في هذا القسم، سنعمل على إنشاء وتدريب وتقييم
الأمثل. في الخطوة 3،
اخترنا استخدام نموذج ن جرام أو نموذج تسلسل، باستخدام نسبة S/W.
والآن، حان الوقت لكتابة خوارزمية التصنيف وتدريبها. سنستخدم
TensorFlow مع
tf.keras
واجهة برمجة التطبيقات لهذا الغرض.
إن إنشاء نماذج التعلم الآلي بالتعاون مع Keras يدور حول تجميع البيانات والطبقات والكتل البرمجية الإنشائية لمعالجة البيانات، تمامًا مثل تجميع ليغو طوب. تسمح لنا هذه الطبقات بتحديد تسلسل التحولات التي نريدها تنفيذها بناءً على المدخلات لدينا. بما أنّ خوارزمية التعلُّم لدينا تستقبل إدخالاً نصيًا واحدًا وينتج عن ذلك تصنيف واحد، يمكننا إنشاء مجموعة خطية من الطبقات باستخدام النموذج التسلسلي واجهة برمجة التطبيقات.
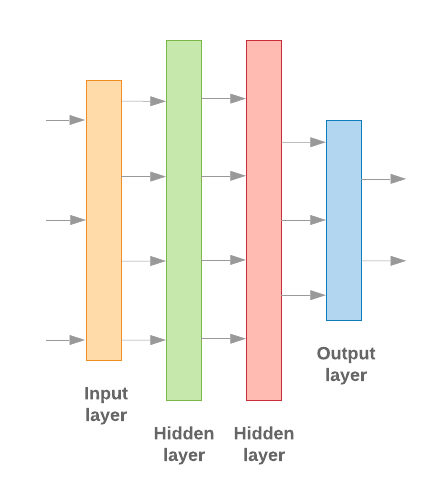
الشكل 9: مكدّس خطي للطبقات
سيتم إنشاء طبقة الإدخال والطبقات الوسيطة بشكل مختلف، اعتمادًا على ما إذا كنا نبني نموذج ن جرام أو نموذج تسلسل. لَكِنْ بغض النظر عن نوع النموذج، ستكون الطبقة الأخيرة هي نفسها عند مشكلة معينة.
إنشاء الطبقة الأخيرة
عندما يكون لدينا فئتان فقط (تصنيف ثنائي)، يجب أن ينتج عن نموذجنا
لنتيجة احتمالية فردية. على سبيل المثال، إخراج 0.2 لعيّنة إدخال معيّنة
تعني "ثقة بنسبة 20% في أن هذه العينة في الفئة الأولى (الفئة 1)، و80%"
تكون في الفئة الثانية (الفئة 0)". للحصول على درجة الاحتمالية هذه،
دالة التفعيل
الطبقة الأخيرة ينبغي أن تكون
الدالة السينية،
و
دالة الخسارة
المستخدمة لتطبيق النموذج يجب أن
القصور المشترك الثنائي:
(اطّلِع على الشكل 10، على اليمين).
عندما يكون هناك أكثر من فئتين (التصنيف متعدد الفئات)، فإن نموذجنا
يجب أن يكون ناتجها درجة واحدة للاحتمالية لكل فئة. ينبغي أن يكون مجموع هذه الدرجات
1- على سبيل المثال، يعني إخراج {0: 0.2, 1: 0.7, 2: 0.1} "ثقة بنسبة 20% في أن
أن هذه العينة موجودة في الفئة 0، و% 70 إذا كانت في الفئة 1، و10%
الصف 2". للحصول على هذه الدرجات، تعتمد وظيفة تفعيل الطبقة الأخيرة
ينبغي أن يكون softmax، ودالة الخسارة المستخدمة لتطبيق النموذج
القصور عبري الفئوي. (راجِع الشكل 10، إلى اليسار).
