
Mentre gli sviluppatori di app client e web frontend utilizzano comunemente strumenti come Android Studio CPU Profiler o gli strumenti di profilazione inclusi in Chrome per migliorare le prestazioni del codice, le tecniche equivalenti non sono state altrettanto accessibili o adottate da chi lavora sui servizi di backend. Stackdriver Profiler offre le stesse funzionalità agli sviluppatori di servizi, indipendentemente dal fatto che il codice sia eseguito su Google Cloud Platform o altrove.
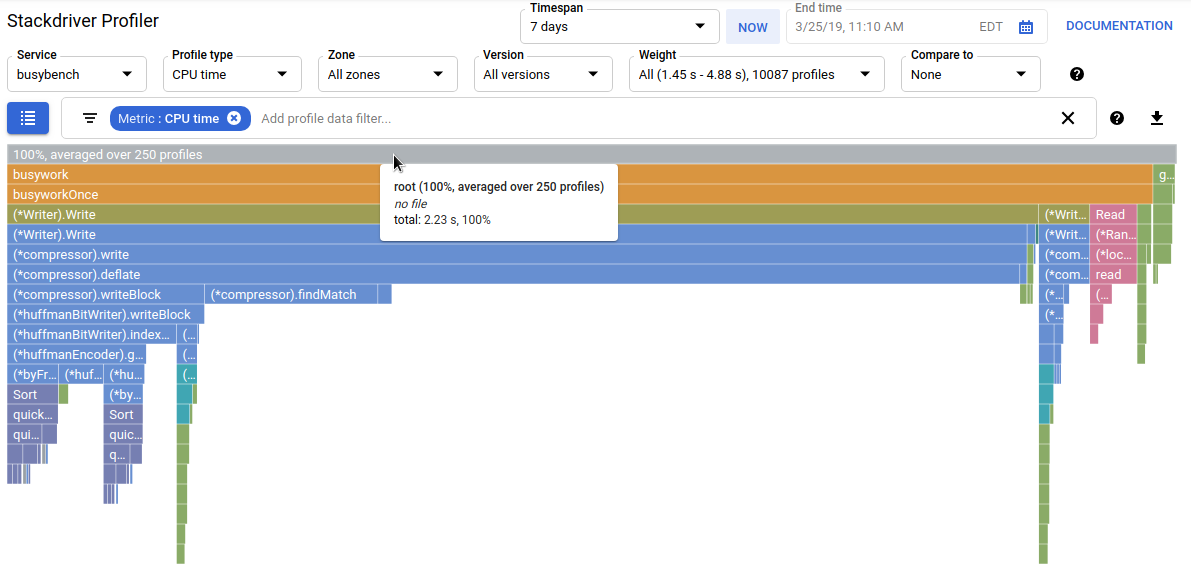
Lo strumento raccoglie informazioni sull'utilizzo della CPU e sull'allocazione della memoria dalle tue applicazioni di produzione. Attribuisce queste informazioni al codice sorgente dell'applicazione, aiutandoti a identificare le parti dell'applicazione che consumano più risorse e a comprendere meglio le caratteristiche di rendimento del codice. Il basso overhead delle tecniche di raccolta utilizzate dallo strumento lo rende adatto all'uso continuo negli ambienti di produzione.
In questo codelab imparerai a configurare Stackdriver Profiler per un programma Go e a familiarizzare con il tipo di informazioni sulle prestazioni dell'applicazione che lo strumento può presentare.
Cosa imparerai a fare
- Come configurare un programma Go per la profilazione con Stackdriver Profiler.
- Come raccogliere, visualizzare e analizzare i dati sul rendimento con Stackdriver Profiler.
Che cosa ti serve
- Un progetto Google Cloud
- Un browser, ad esempio Chrome o Firefox
- Familiarità con gli editor di testo standard di Linux, ad esempio Vim, EMAC o Nano
Come utilizzerai questo tutorial?
