Trong phần này, chúng tôi sẽ nỗ lực xây dựng, huấn luyện và đánh giá
mô hình. Trong Bước 3, chúng ta
đã chọn sử dụng mô hình n-gram hoặc mô hình trình tự, sử dụng tỷ lệ S/W của chúng tôi.
Giờ là lúc chúng ta viết và huấn luyện thuật toán phân loại. Chúng tôi sẽ sử dụng
TensorFlow có
tf.keras
API cho việc này.
Việc xây dựng các mô hình học máy bằng Keras chỉ tập hợp với nhau nhiều lớp, các thành phần xử lý dữ liệu, giống như việc chúng ta lắp ráp Lego gạch. Các lớp này cho phép chỉ định chuỗi phép biến đổi mà chúng ta muốn để thực hiện dựa trên thông tin đầu vào của mình. Vì thuật toán học tập của chúng tôi chỉ nhập một văn bản và xuất ra một phân loại duy nhất, chúng ta có thể tạo một ngăn xếp tuyến tính gồm các lớp sử dụng Mô hình tuần tự API.
Hình 9: Ngăn xếp tuyến tính của các lớp
Lớp đầu vào và lớp trung gian sẽ được xây dựng khác nhau, tuỳ thuộc vào việc chúng ta xây dựng mô hình n-gram hay mô hình chuỗi. Nhưng bất kể loại mô hình là gì, lớp cuối cùng sẽ giống nhau cho một vấn đề nhất định.
Xây dựng lớp cuối cùng
Khi chỉ có 2 lớp (phân loại nhị phân), mô hình của chúng ta sẽ cho ra một
điểm xác suất duy nhất. Ví dụ: xuất 0.2 cho một mẫu đầu vào nhất định
có nghĩa là "độ tin cậy 20% rằng mẫu này nằm trong lớp đầu tiên (loại 1), 80% rằng
nó ở lớp thứ hai (lớp 0)." Để đưa ra điểm xác suất như vậy,
chức năng kích hoạt
của lớp cuối cùng sẽ là
hàm sigmoid,
và
hàm mất
được dùng để huấn luyện mô hình
xentropy nhị phân.
(Xem Hình 10, bên trái).
Khi có nhiều hơn 2 lớp (phân loại nhiều lớp), mô hình của chúng tôi
sẽ đưa ra một điểm xác suất cho mỗi lớp. Tổng các điểm này sẽ bằng
1. Ví dụ: khi xuất {0: 0.2, 1: 0.7, 2: 0.1} có nghĩa là "độ tin cậy 20% rằng
mẫu này nằm trong lớp 0, 70% là lớp 1 và 10% là ở lớp 1
lớp 2". Để xuất các điểm số này, hàm kích hoạt của lớp cuối cùng
phải là Softmax và hàm mất dùng để huấn luyện mô hình là
đồng entropy phân loại. (Xem Hình 10, bên phải).
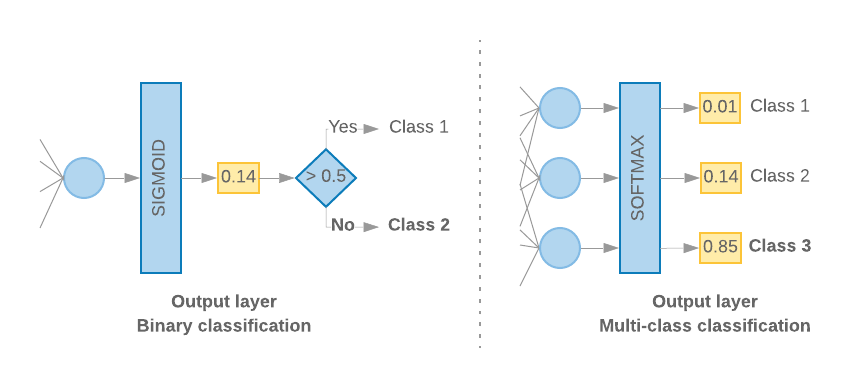
Hình 10: Lớp cuối cùng
Mã sau đây định nghĩa một hàm nhận số lượng lớp làm dữ liệu đầu vào, và xuất ra số lượng đơn vị lớp thích hợp (1 đơn vị cho nhị phân) phân loại; nếu không thì là 1 đơn vị cho mỗi lớp) và kích hoạt phù hợp hàm:
def _get_last_layer_units_and_activation(num_classes):
"""Gets the # units and activation function for the last network layer.
