
Cloud Natural Language API מאפשר לכם לחלץ ישויות מטקסט, לבצע ניתוח סנטימנט וניתוח תחבירי ולסווג טקסט לקטגוריות.
בשיעור ה-Lab הזה נלמד איך להשתמש ב-Natural Language API כדי לנתח ישויות, סנטימנט ותחביר.
מה תלמדו
- יצירת בקשה ל-Natural Language API והפעלת ה-API באמצעות curl
- חילוץ ישויות והרצת ניתוח סנטימנט בטקסט באמצעות Natural Language API
- ביצוע ניתוח לשוני של טקסט באמצעות Natural Language API
- יצירת בקשה ל-Natural Language API בשפה אחרת
מה צריך לעשות
איך תשתמשו במדריך הזה?
איזה דירוג מגיע לדעתך לחוויית השימוש שלך ב-Google Cloud Platform?
הגדרת סביבה בקצב אישי
אם עדיין אין לכם חשבון Google (Gmail או Google Apps), אתם צריכים ליצור חשבון. נכנסים ל-Google Cloud Platform Console (console.cloud.google.com) ויוצרים פרויקט חדש:



חשוב לזכור את מזהה הפרויקט, שהוא שם ייחודי בכל הפרויקטים ב-Google Cloud (השם שמופיע למעלה כבר תפוס ולא יתאים לכם, מצטערים!). בהמשך ה-codelab הזה, נתייחס אליו כאל PROJECT_ID.
בשלב הבא, תצטרכו להפעיל את החיוב ב-Cloud Console כדי להשתמש במשאבים של Google Cloud.
העלות של התרגיל הזה לא אמורה להיות גבוהה, אבל היא יכולה להיות גבוהה יותר אם תחליטו להשתמש ביותר משאבים או אם תשאירו אותם פועלים (ראו את הקטע 'ניקוי' בסוף המסמך הזה).
משתמשים חדשים ב-Google Cloud Platform זכאים לתקופת ניסיון בחינם בשווי 300$.
לוחצים על סמל התפריט בפינה השמאלית העליונה.

ברשימה הנפתחת לוחצים על APIs & services ואז על Dashboard.
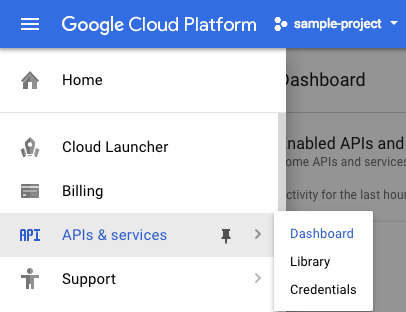
לוחצים על Enable APIs and services.
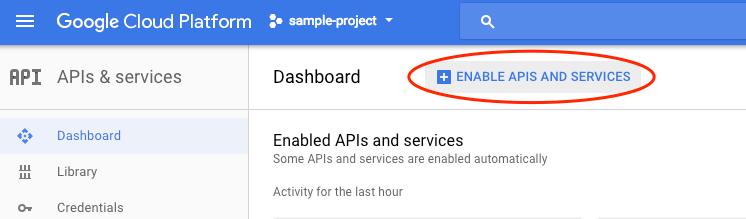
לאחר מכן מחפשים 'שפה' בתיבת החיפוש. לוחצים על Google Cloud Natural Language API:
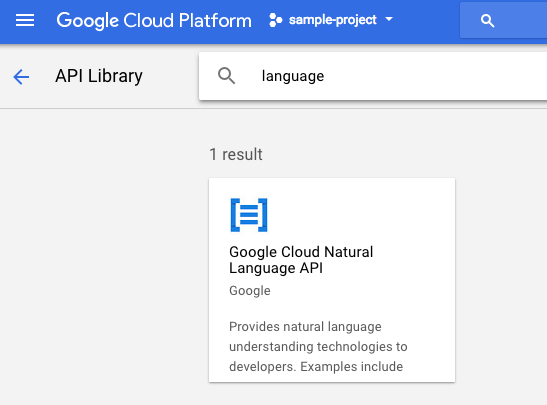
לוחצים על Enable (הפעלה) כדי להפעיל את Cloud Natural Language API:
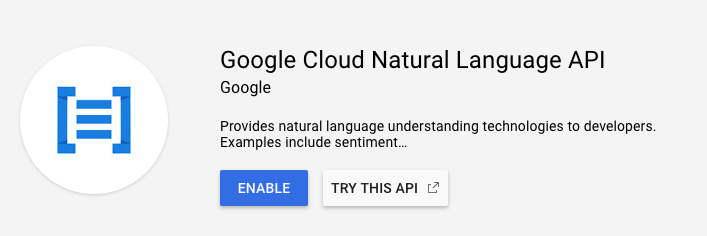
מחכים כמה שניות עד שהאפשרות תופעל. אחרי ההפעלה, תראו את ההודעה הבאה:

Google Cloud Shell היא סביבת שורת פקודה שפועלת בענן. המכונה הווירטואלית הזו מבוססת על Debian, וטעונים בה כל הכלים הדרושים למפתחים (gcloud, bq, git וכלים אחרים), ועם ספריית בית בעלת אחסון מתמיד בגודל 5GB. נשתמש ב-Cloud Shell כדי ליצור את הבקשה שלנו ל-Natural Language API.
כדי להתחיל להשתמש ב-Cloud Shell, לוחצים על הסמל 'הפעלת Google Cloud Shell'  בפינה השמאלית העליונה של סרגל הכותרת.
בפינה השמאלית העליונה של סרגל הכותרת.

בחלק התחתון של המסוף ייפתח סשן של Cloud Shell בתוך מסגרת חדשה ותופיע הודעה של שורת הפקודה. ממתינים עד להופעת ההנחיה user@project:~$
אנחנו נשתמש ב-curl כדי לשלוח בקשה ל-Natural Language API, ולכן נצטרך ליצור מפתח API כדי להעביר אותו בכתובת ה-URL של הבקשה. כדי ליצור מפתח API, עוברים לקטע Credentials (פרטי כניסה) של APIs & services (ממשקי API ושירותים) במסוף Cloud:
בתפריט הנפתח, בוחרים באפשרות API key:
לאחר מכן, מעתיקים את המפתח שנוצר. תצטרכו את המפתח הזה בהמשך שיעור ה-Lab.
אחרי שיצרתם מפתח API, כדאי לשמור אותו במשתנה סביבה כדי שלא תצטרכו להוסיף את הערך של מפתח ה-API בכל בקשה. אפשר לעשות את זה ב-Cloud Shell. חשוב להחליף את <your_api_key> במפתח שהעתקתם.
export API_KEY=<YOUR_API_KEY>ה-method הראשון של Natural Language API שבו נשתמש הוא analyzeEntities. באמצעות השיטה הזו, ה-API יכול לחלץ ישויות (כמו אנשים, מקומות ואירועים) מטקסט. כדי לנסות את ניתוח הישויות של ה-API, נשתמש במשפט הבא:
ג'ואן רולינג, שכותבת בשמות העט ג'יי. K. רוברט גלבריית' (Robert Galbraith), הוא שם העט של ג'יי קיי רולינג (J. K. Rowling), סופרת ותסריטאית בריטית שכתבה את סדרת ספרי הפנטזיה של הארי פוטר.
ניצור את הבקשה ל-Natural Language API בקובץ request.json. בסביבת Cloud Shell, יוצרים את הקובץ request.json עם הקוד שלמטה. אפשר ליצור את הקובץ באמצעות אחד מעורכי שורת הפקודה המועדפים (nano, vim, emacs) או להשתמש בעורך Orion המובנה ב-Cloud Shell:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"Joanne Rowling, who writes under the pen names J. K. Rowling and Robert Galbraith, is a British novelist and screenwriter who wrote the Harry Potter fantasy series."