Come valuteresti la tua esperienza con Google Cloud Platform?
Configurazione dell'ambiente autonoma
Se non hai ancora un Account Google (Gmail o Google Apps), devi crearne uno. Accedi alla console di Google Cloud (console.cloud.google.com) e crea un nuovo progetto:



Ricorda l'ID progetto, un nome univoco per tutti i progetti Google Cloud (il nome riportato sopra è già stato utilizzato e non funzionerà per te, mi dispiace). In questo codelab verrà chiamato PROJECT_ID.
Successivamente, dovrai abilitare la fatturazione nella console Cloud per utilizzare le risorse Google Cloud.
L'esecuzione di questo codelab non dovrebbe costarti più di qualche dollaro, ma potrebbe essere più cara se decidi di utilizzare più risorse o se le lasci in esecuzione (vedi la sezione "Pulizia" alla fine di questo documento).
I nuovi utenti di Google Cloud Platform possono beneficiare di una prova senza costi di 300$.
Google Cloud Shell
Anche se Google Cloud può essere gestito da remoto dal tuo laptop, per semplificare la configurazione in questo codelab utilizzeremo Google Cloud Shell, un ambiente a riga di comando in esecuzione nel cloud.
Attiva Google Cloud Shell
Nella console GCP, fai clic sull'icona di Cloud Shell nella barra degli strumenti in alto a destra:

Poi fai clic su "Avvia Cloud Shell":

Bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente:

Questa macchina virtuale è caricata con tutti gli strumenti di sviluppo di cui avrai bisogno. Offre una home directory permanente da 5 GB e viene eseguita su Google Cloud, migliorando notevolmente le prestazioni di rete e l'autenticazione. Gran parte, se non tutto, il lavoro in questo lab può essere svolgersi semplicemente con un browser o con Google Chromebook.
Una volta eseguita la connessione a Cloud Shell, dovresti vedere che il tuo account è già autenticato e il progetto è già impostato sul tuo PROJECT_ID.
Esegui questo comando in Cloud Shell per verificare che l'account sia autenticato:
gcloud auth list
Output comando
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Output comando
[core] project = <PROJECT_ID>
In caso contrario, puoi impostarlo con questo comando:
gcloud config set project <PROJECT_ID>
Output comando
Updated property [core/project].
Nella console Cloud, vai all'interfaccia utente di Profiler facendo clic su "Profiler" nella barra di navigazione a sinistra:
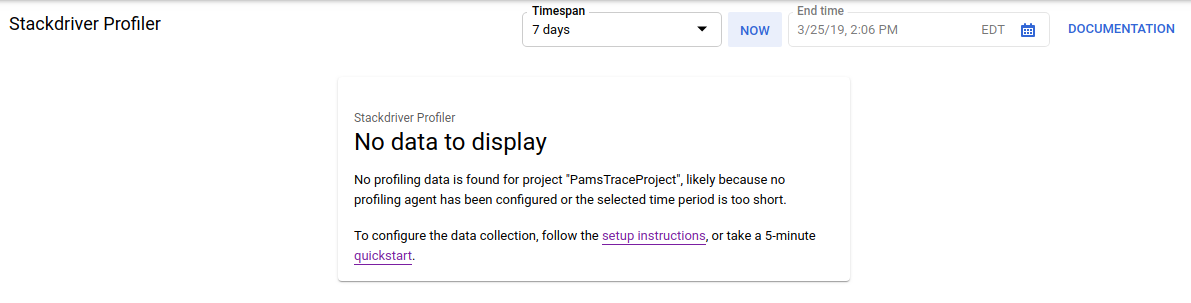
In alternativa, puoi utilizzare la barra di ricerca di Cloud Console per accedere all'interfaccia utente di Profiler: digita "Stackdriver Profiler" e seleziona l'elemento trovato. In entrambi i casi, dovresti visualizzare l'interfaccia utente di Profiler con il messaggio "Nessun dato da visualizzare", come mostrato di seguito. Il progetto è nuovo, quindi non sono ancora stati raccolti dati di profilazione.
