
本程式碼研究室將介紹一些 BigQuery 進階功能的使用方法,包括:
- JavaScript 中的使用者定義函式
- 分區資料表
- 直接查詢 Google Cloud Storage 和 Google 雲端硬碟中的資料。
您將取得美國聯邦選舉委員會的資料,予以清理並載入至 BigQuery。您也有機會對該資料集提出一些有趣的問題。
雖然這個程式碼研究室不認為之前有 BigQuery 經驗,但熟悉 SQL 將有助於您充分運用這項服務。
課程內容
- 如何使用 JavaScript 使用者定義的函式來執行 SQL 中難以執行的操作。
- 如何使用 BigQuery 對儲存在其他資料儲存庫 (例如 Google Cloud Storage 和 Google 雲端硬碟) 中的資料執行 ETL (擷取、轉換、載入) 作業。
軟硬體需求
- Google Cloud 專案已啟用計費功能。
- Google Cloud Storage 值區
- 已安裝 Google Cloud SDK
您要如何使用本教學課程?
您對於 BigQuery 使用體驗的評價如何?
自行調整環境設定
如果您還沒有 Google 帳戶 (Gmail 或 Google Apps),請先建立帳戶。登入 Google Cloud Platform 主控台 (console.cloud.google.com),然後建立新專案:



提醒您,專案編號是所有 Google Cloud 專案的不重複名稱 (使用上述名稱後就無法使用,敬請見諒!)此程式碼研究室稍後將稱為 PROJECT_ID。
接著,您必須在 Cloud Console 中啟用計費功能,才能使用 Google Cloud 資源。
完成這個程式碼研究室的成本應該不會超過新臺幣 $300 元,但如果您決定繼續使用更多資源,或是讓資源繼續運作 (請參閱本文件結尾的「清除設定」一節),就有可能需要更多成本。
新加入 Google Cloud Platform 的使用者可免費試用 $300 美元。
Google Cloud Shell
雖然 Google Cloud 和 BigQuery 可以在您的筆記型電腦上執行遠端作業,但在這個程式碼研究室中,我們會使用 Google Cloud Shell,這是一個在 Cloud 上執行的指令列環境。
這款以 Debian 為基礎的虛擬機器會載入您需要的所有開發工具。這項服務提供永久性的 5GB 主目錄,可在 Google Cloud 中運作,大幅提升網路效能和驗證效能。也就是說,這個程式碼研究室只需使用瀏覽器 (是,您可以在 Chromebook 上使用)。
如要啟用 Google Cloud Shell,只要在開發人員控制台中,按一下右上角的按鈕 (只需幾分鐘即可佈建並連線至環境):

按一下 [Start Cloud Shell] 按鈕:


連線至 Cloud Shell 之後,您應該會看到您已經通過驗證,且專案已設為 PROJECT_ID。
gcloud auth list
指令輸出
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
指令輸出
[core] project = <PROJECT_ID>
根據預設,Cloud Shell 也會設定某些環境變數,當您執行未來指令時可能會用到這個變數。
echo $GOOGLE_CLOUD_PROJECT
指令輸出
<PROJECT_ID>
如果因為某些原因而無法設定專案,只要發出下列指令即可:
gcloud config set project <PROJECT_ID>
正在尋找您的 PROJECT_ID 嗎?您可以查看在設定步驟中使用的 ID,或是在控制台資訊主頁查詢 ID:

重要事項:最後,請設定預設區域和專案設定:
gcloud config set compute/zone us-central1-f
您可以選擇多種不同的區域。詳情請參閱地區和區域說明文件。
為了在此程式碼研究室中執行 BigQuery 查詢,您需要自己的資料集。選擇一個名稱,例如 campaign_funding。在殼層中執行下列指令 (例如 Cloud Shell):
$ DATASET=campaign_funding
$ bq mk -d ${DATASET}
Dataset 'bq-campaign:campaign_funding' successfully created.
