
En este codelab, aprenderás a usar algunas funciones avanzadas de BigQuery, por ejemplo:
- Funciones definidas por el usuario en JavaScript
- Tablas particionadas
- Dirige las consultas a los datos almacenados en Google Cloud Storage y Google Drive.
Tomarás los datos de la Comisión Electoral Federal de EE.UU., los limpiarás y los cargarás en BigQuery. También tendrá la oportunidad de hacer algunas preguntas interesantes sobre ese conjunto de datos.
Si bien en este codelab no se supone que tengas experiencia previa con BigQuery, comprender algo de SQL te ayudará a sacarle más provecho.
Qué aprenderás
- Cómo usar las funciones definidas por el usuario de JavaScript para realizar operaciones que son difíciles de hacer en SQL.
- Cómo usar BigQuery para realizar operaciones de ETL (extraer, transformar, cargar) en datos que se encuentran en otros almacenes de datos, como Google Cloud Storage y Google Drive
Requisitos
- Un proyecto de Google Cloud con facturación habilitada
- Un bucket de Google Cloud Storage
- Se instaló el SDK de Google Cloud
¿Cómo usarás este instructivo?
¿Cómo calificarías tu nivel de experiencia con BigQuery?
Configuración del entorno a su propio ritmo
Si aún no tienes una Cuenta de Google (Gmail o Google Apps), debes crear una. Accede a Google Cloud Platform Console (console.cloud.google.com) y crea un proyecto nuevo:



Recuerde el ID de proyecto, un nombre único en todos los proyectos de Google Cloud (el nombre anterior ya se encuentra en uso y no lo podrá usar). Se mencionará más adelante en este codelab como PROJECT_ID.
A continuación, debes habilitar la facturación en Cloud Console para usar los recursos de Google Cloud.
Ejecutar este codelab debería costar solo unos pocos dólares, pero su costo podría aumentar si decides usar más recursos o si los dejas en ejecución (consulta la sección “Limpiar” al final de este documento).
Los usuarios nuevos de Google Cloud Platform son aptos para obtener una prueba gratuita de USD 300.
Google Cloud Shell
Si bien Google Cloud y BigQuery pueden operarse de manera remota desde su laptop, en este codelab usaremos Google Cloud Shell, un entorno de línea de comandos que se ejecuta en la nube.
Esta máquina virtual basada en Debian está cargada con todas las herramientas de desarrollo que necesitarás. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud, lo que permite mejorar considerablemente el rendimiento de la red y la autenticación. Esto significa que todo lo que necesitarás para este Codelab es un navegador (sí, funciona en una Chromebook).
Para activar Google Cloud Shell, en Developer Console, simplemente haz clic en el botón que se encuentra en la esquina superior derecha (el aprovisionamiento y la conexión al entorno debería llevar solo unos minutos):

Haz clic en el botón “Iniciar Cloud Shell”:


Una vez conectado a Cloud Shell, deberías ver que ya estás autenticado y que el proyecto ya está configurado con tu PROJECT_ID :
gcloud auth list
Resultado del comando
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Resultado del comando
[core] project = <PROJECT_ID>
Cloud Shell también establece algunas variables de entorno de forma predeterminada, que pueden ser útiles cuando ejecute comandos futuros.
echo $GOOGLE_CLOUD_PROJECT
Resultado del comando
<PROJECT_ID>
Si, por algún motivo, el proyecto no se configuró, simplemente ejecuta el siguiente comando :
gcloud config set project <PROJECT_ID>
Si no conoce su PROJECT_ID, Verifica qué ID usaste en los pasos de la configuración o búscalo en el panel de la consola:

IMPORTANTE: Por último, establece la zona y la configuración de proyecto predeterminadas:
gcloud config set compute/zone us-central1-f
Puedes elegir una variedad de zonas diferentes. Obtenga más información en la documentación de regiones y zonas.
Para ejecutar las consultas de BigQuery en este codelab, necesitarás tu propio conjunto de datos. Elige un nombre, como campaign_funding. Ejecute los siguientes comandos en su shell (por ejemplo, Cloud Shell):
$ DATASET=campaign_funding
$ bq mk -d ${DATASET}
Dataset 'bq-campaign:campaign_funding' successfully created.
Cuando tu conjunto de datos se haya creado, deberías estar listo. La ejecución de este comando también debería ayudar a verificar que tienes la configuración de cliente de línea de comandos bq correcta, la autenticación está funcionando y que tienes acceso de escritura al proyecto de nube en el que operas. Si tienes más de un proyecto, se te solicitará que selecciones aquel de la lista que te interese.

