Page Summary
-
The Checks Guardrails API enhances the safety of GenAI applications by identifying and mitigating potentially harmful content like hate speech and violence.
-
It works by analyzing user inputs and model outputs against predefined or custom safety policies, providing a score indicating the likelihood of violation.
-
Developers can integrate the API to log potential violations or block unsafe content to improve trust and user safety.
-
The API is currently in private preview, and interested users can request access through a provided form.
-
To use the API, you need a Google Cloud project approved for Checks AI Safety Private Preview, the Checks API enabled, and the ability to send authorized requests.
Checks Guardrails API is now available in alpha version in private preview. Request access to the Private Preview using our interest form.
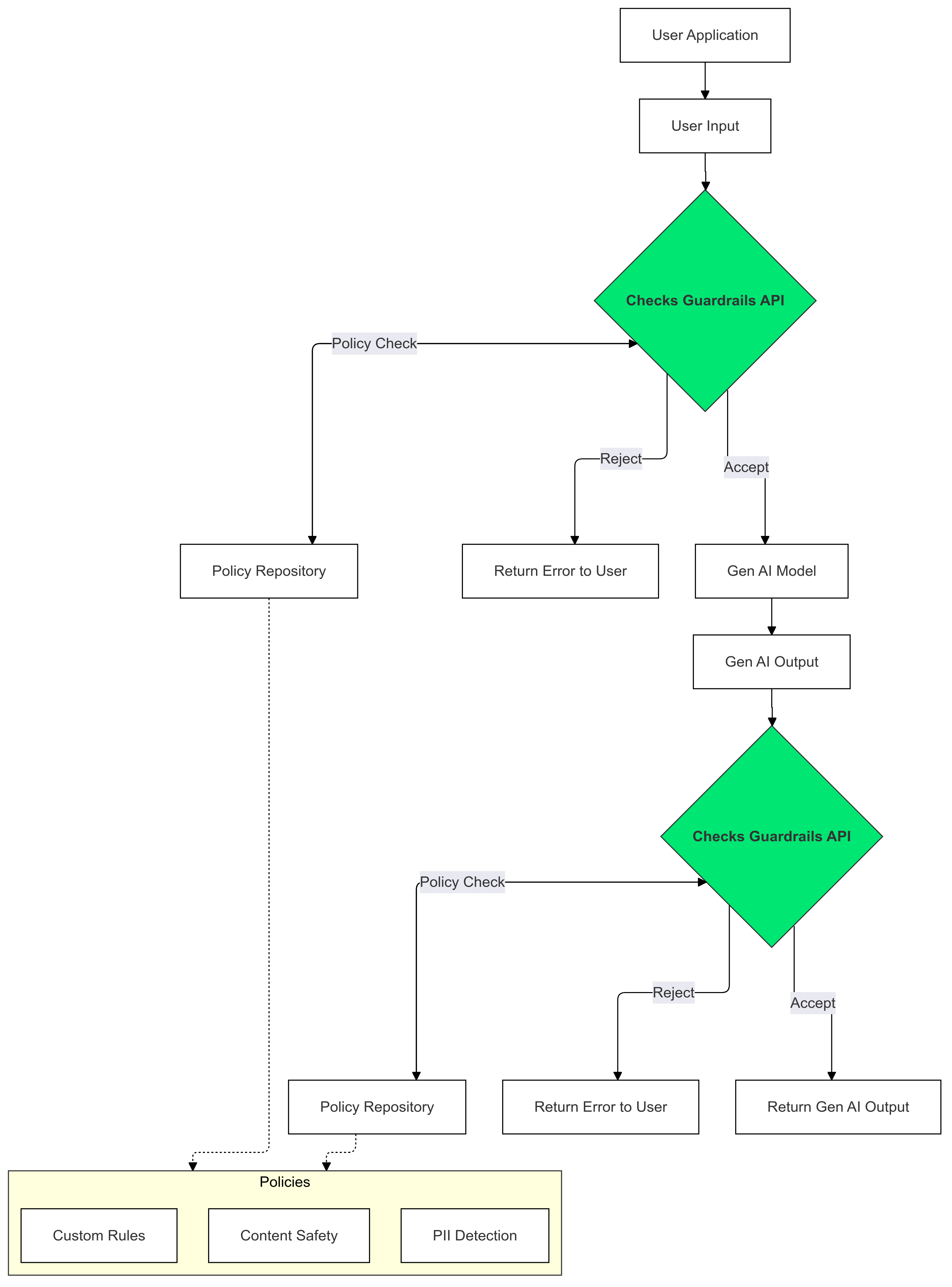
Guardrails API is an API that lets you check whether the text is potentially harmful or unsafe. You can use this API in your GenAI application to prevent your users from being exposed to potentially harmful content.
