
Dataflow — это унифицированная модель программирования и управляемый сервис для разработки и выполнения широкого спектра шаблонов обработки данных, включая ETL, пакетные и непрерывные вычисления. Поскольку Dataflow — управляемый сервис, он может выделять ресурсы по требованию, минимизируя задержки и поддерживая высокую эффективность использования.
Модель Dataflow сочетает пакетную и потоковую обработку, поэтому разработчикам не приходится выбирать между корректностью, стоимостью и временем обработки. В этой лабораторной работе вы научитесь запускать конвейер Dataflow, подсчитывающий количество вхождений уникальных слов в текстовом файле.
Это руководство адаптировано из https://cloud.google.com/dataflow/docs/quickstarts/quickstart-java-maven
Чему вы научитесь
- Как создать проект Maven с помощью Cloud Dataflow SDK
- Запустите пример конвейера с помощью консоли Google Cloud Platform
- Как удалить связанный контейнер Cloud Storage и его содержимое
Что вам понадобится
Как вы будете использовать это руководство?
Как бы вы оценили свой опыт использования сервисов Google Cloud Platform?
Настройка среды для самостоятельного обучения
Если у вас ещё нет учётной записи Google (Gmail или Google Apps), необходимо её создать . Войдите в консоль Google Cloud Platform ( console.cloud.google.com ) и создайте новый проект:



Запомните идентификатор проекта — уникальное имя для всех проектов Google Cloud (имя, указанное выше, уже занято и не будет вам работать, извините!). Далее в этой практической работе он будет обозначаться как PROJECT_ID .
Далее вам необходимо включить биллинг в Cloud Console, чтобы использовать ресурсы Google Cloud.
Выполнение этой лабораторной работы не должно обойтись вам дороже нескольких долларов, но может обойтись дороже, если вы решите использовать больше ресурсов или оставите их запущенными (см. раздел «Очистка» в конце этого документа).
Новые пользователи Google Cloud Platform имеют право на бесплатную пробную версию стоимостью 300 долларов США .
Включить API
Нажмите на значок меню в левом верхнем углу экрана.

В раскрывающемся списке выберите API Manager .