Se descomprimió el conjunto de datos de finanzas de campañas de la Comisión Federal Electoral de EE.UU. y se copió en el bucket gs://campaign-funding/ de GCS.
Descarguemos uno de los archivos de origen de manera local para que podamos verlo. Ejecuta los siguientes comandos desde una ventana de comandos:
$ gsutil cp gs://campaign-funding/indiv16.txt . $ tail indiv16.txt
Se debería mostrar el contenido del archivo de contribuciones individual. Para este codelab, analizaremos tres tipos de archivos: contribuciones individuales (indiv*.txt), candidatos (cn*.txt) y comités (cm*.txt). Si te interesa, usa el mismo mecanismo para ver el contenido de esos archivos.
No cargaremos los datos sin procesar directamente en BigQuery; en su lugar, consultaremos los datos desde Google Cloud Storage. Para ello, necesitamos conocer el esquema y algunos datos sobre él.
El conjunto de datos se describe en el sitio web electoral federal aquí. Los esquemas de las tablas que analizaremos son los siguientes:
Para vincularlos a las tablas, debemos crear una definición de tablas que incluya los esquemas. Ejecute los siguientes comandos para generar las definiciones de la tabla individual:
$ bq mkdef --source_format=CSV \
gs://campaign-funding/indiv*.txt \
"CMTE_ID, AMNDT_IND, RPT_TP, TRANSACTION_PGI, IMAGE_NUM, TRANSACTION_TP, ENTITY_TP, NAME, CITY, STATE, ZIP_CODE, EMPLOYER, OCCUPATION, TRANSACTION_DT, TRANSACTION_AMT:FLOAT, OTHER_ID, TRAN_ID, FILE_NUM, MEMO_CD, MEMO_TEXT, SUB_ID" \
> indiv_def.json
Abre el archivo indiv_dev.json con tu editor de texto favorito y observa el contenido, ya que contendrá JSON que describe cómo interpretar el archivo de datos de la FEC.
Deberemos realizar dos pequeñas modificaciones en la sección csvOptions. Agrega un valor fieldDelimiter de "|" y un valor quote de "" (la string vacía). Esto es necesario porque el archivo de datos no está realmente separado por comas; además, está separado por barras verticales:
$ sed -i 's/"fieldDelimiter": ","/"fieldDelimiter": "|"/g; s/"quote": "\\""/"quote":""/g' indiv_def.json
El archivo indiv_dev.json debería ser :
"fieldDelimiter": "|",
"quote":"",
Dado que la creación de las definiciones de la tabla para el comité y las tablas de candidatos es similar, y el esquema contiene un poco de código estándar, simplemente descargue esos archivos.
$ gsutil cp gs://campaign-funding/candidate_def.json . Copying gs://campaign-funding/candidate_def.json... / [1 files][ 945.0 B/ 945.0 B] Operation completed over 1 objects/945.0 B. $ gsutil cp gs://campaign-funding/committee_def.json . Copying gs://campaign-funding/committee_def.json... / [1 files][ 949.0 B/ 949.0 B] Operation completed over 1 objects/949.0 B.
Estos archivos serán similares al archivo indiv_dev.json. Ten en cuenta que también puedes descargar el archivo indiv_def.json por si tienes problemas para obtener los valores correctos.
A continuación, vincularemos una tabla de BigQuery a estos archivos. Ejecute los siguientes comandos:
$ bq mk --external_table_definition=indiv_def.json -t ${DATASET}.transactions
Table 'bq-campaign:campaign_funding.transactions' successfully created.
$ bq mk --external_table_definition=committee_def.json -t ${DATASET}.committees
Table 'bq-campaign:campaign_funding.committees' successfully created.
$ bq mk --external_table_definition=candidate_def.json -t ${DATASET}.candidates
Table 'bq-campaign:campaign_funding.candidates' successfully created.
Se crearán tres tablas de BigQuery: transacciones, comités y candidatos. Puedes consultar estas tablas como si fueran tablas normales de BigQuery, pero en realidad no se almacenan en BigQuery; están en Google Cloud Storage. Si actualizas los archivos subyacentes, las actualizaciones se reflejarán de inmediato en las consultas que ejecutes.
Ahora, intentamos realizar algunas consultas. Abra la IU web de BigQuery.

