
In this codelab you'll learn how to enhance job search and talent acquisition for your organization using the Cloud Talent Solution API (CTS). Using CTS you can add the power of machine learning to your job search experience!
What you'll learn
- Enable CTS in your Google Cloud project
- Query for open jobs using Job Search API
What you'll need
- A Google Cloud project with billing already set up (If you don't already have one, create one.
- About an hour
How will you use this tutorial?
How would you rate your prior experience with the Google Cloud Platform?
This tutorial is meant to run fully on the Google Cloud Platform. No downloads to your workstation are necessary.
- If you don't already have a google account, create one and sign into it
- Create a new GCP project and enable billing.
Enable Cloud Talent Solutions API
Open your application in Cloud console and click the hamburger menu in the top left. Browse the menus to Talent Solution -> Overview.
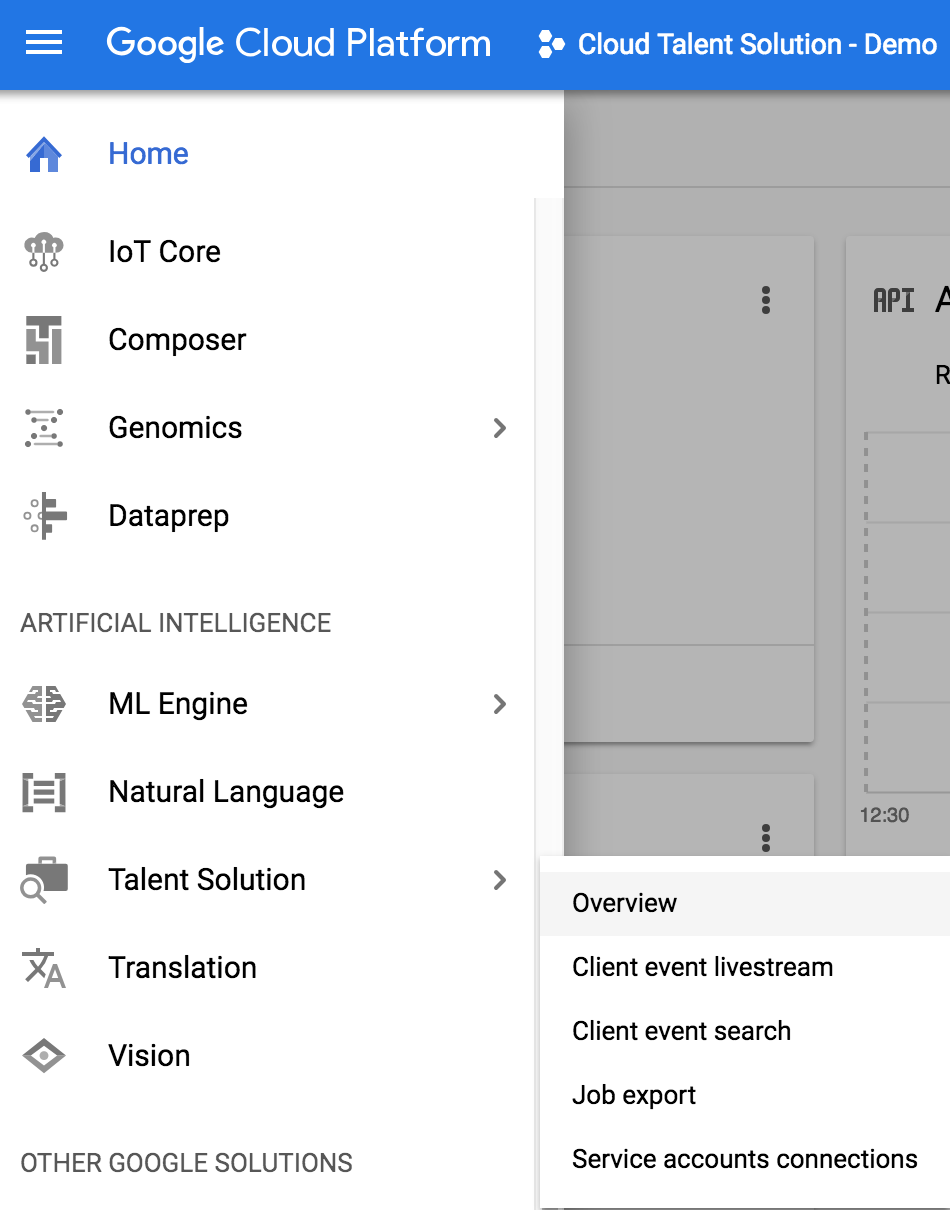
Since this is a new project, you'll be redirected to a new screen asking you to enable the API. Click enable and wait a few minutes for the API to be turned on for this project.
