
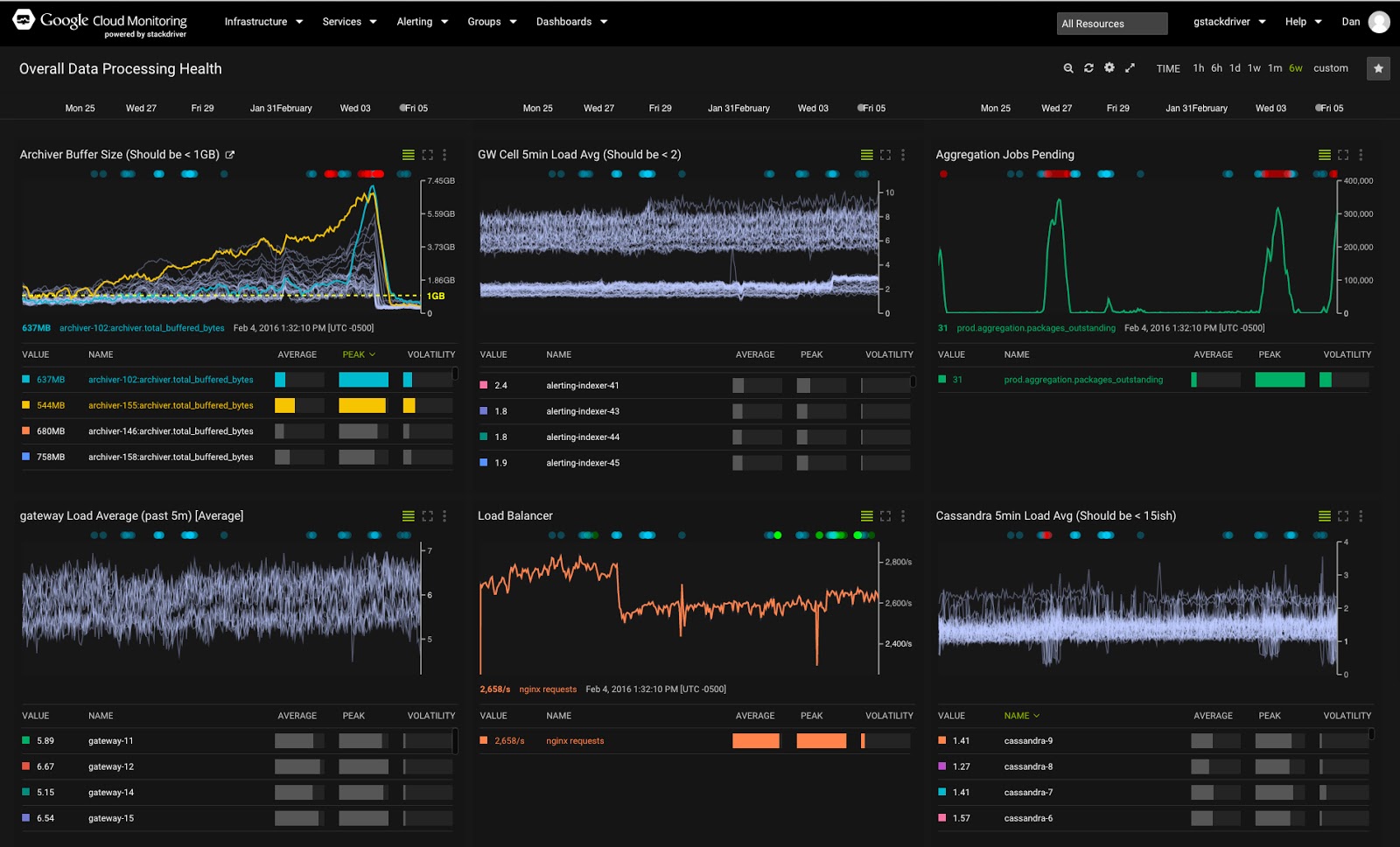
В этом практикуме вы узнаете, как начать использовать Stackdriver для мониторинга и просмотра показателей производительности и журналов для сервисов и виртуальных машин Google Cloud Platform.
В этой лабораторной работе вы
- Ознакомьтесь с домашней страницей Stackdriver.
- Понимание работы информационных панелей и диаграмм.
- Создайте проверку работоспособности.
- Создайте простую политику оповещений.
- Работа с тревожными инцидентами.
- Перейдите в средство просмотра журналов.
Какой у вас опыт использования Stackdriver?
Настройка среды для самостоятельного обучения
Если у вас еще нет учетной записи Google (Gmail или Google Apps), вам необходимо ее создать .
Войдите в консоль Google Cloud Platform ( console.developers.google.com ) и создайте новый проект:
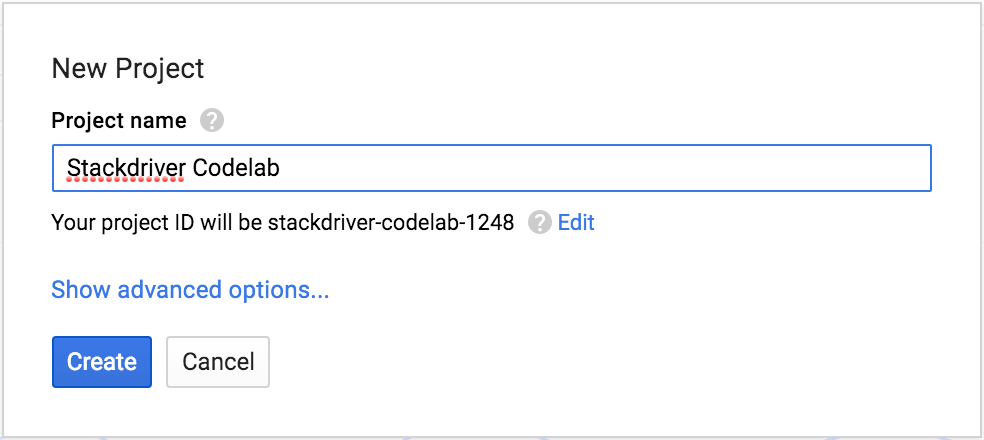
Запомните идентификатор проекта — уникальное имя для всех проектов Google Cloud. Далее в этой практической работе он будет обозначаться как PROJECT_ID .
Очень важно — посетите страницу Compute Engine, чтобы начать включение API Compute Engine:
И затем: Вычисления → Вычислительная машина → Экземпляры виртуальных машин

При первом выполнении вы увидите экран с сообщением «Compute Engine готовится. Это может занять минуту или больше». Вы можете продолжить вход в Google Cloud Shell ниже, но не сможете создавать виртуальные машины, пока эта операция не завершится.
Большую часть работы вы будете выполнять в Google Cloud Shell — среде командной строки, работающей в облаке . Эта виртуальная машина на базе Debian содержит все необходимые инструменты разработки и предоставляет постоянный домашний каталог объёмом 5 ГБ. Откройте Google Cloud Shell, нажав на значок в правом верхнем углу экрана:
Наконец, используя Cloud Shell, задайте зону по умолчанию и конфигурацию проекта:
$ gcloud config set compute/zone us-central1-b $ gcloud config set compute/region us-central
Вы также можете выбрать различные зоны. Подробнее о зонах читайте в документации по регионам и зонам .
В этом разделе вы создадите экземпляры Compute Engine под управлением nginx+ с помощью Cloud Launcher. Эти экземпляры понадобятся нам для демонстрации мониторинга и оповещения. Вы можете создать экземпляр Compute Engine из графической консоли или из командной строки. В этой лабораторной работе вы познакомитесь с командной строкой.