Busca tu conjunto de datos en el panel de navegación izquierdo (es posible que debas cambiar la lista desplegable del proyecto en la esquina superior izquierda), haz clic en el botón grande "COMPOSE QUERY'" y, luego, ingresa la siguiente consulta en el cuadro:
SELECT * FROM [campaign_funding.transactions] WHERE EMPLOYER contains "GOOGLE" ORDER BY TRANSACTION_DT DESC LIMIT 100
Aquí se incluyen las 100 donaciones de campañas más recientes de empleados de Google. Si deseas, puedes buscar y encontrar donaciones de campaña de residentes de tu código postal o buscar las donaciones más grandes de tu ciudad.
La consulta y los resultados se verán de la siguiente manera:
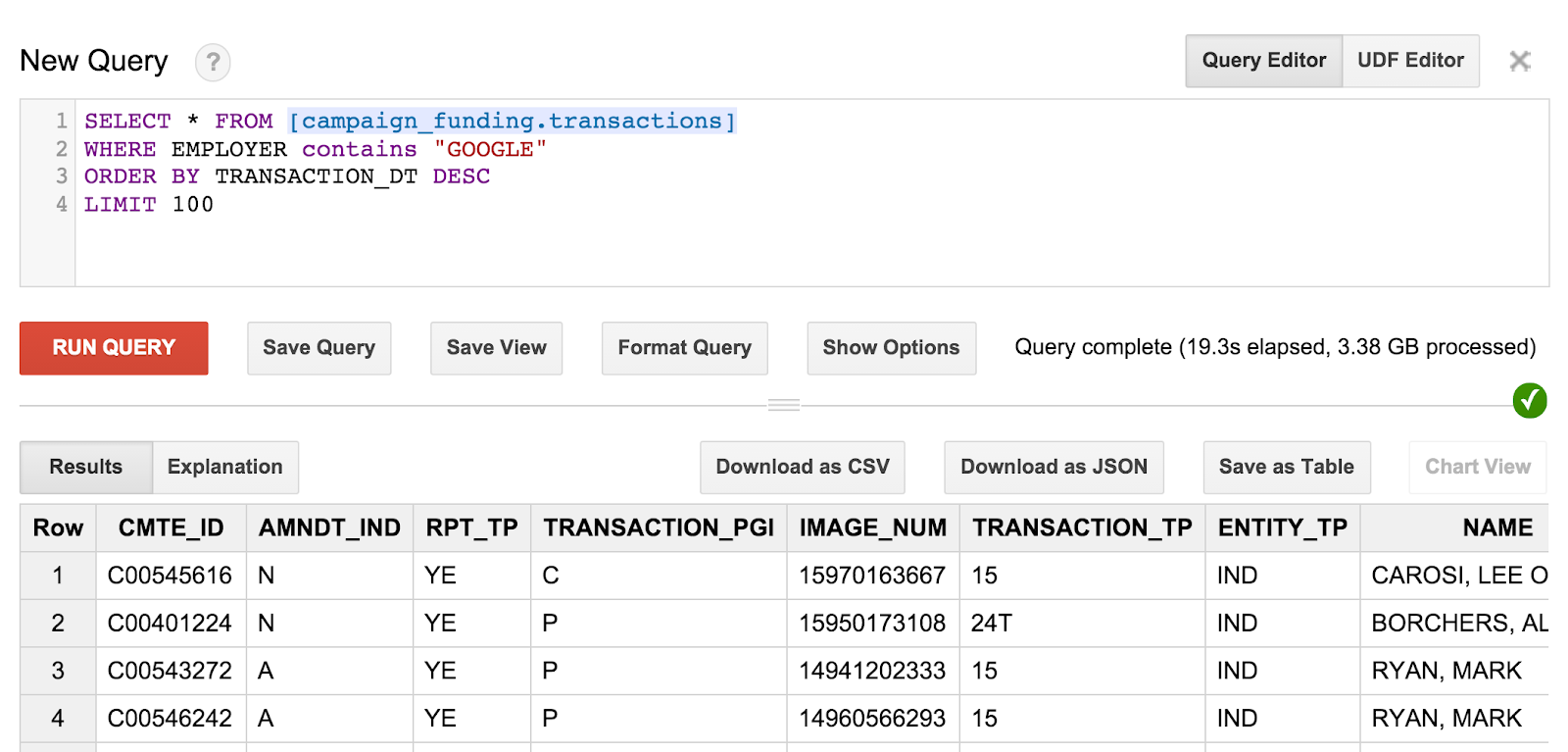
Sin embargo, algo que podrías notar es que no puedes saber realmente quién es el destinatario de estas donaciones. Para obtener esa información, necesitamos hacer algunas consultas más sofisticadas.
