Nesta seção, vamos criar, treinar e avaliar
um modelo de machine learning. Na Etapa 3, nós
escolheu usar um modelo n-grama ou sequencial, usando a proporção S/W.
Agora é hora de escrever e treinar nosso algoritmo de classificação. Vamos usar
TensorFlow com a
tf.keras
API para isso.
Criar modelos de machine learning com o Keras consiste em reunir elementos básicos de processamento de dados, assim como nós montamos um Lego tijolos. Essas camadas nos permitem especificar a sequência de transformações que queremos de executar em nossa entrada. Como nosso algoritmo de aprendizado recebe uma única entrada de texto e gera uma única classificação, podemos criar uma pilha linear de camadas usando o Modelo sequencial API.
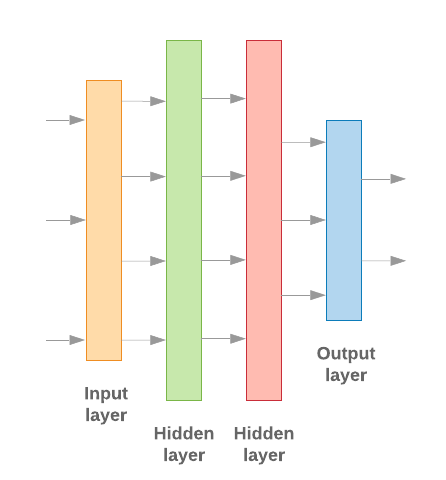
Figura 9: pilha linear de camadas
A camada de entrada e as camadas intermediárias serão construídas de forma diferente, dependendo se estamos criando um modelo "n-gram" ou "sequencial". Mas seja qual for o tipo de modelo, a última camada será a mesma para um determinado problema.
Como criar a última camada
Quando temos apenas 2 classes (classificação binária), o modelo gera uma
uma única pontuação de probabilidade. Por exemplo, gerar 0.2 para uma determinada amostra de entrada
significa “20% de confiança que esta amostra está na primeira classe (classe 1), 80% que
ele está na segunda classe (classe 0)." Para gerar essa pontuação de probabilidade, o
função de ativação
da última camada deve ser uma
função sigmoide,
e o
função de perda
usados para treinar o modelo devem ser
entropia cruzada binária.
Consulte a Figura 10 à esquerda.
Quando há mais de duas classes (classificação multiclasse), nosso modelo
deve gerar uma pontuação de probabilidade por classe. A soma dessas pontuações deve ser
1: Por exemplo, gerar {0: 0.2, 1: 0.7, 2: 0.1} significa "20% de confiança de que
esta amostra está na classe 0, 70% que está na classe 1 e 10% na classe
classe 2". Para gerar essas pontuações, a função de ativação da última camada
deve ser softmax, e a função de perda usada para treinar o modelo deve ser
a entropia cruzada categórica. Consulte a Figura 10, à direita.
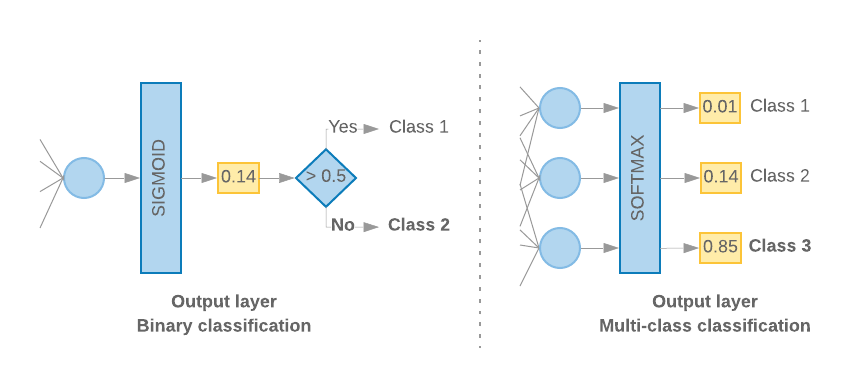
Figura 10: última camada
O código a seguir define uma função que recebe o número de classes como entrada, e gera o número apropriado de unidades de camada (1 unidade para binários classificação; caso contrário, uma unidade para cada classe) e a ativação apropriada função:
def _get_last_layer_units_and_activation(num_classes):
"""Gets the # units and activation function for the last network layer.