Итак, начнем.
Используйте gcloud для установки идентификатора вашего проекта:
$ gcloud config set project PROJECT_ID
Далее обязательно скопируйте и вставьте это как есть:
$ for i in {1..3}; do \
gcloud compute instances create "nginx-plus-$i" \
--machine-type "n1-standard-1" \
--metadata "google-cloud-marketplace-solution-key=nginx-public:nginx-plus" \
--maintenance-policy "MIGRATE" --scopes default="https://www.googleapis.com/auth/cloud-platform" \
--tags "http-server","google-cloud-marketplace" \
--image "https://www.googleapis.com/compute/v1/projects/nginx-public/global/images/nginx-plus-ubuntu1404-v20150916-final" \
--boot-disk-size "10" --boot-disk-type "pd-standard" \
--boot-disk-device-name "nginx-plus-$i"; doneВы увидите предупреждающие сообщения о размере диска, а затем следующий вывод по мере создания каждой виртуальной машины:
NAME ZONE MACHINE_TYPE PREEMPTIBLE INTERNAL_IP EXTERNAL_IP STATUS nginx-plus-1 us-central1-b n1-standard-2 X.X.X.X X.X.X.X RUNNING ...
Запишите EXTERNAL_IP — это важно в дальнейшем.
Выполнение этих операций может занять несколько минут.
По умолчанию Google Cloud Platform разрешает доступ только к нескольким портам. Поскольку мы скоро будем обращаться к Nginx, давайте включим порт 80 в настройках брандмауэра:
$ gcloud compute firewall-rules create allow-80 --allow tcp:80 --target-tags "http-server" Created [...]. NAME NETWORK SRC_RANGES RULES SRC_TAGS TARGET_TAGS allow-80 default 0.0.0.0/0 tcp:80 http-server
Это создаст правило брандмауэра с именем allow-80, которое будет иметь следующие значения по умолчанию:
- Список блоков IP-адресов, которым разрешено устанавливать входящие соединения (
--source-ranges), установлен на0.0.0.0/0(везде). - Список тегов экземпляров, указывающий набор экземпляров в сети, которые могут принимать входящие соединения, установлен на значение none, что означает, что правило брандмауэра применимо ко всем экземплярам.
Запустите gcloud compute firewall-rules create --help чтобы увидеть все значения по умолчанию.
После создания первого экземпляра вы можете проверить, запущен ли и доступен ли nginx, перейдя по адресу http://EXTERNAL_IP/, где EXTERNAL_IP — это публичный IP-адрес nginx-plus-1 , и вы должны увидеть страницу Nginx:
Вы также можете просмотреть запущенные экземпляры, введя:
$ gcloud compute instances list
Google Stackdriver — это мощное решение для мониторинга, объединяющее различные инструменты для упрощения мониторинга и анализа ваших облачных приложений. Stackdriver можно использовать для просмотра показателей производительности, настройки и получения оповещений, добавления собственных панелей мониторинга и метрик, просмотра журналов и трассировок, а также настройки интегрированных панелей мониторинга — и всё это из единого центра.
Следующие шаги помогут вам включить Stackdriver и работать с консолью.
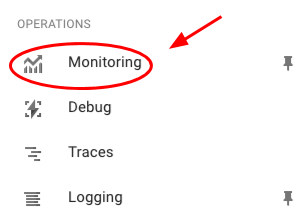
По умолчанию Google Stackdriver находится в стадии бета-тестирования и недоступен для новых проектов. Чтобы включить его, перейдите на левую панель навигации и нажмите «Мониторинг» (возможно, вам придётся прокрутить страницу вниз, чтобы найти этот пункт).
На следующем экране нажмите «Включить мониторинг» и подождите минуту, чтобы он включился.
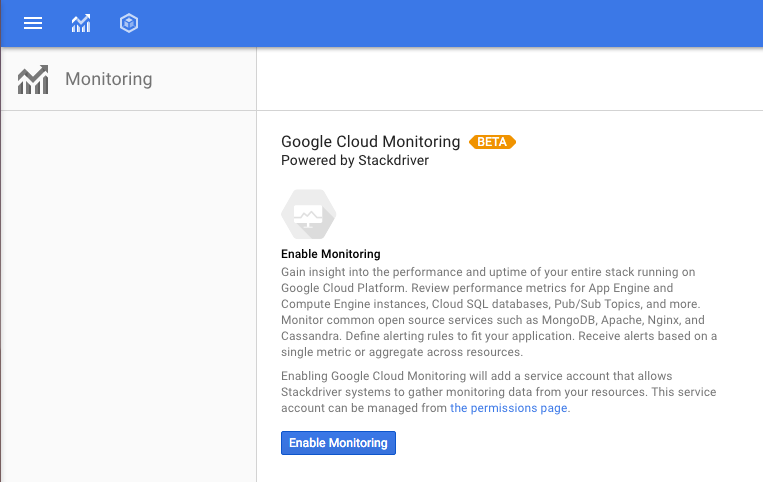
После включения контент изменится, и вы увидите текст ниже. Нажмите «Перейти к мониторингу», чтобы начать! Вам нужно будет войти в систему через Google, после чего вы перейдете в консоль Stackdriver для вашего проекта — здесь вы будете выполнять и анализировать задачи, связанные с мониторингом.
Давайте ознакомимся с домашней страницей.
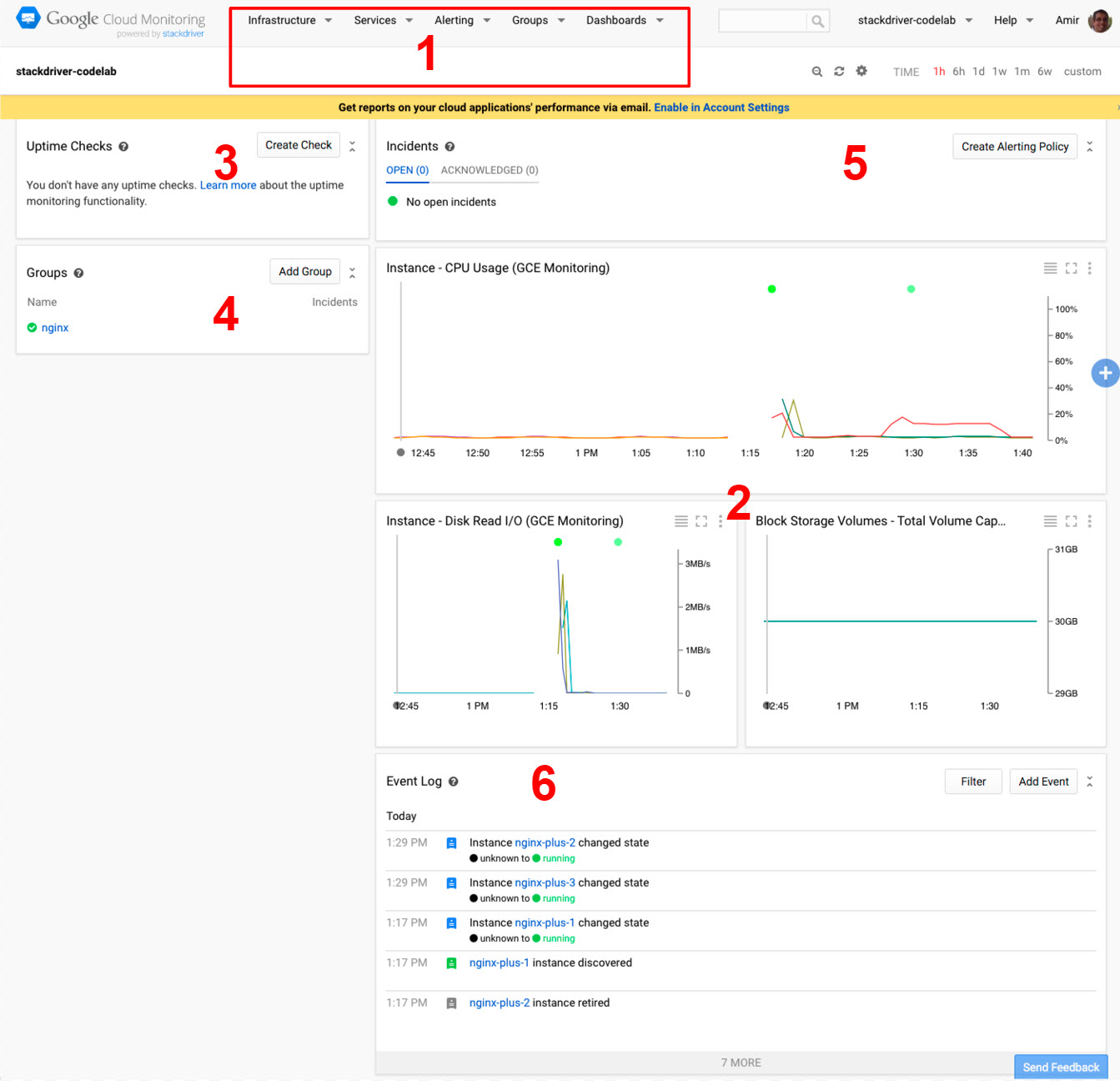
- Верхнее меню: используется для выбора различных представлений/контекстов и доступа ко всем доступным действиям Stackdriver.
