
As práticas recomendadas seguintes dão-lhe técnicas para desenvolver consultas centradas na privacidade e com bom desempenho.
Precisão de dados e privacidade
Desenvolva consultas nos dados do sandbox
Prática recomendada: consulte apenas dados de produção quando estiver em produção.
Sempre que possível, use os dados do sandbox durante o desenvolvimento da consulta. As tarefas que usam dados do sandbox não criam oportunidades adicionais para as verificações de diferenças filtrarem os resultados da consulta. Além disso, devido à falta de verificações de privacidade, as consultas no sandbox são executadas mais rapidamente, o que permite uma iteração mais rápida durante o desenvolvimento da consulta.
Se tiver de desenvolver consultas nos seus dados reais (por exemplo, ao usar tabelas de correspondência), escolha intervalos de datas e outros parâmetros que provavelmente não se sobrepõem em cada iteração da consulta, para reduzir a probabilidade de sobrepor linhas. Por último, execute a consulta no intervalo de dados pretendido.
Considere cuidadosamente os resultados do histórico
Prática recomendada: diminua a probabilidade de sobreposição do conjunto de resultados entre consultas executadas recentemente.
Tenha em atenção que a taxa de variação entre os resultados da consulta terá um efeito sobre a probabilidade de os resultados serem omitidos mais tarde devido a verificações de privacidade. É provável que um segundo conjunto de resultados que se assemelhe a um conjunto de resultados devolvido recentemente seja ignorado.
Em alternativa, modifique os parâmetros principais na consulta, como os intervalos de datas ou os IDs de campanhas, para diminuir a probabilidade de sobreposição significativa.
Não consulte os dados de hoje
Prática recomendada: não execute várias consultas quando a data de fim é o dia de hoje.
Quando executa várias consultas com datas de fim iguais ao dia de hoje, muitas vezes as linhas são filtradas. Estas orientações também se aplicam a executar consultas pouco depois da meia-noite nos dados de ontem.
Não consulte os mesmos dados mais do que o necessário
Práticas recomendadas:
- Selecione datas de início e de fim bem vinculadas.
- Em vez de consultar períodos sobrepostos, execute as consultas em conjuntos de dados separados e, em seguida, agregue os resultados no BigQuery.
- Use os resultados guardados em vez de executar novamente a consulta.
- Crie tabelas temporárias para cada intervalo de datas que está a consultar.
O Ads Data Hub restringe o número total de vezes que pode consultar os mesmos dados. Como tal, deve tentar limitar o número de vezes que acede a um determinado fragmento de dados.
Não use mais agregações do que o necessário na mesma consulta
Práticas recomendadas:
- Minimize o número de agregações numa consulta
- Reescreva consultas para combinar agregações sempre que possível
O Ads Data Hub limita para 100 o número de agregações entre utilizadores que podem ser usadas numa subconsulta. Deste modo, recomendamos que escreva consultas que apresentem mais linhas com chaves de agrupamento focadas e agregações simples, em vez de mais colunas com chaves de agrupamento amplas e agregações complexas. Deve evitar o seguinte padrão:
SELECT
COUNTIF(field_1 = a_1 AND field_2 = b_1) AS cnt_1,
COUNTIF(field_1 = a_2 AND field_2 = b_2) AS cnt_2
FROM
table
As consultas que contabilizam eventos consoante o mesmo conjunto de campos devem ser reescritas com a declaração GROUP BY.
SELECT
field_1,
field_2,
COUNT(1) AS cnt
FROM
table
GROUP BY
1, 2
O resultado pode ser agregado da mesma forma no BigQuery.
As consultas que criam colunas a partir de uma matriz e que as agregam posteriormente devem ser reescritas para unir estes passos.
