
虽然客户端应用和前端 Web 开发者通常会使用 Android Studio CPU 性能分析器或 Chrome 中包含的性能分析工具等工具来提高代码的性能,但后端服务开发者几乎无法使用或采用同等技术。Stackdriver Profiler 为服务开发者提供了同样的功能,无论他们的代码是在 Google Cloud Platform 上还是在其他位置运行。
该工具可从生产应用中收集 CPU 使用情况和内存分配信息。该性能剖析器会将获得的信息归因于应用的源代码,从而帮助您找出应用中资源耗用量最大的部分,还可以阐明代码的性能特征。该工具采用的收集技术开销较低,因此适合在生产环境中持续使用。
在此 Codelab 中,您将学习如何为 Go 程序设置 Stackdriver Profiler,并熟悉该工具可以提供哪些有关应用性能的深入分析。
学习内容
- 如何配置 Go 程序以使用 Stackdriver Profiler 进行性能剖析。
- 如何使用 Stackdriver Profiler 收集、查看和分析性能数据。
所需条件
您将如何使用本教程?
您如何评价自己在 Google Cloud Platform 方面的经验水平?
自定进度的环境设置
如果您还没有 Google 账号(Gmail 或 Google Apps),则必须创建一个。登录 Google Cloud Platform Console (console.cloud.google.com) 并创建一个新项目:



请记住项目 ID,它在所有 Google Cloud 项目中都是唯一名称(很抱歉,上述名称已被占用,您无法使用!)。它稍后将在此 Codelab 中被称为 PROJECT_ID。
接下来,您需要在 Cloud Console 中启用结算功能,才能使用 Google Cloud 资源。
在此 Codelab 中运行仅花费几美元,但是如果您决定使用更多资源或继续让它们运行,费用可能更高(请参阅本文档末尾的“清理”部分)。
Google Cloud Platform 的新用户有资格获享 $300 免费试用。
Google Cloud Shell
虽然 Google Cloud 可以从笔记本电脑远程操作,但为了简化此 Codelab 中的设置,我们将使用 Google Cloud Shell,这是一个在云端运行的命令行环境。
激活 Google Cloud Shell
在 GCP 控制台中,点击右上角工具栏上的 Cloud Shell 图标:

然后点击“启动 Cloud Shell”:

配置和连接到环境应该只需要片刻时间:

这个虚拟机已加载了您需要的所有开发工具。它提供了一个永久性的 5GB 主目录,并且在 Google Cloud 上运行,从而大大增强了网络性能和身份验证功能。只需使用一个浏览器或 Google Chromebook 即可完成本实验中的大部分(甚至全部)工作。
在连接到 Cloud Shell 后,您应该会看到自己已通过身份验证,并且相关项目已设置为您的 PROJECT_ID。
在 Cloud Shell 中运行以下命令以确认您已通过身份验证:
gcloud auth list
命令输出
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
命令输出
[core] project = <PROJECT_ID>
如果不是上述结果,您可以使用以下命令进行设置:
gcloud config set project <PROJECT_ID>
命令输出
Updated property [core/project].
在 Cloud 控制台中,点击左侧导航栏中的“Profiler”,前往 Profiler 界面:
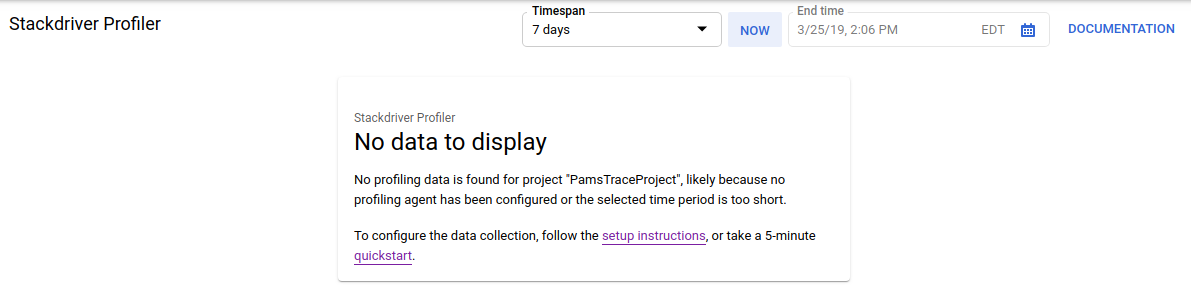
或者,您也可以使用 Cloud 控制台搜索栏导航到 Profiler 界面:只需输入“Stackdriver Profiler”,然后选择找到的项即可。无论使用哪种方式,您都应该会看到性能剖析器界面,其中显示“没有可显示的数据”消息,如下所示。由于项目是新项目,因此尚未收集任何分析数据。
现在可以开始分析了!
