
ক্লাউড ন্যাচারাল ল্যাঙ্গুয়েজ এপিআই আপনাকে টেক্সট থেকে সত্তা বের করতে দেয়, সেন্টিমেন্ট এবং সিনট্যাকটিক অ্যানালাইসিস করতে এবং টেক্সটকে ক্যাটাগরিতে শ্রেণীবদ্ধ করতে দেয়।
এই ল্যাবে, আমরা শিখব কীভাবে সত্তা, অনুভূতি এবং বাক্য গঠন বিশ্লেষণ করতে প্রাকৃতিক ভাষা API ব্যবহার করতে হয়।
আপনি কি শিখবেন
- একটি প্রাকৃতিক ভাষা API অনুরোধ তৈরি করা এবং কার্ল দিয়ে API কল করা
- ন্যাচারাল ল্যাঙ্গুয়েজ এপিআই-এর সাথে টেক্সটে সত্ত্বা বের করা এবং সেন্টিমেন্ট অ্যানালাইসিস চালানো
- ন্যাচারাল ল্যাঙ্গুয়েজ এপিআই-এর সাহায্যে টেক্সটে ভাষাগত বিশ্লেষণ করা
- একটি ভিন্ন ভাষায় একটি প্রাকৃতিক ভাষা API অনুরোধ তৈরি করা
W কি আপনার প্রয়োজন হবে
- একটি Google ক্লাউড প্ল্যাটফর্ম প্রকল্প
- একটি ব্রাউজার, যেমন ক্রোম বা ফায়ারফক্স
আপনি কিভাবে এই টিউটোরিয়াল ব্যবহার করবেন?
Google ক্লাউড প্ল্যাটফর্মের সাথে আপনার অভিজ্ঞতাকে কীভাবে মূল্যায়ন করবে?
স্ব-গতিসম্পন্ন পরিবেশ সেটআপ
আপনার যদি ইতিমধ্যে একটি Google অ্যাকাউন্ট না থাকে (Gmail বা Google Apps), তাহলে আপনাকে অবশ্যই একটি তৈরি করতে হবে। Google ক্লাউড প্ল্যাটফর্ম কনসোলে সাইন-ইন করুন ( console.cloud.google.com ) এবং একটি নতুন প্রকল্প তৈরি করুন:



প্রজেক্ট আইডিটি মনে রাখবেন, সমস্ত Google ক্লাউড প্রকল্প জুড়ে একটি অনন্য নাম (উপরের নামটি ইতিমধ্যে নেওয়া হয়েছে এবং আপনার জন্য কাজ করবে না, দুঃখিত!)। এটি পরে এই কোডল্যাবে PROJECT_ID হিসাবে উল্লেখ করা হবে।
এর পরে, Google ক্লাউড সংস্থানগুলি ব্যবহার করার জন্য আপনাকে ক্লাউড কনসোলে বিলিং সক্ষম করতে হবে৷
এই কোডল্যাবের মাধ্যমে চালানোর জন্য আপনার কয়েক ডলারের বেশি খরচ করা উচিত নয়, তবে আপনি যদি আরও সংস্থান ব্যবহার করার সিদ্ধান্ত নেন বা আপনি যদি সেগুলিকে চলমান রেখে দেন তবে এটি আরও বেশি হতে পারে (এই নথির শেষে "পরিষ্কার" বিভাগটি দেখুন)।
Google ক্লাউড প্ল্যাটফর্মের নতুন ব্যবহারকারীরা $300 বিনামূল্যের ট্রায়ালের জন্য যোগ্য৷
স্ক্রিনের উপরের বাম দিকে মেনু আইকনে ক্লিক করুন।

ড্রপ ডাউন থেকে APIs এবং পরিষেবাগুলি নির্বাচন করুন এবং ড্যাশবোর্ডে ক্লিক করুন
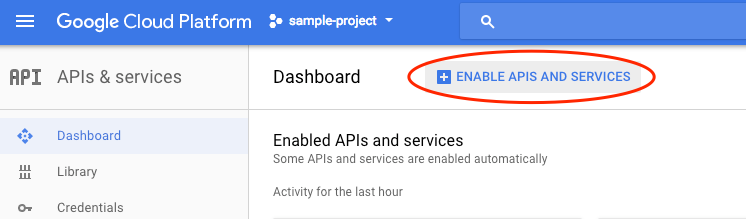
APIs এবং পরিষেবাগুলি সক্ষম করুন -এ ক্লিক করুন।
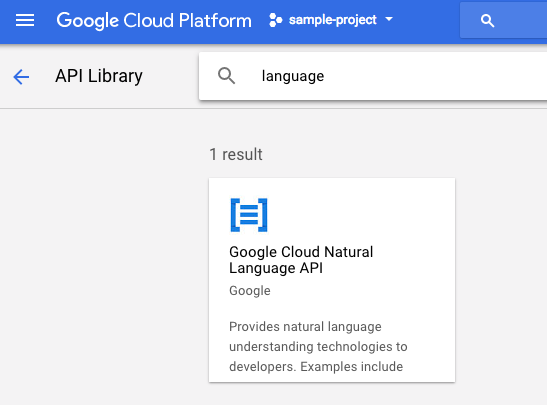
