
Cloud Natural Language API की मदद से, टेक्स्ट से इकाइयां निकाली जा सकती हैं. साथ ही, भावना और सिंटैक्टिक का विश्लेषण किया जा सकता है. इसके अलावा, टेक्स्ट को कैटगरी में बांटा जा सकता है.
इस लैब में, हम Natural Language API का इस्तेमाल करके, इकाइयों, भावना, और सिंटैक्स का विश्लेषण करने का तरीका जानेंगे.
आपको क्या सीखने को मिलेगा
- Natural Language API का अनुरोध बनाना और curl की मदद से एपीआई को कॉल करना
- Natural Language API की मदद से, टेक्स्ट में मौजूद इकाइयों का पता लगाना और उसके बारे में लोगों की राय का विश्लेषण करना
- Natural Language API की मदद से, टेक्स्ट का भाषाई विश्लेषण करना
- किसी दूसरी भाषा में Natural Language API का अनुरोध करना
आपको इन चीज़ों की ज़रूरत होगी
इस ट्यूटोरियल का इस्तेमाल कैसे किया जाएगा?
Google Cloud Platform इस्तेमाल करने के अपने अनुभव को आप क्या रेटिंग देंगे?
अपने हिसाब से एनवायरमेंट सेट अप करना
अगर आपके पास पहले से कोई Google खाता (Gmail या Google Apps) नहीं है, तो आपको एक खाता बनाना होगा. Google Cloud Platform Console (console.cloud.google.com) में साइन इन करें और एक नया प्रोजेक्ट बनाएं:



प्रोजेक्ट आईडी याद रखें. यह सभी Google Cloud प्रोजेक्ट के लिए एक यूनीक नाम होता है. ऊपर दिया गया नाम पहले ही इस्तेमाल किया जा चुका है. इसलिए, यह आपके लिए काम नहीं करेगा. माफ़ करें! इस कोड लैब में इसे बाद में PROJECT_ID के तौर पर दिखाया जाएगा.
इसके बाद, Google Cloud संसाधनों का इस्तेमाल करने के लिए, आपको Cloud Console में बिलिंग चालू करनी होगी.
इस कोडलैब को पूरा करने में आपको कुछ डॉलर से ज़्यादा खर्च नहीं करने पड़ेंगे. हालांकि, अगर आपको ज़्यादा संसाधनों का इस्तेमाल करना है या उन्हें चालू रखना है, तो यह खर्च बढ़ सकता है. इस दस्तावेज़ के आखिर में "सफ़ाई" सेक्शन देखें.
Google Cloud Platform के नए उपयोगकर्ता, 300 डॉलर के क्रेडिट के साथ मुफ़्त में आज़माने की सुविधा पा सकते हैं.
स्क्रीन पर सबसे ऊपर बाईं ओर मौजूद, मेन्यू आइकॉन पर क्लिक करें.

ड्रॉप-डाउन मेन्यू से एपीआई और सेवाएं चुनें. इसके बाद, डैशबोर्ड पर क्लिक करें
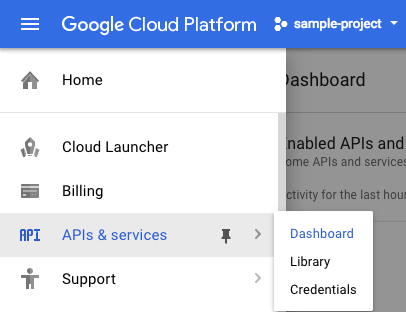
एपीआई और सेवाएं चालू करें पर क्लिक करें.