我们将使用 GitHub 上提供的一个简单的合成 Go 应用。在您仍处于打开状态的 Cloud Shell 终端中(并且在分析器界面中仍显示“没有要显示的数据”消息时),运行以下命令:
$ go get -u github.com/GoogleCloudPlatform/golang-samples/profiler/...
然后切换到应用目录:
$ cd ~/gopath/src/github.com/GoogleCloudPlatform/golang-samples/profiler/hotapp
该目录包含“main.go”文件,这是一个启用了分析代理的合成应用:
main.go
...
import (
...
"cloud.google.com/go/profiler"
)
...
func main() {
err := profiler.Start(profiler.Config{
Service: "hotapp-service",
DebugLogging: true,
MutexProfiling: true,
})
if err != nil {
log.Fatalf("failed to start the profiler: %v", err)
}
...
}分析代理默认会收集 CPU、堆和线程性能剖析文件。此处的代码可启用互斥(也称为“争用”)性能剖析文件的收集。
现在,运行程序:
$ go run main.go
在程序运行时,性能剖析代理会定期收集五种已配置类型的性能剖析文件。收集过程会随时间随机进行(每种类型的平均收集速率为每分钟一个性能剖析文件),因此可能需要最多三分钟才能收集到每种类型的性能剖析文件。该程序会在创建个人资料时告知您。上述配置中的 DebugLogging 标志可启用消息;否则,代理会静默运行:
$ go run main.go 2018/03/28 15:10:24 profiler has started 2018/03/28 15:10:57 successfully created profile THREADS 2018/03/28 15:10:57 start uploading profile 2018/03/28 15:11:19 successfully created profile CONTENTION 2018/03/28 15:11:30 start uploading profile 2018/03/28 15:11:40 successfully created profile CPU 2018/03/28 15:11:51 start uploading profile 2018/03/28 15:11:53 successfully created profile CONTENTION 2018/03/28 15:12:03 start uploading profile 2018/03/28 15:12:04 successfully created profile HEAP 2018/03/28 15:12:04 start uploading profile 2018/03/28 15:12:04 successfully created profile THREADS 2018/03/28 15:12:04 start uploading profile 2018/03/28 15:12:25 successfully created profile HEAP 2018/03/28 15:12:25 start uploading profile 2018/03/28 15:12:37 successfully created profile CPU ...