# Arguments
num_classes: int, number of classes.
# Returns
units, activation values.
"""
if num_classes == 2:
activation = 'sigmoid'
units = 1
else:
activation = 'softmax'
units = num_classes
return units, activation
Hai phần sau đây trình bày việc tạo mô hình còn lại cho mô hình n-gram và mô hình trình tự.
Khi tỷ lệ S/W nhỏ, chúng tôi nhận thấy rằng mô hình n-gram hoạt động tốt hơn
so với mô hình trình tự. Mô hình trình tự sẽ hiệu quả hơn khi có một số lượng lớn
về các vectơ nhỏ, đậm đặc. Điều này là do mối quan hệ bao hàm được học trong
và điều này xảy ra tốt nhất trên nhiều mẫu.
Xây dựng mô hình n-gram [Lựa chọn A]
Chúng tôi tham chiếu đến các mô hình xử lý mã thông báo một cách độc lập (không tính đến thứ tự từ của tài khoản) dưới dạng mô hình n-gram. Cảm biến nhiều lớp đơn giản (bao gồm hồi quy logistic máy tăng độ dốc và mô hình máy vectơ hỗ trợ) tất cả đều thuộc danh mục này; họ không được sử dụng bất kỳ thông tin nào về sắp xếp văn bản.
Chúng tôi so sánh hiệu suất của một số mô hình n-gram nêu trên và quan sát thấy rằng perceptron nhiều lớp (MLP) thường hoạt động tốt hơn các lựa chọn khác. MLP rất dễ định nghĩa và dễ hiểu, mang lại độ chính xác cao, và yêu cầu tính toán tương đối ít.
Mã sau đây xác định mô hình MLP hai lớp trong tf.keras, thêm một vài Các lớp bỏ qua để điều chỉnh để ngăn chặn trang bị quá mức cho các mẫu huấn luyện.
from tensorflow.python.keras import models
from tensorflow.python.keras.layers import Dense
from tensorflow.python.keras.layers import Dropout
def mlp_model(layers, units, dropout_rate, input_shape, num_classes):
"""Creates an instance of a multi-layer perceptron model.
# Arguments
layers: int, number of `Dense` layers in the model.
units: int, output dimension of the layers.
dropout_rate: float, percentage of input to drop at Dropout layers.
input_shape: tuple, shape of input to the model.
num_classes: int, number of output classes.
# Returns
An MLP model instance.
"""
op_units, op_activation = _get_last_layer_units_and_activation(num_classes)
model = models.Sequential()
model.add(Dropout(rate=dropout_rate, input_shape=input_shape))
for _ in range(layers-1):
model.add(Dense(units=units, activation='relu'))
model.add(Dropout(rate=dropout_rate))
model.add(Dense(units=op_units, activation=op_activation))
return model
Mô hình trình tự xây dựng [Lựa chọn B]
Chúng tôi đề cập đến các mô hình có thể học hỏi từ sự liền kề của mã thông báo dưới dạng trình tự người mẫu. Điều này bao gồm các lớp CNN và RNN của các mô hình. Dữ liệu được xử lý trước dưới dạng vectơ trình tự cho các mô hình này.
Mô hình trình tự thường có số lượng tham số lớn hơn cần tìm hiểu. Đầu tiên trong các mô hình này là một lớp nhúng, lớp này sẽ học mối quan hệ giữa các từ trong một không gian vectơ dày đặc. Việc học mối quan hệ giữa các từ tốt nhất so với nhiều mẫu.