Haz clic en la tabla de transacciones en el panel izquierdo y, luego, en la pestaña de esquema. Debería verse como en la siguiente captura de pantalla:
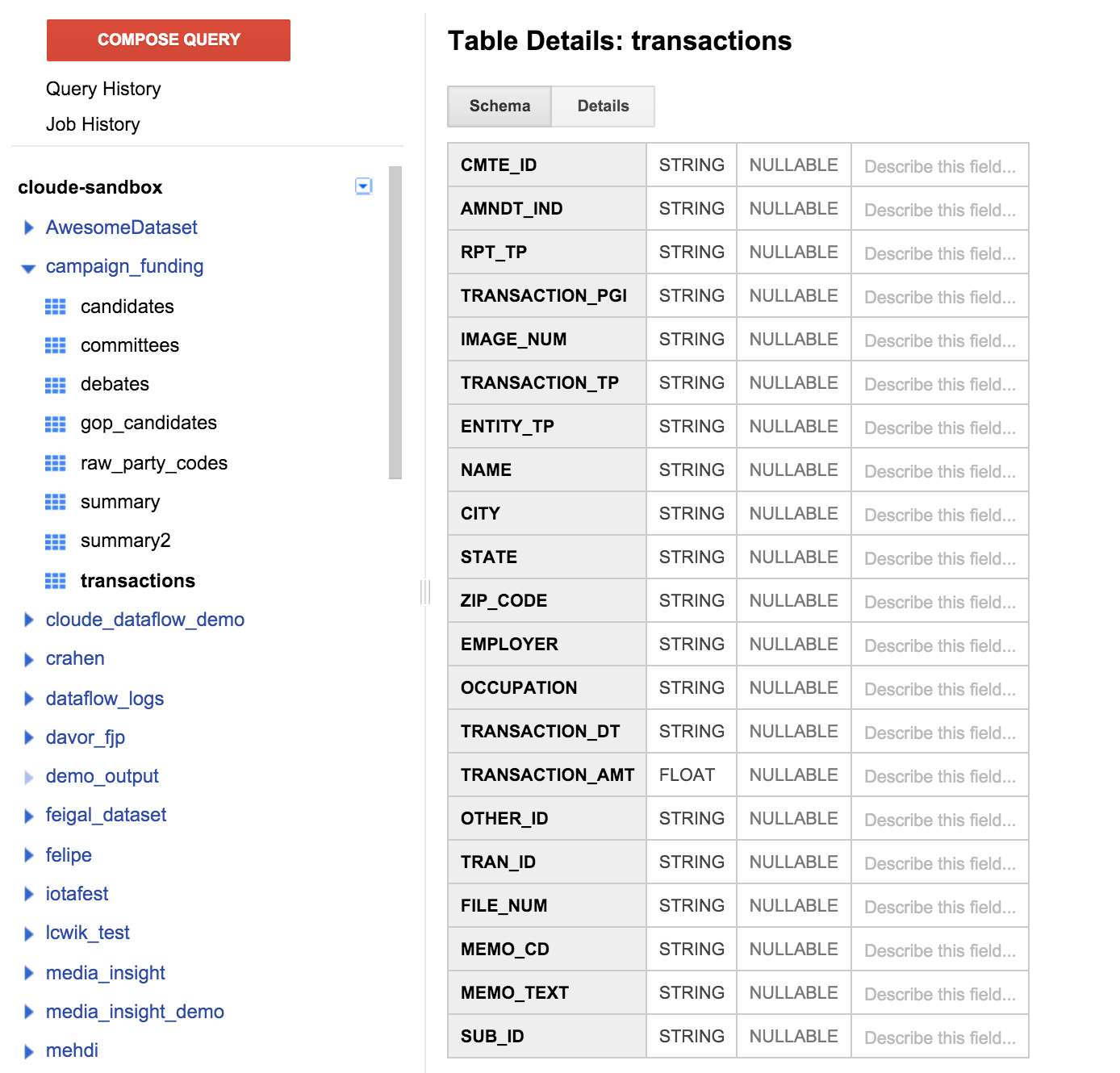
Podemos ver una lista de campos que coinciden con la definición de tabla que especificamos anteriormente. Tal vez notes que no hay ningún campo de destinatario o alguna manera de averiguar qué candidato aceptó la donación. Sin embargo, hay un campo llamado CMTE_ID. Esta acción nos permitirá vincular al comité que recibió la donación. Esto no es tan útil.