在收集到第一个配置文件后,界面会很快自行更新。之后,它不会自动更新,因此您需要手动刷新分析器界面才能看到新数据。为此,请在时间间隔选择器中点击“现在”按钮两次:

界面刷新后,您会看到类似如下的内容:
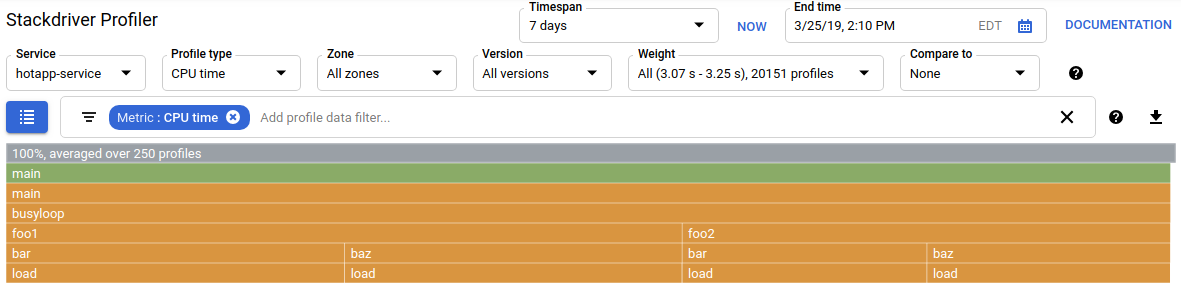
性能剖析类型选择器会显示 5 种可用的性能剖析类型:
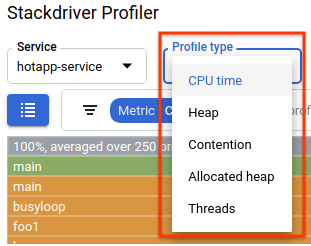
接下来,我们来了解每种配置文件类型和一些重要的界面功能,然后进行一些实验。在此阶段,您不再需要 Cloud Shell 终端,因此可以按 CTRL-C 并输入“exit”来退出。
现在,我们已经收集了一些数据,接下来我们来仔细看看这些数据。我们使用了一个合成应用(源代码可在 GitHub 上获取),该应用可模拟生产环境中不同类型的典型性能问题。
CPU 密集型代码
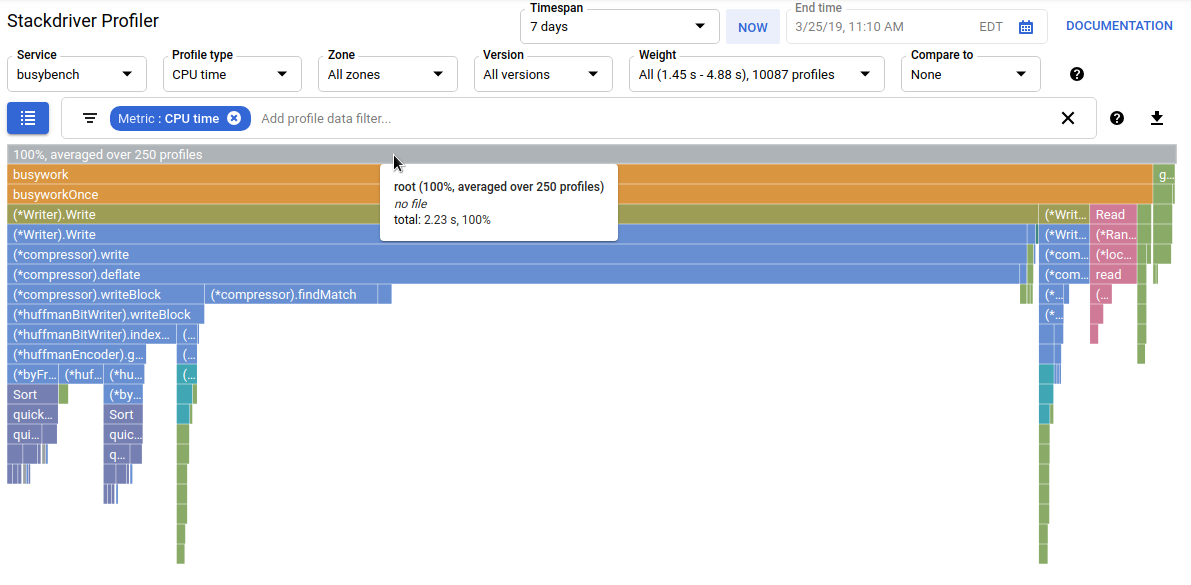
选择 CPU 分析类型。界面加载后,您会在火焰图中看到 load 函数的四个叶块,这些叶块共同构成了所有 CPU 消耗:
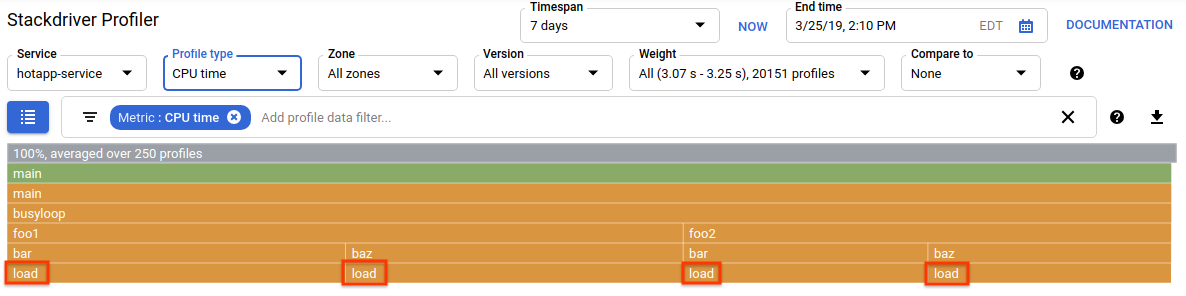
此函数专门用于通过运行紧凑型循环来消耗大量 CPU 周期:
main.go
func load() {