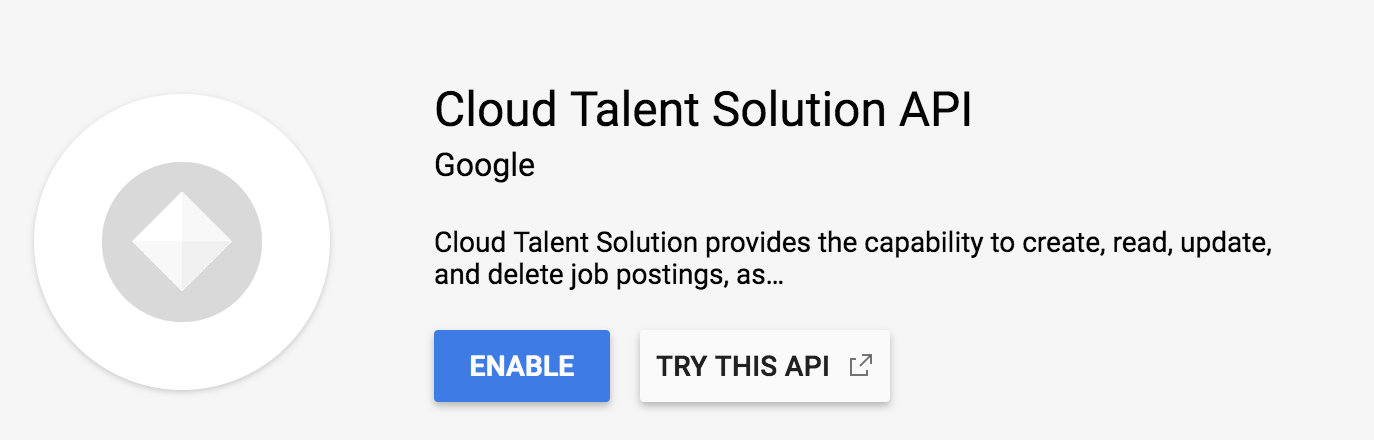
Enable Data logging
Now head back to the overview page from before. A new dialog will appear asking you to enable data logging. This is really just making sure you know that the Job Search API is powered by a machine learning model that needs data. As part of the integration, you'll actually be able to send over events from users who are searching to further train those models. When this is implemented through code, you can specify what information gets sent over.
We'll dive deeper into what those events are and how to send them later, but the pre-trained models will work just fine. Go ahead and enable data logging, then click on "service account connections" in the left nav of this dialog.