তারপরে, অনুসন্ধান বাক্সে "ভাষা" অনুসন্ধান করুন। Google Cloud Natural Language API এ ক্লিক করুন:
ক্লাউড ন্যাচারাল ল্যাঙ্গুয়েজ এপিআই সক্ষম করতে সক্ষম করুন ক্লিক করুন:
এটি সক্ষম করার জন্য কয়েক সেকেন্ডের জন্য অপেক্ষা করুন। এটি সক্রিয় হয়ে গেলে আপনি এটি দেখতে পাবেন:

Google ক্লাউড শেল হল একটি কমান্ড লাইন পরিবেশ যা ক্লাউডে চলে । এই ডেবিয়ান-ভিত্তিক ভার্চুয়াল মেশিনটি আপনার প্রয়োজনীয় সমস্ত ডেভেলপমেন্ট টুলের সাথে লোড করা হয়েছে ( gcloud , bq , git এবং অন্যান্য) এবং একটি স্থায়ী 5GB হোম ডিরেক্টরি অফার করে। আমরা ন্যাচারাল ল্যাঙ্গুয়েজ এপিআই-তে আমাদের অনুরোধ তৈরি করতে ক্লাউড শেল ব্যবহার করব।
ক্লাউড শেল দিয়ে শুরু করতে, "Google ক্লাউড শেল সক্রিয় করুন" এ ক্লিক করুন  হেডার বারের উপরে ডানদিকের কোণায় আইকন
হেডার বারের উপরে ডানদিকের কোণায় আইকন

একটি ক্লাউড শেল সেশন কনসোলের নীচে একটি নতুন ফ্রেমের ভিতরে খোলে এবং একটি কমান্ড-লাইন প্রম্পট প্রদর্শন করে। user@project:~$ প্রম্পট প্রদর্শিত না হওয়া পর্যন্ত অপেক্ষা করুন
যেহেতু আমরা ন্যাচারাল ল্যাঙ্গুয়েজ এপিআই-তে একটি অনুরোধ পাঠাতে কার্ল ব্যবহার করব, তাই আমাদের অনুরোধ URL পাস করার জন্য আমাদের একটি API কী তৈরি করতে হবে। একটি API কী তৈরি করতে, আপনার ক্লাউড কনসোলে API এবং পরিষেবাগুলির শংসাপত্র বিভাগে নেভিগেট করুন:
ড্রপ ডাউন মেনুতে, API কী নির্বাচন করুন:
এরপরে, আপনি যে কী তৈরি করেছেন তা অনুলিপি করুন। পরে ল্যাবে আপনার এই চাবিটির প্রয়োজন হবে।
এখন আপনার কাছে একটি API কী আছে, প্রতিটি অনুরোধে আপনার API কীটির মান সন্নিবেশ করা এড়াতে এটিকে একটি পরিবেশ পরিবর্তনশীলে সংরক্ষণ করুন। আপনি Cloud Shell এ এটি করতে পারেন। আপনি এইমাত্র কপি করা কী দিয়ে <your_api_key> প্রতিস্থাপন করতে ভুলবেন না।
export API_KEY=<YOUR_API_KEY> আমরা যে প্রথম প্রাকৃতিক ভাষা API পদ্ধতিটি ব্যবহার করব তা হল analyzeEntities . এই পদ্ধতির সাহায্যে, API টেক্সট থেকে সত্তা (যেমন মানুষ, স্থান এবং ঘটনা) বের করতে পারে। API এর সত্তা বিশ্লেষণ করে দেখতে, আমরা নিম্নলিখিত বাক্যটি ব্যবহার করব:
জোয়ান রাউলিং, যিনি জে কে রাউলিং এবং রবার্ট গালব্রেথ নামে কলম নামে লেখেন, তিনি একজন ব্রিটিশ ঔপন্যাসিক এবং চিত্রনাট্যকার যিনি হ্যারি পটার ফ্যান্টাসি সিরিজ লিখেছেন।
