতে লেখা অঙ্কগুলি চিনতে এটি ব্যবহার করতে পারি। পরবর্তী ভিজ্যুয়ালাইজেশন দেখায় যে এটি স্থানীয় ফন্ট (প্রথম লাইন) থেকে রেন্ডার করা কয়েকটি সংখ্যা এবং তারপর বৈধতা ডেটাসেটের 10,000 সংখ্যাগুলিতে কতটা ভাল কাজ করে৷ ভবিষ্যদ্বাণী করা শ্রেণীটি ভুল হলে লাল রঙে প্রতিটি অঙ্কের নিচে প্রদর্শিত হবে।

আপনি দেখতে পাচ্ছেন, এই প্রাথমিক মডেলটি খুব ভাল নয় তবে এখনও কিছু সংখ্যা সঠিকভাবে চিনতে পারে। এর চূড়ান্ত বৈধতা নির্ভুলতা প্রায় 90% যা আমরা যে সরলীকৃত মডেল দিয়ে শুরু করছি তার জন্য এতটা খারাপ নয়, তবে এর মানে হল যে এটি 10,000টির মধ্যে 1000টি যাচাইকরণ সংখ্যা মিস করে। এটি আরও অনেক বেশি যা প্রদর্শিত হতে পারে, এই কারণেই মনে হচ্ছে সমস্ত উত্তর ভুল (লাল)।
টেনসর
ডেটা ম্যাট্রিসে সংরক্ষণ করা হয়। একটি 28x28 পিক্সেল গ্রেস্কেল চিত্র একটি 28x28 দ্বি-মাত্রিক ম্যাট্রিক্সে ফিট করে৷ কিন্তু একটি রঙিন ছবির জন্য, আমাদের আরও মাত্রা প্রয়োজন। প্রতি পিক্সেলে 3টি রঙের মান রয়েছে (লাল, সবুজ, নীল), তাই মাত্রা সহ একটি ত্রিমাত্রিক টেবিলের প্রয়োজন হবে [28, 28, 3]। এবং 128টি রঙিন চিত্রের একটি ব্যাচ সংরক্ষণ করতে, মাত্রা সহ একটি চার-মাত্রিক টেবিল প্রয়োজন [128, 28, 28, 3]।
এই বহুমাত্রিক টেবিলগুলিকে "টেনসর" বলা হয় এবং তাদের মাত্রাগুলির তালিকা হল তাদের "আকৃতি" ।
সংক্ষেপে
যদি পরবর্তী অনুচ্ছেদে গাঢ় সব পদ আপনার কাছে ইতিমধ্যেই পরিচিত হয়, তাহলে আপনি পরবর্তী অনুশীলনে যেতে পারেন। আপনি যদি সবেমাত্র গভীর শিক্ষা শুরু করেন তাহলে স্বাগতম, এবং অনুগ্রহ করে পড়ুন।

স্তরগুলির একটি ক্রম হিসাবে নির্মিত মডেলগুলির জন্য কেরাস অনুক্রমিক API অফার করে। উদাহরণস্বরূপ, তিনটি ঘন স্তর ব্যবহার করে একটি ইমেজ ক্লাসিফায়ার কেরাসে এভাবে লেখা যেতে পারে:
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[28, 28, 1]),
tf.keras.layers.Dense(200, activation="relu"),
tf.keras.layers.Dense(60, activation="relu"),
tf.keras.layers.Dense(10, activation='softmax') # classifying into 10 classes
])
# this configures the training of the model. Keras calls it "compiling" the model.
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy']) # % of correct answers
# train the model
model.fit(dataset, ... )
একটি একক ঘন স্তর
MNIST ডেটাসেটে হাতে লেখা অঙ্কগুলি হল 28x28 পিক্সেল গ্রেস্কেল ছবি৷ তাদের শ্রেণীবদ্ধ করার জন্য সবচেয়ে সহজ পদ্ধতি হল 1-স্তর নিউরাল নেটওয়ার্কের জন্য ইনপুট হিসাবে 28x28=784 পিক্সেল ব্যবহার করা।
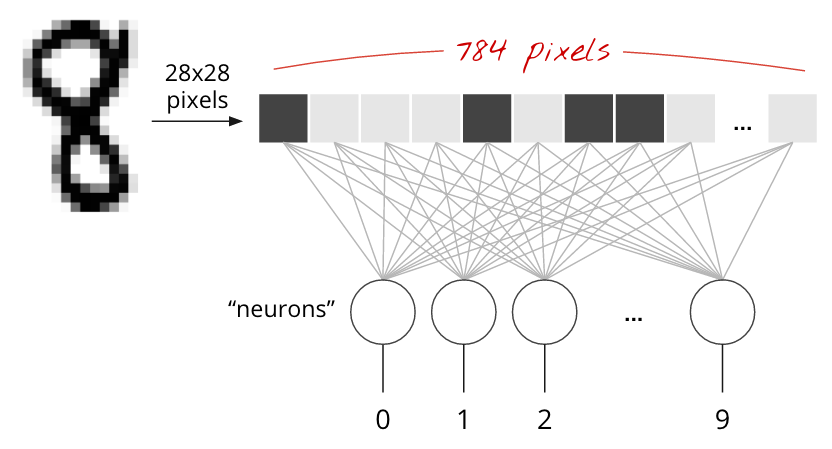
একটি নিউরাল নেটওয়ার্কের প্রতিটি "নিউরন" তার সমস্ত ইনপুটগুলির একটি ওজনযুক্ত যোগফল করে, "পক্ষপাত" নামে একটি ধ্রুবক যোগ করে এবং তারপর কিছু নন-লিনিয়ার "অ্যাক্টিভেশন ফাংশন" এর মাধ্যমে ফলাফলকে ফিড করে। "ওজন" এবং "পক্ষপাত" হল পরামিতি যা প্রশিক্ষণের মাধ্যমে নির্ধারণ করা হবে। এগুলি প্রথমে র্যান্ডম মান দিয়ে শুরু করা হয়।
উপরের ছবিটি 10 আউটপুট নিউরন সহ একটি 1-স্তর নিউরাল নেটওয়ার্ককে উপস্থাপন করে যেহেতু আমরা সংখ্যাগুলিকে 10টি শ্রেণীতে (0 থেকে 9) শ্রেণীবদ্ধ করতে চাই।
ম্যাট্রিক্স গুন সহ
এখানে কিভাবে একটি নিউরাল নেটওয়ার্ক স্তর, চিত্রের একটি সংগ্রহ প্রক্রিয়াকরণ, একটি ম্যাট্রিক্স গুণ দ্বারা প্রতিনিধিত্ব করা যেতে পারে:
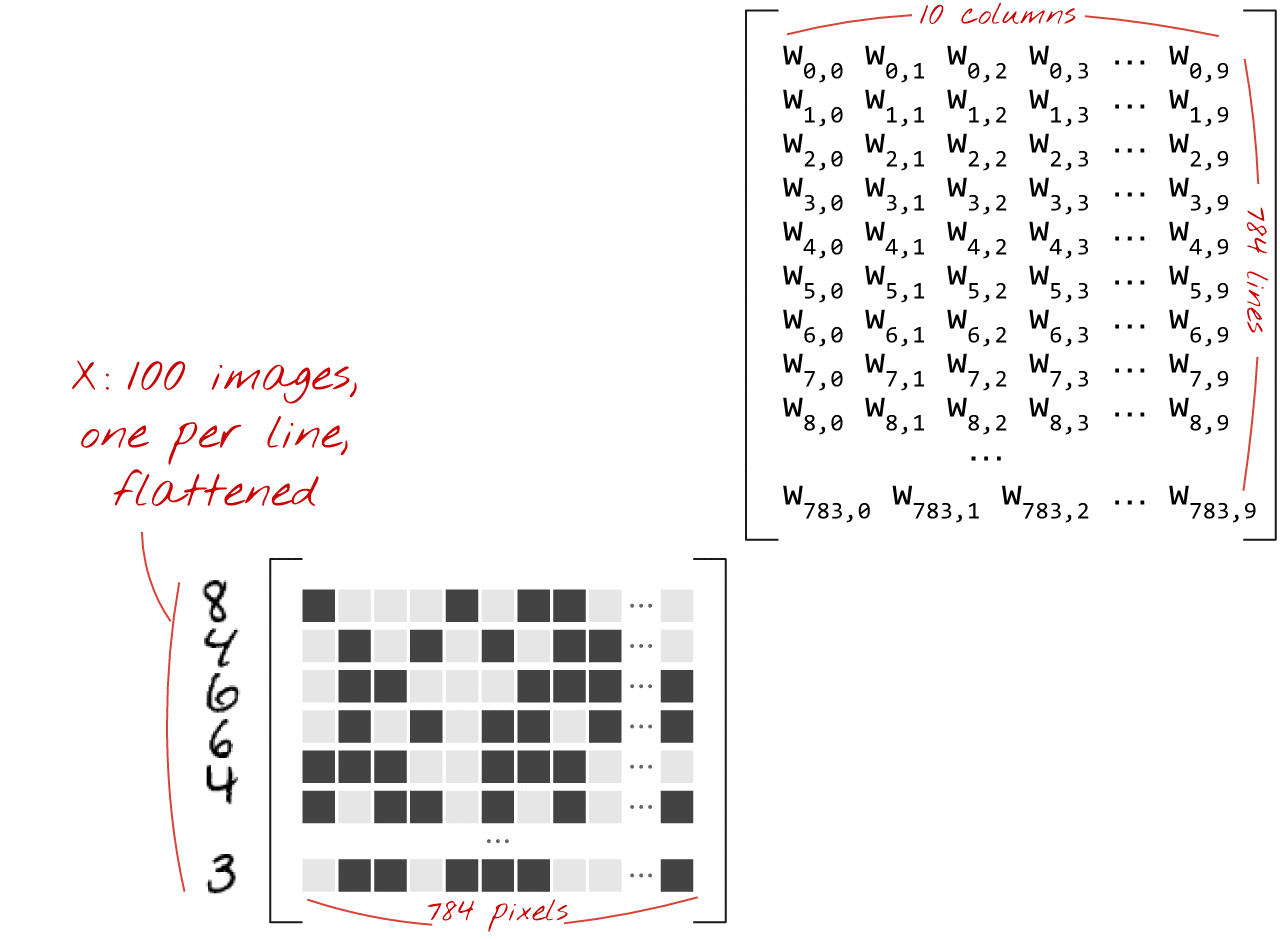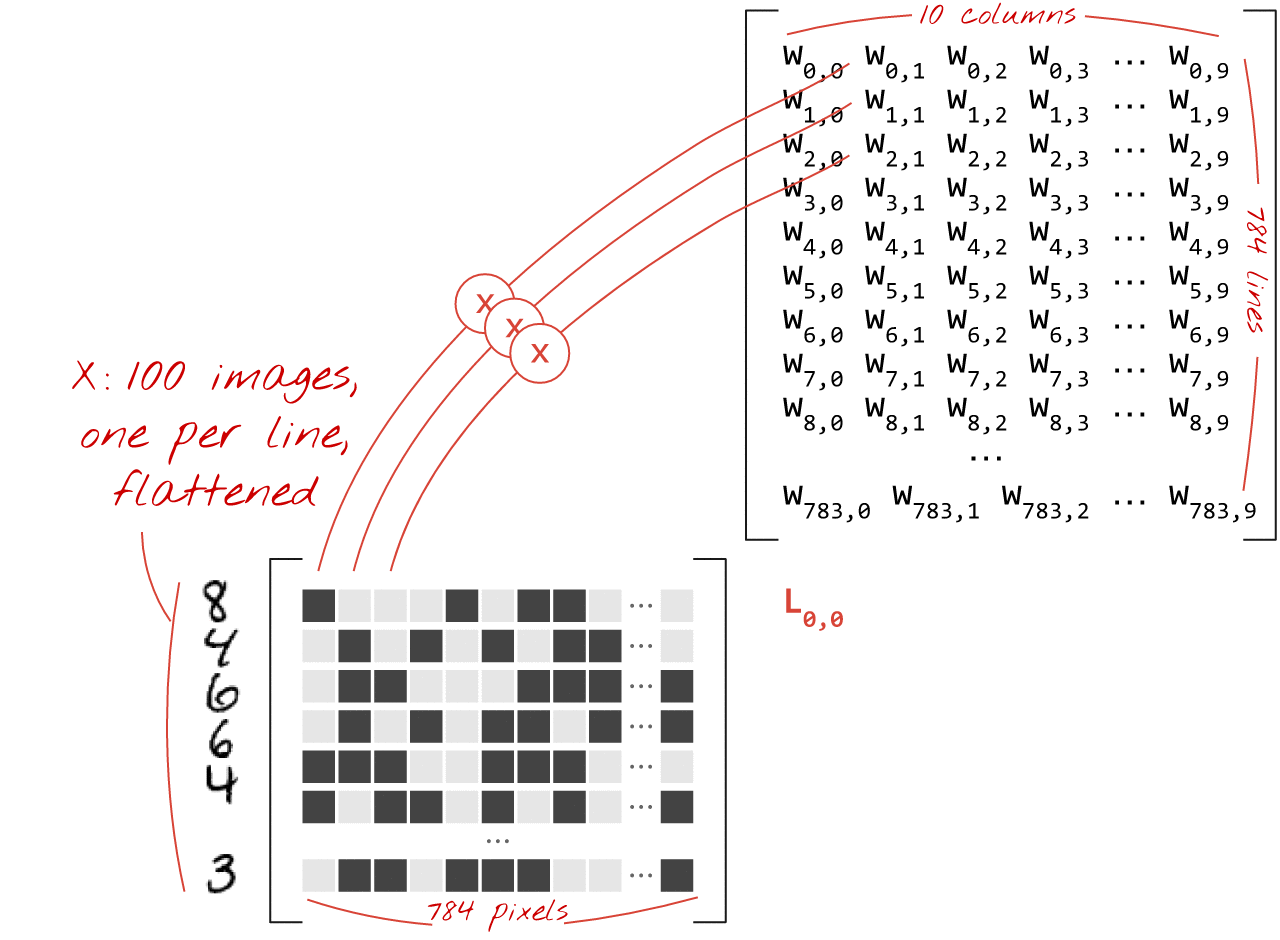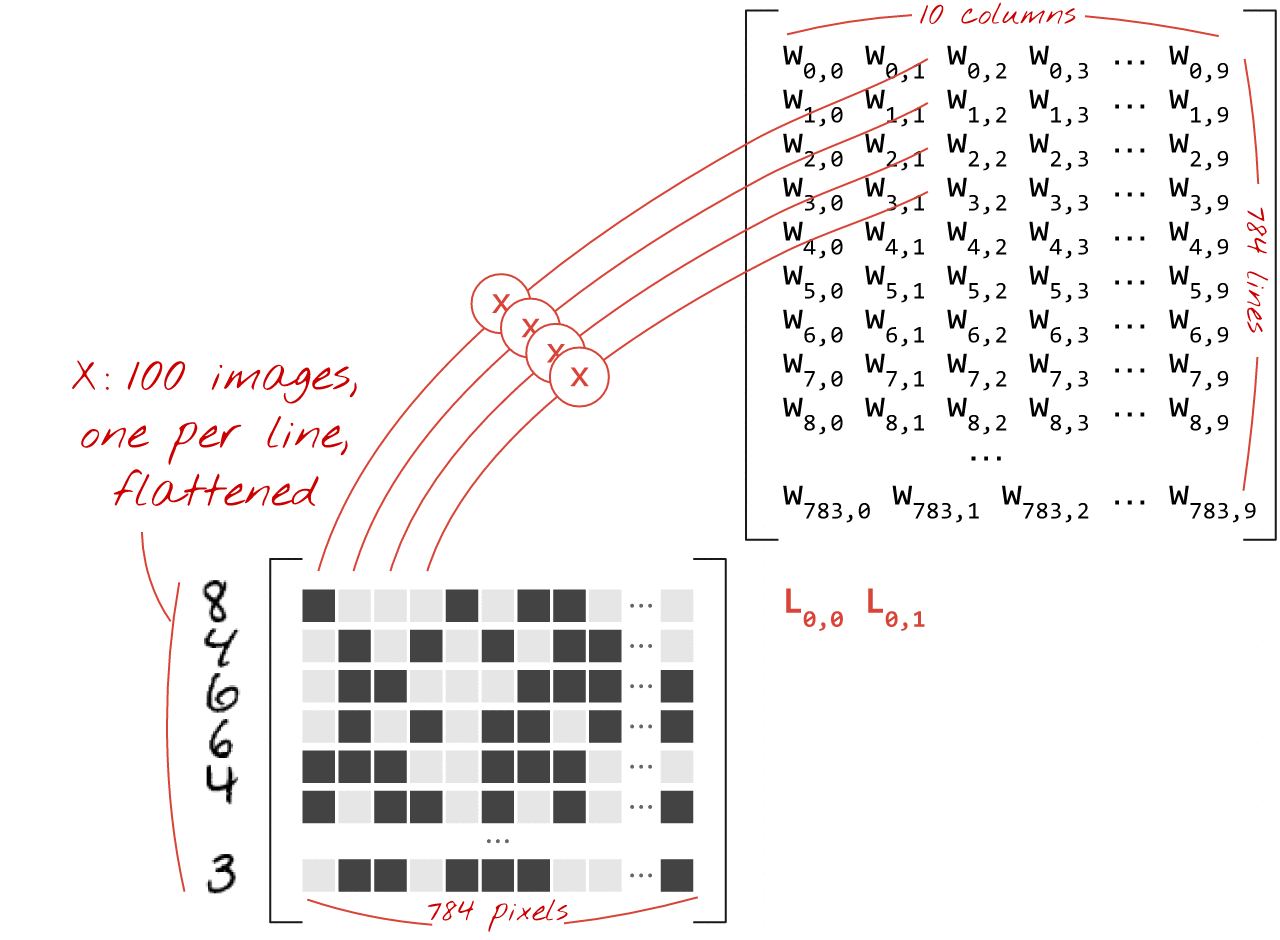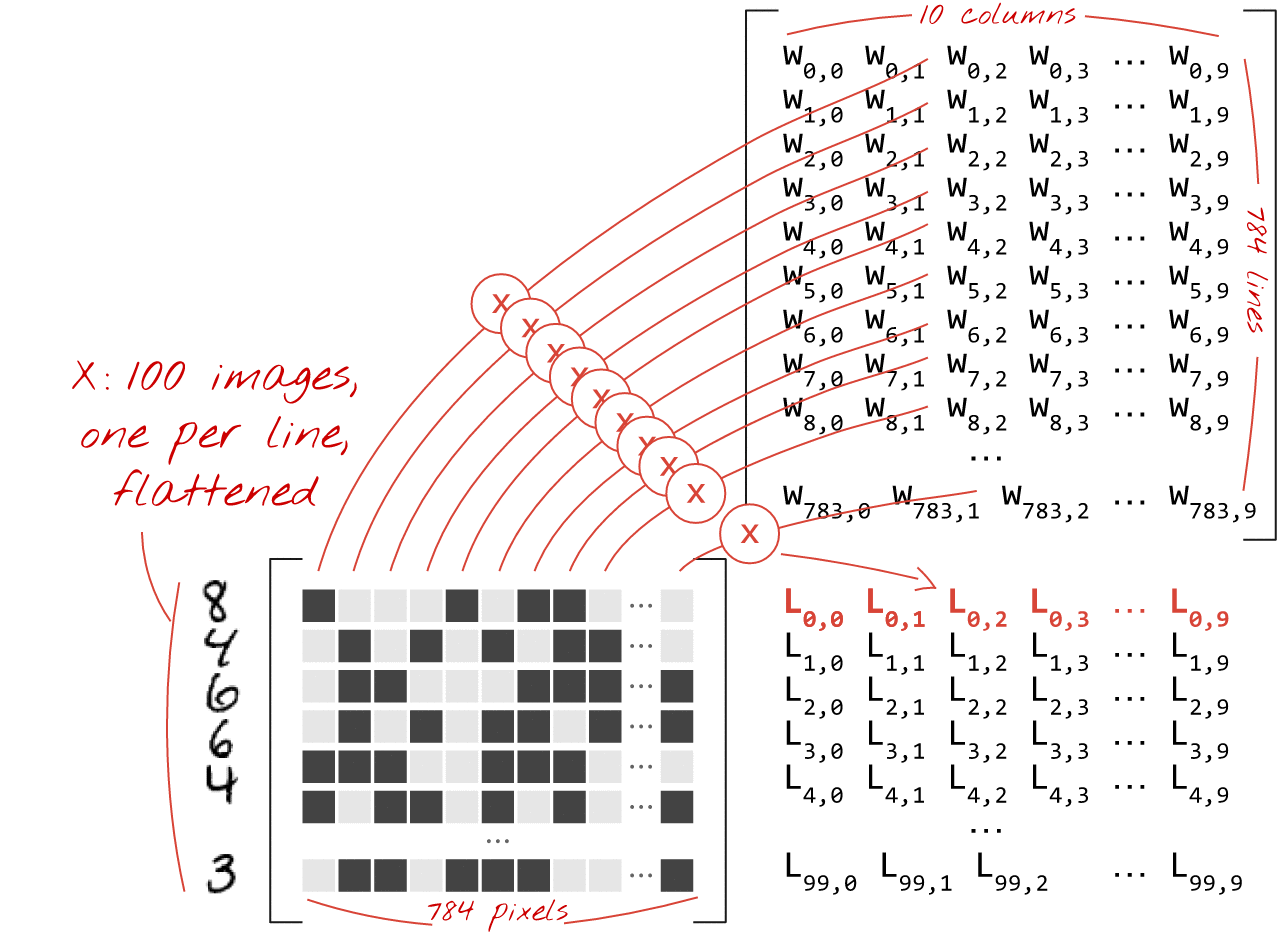
ওজন ম্যাট্রিক্স W-তে ওজনের প্রথম কলামটি ব্যবহার করে, আমরা প্রথম চিত্রের সমস্ত পিক্সেলের ওজনযুক্ত যোগফল গণনা করি। এই যোগফল প্রথম নিউরনের সাথে মিলে যায়। ওজনের দ্বিতীয় কলাম ব্যবহার করে, আমরা দ্বিতীয় নিউরনের জন্য একই কাজ করি এবং 10 তম নিউরন পর্যন্ত। তারপরে আমরা অবশিষ্ট 99টি চিত্রের জন্য অপারেশনটি পুনরাবৃত্তি করতে পারি। যদি আমরা X কে আমাদের 100টি ছবি সম্বলিত ম্যাট্রিক্স বলি, তাহলে 100টি চিত্রের উপর গণনা করা আমাদের 10টি নিউরনের সমস্ত ওজনযুক্ত যোগফল হল XW, একটি ম্যাট্রিক্স গুণ।
প্রতিটি নিউরনকে এখন তার পক্ষপাত (একটি ধ্রুবক) যোগ করতে হবে। যেহেতু আমাদের 10টি নিউরন রয়েছে, তাই আমাদের 10টি পক্ষপাত ধ্রুবক রয়েছে। আমরা 10 মানের এই ভেক্টরটিকে b বলব। এটি অবশ্যই পূর্বে গণনা করা ম্যাট্রিক্সের প্রতিটি লাইনে যোগ করতে হবে। "সম্প্রচার" নামক কিছুটা জাদু ব্যবহার করে আমরা এটিকে একটি সাধারণ প্লাস চিহ্ন দিয়ে লিখব।
আমরা অবশেষে একটি অ্যাক্টিভেশন ফাংশন প্রয়োগ করি, উদাহরণস্বরূপ "softmax" (নীচে ব্যাখ্যা করা হয়েছে) এবং 100টি ছবিতে প্রয়োগ করা একটি 1-স্তর নিউরাল নেটওয়ার্ক বর্ণনাকারী সূত্রটি পাই:
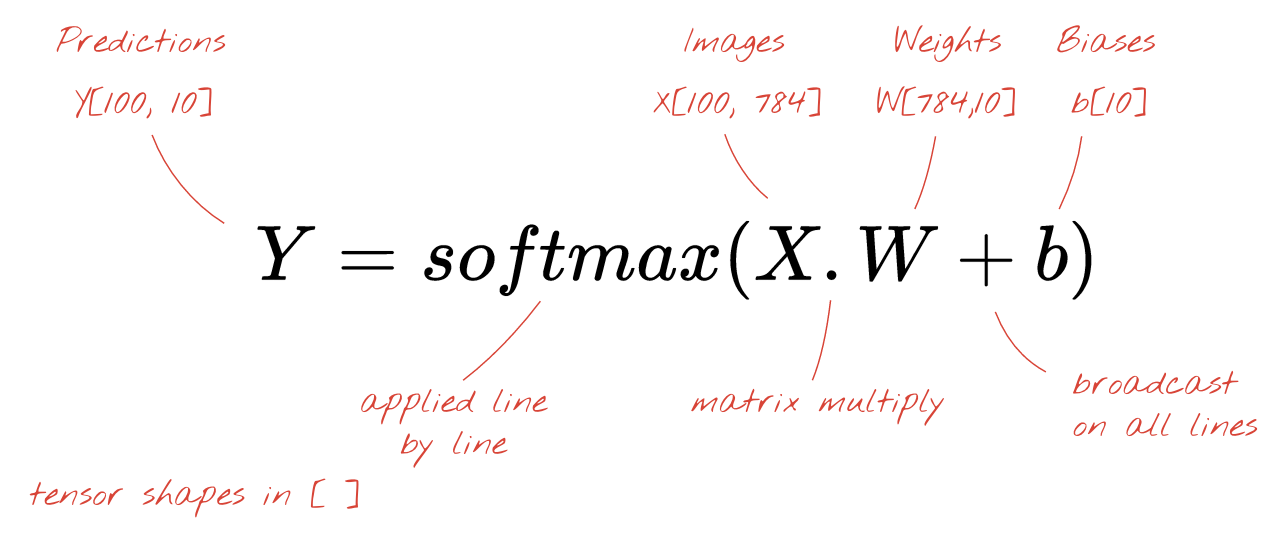
কেরাসে
কেরাসের মতো উচ্চ-স্তরের নিউরাল নেটওয়ার্ক লাইব্রেরির সাথে, আমাদের এই সূত্রটি বাস্তবায়নের প্রয়োজন হবে না। যাইহোক, এটা বোঝা গুরুত্বপূর্ণ যে একটি নিউরাল নেটওয়ার্ক স্তর গুণ এবং সংযোজনের একটি গুচ্ছ মাত্র। কেরাসে, একটি ঘন স্তর লেখা হবে:
tf.keras.layers.Dense(10, activation='softmax')গভীরে যান
এটা চেইন নিউরাল নেটওয়ার্ক স্তর তুচ্ছ. প্রথম স্তরটি পিক্সেলের ওজনযুক্ত যোগফল গণনা করে। পরবর্তী স্তরগুলি পূর্ববর্তী স্তরগুলির আউটপুটগুলির ওজনযুক্ত যোগফল গণনা করে।
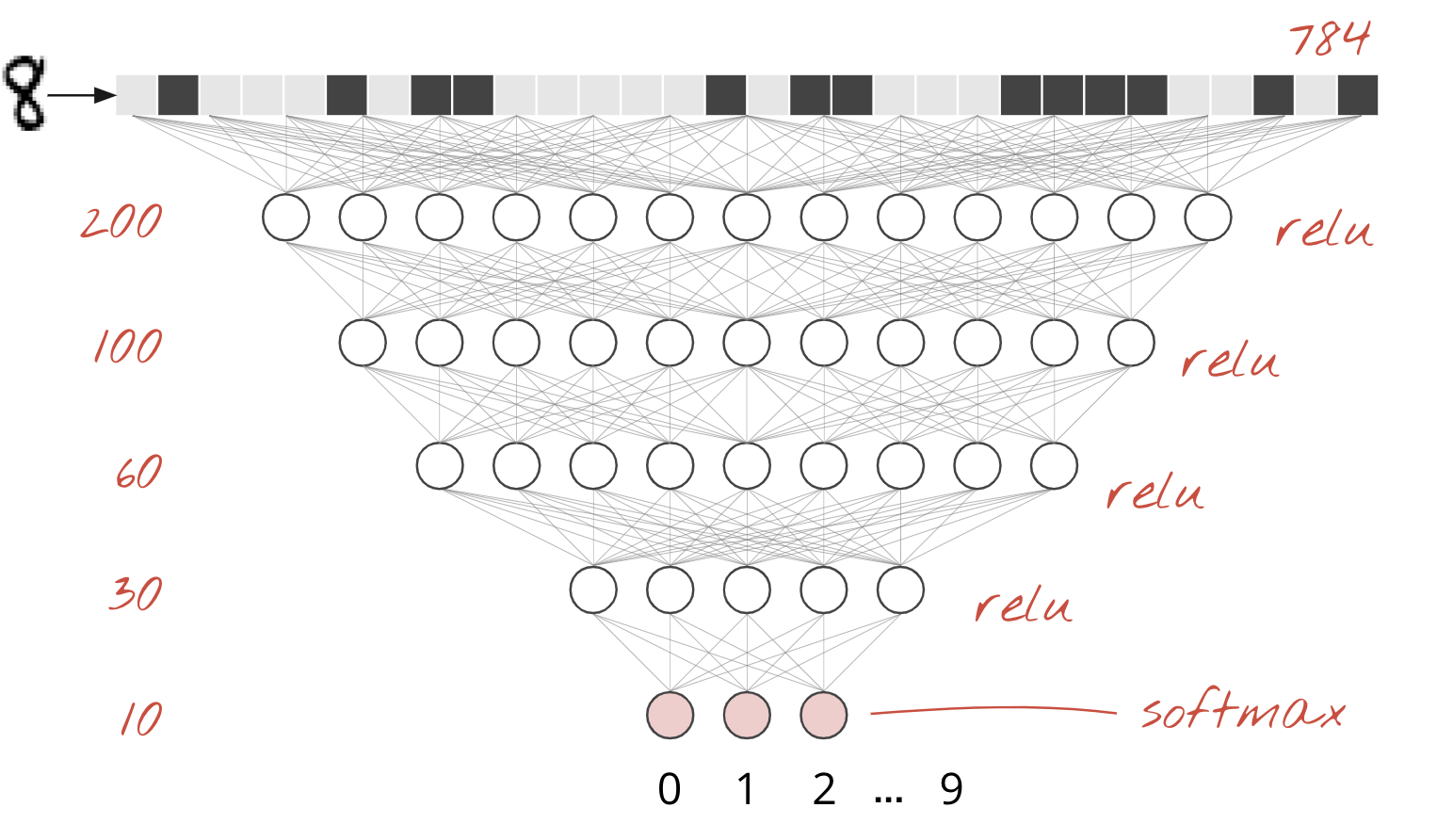
শুধুমাত্র পার্থক্য, নিউরনের সংখ্যা ছাড়াও, সক্রিয়করণ ফাংশনের পছন্দ হবে।
