
在此 Codelab 中,您将学习如何使用 BigQuery 的一些高级功能,包括:
- JavaScript 中的用户定义函数
- 分区表
- 直接查询存储在 Google Cloud Storage 和 Google 云端硬盘中的数据。
您将从美国联邦选举委员会获取数据,清理这些数据,并将其加载到 BigQuery 中。此外,您还有机会就该数据集提出一些有趣的问题。
虽然本 Codelab 并不假定您具备使用 BigQuery 的任何经验,但对 SQL 的一些了解将有助于您充分利用它。
学习内容
- 如何使用 JavaScript 用户定义函数执行难以使用 SQL 执行的操作。
- 如何使用 BigQuery 对其他数据存储区(如 Google Cloud Storage 和 Google 云端硬盘)中的数据执行 ETL(提取、转换、加载)操作。
您需要满足的条件
- 启用了结算功能的 Google Cloud 项目。
- Google Cloud Storage 存储分区
- 已安装 Google Cloud SDK
您打算如何使用本教程?
您如何评价自己在使用 BigQuery 方面的经验水平?
自定进度的环境设置
如果您还没有 Google 帐号(Gmail 或 Google Apps),则必须创建一个。登录 Google Cloud Platform Console (console.cloud.google.com) 并创建一个新项目:



请记住项目 ID,它在所有 Google Cloud 项目中都是唯一名称(很抱歉,上述名称已被占用,您无法使用!)。它稍后将在此 Codelab 中被称为 PROJECT_ID。
接下来,您需要在 Cloud Console 中启用结算功能,才能使用 Google Cloud 资源。
在此 Codelab 中运行仅花费几美元,但是如果您决定使用更多资源或继续让它们运行,费用可能更高(请参阅本文档末尾的“清理”部分)。
Google Cloud Platform 的新用户有资格获享 $300 免费试用。
Google Cloud Shell
虽然 Google Cloud 和 BigQuery 可以从笔记本电脑远程操作,但在此 Codelab 中,我们将使用 Google Cloud Shell,这是一个在云端运行的命令行环境。
基于 Debian 的这个虚拟机已加载了您需要的所有开发工具。它提供了一个持久的 5GB 主目录,并在 Google Cloud 上运行,大大增强了网络性能和身份验证。这意味着在本 Codelab 中,您只需要一个浏览器(没错,它适用于 Chromebook)。
要激活 Google Cloud Shell,只需在开发者控制台中点击右上方的按钮(配置和连接到环境应该只需要片刻时间):

点击“启动 Cloud Shell”按钮:


在连接到 Cloud Shell 后,您应该会看到自己已通过身份验证,并且相关项目已设置为您的 PROJECT_ID:
gcloud auth list
命令输出
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
命令输出
[core] project = <PROJECT_ID>
默认情况下,Cloud Shell 还会设置一些环境变量,这对您日后运行命令可能会很有用。
echo $GOOGLE_CLOUD_PROJECT
命令输出
<PROJECT_ID>
如果出于某种原因未设置项目,只需发出以下命令即可:
gcloud config set project <PROJECT_ID>
正在查找您的 PROJECT_ID?请查看您在设置步骤中使用的 ID,或在控制台信息中心内查找:

重要提示:最后,设置默认可用区和项目配置:
gcloud config set compute/zone us-central1-f
您可以选择各种不同的可用区。如需了解详情,请参阅“区域和可用区”文档。
为了在本 Codelab 中运行 BigQuery 查询,您需要拥有自己的数据集。为它选择一个名称,例如 campaign_funding。在 shell 中运行以下命令(例如 CloudShell):
$ DATASET=campaign_funding
$ bq mk -d ${DATASET}
Dataset 'bq-campaign:campaign_funding' successfully created.
