בחלק הזה נעבוד על בנייה, אימון והערכה של
מודל טרנספורמר. בשלב 3, אנחנו
בחרו להשתמש במודל n-gram או במודל רצף, תוך שימוש ביחס S/W שלנו.
זה הזמן לכתוב את אלגוריתם הסיווג שלנו ולאמן אותו. נשתמש
TensorFlow עם הפונקציה
tf.keras
בנושא הזה.
פיתוח מודלים של למידת מכונה עם Keras מבוסס על הרכבה משותפת אבני בניין של עיבוד נתונים, בדומה להרכבת לגו לבנים. השכבות האלה מאפשרות לנו לציין את רצף הטרנספורמציות לבצע על הקלט שלנו. מכיוון שאלגוריתם הלמידה שלנו מקבל קלט טקסט יחיד ופלט סיווג יחיד, אנחנו יכולים ליצור סטאק ליניארי של שכבות באמצעות מודל רציף API.
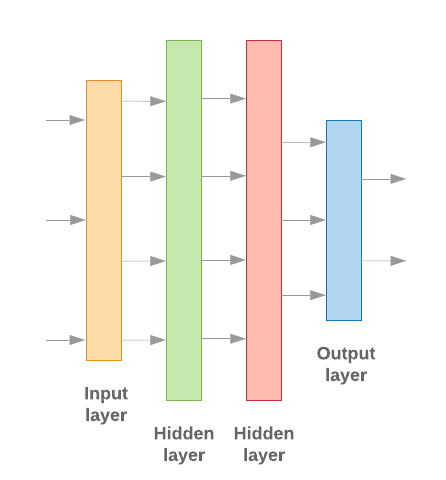
איור 9: מקבץ שכבות לינארי
שכבת הקלט ושכבות הביניים ייבנו בצורה שונה, בהתאם לאופן שבו אנחנו בונים מודל n-gram או מודל רצף. אבל ללא קשר לסוג המודל, השכבה האחרונה תהיה זהה לבעיה נתונה.
בניית השכבה האחרונה
כשיש לנו רק 2 סיווגים (סיווג בינארי), המודל שלנו צריך להפיק את הפלט
בציון הסתברות אחת. לדוגמה, פלט 0.2 עבור דגימת קלט נתונה
פירושו "רמת ודאות של 20% שהדגימה הזו נמצאת במחלקה הראשונה (מחלקה 1), 80% שהדגימה
הוא במחלקה השנייה (מחלקה 0)." כדי להפיק ציון הסתברות כזה,
פונקציית הפעלה
השכבה האחרונה צריכה להיות
פונקציית sigmoid,
את הרצף
פונקציית הפסד
ששימשו לאימון המודל,
חוצה אנטרופיה בינארית.
(ראו איור 10, בצד ימין).
כשיש יותר מ-2 מחלקות (סיווג רב-מחלקות), המודל שלנו
צריך להפיק ציון הסתברות אחד לכל כיתה. הסכום של הציונים האלה צריך להיות
1. לדוגמה, פלט {0: 0.2, 1: 0.7, 2: 0.1} פירושו "20% ודאות
הדוגמה היא בכיתה 0, 70% מכיתה 1 ו-10% מכיתה 1.
כיתה 2". כדי להפיק את הציונים האלה, פונקציית ההפעלה של השכבה האחרונה
צריך להיות softmax, ופונקציית האובדן שמשמשת לאימון המודל צריכה להיות
SparseCatagoricalCrossentropy (ראו איור 10, בצד ימין).
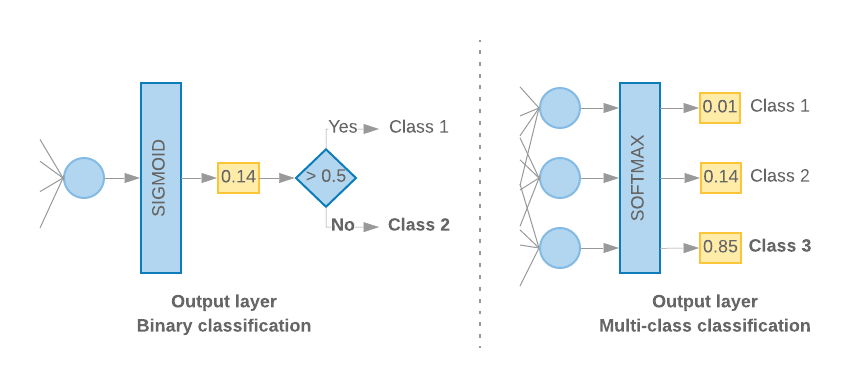
איור 10: השכבה האחרונה
הקוד הבא מגדיר פונקציה שמקבלת את מספר המחלקות כקלט, ומפיק פלט של המספר המתאים של יחידות שכבות (יחידה אחת לפורמט בינארי) סיווג; אחרת, יחידה אחת לכל כיתה) ואת ההפעלה המתאימה פונקציה:
def _get_last_layer_units_and_activation(num_classes):
"""Gets the # units and activation function for the last network layer.
