
Dataflow to ujednolicony model programowania i usługa zarządzana do opracowywania i wykonywania różnych wzorców przetwarzania danych, w tym ETL, obliczeń wsadowych i ciągłych. Dataflow to usługa zarządzana, która może przydzielać zasoby na żądanie, aby zminimalizować opóźnienia przy zachowaniu wysokiej wydajności wykorzystania.
Model Dataflow łączy przetwarzanie wsadowe i strumieniowe, dzięki czemu programiści nie muszą wybierać między poprawnością, kosztem a czasem przetwarzania. Z tego przewodnika dowiesz się, jak uruchomić potok Dataflow, który zlicza wystąpienia unikalnych słów w pliku tekstowym.
Ten samouczek jest oparty na artykule https://cloud.google.com/dataflow/docs/quickstarts/quickstart-java-maven.
Czego się nauczysz
- Tworzenie projektu Maven za pomocą pakietu SDK Cloud Dataflow
- Uruchamianie przykładowego potoku za pomocą konsoli Google Cloud Platform
- Jak usunąć powiązany zasobnik Cloud Storage i jego zawartość
Czego potrzebujesz
Jak zamierzasz wykorzystać ten samouczek?
Jak oceniasz korzystanie z usług Google Cloud Platform?
Samodzielne konfigurowanie środowiska
Jeśli nie masz jeszcze konta Google (Gmail lub Google Apps), musisz je utworzyć. Zaloguj się w konsoli Google Cloud Platform (console.cloud.google.com) i utwórz nowy projekt:



Zapamiętaj identyfikator projektu, czyli unikalną nazwę we wszystkich projektach Google Cloud (podana powyżej nazwa jest już zajęta i nie będzie działać w Twoim przypadku). W dalszej części tego laboratorium będzie on nazywany PROJECT_ID.
Następnie musisz włączyć płatności w konsoli Cloud, aby móc korzystać z zasobów Google Cloud.
Wykonanie tego samouczka nie powinno kosztować więcej niż kilka dolarów, ale może okazać się droższe, jeśli zdecydujesz się wykorzystać więcej zasobów lub pozostawisz je uruchomione (patrz sekcja „Czyszczenie” na końcu tego dokumentu).
Nowi użytkownicy Google Cloud Platform mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD.
Włączanie interfejsów API
Kliknij ikonę menu w lewym górnym rogu ekranu.

W menu kliknij Menedżer interfejsów API.

W polu wyszukiwania wyszukaj „Google Compute Engine”. Na liście wyników, która się pojawi, kliknij „Google Compute Engine API”.
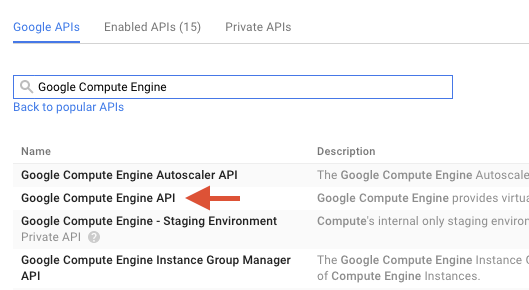
Na stronie Google Compute Engine kliknij Włącz.
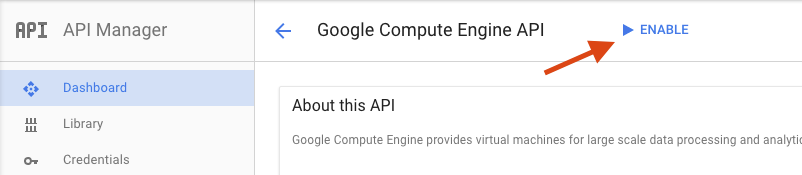
Gdy to zrobisz, kliknij strzałkę, aby wrócić.