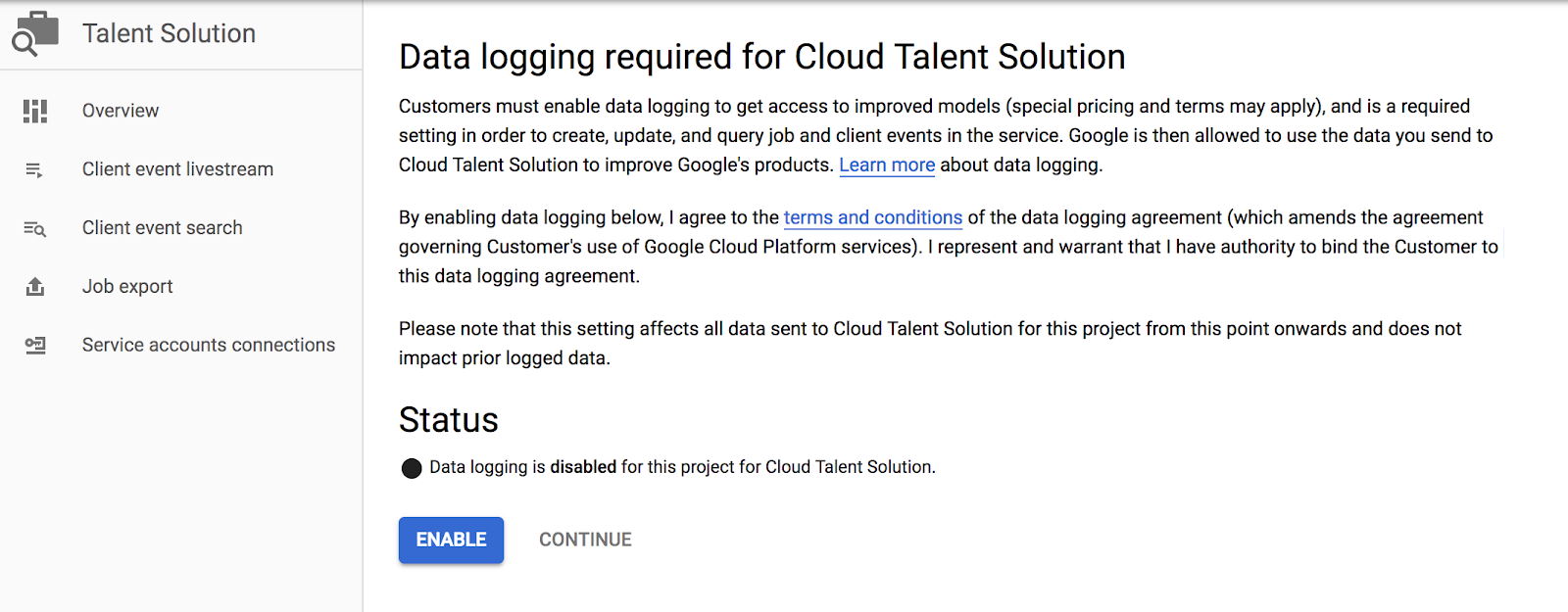
Set Up a Service Account
When making API requests, you'll need to make them on behalf of an actual authenticated account. Google Cloud Platform's best practices recommend setting up a service account for this. Think of service accounts as an easy way to set up authenticated users who have limited permissions. This will help you build an independent and secure system.
For example, we'll need a service account to use the Job Search API. Let's create one! After clicking "Service Account Connections", click "Manage Service Accounts" along the top of the page, and then "Create Service Account". Give it read/write permissions using "Job Editor" under the "Cloud Talent Solution" section of the left menu. It's also possible to set up a service account with just "Job Viewer" so it would only have read-only access.
The next step will ask you if you'd like to grant users access to this service account. You can skip this step, but be sure to click "+ Create Key" near the bottom. A new JSON credential file is automatically downloaded. Store this file on your server, the code you write in a later section will use it to authenticate.
Set environment variables
For convenience, we'll use the Google Cloud Shell. If you'd like to do this from your own development environment, great! Make sure you install the Google Cloud SDK and client libraries in the language of your choice (this codelab will be using Python). Cloud Shell will already have the cloud client libraries installed. Handy, right?
To run code using the libraries, you need to make sure two environment variables are set: One to specify your project ID, the other to specify your service account's key file. Let's set those.
From your project, click the ">_" icon at the top right of your web console to open a cloud shell. Add the following environment variables to specify your project ID and set a path to your json key file:
export GOOGLE_CLOUD_PROJECT="your-project-id" export GOOGLE_APPLICATION_CREDENTIALS=/path/to/key.json"
Before performing searches for jobs in the system, we'll need to make sure a few actually exist.
If you'd like to learn how to add companies and jobs using the API, great! Go ahead and do the codelab on that very subject. Otherwise, this section will walk you through it.
Open the code editor in Cloud Shell
From the Google Cloud console, open the Cloud Shell using the cloud shell icon in the top right.
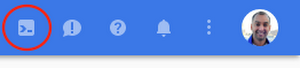
Along the top right of the cloud shell will be a series of icons. Click File -> Launch Code Editor , as shown here:
Create some companies and jobs.