Ora è il momento di profilare qualcosa.
Utilizzeremo una semplice applicazione Go sintetica disponibile su GitHub. Nel terminale Cloud Shell ancora aperto (e mentre nell'interfaccia utente di Profiler è ancora visualizzato il messaggio "Nessun dato da visualizzare"), esegui questo comando:
$ go get -u github.com/GoogleCloudPlatform/golang-samples/profiler/...
Quindi passa alla directory dell'applicazione:
$ cd ~/gopath/src/github.com/GoogleCloudPlatform/golang-samples/profiler/hotapp
La directory contiene il file "main.go", che è un'app sintetica con l'agente di profilazione abilitato:
main.go
...
import (
...
"cloud.google.com/go/profiler"
)
...
func main() {
err := profiler.Start(profiler.Config{
Service: "hotapp-service",
DebugLogging: true,
MutexProfiling: true,
})
if err != nil {
log.Fatalf("failed to start the profiler: %v", err)
}
...
}Per impostazione predefinita, l'agente di profilazione raccoglie i profili di CPU, heap e thread. Il codice qui consente la raccolta di profili mutex (noti anche come "contesa").
Ora esegui il programma:
$ go run main.go
Durante l'esecuzione del programma, l'agente di profilazione raccoglierà periodicamente i profili dei cinque tipi configurati. La raccolta viene eseguita in modo casuale nel tempo (con una velocità media di un profilo al minuto per ciascun tipo), pertanto potrebbero essere necessari fino a tre minuti per raccogliere ciascun tipo. Il programma ti comunica quando crea un profilo. I messaggi sono abilitati dal flag DebugLogging nella configurazione precedente; in caso contrario, l'agente viene eseguito in modalità silenziosa:
$ go run main.go 2018/03/28 15:10:24 profiler has started 2018/03/28 15:10:57 successfully created profile THREADS 2018/03/28 15:10:57 start uploading profile 2018/03/28 15:11:19 successfully created profile CONTENTION 2018/03/28 15:11:30 start uploading profile 2018/03/28 15:11:40 successfully created profile CPU 2018/03/28 15:11:51 start uploading profile 2018/03/28 15:11:53 successfully created profile CONTENTION 2018/03/28 15:12:03 start uploading profile 2018/03/28 15:12:04 successfully created profile HEAP 2018/03/28 15:12:04 start uploading profile 2018/03/28 15:12:04 successfully created profile THREADS 2018/03/28 15:12:04 start uploading profile 2018/03/28 15:12:25 successfully created profile HEAP 2018/03/28 15:12:25 start uploading profile 2018/03/28 15:12:37 successfully created profile CPU ...