- Панели мониторинга: это панели мониторинга отслеживаемых показателей и событий. Изначально это предопределенные системные панели мониторинга, основанные на ресурсах вашего проекта, но вы также можете создавать собственные.
- Проверки работоспособности: они периодически проверяют доступность ресурсов, доступных пользователю, и включают оповещения, когда они становятся недоступными.
- Список групп: группы используются для объединения ресурсов с общими свойствами и характеристиками, чтобы их можно было обрабатывать как группу или кластер для таких задач, как мониторинг и оповещения. Группы могут быть обнаружены автоматически или определены пользователем.
- Панель «Инциденты»: панель «Инциденты» отслеживает инциденты с оповещениями. Вы ничего не увидите здесь, пока не определите политики оповещений.
- Журнал событий: содержит список событий, связанных с отслеживаемыми ресурсами, например, изменения экземпляров, инциденты и т. д.
Прежде чем мы рассмотрим графики, обратите внимание, что большинство линий выровнялись после инициализации первого экземпляра. Давайте посмотрим, сможем ли мы «распрямить» некоторые из них, создав нагрузку на один из экземпляров.
Чтобы подключиться к экземпляру по SSH из командной строки Cloud Shell:
$ gcloud compute ssh nginx-plus-1 ... Do you want to continue (Y/n)? Y ... Generating public/private rsa key pair. Enter passphrase (empty for no passphrase): [Hit Enter] Enter same passphrase again: [Hit Enter] ... yourusername@nginx-plus-1:~$
Вот и всё! Довольно просто. (В процессе работы не забудьте ввести пароль :) Также учтите, что вам может не потребоваться добавить пароль.
Кроме того, вы также можете подключиться к экземпляру по SSH непосредственно из консоли, перейдя в Compute Engine > VM Instances и нажав SSH .
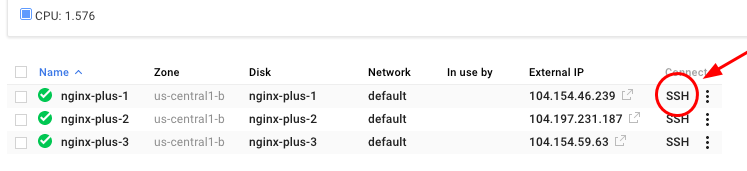
In the SSH window, type:
yourusername@nginx-plus-1:~$ sudo apt-get install rand
yourusername@nginx-plus-1:~$ for i in {1..10}; do dd if=/dev/zero of=/dev/null count=$(rand -M 80)M; sleep 60; done &Теперь процессор экземпляра nginx-plus-1 загружается. Мы можем вернуться на вкладку панели мониторинга Stackdriver и начать изучение, но прежде чем вернуться на страницу панелей мониторинга Stackdriver, давайте воспользуемся возможностью установить агент Cloud Logging.
Fetch and install the script:
yourusername@nginx-plus-1:~$ curl -sS https://dl.google.com/cloudagents/add-logging-agent-repo.sh | sudo bash /dev/stdin --also-install
Обратите внимание: при установке в продакшн-режиме обязательно проверьте хэш SHA-256. Подробнее об установке можно узнать здесь .
Теперь пора вернуться в консоль Google Stackdriver.
Уделите время освоению навигации и использования панелей мониторинга и диаграмм. Наведите указатель мыши на линии диаграммы и посмотрите, что произойдёт. Измените временной интервал для диаграмм (элементы управления находятся в правом верхнем углу). Вы всегда можете вернуться на главную страницу, нажав на логотип Stackdriver в левом верхнем углу консоли.
Давайте посмотрим на график загрузки ЦП:
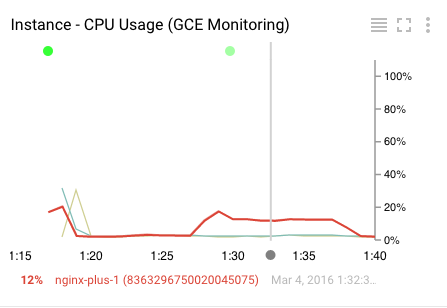
Некоторые элементы диаграммы:
- Выделенная линия — это текущая выбранная метрика (диаграмма может отображать несколько метрик).
- Серая горизонтальная линия представляет момент времени, на который указывает курсор мыши.
- Внизу указано название ресурса и его значение на выбранный момент времени.
- В верхней части диаграммы находятся цветные точки, представляющие события, подробно описанные в журнале событий. Щёлкните по ним, чтобы открыть список событий. Примечание: вы можете не видеть ни одного события, если у вас ещё нет событий.
- В правом верхнем углу диаграммы находятся три элемента управления (слева направо):
- Скрыть/показать список показателей под диаграммой
- Включить полноэкранный режим
- Меню с различными полезными функциями (обязательно попробуйте режим «Рентген», если у вас очень подробная диаграмма!). Обратите внимание на опцию «Просмотр журналов» — мы вернёмся к ней позже.
Проверки работоспособности позволяют быстро оценить работоспособность любой веб-страницы, экземпляра или группы ресурсов. Каждая настроенная проверка регулярно проверяется из разных точек по всему миру. Проверки работоспособности можно использовать в качестве условий в определениях политик оповещения .
Вы можете просматривать проверки и их статус, выбрав «Оповещения» > «Проверки работоспособности» в верхнем меню. Раздел «Проверки работоспособности» также находится на панели управления Google Stackdriver и на страницах, посвящённых отдельным ресурсам. Для проверок работоспособности, охватывающих группу ресурсов, вы можете развернуть проверку, чтобы отобразить статус отдельных элементов группы.
