
L'API Cloud Natural Language consente di estrarre entità da un testo, analizzarne sentiment e sintassi e classificarlo in categorie.
In questo lab impareremo a utilizzare l'API Natural Language per analizzare entità, sentiment e sintassi.
Cosa imparerai a fare
- Creazione di una richiesta API Natural Language e chiamata all'API con curl
- Estrazione di entità ed esecuzione di analisi del sentiment sul testo con l'API Natural Language
- Esecuzione di analisi linguistiche sul testo con l'API Natural Language
- Creazione di una richiesta API Natural Language in una lingua diversa
Cosa ti serve
Come utilizzerai questo tutorial?
Come valuteresti la tua esperienza con Google Cloud Platform?
Configurazione dell'ambiente autonoma
Se non hai ancora un Account Google (Gmail o Google Apps), devi crearne uno. Accedi alla console di Google Cloud (console.cloud.google.com) e crea un nuovo progetto:



Ricorda l'ID progetto, un nome univoco per tutti i progetti Google Cloud (il nome riportato sopra è già stato utilizzato e non funzionerà per te, mi dispiace). In questo codelab verrà chiamato PROJECT_ID.
Successivamente, dovrai abilitare la fatturazione nella console Cloud per utilizzare le risorse Google Cloud.
L'esecuzione di questo codelab non dovrebbe costarti più di qualche dollaro, ma potrebbe essere più cara se decidi di utilizzare più risorse o se le lasci in esecuzione (vedi la sezione "Pulizia" alla fine di questo documento).
I nuovi utenti di Google Cloud Platform possono beneficiare di una prova senza costi di 300$.
Fai clic sull'icona del menu nella parte superiore sinistra dello schermo.

Seleziona API e servizi dal menu a discesa e fai clic su Dashboard.
Fai clic su Abilita API e servizi.
Cerca "language" nella casella di ricerca. Fai clic su Google Cloud Natural Language API:
Fai clic su Abilita per abilitare l'API Cloud Natural Language:
Attendi qualche secondo affinché venga attivato. Una volta attivata, vedrai questo:

Google Cloud Shell è un ambiente a riga di comando in esecuzione nel cloud. Questa macchina virtuale basata su Debian viene caricata con tutti gli strumenti di sviluppo di cui avrai bisogno (gcloud, bq, git e altri) e mette a tua disposizione una home directory permanente di 5 GB. Utilizzeremo Cloud Shell per creare la nostra richiesta all'API Natural Language.
Per iniziare a utilizzare Cloud Shell, fai clic sull'icona "Attiva Google Cloud Shell"  nell'angolo in alto a destra della barra dell'intestazione.
nell'angolo in alto a destra della barra dell'intestazione.

All'interno di un nuovo frame nella parte inferiore della console si apre una sessione di Cloud Shell e viene visualizzato un prompt della riga di comando. Attendi finché non viene visualizzato il prompt user@project:~$
Poiché utilizzeremo curl per inviare una richiesta all'API Natural Language, dobbiamo generare una chiave API da passare nell'URL della richiesta. Per creare una chiave API, vai alla sezione Credenziali di API e servizi nella console Cloud:
Seleziona Chiave API dal menu a discesa:
Copia la chiave appena generata. Ti servirà più avanti nel lab.
Ora che hai una chiave API, salvala come variabile di ambiente per evitare di doverne inserirne il valore in ogni richiesta. Puoi farlo in Cloud Shell. Assicurati di sostituire <your_api_key> con la chiave che hai appena copiato.
export API_KEY=<YOUR_API_KEY>Il primo metodo dell'API Natural Language che utilizzeremo è analyzeEntities. Con questo metodo, l'API può estrarre entità (come persone, luoghi ed eventi) dal testo. Per provare l'analisi delle entità dell'API, utilizzeremo la seguente frase:
Joanne Rowling, who writes under the pen names J. K. Rowling and Robert Galbraith, is a British novelist and screenwriter who wrote the Harry Potter fantasy series.