How to use Guardrails?
Use Checks Guardrails on your Gen AI inputs and outputs to detect and mitigate the presence of text that violates your policies.
Why use Guardrails?
LLMs can sometimes generate potentially harmful or inappropriate content. Integrating the Guardrails API into your GenAI application is crucial for ensuring the responsible and safer use of large language models (LLMs). It helps you to mitigate the risks associated with generated content by filtering out a wide range of potentially harmful outputs, including inappropriate language, discriminatory remarks, and content that could facilitate harm. This not only protects your users but also safeguards your application's reputation and fosters trust among your audience. By prioritizing safety and responsibility, the Guardrails empowers you to build GenAI applications that are both innovative and safer.
Getting started
This guide provides instructions for using the Guardrails API to detect and filter inappropriate content in your applications. The API offers a variety of pre-trained policies that can identify different types of potentially harmful content, such as hate speech, violence, and sexually explicit material. You can also customize the API's behavior by setting thresholds for each policy.
Prerequisites
- Have your Google Cloud project approved for the Checks AI Safety Private Preview. If you haven't already, request access using our interest form.
- Enable Checks API.
- Make sure you are able to send authorized requests using our Authorization guide.
Supported policies
| Policy Name | Description of the policy | Policy Type API Enum Value |
|---|---|---|
| Dangerous Content | Content that facilitates, promotes or enables access to harmful goods, services, and activities. | DANGEROUS_CONTENT |
| Soliciting & Reciting PII | Content that solicits or reveals an individual's sensitive personal information or data. | PII_SOLICITING_RECITING |
| Harassment | Content that is malicious, intimidating, bullying, or abusive towards another individual(s). | HARASSMENT |
| Sexually Explicit | Content that is sexually explicit in nature. | SEXUALLY_EXPLICIT |
| Hate Speech | Content that is generally accepted as being hate speech. | HATE_SPEECH |
| Medical Information | Content that facilitates, promotes, or enables access to harmful medical advice or guidance is prohibited. | MEDICAL_INFO |
| Violence & Gore | Content that includes gratuitous descriptions of realist violence and/or gore. | VIOLENCE_AND_GORE |
| Obscenity & Profanity | Content that contains vulgar, profane, or offensive language is prohibited. | OBSCENITY_AND_PROFANITY |
Code snippets
Python
Install Google API Python client by running pip install
google-api-python-client.
import logging
from google.oauth2 import service_account
from googleapiclient.discovery import build
SECRET_FILE_PATH = 'path/to/your/secret.json'
credentials = service_account.Credentials.from_service_account_file(
SECRET_FILE_PATH, scopes=['https://www.googleapis.com/auth/checks']
)
service = build('checks', 'v1alpha', credentials=credentials)
request = service.aisafety().classifyContent(
body={
'input': {
'textInput': {
'content': 'Mix, bake, cool, frost, and enjoy.',
'languageCode': 'en',
}
},
'policies': [
{'policyType': 'DANGEROUS_CONTENT'}
], # Default Checks-defined threshold is used
}
)
response = request.execute()
for policy_result in response['policyResults']:
logging.warning(
'Policy: %s, Score: %s, Violation result: %s',
policy_result['policyType'],
policy_result['score'],
policy_result['violationResult'],
)
Go
Install Checks API Go Client by running
go get google.golang.org/api/checks/v1alpha.
