
Com a API Cloud Natural Language, é possível extrair entidades do texto, fazer análises sintáticas e de sentimento e classificar o texto em categorias.
Neste laboratório, você aprenderá a usar a API Natural Language para analisar entidades, sentimento e sintaxe.
O que você vai aprender
- Criar uma solicitação da API Natural Language e chamar a API com curl
- Extrair entidades e fazer análises de sentimento no texto com a API Natural Language
- Realizar análise linguística no texto com a API Natural Language
- Criar uma solicitação da API Natural Language em outro idioma
O que é necessário
Como você vai usar este tutorial?
Como você classificaria sua experiência com o Google Cloud Platform?
Configuração de ambiente autoguiada
Se você ainda não tem uma Conta do Google (Gmail ou Google Apps), crie uma. Faça login no Console do Google Cloud Platform (console.cloud.google.com) e crie um projeto:



Lembre-se do código do projeto, um nome exclusivo em todos os projetos do Google Cloud. O nome acima já foi escolhido e não servirá para você. Faremos referência a ele mais adiante neste codelab como PROJECT_ID.
Em seguida, ative o faturamento no console do Cloud para usar os recursos do Google Cloud.
A execução por meio deste codelab terá um custo baixo, mas poderá ser mais se você decidir usar mais recursos ou se deixá-los em execução. Consulte a seção "limpeza" no final deste documento.
Novos usuários do Google Cloud Platform têm direito a uma avaliação sem custo financeiro de US$300.
Clique no ícone de menu no canto superior esquerdo da tela.

Selecione APIs e serviços no menu suspenso e clique em Painel.
Clique em Ativar APIs e serviços.
Digite "language" na caixa de pesquisa. Clique em API Google Cloud Natural Language:
Clique em Ativar para ativar a API Cloud Natural Language:
Aguarde alguns segundos para que ele seja ativado. Quando ele estiver ativado, você verá isto:

O Google Cloud Shell é um ambiente de linha de comando executado na nuvem. Essa máquina virtual baseada em Debian contém todas as ferramentas de desenvolvimento necessárias (gcloud, bq, git e outras) e oferece um diretório principal permanente de 5 GB. Vamos usar o Cloud Shell para criar nossa solicitação à API Natural Language.
Para começar a usar o Cloud Shell, clique no ícone  "Ativar o Google Cloud Shell" no canto superior direito da barra de cabeçalho.
"Ativar o Google Cloud Shell" no canto superior direito da barra de cabeçalho.

Uma sessão do Cloud Shell é aberta em um novo frame na parte inferior do console e um prompt de linha de comando é exibido. Aguarde até que o prompt user@project:~$ apareça.
Como vamos usar curl para enviar uma solicitação à API Natural Language, será necessário gerar uma chave de API para transmitir o URL da solicitação. Para criar uma chave de API, navegue até a seção "Credenciais" de "APIs e serviços" no console do Cloud:
No menu suspenso, selecione Chave de API:
Em seguida, copie a chave que você acabou de gerar. Você vai precisar dessa chave mais adiante no laboratório.
Agora salve a chave de API em uma variável de ambiente para não precisar inserir o valor dela em cada solicitação. É possível fazer isso no Cloud Shell. Lembre-se de substituir <your_api_key> pela chave que você copiou.
export API_KEY=<YOUR_API_KEY>O primeiro método da API Natural Language que vamos usar é analyzeEntities. Com esse método, a API poderá extrair entidades (como pessoas, lugares e eventos) do texto. Para testar a análise de entidades da API, usaremos a seguinte frase:
Joanne Rowling, who writes under the pen names J. K. Rowling and Robert Galbraith, is a British novelist and screenwriter who wrote the Harry Potter fantasy series.
Vamos criar nossa solicitação para a API Natural Language em um arquivo request.json. No seu ambiente do Cloud Shell, crie o arquivo request.json com o código abaixo. É possível criar o arquivo usando um dos editores de linha de comando que preferir (nano, vim, emacs) ou usar o editor Orion integrado no Cloud Shell:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"Joanne Rowling, who writes under the pen names J. K. Rowling and Robert Galbraith, is a British novelist and screenwriter who wrote the Harry Potter fantasy series."
},
"encodingType":"UTF8"
}Na solicitação, informamos à API Natural Language sobre o texto que será enviado. Os valores de tipo aceitos são PLAIN_TEXT ou HTML. No conteúdo, transmitimos o texto que será enviado à API Natural Language para análise. A API Natural Language também aceita o envio de arquivos armazenados no Cloud Storage para processamento de texto. Para enviar um arquivo do Cloud Storage, é necessário substituir content por gcsContentUri e atribuir a ele o valor do URI do arquivo de texto no Cloud Storage. encodingType informa à API qual tipo de codificação de texto usar no processamento. A API vai usar essa informação para calcular onde determinadas entidades aparecem no texto.
