تحتوي هذه الصفحة على مصطلحات مسرد المقاييس. للاطّلاع على جميع مصطلحات المسرد، يُرجى النقر هنا.
A
الدقة
عدد التوقّعات الصحيحة للتصنيف مقسومًا على إجمالي عدد التوقّعات والمقصود:
على سبيل المثال، إذا قدّم نموذج 40 توقّعًا صحيحًا و10 توقّعات غير صحيحة، ستكون دقة النموذج كما يلي:
يقدّم التصنيف الثنائي أسماء محدّدة لمختلف فئات التوقعات الصحيحة والتوقعات غير الصحيحة. لذا، تكون صيغة الدقة للتصنيف الثنائي كما يلي:
where:
- TP هو عدد الحالات الموجبة الصحيحة (التوقّعات الصحيحة).
- TN هو عدد الحالات السالبة الصحيحة (التوقعات الصحيحة).
- FP هو عدد الحالات الموجبة الخاطئة (التوقعات غير الصحيحة).
- FN هو عدد الحالات السالبة الخاطئة (التوقعات غير الصحيحة).
مقارنة الدقة بـ مقياس صحة النموذج ومقياس المراجعة.
يمكنك الاطّلاع على التصنيف: الدقة ومقياس المراجعة ومقياس صحة النموذج والمقاييس ذات الصلة في "دورة مكثّفة عن تعلّم الآلة" للحصول على مزيد من المعلومات.
المساحة تحت منحنى الدقة والاستدعاء
اطّلِع على المساحة تحت منحنى الدقة والاستدعاء (PR AUC).
المساحة تحت منحنى ROC
اطّلِع على المساحة تحت منحنى ROC.
المساحة تحت منحنى ROC
رقم يتراوح بين 0.0 و1.0 يمثّل قدرة نموذج التصنيف الثنائي على فصل الفئات الإيجابية عن الفئات السلبية. كلما اقتربت قيمة AUC من 1.0، تحسّنت قدرة النموذج على فصل الفئات عن بعضها.
على سبيل المثال، توضّح الصورة التالية نموذج تصنيف يفصل تمامًا بين الفئات الإيجابية (الدوائر الخضراء) والفئات السلبية (المستطيلات الأرجوانية). يحقّق هذا النموذج المثالي غير الواقعي قيمة AUC تبلغ 1.0:

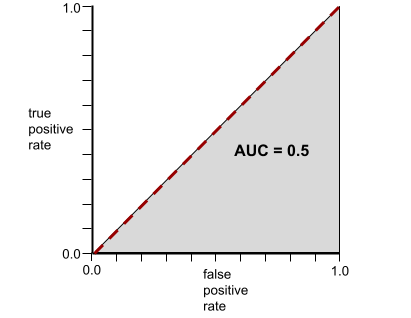
في المقابل، يوضّح الرسم التوضيحي التالي نتائج نموذج تصنيف أنشأ نتائج عشوائية. يحتوي هذا النموذج على قيمة AUC تبلغ 0.5:

نعم، النموذج السابق لديه قيمة AUC تبلغ 0.5، وليس 0.0.
وتقع معظم النماذج في مكان ما بين هذين الحدّين الأقصيين. على سبيل المثال، يفصل النموذج التالي بين القيم الموجبة والسالبة إلى حد ما، وبالتالي يكون لديه قيمة AUC تتراوح بين 0.5 و1.0:

تتجاهل مقياس AUC أي قيمة تحدّدها لحدّ التصنيف. بدلاً من ذلك، تأخذ المساحة تحت منحنى ROC في الاعتبار جميع عتبات التصنيف الممكنة.
انقر على الرمز للتعرّف على العلاقة بين منحنيَي AUC وROC.
تمثّل المساحة تحت منحنى ROC المساحة تحت منحنى ROC. على سبيل المثال، يبدو منحنى ROC لنموذج يفصل الإيجابيات عن السلبيات بشكل مثالي كما يلي:
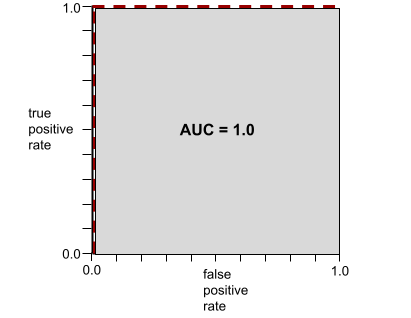
مساحة AUC هي مساحة المنطقة الرمادية في الرسم التوضيحي السابق. في هذه الحالة غير العادية، تكون المساحة ببساطة هي طول المنطقة الرمادية (1.0) مضروبًا في عرض المنطقة الرمادية (1.0). وبالتالي، فإنّ ناتج ضرب 1.0 في 1.0 يعطي قيمة AUC تساوي 1.0 بالضبط، وهي أعلى قيمة ممكنة لنتيجة AUC.
في المقابل، يكون منحنى ROC الخاص بنموذج التصنيف الذي لا يمكنه فصل الفئات على الإطلاق كما يلي. مساحة هذه المنطقة الرمادية هي 0.5.
يبدو منحنى ROC الأكثر شيوعًا على النحو التالي تقريبًا:
سيكون من الصعب احتساب المساحة تحت هذا المنحنى يدويًا، ولهذا السبب يتم عادةً احتساب معظم قيم AUC باستخدام برنامج.
يمكنك الاطّلاع على التصنيف: منحنى ROC ومقياس AUC في "دورة مكثّفة عن تعلّم الآلة" للحصول على مزيد من المعلومات.
متوسط الدقة عند k
مقياس لتلخيص أداء نموذج بشأن طلب واحد يؤدي إلى إنشاء نتائج مرتبة، مثل قائمة مرقّمة باقتراحات كتب متوسط الدقة عند k هو، حسنًا، متوسط قيم الدقة عند k لكل نتيجة ذات صلة. وبالتالي، فإنّ صيغة متوسط مقياس صحة النموذج عند k هي:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
where:
- تمثّل السمة\(n\) عدد العناصر ذات الصلة في القائمة.
يختلف هذا المقياس عن مقياس الاسترجاع عند k.
B
الخط الأساسي
نموذج يُستخدَم كنقطة مرجعية لمقارنة مستوى أداء نموذج آخر (عادةً ما يكون أكثر تعقيدًا). على سبيل المثال، يمكن أن يكون نموذج الانحدار اللوجستي أساسًا جيدًا للنموذج العميق.
بالنسبة إلى مشكلة معيّنة، يساعد خط الأساس مطوّري النماذج في تحديد الحد الأدنى المتوقّع للأداء الذي يجب أن يحقّقه النموذج الجديد ليكون مفيدًا.
أسئلة منطقية (BoolQ)
مجموعة بيانات لتقييم كفاءة نموذج لغوي كبير في الإجابة عن الأسئلة بنعم أو لا يتضمّن كل تحدٍّ في مجموعة البيانات ثلاثة عناصر:
- طلب بحث
- تمثّل هذه السمة فقرة تشير إلى الإجابة عن طلب البحث.
- الإجابة الصحيحة، وهي إما نعم أو لا
على سبيل المثال:
- طلب البحث: هل هناك أي محطات طاقة نووية في ميشيغان؟
- المقطع: ...توفّر ثلاث محطات للطاقة النووية في ميشيغان حوالي% 30 من الكهرباء.
- الإجابة الصحيحة: نعم
جمع الباحثون الأسئلة من طلبات بحث مجمّعة ومجهولة المصدر على بحث Google، ثم استخدموا صفحات Wikipedia لتحديد المعلومات الأساسية.
لمزيد من المعلومات، يُرجى الاطّلاع على BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions.
BoolQ هي أحد مكوّنات مجموعة SuperGLUE.
BoolQ
اختصار الأسئلة المنطقية
C
CB
اختصار CommitmentBank
مقياس دقة الاختبار (F-score) لعدد N من الأحرف المتجاورة (ChrF)
مقياس لتقييم نماذج الترجمة الآلية تحدّد نتيجة F الخاصة بـ N-gram للأحرف درجة تطابق N-gram في النص المرجعي مع N-gram في النص الذي تم إنشاؤه بواسطة نموذج تعلّم آلي.
يشبه مقياس F-score الخاص بـ N-gram للأحرف المقاييس في عائلتَي ROUGE وBLEU، باستثناء ما يلي:
- تعمل نتيجة F-score لـ N-gram الأحرف على N-gram الأحرف.
- تعمل مقياسا ROUGE وBLEU على كلمات N-grams أو رموز.
اختيار البدائل المعقولة (COPA)
مجموعة بيانات لتقييم مدى قدرة نموذج لغوي كبير على تحديد أفضل إجابتَين بديلتَين لفرضية معيّنة. يتألف كل تحدٍ في مجموعة البيانات من ثلاثة عناصر:
- مقدمة، وهي عادةً عبارة متبوعة بسؤال
- إجابتان محتملتان عن السؤال المطروح في الفرضية، إحداهما صحيحة والأخرى غير صحيحة
- الإجابة الصحيحة
على سبيل المثال:
- الفرضية: كسر الرجل إصبع قدمه. ما هو سبب حدوث ذلك؟
- الإجابات المحتملة:
- ظهر ثقب في جوربه.
- سقط مطرقة على قدمه.
- الإجابة الصحيحة: 2
COPA هي أحد مكوّنات مجموعة SuperGLUE.