資料集建立完成後,您應該就可以開始執行了。執行這個步驟也應該有助於確認是否已正確設定 bq 指令列用戶端、驗證作業是否正常運作,以及您具備操作的雲端專案寫入權限。如果您有多個專案,系統會提示您從清單中選取您感興趣的專案。

美國聯邦選舉委員會的廣告活動財務資料集已壓縮並複製到 GCS 值區 gs://campaign-funding/。
讓我們將本機來源檔案下載到本機,以便檢視其中內容。在命令視窗中執行下列指令:
$ gsutil cp gs://campaign-funding/indiv16.txt . $ tail indiv16.txt
系統應會顯示個別貢獻檔案的內容。我們為這個程式碼研究室尋找了三類檔案,包括:個人貢獻 (indiv*.txt)、求職者 (cn*.txt) 和委員會 (cm*.txt)。如果您有興趣,請運用相同機制,看看其中有哪些檔案。
我們不會直接在原始資料中載入原始資料,而是從 Google Cloud Storage 查詢資料。因此,我們必須瞭解架構以及一些相關資訊。
如要瞭解此資料集,請參閱聯邦選舉網站。我們看到的表格結構定義如下:
為了連結到資料表,我們必須為包含結構定義的表格建立資料表定義。執行下列指令來產生個別資料表定義:
$ bq mkdef --source_format=CSV \
gs://campaign-funding/indiv*.txt \
"CMTE_ID, AMNDT_IND, RPT_TP, TRANSACTION_PGI, IMAGE_NUM, TRANSACTION_TP, ENTITY_TP, NAME, CITY, STATE, ZIP_CODE, EMPLOYER, OCCUPATION, TRANSACTION_DT, TRANSACTION_AMT:FLOAT, OTHER_ID, TRAN_ID, FILE_NUM, MEMO_CD, MEMO_TEXT, SUB_ID" \
> indiv_def.json
使用您慣用的文字編輯器開啟 indiv_dev.json 檔案並查看內容,其中會包含說明如何解讀 FEC 資料檔案的 json 檔案。
我們必須對 csvOptions 區段進行小幅修改。加入「||」的 fieldDelimiter 值,並將 quote 的值設為 "" (空字串)。這是必要的,因為資料檔案實際上是以半形逗號分隔,而且是用直立線分隔:
$ sed -i 's/"fieldDelimiter": ","/"fieldDelimiter": "|"/g; s/"quote": "\\""/"quote":""/g' indiv_def.json
indiv_dev.json 檔案現在應已讀取:
"fieldDelimiter": "|",
"quote":"",
由於委員會和候選表格的表格定義類似,而且架構包含公式化的公式,因此請下載這些檔案。
$ gsutil cp gs://campaign-funding/candidate_def.json . Copying gs://campaign-funding/candidate_def.json... / [1 files][ 945.0 B/ 945.0 B] Operation completed over 1 objects/945.0 B. $ gsutil cp gs://campaign-funding/committee_def.json . Copying gs://campaign-funding/committee_def.json... / [1 files][ 949.0 B/ 949.0 B] Operation completed over 1 objects/949.0 B.
這些檔案的格式與 indiv_dev.json 檔案類似。請注意,您也可以下載 indiv_def.json 檔案,以協助獲得正確的值。
接著,我們開始將 BigQuery 資料表連結至這些檔案。執行下列指令:
$ bq mk --external_table_definition=indiv_def.json -t ${DATASET}.transactions
Table 'bq-campaign:campaign_funding.transactions' successfully created.
$ bq mk --external_table_definition=committee_def.json -t ${DATASET}.committees
Table 'bq-campaign:campaign_funding.committees' successfully created.
$ bq mk --external_table_definition=candidate_def.json -t ${DATASET}.candidates
Table 'bq-campaign:campaign_funding.candidates' successfully created.