Давайте создадим проверку работоспособности. Найдите виджет проверки работоспособности на главном экране Stackdriver:
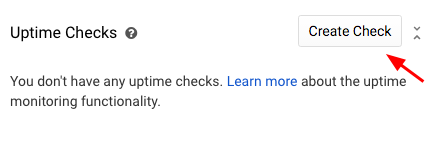
Появится новое всплывающее окно. Мы можем настроить проверки работоспособности для отдельного ресурса или группы ресурсов, использовать собственные заголовки и полезные данные, добавить аутентификацию и другие параметры. Сейчас мы будем использовать проверку HTTP по умолчанию, которая будет проверять автоматически созданную группу nginx каждую минуту.
Используйте снимок экрана ниже, чтобы заполнить различные варианты:
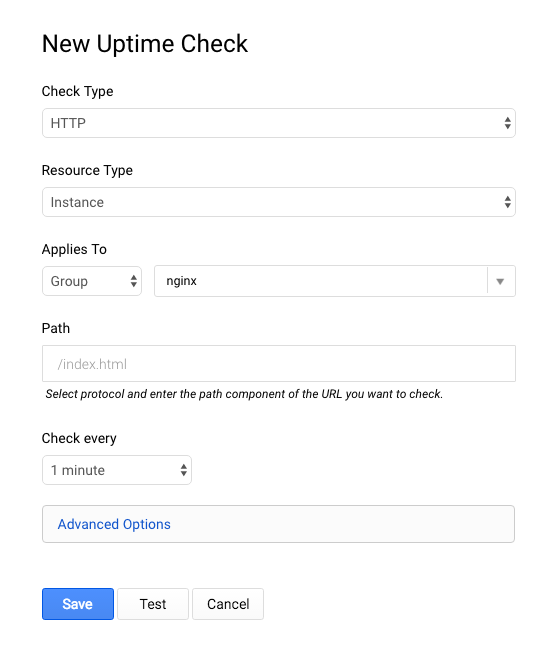
Нажмите кнопку «Тест», чтобы убедиться, что ваши конечные точки доступны (должны быть три зелёных подтверждения), и нажмите «Сохранить». Примечание: если вы не получите подтверждения, вы всё равно можете продолжить выполнение лабораторной работы, поскольку это может быть связано с несоблюдением сроков проверки.
Затем появится поле «Проверка работоспособности создана» и вам будет предложено создать политику оповещений для этой проверки. Давайте сделаем это в следующем разделе — пока ничего не нажимайте.
Вы можете настроить политики оповещений, чтобы определить условия, определяющие, нормально ли работают ваши облачные сервисы и платформы. Cloud Monitoring предоставляет множество различных метрик и проверок работоспособности, которые можно использовать в политиках.
При нарушении условий политики оповещения создаётся инцидент, который отображается в консоли Stackdriver в разделе «Инцидент». Специалисты по реагированию могут подтвердить получение уведомления и закрыть инцидент после его устранения.
Нажмите «Создать политику оповещений» и перейдем к настройке политики.
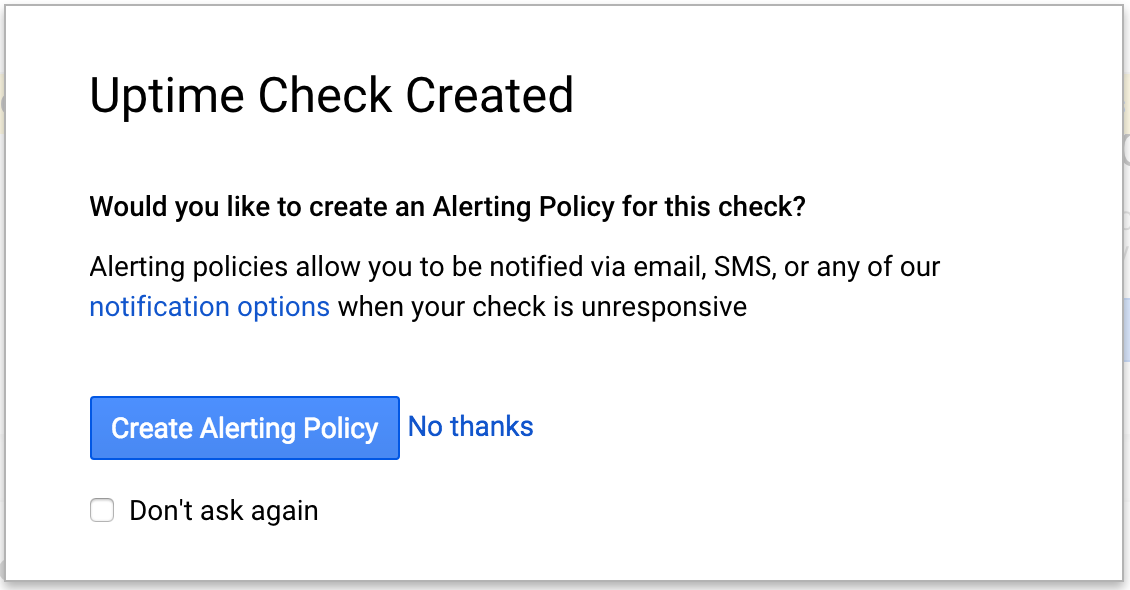
Теперь вы должны увидеть этот экран:
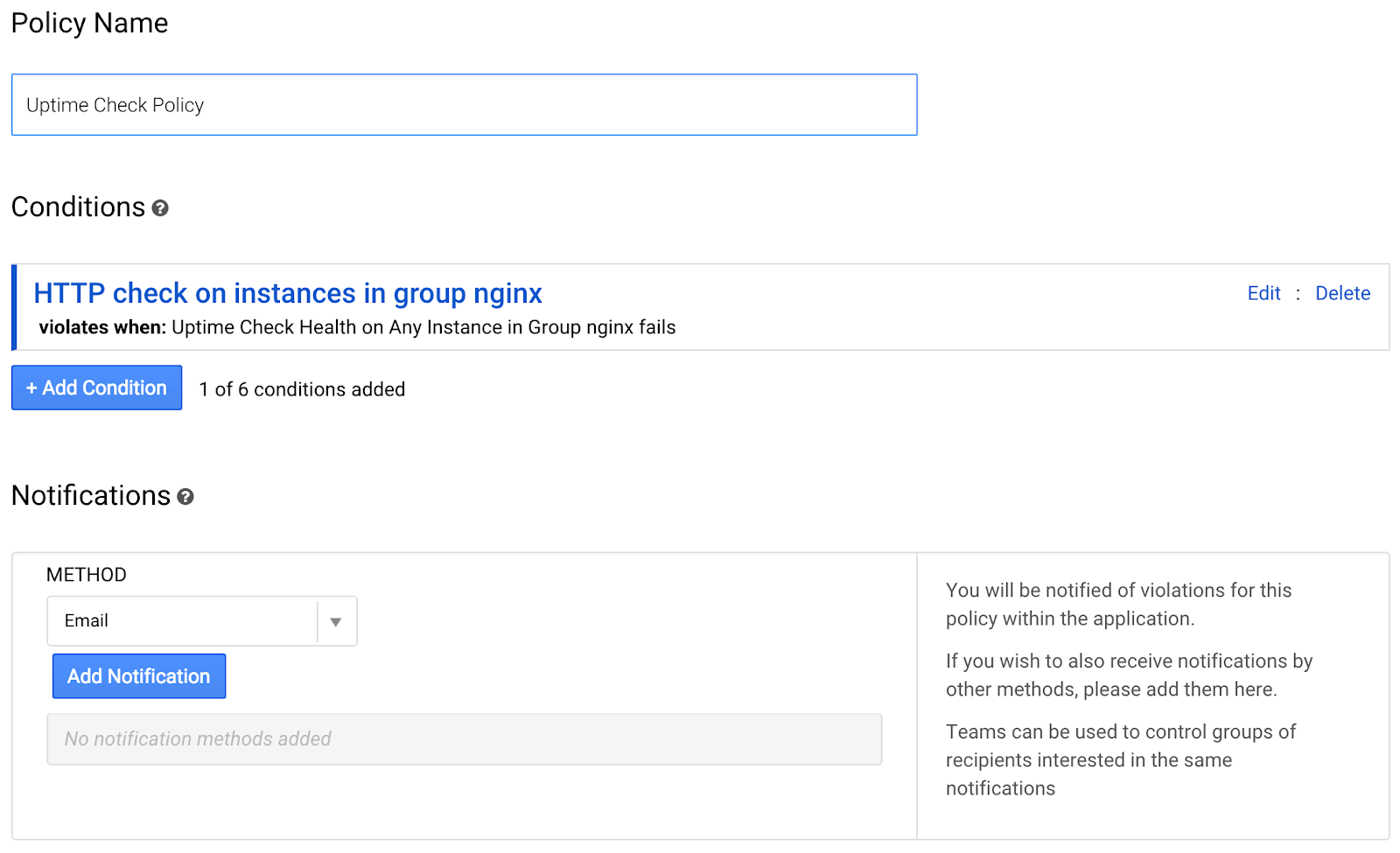
Введите имя политики: «Проверка времени работы для группы nginx».