Teraz wyszukaj te interfejsy API i też je włącz:
- Google Dataflow API
- Stackdriver Logging API
- Google Cloud Storage
- Google Cloud Storage JSON API
- BigQuery API
- Google Cloud Pub/Sub API
- Google Cloud Datastore API
W konsoli Google Cloud Platform kliknij ikonę Menu w lewym górnym rogu ekranu:
Przewiń w dół i w podsekcji Miejsce na dane wybierz Cloud Storage:
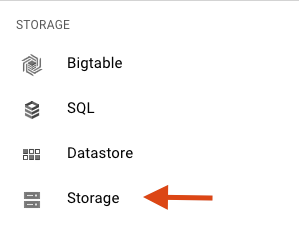
Powinna się teraz wyświetlić przeglądarka Cloud Storage. Jeśli używasz projektu, który nie ma obecnie żadnych zasobników Cloud Storage, zobaczysz okno z prośbą o utworzenie nowego zasobnika:
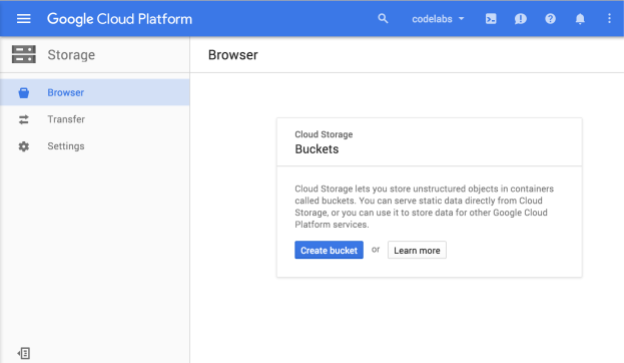
Aby utworzyć zasobnik, kliknij przycisk Utwórz zasobnik:
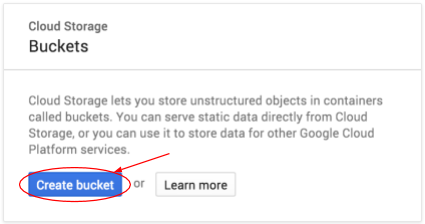
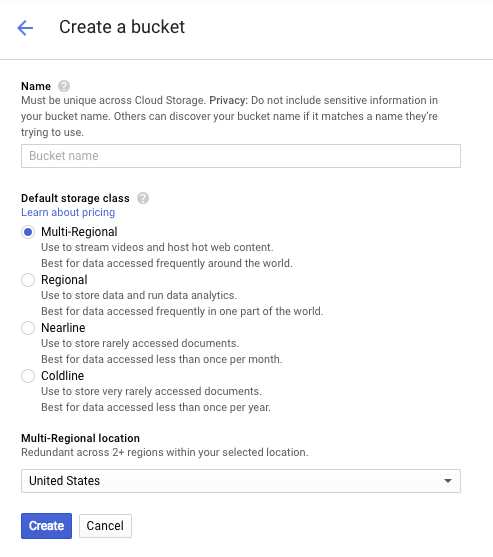
Wpisz nazwę zasobnika. Jak wspomnieliśmy w oknie dialogowym, nazwy zasobników muszą być unikalne w całej usłudze Cloud Storage. Jeśli więc wybierzesz oczywistą nazwę, np. „test”, prawdopodobnie okaże się, że ktoś już utworzył zasobnik o tej nazwie, i wyświetli się błąd.
Istnieją też pewne reguły dotyczące znaków, które mogą być używane w nazwach zasobników. Jeśli nazwa zasobnika zaczyna się i kończy literą lub cyfrą, a w środku zawiera tylko łączniki, nie będzie problemu. Jeśli spróbujesz użyć znaków specjalnych lub rozpocząć lub zakończyć nazwę zasobnika czymś innym niż literą lub cyfrą, w oknie dialogowym pojawi się przypomnienie o zasadach.
Wpisz unikalną nazwę zasobnika i kliknij Utwórz. Jeśli wybierzesz coś, co jest już używane, zobaczysz komunikat o błędzie pokazany powyżej. Po utworzeniu zasobnika w przeglądarce otworzy się nowy, pusty zasobnik:
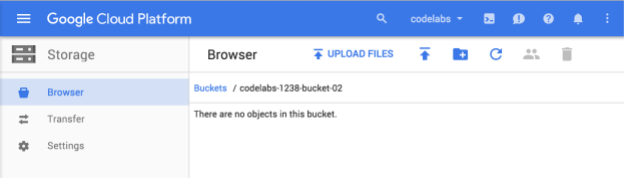
Nazwa zasobnika, którą widzisz, będzie oczywiście inna, ponieważ musi być unikalna we wszystkich projektach.
Aktywuj Google Cloud Shell
W konsoli GCP kliknij ikonę Cloud Shell na pasku narzędzi w prawym górnym rogu:

Następnie kliknij „Uruchom Cloud Shell”:

Udostępnienie środowiska i połączenie się z nim powinno zająć tylko kilka chwil:

Ta maszyna wirtualna zawiera wszystkie potrzebne narzędzia dla programistów. Zawiera stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i uwierzytelniania. Większość, jeśli nie wszystkie, zadań w tym laboratorium można wykonać za pomocą przeglądarki lub Chromebooka Google.
