
Umożliwia on kategoryzowanie tekstu, analizowanie go pod kątem składni i nastawienia oraz wyodrębnianie z niego encji.
W tym module dowiesz się, jak używać interfejsu Natural Language API do analizowania encji, nastawienia i składni.
Czego się nauczysz
- Tworzenie żądania do interfejsu Natural Language API i wywoływanie tego interfejsu za pomocą polecenia curl
- Wyodrębnianie encji i przeprowadzanie analizy nastawienia w tekście za pomocą interfejsu Natural Language API
- Przeprowadzanie analizy językowej tekstu za pomocą interfejsu Natural Language API
- Tworzenie żądania do interfejsu Natural Language API w innym języku
Czego potrzebujesz
Jak zamierzasz wykorzystać ten samouczek?
Jak oceniasz korzystanie z Google Cloud Platform?
Samodzielne konfigurowanie środowiska
Jeśli nie masz jeszcze konta Google (Gmail lub Google Apps), musisz je utworzyć. Zaloguj się w konsoli Google Cloud Platform (console.cloud.google.com) i utwórz nowy projekt:



Zapamiętaj identyfikator projektu, czyli unikalną nazwę we wszystkich projektach Google Cloud (podana powyżej nazwa jest już zajęta i nie będzie działać w Twoim przypadku). W dalszej części tego laboratorium będzie on nazywany PROJECT_ID.
Następnie musisz włączyć płatności w konsoli Cloud, aby móc korzystać z zasobów Google Cloud.
Wykonanie tego samouczka nie powinno kosztować więcej niż kilka dolarów, ale może okazać się droższe, jeśli zdecydujesz się wykorzystać więcej zasobów lub pozostawisz je uruchomione (patrz sekcja „Czyszczenie” na końcu tego dokumentu).
Nowi użytkownicy Google Cloud Platform mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD.
Kliknij ikonę menu w lewym górnym rogu ekranu.

Wybierz Interfejsy API i usługi z menu i kliknij Panel.
Kliknij Włącz interfejsy API i usługi.
Następnie w polu wyszukiwania wpisz „język”. Kliknij Google Cloud Natural Language API:
Aby włączyć interfejs Cloud Natural Language API, kliknij Włącz:
Odczekaj kilka sekund, aż się włączy. Gdy ta funkcja będzie włączona, zobaczysz:

Google Cloud Shell to środowisko wiersza poleceń działające w chmurze. Ta maszyna wirtualna oparta na Debianie zawiera wszystkie potrzebne narzędzia dla programistów (gcloud, bq, git i inne) i oferuje trwały katalog domowy o pojemności 5 GB. Za pomocą Cloud Shell utworzymy żądanie do interfejsu Natural Language API.
Aby rozpocząć korzystanie z Cloud Shell, kliknij ikonę „Aktywuj Google Cloud Shell”  w prawym górnym rogu paska nagłówka.
w prawym górnym rogu paska nagłówka.

Sesja Cloud Shell otworzy się w nowej ramce u dołu konsoli, zostanie również wyświetlony monit wiersza poleceń. Poczekaj, aż pojawi się prompt user@project:~$
Ponieważ w celu wysłania żądania do Natural Language API będziesz korzystać z narzędzia curl, musisz wygenerować klucz interfejsu API, aby przekazać go w URL żądania. Aby utworzyć klucz interfejsu API, w konsoli Cloud otwórz sekcję Dane logowania w sekcji Interfejsy API i usługi:
Z menu wybierz Klucz interfejsu API:
Następnie skopiuj wygenerowany klucz. Będzie on potrzebny w dalszej części modułu.
Po utworzeniu klucza interfejsu API należy zapisać go jako zmienną środowiskową, dzięki czemu unikniesz wprowadzania jego wartości przy każdym żądaniu. Możesz to zrobić w Cloud Shell. Pamiętaj, aby zastąpić <your_api_key> skopiowanym właśnie kluczem.
export API_KEY=<YOUR_API_KEY>Pierwszą metodą interfejsu Natural Language API, której użyjemy, jest analyzeEntities. Dzięki tej metodzie interfejs API może wyodrębniać z tekstu encje (np. osoby, miejsca i wydarzenia). Aby wypróbować funkcję analizy encji w interfejsie API, użyjemy tego zdania:
Joanne Rowling, która pisze pod pseudonimami J. K. Rowling i Robert Galbraith, to brytyjska pisarka i scenarzystka, która napisała serię książek fantasy o Harrym Potterze.
