
Dataflow è un modello di programmazione unificato e un servizio gestito per lo sviluppo e l'esecuzione di un'ampia gamma di pattern di elaborazione dati, tra cui ETL, calcolo in batch e calcolo continuo. Poiché Dataflow è un servizio gestito, può allocare risorse on demand per ridurre al minimo la latenza, mantenendo al contempo un'elevata efficienza di utilizzo.
Il modello Dataflow combina l'elaborazione batch e di flusso, in modo che gli sviluppatori non debbano scendere a compromessi tra correttezza, costi e tempi di elaborazione. In questo codelab imparerai a eseguire una pipeline Dataflow che conta le occorrenze di parole uniche in un file di testo.
Questo tutorial è adattato da https://cloud.google.com/dataflow/docs/quickstarts/quickstart-java-maven
Cosa imparerai a fare
- Come creare un progetto Maven con Cloud Dataflow SDK
- Esegui una pipeline di esempio utilizzando la console di Google Cloud
- Come eliminare il bucket Cloud Storage associato e i relativi contenuti
Che cosa ti serve
Come utilizzerai questo tutorial?
Come valuti la tua esperienza di utilizzo dei servizi Google Cloud Platform?
Configurazione dell'ambiente autonoma
Se non hai ancora un Account Google (Gmail o Google Apps), devi crearne uno. Accedi alla console di Google Cloud (console.cloud.google.com) e crea un nuovo progetto:



Ricorda l'ID progetto, un nome univoco per tutti i progetti Google Cloud (il nome riportato sopra è già stato utilizzato e non funzionerà per te, mi dispiace). In questo codelab verrà chiamato PROJECT_ID.
Successivamente, dovrai abilitare la fatturazione nella console Cloud per utilizzare le risorse Google Cloud.
L'esecuzione di questo codelab non dovrebbe costarti più di qualche dollaro, ma potrebbe essere più cara se decidi di utilizzare più risorse o se le lasci in esecuzione (vedi la sezione "Pulizia" alla fine di questo documento).
I nuovi utenti di Google Cloud Platform possono beneficiare di una prova senza costi di 300$.
Abilita le API
Fai clic sull'icona del menu nella parte superiore sinistra dello schermo.

Seleziona API Manager dal menu a discesa.

Cerca "Google Compute Engine" nella casella di ricerca. Fai clic su "API Google Compute Engine" nell'elenco dei risultati visualizzato.
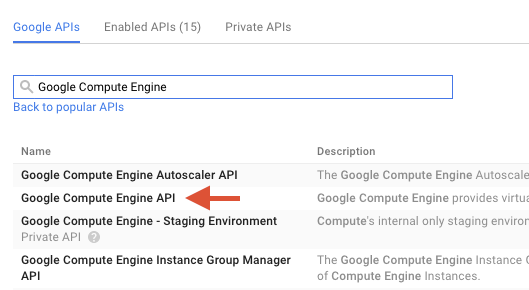
Nella pagina di Google Compute Engine, fai clic su Attiva.
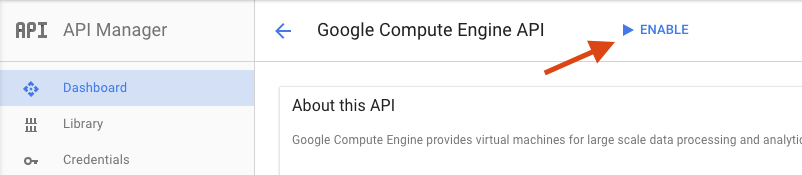
Una volta attivata, fai clic sulla freccia per tornare indietro.
