
Saat menampilkan respons ke Asisten Google, Anda dapat menggunakan subset Bahasa Markup Sintesis Ucapan (SSML) dalam respons Anda. Menurut menggunakan SSML, Anda dapat membuat respons percakapan tampak lebih alami ucapan. Berikut ini contoh markup SSML dan bagaimana dibaca kembali oleh Asisten Google.
function saySSML(conv) { const ssml = '<speak>' + 'Here are <say-as interpret-as="characters">SSML</say-as> samples. ' + 'I can pause <break time="3" />. ' + 'I can play a sound <audio src="https://www.example.com/MY_WAVE_FILE.wav">your wave file</audio>. ' + 'I can speak in cardinals. Your position is <say-as interpret-as="cardinal">10</say-as> in line. ' + 'Or I can speak in ordinals. You are <say-as interpret-as="ordinal">10</say-as> in line. ' + 'Or I can even speak in digits. Your position in line is <say-as interpret-as="digits">10</say-as>. ' + 'I can also substitute phrases, like the <sub alias="World Wide Web Consortium">W3C</sub>. ' + 'Finally, I can speak a paragraph with two sentences. ' + '<p><s>This is sentence one.</s><s>This is sentence two.</s></p>' + '</speak>'; conv.ask(ssml); }
{ "expectUserResponse": true, "expectedInputs": [ { "possibleIntents": [ { "intent": "actions.intent.TEXT" } ], "inputPrompt": { "richInitialPrompt": { "items": [ { "simpleResponse": { "textToSpeech": "<speak>Here are <say-as interpret-as=\"characters\">SSML</say-as> samples. I can pause <break time=\"3\" />. I can play a sound <audio src=\"https://www.example.com/MY_WAVE_FILE.wav\">your wave file</audio>. I can speak in cardinals. Your position is <say-as interpret-as=\"cardinal\">10</say-as> in line. Or I can speak in ordinals. You are <say-as interpret-as=\"ordinal\">10</say-as> in line. Or I can even speak in digits. Your position in line is <say-as interpret-as=\"digits\">10</say-as>. I can also substitute phrases, like the <sub alias=\"World Wide Web Consortium\">W3C</sub>. Finally, I can speak a paragraph with two sentences. <p><s>This is sentence one.</s><s>This is sentence two.</s></p></speak>" } } ] } } } ] }
Audio
SSML didukung di simulator Actions, tetapi tidak di Dialogflow simulator.
URL dalam SSML
Saat menentukan respons SSML yang hanya menyertakan URL, ampersand di URL tersebut
dapat menyebabkan masalah karena pemformatan XML. Untuk memastikan URL sudah benar
direferensikan, ganti instance & dengan &.
Meskipun respons SSML Anda hanya menyertakan URL, Actions on Google memerlukan
teks tampilan untuk respons. Karena teks di dalam tag <audio> tidak akan
diucapkan oleh Asisten, Anda dapat menyisipkan teks pengisi atau deskripsi singkat di
<audio> tag untuk memenuhi persyaratan ini. Teks di dalam tag <audio> tidak akan
diucapkan oleh Asisten setelah audio diputar, dan memenuhi
persyaratan untuk versi teks tampilan SSML Anda.
Berikut adalah contoh respons SSML yang bermasalah:
<speak>
<audio src="https://firebasestorage.googleapis.com/v0/b/project-name.appspot.com/o/audio-file-name.ogg?alt=media&token=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX">
</audio>
</speak>
Contoh di atas tidak meng-escape & untuk pemformatan XML yang tepat.
Versi tetap dari respons SSML yang sama terlihat seperti ini:
<speak>
<audio src="https://firebasestorage.googleapis.com/v0/b/project-name.appspot.com/o/audio-file-name.ogg?alt=media&token=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX">
text
</audio>
</speak>
Dukungan untuk elemen SSML
Bagian berikut menjelaskan elemen dan opsi SSML yang dapat digunakan dalam Action Anda.
<speak>
Elemen root respons SSML.