Agora você pode transmitir o corpo da solicitação para a API Natural Language, junto com a variável de ambiente da chave de API que você salvou antes, usando o comando curl a seguir (em uma única linha):
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonO início da sua resposta será semelhante a este:
{
"entities": [
{
"name": "Robert Galbraith",
"type": "PERSON",
"metadata": {
"mid": "/m/042xh",
"wikipedia_url": "https://en.wikipedia.org/wiki/J._K._Rowling"
},
"salience": 0.7980405,
"mentions": [
{
"text": {
"content": "Joanne Rowling",
"beginOffset": 0
},
"type": "PROPER"
},
{
"text": {
"content": "Rowling",
"beginOffset": 53
},
"type": "PROPER"
},
{
"text": {
"content": "novelist",
"beginOffset": 96
},
"type": "COMMON"
},
{
"text": {
"content": "Robert Galbraith",
"beginOffset": 65
},
"type": "PROPER"
}
]
},
...
]
}Para cada entidade na resposta, recebemos o respectivo campo type, o URL da Wikipédia associado (se houver), salience e os índices de onde essa entidade apareceu no texto. A saliência é um número no intervalo [0,1] que se refere à centralidade da entidade no texto como um todo. A API Natural Language também reconhece a mesma entidade mencionada de maneiras diferentes. Confira a lista de mentions na resposta: a API consegue identificar que "Joanne Rowling", "Rowling", "escritora" e "Robert Galbraith" apontam para a mesma coisa.
Além de extrair entidades, é possível executar análise de sentimento em um bloco de texto com a API Natural Language. Nossa solicitação JSON vai incluir os mesmos parâmetros da solicitação acima, mas desta vez vamos mudar o texto para incluir algo com um sentimento mais intenso. Substitua o arquivo request.json pelo seguinte e, se quiser, substitua content por um texto próprio:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"Harry Potter is the best book. I think everyone should read it."
},
"encodingType": "UTF8"
}Em seguida, enviaremos a solicitação ao endpoint analyzeSentiment da API:
curl "https://language.googleapis.com/v1/documents:analyzeSentiment?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
Sua resposta será semelhante a esta:
{
"documentSentiment": {
"magnitude": 0.8,
"score": 0.4
},
"language": "en",
"sentences": [
{
"text": {
"content": "Harry Potter is the best book.",
"beginOffset": 0
},
"sentiment": {
"magnitude": 0.7,
"score": 0.7
}
},
{
"text": {
"content": "I think everyone should read it.",
"beginOffset": 31
},
"sentiment": {
"magnitude": 0.1,
"score": 0.1
}
}
]
}Chegamos a dois tipos de valores de sentimento: o do documento como um todo e o detalhado por frase. O método "sentiment" retorna dois valores: score e magnitude. score é um número entre -1,0 e 1,0 que indica o quanto a declaração é positiva ou negativa. magnitude é um número que varia de 0 a infinito e representa o peso do sentimento expresso na declaração, sem importar se ele é positivo ou negativo. Blocos mais longos de texto com declarações ponderadas têm valores de magnitude mais altos. A pontuação da primeira frase é positiva (0,7) e a da segunda é neutra (0,1).
Além de fornecer detalhes de sentimento em todo o documento de texto que enviamos à API NL, ela também pode dividir o sentimento pelas entidades no texto. Vamos usar esta frase como exemplo:
I liked the sushi but the service was terrible.
Nesse caso, calcular uma pontuação de sentimento para a frase inteira como fizemos acima pode não ser tão útil. Se houvesse outras centenas de avaliações para o mesmo restaurante, seria interessante saber exatamente do que as pessoas gostaram ou não gostaram nas avaliações. Felizmente, a API NL tem um método que permite extrair o sentimento de cada entidade no texto, chamado analyzeEntitySentiment. Atualize seu request.json com a frase acima para testar:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"I liked the sushi but the service was terrible."
},
"encodingType": "UTF8"
}Em seguida, chame o endpoint analyzeEntitySentiment com o seguinte comando curl:
curl "https://language.googleapis.com/v1/documents:analyzeEntitySentiment?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
Na resposta, extraímos dois objetos de entidade: um para "sushi" e outro para "service". Confira a resposta JSON completa:
{
"entities": [
{
"name": "sushi",
"type": "CONSUMER_GOOD",
"metadata": {},
"salience": 0.52716845,
"mentions": [
{
"text": {
"content": "sushi",
"beginOffset": 12
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
}
],
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
},
{
"name": "service",
"type": "OTHER",
"metadata": {},
"salience": 0.47283158,
"mentions": [
{
"text": {
"content": "service",
"beginOffset": 26
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
}
],
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
}
],
"language": "en"
}
A pontuação retornada para "sushi" foi de 0,9 e a de "service" alcançou -0,9. Legal! Você também deve ter percebido que dois objetos de sentimento foram retornados para cada entidade. Se qualquer um desses termos fosse mencionado mais de uma vez, a API retornaria uma pontuação de sentimento e magnitude diferentes para cada menção, além de um sentimento agregado para a entidade.
