
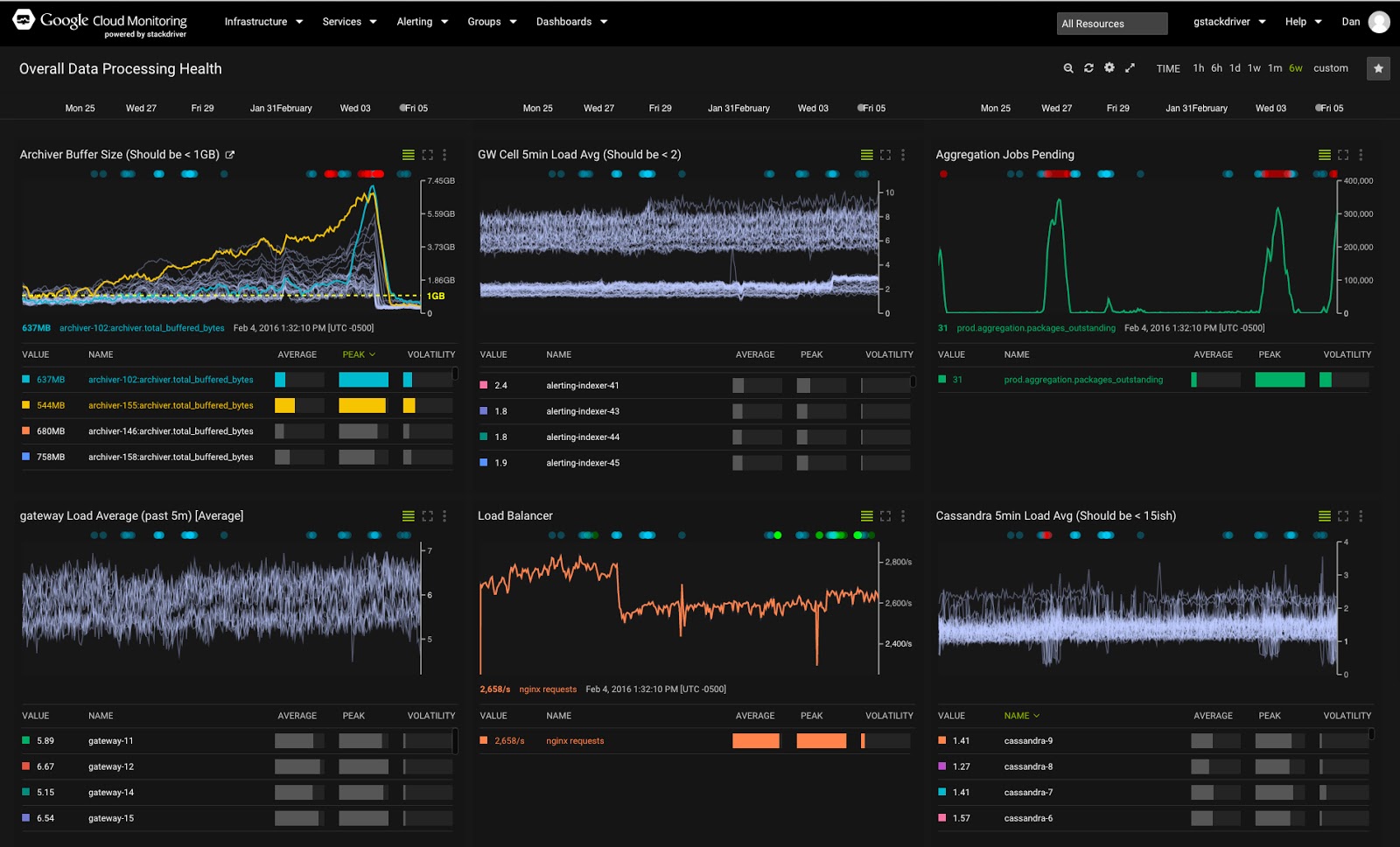
در این کد لبه، یاد خواهید گرفت که چگونه با استفاده از Stackdriver برای نظارت و بررسی معیارهای عملکرد و گزارشهای سرویسهای پلتفرم ابری Google و ماشینهای مجازی شروع کنید.
در این کد لبه شما
- با صفحه اصلی Stackdriver آشنا شوید.
- داشبوردها و نمودارها را درک کنید.
- یک چک آپ تایم ایجاد کنید.
- یک خط مشی هشدار ساده ایجاد کنید.
- با حوادث هشدار کار کنید.
- در Logs Viewer حرکت کنید.
تجربه شما از Stackdriver چیست؟
تنظیم محیط خود به خود
اگر قبلاً یک حساب Google (Gmail یا Google Apps) ندارید، باید یک حساب ایجاد کنید .
به کنسول Google Cloud Platform ( consol.developers.google.com ) وارد شوید و یک پروژه جدید ایجاد کنید:

شناسه پروژه را به خاطر بسپارید، یک نام منحصر به فرد در تمام پروژه های Google Cloud. بعداً در این آزمایشگاه کد به عنوان PROJECT_ID نامیده خواهد شد.
بسیار مهم - برای شروع فعال کردن Compute Engine API از صفحه Compute Engine دیدن کنید:

و سپس: Compute → Compute Engine → VM Instances

اولین باری که این کار را انجام می دهید، صفحه ای با پیام "موتور محاسباتی آماده می شود. ممکن است یک دقیقه یا بیشتر طول بکشد" را مشاهده خواهید کرد. میتوانید وارد Google Cloud Shell زیر شوید، اما تا زمانی که این عملیات کامل نشود، نمیتوانید ماشین مجازی ایجاد کنید.
شما بیشتر کارها را از Google Cloud Shell انجام خواهید داد، یک محیط خط فرمان در حال اجرا در Cloud . این ماشین مجازی مبتنی بر دبیان با تمام ابزارهای توسعه ای که شما نیاز دارید بارگذاری شده است و یک فهرست اصلی 5 گیگابایتی دائمی را ارائه می دهد. Google Cloud Shell را با کلیک بر روی نماد در سمت راست بالای صفحه باز کنید:

در نهایت، با استفاده از Cloud Shell، منطقه پیشفرض و پیکربندی پروژه را تنظیم کنید:
$ gcloud config set compute/zone us-central1-b $ gcloud config set compute/region us-central
همچنین می توانید مناطق مختلف را انتخاب و انتخاب کنید. درباره مناطق در اسناد مناطق و مناطق بیشتر بیاموزید.
در این بخش، نمونههای Compute Engine را با استفاده از Cloud Launcher در حال اجرا nginx+ میسازید. ما به این موارد برای نشان دادن نظارت و هشدار نیاز خواهیم داشت. می توانید یک نمونه Compute Engine را از کنسول گرافیکی یا از خط فرمان ایجاد کنید. این آزمایشگاه شما را از طریق خطوط فرمان راهنمایی می کند.
حالا بیایید شروع کنیم.
از gcloud برای تنظیم ID پروژه خود استفاده کنید:
$ gcloud config set project PROJECT_ID
بعد، مطمئن شوید که این مورد را به صورت زیر کپی و جایگذاری کنید:
$ for i in {1..3}; do \
gcloud compute instances create "nginx-plus-$i" \
--machine-type "n1-standard-1" \
--metadata "google-cloud-marketplace-solution-key=nginx-public:nginx-plus" \
--maintenance-policy "MIGRATE" --scopes default="https://www.googleapis.com/auth/cloud-platform" \
--tags "http-server","google-cloud-marketplace" \
--image "https://www.googleapis.com/compute/v1/projects/nginx-public/global/images/nginx-plus-ubuntu1404-v20150916-final" \
--boot-disk-size "10" --boot-disk-type "pd-standard" \
--boot-disk-device-name "nginx-plus-$i"; doneپیام های هشدار دهنده ای در مورد اندازه دیسک مشاهده خواهید کرد و سپس خروجی زیر را با ایجاد هر VM مشاهده خواهید کرد:
NAME ZONE MACHINE_TYPE PREEMPTIBLE INTERNAL_IP EXTERNAL_IP STATUS nginx-plus-1 us-central1-b n1-standard-2 X.X.X.X X.X.X.X RUNNING ...
EXTERNAL_IP را یادداشت کنید - این در آینده مهم است.
تکمیل این عملیات ممکن است چند دقیقه طول بکشد.
به طور پیشفرض، Google Cloud Platform تنها به تعداد کمی از پورتها اجازه دسترسی میدهد. از آنجایی که به زودی به Nginx دسترسی خواهیم داشت - اجازه دهید پورت 80 را در پیکربندی فایروال فعال کنیم:
$ gcloud compute firewall-rules create allow-80 --allow tcp:80 --target-tags "http-server" Created [...]. NAME NETWORK SRC_RANGES RULES SRC_TAGS TARGET_TAGS allow-80 default 0.0.0.0/0 tcp:80 http-server
این یک قانون فایروال به نام اجازه-80 ایجاد می کند که مقادیر پیش فرض زیر را دارد:
- لیست بلوک های آدرس IP که مجاز به ایجاد اتصالات ورودی هستند (
--source-ranges) روی0.0.0.0/0(Everywhere) تنظیم شده است. - فهرستی از تگهای نمونه نشاندهنده مجموعه نمونههایی در شبکه که ممکن است اتصالات ورودی را بپذیرند، روی هیچ تنظیم شده است که به این معنی است که قانون فایروال برای همه نمونهها قابل اجرا است.
برای دیدن همه پیشفرضها gcloud compute firewall-rules create --help اجرا کنید.
پس از ایجاد اولین نمونه، می توانید با رفتن به http://EXTERNAL_IP/ که در آن EXTERNAL_IP IP عمومی nginx-plus-1 است ، آزمایش کنید که آیا nginx در حال اجرا و قابل دسترسی است یا خیر و باید بتوانید صفحه Nginx را ببینید:

همچنین می توانید نمونه های در حال اجرا خود را با تایپ کردن مشاهده کنید:
$ gcloud compute instances list
Google Stackdriver یک راه حل نظارتی قدرتمند است که ابزارهای مختلفی را برای تسهیل نظارت و تجزیه و تحلیل برنامه های کاربردی ابری شما یکپارچه می کند. میتوانید از Stackdriver برای مشاهده معیارهای عملکرد، تنظیم و دریافت هشدارها، افزودن داشبوردها و معیارهای سفارشی خود، مشاهده گزارشها و ردیابیها، راهاندازی داشبوردهای یکپارچه - همه از یک مکان مرکزی استفاده کنید.
مراحل بعدی شما را از طریق فعال کردن Stackdriver و کار با کنسول هدایت می کند.
به طور پیش فرض، Google Stackdriver در حال حاضر در نسخه بتا است و برای پروژه های جدید فعال نیست. برای فعال کردن آن، به نوار ناوبری سمت چپ بروید و روی "مانیتورینگ" کلیک کنید (شاید مجبور باشید برای پیدا کردن آن به پایین بروید)

در صفحه بعدی، روی "فعال کردن نظارت" کلیک کنید و یک دقیقه صبر کنید تا آن را فعال کنید.

پس از فعال شدن، محتوا تغییر خواهد کرد و متن زیر را مشاهده خواهید کرد. برای شروع کاوش روی "برو به نظارت" کلیک کنید! شما باید با Google وارد شوید و سپس برای پروژه خود به کنسول Stackdriver منتقل شوید - اینجاست که وظایف مربوط به نظارت را انجام و تجزیه و تحلیل خواهید کرد.

بیایید خود را با صفحه اصلی آشنا کنیم.