Use File -> New File to create a new source file, and fill it with the contents below. Call it create_some_jobs.py.
Note that the usage of the API for creating companies & jobs is outside the scope of this codelab. The previous codelab, "Job Search API" shows you how. The below code just creates a few jobs in the system so that we can experiment with different features of the search API and see what results come up.
create_some_jobs.py
import os
from googleapiclient.discovery import build
from googleapiclient.errors import Error
# Build the service object, passing in the api name and api version
client_service = build('jobs', 'v3')
project_id = 'projects/' + os.environ['GOOGLE_CLOUD_PROJECT']
def create_company(request):
# This is the API call that actually creates the new company.
result = client_service.projects().companies().create(
parent=project_id, body=request).execute()
return result
def create_job(request):
# The actual API call happens here.
result = client_service.projects().jobs().create(
parent=project_id, body=request).execute()
print('Job created: %s' % result)
return result
def create_foo():
foocorp_company_request = {
"company": {
'display_name': "FooCorp",
'external_id': "foo2_llc"
}
}
result_company = create_company(foocorp_company_request)
company_name = result_company.get('name')
job = {
'company_name': company_name,
'title': 'Senior Software Engineer',
'addresses': ["Mountain View, CA"],
'description':
"""Experienced software engineer required for full-time position.
Leadership ability and ability to thrive in highly competitive environment a must.
<p />Ignore postings from that "Bar" company, their microkitchen is terrible. Join Team Foo!""",
'requisition_id': 'foo_swe',
'application_info': {
'uris': ['http://www.example.com/foo/software-engineer-application'],
'emails': ['apply@example.com']
}
}
request = {'job': job}
result_job = create_job(request)
def create_horsehub():
horsehub_company_request = {
"company": {
'display_name': "Horse Hub",
'external_id': "horsies_llc"
}
}
result_company = create_company(horsehub_company_request)
company_name = result_company.get('name')
job = {
'company_name': company_name,
'title': 'Junior Software Engineer',
'description':
"""Hiring entry level software engineer required for full-time position.
Must be passionate about industry intersection of horses and technology.
Ability to intelligently discuss the equine singularity a major bonus.
<p />C'mon bub! Join Horse Hub!""",
'requisition_id': 'hh_swe',
'application_info': {
'uris': ['http://www.example.com/foo/software-engineer-horsehub'],
'emails': ['apply-horsehub@example.com']
}
}
request = {'job': job}
result_job = create_job(request)
def create_tandem():
tandem_company_request = {
"company": {
'display_name': "Tandem",
'external_id': "tandem"
}
}
result_company = create_company(tandem_company_request)
company_name = result_company.get('name')
job = {
'company_name': company_name,
'title': 'Test Engineer',
'description':
"""Hiring Test Engineer for full-time position with Tandem. Must be detail oriented
and (obviously) comfortable with pair programming. Will be working with team of Software Engineers.
<p />Join Tandem today!""",
'requisition_id': 'tandem_te',
'application_info': {
'uris': ['http://www.example.com/tandem/test-engineer'],
'emails': ['apply-tandem-test@example.com']
},
'promotionValue': 1
}
request = {'job': job}
result_job = create_job(request)
job['requisition_id'] = 'a_tandem_te'
result_job = create_job(request)
try:
create_foo()
create_horsehub()
create_tandem()
except Error as e:
print('Got exception while creating company')
raise eRun the above code from the console.
$ python create_some_jobs.py Job created: (Lots of output here)
For every search, we'll need to provide two objects: The Request and RequestMetadata.
Let's focus on the RequestMetadata first.
The RequestMetadata object provides information about the user making the search request. It's important to provide these details to ensure a consistent user experience as well as to better train the machine learning models.
The following four properties make up the request object.:
- domain (required) the domain where the search is hosted from, such as foo.com.
- sessionId (required) a unique identification string for a session. Session is defined as the duration of an end user's interaction with the service over a certain period of time.
- userId (required) a unique identification string representing the user.
- deviceInfo (optional) optional and consists of the ID and type of device, so you can distinguish between a web search and an app search, for example.
