
Cloud Natural Language API, metinden varlıkları ayıklamanıza, duygu ve söz dizimi analizi yapmanıza ve metni kategorilere ayırmanıza olanak tanır.
Bu laboratuvarda, varlıkları, duyguları ve söz dizimini analiz etmek için Natural Language API'yi nasıl kullanacağımızı öğreneceğiz.
Neler öğreneceksiniz?
- Natural Language API isteği oluşturma ve API'yi curl ile çağırma
- Natural Language API ile metinden varlık ayıklama ve metin üzerinde yaklaşım analizi çalıştırma
- Natural Language API ile metin üzerinde dil analizi yapma
- Farklı bir dilde Natural Language API isteği oluşturma
Gerekenler
Bu eğitimi nasıl kullanacaksınız?
Google Cloud Platform deneyiminizi nasıl değerlendirirsiniz?
Kendi hızınızda ortam kurulumu
Henüz bir Google Hesabınız (Gmail veya Google Apps) yoksa oluşturmanız gerekir. Google Cloud Platform Console'da (console.cloud.google.com) oturum açın ve yeni bir proje oluşturun:



Proje kimliğini unutmayın. Bu kimlik, tüm Google Cloud projelerinde benzersiz bir addır (Yukarıdaki ad zaten alınmış olduğundan sizin için çalışmayacaktır). Bu codelab'in ilerleyen kısımlarında PROJECT_ID olarak adlandırılacaktır.
Ardından, Google Cloud kaynaklarını kullanmak için Cloud Console'da faturalandırmayı etkinleştirmeniz gerekir.
Bu codelab'i tamamlamak size birkaç dolardan fazla maliyet getirmemelidir. Ancak daha fazla kaynak kullanmaya karar verirseniz veya kaynakları çalışır durumda bırakırsanız maliyet daha yüksek olabilir (bu belgenin sonundaki "temizleme" bölümüne bakın).
Google Cloud Platform'un yeni kullanıcıları 300 ABD doları değerindeki ücretsiz deneme sürümünden yararlanabilir.
Ekranın sol üst kısmındaki menü simgesini tıklayın.

Açılır menüden API'ler ve hizmetler'i seçip Kontrol Paneli'ni tıklayın.
API'leri ve hizmetleri etkinleştir'i tıklayın.
Ardından, arama kutusunda "dil"i arayın. Google Cloud Natural Language API'yi tıklayın:
Cloud Natural Language API'yi etkinleştirmek için Etkinleştir'i tıklayın:
Etkinleşmesi için birkaç saniye bekleyin. Etkinleştirildikten sonra şunları görürsünüz:

Google Cloud Shell, Cloud'da çalışan bir komut satırı ortamıdır. Bu Debian tabanlı sanal makine, ihtiyaç duyacağınız tüm geliştirme araçları (gcloud, bq, git ve diğerleri) yüklü olarak gelir ve 5 GB kalıcı ana dizin sunar. Natural Language API'ye isteğimizi oluşturmak için Cloud Shell'i kullanacağız.
Cloud Shell'i kullanmaya başlamak için başlık çubuğunun sağ üst köşesindeki "Google Cloud Shell'i etkinleştir"  simgesini tıklayın.
simgesini tıklayın.

Konsolun altındaki yeni bir çerçevede Cloud Shell oturumu açılır ve komut satırı istemi görüntülenir. user@project:~$ istemi görünene kadar bekleyin.
Natural Language API'ye istek göndermek için curl kullanacağımızdan istek URL'sini iletmek için bir API anahtarı oluşturmamız gerekecektir. API anahtarı oluşturmak için Cloud Console'unuzda API'ler ve hizmetler bölümündeki Kimlik bilgileri kısmına gidin:
Açılır menüde, API anahtarı'nı seçin:
Ardından, az önce oluşturduğunuz anahtarı kopyalayın. Bu anahtara laboratuvarın ilerleyen bölümlerinde ihtiyacınız olacak.
Artık bir API anahtarınız var. Şimdi bu anahtarı bir ortam değişkenine kaydedip her istekte API anahtarınızın değerini ekleme zahmetinden kurtulabilirsiniz. Bu işlemi Cloud Shell'de yapabilirsiniz. <your_api_key> yerine az önce kopyaladığınız anahtarı yapıştırdığınızdan emin olun.
export API_KEY=<YOUR_API_KEY>Kullanacağımız ilk Natural Language API yöntemi analyzeEntities. Bu yöntemle API, metinlerdeki varlıkları (ör. kişiler, yerler ve etkinlikler) ayıklayabilir. API'nin varlık analizi özelliğini denemek için aşağıdaki cümleyi kullanacağız:
Joanne Rowling, who writes under the pen names J. K. Rowling ve Robert Galbraith, Harry Potter fantastik serisini yazan İngiliz romancı ve senaristtir.