Luego, haga clic en la tabla de comités para consultar su esquema. Tenemos un CMET_ID, que puede unirse a la tabla de transacciones. Otro campo es CAND_ID; se puede unir con una tabla CAND_ID en la tabla de candidatos. Por último, hay un vínculo entre las transacciones y los candidatos en la tabla de comités.
Tenga en cuenta que no hay una pestaña de vista previa para las tablas basadas en GCS. Esto se debe a que, para leer los datos, BigQuery debe leer desde una fuente de datos externa. Ejecutemos una consulta simple de"SELECT *"en la tabla de candidatos para obtener una muestra de los datos.
SELECT * FROM [campaign_funding.candidates] LIMIT 100
El resultado debería ser similar a este:
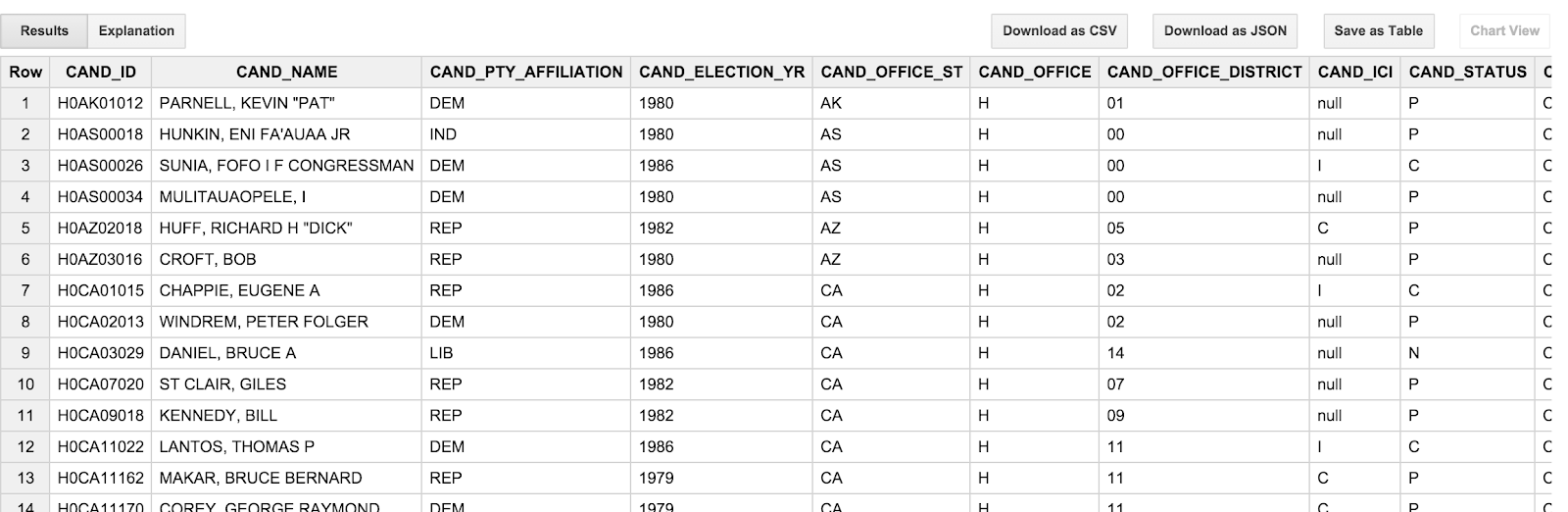
Algo que posiblemente note es que los nombres de los candidatos son SOLO MAYÚSCULAS y se presentan en orden de apellido, nombre. Esto es un poco molesto, ya que no pensamos en los candidatos; preferimos ver a Barack Obama en lugar de Obama, BARACK. Además, las fechas de las transacciones (TRANSACTION_DT) de la tabla de transacciones también son un poco incómodas. Son valores de string en el formato YYYYMMDD. En la siguiente sección abordaremos estas particularidades.