Введите «Google Compute Engine» в строку поиска. В появившемся списке результатов нажмите «Google Compute Engine API».
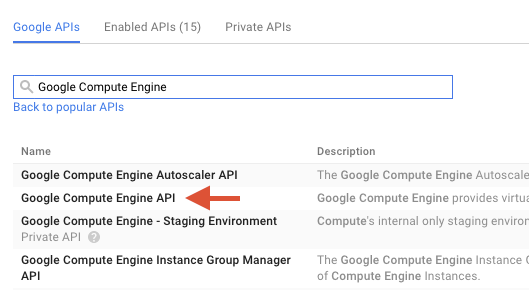
На странице Google Compute Engine нажмите «Включить».
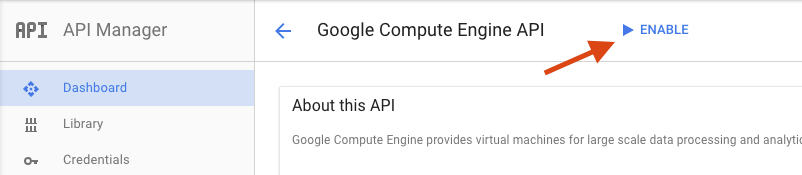
После включения нажмите стрелку, чтобы вернуться назад.
Теперь найдите следующие API и включите их:
- API потока данных Google
- API журналирования Stackdriver
- Облачное хранилище Google
- JSON API облачного хранилища Google
- API BigQuery
- API Google Cloud Pub/Sub
- API хранилища данных Google Cloud
В консоли Google Cloud Platform нажмите значок меню в левом верхнем углу экрана:
Прокрутите вниз и в подразделе «Хранилище» выберите «Облачное хранилище» :
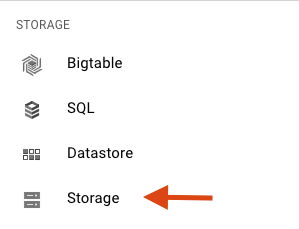
Теперь вы должны увидеть браузер облачного хранилища, и если вы используете проект, в котором в данный момент нет контейнеров облачного хранилища, вы увидите диалоговое окно с приглашением создать новый контейнер:
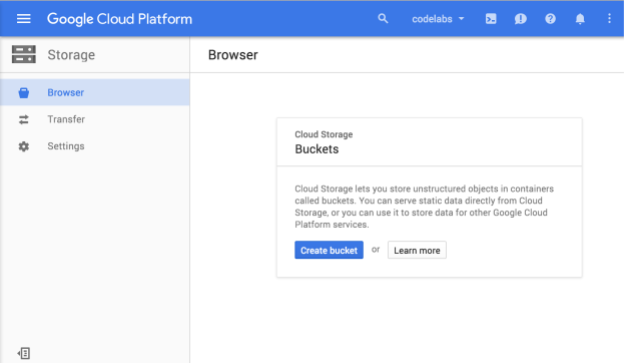
Нажмите кнопку «Создать контейнер» , чтобы создать его:
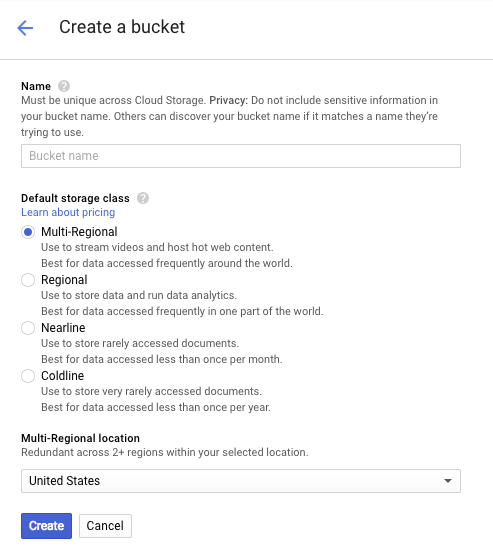
Введите имя для вашего контейнера. Как указано в диалоговом окне, имена контейнеров должны быть уникальными во всём облачном хранилище. Поэтому, если вы выберете очевидное имя, например, «test», вы, вероятно, обнаружите, что кто-то уже создал контейнер с таким именем, и получите сообщение об ошибке.
Существуют также некоторые правила относительно допустимых символов в именах контейнеров. Если имя контейнера начинается и заканчивается буквой или цифрой, а дефисы используются только в середине, то всё будет в порядке. Если вы попытаетесь использовать специальные символы или начать или закончить имя контейнера чем-то, отличным от буквы или цифры, диалоговое окно напомнит вам о правилах.
Введите уникальное имя для вашего контейнера и нажмите «Создать» . Если вы выберете уже используемый контейнер, вы увидите сообщение об ошибке, показанное выше. После успешного создания контейнера вы будете перенаправлены в новый, пустой контейнер в браузере:
Имя контейнера, которое вы увидите, конечно, будет другим, поскольку оно должно быть уникальным для всех проектов.
Активировать Google Cloud Shell
В консоли GCP щелкните значок Cloud Shell на верхней правой панели инструментов:

Затем нажмите «Запустить Cloud Shell»:

Подготовка и подключение к среде займет всего несколько минут:

Эта виртуальная машина оснащена всеми необходимыми инструментами разработки. Она предлагает постоянный домашний каталог объёмом 5 ГБ и работает в облаке Google Cloud, что значительно повышает производительность сети и аутентификацию. Значительную часть работы в этой лаборатории, если не всю, можно выполнить, просто используя браузер или Chromebook от Google.
После подключения к Cloud Shell вы должны увидеть, что вы уже аутентифицированы и что проекту уже присвоен ваш PROJECT_ID .
Выполните следующую команду в Cloud Shell, чтобы подтвердить, что вы прошли аутентификацию:
gcloud auth list
Вывод команды
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Вывод команды
[core] project = <PROJECT_ID>
Если это не так, вы можете установить его с помощью этой команды:
gcloud config set project <PROJECT_ID>
Вывод команды
Updated property [core/project].
После запуска Cloud Shell давайте начнем с создания проекта Maven, содержащего Cloud Dataflow SDK для Java.
Запустите команду mvn archetype:generate в своей оболочке следующим образом:
mvn archetype:generate \
-DarchetypeArtifactId=google-cloud-dataflow-java-archetypes-examples \
-DarchetypeGroupId=com.google.cloud.dataflow \
-DarchetypeVersion=1.9.0 \
-DgroupId=com.example \
-DartifactId=first-dataflow \
-Dversion="0.1" \
-DinteractiveMode=false \
-Dpackage=com.example После выполнения команды вы должны увидеть новый каталог с именем first-dataflow в текущем каталоге. first-dataflow содержит проект Maven, который включает Cloud Dataflow SDK для Java и примеры конвейеров.
Начнём с сохранения идентификатора нашего проекта и названий контейнеров Cloud Storage как переменных среды. Это можно сделать в Cloud Shell. Не забудьте заменить <your_project_id> на идентификатор вашего проекта.
export PROJECT_ID=<your_project_id> Теперь сделаем то же самое для контейнера Cloud Storage. Не забудьте заменить <your_bucket_name> на уникальное имя, которое вы использовали при создании контейнера на предыдущем шаге.
export BUCKET_NAME=<your_bucket_name> Перейдите в каталог first-dataflow/ .
cd first-dataflowМы запустим конвейер под названием WordCount, который считывает текст, разбивает строки текста на отдельные слова и подсчитывает частоту каждого из них. Сначала мы запустим конвейер, и пока он работает, посмотрим, что происходит на каждом этапе.
Запустите конвейер, выполнив команду mvn compile exec:java в командной оболочке или окне терминала. Для аргументов --project, --stagingLocation, и --output приведенная ниже команда ссылается на переменные окружения, настроенные ранее на этом этапе.
mvn compile exec:java \
-Dexec.mainClass=com.example.WordCount \
-Dexec.args="--project=${PROJECT_ID} \
--stagingLocation=gs://${BUCKET_NAME}/staging/ \
--output=gs://${BUCKET_NAME}/output \
--runner=BlockingDataflowPipelineRunner"Пока задание выполняется, давайте найдем его в списке заданий.
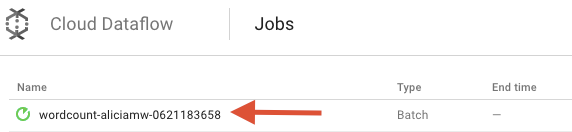
Откройте пользовательский интерфейс Cloud Dataflow Monitoring в консоли Google Cloud Platform . Вы увидите задание по подсчёту слов со статусом « Выполняется» :