# Arguments
num_classes: int, number of classes.
# Returns
units, activation values.
"""
if num_classes == 2:
activation = 'sigmoid'
units = 1
else:
activation = 'softmax'
units = num_classes
return units, activation
As duas seções a seguir mostram a criação do modelo restante camadas para modelos n-gram e modelos sequenciais.
Quando a proporção S/W é pequena, descobrimos que modelos n-gram têm melhor desempenho
do que os modelos sequenciais. Os modelos sequenciais são melhores quando há um grande número
vetores pequenos e densos. Isso ocorre porque as relações de embedding são aprendidas
espaço denso, o que acontece melhor em muitas amostras.
Criar um modelo n-grama [opção A]
Nos referimos a modelos que processam os tokens de maneira independente (sem considerar ordem de palavras da conta) como modelos "n-gram". Perceptrons simples de várias camadas (incluindo regressão logística máquinas que aumentam o gradiente, e máquinas de vetor de suporte) todos se enquadram nessa categoria; eles não podem usar nenhuma informação sobre a ordenação de textos.
Comparamos o desempenho de alguns dos modelos "n-gram" mencionados acima e observou que perceptrons de várias camadas (MLPs) normalmente têm melhor desempenho outras opções. As MLPs são simples de definir e entender, fornecem boa acurácia, e exigem pouca computação.
O código abaixo define um modelo MLP de duas camadas no tf.keras, adicionando alguns Camadas de descarte para regularização para evitar overfitting até amostras de treinamento.
from tensorflow.python.keras import models
from tensorflow.python.keras.layers import Dense
from tensorflow.python.keras.layers import Dropout
def mlp_model(layers, units, dropout_rate, input_shape, num_classes):
"""Creates an instance of a multi-layer perceptron model.
# Arguments
layers: int, number of `Dense` layers in the model.
units: int, output dimension of the layers.
dropout_rate: float, percentage of input to drop at Dropout layers.
input_shape: tuple, shape of input to the model.
num_classes: int, number of output classes.
# Returns
An MLP model instance.
"""
op_units, op_activation = _get_last_layer_units_and_activation(num_classes)
model = models.Sequential()
model.add(Dropout(rate=dropout_rate, input_shape=input_shape))
for _ in range(layers-1):
model.add(Dense(units=units, activation='relu'))
model.add(Dropout(rate=dropout_rate))
model.add(Dense(units=op_units, activation=op_activation))
return model
Criar modelo sequencial [Opção B]
Nos referimos aos modelos que podem aprender com a contingência dos tokens como sequências de modelos de machine learning. Isso inclui classes de modelos CNN e RNN. Os dados são pré-processados como e vetores sequenciais para esses modelos.
Os modelos sequenciais geralmente têm um número maior de parâmetros para aprender. A primeira nesses modelos é a de embedding, que aprende a relação entre as palavras em um espaço vetorial denso. Aprender relações entre palavras melhor do que muitas amostras.
As palavras de um determinado conjunto de dados provavelmente não são exclusivas desse conjunto. Podemos, assim, aprender a relação entre as palavras do conjunto de dados usando outros conjuntos de dados. Para isso, podemos transferir um embedding aprendido de outro conjunto de dados para nosso camada de embedding. Esses embeddings são chamados de pré-treinados embeddings. Usar um embedding pré-treinado dá ao modelo uma vantagem no de machine learning.
Há embeddings pré-treinados disponíveis que foram treinados usando grandes corpora, como o GloVe. O GloVe tem foram treinados em vários corpora (principalmente na Wikipédia). Testamos o treinamento modelos usando uma versão de embeddings do GloVe e observamos que, se congelamos os pesos dos embeddings pré-treinados e treinamos apenas o restante os modelos não tiveram um bom desempenho. Isso pode ser porque o contexto em em que a camada de embedding foi treinada pode ser diferente do contexto em que o estávamos usando.
