W tej sekcji skupimy się na tworzeniu, szkoleniu i ocenianiu naszych
model atrybucji. W kroku 3
zdecydowano się użyć modelu n-gramu lub modelu sekwencyjnego z użyciem naszego współczynnika S/W.
Teraz czas napisać i wytrenować nasz algorytm klasyfikacji. Wykorzystamy
TensorFlow z
tf.keras
API do tego celu.
Tworzenie modeli systemów uczących się za pomocą Keras polega na ich łączeniu warstwy, elementy składowe przetwarzania danych, jak z klocków Lego. klocków. Te warstwy umożliwiają nam określenie sekwencji przekształceń, które i działania na podstawie danych wejściowych. Nasz algorytm uczenia się pobiera pojedynczy tekst i daje jedną klasyfikację, możemy utworzyć liniowy stos warstw za pomocą Model sekwencyjny API.
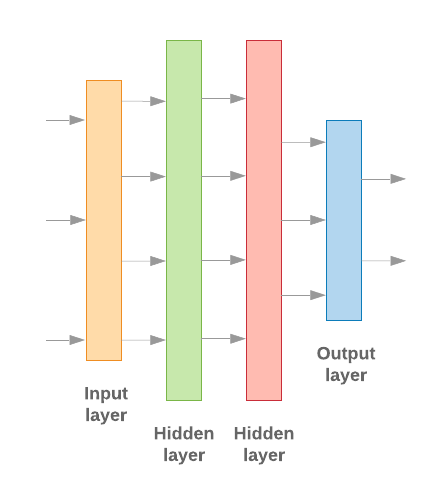
Rys. 9. Liniowy stos warstw
Warstwa wejściowa i warstwy pośrednie będą skonstruowane w różny sposób, w zależności od tego, czy tworzymy model n-gram czy model sekwencyjny. Ale Niezależnie od typu modelu ostatnia warstwa jest taka sama w przypadku danego problemu.
Tworzenie ostatniej warstwy
Gdy mamy tylko 2 klasy (klasyfikacja binarna), nasz model powinien zwrócić błąd
pojedynczy wynik prawdopodobieństwa. Na przykład wysyłanie 0.2 dla danej próbki wejściowej
oznacza „20% pewności, że ta próbka należy do pierwszej klasy (klasa 1), a 80%
jest 2 klasa (klasa 0)”. Aby wyświetlić taki wynik prawdopodobieństwa, funkcja
funkcja aktywacji
ostatniej warstwy powinna być
funkcja sigmoidalna,
oraz
funkcja straty
używana do trenowania modelu powinna być
binarna entropia krzyżowa.
(zobacz Rys. 10 po lewej stronie).
Jeśli istnieją więcej niż 2 klasy (klasyfikacja wieloklasowa), nasz model
powinien zwrócić jeden wynik prawdopodobieństwa na klasę. Suma tych wyników powinna być
1. Na przykład wynik {0: 0.2, 1: 0.7, 2: 0.1} oznacza „20% pewności, że
ten przykład jest w klasie 0, 70% że jest w klasie 1 i 10% że jest w
zajęcia 2”. Aby uzyskać te wyniki, należy aktywować funkcję aktywacji ostatniej warstwy
powinna być wartością softmax, a funkcja utraty używana do trenowania modelu powinna być
kategoryczną entropię krzyżową. (zobacz Rys. 10 po prawej stronie).
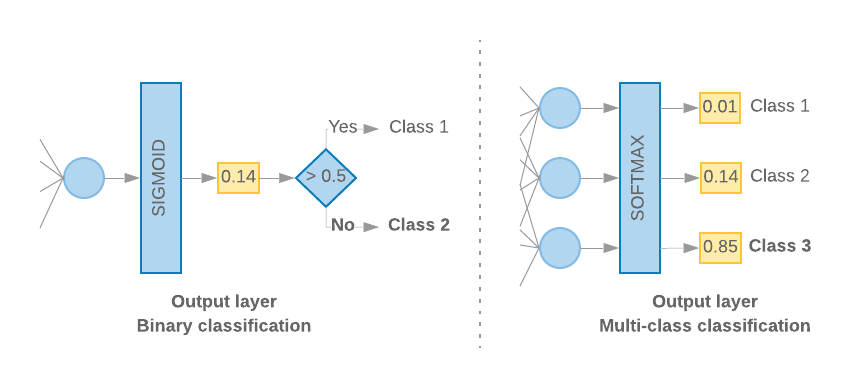
Rysunek 10. Ostatnia warstwa
Następujący kod definiuje funkcję, która przyjmuje liczbę klas jako dane wejściowe: i zwraca odpowiednią liczbę jednostek warstwy (1 jednostka w przypadku wartości binarnej klasyfikacja; w przeciwnym razie 1 jednostkę na każde zajęcia) i odpowiednią aktywację. funkcja:
def _get_last_layer_units_and_activation(num_classes):
"""Gets the # units and activation function for the last network layer.