CommitmentBank (CB)
مجموعة بيانات لتقييم مدى إتقان نموذج لغوي كبير في تحديد ما إذا كان مؤلف مقطع نصي يعتقد بصحة عبارة مستهدَفة ضمن هذا المقطع. يحتوي كل إدخال في مجموعة البيانات على ما يلي:
- فقرة
- عبارة مستهدَفة ضمن هذه الفقرة
- قيمة منطقية تشير إلى ما إذا كان مؤلف المقطع يعتقد أنّ الجملة المستهدَفة
على سبيل المثال:
- الفقرة: كم كان من الممتع سماع ضحكة أرتميس. إنّها طفلة جدّية للغاية. لم أكن أعرف أنّ لديها حس فكاهي.
- الجملة المستهدَفة: كانت تتمتّع بروح الدعابة
- قيمة منطقية: True، ما يعني أنّ المؤلف يعتقد أنّ الجملة المستهدَفة
CommitmentBank هو أحد مكوّنات مجموعة SuperGLUE.
COPA
الاختصار الخاص بـ اختيار البدائل المعقولة
التكلفة
مرادف لكلمة خسارة
العدالة في الحالات الافتراضية
مقياس الإنصاف الذي يتحقّق مما إذا كان نموذج التصنيف يعرض النتيجة نفسها لشخص ما كما يعرضها لشخص آخر مطابق للأول، باستثناء ما يتعلق بواحدة أو أكثر من السمات الحسّاسة. يُعدّ تقييم نموذج التصنيف من حيث الإنصاف المضاد للواقع إحدى الطرق للكشف عن المصادر المحتملة للانحياز في النموذج.
يمكنك الاطّلاع على أيّ مما يلي للحصول على مزيد من المعلومات:
- الإنصاف: الإنصاف الافتراضي في دورة مكثّفة عن تعلّم الآلة.
- When Worlds Collide: Integrating Different Counterfactual Assumptions in Fairness
الإنتروبيا المتقاطعة
هي تعميم الخسارة اللوغاريتمية على مشاكل التصنيف المتعدد الفئات. يقيس الانتروبيا المتقاطعة الفرق بين توزيعَين للاحتمالات. يمكنك الاطّلاع أيضًا على مقياس الارتباك.
دالة التوزيع التراكمي (CDF)
دالة تحدّد عدد المرّات التي تكون فيها العيّنات أقل من أو تساوي قيمة مستهدَفة. على سبيل المثال، لنفترض أنّ هناك توزيعًا طبيعيًا للقيم المستمرة. يخبرك التوزيع التراكمي بأنّ% 50 تقريبًا من العيّنات يجب أن تكون أقل من أو تساوي المتوسط، وأنّ% 84 تقريبًا من العيّنات يجب أن تكون أقل من أو تساوي الانحراف المعياري الواحد فوق المتوسط.
D
التكافؤ بين الجنسين
مقياس العدالة الذي يتم استيفاؤه إذا كانت نتائج تصنيف النموذج لا تعتمد على سمة حساسة معيّنة.
على سبيل المثال، إذا كان كل من سكان ليليبوت وبروبدينغناغ يتقدّمون بطلبات إلى جامعة غلوبدوبدريب، يتم تحقيق التكافؤ الديموغرافي إذا كانت النسبة المئوية للطلاب المقبولين من ليليبوت هي نفسها النسبة المئوية للطلاب المقبولين من بروبدينغناغ، بغض النظر عمّا إذا كانت إحدى المجموعتين أكثر تأهيلاً من الأخرى في المتوسط.
يختلف هذا المقياس عن تساوي الاحتمالات وتساوي الفرص، اللذين يسمحان بأن تعتمد نتائج التصنيف بشكل إجمالي على السمات الحسّاسة، ولكنّهما لا يسمحان بأن تعتمد نتائج التصنيف لبعض التصنيفات المحدّدة للحقيقة الأساسية على السمات الحسّاسة. يمكنك الاطّلاع على "مكافحة التمييز من خلال تعلُّم الآلة الأذكى" للحصول على عرض مرئي يستكشف المفاضلة عند تحسين التكافؤ الديمغرافي.
يمكنك الاطّلاع على الإنصاف: التكافؤ الديمغرافي في "دورة مكثّفة عن تعلّم الآلة" للحصول على مزيد من المعلومات.
E
مسافة نقل التراب (EMD)
مقياس للتشابه النسبي بين توزيعَين كلّما كانت مسافة نقل التراب أقل، تشابهت التوزيعات أكثر.
مسافة التعديل
مقياس لمدى تشابه سلسلتَي نص مع بعضهما البعض. في التعلّم الآلي، تكون مسافة التعديل مفيدة للأسباب التالية:
- يسهل احتساب مسافة التعديل.
- يمكن أن تقارن مسافة التعديل بين سلسلتَين معروفتَين بأنّهما متشابهتَين.
- يمكن أن تحدّد مسافة التعديل درجة تشابه السلاسل المختلفة مع سلسلة معيّنة.
تتوفّر عدة تعريفات لمسافة التعديل، ويستخدم كل منها عمليات مختلفة على السلاسل. يمكنك الاطّلاع على مسافة ليفنشتاين للحصول على مثال.
دالة التوزيع التراكمي التجريبية (eCDF أو EDF)
دالة التوزيع التراكمي استنادًا إلى القياسات التجريبية من مجموعة بيانات حقيقية قيمة الدالة عند أي نقطة على طول المحور x هي جزء الملاحظات في مجموعة البيانات التي تكون أقل من القيمة المحددة أو تساويها.
الإنتروبيا
في نظرية المعلومات، القصور هو وصف لمدى عدم القدرة على التنبؤ بتوزيع الاحتمالات. ويمكن تعريف القصور أيضًا بأنه مقدار المعلومات التي يحتوي عليها كل مثال. يكون التوزيع بأعلى إنتروبيا ممكنة عندما تكون جميع قيم المتغيّر العشوائي متساوية الاحتمالية.
إنّ إنتروبيا مجموعة تتضمّن قيمتَين محتملتَين هما "0" و "1" (على سبيل المثال، التصنيفات في مسألة تصنيف ثنائي) تخضع للصيغة التالية:
H = -p log p - q log q = -p log p - (1-p) * log (1-p)
where:
- H هو القصور.
- p هي نسبة الأمثلة التي تكون فيها القيمة "1".
- q هو نسبة الأمثلة التي تكون فيها القيمة "0". يُرجى العِلم أنّ q = (1 - p)
- log هو بشكل عام log2. في هذه الحالة، وحدة الإنتروبيا هي بت.
على سبيل المثال، لنفترض ما يلي:
- تحتوي 100 عينة على القيمة "1"
- تحتوي 300 عينة على القيمة "0"
وبالتالي، تكون قيمة القصور كما يلي:
- p = 0.25
- q = 0.75
- H = (-0.25)log2(0.25) - (0.75)log2(0.75) = 0.81 بت لكل مثال
المجموعة المتوازنة تمامًا (على سبيل المثال، 200 من القيمة "0" و200 من القيمة "1") ستكون قيمة الإنتروبيا فيها 1.0 بت لكل مثال. كلما أصبحت المجموعة أكثر عدم توازن، اقترب القصور فيها من 0.0.
في أشجار القرارات، يساعد الانتروبيا في صياغة مكسب المعلومات لمساعدة المقسّم في اختيار الشروط أثناء نمو شجرة قرارات التصنيف.
مقارنة الإنتروبيا مع:
- مقياس جيني للتفاوت
- دالة الخسارة الإنتروبيا المتقاطعة
يُطلق على القصور غالبًا اسم قصور شانون.
لمزيد من المعلومات، راجِع Exact splitter for binary classification with numerical features في دورة "أشجار القرار العشوائية".
تكافؤ الفرص
مقياس الإنصاف لتقييم ما إذا كان النموذج يتوقّع النتيجة المرغوبة بشكل جيد وبالمقدار نفسه لجميع قيم السمة الحسّاسة بعبارة أخرى، إذا كانت النتيجة المرغوبة لنموذج هي الفئة الإيجابية، سيكون الهدف هو أن يكون معدّل الإيجابية الحقيقية هو نفسه لجميع المجموعات.
يرتبط تكافؤ الفرص بتكافؤ الاحتمالات، الذي يتطلّب أن يكون كلّ من معدلات الموجب الصائب ومعدلات الموجب الخاطئ متطابقًا لجميع المجموعات.
لنفترض أنّ جامعة Glubbdubdrib تقبل طلابًا من Lilliput وBrobdingnag في برنامج رياضيات صارم. تقدّم المدارس الثانوية في ليليبت منهجًا دراسيًا قويًا في الرياضيات، ومعظم الطلاب مؤهّلون للالتحاق بالبرنامج الجامعي. لا تقدّم المدارس الثانوية في بروبدينغناغ أي دروس في الرياضيات، ونتيجةً لذلك، يكون عدد الطلاب المؤهّلين أقل بكثير. يتم استيفاء شرط تكافؤ الفرص للتصنيف المفضّل "مقبول" فيما يتعلق بالجنسية (ليليبوتية أو بروبدينغناغية) إذا كان من المرجّح أن يتم قبول الطلاب المؤهّلين بالتساوي بغض النظر عما إذا كانوا ليليبوتايين أو بروبدينغناغيين.