這項操作會建立三個 BigQuery 資料表:交易、修訂版本和候選項目。您可以查詢這些資料表,就像一般的 BigQuery 資料表一樣,但實際上不儲存在 BigQuery 中,而是儲存在 Google Cloud Storage 中。如果您更新基礎檔案,變更內容會立即反映在您所執行的查詢中。
接著,我們開始嘗試執行幾項查詢。開啟 BigQuery 網頁 UI。

在左側導覽窗格中找出資料集 (您可能需要變更左上角的專案下拉式選單),按一下紅色的 [COMQUERYE QUERY'] 按鈕,然後在方塊中輸入下列查詢:
SELECT * FROM [campaign_funding.transactions] WHERE EMPLOYER contains "GOOGLE" ORDER BY TRANSACTION_DT DESC LIMIT 100
這樣會找到 Google 員工最近捐款的 100 項廣告活動。如果您願意,也可以試著尋找您居住地的居民捐款活動,或尋找市內最大的捐款金額。
查詢和結果看起來會像這樣:
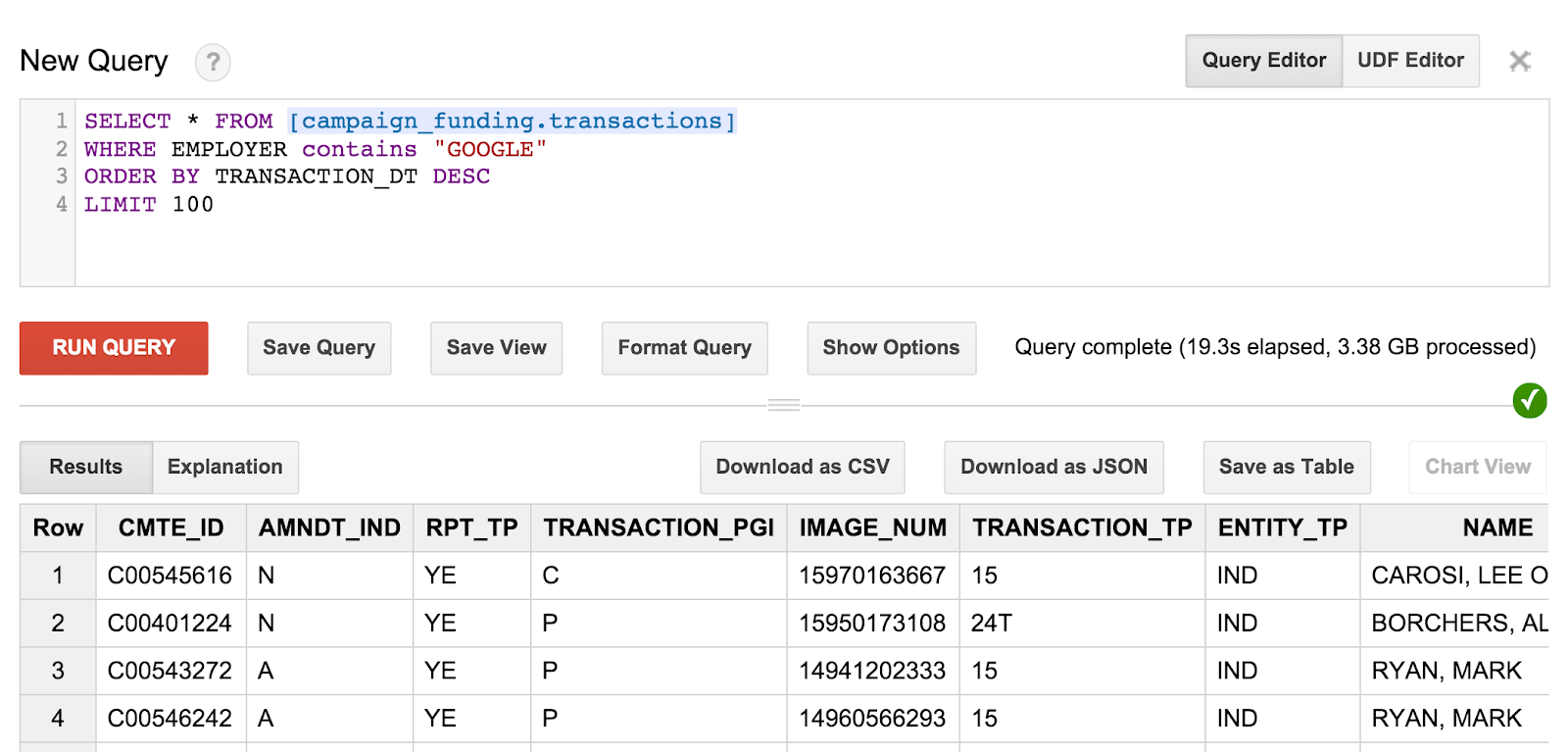
不過,您也許會注意到,您無法確實判斷受款人是誰。為了獲得這些資訊,我們必須提出一些更籠統的查詢。
按一下左側窗格中的交易表格,然後按一下 [架構] 標籤。螢幕截圖應如下所示:
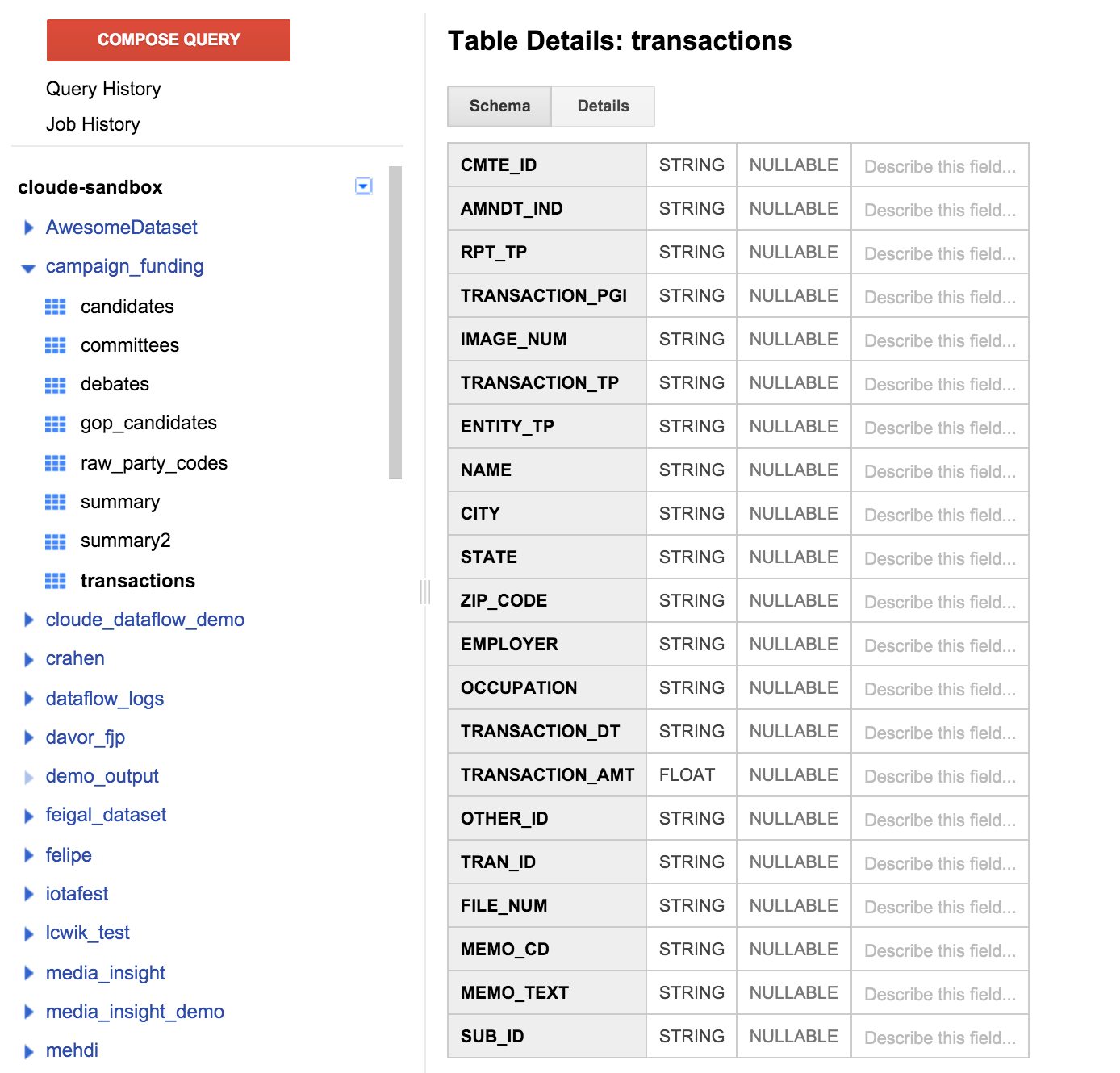
我們可以看到一份欄位,與先前指定的表格定義相符。你可能會發現沒有填寫欄位,或以任何方式來確認你支持的捐款項目。不過,有一個名為 CMTE_ID 的欄位。方便我們為捐助者的捐款連至該委員會。這樣還是不實用。
接下來,按一下「佣金」資料表即可查看其結構定義。我們有一組 CMET_ID,可加入交易表格。另一個欄位為 CAND_ID;可與候選表格中的 CAND_ID 資料表合併。最後,我們將透過佣金表格,針對交易和候選人之間建立連結。
