
Cloud Speech API ช่วยให้คุณถอดเสียงพูดเป็นข้อความจากไฟล์เสียงได้ในกว่า 80 ภาษา
ในแล็บนี้ เราจะบันทึกไฟล์เสียงและส่งไปยัง Cloud Speech API เพื่อถอดเสียง
สิ่งที่คุณจะได้เรียนรู้
- การสร้างคำขอ Speech API และการเรียก API ด้วย curl
- การเรียกใช้ Speech API ด้วยไฟล์เสียงในภาษาต่างๆ
สิ่งที่คุณต้องมี
คุณจะใช้บทแนะนำนี้อย่างไร
คุณจะให้คะแนนประสบการณ์การใช้งาน Google Cloud Platform เท่าไร
การตั้งค่าสภาพแวดล้อมแบบเรียนรู้ด้วยตนเอง
หากยังไม่มีบัญชี Google (Gmail หรือ Google Apps) คุณต้องสร้างบัญชี ลงชื่อเข้าใช้คอนโซล Google Cloud Platform (console.cloud.google.com) แล้วสร้างโปรเจ็กต์ใหม่โดยทำดังนี้


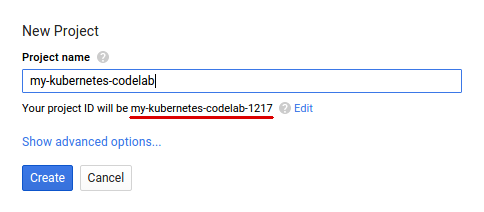
โปรดจดจำรหัสโปรเจ็กต์ ซึ่งเป็นชื่อที่ไม่ซ้ำกันในโปรเจ็กต์ Google Cloud ทั้งหมด (ชื่อด้านบนถูกใช้ไปแล้วและจะใช้ไม่ได้ ขออภัย) ซึ่งจะเรียกว่า PROJECT_ID ในภายหลังใน Codelab นี้
จากนั้นคุณจะต้องเปิดใช้การเรียกเก็บเงินใน Cloud Console เพื่อใช้ทรัพยากร Google Cloud
การทำ Codelab นี้ไม่ควรมีค่าใช้จ่ายเกิน 2-3 ดอลลาร์ แต่ก็อาจมีค่าใช้จ่ายมากกว่านี้หากคุณตัดสินใจใช้ทรัพยากรเพิ่มเติมหรือปล่อยให้ทรัพยากรทำงานต่อไป (ดูส่วน "การล้างข้อมูล" ที่ท้ายเอกสารนี้)
ผู้ใช้ใหม่ของ Google Cloud Platform มีสิทธิ์ทดลองใช้ฟรี$300
คลิกไอคอนเมนูที่ด้านซ้ายบนของหน้าจอ

เลือกแดชบอร์ด API และบริการ จากเมนูแบบเลื่อนลง

คลิกเปิดใช้ API และบริการ

จากนั้นค้นหา "คำพูด" ในช่องค้นหา คลิก Google Cloud Speech API
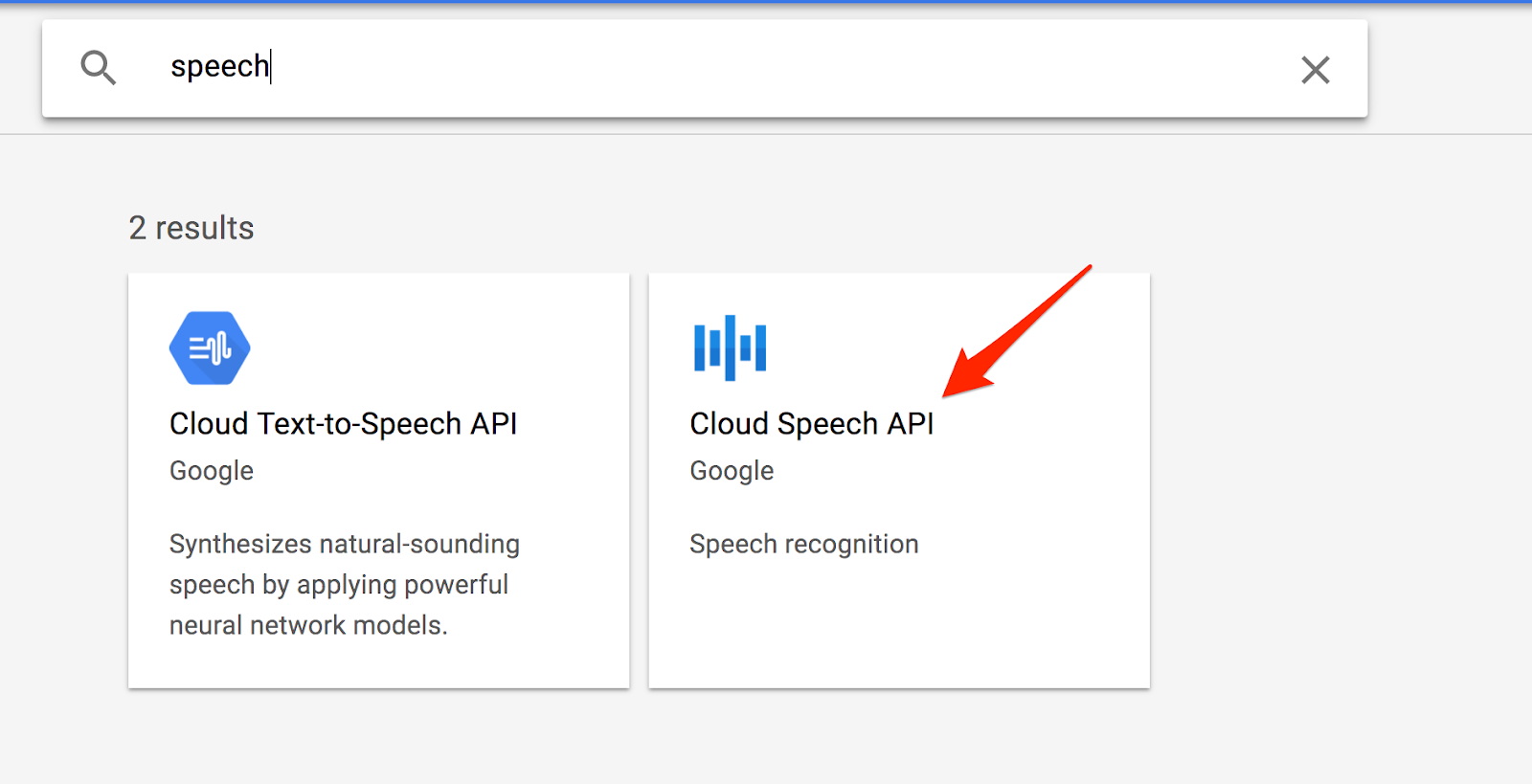
คลิกเปิดใช้เพื่อเปิดใช้ Cloud Speech API