for i := 0; i < (1 << 20); i++ {
}
}该函数通过四条调用路径从 busyloop() 间接调用:busyloop → {foo1, foo2} → {bar, baz} → load。函数框的宽度表示特定调用路径的相对费用。在这种情况下,所有四条路径的费用大致相同。在实际程序中,您需要专注于优化对性能影响最大的调用路径。火焰图会以较大的框直观地突出显示开销较高的路径,从而让您轻松识别这些路径。
您可以使用个人资料数据过滤条件进一步优化显示内容。例如,尝试添加一个“显示堆栈”过滤条件,并将“baz”指定为过滤字符串。您应该会看到类似以下屏幕截图的内容,其中仅显示了 load() 的四条调用路径中的两条。这两个路径是唯一会经过名称中包含字符串“baz”的函数的路径。如果您只想关注某个大型计划的一部分(例如,因为您只拥有该计划的一部分),这种过滤方式就非常有用。
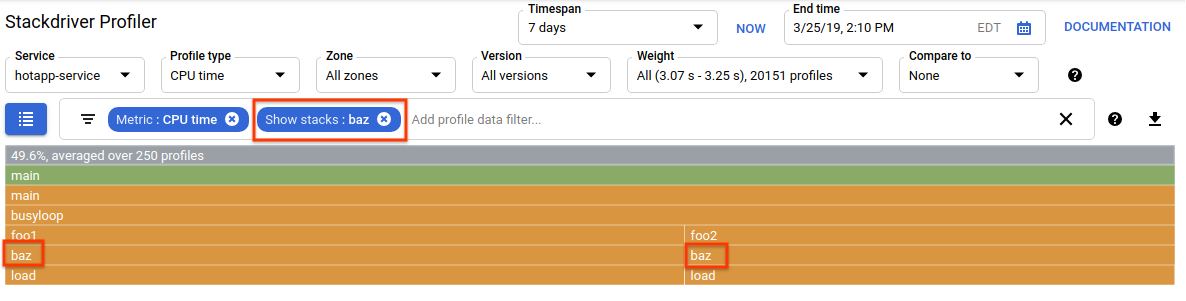
内存密集型代码
现在切换到“Heap”个人资料类型。请务必移除您在之前的实验中创建的所有过滤条件。您现在应该会看到一个火焰图,其中由 alloc 调用的 allocImpl 显示为应用中的主要内存消耗者:
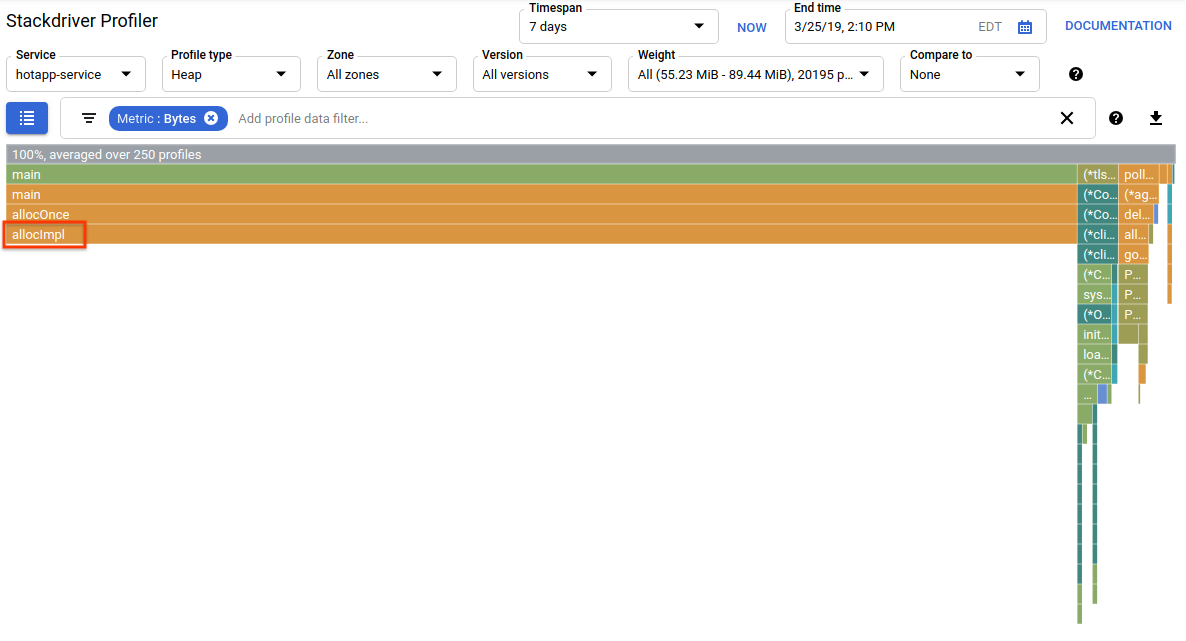