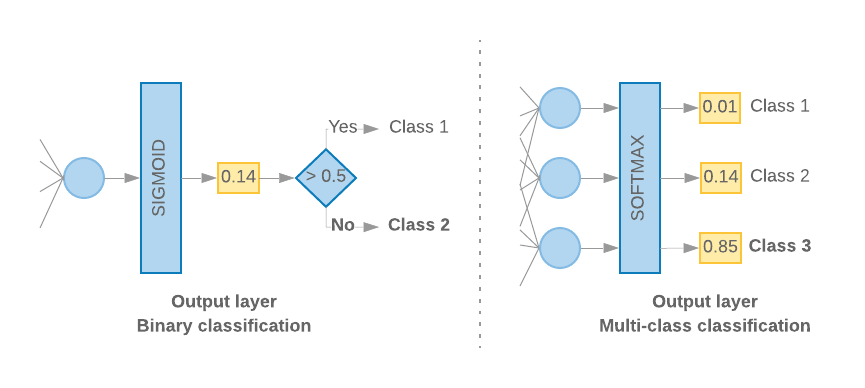
الشكل 10: الطبقة الأخيرة
تحدد التعليمة البرمجية التالية دالة تأخذ عدد الفئات كمدخلات، وتخرج العدد المناسب من وحدات الطبقات (وحدة واحدة بنظام النظام الثنائي التصنيف أو وحدة واحدة لكل فئة) والتفعيل المناسب الدالة:
def _get_last_layer_units_and_activation(num_classes):
"""Gets the # units and activation function for the last network layer.
# Arguments
num_classes: int, number of classes.
# Returns
units, activation values.
"""
if num_classes == 2:
activation = 'sigmoid'
units = 1
else:
activation = 'softmax'
units = num_classes
return units, activation
ويستعرض القسمان التاليان عملية إنشاء النموذج المتبقي. طبقات نماذج ن غرام ونماذج التسلسل.
عندما تكون نسبة S/W صغيرة، يكون أداء نماذج الن جرام أفضل.
من نماذج التسلسل تكون نماذج التسلسل أفضل عند توفّر عدد كبير.
المتجهات الصغيرة والكثيفة. وذلك لأنه يتم تعلم علاقات التضمين في
مساحة كثيفة، وهذا يحدث بشكل أفضل مع العديد من العينات.
إنشاء نموذج n-gram [الخيار A]
نشير إلى النماذج التي تعالج الرموز المميزة بشكل مستقل (وليس مع ترتيب كلمة الحساب) كنماذج ن غرام. المُركّبات البسيطة متعددة الطبقات (بما في ذلك الانحدار اللوجستي آلات تعزيز التدرّج وأجهزة متجه الدعم) تندرج جميعها ضمن هذه الفئة؛ فلا يمكنه استخدام أي معلومات حول ترتيب النصوص.
لقد قمنا بمقارنة أداء بعض نماذج n غرام المذكورة أعلاه أنّ المصوّرات متعددة الطبقات (MLP) عادةً ما تحقّق أداءً أفضل من خيارات أخرى. تعد MLP سهلة التحديد والفهم وتوفر دقة جيدة وتتطلب عملية حسابية قليلة نسبيًا.
تحدد التعليمة البرمجية التالية نموذج MLP ثنائي الطبقة في tf.keras، مع إضافة اثنين طبقات القوائم المنسدلة لضبطها لمنع فرط التخصيص لعينات التدريب.
from tensorflow.python.keras import models
from tensorflow.python.keras.layers import Dense
from tensorflow.python.keras.layers import Dropout
def mlp_model(layers, units, dropout_rate, input_shape, num_classes):
"""Creates an instance of a multi-layer perceptron model.
# Arguments
layers: int, number of `Dense` layers in the model.
units: int, output dimension of the layers.
dropout_rate: float, percentage of input to drop at Dropout layers.
input_shape: tuple, shape of input to the model.
num_classes: int, number of output classes.
# Returns
An MLP model instance.