Ahora que entendemos cómo se relacionan las transacciones con los candidatos, ejecutemos una consulta para averiguar quién está dando dinero a quién. Corta y pega la siguiente consulta en el cuadro de redacción:
SELECT affiliation, SUM(amount) AS amount
FROM (
SELECT *
FROM (
SELECT
t.amt AS amount,
t.occupation AS occupation,
c.affiliation AS affiliation,
FROM (
SELECT
trans.TRANSACTION_AMT AS amt,
trans.OCCUPATION AS occupation,
cmte.CAND_ID AS CAND_ID
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CAND_ID) AS CAND_ID
FROM [campaign_funding.committees]
GROUP EACH BY CMTE_ID ) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) AS t
RIGHT OUTER JOIN EACH (
SELECT
CAND_ID,
FIRST(CAND_PTY_AFFILIATION) AS affiliation,
FROM [campaign_funding.candidates]
GROUP EACH BY CAND_ID) c
ON t.CAND_ID = c.CAND_ID )
WHERE occupation CONTAINS "ENGINEER")
GROUP BY affiliation
ORDER BY amount DESC
Esta consulta une la tabla de transacciones con la tabla de comités y, luego, con la tabla de candidatos. Solo analiza las transacciones de personas que tienen la palabra"ENGINEER"en su cargo. La consulta agrupa los resultados por afiliación a un partido, lo que nos permite ver la distribución de la donación a varios partidos políticos entre ingenieros.
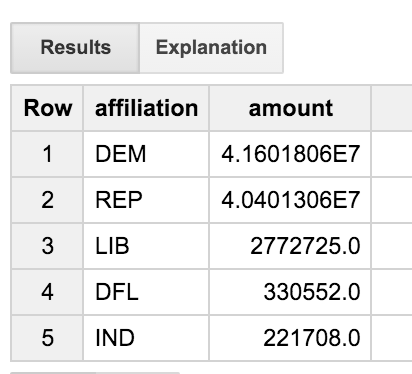
Podemos ver que los ingenieros son bastante equilibrados, lo que proporciona de forma más o menos uniforme a los democráticos y republicanos. ¿Pero qué es la fiesta de "DFL"? ¿No sería lindo obtener nombres completos en lugar de un código de tres letras?
Los códigos de los grupos se definen en el sitio web de la FEC. Hay una tabla que hace coincidir el código del partido con el nombre completo (resulta que "DFL' es "Democratic-Farmer-Labor'"). Si bien podríamos realizar las traducciones manualmente en nuestra consulta, esto parece realizar mucho trabajo y es difícil mantenerlas sincronizadas.
¿Qué sucedería si pudiéramos analizar el HTML como parte de la consulta? Haz clic con el botón derecho en cualquier parte de esa página y observa el código fuente de la página. Hay mucha información de encabezado y código fuente en la fuente, pero busca la etiqueta <table>. Cada fila de asignación está en un elemento HTML <tr>, el nombre y el código están unidos en elementos <td>. Cada fila se verá de la siguiente manera:
El código HTML debería ser similar al siguiente:
<tr bgcolor="#F5F0FF">
<td scope="row"><div align="left">ACE</div></td>
<td scope="row">Ace Party</td>
<td scope="row"></td>
</tr>
Tenga en cuenta que BigQuery no puede leer el archivo directamente desde la Web, ya que BigQuery puede encontrar una fuente de miles de trabajadores de manera simultánea. Si se pudiera ejecutar en páginas web aleatorias, básicamente sería un ataque de denegación de servicio distribuido (DSD). El archivo HTML de la página web de la FEC se almacena en el bucket gs://campaign-funding.
Necesitaremos crear una tabla con los datos de financiación de las campañas. Esto será similar a las otras tablas respaldadas por GCS que creamos. La diferencia es que, en realidad, no tenemos un esquema. Solo usaremos un campo por fila y le llamaremos "data". Supongamos que es un archivo CSV y, en lugar de un límite de comas, usaremos un delimitador falso (`) y ningún carácter de comillas.
Para crear la tabla de consulta de grupos, ejecuta los siguientes comandos desde la línea de comandos:
$ echo '{"csvOptions": {"allowJaggedRows": false, "skipLeadingRows": 0, "quote": "", "encoding": "UTF-8", "fieldDelimiter": "`", "allowQuotedNewlines": false}, "ignoreUnknownValues": true, "sourceFormat": "CSV", "sourceUris": ["gs://campaign-funding/party_codes.shtml"], "schema": {"fields": [{"type": "STRING", "name": "data"}]}}' > party_raw_def.json
$ bq mk --external_table_definition=party_raw_def.json \
-t ${DATASET}.raw_party_codes
Table 'bq-campaign:campaign_funding.raw_party_codes' successfully created.
Ahora usaremos JavaScript para analizar el archivo. En la parte superior derecha del Editor de consultas de BigQuery debería haber un botón etiquetado como Editor de UDF. Haz clic en ella para cambiar a una UDF de JavaScript. El editor de UDF se propagará con texto estándar comentado.