Ora cerca le seguenti API e abilita anche queste:
- API Google Dataflow
- API Stackdriver Logging
- Google Cloud Storage
- API JSON di Google Cloud Storage
- API BigQuery
- API Google Cloud Pub/Sub
- API Google Cloud Datastore
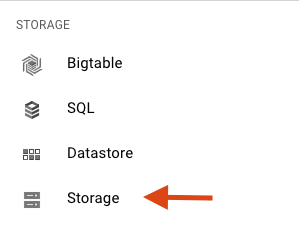
Nella console di Google Cloud Platform, fai clic sull'icona Menu in alto a sinistra dello schermo:
Scorri verso il basso e seleziona Cloud Storage nella sottosezione Spazio di archiviazione:
Ora dovresti vedere il browser Cloud Storage e, supponendo che tu stia utilizzando un progetto che attualmente non ha bucket Cloud Storage, vedrai una finestra di dialogo che ti invita a creare un nuovo bucket:
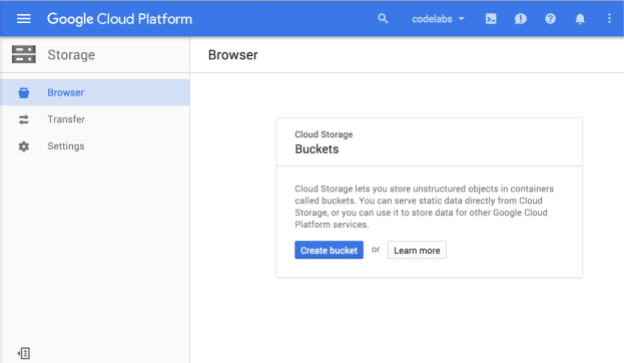
Premi il pulsante Crea bucket per crearne uno:
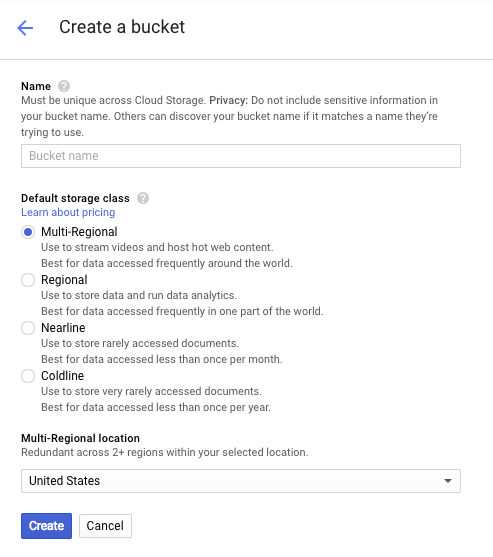
Inserisci un nome per il bucket. Come indicato nella finestra di dialogo, i nomi dei bucket devono essere univoci in tutto Cloud Storage. Pertanto, se scegli un nome ovvio, ad esempio "test", probabilmente scoprirai che qualcun altro ha già creato un bucket con quel nome e riceverai un errore.
Esistono anche alcune regole relative ai caratteri consentiti nei nomi dei bucket. Se il nome del bucket inizia e termina con una lettera o un numero e contiene solo trattini al centro, non avrai problemi. Se provi a utilizzare caratteri speciali o a iniziare o terminare il nome del bucket con un carattere diverso da una lettera o un numero, la finestra di dialogo ti ricorderà le regole.
Inserisci un nome univoco per il bucket e premi Crea. Se scegli un nome già in uso, verrà visualizzato il messaggio di errore mostrato sopra. Una volta creato correttamente un bucket, si aprirà nel browser il nuovo bucket vuoto:
Il nome del bucket che vedi sarà ovviamente diverso, poiché deve essere univoco in tutti i progetti.
Attiva Google Cloud Shell
Nella console GCP, fai clic sull'icona di Cloud Shell nella barra degli strumenti in alto a destra:

Poi fai clic su "Avvia Cloud Shell":

Bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente:

Questa macchina virtuale è caricata con tutti gli strumenti di sviluppo di cui avrai bisogno. Offre una home directory permanente da 5 GB e viene eseguita su Google Cloud, migliorando notevolmente le prestazioni di rete e l'autenticazione. Gran parte, se non tutto, il lavoro in questo lab può essere svolgersi semplicemente con un browser o con Google Chromebook.
Una volta eseguita la connessione a Cloud Shell, dovresti vedere che il tuo account è già autenticato e il progetto è già impostato sul tuo PROJECT_ID.
Esegui questo comando in Cloud Shell per verificare che l'account sia autenticato:
gcloud auth list
Output comando
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Output comando
[core] project = <PROJECT_ID>
In caso contrario, puoi impostarlo con questo comando:
gcloud config set project <PROJECT_ID>
Output comando
Updated property [core/project].