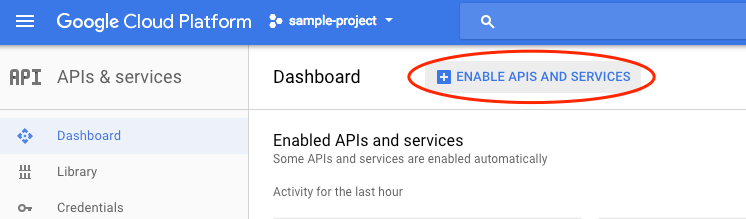
इसके बाद, खोज बॉक्स में "भाषा" खोजें. Google Cloud Natural Language API पर क्लिक करें:
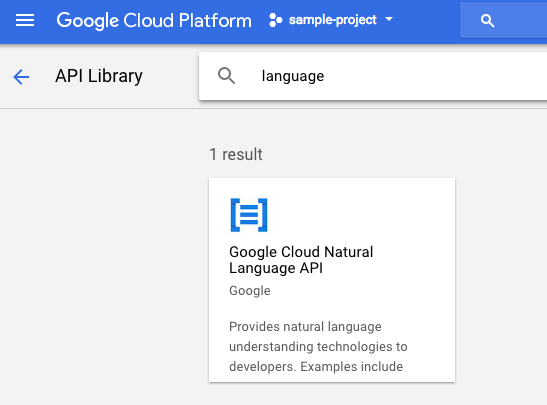
Cloud Natural Language API को चालू करने के लिए, चालू करें पर क्लिक करें:
इसे चालू होने में कुछ सेकंड लगेंगे. इस सुविधा के चालू होने पर, आपको यह दिखेगा:

Google Cloud Shell, क्लाउड में चलने वाला कमांड लाइन एनवायरमेंट है. Debian पर आधारित इस वर्चुअल मशीन में, आपको ज़रूरी सभी डेवलपमेंट टूल (gcloud, bq, git वगैरह) मिलेंगे. साथ ही, इसमें 5 जीबी की होम डायरेक्ट्री भी मिलती है. हम Natural Language API से अनुरोध करने के लिए, Cloud Shell का इस्तेमाल करेंगे.
Cloud Shell का इस्तेमाल शुरू करने के लिए, हेडर बार में सबसे ऊपर दाएं कोने में मौजूद "Google Cloud Shell चालू करें"  आइकॉन पर क्लिक करें
आइकॉन पर क्लिक करें

Cloud Shell सेशन, कंसोल में सबसे नीचे मौजूद नए फ़्रेम में खुलता है. इसमें कमांड-लाइन प्रॉम्प्ट दिखता है. जब तक user@project:~$ प्रॉम्प्ट न दिखे, तब तक इंतज़ार करें
हम Natural Language API को अनुरोध भेजने के लिए curl का इस्तेमाल करेंगे. इसलिए, हमें एक एपीआई कुंजी जनरेट करनी होगी, ताकि हम उसे अपने अनुरोध यूआरएल में पास कर सकें. एपीआई पासकोड बनाने के लिए, अपने Cloud Console में एपीआई और सेवाओं के क्रेडेंशियल सेक्शन पर जाएं:
ड्रॉप-डाउन मेन्यू में, एपीआई पासकोड चुनें:
इसके बाद, अभी जनरेट की गई कुंजी को कॉपी करें. आपको इस कुंजी की ज़रूरत लैब में बाद में पड़ेगी.
अब आपके पास एपीआई पासकोड है. इसे एनवायरमेंट वैरिएबल में सेव करें, ताकि आपको हर अनुरोध में एपीआई पासकोड की वैल्यू न डालनी पड़े. यह काम Cloud Shell में किया जा सकता है. <your_api_key> की जगह, अभी कॉपी की गई कुंजी का इस्तेमाल करना न भूलें.
export API_KEY=<YOUR_API_KEY>हम Natural Language API के analyzeEntities तरीके का इस्तेमाल करेंगे. इस तरीके से, एपीआई टेक्स्ट से इकाइयां (जैसे कि लोग, जगहें, और इवेंट) निकाल सकता है. एपीआई की इकाई विश्लेषण सुविधा को आज़माने के लिए, हम इस वाक्य का इस्तेमाल करेंगे:
जोऐन रोलिंग, जो जे. के॰ रोलिंग और रॉबर्ट गैलब्रेथ, एक ब्रिटिश उपन्यासकार और स्क्रीनराइटर हैं. उन्होंने हैरी पॉटर की फ़ैंटसी सीरीज़ लिखी है.
हम Natural Language API के लिए अनुरोध, request.json फ़ाइल में बनाएंगे. अपने Cloud Shell एनवायरमेंट में, नीचे दिए गए कोड का इस्तेमाल करके request.json फ़ाइल बनाएं. फ़ाइल बनाने के लिए, अपनी पसंद के कमांड लाइन एडिटर (nano, vim, emacs) में से किसी एक का इस्तेमाल करें. इसके अलावा, Cloud Shell में मौजूद Orion एडिटर का भी इस्तेमाल किया जा सकता है:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"Joanne Rowling, who writes under the pen names J. K. Rowling and Robert Galbraith, is a British novelist and screenwriter who wrote the Harry Potter fantasy series."