Po połączeniu z Cloud Shell zobaczysz, że jesteś już uwierzytelniony, a projekt jest już ustawiony na PROJECT_ID.
Aby potwierdzić, że masz autoryzację, uruchom w Cloud Shell to polecenie:
gcloud auth list
Wynik polecenia
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Wynik polecenia
[core] project = <PROJECT_ID>
Jeśli nie, możesz ustawić go za pomocą tego polecenia:
gcloud config set project <PROJECT_ID>
Wynik polecenia
Updated property [core/project].
Po uruchomieniu Cloud Shell zacznij od utworzenia projektu Maven zawierającego pakiet Cloud Dataflow SDK dla Javy.
Uruchom w powłoce polecenie mvn archetype:generate w ten sposób:
mvn archetype:generate \
-DarchetypeArtifactId=google-cloud-dataflow-java-archetypes-examples \
-DarchetypeGroupId=com.google.cloud.dataflow \
-DarchetypeVersion=1.9.0 \
-DgroupId=com.example \
-DartifactId=first-dataflow \
-Dversion="0.1" \
-DinteractiveMode=false \
-Dpackage=com.examplePo uruchomieniu polecenia w bieżącym katalogu powinien pojawić się nowy katalog o nazwie first-dataflow. first-dataflow zawiera projekt Maven, który obejmuje pakiet Cloud Dataflow SDK for Java i przykładowe potoki.
Zacznijmy od zapisania identyfikatora projektu i nazw zasobników Cloud Storage jako zmiennych środowiskowych. Możesz to zrobić w Cloud Shell. Pamiętaj, aby zastąpić <your_project_id> identyfikatorem własnego projektu.
export PROJECT_ID=<your_project_id>Teraz zrobimy to samo w przypadku zasobnika Cloud Storage. Pamiętaj, aby zastąpić <your_bucket_name> unikalną nazwą używaną do utworzenia zasobnika w poprzednim kroku.
export BUCKET_NAME=<your_bucket_name>Przejdź do katalogu first-dataflow/.
cd first-dataflowUruchomimy potok o nazwie WordCount, który odczytuje tekst, dzieli wiersze tekstu na tokeny będące poszczególnymi słowami i zlicza częstotliwość występowania poszczególnych słów. Najpierw uruchomimy potok, a potem przyjrzymy się, co dzieje się na każdym etapie.
Uruchom potok, wpisując w powłoce lub oknie terminala polecenie mvn compile exec:java. W przypadku argumentów --project, --stagingLocation, i --output poniższe polecenie odwołuje się do zmiennych środowiskowych skonfigurowanych wcześniej w tym kroku.
mvn compile exec:java \
-Dexec.mainClass=com.example.WordCount \
-Dexec.args="--project=${PROJECT_ID} \
--stagingLocation=gs://${BUCKET_NAME}/staging/ \
--output=gs://${BUCKET_NAME}/output \
--runner=BlockingDataflowPipelineRunner"Gdy zadanie jest uruchomione, znajdź je na liście zadań.