- منوی بالا: برای انتخاب نماها / زمینه های مختلف و دسترسی به تمام اقدامات موجود Stackdriver استفاده کنید.
- داشبوردها: اینها داشبوردهایی از معیارها و رویدادهایی هستند که تحت نظارت هستند. در ابتدا این داشبوردهای سیستمی از پیش تعریف شده بر اساس منابع موجود در پروژه شما هستند، اما شما همچنین می توانید داشبوردهای سفارشی خود را بسازید.
- بررسی های Uptime: این موارد به صورت دوره ای منابع رو به روی کاربر را از نظر در دسترس بودن بررسی می کنند و زمانی که این منابع در دسترس نیستند، هشدار را فعال می کنند.
- فهرست گروهها: گروهها برای گروهبندی منابعی که دارای ویژگیها و ویژگیهای مشترک هستند، استفاده میشوند تا بتوان آنها را به عنوان یک گروه یا خوشه برای کارهایی مانند نظارت و هشدار مدیریت کرد. اینها را می توان به صورت خودکار کشف کرد و همچنین توسط کاربر تعریف کرد.
- صفحه حوادث: صفحه حوادث حوادث هشدار را ردیابی می کند. تا زمانی که خطمشیهای هشدار را تعریف نکنید، چیزی در اینجا نمیبینید.
- گزارش رویداد: رویدادهایی را فهرست می کند که به منابع نظارت شده شما مرتبط هستند، به عنوان مثال تغییرات نمونه، رویدادهای رویداد و غیره.
قبل از بررسی نمودارها، متوجه خواهید شد که بیشتر خطوط پس از مقداردهی اولیه نمونه اولیه صاف شده اند. بیایید ببینیم آیا میتوانیم با ایجاد مقداری بار روی یکی از نمونهها، برخی از آنها را "غیرصاف" کنیم.
برای SSH به نمونه از خط فرمان Cloud Shell:
$ gcloud compute ssh nginx-plus-1 ... Do you want to continue (Y/n)? Y ... Generating public/private rsa key pair. Enter passphrase (empty for no passphrase): [Hit Enter] Enter same passphrase again: [Hit Enter] ... yourusername@nginx-plus-1:~$
همین! بسیار آسان (در تولید، مطمئن شوید که یک عبارت عبور وارد کرده اید :) همچنین، توجه داشته باشید که ممکن است از شما خواسته نشود که یک عبارت عبور اضافه کنید.
همچنین، میتوانید مستقیماً از کنسول، با رفتن به Compute Engine > VM Instances و کلیک کردن بر روی SSH ، SSH را وارد نمونه کنید.

In the SSH window, type:
yourusername@nginx-plus-1:~$ sudo apt-get install rand
yourusername@nginx-plus-1:~$ for i in {1..10}; do dd if=/dev/zero of=/dev/null count=$(rand -M 80)M; sleep 60; done &اکنون CPU نمونه nginx-plus-1 در حال بارگیری است. میتوانیم به برگه داشبورد Stackdriver برگردیم و شروع به کاوش کنیم، اما قبل از اینکه به صفحه داشبوردهای Stackdriver برگردیم، اجازه دهید از فرصت استفاده کنیم و عامل Cloud Logging را نصب کنیم.
Fetch and install the script:
yourusername@nginx-plus-1:~$ curl -sS https://dl.google.com/cloudagents/add-logging-agent-repo.sh | sudo bash /dev/stdin --also-install
توجه داشته باشید که هنگام نصب در تولید، حتما هش SHA-256 را بررسی کنید. در اینجا می توانید اطلاعات بیشتری در مورد مراحل نصب دریافت کنید.
اکنون زمان بازگشت به کنسول Google Stackdriver است.
برای آشنایی با پیمایش و استفاده از داشبوردها و نمودارها وقت بگذارید. با استفاده از ماوس روی خطوط نمودار حرکت کنید و ببینید چه اتفاقی می افتد. تغییر مدت زمان برای نمودارها (کنترل ها در گوشه سمت راست بالا هستند). همیشه میتوانید با کلیک کردن روی نشانواره Stackdriver در گوشه سمت چپ بالای کنسول، به نمای «صفحه اصلی» بازگردید.
بیایید به نمودار استفاده از CPU نگاه کنیم:

برخی از عناصر در نمودار عبارتند از:
- خط برجسته متریک انتخابی فعلی است (یک نمودار می تواند چندین معیار را نمایش دهد).
- خط افقی خاکستری نشان دهنده نقطه ای در زمان است که ماوس به آن اشاره می کند.
- در پایین نام منبع به همراه مقدار در نقطه انتخاب شده در زمان وجود دارد.
- در بالای نمودار، نقاط رنگی نشان دهنده رویدادهایی است که در گزارش رویداد به تفصیل آمده است. برای دریافت لیست رویدادها می توانید روی آنها کلیک کنید. توجه: اگر هنوز هیچ رویدادی نداشته باشید، ممکن است هیچ رویدادی را مشاهده نکنید.
- در سمت راست بالای نمودار سه کنترل وجود دارد (از چپ به راست):
- پنهان کردن/نمایش فهرستی از معیارها را در زیر نمودار تغییر دهید
- حالت تمام صفحه را تغییر دهید
- منوی با چیزهای مختلف (شما باید حالت اشعه ایکس را زمانی که نمودار بسیار پرمخاطب دارید امتحان کنید!). به گزینه "View Logs" توجه کنید - بعداً به آن خواهیم رسید.
بررسی های Uptime به شما امکان می دهد تا به سرعت سلامت هر صفحه وب، نمونه یا گروهی از منابع را تأیید کنید. با هر چک پیکربندی شده به طور مرتب از مکانهای مختلف در سراسر جهان تماس گرفته میشود. بررسی های آپتایم را می توان به عنوان شرایط در تعاریف خط مشی هشدار استفاده کرد.
می توانید چک های خود و وضعیت آنها را با انتخاب Alerting > Uptime Checks در منوی بالا نمایش دهید. همچنین بخشهای Uptime Checks را در داشبورد Google Stackdriver و در صفحات اختصاص داده شده به منابع خاص پیدا خواهید کرد. برای بررسی های آپتایم که گروهی از منابع را پوشش می دهد، می توانید چک را برای نشان دادن وضعیت تک تک اعضای گروه گسترش دهید.
بیایید یک چک آپتایم ایجاد کنیم. ویجت بررسی های زمان کار را در صفحه اصلی Stackdriver پیدا کنید:

یک پاپ آپ جدید ظاهر می شود. ما میتوانیم بررسیهای uptime را برای یک منبع یا گروهی از منابع پیکربندی کنیم، از هدرها و بارهای سفارشی استفاده کنیم، احراز هویت و گزینههای دیگر را اضافه کنیم. در حال حاضر، ما فقط از یک چک http پیشفرض استفاده میکنیم که گروه nginx ایجاد شده خودکار را هر ۱ دقیقه بررسی میکند.
از اسکرین شات زیر برای پر کردن گزینه های مختلف استفاده کنید:

بر روی دکمه "تست" کلیک کنید تا مطمئن شوید که نقاط پایانی شما قابل دسترسی هستند (باید 3 رنگ سبز دریافت کنید) و روی ذخیره کلیک کنید. توجه: اگر مشکلی ندارید، همچنان میتوانید با آزمایشگاه پیشرفت کنید زیرا ممکن است فقط یک مشکل زمانبندی آزمایش باشد.
در مرحله بعد یک کادر "Uptime Check Created" دریافت می کنید و از شما پرسیده می شود که آیا می خواهید یک خط مشی هشدار برای این بررسی ایجاد کنید. بیایید این کار را در بخش بعدی انجام دهیم - هنوز روی چیزی کلیک نکنید.
میتوانید خطمشیهای هشدار را برای تعریف شرایطی تنظیم کنید که تعیین میکند سرویسها و پلتفرمهای ابری شما به طور عادی کار میکنند یا خیر. Cloud Monitoring انواع مختلفی از معیارها و بررسی های سلامت را ارائه می دهد که می توانید در خط مشی ها از آنها استفاده کنید.
هنگامی که شرایط یک خط مشی هشدار نقض می شود، یک حادثه ایجاد می شود و در کنسول Stackdriver در بخش Incident نمایش داده می شود. پاسخدهندگان میتوانند دریافت اعلان را تأیید کنند و میتوانند پس از رسیدگی به آن حادثه را ببندند.
روی "ایجاد خط مشی هشدار" کلیک کنید و بیایید به پیکربندی خط مشی برویم.

حالا باید این صفحه را ببینید:

یک نام برای خط مشی وارد کنید: "بررسی آپتایم برای گروه nginx"

اکنون در قسمت روش اطلاع رسانی، روی «افزودن اعلان» کلیک کنید.

آدرس ایمیل مرتبط با حساب Google Cloud خود را وارد کنید. به پایین صفحه بروید و روی "Save Policy" کلیک کنید.
به صفحه اصلی Stackdriver برگردید (با کلیک بر روی لوگو در گوشه سمت چپ بالا).
اکنون باید چک آپتایمی را که ایجاد کرده اید در قسمت بررسی های زمان کار داشبورد ببینید. در حال حاضر وضعیت باید سبز باشد.