Untuk mempelajari elemen speak lebih lanjut, lihat spesifikasi W3.
Contoh
<speak> my SSML content </speak>
<break>
Elemen kosong yang mengontrol jeda atau batas prosodi lainnya di antara kata. Penggunaan <break> di antara pasangan token bersifat opsional. Jika elemen ini tidak ada di antara kata, jeda akan otomatis ditentukan berdasarkan konteks linguistik.
Untuk mempelajari elemen break lebih lanjut, lihat spesifikasi W3.
Atribut
| Atribut | Deskripsi |
|---|---|
time |
Menetapkan durasi jeda menurut detik atau milidetik (misalnya, "3s" atau "250ms"). |
strength |
Menetapkan kekuatan jeda prosodi output berdasarkan suku relatif. Nilai yang valid adalah: "x-weak", weak", "medium", "strong", dan "x-strong". Nilai "none" menunjukkan bahwa tidak ada batas jeda prosodi yang harus dihasilkan, yang dapat digunakan untuk mencegah jeda prosodi yang akan dihasilkan pemroses. Nilai lainnya menunjukkan kekuatan jeda yang tidak menurun secara monoton (meningkat secara konseptual) di antara token. Batasan yang lebih kuat biasanya disertai dengan jeda. |
Contoh
Contoh berikut menunjukkan cara menggunakan elemen <break> untuk memberikan jeda di antara langkah-langkah:
<speak> Step 1, take a deep breath. <break time="200ms"/> Step 2, exhale. Step 3, take a deep breath again. <break strength="weak"/> Step 4, exhale. </speak>
<say‑as>
Elemen ini memungkinkan Anda menunjukkan informasi tentang jenis konstruksi teks yang terdapat dalam elemen. Hal ini juga membantu menentukan tingkat detail untuk merender teks yang ada.
Elemen <say‑as> memiliki atribut yang diperlukan, interpret-as, yang menentukan cara nilai diucapkan. Atribut opsional format dan detail dapat digunakan bergantung pada nilai interpret-as tertentu.
Contoh
Atribut interpret-as mendukung nilai berikut:
-
currencyContoh berikut diucapkan sebagai "forty two dollars and one cent". Jika atribut bahasa dihilangkan, atribut akan menggunakan lokalitas yang saat ini digunakan.
<speak> <say-as interpret-as='currency' language='en-US'>$42.01</say-as> </speak> -
telephoneLihat deskripsi
interpret-as='telephone'dalam catatan WG nilai atribut say-as W3C SSML 1.0.Contoh berikut diucapkan sebagai "one eight zero zero two zero two one two one two". Jika atribut "google:style" dihilangkan, atribut akan menyatakan nol sebagai huruf O.
Atribut "google:style='zero-as-zero'" saat ini hanya bekerja dalam lokalitas EN.
<speak> <say-as interpret-as='telephone' google:style='zero-as-zero'>1800-202-1212</say-as> </speak> -
verbatimatauspell-outContoh berikut dieja huruf demi huruf:
<speak> <say-as interpret-as="verbatim">abcdefg</say-as> </speak> -
dateAtribut
formatadalah pengurutan kode karakter kolom tanggal. Kode karakter kolom yang didukung diformatmasing-masing adalah {y,m,d} untuk tahun, bulan, dan hari (dalam sebulan). Jika kode kolom muncul sekali untuk tahun, bulan, atau hari, maka jumlah digit yang diharapkan adalah 4, 2, dan 2. Jika kode kolom diulang, jumlah digit yang diharapkan adalah frekuensi kode tersebut diulang. Kolom pada teks tanggal dapat dipisahkan dengan tanda baca dan/atau spasi.Atribut