# Arguments
num_classes: int, number of classes.
# Returns
units, activation values.
"""
if num_classes == 2:
activation = 'sigmoid'
units = 1
else:
activation = 'softmax'
units = num_classes
return units, activation
בשני הקטעים הבאים מתואר תהליך היצירה של המודל הנותר למודלים של n-gram ולמודלים של רצף.
כשהיחס של S/W קטן, גילינו שמודלים של n-gram מניבים ביצועים טובים יותר
מאשר במודלים של רצף. מודלים של רצף טובים יותר כשיש מספר גדול
של וקטורים קטנים וצפופים. הסיבה לכך היא שקשרי הטמעה נלמדים
מאוד צפוף, וזה קורה בצורה הטובה ביותר עם דגימות רבות.
בניית מודל n-gram [אפשרות א']
אנחנו מתייחסים למודלים שמעבדים את האסימונים באופן עצמאי (בלי של החשבון בסדר המילים) בתור מודלים של n-gram. פרספקטרום פשוט רב-שכבתיות (כולל רגרסיה לוגיסטית מכונות להגדלת הדרגתיות, ותמיכה במכונות וקטוריות) כולם משתייכים לקטגוריה הזו, הם לא יכולים להשתמש במידע על לסידור הטקסטים.
השווינו בין הביצועים של חלק מהמודלים של ה-n-gram שצוינו למעלה, הם מרובה-שכבות (MLP) משיגים בדרך כלל ביצועים טובים יותר אפשרויות אחרות. קל להגדיר ולהבנה של MLP, הן מספקות רמת דיוק גבוהה, ודורשים מעט מאוד חישוב.
הקוד הבא מגדיר מודל MLP דו-שכבתי ב-tf.keras, ומוסיפים שכבות עזיבה מהדף הראשון כדי למנוע התאמת יתר ועד דגימות אימון.
from tensorflow.python.keras import models
from tensorflow.python.keras.layers import Dense
from tensorflow.python.keras.layers import Dropout
def mlp_model(layers, units, dropout_rate, input_shape, num_classes):
"""Creates an instance of a multi-layer perceptron model.
# Arguments
layers: int, number of `Dense` layers in the model.
units: int, output dimension of the layers.
dropout_rate: float, percentage of input to drop at Dropout layers.
input_shape: tuple, shape of input to the model.
num_classes: int, number of output classes.
# Returns
An MLP model instance.
"""
op_units, op_activation = _get_last_layer_units_and_activation(num_classes)
model = models.Sequential()
model.add(Dropout(rate=dropout_rate, input_shape=input_shape))
for _ in range(layers-1):
model.add(Dense(units=units, activation='relu'))
model.add(Dropout(rate=dropout_rate))
model.add(Dense(units=op_units, activation=op_activation))
return model
מודל רצף של מבנים [אפשרות ב']
אנחנו מתייחסים למודלים שיכולים ללמוד מהשכיחות של אסימונים בתור רצף למשימות ספציפיות. זה כולל את סוגי המודלים CNN ו-RNN. הנתונים מעובדים מראש באופן הבא: של הרצף למודלים האלה.
בדרך כלל, מודלים של רצף צריכים ללמוד מספר גדול יותר של פרמטרים. הראשון במודלים האלה היא שכבת הטמעה, שלומדת את הקשרים בין המילים במרחב וקטורי צפוף. למידה של קשרים בין מילים עובדת הכי טוב על פני דגימות רבות.
סביר להניח שהמילים במערך נתונים מסוים אינן ייחודיות לאותו מערך נתונים. אנחנו יכולים ללמוד את הקשר בין המילים במערך הנתונים שלנו באמצעות מערכי נתונים אחרים. לשם כך, אנחנו יכולים להעביר הטמעה שנלמדה ממערך נתונים אחר לתוך לשכבת הטמעה. הטמעות אלה נקראות מודלים שעברו אימון מראש הטמעות. השימוש בהטמעה שאומנה מראש מאפשר למודל להתחיל את או בלתי מונחית.
יש הטמעות שאומנו מראש והוכשרו באמצעות הטמעות קורפורה, כמו GloVe. ל-GloVe יש אומן על סמך מספר תאגידים (בעיקר ויקיפדיה). בדקנו את ההדרכה באמצעות גרסה של הטמעות GloVe, ראינו שאם הקפאה את המשקולות של ההטמעות שאומנו מראש ואימנו רק את שאר הרשת, הביצועים של המודלים לא הניבו ביצועים טובים. הסיבה לכך יכולה להיות שההקשר ששכבת ההטמעה אומנה הייתה שונה מההקשר שבה השתמשנו בו.