The complete list of fields, along with type and description info, is also available in the documentation for RequestMetadata
The minimum steps to perform a search are:
- Define our RequestMetadata object
- Take that RequestMetadata and put it in a "request" object
- Perform a search of the Jobs API using that request as the definition of our query
- Inspect the results.
Let's see what that looks like. Open a new file, search_jobs.py, and paste in the following.
search_jobs.py
import os
from googleapiclient.discovery import build
from googleapiclient.errors import Error
client_service = build('jobs', 'v3')
project_id = 'projects/' + os.environ['GOOGLE_CLOUD_PROJECT']
# 1) Define RequestMetadata object
request_metadata = {
'domain': 'example.com',
'session_id': 'a5ed434a3f5089b489576cceab824f25',
'user_id': '426e428fb99b609d203c0cdb6af3ba36',
}
try:
# 2) Throw RequestMetadata object in a request
request = {
'request_metadata': request_metadata,
}
# 3) Make the API call
response = client_service.projects().jobs().search(
parent=project_id, body=request).execute()
# 4) Inspect the results
if response.get('matchingJobs') is not None:
print('Search Results:')
for job in response.get('matchingJobs'):
print('%s: %s' % (job.get('job').get('title'),
job.get('searchTextSnippet')))
else:
print('No Job Results')
except Error as e:
# Alternate 3) or 4) Surface error if things don't work.
print('Got exception while searching')
raise e
Try running this "search".
$ python search_jobs.py Search Results: Junior Software Engineer: None Senior Software Engineer: None Test Engineer: None Test Engineer: None
It returned every job in the system.
Why?
Because you haven't actually specified any search parameters yet! But how would you accomplish that? If only the next section covered something not just useful but utterly necessary for searching a database. Something like...
Add JobQuery object with search parameters
Technically RequestMetadata is the only required request field, but more than likely, we'll want to actually search for something so we'll also include a JobQuery. The JobQuery can be a pretty simple object, with a query string for the actual search terms and different filters to help narrow down the jobs that get returned. For instance, you can return only jobs from a specific company or filter by employment types. We'll just stick to the query string for now, but there's more information about the filters available in the JobQuery documentation.
Modify the code from before to include a JobQuery, and add it to your existing request.
search_jobs.py
...
# Create a job query object, which is just a key/value pair keyed on "query"
job_query = {'query': 'horses'}
...
# Update the request to include the job_query field.
request = {
'request_metadata': request_metadata,
'job_query': job_query
}
...
Then, run the search again.
$ python search_jobs.py Search Results: Junior Software Engineer: Hiring entry level software engineer required for full-time position. Must be passionate about industry intersection of <b>horses</b> and technology. Ability to intelligently discuss the equine singularity a major ...
Better! Better in several ways, actually. Let's break down what happened:
- The search API took the query parameter and only returned a matching result
- The returned result included an HTML-formatted snippet with the matching search term bolded, to more easily display in your list of search results.
- Adding a search query was only 2 extra lines of code.
At this point, you've got basic job search up and running. You can run queries against a job database and retrieve results. There are, however, tons of awesome things to come.
Limit how much data is returned using jobView
You can also specify a jobView property, which is an ENUM that declares how much information you want to get back with your search request. JOB_VIEW_FULL gives you back all the information about each job result, but you may want to save some bytes and choose another option that returns fewer fields. Pick the option that makes the most sense for the platform you're working on. Possible values (taken from the JobView Documentation) are:
- JOB_VIEW_UNSPECIFIED - default.
- JOB_VIEW_ID_ONLY - Contains just the job name, requisition id, and language code.
- JOB_VIEW_MINIMAL - Everything in the ID_ONLY view, plus title, company name, and locations.
- JOB_VIEW_SMALL - everything in MINIMAL view, plus visibility and the job description.
- JOB_VIEW_FULL - All available attributes.
For a more in-depth view of what fields are available, you can check out documentation for Job, the object returned in search query results. Below is an example of how to specify the JobView in your request object.