创建数据集后,您应该就可以开始使用了。运行此命令还有助于验证您是否正确设置了 bq 命令行客户端设置、身份验证是否正常运行,以及您是否对您所运行的云项目拥有写入权限。如果您有多个项目,系统会提示您从列表中选择您感兴趣的项目。

美国联邦选举委员会的广告系列财务数据集已解压缩并复制到 GCS 存储分区 gs://campaign-funding/ 中。
让我们在本地下载一个源文件,以便查看显示效果。在命令窗口中运行以下命令:
$ gsutil cp gs://campaign-funding/indiv16.txt . $ tail indiv16.txt
此时应显示单个贡献文件的内容。在本 Codelab 中,我们将探讨三种类型的文件:个人贡献 (indiv*.txt)、候选人 (cn*.txt) 和委员会 (cm*.txt)。如果您有兴趣,请使用相同的机制检查这些其他文件中的内容。
我们不会将原始数据直接加载到 BigQuery,而是从 Google Cloud Storage 进行查询。为此,我们需要了解架构及其一些信息。
如需了解该数据集,请访问此处的联邦选举网站。我们将看到的表架构为:
为了链接到这些表,我们需要为它们创建包含架构的表定义。运行以下命令以生成各个表定义:
$ bq mkdef --source_format=CSV \
gs://campaign-funding/indiv*.txt \
"CMTE_ID, AMNDT_IND, RPT_TP, TRANSACTION_PGI, IMAGE_NUM, TRANSACTION_TP, ENTITY_TP, NAME, CITY, STATE, ZIP_CODE, EMPLOYER, OCCUPATION, TRANSACTION_DT, TRANSACTION_AMT:FLOAT, OTHER_ID, TRAN_ID, FILE_NUM, MEMO_CD, MEMO_TEXT, SUB_ID" \
> indiv_def.json
使用您常用的文本编辑器打开 indiv_dev.json 文件并查看内容,其中将包含介绍如何解析 FEC 数据文件的 json。
我们需要对 csvOptions 部分进行两处细微的修改。添加 fieldDelimiter 值 "|" 和 quote 值 ""(空字符串)。这种做法非常必要,因为数据文件实际上并非以逗号分隔,而是以竖线分隔:
$ sed -i 's/"fieldDelimiter": ","/"fieldDelimiter": "|"/g; s/"quote": "\\""/"quote":""/g' indiv_def.json
indiv_dev.json 文件现在应如下所示:
"fieldDelimiter": "|",
"quote":"",
由于为委员会表和候选人表创建的表定义类似,并且架构中包含相当多的样板文件,我们只需下载这些文件即可。
$ gsutil cp gs://campaign-funding/candidate_def.json . Copying gs://campaign-funding/candidate_def.json... / [1 files][ 945.0 B/ 945.0 B] Operation completed over 1 objects/945.0 B. $ gsutil cp gs://campaign-funding/committee_def.json . Copying gs://campaign-funding/committee_def.json... / [1 files][ 949.0 B/ 949.0 B] Operation completed over 1 objects/949.0 B.
这些文件将类似于 indiv_dev.json 文件。请注意,您还可以下载 indiv_def.json 文件,以防您在获取正确的值时遇到问题。
接下来,我们来将 BigQuery 表实际与这些文件关联。运行以下命令:
$ bq mk --external_table_definition=indiv_def.json -t ${DATASET}.transactions
Table 'bq-campaign:campaign_funding.transactions' successfully created.
$ bq mk --external_table_definition=committee_def.json -t ${DATASET}.committees
Table 'bq-campaign:campaign_funding.committees' successfully created.
$ bq mk --external_table_definition=candidate_def.json -t ${DATASET}.candidates
Table 'bq-campaign:campaign_funding.candidates' successfully created.