火焰图上方的摘要表格显示,应用中使用的内存总量平均约为 57.4 MiB,其中大部分由 allocImpl 函数分配。鉴于此函数的实现,这并不令人意外:
main.go
func allocImpl() {
// Allocate 64 MiB in 64 KiB chunks
for i := 0; i < 64*16; i++ {
mem = append(mem, make([]byte, 64*1024))
}
}该函数执行一次,以较小的块分配 64 MiB,然后将指向这些块的指针存储在全局变量中,以防止它们被垃圾回收。请注意,分析器显示的内存用量与 64 MiB 略有不同:Go 堆分析器是一种统计工具,因此测量结果的开销较低,但并非精确到字节。看到这种大约 10% 的差异时,请不要感到意外。
IO 密集型代码
如果您在个人资料类型选择器中选择“线程”,显示内容将切换为火焰图,其中大部分宽度由 wait 和 waitImpl 函数占据:
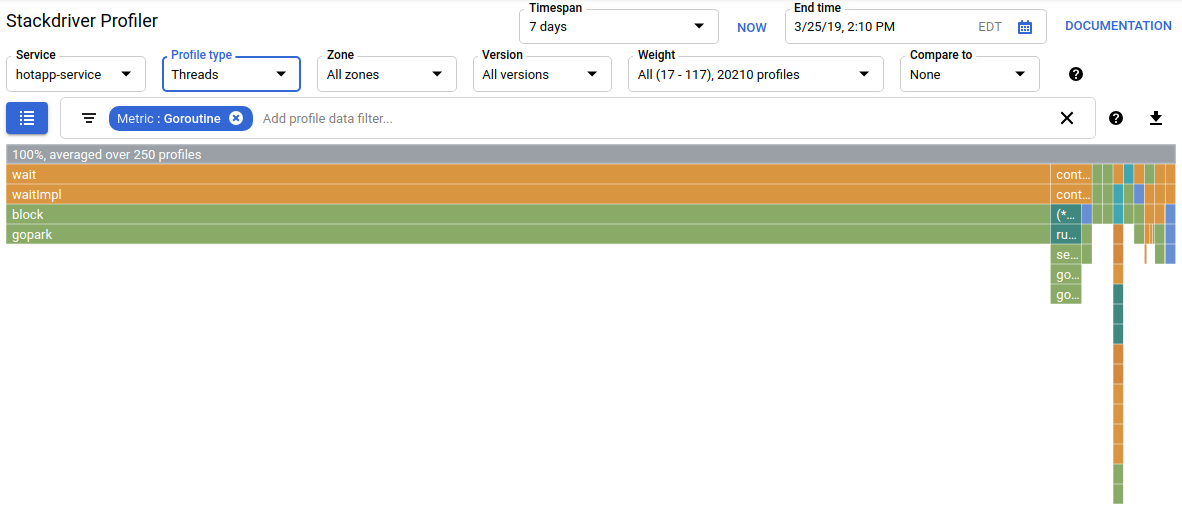
在火焰图上方的摘要中,您可以看到有 100 个 goroutine 从 wait 函数开始增长其调用堆栈。这是完全正确的,因为启动这些等待的代码如下所示:
main.go
func main() {
...