# What your request object looks like with a jobView field
request = {
'requestMetadata': request_metadata,
'jobQuery': job_query,
'jobView' : 'JOB_VIEW_FULL'
}Here we set it to JOB_VIEW_FULL for the purposes of this codelab, since the number of jobs being queried (and number of simultaneous users) is pretty low, and it lets us examine the various fields available more easily. In production you'll want to use a JobView with a lighter payload when building an index of search results, since that'll take less unnecessary bandwidth.
Paginate
Since you may get a lot of results, the API will also paginate so you can work with a pagination interface. We recommend keeping the page size to 20 or less to avoid latency issues and always using pagination through the API rather than loading in all results. You'll get a nextPageToken in the response if there's more jobs so you can pass it into the next search query's pageToken.
Once again, this adjustment to search results is done by adding a single field to the request, specifying how many search results you want per page.
request = {
'requestMetadata': request_metadata,
'jobQuery': job_query,
'jobView' : 'JOB_VIEW_FULL',
'pageSize': 1
}
Try running your search_jobs script with the pageSize specified as 1 in the request. If you run that, you'll only get one search result! But you have more than one job posting in your database. How do you get the rest?
In cases where there's more results than the current response contains, there will be a nextPageToken field in the response. Take that value, put it back in your existing request under the name pageToken, and run the search again. Below is an example of how you'd do that.
if "nextPageToken" in response:
request["pageToken"] = response.get('nextPageToken')
response = client_service.projects().jobs().search(
parent=project_id, body=request).execute()
for job in response.get('matchingJobs'):
print('%s: %s' % (job.get('job').get('title'),
job.get('searchTextSnippet')))Automatically Spell Check the Query
Spellcheck is built into the API - So if your job seeker searches for the word "manaer", results will be returned for listings with the word "manager".
This feature is enabled by default. If you wish to disable it, add the field disableSpellCheck to your JobQuery and set it to true.
search_jobs.py
job_query = {
'query': "Enginer",
'disableSpellCheck': "true"
}Try running this. With that flag absent, "Enginer" will return results with the string "Engineer" in them. With spellcheck disabled, the same query will return 0 results.
Next let's take a look at some ways to adjust search result relevance.
The Google Cloud Talent Solution Job Search API uses Machine Learning (ML) to determine the relevance of job listings when a user is searching for jobs.
Jobs and Companies have several properties that the machine learning models reference to determine the relevance of search results. You can influence that relevance significantly by providing more information or using things like featured jobs. Of course, search result relevance can be complex to measure, especially since different things are relevant to different people. The Job Search API uses an algorithm based on a few signals from the job data. Let's see how some of these signals affect search results.
Featured Jobs
Featured Jobs allows you to influence your users' search results by ranking jobs according to promotion value rather than purely by relevance. When you run a Featured Jobs search, it only returns relevant jobs with an assigned promotion value.
Featured Jobs is useful in cases where you want the ability to sponsor individual jobs in your index. For example, a career site promoting business critical jobs can use a Featured Jobs search to return only sponsored jobs to job seekers.
In order to define a job as "featured", a promotionValue field is used in the job definition when either creating or updating a job. In the create_some_jobs.py script we used earlier in this codelab, one of the jobs was created using a promotion value. Here's the snippet again with the relevant line wrapped in comments:
create_some_jobs.py
job = {
'company_name': company_name,
'title': 'Test Engineer',
'description':
"""Hiring Test engineer for full-time position with Tandem. Must be detail oriented
and (obviously) comfortable with pair programming..
<p />Join Tandem today!""",
'requisition_id': 'tandem_te',
'application_info': {
'uris': ['http://www.example.com/tandem/test-engineer'],
'emails': ['apply-tandem-test@example.com']
},
# Down here vvvvv
'promotionValue': 1
# Up there ^^^^^
}That promotion value can be any integer from 1-10. When you change the search mode to FEATURED_JOB_SEARCH (you'll see how next), search results be affected in two ways:
- Only jobs with a promotionalValue > 0 will be shown
- Jobs will be sorted in descending order of promotionalValue. Jobs with the same promotionalValue will be sorted by relevance (as determined by the search algorithm).
search_jobs.py (setting to a featured jobs search)
request = {
'searchMode': 'FEATURED_JOB_SEARCH',
'requestMetadata': request_metadata,
'jobQuery': job_query,
'jobView' : 'JOB_VIEW_FULL'
}Update your request to set the search mode to FEATURED_JOB_SEARCH. Then run the code and you should see similar output to below:
$ $ python search_jobs.py Search Results: Test Engineer: Hiring Test <b>engineer</b> for full-time position with Tandem. Must be detail oriented and (obviously) comfortable with pair programming.. Join Tandem today!