"""
op_units, op_activation = _get_last_layer_units_and_activation(num_classes)
model = models.Sequential()
model.add(Dropout(rate=dropout_rate, input_shape=input_shape))
for _ in range(layers-1):
model.add(Dense(units=units, activation='relu'))
model.add(Dropout(rate=dropout_rate))
model.add(Dense(units=op_units, activation=op_activation))
return model
إنشاء نموذج تسلسلي [الخيار B]
ونشير إلى النماذج التي يمكن أن تتعلّم من بجوار الرموز المميّزة في صورة متتابعة النماذج. ويتضمن ذلك فئتي نماذج CNN وRNN. تتم معالجة البيانات مسبقًا الخطوط المتجهة المتسلسلة لهذه النماذج.
تحتوي نماذج التسلسل عمومًا على عدد أكبر من المعاملات للتعلم. الأول في هذه النماذج هي طبقة تضمين، تتعرف على العلاقة بين الكلمات في مساحة متجهة كثيفة. تعلم علاقات الكلمات يعمل بشكل أفضل عبر العديد من العينات.
من المرجح أن تكون الكلمات في مجموعة بيانات معينة ليست فريدة من نوعها لمجموعة البيانات هذه. يمكننا بالتالي التعرف على العلاقة بين الكلمات في مجموعة البيانات باستخدام مجموعات البيانات الأخرى. وللقيام بذلك، يمكننا نقل التضمين الذي تم تعلمه من مجموعة بيانات أخرى إلى طبقة التضمين. ويُشار إلى هذه التضمينات بأنّها مُدرَّبة مسبقًا التضمينات. إن استخدام تضمين مدرَّب مسبقًا يمنح النموذج الأولوية في عملية التعلم.
كما أنّ هناك تضمينات مدرَّبة مسبقًا تم تدريبها على استخدام أحجام كبيرة الشركات، مثل GloVe. يمتلك GloVe تم تدريبه على مجموعات متعددة (ويكيبيديا في المقام الأول). لقد اختبرنا تدريبنا باستخدام إصدار من تضمينات GloVe ولاحظنا أنه إذا وتجميد أوزان التضمينات المدرَّبة مسبقًا وتدريب بقية الشبكة، فإن النماذج لم تكن تعمل بشكل جيد. قد يكون هذا بسبب السياق في الذي تم تدريبه لطبقة التضمين قد يكون مختلفًا عن السياق التي كنا نستخدمها فيه.
قد لا تتوافق عمليات تضمين GloVe المدرَّبة على بيانات Wikipedia مع اللغة. الأنماط في مجموعة بيانات IMDb. قد تحتاج العلاقات التي يتم استنتاجها إلى بعض قيد التحديث، بمعنى أنّ القيم التقديرية للتضمين قد تحتاج إلى ضبط سياقي. نفعل ذلك في مرحلتين:
في المرحلة الأولى، وبعد تجميد ترجيحات طبقة التضمين، نسمح ببقية العناصر الشبكة للتعلم. في نهاية تمرين الجري هذا، تصل القيم التقديرية للنموذج إلى حالة وهي أفضل بكثير من قيمها غير المهيأة. فيما يتعلق بالجري الثاني، تسمح لطبقة التضمين بالتعلم أيضًا، مع إجراء تعديلات دقيقة على كل القيم التقديرية في الشبكة. نشير إلى هذه العملية باسم استخدام تضمين محسنًا.
إنّ عمليات التضمين الدقيقة تساهم في الحصول على دقة أفضل. ومع ذلك، فإن هذا يأتي في الطاقة الحوسبية المتزايدة المطلوبة لتدريب الشبكة. استنادًا إلى من عدد كافٍ من العينات، فيمكننا كذلك التعرف على كيفية تضمين من الصفر. لاحظنا أنّه بالنسبة إلى
S/W > 15K، بدءًا من نقطة الصفر بفعالية ينتج عنهما الدقة نفسها التي تحصل عليها عند استخدام التضمين المحسَّن.
لقد أجرينا مقارنة بين نماذج التسلسل المختلفة، مثل CNN وsepCNN RNN (LSTM وGRU) وCNN-RNN وRNN المكدس بُنى النماذج. وتبيّن لنا أنّ sepCNN هو أحد متغيرات الشبكة الالتفافية غالبًا ما تكون أكثر كفاءة من حيث البيانات وكفاءة الحوسبة، فإنها تحقق أداءً أفضل من النماذج الأخرى.
