
Dataflow; ETL, toplu işleme ve sürekli işleme gibi çok çeşitli veri işleme kalıplarını geliştirip yürütmek için kullanılan birleşik bir programlama modeli ve yönetilen bir hizmettir. Dataflow, yönetilen bir hizmet olduğundan yüksek kullanım verimliliğini korurken gecikmeyi en aza indirmek için kaynakları isteğe bağlı olarak ayırabilir.
Dataflow modeli, toplu ve akış işlemeyi birleştirir. Böylece geliştiricilerin doğruluk, maliyet ve işleme süresi arasında seçim yapması gerekmez. Bu codelab'de, bir metin dosyasındaki benzersiz kelimelerin oluşum sayısını hesaplayan bir Dataflow ardışık düzenini çalıştırmayı öğreneceksiniz.
Bu eğitim, https://cloud.google.com/dataflow/docs/quickstarts/quickstart-java-maven adresinden uyarlanmıştır.
Neler öğreneceksiniz?
- Cloud Dataflow SDK ile Maven projesi oluşturma
- Google Cloud Platform Console'u kullanarak örnek bir ardışık düzen çalıştırma
- İlişkili Cloud Storage paketini ve içeriklerini silme
Gerekenler
Bu eğitimi nasıl kullanacaksınız?
Google Cloud Platform hizmetlerini kullanma deneyiminizi nasıl değerlendirirsiniz?
Kendi hızınızda ortam kurulumu
Henüz bir Google Hesabınız (Gmail veya Google Apps) yoksa oluşturmanız gerekir. Google Cloud Platform Console'da (console.cloud.google.com) oturum açın ve yeni bir proje oluşturun:



Proje kimliğini unutmayın. Bu kimlik, tüm Google Cloud projelerinde benzersiz bir addır (Yukarıdaki ad zaten alınmış olduğundan sizin için çalışmayacaktır). Bu codelab'in ilerleyen kısımlarında PROJECT_ID olarak adlandırılacaktır.
Ardından, Google Cloud kaynaklarını kullanmak için Cloud Console'da faturalandırmayı etkinleştirmeniz gerekir.
Bu codelab'i tamamlamak size birkaç dolardan fazla maliyet getirmemelidir. Ancak daha fazla kaynak kullanmaya karar verirseniz veya kaynakları çalışır durumda bırakırsanız maliyet daha yüksek olabilir (bu belgenin sonundaki "temizleme" bölümüne bakın).
Google Cloud Platform'un yeni kullanıcıları 300 ABD doları değerindeki ücretsiz deneme sürümünden yararlanabilir.
API'leri etkinleştirme
Ekranın sol üst kısmındaki menü simgesini tıklayın.

Açılır menüden API Yöneticisi'ni seçin.