detailmengontrol bentuk tanggal yang diucapkan. Untukdetail='1', hanya kolom hari dan salah satu kolom bulan atau tahun yang wajib diisi, meskipun keduanya mungkin disediakan. Ini adalah setelan default jika yang disediakan kurang dari ketiga kolom tersebut. Format yang diucapkan adalah "The {tanggal} of {bulan}, {tahun}".Contoh berikut diucapkan sebagai "The tenth of September, nineteen sixty":
<speak> <say-as interpret-as="date" format="yyyymmdd" detail="1"> 1960-09-10 </say-as> </speak>Contoh berikut diucapkan sebagai "The tenth of September":
<speak> <say-as interpret-as="date" format="dm">10-9</say-as> </speak>Untuk
detail='2', kolom hari, bulan, dan tahun wajib diisi dan ini adalah setelan default saat ketiga kolom disediakan. Format pengucapannya adalah "{bulan} {tanggal}, {tahun}".Contoh berikut diucapkan sebagai "September tenth, nineteen sixty":
<speak> <say-as interpret-as="date" format="dmy" detail="2"> 10-9-1960 </say-as> </speak> -
charactersContoh berikut diucapkan sebagai "C A N":
<speak> <say-as interpret-as="characters">can</say-as> </speak> -
cardinalContoh berikut diucapkan sebagai "Twelve thousand three hundred forty five" (untuk bahasa Inggris AS) atau "Twelve thousand three hundred and forty five (untuk bahasa Inggris di Inggris Raya)":
<speak> <say-as interpret-as="cardinal">12345</say-as> </speak> -
ordinalContoh berikut diucapkan sebagai "First":
<speak> <say-as interpret-as="ordinal">1</say-as> </speak> -
fractionContoh berikut diucapkan sebagai "five and a half":
<speak> <say-as interpret-as="fraction">5+1/2</say-as> </speak> -
expletiveataubleepContoh berikut berbunyi sebagai bip, seperti disensor:
<speak> <say-as interpret-as="expletive">censor this</say-as> </speak> -
unitMengonversi unit menjadi tunggal atau jamak, tergantung pada angkanya. Contoh berikut diucapkan sebagai "10 feet":
<speak> <say-as interpret-as="unit">10 foot</say-as> </speak> -
timeContoh berikut diucapkan sebagai "Two thirty P.M.":
<speak> <say-as interpret-as="time" format="hms12">2:30pm</say-as> </speak>Atribut
formatadalah pengurutan kode karakter kolom waktu. Kode karakter kolom yang didukung diformatadalah {h,m,s,Z,12,24} untuk jam, menit (dalam sejam itu), detik (dalam semenit itu), zona waktu, format waktu 12 jam, dan format waktu 24 jam. Jika kode kolom muncul sekali untuk jam, menit, atau detik, maka jumlah digit yang diharapkan untuk masing-masing adalah 1, 2, dan 2. Jika kode kolom diulang, jumlah digit yang diharapkan adalah frekuensi kode tersebut diulang. Kolom dalam teks waktu dapat dipisahkan dengan tanda baca dan/atau spasi. Jika jam, menit, atau detik tidak ditentukan dalam format atau tidak ada digit yang cocok, kolom akan diperlakukan sebagai nilai nol.formatdefault-nya adalah "hms12".Atribut
detailmengontrol apakah format waktu yang diucapkan menggunakan format 12 jam atau 24 jam. Format waktu yang diucapkan menggunakan format 24 jam jikadetail='1'ataudetaildihilangkan dan format waktunya ditetapkan menjadi 24 jam. Format waktu yang diucapkan menggunakan format 12 jam jikadetail='2'ataudetaildihilangkan dan format waktunya ditetapkan menjadi 12 jam.
Untuk mempelajari selengkapnya tentang elemen say-as, lihat spesifikasi W3.
<audio>
Mendukung penyisipan file audio yang direkam dan penyisipan format audio lain bersama dengan output ucapan yang disintesis.