請注意,GCS 表格沒有預覽分頁。這是因為為了讀取資料,BigQuery 需要從外部資料來源讀取資料。執行簡單的「SELECT *'」查詢候選項目表格,取得資料樣本。
SELECT * FROM [campaign_funding.candidates] LIMIT 100
結果應如下所示:
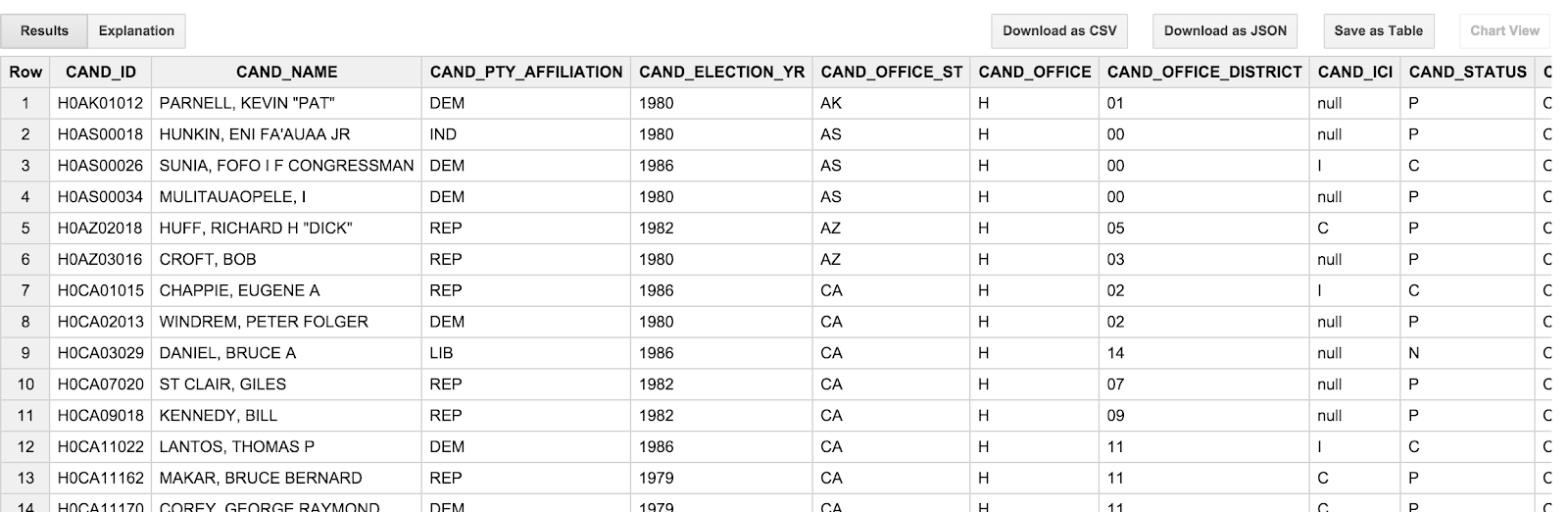
您可能會注意到,候選者的名字都是「全大寫」,並以「姓氏、名字」的順序顯示。這有點令人困擾,因為其實這並不代表我們對於候選者的看法;我們不認為「歐巴馬」要比「OBAMA, BARACK」多了。此外,交易表格中的交易日期 (TRANSACTION_DT) 也有點尷尬,格式為 YYYYMMDD 的字串值。我們將在下一節說明這些疑難雜症。
釐清交易與候選資料的關聯後,現在您可以執行查詢,看看有哪些人為對象。剪下以下查詢,並貼到撰寫方塊中:
SELECT affiliation, SUM(amount) AS amount
FROM (
SELECT *
FROM (
SELECT
t.amt AS amount,
t.occupation AS occupation,
c.affiliation AS affiliation,
FROM (
SELECT
trans.TRANSACTION_AMT AS amt,
trans.OCCUPATION AS occupation,
cmte.CAND_ID AS CAND_ID
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CAND_ID) AS CAND_ID
FROM [campaign_funding.committees]
GROUP EACH BY CMTE_ID ) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) AS t