Arama kutusuna "Google Compute Engine" yazın. Görünen sonuç listesinde "Google Compute Engine API"yi tıklayın.
Google Compute Engine sayfasında Etkinleştir'i tıklayın.
Etkinleştirildikten sonra geri gitmek için oku tıklayın.
Şimdi aşağıdaki API'leri arayın ve bunları da etkinleştirin:
- Google Dataflow API
- Stackdriver Logging API
- Google Cloud Storage
- Google Cloud Storage JSON API
- BigQuery API
- Google Cloud Pub/Sub API
- Google Cloud Datastore API'si
Google Cloud Platform Console'da ekranın sol üst kısmındaki Menü simgesini tıklayın:
Aşağı kaydırın ve Depolama alt bölümünde Cloud Storage'ı seçin:
Şimdi Cloud Storage Tarayıcı'yı görmelisiniz. Şu anda Cloud Storage paketi içermeyen bir proje kullandığınızı varsayarsak yeni bir paket oluşturmaya davet eden bir iletişim kutusu görürsünüz:
Oluşturmak için Paket oluştur düğmesine basın:
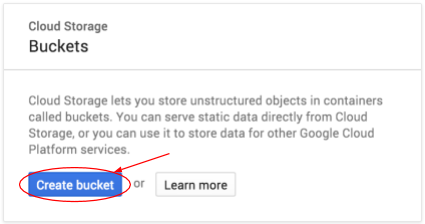
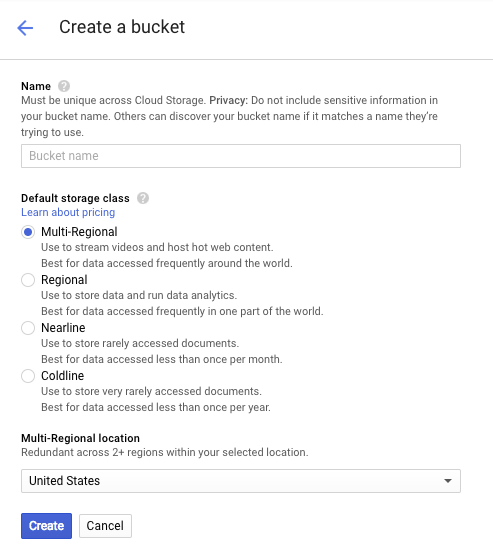
Paketiniz için bir ad girin. İletişim kutusunda belirtildiği gibi, paket adları Cloud Storage'ın tamamında benzersiz olmalıdır. Bu nedenle, "test" gibi belirgin bir ad seçerseniz büyük olasılıkla başka bir kullanıcının bu adla bir paket oluşturduğunu görür ve hata mesajı alırsınız.
Paket adlarında hangi karakterlere izin verildiğiyle ilgili de bazı kurallar vardır. Paket adınızın başına ve sonuna harf veya rakam ekleyip ortasında yalnızca kısa çizgi kullanırsanız sorun yaşamazsınız. Özel karakterler kullanmaya veya paket adınızı harf ya da sayı dışında bir karakterle başlatmaya ya da bitirmeye çalışırsanız iletişim kutusunda kurallar hatırlatılır.
Paketiniz için benzersiz bir ad girin ve Oluştur'a basın. Zaten kullanılmakta olan bir öğe seçerseniz yukarıda gösterilen hata mesajını görürsünüz. Bir paketi başarıyla oluşturduğunuzda tarayıcıda yeni ve boş paketinize yönlendirilirsiniz:
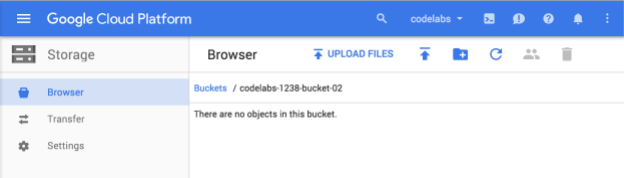
Gördüğünüz paket adı, tüm projelerde benzersiz olması gerektiğinden farklı olacaktır.
Google Cloud Shell'i etkinleştir
GCP Console'da sağ üstteki araç çubuğunda Cloud Shell simgesini tıklayın:

Ardından "Cloud Shell'i başlat"ı tıklayın:

Ortamın sağlanması ve bağlantının kurulması yalnızca birkaç saniye sürer:

Bu sanal makine, ihtiyaç duyacağınız tüm geliştirme araçlarını içerir. 5 GB boyutunda kalıcı bir ana dizin sunar ve Google Cloud üzerinde çalışır. Bu sayede ağ performansı ve kimlik doğrulama önemli ölçüde iyileştirilir. Bu laboratuvardaki çalışmalarınızın neredeyse tamamını yalnızca bir tarayıcı veya Google Chromebook'unuzla yapabilirsiniz.
Cloud Shell'e bağlandıktan sonra kimliğinizin zaten doğrulandığını ve projenin PROJECT_ID'nize göre ayarlandığını görürsünüz.
Kimliğinizin doğrulandığını onaylamak için Cloud Shell'de aşağıdaki komutu çalıştırın:
gcloud auth list
Komut çıkışı
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Komut çıkışı
[core] project = <PROJECT_ID>
Değilse aşağıdaki komutla ayarlayabilirsiniz:
gcloud config set project <PROJECT_ID>
Komut çıkışı
Updated property [core/project].
Cloud Shell başlatıldıktan sonra, Java için Cloud Dataflow SDK'sını içeren bir Maven projesi oluşturarak başlayalım.
Kabuğunuzda mvn archetype:generate komutunu aşağıdaki gibi çalıştırın:
mvn archetype:generate \
-DarchetypeArtifactId=google-cloud-dataflow-java-archetypes-examples \
-DarchetypeGroupId=com.google.cloud.dataflow \
-DarchetypeVersion=1.9.0 \
-DgroupId=com.example \
-DartifactId=first-dataflow \
-Dversion="0.1" \
-DinteractiveMode=false \
-Dpackage=com.exampleKomutu çalıştırdıktan sonra mevcut dizininizde first-dataflow adlı yeni bir dizin görmeniz gerekir. first-dataflow, Java için Cloud Dataflow SDK'sını ve örnek ardışık düzenleri içeren bir Maven projesi içerir.
Proje kimliğimizi ve Cloud Storage paketi adlarımızı ortam değişkenleri olarak kaydederek başlayalım. Bu işlemi Cloud Shell'de yapabilirsiniz. <your_project_id> yerine kendi proje kimliğinizi yazdığınızdan emin olun.
export PROJECT_ID=<your_project_id>Şimdi Cloud Storage paketi için de aynı işlemi yapacağız. <your_bucket_name> ifadesini, önceki bir adımda paketinizi oluştururken kullandığınız benzersiz adla değiştirmeyi unutmayın.
export BUCKET_NAME=<your_bucket_name>first-dataflow/ dizinine geçin.
cd first-dataflowMetin okuyan, metin satırlarını tek tek kelime olarak sınıflandıran ve her bir kelimenin kaç kere geçtiğini sayan WordCount adlı bir ardışık düzen çalıştıracağız. Öncelikle işlem hattını çalıştıracağız ve çalışırken her adımda neler olduğuna bakacağız.
Kabuğunuzda veya terminal pencerenizde mvn compile exec:java komutunu çalıştırarak işlem hattını başlatın. --project, --stagingLocation, ve --output bağımsız değişkenleri için aşağıdaki komut, bu adımda daha önce ayarladığınız ortam değişkenlerine referans verir.
mvn compile exec:java \
-Dexec.mainClass=com.example.WordCount \
-Dexec.args="--project=${PROJECT_ID} \
--stagingLocation=gs://${BUCKET_NAME}/staging/ \
--output=gs://${BUCKET_NAME}/output \
--runner=BlockingDataflowPipelineRunner"İş çalışırken iş listesinde işi bulalım.
Google Cloud Platform Console'da Cloud Dataflow Monitoring kullanıcı arayüzünü açın. wordcount işinizin durumunun Çalışıyor olduğunu göreceksiniz:

Şimdi de işlem hattı parametrelerine bakalım. İşinizin adını tıklayarak başlayın:
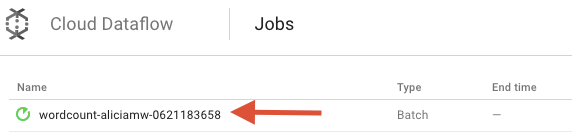
Bir iş seçtiğinizde yürütme grafiğini görüntüleyebilirsiniz. Ardışık düzenin yürütme grafiği, ardışık düzendeki her dönüşümü, dönüşüm adını ve bazı durum bilgilerini içeren bir kutu olarak gösterir. Daha fazla ayrıntı görmek için her adımın sağ üst köşesindeki şapkayı tıklayabilirsiniz:
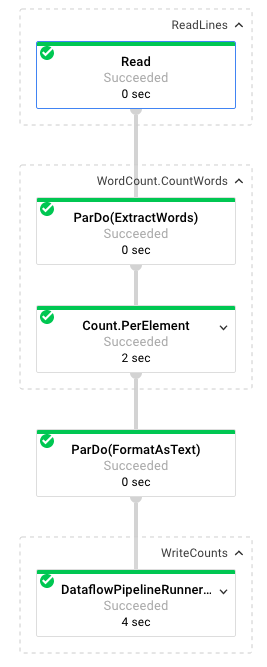
Dönüşüm hunisinin her adımda verileri nasıl dönüştürdüğüne bakalım:
- Okuma: Bu adımda ardışık düzen, bir giriş kaynağından okuma yapar. Bu örnekte, Shakespeare'in Kral Lear oyununun tamamını içeren bir Cloud Storage metin dosyası kullanılıyor. İşlem hattımız dosyayı satır satır okur ve her satır için bir
PCollectionçıktısı verir. Metin dosyamızdaki her satır, koleksiyondaki bir öğedir. - CountWords:
CountWordsadımının iki bölümü vardır. İlk olarak, her satırı ayrı kelimelere ayırmak içinExtractWordsadlı paralel do işlevini (ParDo) kullanır. ExtractWords'ün çıkışı, her öğenin bir kelime olduğu yeni bir PCollection'dır. Bir sonraki adım olanCount, Dataflow SDK tarafından sağlanan ve anahtarın benzersiz bir kelime, değerin ise bu kelimenin kaç kez geçtiği anahtar/değer çiftlerini döndüren bir dönüşümü kullanır.CountWordsuygulayan yöntem aşağıda verilmiştir. WordCount.java dosyasının tamamını GitHub'da inceleyebilirsiniz:
/**
* A PTransform that converts a PCollection containing lines of text
* into a PCollection of formatted word counts.
*/
public static class CountWords extends PTransform<PCollection<String>,