Com o terceiro método da API Natural Language, a anotação de sintaxe, vamos analisar mais detalhes sobre os aspectos linguísticos do texto. analyzeSyntax é um método que fornece um conjunto completo de detalhes sobre os elementos semânticos e sintáticos do texto. Para cada palavra do texto, a API informará a classe gramatical (substantivo, verbo, adjetivo etc.) e como ela se relaciona com outras palavras da frase (se é o radical do verbo, um modificador de substantivo etc.).
Vamos fazer um teste com uma frase simples. Nossa solicitação JSON será semelhante às anteriores e incluirá uma chave de atributos. Ela informará à API que queremos fazer anotações de sintaxe. Substitua o arquivo request.json pelo seguinte:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content": "Hermione often uses her quick wit, deft recall, and encyclopaedic knowledge to help Harry and Ron."
},
"encodingType": "UTF8"
}Em seguida, chame o método analyzeSyntax da API:
curl "https://language.googleapis.com/v1/documents:analyzeSyntax?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonA resposta vai retornar um objeto como o seguinte para cada token da frase: Aqui, vamos analisar a resposta para a palavra "uses":
{
"text": {
"content": "uses",
"beginOffset": 15
},
"partOfSpeech": {
"tag": "VERB",
"aspect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "INDICATIVE",
"number": "SINGULAR",
"person": "THIRD",
"proper": "PROPER_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tense": "PRESENT",
"voice": "VOICE_UNKNOWN"
},
"dependencyEdge": {
"headTokenIndex": 2,
"label": "ROOT"
},
"lemma": "use"
}Agora, vejamos os detalhes da resposta. partOfSpeech nos dá detalhes linguísticos sobre cada palavra (muitos são desconhecidos porque não se aplicam ao inglês ou a essa palavra específica). tag informa a classe gramatical da palavra, neste caso, um verbo. Também recebemos detalhes sobre o tempo verbal, a modalidade e se a palavra está no singular ou no plural. lemma é a forma canônica da palavra (para "uses", é "use"). Por exemplo, as palavras executar, executa, executou e executando têm todas o lema executar. O valor do "lemma" é útil para rastrear ocorrências de uma palavra em um texto longo.
dependencyEdge inclui dados que você pode usar para criar uma árvore de dependência sintática do texto. É um diagrama que mostra como as palavras de uma frase se relacionam umas com as outras. Uma árvore de dependência sintática da frase acima ficaria assim:
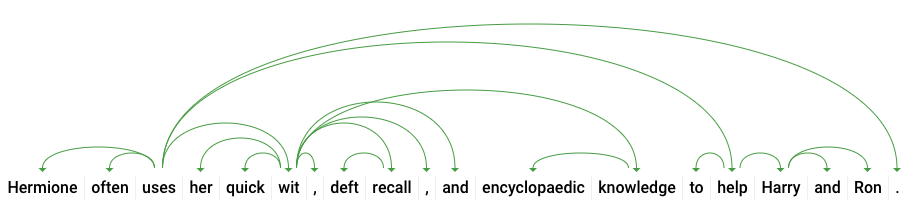
O headTokenIndex na resposta acima é o índice do token com um arco que aponta para "uses". Pense em cada token da frase como uma palavra de uma matriz. O headTokenIndex de 2 para "uses" se refere à palavra "often", a que está conectada na árvore.
A API Natural Language também é compatível com outros idiomas além do inglês (veja a lista completa aqui). Vamos testar a seguinte solicitação de entidade com uma frase em japonês:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"日本のグーグルのオフィスは、東京の六本木ヒルズにあります"
},
"encodingType": "UTF8"
}Você não informou à API em qual idioma o texto está, mas ela detectou o idioma automaticamente. Em seguida, vamos enviar o arquivo ao endpoint analyzeEntities:
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonEstas são as duas primeiras entidades na nossa resposta:
{
"entities": [
{
"name": "日本",
"type": "LOCATION",
"metadata": {
"mid": "/m/03_3d",
"wikipedia_url": "https://en.wikipedia.org/wiki/Japan"
},
"salience": 0.23854347,
"mentions": [
{
"text": {
"content": "日本",
"beginOffset": 0
},
"type": "PROPER"
}
]
},
{
"name": "グーグル",
"type": "ORGANIZATION",
"metadata": {
"mid": "/m/045c7b",
"wikipedia_url": "https://en.wikipedia.org/wiki/Google"
},
"salience": 0.21155767,
"mentions": [
{
"text": {
"content": "グーグル",
"beginOffset": 9
},
"type": "PROPER"
}
]
},
...
]
"language": "ja"
}A API extrai Japão como um local e Google como uma organização, além das páginas da Wikipédia para cada um.
Você aprendeu a realizar uma análise de texto com a API Cloud Natural Language extraindo entidades, analisando sentimento e fazendo anotações de sintaxe.
O que vimos
- Como criar uma solicitação da API Natural Language e chamar a API com curl
- Extraiu entidades e fez análises de sentimento no texto com a API Natural Language
- Realizou uma análise linguística no texto para criar árvores de dependência sintática
- Criou uma solicitação da API Natural Language em japonês
Próximas etapas
- Confira os tutoriais da API Natural Language na documentação.
- Teste a API Vision e a API Speech.