সক্রিয়করণ ফাংশন: relu, softmax এবং sigmoid
আপনি সাধারণত সব স্তরের জন্য "relu" অ্যাক্টিভেশন ফাংশন ব্যবহার করবেন কিন্তু শেষের জন্য। শেষ স্তর, একটি শ্রেণীবিভাগে, "softmax" সক্রিয়করণ ব্যবহার করবে।
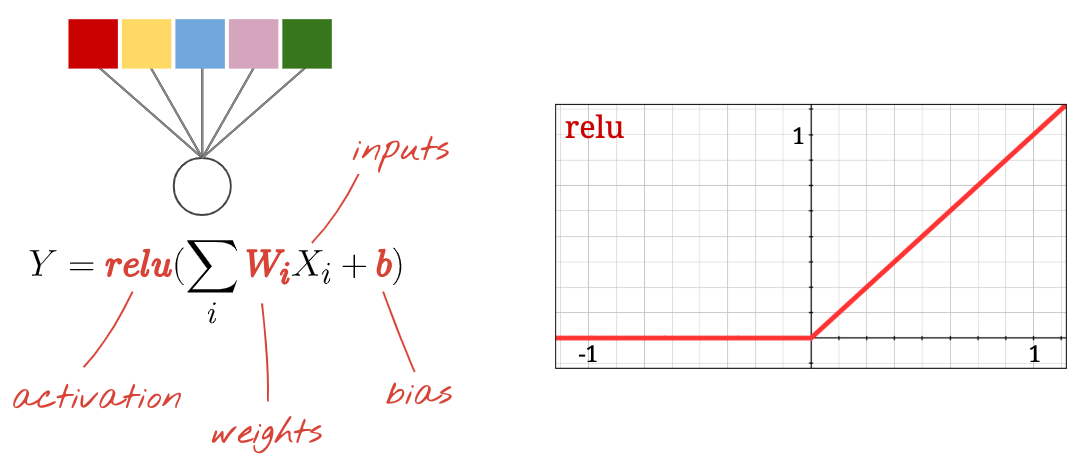
আবার, একটি "নিউরন" তার সমস্ত ইনপুটগুলির একটি ওজনযুক্ত যোগফল গণনা করে, "বায়াস" নামে একটি মান যোগ করে এবং সক্রিয়করণ ফাংশনের মাধ্যমে ফলাফলকে ফিড করে।
রেক্টিফায়েড লিনিয়ার ইউনিটের জন্য সবচেয়ে জনপ্রিয় অ্যাক্টিভেশন ফাংশনটিকে "RELU" বলা হয়। এটি একটি খুব সাধারণ ফাংশন যা আপনি উপরের গ্রাফে দেখতে পাচ্ছেন।
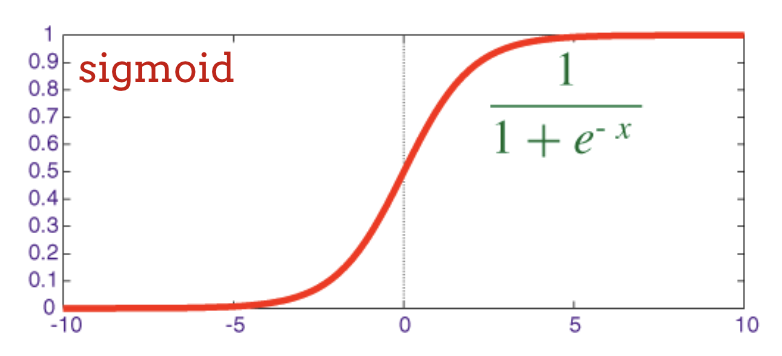
নিউরাল নেটওয়ার্কে প্রথাগত অ্যাক্টিভেশন ফাংশন ছিল "সিগময়েড" কিন্তু "রেলু" প্রায় সর্বত্রই ভালো কনভারজেন্স বৈশিষ্ট্য দেখায় এবং এখন এটি পছন্দের।
শ্রেণীবিভাগের জন্য Softmax অ্যাক্টিভেশন
আমাদের নিউরাল নেটওয়ার্কের শেষ স্তরে 10টি নিউরন রয়েছে কারণ আমরা হাতে লেখা অঙ্কগুলিকে 10টি শ্রেণীতে (0,..9) শ্রেণীবদ্ধ করতে চাই। এটি 0 এবং 1 এর মধ্যে 10টি সংখ্যা আউটপুট করবে যা এই সংখ্যাটি 0, একটি 1, একটি 2 ইত্যাদি হওয়ার সম্ভাবনাকে উপস্থাপন করে। এর জন্য, শেষ স্তরে, আমরা "softmax" নামক একটি অ্যাক্টিভেশন ফাংশন ব্যবহার করব।
একটি ভেক্টরের উপর সফ্টম্যাক্স প্রয়োগ করা হয় প্রতিটি উপাদানের সূচক নিয়ে এবং তারপর ভেক্টরটিকে স্বাভাবিক করার মাধ্যমে, সাধারণত এটিকে "L1" আদর্শ দ্বারা ভাগ করে (অর্থাৎ পরম মানের সমষ্টি) যাতে স্বাভাবিক মানগুলি 1 পর্যন্ত যোগ হয় এবং সম্ভাব্যতা হিসাবে ব্যাখ্যা করা যায়।
সক্রিয়করণের আগে শেষ স্তরের আউটপুটকে কখনও কখনও "লগিটস" বলা হয়। যদি এই ভেক্টর হয় L = [L0, L1, L2, L3, L4, L5, L6, L7, L8, L9], তাহলে:
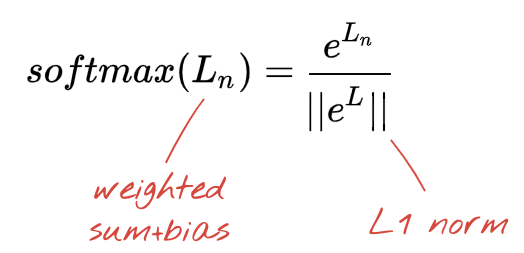
ক্রস-এনট্রপি ক্ষতি
এখন যেহেতু আমাদের নিউরাল নেটওয়ার্ক ইনপুট ইমেজগুলি থেকে ভবিষ্যদ্বাণী তৈরি করে, আমাদের সেগুলি কতটা ভাল তা পরিমাপ করতে হবে, অর্থাৎ নেটওয়ার্ক আমাদের যা বলে এবং সঠিক উত্তরগুলির মধ্যে দূরত্ব, প্রায়ই "লেবেল" বলা হয়। মনে রাখবেন যে ডেটাসেটের সমস্ত ছবির জন্য আমাদের কাছে সঠিক লেবেল রয়েছে।
যেকোনো দূরত্ব কাজ করবে, কিন্তু শ্রেণীবিভাগের সমস্যার জন্য তথাকথিত "ক্রস-এনট্রপি দূরত্ব" সবচেয়ে কার্যকর । আমরা এটিকে আমাদের ত্রুটি বা "ক্ষতি" ফাংশন বলব:
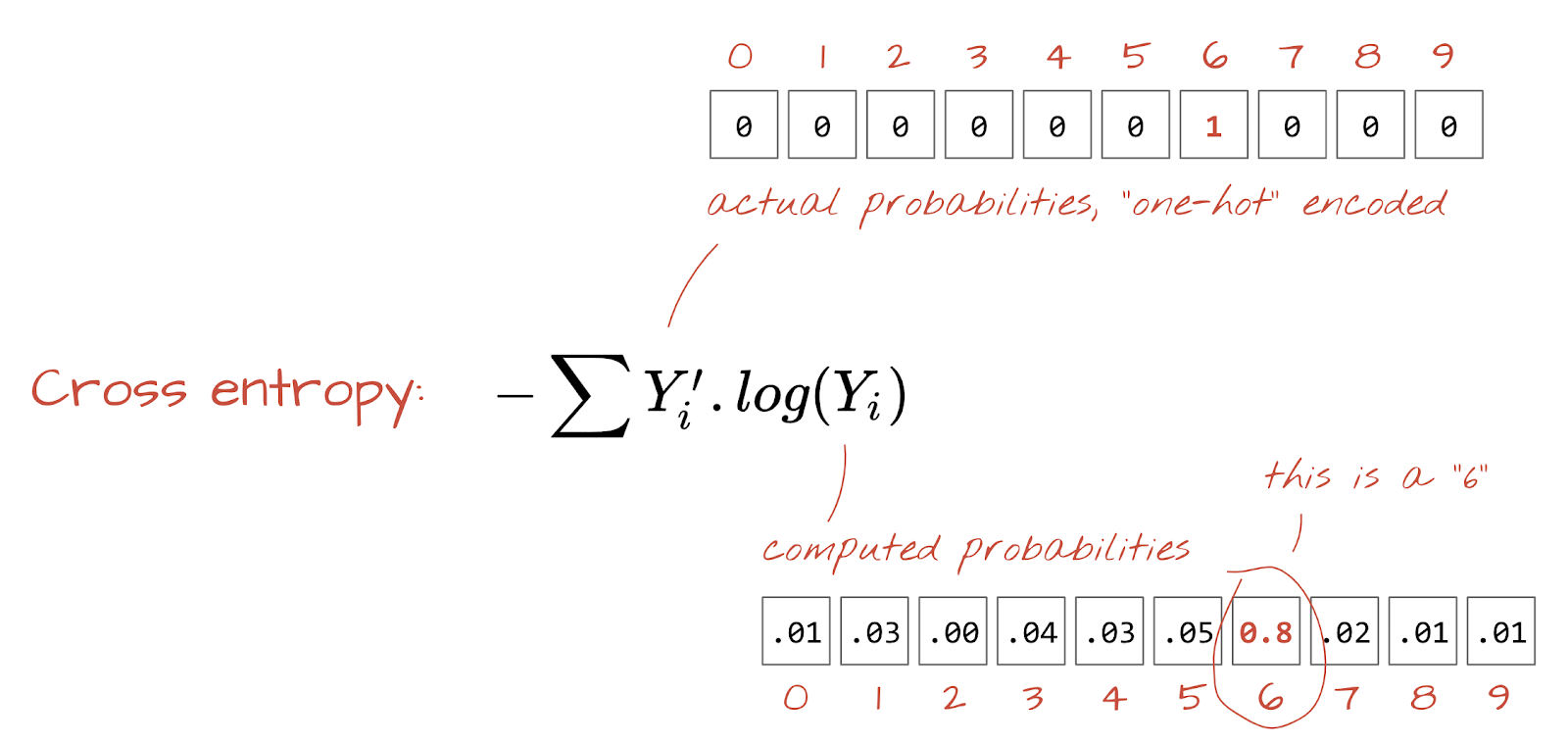
গ্রেডিয়েন্ট ডিসেন্ট
নিউরাল নেটওয়ার্কের "প্রশিক্ষণ" আসলে বোঝায় ওজন এবং পক্ষপাতগুলি সামঞ্জস্য করার জন্য প্রশিক্ষণের চিত্র এবং লেবেল ব্যবহার করা যাতে ক্রস-এনট্রপি লস ফাংশন কম করা যায়। এখানে এটা কিভাবে কাজ করে.
ক্রস-এনট্রপি হল ওজন, পক্ষপাত, প্রশিক্ষণ চিত্রের পিক্সেল এবং এর পরিচিত শ্রেণির একটি ফাংশন।
যদি আমরা ক্রস-এনট্রপির আংশিক ডেরিভেটিভগুলিকে তুলনা করি সমস্ত ওজন এবং সমস্ত পক্ষপাতের সাথে তুলনা করে আমরা একটি "গ্রেডিয়েন্ট" পাই, একটি প্রদত্ত চিত্র, লেবেল এবং ওজন এবং পক্ষপাতের বর্তমান মানের জন্য গণনা করা হয়। মনে রাখবেন যে আমাদের লক্ষ লক্ষ ওজন এবং পক্ষপাত থাকতে পারে তাই গ্রেডিয়েন্ট কম্পিউট করা অনেক কাজের মত মনে হয়। সৌভাগ্যবশত, TensorFlow আমাদের জন্য এটি করে। একটি গ্রেডিয়েন্টের গাণিতিক বৈশিষ্ট্য হল এটি "উপর" নির্দেশ করে। যেহেতু আমরা যেতে চাই যেখানে ক্রস-এনট্রপি কম, আমরা বিপরীত দিকে যাই। আমরা গ্রেডিয়েন্টের একটি ভগ্নাংশ দ্বারা ওজন এবং পক্ষপাত আপডেট করি। তারপরে আমরা ট্রেনিং লুপে পরবর্তী ব্যাচের ট্রেনিং ইমেজ এবং লেবেল ব্যবহার করে একই জিনিস বার বার করি। আশা করা যায়, এটি এমন একটি জায়গায় রূপান্তরিত হয় যেখানে ক্রস-এনট্রপি ন্যূনতম যদিও কিছুই গ্যারান্টি দেয় না যে এই ন্যূনতমটি অনন্য।
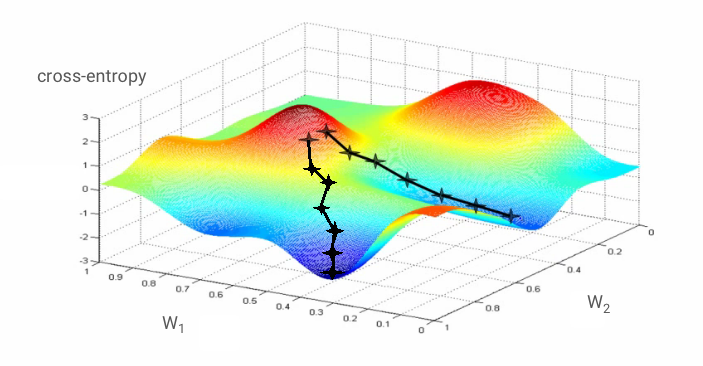
মিনি-ব্যাচিং এবং ভরবেগ
আপনি শুধুমাত্র একটি উদাহরণ চিত্রের উপর আপনার গ্রেডিয়েন্ট গণনা করতে পারেন এবং ওজন এবং পক্ষপাতগুলি অবিলম্বে আপডেট করতে পারেন, কিন্তু এটি করার ফলে, উদাহরণস্বরূপ, 128টি চিত্র একটি গ্রেডিয়েন্ট দেয় যা বিভিন্ন উদাহরণ চিত্র দ্বারা আরোপিত সীমাবদ্ধতাগুলিকে আরও ভালভাবে উপস্থাপন করে এবং তাই দ্রুত সমাধানের দিকে একত্রিত হওয়ার সম্ভাবনা রয়েছে। মিনি-ব্যাচের আকার একটি সামঞ্জস্যযোগ্য পরামিতি।
এই কৌশলটি, যাকে কখনও কখনও "স্টোকাস্টিক গ্রেডিয়েন্ট ডিসেন্ট" বলা হয়, এর আরও একটি, আরও বাস্তবসম্মত সুবিধা রয়েছে: ব্যাচগুলির সাথে কাজ করার অর্থ আরও বড় ম্যাট্রিক্সের সাথে কাজ করা এবং এগুলি সাধারণত GPU এবং TPU-তে অপ্টিমাইজ করা সহজ।
কনভারজেন্স এখনও একটু বিশৃঙ্খল হতে পারে এবং গ্রেডিয়েন্ট ভেক্টর সব শূন্য হলে এটি থামতে পারে। যে আমরা একটি ন্যূনতম পাওয়া গেছে যে মানে? সবসময় নয়। একটি গ্রেডিয়েন্ট উপাদান সর্বনিম্ন বা সর্বোচ্চ শূন্য হতে পারে। লক্ষ লক্ষ উপাদান সহ একটি গ্রেডিয়েন্ট ভেক্টরের সাথে, যদি সেগুলি সব শূন্য হয়, সম্ভাব্যতা যে প্রতিটি শূন্য একটি ন্যূনতম এবং কোনটি সর্বাধিক বিন্দুর সাথে সামঞ্জস্যপূর্ণ নয়। অনেক মাত্রার জায়গায়, স্যাডল পয়েন্টগুলি বেশ সাধারণ এবং আমরা সেগুলিতে থামতে চাই না।
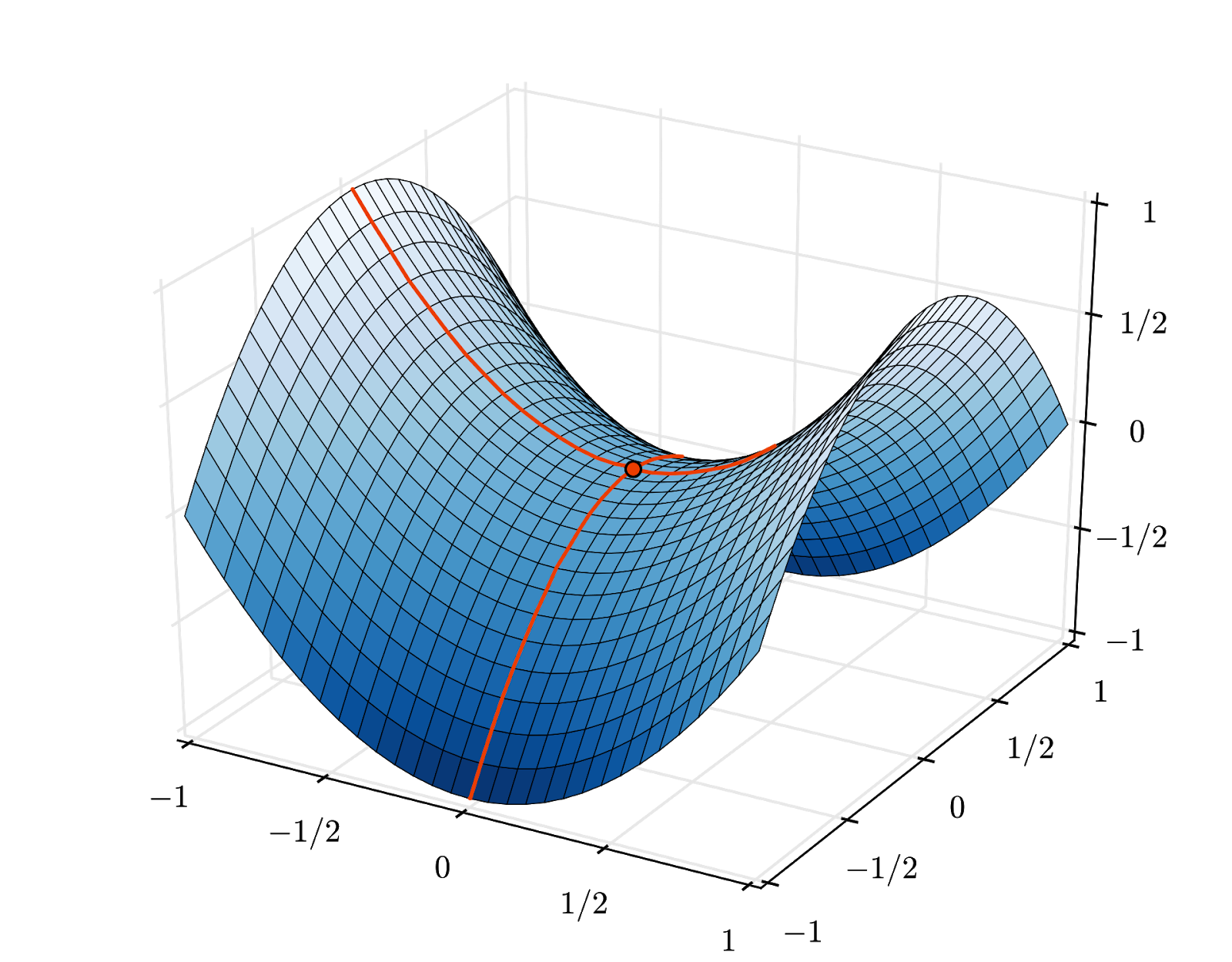
উদাহরণ: একটি স্যাডল পয়েন্ট। গ্রেডিয়েন্ট 0 কিন্তু এটি সব দিক থেকে ন্যূনতম নয়। (ইমেজ অ্যাট্রিবিউশন উইকিমিডিয়া: নিকোগুয়ারো দ্বারা - নিজের কাজ, CC BY 3.0 )
সমাধান হল অপ্টিমাইজেশান অ্যালগরিদমে কিছু গতিবেগ যোগ করা যাতে এটি থেমে না গিয়ে অতীতের স্যাডল পয়েন্টে যেতে পারে।