Natural Language API'ye yönelik isteğimizi request.json dosyasında oluşturacağız. Cloud Shell ortamınızda aşağıdaki kodu kullanarak request.json dosyasını oluşturun. Dosyayı tercih ettiğiniz komut satırı düzenleyicilerinden (nano, vim, emacs) birini kullanarak oluşturabilir veya Cloud Shell'deki yerleşik Orion düzenleyiciyi kullanabilirsiniz:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"Joanne Rowling, who writes under the pen names J. K. Rowling and Robert Galbraith, is a British novelist and screenwriter who wrote the Harry Potter fantasy series."
},
"encodingType":"UTF8"
}İstekle birlikte, Natural Language API'ye göndereceğimiz metin hakkında bilgi veriyoruz. Desteklenen tür değerleri PLAIN_TEXT veya HTML'dir. İçerikte, analize tabi tutulmak üzere Natural Language API'ye gönderilecek metni iletiyoruz. Natural Language API, metin işleme için Cloud Storage'da depolanan dosyaların gönderilmesini de destekler. Cloud Storage'dan bir dosya göndermek isteseydik content yerine gcsContentUri yazıp Cloud Storage'daki metin dosyamızın URI'sini değer olarak verirdik. encodingType, metnimizi işlerken hangi metin kodlama türünün kullanılacağını API'ye bildirir. API, belirli varlıkların metnimizde nerede göründüğünü hesaplamak için bunu kullanır.
Artık isteğinizin gövdesini, daha önce kaydettiğiniz API anahtarı ortam değişkeniyle birlikte aşağıdaki curl komutunu kullanarak Natural Language API'ye iletebilirsiniz (hepsi tek bir komut satırında):
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonYanıtınızın başlangıcı aşağıdaki gibi olmalıdır:
{
"entities": [
{
"name": "Robert Galbraith",
"type": "PERSON",
"metadata": {
"mid": "/m/042xh",
"wikipedia_url": "https://en.wikipedia.org/wiki/J._K._Rowling"
},
"salience": 0.7980405,
"mentions": [
{
"text": {
"content": "Joanne Rowling",
"beginOffset": 0
},
"type": "PROPER"
},
{
"text": {
"content": "Rowling",
"beginOffset": 53
},
"type": "PROPER"
},
{
"text": {
"content": "novelist",
"beginOffset": 96
},
"type": "COMMON"
},
{
"text": {
"content": "Robert Galbraith",
"beginOffset": 65
},
"type": "PROPER"
}
]
},
...
]
}Yanıttaki her öğe için öğe type, varsa ilişkili Wikipedia URL'si, salience ve bu öğenin metinde geçtiği yerlerin indeksleri alınır. Salience, [0,1] aralığında bir sayıdır ve varlığın, bir bütün olarak metnin ne kadar merkezinde olduğunu gösterir. Natural Language API, aynı varlıktan farklı şekillerde bahsedildiğinde de bunu tanıyabilir. Yanıtın mentions listesine göz atın: API, "Joanne Rowling", "Rowling", "romancı" ve "Robert Galbriath" ifadelerinin aynı şeyi işaret ettiğini anlayabiliyor.
Natural Language API, varlıkları ayıklamanın yanı sıra bir metin bloğu üzerinde yaklaşım analizi yapmanıza da olanak tanır. JSON isteğimiz, yukarıdaki isteğimizle aynı parametreleri içerecek ancak bu kez metni daha güçlü bir duygu içeren bir ifadeyle değiştireceğiz. request.json dosyanızı aşağıdakilerle değiştirin. Aşağıdaki content simgesini kendi metninizle değiştirebilirsiniz:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"Harry Potter is the best book. I think everyone should read it."