يُنشئ الرمز البرمجي التالي نموذج sepCNN من أربع طبقات:
from tensorflow.python.keras import models from tensorflow.python.keras import initializers from tensorflow.python.keras import regularizers from tensorflow.python.keras.layers import Dense from tensorflow.python.keras.layers import Dropout from tensorflow.python.keras.layers import Embedding from tensorflow.python.keras.layers import SeparableConv1D from tensorflow.python.keras.layers import MaxPooling1D from tensorflow.python.keras.layers import GlobalAveragePooling1D def sepcnn_model(blocks, filters, kernel_size, embedding_dim, dropout_rate, pool_size, input_shape, num_classes, num_features, use_pretrained_embedding=False, is_embedding_trainable=False, embedding_matrix=None): """Creates an instance of a separable CNN model. # Arguments blocks: int, number of pairs of sepCNN and pooling blocks in the model. filters: int, output dimension of the layers. kernel_size: int, length of the convolution window. embedding_dim: int, dimension of the embedding vectors. dropout_rate: float, percentage of input to drop at Dropout layers. pool_size: int, factor by which to downscale input at MaxPooling layer. input_shape: tuple, shape of input to the model. num_classes: int, number of output classes. num_features: int, number of words (embedding input dimension). use_pretrained_embedding: bool, true if pre-trained embedding is on. is_embedding_trainable: bool, true if embedding layer is trainable. embedding_matrix: dict, dictionary with embedding coefficients. # Returns A sepCNN model instance. """ op_units, op_activation = _get_last_layer_units_and_activation(num_classes) model = models.Sequential() # Add embedding layer. If pre-trained embedding is used add weights to the # embeddings layer and set trainable to input is_embedding_trainable flag. if use_pretrained_embedding: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0], weights=[embedding_matrix], trainable=is_embedding_trainable)) else: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0])) for _ in range(blocks-1): model.add(Dropout(rate=dropout_rate)) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(MaxPooling1D(pool_size=pool_size)) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(GlobalAveragePooling1D()) model.add(Dropout(rate=dropout_rate)) model.add(Dense(op_units, activation=op_activation)) return model
تدريب النموذج
والآن بعد أن قمنا ببناء بنية النموذج، نحتاج إلى تطبيق النموذج. يتضمن التدريب إجراء تنبؤ بناءً على الحالة الحالية للنموذج، وحساب مدى عدم صحة التنبؤ، وتحديث الأوزان أو لمعاملات الشبكة لتقليل هذا الخطأ وجعل النموذج يتنبأ أَفْضَلْ. ونكرر هذه العملية حتى يتقارب نموذجنا ولم يعد من الممكن التعلم. هناك ثلاث معلمات رئيسية يجب اختيارها لهذه العملية (راجع الجدول 2.
- المقياس: كيفية قياس أداء النموذج باستخدام المقياس. استخدمنا أسلوب الدقة كمقياس في تجاربنا.
- دالة الخسارة: دالة تُستخدم لحساب قيمة الخسارة من أن عملية التطبيق تحاول بعد ذلك تقليلها من خلال ضبط أوزان الشبكة. بالنسبة لمشكلات التصنيف، تكون نسبة فقدان الإنتروبيا الأفضل أداءً.
- أداة التحسين: دالة تحدِّد طريقة ترجيح الشبكة بناءً على ناتج دالة الخسارة. استخدمنا الطريقة الشائعة مُحسِّن آدم في تجاربنا.
وفي كيراس، يمكننا تمرير معاملات التعلم هذه إلى نموذج باستخدام تجميع .
الجدول 2: مَعلمات التعلُّم
| مَعلمة التعلُّم | القيمة |
|---|---|
| المقياس | الدقة |
| دالة الخسارة - التصنيف الثنائي | binary_crossentropy |
| دالة الخسارة - التصنيف متعدد الفئات | sparse_categorical_crossentropy |
| مُشاهد عملي | آدم |
يحدث التدريب الفعلي باستخدام
fit.