Теперь давайте посмотрим на параметры конвейера. Для начала нажмите на название вашей работы:
При выборе задания вы можете просмотреть график выполнения . График выполнения конвейера представляет каждое преобразование в конвейере в виде поля, содержащего имя преобразования и некоторую информацию о его статусе. Чтобы увидеть более подробную информацию, нажмите на значок в правом верхнем углу каждого шага:
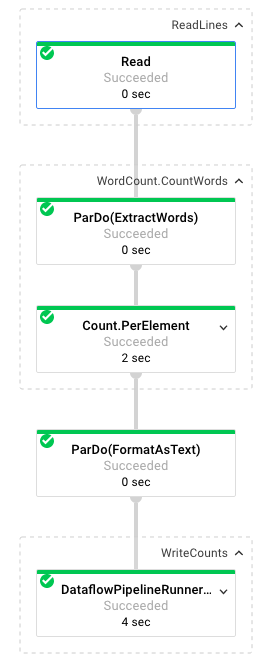
Давайте посмотрим, как конвейер преобразует данные на каждом этапе:
- Чтение : на этом этапе конвейер считывает данные из входного источника. В данном случае это текстовый файл из облачного хранилища с полным текстом пьесы Шекспира «Король Лир» . Наш конвейер считывает файл построчно и выводит каждую строку в виде
PCollection, где каждая строка текстового файла является элементом коллекции. - CountWords : Шаг
CountWordsсостоит из двух частей. Во-первых, он использует параллельную функцию do (ParDo) с именемExtractWordsдля разбиения каждой строки на отдельные слова. Результатом ExtractWords является новый объект PCollection, где каждый элемент — слово. Следующий шаг,Count, использует преобразование, предоставляемое Dataflow SDK, которое возвращает пары ключ-значение, где ключ — уникальное слово, а значение — количество его вхождений. Вот метод, реализующийCountWords, а полный файл WordCount.java можно посмотреть на GitHub :
/**
* A PTransform that converts a PCollection containing lines of text
* into a PCollection of formatted word counts.
*/
public static class CountWords extends PTransform<PCollection<String>,
PCollection<KV<String, Long>>> {
@Override
public PCollection<KV<String, Long>> apply(PCollection<String> lines) {
// Convert lines of text into individual words.
PCollection<String> words = lines.apply(
ParDo.of(new ExtractWordsFn()));
// Count the number of times each word occurs.
PCollection<KV<String, Long>> wordCounts =
words.apply(Count.<String>perElement());
return wordCounts;
}
}- FormatAsText : эта функция форматирует каждую пару «ключ-значение» в печатную строку. Вот преобразование
FormatAsTextдля реализации этой функции:
/** A SimpleFunction that converts a Word and Count into a printable string. */
public static class FormatAsTextFn extends SimpleFunction<KV<String, Long>, String> {
@Override
public String apply(KV<String, Long> input) {
return input.getKey() + ": " + input.getValue();
}
}- WriteCounts : на этом этапе мы записываем печатаемые строки в несколько фрагментированных текстовых файлов.
Через несколько минут мы посмотрим на конечный результат работы конвейера.
Теперь взгляните на страницу «Сводка» справа от графика, на которой указаны параметры конвейера, которые мы включили в команду mvn compile exec:java .
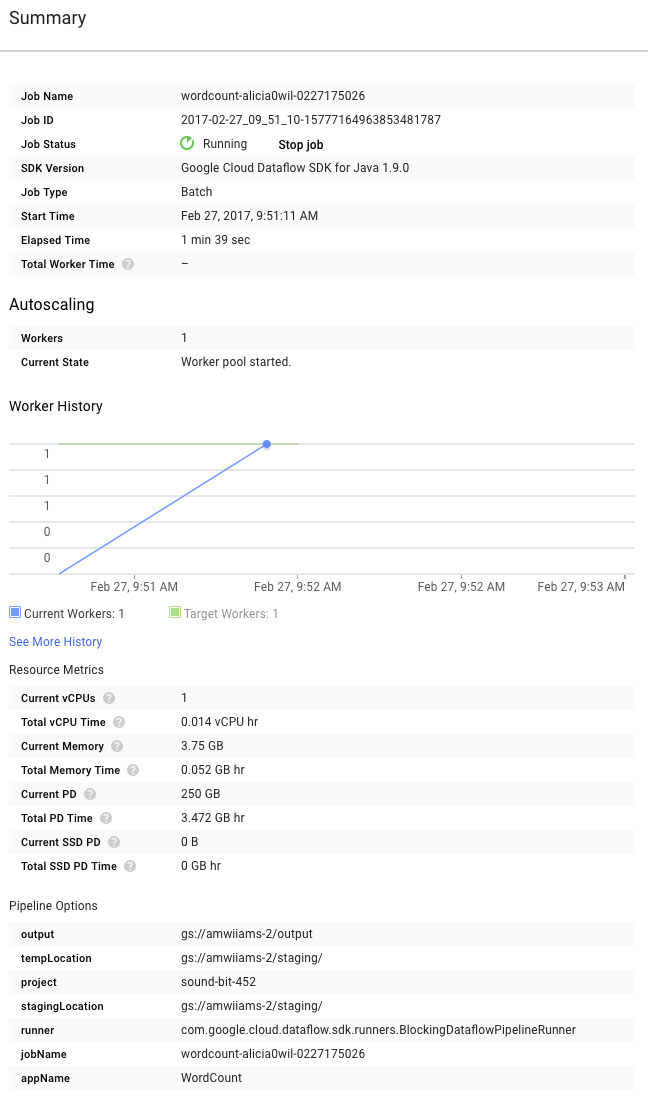
Вы также можете увидеть пользовательские счётчики для конвейера, которые в данном случае показывают количество пустых строк, обнаруженных во время выполнения. Вы можете добавить новые счётчики в свой конвейер для отслеживания показателей, специфичных для приложения.
Вы можете нажать на значок «Журналы» , чтобы просмотреть конкретные сообщения об ошибках.

Фильтрация сообщений, отображаемых на вкладке «Журнал заданий», осуществляется с помощью раскрывающегося меню «Минимальная серьезность».