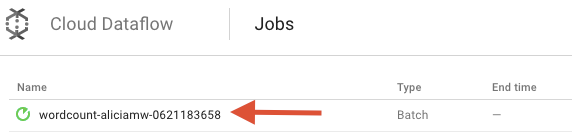
Otwórz interfejs monitorujący Cloud Dataflow w konsoli Google Cloud Platform. Zadanie wordcount powinno być widoczne ze stanem Uruchomiono:

Przyjrzyjmy się teraz parametrom potoku. Zacznij od kliknięcia nazwy zadania:
Po wybraniu zadania możesz wyświetlić wykres wykonania. Wykres wykonania potoku przedstawia każdą transformację w potoku jako pole zawierające nazwę transformacji i informacje o stanie. Aby wyświetlić więcej szczegółów, kliknij znak ^ w prawym górnym rogu każdego kroku:
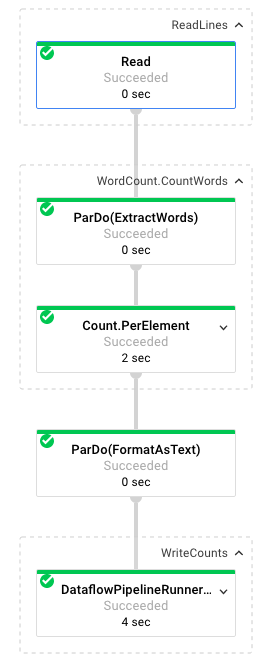
Zobaczmy, jak potok przekształca dane na każdym etapie:
- Odczyt: na tym etapie potok odczytuje dane ze źródła wejściowego. W tym przypadku jest to plik tekstowy z Cloud Storage zawierający cały tekst sztuki Szekspira Król Lear. Nasz potok odczytuje plik wiersz po wierszu i wyświetla każdy wiersz jako
PCollection, gdzie każdy wiersz w pliku tekstowym jest elementem kolekcji. - CountWords: krok
CountWordsskłada się z 2 części. Najpierw używa funkcji równoległej do (ParDo) o nazwieExtractWords, aby podzielić każdy wiersz na poszczególne słowa. Wynikiem działania funkcji ExtractWords jest nowa kolekcja PCollection, w której każdy element to słowo. Następny krok,Count, wykorzystuje transformację dostarczoną przez pakiet Dataflow SDK, która zwraca pary klucz-wartość, gdzie kluczem jest unikalne słowo, a wartością liczba jego wystąpień. Oto metoda implementującaCountWords. Pełny plik WordCount.java znajdziesz na GitHub:
/**
* A PTransform that converts a PCollection containing lines of text
* into a PCollection of formatted word counts.
*/
public static class CountWords extends PTransform<PCollection<String>,
PCollection<KV<String, Long>>> {
@Override
public PCollection<KV<String, Long>> apply(PCollection<String> lines) {
// Convert lines of text into individual words.
PCollection<String> words = lines.apply(
ParDo.of(new ExtractWordsFn()));
// Count the number of times each word occurs.
PCollection<KV<String, Long>> wordCounts =
words.apply(Count.<String>perElement());
return wordCounts;
}
}- FormatAsText: funkcja, która formatuje każdą parę klucz-wartość w ciąg do wydrukowania. Oto
FormatAsTextprzekształcenie, które należy zastosować:
/** A SimpleFunction that converts a Word and Count into a printable string. */
public static class FormatAsTextFn extends SimpleFunction<KV<String, Long>, String> {
@Override
public String apply(KV<String, Long> input) {
return input.getKey() + ": " + input.getValue();
}
}- WriteCounts: w tym kroku zapisujemy ciągi znaków do wydrukowania w wielu podzielonych plikach tekstowych.
Za kilka minut przyjrzymy się wynikom potoku.
Teraz spójrz na stronę Podsumowanie po prawej stronie wykresu. Zawiera ona parametry potoku, które uwzględniliśmy w poleceniu mvn compile exec:java.
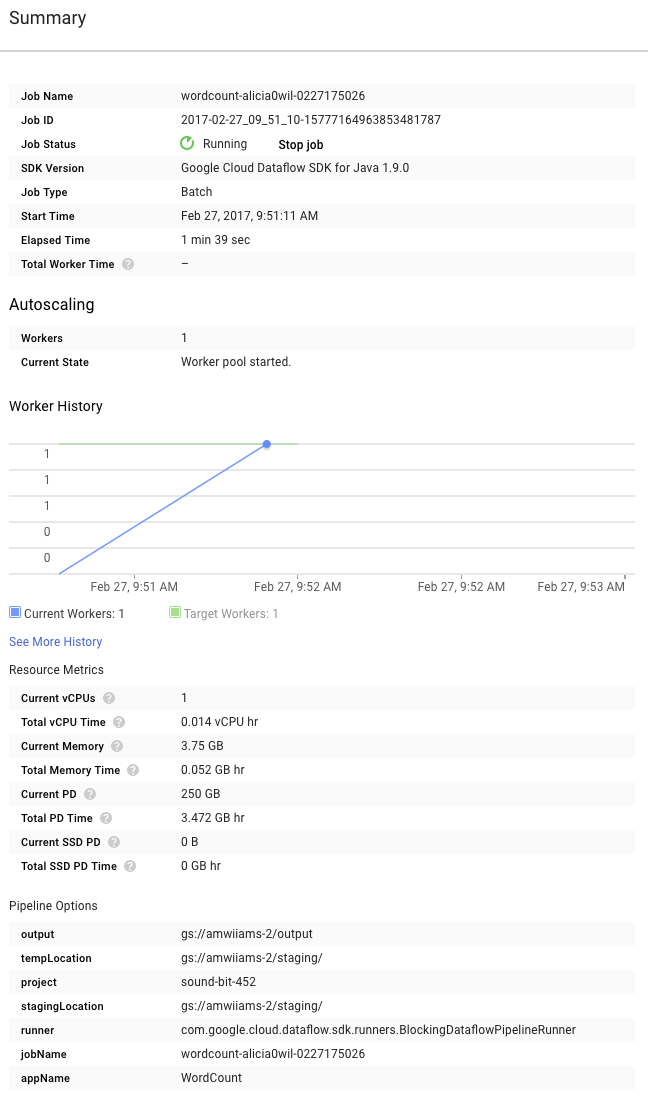
Możesz też wyświetlić liczniki niestandardowe potoku, które w tym przypadku pokazują, ile pustych wierszy napotkano do tej pory podczas wykonywania. Możesz dodawać do potoku nowe liczniki, aby śledzić dane dotyczące konkretnej aplikacji.
