Antes que nossos dados possam ser alimentados em um modelo, eles precisam ser transformados em um formato que o modelo consegue entender.
Primeiro, as amostras de dados que coletamos podem estar em uma ordem específica. Nós não querem que nenhuma informação associada ao pedido de amostras influencie a relação entre textos e rótulos. Por exemplo, se um conjunto de dados for classificado por classe e, em seguida, são divididos em conjuntos de treinamento/validação, esses conjuntos não representativos da distribuição geral dos dados.
Uma prática recomendada simples para garantir que o modelo não seja afetado pela ordem dos dados é sempre misture os dados antes de fazer qualquer outra coisa. Se seus dados já estão em conjuntos de treinamento e validação, transforme os dados da mesma forma que os dados de treinamento. Se você ainda não tiver conjuntos de treinamento e validação separados, é possível dividir as amostras depois embaralhamento é típico usar 80% das amostras para treinamento e 20% para validação.
Segundo, os algoritmos de machine learning usam números como entradas. Isso significa que nós precisam converter os textos em vetores numéricos. Há duas etapas esse processo:
Tokenização: divida os textos em palavras ou subtextos menores, o que permitem uma boa generalização das relações entre os textos e os rótulos. Isso determina o "vocabulário" do conjunto de dados (conjunto de tokens exclusivos presente em os dados).
Vetorização: defina uma boa medida numérica para caracterizar esses e textos.
Vamos aprender a executar essas duas etapas para vetores "n-gram" e sequência vetores, bem como otimizar representações vetoriais usando atributos seleção e normalização.
N-gram vetores [Opção A]
Nos próximos parágrafos, vamos aprender a fazer a tokenização e vetorização para modelos n-gram. Também abordaremos como podemos otimizar de grama sintética usando técnicas de seleção e normalização de atributos.
Em um vetor "n-gram", o texto é representado como uma coleção de n-gramas exclusivos:
grupos de n tokens adjacentes (normalmente, palavras). Considere o texto The mouse ran
up the clock. Aqui:
- A palavra unigrama (n = 1) é
['the', 'mouse', 'ran', 'up', 'clock']. - As palavras bigramas (n = 2) são
['the mouse', 'mouse ran', 'ran up', 'up the', 'the clock'] - E assim por diante.
Tokenização
Descobrimos que a tokenização em unigramas de palavras + bigramas proporciona boas precisão, ocupando menos tempo de computação.
Vetorização
Depois de dividir nossos exemplos de texto em n-gramas, precisamos transformar esses n-gramas em vetores numéricos que os modelos de machine learning podem processar. O exemplo abaixo mostra os índices atribuídos aos unigramas e bigramas gerados para dois e textos.
Texts: 'The mouse ran up the clock' and 'The mouse ran down' Index assigned for every token: {'the': 7, 'mouse': 2, 'ran': 4, 'up': 10, 'clock': 0, 'the mouse': 9, 'mouse ran': 3, 'ran up': 6, 'up the': 11, 'the clock': 8, 'down': 1, 'ran down': 5}
Quando os índices são atribuídos aos n-gramas, normalmente vetorizamos usando um dos as opções a seguir.
Codificação one-hot: todo texto de amostra é representado como um vetor que indica a presença ou ausência de um token no texto.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1]
Codificação de contagem: cada amostra de texto é representada como um vetor que indica o
contagem de um token no texto. O elemento que corresponde ao
unigrama "o" agora é representado como 2 porque a palavra "the"
aparece duas vezes no texto.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 2, 1, 1, 1, 1]
Codificação Tf-idf: o problema com as duas abordagens acima é que palavras comuns que ocorrem em frequências em todos os documentos (ou seja, palavras que não são especialmente exclusivas de as amostras de texto no conjunto de dados) não são penalizadas. Por exemplo, palavras como "um" ocorrerão com muita frequência em todos os textos. Portanto, uma contagem de tokens maior para “o” do que para outras palavras mais significativas não é muito útil.
'The mouse ran up the clock' = [0.33, 0, 0.23, 0.23, 0.23, 0, 0.33, 0.47, 0.33, 0.23, 0.33, 0.33]
Consulte Scikit-learn TfidfTransformer.
Há muitas outras representações vetoriais, mas as três anteriores são mais usada.
Observamos que a codificação tf-idf é ligeiramente melhor do que as outras duas em termos de precisão (em média: 0,25-15% maior) e recomendamos o uso desse método para vetorizar n-gramas. No entanto, ele ocupa mais memória (conforme usa representação de ponto flutuante) e leva mais tempo para calcular, especialmente para grandes conjuntos de dados (pode demorar duas vezes mais tempo, em alguns casos).