},
"encodingType": "UTF8"
}Ardından, isteği API'nin analyzeSentiment uç noktasına göndeririz:
curl "https://language.googleapis.com/v1/documents:analyzeSentiment?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
Yanıtınız aşağıdaki gibi görünmelidir:
{
"documentSentiment": {
"magnitude": 0.8,
"score": 0.4
},
"language": "en",
"sentences": [
{
"text": {
"content": "Harry Potter is the best book.",
"beginOffset": 0
},
"sentiment": {
"magnitude": 0.7,
"score": 0.7
}
},
{
"text": {
"content": "I think everyone should read it.",
"beginOffset": 31
},
"sentiment": {
"magnitude": 0.1,
"score": 0.1
}
}
]
}İki tür duygu değeri elde ettiğimizi unutmayın: Belgemizin tamamı için duygu ve cümle bazında duygu. Sentiment yöntemi iki değer döndürür: score ve magnitude. score, ifadenin ne kadar olumlu veya olumsuz olduğunu gösteren -1,0 ile 1,0 arasındaki bir sayıdır. magnitude, ifadenin olumlu veya olumsuz olmasına bakılmaksızın, ifadede belirtilen yaklaşımın ağırlığını temsil eden 0 ile sonsuz arasındaki bir sayıdır. Ağırlıklı ifadeler içeren daha uzun metin blokları daha yüksek büyüklük değerlerine sahiptir. İlk cümlenin puanı olumlu (0,7), ikinci cümlenin puanı ise nötr (0,1).
NL API'ye gönderdiğimiz metin belgesinin tamamıyla ilgili duygu ayrıntılarını sağlamanın yanı sıra, metnimizdeki öğelere göre duyguyu da analiz edebilir. Örnek olarak şu cümleyi kullanalım:
Suşiyi beğendim ama hizmet çok kötüydü.
Bu durumda, yukarıda yaptığımız gibi cümlenin tamamı için bir duygu puanı almak pek yararlı olmayabilir. Bu bir restoran yorumuysa ve aynı restoranla ilgili yüzlerce yorum varsa kullanıcıların yorumlarında tam olarak neleri beğendiğini ve beğenmediğini bilmek isteriz. Neyse ki Natural Language API'de, metnimizdeki her bir öğenin duygu durumunu almamıza olanak tanıyan analyzeEntitySentiment adlı bir yöntem var. Denemek için request.json dosyanızı yukarıdaki cümleyle güncelleyin:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"I liked the sushi but the service was terrible."
},
"encodingType": "UTF8"
}Ardından, aşağıdaki curl komutuyla analyzeEntitySentiment uç noktasını çağırın:
curl "https://language.googleapis.com/v1/documents:analyzeEntitySentiment?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
Yanıtta iki öğe nesnesi döndürülür: biri "suşi", diğeri "hizmet" için. Tam JSON yanıtı:
{
"entities": [
{
"name": "sushi",
"type": "CONSUMER_GOOD",
"metadata": {},
"salience": 0.52716845,
"mentions": [
{
"text": {
"content": "sushi",
"beginOffset": 12
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
}
],
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
},
{
"name": "service",
"type": "OTHER",
"metadata": {},
"salience": 0.47283158,
"mentions": [
{
"text": {
"content": "service",
"beginOffset": 26
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
}
],
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
}
],
"language": "en"
}
"Suşi" için döndürülen puanın 0,9, "hizmet" için döndürülen puanın ise -0,9 olduğunu görüyoruz. Güzel! Ayrıca, her bir öğe için iki duygu nesnesi döndürüldüğünü de fark edebilirsiniz. Bu terimlerden biri birden fazla kez bahsedildiyse API, her bahsetme için farklı bir duygu puanı ve büyüklük değeriyle birlikte varlığın toplu duygu puanını döndürür.
Natural Language API'nin üçüncü yöntemi olan söz dizimi ek açıklamasına bakarak metnimizin dilbilimsel ayrıntılarını daha ayrıntılı bir şekilde inceleyeceğiz. analyzeSyntax, metnin anlamsal ve söz dizimsel öğeleri hakkında eksiksiz bir ayrıntı kümesi sağlayan bir yöntemdir. API, metindeki her kelime için sözcük türünü (isim, fiil, sıfat vb.) ve kelimenin cümledeki diğer kelimelerle ilişkisini (ör. temel fiil mi?) belirtir. Değiştirici mi?).
Basit bir cümleyle deneyelim. JSON isteğimiz, yukarıdakilere benzer olacak ve özellikler anahtarı eklenecek. Bu, API'ye söz dizimi ek açıklaması yapmak istediğimizi bildirir. request.json dosyanızı aşağıdakilerle değiştirin:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content": "Hermione often uses her quick wit, deft recall, and encyclopaedic knowledge to help Harry and Ron."