على سبيل المثال، لنفترض أنّ 100 شخص من ليليبوت و100 شخص من بروبدينغناغ يقدّمون طلبات التحاق بجامعة غلوبدوبدريب، ويتم اتخاذ قرارات القبول على النحو التالي:
الجدول 1. مقدّمو الطلبات من ليليبيوت (90% منهم مؤهّلون)
| مؤهَّل | غير معرَّف | |
|---|---|---|
| تم قبول الطلب | 45 | 3 |
| تم الرفض | 45 | 7 |
| المجموع | 90 | 10 |
|
نسبة الطلاب المؤهّلين المقبولين: 45/90 =%50 نسبة الطلاب غير المؤهّلين المرفوضين: 7/10 =%70 النسبة الإجمالية للطلاب المقبولين من Lilliputian: (45+3)/100 = %48 |
||
الجدول 2. مقدّمو الطلبات من Brobdingnagian (10% مؤهَّلون):
| مؤهَّل | غير معرَّف | |
|---|---|---|
| تم قبول الطلب | 5 | 9 |
| تم الرفض | 5 | 81 |
| المجموع | 10 | 90 |
|
نسبة الطلاب المؤهّلين المقبولين: 5/10 =%50 نسبة الطلاب غير المؤهّلين المرفوضين: 81/90 =%90 النسبة الإجمالية للطلاب المقبولين من Brobdingnagian: (5+9)/100 = %14 |
||
تستوفي الأمثلة السابقة شرط تكافؤ الفرص لقبول الطلاب المؤهّلين لأنّ كلّاً من سكان ليليبوت وبروبدينغناغ المؤهّلين لديهم فرصة بنسبة% 50 للقبول.
على الرغم من استيفاء شرط تكافؤ الفرص، لم يتم استيفاء مقياسَي العدالة التاليَين:
- التكافؤ الديمغرافي: يتم قبول سكان ليليبوت وبروبدينغناغ في الجامعة بمعدلات مختلفة، إذ يتم قبول% 48 من الطلاب من ليليبوت، ولكن يتم قبول% 14 فقط من الطلاب من بروبدينغناغ.
- تكافؤ الفرص: على الرغم من أنّ الطلاب المؤهَّلين من ليليبوت وبروبدينغناغ لديهم فرصة متساوية للقبول، لا يتم استيفاء الشرط الإضافي الذي ينص على أنّ الطلاب غير المؤهَّلين من ليليبوت وبروبدينغناغ لديهم فرصة متساوية للرفض. يبلغ معدّل الرفض لدى Lilliputians غير المؤهّلين% 70، بينما يبلغ معدّل الرفض لدى Brobdingnagians غير المؤهّلين% 90.
يمكنك الاطّلاع على الإنصاف: تكافؤ الفرص في "دورة مكثّفة عن تعلّم الآلة" للحصول على مزيد من المعلومات.
المعدّلات المتساوية
مقياس عدالة لتقييم ما إذا كان النموذج يتنبأ بالنتائج بشكل جيد وبدرجة متساوية لجميع قيم السمة الحسّاسة، وذلك فيما يتعلق بكل من الفئة الموجبة والفئة السالبة، وليس فئة واحدة فقط. بعبارة أخرى، يجب أن يكون كل من معدّل الموجب الصائب ومعدّل السالب الخاطئ متساويَين بالنسبة إلى جميع المجموعات.
ترتبط تكافؤ الفرص بتكافؤ الفرص، الذي يركّز فقط على معدّلات الخطأ لفئة واحدة (موجبة أو سالبة).
على سبيل المثال، لنفترض أنّ جامعة Glubbdubdrib تقبل الطلاب من Lilliput وBrobdingnag في برنامج رياضيات صارم. تقدّم المدارس الثانوية في ليليبوث مناهج دراسية قوية في الرياضيات، ومعظم الطلاب مؤهّلون للالتحاق بالبرنامج الجامعي. لا تقدّم المدارس الثانوية في بروبدينغناغ دروسًا في الرياضيات على الإطلاق، ونتيجةً لذلك، يكون عدد الطلاب المؤهّلين أقل بكثير. يتم استيفاء شرط تكافؤ الفرص إذا كان احتمال قبول المتقدّمين المؤهّلين في البرنامج متساويًا بغض النظر عن حجمهم، وإذا كان احتمال رفض المتقدّمين غير المؤهّلين متساويًا بغض النظر عن حجمهم.
لنفترض أنّ 100 شخص من ليليبوت و100 شخص من بروبدينغناغ يقدّمون طلبات إلى جامعة غلوبدوبدريب، ويتم اتخاذ قرارات القبول على النحو التالي:
الجدول 3. مقدّمو الطلبات من ليليبيوت (90% منهم مؤهّلون)
| مؤهَّل | غير معرَّف | |
|---|---|---|
| تم قبول الطلب | 45 | 2 |
| تم الرفض | 45 | 8 |
| المجموع | 90 | 10 |
|
نسبة الطلاب المؤهّلين المقبولين: 45/90 =%50 نسبة الطلاب غير المؤهّلين المرفوضين: 8/10 =%80 النسبة الإجمالية للطلاب المقبولين من Lilliputian: (45+2)/100 = %47 |
||
الجدول 4. مقدّمو الطلبات من Brobdingnagian (10% مؤهَّلون):
| مؤهَّل | غير معرَّف | |
|---|---|---|
| تم قبول الطلب | 5 | 18 |
| تم الرفض | 5 | 72 |
| المجموع | 10 | 90 |
|
نسبة الطلاب المؤهّلين المقبولين: 5/10 =%50 نسبة الطلاب غير المؤهّلين المرفوضين: 72/90 =%80 النسبة الإجمالية للطلاب المقبولين من Brobdingnagian: (5+18)/100 = %23 |
||
يتم استيفاء شرط تكافؤ الفرص لأنّ الطلاب المؤهّلين من ليليبوت وبروبدينغناغ لديهم فرصة قبول بنسبة% 50، بينما تبلغ نسبة رفض الطلاب غير المؤهّلين من ليليبوت وبروبدينغناغ% 80.
يتم قبول الطلاب من ليليبوت وبروبدينغناغ في جامعة غلوبدوبدريب بنسب مختلفة، حيث يتم قبول% 47 من الطلاب من ليليبوت و% 23 من الطلاب من بروبدينغناغ.يتم تعريف تكافؤ الفرص رسميًا في "تكافؤ الفرص في التعلّم الخاضع للإشراف" على النحو التالي: "يتوافق المتنبئ Ŷ مع تكافؤ الفرص فيما يتعلق بالسمة المحمية A والنتيجة Y إذا كان Ŷ وA مستقلين، بشرط Y".
التقييمات
تُستخدَم في المقام الأول كاختصار لتقييمات النماذج اللغوية الكبيرة. بشكل عام، التقييمات هي اختصار لأي شكل من أشكال التقييم.
التقييم
تشير هذه العملية إلى قياس جودة نموذج أو مقارنة نماذج مختلفة ببعضها.
لتقييم نموذج تعلُّم الآلة المُوجّه، يتم عادةً مقارنته بمجموعة التحقّق ومجموعة الاختبار. يتضمّن تقييم النماذج اللغوية الكبيرة عادةً تقييمات أوسع للجودة والأمان.
مطابقة تامة
مقياس شامل لا يسمح إلا بنتيجتَين: إمّا أن تتطابق نتيجة النموذج مع الحقيقة الأساسية أو النص المرجعي تمامًا، أو لا تتطابق. على سبيل المثال، إذا كانت البيانات الصحيحة هي برتقالي، فإنّ مخرجات النموذج الوحيدة التي تحقّق المطابقة التامة هي برتقالي.
يمكن أن تقيّم المطابقة التامة أيضًا النماذج التي يكون ناتجها تسلسلاً (قائمة مرتبة من العناصر). بشكل عام، تتطلّب المطابقة التامة أن تتطابق القائمة المرتبة التي تم إنشاؤها مع البيانات الأساسية، أي يجب أن يكون ترتيب كل عنصر في القائمتين هو نفسه. ومع ذلك، إذا كانت البيانات الأساسية تتضمّن تسلسلات صحيحة متعدّدة، تتطلّب المطابقة التامة أن يطابق الناتج الذي يقدّمه النموذج أحد التسلسلات الصحيحة.
Extreme Summarization (xsum)
مجموعة بيانات لتقييم قدرة نموذج لغوي كبير على تلخيص مستند واحد. يتألف كل إدخال في مجموعة البيانات مما يلي:
- مستند من تأليف هيئة الإذاعة البريطانية (BBC)
- ملخّص للمستند في جملة واحدة
لمزيد من التفاصيل، يُرجى الاطّلاع على لا أريد التفاصيل، أريد الملخّص فقط! شبكات عصبونية التفافية تراعي الموضوعات لتلخيص النصوص بشكل مكثّف
F
F1
مقياس تصنيف ثنائي "مجمّع" يعتمد على كل من مقياس صحة النموذج ومقياس المراجعة. في ما يلي الصيغة:
مقياس العدالة
تعريف رياضي "للإنصاف" يمكن قياسه تشمل بعض مقاييس العدالة الشائعة الاستخدام ما يلي:
- تكافؤ الفرص
- تعادل الأداء المستند إلى التوقّعات
- العدالة القائمة على التفكير في الاحتمالات
- التكافؤ الديمغرافي
تتداخل العديد من مقاييس العدالة مع بعضها البعض، راجِع عدم توافق مقاييس العدالة.
سالب خاطئ
مثال يخطئ فيه النموذج في التنبؤ بالفئة السلبية. على سبيل المثال، يتوقّع النموذج أنّ رسالة إلكترونية معيّنة ليست رسالة غير مرغوب فيها (الفئة السلبية)، ولكنّ هذه الرسالة الإلكترونية هي في الواقع رسالة غير مرغوب فيها.
