 Google uses AI technology to translate content into your preferred language. AI translations can contain errors.
Google uses AI technology to translate content into your preferred language. AI translations can contain errors.
FHIR 分析
使用集合让一切井井有条
根据您的偏好保存内容并对其进行分类。
以数据为依据的医疗保健需要能够快速生成可信且切实可行的洞见。
虽然 FHIR 标准为构建新一代数字健康解决方案的开发者提供了诸多优势,但其深层嵌套的结构在进行分析时可能很难处理。
为了让开发者更轻松地构建解决方案,从而降低处理 FHIR 数据的复杂性,我们提供了 FHIR 数据流水线,这是一套工具:用于将资源转换为 Parquet-on-FHIR 架构的 ETL 流水线、视图定义层和查询引擎连接器。
FHIR 数据管道旨在实现横向扩展和灵活的部署选项(本地或云端)。同时,它也可以部署在单台机器上。
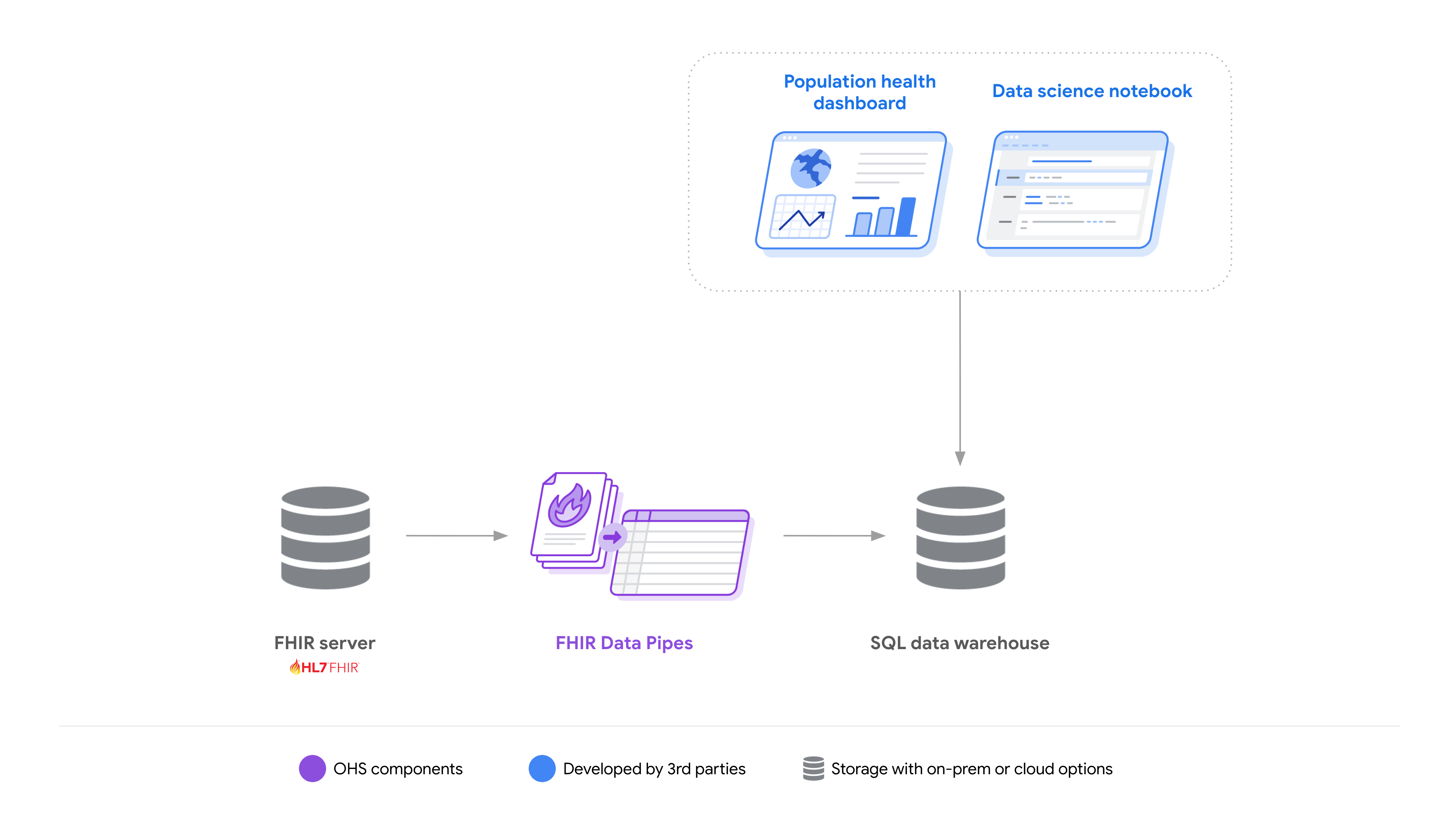
这些功能相辅相成,可让开发者更轻松地使用不同的技术构建和部署适用于各种用例的分析解决方案。
详细了解 FHIR 数据流及其组成部分:
如未另行说明,那么本页面中的内容已根据知识共享署名 4.0 许可获得了许可,并且代码示例已根据 Apache 2.0 许可获得了许可。有关详情,请参阅 Google 开发者网站政策。Java 是 Oracle 和/或其关联公司的注册商标。
最后更新时间 (UTC):2025-07-25。
[[["易于理解","easyToUnderstand","thumb-up"],["解决了我的问题","solvedMyProblem","thumb-up"],["其他","otherUp","thumb-up"]],[["没有我需要的信息","missingTheInformationINeed","thumb-down"],["太复杂/步骤太多","tooComplicatedTooManySteps","thumb-down"],["内容需要更新","outOfDate","thumb-down"],["翻译问题","translationIssue","thumb-down"],["示例/代码问题","samplesCodeIssue","thumb-down"],["其他","otherDown","thumb-down"]],["最后更新时间 (UTC):2025-07-25。"],[],["FHIR Data Pipes addresses the complexity of analyzing FHIR data by providing tools for developers. It includes ETL pipelines that convert FHIR resources to Parquet-on-FHIR schema, a view definition layer, and query engine connectors. Designed for scalability and flexible deployment, it can run on-premises, in the cloud, or on a single machine. These tools facilitate the development and deployment of analytics solutions across diverse use cases by simplifying FHIR data handling.\n"]]