Żądanie do interfejsu Natural Language API utworzymy w pliku request.json. W środowisku Cloud Shell utwórz plik request.json z poniższym kodem. Możesz utworzyć plik za pomocą jednego z preferowanych edytorów wiersza poleceń (nano, vim, emacs) lub użyć wbudowanego edytora Orion w Cloud Shell:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"Joanne Rowling, who writes under the pen names J. K. Rowling and Robert Galbraith, is a British novelist and screenwriter who wrote the Harry Potter fantasy series."
},
"encodingType":"UTF8"
}W żądaniu informujemy interfejs Natural Language API o tekście, który będziemy wysyłać. Obsługiwane wartości typu to PLAIN_TEXT i HTML. W parametrze content przekazujemy tekst, który ma zostać wysłany do interfejsu Natural Language API w celu analizy. Natural Language API obsługuje też wysyłanie plików przechowywanych w Cloud Storage do przetwarzania tekstu. Jeśli chcemy wysłać plik z Cloud Storage, zastąpimy content wartością gcsContentUri i podamy adres URI pliku tekstowego w Cloud Storage. Parametr encodingType przekazuje interfejsowi API informacje o typie kodowania tekstu, którego należy użyć podczas przetwarzania tekstu. Interfejs API będzie używać tych informacji do obliczania, gdzie w tekście pojawiają się określone encje.
Teraz możesz przekazać do interfejsu Natural Language API treść żądania wraz z zapisaną wcześniej zmienną środowiskową klucza interfejsu API. Użyj następującego polecenia curl (umieść wszystko w jednym wierszu poleceń):
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonPoczątek odpowiedzi powinien wyglądać tak:
{
"entities": [
{
"name": "Robert Galbraith",
"type": "PERSON",
"metadata": {
"mid": "/m/042xh",
"wikipedia_url": "https://en.wikipedia.org/wiki/J._K._Rowling"
},
"salience": 0.7980405,
"mentions": [
{
"text": {
"content": "Joanne Rowling",
"beginOffset": 0
},
"type": "PROPER"
},
{
"text": {
"content": "Rowling",
"beginOffset": 53
},
"type": "PROPER"
},
{
"text": {
"content": "novelist",
"beginOffset": 96
},
"type": "COMMON"
},
{
"text": {
"content": "Robert Galbraith",
"beginOffset": 65
},
"type": "PROPER"
}
]
},
...
]
}Każda encja w odpowiedzi zawiera type, powiązany adres URL Wikipedii (jeśli istnieje), salience oraz indeksy dotyczące miejsc w tekście, w których występuje encja. przy czym waga jest tu liczbą w zakresie od 0 do 1, która informuje o tym, jak istotna jest dana encja w odniesieniu do całego tekstu; Interfejs Natural Language API może też rozpoznawać tę samą encję, o której wspomina się na różne sposoby. Spójrz na mentions na liście w odpowiedzi: interfejs API rozpoznaje, że „Joanne Rowling”, „Rowling”, „pisarka” i „Robert Galbriath” odnoszą się do tej samej osoby.
Oprócz wyodrębniania encji interfejs Natural Language API umożliwia też analizowanie nastawienia w bloku tekstu. Nasze żądanie JSON będzie zawierać te same parametry co powyższe żądanie, ale tym razem zmienimy tekst, aby zawierał coś o silniejszym wydźwięku. Zastąp plik request.json tym tekstem. Możesz też zastąpić tekst content własnym tekstem:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"Harry Potter is the best book. I think everyone should read it."
},
"encodingType": "UTF8"
}Następnie wyślemy żądanie do punktu końcowego analyzeSentiment interfejsu API:
curl "https://language.googleapis.com/v1/documents:analyzeSentiment?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
Odpowiedź powinna wyglądać tak:
{
"documentSentiment": {
"magnitude": 0.8,
"score": 0.4
},
"language": "en",
"sentences": [
{
"text": {
"content": "Harry Potter is the best book.",
"beginOffset": 0
},
"sentiment": {
"magnitude": 0.7,
"score": 0.7
}
},
{
"text": {
"content": "I think everyone should read it.",
"beginOffset": 31
},
"sentiment": {
"magnitude": 0.1,
"score": 0.1
}
}
]
}Zwróć uwagę, że otrzymujemy 2 rodzaje wartości sentymentu: sentyment dla całego dokumentu i sentyment podzielony na zdania. Metoda sentiment zwraca 2 wartości: score i magnitude. score to liczba z zakresu od -1,0 do 1,0, która wskazuje, jak pozytywne lub negatywne jest stwierdzenie. magnitude to liczba z zakresu od 0 do nieskończoności, która reprezentuje wagę nastawienia wyrażonego w stwierdzeniu, niezależnie od tego, czy jest ono pozytywne czy negatywne. Dłuższe bloki tekstu z mocno ważonymi stwierdzeniami mają wyższe wartości wielkości. Ocena pierwszego zdania jest pozytywna (0,7), a drugiego – neutralna (0,1).