معدّل السالب الخاطئ
يشير ذلك المصطلح إلى نسبة الأمثلة الإيجابية الفعلية التي توقّع النموذج بشكل خاطئ أنّها تنتمي إلى الفئة السلبية. تحتسب الصيغة التالية معدّل النتائج السلبية الخاطئة:
يمكنك الاطّلاع على الحدود ومصفوفة الالتباس في "دورة مكثّفة عن تعلّم الآلة" للحصول على مزيد من المعلومات.
موجب خاطئ
مثال يخطئ فيه النموذج في التنبؤ بالفئة الإيجابية. على سبيل المثال، يتوقّع النموذج أنّ رسالة إلكترونية معيّنة هي رسالة غير مرغوب فيها (الفئة الإيجابية)، ولكن في الواقع، هذه الرسالة ليست رسالة غير مرغوب فيها.
يمكنك الاطّلاع على الحدود ومصفوفة الالتباس في "دورة مكثّفة عن تعلّم الآلة" للحصول على مزيد من المعلومات.
معدّل الموجب الخاطئ
يشير ذلك المصطلح إلى نسبة الأمثلة السلبية الفعلية التي توقّع النموذج بشكل خاطئ أنّها تنتمي إلى الفئة الإيجابية. تحتسب الصيغة التالية معدّل الإيجابية الخاطئة:
معدل الموجب الخاطئ هو المحور السيني في منحنى خاصية تشغيل جهاز الاستقبال.
يمكنك الاطّلاع على التصنيف: منحنى ROC ومقياس AUC في "دورة مكثّفة عن تعلّم الآلة" للحصول على مزيد من المعلومات.
أهمية الميزات
مرادف أهمية المتغيرات
النموذج الأساسي
نموذج مدرَّب مسبقًا كبير جدًا تم تدريبه على مجموعة تدريب هائلة ومتنوّعة. يمكن للنموذج الأساسي تنفيذ ما يلي:
- الاستجابة بشكل جيد لمجموعة كبيرة من الطلبات
- يمكن استخدامه كنموذج أساسي لإجراء المزيد من عمليات الضبط الدقيق أو التخصيص الأخرى.
بعبارة أخرى، يكون النموذج الأساسي فعّالاً جدًا بشكل عام، ولكن يمكن تخصيصه بشكل أكبر ليصبح أكثر فائدةً في مهمة معيّنة.
نسبة النجاحات
مقياس لتقييم النص الذي تم إنشاؤه بواسطة نموذج تعلُّم آلي نسبة النجاح هي عدد مخرجات النصوص التي تم إنشاؤها "بنجاح" مقسومًا على إجمالي عدد مخرجات النصوص التي تم إنشاؤها. على سبيل المثال، إذا أنشأ نموذج لغوي كبير 10 مقاطع برمجية، ونجح خمسة منها، سيكون معدّل النجاح 50%.
على الرغم من أنّ مقياس "نسبة النجاح" مفيد بشكل عام في الإحصاء، إلا أنّه في تعلُّم الآلة، يكون هذا المقياس مفيدًا بشكل أساسي لقياس المهام التي يمكن التحقّق منها، مثل إنشاء الرموز البرمجية أو حلّ المسائل الرياضية.
G
gini impurity
مقياس مشابه لإنتروبيا تستخدم أدوات التقسيم قيمًا مشتقة من عدم المساواة في جيني أو الإنتروبيا لإنشاء شروط لتصنيف أشجار القرارات. يتم استنتاج تحصيل المعلومات من قصور المعلومات. لا يوجد مصطلح مكافئ مقبول عالميًا للمقياس المستمد من عدم نقاء جيني، ولكن هذا المقياس غير المسمى لا يقل أهمية عن اكتساب المعلومات.
يُطلق على عدم نقاء جيني أيضًا اسم مؤشر جيني أو ببساطة جيني.
H
الخسارة المفصلية
مجموعة من دوال الخسارة الخاصة بالتصنيف والمصمّمة للعثور على حدود القرار بأكبر مسافة ممكنة من كل مثال تدريبي، وبالتالي زيادة الهامش بين الأمثلة والحدود إلى أقصى حد. تستخدم آلات متّجهات الدعم الأساسية خسارة مفصلية (أو دالة ذات صلة، مثل تربيع الخسارة المفصلية). بالنسبة إلى التصنيف الثنائي، يتم تعريف دالة الخسارة المفصلية على النحو التالي:
حيث y هي التصنيف الصحيح، إما -1 أو +1، وy' هي الناتج الأولي لنموذج التصنيف:
نتيجةً لذلك، يبدو الرسم البياني لدالة الخسارة المفصلية مقابل (y * y') على النحو التالي:

I
عدم توافق مقاييس الإنصاف
يشير هذا المصطلح إلى فكرة أنّ بعض مفاهيم العدالة غير متوافقة مع بعضها البعض ولا يمكن تحقيقها في الوقت نفسه. نتيجةً لذلك، لا يوجد مقياس عالمي واحد لتحديد مدى العدل يمكن تطبيقه على جميع مشاكل تعلُّم الآلة.
على الرغم من أنّ ذلك قد يبدو محبطًا، إلا أنّ عدم التوافق بين مقاييس العدالة لا يعني أنّ الجهود المبذولة لتحقيق العدالة غير مثمرة. بدلاً من ذلك، تقترح هذه الإرشادات تعريف العدالة بشكل سياقي لمشكلة معيّنة في تعلُّم الآلة، وذلك بهدف منع الأضرار المرتبطة بحالات الاستخدام المحدّدة.
يمكنك الاطّلاع على "حول إمكانية تحقيق العدالة" للحصول على مناقشة أكثر تفصيلاً حول عدم توافق مقاييس العدالة.
العدالة الفردية
مقياس عدالة يتحقّق مما إذا تم تصنيف الأفراد المتشابهين بشكل مماثل. على سبيل المثال، قد ترغب أكاديمية Brobdingnagian في تحقيق العدالة الفردية من خلال ضمان أنّ فرص قبول طالبَين متطابقَين في الدرجات ونتائج الاختبارات الموحّدة متساوية.
يُرجى العِلم أنّ العدالة الفردية تعتمد بشكل كامل على طريقة تحديد "التشابه" (في هذه الحالة، الدرجات ونتائج الاختبارات)، وقد تواجه خطر حدوث مشاكل جديدة في العدالة إذا لم يتضمّن مقياس التشابه معلومات مهمة (مثل مدى صعوبة المناهج الدراسية للطالب).
يمكنك الاطّلاع على "العدالة من خلال الوعي" للحصول على مناقشة أكثر تفصيلاً حول العدالة الفردية.
تحصيل المعلومات
في غابات القرارات، يشير هذا المقياس إلى الفرق بين القصور في أحد الأجزاء ومجموع القصور في الأجزاء الفرعية المرجّح (حسب عدد الأمثلة). القصور في أحد الأجزاء هو القصور في الأمثلة الواردة في هذا الجزء.
على سبيل المثال، إليك قيم الإنتروبيا التالية:
- إنتروبيا العقدة الرئيسية = 0.6
- قصور إحدى العُقد الفرعية التي تتضمّن 16 مثالاً ذا صلة = 0.2
- مقياس القصور في عقدة فرعية أخرى تتضمّن 24 مثالاً ذا صلة = 0.1
لذا، %40 من الأمثلة موجودة في إحدى العُقد الفرعية و% 60 في العقدة الفرعية الأخرى. ولذلك:
- مجموع القصور المرجّح للعُقد الثانوية = (0.4 * 0.2) + (0.6 * 0.1) = 0.14
إذًا، يساوي تحصيل المعلومات:
- تحصيل المعلومات = قصور الجزء الأصلي - مجموع القصور المرجّح للأجزاء الفرعية
- تحصيل المعلومات = 0.6 - 0.14 = 0.46
تسعى معظم أدوات التقسيم إلى إنشاء شروط تزيد من اكتساب المعلومات إلى أقصى حد.
توافق المقيّمين
هو مقياس لمدى توافق المقيمين البشريين عند تنفيذ مهمة ما. إذا لم يتفق المقيّمون، قد يكون من الضروري تحسين تعليمات المهمة. يُعرف هذا المقياس أيضًا باسم اتفاقية بين المعلقين أو موثوقية التقييم بين المقيمين. يُرجى الاطّلاع أيضًا على معامل كابا لكوهين، وهو أحد مقاييس توافق المقيّمين الأكثر شيوعًا.
لمزيد من المعلومات، راجِع البيانات الفئوية: المشاكل الشائعة في "دورة مكثّفة عن تعلّم الآلة".
L
خسارة 1
دالة الخسارة التي تحسب القيمة المطلقة للفرق بين قيم التصنيف الفعلية والقيم التي يتوقّعها النموذج. على سبيل المثال، إليك طريقة حساب خسارة L1 لمجموعة من خمسة أمثلة:
| القيمة الفعلية للمثال | القيمة المتوقّعة للنموذج | القيمة المطلقة للتغيير |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = خسارة L1 | ||
يكون مقياس فقدان 1 أقل حساسية للقيم الشاذة من مقياس فقدان 2.
متوسط الخطأ المطلق هو متوسط خسارة 1 لكل مثال.
يمكنك الاطّلاع على الانحدار الخطي: الخسارة في "دورة مكثّفة عن تعلّم الآلة" للحصول على مزيد من المعلومات.