Creeremo la nostra richiesta all'API Natural Language in un file request.json. Nell'ambiente Cloud Shell, crea il file request.json con il codice riportato di seguito. Puoi creare il file utilizzando uno dei tuoi editor di riga di comando preferiti (nano, vim, emacs) oppure utilizzare l'editor Orion integrato in Cloud Shell:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"Joanne Rowling, who writes under the pen names J. K. Rowling and Robert Galbraith, is a British novelist and screenwriter who wrote the Harry Potter fantasy series."
},
"encodingType":"UTF8"
}Nella richiesta, indichiamo all'API Natural Language il testo che invieremo. I valori del tipo supportati sono PLAIN_TEXT o HTML. In content, passiamo il testo da inviare all'API Natural Language per l'analisi. L'API Natural Language supporta anche l'invio di file archiviati in Cloud Storage per l'elaborazione del testo. Se volessimo inviare un file da Cloud Storage, sostituiremmo content con gcsContentUri e gli assegneremmo un valore pari all'URI del file di testo in Cloud Storage. encodingType indica all'API il tipo di codifica del testo da utilizzare durante l'elaborazione del nostro testo. L'API lo utilizzerà per calcolare dove determinate entità compaiono nel nostro testo.
Ora puoi passare all'API Natural Language il corpo della richiesta, insieme alla variabile di ambiente della chiave API salvata in precedenza, con il seguente comando curl (tutto in un'unica riga di comando):
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonL'inizio della risposta dovrebbe essere simile al seguente:
{
"entities": [
{
"name": "Robert Galbraith",
"type": "PERSON",
"metadata": {
"mid": "/m/042xh",
"wikipedia_url": "https://en.wikipedia.org/wiki/J._K._Rowling"
},
"salience": 0.7980405,
"mentions": [
{
"text": {
"content": "Joanne Rowling",
"beginOffset": 0
},
"type": "PROPER"
},
{
"text": {
"content": "Rowling",
"beginOffset": 53
},
"type": "PROPER"
},
{
"text": {
"content": "novelist",
"beginOffset": 96
},
"type": "COMMON"
},
{
"text": {
"content": "Robert Galbraith",
"beginOffset": 65
},
"type": "PROPER"
}
]
},
...
]
}Per ogni entità nella risposta, ottieni i seguenti elementi: type dell'entità, URL di Wikipedia associato, se presente, salience e indici della posizione in cui l'entità compare nel testo. Il valore di salience è un numero compreso tra 0 e 1 e si riferisce alla centralità dell'entità rispetto al testo nel suo insieme. L'API Natural Language può anche riconoscere stessa entità menzionata in modi diversi. Dai un'occhiata all'elenco mentions nella risposta: l'API è in grado di dire che "Joanne Rowling", "Rowling", "novelist" e "Robert Galbriath" puntano tutti alla stessa cosa.
Oltre a estrarre entità, l'API Natural Language consente anche di eseguire l'analisi del sentiment su un blocco di testo. La richiesta JSON includerà gli stessi parametri della richiesta precedente, ma questa volta cambierà il testo per includere un elemento con un sentiment più forte. Sostituisci il file request.json con quanto segue e, se vuoi, sostituisci content con il tuo testo:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"Harry Potter is the best book. I think everyone should read it."
},
"encodingType": "UTF8"
}Dopodiché, invia la richiesta all'endpoint analyzeSentiment dell'API:
curl "https://language.googleapis.com/v1/documents:analyzeSentiment?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
La tua risposta dovrebbe essere simile alla seguente:
{
"documentSentiment": {
"magnitude": 0.8,
"score": 0.4
},
"language": "en",
"sentences": [
{
"text": {
"content": "Harry Potter is the best book.",
"beginOffset": 0
},
"sentiment": {
"magnitude": 0.7,
"score": 0.7
}
},
{
"text": {
"content": "I think everyone should read it.",
"beginOffset": 31
},
"sentiment": {
"magnitude": 0.1,
"score": 0.1
}
}
]
}Tieni presente che otteniamo due tipi di valori di sentiment: un sentiment per il documento nel suo insieme e un sentiment scomposto per frase. Il metodo sentiment restituisce due valori: score e magnitude. score è un numero compreso tra -1,0 e 1,0 che indica quanto sia positiva o negativa l'affermazione. magnitude è un numero compreso tra 0 e infinito che rappresenta il peso del sentiment espresso nell'affermazione, indipendentemente dal fatto che sia positiva o negativa. Blocchi di testo più lunghi con affermazioni molto pesanti hanno valori di magnitude più elevati. Lo score per la prima frase è positivo (0,7), mentre quello per la seconda è neutro (0,1).