Seleção de atributos
Quando convertemos todos os textos de um conjunto de dados em tokens uni+bigram de palavras, pode resultar em dezenas de milhares de tokens. Nem todos esses tokens/recursos contribuem para a previsão de rótulos. Podemos remover certos tokens, por exemplo aqueles que ocorrem raramente no conjunto de dados. Também podemos medir importância do atributo (quanto cada token contribui para as previsões de rótulo) e incluir apenas os tokens mais informativos.
Há muitas funções estatísticas que usam atributos e os e gera a pontuação de importância do atributo. Duas funções comumente usadas são f_classif e chi2 (link em inglês). Nossos mostram que ambas as funções têm o mesmo desempenho.
Mais importante ainda, notamos que a precisão atinge o pico em torno de 20.000 atributos em muitos (consulte a Figura 6). Adicionar mais recursos acima desse limite contribui muito pouco e, às vezes, até resulta overfitting (link em inglês) e prejudica o desempenho.

Figura 6: atributos Top-K versus acurácia. Nos conjuntos de dados, a precisão alcança cerca de 20 mil recursos principais.
Normalização
A normalização converte todos os valores de atributos/amostras em valores pequenos e semelhantes. Isso simplifica a convergência do gradiente descendente nos algoritmos de aprendizado. De quê que a normalização durante o pré-processamento de dados não agrega muito em problemas de classificação de texto, recomendamos pular esta etapa.
O código a seguir reúne todas as etapas acima:
- tokenizar amostras de texto em uni+bigrams de palavras
- Vetorize usando a codificação tf-idf.
- Selecione apenas os 20.000 principais atributos do vetor de tokens,descartando tokens que aparecem menos de 2 vezes e usando f_classif para calcular o atributo importância.
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import f_classif # Vectorization parameters # Range (inclusive) of n-gram sizes for tokenizing text. NGRAM_RANGE = (1, 2) # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Whether text should be split into word or character n-grams. # One of 'word', 'char'. TOKEN_MODE = 'word' # Minimum document/corpus frequency below which a token will be discarded. MIN_DOCUMENT_FREQUENCY = 2 def ngram_vectorize(train_texts, train_labels, val_texts): """Vectorizes texts as n-gram vectors. 1 text = 1 tf-idf vector the length of vocabulary of unigrams + bigrams. # Arguments train_texts: list, training text strings. train_labels: np.ndarray, training labels. val_texts: list, validation text strings. # Returns x_train, x_val: vectorized training and validation texts """ # Create keyword arguments to pass to the 'tf-idf' vectorizer. kwargs = { 'ngram_range': NGRAM_RANGE, # Use 1-grams + 2-grams. 'dtype': 'int32', 'strip_accents': 'unicode', 'decode_error': 'replace', 'analyzer': TOKEN_MODE, # Split text into word tokens. 'min_df': MIN_DOCUMENT_FREQUENCY, } vectorizer = TfidfVectorizer(**kwargs) # Learn vocabulary from training texts and vectorize training texts. x_train = vectorizer.fit_transform(train_texts) # Vectorize validation texts. x_val = vectorizer.transform(val_texts) # Select top 'k' of the vectorized features. selector = SelectKBest(f_classif, k=min(TOP_K, x_train.shape[1])) selector.fit(x_train, train_labels) x_train = selector.transform(x_train).astype('float32') x_val = selector.transform(x_val).astype('float32') return x_train, x_val
Com a representação vetorial de n-gramas, descartamos muitas informações sobre a ordem e a gramática. Na melhor das hipóteses, podemos manter algumas informações parciais sobre a ordem quando n > 1) Isso é chamado de abordagem de "saco de palavras". Essa representação é usada junto com modelos que não consideram a ordem, como regressão logística, perceptrons de várias camadas, máquinas de aumento de gradiente e máquinas de vetor de suporte.
Vetores da sequência [Option B]
Nos próximos parágrafos, vamos aprender a fazer a tokenização e vetorização para modelos sequenciais. Também vamos conferir como otimizar representação de sequência usando técnicas de seleção e normalização de atributos.
Em alguns exemplos de texto, a ordem das palavras é fundamental para o significado do texto. Para por exemplo, as frases: “Eu odiava meu deslocamento diário. Minha nova bicicleta mudou isso completamente” podem ser entendidas somente quando lidas em ordem. Modelos como CNNs/RNNs pode inferir o significado a partir da ordem das palavras em uma amostra. Para esses modelos, representar o texto como uma sequência de tokens, preservando a ordem.