},
"encodingType":"UTF8"
}अनुरोध में, हम Natural Language API को उस टेक्स्ट के बारे में बताते हैं जिसे हमें भेजना है. PLAIN_TEXT या HTML को वैल्यू के तौर पर इस्तेमाल किया जा सकता है. कॉन्टेंट में, हम टेक्स्ट को Natural Language API को भेजते हैं, ताकि उसका विश्लेषण किया जा सके. Natural Language API, Cloud Storage में सेव की गई फ़ाइलों को भी टेक्स्ट प्रोसेसिंग के लिए भेजने की सुविधा देता है. अगर हमें Cloud Storage से कोई फ़ाइल भेजनी होती, तो हम content को gcsContentUri से बदल देते और Cloud Storage में मौजूद अपनी टेक्स्ट फ़ाइल के यूआरआई की वैल्यू दे देते. encodingType से एपीआई को यह पता चलता है कि हमारे टेक्स्ट को प्रोसेस करते समय, किस तरह की टेक्स्ट एन्कोडिंग का इस्तेमाल करना है. एपीआई इसका इस्तेमाल यह पता लगाने के लिए करेगा कि हमारे टेक्स्ट में कुछ खास इकाइयां कहां दिखती हैं.
अब अपने अनुरोध के मुख्य हिस्से को Natural Language API पर भेजा जा सकता है. इसके लिए, आपको पहले से सेव की गई एपीआई पासकोड एनवायरमेंट वैरिएबल के साथ, यहां दी गई curl कमांड का इस्तेमाल करना होगा. यह पूरी कमांड एक ही कमांड लाइन में होनी चाहिए:
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonआपके जवाब की शुरुआत कुछ इस तरह होनी चाहिए:
{
"entities": [
{
"name": "Robert Galbraith",
"type": "PERSON",
"metadata": {
"mid": "/m/042xh",
"wikipedia_url": "https://en.wikipedia.org/wiki/J._K._Rowling"
},
"salience": 0.7980405,
"mentions": [
{
"text": {
"content": "Joanne Rowling",
"beginOffset": 0
},
"type": "PROPER"
},
{
"text": {
"content": "Rowling",
"beginOffset": 53
},
"type": "PROPER"
},
{
"text": {
"content": "novelist",
"beginOffset": 96
},
"type": "COMMON"
},
{
"text": {
"content": "Robert Galbraith",
"beginOffset": 65
},
"type": "PROPER"
}
]
},
...
]
}जवाब में मौजूद हर इकाई के लिए, हमें इकाई type, उससे जुड़ा Wikipedia यूआरएल (अगर कोई है), salience, और इंडेक्स मिलते हैं. इनसे पता चलता है कि यह इकाई टेक्स्ट में कहां-कहां मौजूद है. सैलियंस, [0,1] रेंज में मौजूद एक संख्या होती है. यह बताती है कि इकाई, पूरे टेक्स्ट के लिए कितनी अहम है. Natural Language API, एक ही इकाई को अलग-अलग तरीकों से पहचाने में भी मदद कर सकता है. जवाब में दी गई mentions सूची देखें: एपीआई यह बता सकता है कि "जोऐन रोलिंग", "रोलिंग", "उपन्यासकार", और "रॉबर्ट गैलब्रेथ" सभी एक ही व्यक्ति के बारे में जानकारी देते हैं.
Natural Language API, इकाइयों को निकालने के साथ-साथ, टेक्स्ट के किसी ब्लॉक पर भावना का विश्लेषण करने की सुविधा भी देता है. हमारे JSON अनुरोध में, ऊपर दिए गए अनुरोध के पैरामीटर शामिल होंगे. हालांकि, इस बार हम टेक्स्ट को बदलकर, ज़्यादा सकारात्मक भावना वाला टेक्स्ट शामिल करेंगे. अपनी request.json फ़ाइल को इससे बदलें. साथ ही, यहां दिए गए content को अपनी पसंद के टेक्स्ट से बदलें:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"Harry Potter is the best book. I think everyone should read it."