Dopo l'avvio di Cloud Shell, iniziamo creando un progetto Maven contenente l'SDK Cloud Dataflow per Java.
Esegui il comando mvn archetype:generate nella shell nel seguente modo:
mvn archetype:generate \
-DarchetypeArtifactId=google-cloud-dataflow-java-archetypes-examples \
-DarchetypeGroupId=com.google.cloud.dataflow \
-DarchetypeVersion=1.9.0 \
-DgroupId=com.example \
-DartifactId=first-dataflow \
-Dversion="0.1" \
-DinteractiveMode=false \
-Dpackage=com.exampleDopo aver eseguito il comando, dovresti visualizzare una nuova directory denominata first-dataflow nella directory corrente. first-dataflow contiene un progetto Maven che include l'SDK Cloud Dataflow per Java e pipeline di esempio.
Iniziamo salvando l'ID progetto e i nomi dei bucket Cloud Storage come variabili di ambiente. Puoi farlo in Cloud Shell. Assicurati di sostituire <your_project_id> con l'ID del tuo progetto.
export PROJECT_ID=<your_project_id>Ora faremo lo stesso per il bucket Cloud Storage. Ricorda di sostituire <your_bucket_name> con il nome univoco che hai utilizzato per creare il bucket in un passaggio precedente.
export BUCKET_NAME=<your_bucket_name>Passa alla directory first-dataflow/.
cd first-dataflowEseguiremo una pipeline chiamata WordCount, che legge il testo, tokenizza le righe di testo in singole parole ed esegue un conteggio della frequenza per ciascuna parola. Innanzitutto, eseguiamo la pipeline e, mentre è in esecuzione, diamo un'occhiata a cosa succede in ogni passaggio.
Avvia la pipeline eseguendo il comando mvn compile exec:java nella finestra della shell o del terminale. Per gli argomenti --project, --stagingLocation, e --output, il comando riportato di seguito fa riferimento alle variabili di ambiente che hai configurato in precedenza in questo passaggio.
mvn compile exec:java \
-Dexec.mainClass=com.example.WordCount \
-Dexec.args="--project=${PROJECT_ID} \
--stagingLocation=gs://${BUCKET_NAME}/staging/ \
--output=gs://${BUCKET_NAME}/output \
--runner=BlockingDataflowPipelineRunner"Mentre il job è in esecuzione, cerchiamolo nell'elenco dei job.
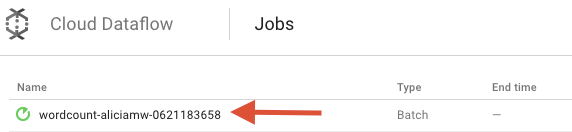
Apri l'interfaccia utente di monitoraggio di Cloud Dataflow nella console della piattaforma Google Cloud. Dovresti vedere il tuo job wordcount con lo stato In esecuzione:

Ora esaminiamo i parametri della pipeline. Inizia facendo clic sul nome del job:
Quando selezioni un job, puoi visualizzare il grafico di esecuzione. Il grafico di esecuzione di una pipeline rappresenta ogni trasformazione nella pipeline come una casella che contiene il nome della trasformazione e alcune informazioni sullo stato. Puoi fare clic sul simbolo a V nell'angolo in alto a destra di ogni passaggio per visualizzare ulteriori dettagli:
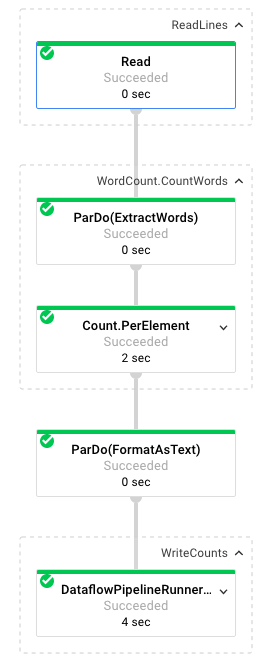
Vediamo come la pipeline trasforma i dati in ogni passaggio:
- Lettura: in questo passaggio, la pipeline legge da un'origine di input. In questo caso, si tratta di un file di testo di Cloud Storage con l'intero testo dell'opera teatrale King Lear di Shakespeare. La nostra pipeline legge il file riga per riga e restituisce un
PCollection, in cui ogni riga del file di testo è un elemento della raccolta. - CountWords: il passaggio
CountWordsè composto da due parti. Innanzitutto, utilizza una funzione parallela do (ParDo) denominataExtractWordsper tokenizzare ogni riga in singole parole. L'output di ExtractWords è un nuovo PCollection in cui ogni elemento è una parola. Il passaggio successivo,Count, utilizza una trasformazione fornita dall'SDK Dataflow che restituisce coppie chiave-valore in cui la chiave è una parola univoca e il valore è il numero di volte in cui si verifica. Ecco il metodo che implementaCountWords. Puoi consultare il file WordCount.java completo su GitHub:
/**
* A PTransform that converts a PCollection containing lines of text
* into a PCollection of formatted word counts.