আমরা ন্যাচারাল ল্যাঙ্গুয়েজ এপিআই-এ আমাদের অনুরোধ একটি request.json ফাইলে তৈরি করব। আপনার ক্লাউড শেল পরিবেশে, নীচের কোডটি দিয়ে request.json ফাইলটি তৈরি করুন। আপনি আপনার পছন্দের কমান্ড লাইন সম্পাদক (ন্যানো, ভিম, ইমাক্স) ব্যবহার করে ফাইলটি তৈরি করতে পারেন বা ক্লাউড শেল-এ অন্তর্নির্মিত ওরিয়ন সম্পাদক ব্যবহার করতে পারেন:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"Joanne Rowling, who writes under the pen names J. K. Rowling and Robert Galbraith, is a British novelist and screenwriter who wrote the Harry Potter fantasy series."
},
"encodingType":"UTF8"
} অনুরোধে, আমরা ন্যাচারাল ল্যাঙ্গুয়েজ এপিআই-কে আমরা যে টেক্সট পাঠাব সে সম্পর্কে বলি। সমর্থিত প্রকারের মানগুলি হল PLAIN_TEXT বা HTML ৷ বিষয়বস্তুতে, আমরা বিশ্লেষণের জন্য ন্যাচারাল ল্যাঙ্গুয়েজ এপিআইতে পাঠাতে পাঠ্য পাস করি। ন্যাচারাল ল্যাঙ্গুয়েজ এপিআই টেক্সট প্রসেসিংয়ের জন্য ক্লাউড স্টোরেজে সঞ্চিত ফাইল পাঠাতেও সমর্থন করে। যদি আমরা ক্লাউড স্টোরেজ থেকে একটি ফাইল পাঠাতে চাই, তাহলে আমরা gcsContentUri দিয়ে content প্রতিস্থাপন করব এবং ক্লাউড স্টোরেজে আমাদের টেক্সট ফাইলের uri-এর একটি মান দেব। encodingType API-কে বলে যে আমাদের টেক্সট প্রক্রিয়া করার সময় কোন ধরনের টেক্সট এনকোডিং ব্যবহার করতে হবে। API আমাদের পাঠ্যে নির্দিষ্ট সত্তা কোথায় উপস্থিত হবে তা গণনা করতে এটি ব্যবহার করবে।
আপনি এখন আপনার অনুরোধের মূল অংশটি, আপনার পূর্বে সংরক্ষিত API কী এনভায়রনমেন্ট ভেরিয়েবল সহ, নিম্নলিখিত curl কমান্ড সহ প্রাকৃতিক ভাষা API-তে পাস করতে পারেন (সমস্ত একক কমান্ড লাইনে):
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonআপনার প্রতিক্রিয়ার শুরু নিম্নলিখিত মত হওয়া উচিত:
{
"entities": [
{
"name": "Robert Galbraith",
"type": "PERSON",
"metadata": {
"mid": "/m/042xh",
"wikipedia_url": "https://en.wikipedia.org/wiki/J._K._Rowling"
},
"salience": 0.7980405,
"mentions": [
{
"text": {
"content": "Joanne Rowling",
"beginOffset": 0
},
"type": "PROPER"
},
{
"text": {
"content": "Rowling",
"beginOffset": 53
},
"type": "PROPER"
},
{
"text": {
"content": "novelist",
"beginOffset": 96
},
"type": "COMMON"
},
{
"text": {
"content": "Robert Galbraith",
"beginOffset": 65
},
"type": "PROPER"
}
]
},
...