Вы можете использовать кнопку «Журналы рабочих процессов» на вкладке «Журналы», чтобы просмотреть журналы рабочих процессов для экземпляров Compute Engine, которые запускают ваш конвейер. Журналы рабочих процессов состоят из строк журнала, сгенерированных вашим кодом и кодом Dataflow, который его запускает.
Если вы пытаетесь устранить сбой в конвейере, в журналах рабочих процессов часто можно найти дополнительные записи, которые помогут решить проблему. Имейте в виду, что эти журналы агрегируются по всем рабочим процессам и могут быть отфильтрованы и доступны для поиска.
На следующем этапе мы проверим, что ваша работа выполнена успешно.
Откройте пользовательский интерфейс Cloud Dataflow Monitoring в консоли Google Cloud Platform .
Сначала вы увидите задание по подсчету слов со статусом « Выполняется» , а затем «Успешно» :

Выполнение задания займет примерно 3–4 минуты.
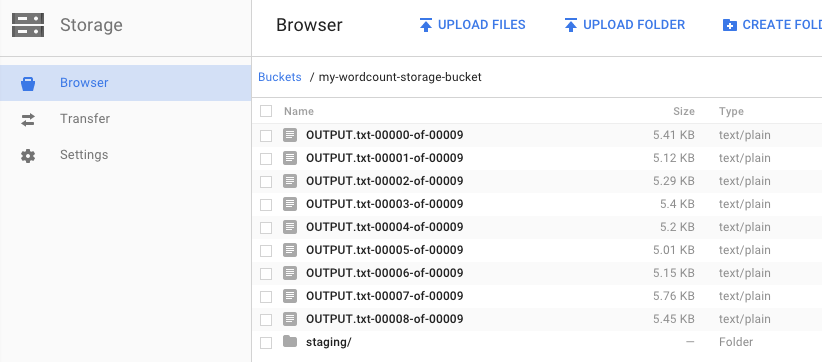
Помните, как вы запускали конвейер и указывали выходной контейнер? Давайте посмотрим на результат (ведь разве не интересно узнать, сколько раз встречается каждое слово в «Короле Лире» ?!). Вернитесь в браузер облачного хранилища в консоли Google Cloud Platform. В контейнере вы должны увидеть выходные и промежуточные файлы, созданные вашим заданием:
Вы можете отключить свои ресурсы из консоли Google Cloud Platform .
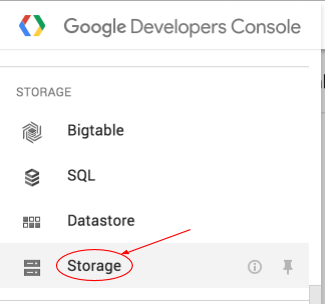
Откройте браузер облачного хранилища в консоли Google Cloud Platform.
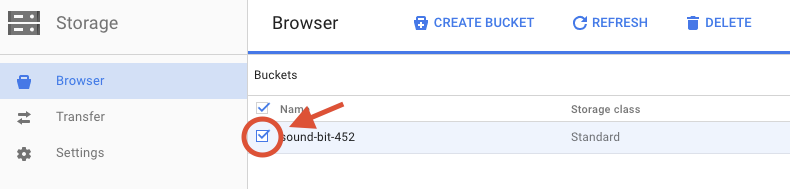
Установите флажок рядом с созданным вами контейнером.
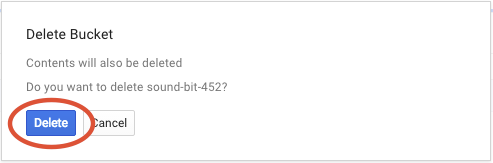
Нажмите кнопку УДАЛИТЬ , чтобы окончательно удалить контейнер и его содержимое. 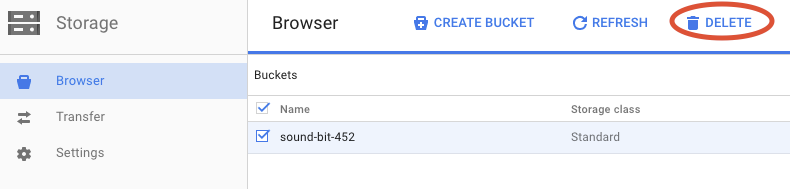
Вы узнали, как создать проект Maven с помощью Cloud Dataflow SDK, запустить пример конвейера с помощью консоли Google Cloud Platform и удалить связанный контейнер Cloud Storage и его содержимое.
Узнать больше
- Документация по потоку данных: https://cloud.google.com/dataflow/docs/
Лицензия
Данная работа лицензирована в соответствии с лицензией Creative Commons Attribution 3.0 Generic License и лицензией Apache 2.0.