Aby wyświetlić konkretne komunikaty o błędach, możesz kliknąć ikonę Logi.

Wiadomości wyświetlane na karcie Dziennik zadań możesz filtrować za pomocą menu Minimalny poziom ważności.

Aby wyświetlić logi procesów roboczych instancji Compute Engine, które obsługują potok, na karcie logów kliknij przycisk Logi procesów roboczych. Logi procesów roboczych zawierają wiersze logów generowane przez Twój kod i kod wygenerowany przez Dataflow, który go uruchamia.
Jeśli próbujesz debugować błąd w potoku, w dziennikach procesów często znajdziesz dodatkowe informacje, które pomogą Ci rozwiązać problem. Pamiętaj, że te logi są agregowane we wszystkich instancjach roboczych i można je filtrować oraz w nich wyszukiwać.
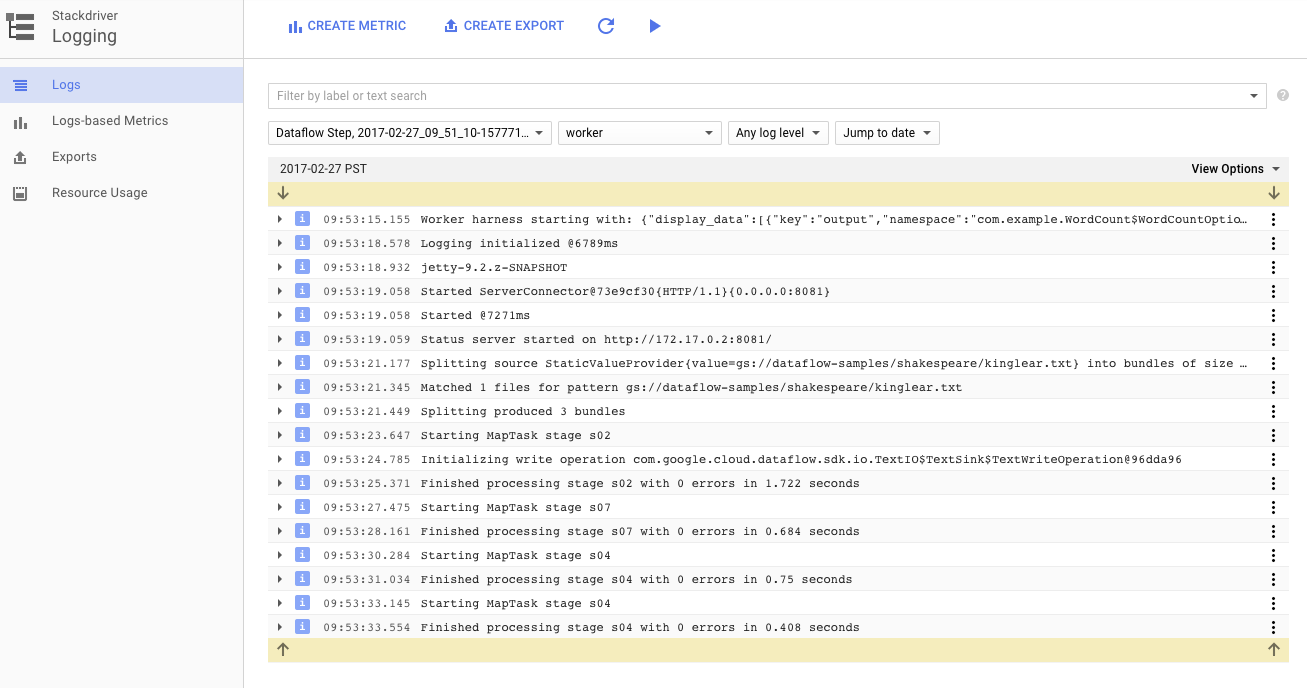
W następnym kroku sprawdzimy, czy zadanie zakończyło się sukcesem.