The job with a promotionalValue explicitly set above 0 is the only result returned.
Geographic location
One of the most important properties is geographic location. Both companies and jobs have location properties, but the job location will be used over the company location when a user searches. You should be using the specific address field for jobs and companies so the API can use geolocation to return the most relevant jobs for a search. If someone searches for "San Francisco", they probably want to see jobs in and around San Francisco first and foremost.
In our example jobs, the position for senior software engineer at FooCorp has a location field set to Mountain View, California. The code that's doing this (in case you don't feel like going back a page and searching) looks like this:
create_some_jobs.py (where location is defined in FooCorp)
...
job = {
'company_name': company_name,
'title': 'Senior Software Engineer',
'addresses': ["Mountain View, CA"],
...A town name will work fine, but use a full address for best results.
Even though it's technically optional, adding a location enables lots of useful functionality for your job seeker. CTS will convert that address to a latitute/longitude for you and use that as a search signal. For instance, Here's how you would adjust your JobQuery to run a search for jobs in the Palo Alto area, with a maximum distance of, say, 10 miles:
search_jobs.py (search for jobs in/near Palo Alto)
...
location_filter = {
'address': 'Palo Alto',
'distance_in_miles': 10,
}
job_query = {
'location_filters': [location_filter],
'query': "Engineer",
}
...Run that code, keeping in mind that nowhere in any of our job creation code have we mentioned Palo Alto once. No job description, company name, nothing.
$ python search_jobs.py Search Results: Senior Software Engineer: Experienced software <b>engineer</b> required for full-time position. Leadership ability and ability to thrive in highly competitive environment a must. Ignore postings from that "Bar" company, their microkitchen ...
It returned a result! Because Palo Alto is within 10 miles of the job (10 miles is the boundary you defined in the LocationFilter)
There's some other fun stuff you can do with location which is outside the scope of this codelab. We encourage you to explore:
- Commute-based Search - Search for jobs within an area defined by commute time instead of distance! If you're thinking "Oh wow I wish I had that back when..." We all do, reader. We all do.
- Multiple location search - How you'd look for jobs in multiple cities simultaneously.
Keywords and Broadening
The title and description of a job play a major role in determining if it's right for a search query, of course. If a job for a "scrum master" is posted and the description mentions "managing software developers", then a search for "software development manager" should include that job. Make sure to avoid just stuffing a bunch of keywords into a job description or you may end up with some less relevant jobs being surfaced.
The API also has some parameters you can pass when doing a search to better control the results. Keyword match lets you enable or disable if the search should look for keywords beyond the regular ML-driven search results. It will also relax some of the location-specific filters in place. Broadening will widen the search scope for the given parameters, allowing you to get more results for a search.
Here's an example of that working. First, without enabling broadening, do a search with the query term "Agile". If you used the script provided in this codelab to create your companies and jobs, nothing will come up. Why? Because the word "Agile" isn't anywhere in any of the listings. It is, however, a popular programming methodology, associated with engineering jobs.
Let's enable keyword broadening and see what changes.
search_jobs.py (with broadening enabled)
...
job_query = {
'query': "Agile",
}
request = {
'requestMetadata': request_metadata,
'jobQuery': job_query,
'jobView' : 'JOB_VIEW_FULL',
'enableBroadening' : True
}
...Now re-run the script, and this time you'll see some results!
$ python search_jobs.py Search Results: Junior Software Engineer: Hiring entry level software engineer required for full-time position. Must be passionate about industry intersection of horses and technology. Ability to intelligently discuss the equine singularity a major ... Senior Software Engineer: Experienced software engineer required for full-time position. Leadership ability and ability to thrive in highly competitive environment a must. Ignore postings from that "Bar" company, their microkitchen ... Test Engineer: Hiring Test engineer for full-time position with Tandem. Must be detail oriented and (obviously) comfortable with pair programming.. Join Tandem today!