শব্দকোষ
ব্যাচ বা মিনি-ব্যাচ : প্রশিক্ষণ সর্বদা প্রশিক্ষণ ডেটা এবং লেবেলের ব্যাচে সঞ্চালিত হয়। এটি করা অ্যালগরিদমকে একত্রিত করতে সহায়তা করে। "ব্যাচ" মাত্রা সাধারণত ডেটা টেনসরের প্রথম মাত্রা। উদাহরণস্বরূপ আকৃতির একটি টেনসর [100, 192, 192, 3] প্রতি পিক্সেল (RGB) তিনটি মান সহ 192x192 পিক্সেলের 100টি চিত্র রয়েছে।
ক্রস-এনট্রপি লস : একটি বিশেষ ক্ষতি ফাংশন যা প্রায়ই ক্লাসিফায়ারে ব্যবহৃত হয়।
ঘন স্তর : নিউরনের একটি স্তর যেখানে প্রতিটি নিউরন পূর্ববর্তী স্তরের সমস্ত নিউরনের সাথে সংযুক্ত থাকে।
বৈশিষ্ট্য : একটি নিউরাল নেটওয়ার্কের ইনপুট কখনও কখনও "বৈশিষ্ট্য" বলা হয়। ভাল ভবিষ্যদ্বাণী পেতে একটি ডেটাসেটের কোন অংশগুলি (বা অংশগুলির সংমিশ্রণ) একটি নিউরাল নেটওয়ার্কে ফিড করতে হবে তা খুঁজে বের করার শিল্পকে "ফিচার ইঞ্জিনিয়ারিং" বলা হয়।
লেবেল : তত্ত্বাবধানে শ্রেণীবিভাগের সমস্যায় "ক্লাস" বা সঠিক উত্তরের অন্য নাম
শেখার হার : গ্রেডিয়েন্টের ভগ্নাংশ যার দ্বারা প্রশিক্ষণ লুপের প্রতিটি পুনরাবৃত্তিতে ওজন এবং পক্ষপাতগুলি আপডেট করা হয়।
logits : অ্যাক্টিভেশন ফাংশন প্রয়োগ করার আগে নিউরনের একটি স্তরের আউটপুটকে "লগিট" বলা হয়। শব্দটি "লজিস্টিক ফাংশন" ওরফে "সিগময়েড ফাংশন" থেকে এসেছে যা সবচেয়ে জনপ্রিয় অ্যাক্টিভেশন ফাংশন হিসাবে ব্যবহৃত হত। "লজিস্টিক ফাংশনের আগে নিউরন আউটপুট" কে সংক্ষিপ্ত করে "লজিট" করা হয়েছিল।
ক্ষতি : সঠিক উত্তরের সাথে নিউরাল নেটওয়ার্ক আউটপুট তুলনা করার ত্রুটি ফাংশন
নিউরন : এর ইনপুটগুলির ওজনযুক্ত যোগফল গণনা করে, একটি পক্ষপাত যোগ করে এবং একটি সক্রিয়করণ ফাংশনের মাধ্যমে ফলাফলকে ফিড করে।
ওয়ান-হট এনকোডিং : 5 এর মধ্যে 3 ক্লাস 5টি উপাদানের ভেক্টর হিসাবে এনকোড করা হয়েছে, 3য়টি ব্যতীত সমস্ত শূন্য যা 1।
relu : সংশোধনকৃত লিনিয়ার ইউনিট। নিউরনের জন্য একটি জনপ্রিয় অ্যাক্টিভেশন ফাংশন।
সিগমায়েড : আরেকটি অ্যাক্টিভেশন ফাংশন যা জনপ্রিয় ছিল এবং এখনও বিশেষ ক্ষেত্রে কার্যকর।
সফটম্যাক্স : একটি বিশেষ অ্যাক্টিভেশন ফাংশন যা একটি ভেক্টরের উপর কাজ করে, বৃহত্তম উপাদান এবং অন্য সকলের মধ্যে পার্থক্য বাড়ায় এবং ভেক্টরটিকে 1 এর সমষ্টিতে স্বাভাবিক করে তোলে যাতে এটি সম্ভাব্যতার ভেক্টর হিসাবে ব্যাখ্যা করা যায়। ক্লাসিফায়ারে শেষ ধাপ হিসেবে ব্যবহৃত হয়।
tensor : একটি "টেনসর" একটি ম্যাট্রিক্সের মত কিন্তু মাত্রার একটি ইচ্ছামত সংখ্যা সহ। একটি 1-মাত্রিক টেনসর একটি ভেক্টর। একটি 2-মাত্রা টেনসর একটি ম্যাট্রিক্স। এবং তারপরে আপনার 3, 4, 5 বা তার বেশি মাত্রা সহ টেনসর থাকতে পারে।
অধ্যয়নের নোটবুকে ফিরে আসুন এবং এইবার, আসুন কোডটি পড়ি।
আসুন এই নোটবুকের সমস্ত কক্ষের মাধ্যমে যান।
সেল "প্যারামিটার"
ব্যাচের আকার, প্রশিক্ষণ যুগের সংখ্যা এবং ডেটা ফাইলের অবস্থান এখানে সংজ্ঞায়িত করা হয়েছে। ডেটা ফাইলগুলি একটি Google ক্লাউড স্টোরেজ (GCS) বালতিতে হোস্ট করা হয় যার কারণে তাদের ঠিকানা gs:// দিয়ে শুরু হয়
সেল "আমদানি"
সমস্ত প্রয়োজনীয় পাইথন লাইব্রেরি এখানে আমদানি করা হয়েছে, যার মধ্যে TensorFlow এবং এছাড়াও ভিজ্যুয়ালাইজেশনের জন্য matplotlib রয়েছে।
সেল " ভিজ্যুয়ালাইজেশন ইউটিলিটিগুলি [আমার চালান] "
এই কক্ষে অরুচিকর ভিজ্যুয়ালাইজেশন কোড রয়েছে। এটি ডিফল্টরূপে ধসে পড়ে তবে আপনি এটি খুলতে পারেন এবং কোডটি দেখতে পারেন যখন আপনার সময় থাকে তখন এটিতে ডাবল ক্লিক করে৷
সেল " tf.data.Dataset: ফাইল পার্স করুন এবং প্রশিক্ষণ এবং বৈধকরণ ডেটাসেট প্রস্তুত করুন "
এই সেলটি ডাটা ফাইলগুলির আকারে MNIST ডেটাসেট লোড করতে tf.data.Dataset API ব্যবহার করে। এই কোষে খুব বেশি সময় ব্যয় করার প্রয়োজন নেই। আপনি যদি tf.data.Dataset API তে আগ্রহী হন, এখানে একটি টিউটোরিয়াল রয়েছে যা এটি ব্যাখ্যা করে: TPU-গতি ডেটা পাইপলাইন । আপাতত, বেসিকগুলি হল:
MNIST ডেটাসেট থেকে ছবি এবং লেবেল (সঠিক উত্তর) 4টি ফাইলে নির্দিষ্ট দৈর্ঘ্যের রেকর্ডে সংরক্ষণ করা হয়। ফাইলগুলি ডেডিকেটেড ফিক্সড রেকর্ড ফাংশন দিয়ে লোড করা যেতে পারে:
imagedataset = tf.data.FixedLengthRecordDataset(image_filename, 28*28, header_bytes=16) আমাদের কাছে এখন ইমেজ বাইটের একটি ডেটাসেট আছে। তারা ইমেজ মধ্যে ডিকোড করা প্রয়োজন. আমরা এটা করার জন্য একটি ফাংশন সংজ্ঞায়িত. ইমেজটি সংকুচিত নয় তাই ফাংশনটির কিছু ডিকোড করার প্রয়োজন নেই ( decode_raw মূলত কিছুই করে না)। তারপরে ছবিটি 0 এবং 1-এর মধ্যে ফ্লোটিং পয়েন্টের মানগুলিতে রূপান্তরিত হয়। আমরা এটিকে এখানে 2D চিত্র হিসাবে পুনরায় আকার দিতে পারি কিন্তু আসলে আমরা এটিকে 28*28 আকারের পিক্সেলের একটি ফ্ল্যাট অ্যারে হিসাবে রাখি কারণ এটিই আমাদের প্রাথমিক ঘন স্তর প্রত্যাশা করে।
def read_image(tf_bytestring):
image = tf.decode_raw(tf_bytestring, tf.uint8)
image = tf.cast(image, tf.float32)/256.0
image = tf.reshape(image, [28*28])
return image আমরা .map ব্যবহার করে ডেটাসেটে এই ফাংশনটি প্রয়োগ করি এবং চিত্রগুলির একটি ডেটাসেট পাই:
imagedataset = imagedataset.map(read_image, num_parallel_calls=16) আমরা লেবেলের জন্য একই ধরনের রিডিং এবং ডিকোডিং করি এবং আমরা ছবি এবং লেবেল একসাথে .zip :
dataset = tf.data.Dataset.zip((imagedataset, labelsdataset))আমাদের কাছে এখন জোড়ার একটি ডেটাসেট আছে (ছবি, লেবেল)। আমাদের মডেল এটাই প্রত্যাশা করে। আমরা এখনও প্রশিক্ষণ ফাংশনে এটি ব্যবহার করার জন্য পুরোপুরি প্রস্তুত নই:
dataset = dataset.cache()
dataset = dataset.shuffle(5000, reshuffle_each_iteration=True)
dataset = dataset.repeat()
dataset = dataset.batch(batch_size)
dataset = dataset.prefetch(tf.data.experimental.AUTOTUNE)tf.data.Dataset API-এ ডেটাসেট প্রস্তুত করার জন্য প্রয়োজনীয় সমস্ত ইউটিলিটি ফাংশন রয়েছে:
.cache RAM এ ডেটাসেট ক্যাশে করে। এটি একটি ছোট ডেটাসেট তাই এটি কাজ করবে। .shuffle 5000 উপাদানের একটি বাফার দিয়ে শাফেল। এটি গুরুত্বপূর্ণ যে প্রশিক্ষণের ডেটা ভালভাবে এলোমেলো করা হয়। .repeat ডেটাসেট লুপ করে। আমরা এটিতে একাধিকবার প্রশিক্ষণ দেব (একাধিক যুগ)। .batch একটি মিনি-ন্যাচে একসাথে একাধিক ছবি এবং লেবেল টানে৷ অবশেষে, .prefetch পরবর্তী ব্যাচ প্রস্তুত করতে CPU ব্যবহার করতে পারে যখন বর্তমান ব্যাচটি GPU-তে প্রশিক্ষিত হচ্ছে।
বৈধতা ডেটাসেট একইভাবে প্রস্তুত করা হয়। আমরা এখন একটি মডেল সংজ্ঞায়িত করতে এবং এই ডেটাসেটটি প্রশিক্ষণের জন্য ব্যবহার করতে প্রস্তুত।
সেল "কেরাস মডেল"
আমাদের সকল মডেল হবে লেয়ারের সোজা ক্রম যাতে আমরা tf.keras.Sequential শৈলী ব্যবহার করতে পারি। প্রাথমিকভাবে এখানে, এটি একটি একক ঘন স্তর। এটিতে 10টি নিউরন রয়েছে কারণ আমরা হস্তলিখিত সংখ্যাগুলিকে 10টি শ্রেণিতে শ্রেণীবদ্ধ করছি। এটি "softmax" অ্যাক্টিভেশন ব্যবহার করে কারণ এটি একটি ক্লাসিফায়ারের শেষ স্তর।
একটি কেরাস মডেলের ইনপুটগুলির আকারও জানতে হবে। tf.keras.layers.Input এটি সংজ্ঞায়িত করতে ব্যবহার করা যেতে পারে। এখানে, ইনপুট ভেক্টর হল 28*28 দৈর্ঘ্যের পিক্সেল মানের সমতল ভেক্টর।
model = tf.keras.Sequential(
[
tf.keras.layers.Input(shape=(28*28,)),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
# print model layers
model.summary()
# utility callback that displays training curves
plot_training = PlotTraining(sample_rate=10, zoom=1) মডেল কনফিগার করা কেরাসে model.compile ফাংশন ব্যবহার করে করা হয়। এখানে আমরা মৌলিক অপ্টিমাইজার 'sgd' (স্টোকাস্টিক গ্রেডিয়েন্ট ডিসেন্ট) ব্যবহার করি। একটি শ্রেণীবিন্যাস মডেলের জন্য একটি ক্রস-এনট্রপি লস ফাংশন প্রয়োজন, কেরাসে 'categorical_crossentropy' বলা হয়। অবশেষে, আমরা মডেলটিকে 'accuracy' মেট্রিক গণনা করতে বলি, যা সঠিকভাবে শ্রেণীবদ্ধ চিত্রগুলির শতাংশ।
Keras খুব সুন্দর model.summary() ইউটিলিটি অফার করে যা আপনার তৈরি করা মডেলের বিবরণ প্রিন্ট করে। আপনার সদয় প্রশিক্ষক PlotTraining ইউটিলিটি ("ভিজ্যুয়ালাইজেশন ইউটিলিটিস" কক্ষে সংজ্ঞায়িত) যোগ করেছেন যা প্রশিক্ষণের সময় বিভিন্ন প্রশিক্ষণ বক্ররেখা প্রদর্শন করবে।
সেল "ট্রেন এবং মডেল যাচাই করুন"
model.fit এ কল করে এবং প্রশিক্ষণ এবং বৈধতা ডেটাসেট উভয়ই পাস করার মাধ্যমে প্রশিক্ষণটি এখানেই ঘটে। ডিফল্টরূপে, কেরাস প্রতিটি যুগের শেষে যাচাইকরণের একটি রাউন্ড চালায়।
model.fit(training_dataset, steps_per_epoch=steps_per_epoch, epochs=EPOCHS,
validation_data=validation_dataset, validation_steps=1,
callbacks=[plot_training])কেরাসে, কলব্যাক ব্যবহার করে প্রশিক্ষণের সময় কাস্টম আচরণ যোগ করা সম্ভব। এই কর্মশালার জন্য গতিশীলভাবে আপডেট করার প্রশিক্ষণ প্লটটি এভাবেই বাস্তবায়িত হয়েছিল।
সেল "ভিজুয়ালাইজ ভবিষ্যদ্বাণী"
মডেলটি প্রশিক্ষিত হয়ে গেলে, আমরা model.predict() কল করে এটি থেকে ভবিষ্যদ্বাণী পেতে পারি :
probabilities = model.predict(font_digits, steps=1)
predicted_labels = np.argmax(probabilities, axis=1)এখানে আমরা একটি পরীক্ষা হিসাবে স্থানীয় ফন্ট থেকে রেন্ডার করা মুদ্রিত সংখ্যাগুলির একটি সেট প্রস্তুত করেছি। মনে রাখবেন যে নিউরাল নেটওয়ার্ক তার চূড়ান্ত "softmax" থেকে 10 সম্ভাব্যতার একটি ভেক্টর প্রদান করে। লেবেল পেতে, আমাদের খুঁজে বের করতে হবে কোন সম্ভাবনা সবচেয়ে বেশি। নম্পি লাইব্রেরি থেকে np.argmax এটি করে।
কেন axis=1 প্যারামিটার প্রয়োজন তা বোঝার জন্য, অনুগ্রহ করে মনে রাখবেন যে আমরা 128টি চিত্রের একটি ব্যাচ প্রক্রিয়া করেছি এবং তাই মডেলটি সম্ভাব্যতার 128 ভেক্টর প্রদান করে। আউটপুট টেনসরের আকৃতি হল [128, 10]। আমরা প্রতিটি চিত্রের জন্য 10টি সম্ভাব্যতা জুড়ে আর্গম্যাক্স গণনা করছি, এইভাবে axis=1 (প্রথম অক্ষটি 0)।
এই সাধারণ মডেলটি ইতিমধ্যে 90% সংখ্যাকে স্বীকৃতি দেয়। খারাপ নয়, তবে আপনি এখন এটি উল্লেখযোগ্যভাবে উন্নত করবেন।
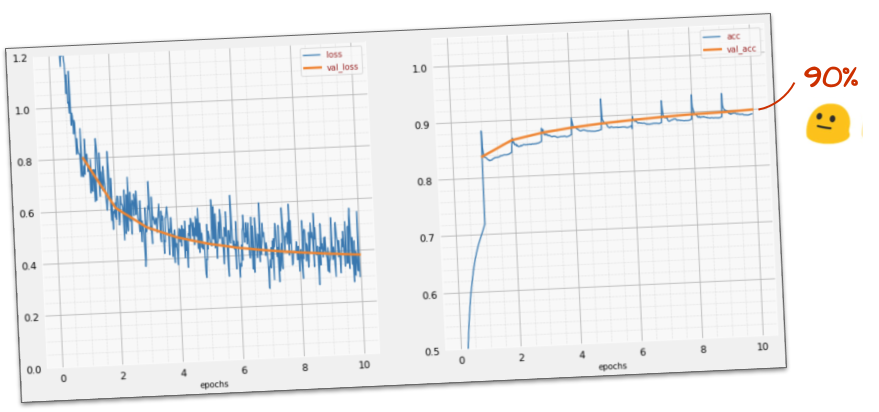

স্বীকৃতির সঠিকতা উন্নত করতে আমরা নিউরাল নেটওয়ার্কে আরও স্তর যুক্ত করব।
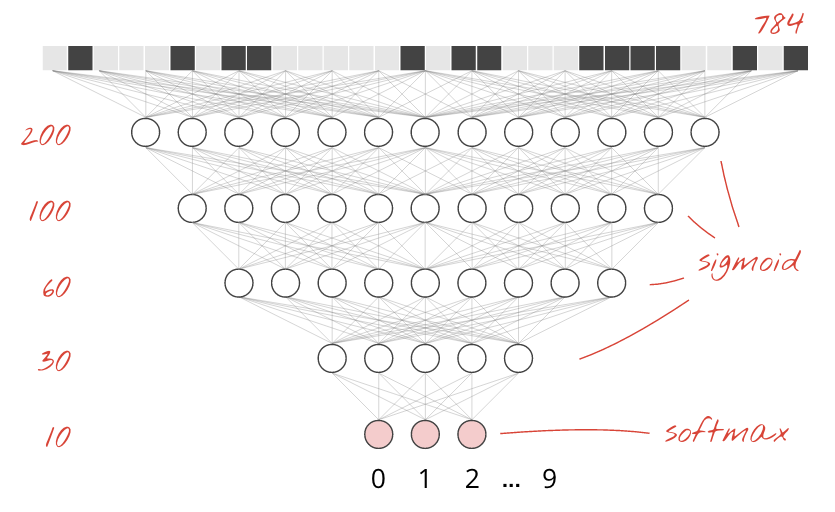
আমরা সফটম্যাক্সকে শেষ স্তরে অ্যাক্টিভেশন ফাংশন হিসাবে রাখি কারণ এটিই শ্রেণিবিন্যাসের জন্য সবচেয়ে ভাল কাজ করে। মধ্যবর্তী স্তরগুলিতে তবে আমরা সবচেয়ে ক্লাসিক্যাল অ্যাক্টিভেশন ফাংশন ব্যবহার করব: সিগমায়েড:
উদাহরণস্বরূপ, আপনার মডেলটি এইরকম দেখতে পারে (কমাগুলি ভুলে যাবেন না, tf.keras.Sequential স্তরগুলির একটি কমা দ্বারা পৃথক করা তালিকা নেয়):
model = tf.keras.Sequential(
[
tf.keras.layers.Input(shape=(28*28,)),
tf.keras.layers.Dense(200, activation='sigmoid'),
tf.keras.layers.Dense(60, activation='sigmoid'),
tf.keras.layers.Dense(10, activation='softmax')
])আপনার মডেলের "সারাংশ" দেখুন। এটিতে এখন কমপক্ষে 10 গুণ বেশি পরামিতি রয়েছে। এটা 10x ভাল হওয়া উচিত! কিন্তু কিছু কারণে, এটা হয় না ...