RIGHT OUTER JOIN EACH (
SELECT
CAND_ID,
FIRST(CAND_PTY_AFFILIATION) AS affiliation,
FROM [campaign_funding.candidates]
GROUP EACH BY CAND_ID) c
ON t.CAND_ID = c.CAND_ID )
WHERE occupation CONTAINS "ENGINEER")
GROUP BY affiliation
ORDER BY amount DESC
這個查詢會將交易資料表彙整至資料表資料表,再加入候選資料表。只會查看職稱中「ENGINEER」一詞的交易。這項查詢會彙整各方聯盟的結果,方便我們查看工程師在各政黨中的分佈情形。
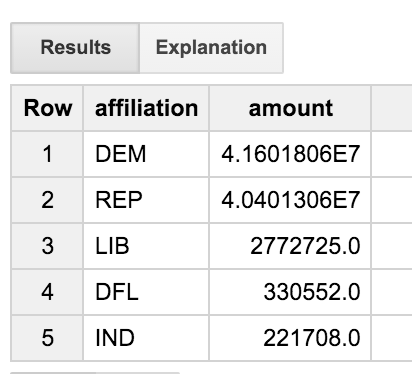
我們發現,工程師的平衡相當成熟,讓民主和共和國民眾平均增加或減少。但什麼是「DFL' Party」?如果只輸入 3 個字母的代碼,不算實際會用到全名,這樣是不是很好的?
派對代碼是由 FEC 網站定義。有一份表格比對派對代碼與全名 (例如「DFL' is “Democratic-Farmer-Labor'{/1}」)。雖然我們可以手動在查詢中執行翻譯,但這似乎是相當費工的工作,而且很難保持同步。
如果我們可以在查詢中剖析 HTML,那該怎麼處理呢?在網頁上的任何位置按一下滑鼠右鍵,然後查看「檢視網頁原始碼」。來源中有許多標頭 / 樣板資訊,但要找出 <table> 標記。每個對應資料列都屬於 HTML <tr> 元素,因此名稱和程式碼會分別納入 <td> 元素中。每列如下所示:
HTML 格式如下所示:
<tr bgcolor="#F5F0FF">
<td scope="row"><div align="left">ACE</div></td>
<td scope="row">Ace Party</td>