خسارة 2
يشير ذلك المصطلح إلى دالة خسارة تحسب مربع الفرق بين قيم التصنيف الفعلية والقيم التي يتوقّعها النموذج. على سبيل المثال، إليك طريقة حساب خسارة L2 لمجموعة من خمسة أمثلة:
| القيمة الفعلية للمثال | القيمة المتوقّعة للنموذج | مربع دلتا |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = L2 خسارة | ||
بسبب التربيع، يؤدي فقدان L2 إلى تضخيم تأثير القيم الشاذة. أي أنّ دالة الخسارة L2 تتأثر بشكل أكبر بالتوقعات السيئة مقارنةً بدالة الخسارة L1. على سبيل المثال، سيكون معدّل فقدان حزمة L1 السابقة 8 بدلاً من 16. لاحظ أنّ قيمة متطرفة واحدة تمثّل 9 من أصل 16.
تستخدم نماذج الانحدار عادةً دالة الخسارة L2 كدالة خسارة.
الخطأ التربيعي المتوسّط هو متوسط خسارة 2 لكل مثال. الخسارة التربيعية هي اسم آخر للخسارة من النوع L2.
يمكنك الاطّلاع على الانحدار اللوجستي: الخسارة والتسوية في "دورة مكثّفة عن تعلّم الآلة" للحصول على مزيد من المعلومات.
تقييمات النماذج اللغوية الكبيرة
مجموعة من المقاييس ومقاييس الأداء لتقييم أداء النماذج اللغوية الكبيرة (LLM). بشكل عام، تتضمّن عمليات تقييم النماذج اللغوية الكبيرة ما يلي:
- مساعدة الباحثين في تحديد المجالات التي تحتاج فيها النماذج اللغوية الكبيرة إلى تحسين
- وهي مفيدة في مقارنة النماذج اللغوية الكبيرة المختلفة وتحديد أفضل نموذج لغوي كبير لمهمة معيّنة.
- المساعدة في ضمان أنّ استخدام النماذج اللغوية الكبيرة آمن وأخلاقي
لمزيد من المعلومات، يمكنك الاطّلاع على النماذج اللغوية الكبيرة (LLM) في "دورة مكثّفة عن تعلُّم الآلة".
خسارة
أثناء تدريب نموذج خاضع للإشراف، يتم قياس مدى بُعد التوقّع الذي يقدّمه النموذج عن التصنيف.
تحسب دالة الخسارة الخسارة.
يمكنك الاطّلاع على الانحدار الخطي: الخسارة في دورة مكثّفة عن تعلّم الآلة للحصول على مزيد من المعلومات.
دالة الخسارة
أثناء التدريب أو الاختبار، يتم استخدام دالة رياضية تحسب مقدار الخطأ في دفعة من الأمثلة. تعرض دالة الخسارة قيمة خسارة أقل للنماذج التي تقدّم توقّعات جيدة مقارنةً بالنماذج التي تقدّم توقّعات سيئة.
عادةً ما يكون الهدف من التدريب هو تقليل الخسارة التي تعرضها دالة الخسارة.
تتوفّر العديد من أنواع دوال الخسارة المختلفة. اختَر دالة الخسارة المناسبة لنوع النموذج الذي تنشئه. على سبيل المثال:
- فقدان L2 (أو الخطأ التربيعي المتوسّط) هو دالة الفقدان للانحدار الخطي.
- الخسارة اللوغارتمية هي دالة الخسارة في الانحدار اللوجستي.
M
MBPP
اختصار معظم المشاكل الأساسية في لغة Python
متوسّط الخطأ المطلق (MAE)
متوسط الخسارة لكل مثال عند استخدام L1 loss احسب متوسّط الخطأ المطلق على النحو التالي:
- احسب خسارة L1 لمجموعة.
- قسِّم خسارة L1 على عدد الأمثلة في المجموعة.
على سبيل المثال، لنفترض أنّنا نريد حساب خسارة L1 على مجموعة من خمسة أمثلة كما يلي:
| القيمة الفعلية للمثال | القيمة المتوقّعة للنموذج | الخسارة (الفرق بين القيمة الفعلية والقيمة المتوقّعة) |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = خسارة L1 | ||
إذًا، قيمة L1 هي 8 وعدد الأمثلة هو 5. وبالتالي، فإنّ متوسّط الخطأ المطلق هو:
Mean Absolute Error = L1 loss / Number of Examples Mean Absolute Error = 8/5 = 1.6
قارِن بين متوسط الخطأ المطلق والخطأ التربيعي المتوسّط وجذر الخطأ التربيعي المتوسّط.
متوسط الدقة عند k (mAP@k)
المتوسط الإحصائي لكل نتائج متوسط الدقة عند k في مجموعة بيانات التحقّق. يُستخدم متوسط الدقة عند k في تقييم جودة المحتوى المقترح الذي يقدّمه نظام التوصية.
على الرغم من أنّ عبارة "المتوسط الحسابي" تبدو مكرّرة، إلا أنّ اسم المقياس مناسب. ففي النهاية، يعثر هذا المقياس على متوسط قيم متوسط الدقة عند k المتعددة.
الخطأ التربيعي المتوسّط (MSE)
متوسط الخسارة لكل مثال عند استخدام خسارة 2 احسب الخطأ التربيعي المتوسّط على النحو التالي:
- احسب خسارة L2 لمجموعة.
- قسِّم خسارة L2 على عدد الأمثلة في المجموعة.
على سبيل المثال، لنفترض أنّك تريد حساب الخسارة في المجموعة التالية المكوّنة من خمسة أمثلة:
| القيمة الفعلية | توقّعات النموذج | فقدان البيانات | الخسارة التربيعية |
|---|---|---|---|
| 7 | 6 | 1 | 1 |
| 5 | 4 | 1 | 1 |
| 8 | 11 | 3 | 9 |
| 4 | 6 | 2 | 4 |
| 9 | 8 | 1 | 1 |
| 16 = L2 خسارة | |||
وبالتالي، يكون الخطأ التربيعي المتوسّط كما يلي:
Mean Squared Error = L2 loss / Number of Examples Mean Squared Error = 16/5 = 3.2
الخطأ التربيعي المتوسّط هو مُحسِّن شائع للتدريب، خاصةً في الانحدار الخطي.
قارِن بين "الخطأ التربيعي المتوسّط" و"متوسط الخطأ المطلق" و"جذر الخطأ التربيعي المتوسّط".
تستخدم TensorFlow Playground الخطأ التربيعي المتوسّط لاحتساب قيم الخسارة.
المقياس
إحصاء يهمّك
الهدف هو مقياس يحاول نظام تعلُّم الآلة تحسينه.
Metrics API (tf.metrics)
واجهة برمجة تطبيقات TensorFlow لتقييم النماذج على سبيل المثال، تحدّد tf.metrics.accuracy
عدد المرات التي تتطابق فيها توقّعات النموذج مع التصنيفات.
دالة الخسارة القصوى الدنيا
هي دالة خسارة لشبكات الخصومة التوليدية، تستند إلى الإنتروبيا المتقاطعة بين توزيع البيانات التي تم إنشاؤها والبيانات الحقيقية.
تم استخدام دالة الخسارة Minimax في الورقة البحثية الأولى لوصف الشبكات التوليدية الخصومية.
يمكنك الاطّلاع على دوالّ الخسارة في دورة الشبكات الخصومية التوليدية للحصول على مزيد من المعلومات.
سعة النموذج
مدى تعقيد المشاكل التي يمكن أن يتعلّمها النموذج وكلما زادت درجة تعقيد المشاكل التي يمكن أن يتعلّمها النموذج، زادت قدرته. تزداد سعة النموذج عادةً مع عدد مَعلمات النموذج. للحصول على تعريف رسمي لقدرة نموذج التصنيف، يُرجى الاطّلاع على سمة VC.
Mostly Basic Python Problems (MBPP)
مجموعة بيانات لتقييم كفاءة نموذج لغوي كبير في إنشاء رمز Python البرمجي يوفّر موقع Mostly Basic Python Problems حوالي 1,000 مشكلة برمجة من مصادر جماعية. يحتوي كل سؤال في مجموعة البيانات على ما يلي:
- وصف المهمة
- رمز الحلّ
- ثلاث حالات اختبار مبرمَجة
لا
فئة سالبة
في التصنيف الثنائي، يُطلق على إحدى الفئتَين اسم إيجابية ويُطلق على الأخرى اسم سلبية. الفئة الإيجابية هي الشيء أو الحدث الذي يختبره النموذج، والفئة السلبية هي الاحتمال الآخر. على سبيل المثال:
- قد تكون الفئة السلبية في اختبار طبي هي "ليس ورمًا".
- قد تكون الفئة السلبية في نموذج تصنيف الرسائل الإلكترونية هي "ليست رسالة غير مرغوب فيها".
يجب التمييز بينها وبين الفئة الموجبة.
O
هدف
مقياس تحاول الخوارزمية تحسينه.
دالة الهدف
الصيغة الرياضية أو المقياس الذي يهدف النموذج إلى تحسينه. على سبيل المثال، تكون دالة الهدف في الانحدار الخطي عادةً متوسط الخطأ التربيعي. لذلك، عند تدريب نموذج انحدار خطي، يهدف التدريب إلى تقليل متوسط الخطأ التربيعي.
في بعض الحالات، يكون الهدف هو زيادة دالة الهدف إلى أقصى حد. على سبيل المثال، إذا كانت دالة الهدف هي الدقة، يكون الهدف هو زيادة الدقة إلى أقصى حد.