Oltre a fornire dettagli sul sentiment dell'intero documento di testo che inviamo all'API Natural Language, può anche scomporre il sentiment in base alle entità nel testo. Usiamo questa frase come esempio:
I liked the sushi but the service was terrible.
In questo caso, ottenere un punteggio relativo al sentiment per l'intera frase come abbiamo fatto in precedenza potrebbe non essere così utile. Se si trattasse della recensione di un ristorante per cui esistono centinaia di recensioni, vorremmo sapere esattamente quali cose sono piaciute e quali non sono piaciute alle persone che lo hanno recensito. Fortunatamente, l'API Natural Language dispone di un metodo che consente di ottenere il sentiment per ciascuna entità nel testo, chiamato analyzeEntitySentiment. Aggiorna request.json con la frase riportata sopra per provarla:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"I liked the sushi but the service was terrible."
},
"encodingType": "UTF8"
}Quindi chiama l'endpoint analyzeEntitySentiment con il seguente comando curl:
curl "https://language.googleapis.com/v1/documents:analyzeEntitySentiment?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
Nella risposta ottieni due oggetti entità: uno per "sushi" e uno per "service" (servizio). Ecco la risposta JSON completa:
{
"entities": [
{
"name": "sushi",
"type": "CONSUMER_GOOD",
"metadata": {},
"salience": 0.52716845,
"mentions": [
{
"text": {
"content": "sushi",
"beginOffset": 12
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
}
],
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
},
{
"name": "service",
"type": "OTHER",
"metadata": {},
"salience": 0.47283158,
"mentions": [
{
"text": {
"content": "service",
"beginOffset": 26
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
}
],
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
}
],
"language": "en"
}
Possiamo notare che il punteggio restituito per "sushi" è 0,9, mentre "service" ha ottenuto un punteggio di -0,9. Interessante! Potresti anche notare che vengono restituiti due oggetti sentiment per ciascuna entità. Se uno di questi termini venisse menzionato più di una volta, l'API restituirebbe valori score e magnitude per il sentiment diversi per ogni menzione, insieme a un sentiment aggregato per l'entità.
Esaminando il terzo metodo dell'API Natural Language, l'annotazione della sintassi, approfondiremo i dettagli linguistici del nostro testo. analyzeSyntax è un metodo che fornisce un insieme completo di dettagli sugli elementi semantici e sintattici del testo. Per ogni parola nel testo, l'API indica la parte del discorso (sostantivo, verbo, aggettivo ecc.) e come quest'ultima si collega alle altre parole nella frase (ad esempio, se è la radice del verbo o un modificatore).
Proviamo con una frase semplice. La nostra richiesta JSON sarà simile a quelle precedenti, con l'aggiunta di una chiave di funzionalità, che indica all'API di eseguire l'annotazione della sintassi. Sostituisci request.json con quanto segue:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content": "Hermione often uses her quick wit, deft recall, and encyclopaedic knowledge to help Harry and Ron."