รอสักครู่เพื่อให้ระบบเปิดใช้ คุณจะเห็นข้อความต่อไปนี้เมื่อเปิดใช้

Google Cloud Shell เป็น สภาพแวดล้อมบรรทัดคำสั่งที่ทำงานในระบบคลาวด์ เครื่องเสมือนที่ใช้ Debian นี้มาพร้อมเครื่องมือพัฒนาทั้งหมดที่คุณต้องการ (gcloud, bq, git และอื่นๆ) และมีไดเรกทอรีแรกขนาด 5 GB แบบถาวร เราจะใช้ Cloud Shell เพื่อสร้างคำขอไปยัง Speech API
หากต้องการเริ่มต้นใช้งาน Cloud Shell ให้คลิกไอคอน "เปิดใช้งาน Google Cloud Shell"  ที่มุมขวาบนของแถบส่วนหัว
ที่มุมขวาบนของแถบส่วนหัว

เซสชัน Cloud Shell จะเปิดในเฟรมใหม่ที่ด้านล่างของคอนโซลและแสดงข้อความแจ้งบรรทัดคำสั่ง รอจนกว่าพรอมต์ user@project:~$ จะปรากฏขึ้น

เนื่องจากเราจะใช้ curl เพื่อส่งคำขอไปยัง Speech API เราจึงต้องสร้างคีย์ API เพื่อส่งใน URL ของคำขอ หากต้องการสร้างคีย์ API ให้ไปที่ส่วน API และบริการ > ข้อมูลเข้าสู่ระบบ ในแดชบอร์ดโปรเจ็กต์

จากนั้นคลิกสร้างข้อมูลเข้าสู่ระบบ

ในเมนูแบบเลื่อนลง ให้เลือกคีย์ API

จากนั้นคัดลอกคีย์ที่คุณเพิ่งสร้าง แล้วเลือกปิด (อย่าจำกัดคีย์)
ตอนนี้คุณมีคีย์ API แล้ว ให้บันทึกลงในตัวแปรสภาพแวดล้อมเพื่อหลีกเลี่ยงการต้องแทรกค่าของคีย์ API ในแต่ละคำขอ โดยทำได้ใน Cloud Shell อย่าลืมแทนที่ <your_api_key> ด้วยคีย์ที่คุณเพิ่งคัดลอก
export API_KEY=<YOUR_API_KEY>คุณสร้างคำขอไปยัง Speech API ได้ในไฟล์ request.json หากต้องการสร้างและแก้ไขไฟล์นี้ คุณสามารถใช้เครื่องมือแก้ไขบรรทัดคำสั่งที่ต้องการ (nano, vim, emacs) หรือใช้เครื่องมือแก้ไขเว็บในตัวใน Cloud Shell ก็ได้