اعتمادًا على حجم
مجموعة البيانات، فهذه هي الطريقة التي سيتم بها إنفاق معظم دورات الحوسبة. في كل
التكرار التطبيقي، هناك batch_size عدد من العينات من بيانات التدريب
لحساب الخسارة، ويتم تحديث الترجيحات مرة واحدة، بناءً على هذه القيمة.
وتكتمل عملية التدريب epoch بعد أن يتعرّف النموذج على كامل
مجموعة بيانات التدريب. وفي نهاية كل حقبة، نستخدم مجموعة بيانات التحقق من الصحة
لتقييم مدى جودة تعلم النموذج. نكرر التدريب باستخدام مجموعة البيانات
لعدد محدد مسبقًا من الحقبات. قد نحسّن ذلك من خلال التوقف مبكرًا
عند استقرار دقة التحقق بين الفترات المتتالية، مما يوضح أن
لم يعد النموذج يتدرب.
| المَعلمة الفائقة للتدريب | القيمة |
|---|---|
| معدّل التعلّم | 1e-3 |
| الحقبات | 1000 |
| حجم الدفعة | 512 |
| التوقف المبكر | المعلمة: val_loss، الصبر: 1 |
الجدول 3: المعلَمات الفائقة للتدريب
تنفذ التعليمة البرمجية لـ Keras التالية عملية التدريب باستخدام المعلمات تم اختيارها في الجدول 2 3 أعلاه:
def train_ngram_model(data, learning_rate=1e-3, epochs=1000, batch_size=128, layers=2, units=64, dropout_rate=0.2): """Trains n-gram model on the given dataset. # Arguments data: tuples of training and test texts and labels. learning_rate: float, learning rate for training model. epochs: int, number of epochs. batch_size: int, number of samples per batch. layers: int, number of `Dense` layers in the model. units: int, output dimension of Dense layers in the model. dropout_rate: float: percentage of input to drop at Dropout layers. # Raises ValueError: If validation data has label values which were not seen in the training data. """ # Get the data. (train_texts, train_labels), (val_texts, val_labels) = data # Verify that validation labels are in the same range as training labels. num_classes = explore_data.get_num_classes(train_labels) unexpected_labels = [v for v in val_labels if v not in range(num_classes)] if len(unexpected_labels): raise ValueError('Unexpected label values found in the validation set:' ' {unexpected_labels}. Please make sure that the ' 'labels in the validation set are in the same range ' 'as training labels.'.format( unexpected_labels=unexpected_labels)) # Vectorize texts. x_train, x_val = vectorize_data.ngram_vectorize( train_texts, train_labels, val_texts) # Create model instance. model = build_model.mlp_model(layers=layers, units=units, dropout_rate=dropout_rate, input_shape=x_train.shape[1:], num_classes=num_classes) # Compile model with learning parameters. if num_classes == 2: loss = 'binary_crossentropy' else: loss = 'sparse_categorical_crossentropy' optimizer = tf.keras.optimizers.Adam(lr=learning_rate) model.compile(optimizer=optimizer, loss=loss, metrics=['acc']) # Create callback for early stopping on validation loss. If the loss does # not decrease in two consecutive tries, stop training. callbacks = [tf.keras.callbacks.EarlyStopping( monitor='val_loss', patience=2)] # Train and validate model. history = model.fit( x_train, train_labels, epochs=epochs, callbacks=callbacks, validation_data=(x_val, val_labels), verbose=2, # Logs once per epoch. batch_size=batch_size) # Print results. history = history.history print('Validation accuracy: {acc}, loss: {loss}'.format( acc=history['val_acc'][-1], loss=history['val_loss'][-1])) # Save model. model.save('IMDb_mlp_model.h5') return history['val_acc'][-1], history['val_loss'][-1]
يُرجى الاطّلاع على أمثلة الرموز لتدريب نموذج التسلسل هنا.