PCollection<KV<String, Long>>> {
@Override
public PCollection<KV<String, Long>> apply(PCollection<String> lines) {
// Convert lines of text into individual words.
PCollection<String> words = lines.apply(
ParDo.of(new ExtractWordsFn()));
// Count the number of times each word occurs.
PCollection<KV<String, Long>> wordCounts =
words.apply(Count.<String>perElement());
return wordCounts;
}
}- FormatAsText: Bu işlev, her anahtar/değer çiftini yazdırılabilir bir dize olarak biçimlendirir. Bunu uygulamak için
FormatAsTextdönüşümü aşağıda verilmiştir:
/** A SimpleFunction that converts a Word and Count into a printable string. */
public static class FormatAsTextFn extends SimpleFunction<KV<String, Long>, String> {
@Override
public String apply(KV<String, Long> input) {
return input.getKey() + ": " + input.getValue();
}
}- WriteCounts: Bu adımda, yazdırılabilir dizeleri birden fazla parçalanmış metin dosyasına yazarız.
Ardışık düzenden elde edilen çıkışı birkaç dakika içinde inceleyeceğiz.
Şimdi de grafiğin sağındaki Özet sayfasına göz atın. Bu sayfada, mvn compile exec:java komutuna eklediğimiz kanal parametreleri yer alır.
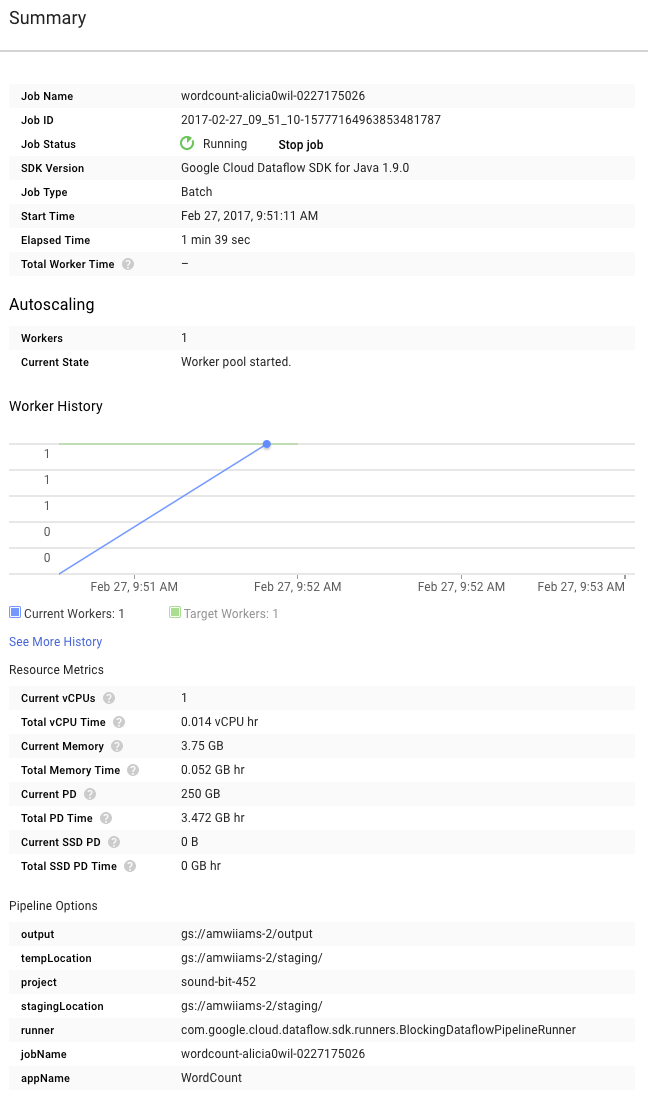
Ayrıca, işlem hattı için özel sayaçları da görebilirsiniz. Bu sayaçlar, yürütme sırasında şu ana kadar kaç boş satırla karşılaşıldığını gösterir. Uygulamaya özgü metrikleri izlemek için işlem hattınıza yeni sayaçlar ekleyebilirsiniz.
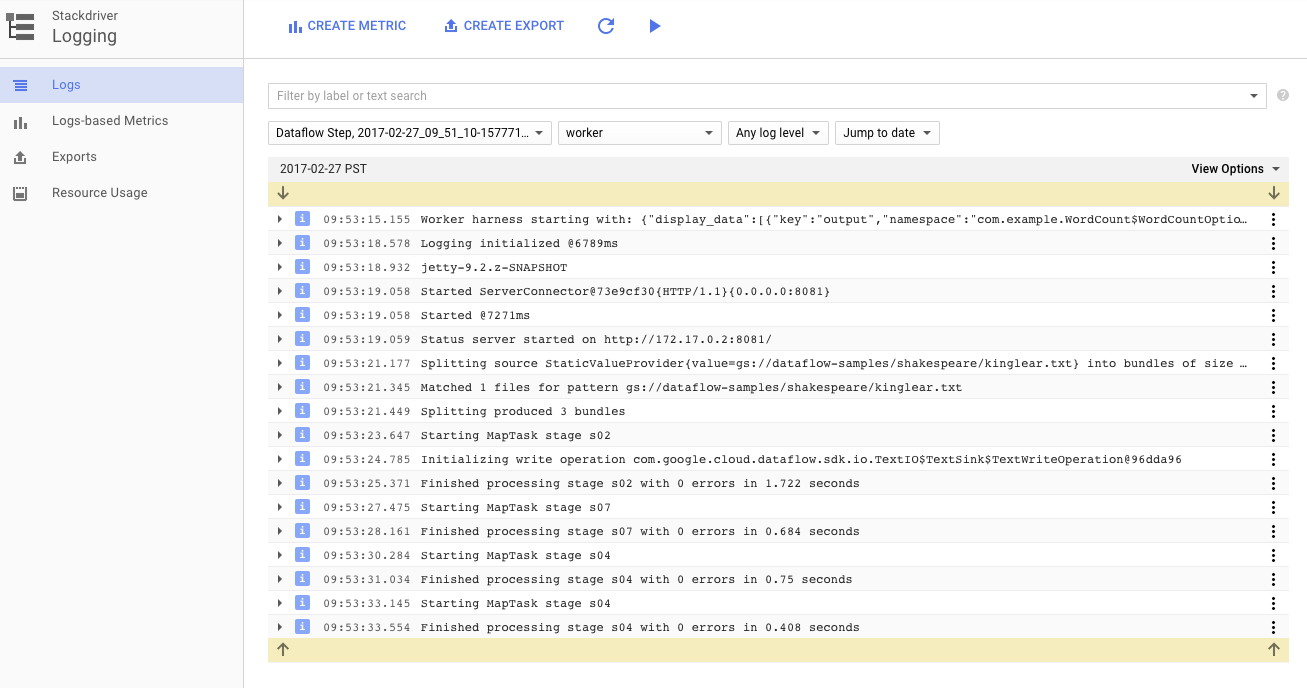
Belirli hata mesajlarını görüntülemek için Günlükler simgesini tıklayabilirsiniz.