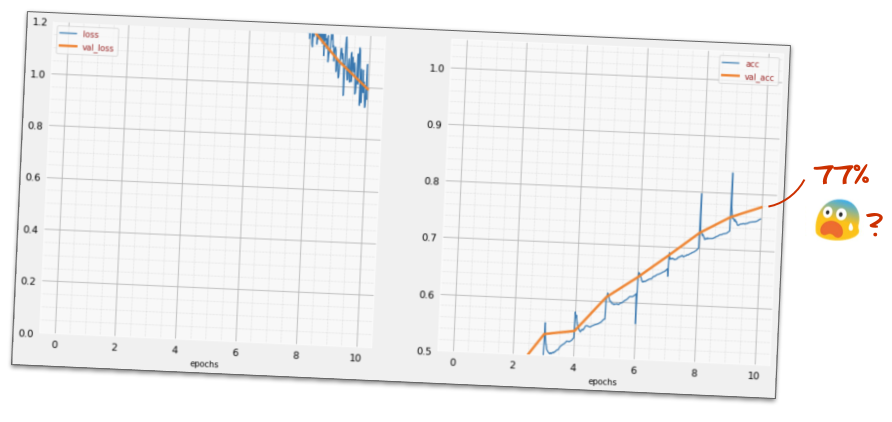
ক্ষতিটা ছাদ দিয়েও গুলি করেছে বলে মনে হচ্ছে। কিছু একদম ঠিক নয়।
আপনি সবেমাত্র নিউরাল নেটওয়ার্কের অভিজ্ঞতা পেয়েছেন, যেমনটি লোকেরা 80 এবং 90 এর দশকে তাদের ডিজাইন করত। আশ্চর্যের কিছু নেই যে তারা তথাকথিত "এআই শীত" শুরু করে ধারণাটি ছেড়ে দিয়েছে। প্রকৃতপক্ষে, আপনি স্তরগুলি যুক্ত করার সাথে সাথে, নিউরাল নেটওয়ার্কগুলিকে একত্রিত হতে আরও বেশি সমস্যা হয়।
দেখা যাচ্ছে যে অনেক স্তর সহ গভীর নিউরাল নেটওয়ার্কগুলি (20, 50, এমনকি 100টি আজ) সত্যিই ভাল কাজ করতে পারে, তাদের একত্রিত করার জন্য কয়েকটি গাণিতিক নোংরা কৌশল সরবরাহ করে। এই সহজ কৌশলগুলির আবিষ্কার 2010-এর দশকে গভীর শিক্ষার পুনর্জাগরণের অন্যতম কারণ।
RELU সক্রিয়করণ

সিগময়েড অ্যাক্টিভেশন ফাংশন আসলে গভীর নেটওয়ার্কে বেশ সমস্যাযুক্ত। এটি 0 এবং 1 এর মধ্যে সমস্ত মান স্কোয়াশ করে এবং আপনি যখন এটি বারবার করেন, তখন নিউরন আউটপুট এবং তাদের গ্রেডিয়েন্ট সম্পূর্ণরূপে অদৃশ্য হয়ে যেতে পারে। এটি ঐতিহাসিক কারণে উল্লেখ করা হয়েছিল, তবে আধুনিক নেটওয়ার্কগুলি RELU (রেক্টিফায়েড লিনিয়ার ইউনিট) ব্যবহার করে যা দেখতে এইরকম:
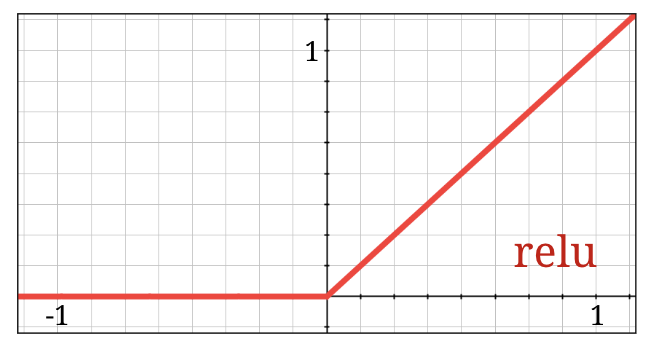
অন্যদিকে relu-এর একটি ডেরিভেটিভ আছে 1, অন্তত ডান পাশে। RELU অ্যাক্টিভেশনের মাধ্যমে, এমনকি কিছু নিউরন থেকে আসা গ্রেডিয়েন্ট শূন্য হতে পারলেও, অন্যরা সবসময় একটি পরিষ্কার নন-জিরো গ্রেডিয়েন্ট দেবে এবং প্রশিক্ষণ একটি ভাল গতিতে চলতে পারে।
একটি ভাল অপ্টিমাইজার
এখানের মতো খুব উচ্চ-মাত্রিক স্থানগুলিতে - আমাদের 10K ওজন এবং পক্ষপাতের ক্রম রয়েছে - "স্যাডল পয়েন্ট" ঘন ঘন হয়। এগুলি এমন বিন্দু যা স্থানীয় মিনিমা নয়, তবে যেখানে গ্রেডিয়েন্ট তবুও শূন্য এবং গ্রেডিয়েন্ট ডিসেন্ট অপ্টিমাইজার সেখানে আটকে থাকে। TensorFlow-এ উপলব্ধ অপ্টিমাইজারগুলির একটি সম্পূর্ণ অ্যারে রয়েছে, যার মধ্যে কিছু রয়েছে যেগুলি প্রচুর পরিমাণে জড়তার সাথে কাজ করে এবং নিরাপদে অতীতের স্যাডল পয়েন্টগুলিতে যাত্রা করবে।
এলোমেলো প্রাথমিককরণ
প্রশিক্ষণের আগে ওজনের পক্ষপাত শুরু করার শিল্পটি নিজেই গবেষণার একটি ক্ষেত্র, এই বিষয়ে প্রকাশিত অসংখ্য গবেষণাপত্র সহ। আপনি এখানে কেরাসে উপলব্ধ সমস্ত ইনিশিয়ালাইজার দেখতে পারেন। সৌভাগ্যবশত, কেরাস ডিফল্টরূপে সঠিক কাজ করে এবং 'glorot_uniform' ইনিশিয়ালাইজার ব্যবহার করে যা প্রায় সব ক্ষেত্রেই সেরা।
আপনার জন্য কিছুই করার নেই, যেহেতু কেরাস ইতিমধ্যেই সঠিক কাজ করে।
NaN???
ক্রস-এনট্রপি সূত্রে একটি লগারিদম জড়িত এবং লগ(0) একটি সংখ্যা নয় (NaN, যদি আপনি পছন্দ করেন তবে একটি সংখ্যাগত ক্র্যাশ)। ক্রস-এনট্রপিতে ইনপুট কি 0 হতে পারে? ইনপুট softmax থেকে আসে যা মূলত একটি সূচকীয় এবং একটি সূচক কখনই শূন্য হয় না। তাই আমরা নিরাপদ!
সত্যিই? গণিতের সুন্দর বিশ্বে, আমরা নিরাপদ থাকব, কিন্তু কম্পিউটার জগতে, exp(-150), float32 ফরম্যাটে উপস্থাপিত, এটি যতটা শূন্য হয় এবং ক্রস-এনট্রপি ক্র্যাশ হয়।
সৌভাগ্যবশত, এখানেও আপনার করার কিছু নেই, যেহেতু কেরাস এটির যত্ন নেয় এবং সংখ্যার স্থিতিশীলতা নিশ্চিত করতে এবং ভয়ঙ্কর NaN এড়াতে বিশেষভাবে সতর্কতার সাথে ক্রস-এনট্রপি অনুসরণ করে সফটম্যাক্স গণনা করে।
সফলতা?
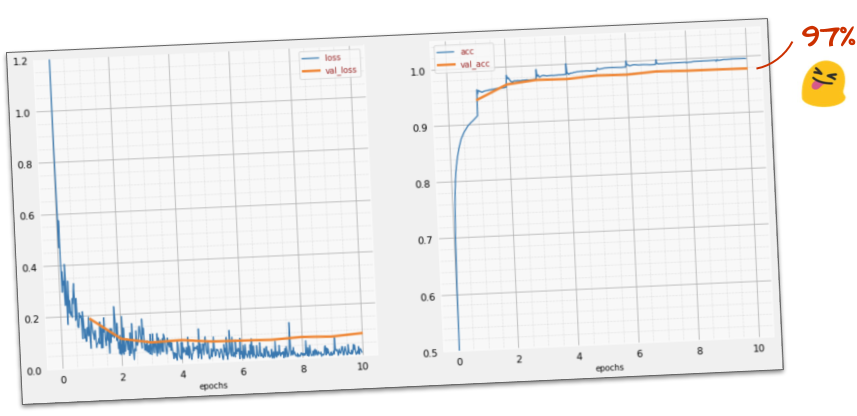
আপনার এখন 97% নির্ভুলতা পাওয়া উচিত। এই কর্মশালার লক্ষ্য হল উল্লেখযোগ্যভাবে 99% এর উপরে অর্জন করা তাই আসুন চালিয়ে যাই।
আপনি যদি আটকে থাকেন তবে এই মুহুর্তে সমাধানটি এখানে রয়েছে:
হয়তো আমরা দ্রুত প্রশিক্ষণের চেষ্টা করতে পারি? অ্যাডাম অপটিমাইজারে ডিফল্ট শেখার হার হল 0.001। আসুন এটি বাড়ানোর চেষ্টা করি।
দ্রুত যাওয়া খুব একটা সাহায্য করবে বলে মনে হয় না আর এই সব গোলমাল কিসের?
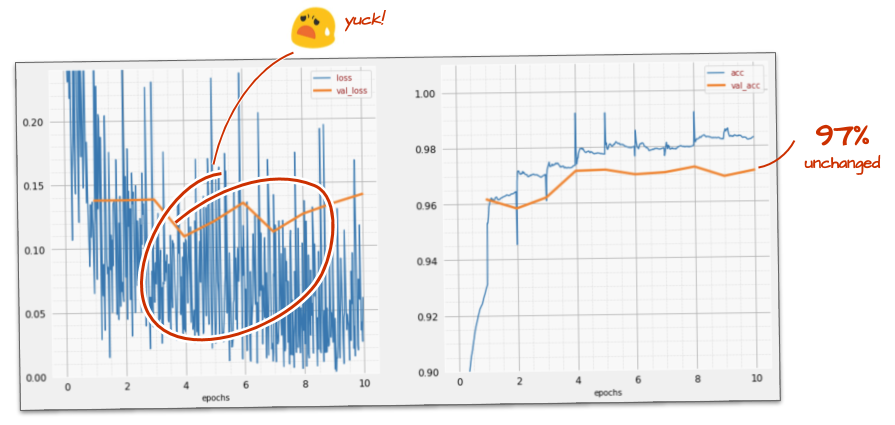
প্রশিক্ষণ বক্ররেখা সত্যিই শোরগোল এবং উভয় বৈধকরণ বক্ররেখার দিকে তাকান: তারা উপরে এবং নিচে লাফিয়ে উঠছে। এর মানে আমরা খুব দ্রুত যাচ্ছি। আমরা আমাদের আগের গতিতে ফিরে যেতে পারি, তবে আরও ভাল উপায় আছে।

ভাল সমাধান হল দ্রুত শুরু করা এবং শেখার হার দ্রুত ক্ষয় করা। কেরাসে, আপনি tf.keras.callbacks.LearningRateScheduler কলব্যাক দিয়ে এটি করতে পারেন।
কপি-পেস্ট করার জন্য দরকারী কোড:
# lr decay function
def lr_decay(epoch):
return 0.01 * math.pow(0.6, epoch)
# lr schedule callback
lr_decay_callback = tf.keras.callbacks.LearningRateScheduler(lr_decay, verbose=True)
# important to see what you are doing
plot_learning_rate(lr_decay, EPOCHS)আপনার তৈরি করা lr_decay_callback ব্যবহার করতে ভুলবেন না। model.fit কলব্যাকের তালিকায় এটি যোগ করুন:
model.fit(..., callbacks=[plot_training, lr_decay_callback])এই সামান্য পরিবর্তনের প্রভাব দর্শনীয়। আপনি দেখতে পাচ্ছেন যে বেশিরভাগ গোলমাল চলে গেছে এবং পরীক্ষার নির্ভুলতা এখন স্থিতিশীল উপায়ে 98% এর উপরে।
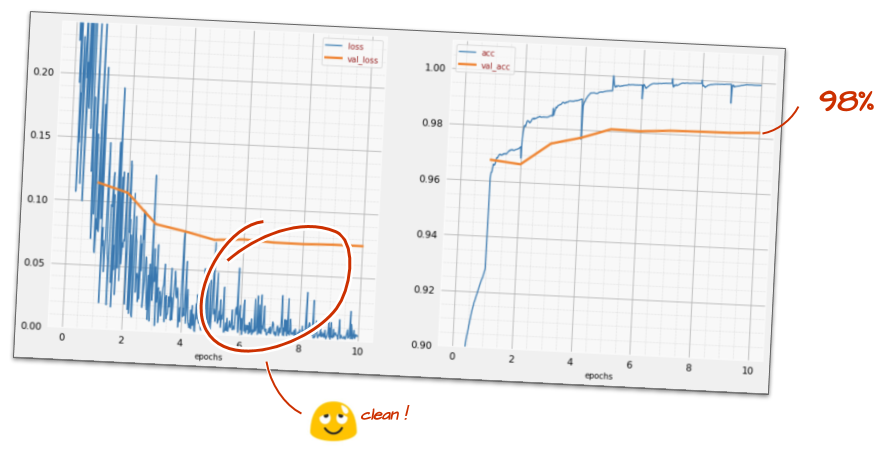
মডেলটি এখন সুন্দরভাবে রূপান্তরিত হচ্ছে বলে মনে হচ্ছে। এর আরও গভীরে যাওয়ার চেষ্টা করা যাক।
এটা সাহায্য করে?
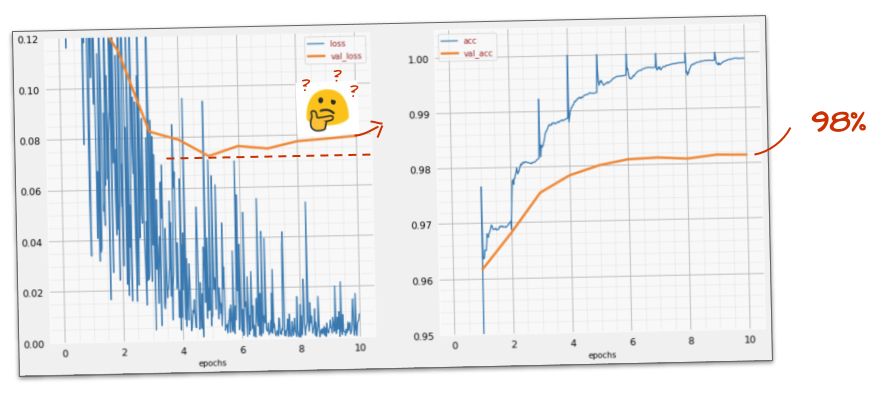
সত্যিই নয়, নির্ভুলতা এখনও 98% এ আটকে আছে এবং বৈধতা ক্ষতির দিকে তাকান। এটা উঠে যাচ্ছে! শেখার অ্যালগরিদম শুধুমাত্র প্রশিক্ষণ ডেটার উপর কাজ করে এবং সেই অনুযায়ী প্রশিক্ষণের ক্ষতিকে অপ্টিমাইজ করে। এটি কখনই বৈধকরণের ডেটা দেখতে পায় না তাই এটি আশ্চর্যজনক নয় যে কিছুক্ষণ পরে এটির কাজটি বৈধকরণের ক্ষতির উপর আর প্রভাব ফেলে না যা ড্রপ করা বন্ধ করে দেয় এবং কখনও কখনও এমনকি ব্যাক আপ বাউন্স করে।
এটি অবিলম্বে আপনার মডেলের বাস্তব-বিশ্বের স্বীকৃতির ক্ষমতাকে প্রভাবিত করে না, তবে এটি আপনাকে অনেক পুনরাবৃত্তি চালানো থেকে বাধা দেবে এবং সাধারণত একটি চিহ্ন যে প্রশিক্ষণটি আর ইতিবাচক প্রভাব ফেলছে না।

এই সংযোগ বিচ্ছিন্নকে সাধারণত "ওভারফিটিং" বলা হয় এবং আপনি যখন এটি দেখতে পান, আপনি "ড্রপআউট" নামে একটি নিয়মিতকরণ কৌশল প্রয়োগ করার চেষ্টা করতে পারেন। ড্রপআউট কৌশল প্রতিটি প্রশিক্ষণের পুনরাবৃত্তিতে এলোমেলো নিউরনগুলিকে গুলি করে।
এটা কি কাজ করেছে?