*/
public static class CountWords extends PTransform<PCollection<String>,
PCollection<KV<String, Long>>> {
@Override
public PCollection<KV<String, Long>> apply(PCollection<String> lines) {
// Convert lines of text into individual words.
PCollection<String> words = lines.apply(
ParDo.of(new ExtractWordsFn()));
// Count the number of times each word occurs.
PCollection<KV<String, Long>> wordCounts =
words.apply(Count.<String>perElement());
return wordCounts;
}
}- FormatAsText: questa è una funzione che formatta ogni coppia chiave-valore in una stringa stampabile. Ecco la trasformazione
FormatAsTextda implementare:
/** A SimpleFunction that converts a Word and Count into a printable string. */
public static class FormatAsTextFn extends SimpleFunction<KV<String, Long>, String> {
@Override
public String apply(KV<String, Long> input) {
return input.getKey() + ": " + input.getValue();
}
}- WriteCounts: in questo passaggio scriviamo le stringhe stampabili in più file di testo suddivisi in shard.
Esamineremo l'output risultante della pipeline tra qualche minuto.
Ora dai un'occhiata alla pagina Riepilogo a destra del grafico, che include i parametri della pipeline che abbiamo incluso nel comando mvn compile exec:java.
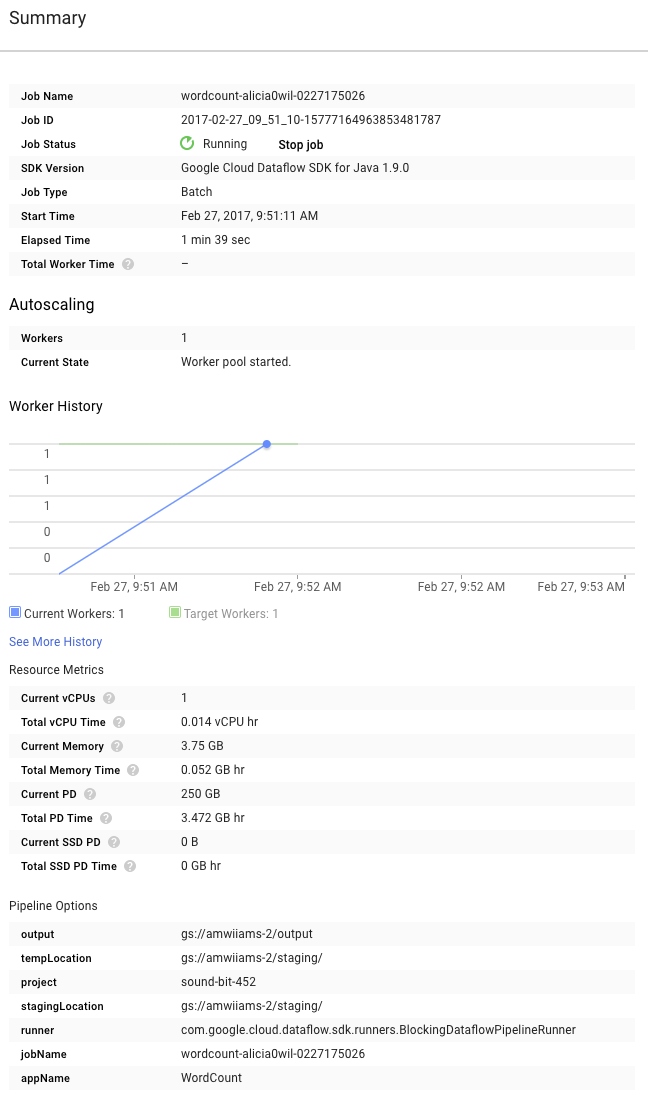
Puoi anche visualizzare i contatori personalizzati per la pipeline, che in questo caso mostrano quante righe vuote sono state rilevate finora durante l'esecuzione. Puoi aggiungere nuovi contatori alla pipeline per monitorare le metriche specifiche dell'applicazione.