这将创建三个 BigQuery 表:事务、佣金和候选表。您可以像查询普通 BigQuery 表一样查询这些表,但它们实际上不会存储在 BigQuery 中,而是存储在 Google Cloud Storage 中。如果您更新底层文件,更新会立即反映在您运行的查询中。
接下来,我们来尝试运行一些查询。打开 BigQuery 网页界面。

在左侧的导航窗格中找到数据集(您可能需要更改左上角的项目下拉菜单),点击红色的“COMPOSE QUERY'”按钮,然后在框中输入以下查询:
SELECT * FROM [campaign_funding.transactions] WHERE EMPLOYER contains "GOOGLE" ORDER BY TRANSACTION_DT DESC LIMIT 100
此举包含 Google 员工最近捐赠的 100 笔捐款。如果您愿意,不妨尝试玩一玩您的筹款活动,找到您的邮政编码对应的居民,或寻找您所在城市的捐款最多。
查询和结果将如下所示:
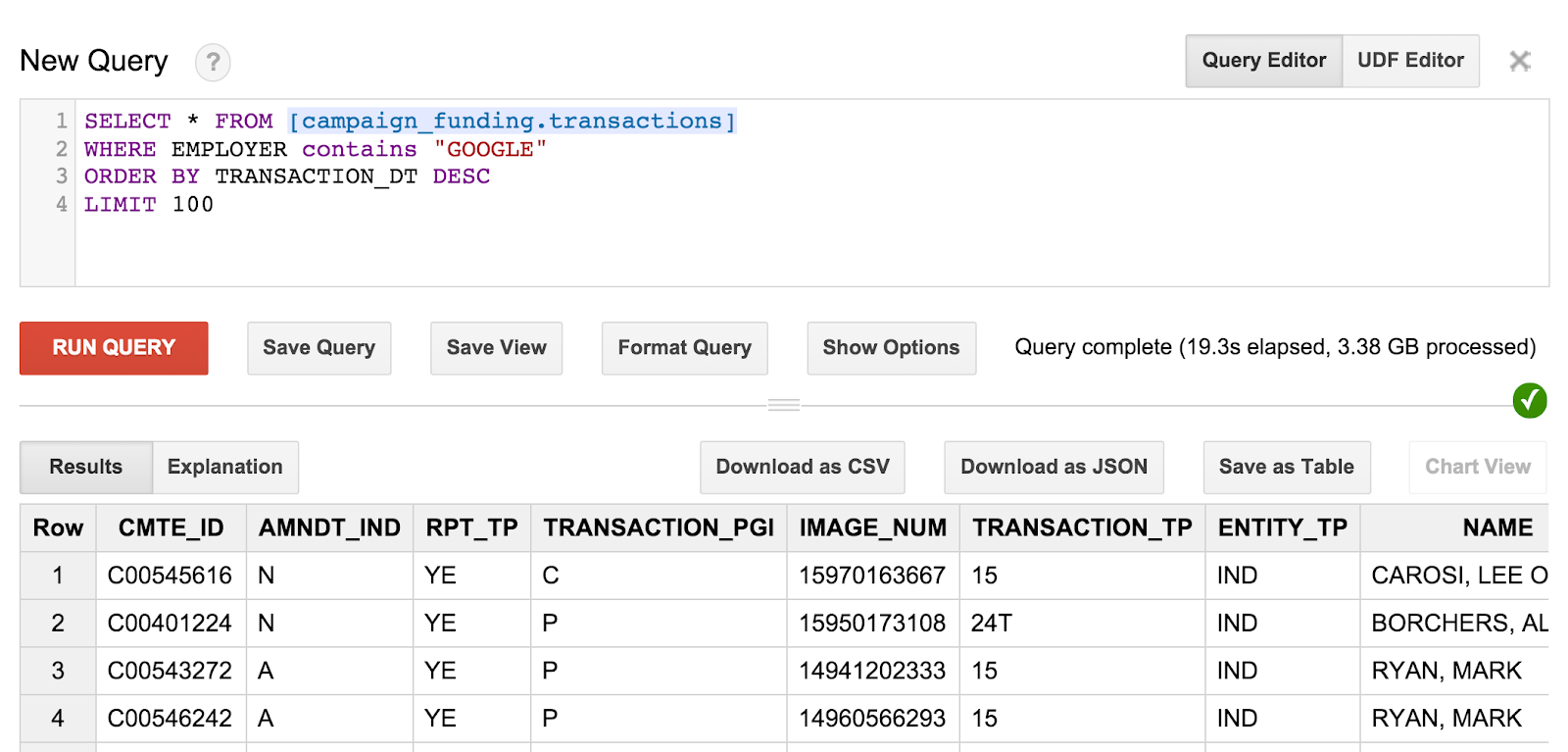
但您可能会注意到,您无法真正分辨这些捐款的接收人是谁。我们需要编写一些更精细的查询来获取这些信息。
在左侧窗格中,依次点击“事务”表格和“架构”标签页。它应如下面的屏幕截图所示:
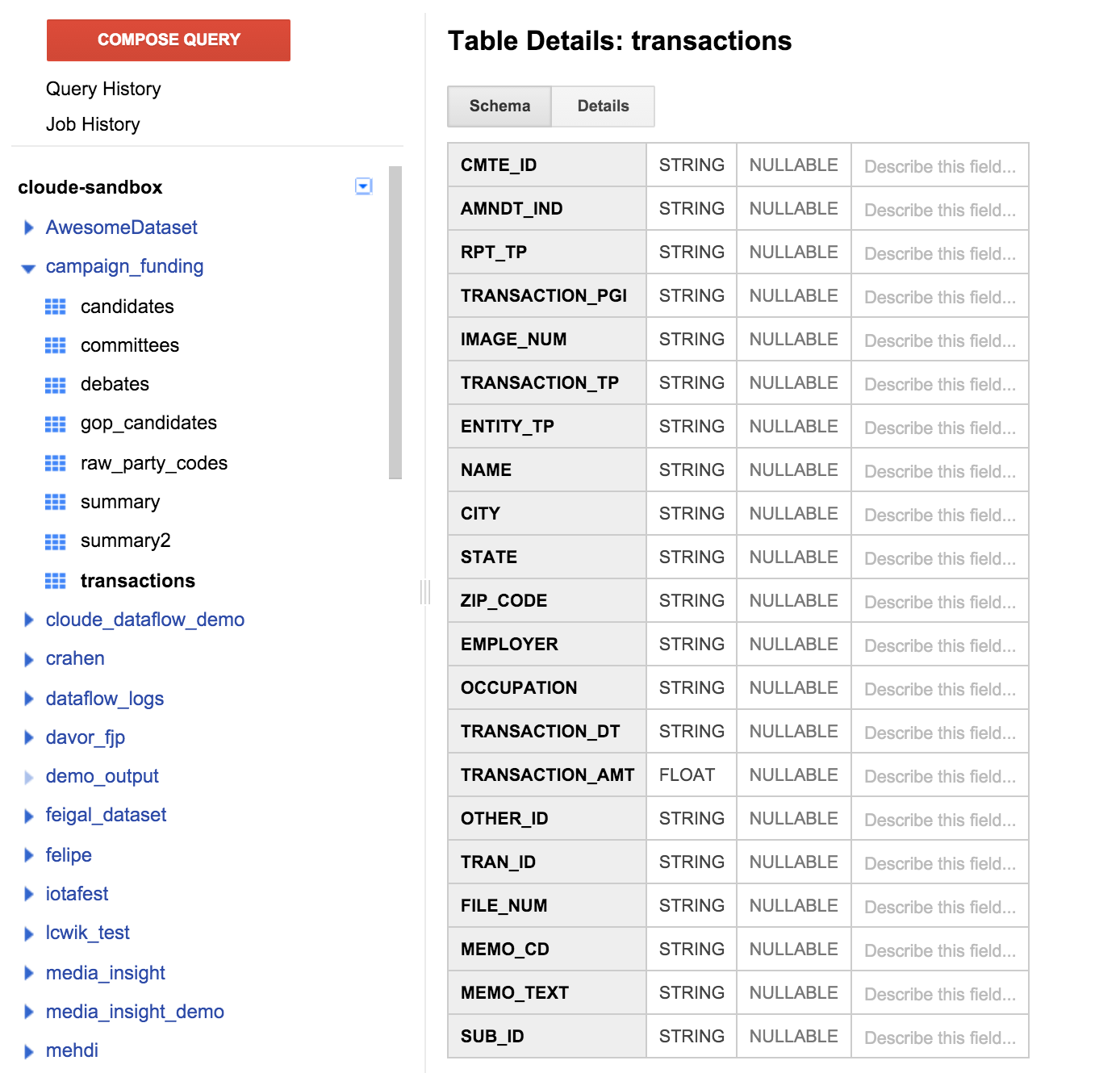
我们可以看到与之前指定的表格定义匹配的字段列表。您可能会注意到,没有针对受助人的捐款字段,也没有找到任何方法以确定捐款支持的候选人。不过,有一个名为 CMTE_ID 的字段。这样一来,我们便能将接收捐款的委员会与该捐款关联起来。但这还不够。
接下来,点击“佣金”表以查看其架构。我们设置了 CMET_ID,可用于加入事务表。另一个字段是 CAND_ID;此字段可与候选表中的 CAND_ID 表联接。最后,我们会查看委员会表,了解交易与候选人之间的关联。