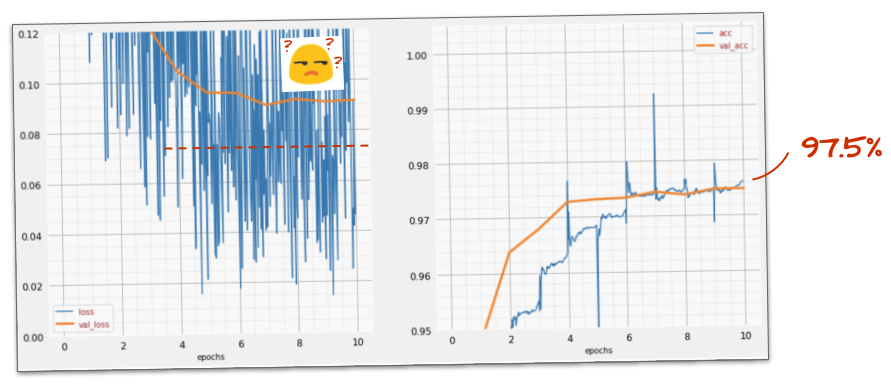
শব্দটি আবার উপস্থিত হয় (ড্রপআউট কীভাবে কাজ করে তা আশ্চর্যজনকভাবে দেওয়া)। বৈধতা ক্ষতি আর ক্রাইপ আপ হচ্ছে বলে মনে হয় না, তবে এটি ড্রপআউট ছাড়াই সামগ্রিকভাবে বেশি। এবং বৈধতা নির্ভুলতা কিছুটা কমেছে। এটি মোটামুটি হতাশার ফলাফল।
দেখে মনে হচ্ছে ড্রপআউট সঠিক সমাধান ছিল না, বা সম্ভবত "ওভারফিটিং" আরও জটিল ধারণা এবং এর কিছু কারণগুলি "ড্রপআউট" ফিক্সের পক্ষে উপযুক্ত নয়?
"ওভারফিটিং" কী? যখন কোনও নিউরাল নেটওয়ার্ক "খারাপভাবে" শিখেন, এমনভাবে যা প্রশিক্ষণের উদাহরণগুলির জন্য কাজ করে তবে বাস্তব-বিশ্বের ডেটাতে এতটা ভাল নয়। ড্রপআউটের মতো নিয়মিতকরণের কৌশল রয়েছে যা এটিকে আরও ভাল উপায়ে শিখতে বাধ্য করতে পারে তবে অতিরিক্ত পরিমাণে আরও গভীর শিকড় রয়েছে।

বেসিক ওভারফিটিং ঘটে যখন কোনও নিউরাল নেটওয়ার্কের হাতের সমস্যার জন্য অনেক ডিগ্রি স্বাধীনতা থাকে। কল্পনা করুন যে আমাদের কাছে এতগুলি নিউরন রয়েছে যে নেটওয়ার্কগুলি আমাদের সমস্ত প্রশিক্ষণের চিত্রগুলি সেগুলিতে সঞ্চয় করতে পারে এবং তারপরে প্যাটার্ন ম্যাচিংয়ের মাধ্যমে সেগুলি সনাক্ত করতে পারে। এটি পুরোপুরি বাস্তব-বিশ্বের ডেটাতে ব্যর্থ হবে। একটি নিউরাল নেটওয়ার্ক অবশ্যই কিছুটা সীমাবদ্ধ থাকতে হবে যাতে এটি প্রশিক্ষণের সময় যা শিখতে পারে তা সাধারণীকরণ করতে বাধ্য হয়।
আপনার যদি খুব কম প্রশিক্ষণের ডেটা থাকে তবে এমনকি একটি ছোট নেটওয়ার্ক এটি হৃদয় দিয়ে শিখতে পারে এবং আপনি "ওভারফিটিং" দেখতে পাবেন। সাধারণভাবে বলতে গেলে, নিউরাল নেটওয়ার্কগুলি প্রশিক্ষণের জন্য আপনার সর্বদা প্রচুর ডেটা প্রয়োজন।
পরিশেষে, আপনি যদি বইটির মাধ্যমে সবকিছু করেন তবে তার স্বাধীনতার ডিগ্রিগুলি সীমাবদ্ধ, প্রয়োগকৃত ড্রপআউট এবং প্রচুর ডেটাতে প্রশিক্ষিত হয়েছে তা নিশ্চিত করার জন্য বিভিন্ন আকারের নেটওয়ার্কের সাথে পরীক্ষা -নিরীক্ষা করেছেন আপনি এখনও এমন একটি পারফরম্যান্স স্তরে আটকে থাকতে পারেন যা কোনও উন্নতি করতে সক্ষম বলে মনে হয় না। এর অর্থ হ'ল আপনার নিউরাল নেটওয়ার্ক, বর্তমান আকারে, এখানে আমাদের ক্ষেত্রে যেমন আপনার ডেটা থেকে আরও তথ্য আহরণ করতে সক্ষম নয়।
মনে রাখবেন আমরা কীভাবে আমাদের চিত্রগুলি ব্যবহার করছি, একক ভেক্টরে সমতল? এটি সত্যিই খারাপ ধারণা ছিল। হাতে লেখা অঙ্কগুলি আকার দিয়ে তৈরি এবং আমরা পিক্সেলগুলি সমতল করার সময় আমরা আকারের তথ্যটি বাতিল করে দিয়েছি। তবে, এক ধরণের নিউরাল নেটওয়ার্ক রয়েছে যা শেপ তথ্যের সুবিধা নিতে পারে: কনভোলিউশনাল নেটওয়ার্কগুলি। আমাদের তাদের চেষ্টা করুন।
আপনি যদি আটকে থাকেন তবে এই মুহুর্তে সমাধান এখানে:
সংক্ষেপে
যদি পরবর্তী অনুচ্ছেদে সাহসী সমস্ত শর্তাদি ইতিমধ্যে আপনার কাছে পরিচিত হয় তবে আপনি পরবর্তী অনুশীলনে যেতে পারেন। যদি আপনার সবেমাত্র কনভলিউশনাল নিউরাল নেটওয়ার্কগুলি দিয়ে শুরু হয় তবে দয়া করে পড়ুন।
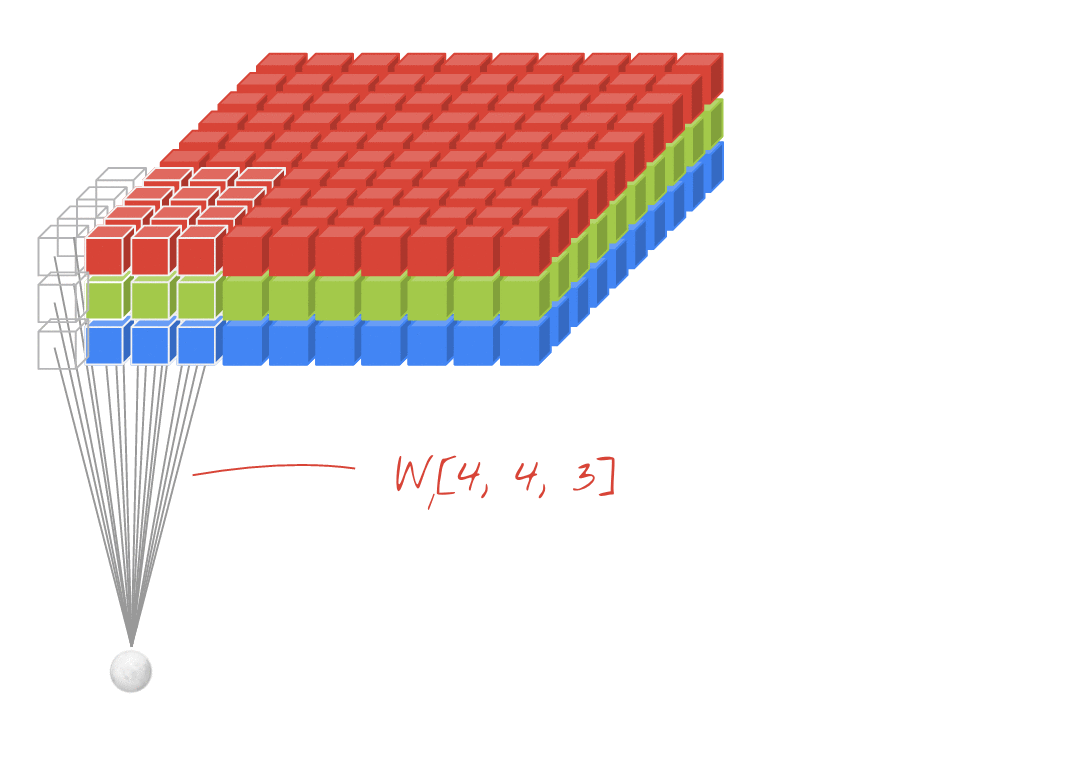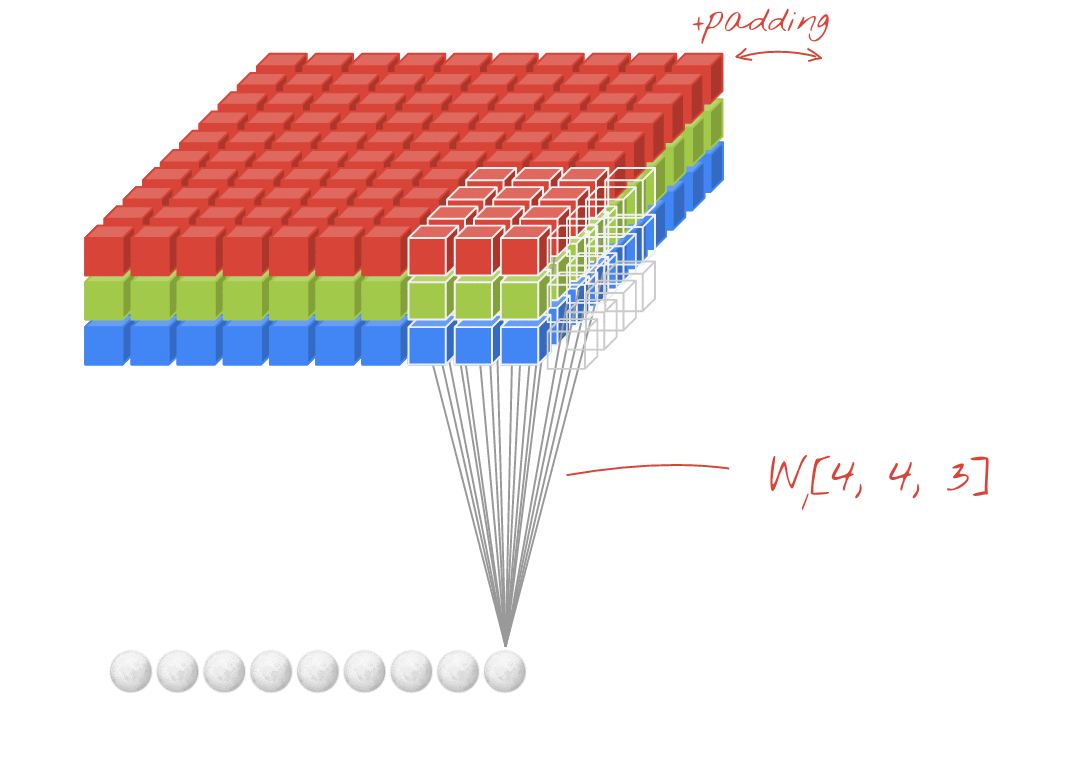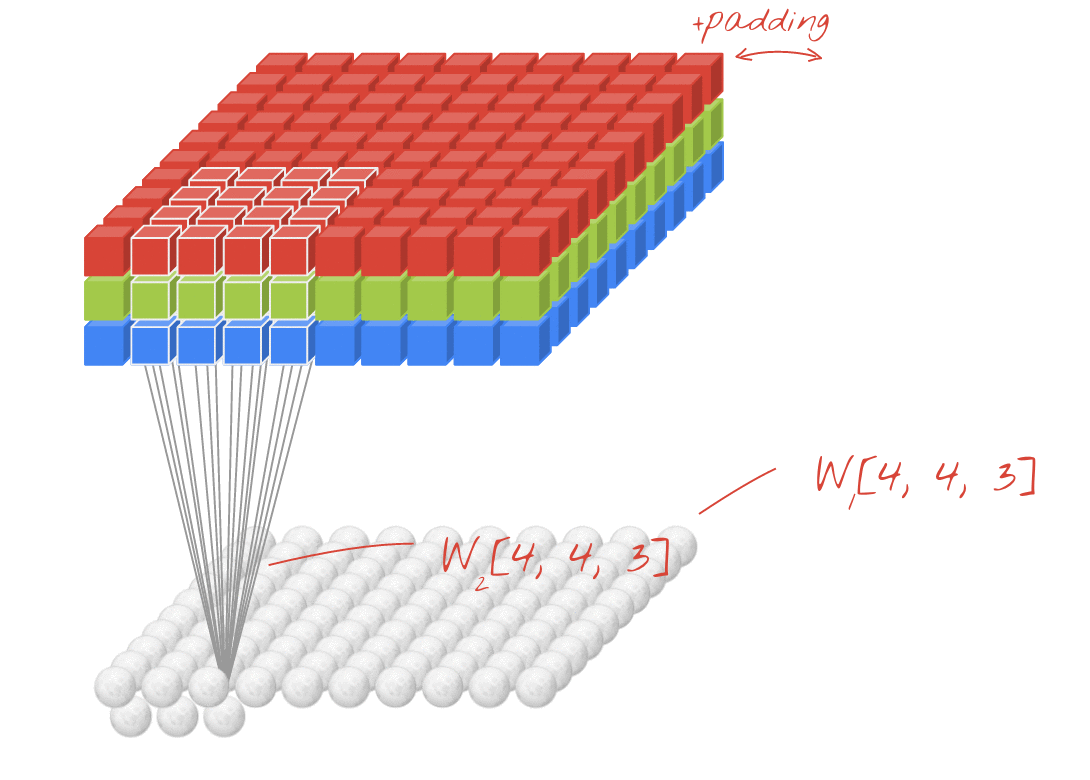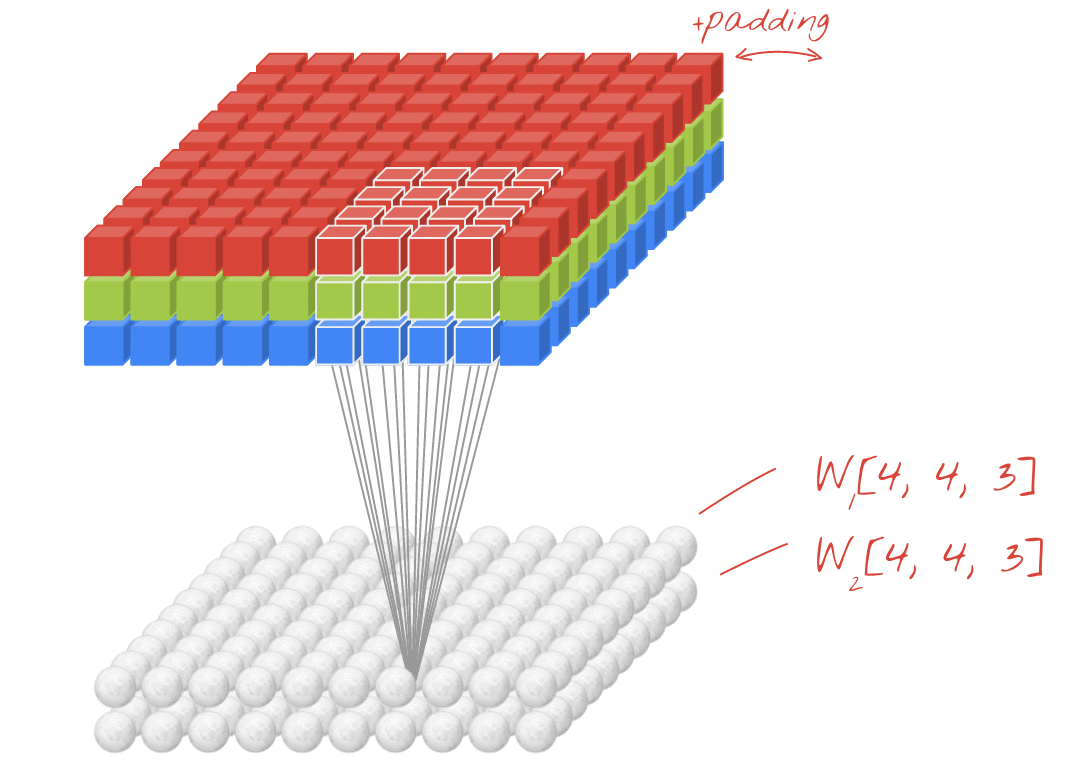
চিত্র: 4x4x3 = 48 প্রতিটি শিখতে পারে এমন দুটি ক্রমাগত ফিল্টার সহ একটি চিত্র ফিল্টার করা।
এভাবেই একটি সাধারণ কনভোলিউশনাল নিউরাল নেটওয়ার্ক কেরাসে দেখায়:
model = tf.keras.Sequential([
tf.keras.layers.Reshape(input_shape=(28*28,), target_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(kernel_size=3, filters=12, activation='relu'),
tf.keras.layers.Conv2D(kernel_size=6, filters=24, strides=2, activation='relu'),
tf.keras.layers.Conv2D(kernel_size=6, filters=32, strides=2, activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10, activation='softmax')
])
একটি কনভোলিউশনাল নেটওয়ার্কের একটি স্তরে, একটি "নিউরন" কেবল চিত্রের একটি ছোট অঞ্চল জুড়ে এর উপরে পিক্সেলের একটি ওজনযুক্ত যোগফল করে। এটি একটি পক্ষপাত যুক্ত করে এবং একটি অ্যাক্টিভেশন ফাংশনের মাধ্যমে যোগফলকে ফিড দেয়, ঠিক যেমন নিয়মিত ঘন স্তরের নিউরন হয়। এই অপারেশনটি একই ওজন ব্যবহার করে পুরো চিত্র জুড়ে পুনরাবৃত্তি হয়। মনে রাখবেন যে ঘন স্তরগুলিতে, প্রতিটি নিউরনের নিজস্ব ওজন ছিল। এখানে, ওজনের একটি একক "প্যাচ" উভয় দিকের চিত্র জুড়ে স্লাইড করে (একটি "কনভোলিউশন")। চিত্রটিতে পিক্সেল যতটা আউটপুট রয়েছে তত বেশি মান রয়েছে (যদিও প্রান্তগুলিতে কিছু প্যাডিং প্রয়োজনীয়)। এটি একটি ফিল্টারিং অপারেশন। উপরের চিত্রটিতে, এটি 4x4x3 = 48 ওজনের একটি ফিল্টার ব্যবহার করে।