L'UI si aggiornerà poco dopo la raccolta del primo profilo. Dopo questo aggiornamento, non verrà eseguito automaticamente, quindi per visualizzare i nuovi dati dovrai aggiornare manualmente l'interfaccia utente di Profiler. Per farlo, fai clic due volte sul pulsante Ora nel selettore dell'intervallo di tempo:

Dopo l'aggiornamento della UI, vedrai qualcosa di simile a questo:
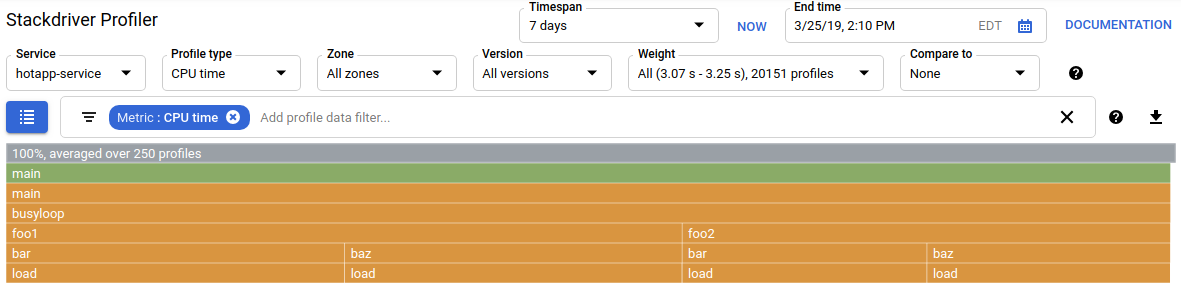
Il selettore del tipo di profilo mostra i cinque tipi di profilo disponibili:
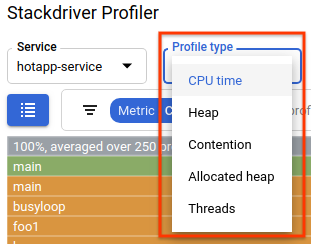
Ora esaminiamo ciascun tipo di profilo e alcune importanti funzionalità della UI, quindi conduciamo alcuni esperimenti. A questo punto, non hai più bisogno del terminale Cloud Shell, quindi puoi uscire premendo Ctrl+C e digitando "exit".
Ora che abbiamo raccolto alcuni dati, esaminiamoli più da vicino. Utilizziamo un'app sintetica (l'origine è disponibile su GitHub) che simula comportamenti tipici di diversi tipi di problemi di rendimento in produzione.
Codice che richiede un utilizzo elevato della CPU
Seleziona il tipo di profilo CPU. Dopo il caricamento dell'interfaccia utente, nel grafico a fiamma vedrai i quattro blocchi foglia per la funzione load, che rappresentano collettivamente tutto il consumo di CPU:
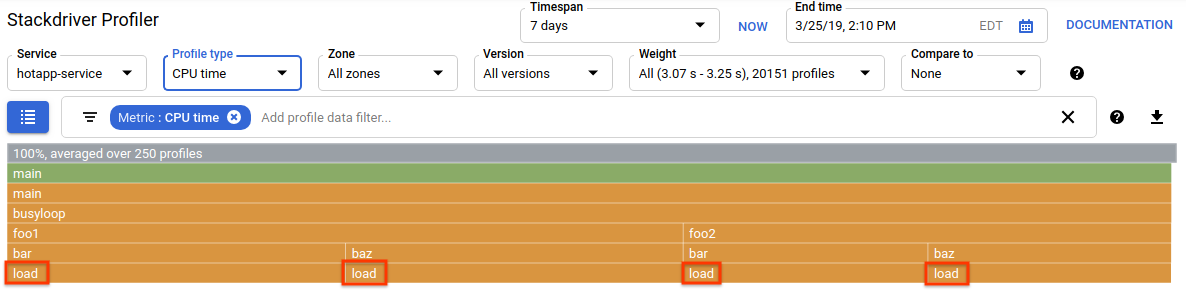
Questa funzione è scritta appositamente per consumare molti cicli della CPU eseguendo un ciclo stretto:
main.go
func load() {
for i := 0; i < (1 << 20); i++ {
}
}La funzione viene chiamata indirettamente da busyloop() tramite quattro percorsi di chiamata: busyloop → {foo1, foo2} → {bar, baz} → load. La larghezza di una casella di funzione rappresenta il costo relativo del percorso di chiamata specifico. In questo caso, tutti e quattro i percorsi hanno lo stesso costo. In un programma reale, devi concentrarti sull'ottimizzazione dei percorsi di chiamata più importanti in termini di rendimento. Il grafico a fiamma, che mette in evidenza visivamente i percorsi più costosi con caselle più grandi, rende questi percorsi facili da identificare.