Atribut
| Atribut | Wajib | Default | Nilai |
|---|---|---|---|
src |
ya | t/a | URI yang merujuk ke sumber media audio. Protokol yang didukung adalah https. |
clipBegin |
tidak | 0 | TimeDesignation yang merupakan offset dari awal sumber audio untuk memulai pemutaran audio. Jika nilai ini lebih besar dari atau sama dengan durasi sumber audio yang sebenarnya, maka tidak ada audio yang akan disisipkan. |
clipEnd |
tidak | tak terhingga | TimeDesignation yang merupakan offset dari awal sumber audio untuk menghentikan pemutaran audio. Jika durasi sumber audio yang sebenarnya kurang dari nilai ini, pemutaran berakhir pada waktu tersebut. Jika clipBegin lebih besar dari atau sama dengan clipEnd, maka tidak ada audio yang akan disisipkan. |
speed |
tidak | 100% | Rasio output kecepatan pemutaran relatif terhadap kecepatan input normal yang dinyatakan dalam persentase. Formatnya adalah Bilangan Riil positif yang diikuti dengan %. Rentang yang saat ini didukung adalah [50% (pelan - kecepatan setengah), 200% (cepat - kecepatan ganda)]. Nilai di luar rentang itu dapat (atau mungkin tidak) disesuaikan agar berada di dalamnya. |
repeatCount |
tidak | 1, atau 10 jika repeatDur ditetapkan |
Bilangan Riil yang menentukan frekuensi penyisipan audio (setelah kliping, jika ada, dari clipBegin dan/atau clipEnd). Pengulangan pecahan tidak didukung, sehingga nilai akan dibulatkan ke bilangan bulat terdekat. Nol bukan nilai yang valid sehingga dianggap belum ditentukan dan memiliki nilai default dalam kasus tersebut. |
repeatDur |
tidak | tak terhingga | TimeDesignation yang merupakan batas durasi audio yang disisipkan setelah sumber diproses untuk atribut clipBegin, clipEnd, repeatCount, dan speed (bukannya durasi pemutaran normal). Jika durasi audio yang diproses kurang dari nilai ini, pemutaran berakhir pada saat itu. |
soundLevel |
tidak | +0dB | Sesuaikan tingkat suara audio sebesar soundLevel desibel. Rentang maksimum adalah +/-40 dB namun rentang sebenarnya mungkin lebih rendah keefektifannya, dan kualitas output mungkin tidak memberikan hasil yang baik untuk seluruh rentang. |
Berikut adalah setelan audio yang saat ini didukung untuk audio:
- Format: MP3 (MPEG v2)
- 24 ribu sampel per detik
- 24 ribu ~ 96 ribu bit per detik, kecepatan tetap
- Format: Opus di Ogg
- 24 ribu sampel per detik (super-wideband)
- 24K - 96K bit per detik, kecepatan tetap
- Format (tidak digunakan lagi): WAV (RIFF)
- PCM 16-bit bertanda, little endian
- 24 ribu sampel per detik
- Untuk semua format:
- Saluran tunggal lebih disarankan, tetapi stereo diperbolehkan.
- Durasi maksimum 240 detik. Jika Anda ingin memutar audio dengan durasi yang lebih lama, pertimbangkan untuk menerapkan respons media.
- Batas ukuran file 5 megabyte.
- URL sumber harus menggunakan protokol HTTPS.
- UserAgent kami saat mengambil audio adalah "Google-Speech-Actions".
Konten elemen <audio> bersifat opsional dan digunakan jika file audio tidak dapat diputar atau jika perangkat output tidak mendukung audio. Konten dapat menyertakan elemen <desc> yang dalam hal ini konten teks dari elemen tersebut akan digunakan untuk ditampilkan. Untuk mengetahui informasi selengkapnya, lihat bagian Audio yang Direkam di Checklist Respons.
URL src juga harus berupa URL https (Google Cloud Storage dapat menghosting file audio Anda di URL https).
Untuk mempelajari respons media lebih lanjut, lihat bagian respons media di panduan Respons.
Untuk mempelajari elemen audio lebih lanjut, lihat spesifikasi W3.
Contoh
<speak> <audio src="cat_purr_close.ogg"> <desc>a cat purring</desc> PURR (sound didn't load) </audio> </speak>
<p>,<s>
Elemen kalimat dan paragraf.
Untuk mempelajari selengkapnya tentang elemen p dan s, lihat spesifikasi W3.