# Arguments
num_classes: int, number of classes.
# Returns
units, activation values.
"""
if num_classes == 2:
activation = 'sigmoid'
units = 1
else:
activation = 'softmax'
units = num_classes
return units, activation
W 2 sekcjach poniżej znajdziesz opis tworzenia pozostałego modelu. warstwy dla modeli n-gramów i modeli sekwencji.
Jeśli współczynnik S/W jest mały, zauważyliśmy, że modele n-gram są skuteczniejsze
niż modele sekwencyjne. Modele sekwencyjne działają lepiej, gdy jest duża liczba
małych, gęstych wektorów. Dzieje się tak, ponieważ relacje między zasobami osadzonymi są poznawane w
w przypadku dużej ilości miejsca, co sprawdza się najlepiej w przypadku wielu próbek.
Tworzenie modelu n-gram [opcja A]
Omawiamy modele, które przetwarzają tokeny niezależnie (bez uwzględniania kolejność słów na koncie) jako modele n-gramów. Proste wielowarstwowe perceptrony (w tym regresja logistyczna maszyn wzmacniających gradient, i obsługują modele maszyn wektorowych) do tej kategorii należą: nie mogą używać żadnych informacji porządkowanie tekstu.
Porównaliśmy skuteczność niektórych z wymienionych wyżej modeli n-gram oraz zaobserwował, że perceptrony wielowarstwowe (MLP) są zwykle skuteczniejsze niż inne opcje. MLP można łatwo zdefiniować i zrozumieć, zapewniają wysoką dokładność i wymagają stosunkowo małej ilości obliczeń.
Poniższy kod definiuje dwuwarstwowy model MLP w tf.keras, dodając kilka funkcji Warstwy porzucania na potrzeby regularyzacji aby zapobiec nadmierne dopasowanie do przykładów treningowych.
from tensorflow.python.keras import models
from tensorflow.python.keras.layers import Dense
from tensorflow.python.keras.layers import Dropout
def mlp_model(layers, units, dropout_rate, input_shape, num_classes):
"""Creates an instance of a multi-layer perceptron model.
# Arguments
layers: int, number of `Dense` layers in the model.
units: int, output dimension of the layers.
dropout_rate: float, percentage of input to drop at Dropout layers.
input_shape: tuple, shape of input to the model.
num_classes: int, number of output classes.
# Returns
An MLP model instance.
"""
op_units, op_activation = _get_last_layer_units_and_activation(num_classes)
model = models.Sequential()
model.add(Dropout(rate=dropout_rate, input_shape=input_shape))
for _ in range(layers-1):
model.add(Dense(units=units, activation='relu'))
model.add(Dropout(rate=dropout_rate))
model.add(Dense(units=op_units, activation=op_activation))
return model
Tworzenie modelu sekwencji [opcja B]
Omawiamy modele, które potrafią uczyć się na podstawie sąsiadujących tokenów z tokenami modeli ML. Obejmuje to klasy modeli CNN i RNN. Dane są wstępnie przetwarzane jako: wektory sekwencji dla tych modeli.
Modele sekwencyjne zwykle mają większą liczbę parametrów, które trzeba się nauczyć. Pierwszy warstwa w tych modelach jest warstwą wektora dystrybucyjnego, która uczy się relacji między słowami w gęstej przestrzeni wektorowej. Nauka relacji między słowami działa która najlepiej sprawdza się w różnych próbach.
Słowa w danym zbiorze danych prawdopodobnie nie są w nim unikalne. Możemy zatem poznaj zależności między słowami w naszym zbiorze danych przy użyciu innych zbiorów danych. W tym celu możemy przenieść wektor dystrybucyjny uzyskany z innego zbioru danych do i warstwy wektora dystrybucyjnego. Wektory dystrybucyjne są nazywane wstępnie wytrenowanymi wektory dystrybucyjne. Użycie wytrenowanego wektora dystrybucyjnego daje modelowi przewagę proces uczenia się.
Dostępne są już wytrenowane wektory dystrybucyjne, które zostały wytrenowane z użyciem dużych korpusy, takie jak GloVe. Rękawica została wytrenowana na wielu korpusach (głównie w Wikipedii). Przetestowaliśmy trenowanie, stosując modele sekwencji z użyciem wersji wektorów dystrybucyjnych GloVe. Zaobserwowaliśmy, że jeśli zamrożenie ciężarów już wytrenowanych wektorów dystrybucyjnych i wytrenowanych modele nie miały dobrych wyników. Może to wynikać z tego, że kontekst w wytrenowanych w warstwie wektora dystrybucyjnego mogło różnić się od kontekstu na których korzystaliśmy.