Oprócz podawania szczegółowych informacji o opinii na temat całego dokumentu tekstowego, który wysyłamy do interfejsu NL API, może on też rozdzielać opinię według podmiotów w naszym tekście. Weźmy na przykład to zdanie:
Sushi mi smakowało, ale obsługa była okropna.
W takim przypadku uzyskanie wyniku sentymentu dla całego zdania, jak w przykładzie powyżej, może nie być zbyt przydatne. Jeśli byłaby to opinia o restauracji, a dla tej samej restauracji byłyby setki opinii, chcielibyśmy wiedzieć, co dokładnie podobało się i nie podobało się osobom, które je napisały. Na szczęście interfejs Natural Language API ma metodę, która pozwala nam uzyskać nastawienie dla każdej encji w tekście. Nazywa się ona analyzeEntitySentiment. Aby wypróbować tę funkcję, zaktualizuj plik request.json o powyższe zdanie:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"I liked the sushi but the service was terrible."
},
"encodingType": "UTF8"
}Następnie wywołaj punkt końcowy analyzeEntitySentiment za pomocą tego polecenia curl:
curl "https://language.googleapis.com/v1/documents:analyzeEntitySentiment?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
W odpowiedzi otrzymujemy 2 obiekty encji: jeden dla „sushi” i jeden dla „obsługi”. Oto pełna odpowiedź JSON:
{
"entities": [
{
"name": "sushi",
"type": "CONSUMER_GOOD",
"metadata": {},
"salience": 0.52716845,
"mentions": [
{
"text": {
"content": "sushi",
"beginOffset": 12
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
}
],
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
},
{
"name": "service",
"type": "OTHER",
"metadata": {},
"salience": 0.47283158,
"mentions": [
{
"text": {
"content": "service",
"beginOffset": 26
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
}
],
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
}
],
"language": "en"
}
Widzimy, że wynik zwrócony dla słowa „sushi” to 0,9, a dla słowa „obsługa” to -0,9. Super! Możesz też zauważyć, że w przypadku każdej jednostki zwracane są 2 obiekty sentymentu. Jeśli któryś z tych terminów został wspomniany więcej niż raz, API zwróci inny wynik i wartość dla każdego wystąpienia, a także ogólny wynik dla podmiotu.
Przyjrzyjmy się trzeciej metodzie interfejsu Natural Language API – adnotacji składniowej – i zagłębmy się w szczegóły językowe naszego tekstu. analyzeSyntax to metoda, która dostarcza pełny zestaw szczegółów dotyczących elementów semantycznych i syntaktycznych tekstu. W przypadku każdego słowa w tekście interfejs API określi część mowy (rzeczownik, czasownik, przymiotnik itp.) i jego związek z innymi słowami w zdaniu (czy jest to czasownik główny? modyfikator?).
Wypróbujmy to na prostym zdaniu. Nasze żądanie JSON będzie podobne do powyższych, ale będzie zawierać klucz features. Informuje to interfejs API, że chcemy wykonać adnotację składniową. Zastąp plik request.json tym kodem:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content": "Hermione often uses her quick wit, deft recall, and encyclopaedic knowledge to help Harry and Ron."