Các từ trong một tập dữ liệu nhất định có nhiều khả năng không phải là duy nhất cho tập dữ liệu đó. Do đó, chúng tôi có thể tìm hiểu mối quan hệ giữa các từ trong tập dữ liệu của chúng tôi bằng cách sử dụng(các) tập dữ liệu khác. Để làm như vậy, chúng ta có thể chuyển một nhúng đã học được từ một tập dữ liệu khác vào lớp nhúng. Các mục nhúng này được gọi là được huấn luyện trước mục nhúng. Việc sử dụng phương thức nhúng đã huấn luyện trước sẽ giúp mô hình này có được khởi đầu thuận lợi trong quá trình học tập.
Có sẵn các mục nhúng được huấn luyện trước đã được huấn luyện bằng cách sử dụng các tập sao lục, chẳng hạn như GloVe. GloVe có được đào tạo trên nhiều tập sao lục (chủ yếu trên Wikipedia). Chúng tôi đã thử nghiệm việc huấn luyện các mô hình trình tự bằng phiên bản nhúng GloVe và quan sát thấy rằng nếu chúng ta cố định trọng số của các mục nhúng được huấn luyện trước và chỉ huấn luyện phần còn lại của thì các mô hình đã không hoạt động hiệu quả. Điều này có thể là do bối cảnh trong mà lớp nhúng được huấn luyện có thể khác với ngữ cảnh mà chúng tôi sử dụng.
Các mục nhúng GloVe được huấn luyện dựa trên dữ liệu trên Wikipedia có thể không phù hợp với ngôn ngữ trong tập dữ liệu IMDb của chúng tôi. Các mối quan hệ được suy luận có thể cần một số cập nhật—tức là các trọng số nhúng có thể cần được điều chỉnh theo ngữ cảnh. Chúng tôi thực hiện việc này trong hai giai đoạn:
Trong lần chạy đầu tiên, với trọng số của lớp nhúng bị đóng băng, chúng tôi cho phép phần còn lại của mạng để tìm hiểu. Khi kết thúc lần chạy này, trọng số mô hình sẽ đạt đến trạng thái tốt hơn nhiều so với giá trị chưa khởi tạo của chúng. Đối với lần chạy thứ hai, chúng tôi cho phép lớp nhúng học hỏi, điều chỉnh tinh giản tất cả các trọng số trong mạng. Chúng tôi gọi quá trình này là sử dụng phương thức nhúng được tinh chỉnh.
Các mục nhúng được tinh chỉnh mang lại độ chính xác cao hơn. Tuy nhiên, việc này liên quan đến việc để tăng công suất tính toán cần thiết để huấn luyện mạng. Cho trước đủ số lượng mẫu, chúng tôi cũng có thể tìm hiểu kỹ thuật nhúng từ đầu. Chúng tôi quan sát thấy rằng đối với
S/W > 15K, việc tạo chiến dịch từ đầu một cách hiệu quả mang lại độ chính xác tương tự như khi sử dụng tính năng nhúng tinh chỉnh.
Chúng tôi đã so sánh các mô hình trình tự khác nhau như CNN, sepCNN, RNN (LSTM &GRU), CNN-RNN và RNN xếp chồng, thay đổi cấu trúc mô hình. Chúng tôi nhận thấy rằng sepCNN, một biến thể mạng tích chập thường có hiệu quả về dữ liệu và điện toán cao hơn, hoạt động tốt hơn so với các mô hình khác.