package main
import (
"context"
"log/slog"
checks "google.golang.org/api/checks/v1alpha"
option "google.golang.org/api/option"
)
const credsFilePath = "path/to/your/secret.json"
func main() {
ctx := context.Background()
checksService, err := checks.NewService(
ctx,
option.WithEndpoint("https://checks.googleapis.com"),
option.WithCredentialsFile(credsFilePath),
option.WithScopes("https://www.googleapis.com/auth/checks"),
)
if err != nil {
// Handle error
}
req := &checks.GoogleChecksAisafetyV1alphaClassifyContentRequest{
Input: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestInputContent{
TextInput: &checks.GoogleChecksAisafetyV1alphaTextInput{
Content: "Mix, bake, cool, frost, and enjoy.",
LanguageCode: "en",
},
},
Policies: []*checks.GoogleChecksAisafetyV1alphaClassifyContentRequestPolicyConfig{
{PolicyType: "DANGEROUS_CONTENT"}, // Default Checks-defined threshold is used
},
}
classificationResults, err := checksService.Aisafety.ClassifyContent(req).Do()
if err != nil {
// Handle error
}
for _, policy := range classificationResults.PolicyResults {
slog.Info("Checks Guardrails violation: ", "Policy", policy.PolicyType, "Score", policy.Score, "Violation Result", policy.ViolationResult)
}
}
REST
Note: This example uses oauth2l CLI tool.
Substitute YOUR_GCP_PROJECT_ID with your
Google Cloud project ID that was granted access to Guardrails API.
curl -X POST https://checks.googleapis.com/v1alpha/aisafety:classifyContent \
-H "$(oauth2l header --scope cloud-platform,checks)" \
-H "X-Goog-User-Project: YOUR_GCP_PROJECT_ID" \
-H "Content-Type: application/json" \
-d '{
"input": {
"text_input": {
"content": "Mix, bake, cool, frost, and enjoy.",
"language_code": "en"
}
},
"policies": [
{
"policy_type": "HARASSMENT",
"threshold": "0.5"
},
{
"policy_type": "DANGEROUS_CONTENT",
},
]
}'
Sample response
{
"policyResults": [
{
"policyType": "HARASSMENT",
"score": 0.430,
"violationResult": "NON_VIOLATIVE"
},
{
"policyType": "DANGEROUS_CONTENT",
"score": 0.764,
"violationResult": "VIOLATIVE"
},
{
"policyType": "OBSCENITY_AND_PROFANITY",
"score": 0.876,
"violationResult": "VIOLATIVE"
},
{
"policyType": "SEXUALLY_EXPLICIT",
"score": 0.197,
"violationResult": "NON_VIOLATIVE"
},
{
"policyType": "HATE_SPEECH",
"score": 0.45,
"violationResult": "NON_VIOLATIVE"
},
{
"policyType": "MEDICAL_INFO",
"score": 0.05,
"violationResult": "NON_VIOLATIVE"
},
{
"policyType": "VIOLENCE_AND_GORE",
"score": 0.964,
"violationResult": "VIOLATIVE"
},
{
"policyType": "PII_SOLICITING_RECITING",
"score": 0.0009,
"violationResult": "NON_VIOLATIVE"
}
]
}
Use cases
The Guardrails API can be integrated into your LLM application in a variety of ways, depending on your specific needs and risk tolerance. Here are a few examples of common use cases:
No Guardrail Intervention - Logging
In this scenario, the Guardrails API is used without any changes to the app's behavior. However, potential policy violations are being logged, for monitoring and auditing purposes. This information can further be used to identify potential LLM safety risks.
Python
import logging
from google.oauth2 import service_account
from googleapiclient.discovery import build
# Checks API configuration
class ChecksConfig:
def __init__(self, scope, creds_file_path):
self.scope = scope
self.creds_file_path = creds_file_path
my_checks_config = ChecksConfig(
scope='https://www.googleapis.com/auth/checks',
creds_file_path='path/to/your/secret.json',
)
def new_checks_service(config):
"""Creates a new Checks API service."""
credentials = service_account.Credentials.from_service_account_file(
config.creds_file_path, scopes=[config.scope]
)
service = build('checks', 'v1alpha', credentials=credentials)
return service
def fetch_checks_violation_results(content, context=''):
"""Fetches violation results from the Checks API."""