},
"encodingType":"UTF8"
}בבקשה, אנחנו מציינים ל-Natural Language API את הטקסט שנשלח. הערכים הנתמכים של סוג הם PLAIN_TEXT או HTML. בתוכן, מעבירים את הטקסט לשליחה אל Natural Language API לניתוח. Natural Language API תומך גם בשליחת קבצים שמאוחסנים ב-Cloud Storage לעיבוד טקסט. אם רוצים לשלוח קובץ מ-Cloud Storage, מחליפים את content ב-gcsContentUri ומזינים את כתובת ה-URI של קובץ הטקסט ב-Cloud Storage. encodingType מציין לממשק ה-API באיזה סוג של קידוד טקסט להשתמש כשמעבדים את הטקסט שלנו. ה-API ישתמש בזה כדי לחשב איפה ישויות ספציפיות מופיעות בטקסט.
עכשיו אפשר להעביר את גוף הבקשה, יחד עם משתנה הסביבה של מפתח ה-API ששמרתם קודם, אל Natural Language API באמצעות הפקודה הבאה curl (הכל בשורת פקודה אחת):
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonההתחלה של התגובה אמורה להיראות כך:
{
"entities": [
{
"name": "Robert Galbraith",
"type": "PERSON",
"metadata": {
"mid": "/m/042xh",
"wikipedia_url": "https://en.wikipedia.org/wiki/J._K._Rowling"
},
"salience": 0.7980405,
"mentions": [
{
"text": {
"content": "Joanne Rowling",
"beginOffset": 0
},
"type": "PROPER"
},
{
"text": {
"content": "Rowling",
"beginOffset": 53
},
"type": "PROPER"
},
{
"text": {
"content": "novelist",
"beginOffset": 96
},
"type": "COMMON"
},
{
"text": {
"content": "Robert Galbraith",
"beginOffset": 65
},
"type": "PROPER"
}
]
},
...
]
}עבור כל ישות בתגובה, אנחנו מקבלים את הישות type, את כתובת ה-URL המשויכת בוויקיפדיה אם יש כזו, את salience ואת האינדקסים של המקום שבו הישות הזו הופיעה בטקסט. הערך Salience הוא מספר בטווח [0,1] שמתייחס למרכזיות של הישות בטקסט כולו. בנוסף, Natural Language API יכול לזהות את אותה ישות שמוזכרת בדרכים שונות. אפשר לראות את mentions הרשימה בתשובה: ה-API יודע ש'ג'ואן רולינג', 'רולינג', 'סופרת' ו'רוברט גלבריית' מתייחסים לאותו הדבר.
בנוסף לחילוץ ישויות, Natural Language API מאפשר גם לבצע ניתוח סנטימנט על בלוק טקסט. בקשת ה-JSON שלנו תכלול את אותם פרמטרים כמו הבקשה שלמעלה, אבל הפעם נשנה את הטקסט כך שיכלול משהו עם סנטימנט חזק יותר. מחליפים את קובץ request.json בטקסט הבא, ואפשר להחליף את content בטקסט משלכם:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"Harry Potter is the best book. I think everyone should read it."
},
"encodingType": "UTF8"
}לאחר מכן נשלח את הבקשה לנקודת הקצה analyzeSentiment של ה-API:
curl "https://language.googleapis.com/v1/documents:analyzeSentiment?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
התשובה אמורה להיראות כך:
{
"documentSentiment": {
"magnitude": 0.8,
"score": 0.4
},
"language": "en",
"sentences": [
{
"text": {
"content": "Harry Potter is the best book.",
"beginOffset": 0
},
"sentiment": {
"magnitude": 0.7,
"score": 0.7
}
},
{
"text": {
"content": "I think everyone should read it.",
"beginOffset": 31
},
"sentiment": {
"magnitude": 0.1,
"score": 0.1
}
}
]
}שימו לב שאנחנו מקבלים שני סוגים של ערכי סנטימנט: סנטימנט של המסמך כולו וסנטימנט שמחולק לפי משפטים. השיטה sentiment מחזירה שני ערכים: score ו-magnitude. score הוא מספר מ-1.0- עד 1.0 שמציין עד כמה ההצהרה חיובית או שלילית. magnitude הוא מספר בטווח 0 עד אינסוף שמייצג את משקל הסנטימנט שמופיע בהצהרה, בלי קשר להיותו חיובי או שלילי. בלוקים ארוכים יותר של טקסט עם משפטים משוקללים מאוד מקבלים ערכים גבוהים יותר של עוצמה. הציון של המשפט הראשון הוא חיובי (0.7), ואילו הציון של המשפט השני הוא ניטרלי (0.1).