তবে, 48 ওজন যথেষ্ট হবে না। স্বাধীনতার আরও ডিগ্রি যুক্ত করতে, আমরা ওজনের একটি নতুন সেট সহ একই অপারেশনটির পুনরাবৃত্তি করি। এটি ফিল্টার আউটপুটগুলির একটি নতুন সেট তৈরি করে। আসুন এটিকে ইনপুট চিত্রের আর, জি, বি চ্যানেলগুলির সাথে সাদৃশ্য দ্বারা আউটপুটগুলির একটি "চ্যানেল" বলি।
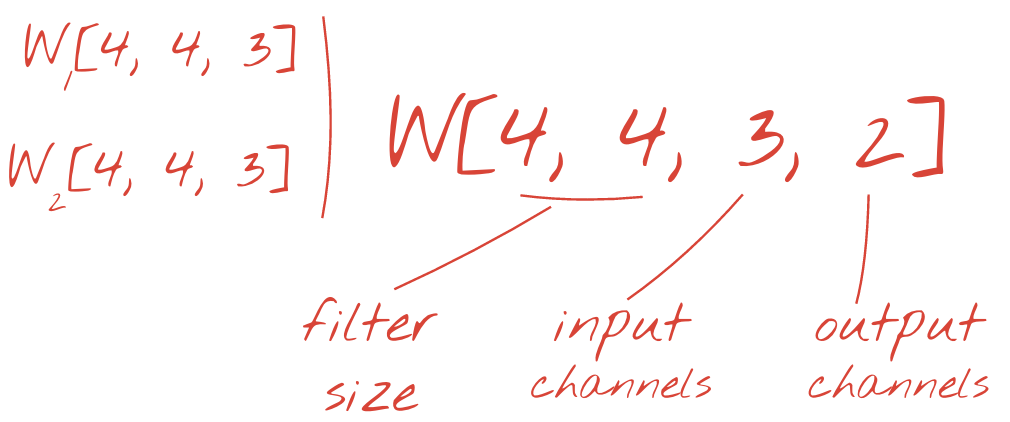
দুটি (বা আরও বেশি) ওজনের সেটগুলি একটি নতুন মাত্রা যুক্ত করে একটি টেনসর হিসাবে সংক্ষিপ্ত করা যেতে পারে। এটি আমাদের একটি কনভোলিউশনাল স্তরটির জন্য ওজন টেনসরের জেনেরিক আকার দেয়। যেহেতু ইনপুট এবং আউটপুট চ্যানেলগুলির সংখ্যা পরামিতি, তাই আমরা কনভোলিউশনাল স্তরগুলি স্ট্যাকিং এবং চেইন শুরু করতে পারি।
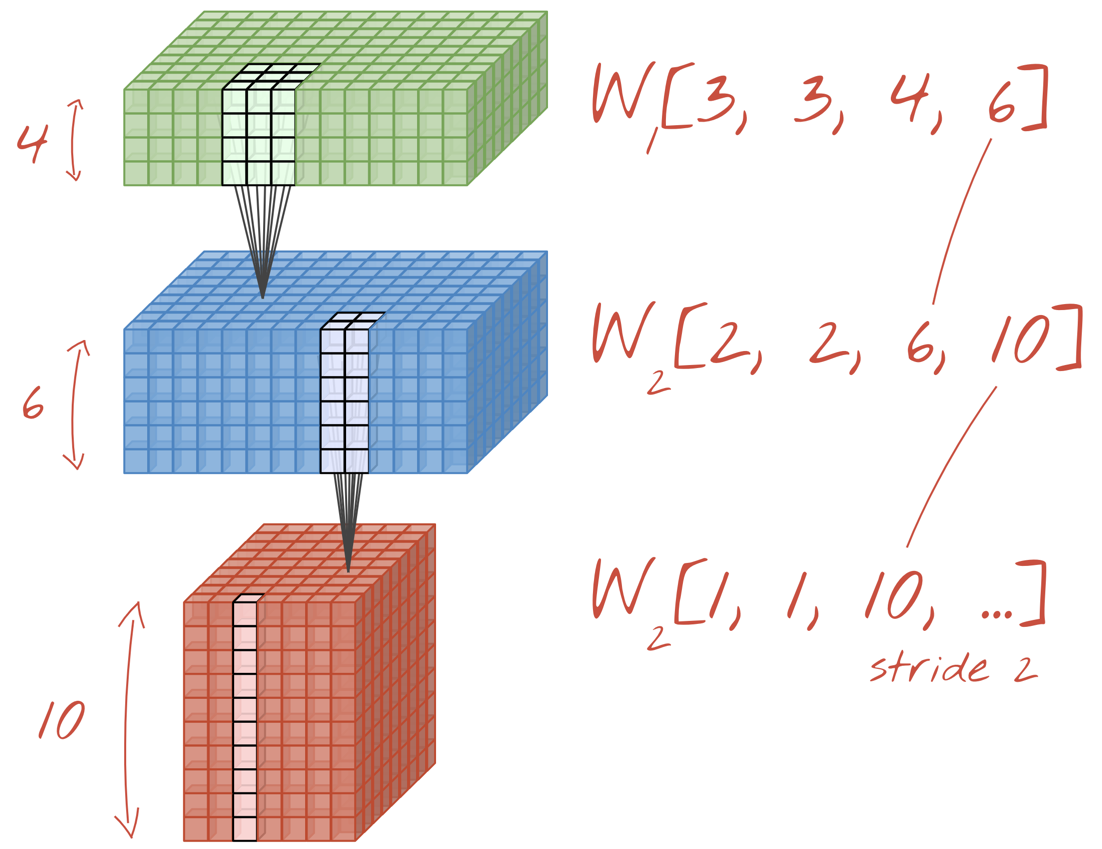
চিত্রণ: একটি কনভোলিউশনাল নিউরাল নেটওয়ার্ক ডেটা "কিউবসকে" ডেটা অন্যান্য "কিউবস" তে রূপান্তর করে।
স্ট্রাইড কনভোলিউশনস, সর্বাধিক পুলিং
2 বা 3 এর স্ট্রাইড সহ কনভোলিউশনগুলি সম্পাদন করে আমরা ফলাফলের ডেটা কিউবটিকে তার অনুভূমিক মাত্রায় সঙ্কুচিত করতে পারি। এটি করার দুটি সাধারণ উপায় রয়েছে:
- স্ট্রাইড কনভোলিউশন: উপরের মতো একটি স্লাইডিং ফিল্টার তবে একটি স্ট্রাইড> 1
- সর্বাধিক পুলিং: সর্বাধিক অপারেশন প্রয়োগ করে একটি স্লাইডিং উইন্ডো (সাধারণত 2x2 প্যাচগুলিতে, প্রতি 2 পিক্সেল পুনরাবৃত্তি করে)

চিত্র: 3 পিক্সেল দ্বারা কম্পিউটিং উইন্ডোটি স্লাইডিং করে ফলাফল কম আউটপুট মানগুলিতে। স্ট্রাইড কনভোলিউশনস বা সর্বাধিক পুলিং (2x2 উইন্ডোতে সর্বোচ্চ 2 এর স্ট্রাইড দ্বারা স্লাইডিং) অনুভূমিক মাত্রাগুলিতে ডেটা কিউব সঙ্কুচিত করার একটি উপায়।
চূড়ান্ত স্তর
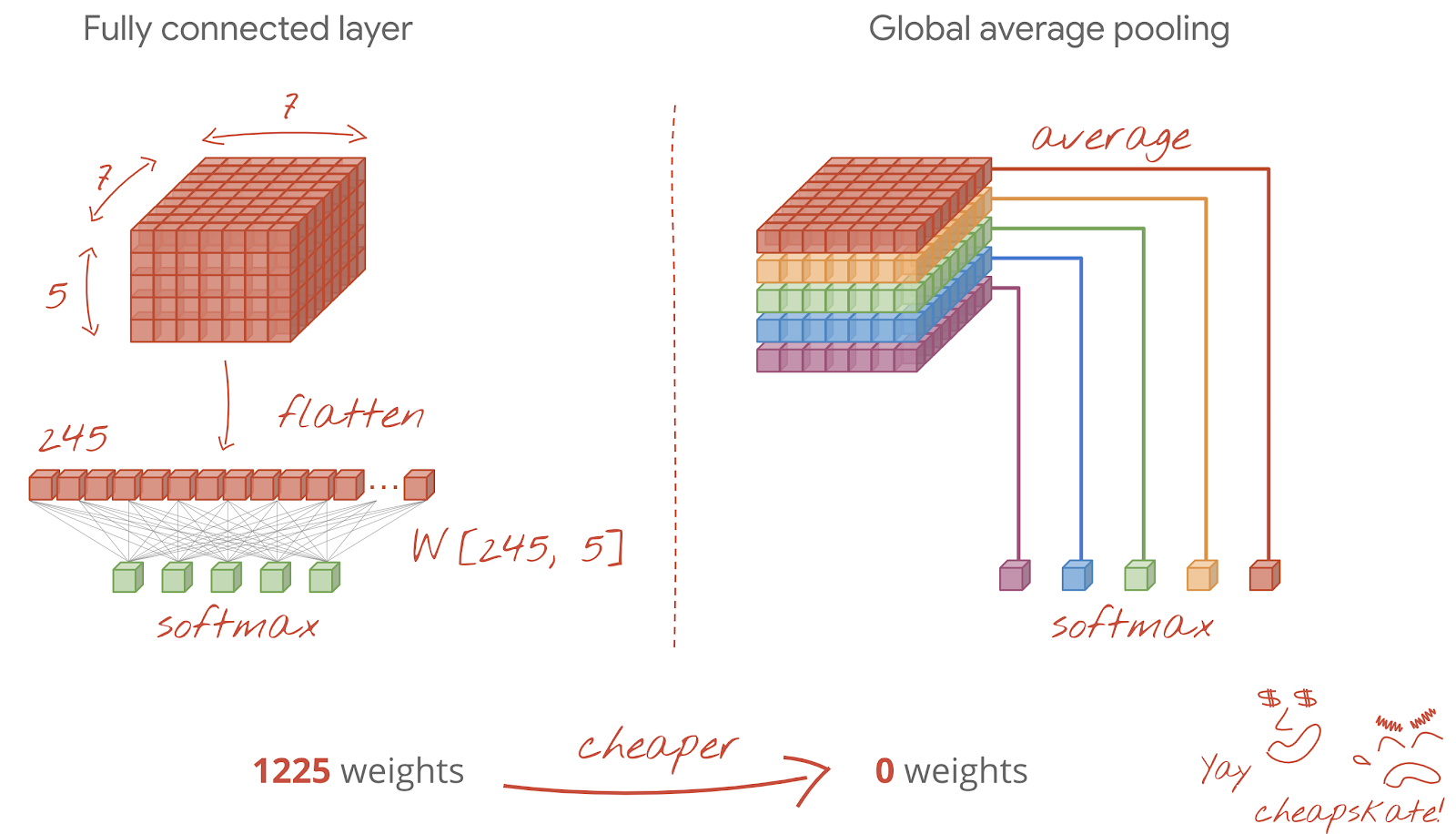
শেষ কনভোলিউশনাল স্তরটির পরে, ডেটা একটি "কিউব" আকারে রয়েছে। চূড়ান্ত ঘন স্তরটির মাধ্যমে এটি খাওয়ানোর দুটি উপায় রয়েছে।
প্রথমটি হ'ল ডেটা কিউবকে একটি ভেক্টরে সমতল করা এবং তারপরে এটি সফটম্যাক্স স্তরে খাওয়ানো। কখনও কখনও, আপনি সফটম্যাক্স স্তরটির আগে একটি ঘন স্তর যুক্ত করতে পারেন। এটি ওজনের সংখ্যার দিক থেকে ব্যয়বহুল হতে থাকে। একটি কনভোলিউশনাল নেটওয়ার্কের শেষে একটি ঘন স্তরটিতে পুরো নিউরাল নেটওয়ার্কের অর্ধেকেরও বেশি ওজন থাকতে পারে।
একটি ব্যয়বহুল ঘন স্তর ব্যবহার করার পরিবর্তে, আমরা আগত ডেটা "কিউব" কে আমাদের ক্লাস হিসাবে যতগুলি অংশে বিভক্ত করতে পারি, তাদের মানগুলি গড় এবং একটি সফটম্যাক্স অ্যাক্টিভেশন ফাংশনের মাধ্যমে এগুলি খাওয়াতে পারি। শ্রেণিবিন্যাসের মাথা তৈরির এই উপায়টির জন্য 0 ওজনের ব্যয় হয়। কেরাসে, এর জন্য একটি স্তর রয়েছে: tf.keras.layers.GlobalAveragePooling2D() ।
হাতের সমস্যার জন্য একটি কনভলিউশনাল নেটওয়ার্ক তৈরি করতে পরবর্তী বিভাগে ঝাঁপুন।
আসুন আমরা হাতে লেখা ডিজিটের স্বীকৃতির জন্য একটি কনভোলিউশনাল নেটওয়ার্ক তৈরি করি। আমরা শীর্ষে তিনটি কনভোলিউশনাল স্তর ব্যবহার করব, আমাদের traditional তিহ্যবাহী সফটম্যাক্স রিডআউট স্তরটি নীচে এবং এগুলিকে একটি সম্পূর্ণ-সংযুক্ত স্তরের সাথে সংযুক্ত করব:
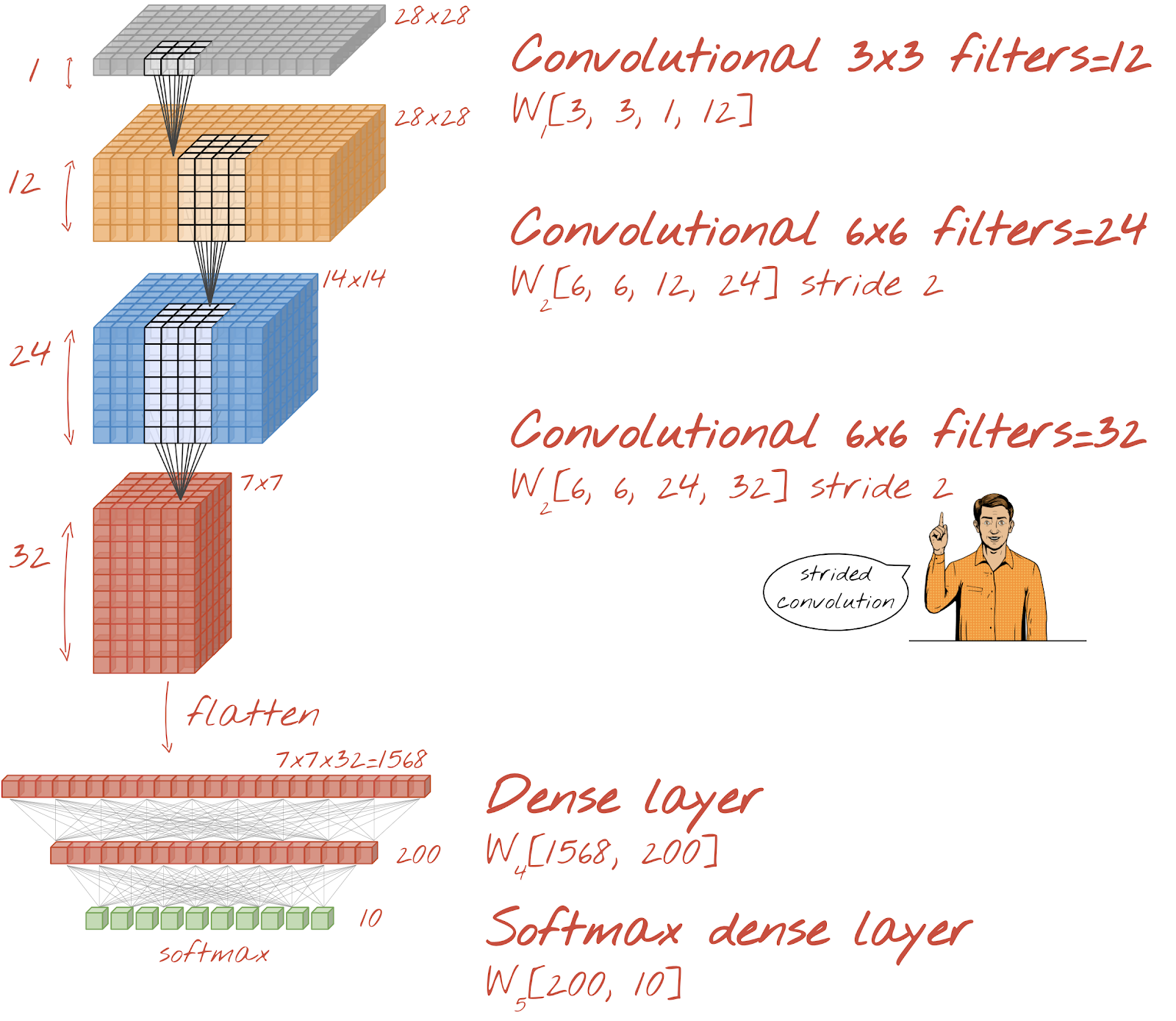
লক্ষ্য করুন যে দ্বিতীয় এবং তৃতীয় কনভোলিউশনাল স্তরগুলির দুটি স্ট্রাইড রয়েছে যা ব্যাখ্যা করে যে তারা কেন আউটপুট মানগুলির সংখ্যা 28x28 থেকে 14x14 এবং তারপরে 7x7 এ নিয়ে আসে।
আসুন কেরাস কোডটি লিখি।
প্রথম কনভোলিউশনাল স্তরটির আগে বিশেষ মনোযোগ প্রয়োজন। প্রকৃতপক্ষে, এটি ডেটাগুলির একটি 3 ডি 'কিউব' প্রত্যাশা করে তবে আমাদের ডেটাসেটটি এখনও অবধি ঘন স্তরগুলির জন্য সেট আপ করা হয়েছে এবং চিত্রগুলির সমস্ত পিক্সেল একটি ভেক্টরে সমতল করা হয়েছে। আমাদের এগুলি আবার 28x28x1 চিত্রগুলিতে পুনরায় আকার দিতে হবে (গ্রেস্কেল চিত্রগুলির জন্য 1 টি চ্যানেল):
tf.keras.layers.Reshape(input_shape=(28*28,), target_shape=(28, 28, 1))আপনি এখন পর্যন্ত tf.keras.layers.Input স্তরটির পরিবর্তে এই লাইনটি ব্যবহার করতে পারেন।
কেরাসে, একটি 'রিলু'-সক্রিয় কনভোলিউশনাল স্তরটির সিনট্যাক্সটি হ'ল:
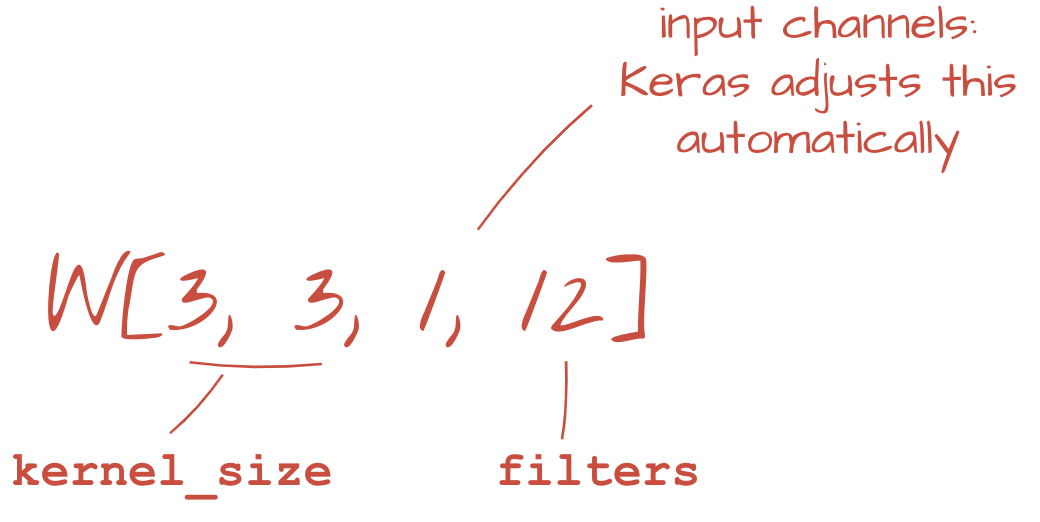
tf.keras.layers.Conv2D(kernel_size=3, filters=12, padding='same', activation='relu')একটি স্ট্রাইড কনভোলিউশনের জন্য, আপনি লিখবেন:
tf.keras.layers.Conv2D(kernel_size=6, filters=24, padding='same', activation='relu', strides=2)কোনও ভেক্টরে ডেটা একটি ঘনক্ষেত্র সমতল করতে যাতে এটি একটি ঘন স্তর দ্বারা গ্রাস করা যায়:
tf.keras.layers.Flatten()এবং ঘন স্তরের জন্য, সিনট্যাক্সটি পরিবর্তন হয়নি:
tf.keras.layers.Dense(200, activation='relu')আপনার মডেল কি 99% নির্ভুলতা বাধা ভঙ্গ করেছে? খুব কাছাকাছি ... তবে বৈধতা ক্ষতির বক্ররেখা দেখুন। এই একটি ঘন্টা রিং কি?