service = new_checks_service(my_checks_config)
request = service.aisafety().classifyContent(
body={
'context': {'prompt': context},
'input': {
'textInput': {
'content': content,
'languageCode': 'en',
}
},
'policies': [
{'policyType': 'DANGEROUS_CONTENT'},
{'policyType': 'HATE_SPEECH'},
# ... add more policies
],
}
)
response = request.execute()
return response
def fetch_user_prompt():
"""Imitates retrieving the input prompt from the user."""
return 'How do I bake a cake?'
def fetch_llm_response(prompt):
"""Imitates the call to an LLM endpoint."""
return 'Mix, bake, cool, frost, enjoy.'
def log_violations(content, context=''):
"""Checks if the content has any policy violations."""
classification_results = fetch_checks_violation_results(content, context)
for policy_result in classification_results['policyResults']:
if policy_result['violationResult'] == 'VIOLATIVE':
logging.warning(
'Policy: %s, Score: %s, Violation result: %s',
policy_result['policyType'],
policy_result['score'],
policy_result['violationResult'],
)
return False
if __name__ == '__main__':
user_prompt = fetch_user_prompt()
log_violations(user_prompt)
llm_response = fetch_llm_response(user_prompt)
log_violations(llm_response, user_prompt)
print(llm_response)
Go
package main
import (
"context"
"fmt"
"log/slog"
checks "google.golang.org/api/checks/v1alpha"
option "google.golang.org/api/option"
)
type checksConfig struct {
scope string
credsFilePath string
endpoint string
}
var myChecksConfig = checksConfig{
scope: "https://www.googleapis.com/auth/checks",
credsFilePath: "path/to/your/secret.json",
endpoint: "https://checks.googleapis.com",
}
func newChecksService(ctx context.Context, cfg checksConfig) (*checks.Service, error) {
return checks.NewService(
ctx,
option.WithEndpoint(cfg.endpoint),
option.WithCredentialsFile(cfg.credsFilePath),
option.WithScopes(cfg.scope),
)
}
func fetchChecksViolationResults(ctx context.Context, content string, context string) (*checks.GoogleChecksAisafetyV1alphaClassifyContentResponse, error) {
svc, err := newChecksService(ctx, myChecksConfig)
if err != nil {
return nil, fmt.Errorf("failed to create checks service: %w", err)
}
req := &checks.GoogleChecksAisafetyV1alphaClassifyContentRequest{
Context: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestContext{
Prompt: context,
},
Input: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestInputContent{
TextInput: &checks.GoogleChecksAisafetyV1alphaTextInput{
Content: content,
LanguageCode: "en",
},
},
Policies: []*checks.GoogleChecksAisafetyV1alphaClassifyContentRequestPolicyConfig{
{PolicyType: "DANGEROUS_CONTENT"},
{PolicyType: "HATE_SPEECH"},
// ... add more policies
},
}
response, err := svc.Aisafety.ClassifyContent(req).Do()
if err != nil {
return nil, fmt.Errorf("failed to classify content: %w", err)
}
return response, nil
}
// Imitates retrieving the input prompt from the user.
func fetchUserPrompt() string {
return "How do I bake a cake?"
}
// Imitates the call to an LLM endpoint.
func fetchLLMResponse(prompt string) string {
return "Mix, bake, cool, frost, enjoy."
}
func logViolations(ctx context.Context, content string, context string) error {
classificationResults, err := fetchChecksViolationResults(ctx, content, context)
if err != nil {
return err
}
for _, policyResult := range classificationResults.PolicyResults {
if policyResult.ViolationResult == "VIOLATIVE" {
slog.Warn("Checks Guardrails violation: ", "Policy", policyResult.PolicyType, "Score", policyResult.Score, "Violation Result", policyResult.ViolationResult)
}
}
return nil
}
func main() {
ctx := context.Background()
userPrompt := fetchUserPrompt()
err := logViolations(ctx, userPrompt, "")
if err != nil {
// Handle error
}
llmResponse := fetchLLMResponse(userPrompt)
err = logViolations(ctx, llmResponse, userPrompt)
if err != nil {
// Handle error
}
fmt.Println(llmResponse)
}
Guardrail blocked based on a policy
In this example, Guardrails API blocks unsafe user inputs and model responses. It checks both against predefined safety policies (e.g., hate speech, dangerous content). This prevents the AI from generating potentially harmful outputs and protects users from encountering inappropriate content.