בנוסף לפרטים על הסנטימנט של כל מסמך הטקסט שאנחנו שולחים ל-NL API, הוא יכול גם לפרט את הסנטימנט לפי הישויות בטקסט. ניקח לדוגמה את המשפט הבא:
אהבתי את הסושי אבל השירות היה נורא.
במקרה הזה, קבלת ציון סנטימנט לכל המשפט כמו בדוגמה שלמעלה לא תהיה שימושית במיוחד. אם מדובר בביקורת על מסעדה ויש מאות ביקורות על אותה מסעדה, נרצה לדעת בדיוק מה אהבו ומה לא אהבו אנשים בביקורות שלהם. למזלנו, ל-NL API יש שיטה שמאפשרת לנו לקבל את הסנטימנט של כל ישות בטקסט, שנקראת analyzeEntitySentiment. כדי לנסות את זה, מעדכנים את הקובץ request.json עם המשפט שלמעלה:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"I liked the sushi but the service was terrible."
},
"encodingType": "UTF8"
}לאחר מכן מפעילים את נקודת הקצה analyzeEntitySentiment באמצעות פקודת ה-curl הבאה:
curl "https://language.googleapis.com/v1/documents:analyzeEntitySentiment?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
בתגובה שמתקבלת יש שני אובייקטים של ישויות: אחד עבור 'סושי' ואחד עבור 'שירות'. זוהי תגובת ה-JSON המלאה:
{
"entities": [
{
"name": "sushi",
"type": "CONSUMER_GOOD",
"metadata": {},
"salience": 0.52716845,
"mentions": [
{
"text": {
"content": "sushi",
"beginOffset": 12
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
}
],
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
},
{
"name": "service",
"type": "OTHER",
"metadata": {},
"salience": 0.47283158,
"mentions": [
{
"text": {
"content": "service",
"beginOffset": 26
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
}
],
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
}
],
"language": "en"
}
אפשר לראות שהציון שהוחזר עבור 'סושי' היה 0.9, בעוד שהציון עבור 'שירות' היה -0.9. מגניב! יכול להיות שתשימו לב שמוחזרים שני אובייקטים של סנטימנט לכל ישות. אם אחד מהמונחים האלה הוזכר יותר מפעם אחת, ה-API יחזיר ציון סנטימנט ועוצמה שונים לכל אזכור, יחד עם סנטימנט מצטבר לישות.
אם נסתכל על השיטה השלישית של Natural Language API – הערת תחביר – נצלול לעומק הפרטים הבלשניים של הטקסט שלנו. analyzeSyntax היא שיטה שמספקת סט מלא של פרטים על הרכיבים הסמנטיים והתחביריים של הטקסט. לכל מילה בטקסט, ה-API יציין את חלק הדיבור (שם עצם, פועל, שם תואר וכו') ואת הקשר שלה למילים אחרות במשפט (האם היא פועל השורש? גורם שינוי?).
ננסה את זה עם משפט פשוט. בקשת ה-JSON שלנו תהיה דומה לבקשות שלמעלה, עם תוספת של מפתח תכונות. הפעולה הזו תציין ל-API שאנחנו רוצים לבצע הערות תחביריות. מחליפים את הקובץ request.json בקובץ הבא:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content": "Hermione often uses her quick wit, deft recall, and encyclopaedic knowledge to help Harry and Ron."