<td scope="row"></td>
</tr>
請注意,BigQuery 無法直接從網路讀取檔案,這是因為 BigQuery 能夠同時從數千個工作站擷取來源。如果已允許隨機網頁執行,基本上就是分散式阻斷服務攻擊 (DDoS)。FEC 網頁的 HTML 檔案會儲存在 gs://campaign-funding 值區中。
我們需要依據廣告活動的資金資料建立表格。這類似於我們建立的其他 GCS 支援資料表。差別在於,我們實際上並沒有採用結構定義,因此每列只會使用一個欄位,並命名為「data'」。我們會將該欄視為 CSV 檔案,但不含逗號分隔,而是使用大分隔符號 (`) 且不含引號字元。
如要建立派對資料表,請從指令列執行下列指令:
$ echo '{"csvOptions": {"allowJaggedRows": false, "skipLeadingRows": 0, "quote": "", "encoding": "UTF-8", "fieldDelimiter": "`", "allowQuotedNewlines": false}, "ignoreUnknownValues": true, "sourceFormat": "CSV", "sourceUris": ["gs://campaign-funding/party_codes.shtml"], "schema": {"fields": [{"type": "STRING", "name": "data"}]}}' > party_raw_def.json
$ bq mk --external_table_definition=party_raw_def.json \
-t ${DATASET}.raw_party_codes
Table 'bq-campaign:campaign_funding.raw_party_codes' successfully created.