},
"encodingType": "UTF8"
}इसके बाद, हम एपीआई के analyzeSentiment एंडपॉइंट पर अनुरोध भेजेंगे:
curl "https://language.googleapis.com/v1/documents:analyzeSentiment?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
आपका जवाब ऐसा दिखना चाहिए:
{
"documentSentiment": {
"magnitude": 0.8,
"score": 0.4
},
"language": "en",
"sentences": [
{
"text": {
"content": "Harry Potter is the best book.",
"beginOffset": 0
},
"sentiment": {
"magnitude": 0.7,
"score": 0.7
}
},
{
"text": {
"content": "I think everyone should read it.",
"beginOffset": 31
},
"sentiment": {
"magnitude": 0.1,
"score": 0.1
}
}
]
}ध्यान दें कि हमें दो तरह की भावनाएं मिलती हैं: पूरे दस्तावेज़ के लिए भावना और वाक्य के हिसाब से भावना. sentiment तरीके से दो वैल्यू मिलती हैं: score और magnitude. score -1.0 से 1.0 तक की संख्या होती है. इससे पता चलता है कि स्टेटमेंट कितना पॉज़िटिव या नेगेटिव है. magnitude 0 से लेकर इनफ़िनिटी तक की संख्या होती है. इससे पता चलता है कि स्टेटमेंट में बताए गए रुझान की अहमियत कितनी है. इससे कोई फ़र्क़ नहीं पड़ता कि रुझान पॉज़िटिव है या नेगेटिव. ज़्यादा शब्दों वाले टेक्स्ट ब्लॉक में, ज़्यादा अहमियत वाले स्टेटमेंट की मैग्नीट्यूड वैल्यू ज़्यादा होती है. हमारे पहले वाक्य का स्कोर पॉज़िटिव (0.7) है, जबकि दूसरे वाक्य का स्कोर न्यूट्रल (0.1) है.
हम NL API को पूरे टेक्स्ट दस्तावेज़ के बारे में भावना की जानकारी भेजते हैं. इसके अलावा, यह हमारे टेक्स्ट में मौजूद इकाइयों के हिसाब से भी भावना की जानकारी दे सकता है. आइए, इस वाक्य को उदाहरण के तौर पर इस्तेमाल करें:
मुझे सुशी पसंद आई, लेकिन सर्विस बहुत खराब थी.
इस मामले में, पूरे वाक्य के लिए सेंटीमेंट स्कोर पाना उतना काम का नहीं हो सकता जितना ऊपर बताया गया है. अगर यह किसी रेस्टोरेंट की समीक्षा है और उसी रेस्टोरेंट के लिए सैकड़ों समीक्षाएं हैं, तो हम यह जानना चाहेंगे कि लोगों को अपनी समीक्षाओं में कौनसी चीज़ें पसंद आईं और कौनसी नहीं. अच्छी बात यह है कि NL API में एक ऐसा तरीका है जिससे हमें अपने टेक्स्ट में मौजूद हर इकाई के लिए भावना का पता चलता है. इसे analyzeEntitySentiment कहा जाता है. इसे आज़माने के लिए, ऊपर दिए गए वाक्य के साथ request.json फ़ाइल को अपडेट करें:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"I liked the sushi but the service was terrible."
},
"encodingType": "UTF8"
}इसके बाद, यहां दिए गए कर्ल कमांड का इस्तेमाल करके, analyzeEntitySentiment एंडपॉइंट को कॉल करें:
curl "https://language.googleapis.com/v1/documents:analyzeEntitySentiment?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
जवाब में हमें दो इकाई ऑब्जेक्ट मिलते हैं: एक "सुशी" के लिए और दूसरा "सेवा" के लिए. यहां पूरा JSON रिस्पॉन्स दिया गया है:
{
"entities": [
{
"name": "sushi",
"type": "CONSUMER_GOOD",
"metadata": {},
"salience": 0.52716845,
"mentions": [
{
"text": {
"content": "sushi",
"beginOffset": 12
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
}
],
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
},
{
"name": "service",
"type": "OTHER",
"metadata": {},
"salience": 0.47283158,
"mentions": [
{
"text": {
"content": "service",
"beginOffset": 26
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
}
],
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
}
],
"language": "en"
}
हम देख सकते हैं कि "सुशी" के लिए 0.9 का स्कोर मिला है, जबकि "सेवा" को -0.9 का स्कोर मिला है. कूल! आपको यह भी दिख सकता है कि हर इकाई के लिए, दो सेंटीमेंट ऑब्जेक्ट दिखाए गए हैं. अगर इनमें से किसी भी शब्द का इस्तेमाल एक से ज़्यादा बार किया गया है, तो एपीआई हर बार इस्तेमाल किए गए शब्द के लिए, अलग-अलग सेंटीमेंट स्कोर और मैग्नीट्यूड देगा. साथ ही, इकाई के लिए कुल सेंटीमेंट भी देगा.