يمكنك الاطّلاع أيضًا على الخسارة.
P
pass at k (pass@k)
مقياس لتحديد جودة الرمز (مثل Python) الذي ينشئه نموذج لغوي كبير وبشكل أكثر تحديدًا، يخبرك مقياس "النجاح عند k" باحتمالية أن تجتاز مجموعة واحدة على الأقل من الرموز البرمجية التي تم إنشاؤها من بين k مجموعة من الرموز البرمجية جميع اختبارات الوحدة.
غالبًا ما تواجه النماذج اللغوية الكبيرة صعوبة في إنشاء رموز برمجية جيدة للمشاكل البرمجية المعقّدة. يتكيّف مهندسو البرمجيات مع هذه المشكلة من خلال مطالبة النموذج اللغوي الكبير بإنشاء حلول متعدّدة (k) للمشكلة نفسها. بعد ذلك، يختبر مهندسو البرامج كل حلّ باستخدام اختبارات الوحدات. يعتمد احتساب "اجتياز عند k" على نتيجة اختبارات الوحدات:
- إذا نجح واحد أو أكثر من هذه الحلول في اختبار الوحدة، يعني ذلك أنّ النموذج اللغوي الكبير اجتاز تحدّي إنشاء الرمز البرمجي هذا.
- إذا لم ينجح أي من الحلول في اجتياز اختبار الوحدة، يفشل النموذج اللغوي الكبير في تحدي إنشاء الرمز البرمجي.
صيغة "النجاح عند k" هي كما يلي:
\[\text{pass at k} = \frac{\text{total number of passes}} {\text{total number of challenges}}\]
بشكل عام، تؤدي القيم الأعلى k إلى تحقيق نتائج أعلى في اختبارات النجاح عند k، ولكن تتطلب القيم الأعلى k المزيد من موارد النماذج اللغوية الكبيرة واختبارات الوحدات.
الأداء
مصطلح مُحمّل بالمعاني التالية:
- المعنى العادي ضمن هندسة البرمجيات وهي: ما مدى سرعة (أو كفاءة) تشغيل هذا البرنامج؟
- المعنى في سياق تعلُّم الآلة في هذه الحالة، يجيب الأداء عن السؤال التالي: ما مدى صحة هذا النموذج؟ أي، ما مدى دقة التوقعات التي يقدّمها النموذج؟
أهمية المتغيرات في التبديل
أحد أنواع أهمية المتغير التي تقيّم الزيادة في خطأ التوقّع للنموذج بعد تبديل قيم الميزة. أهمية المتغيرات في التبديل هي مقياس مستقل عن النموذج.
مقياس الارتباك
مقياس لمدى نجاح النموذج في إنجاز مهمته. على سبيل المثال، لنفترض أنّ مهمتك هي قراءة الأحرف القليلة الأولى من كلمة يكتبها المستخدم على لوحة مفاتيح الهاتف، وتقديم قائمة بالكلمات المحتملة التي يمكن إكمالها. إنّ مقياس الارتباك، P، لهذه المهمة هو تقريبًا عدد التخمينات التي عليك تقديمها لكي تتضمّن قائمتك الكلمة الفعلية التي يحاول المستخدم كتابتها.
يرتبط مقياس الارتباك بالإنتروبيا المتداخلة على النحو التالي:
فئة موجبة
الصف الذي تجري الاختبار فيه
على سبيل المثال، قد تكون الفئة الموجبة في نموذج السرطان هي "ورم". قد تكون الفئة الإيجابية في نموذج تصنيف للرسائل الإلكترونية هي "رسائل غير مرغوب فيها".
يجب التمييز بينها وبين الفئة السلبية.
المساحة تحت منحنى الدقة والاستدعاء (PR AUC)
المساحة تحت منحنى الدقة والاستدعاء الذي تم الحصول عليه من خلال رسم نقاط (الاستدعاء، الدقة) لقيم مختلفة لعتبة التصنيف
الدقة
مقياس لنماذج التصنيف يجيب عن السؤال التالي:
عندما توقّع النموذج الفئة الموجبة، ما هي النسبة المئوية للتوقّعات الصحيحة؟
في ما يلي الصيغة:
where:
- تشير النتيجة الإيجابية الصحيحة إلى أنّ النموذج توقّع بشكل صحيح الفئة الإيجابية.
- تعني النتيجة الموجبة الخاطئة أنّ النموذج توقّع بشكل خاطئ الفئة الموجبة.
على سبيل المثال، لنفترض أنّ نموذجًا قدّم 200 توقّع إيجابي. من بين هذه التوقّعات الإيجابية البالغ عددها 200:
- كانت 150 منها نتائج موجبة صحيحة.
- كانت 50 منها نتائج موجبة خاطئة.
في هذه الحالة:
يجب التمييز بينه وبين الدقة واكتمال التوقعات الإيجابية.
يمكنك الاطّلاع على التصنيف: الدقة ومقياس المراجعة ومقياس صحة النموذج والمقاييس ذات الصلة في "دورة مكثّفة عن تعلّم الآلة" للحصول على مزيد من المعلومات.
الدقة عند k (precision@k)
مقياس لتقييم قائمة مرتبة من العناصر. تحدّد الدقة عند k الجزء من أول k عنصر في تلك القائمة الذي يكون "ملائمًا". والمقصود:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
يجب أن تكون قيمة k أقل من أو تساوي طول القائمة التي تم إرجاعها. يُرجى العلم أنّ طول القائمة التي يتم عرضها ليس جزءًا من عملية الاحتساب.
غالبًا ما يكون مدى الصلة بالموضوع أمرًا شخصيًا، وحتى المقيّمون البشريون الخبراء يختلفون في كثير من الأحيان بشأن العناصر ذات الصلة بالموضوع.
المقارنة بـ:
منحنى الدقة والاستدعاء
منحنى مقياس صحة النموذج مقابل مقياس المراجعة عند عتبات التصنيف المختلفة.
انحياز التوقّعات
تشير هذه القيمة إلى مدى اختلاف متوسط التوقعات عن متوسط التصنيفات في مجموعة البيانات.
يجب عدم الخلط بينها وبين مصطلح الانحياز في نماذج تعلُّم الآلة أو الانحياز في الأخلاق والعدالة.
التكافؤ التوقّعي
مقياس الإنصاف يتحقّق مما إذا كانت معدّلات مقياس صحة النموذج متساوية للمجموعات الفرعية قيد الدراسة في نموذج التصنيف معيّن.
على سبيل المثال، إذا كان هناك نموذج يتوقّع قبول الطلاب في الكلية، سيحقّق هذا النموذج تكافؤ التوقّعات بالنسبة إلى الجنسية إذا كان معدّل دقته متساويًا بالنسبة إلى الأشخاص من ليليبوت وبروبدينغناغ.
يُطلق على ميزة "تطابق الأسعار التوقّعية" أحيانًا اسم تطابق الأسعار التوقّعية.
يمكنك الاطّلاع على "تعريفات العدالة مشروحة" (الفقرة 3.2.1) للحصول على مناقشة أكثر تفصيلاً بشأن التكافؤ التوقعي.
ميزة "تساوي الأسعار التوقّعي"
اسم آخر للتكافؤ التوقعي
دالة الكثافة الاحتمالية
دالة تحدّد عدد مرات تكرار عيّنات البيانات التي تتضمّن بالضبط قيمة معيّنة. عندما تكون قيم مجموعة البيانات عبارة عن أرقام نقطة عائمة مستمرة، نادرًا ما تحدث تطابقات تامة. ومع ذلك، يؤدي تكامل دالة كثافة الاحتمال من القيمة x إلى القيمة y إلى الحصول على التكرار المتوقّع لعيّنات البيانات بين x وy.
على سبيل المثال، لنفترض أنّ لدينا توزيعًا عاديًا بمتوسط 200 وانحراف معياري يبلغ 30. لتحديد التكرار المتوقّع لعينات البيانات التي تقع ضمن النطاق من 211.4 إلى 218.7، يمكنك دمج دالة كثافة الاحتمال للتوزيع الطبيعي من 211.4 إلى 218.7.
R
مجموعة بيانات الفهم أثناء القراءة باستخدام الاستدلال المنطقي (ReCoRD)
مجموعة بيانات لتقييم قدرة نموذج لغوي كبير على إجراء استدلال منطقي سليم يحتوي كل مثال في مجموعة البيانات على ثلاثة عناصر:
- فقرة أو فقرتان من مقالة إخبارية
- طلب بحث يتم فيه إخفاء أحد الكيانات المحدّدة بشكل صريح أو ضِمني في الفقرة.
- الإجابة (اسم العنصر الذي ينتمي إلى القناع)
يمكنك الاطّلاع على ReCoRD للحصول على قائمة شاملة بالأمثلة.
ReCoRD هو أحد مكوّنات مجموعة SuperGLUE.
RealToxicityPrompts
مجموعة بيانات تحتوي على مجموعة من بدايات الجمل التي قد تتضمّن محتوًى سامًا. استخدِم مجموعة البيانات هذه لتقييم قدرة نموذج لغوي كبير على إنشاء نص غير سام لإكمال الجملة. عادةً، يتم استخدام Perspective API لتحديد مدى جودة أداء النموذج اللغوي الكبير في هذه المهمة.
لمزيد من التفاصيل، يمكنك الاطّلاع على مقالة RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models.