},
"encodingType": "UTF8"
}Quindi chiama il metodo analyzeSyntax dell'API:
curl "https://language.googleapis.com/v1/documents:analyzeSyntax?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonLa risposta dovrebbe restituire un oggetto come quello seguente per ogni token nella frase. Qui esamineremo la risposta per la parola "utilizza":
{
"text": {
"content": "uses",
"beginOffset": 15
},
"partOfSpeech": {
"tag": "VERB",
"aspect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "INDICATIVE",
"number": "SINGULAR",
"person": "THIRD",
"proper": "PROPER_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tense": "PRESENT",
"voice": "VOICE_UNKNOWN"
},
"dependencyEdge": {
"headTokenIndex": 2,
"label": "ROOT"
},
"lemma": "use"
}Analizziamo la risposta. partOfSpeech ci fornisce dettagli linguistici su ogni parola (molti sono sconosciuti perché non si applicano all'inglese o a questa parola specifica). tag indica la parte del discorso di questa parola, in questo caso un verbo. Riceviamo anche dettagli sul tempo verbale, sulla modalità e se la parola è singolare o plurale. lemma è la forma canonica della parola (per "utilizza" è "utilizzare"). Ad esempio, le parole run, runs, ran e running hanno tutte il lemma run. Il valore lemma è utile per tenere traccia delle occorrenze di una parola in una porzione di testo di grandi dimensioni nel tempo.
dependencyEdge include dati che puoi utilizzare per creare un albero di analisi delle dipendenze del testo. Si tratta di un diagramma che mostra come le parole in una frase si relazionano tra loro. Un albero di analisi delle dipendenze per la frase precedente sarebbe simile a questo:
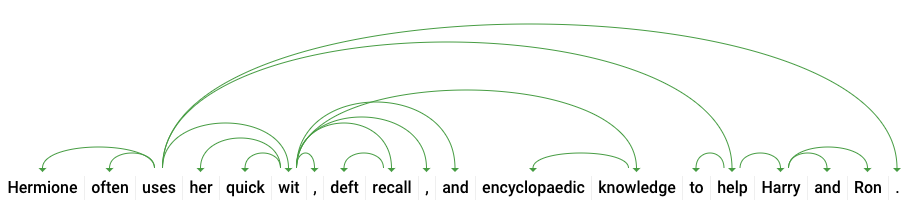
headTokenIndex nella risposta precedente è l'indice del token che ha un arco che punta a "uses". Possiamo pensare a ciascun token nella frase come a una parola in un array e il headTokenIndex di 2 per "usa" si riferisce alla parola "spesso", a cui è collegato nell'albero.
L'API Natural Language supporta anche altre lingue diverse dall'inglese (l'elenco completo è disponibile qui). Proviamo la seguente richiesta di entità con una frase in giapponese:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"日本のグーグルのオフィスは、東京の六本木ヒルズにあります"
},
"encodingType": "UTF8"
}Nota che, anche se non abbiamo incluso questa informazione, l'API è in grado di rilevare automaticamente la lingua. Dopodiché, lo invieremo all'endpoint analyzeEntities:
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonEcco le prime due entità nella nostra risposta:
{
"entities": [
{
"name": "日本",
"type": "LOCATION",
"metadata": {
"mid": "/m/03_3d",
"wikipedia_url": "https://en.wikipedia.org/wiki/Japan"
},
"salience": 0.23854347,
"mentions": [
{
"text": {
"content": "日本",
"beginOffset": 0
},
"type": "PROPER"
}
]
},
{
"name": "グーグル",
"type": "ORGANIZATION",
"metadata": {
"mid": "/m/045c7b",
"wikipedia_url": "https://en.wikipedia.org/wiki/Google"
},
"salience": 0.21155767,
"mentions": [
{
"text": {
"content": "グーグル",
"beginOffset": 9
},
"type": "PROPER"
}
]
},
...
]
"language": "ja"
}L'API estrae il Giappone come località e Google come organizzazione, insieme alle pagine di Wikipedia per ciascuno.
Hai imparato come eseguire l'analisi del testo con l'API Cloud Natural Language estraendo entità, analizzando il sentiment ed eseguendo l'annotazione della sintassi.
Argomenti trattati
- Creazione di una richiesta API Natural Language e chiamata all'API con curl
- Estrazione di entità ed esecuzione di analisi del sentiment sul testo con l'API Natural Language
- Esecuzione di analisi linguistiche sul testo per creare alberi di analisi delle dipendenze
- Creazione di una richiesta API Natural Language in giapponese
Passaggi successivi
- Guarda i tutorial relativi all'API Natural Language nella documentazione.
- Prova l'API Vision e l'API Speech.