
La API de detección de poses del Kit de AA es una solución liviana y versátil para que los desarrolladores de apps detecten la pose del cuerpo de un sujeto en tiempo real a partir de un video continuo o una imagen estática. Una pose describe la posición del cuerpo en un momento determinado con un conjunto de puntos de referencia esqueléticas. Los puntos de referencia corresponden a diferentes partes del cuerpo, como los hombros y las caderas. Las posiciones relativas de los puntos de referencia se pueden usar para distinguir una pose de otra.
La detección de poses del Kit de AA produce una coincidencia de esqueleto de 33 puntos de cuerpo completo que incluye puntos de referencia faciales (orejas, ojos, boca y nariz) y puntos en las manos y los pies. En la Figura 1 que aparece a continuación, se muestran los puntos de referencia que miran al usuario a través de la cámara, por lo que es una imagen duplicada. El lado derecho del usuario aparece a la izquierda de la imagen:
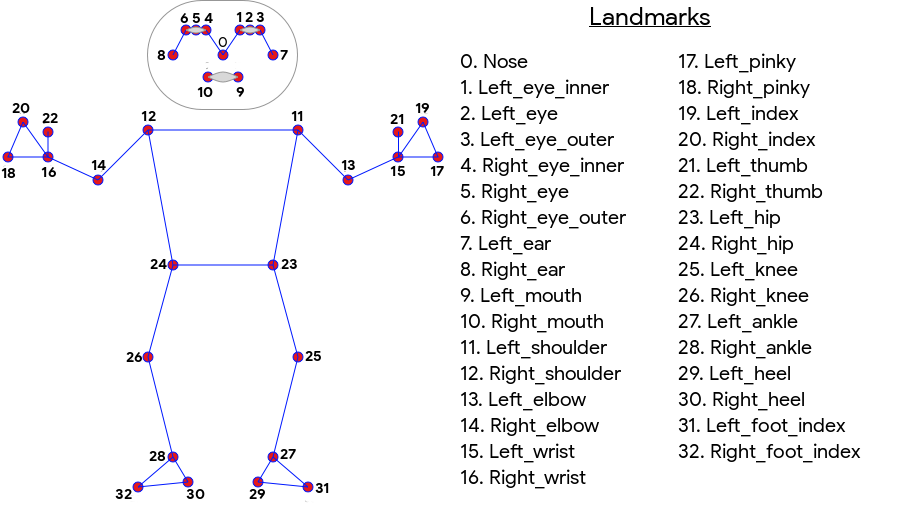
La detección de poses del kit de AA no requiere equipos especializados ni experiencia en AA para lograr excelentes resultados. Con esta tecnología, los desarrolladores pueden crear experiencias únicas para sus usuarios con solo unas pocas líneas de código.
El rostro del usuario debe estar presente para que se detecte una postura. La detección de poses funciona mejor cuando todo el cuerpo del sujeto está visible en el marco, pero también detecta una pose parcial del cuerpo. En ese caso, a los puntos de referencia que no se reconocen se les asignan coordenadas fuera de la imagen.
Funciones clave
- Asistencia multiplataforma: Disfruta de la misma experiencia en iOS y Android.
- Seguimiento del cuerpo completo: El modelo muestra 33 puntos de referencia esqueléticas clave, incluidas las posiciones de las manos y los pies.
- Puntuación de InFrameLikelihood de cada punto de referencia, una medida que indica la probabilidad de que este se encuentre dentro del marco de la imagen. La puntuación tiene un rango de 0.0 a 1.0, en el que 1.0 indica un nivel de confianza alto.
- Dos SDK optimizados El SDK base se ejecuta en tiempo real en teléfonos modernos, como Pixel 4 y iPhone X. Muestra los resultados a una velocidad de alrededor de 30 y 45 FPS, respectivamente. Sin embargo, la precisión de las coordenadas del punto de referencia puede variar. Un SDK preciso muestra resultados con una velocidad de fotogramas más lenta, pero produce valores de coordenadas más precisos.
- Z Coordinación para el análisis de profundidad Este valor puede ayudar a determinar si partes del cuerpo del usuario se encuentran delante o detrás de las caderas. Para obtener más información, consulte la sección Coordenada Z a continuación.
La API de Pose Detection es similar a la API de reconocimiento facial, ya que muestra un conjunto de puntos de referencia y su ubicación. Sin embargo, si bien la Detección de rostro también intenta reconocer rasgos como la boca sonriente o los ojos abiertos, la Detección de la postura no asigna ningún significado a los puntos de referencia de una pose ni la pose en sí. Puedes crear tus propios algoritmos para interpretar una postura. Consulta las Sugerencias para clasificar poses a fin de ver algunos ejemplos.
La detección de poses solo puede detectar una persona en una imagen. Si hay dos personas en la imagen, el modelo asignará puntos de referencia a la persona detectada con la mayor confianza.
Coordenada Z
La Coordenada Z es un valor experimental que se calcula para cada punto de referencia. Se mide en "píxeles de imagen", como las coordenadas X e Y, pero no es un valor 3D verdadero. El eje Z es perpendicular a la cámara y pasa entre las caderas de un sujeto. El origen del eje Z es aproximadamente el punto central entre las caderas (izquierda/derecha y frontal/posterior en relación con la cámara). Los valores Z negativos se apuntan hacia la cámara; los positivos se alejan de ella. La coordenada Z no tiene un límite superior o inferior.
Resultados de muestra
En la siguiente tabla, se muestran las coordenadas y el valor InFrameLikelihood de algunos puntos de referencia en la pose del lado derecho. Ten en cuenta que las coordenadas Z de la mano izquierda del usuario son negativas, ya que se ubican delante del centro de las caderas del sujeto y hacia la cámara.

| Punto de referencia | Tipo | Cargo | InFrameLikelihood |
|---|---|---|---|
| 11 | LEFT_SHOULDER | (734.9671, 550.7924, -118.11934). | 0,9999038 |
| 12 | RIGHT_SHOULDER | (391.27032, 583.2485, -321.15836). | 0,9999894 |
| 13 | LEFT_ELBOW | (903.83704, 754.676, -219.67009). | 0,9836427 |
| 14 | RIGHT_ELBOW | (322.18152, 842.5973, -179.28519). | 0,99970156 |
| 15 | LEFT_WRIST | (1073.8956, 654.9725, -820.93463). | 0,9737737 |
| 16 | RIGHT_WRIST | (218.27956, 1015.70435, -683.6567). | 0,995568 |
| 17 | LEFT_PINKY | (1146.1635, 609.6432, -956.9976). | 0,95273364 |
| 18 | RIGHT_PINKY | (176.17755, 1065.838, -776.5006). | 0,9785348 |
Detrás de escena
Para obtener más detalles sobre la implementación de los modelos de AA subyacentes de esta API, consulta nuestra entrada de blog de IA de Google.
Para obtener más información sobre nuestras prácticas de equidad en el AA y cómo se entrenaron los modelos, consulta nuestra tarjeta de modelo.