Contoh
<p><s>This is sentence one.</s><s>This is sentence two.</s></p>
Praktik terbaik
- Gunakan tag <s>...</s> untuk menggabungkan kalimat lengkap, terutama jika berisi elemen SSML yang mengubah prosodi (yaitu, <audio>, <break>, <emphasis>, <par>, <prosody>, <say-as>, <seq>, dan <sub>).
- Jika jeda dalam ucapan dimaksudkan agar cukup panjang sehingga Anda dapat mendengarnya, gunakan tag <s>...</s> dan tempatkan jeda di antara kalimat.
<sub>
Menunjukkan bahwa teks dalam nilai atribut alias menggantikan teks yang ada untuk pengucapan.
Anda juga dapat menggunakan elemen sub untuk memberikan pengucapan sederhana dari kata yang sulit dibaca. Contoh terakhir di bawah ini menunjukkan kasus penggunaan ini dalam bahasa Jepang.
Untuk mempelajari elemen sub lebih lanjut, lihat spesifikasi W3.
Contoh
<sub alias="World Wide Web Consortium">W3C</sub>
<sub alias="にっぽんばし">日本橋</sub>
<mark>
Elemen kosong yang menempatkan penanda ke dalam pengurutan teks atau tag. Ini dapat digunakan untuk mereferensikan lokasi tertentu dalam pengurutan atau menyisipkan penanda ke dalam aliran output untuk notifikasi asinkron.
Untuk mempelajari elemen mark lebih lanjut, lihat spesifikasi W3.
Contoh
<speak> Go from <mark name="here"/> here, to <mark name="there"/> there! </speak>
<prosody>
Digunakan untuk menyesuaikan nada, kecepatan bicara, dan volume teks yang terkandung oleh elemen. Saat ini, atribut rate, pitch, dan volume didukung.
Atribut rate dan volume dapat ditetapkan sesuai dengan spesifikasi W3. Ada tiga opsi untuk menetapkan nilai atribut pitch:
| Atribut | Deskripsi |
|---|---|
name |
ID string untuk setiap tanda. |
| Opsi | Deskripsi |
|---|---|
| Relatif | Menentukan nilai relatif (misalnya "low", "medium", "high", dll.) dengan "medium" sebagai nada default-nya. |
| Semitone | Meningkatkan atau mengurangi nada sebesar "N" semitone menggunakan "+Nst" atau "-Nst". Perhatikan bahwa "+/-" dan "st" diperlukan. |
| Persentase | Meningkatkan atau menurunkan nada sebesar "N" persen menggunakan "+N%" atau "-N%". Perhatikan bahwa "%" diperlukan, tetapi "+/-" bersifat opsional. |
Untuk mempelajari elemen prosody lebih lanjut, lihat spesifikasi W3.
Contoh
Contoh berikut menggunakan elemen <prosody> untuk berbicara perlahan pada 2 semitone lebih rendah dari biasanya:
<prosody rate="slow" pitch="-2st">Can you hear me now?</prosody>
<emphasis>
Digunakan untuk menambahkan atau menghapus penekanan dari teks yang terkandung oleh elemen. Elemen <emphasis> mengubah ucapan yang mirip dengan <prosody>, tetapi tanpa perlu menetapkan atribut ucapan satu per satu.
Elemen ini mendukung atribut "level" opsional dengan nilai valid berikut:
strongmoderatenonereduced
Untuk mempelajari elemen emphasis lebih lanjut, lihat spesifikasi W3.
Contoh
Contoh berikut menggunakan elemen <emphasis> untuk membuat pengumuman:
<emphasis level="moderate">This is an important announcement</emphasis>
<par>
Container media paralel yang memungkinkan Anda memutar beberapa elemen media sekaligus. Konten yang diizinkan adalah kumpulan dari satu atau beberapa elemen <par>, <seq>, dan <media>. Urutan elemen <media> tidak signifikan.