SELECT
COUNTIF(a_1) AS cnt_1,
COUNTIF(a_2) AS cnt_2
FROM
(SELECT
1 IN UNNEST(field) AS a_1,
2 IN UNNEST(field) AS a_2,
FROM
table)
A consulta anterior pode ser reescrita como:
SELECT f, COUNT(1) FROM table, UNNEST(field) AS f GROUP BY 1
As consultas que usam combinações diferentes de campos em diferentes agregações podem ser reescritas em várias consultas mais focadas.
SELECT
COUNTIF(field_1 = a_1) AS cnt_a_1,
COUNTIF(field_1 = b_1) AS cnt_b_1,
COUNTIF(field_2 = a_2) AS cnt_a_2,
COUNTIF(field_2 = b_2) AS cnt_b_2,
FROM table
A consulta anterior pode ser dividida em:
SELECT
field_1, COUNT(*) AS cnt
FROM table
GROUP BY 1
e
SELECT
field_2, COUNT(*) AS cnt
FROM table
GROUP BY 1
Pode dividir estes resultados em consultas separadas, criar e juntar as tabelas numa única consulta ou combiná-las com um UNION se os esquemas forem compatíveis.
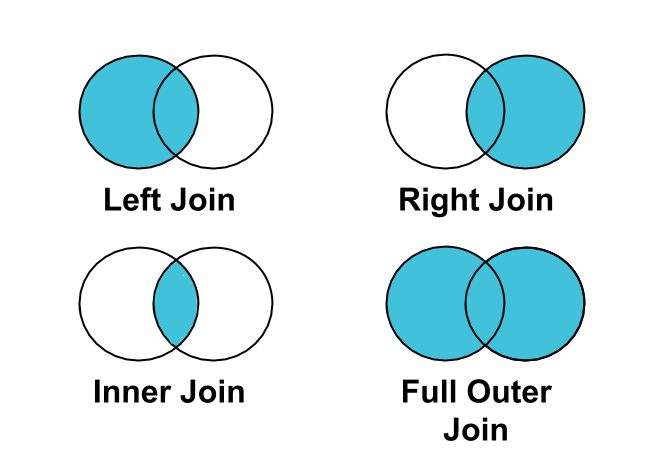
Otimize e compreenda as junções
Prática recomendada: use um LEFT JOIN em vez de um INNER JOIN para juntar cliques ou conversões a impressões.
Nem todas as impressões estão associadas a cliques ou conversões. Por conseguinte, se usar INNER JOIN para cliques ou conversões em impressões, as impressões que não estão associadas a cliques ou conversões serão filtradas dos seus resultados.
Junte alguns resultados finais no BigQuery
Prática recomendada: evite consultas do Ads Data Hub que juntem resultados agregados. Em alternativa, escreva duas consultas separadas e junte os resultados no BigQuery.
As linhas que não cumpram os requisitos de agregação são filtradas dos resultados. Assim, se a consulta juntar uma linha insuficientemente agregada a uma linha agregada o suficiente, a linha resultante será filtrada. Além disso, as consultas com várias agregações têm um desempenho inferior no Ads Data Hub.
Pode juntar os resultados (no BigQuery) a partir de várias consultas de agregação (do Ads Data Hub). Os resultados calculados através de consultas comuns partilham esquemas finais.
A seguinte consulta usa resultados individuais do Ads Data Hub (campaign_data_123 e campaign_data_456) e junta-os no BigQuery:
SELECT t1.campaign_id, t1.city, t1.X, t2.Y
FROM `campaign_data_123` AS t1
FULL JOIN `campaign_data_456` AS t2
USING (campaign_id, city)
Use resumos das linhas filtradas
Prática recomendada: adicione resumos das linhas filtradas às consultas.
Resumos das linhas filtradas: dados de registos que foram filtrados devido a verificações de privacidade. Os dados das linhas filtradas são somados e adicionados a uma linha geral. Embora não seja possível analisar mais detalhadamente os dados filtrados, fornece um resumo da quantidade de dados filtrados dos resultados.
Tenha em conta IDs dos utilizadores a zero
Prática recomendada: tenha em conta os IDs dos utilizadores a zero nos seus resultados.