Wektory dystrybucyjne GloVe wytrenowane na podstawie danych z Wikipedii mogą nie być zgodne z językiem. w naszym zbiorze danych IMDb. Ustalone relacje mogą wymagać aktualizowanie, np. wagi wektora dystrybucyjnego mogą wymagać dostosowania kontekstowego. Robimy to w 2 etapów:
Przy pierwszym uruchomieniu przy zablokowanym wadze warstwy wektora dystrybucyjnego pozwalamy sieci do nauki. Po zakończeniu tego uruchomienia wagi modelu osiągają stan która jest znacznie lepsza niż ich niezainicjowane wartości. W drugim uruchomieniu aby warstwa osadzona również się nauczyła, wprowadzając drobne korekty wszystkich wag w sieci. Ten proces określamy jako użycie dostrojonego wektora dystrybucyjnego.
Dostrojone wektory dystrybucyjne zapewniają większą dokładność. Jednak to dotyczy wydatków na zwiększoną moc obliczeniową wymaganą do trenowania sieci. Jeśli wystarczającej liczby próbek, równie dobrze moglibyśmy nauczyć się osadzania od podstaw. Zauważyliśmy, że w przypadku
S/W > 15K, zaczynając od zera, daje mniej więcej taką samą dokładność jak w przypadku dostrojonego wektora dystrybucyjnego.
Porównaliśmy różne modele sekwencji, takie jak CNN, sepCNN, RNN (LSTM i GRU), CNN-RNN i skumulowany RNN, różniąc się architektur modelu. Odkryliśmy, że sepCNN, czyli splotowy wariant sieci, są często bardziej wydajne pod względem ilości danych i mocy obliczeniowej, mają większą skuteczność niż innych modeli.
Ten kod tworzy czterowarstwowy model sepCNN:
from tensorflow.python.keras import models from tensorflow.python.keras import initializers from tensorflow.python.keras import regularizers from tensorflow.python.keras.layers import Dense from tensorflow.python.keras.layers import Dropout from tensorflow.python.keras.layers import Embedding from tensorflow.python.keras.layers import SeparableConv1D from tensorflow.python.keras.layers import MaxPooling1D from tensorflow.python.keras.layers import GlobalAveragePooling1D def sepcnn_model(blocks, filters, kernel_size, embedding_dim, dropout_rate, pool_size, input_shape, num_classes, num_features, use_pretrained_embedding=False, is_embedding_trainable=False, embedding_matrix=None): """Creates an instance of a separable CNN model. # Arguments blocks: int, number of pairs of sepCNN and pooling blocks in the model. filters: int, output dimension of the layers. kernel_size: int, length of the convolution window. embedding_dim: int, dimension of the embedding vectors. dropout_rate: float, percentage of input to drop at Dropout layers. pool_size: int, factor by which to downscale input at MaxPooling layer. input_shape: tuple, shape of input to the model. num_classes: int, number of output classes. num_features: int, number of words (embedding input dimension). use_pretrained_embedding: bool, true if pre-trained embedding is on. is_embedding_trainable: bool, true if embedding layer is trainable. embedding_matrix: dict, dictionary with embedding coefficients. # Returns A sepCNN model instance. """ op_units, op_activation = _get_last_layer_units_and_activation(num_classes) model = models.Sequential() # Add embedding layer. If pre-trained embedding is used add weights to the # embeddings layer and set trainable to input is_embedding_trainable flag. if use_pretrained_embedding: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0], weights=[embedding_matrix], trainable=is_embedding_trainable)) else: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0])) for _ in range(blocks-1): model.add(Dropout(rate=dropout_rate)) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(MaxPooling1D(pool_size=pool_size)) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(GlobalAveragePooling1D()) model.add(Dropout(rate=dropout_rate)) model.add(Dense(op_units, activation=op_activation)) return model
Wytrenuj model
Po skonstruowaniu architektury modelu musimy go wytrenować. Trenowanie obejmuje przygotowanie prognozy na podstawie bieżącego stanu modelu, obliczanie trafności prognozy i aktualizowanie wag lub parametrów sieci, aby zminimalizować ten błąd i umożliwić modelowi prognozowanie . Powtarzamy ten proces, aż nasz model się zbieżnie i nie będzie można i zdobywania wiedzy. W przypadku tego procesu należy wybrać trzy kluczowe parametry (patrz Tabela 2)
- Dane: jak mierzyć wydajność modelu za pomocą dane. Zastosowaliśmy dokładność jako wskaźnik w naszych eksperymentach.