请注意,基于 GCS 的表没有预览标签页。这是因为 BigQuery 需要从外部数据源读取数据才能读取数据。让我们通过对候选表运行简单的“SELECT *' 查询”来获取数据样本。
SELECT * FROM [campaign_funding.candidates] LIMIT 100
结果应如下所示:
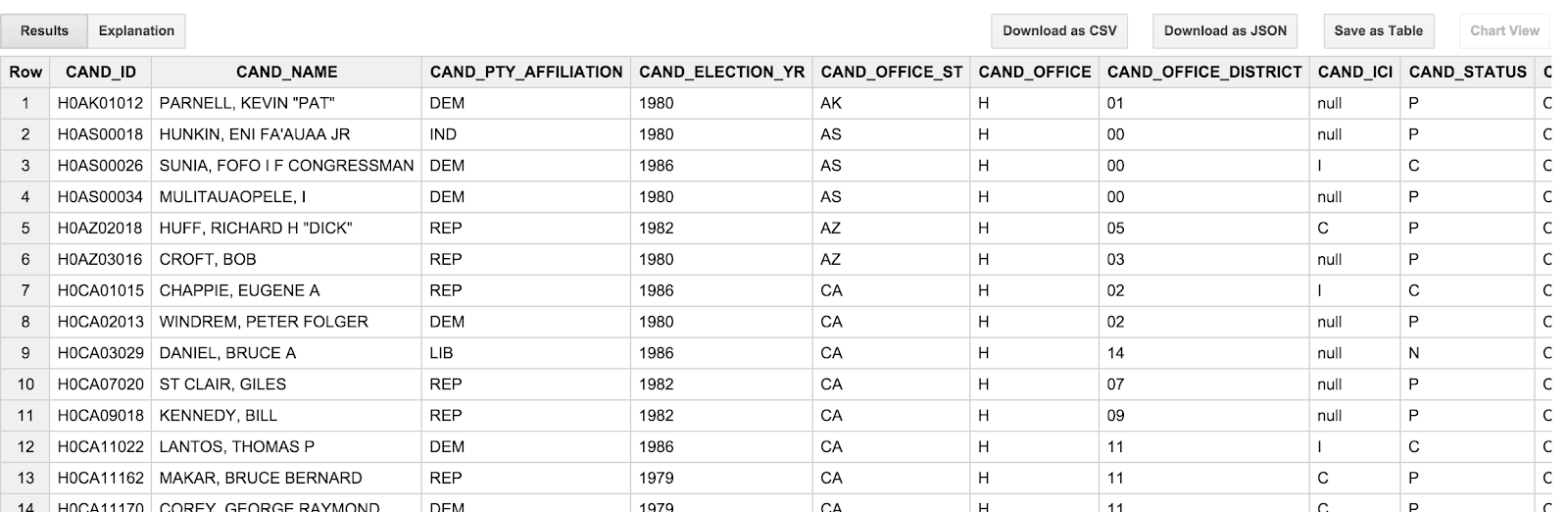
您可能会注意到,候选名称全部为大写字母,并且按“姓氏,名字”的顺序呈现。这有点令人厌烦,因为这实际上并不是我们想到的候选人;我们更愿意看到“Barack Obama”,而不是“OBAMA, BARACK”。此外,事务表中的交易日期 (TRANSACTION_DT) 也有点奇怪。它们是格式为 YYYYMMDD 的字符串值。我们将在下一部分中解决这些异常问题。
至此,我们已经了解了交易与候选人之间的关系,接下来让我们进行一项查询,看看谁在向谁汇款。将以下查询剪切并粘贴到撰写框中:
SELECT affiliation, SUM(amount) AS amount
FROM (
SELECT *
FROM (
SELECT
t.amt AS amount,
t.occupation AS occupation,
c.affiliation AS affiliation,
FROM (
SELECT
trans.TRANSACTION_AMT AS amt,
trans.OCCUPATION AS occupation,
cmte.CAND_ID AS CAND_ID
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CAND_ID) AS CAND_ID
FROM [campaign_funding.committees]
GROUP EACH BY CMTE_ID ) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) AS t