Tokenização
O texto pode ser representado como uma sequência de caracteres ou uma sequência de palavras Descobrimos que usar a representação em nível de palavra oferece melhor desempenho do que os tokens de caracteres. Essa também é a norma geral seguido pelo setor. O uso de tokens de caracteres só faz sentido se os textos tiverem muitos erros de digitação, o que normalmente não é o caso.
Vetorização
Depois de converter nossos exemplos de texto em sequências de palavras, precisamos transformar essas sequências em vetores numéricos. O exemplo abaixo mostra os índices atribuído aos unigramas gerados por dois textos, e a sequência de tokens índices em que o primeiro texto é convertido.
Texts: 'The mouse ran up the clock' and 'The mouse ran down'
Índice atribuído a cada token:
{'clock': 5, 'ran': 3, 'up': 4, 'down': 6, 'the': 1, 'mouse': 2}
OBSERVAÇÃO: a palavra "the" ocorre com mais frequência, de modo que o valor de índice 1 é atribuídas a ele. Algumas bibliotecas reservam o índice 0 para tokens desconhecidos, assim como o o caso aqui.
Sequência de índices de token:
'The mouse ran up the clock' = [1, 2, 3, 4, 1, 5]
Há duas opções disponíveis para vetorizar as sequências de token:
Codificação one-hot: as sequências são representadas usando vetores de palavras em n- espaço dimensional, onde n = tamanho do vocabulário. Essa representação funciona muito bem quando estamos tokenizando como caracteres. Portanto, o vocabulário é pequeno. Quando usamos tokenização como palavras, o vocabulário normalmente contém dezenas de milhares de tokens, tornando os vetores one-hot muito esparsos e ineficientes. Exemplo:
'The mouse ran up the clock' = [
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0]
]
Embeddings de palavras: as palavras têm significados associados a elas. Como resultado, possa representar tokens de palavras em um espaço vetorial denso (cerca de algumas centenas de números reais); onde a localização e a distância entre as palavras indicam a semelhança entre elas semanticamente (veja a Figura 7). Essa representação é chamada embeddings de palavras.
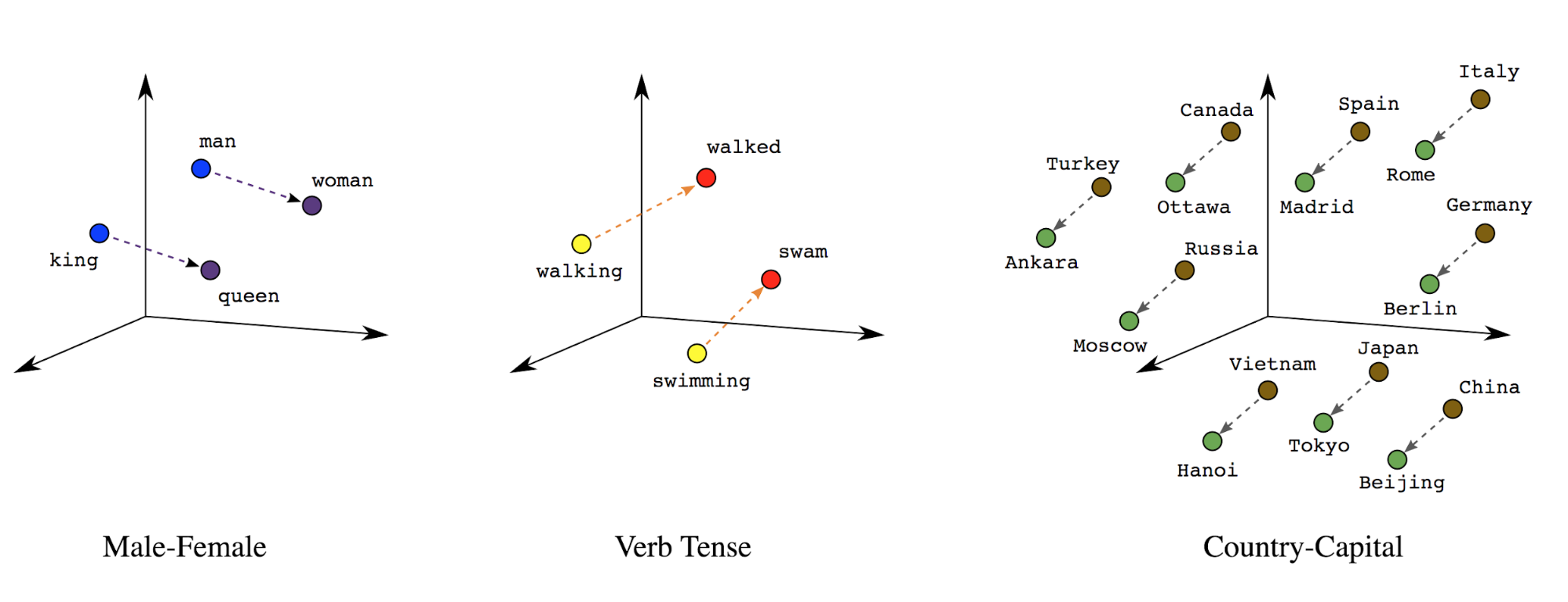
Figura 7: embeddings de palavras
Os modelos sequenciais geralmente têm uma camada de embedding como a primeira. Isso a camada aprende a transformar sequências do índice de palavras em vetores de embedding de palavras durante a de treinamento, de modo que cada índice de palavra seja mapeado para um vetor denso de valores reais que representam a localização dessa palavra no espaço semântico (veja a Figura 8).