تذكُّر الإعلان
مقياس لنماذج التصنيف يجيب عن السؤال التالي:
عندما كانت الحقيقة الأساسية هي الفئة الموجبة، ما هي النسبة المئوية للتوقّعات التي حدّدها النموذج بشكل صحيح على أنّها الفئة الموجبة؟
في ما يلي الصيغة:
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
where:
- تشير النتيجة الإيجابية الصحيحة إلى أنّ النموذج توقّع بشكل صحيح الفئة الإيجابية.
- يعني السلبي الخاطئ أنّ النموذج توقّع بشكل خاطئ الفئة السلبية.
على سبيل المثال، لنفترض أنّ نموذجك قدّم 200 توقّع بشأن أمثلة كانت الحقيقة الأساسية فيها هي الفئة الموجبة. من بين هذه التوقعات الـ 200:
- كانت 180 منها نتائج موجبة صحيحة.
- كانت 20 منها نتائج سلبية خاطئة.
في هذه الحالة:
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
يمكنك الاطّلاع على التصنيف: الدقة ومقياس المراجعة ومقياس صحة النموذج والمقاييس ذات الصلة للحصول على مزيد من المعلومات.
معدّل التذكّر عند k (recall@k)
مقياس لتقييم الأنظمة التي تعرض قائمة مرتبة (منظَّمة) من العناصر. يشير مقياس "الاسترجاع عند k" إلى نسبة العناصر ذات الصلة في أول k عنصر في تلك القائمة من إجمالي عدد العناصر ذات الصلة التي تم عرضها.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
التباين مع الدقة عند k
التعرّف على الاستلزام النصي (RTE)
مجموعة بيانات لتقييم قدرة نموذج لغوي كبير على تحديد ما إذا كان يمكن استنتاج فرضية (استنتاج منطقي) من مقطع نصي. يتألف كل مثال في تقييم بيئة التنفيذ الغنية (RTE) من ثلاثة أجزاء:
- فقرة، عادةً من مقالات إخبارية أو مقالات ويكيبيديا
- الفرضية
- الإجابة الصحيحة، وهي إحدى القيمتين التاليتين:
- صحيح، ما يعني أنّه يمكن استنتاج الفرضية من الفقرة
- False، ما يعني أنّه لا يمكن استنتاج الفرضية من المقطع
على سبيل المثال:
- المقطع: اليورو هو عملة الاتحاد الأوروبي.
- الفرضية: تستخدم فرنسا اليورو كعملة.
- الاستلزام: صحيح، لأنّ فرنسا جزء من الاتحاد الأوروبي.
RTE هو أحد مكوّنات مجموعة SuperGLUE.
ReCoRD
الاختصار الخاص بـ مجموعة بيانات الفهم أثناء القراءة باستخدام الاستدلال المنطقي
منحنى الأمثلة الإيجابية
رسم بياني لمعدّل الموجب الصحيح مقابل معدّل الموجب الخاطئ لقيم مختلفة لحدود التصنيف في التصنيف الثنائي.
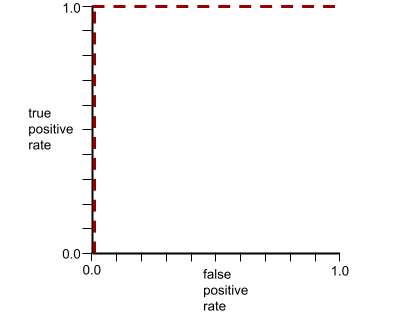
يشير شكل منحنى ROC إلى قدرة نموذج التصنيف الثنائي على فصل الفئات الإيجابية عن الفئات السلبية. لنفترض مثلاً أنّ نموذج تصنيف ثنائي يفصل تمامًا بين جميع الفئات السلبية وجميع الفئات الإيجابية:
يبدو منحنى ROC للنموذج السابق على النحو التالي:
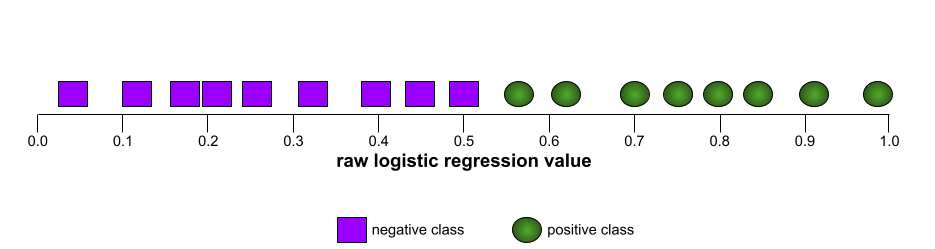
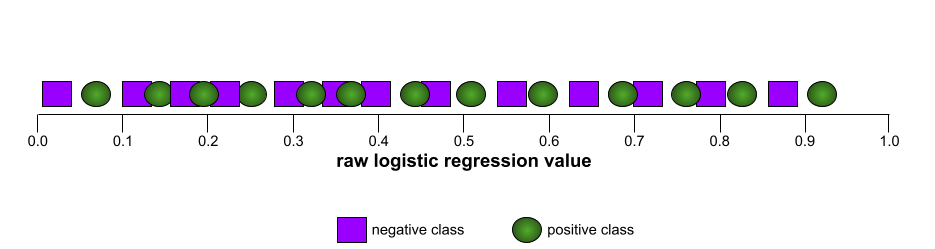
في المقابل، يوضح الرسم البياني التالي قيم الانحدار اللوجستي الأولية لنموذج سيئ لا يمكنه الفصل بين الفئات السلبية والفئات الإيجابية على الإطلاق:
يبدو منحنى ROC لهذا النموذج على النحو التالي:
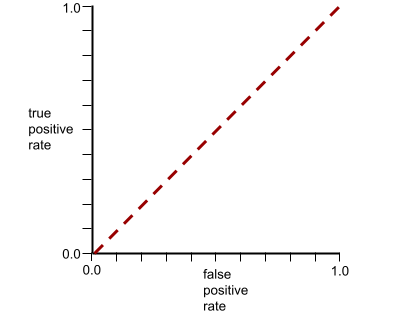
في الوقت نفسه، في العالم الحقيقي، تفصل معظم نماذج التصنيف الثنائي بين الفئات الإيجابية والسلبية إلى حد ما، ولكن ليس بشكل مثالي عادةً. لذا، يقع منحنى ROC النموذجي في مكان ما بين الحدّين الأقصى والأدنى:
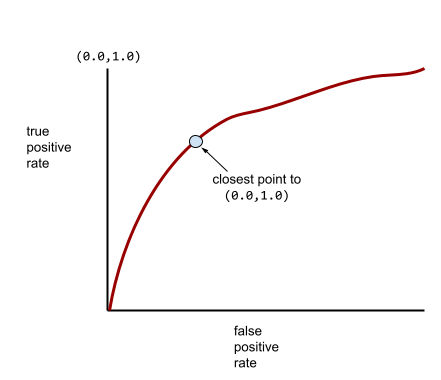
تحدّد النقطة الأقرب إلى (0.0,1.0) على منحنى ROC نظريًا عتبة التصنيف المثالية. ومع ذلك، تؤثر العديد من المشاكل الأخرى في العالم الحقيقي على اختيار عتبة التصنيف المثلى. على سبيل المثال، قد تتسبّب النتائج السلبية الخاطئة في مشاكل أكثر من النتائج الإيجابية الخاطئة.
يلخّص مقياس عددي يُسمى AUC منحنى ROC في قيمة واحدة ذات فاصلة عائمة.
جذر الخطأ التربيعي المتوسّط (RMSE)
الجذر التربيعي للخطأ التربيعي المتوسّط
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
مجموعة من المقاييس التي تقيّم نماذج التلخيص التلقائي والترجمة الآلية. تحدّد مقاييس ROUGE مدى تطابق النص المرجعي مع النص الذي أنشأه نموذج تعلُّم الآلة. يقيس كل مقياس من مقاييس عائلة ROUGE التداخل بطريقة مختلفة. تشير نتائج ROUGE الأعلى إلى تشابه أكبر بين النص المرجعي والنص الذي تم إنشاؤه مقارنةً بنتائج ROUGE الأقل.
ينتج عادةً كل فرد من عائلة مقاييس ROUGE المقاييس التالية:
- الدقة
- التذكُّر
- F1
للاطّلاع على التفاصيل والأمثلة، يُرجى مراجعة:
ROUGE-L
أحد مقاييس عائلة ROUGE يركّز على طول أطول تسلسل فرعي مشترك في النص المرجعي والنص الذي تم إنشاؤه. تحسب الصيغ التالية مقياسَي المراجعة ومقياس صحة النموذج لمقياس ROUGE-L:
يمكنك بعد ذلك استخدام F1 لتجميع مقياسَي ROUGE-L recall وROUGE-L precision في مقياس واحد:
يتجاهل مقياس ROUGE-L أي أسطر جديدة في النص المرجعي والنص الذي تم إنشاؤه، لذا يمكن أن يتضمّن أطول تسلسل فرعي مشترك عدة جمل. عندما يتضمّن النص المرجعي والنص الذي تم إنشاؤه جملًا متعددة، يكون مقياس ROUGE-Lsum، وهو صيغة من مقياس ROUGE-L، أفضل بشكل عام. تحدّد مقياس ROUGE-Lsum أطول تسلسل فرعي مشترك لكل جملة في فقرة، ثم يحسب متوسط أطول التسلسلات الفرعية المشتركة.