Теперь в разделе «Способ оповещения» нажмите «Добавить уведомление».
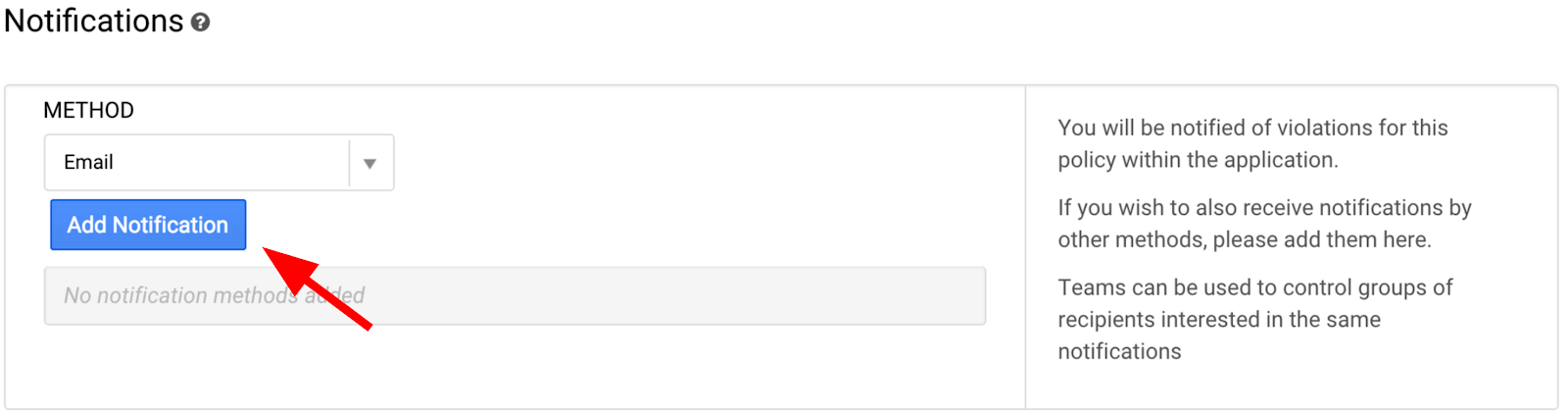
Введите адрес электронной почты, связанный с вашей учётной записью Google Cloud. Прокрутите экран вниз и нажмите «Сохранить политику».
Вернитесь на домашнюю страницу Stackdriver (нажав на логотип в левом верхнем углу).
Теперь вы должны увидеть созданную вами проверку работоспособности в разделе «Проверки работоспособности» на панели управления. На данный момент статус должен быть зелёным.
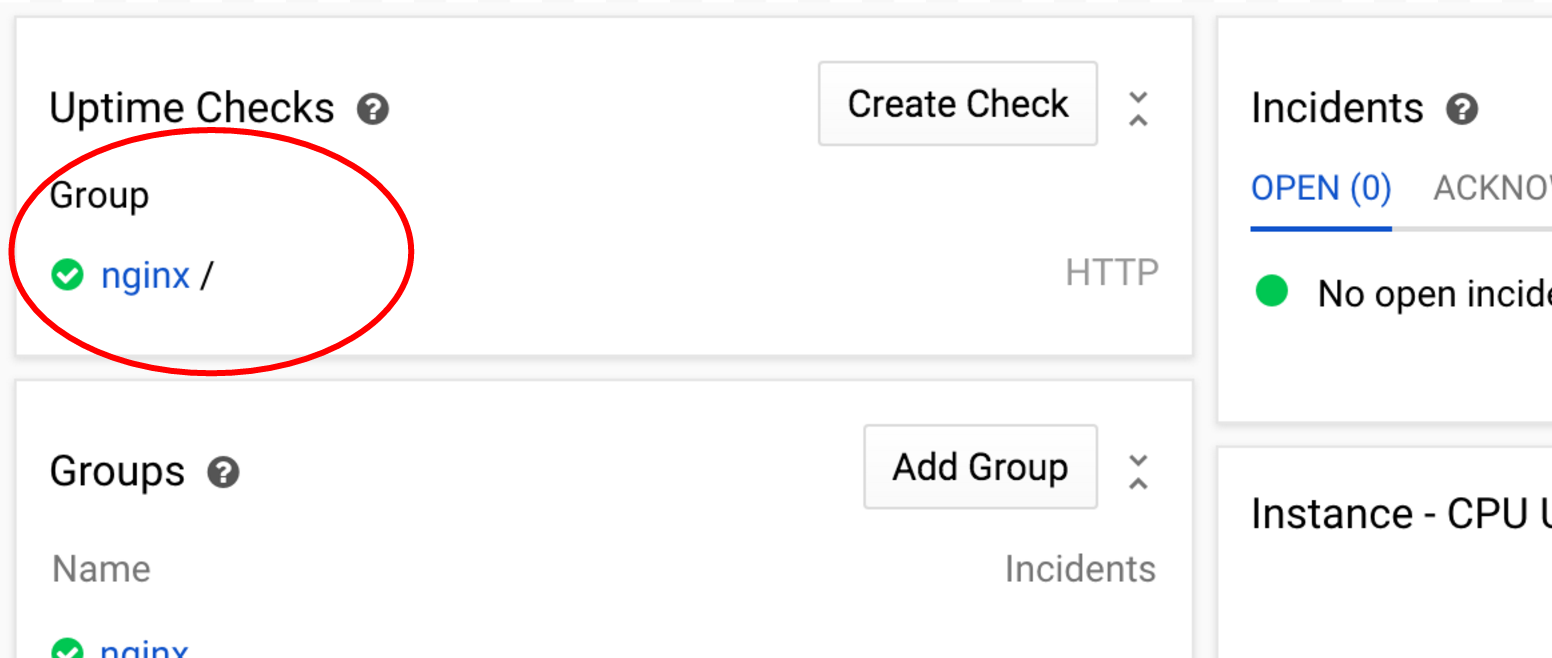
Прокрутите вниз до журнала событий, и вы увидите событие о создании политики оповещения.