},
"encodingType": "UTF8"
}Ardından API'nin analyzeSyntax yöntemini çağırın:
curl "https://language.googleapis.com/v1/documents:analyzeSyntax?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonYanıt, cümledeki her jeton için aşağıdaki gibi bir nesne döndürmelidir. Burada "kullanır" kelimesinin yanıtına bakacağız:
{
"text": {
"content": "uses",
"beginOffset": 15
},
"partOfSpeech": {
"tag": "VERB",
"aspect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "INDICATIVE",
"number": "SINGULAR",
"person": "THIRD",
"proper": "PROPER_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tense": "PRESENT",
"voice": "VOICE_UNKNOWN"
},
"dependencyEdge": {
"headTokenIndex": 2,
"label": "ROOT"
},
"lemma": "use"
}Yanıtı inceleyelim. partOfSpeech, her kelimeyle ilgili dilbilimsel ayrıntılar verir (İngilizce'ye veya bu kelimeye uygulanmadığı için çoğu bilinmemektedir). tag, bu kelimenin sözcük türünü (bu örnekte fiil) verir. Ayrıca zaman, kiplik ve kelimenin tekil mi yoksa çoğul mu olduğu hakkında da bilgi alırız. lemma, kelimenin standart biçimidir ("uses" için "use" olur). Örneğin, run, runs, ran ve running kelimelerinin hepsinin temel biçimi run'dır. Lemma değeri, bir kelimenin büyük bir metinde zaman içindeki oluşumlarını izlemek için yararlıdır.
dependencyEdge, metnin bağımlılık ayrıştırma ağacını oluşturmak için kullanabileceğiniz verileri içerir. Bu, bir cümledeki kelimelerin birbirleriyle nasıl ilişkili olduğunu gösteren bir şemadır. Yukarıdaki cümle için bağımlılık ayrıştırma ağacı şu şekilde görünür:
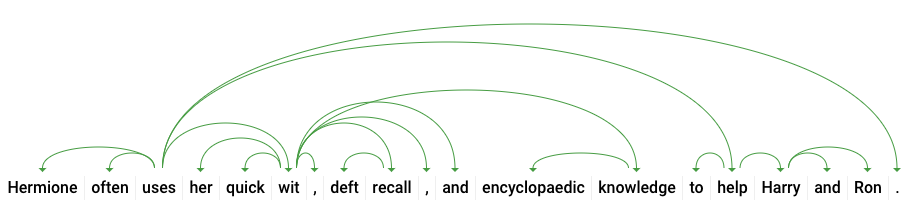
Yukarıdaki yanıtımızda headTokenIndex, "uses" kelimesini işaret eden bir yaya sahip jetonun dizinidir. Cümledeki her bir jetonu dizideki bir kelime olarak düşünebiliriz. "Kullanır" için 2 olan headTokenIndex, ağaçta bağlı olduğu "sık sık" kelimesini ifade eder.
Natural Language API, İngilizce dışındaki dilleri de destekler (tam liste için burayı tıklayın). Şimdi Japonca bir cümleyle aşağıdaki varlık isteğini deneyelim:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"日本のグーグルのオフィスは、東京の六本木ヒルズにあります"
},
"encodingType": "UTF8"
}API'ye metnimizin hangi dilde olduğunu söylemediğimizi fark edin. API, dili otomatik olarak algılayabilir. Ardından, analyzeEntities uç noktasına göndeririz:
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonYanıttaki ilk iki öğe:
{
"entities": [
{
"name": "日本",
"type": "LOCATION",
"metadata": {
"mid": "/m/03_3d",
"wikipedia_url": "https://en.wikipedia.org/wiki/Japan"
},
"salience": 0.23854347,
"mentions": [
{
"text": {
"content": "日本",
"beginOffset": 0
},
"type": "PROPER"
}
]
},
{
"name": "グーグル",
"type": "ORGANIZATION",
"metadata": {
"mid": "/m/045c7b",
"wikipedia_url": "https://en.wikipedia.org/wiki/Google"
},
"salience": 0.21155767,
"mentions": [
{
"text": {
"content": "グーグル",
"beginOffset": 9
},
"type": "PROPER"
}
]
},
...
]
"language": "ja"
}API, her biri için Wikipedia sayfalarıyla birlikte Japonya'yı konum, Google'ı ise kuruluş olarak ayıklar.
Varlıkları ayıklayarak, duyguyu analiz ederek ve söz dizimi ek açıklaması yaparak Cloud Natural Language API ile metin analizi yapmayı öğrendiniz.
İşlediğimiz konular
- Natural Language API isteği oluşturma ve API'yi curl ile çağırma
- Natural Language API ile metinden varlık ayıklama ve metin üzerinde yaklaşım analizi çalıştırma
- Bağımlılık ayrıştırma ağaçları oluşturmak için metin üzerinde dil analizi yapma
- Japonca Natural Language API isteği oluşturma
Sonraki Adımlar
- Belgelerdeki Natural Language API eğitimlerini inceleyin.
- Vision API ve Speech API'yi deneyin.