- Funkcja utraty: funkcja służąca do obliczania wartości straty. którą proces trenowania próbuje następnie zminimalizować, dostrajając wagi sieci. W przypadku problemów z klasyfikacją dobrze sprawdza się utrata entropii krzyżowej.
- Optymalizujący: funkcja określająca wagi sieci zaktualizowano na podstawie danych wyjściowych funkcji utraty. Użyliśmy popularnych Adam.
W Keraście możemy przekazać te parametry uczenia się do modelu za pomocą kompiluj .
Tabela 2. Parametry uczenia się
| Parametr szkoleniowy | Wartość |
|---|---|
| Dane | dokładność |
| Funkcja utraty - klasyfikacja binarna | binary_crossentropy |
| Funkcja utraty – klasyfikacja wieloklasowa | sparse_categorical_crossentropy |
| Optymalizator | Adam |
Właściwie trenowanie odbywa się na podstawie
fit.
W zależności od rozmiaru
zbioru danych, jest to metoda, w której zostanie wykorzystana większość cykli obliczeniowych. W każdym
powtórzenia, batch_size próbek z danych treningowych jest
używane do obliczania straty, a wagi są aktualizowane jednorazowo na podstawie tej wartości.
Proces trenowania kończy się epoch, gdy model obejrzy całą
do trenowania
zbioru danych treningowych. Na końcu każdej epoki używamy zbioru danych do weryfikacji,
ocenić, jak dobrze model się uczy. Powtarzamy trenowanie za pomocą zbioru danych.
dla wcześniej określonej liczby epok. Możemy je zoptymalizować, rezygnując z wczesnych testów,
gdy dokładność walidacji stabilizuje się między kolejnymi okresami, co pokazuje,
model nie jest już trenowany.
| Hiperparametr treningowy | Wartość |
|---|---|
| Tempo uczenia się | 1–3 |
| Epoki | 1000 |
| Wielkość wsadu | 512 |
| Wczesne zatrzymanie | parametr: val_loss, cierpliwość: 1 |
Tabela 3. Trenowanie hiperparametrów
Poniższy kod Keras implementuje proces trenowania przy użyciu parametrów wybrane w tabelach 2 i 3 powyżej:
def train_ngram_model(data, learning_rate=1e-3, epochs=1000, batch_size=128, layers=2, units=64, dropout_rate=0.2): """Trains n-gram model on the given dataset. # Arguments data: tuples of training and test texts and labels. learning_rate: float, learning rate for training model. epochs: int, number of epochs. batch_size: int, number of samples per batch. layers: int, number of `Dense` layers in the model. units: int, output dimension of Dense layers in the model. dropout_rate: float: percentage of input to drop at Dropout layers. # Raises ValueError: If validation data has label values which were not seen in the training data. """ # Get the data. (train_texts, train_labels), (val_texts, val_labels) = data # Verify that validation labels are in the same range as training labels. num_classes = explore_data.get_num_classes(train_labels) unexpected_labels = [v for v in val_labels if v not in range(num_classes)] if len(unexpected_labels): raise ValueError('Unexpected label values found in the validation set:' ' {unexpected_labels}. Please make sure that the ' 'labels in the validation set are in the same range ' 'as training labels.'.format( unexpected_labels=unexpected_labels)) # Vectorize texts. x_train, x_val = vectorize_data.ngram_vectorize( train_texts, train_labels, val_texts) # Create model instance. model = build_model.mlp_model(layers=layers, units=units, dropout_rate=dropout_rate, input_shape=x_train.shape[1:], num_classes=num_classes) # Compile model with learning parameters. if num_classes == 2: loss = 'binary_crossentropy' else: loss = 'sparse_categorical_crossentropy' optimizer = tf.keras.optimizers.Adam(lr=learning_rate) model.compile(optimizer=optimizer, loss=loss, metrics=['acc']) # Create callback for early stopping on validation loss. If the loss does # not decrease in two consecutive tries, stop training. callbacks = [tf.keras.callbacks.EarlyStopping( monitor='val_loss', patience=2)] # Train and validate model. history = model.fit( x_train, train_labels, epochs=epochs, callbacks=callbacks, validation_data=(x_val, val_labels), verbose=2, # Logs once per epoch. batch_size=batch_size) # Print results. history = history.history print('Validation accuracy: {acc}, loss: {loss}'.format( acc=history['val_acc'][-1], loss=history['val_loss'][-1])) # Save model. model.save('IMDb_mlp_model.h5') return history['val_acc'][-1], history['val_loss'][-1]
Przykłady kodu do trenowania modelu sekwencji znajdziesz tutaj.