]
} প্রতিক্রিয়াতে প্রতিটি সত্তার জন্য, আমরা সত্তার type , সংশ্লিষ্ট উইকিপিডিয়া URL যদি একটি থাকে, তাহলে salience এবং টেক্সটে এই সত্তাটি কোথায় উপস্থিত হয়েছে তার সূচকগুলি পাই। স্যালিয়েন্স হল [0,1] পরিসরের একটি সংখ্যা যা সমগ্র টেক্সটে সত্তার কেন্দ্রীয়তাকে নির্দেশ করে। Natural Language API বিভিন্ন উপায়ে উল্লেখিত একই সত্তাকে চিনতে পারে। প্রতিক্রিয়ায় mentions তালিকাটি একবার দেখুন: API বলতে সক্ষম যে "জোয়ান রাউলিং", "রাউলিং", "ঔপন্যাসিক" এবং "রবার্ট গালব্রিথ" সব একই জিনিসের দিকে নির্দেশ করে৷
সত্তা নিষ্কাশনের পাশাপাশি, প্রাকৃতিক ভাষা API আপনাকে পাঠ্যের একটি ব্লকে অনুভূতি বিশ্লেষণ করতে দেয়। আমাদের JSON অনুরোধে আমাদের উপরের অনুরোধের মতো একই পরামিতি অন্তর্ভুক্ত করা হবে, কিন্তু এবার আমরা আরও শক্তিশালী অনুভূতি সহ কিছু অন্তর্ভুক্ত করতে পাঠ্যটি পরিবর্তন করব। আপনার request.json ফাইলটি নিম্নলিখিত দিয়ে প্রতিস্থাপন করুন এবং আপনার নিজের পাঠ্যের সাথে নীচের content প্রতিস্থাপন করতে দ্বিধা বোধ করুন:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"Harry Potter is the best book. I think everyone should read it."
},
"encodingType": "UTF8"
} এরপরে আমরা অনুরোধটি API এর analyzeSentiment এন্ডপয়েন্টে পাঠাব:
curl "https://language.googleapis.com/v1/documents:analyzeSentiment?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
আপনার প্রতিক্রিয়া এই মত হওয়া উচিত:
{
"documentSentiment": {
"magnitude": 0.8,
"score": 0.4
},
"language": "en",
"sentences": [
{
"text": {
"content": "Harry Potter is the best book.",
"beginOffset": 0
},
"sentiment": {
"magnitude": 0.7,
"score": 0.7
}
},
{
"text": {
"content": "I think everyone should read it.",
"beginOffset": 31
},
"sentiment": {
"magnitude": 0.1,
"score": 0.1
}
}
]
} লক্ষ্য করুন যে আমরা দুটি ধরণের অনুভূতির মান পাই: সম্পূর্ণরূপে আমাদের নথির জন্য অনুভূতি এবং বাক্য দ্বারা বিভক্ত অনুভূতি। সেন্টিমেন্ট পদ্ধতি দুটি মান প্রদান করে: score এবং magnitude । score হল -1.0 থেকে 1.0 পর্যন্ত একটি সংখ্যা যা নির্দেশ করে যে বিবৃতিটি কতটা ইতিবাচক বা নেতিবাচক। magnitude হল 0 থেকে অসীম পর্যন্ত একটি সংখ্যা যা ইতিবাচক বা নেতিবাচক নির্বিশেষে বিবৃতিতে প্রকাশিত অনুভূতির ওজনকে প্রতিনিধিত্ব করে। ভারী ভারযুক্ত বিবৃতি সহ পাঠ্যের দীর্ঘ ব্লকগুলির উচ্চ মাত্রার মান রয়েছে। আমাদের প্রথম বাক্যের স্কোর হল ইতিবাচক (0.7), যেখানে দ্বিতীয় বাক্যের স্কোর হল নিরপেক্ষ (0.1)।
সম্পূর্ণ পাঠ্য নথিতে অনুভূতির বিশদ প্রদান করার পাশাপাশি আমরা NL API পাঠাই, এটি আমাদের পাঠ্যের সত্তার অনুভূতিকে ভেঙে দিতে পারে। একটি উদাহরণ হিসাবে এই বাক্য ব্যবহার করা যাক:
আমি সুশি পছন্দ করেছি কিন্তু সেবা ভয়ানক ছিল .