RIGHT OUTER JOIN EACH (
SELECT
CAND_ID,
FIRST(CAND_PTY_AFFILIATION) AS affiliation,
FROM [campaign_funding.candidates]
GROUP EACH BY CAND_ID) c
ON t.CAND_ID = c.CAND_ID )
WHERE occupation CONTAINS "ENGINEER")
GROUP BY affiliation
ORDER BY amount DESC
此查询将事务表联接到佣金表,然后再联接到表。它只考虑职位名称中包含“ENGINEER”一词的交易。该查询按政党派别汇总结果;这使我们能够了解向各政党分发的捐款在工程师中的分布情况。
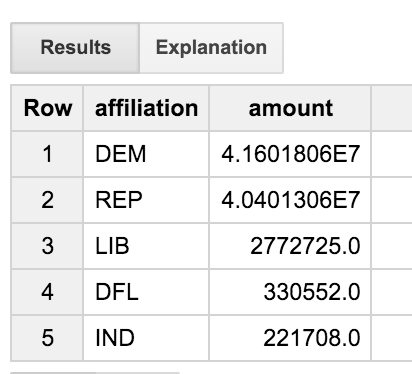
我们可以看到,工程师们的构成相当均衡,为民主党和共和党提供或多或少地平均分配了资金。但“DFL”派对是什么?如果能获取全名,而不只是一个由三个字母组成的代码,不是很好吗?
各方代码在 FEC 网站上定义。有一个表格将派对代码与全名相匹配(原来是“DFL'”是“Democratic-Farmer-Labor'”)。虽然我们可以在查询中手动执行转换,这似乎需要执行大量工作,并且很难保持同步。
如果我们能够解析 HTML 作为查询的一部分,会怎样?右键点击该页面上的任意位置,查看“查看网页源代码”。源文件中有许多头文件/样板信息,但可以查找 <table> 标记。每个映射行均位于 HTML <tr> 元素中,其名称和代码均封装在 <td> 元素中。每行将如下所示:
HTML 如下所示:
<tr bgcolor="#F5F0FF">
<td scope="row"><div align="left">ACE</div></td>
<td scope="row">Ace Party</td>