Os embeddings do GloVe treinados com dados da Wikipédia podem não estar alinhados com a linguagem em nosso conjunto de dados IMDb. As relações inferidas podem precisar de alguns atualizando, ou seja, os pesos de embedding podem precisar de ajuste contextual. Fazemos isso em dois estágios:
Na primeira execução, com os pesos da camada de embedding congelados, permitimos o restante da rede para aprender. No final da execução, os pesos do modelo alcançam um estado muito melhor do que seus valores não inicializados. Para a segunda execução, permitem que a camada de embedding também aprenda, fazendo ajustes minuciosos em todos os pesos. na rede. Chamamos esse processo de uso de uma incorporação ajustada.
Os embeddings ajustados produzem mais precisão. No entanto, isso ocorre às despesas com o aumento da capacidade de computação exigida para treinar a rede. Considerando um número suficiente de amostras, também poderíamos aprender um embedding do zero. Observamos que, para
S/W > 15K, começar do zero de maneira eficaz produz aproximadamente a mesma acurácia que usar incorporação ajustada.
Comparamos diferentes modelos sequenciais, como CNN, sepCNN, RNN (LSTM e GRU), CNN-RNN e RNN empilhada, variando arquiteturas de modelos. Descobrimos que a sepCNNs, uma variante da rede convolucional que costuma ser mais eficiente em termos de dados e computação, além de ter um desempenho melhor outros modelos.
O código a seguir constrói um modelo sepCNN de quatro camadas:
from tensorflow.python.keras import models from tensorflow.python.keras import initializers from tensorflow.python.keras import regularizers from tensorflow.python.keras.layers import Dense from tensorflow.python.keras.layers import Dropout from tensorflow.python.keras.layers import Embedding from tensorflow.python.keras.layers import SeparableConv1D from tensorflow.python.keras.layers import MaxPooling1D from tensorflow.python.keras.layers import GlobalAveragePooling1D def sepcnn_model(blocks, filters, kernel_size, embedding_dim, dropout_rate, pool_size, input_shape, num_classes, num_features, use_pretrained_embedding=False, is_embedding_trainable=False, embedding_matrix=None): """Creates an instance of a separable CNN model. # Arguments blocks: int, number of pairs of sepCNN and pooling blocks in the model. filters: int, output dimension of the layers. kernel_size: int, length of the convolution window. embedding_dim: int, dimension of the embedding vectors. dropout_rate: float, percentage of input to drop at Dropout layers. pool_size: int, factor by which to downscale input at MaxPooling layer. input_shape: tuple, shape of input to the model. num_classes: int, number of output classes. num_features: int, number of words (embedding input dimension). use_pretrained_embedding: bool, true if pre-trained embedding is on. is_embedding_trainable: bool, true if embedding layer is trainable. embedding_matrix: dict, dictionary with embedding coefficients. # Returns A sepCNN model instance. """ op_units, op_activation = _get_last_layer_units_and_activation(num_classes) model = models.Sequential() # Add embedding layer. If pre-trained embedding is used add weights to the # embeddings layer and set trainable to input is_embedding_trainable flag. if use_pretrained_embedding: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0], weights=[embedding_matrix], trainable=is_embedding_trainable)) else: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0])) for _ in range(blocks-1): model.add(Dropout(rate=dropout_rate)) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(MaxPooling1D(pool_size=pool_size)) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(GlobalAveragePooling1D()) model.add(Dropout(rate=dropout_rate)) model.add(Dense(op_units, activation=op_activation)) return model
Treine seu modelo
Agora que construímos a arquitetura do modelo, precisamos treiná-lo. O treinamento envolve fazer uma previsão com base no estado atual do modelo, calcular o quão incorreta está a previsão e atualizar os pesos ou da rede para minimizar esse erro e fazer o modelo prever melhor. Repetimos esse processo até o modelo convergir e não conseguir mais aprender. Existem três parâmetros principais que precisam ser escolhidos para esse processo (consulte a Tabela 2.
- Métrica: como medir o desempenho do nosso modelo usando uma métrica. Usamos acurácia como a métrica em nossos experimentos.
- Função de perda: usada para calcular um valor de perda que o processo de treinamento tenta minimizar, ajustando a pesos de rede. Para problemas de classificação, a perda de entropia cruzada funciona bem.