به پایین بروید و به گزارش رویداد بروید و باید رویدادی را ببینید که یک خط مشی هشدار ایجاد شده است.
حالا بیایید کمی دردسر درست کنیم :)
بیایید ببینیم وقتی سرویس Ngnix را متوقف می کنیم چه اتفاقی می افتد.
SSH دوباره به نمونه از خط فرمان Cloud Shell:
$ gcloud compute ssh nginx-plus-1
و تایپ کنید:
yourusername@nginx-plus-1:~$ sudo service nginx stop
اکنون بررسی آپتایمی که ایجاد کرده ایم باید با شکست مواجه شود. در نتیجه، یک حادثه ایجاد میشود و یک ایمیل اعلان هشدار به آدرسی که در بالا وارد کردهاید ارسال میشود. یک دقیقه طول می کشد تا شرایط شناسایی شود (مدت زمان 1 دقیقه هنگام تنظیم بررسی آپتایم را به خاطر دارید؟) پس بیایید برویم و صفحه گروه nginx را بررسی کنیم.
چندین راه برای پیمایش به داشبورد یک گروه منبع خاص وجود دارد:
- می توانید روی نام گروه در صفحه اصلی کلیک کنید. این به داشبوردی تبدیل می شود که به طور خاص برای نظارت بر منابع گروه ساخته شده است. همچنین می توانید این داشبورد را سفارشی کنید.

- از منوی سطح بالا، Groups را انتخاب کنید و سپس گروه خاص خود را پیدا کنید.
اکنون، روی دکمه بازخوانی خودکار کلیک کنید تا مطمئن شوید داشبوردها به طور خودکار رفرش می شوند. نماد قرمز خواهد شد.

اکنون به داشبوردی نگاه میکنید که مختص گروه nginx است که به صورت خودکار ایجاد شده است. در سمت راست نمودارهایی از چندین معیار کلیدی مربوط به گروه وجود دارد. به عبارت دیگر، این نمودارها معیارهایی را نشان میدهند که به همه منابع در گروه nginx مربوط میشوند (3 ماشین مجازی nginx+ ما که قبلا ایجاد کردیم).
در سمت چپ، اطلاعات مختلف مربوط به گروه را مشاهده می کنید:
- وضعیت حادثه
- بررسی های آپتایم
- گزارش رویداد
- فهرستی از منابع (نمونه ها، جلدها و غیره)
توجه داشته باشید که اینها فقط به گروه مربوط می شوند و بنابراین گزارش رویداد فقط رویدادهای گروه را فهرست می کند.
برای انتقال به داشبوردهای خاص خود می توانید بر روی منابع یا زیر گروه های مختلف کلیک کنید. برای مثال، با کلیک بر روی nginx-plus-1 به داشبوردی هدایت میشوید که فقط از معیارها و بررسیهای مربوط به آن نمونه تشکیل شده است. اکنون آن را امتحان کنید:

حوادث Stackdriver زمانی باز می شوند که مجموعه ای از شرایط هشدار با معیارهای خاصی مطابقت داشته باشد. در مورد ما، یک هشدار برای بررسی آپتایم nginx تنظیم کردهایم که در حال حاضر در nginx-plus-1 ناموفق است. حوادث به شما کمک می کند تا شرایط فعلی را ردیابی کنید، و همچنین هنگام کار بر روی مسائل با سایر اعضای تیم همکاری کنید.
بیایید این حادثه را تصدیق کنیم و به سایر اعضای تیم اطلاع دهیم که در حال بررسی موارد هستیم:

توجه داشته باشید که این حالت وضعیت حادثه را از Open به Acknowledg تغییر می دهد. این وضعیت همچنان ادامه دارد (شرایط خط مشی هشدار همچنان نقض می شود)، اما شما به اعضای تیم نشان می دهید که در حال انجام آن هستید. این نیز در گزارش رویداد ثبت خواهد شد.
حوادث را می توان به صورت دستی حل کرد یا می توان آنها را به صورت خودکار حل کرد. برای مشاهده مورد دوم، ssh را به nginx-plus-1 وارد کرده و مشکل را برطرف کنید:
yourusername@nginx-plus-1:~$ sudo service nginx start
اکنون پس از اینکه بررسی uptime به حالت عادی بازگردد، این حادثه به طور خودکار حل می شود. شما همچنین می توانید آن را خودتان با انتخاب آیتم منوی حل و فصل حل کنید.
Cloud Logging یک راه حل ورود به سیستم به عنوان یک سرویس است که مکانی مناسب و مرکزی را برای مشاهده و جستجوی گزارش ها از منابع متعدد ارائه می دهد. همچنین میتوانید از گزارشها برای صادر کردن آنها به مقاصد دیگر (Google Cloud Storage، Google BigQuery یا Google Cloud Pub/Sub) استفاده کنید.
برای دسترسی به Cloud Logs Viewer، آن را از منوی سمت چپ Cloud Console انتخاب کنید:

شما به نمایشگر گزارشها هدایت میشوید، جایی که میتوانید پرسوجوهای از پیش تعریفشده را استفاده کنید یا پرسوجوهای سفارشی خود را ایجاد و ذخیره کنید، جریانی زنده از گزارشها را دریافت کنید که از منابع متعدد در سراسر استقرار ابری خود میآیند، معیارهایی را از گزارشها ایجاد کنید، صادر کنید و موارد دیگر.
چند کنترل مفید برای فیلتر کردن سریع اطلاعات مربوطه وجود دارد:

- فیلتر بر اساس انواع منابع
- به انواع گزارش های خاص منابع انتخاب شده فیلتر کنید
- سطوح گزارش خاص را فیلتر کنید
- برای بررسی مسائل گذشته به تاریخ(های) خاصی فیلتر کنید
- پخش جریانی مداوم را تغییر دهید
- یک کادر جستجو برای جستجوی متن، برچسب یا عبارت منظم
حالا بیایید باریک کردن به سیاهههای مربوط را تمرین کنیم.
از انتخابگر نوع منبع (1 در تصویر) Compute Engine -> All Resource Types را انتخاب کنید
بعد از انتخابگر log-type (2 در تصویر) nginx-access را برای مشاهده همه گزارش های دسترسی انتخاب کنید
اکنون، پخش مداوم را روی (5) تغییر دهید تا گزارشها را هنگام ورود مشاهده کنید. اگر گزارش جدیدی نمیبینید، آدرس IP خارجی یکی از ماشینهای مجازی nginx-plus را در مرورگر خود وارد کنید.
در حالی که این کد لبه روی گزارشها تمرکز عمیقی ندارد، قبل از تمیز کردن، بعداً کاوش کنید. شما می توانید اطلاعات بیشتر در مورد پیمایش بیننده را در اینجا بیابید. اگر اطلاعات گستردهتری در مورد آنچه که میتوانید از Cloud Logging برای آن استفاده کنید میخواهید، در اینجا دایرکتوری سطح بالا برای اسناد مربوطه است.
بیایید منابع محاسباتی ایجاد شده در آزمایشگاه کد را آزاد کنیم. دستورات زیر را در Cloud Shell اجرا کنید:
$ for i in {1..3}; do \
gcloud -q --user-output-enabled=false compute instances delete nginx-plus-$i ; doneدر مرحله بعد، به کنسول Google Stackdriver ("مانیتورینگ" از منوی سمت چپ کنسول Cloud) بروید و خطمشیهای بررسی زمان فعال و هشداری را که ایجاد کردهایم حذف کنید. میتوانید این کار را از طریق آیتمهای منوی سطح بالا Alerting -> Policies Overview و Alerting -> Uptime Checks انجام دهید.
اکنون آماده نظارت بر برنامه های کاربردی ابری خود هستید.
آنچه را پوشش داده ایم
- با صفحه اصلی Stackdriver آشنا شوید.
- آشنایی با داشبوردها و نمودارها
- ایجاد چک آپتایم
- ایجاد یک خط مشی هشدار ساده
- کار با حوادث هشدار دهنده
- پیمایش در Logs Viewer.
مراحل بعدی
- سعی کنید یک داشبورد سفارشی ایجاد کنید.
- هنگام ایجاد یک خط مشی هشدار، گزینه های مختلف را بررسی کنید.
- هنگام استفاده از Cloud Logging گزینه های مختلف موجود را کاوش کنید.
سنگ معدن M را یاد بگیرید
- درباره استفاده از API نظارت بیشتر بیاموزید.
- از معیارهای سفارشی استفاده کنید.
نظرات خود را با ما در میان بگذارید
- لطفا یک لحظه برای تکمیل نظرسنجی بسیار کوتاه ما وقت بگذارید