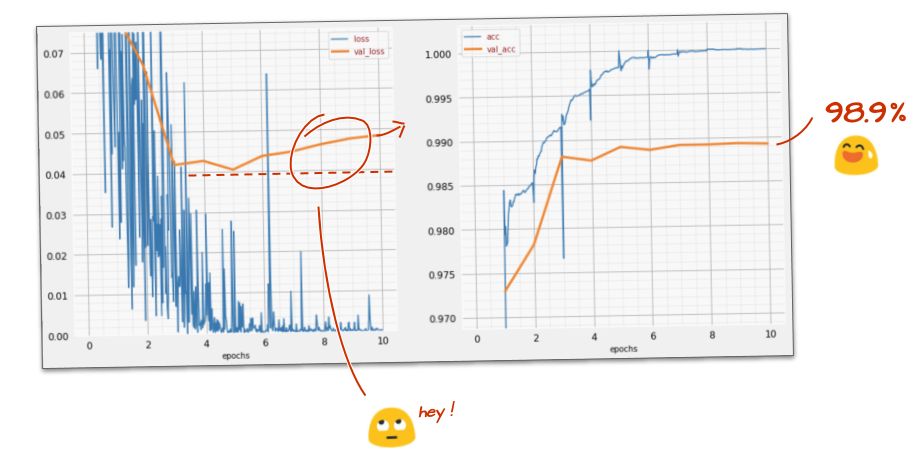
ভবিষ্যদ্বাণীগুলিও দেখুন। প্রথমবারের জন্য, আপনার দেখতে হবে যে বেশিরভাগ 10,000 পরীক্ষার সংখ্যা এখন সঠিকভাবে স্বীকৃত। প্রায় 4½ সারি ভুল তারিখ রয়ে গেছে (10,000 এর মধ্যে প্রায় 110 টি)

আপনি যদি আটকে থাকেন তবে এই মুহুর্তে সমাধান এখানে:
পূর্ববর্তী প্রশিক্ষণ ওভারফিটিংয়ের সুস্পষ্ট লক্ষণগুলি প্রদর্শন করে (এবং এখনও 99% নির্ভুলতার চেয়ে কম)। আমাদের আবার ড্রপআউট চেষ্টা করা উচিত?
এবার কীভাবে গেল?
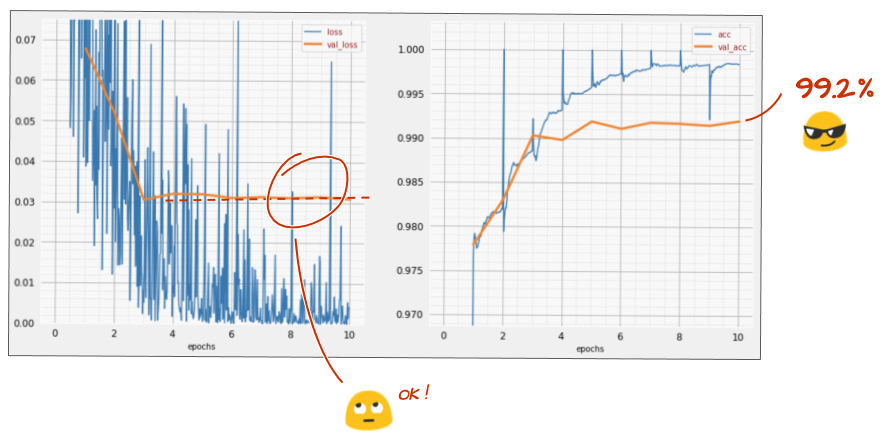
দেখে মনে হচ্ছে ড্রপআউট এবার কাজ করেছে। বৈধতা ক্ষতি আর ক্রাইপিং হয় না এবং চূড়ান্ত নির্ভুলতা 99%এর উপরে হওয়া উচিত। অভিনন্দন!
প্রথমবার আমরা ড্রপআউট প্রয়োগ করার চেষ্টা করেছি, আমরা ভেবেছিলাম আমাদের একটি অতিরিক্ত সমস্যা রয়েছে, যখন বাস্তবে সমস্যাটি নিউরাল নেটওয়ার্কের স্থাপত্যে ছিল। আমরা কনভোলিউশনাল স্তরগুলি ছাড়া আর যেতে পারিনি এবং এ সম্পর্কে ড্রপআউট কিছু করতে পারে না।
এবার, দেখে মনে হচ্ছে যে ওভারফিটিংয়ের কারণ হ'ল সমস্যার কারণ এবং ড্রপআউট আসলে সহায়তা করেছিল। মনে রাখবেন, এমন অনেকগুলি বিষয় রয়েছে যা বৈধতা হ্রাসের ফলে প্রশিক্ষণ এবং বৈধতা হ্রাস বক্ররেখার মধ্যে সংযোগ বিচ্ছিন্ন করতে পারে। ওভারফিটিং (নেটওয়ার্ক দ্বারা খারাপভাবে ব্যবহৃত স্বাধীনতার অনেকগুলি ডিগ্রি) তাদের মধ্যে একটি মাত্র। যদি আপনার ডেটাসেটটি খুব ছোট হয় বা আপনার নিউরাল নেটওয়ার্কের আর্কিটেকচারটি পর্যাপ্ত না হয় তবে আপনি ক্ষতির বক্ররেখাগুলিতে একই রকম আচরণ দেখতে পাবেন, তবে ড্রপআউট কোনও উপকারে আসবে না।

অবশেষে, আসুন ব্যাচের নরমালাইজেশন যুক্ত করার চেষ্টা করি।
এটি তত্ত্ব, বাস্তবে, কেবল কয়েকটি নিয়ম মনে রাখবেন:
আসুন আপাতত বইটি দিয়ে খেলি এবং প্রতিটি নিউরাল নেটওয়ার্ক স্তরটিতে একটি ব্যাচের আদর্শ স্তর যুক্ত করুন তবে শেষটি। এটি শেষ "সফটম্যাক্স" স্তরে যুক্ত করবেন না। এটি সেখানে কার্যকর হবে না।
# Modify each layer: remove the activation from the layer itself.
# Set use_bias=False since batch norm will play the role of biases.
tf.keras.layers.Conv2D(..., use_bias=False),
# Batch norm goes between the layer and its activation.
# The scale factor can be turned off for Relu activation.
tf.keras.layers.BatchNormalization(scale=False, center=True),
# Finish with the activation.
tf.keras.layers.Activation('relu'),এখন নির্ভুলতা কেমন?
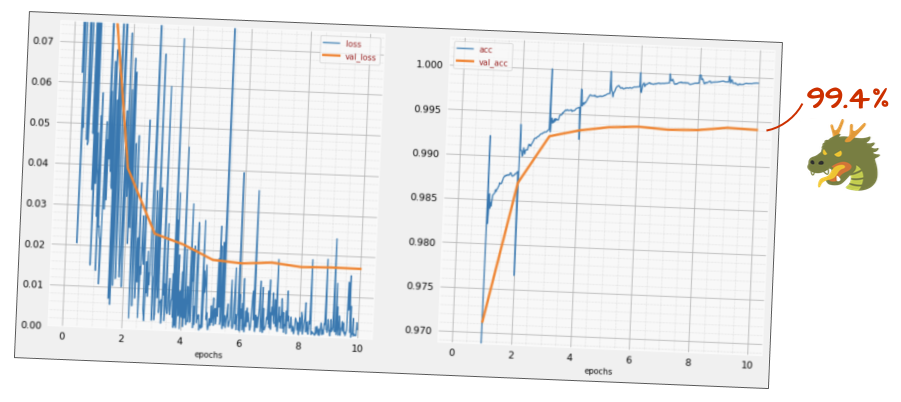
কিছুটা টুইট করার সাথে (ব্যাচ_সাইজ = 64, লার্নিং রেট ক্ষয় প্যারামিটার 0.666, ঘন স্তর 0.3 এ ড্রপআউট রেট) এবং কিছুটা ভাগ্য, আপনি 99.5%এ পেতে পারেন। ব্যাচের আদর্শ ব্যবহারের জন্য "সেরা অনুশীলনগুলি" অনুসরণ করে শেখার হার এবং ড্রপআউট সামঞ্জস্যগুলি করা হয়েছিল:
- ব্যাচ নর্ম নিউরাল নেটওয়ার্কগুলিকে রূপান্তর করতে সহায়তা করে এবং সাধারণত আপনাকে দ্রুত প্রশিক্ষণের অনুমতি দেয়।
- ব্যাচ নর্ম একটি নিয়মিত। আপনি সাধারণত যে পরিমাণ ড্রপআউট ব্যবহার করেন তা হ্রাস করতে পারেন, বা ড্রপআউট ব্যবহারও করতে পারেন না।
সমাধান নোটবুকটিতে 99.5% প্রশিক্ষণ রান রয়েছে:

আপনি গিটল এআই প্ল্যাটফর্মে চালানোর নির্দেশাবলী সহ গিটহাবের ম্লেজাইন ফোল্ডারে কোডের একটি ক্লাউড-রেডি সংস্করণ পাবেন। আপনি এই অংশটি চালানোর আগে, আপনাকে একটি গুগল ক্লাউড অ্যাকাউন্ট তৈরি করতে হবে এবং বিলিং সক্ষম করতে হবে। ল্যাবটি সম্পূর্ণ করার জন্য প্রয়োজনীয় সংস্থানগুলি কয়েক ডলারের চেয়ে কম হওয়া উচিত (একটি জিপিইউতে প্রশিক্ষণের সময় 1 ঘন্টা ধরে নেওয়া)। আপনার অ্যাকাউন্ট প্রস্তুত করতে:
- একটি গুগল ক্লাউড প্ল্যাটফর্ম প্রকল্প তৈরি করুন ( http://cloud.google.com/console )।
- বিলিং সক্ষম করুন।
- জিসিপি কমান্ড লাইন সরঞ্জামগুলি ইনস্টল করুন ( জিসিপি এসডিকে এখানে )।
- একটি গুগল ক্লাউড স্টোরেজ বালতি তৈরি করুন (অঞ্চলটি
us-central1এ রাখুন)। এটি প্রশিক্ষণ কোডটি মঞ্চে এবং আপনার প্রশিক্ষিত মডেল সঞ্চয় করতে ব্যবহৃত হবে। - প্রয়োজনীয় এপিআই সক্ষম করুন এবং প্রয়োজনীয় কোটাগুলির জন্য অনুরোধ করুন (একবার প্রশিক্ষণ কমান্ডটি চালান এবং আপনার কী সক্ষম করতে হবে তা বলার জন্য আপনার ত্রুটি বার্তাগুলি পাওয়া উচিত)।
আপনি আপনার প্রথম নিউরাল নেটওয়ার্ক তৈরি করেছেন এবং 99% নির্ভুলতার জন্য এটি সমস্তভাবে প্রশিক্ষণ দিয়েছেন। পথে শেখা কৌশলগুলি এমএনআইএসটি ডেটাসেটের সাথে সুনির্দিষ্ট নয়, প্রকৃতপক্ষে নিউরাল নেটওয়ার্কগুলির সাথে কাজ করার সময় এগুলি ব্যাপকভাবে ব্যবহৃত হয়। বিভাজন উপহার হিসাবে, এখানে কার্টুন সংস্করণে ল্যাবটির জন্য "ক্লিফের নোটস" কার্ড রয়েছে। আপনি যা শিখেছেন তা মনে রাখতে আপনি এটি ব্যবহার করতে পারেন:

পরবর্তী পদক্ষেপ
- সম্পূর্ণ সংযুক্ত এবং কনভোলিউশনাল নেটওয়ার্কগুলির পরে, আপনার পুনরাবৃত্ত নিউরাল নেটওয়ার্কগুলিতে নজর রাখা উচিত।
- বিতরণ করা অবকাঠামোতে মেঘে আপনার প্রশিক্ষণ বা অনুমান চালানোর জন্য, গুগল ক্লাউড এআই প্ল্যাটফর্ম সরবরাহ করে।
- অবশেষে, আমরা প্রতিক্রিয়া পছন্দ করি। আপনি যদি এই ল্যাবটিতে কিছু ভুল দেখেন বা আপনি যদি মনে করেন এটির উন্নতি করা উচিত তবে দয়া করে আমাদের বলুন। আমরা গিটহাব ইস্যুগুলির মাধ্যমে প্রতিক্রিয়া পরিচালনা করি [ প্রতিক্রিয়া লিঙ্ক ]।

লেখক: মার্টিন গারনার টুইটার: @মার্টিন_গর্নার |
|


এই ল্যাব কপিরাইটে সমস্ত কার্টুন চিত্র: অ্যালেক্সপোকুসে / 123 আরএফ স্টক ফটো