- Optimizer: uma função que decide como os pesos da rede serão atualizada com base na saída da função de perda. Usamos a famosa otimizador Adam nos experimentos.
No Keras, podemos transmitir esses parâmetros de aprendizado para um modelo usando o compilar .
Tabela 2: parâmetros de aprendizado
| Parâmetro de aprendizado | Valor |
|---|---|
| Métrica | precisão |
| Função de perda - classificação binária | binary_crossentropy |
| Função de perda - classificação multiclasse | sparse_categorical_crossentropy |
| Otimizador | adam |
O treinamento real acontece
fit.
Dependendo do tamanho do seu
é o método em que a maioria dos ciclos de computação serão gastos. Em cada
iteração de treinamento, o número batch_size de amostras de seus dados de treinamento está
usada para calcular a perda, e os pesos são atualizados uma vez, com base nesse valor.
O processo de treinamento conclui uma epoch quando o modelo tem acesso a todo o
conjunto de dados de treinamento. Ao final de cada período, usamos o conjunto de dados de validação para
avaliar o desempenho do modelo de aprendizado. Repetimos o treinamento usando o conjunto de dados
para um número predeterminado de períodos. Podemos otimizar isso interrompendo o processo antes,
quando a precisão da validação se estabiliza entre períodos consecutivos, mostrando que
o modelo não está mais treinando.
| Treinamento de hiperparâmetros | Valor |
|---|---|
| Taxa de aprendizado | 1e a 3 |
| Períodos | 1000 |
| Tamanho do lote | 512 |
| Parada antecipada | parâmetro: val_loss, paciência: 1 |
Tabela 3: treinar hiperparâmetros
O código Keras a seguir implementa o processo de treinamento usando os parâmetros escolhidas nas tabelas 2 e 3 acima:
def train_ngram_model(data, learning_rate=1e-3, epochs=1000, batch_size=128, layers=2, units=64, dropout_rate=0.2): """Trains n-gram model on the given dataset. # Arguments data: tuples of training and test texts and labels. learning_rate: float, learning rate for training model. epochs: int, number of epochs. batch_size: int, number of samples per batch. layers: int, number of `Dense` layers in the model. units: int, output dimension of Dense layers in the model. dropout_rate: float: percentage of input to drop at Dropout layers. # Raises ValueError: If validation data has label values which were not seen in the training data. """ # Get the data. (train_texts, train_labels), (val_texts, val_labels) = data # Verify that validation labels are in the same range as training labels. num_classes = explore_data.get_num_classes(train_labels) unexpected_labels = [v for v in val_labels if v not in range(num_classes)] if len(unexpected_labels): raise ValueError('Unexpected label values found in the validation set:' ' {unexpected_labels}. Please make sure that the ' 'labels in the validation set are in the same range ' 'as training labels.'.format( unexpected_labels=unexpected_labels)) # Vectorize texts. x_train, x_val = vectorize_data.ngram_vectorize( train_texts, train_labels, val_texts) # Create model instance. model = build_model.mlp_model(layers=layers, units=units, dropout_rate=dropout_rate, input_shape=x_train.shape[1:], num_classes=num_classes) # Compile model with learning parameters. if num_classes == 2: loss = 'binary_crossentropy' else: loss = 'sparse_categorical_crossentropy' optimizer = tf.keras.optimizers.Adam(lr=learning_rate) model.compile(optimizer=optimizer, loss=loss, metrics=['acc']) # Create callback for early stopping on validation loss. If the loss does # not decrease in two consecutive tries, stop training. callbacks = [tf.keras.callbacks.EarlyStopping( monitor='val_loss', patience=2)] # Train and validate model. history = model.fit( x_train, train_labels, epochs=epochs, callbacks=callbacks, validation_data=(x_val, val_labels), verbose=2, # Logs once per epoch. batch_size=batch_size) # Print results. history = history.history print('Validation accuracy: {acc}, loss: {loss}'.format( acc=history['val_acc'][-1], loss=history['val_loss'][-1])) # Save model. model.save('IMDb_mlp_model.h5') return history['val_acc'][-1], history['val_loss'][-1]
Veja exemplos de código para treinar o modelo sequencial aqui.