<td scope="row"></td>
</tr>
请注意,BigQuery 无法直接从网络中读取文件,因为 BigQuery 能够同时从数千个工作器匹配源。如果允许攻击者对随机网页运行这种攻击,那么它本质上是一种分布式拒绝服务攻击 (DDoS)。FEC 网页中的 HTML 文件存储在 gs://campaign-funding 存储分区中。
我们需要根据广告系列资金数据制作表格。这将与我们创建的其他由 GCS 支持的表类似。这里的区别在于,我们实际上没有架构;我们只是在每行使用一个字段,并将其命名为“data'”。我们假装它是一个 CSV 文件,但我们使用分隔符 (`) 而不是引号字符,而不是分隔符。
要创建派对对照表,请在命令行中运行以下命令:
$ echo '{"csvOptions": {"allowJaggedRows": false, "skipLeadingRows": 0, "quote": "", "encoding": "UTF-8", "fieldDelimiter": "`", "allowQuotedNewlines": false}, "ignoreUnknownValues": true, "sourceFormat": "CSV", "sourceUris": ["gs://campaign-funding/party_codes.shtml"], "schema": {"fields": [{"type": "STRING", "name": "data"}]}}' > party_raw_def.json
$ bq mk --external_table_definition=party_raw_def.json \
-t ${DATASET}.raw_party_codes
Table 'bq-campaign:campaign_funding.raw_party_codes' successfully created.