},
"encodingType": "UTF8"
}לאחר מכן קוראים ל-method analyzeSyntax של ה-API:
curl "https://language.googleapis.com/v1/documents:analyzeSyntax?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonהתשובה צריכה להחזיר אובייקט כמו זה שבהמשך לכל טוקן במשפט. כאן נבדוק את התגובה למילה 'uses':
{
"text": {
"content": "uses",
"beginOffset": 15
},
"partOfSpeech": {
"tag": "VERB",
"aspect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "INDICATIVE",
"number": "SINGULAR",
"person": "THIRD",
"proper": "PROPER_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tense": "PRESENT",
"voice": "VOICE_UNKNOWN"
},
"dependencyEdge": {
"headTokenIndex": 2,
"label": "ROOT"
},
"lemma": "use"
}ננסה להסביר את התשובה. partOfSpeech מספק לנו פרטים לשוניים על כל מילה (הרבה מהפרטים לא ידועים כי הם לא רלוונטיים לאנגלית או למילה הספציפית הזו). tag מציין את חלק הדיבור של המילה, במקרה הזה פועל. אנחנו מקבלים גם פרטים על הזמן, האופן והאם המילה היא יחיד או רבים. lemma הוא הצורה הקנונית של המילה (למשל, הצורה הקנונית של המילה uses היא use). לדוגמה, המילים run, runs, ran ו-running הן בעלות למה run. ערך הלמה שימושי למעקב אחרי מופעים של מילה בקטע טקסט גדול לאורך זמן.
dependencyEdge כולל נתונים שאפשר להשתמש בהם כדי ליצור עץ ניתוח תלות של הטקסט. תרשים שמראה את הקשר בין המילים במשפט. עץ ניתוח התלות של המשפט שלמעלה ייראה כך:

המספר headTokenIndex בתשובה שלמעלה הוא האינדקס של האסימון שממנו יוצא חץ אל המילה 'uses'. אפשר לחשוב על כל טוקן במשפט כמילה במערך, והערך headTokenIndex של 2 עבור המילה 'uses' מתייחס למילה 'often', שאליה היא מקושרת בעץ.
Natural Language API תומך גם בשפות אחרות מלבד אנגלית (רשימה מלאה כאן). ננסה לשלוח בקשה לזיהוי ישויות עם משפט ביפנית:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"日本のグーグルのオフィスは、東京の六本木ヒルズにあります"
},
"encodingType": "UTF8"
}שימו לב שלא אמרנו ל-API באיזו שפה הטקסט שלנו, הוא יכול לזהות אותה באופן אוטומטי. בשלב הבא, נשלח אותו לנקודת הקצה analyzeEntities:
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonאלה שתי הישויות הראשונות בתשובה שלנו:
{
"entities": [
{
"name": "日本",
"type": "LOCATION",
"metadata": {
"mid": "/m/03_3d",
"wikipedia_url": "https://en.wikipedia.org/wiki/Japan"
},
"salience": 0.23854347,
"mentions": [
{
"text": {
"content": "日本",
"beginOffset": 0
},
"type": "PROPER"
}
]
},
{
"name": "グーグル",
"type": "ORGANIZATION",
"metadata": {
"mid": "/m/045c7b",
"wikipedia_url": "https://en.wikipedia.org/wiki/Google"
},
"salience": 0.21155767,
"mentions": [
{
"text": {
"content": "グーグル",
"beginOffset": 9
},
"type": "PROPER"
}
]
},
...
]
"language": "ja"
}ה-API מחלץ את יפן כמיקום ואת Google כארגון, יחד עם דפי ויקיפדיה של כל אחד מהם.
למדתם איך לבצע ניתוח טקסט באמצעות Cloud Natural Language API על ידי חילוץ ישויות, ניתוח סנטימנט וביצוע הערות תחביריות.
מה למדנו
- יצירת בקשה ל-Natural Language API והפעלת ה-API באמצעות curl
- חילוץ ישויות והרצת ניתוח סנטימנט בטקסט באמצעות Natural Language API
- ביצוע ניתוח לשוני של טקסט כדי ליצור עצי ניתוח תלות
- יצירת בקשה ל-Natural Language API ביפנית
השלבים הבאים
- אפשר לעיין במדריכים של Natural Language API במסמכי העזרה.
- מומלץ להתנסות ב-Vision API וב-Speech API.