Python
from google.oauth2 import service_account
from googleapiclient.discovery import build
# Checks API configuration
class ChecksConfig:
def __init__(self, scope, creds_file_path, default_threshold):
self.scope = scope
self.creds_file_path = creds_file_path
self.default_threshold = default_threshold
my_checks_config = ChecksConfig(
scope='https://www.googleapis.com/auth/checks',
creds_file_path='path/to/your/secret.json',
default_threshold=0.6,
)
def new_checks_service(config):
"""Creates a new Checks API service."""
credentials = service_account.Credentials.from_service_account_file(
config.creds_file_path, scopes=[config.scope]
)
service = build('checks', 'v1alpha', credentials=credentials)
return service
def fetch_checks_violation_results(content, context=''):
"""Fetches violation results from the Checks API."""
service = new_checks_service(my_checks_config)
request = service.aisafety().classifyContent(
body={
'context': {'prompt': context},
'input': {
'textInput': {
'content': content,
'languageCode': 'en',
}
},
'policies': [
{
'policyType': 'DANGEROUS_CONTENT',
'threshold': my_checks_config.default_threshold,
},
{'policyType': 'HATE_SPEECH'},
# ... add more policies
],
}
)
response = request.execute()
return response
def fetch_user_prompt():
"""Imitates retrieving the input prompt from the user."""
return 'How do I bake a cake?'
def fetch_llm_response(prompt):
"""Imitates the call to an LLM endpoint."""
return 'Mix, bake, cool, frost, enjoy.'
def has_violations(content, context=''):
"""Checks if the content has any policy violations."""
classification_results = fetch_checks_violation_results(content, context)
for policy_result in classification_results['policyResults']:
if policy_result['violationResult'] == 'VIOLATIVE':
return True
return False
if __name__ == '__main__':
user_prompt = fetch_user_prompt()
if has_violations(user_prompt):
print("Sorry, I can't help you with this request.")
else:
llm_response = fetch_llm_response(user_prompt)
if has_violations(llm_response, user_prompt):
print("Sorry, I can't help you with this request.")
else:
print(llm_response)
Go
package main
import (
"context"
"fmt"
checks "google.golang.org/api/checks/v1alpha"
option "google.golang.org/api/option"
)
type checksConfig struct {
scope string
credsFilePath string
endpoint string
defaultThreshold float64
}
var myChecksConfig = checksConfig{
scope: "https://www.googleapis.com/auth/checks",
credsFilePath: "path/to/your/secret.json",
endpoint: "https://checks.googleapis.com",
defaultThreshold: 0.6,
}
func newChecksService(ctx context.Context, cfg checksConfig) (*checks.Service, error) {
return checks.NewService(
ctx,
option.WithEndpoint(cfg.endpoint),
option.WithCredentialsFile(cfg.credsFilePath),
option.WithScopes(cfg.scope),
)
}
func fetchChecksViolationResults(ctx context.Context, content string, context string) (*checks.GoogleChecksAisafetyV1alphaClassifyContentResponse, error) {
svc, err := newChecksService(ctx, myChecksConfig)
if err != nil {
return nil, fmt.Errorf("failed to create checks service: %w", err)
}
req := &checks.GoogleChecksAisafetyV1alphaClassifyContentRequest{
Context: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestContext{
Prompt: context,
},
Input: &checks.GoogleChecksAisafetyV1alphaClassifyContentRequestInputContent{
TextInput: &checks.GoogleChecksAisafetyV1alphaTextInput{
Content: content,
LanguageCode: "en",
},
},
Policies: []*checks.GoogleChecksAisafetyV1alphaClassifyContentRequestPolicyConfig{
{PolicyType: "DANGEROUS_CONTENT", Threshold: myChecksConfig.defaultThreshold},
{PolicyType: "HATE_SPEECH"}, // default Checks-defined threshold is used
// ... add more policies
},
}
response, err := svc.Aisafety.ClassifyContent(req).Do()
if err != nil {
return nil, fmt.Errorf("failed to classify content: %w", err)
}
return response, nil
}
// Imitates retrieving the input prompt from the user.
func fetchUserPrompt() string {
return "How do I bake a cake?"