O ID de um utilizador final pode ser definido como 0 por vários motivos, incluindo: desativação da personalização de anúncios, motivos regulamentares, etc. Como tal, os dados provenientes de vários utilizadores serão codificados com um user_id de 0.
Se quiser compreender os totais de dados, como o número de impressões ou cliques, deve incluir estes eventos. No entanto, estes dados não serão úteis para obter estatísticas sobre os clientes e devem ser filtrados se vai fazer essa análise.
Pode excluir estes dados dos seus resultados ao adicionar WHERE user_id != "0" às suas consultas.
Desempenho
Evite a agregação repetida
Prática recomendada: evite várias camadas de agregação entre utilizadores.
As consultas que combinam resultados que já foram agregados, como no caso de uma consulta com vários GROUP BYs ou agregação aninhada, necessitam de mais recursos para o processamento.
Muitas vezes, as consultas com várias camadas de agregação podem ser divididas, o que melhora o desempenho. Deve tentar manter as linhas ao nível do evento ou do utilizador durante o processamento e, em seguida, fazer a combinação com uma única agregação.
Deve evitar os seguintes padrões:
SELECT SUM(count)
FROM
(SELECT campaign_id, COUNT(0) AS count FROM ... GROUP BY 1)
As consultas que usam várias camadas de agregação devem ser reescritas para usar uma única camada de agregação.
(SELECT ... GROUP BY ... )
JOIN USING (...)
(SELECT ... GROUP BY ... )
As consultas que podem ser divididas facilmente devem ser divididas. Pode juntar os resultados no BigQuery.
Otimize em função do BigQuery
Geralmente, as consultas que requerem menos trabalho têm um desempenho superior. Ao avaliar o desempenho da consulta, a quantidade de trabalho necessária depende dos seguintes fatores:
- Dados de entrada e origens de dados (I/O): quantos bytes é que a consulta lê?
- Comunicação entre nós (classificação): quantos bytes é que a consulta transmite para a fase seguinte?
- Cálculo: qual é o volume de CPU que a consulta requer?
- Saídas (materialização): quantos bytes é que a consulta escreve?
- Antipadrões da consulta: as consultas seguem as práticas recomendadas de SQL?
Se a execução da consulta não cumprir os contratos de nível de serviço, ou estiver a deparar-se com erros devido ao esgotamento de recursos ou ao limite de tempo, pondere o seguinte:
- Use os resultados de consultas anteriores em vez de fazer novos cálculos. Por exemplo, o total semanal pode ser a soma calculada no BigQuery de 7 consultas agregadas de um único dia.
- Decomponha consultas em subconsultas lógicas (como dividir várias junções em várias consultas) ou restrinja o conjunto de dados processados. Pode combinar resultados de tarefas individuais num único conjunto de dados no BigQuery. Embora isto possa ajudar em termos do esgotamento dos recursos, pode tornar a consulta mais lenta.
- Caso se depare com erros de recursos ultrapassados no BigQuery, experimente usar tabelas temporárias para dividir a consulta em várias consultas do BigQuery.
- Referencie menos tabelas numa única consulta, uma vez que tal usa grandes quantidades de memória e pode provocar uma falha na consulta.
- Reescreva as consultas para que juntem menos tabelas de utilizadores.
- Reescreva as consultas para evitar juntar a mesma tabela a si própria.
Assessor de consultas
Se o SQL é válido, mas pode acionar uma filtragem excessiva, o assessor de consultas apresenta ações recomendadas durante o processo de desenvolvimento da consulta para ajudar a evitar resultados indesejados.
Os acionadores incluem os seguintes padrões:
- Junção de subconsultas agregadas
- Junção de dados não agregados com utilizadores potencialmente diferentes
- Tabelas temporárias definidas de forma recorrente
Para usar o assessor de consultas:
- IU. As recomendações são apresentadas no editor de consultas, acima do texto da consulta.
- API. Use o método
customers.analysisQueries.validate.