Natural Language API के तीसरे तरीके, सिंटैक्स एनोटेशन की मदद से, हम अपने टेक्स्ट की भाषाई जानकारी के बारे में ज़्यादा जानेंगे. analyzeSyntax एक ऐसा तरीका है जिससे टेक्स्ट के सिमैंटिक और सिंटैक्टिक एलिमेंट के बारे में पूरी जानकारी मिलती है. टेक्स्ट में मौजूद हर शब्द के लिए, एपीआई हमें बताएगा कि वह शब्द किस तरह का है (संज्ञा, क्रिया, विशेषण वगैरह). साथ ही, यह भी बताएगा कि वह शब्द वाक्य में मौजूद अन्य शब्दों से कैसे जुड़ा है (क्या यह मूल क्रिया है? मॉडिफ़ायर?).
आइए, इसे एक सामान्य वाक्य के साथ आज़माएं. हमारा JSON अनुरोध, ऊपर दिए गए अनुरोधों जैसा ही होगा. हालांकि, इसमें सुविधाओं की जानकारी देने वाली एक कुंजी जोड़ी जाएगी. इससे एपीआई को पता चलेगा कि हमें सिंटैक्स एनोटेशन करना है. request.json फ़ाइल को इस कोड से बदलें:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content": "Hermione often uses her quick wit, deft recall, and encyclopaedic knowledge to help Harry and Ron."
},
"encodingType": "UTF8"
}इसके बाद, एपीआई के analyzeSyntax तरीके को कॉल करें:
curl "https://language.googleapis.com/v1/documents:analyzeSyntax?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonजवाब में, वाक्य के हर टोकन के लिए नीचे दिए गए ऑब्जेक्ट जैसा ऑब्जेक्ट दिखना चाहिए. यहां हम "इस्तेमाल करता है" शब्द के जवाब को देखेंगे:
{
"text": {
"content": "uses",
"beginOffset": 15
},
"partOfSpeech": {
"tag": "VERB",
"aspect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "INDICATIVE",
"number": "SINGULAR",
"person": "THIRD",
"proper": "PROPER_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tense": "PRESENT",
"voice": "VOICE_UNKNOWN"
},
"dependencyEdge": {
"headTokenIndex": 2,
"label": "ROOT"
},
"lemma": "use"
}आइए, जवाब के बारे में विस्तार से जानते हैं. partOfSpeech से हमें हर शब्द के बारे में भाषाई जानकारी मिलती है. इनमें से कई शब्द ऐसे हैं जिनके बारे में हमें जानकारी नहीं है, क्योंकि वे अंग्रेज़ी या इस खास शब्द पर लागू नहीं होते. tag इस शब्द का पार्ट ऑफ़ स्पीच बताता है. इस मामले में, यह एक क्रिया है. हमें काल, मोडालिटी, और यह जानकारी भी मिलती है कि शब्द एकवचन है या बहुवचन. lemma, शब्द का कैननिकल फ़ॉर्म है. जैसे, "इस्तेमाल करता है" के लिए कैननिकल फ़ॉर्म "इस्तेमाल करें" है. उदाहरण के लिए, run, runs, ran, और running, इन सभी शब्दों का लेमा run है. लेमा वैल्यू, समय के साथ किसी बड़े टेक्स्ट में किसी शब्द के इस्तेमाल को ट्रैक करने के लिए काम आती है.