এই ক্ষেত্রে, পুরো বাক্যটির জন্য একটি সেন্টিমেন্ট স্কোর পাওয়া যেমন আমরা উপরে করেছি তেমন কার্যকর নাও হতে পারে। যদি এটি একটি রেস্তোরাঁর পর্যালোচনা হয় এবং একই রেস্তোরাঁর জন্য শত শত পর্যালোচনা থাকে, তাহলে আমরা তাদের পর্যালোচনাগুলিতে ঠিক কোন জিনিসগুলি পছন্দ করে এবং কোনটি পছন্দ করে না তা জানতে চাই৷ সৌভাগ্যবশত NL API-এর একটি পদ্ধতি রয়েছে যা আমাদের পাঠ্যের প্রতিটি সত্তার অনুভূতি পেতে দেয়, যাকে analyzeEntitySentiment বলা হয়। এটি ব্যবহার করে দেখতে উপরের বাক্যটির সাথে আপনার request.json আপডেট করুন:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"I liked the sushi but the service was terrible."
},
"encodingType": "UTF8"
} তারপর নিচের কার্ল কমান্ডের সাথে analyzeEntitySentiment এন্ডপয়েন্টকে কল করুন:
curl "https://language.googleapis.com/v1/documents:analyzeEntitySentiment?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
প্রতিক্রিয়াতে আমরা দুটি সত্তা বস্তু ফিরে পাই: একটি "সুশি" এর জন্য এবং একটি "পরিষেবা" এর জন্য। এখানে সম্পূর্ণ JSON প্রতিক্রিয়া:
{
"entities": [
{
"name": "sushi",
"type": "CONSUMER_GOOD",
"metadata": {},
"salience": 0.52716845,
"mentions": [
{
"text": {
"content": "sushi",
"beginOffset": 12
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
}
],
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
},
{
"name": "service",
"type": "OTHER",
"metadata": {},
"salience": 0.47283158,
"mentions": [
{
"text": {
"content": "service",
"beginOffset": 26
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
}
],
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
}
],
"language": "en"
}
আমরা দেখতে পাচ্ছি যে "সুশি" এর জন্য স্কোর ফিরে এসেছে 0.9, যেখানে "পরিষেবা" -0.9 স্কোর পেয়েছে৷ শান্ত! আপনি আরও লক্ষ্য করতে পারেন যে প্রতিটি সত্তার জন্য দুটি অনুভূতির বস্তু ফিরে এসেছে। যদি এই শর্তগুলির মধ্যে যেকোন একটি একাধিকবার উল্লেখ করা হয়, তাহলে API প্রতিটি উল্লেখের জন্য একটি আলাদা সেন্টিমেন্ট স্কোর এবং মাত্রা প্রদান করবে, সত্তার জন্য একটি সমষ্টিগত অনুভূতি সহ।