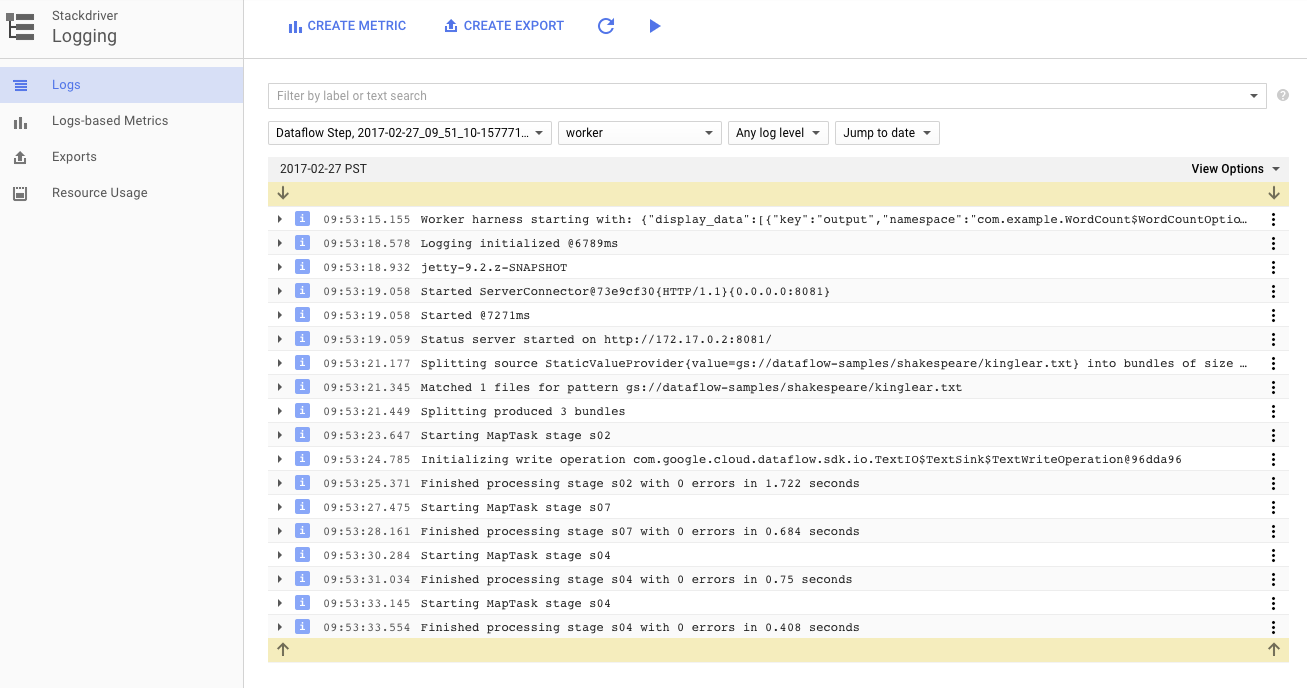
Puoi fare clic sull'icona Log per visualizzare i messaggi di errore specifici.

Puoi filtrare i messaggi visualizzati nella scheda Log job utilizzando il menu a discesa Gravità minima.

Puoi utilizzare il pulsante Log worker nella scheda Log per visualizzare i log worker per le istanze di Compute Engine che eseguono la pipeline. I log dei worker sono costituiti da righe di log generate dal tuo codice e dal codice generato da Dataflow che lo esegue.
Se stai tentando di eseguire il debug di un errore nella pipeline, spesso nei log dei worker sono presenti log aggiuntivi che aiutano a risolvere il problema. Tieni presente che questi log vengono aggregati in tutti i worker e possono essere filtrati e cercati.