現在我們將使用 JavaScript 剖析檔案。「BigQuery 查詢編輯器」的右上角應該有 [UDF 編輯器] 按鈕。按一下即可切換以編輯 JavaScript UDF。UDF 編輯器會填入一些已加註的樣板。

請直接刪除當中的程式碼,然後輸入以下程式碼:
function tableParserFun(row, emitFn) {
if (row.data != null && row.data.match(/<tr.*<\/tr>/) !== null) {
var txt = row.data
var re = />\s*(\w[^\t<]*)\t*<.*>\s*(\w[^\t<]*)\t*</;
matches = txt.match(re);
if (matches !== null && matches.length > 2) {
var result = {code: matches[1], name: matches[2]};
emitFn(result);
} else {
var result = { code: 'ERROR', name: matches};
emitFn(result);
}
}
}
bigquery.defineFunction(
'tableParser', // Name of the function exported to SQL
['data'], // Names of input columns
[{'name': 'code', 'type': 'string'}, // Output schema
{'name': 'name', 'type': 'string'}],
tableParserFun // Reference to JavaScript UDF
);
這裡的 JavaScript 分成兩部分,第一種函式會擷取一列的輸入內容,以產生剖析的輸出。另一個則是將函式登錄為「使用者定義函式 (UDF)」中,名稱為「tableParser」,代表其會採用名為「data'」的輸入資料欄,並輸出兩個資料欄、程式碼和名稱。代碼欄是 3 個字母的代碼,「名稱」欄則是政黨的全名。
切換回「查詢編輯器」分頁,然後輸入以下查詢:
SELECT code, name FROM tableParser([campaign_funding.raw_party_codes]) ORDER BY code
執行這項查詢會剖析原始 HTML 檔案,並以結構化格式輸出欄位值。非常漂亮,對吧?試著找出「DFL'」是什麼意思。
現在,我們可以將派對代碼轉換成名字,再嘗試改用另一個查詢來找出有趣的查詢。執行下列查詢:
SELECT
candidate,
election_year,
FIRST(candidate_affiliation) AS affiliation,
SUM(amount) AS amount
FROM (
SELECT
CONCAT(REGEXP_EXTRACT(c.candidate_name,r'\w+,[ ]+([\w ]+)'), ' ',
REGEXP_EXTRACT(c.candidate_name,r'(\w+),')) AS candidate,
pty.candidate_affiliation_name AS candidate_affiliation,
c.election_year AS election_year,
t.amt AS amount,
FROM (
SELECT
trans.TRANSACTION_AMT AS amt,
cmte.committee_candidate_id AS committee_candidate_id
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CAND_ID) AS committee_candidate_id
FROM [campaign_funding.committees]
GROUP BY CMTE_ID ) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) AS t
RIGHT OUTER JOIN EACH (
SELECT
CAND_ID AS candidate_id,
FIRST(CAND_NAME) AS candidate_name,
FIRST(CAND_PTY_AFFILIATION) AS affiliation,
FIRST(CAND_ELECTION_YR) AS election_year,
FROM [campaign_funding.candidates]
GROUP BY candidate_id) c
ON t.committee_candidate_id = c.candidate_id
JOIN (
SELECT
code,
name AS candidate_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty
ON pty.code = c.affiliation )
GROUP BY candidate, election_year
ORDER BY amount DESC
LIMIT 100
這項查詢會顯示哪些候選人獲得最多廣告活動捐款,並拼出自己的政黨。
這些表格的大小不大,查詢大約需要 30 秒。如果要為表格進行許多工作,建議您將這些資料匯入 BigQuery。您可以對資料表執行 ETL 查詢,將資料整理成易於使用的操作,然後將其儲存為永久資料表。這表示,您不一定要記住如何翻譯派對代碼,您也可以在執行搜尋時排除錯誤資料。
按一下 [顯示選項] 按鈕,然後按一下 [選取表格] 按鈕旁的「選取表格」按鈕。Destination Table挑選您的campaign_funding資料集,並輸入表格 ID 為「summary'」。選取「allow large results' 核取方塊」。

現在,請執行下列查詢:
SELECT
CONCAT(REGEXP_EXTRACT(c.candidate_name,r'\w+,[ ]+([\w ]+)'), ' ', REGEXP_EXTRACT(c.candidate_name,r'(\w+),'))
AS candidate,
pty.candidate_affiliation_name as candidate_affiliation,
INTEGER(c.election_year) as election_year,
c.candidate_state as candidate_state,
c.office as candidate_office,
t.name as name,
t.city as city,
t.amt as amount,
c.district as candidate_district,
c.ici as candidate_ici,
c.status as candidate_status,
t.memo as memo,