А теперь давайте создадим немного проблем :)
Давайте посмотрим, что произойдет, если остановить службу Ngnix.
Снова подключитесь к экземпляру по SSH из командной строки Cloud Shell:
$ gcloud compute ssh nginx-plus-1
И введите:
yourusername@nginx-plus-1:~$ sudo service nginx stop
Теперь созданная нами проверка работоспособности должна завершиться неудачей. В результате будет создан инцидент и на указанный вами адрес электронной почты будет отправлено уведомление. Обнаружение условия займёт минуту (помните про продолжительность в 1 минуту при настройке проверки работоспособности?), поэтому давайте проверим страницу группы nginx.
Существует несколько способов перехода на панель управления определенной группы ресурсов:
- Вы можете нажать на название группы на главной странице. Это переключит вас на панель управления, специально созданную для мониторинга ресурсов группы. Вы также можете настроить эту панель управления.
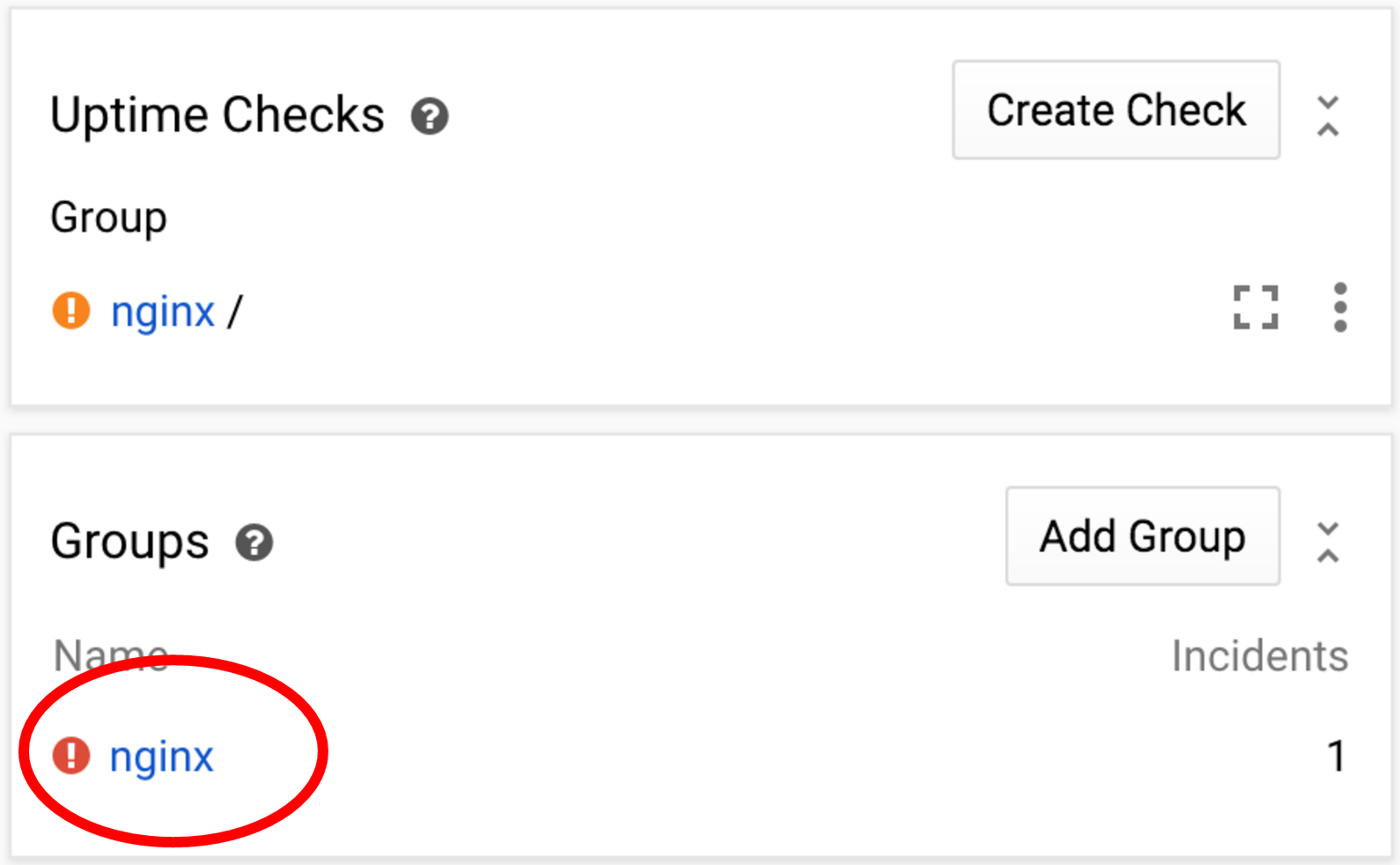
- В меню верхнего уровня выберите «Группы», а затем найдите нужную группу.
Теперь нажмите кнопку автоматического обновления, чтобы панели мониторинга обновлялись автоматически. Значок станет красным.

Теперь вы видите панель мониторинга, относящуюся к автоматически созданной группе nginx. Справа представлены графики нескольких ключевых показателей, относящихся к группе. Другими словами, эти графики показывают метрики, относящиеся ко всем ресурсам в группе nginx (трём нашим виртуальным машинам nginx+, созданным ранее).
С левой стороны вы видите различную информацию, касающуюся группы:
- Статус инцидента
- Проверки работоспособности
- Журнал событий
- Список ресурсов (экземпляров, томов и т. д.)
Обратите внимание, что они относятся только к группе, поэтому в журнале событий перечислены только события для этой группы.