// Simulate some waiting goroutines.
for i := 0; i < 100; i++ {
go wait()
}此性能剖析类型有助于了解程序是否在等待(例如 I/O)中花费了任何意外的时间。CPU 分析器通常不会对这类调用堆栈进行抽样,因为它们不会消耗任何显著的 CPU 时间。您通常会希望将“隐藏堆栈”过滤条件与线程配置文件搭配使用 - 例如,隐藏所有以调用 gopark, 结尾的堆栈,因为这些通常是空闲的 goroutine,不如等待 I/O 的堆栈有趣。
线程配置文件类型还可以帮助识别程序中线程长时间等待程序另一部分拥有的互斥锁的点,但以下配置文件类型在这方面更有用。
竞争激烈的代码
争用配置文件类型用于标识程序中最“需要”的锁。此配置文件类型适用于 Go 程序,但必须通过在代理配置代码中指定“MutexProfiling: true”来明确启用。该收集器通过记录(在“争用”指标下)以下情况的次数来工作:当特定锁被 goroutine A 解锁时,另一个 goroutine B 正在等待该锁被解锁。它还会记录阻塞的 goroutine 等待锁的时间(在“延迟”指标下)。在此示例中,只有一个争用堆栈,锁的总等待时间为 11.03 秒:
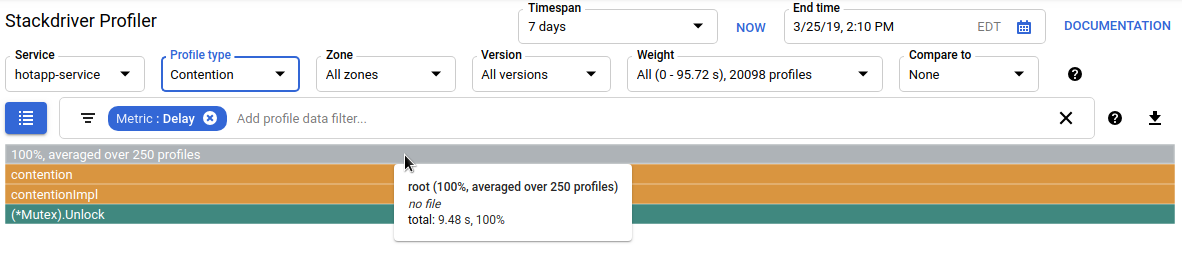
生成此配置文件的代码包含 4 个争夺互斥锁的 goroutine:
main.go
func contention(d time.Duration) {
contentionImpl(d)
}
func contentionImpl(d time.Duration) {
for {
mu.Lock()
time.Sleep(d)
mu.Unlock()
}
}
...
func main() {
...
for i := 0; i < 4; i++ {
go contention(time.Duration(i) * 50 * time.Millisecond)
}
}在本实验中,您学习了如何配置 Go 程序以搭配 Stackdriver Profiler 使用。您还了解了如何使用此工具收集、查看和分析性能数据。现在,您可以将新学到的技能应用于在 Google Cloud Platform 上运行的实际服务。
您已了解如何配置和使用 Stackdriver Profiler!
了解详情
- Stackdriver Profiler:https://cloud.google.com/profiler/
- Stackdriver Profiler 使用的 Go 运行时/pprof 软件包:https://golang.org/pkg/runtime/pprof/
许可
此作品已获得 Creative Commons Attribution 2.0 通用许可授权。