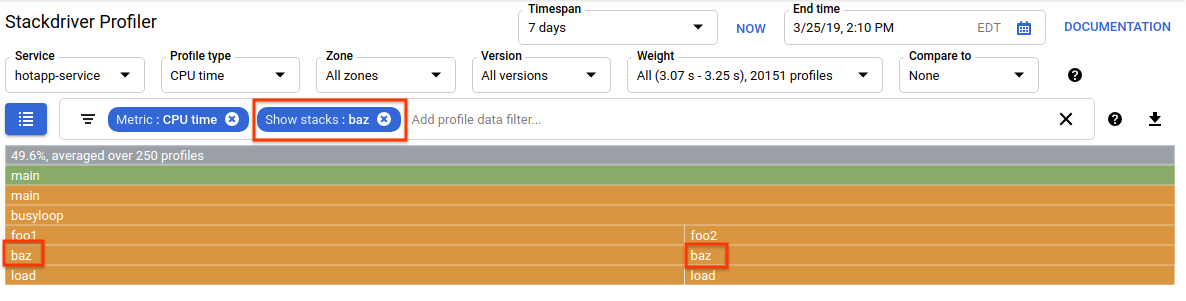
Puoi utilizzare il filtro dei dati del profilo per perfezionare ulteriormente la visualizzazione. Ad esempio, prova ad aggiungere un filtro "Mostra stack" specificando "baz" come stringa di filtro. Dovresti visualizzare una schermata simile a quella riportata di seguito, in cui vengono visualizzati solo due dei quattro percorsi di chiamata a load(). Questi due percorsi sono gli unici che passano attraverso una funzione con la stringa "baz" nel nome. Questo filtro è utile quando vuoi concentrarti su una parte di un programma più grande (ad esempio, perché ne possiedi solo una parte).
Codice che utilizza molta memoria
Ora passa al tipo di profilo "Heap". Assicurati di rimuovere tutti i filtri che hai creato negli esperimenti precedenti. Ora dovresti vedere un grafico a fiamma in cui allocImpl, chiamato da alloc, viene visualizzato come il principale consumatore di memoria nell'app:
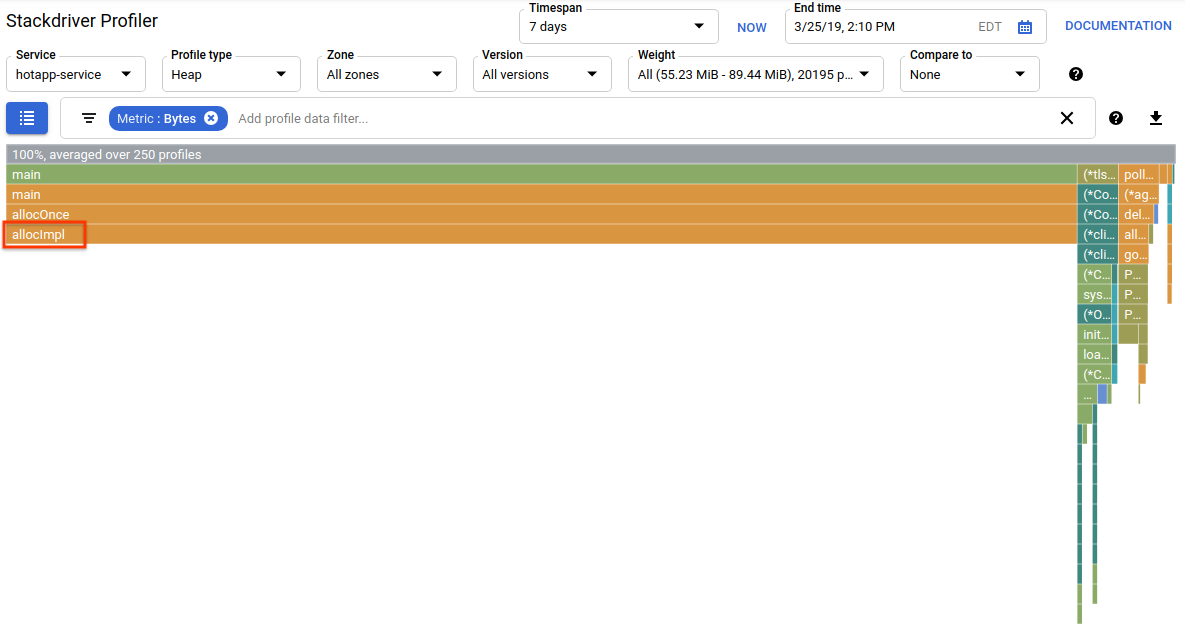
La tabella riepilogativa sopra il grafico a fiamme indica che la quantità totale di memoria utilizzata nell'app è in media di circa 57,4 MiB, la maggior parte dei quali è allocata dalla funzione allocImpl. Ciò non sorprende, data l'implementazione di questa funzione:
main.go
func allocImpl() {
// Allocate 64 MiB in 64 KiB chunks
for i := 0; i < 64*16; i++ {
mem = append(mem, make([]byte, 64*1024))
}
}La funzione viene eseguita una volta, allocando 64 MiB in blocchi più piccoli, quindi memorizzando i puntatori a questi blocchi in una variabile globale per proteggerli dalla garbage collection. Tieni presente che la quantità di memoria mostrata come utilizzata da Profiler è leggermente diversa da 64 MiB: il profiler heap Go è uno strumento statistico, quindi le misurazioni sono a basso overhead, ma non accurate al byte. Non sorprenderti se noti una differenza di circa il 10% come questa.
Codice con uso intensivo di I/O
Se scegli "Thread" nel selettore del tipo di profilo, la visualizzazione passerà a un grafico a fiamma in cui la maggior parte della larghezza è occupata dalle funzioni wait e waitImpl:
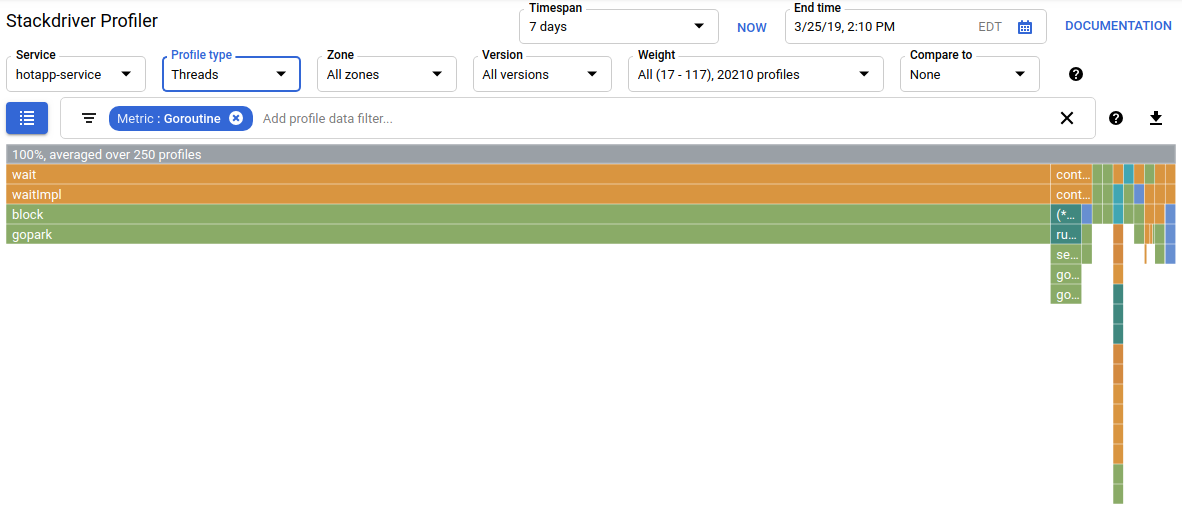
Nel riepilogo sopra il grafico a fiamma, puoi vedere che ci sono 100 goroutine che aumentano lo stack di chiamate dalla funzione wait. È esattamente così, dato che il codice che avvia queste attese ha il seguente aspetto:
main.go
func main() {
...