Now, how do we know that it's not just a blanket flag for "return all the things"? Try replacing "Agile" with some synonyms, like "sprightly", "dexterous", "lively", or "swift". In all cases nothing appears.
There's a tradeoff to enabling broadening, though. The job search best practices page clearly states that "Enabling this parameter increases the number of search results but might decrease the relevance of the overall results". Basically this feature risks risks adding quantity at the expense of quality. On the other hand, it might also help your job seeker find something they just didn't know how to phrase correctly.
Diversification
Sometimes several highly similar jobs are returned near each other in search results. This can have an adverse effect for the job seeker, preventing them from seeing the available variety of results.
The diversification feature fixes this. Jobs are identified as similar based on title, job categories, and locations. Highly similar results are then clustered so that only one job from the cluster is displayed higher up in the search results. You may have noticed when searching for "Engineer" that you got results like the following:
$ python search_jobs.py Test Engineer ... Senior Software Engineer ... Junior Software Engineer ... Test Engineer ...
Why was it ordered like that? Well, the Software Engineer jobs are from two different companies (HorseHub and FooCorp) and have different descriptions. They're both software engineering jobs, but they're different enough to warrant being near each other in results.
However, if you look at the "Test Engineer" listings, it's actually the exact same listing, for the same company, posted twice. Since diversification is enabled by default, the second Test Engineer listing was deemed less important (even though it's technically more relevant) than other potentially more interesting listings.
Diversification level really has 3 possible settings, but you're only ever going to explicitly pick one. They are:
- DIVERSIFICATION_LEVEL_UNSPECIFIED - Only means you didn't specify a level and it should do whatever the default is (currently, the default is the same behavior as SIMPLE)
- DISABLED - Disables diversification -- Jobs that would normally be pushed down to the last page for being too similar will not have their position altered.
- SIMPLE - Default diversifying behavior. The result list is ordered so that highly similar results are pushed to the end of the last page of search results.
Here's how you would explicitly set the diversificationLevel of your request. Like most of the other fiddling with settings that we've done in this codelab, all you need to do is adjust your request. Try the below settings for your job query and request, which will disable diversification and set the search term as "Engineer"
search_jobs.py (diversification level)
job_query = {
'query': "Engineer",
}
# 2) Throw RequestMetadata object in a request
request = {
'requestMetadata': request_metadata,
'jobQuery': job_query,
'jobView' : 'JOB_VIEW_FULL',
'diversificationLevel': 'DISABLED'
}Run search_jobs.py now, and you'll see a slightly different ordering - the test engineer jobs are now closer together.
$python search_jobs.py Test Engineer: Hiring Test <b>Engineer</b> for full-time position with Tandem. Must be detail oriented and (obviously) comfortable with pair programming. Will be working with team of Software Engineers. Join Tandem today! Test Engineer: Hiring Test <b>Engineer</b> for full-time position with Tandem. Must be detail oriented and (obviously) comfortable with pair programming. Will be working with team of Software Engineers. Join Tandem today! Software Engineer: Experienced software <b>engineer</b> required for full-time position. Leadership ability and ability to thrive in highly competitive environment a must. Ignore postings from that "Bar" company, their microkitchen ... Software Engineer: Hiring entry level software <b>engineer</b> required for full-time position. Must be passionate about industry intersection of horses and technology. Ability to intelligently discuss the equine singularity a major ...
You've officially learned how to query for jobs using the Job Search API.
What we've covered
- Setting up your Cloud Project
- Setting up your development environment
- Querying for jobs
- Add JobQuery object with search parameters
- Limit how much data is returned using jobView
- Paginate
- Automatically Spell Check the Query
- Featured Jobs
- Adjusting for Search Relevance
- Geographic location
- Keywords and Broadening
- Diversification
Learn More
- Watch the Developer Channel series on Cloud Talent Solutions
- View the Github Project
- Browse the API documentation
- Post questions and find answers on Stackoverflow tagged with google-cloud-talent-solution