Nel passaggio successivo, verificheremo che il job sia stato eseguito correttamente.
Apri l'interfaccia utente di monitoraggio di Cloud Dataflow nella console della piattaforma Google Cloud.
Inizialmente dovresti vedere il tuo job wordcount con stato In esecuzione, poi Riuscito:

L'esecuzione del job richiederà circa 3-4 minuti.
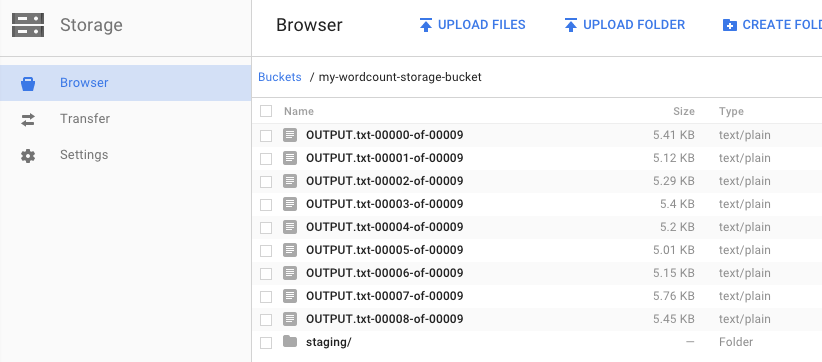
Ricordi quando hai eseguito la pipeline e hai specificato un bucket di output? Diamo un'occhiata al risultato (perché non vuoi vedere quante volte compare ogni parola in Re Lear?). Torna al browser Cloud Storage nella console Google Cloud. Nel bucket dovresti vedere i file di output e di staging creati dal job:
Puoi arrestare le risorse dalla console di Google Cloud Platform.
Apri il browser Cloud Storage nella console Google Cloud.
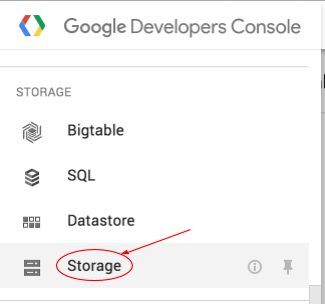
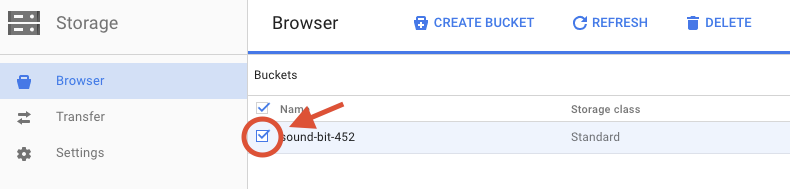
Seleziona la casella di controllo accanto al bucket che hai creato.
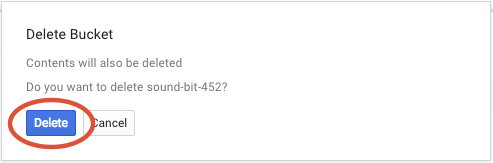
Fai clic su ELIMINA per eliminare definitivamente il bucket e i relativi contenuti.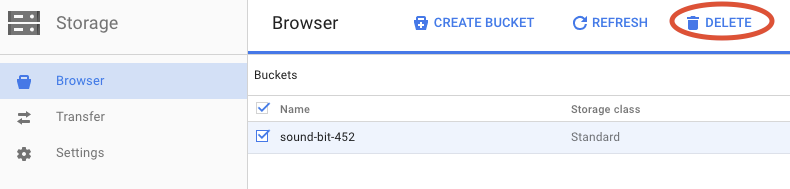
Hai imparato a creare un progetto Maven con l'SDK di Cloud Dataflow, a eseguire una pipeline di esempio utilizzando la console Google Cloud e a eliminare il bucket Cloud Storage associato e i relativi contenuti.
Scopri di più
- Documentazione di Dataflow: https://cloud.google.com/dataflow/docs/
Licenza
Questo lavoro è concesso in licenza ai sensi di una licenza Creative Commons Attribution 3.0 Generic e di una licenza Apache 2.0.