Đoạn mã sau đây xây dựng mô hình sepCNN bốn lớp:
from tensorflow.python.keras import models from tensorflow.python.keras import initializers from tensorflow.python.keras import regularizers from tensorflow.python.keras.layers import Dense from tensorflow.python.keras.layers import Dropout from tensorflow.python.keras.layers import Embedding from tensorflow.python.keras.layers import SeparableConv1D from tensorflow.python.keras.layers import MaxPooling1D from tensorflow.python.keras.layers import GlobalAveragePooling1D def sepcnn_model(blocks, filters, kernel_size, embedding_dim, dropout_rate, pool_size, input_shape, num_classes, num_features, use_pretrained_embedding=False, is_embedding_trainable=False, embedding_matrix=None): """Creates an instance of a separable CNN model. # Arguments blocks: int, number of pairs of sepCNN and pooling blocks in the model. filters: int, output dimension of the layers. kernel_size: int, length of the convolution window. embedding_dim: int, dimension of the embedding vectors. dropout_rate: float, percentage of input to drop at Dropout layers. pool_size: int, factor by which to downscale input at MaxPooling layer. input_shape: tuple, shape of input to the model. num_classes: int, number of output classes. num_features: int, number of words (embedding input dimension). use_pretrained_embedding: bool, true if pre-trained embedding is on. is_embedding_trainable: bool, true if embedding layer is trainable. embedding_matrix: dict, dictionary with embedding coefficients. # Returns A sepCNN model instance. """ op_units, op_activation = _get_last_layer_units_and_activation(num_classes) model = models.Sequential() # Add embedding layer. If pre-trained embedding is used add weights to the # embeddings layer and set trainable to input is_embedding_trainable flag. if use_pretrained_embedding: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0], weights=[embedding_matrix], trainable=is_embedding_trainable)) else: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0])) for _ in range(blocks-1): model.add(Dropout(rate=dropout_rate)) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(MaxPooling1D(pool_size=pool_size)) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(GlobalAveragePooling1D()) model.add(Dropout(rate=dropout_rate)) model.add(Dense(op_units, activation=op_activation)) return model
Huấn luyện mô hình của bạn
Bây giờ, chúng ta đã xây dựng kiến trúc mô hình, chúng ta cần huấn luyện mô hình. Quá trình huấn luyện bao gồm việc đưa ra dự đoán dựa trên trạng thái hiện tại của mô hình, tính toán độ chính xác của dự đoán và cập nhật trọng số hoặc các tham số của mạng để giảm thiểu lỗi này và giúp mô hình dự đoán tốt hơn. Chúng tôi lặp lại quá trình này cho đến khi mô hình của chúng tôi hội tụ và không thể tiếp tục học hỏi. Có 3 thông số chính được chọn cho quá trình này (Xem Bảng 2.)
- Chỉ số: Cách đo lường hiệu suất của mô hình bằng chỉ số. Chúng tôi đã sử dụng độ chính xác làm chỉ số trong thử nghiệm của chúng tôi.
- Hàm mất: Hàm dùng để tính giá trị tổn thất mà quá trình đào tạo sau đó cố gắng giảm thiểu bằng cách điều chỉnh trọng số mạng. Đối với các bài toán phân loại, tổn thất chéo entropy hoạt động tốt.
- Trình tối ưu hoá: Một hàm quyết định trọng số mạng được cập nhật dựa trên kết quả của hàm mất. Chúng tôi đã sử dụng Adam trong các thử nghiệm của chúng tôi.
Ở Keras, chúng ta có thể truyền các tham số học tập này đến một mô hình bằng cách sử dụng biên dịch .
Bảng 2: Các tham số học
| Thông số tìm hiểu | Giá trị |
|---|---|
| Chỉ số | độ chính xác |
| Hàm mất – phân loại nhị phân | binary_crossentropy |
| Hàm mất – phân loại nhiều lớp | sparse_categorical_crossentropy |
| Cao thủ tối ưu hoá | adam |
Quá trình đào tạo thực tế diễn ra thông qua
phù hợp.