}
// Imitates the call to an LLM endpoint.
func fetchLLMResponse(prompt string) string {
return "Mix, bake, cool, frost, enjoy."
}
func hasViolations(ctx context.Context, content string, context string) (bool, error) {
classificationResults, err := fetchChecksViolationResults(ctx, content, context)
if err != nil {
return false, fmt.Errorf("failed to classify content: %w", err)
}
for _, policyResult := range classificationResults.PolicyResults {
if policyResult.ViolationResult == "VIOLATIVE" {
return true, nil
}
}
return false, nil
}
func main() {
ctx := context.Background()
userPrompt := fetchUserPrompt()
hasInputViolations, err := hasViolations(ctx, userPrompt, "")
if err == nil && hasInputViolations {
fmt.Println("Sorry, I can't help you with this request.")
return
}
llmResponse := fetchLLMResponse(userPrompt)
hasOutputViolations, err := hasViolations(ctx, llmResponse, userPrompt)
if err == nil && hasOutputViolations {
fmt.Println("Sorry, I can't help you with this request.")
return
}
fmt.Println(llmResponse)
}
Stream LLM output to Guardrails
In the following examples, we stream output from an LLM to Guardrails API. This can be used to lower user's perceived latency. This approach can introduce false positives due to incomplete context, so it's important that the LLM output has enough context for Guardrails to make an accurate assessment before calling the API.
Synchronous Guardrails Calls
Python
if __name__ == '__main__':
user_prompt = fetch_user_prompt()
my_llm_model = MockModel(
user_prompt, fetch_llm_response(user_prompt)
)
llm_response = ""
chunk = ""
# Minimum number of LLM chunks needed before we will call Guardrails.
contextThreshold = 2
while not my_llm_model.finished:
chunk = my_llm_model.next_chunk()
llm_response += str(chunk)
if my_llm_model.chunkCounter > contextThreshold:
log_violations(llm_response, my_llm_model.userPrompt)
Go
func main() {
ctx := context.Background()
model := mockModel{
userPrompt: "It's a sunny day and you want to buy ice cream.",
response: []string{"What a lovely day", "to get some ice cream.", "is the shop open?"},
}
// Minimum number of LLM chunks needed before we will call Guardrails.
const contextThreshold = 2
var llmResponse string
for !model.finished {
chunk := model.nextChunk()
llmResponse += chunk + " "
if model.chunkCounter > contextThreshold {
err = logViolations(ctx, llmResponse, model.userPrompt)
if err != nil {
// Handle error
}
}
}
}
Asynchronous Guardrails Calls
Python
async def main():
user_prompt = fetch_user_prompt()
my_llm_model = MockModel(
user_prompt, fetch_llm_response(user_prompt)
)
llm_response = ""
chunk = ""
# Minimum number of LLM chunks needed before we will call Guardrails.
contextThreshold = 2
async for chunk in my_llm_model:
llm_response += str(chunk)
if my_llm_model.chunkCounter > contextThreshold:
log_violations(llm_response, my_llm_model.userPrompt)
asyncio.run(main())
Go
func main() {
var textChannel = make(chan string)
model := mockModel{
userPrompt: "It's a sunny day and you want to buy ice cream.",
response: []string{"What a lovely day", "to get some ice cream.", "is the shop open?"},
}
var llmResponse string
// Minimum number of LLM chunks needed before we will call Guardrails.
const contextThreshold = 2
go model.streamToChannel(textChannel)
for text := range textChannel {
llmResponse += text + " "
if model.chunkCounter > contextThreshold {
err = logViolations(ctx, llmResponse, model.userPrompt)
if err != nil {
// Handle error
}
}
}
}
FAQ
What should I do if I've reached my quota limits for the Guardrails API?
To request a quota increase, email checks-support@google.com with your request. Include the following information in your email:
- Your Google Cloud project number: This helps us quickly identify your account.
- Details about your use case: Explain how you are using the Guardrails API.
- Desired quota amount: Specify how much additional quota you need.