t.state as state,
LEFT(t.zip_code, 5) as zip_code,
t.employer as employer,
t.occupation as occupation,
USEC_TO_TIMESTAMP(PARSE_UTC_USEC(
CONCAT(RIGHT(t.transaction_date, 4), "-",
LEFT(t.transaction_date,2), "-",
RIGHT(LEFT(t.transaction_date,4), 2),
" 00:00:00"))) as transaction_date,
t.committee_name as committee_name,
t.committe_designation as committee_designation,
t.committee_type as committee_type,
pty_cmte.committee_affiliation_name as committee_affiliation,
t.committee_org_type as committee_organization_type,
t.committee_connected_org_name as committee_organization_name,
t.entity_type as entity_type,
FROM (
SELECT
trans.ENTITY_TP as entity_type,
trans.NAME as name,
trans.CITY as city,
trans.STATE as state,
trans.ZIP_CODE as zip_code,
trans.EMPLOYER as employer,
trans.OCCUPATION as occupation,
trans.TRANSACTION_DT as transaction_date,
trans.TRANSACTION_AMT as amt,
trans.MEMO_TEXT as memo,
cmte.committee_name as committee_name,
cmte.committe_designation as committe_designation,
cmte.committee_type as committee_type,
cmte.committee_affiliation as committee_affiliation,
cmte.committee_org_type as committee_org_type,
cmte.committee_connected_org_name as committee_connected_org_name,
cmte.committee_candidate_id as committee_candidate_id
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CMTE_NM) as committee_name,
FIRST(CMTE_DSGN) as committe_designation,
FIRST(CMTE_TP) as committee_type,
FIRST(CMTE_PTY_AFFILIATION) as committee_affiliation,
FIRST(ORG_TP) as committee_org_type,
FIRST(CONNECTED_ORG_NM) as committee_connected_org_name,
FIRST(CAND_ID) as committee_candidate_id
FROM [campaign_funding.committees]
GROUP BY CMTE_ID
) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) as t
RIGHT OUTER JOIN EACH
(SELECT CAND_ID as candidate_id,
FIRST(CAND_NAME) as candidate_name,
FIRST(CAND_PTY_AFFILIATION) as affiliation,
INTEGER(FIRST(CAND_ELECTION_YR)) as election_year,
FIRST(CAND_OFFICE_ST) as candidate_state,
FIRST(CAND_OFFICE) as office,
FIRST(CAND_OFFICE_DISTRICT) as district,
FIRST(CAND_ICI) as ici,
FIRST(CAND_STATUS) as status,
FROM [campaign_funding.candidates]
GROUP BY candidate_id) c
ON t.committee_candidate_id = c.candidate_id
JOIN (
SELECT code, name as candidate_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty
ON pty.code = c.affiliation
JOIN (
SELECT code, name as committee_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty_cmte
ON pty_cmte.code = t.committee_affiliation
WHERE t.amt > 0.0 and REGEXP_MATCH(t.state, "^[A-Z]{2}$") and t.amt < 1000000.0
此查詢大幅延長,且還包含其他清理選項。舉例來說,系統會忽略金額超過 $100 萬美元的任何金額。它也會使用規則運算式將「LASTNAME, FIRSTNAME」改為「FIRSTNAME LASTNAME」。如果您喜歡嘗試新方法,請試著撰寫 UDF 來做到更好,並修正大小寫 (例如「Firstname Lastname」)。
最後,請試著對 campaign_funding.summary 資料表執行幾項查詢,確認對該查詢的查詢速度較快。別忘了先移除目的地資料表查詢選項,否則可能會覆寫摘要表格!
您已經從 FEC 網站清理資料並匯入 BigQuery!
適用範圍
- 在 BigQuery 中使用 GCS 支援的資料表。
- 在 BigQuery 中使用使用者定義的函式。
後續步驟
- 嘗試一些有趣的查詢,看看誰為這個選舉週期提供金錢。
瞭解詳情
- 進一步瞭解使用者定義的函式的用途。
- 瞭解聯合資料來源(包括 GCS)。
- 在 Stack Overflow 上張貼問題並在 google-bigquery 標記中尋找答案。
請提供您寶貴的意見
- 歡迎透過本網頁左下角的連結來提交問題或提供意見!