dependencyEdge में ऐसा डेटा शामिल होता है जिसका इस्तेमाल करके, टेक्स्ट का डिपेंडेंसी पार्स ट्री बनाया जा सकता है. इस डायग्राम में दिखाया गया है कि किसी वाक्य में मौजूद शब्द एक-दूसरे से कैसे जुड़े होते हैं. ऊपर दिए गए वाक्य के लिए, डिपेंडेंसी पार्स ट्री इस तरह दिखेगा:
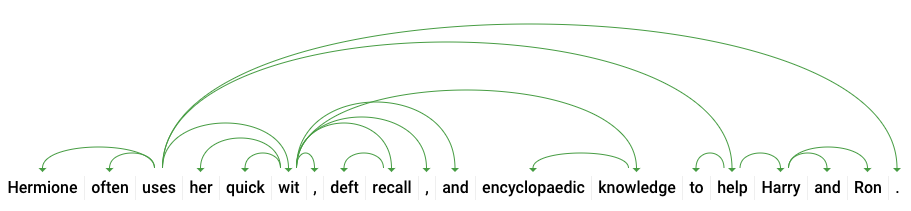
ऊपर दिए गए जवाब में मौजूद headTokenIndex, उस टोकन का इंडेक्स है जिसमें "इस्तेमाल करता है" की ओर इशारा करने वाला एक आर्क है. हम वाक्य के हर टोकन को ऐरे में मौजूद एक शब्द के तौर पर देख सकते हैं. साथ ही, "uses" के लिए 2 का headTokenIndex, "often" शब्द को दिखाता है, जो ट्री में इससे जुड़ा होता है.
Natural Language API, अंग्रेज़ी के अलावा अन्य भाषाओं के साथ भी काम करता है. इसकी पूरी सूची यहां दी गई है. आइए, जैपनीज़ भाषा में लिखे गए इस वाक्य के साथ, इकाई के बारे में जानकारी पाने का अनुरोध करके देखते हैं:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"日本のグーグルのオフィスは、東京の六本木ヒルズにあります"
},
"encodingType": "UTF8"
}ध्यान दें कि हमने एपीआई को यह नहीं बताया कि हमारा टेक्स्ट किस भाषा में है. यह अपने-आप इसका पता लगा सकता है. इसके बाद, हम इसे analyzeEntities एंडपॉइंट पर भेजेंगे:
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonयहां हमारे जवाब में मौजूद पहली दो इकाइयां दी गई हैं:
{
"entities": [
{
"name": "日本",
"type": "LOCATION",
"metadata": {
"mid": "/m/03_3d",
"wikipedia_url": "https://en.wikipedia.org/wiki/Japan"
},
"salience": 0.23854347,
"mentions": [
{
"text": {
"content": "日本",
"beginOffset": 0
},
"type": "PROPER"
}
]
},
{
"name": "グーグル",
"type": "ORGANIZATION",
"metadata": {
"mid": "/m/045c7b",
"wikipedia_url": "https://en.wikipedia.org/wiki/Google"
},
"salience": 0.21155767,
"mentions": [
{
"text": {
"content": "グーグル",
"beginOffset": 9
},
"type": "PROPER"
}
]
},
...
]
"language": "ja"
}इस उदाहरण में, एपीआई ने जापान को जगह और Google को संगठन के तौर पर पहचाना है. साथ ही, दोनों के लिए Wikipedia पेज भी निकाले हैं.
आपने Cloud Natural Language API की मदद से, टेक्स्ट का विश्लेषण करने का तरीका सीखा. इसके लिए, आपने इकाइयों को निकाला, भावना का विश्लेषण किया, और सिंटैक्स एनोटेशन किया.
हमने क्या-क्या बताया
- Natural Language API का अनुरोध बनाना और curl की मदद से एपीआई को कॉल करना
- Natural Language API की मदद से, टेक्स्ट में मौजूद इकाइयों का पता लगाना और उसके बारे में लोगों की राय का विश्लेषण करना
- टेक्स्ट का भाषाई विश्लेषण करके, डिपेंडेंसी पार्स ट्री बनाना
- जापानी भाषा में Natural Language API का अनुरोध करना
अगले चरण
- दस्तावेज़ में, Natural Language API के ट्यूटोरियल देखें.
- Vision API और Speech API को आज़माएं!