Borra el código que contiene y, luego, ingresa el siguiente código:
function tableParserFun(row, emitFn) {
if (row.data != null && row.data.match(/<tr.*<\/tr>/) !== null) {
var txt = row.data
var re = />\s*(\w[^\t<]*)\t*<.*>\s*(\w[^\t<]*)\t*</;
matches = txt.match(re);
if (matches !== null && matches.length > 2) {
var result = {code: matches[1], name: matches[2]};
emitFn(result);
} else {
var result = { code: 'ERROR', name: matches};
emitFn(result);
}
}
}
bigquery.defineFunction(
'tableParser', // Name of the function exported to SQL
['data'], // Names of input columns
[{'name': 'code', 'type': 'string'}, // Output schema
{'name': 'name', 'type': 'string'}],
tableParserFun // Reference to JavaScript UDF
);
Aquí, JavaScript se divide en dos partes. La primera es una función que toma una fila de entrada y emite una salida analizada. La otra es una definición que registra esa función como una función definida por el usuario (UDF) con el nombre tableParser y, además, indica que toma una columna de entrada llamada "data'" y da como resultado dos columnas, código y nombre. La columna del código será el código de tres letras y la columna del nombre es el nombre completo de la parte.
Regresa a la pestaña "Editor de consultas" y, luego, ingresa la siguiente consulta:
SELECT code, name FROM tableParser([campaign_funding.raw_party_codes]) ORDER BY code
Si ejecuta esta consulta, se analizará el archivo HTML sin procesar y se mostrarán los valores de campo en formato estructurado. Muy elegante, ¿no? Intenta comprender qué significa "DFL"
Ahora que podemos traducir los códigos de grupo a nombres, veamos otra consulta que use esta función para averiguar algo interesante. Ejecute la siguiente consulta:
SELECT
candidate,
election_year,
FIRST(candidate_affiliation) AS affiliation,
SUM(amount) AS amount
FROM (
SELECT
CONCAT(REGEXP_EXTRACT(c.candidate_name,r'\w+,[ ]+([\w ]+)'), ' ',
REGEXP_EXTRACT(c.candidate_name,r'(\w+),')) AS candidate,
pty.candidate_affiliation_name AS candidate_affiliation,
c.election_year AS election_year,
t.amt AS amount,
FROM (
SELECT
trans.TRANSACTION_AMT AS amt,
cmte.committee_candidate_id AS committee_candidate_id
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CAND_ID) AS committee_candidate_id
FROM [campaign_funding.committees]
GROUP BY CMTE_ID ) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) AS t
RIGHT OUTER JOIN EACH (
SELECT
CAND_ID AS candidate_id,
FIRST(CAND_NAME) AS candidate_name,
FIRST(CAND_PTY_AFFILIATION) AS affiliation,
FIRST(CAND_ELECTION_YR) AS election_year,
FROM [campaign_funding.candidates]
GROUP BY candidate_id) c
ON t.committee_candidate_id = c.candidate_id
JOIN (
SELECT
code,
name AS candidate_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty
ON pty.code = c.affiliation )
GROUP BY candidate, election_year
ORDER BY amount DESC
LIMIT 100
Esta consulta mostrará qué candidatos recibieron las donaciones de campaña más grandes y detallará sus afiliaciones a grupos.
Estas tablas no son muy grandes y tardan aproximadamente 30 segundos en consultarse. Si tienes que trabajar mucho con las tablas, es probable que quieras importarlas a BigQuery. Puede ejecutar una consulta ETL en la tabla para convertir los datos en algo fácil de usar y, luego, guardarlos como una tabla permanente. Esto significa que no es necesario que siempre recuerdes cómo traducir códigos de grupo, y que también puedes filtrar datos erróneos mientras lo haces.