ন্যাচারাল ল্যাঙ্গুয়েজ এপিআই-এর তৃতীয় পদ্ধতির দিকে তাকিয়ে - সিনট্যাক্স টীকা - আমরা আমাদের পাঠ্যের ভাষাগত বিবরণে গভীরভাবে ডুব দেব। analyzeSyntax হল এমন একটি পদ্ধতি যা পাঠ্যের শব্দার্থগত এবং সিনট্যাকটিক উপাদানগুলির বিশদ বিবরণের একটি সম্পূর্ণ সেট প্রদান করে। পাঠ্যের প্রতিটি শব্দের জন্য, API আমাদেরকে বক্তৃতার অংশ (বিশেষ্য, ক্রিয়া, বিশেষণ, ইত্যাদি) এবং বাক্যটির অন্যান্য শব্দের সাথে কীভাবে সম্পর্কযুক্ত তা জানাবে (এটি কি মূল ক্রিয়া? একটি পরিবর্তনকারী?)।
আসুন একটি সহজ বাক্য দিয়ে চেষ্টা করে দেখি। আমাদের JSON অনুরোধটি একটি বৈশিষ্ট্য কী যুক্ত করে উপরেরগুলির মতোই হবে৷ এটি API কে বলবে যে আমরা সিনট্যাক্স টীকা করতে চাই। নিম্নলিখিত দিয়ে আপনার request.json প্রতিস্থাপন করুন:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content": "Hermione often uses her quick wit, deft recall, and encyclopaedic knowledge to help Harry and Ron."
},
"encodingType": "UTF8"
}তারপর API এর analyzeSyntax পদ্ধতিতে কল করুন:
curl "https://language.googleapis.com/v1/documents:analyzeSyntax?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonপ্রতিক্রিয়া বাক্যে প্রতিটি টোকেনের জন্য নীচের মত একটি বস্তু ফেরত দেওয়া উচিত। এখানে আমরা "ব্যবহার" শব্দের প্রতিক্রিয়া দেখব:
{
"text": {
"content": "uses",
"beginOffset": 15
},
"partOfSpeech": {
"tag": "VERB",
"aspect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "INDICATIVE",
"number": "SINGULAR",
"person": "THIRD",
"proper": "PROPER_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tense": "PRESENT",
"voice": "VOICE_UNKNOWN"
},
"dependencyEdge": {
"headTokenIndex": 2,
"label": "ROOT"
},
"lemma": "use"
}এর প্রতিক্রিয়া ভেঙ্গে দেওয়া যাক. partOfSpeech আমাদের প্রতিটি শব্দের ভাষাগত বিবরণ দেয় (অনেকে অজানা কারণ তারা ইংরেজি বা এই নির্দিষ্ট শব্দের ক্ষেত্রে প্রযোজ্য নয়)। tag এই শব্দের বক্তব্যের অংশ দেয়, এই ক্ষেত্রে একটি ক্রিয়া। আমরা কাল, মোডালিটি এবং শব্দটি একবচন বা বহুবচন সম্পর্কেও বিশদ পাই। lemma হল শব্দের ক্যানোনিকাল রূপ ("ব্যবহার" এর জন্য এটি "ব্যবহার")। উদাহরণস্বরূপ, রান , রান , র্যান , এবং রানিং শব্দগুলির একটি লেমা আছে । লেমা মান সময়ের সাথে সাথে একটি বড় অংশে একটি শব্দের ঘটনাগুলি ট্র্যাক করার জন্য দরকারী।
dependencyEdge এমন ডেটা রয়েছে যা আপনি পাঠ্যের নির্ভরতা পার্স ট্রি তৈরি করতে ব্যবহার করতে পারেন। এটি একটি চিত্র যা দেখায় কিভাবে একটি বাক্যে শব্দগুলি একে অপরের সাথে সম্পর্কিত। উপরের বাক্যটির জন্য একটি নির্ভরতা পার্স ট্রি দেখতে এইরকম হবে:
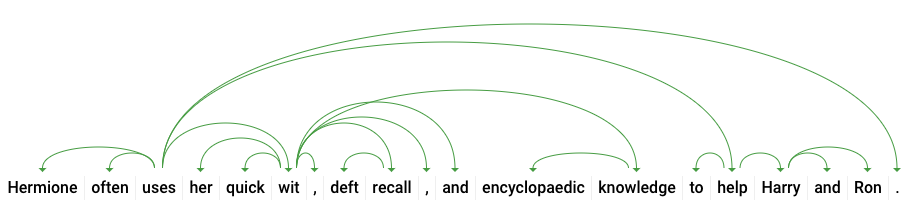
উপরের আমাদের প্রতিক্রিয়ায় headTokenIndex হল টোকেনের সূচী যার "ব্যবহার" এর দিকে একটি চাপ রয়েছে। আমরা বাক্যটির প্রতিটি টোকেনকে একটি অ্যারের একটি শব্দ হিসাবে ভাবতে পারি, এবং "ব্যবহার" এর জন্য 2-এর headTokenIndex "প্রায়শই" শব্দটিকে বোঝায় যা এটি গাছের সাথে সংযুক্ত।
ন্যাচারাল ল্যাঙ্গুয়েজ এপিআই ইংরেজি ছাড়া অন্যান্য ভাষাকেও সমর্থন করে (সম্পূর্ণ তালিকা এখানে )। জাপানি ভাষায় একটি বাক্য সহ নিম্নলিখিত সত্তা অনুরোধটি চেষ্টা করা যাক:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"日本のグーグルのオフィスは、東京の六本木ヒルズにあります"
},
"encodingType": "UTF8"
}লক্ষ্য করুন যে আমরা এপিআইকে বলিনি যে আমাদের পাঠ্য কোন ভাষা, এটি স্বয়ংক্রিয়ভাবে এটি সনাক্ত করতে পারে। এর পরে, আমরা এটিকে analyzeEntities এন্ডপয়েন্টে পাঠাব:
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonএবং এখানে আমাদের প্রতিক্রিয়া প্রথম দুটি সত্তা আছে:
{
"entities": [
{
"name": "日本",
"type": "LOCATION",
"metadata": {
"mid": "/m/03_3d",
"wikipedia_url": "https://en.wikipedia.org/wiki/Japan"
},
"salience": 0.23854347,
"mentions": [
{
"text": {
"content": "日本",
"beginOffset": 0
},
"type": "PROPER"
}
]
},
{
"name": "グーグル",
"type": "ORGANIZATION",
"metadata": {
"mid": "/m/045c7b",
"wikipedia_url": "https://en.wikipedia.org/wiki/Google"
},
"salience": 0.21155767,
"mentions": [
{
"text": {
"content": "グーグル",
"beginOffset": 9
},
"type": "PROPER"
}
]
},
...
]
"language": "ja"
}প্রত্যেকটির জন্য উইকিপিডিয়া পৃষ্ঠা সহ API একটি অবস্থান হিসাবে জাপান এবং একটি সংস্থা হিসাবে Google বের করে।
আপনি শিখেছেন কিভাবে ক্লাউড ন্যাচারাল ল্যাঙ্গুয়েজ এপিআই-এর মাধ্যমে টেক্সট অ্যানালাইসিস করতে হয় সত্তা বের করে, অনুভূতি বিশ্লেষণ করে এবং সিনট্যাক্স টীকা করে।
আমরা কভার করেছি কি
- একটি প্রাকৃতিক ভাষা API অনুরোধ তৈরি করা এবং কার্ল দিয়ে API কল করা
- ন্যাচারাল ল্যাঙ্গুয়েজ এপিআই-এর সাথে টেক্সটে সত্ত্বা বের করা এবং সেন্টিমেন্ট অ্যানালাইসিস চালানো
- নির্ভরতা পার্স ট্রি তৈরি করতে পাঠ্যের উপর ভাষাগত বিশ্লেষণ করা
- জাপানি ভাষায় একটি প্রাকৃতিক ভাষা API অনুরোধ তৈরি করা
পরবর্তী পদক্ষেপ
- ডকুমেন্টেশনে প্রাকৃতিক ভাষা API টিউটোরিয়াল দেখুন।
- ভিশন API এবং স্পিচ API ব্যবহার করে দেখুন!