现在,我们将使用 JavaScript 解析该文件。BigQuery 查询编辑器的右上角应该是一个标有“UDF 编辑器”的按钮。点击该按钮以切换到修改 JavaScript UDF。UDF 编辑器将填充一些已注释掉的样板。

接下来,删除其中包含的代码,然后输入以下代码:
function tableParserFun(row, emitFn) {
if (row.data != null && row.data.match(/<tr.*<\/tr>/) !== null) {
var txt = row.data
var re = />\s*(\w[^\t<]*)\t*<.*>\s*(\w[^\t<]*)\t*</;
matches = txt.match(re);
if (matches !== null && matches.length > 2) {
var result = {code: matches[1], name: matches[2]};
emitFn(result);
} else {
var result = { code: 'ERROR', name: matches};
emitFn(result);
}
}
}
bigquery.defineFunction(
'tableParser', // Name of the function exported to SQL
['data'], // Names of input columns
[{'name': 'code', 'type': 'string'}, // Output schema
{'name': 'name', 'type': 'string'}],
tableParserFun // Reference to JavaScript UDF
);
这里的 JavaScript 分为两部分;第一部分是接受一行输入的函数发出解析的输出。另一个定义是将函数注册为名称为 tableParser 的用户定义函数 (UDF),表示接受名为“data'”的输入列并输出两列:代码和名称。代码列由三字母代码组成,名称列是各方的全名。
切换回“查询编辑器”标签页,然后输入以下查询:
SELECT code, name FROM tableParser([campaign_funding.raw_party_codes]) ORDER BY code
运行此查询会解析原始 HTML 文件,并以结构化格式输出字段值。是不是很酷?看看您能否弄清“DFL”代表什么。
现在我们可以将派对代码转换成名称,接下来,我们尝试用另一个查询找出有趣的活动。请运行以下查询:
SELECT
candidate,
election_year,
FIRST(candidate_affiliation) AS affiliation,
SUM(amount) AS amount
FROM (
SELECT
CONCAT(REGEXP_EXTRACT(c.candidate_name,r'\w+,[ ]+([\w ]+)'), ' ',
REGEXP_EXTRACT(c.candidate_name,r'(\w+),')) AS candidate,
pty.candidate_affiliation_name AS candidate_affiliation,
c.election_year AS election_year,
t.amt AS amount,
FROM (
SELECT
trans.TRANSACTION_AMT AS amt,
cmte.committee_candidate_id AS committee_candidate_id
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CAND_ID) AS committee_candidate_id
FROM [campaign_funding.committees]
GROUP BY CMTE_ID ) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) AS t
RIGHT OUTER JOIN EACH (
SELECT
CAND_ID AS candidate_id,
FIRST(CAND_NAME) AS candidate_name,
FIRST(CAND_PTY_AFFILIATION) AS affiliation,
FIRST(CAND_ELECTION_YR) AS election_year,
FROM [campaign_funding.candidates]
GROUP BY candidate_id) c
ON t.committee_candidate_id = c.candidate_id
JOIN (
SELECT
code,
name AS candidate_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty
ON pty.code = c.affiliation )
GROUP BY candidate, election_year
ORDER BY amount DESC
LIMIT 100
此查询会显示哪些候选人的捐款最多,并详细说明他们的政党派派。
这些表不是很大,需要 30 秒左右才能查询完毕。如果您要处理表格的大量工作,则可能需要将表格导入 BigQuery。您可以对表运行 ETL 查询以强制将数据转换为易于使用的内容,然后将其另存为永久表。这意味着,您并非总是必须要知道如何翻译聚会代码,而且您也可以在执行此操作时滤除错误数据。
点击“显示选项”按钮,然后点击“Destination Table”标签旁边的“选择表”按钮。选择您的 campaign_funding 数据集,然后输入表 ID 为“summary'”。选中“allow large results' 复选框。

现在,运行以下查询:
SELECT
CONCAT(REGEXP_EXTRACT(c.candidate_name,r'\w+,[ ]+([\w ]+)'), ' ', REGEXP_EXTRACT(c.candidate_name,r'(\w+),'))
AS candidate,
pty.candidate_affiliation_name as candidate_affiliation,
INTEGER(c.election_year) as election_year,
c.candidate_state as candidate_state,
c.office as candidate_office,
t.name as name,
t.city as city,
t.amt as amount,
c.district as candidate_district,
c.ici as candidate_ici,