},
"encodingType": "UTF8"
}Następnie wywołaj metodę analyzeSyntax interfejsu API:
curl "https://language.googleapis.com/v1/documents:analyzeSyntax?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonOdpowiedź powinna zawierać obiekt podobny do tego poniżej dla każdego tokena w zdaniu. Przyjrzyjmy się odpowiedzi dla słowa „uses”:
{
"text": {
"content": "uses",
"beginOffset": 15
},
"partOfSpeech": {
"tag": "VERB",
"aspect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "INDICATIVE",
"number": "SINGULAR",
"person": "THIRD",
"proper": "PROPER_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tense": "PRESENT",
"voice": "VOICE_UNKNOWN"
},
"dependencyEdge": {
"headTokenIndex": 2,
"label": "ROOT"
},
"lemma": "use"
}Przeanalizujmy odpowiedź. partOfSpeech podaje szczegóły językowe każdego słowa (wiele z nich jest nieznanych, ponieważ nie dotyczą języka angielskiego ani tego konkretnego słowa). tag podaje część mowy tego słowa, w tym przypadku czasownik. Uzyskujemy też informacje o czasie, trybie i liczbie (pojedynczej lub mnogiej) danego słowa. lemma to forma kanoniczna słowa (w przypadku słowa „uses” jest to „use”). Na przykład słowa run, runs, ran i running mają lemat run. Wartość lematu jest przydatna do śledzenia występowania słowa w długim tekście na przestrzeni czasu.
dependencyEdge zawiera dane, których możesz użyć do utworzenia drzewa analizy zależności tekstu. Jest to diagram pokazujący, jak słowa w zdaniu są ze sobą powiązane. Drzewo analizy zależności dla powyższego zdania wyglądałoby tak:
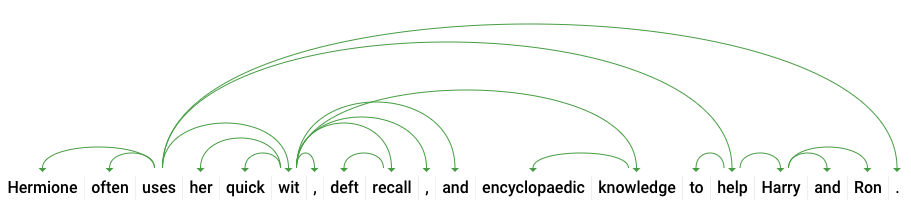
Symbol headTokenIndex w naszej odpowiedzi powyżej to indeks tokena, który ma łuk wskazujący na słowo „uses”. Każdy token w zdaniu możemy traktować jako słowo w tablicy, a wartość headTokenIndex = 2 dla słowa „uses” odnosi się do słowa „often”, z którym jest ono połączone w drzewie.
Natural Language API obsługuje też inne języki niż angielski (pełna lista tutaj). Wypróbujmy to żądanie dotyczące encji w przypadku zdania w języku japońskim:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"日本のグーグルのオフィスは、東京の六本木ヒルズにあります"
},
"encodingType": "UTF8"
}Zwróć uwagę, że nie podaliśmy interfejsowi API, w jakim języku jest nasz tekst. Może on wykryć go automatycznie. Następnie wyślemy go do punktu końcowego analyzeEntities:
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonOto pierwsze 2 elementy w naszej odpowiedzi:
{
"entities": [
{
"name": "日本",
"type": "LOCATION",
"metadata": {
"mid": "/m/03_3d",
"wikipedia_url": "https://en.wikipedia.org/wiki/Japan"
},
"salience": 0.23854347,
"mentions": [
{
"text": {
"content": "日本",
"beginOffset": 0
},
"type": "PROPER"
}
]
},
{
"name": "グーグル",
"type": "ORGANIZATION",
"metadata": {
"mid": "/m/045c7b",
"wikipedia_url": "https://en.wikipedia.org/wiki/Google"
},
"salience": 0.21155767,
"mentions": [
{
"text": {
"content": "グーグル",
"beginOffset": 9
},
"type": "PROPER"
}
]
},
...
]
"language": "ja"
}Interfejs API wyodrębnia Japonię jako lokalizację i Google jako organizację, a także strony w Wikipedii dotyczące tych elementów.
Wiesz już, jak przeprowadzać analizę tekstu za pomocą interfejsu Cloud Natural Language API, wyodrębniając encje, analizując nastawienie i dodając adnotacje do składni.
Omówione zagadnienia
- Tworzenie żądania do interfejsu Natural Language API i wywoływanie tego interfejsu za pomocą polecenia curl
- Wyodrębnianie encji i przeprowadzanie analizy nastawienia w tekście za pomocą interfejsu Natural Language API
- Przeprowadzanie analizy językowej tekstu w celu tworzenia drzew wyprowadzenia dotyczących zależności.
- Tworzenie żądania do interfejsu Natural Language API w języku japońskim
Następne kroki
- Zapoznaj się z samouczkami na temat interfejsu Natural Language API w dokumentacji.
- Wypróbuj interfejsy Vision API i Speech API.