Вы можете нажимать на различные ресурсы или подгруппы, чтобы переходить к их собственным панелям мониторинга. Например, нажав на nginx-plus-1, вы перейдете на панель мониторинга, содержащую только метрики и проверки, относящиеся к этому экземпляру. Попробуйте прямо сейчас:
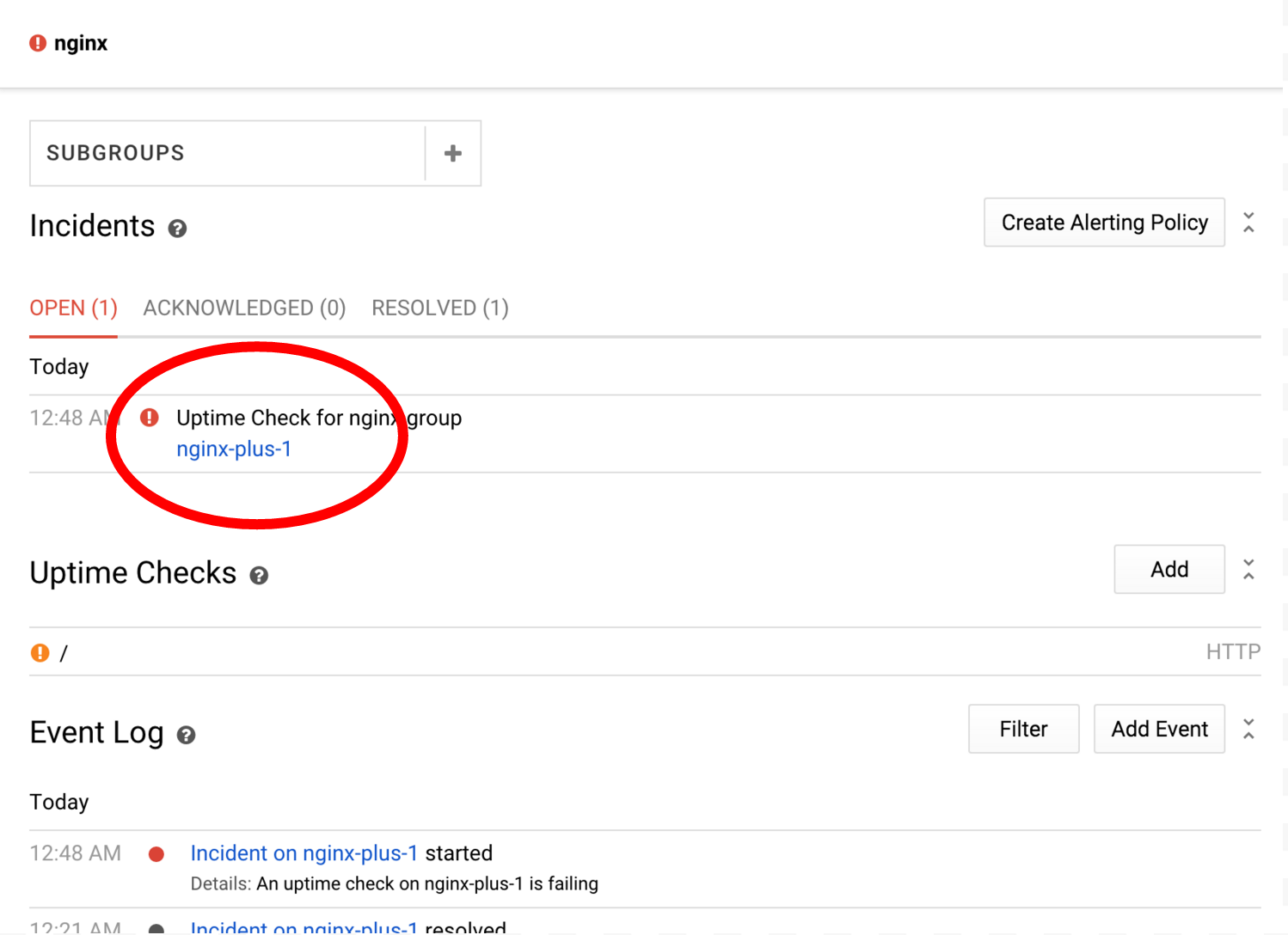
Инциденты Stackdriver создаются, когда набор условий оповещения соответствует определённым критериям. В нашем случае мы создали оповещение для проверки работоспособности nginx, которая в настоящее время не выполняется на nginx-plus-1. Инциденты помогают отслеживать текущее состояние, а также сотрудничать с другими членами команды при работе над проблемами.
Давайте признаем факт инцидента и дадим знать другим членам команды, что мы расследуем ситуацию:
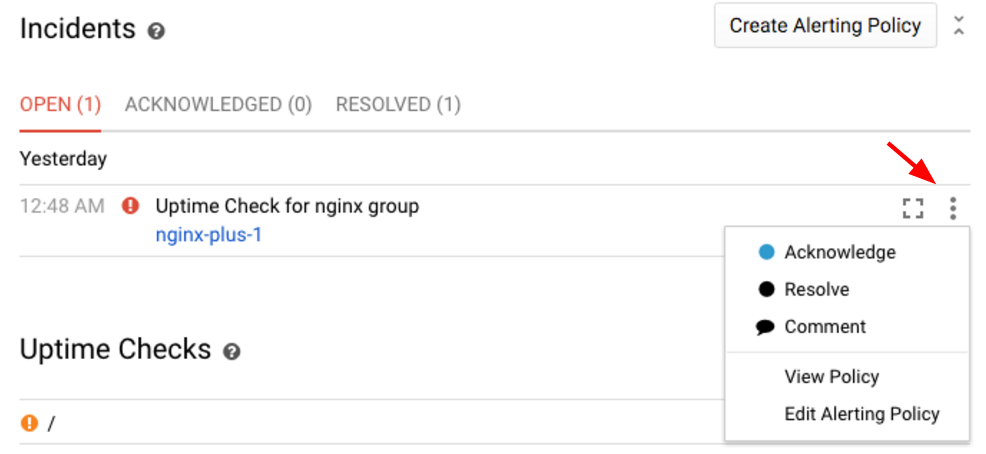
Обратите внимание, что при этом статус инцидента меняется с «Открыто» на «Подтверждено». Ситуация всё ещё продолжается (условия политики оповещения всё ещё нарушены), но вы даёте членам команды сигнал о том, что вы занимаетесь этим вопросом. Это также будет зафиксировано в журнале событий.
Инциденты можно разрешить вручную или автоматически. Чтобы увидеть последний вариант, подключитесь по SSH к nginx-plus-1 и исправьте проблему:
yourusername@nginx-plus-1:~$ sudo service nginx start
Теперь инцидент будет автоматически решён, как только проверка работоспособности восстановится. Вы также можете решить его самостоятельно, выбрав пункт меню «Решить».
Cloud Logging — это решение для ведения журналов как услуги, предлагающее удобное централизованное место для просмотра и запроса журналов из различных источников. Вы также можете использовать журналы для их экспорта в другие хранилища (Google Cloud Storage, Google BigQuery или Google Cloud Pub/Sub).
Чтобы получить доступ к средству просмотра журналов облака, выберите его в левом меню консоли облака:
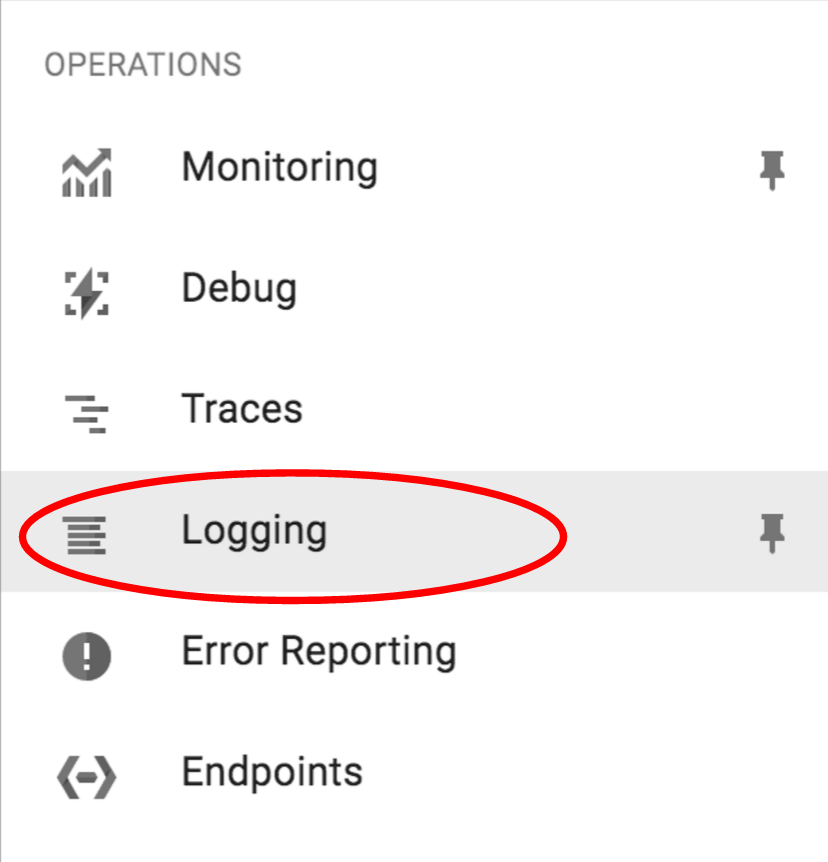
Вы будете перенаправлены в средство просмотра журналов, где вы можете использовать предопределенные запросы или создавать и сохранять собственные запросы, получать прямую трансляцию журналов, поступающих из нескольких ресурсов в вашем облачном развертывании, создавать метрики на основе журналов, экспортировать данные и многое другое.