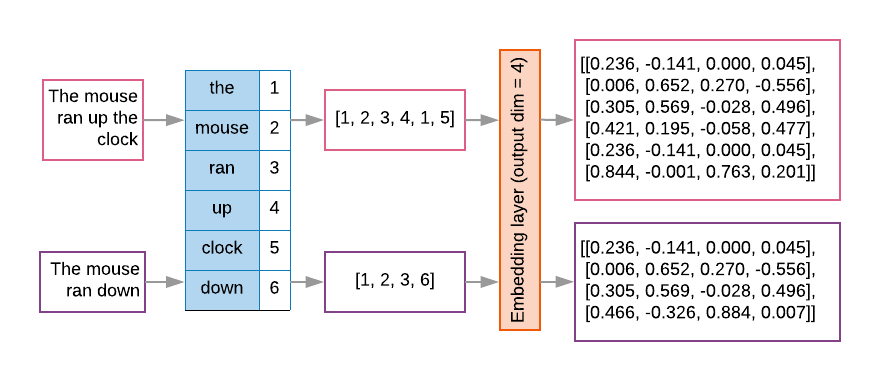
Figura 8: camada de embedding
Seleção de atributos
Nem todas as palavras dos nossos dados contribuem para as previsões de rótulos. Podemos otimizar processo de aprendizado ao descartar palavras raras ou irrelevantes do vocabulário. Em observamos que usar os 20.000 atributos mais frequentes geralmente suficientes. Isso também se aplica a modelos "n-gram" (veja a Figura 6).
Vamos colocar todas as etapas acima na vetorização de sequência em conjunto. A o código a seguir executa essas tarefas:
- Tokeniza os textos em palavras
- Cria um vocabulário usando os 20.000 tokens principais
- Converte os tokens em vetores de sequência
- Fixa as sequências em um tamanho fixo
from tensorflow.python.keras.preprocessing import sequence from tensorflow.python.keras.preprocessing import text # Vectorization parameters # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Limit on the length of text sequences. Sequences longer than this # will be truncated. MAX_SEQUENCE_LENGTH = 500 def sequence_vectorize(train_texts, val_texts): """Vectorizes texts as sequence vectors. 1 text = 1 sequence vector with fixed length. # Arguments train_texts: list, training text strings. val_texts: list, validation text strings. # Returns x_train, x_val, word_index: vectorized training and validation texts and word index dictionary. """ # Create vocabulary with training texts. tokenizer = text.Tokenizer(num_words=TOP_K) tokenizer.fit_on_texts(train_texts) # Vectorize training and validation texts. x_train = tokenizer.texts_to_sequences(train_texts) x_val = tokenizer.texts_to_sequences(val_texts) # Get max sequence length. max_length = len(max(x_train, key=len)) if max_length > MAX_SEQUENCE_LENGTH: max_length = MAX_SEQUENCE_LENGTH # Fix sequence length to max value. Sequences shorter than the length are # padded in the beginning and sequences longer are truncated # at the beginning. x_train = sequence.pad_sequences(x_train, maxlen=max_length) x_val = sequence.pad_sequences(x_val, maxlen=max_length) return x_train, x_val, tokenizer.word_index
Vetorização de rótulos
Vimos como converter dados de texto de amostra em vetores numéricos. Um processo semelhante
precisam ser aplicados aos rótulos. Podemos simplesmente converter rótulos em valores dentro de um intervalo
[0, num_classes - 1]: Por exemplo, se há 3 classes que podemos usar
valores 0, 1 e 2 para representá-las. Internamente, a rede vai usar
vetores para representar esses valores (para evitar inferir uma relação incorreta
entre rótulos). Essa representação depende da função de perda e da
função de ativação da camada que usamos em nossa rede neural. Aprenderemos mais sobre
na próxima seção.