Haz clic en el botón "Mostrar opciones" y, luego, en el botón "Seleccionar tabla" junto a la etiqueta Destination Table. Elige tu conjunto de datos de campaign_funding e ingresa el ID de tabla como “summary'.”. Selecciona la casilla de verificación “allow large results'

Ahora, ejecute la siguiente consulta:
SELECT
CONCAT(REGEXP_EXTRACT(c.candidate_name,r'\w+,[ ]+([\w ]+)'), ' ', REGEXP_EXTRACT(c.candidate_name,r'(\w+),'))
AS candidate,
pty.candidate_affiliation_name as candidate_affiliation,
INTEGER(c.election_year) as election_year,
c.candidate_state as candidate_state,
c.office as candidate_office,
t.name as name,
t.city as city,
t.amt as amount,
c.district as candidate_district,
c.ici as candidate_ici,
c.status as candidate_status,
t.memo as memo,
t.state as state,
LEFT(t.zip_code, 5) as zip_code,
t.employer as employer,
t.occupation as occupation,
USEC_TO_TIMESTAMP(PARSE_UTC_USEC(
CONCAT(RIGHT(t.transaction_date, 4), "-",
LEFT(t.transaction_date,2), "-",
RIGHT(LEFT(t.transaction_date,4), 2),
" 00:00:00"))) as transaction_date,
t.committee_name as committee_name,
t.committe_designation as committee_designation,
t.committee_type as committee_type,
pty_cmte.committee_affiliation_name as committee_affiliation,
t.committee_org_type as committee_organization_type,
t.committee_connected_org_name as committee_organization_name,
t.entity_type as entity_type,
FROM (
SELECT
trans.ENTITY_TP as entity_type,
trans.NAME as name,
trans.CITY as city,
trans.STATE as state,
trans.ZIP_CODE as zip_code,
trans.EMPLOYER as employer,
trans.OCCUPATION as occupation,
trans.TRANSACTION_DT as transaction_date,
trans.TRANSACTION_AMT as amt,
trans.MEMO_TEXT as memo,
cmte.committee_name as committee_name,
cmte.committe_designation as committe_designation,
cmte.committee_type as committee_type,
cmte.committee_affiliation as committee_affiliation,
cmte.committee_org_type as committee_org_type,
cmte.committee_connected_org_name as committee_connected_org_name,
cmte.committee_candidate_id as committee_candidate_id
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CMTE_NM) as committee_name,
FIRST(CMTE_DSGN) as committe_designation,
FIRST(CMTE_TP) as committee_type,
FIRST(CMTE_PTY_AFFILIATION) as committee_affiliation,
FIRST(ORG_TP) as committee_org_type,
FIRST(CONNECTED_ORG_NM) as committee_connected_org_name,
FIRST(CAND_ID) as committee_candidate_id
FROM [campaign_funding.committees]
GROUP BY CMTE_ID
) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) as t
RIGHT OUTER JOIN EACH
(SELECT CAND_ID as candidate_id,
FIRST(CAND_NAME) as candidate_name,
FIRST(CAND_PTY_AFFILIATION) as affiliation,
INTEGER(FIRST(CAND_ELECTION_YR)) as election_year,
FIRST(CAND_OFFICE_ST) as candidate_state,
FIRST(CAND_OFFICE) as office,
FIRST(CAND_OFFICE_DISTRICT) as district,
FIRST(CAND_ICI) as ici,
FIRST(CAND_STATUS) as status,
FROM [campaign_funding.candidates]
GROUP BY candidate_id) c
ON t.committee_candidate_id = c.candidate_id
JOIN (
SELECT code, name as candidate_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty
ON pty.code = c.affiliation
JOIN (
SELECT code, name as committee_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty_cmte
ON pty_cmte.code = t.committee_affiliation
WHERE t.amt > 0.0 and REGEXP_MATCH(t.state, "^[A-Z]{2}$") and t.amt < 1000000.0
Esta consulta es significativamente más larga y tiene algunas opciones adicionales de limpieza. Por ejemplo, ignora cualquier precio superior a USD 1 millón. También usa expresiones regulares para convertir “LASTNAME, FIRSTNAME” en FIRSTNAME LASTNAME. Si te sientes aventurero, intenta escribir una UDF para mejorar aún más el uso de mayúsculas y minúsculas (p.ej.,Firstname Lastname &").
Por último, intenta ejecutar algunas consultas en tu tabla campaign_funding.summary para verificar que las búsquedas en esa tabla sean más rápidas. No te olvides de quitar la opción de consulta de la tabla de destino, ya que, de lo contrario, podrías reemplazar la tabla de resumen.
Limpiaste e importaste datos del sitio web de la FEC a BigQuery.
Temas abordados
- Usar tablas respaldadas por GCS en BigQuery
- Usar funciones definidas por el usuario en BigQuery
Próximos pasos
- Prueba algunas consultas interesantes para descubrir a quién les da dinero este ciclo electoral.
Más información
- Obtenga más información acerca de lo que puede hacer con las funciones definidas por el usuario.
- Lee sobre las fuentes de datos federadas(incluidas las GCS).
- Publique preguntas y encuentre respuestas sobre Stack Overflow en la etiqueta google-bigquery.
Envíanos tus comentarios
- Puedes usar el vínculo de la parte inferior izquierda de esta página para informar o compartir problemas.