Otwórz interfejs monitorujący Cloud Dataflow w konsoli Google Cloud Platform.
Zadanie wordcount powinno być widoczne na początku i mieć stan Uruchomiono, a potem Ukończono:

Wykonanie zadania zajmie około 3–4 minut.
Pamiętasz, kiedy uruchamiałeś potok i wskazałeś zasobnik wyjściowy? Przyjrzyjmy się wynikowi (bo czyż nie chcesz wiedzieć, ile razy każde słowo w Królu Learze się pojawiło?!). Wróć do przeglądarki Cloud Storage w konsoli Google Cloud Platform. W zasobniku powinny wyświetlić się pliki wyjściowe i pliki etapów przejściowych utworzone przez zadanie:
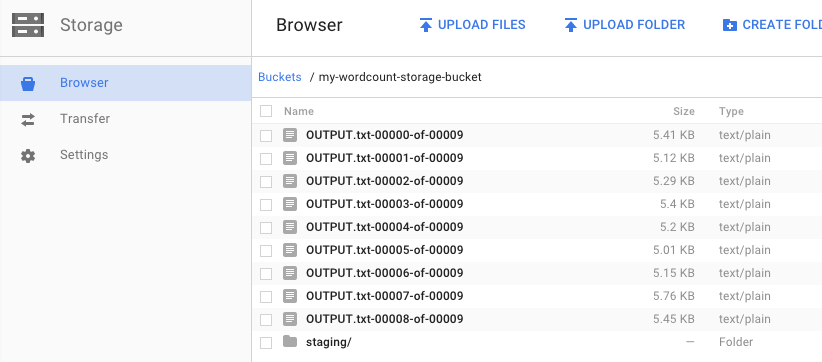
Zasoby możesz zamknąć w konsoli Google Cloud Platform.
Otwórz przeglądarkę Cloud Storage w konsoli Google Cloud Platform.
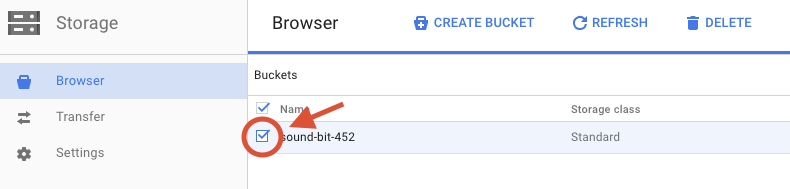
Zaznacz pole wyboru obok utworzonego zasobnika.
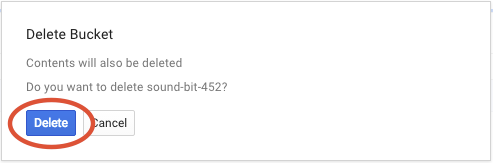
Kliknij USUŃ, aby trwale usunąć zasobnik i jego zawartość.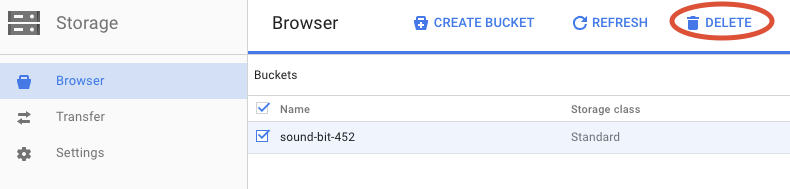
Wiesz już, jak utworzyć projekt Maven z pakietem Cloud Dataflow SDK, uruchomić przykładowy potok za pomocą konsoli Google Cloud Platform oraz usunąć powiązany zasobnik Cloud Storage i jego zawartość.
Więcej informacji
- Dokumentacja Dataflow: https://cloud.google.com/dataflow/docs/
Licencja
Ten utwór jest dostępny na licencji Creative Commons Attribution 3.0 Generic oraz Apache 2.0.