// Simulate some waiting goroutines.
for i := 0; i < 100; i++ {
go wait()
}Questo tipo di profilo è utile per capire se il programma trascorre un tempo imprevisto in attesa (ad esempio I/O). Questi stack di chiamate in genere non vengono campionati dal profiler CPU, in quanto non consumano una parte significativa del tempo di CPU. Spesso è consigliabile utilizzare i filtri "Nascondi stack" con i profili dei thread, ad esempio per nascondere tutti gli stack che terminano con una chiamata a gopark,, poiché spesso si tratta di goroutine inattive e meno interessanti di quelle che attendono I/O.
Il tipo di profilo dei thread può anche aiutare a identificare i punti del programma in cui i thread attendono a lungo un mutex di proprietà di un'altra parte del programma, ma il tipo di profilo seguente è più utile a questo scopo.
Codice con elevata contesa
Il tipo di profilo Contesa identifica le serrature più "richieste" del programma. Questo tipo di profilo è disponibile per i programmi Go, ma deve essere attivato esplicitamente specificando "MutexProfiling: true" nel codice di configurazione dell'agente. La raccolta funziona registrando (nella metrica "Contese") il numero di volte in cui un blocco specifico, quando viene sbloccato da una goroutine A, ha un'altra goroutine B in attesa che il blocco venga sbloccato. Registra anche (nella metrica "Ritardo") il tempo di attesa della goroutine bloccata per il blocco. In questo esempio, è presente un'unica pila di contesa e il tempo di attesa totale per il blocco è stato di 11,03 secondi:
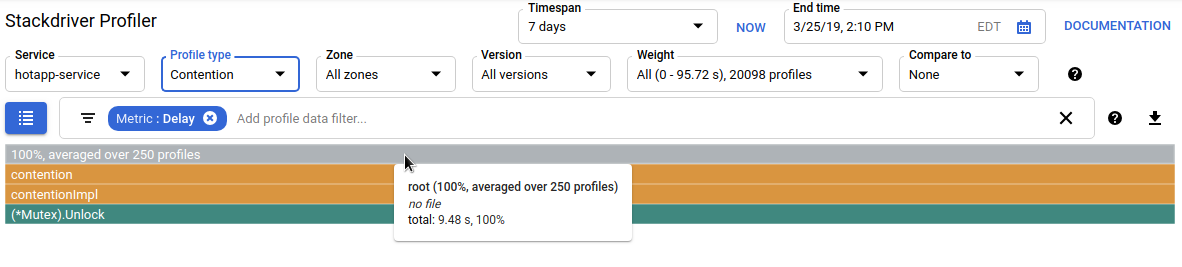
Il codice che genera questo profilo è costituito da quattro goroutine che si contendono un mutex:
main.go
func contention(d time.Duration) {
contentionImpl(d)
}
func contentionImpl(d time.Duration) {
for {
mu.Lock()
time.Sleep(d)
mu.Unlock()
}
}
...
func main() {
...
for i := 0; i < 4; i++ {
go contention(time.Duration(i) * 50 * time.Millisecond)
}
}In questo lab hai imparato come configurare un programma Go per l'utilizzo con Stackdriver Profiler. Hai anche imparato a raccogliere, visualizzare e analizzare i dati sul rendimento con questo strumento. Ora puoi applicare la tua nuova competenza ai servizi reali che esegui su Google Cloud.
Hai imparato a configurare e utilizzare Stackdriver Profiler.
Scopri di più
- Stackdriver Profiler: https://cloud.google.com/profiler/
- Pacchetto runtime/pprof di Go utilizzato da Stackdriver Profiler: https://golang.org/pkg/runtime/pprof/
Licenza
Questo lavoro è concesso in licenza ai sensi di una licenza Creative Commons Attribution 2.0 Generic.