ייתכן שהטמעות GloVe שאומנו על נתוני ויקיפדיה לא תואמות לשפה במערך הנתונים מ-IMDb. יכול להיות שהקשרים שהמערכת מסיקה עדכון – כלומר, ייתכן שצריך כוונון לפי ההקשר של משקלי ההטמעה. אנחנו עושים זאת שני שלבים:
בהרצה הראשונה, כשהמשקולות של שכבת ההטמעה מוקפאות, מאפשרים את השאר של הרשת ללמוד. בסוף הריצה, משקולות המודל מגיעים למצב שזה הרבה יותר טוב מהערכים הלא מאותחלים שלהם. בהפעלה השנייה, כך ששכבת ההטמעה תוכל גם ללמוד, ולעשות התאמות עד כמה שניתן לכל המשקולות ברשת. אנחנו מתייחסים לתהליך הזה כשימוש בהטמעה מותאמת.
הטמעות מכווננות מניבות דיוק משופר. אבל הגישה הוצאה של כוח מחשוב מוגבר שנדרש לאימון הרשת. בהינתן מספיק דגימות, ואפשר גם ללמוד הטמעה מההתחלה. שמנו לב שבעבור
S/W > 15K, הכול התחיל מאפס מניבה רמת דיוק זהה לזו של הטמעה מכווננת.
השווינו בין מודלים שונים של רצף כמו CNN, sepCNN, RNN (LSTM ו-GRU), CNN-RNN ו-RNN בערימה, בהתאם של הארכיטקטורות. גילינו שה-sepCNN, וריאנט של רשת קונבולוציה יעיל יותר בנתונים וחסכוני במחשוב, וביצועים טובים יותר של מודלים אחרים.
הקוד הבא בונה מודל sepCNN בן ארבע שכבות:
from tensorflow.python.keras import models from tensorflow.python.keras import initializers from tensorflow.python.keras import regularizers from tensorflow.python.keras.layers import Dense from tensorflow.python.keras.layers import Dropout from tensorflow.python.keras.layers import Embedding from tensorflow.python.keras.layers import SeparableConv1D from tensorflow.python.keras.layers import MaxPooling1D from tensorflow.python.keras.layers import GlobalAveragePooling1D def sepcnn_model(blocks, filters, kernel_size, embedding_dim, dropout_rate, pool_size, input_shape, num_classes, num_features, use_pretrained_embedding=False, is_embedding_trainable=False, embedding_matrix=None): """Creates an instance of a separable CNN model. # Arguments blocks: int, number of pairs of sepCNN and pooling blocks in the model. filters: int, output dimension of the layers. kernel_size: int, length of the convolution window. embedding_dim: int, dimension of the embedding vectors. dropout_rate: float, percentage of input to drop at Dropout layers. pool_size: int, factor by which to downscale input at MaxPooling layer. input_shape: tuple, shape of input to the model. num_classes: int, number of output classes. num_features: int, number of words (embedding input dimension). use_pretrained_embedding: bool, true if pre-trained embedding is on. is_embedding_trainable: bool, true if embedding layer is trainable. embedding_matrix: dict, dictionary with embedding coefficients. # Returns A sepCNN model instance. """ op_units, op_activation = _get_last_layer_units_and_activation(num_classes) model = models.Sequential() # Add embedding layer. If pre-trained embedding is used add weights to the # embeddings layer and set trainable to input is_embedding_trainable flag. if use_pretrained_embedding: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0], weights=[embedding_matrix], trainable=is_embedding_trainable)) else: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0])) for _ in range(blocks-1): model.add(Dropout(rate=dropout_rate)) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(MaxPooling1D(pool_size=pool_size)) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(GlobalAveragePooling1D()) model.add(Dropout(rate=dropout_rate)) model.add(Dense(op_units, activation=op_activation)) return model
אימון המודל
עכשיו, אחרי שבנינו את ארכיטקטורת המודל, עלינו לאמן את המודל. האימון כולל ביצוע חיזוי שמבוסס על המצב הנוכחי של המודל, חישוב עד כמה החיזוי שגוי, ועדכון המשקולות או של הרשת כדי לצמצם את השגיאה ולהפוך את המודל לחזות טוב יותר. אנחנו חוזרים על התהליך הזה עד שהמודל שלנו מתכנס ולא יכול יותר ללמוד. יש שלושה פרמטרים עיקריים שצריך לבחור בתהליך הזה (ראו טבלה 2).
- מדד: איך מודדים את ביצועי המודל באמצעות . השתמשנו בדיוק בתור המדד בניסויים שלנו.