İş günlüğü sekmesinde görünen iletileri, Minimum Önem Düzeyi açılır menüsünü kullanarak filtreleyebilirsiniz.

Ardışık düzeninizi çalıştıran Compute Engine örneklerinin çalışan günlüklerini görüntülemek için günlükler sekmesindeki Çalışan Günlükleri düğmesini kullanabilirsiniz. Çalışan günlükleri, kodunuz tarafından oluşturulan günlük satırlarından ve kodu çalıştıran Dataflow tarafından oluşturulan koddan oluşur.
Ardışık işlem hattındaki bir hatayı ayıklamaya çalışıyorsanız genellikle Worker Logs'da sorunu çözmenize yardımcı olacak ek günlükler bulunur. Bu günlüklerin tüm çalışanlar arasında toplandığını, filtrelenebileceğini ve aranabileceğini unutmayın.
Sonraki adımda, işinizin başarılı olup olmadığını kontrol edeceğiz.
Google Cloud Platform Console'da Cloud Dataflow Monitoring kullanıcı arayüzünü açın.
İlk olarak wordcount işinizin durumunun Çalışıyor, ardından Başarılı olduğunu göreceksiniz:

İşin çalışması yaklaşık 3-4 dakika sürer.
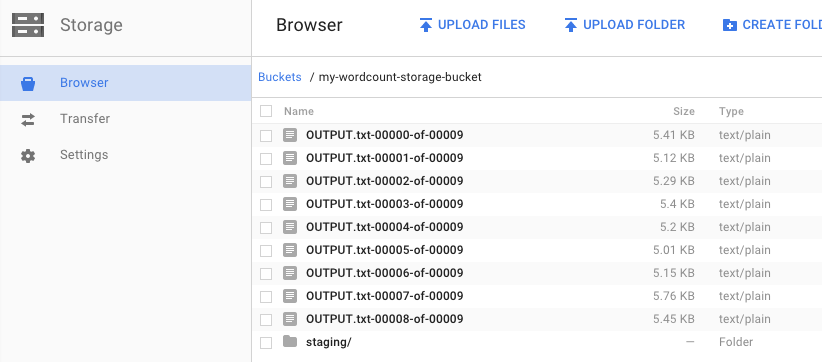
İşlem hattını çalıştırıp bir çıkış paketi belirttiğinizi hatırlıyor musunuz? Sonuca bakalım (çünkü Kral Lear'daki her kelimenin kaç kez geçtiğini görmek istemez misiniz?). Google Cloud Platform Console'da Cloud Storage Tarayıcısı'na geri dönün. Paketinizde, işinizin oluşturduğu çıkış dosyalarını ve hazırlama dosyalarını göreceksiniz:
Kaynaklarınızı Google Cloud Platform Console'dan kapatabilirsiniz.
Google Cloud Platform Console'da Cloud Storage Tarayıcısı'nı açın.
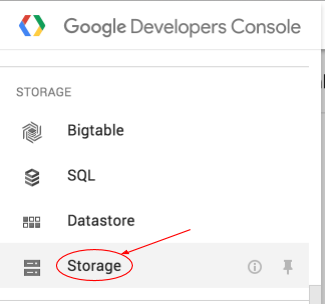
Oluşturduğunuz paketin yanındaki onay kutusunu işaretleyin.

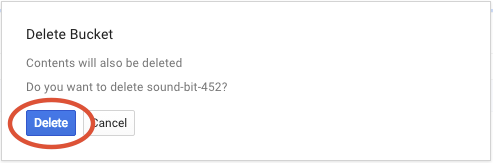
Paketi ve içeriğini kalıcı olarak silmek için SİL'i tıklayın.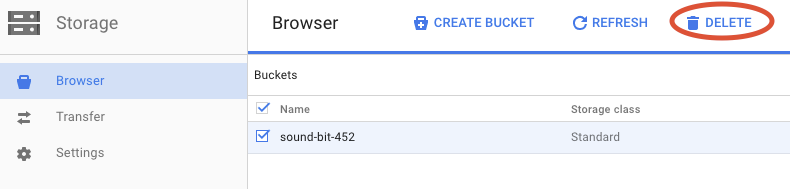
Cloud Dataflow SDK ile Maven projesi oluşturmayı, Google Cloud Platform Console'u kullanarak örnek bir ardışık düzen çalıştırmayı ve ilişkili Cloud Storage paketini ve içeriğini silmeyi öğrendiniz.
Daha Fazla Bilgi
- Dataflow Belgeleri: https://cloud.google.com/dataflow/docs/
Lisans
Bu çalışma, Creative Commons Attribution 3.0 Genel Amaçlı Lisans ve Apache 2.0 lisansı ile lisanslanmıştır.