c.status as candidate_status,
t.memo as memo,
t.state as state,
LEFT(t.zip_code, 5) as zip_code,
t.employer as employer,
t.occupation as occupation,
USEC_TO_TIMESTAMP(PARSE_UTC_USEC(
CONCAT(RIGHT(t.transaction_date, 4), "-",
LEFT(t.transaction_date,2), "-",
RIGHT(LEFT(t.transaction_date,4), 2),
" 00:00:00"))) as transaction_date,
t.committee_name as committee_name,
t.committe_designation as committee_designation,
t.committee_type as committee_type,
pty_cmte.committee_affiliation_name as committee_affiliation,
t.committee_org_type as committee_organization_type,
t.committee_connected_org_name as committee_organization_name,
t.entity_type as entity_type,
FROM (
SELECT
trans.ENTITY_TP as entity_type,
trans.NAME as name,
trans.CITY as city,
trans.STATE as state,
trans.ZIP_CODE as zip_code,
trans.EMPLOYER as employer,
trans.OCCUPATION as occupation,
trans.TRANSACTION_DT as transaction_date,
trans.TRANSACTION_AMT as amt,
trans.MEMO_TEXT as memo,
cmte.committee_name as committee_name,
cmte.committe_designation as committe_designation,
cmte.committee_type as committee_type,
cmte.committee_affiliation as committee_affiliation,
cmte.committee_org_type as committee_org_type,
cmte.committee_connected_org_name as committee_connected_org_name,
cmte.committee_candidate_id as committee_candidate_id
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CMTE_NM) as committee_name,
FIRST(CMTE_DSGN) as committe_designation,
FIRST(CMTE_TP) as committee_type,
FIRST(CMTE_PTY_AFFILIATION) as committee_affiliation,
FIRST(ORG_TP) as committee_org_type,
FIRST(CONNECTED_ORG_NM) as committee_connected_org_name,
FIRST(CAND_ID) as committee_candidate_id
FROM [campaign_funding.committees]
GROUP BY CMTE_ID
) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) as t
RIGHT OUTER JOIN EACH
(SELECT CAND_ID as candidate_id,
FIRST(CAND_NAME) as candidate_name,
FIRST(CAND_PTY_AFFILIATION) as affiliation,
INTEGER(FIRST(CAND_ELECTION_YR)) as election_year,
FIRST(CAND_OFFICE_ST) as candidate_state,
FIRST(CAND_OFFICE) as office,
FIRST(CAND_OFFICE_DISTRICT) as district,
FIRST(CAND_ICI) as ici,
FIRST(CAND_STATUS) as status,
FROM [campaign_funding.candidates]
GROUP BY candidate_id) c
ON t.committee_candidate_id = c.candidate_id
JOIN (
SELECT code, name as candidate_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty
ON pty.code = c.affiliation
JOIN (
SELECT code, name as committee_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty_cmte
ON pty_cmte.code = t.committee_affiliation
WHERE t.amt > 0.0 and REGEXP_MATCH(t.state, "^[A-Z]{2}$") and t.amt < 1000000.0
此查询显著增加,且具有一些额外的清理选项。例如,它会忽略金额大于 100 万美元的所有内容。它还使用正则表达式将“LASTNAME, FIRSTNAME”转变成“FIRSTNAME LASTNAME”;如果您喜欢尝试新鲜事物,可以试着编写 UDF 以表现得更好,并更正大写形式(例如 "Firstname Lastname")。
最后,请尝试对 campaign_funding.summary 表运行一些查询,验证对该表的查询是否更快。别忘了先移除目标表查询选项,否则最终可能会覆盖摘要表!
现在,您已清理数据并将其从 FEC 网站导入到 BigQuery!
所学内容
- 在 BigQuery 中使用由 GCS 支持的表。
- 在 BigQuery 中使用用户定义的函数。
后续步骤
- 尝试一些有趣的查询,看看谁在为此选举周期付款。
了解详情
向我们提供反馈
- 如果您愿意,可以通过本页面左下方的链接提交问题或提供反馈!