Kecuali jika elemen turunan menentukan waktu mulai yang berbeda, waktu mulai implisit untuk elemen sama dengan waktu mulai container <par>. Jika elemen turunan memiliki nilai offset yang ditetapkan untuk atribut begin atau end, offset elemen akan bersifat relatif terhadap waktu mulai container <par>. Untuk elemen <par> root, atribut begin diabaikan dan waktu awalnya adalah saat proses sintesis ucapan SSML mulai menghasilkan output untuk elemen <par> root (yaitu secara efektif mencatat "nol").
Contoh
<speak>
<par>
<media xml:id="question" begin="0.5s">
<speak>Who invented the Internet?</speak>
</media>
<media xml:id="answer" begin="question.end+2.0s">
<speak>The Internet was invented by cats.</speak>
</media>
<media begin="answer.end-0.2s" soundLevel="-6dB">
<audio
src="https://actions.google.com/.../cartoon_boing.ogg"/>
</media>
<media repeatCount="3" soundLevel="+2.28dB"
fadeInDur="2s" fadeOutDur="0.2s">
<audio
src="https://actions.google.com/.../cat_purr_close.ogg"/>
</media>
</par>
</speak><seq>
Container media berurutan yang memungkinkan Anda memutar elemen media satu per satu. Konten yang diizinkan adalah kumpulan dari satu atau beberapa elemen <seq>, <par>, dan <media>. Urutan elemen media adalah urutan render-nya
Atribut begin dan end dari elemen turunan dapat ditetapkan ke nilai offset (lihat Spesifikasi Waktu di bawah). Nilai offset elemen turunan tersebut akan bersifat relatif terhadap akhir elemen sebelumnya dalam urutan atau, untuk elemen pertama dalam urutan, relatif terhadap awal container<seq>-nya.
Contoh
<speak>
<seq>
<media begin="0.5s">
<speak>Who invented the Internet?</speak>
</media>
<media begin="2.0s">
<speak>The Internet was invented by cats.</speak>
</media>
<media soundLevel="-6dB">
<audio
src="https://actions.google.com/.../cartoon_boing.ogg"/>
</media>
<media repeatCount="3" soundLevel="+2.28dB"
fadeInDur="2s" fadeOutDur="0.2s">
<audio
src="https://actions.google.com/.../cat_purr_close.ogg"/>
</media>
</seq>
</speak><media>
Menampilkan lapisan media dalam elemen <par> atau <seq>. Konten yang diizinkan dari elemen <media> adalah elemen <speak> atau <audio> SSML. Tabel berikut menjelaskan atribut yang valid untuk elemen <media>.
Atribut
| Atribut | Wajib | Default | Nilai |
|---|---|---|---|
| xml:id | tidak | tidak ada nilai | ID XML unik untuk elemen ini. Entity yang dienkode tidak didukung. Nilai ID yang diizinkan cocok dengan ekspresi reguler "([-_#]|\p{L}|\p{D})+". Lihat XML-ID untuk mengetahui informasi selengkapnya. |
| begin | tidak | 0 | Waktu mulai untuk container media ini. Diabaikan jika ini adalah elemen container media root (diperlakukan sama dengan default "0"). Lihat bagian Spesifikasi waktu di bawah untuk mengetahui nilai string yang valid. |
| end | tidak | tidak ada nilai | Spesifikasi waktu berakhir untuk container media ini. Lihat bagian Spesifikasi waktu di bawah untuk mengetahui nilai string yang valid. |