- פונקציית הפסד: פונקציה שמשמשת לחישוב ערך הפסד שתהליך האימון מנסה למזער אותו על ידי כוונון המשקולות של הרשת. במקרה של בעיות סיווג, אובדן חוצה-אנטרופיה פועל היטב.
- אופטימיזציה: פונקציה שקובעת מה יהיו משקלי הרשת שמתעדכן בהתאם לפלט של פונקציית האובדן. השתמשנו כלי האופטימיזציה של אדם בניסויים שלנו.
ב-Keras, אנחנו יכולים להעביר את הפרמטרים של הלמידה האלה למודל באמצעות קומפילציה .
טבלה 2: פרמטרים של למידה
| פרמטר למידה | ערך |
|---|---|
| מדד | דיוק |
| פונקציית אובדן – סיווג בינארי | binary_crossentropy |
| פונקציית הפסד – סיווג מרובה-מחלקות | sparse_categorical_crossentropy |
| אליפות ביעילות | אדם |
האימון בפועל מתבצע באמצעות
fit.
בהתאם לגודל
מערך נתונים, זו השיטה שבה יבוצעו רוב מחזורי המחשוב. בכל פעם
באיטרציה של אימון, מספר batch_size של דגימות מנתוני האימון
שמשמשת לחישוב ההפסד, והמשקולות מתעדכנות פעם אחת על סמך הערך הזה.
תהליך האימון משלים epoch אחרי שהמודל ראה את כל
במערך נתונים לאימון. בסוף כל תקופה של זמן מערכת, אנחנו משתמשים במערך הנתונים לאימות כדי
להעריך עד כמה המודל במצב למידה. נחזור על אימון באמצעות מערך הנתונים
למספר קבוע מראש של תקופות של זמן מערכת. יכול להיות שנפסיק בשלב מוקדם יותר לבצע אופטימיזציה,
כשדיוק האימות מייצב בין תקופות של זמן מערכת ברצף, מה שמצביע על כך
המודל כבר לא מאמן.
| היפר-פרמטר לאימון | ערך |
|---|---|
| קצב למידה | 1e-3 |
| תקופות של זמן מערכת | 1000 |
| גודל הקבוצה | 512 |
| עצירה מוקדמת | פרמטר: val_loss, סבלנות: 1 |
טבלה 3: אימון היפר-פרמטרים
קוד Keras הבא מיישם את תהליך האימון באמצעות הפרמטרים שנבחרו בטבלאות 2 ו- 3 למעלה:
def train_ngram_model(data, learning_rate=1e-3, epochs=1000, batch_size=128, layers=2, units=64, dropout_rate=0.2): """Trains n-gram model on the given dataset. # Arguments data: tuples of training and test texts and labels. learning_rate: float, learning rate for training model. epochs: int, number of epochs. batch_size: int, number of samples per batch. layers: int, number of `Dense` layers in the model. units: int, output dimension of Dense layers in the model. dropout_rate: float: percentage of input to drop at Dropout layers. # Raises ValueError: If validation data has label values which were not seen in the training data. """ # Get the data. (train_texts, train_labels), (val_texts, val_labels) = data # Verify that validation labels are in the same range as training labels. num_classes = explore_data.get_num_classes(train_labels) unexpected_labels = [v for v in val_labels if v not in range(num_classes)] if len(unexpected_labels): raise ValueError('Unexpected label values found in the validation set:' ' {unexpected_labels}. Please make sure that the ' 'labels in the validation set are in the same range ' 'as training labels.'.format( unexpected_labels=unexpected_labels)) # Vectorize texts. x_train, x_val = vectorize_data.ngram_vectorize( train_texts, train_labels, val_texts) # Create model instance. model = build_model.mlp_model(layers=layers, units=units, dropout_rate=dropout_rate, input_shape=x_train.shape[1:], num_classes=num_classes) # Compile model with learning parameters. if num_classes == 2: loss = 'binary_crossentropy' else: loss = 'sparse_categorical_crossentropy' optimizer = tf.keras.optimizers.Adam(lr=learning_rate) model.compile(optimizer=optimizer, loss=loss, metrics=['acc']) # Create callback for early stopping on validation loss. If the loss does # not decrease in two consecutive tries, stop training. callbacks = [tf.keras.callbacks.EarlyStopping( monitor='val_loss', patience=2)] # Train and validate model. history = model.fit( x_train, train_labels, epochs=epochs, callbacks=callbacks, validation_data=(x_val, val_labels), verbose=2, # Logs once per epoch. batch_size=batch_size) # Print results. history = history.history print('Validation accuracy: {acc}, loss: {loss}'.format( acc=history['val_acc'][-1], loss=history['val_loss'][-1])) # Save model. model.save('IMDb_mlp_model.h5') return history['val_acc'][-1], history['val_loss'][-1]
כאן אפשר למצוא דוגמאות קוד לאימון של מודל הרצף.