Tuỳ thuộc vào kích thước của
tập dữ liệu, đây là phương pháp mà trong đó hầu hết chu kỳ điện toán sẽ được sử dụng. Trong mỗi
lặp lại quy trình huấn luyện, batch_size số mẫu từ dữ liệu huấn luyện của bạn là
được dùng để tính toán tổn thất và trọng số được cập nhật một lần, dựa trên giá trị này.
Quá trình huấn luyện sẽ hoàn tất epoch sau khi mô hình đã xem được toàn bộ
tập dữ liệu huấn luyện. Vào cuối mỗi thời gian bắt đầu của hệ thống, chúng tôi sẽ sử dụng tập dữ liệu xác thực để
đánh giá mức độ hiệu quả của mô hình. Chúng tôi lặp lại quá trình huấn luyện bằng cách sử dụng tập dữ liệu
trong số thời gian bắt đầu của hệ thống xác định trước. Chúng tôi có thể tối ưu hoá việc này
bằng cách dừng sớm,
khi độ chính xác xác thực ổn định giữa các khoảng thời gian bắt đầu liên tiếp, cho thấy rằng
mô hình không còn được huấn luyện nữa.
| Siêu tham số huấn luyện | Giá trị |
|---|---|
| Tốc độ học | 1e-3 |
| Các thời kỳ | 1000 |
| Kích thước lô | 512 |
| Dừng sớm | tham số: val_loss, kiên nhẫn: 1 |
Bảng 3: Siêu tham số huấn luyện
Mã Keras sau đây triển khai quy trình huấn luyện bằng cách sử dụng các tham số được chọn trong Bảng 2 & 3 ở trên:
def train_ngram_model(data, learning_rate=1e-3, epochs=1000, batch_size=128, layers=2, units=64, dropout_rate=0.2): """Trains n-gram model on the given dataset. # Arguments data: tuples of training and test texts and labels. learning_rate: float, learning rate for training model. epochs: int, number of epochs. batch_size: int, number of samples per batch. layers: int, number of `Dense` layers in the model. units: int, output dimension of Dense layers in the model. dropout_rate: float: percentage of input to drop at Dropout layers. # Raises ValueError: If validation data has label values which were not seen in the training data. """ # Get the data. (train_texts, train_labels), (val_texts, val_labels) = data # Verify that validation labels are in the same range as training labels. num_classes = explore_data.get_num_classes(train_labels) unexpected_labels = [v for v in val_labels if v not in range(num_classes)] if len(unexpected_labels): raise ValueError('Unexpected label values found in the validation set:' ' {unexpected_labels}. Please make sure that the ' 'labels in the validation set are in the same range ' 'as training labels.'.format( unexpected_labels=unexpected_labels)) # Vectorize texts. x_train, x_val = vectorize_data.ngram_vectorize( train_texts, train_labels, val_texts) # Create model instance. model = build_model.mlp_model(layers=layers, units=units, dropout_rate=dropout_rate, input_shape=x_train.shape[1:], num_classes=num_classes) # Compile model with learning parameters. if num_classes == 2: loss = 'binary_crossentropy' else: loss = 'sparse_categorical_crossentropy' optimizer = tf.keras.optimizers.Adam(lr=learning_rate) model.compile(optimizer=optimizer, loss=loss, metrics=['acc']) # Create callback for early stopping on validation loss. If the loss does # not decrease in two consecutive tries, stop training. callbacks = [tf.keras.callbacks.EarlyStopping( monitor='val_loss', patience=2)] # Train and validate model. history = model.fit( x_train, train_labels, epochs=epochs, callbacks=callbacks, validation_data=(x_val, val_labels), verbose=2, # Logs once per epoch. batch_size=batch_size) # Print results. history = history.history print('Validation accuracy: {acc}, loss: {loss}'.format( acc=history['val_acc'][-1], loss=history['val_loss'][-1])) # Save model. model.save('IMDb_mlp_model.h5') return history['val_acc'][-1], history['val_loss'][-1]
Vui lòng tìm ví dụ về mã để huấn luyện mô hình trình tự tại đây.