| repeatCount | tidak | 1 | Bilangan Riil yang menentukan frekuensi penyisipan media. Pengulangan pecahan tidak didukung, sehingga nilai akan dibulatkan ke bilangan bulat terdekat. Nol bukan nilai yang valid sehingga dianggap belum ditentukan dan memiliki nilai default dalam kasus tersebut. |
| repeatDur | tidak | tidak ada nilai | TimeDesignation yang merupakan batas durasi media yang dimasukkan. Jika durasi media kurang dari nilai ini, pemutaran berakhir pada saat itu. |
| soundLevel | tidak | +0dB | Sesuaikan tingkat suara audio sebesar soundLevel desibel. Rentang maksimum adalah +/-40 dB namun rentang sebenarnya mungkin lebih rendah keefektifannya, dan kualitas output mungkin tidak memberikan hasil yang baik untuk seluruh rentang. |
| fadeInDur | tidak | 0s | TimeDesignation yang memungkinkan media melakukan fade-in dari senyap ke soundLevel yang ditentukan secara opsional. Jika durasi media kurang dari nilai ini, fade-in akan berhenti di akhir pemutaran dan tingkat suara tidak akan mencapai tingkat suara yang ditentukan. |
| fadeOutDur | tidak | 0s | TimeDesignation yang memungkinkan media melakukan fade-out dari soundLevel yang ditentukan secara opsional hingga media tersebut senyap. Jika durasi media kurang dari nilai ini, tingkat suara akan disetel ke nilai yang lebih rendah untuk memastikan bagian senyap tercapai di akhir pemutaran. |
Spesifikasi waktu
Spesifikasi waktu, yang digunakan untuk nilai atribut `begin` dan `end` dari elemen <media> serta container media (elemen <par> dan <seq>), merupakan nilai offset (misalnya, +2.5s) atau nilai syncbase (misalnya, foo_id.end-250ms).
- Nilai offset - Nilai offset waktu merupakan Timecount-value SMIL yang memungkinkan nilai yang cocok dengan ekspresi reguler:
"\s\*(+|-)?\s\*(\d+)(\.\d+)?(h|min|s|ms)?\s\*"String digit pertama adalah seluruh bagian dari bilangan desimal dan string digit kedua adalah bagian pecahan desimal. Tanda default (yaitu "(+|-)?") adalah "+". Nilai unit sesuai dengan jam, menit, detik, dan milidetik. Default untuk unit adalah "s" (detik).
- Nilai Syncbase - Nilai syncbase adalah syncbase-value SMIL yang memungkinkan nilai yang cocok dengan ekspresi reguler:
"([-_#]|\p{L}|\p{D})+\.(begin|end)\s\*(+|-)\s\*(\d+)(\.\d+)?(h|min|s|ms)?\s\*"Digit dan unit ditafsirkan dengan cara yang sama seperti nilai offset.
simulator TTS
Konsol Actions menyertakan simulator TTS yang dapat Anda gunakan untuk menguji SSML dengan salah satu elemen di atas. Anda dapat menemukan simulator TTS di konsol di bagian Simulator > Audio. Ketik teks dan SSML di simulator dan klik Update dan Dengarkan untuk mendengarkan output TTS.
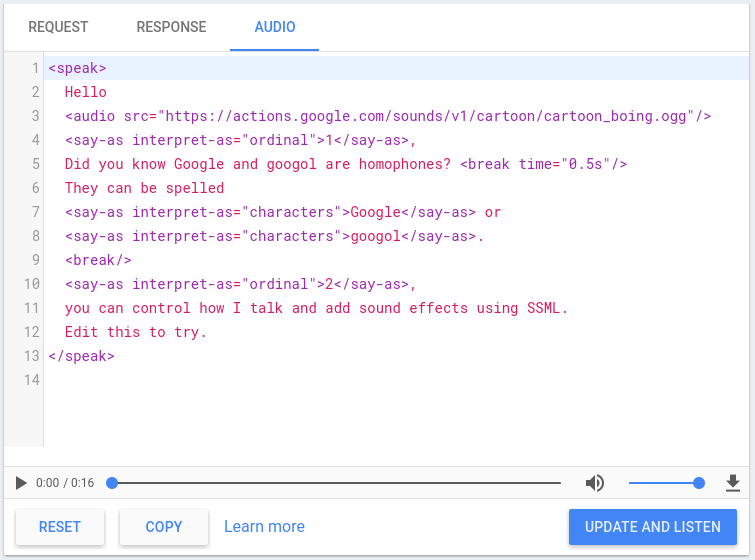
Anda juga dapat mengklik tombol download untuk menyimpan file .mp3 TTS Anda
{i>output<i} tersebut.