สร้างไฟล์ในไดเรกทอรีหลักเพื่อให้ง่ายต่อการอ้างอิงและเพิ่มโค้ดต่อไปนี้ลงในไฟล์ request.json
request.json
{
"config": {
"encoding":"FLAC",
"languageCode": "en-US"
},
"audio": {
"uri":"gs://cloud-samples-tests/speech/brooklyn.flac"
}
}เนื้อหาของคำขอมีออบเจ็กต์ config และ audio ใน config เราจะบอก Speech API ถึงวิธีประมวลผลคำขอ พารามิเตอร์ encoding จะบอก API ว่าคุณใช้การเข้ารหัสเสียงประเภทใดสำหรับไฟล์เสียงที่ส่งไปยัง API FLAC คือประเภทการเข้ารหัสสำหรับไฟล์ .raw (ดูรายละเอียดเพิ่มเติมเกี่ยวกับประเภทการเข้ารหัสได้ในเอกสารประกอบ) คุณเพิ่มพารามิเตอร์อื่นๆ ลงในออบเจ็กต์ config ได้ แต่มีเพียง encoding เท่านั้นที่จำเป็น languageCode จะเป็นภาษาอังกฤษโดยค่าเริ่มต้นหากไม่ได้ระบุไว้ในคำขอ
ในออบเจ็กต์ audio คุณสามารถส่ง API เป็น URI ของไฟล์เสียงใน Cloud Storage หรือส่งเสียงที่เข้ารหัส Base64 เป็นสตริงก็ได้ ในที่นี้เราใช้ URL ของ Cloud Storage ขั้นตอนถัดไปคือการเรียกใช้ Speech API
ตอนนี้คุณส่งเนื้อหาคำขอพร้อมกับตัวแปรสภาพแวดล้อมของคีย์ API ที่บันทึกไว้ก่อนหน้านี้ไปยัง Speech API ได้ด้วยคำสั่ง curl ต่อไปนี้ (ทั้งหมดในบรรทัดคำสั่งเดียว)
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json "https://speech.googleapis.com/v1/speech:recognize?key=${API_KEY}"การตอบกลับที่คำสั่ง curl นี้ส่งคืนควรมีลักษณะดังนี้
{
"results": [
{
"alternatives": [
{
"transcript": "how old is the Brooklyn Bridge",
"confidence": 0.98267895
}
]
}
]
}ค่า transcript จะแสดงข้อความถอดเสียงของ Speech API จากไฟล์เสียง และค่า confidence จะระบุความมั่นใจของ API ว่าได้ถอดเสียงจากเสียงของคุณอย่างถูกต้อง
คุณจะเห็นว่าเราเรียกใช้เมธอด recognize ในคำขอข้างต้น Speech API รองรับทั้งการถอดเสียงพูดเป็นข้อความแบบเรียลไทม์และไม่เรียลไทม์ ในตัวอย่างนี้ เราได้ส่งไฟล์เสียงที่สมบูรณ์ แต่คุณยังสามารถใช้เมธอด longrunningrecognize เพื่อทำการถอดเสียงพูดแบบสตรีมมิงเป็นข้อความในขณะที่ผู้ใช้ยังพูดอยู่ได้ด้วย
คุณพูดได้หลายภาษาไหม Speech API รองรับการถอดเสียงเป็นคำจากเสียงพูดในกว่า 100 ภาษา คุณเปลี่ยนพารามิเตอร์ languageCode ได้ใน request.json ดูรายการภาษาที่รองรับได้ที่นี่
มาลองใช้ไฟล์เสียงภาษาฝรั่งเศสกัน (ฟังได้ที่นี่หากต้องการดูตัวอย่าง) เปลี่ยน request.json เป็นดังนี้
request.json
{
"config": {
"encoding":"FLAC",
"languageCode": "fr"
},
"audio": {
"uri":"gs://speech-language-samples/fr-sample.flac"
}
}
คุณควรเห็นการตอบกลับต่อไปนี้
{
"results": [
{
"alternatives": [
{
"transcript": "maître corbeau sur un arbre perché tenait en son bec un fromage",
"confidence": 0.9710122
}
]
}
]
}นี่คือประโยคจากนิทานสำหรับเด็กยอดนิยมของฝรั่งเศส หากมีไฟล์เสียงในภาษาอื่น คุณสามารถลองเพิ่มไฟล์เหล่านั้นลงใน Cloud Storage และเปลี่ยนพารามิเตอร์ languageCode ในคำขอ
คุณได้เรียนรู้วิธีการถอดเสียงพูดเป็นข้อความด้วย Speech API แล้ว ในตัวอย่างนี้ คุณส่ง URI ของ Google Cloud Storage ของไฟล์เสียงไปยัง API หรือจะส่งสตริงที่เข้ารหัส base64 ของเนื้อหาเสียงก็ได้
สิ่งที่เราได้พูดถึง
- ส่ง URI ของ Google Cloud Storage ของไฟล์เสียงไปยัง Speech API
- การสร้างคำขอ Speech API และการเรียก API ด้วย curl
- การเรียกใช้ Speech API ด้วยไฟล์เสียงในภาษาต่างๆ
ขั้นตอนถัดไป
- ดูบทแนะนำเกี่ยวกับ Speech API ได้ในเอกสารประกอบ
- ลองใช้ Vision API และ Natural Language API