Есть несколько удобных элементов управления для быстрого поиска нужной информации:
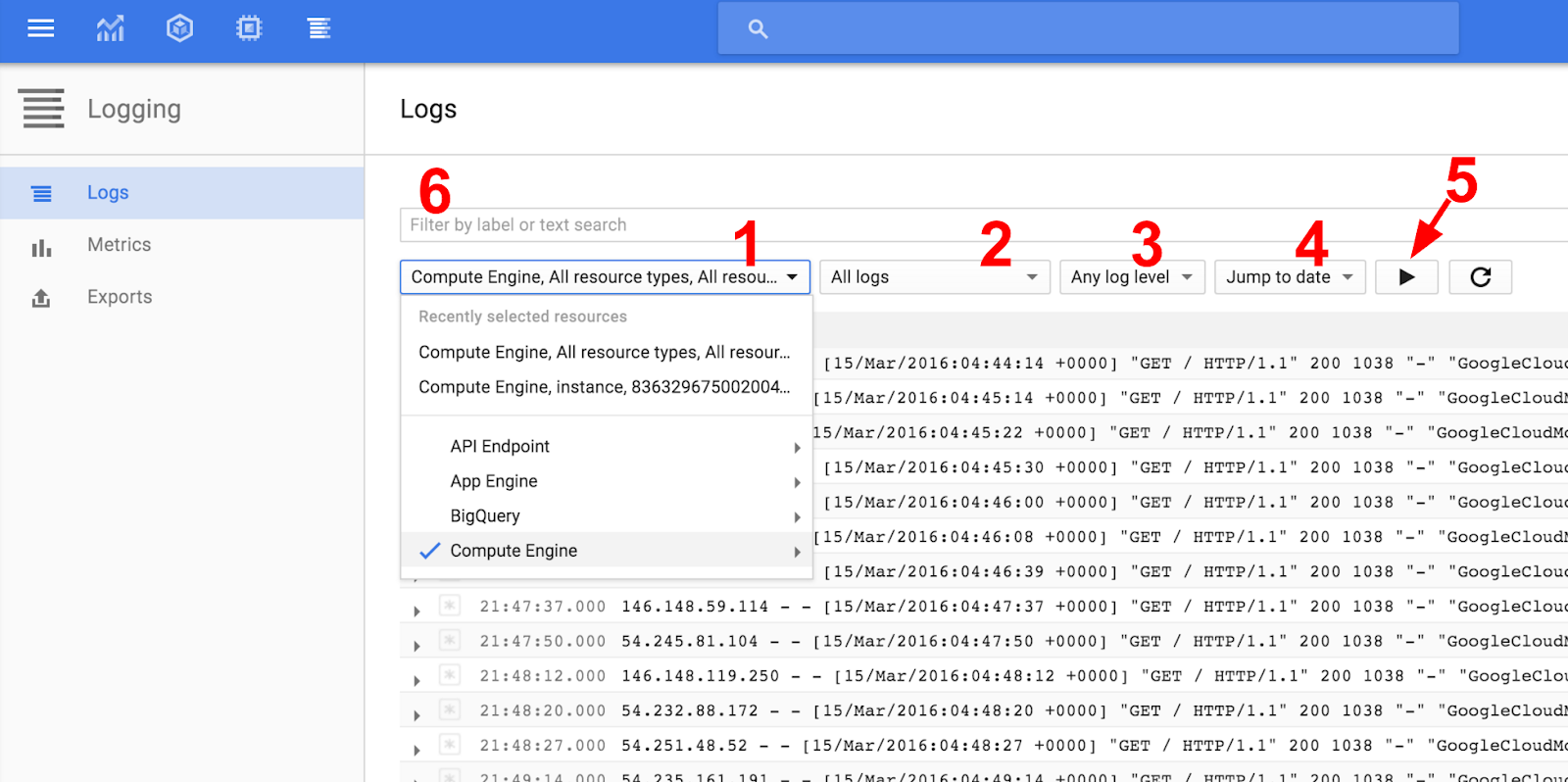
- Фильтр по типам ресурсов
- Фильтр по определенным типам журналов выбранных ресурсов
- Фильтрация определенных уровней журнала
- Фильтр по определенным датам, чтобы просмотреть прошлые выпуски
- Включить непрерывную трансляцию
- Поле поиска для поиска по тексту, метке или регулярному выражению
Теперь давайте попрактикуемся в сужении поиска до конкретных журналов.
В селекторе типов ресурсов (1 на снимке экрана) выберите Compute Engine -> Все типы ресурсов.
Далее в селекторе типа журнала (2 на снимке экрана) выберите nginx-access, чтобы просмотреть все журналы доступа.
Теперь включите непрерывную потоковую передачу (5), чтобы просматривать журналы по мере их поступления. Если вы не видите новых журналов, попробуйте ввести внешний IP-адрес одной из виртуальных машин nginx-plus в браузере.
Хотя эта лабораторная работа не уделяет особого внимания журналам, вы можете изучить её позже, прежде чем приступать к очистке. Подробнее о навигации в окне просмотра можно узнать здесь . Если вам нужна более подробная информация о возможностях использования облачного логирования, вот каталог с соответствующей документацией.
Давайте освободим вычислительные ресурсы, созданные во время лабораторной работы. Выполните следующие команды в Cloud Shell:
$ for i in {1..3}; do \
gcloud -q --user-output-enabled=false compute instances delete nginx-plus-$i ; doneЗатем перейдите в консоль Google Stackdriver (пункт «Мониторинг» в меню левой панели Cloud Console) и удалите созданные нами политики проверки работоспособности и оповещения. Это можно сделать в пунктах меню верхнего уровня «Оповещения» -> «Обзор политик» и «Оповещения» -> «Проверки работоспособности».
Теперь вы готовы к мониторингу своих облачных приложений.
Что мы рассмотрели
- Ознакомьтесь с домашней страницей Stackdriver.
- Понимание панелей мониторинга и диаграмм.
- Создание проверки работоспособности.
- Создание простой политики оповещений.
- Работа с тревожными инцидентами.
- Навигация по средству просмотра журналов.
Следующие шаги
- Попробуйте создать пользовательскую панель инструментов.
- Изучите различные варианты создания политики оповещения.
- Изучите различные возможности, доступные при использовании облачного логирования.
Узнать больше
- Узнайте больше об использовании API мониторинга .
- Используйте пользовательские метрики .
Оставьте нам свой отзыв
- Пожалуйста, уделите немного времени и пройдите наш короткий опрос.