ROUGE-N
مجموعة من المقاييس ضمن عائلة ROUGE تقارن بين N-grams المشتركة بحجم معيّن في النص المرجعي والنص الذي تم إنشاؤه. على سبيل المثال:
- يقيس مقياس ROUGE-1 عدد الرموز المميزة المشتركة في النص المرجعي والنص الذي تم إنشاؤه.
- يقيس مقياس ROUGE-2 عدد ثنائيات الحروف (2-grams) المشتركة بين النص المرجعي والنص الذي تم إنشاؤه.
- يقيس مقياس ROUGE-3 عدد الثلاثيات المشتركة (3-grams) في النص المرجعي والنص الذي تم إنشاؤه.
يمكنك استخدام الصيغ التالية لاحتساب مقياس المراجعة ROUGE-N ومقياس صحة النموذج ROUGE-N لأي عنصر من عناصر عائلة ROUGE-N:
يمكنك بعد ذلك استخدام F1 لتجميع مقياس المراجعة ومقياس صحة النموذج في ROUGE-N في مقياس واحد:
ROUGE-S
شكل متسامح من ROUGE-N يتيح مطابقة skip-gram. أي أنّ مقياس ROUGE-N لا يحتسب سوى N-grams التي تتطابق تمامًا، ولكن مقياس ROUGE-S يحتسب أيضًا N-grams المفصولة بكلمة واحدة أو أكثر. على سبيل المثال، يمكنك القيام بما يلي:
- النص المرجعي: غيوم بيضاء
- النص الذي تم إنشاؤه: سُحب بيضاء متطايرة
عند احتساب مقياس ROUGE-N، لا يتطابق المقطع الثنائي غيوم بيضاء مع غيوم بيضاء منتفخة. ومع ذلك، عند احتساب مقياس ROUGE-S، تتطابق الغيوم البيضاء مع الغيوم البيضاء المتصاعدة.
معامل التحديد
مقياس الانحدار الذي يشير إلى مقدار التباين في تصنيف بسبب ميزة فردية أو مجموعة الخصائص. قيمة R^2 هي قيمة بين 0 و1، ويمكن تفسيرها على النحو التالي:
- تشير قيمة R-squared البالغة 0 إلى أنّ أيًا من الاختلافات في الوسم لا يعود إلى مجموعة الخصائص.
- يشير معامل التحديد البالغ 1 إلى أنّ كل التباين في الوسم يرجع إلى مجموعة الخصائص.
- يشير معامل تحديد بين 0 و1 إلى مدى إمكانية توقّع تباين الوسم من ميزة معيّنة أو مجموعة الخصائص. على سبيل المثال، يعني معامل التحديد البالغ 0.10 أنّ %10 من التباين في الوسم يرجع إلى مجموعة الخصائص، ويعني معامل التحديد البالغ 0.20 أنّ %20 من التباين يرجع إلى مجموعة الخصائص، وهكذا.
معامل تحديد (R-squared) هو مربع معامل ارتباط بيرسون بين القيم التي توقّعها النموذج والحقيقة الأساسية.
RTE
اختصار التعرّف على الاستلزام النصي
S
تسجيل النتائج
الجزء من نظام الاقتراحات الذي يقدّم قيمة أو ترتيبًا لكل عنصر تم إنتاجه في مرحلة إنشاء المرشّحين.
مقياس التشابه
في خوارزميات التجميع، يشير ذلك المصطلح إلى المقياس المستخدَم لتحديد مدى التشابه بين أي مثالَين.
مقياس التناثر
عدد العناصر التي تم ضبطها على صفر (أو قيمة فارغة) في متّجه أو مصفوفة مقسومًا على إجمالي عدد الإدخالات في هذا المتّجه أو المصفوفة على سبيل المثال، لنفترض أنّ لديك مصفوفة تتضمّن 100 عنصر، منها 98 خلية تحتوي على القيمة صفر. يتم احتساب مقياس التباين على النحو التالي:
تشير ندرة الخصائص إلى ندرة خطوط متجهة للخصائص، وتشير ندرة النماذج إلى ندرة أوزان النماذج.
SQuAD
اختصار مجموعة بيانات ستانفورد للأسئلة والأجوبة، تم تقديمه في الورقة البحثية SQuAD: أكثر من 100,000 سؤال حول فهم الآلة للنصوص. تتضمّن مجموعة البيانات هذه أسئلة طرحها مستخدمون حول مقالات ويكيبيديا. تتضمّن بعض الأسئلة في مجموعة بيانات SQuAD إجابات، بينما لا تتضمّن أسئلة أخرى إجابات عن قصد. لذلك، يمكنك استخدام مجموعة بيانات SQuAD لتقييم قدرة نموذج لغوي كبير على تنفيذ ما يلي:
- أجِب عن الأسئلة التي يمكن الإجابة عنها.
- تحديد الأسئلة التي لا يمكن الإجابة عنها
المطابقة التامة مع F1 هما المقياسان الأكثر شيوعًا لتقييم النماذج اللغوية الكبيرة (LLM) مقارنةً بمجموعة بيانات SQuAD.
تربيع الخسارة المفصلية
مربّع الخسارة المفصلية تفرض الخسارة المفصلية المربّعة عقوبة على القيم الشاذة بشكل أكبر من الخسارة المفصلية العادية.
الخسارة التربيعية
مرادف الخسارة التربيعية2
SuperGLUE
مجموعة من مجموعات البيانات لتقييم قدرة النموذج اللغوي الكبير بشكل عام على فهم النصوص وإنشائها تتألف المجموعة الموحدة من مجموعات البيانات التالية:
- أسئلة منطقية (BoolQ)
- CommitmentBank (CB)
- اختيار البدائل المعقولة (COPA)
- فهم القراءة المتعددة الجمل (MultiRC)
- مجموعة بيانات فهم المقروء باستخدام الاستدلال المنطقي السليم (ReCoRD)
- التعرّف على الاستلزام النصي (RTE)
- الكلمات في السياق (WiC)
- تحدي مخطط وينوغراد (WSC)
لمزيد من التفاصيل، يُرجى الاطّلاع على SuperGLUE: معيار تقييم أكثر ثباتًا لأنظمة فهم اللغة للأغراض العامة.
T
الخسارة في مجموعة الاختبار
مقياس يمثّل الخسارة التي يتكبّدها النموذج مقارنةً بمجموعة الاختبار عند إنشاء نموذج، تحاول عادةً تقليل خسارة الاختبار. ويرجع ذلك إلى أنّ انخفاض مقياس القصور في مجموعة الاختبار هو إشارة جودة أقوى من انخفاض مقياس القصور في مجموعة التدريب أو انخفاض مقياس القصور في مجموعة التحقّق.
يشير الفرق الكبير بين خسارة الاختبار وخسارة التدريب أو خسارة التحقّق أحيانًا إلى ضرورة زيادة معدّل التسوية.
دقة أعلى k
النسبة المئوية لعدد المرات التي يظهر فيها "تصنيف مستهدَف" ضمن أول k مواضع في القوائم التي تم إنشاؤها يمكن أن تكون القوائم اقتراحات مخصّصة أو قائمة بعناصر مرتّبة حسب softmax.
يُعرف مقياس "الدقة في أعلى k نتائج" أيضًا باسم الدقة عند k.
لغة غير لائقة
درجة إساءة المحتوى أو تهديده أو إهانته يمكن للعديد من نماذج تعلُّم الآلة تحديد مستوى السمية وقياسه وتصنيفه. تحدّد معظم هذه النماذج مستوى السمية وفقًا لمعايير متعددة، مثل مستوى اللغة المسيئة ومستوى اللغة التي تتضمّن تهديدات.
فقدان التدريب
المقياس الذي يمثّل الخسارة التي يتكبّدها النموذج خلال عملية تدريب معيّنة. على سبيل المثال، لنفترض أنّ دالة الخسارة هي الخطأ التربيعي المتوسّط. على سبيل المثال، قد يكون فقدان التدريب (متوسط الخطأ التربيعي) في التكرار العاشر هو 2.2، بينما يكون فقدان التدريب في التكرار المئة هو 1.9.
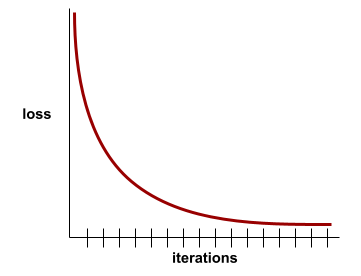
يعرض مخطّط الخسارة الخسارة أثناء التدريب مقابل عدد التكرارات. تقدّم منحنى الخسارة التلميحات التالية حول التدريب:
- يشير الميل الهبوطي إلى أنّ النموذج يتحسّن.
- يشير الميل المتزايد إلى أنّ النموذج يزداد سوءًا.
- يشير الميل المسطّح إلى أنّ النموذج قد بلغ حالة التقارب.
على سبيل المثال، يوضّح منحنى الخسارة المثالي إلى حد ما ما يلي:
- ميل حادّ نحو الأسفل خلال التكرارات الأولية، ما يشير إلى تحسُّن سريع في النموذج
- انحدار يتسطّح تدريجيًا (ولكنّه يظلّ متّجهًا للأسفل) إلى أن يقترب من نهاية التدريب، ما يشير إلى تحسّن مستمرّ في النموذج بوتيرة أبطأ بعض الشيء من الوتيرة التي كانت سائدة خلال التكرارات الأولية
- ميلان مستوٍ نحو نهاية التدريب، ما يشير إلى التقارب
على الرغم من أهمية فقدان التدريب، يمكنك أيضًا الاطّلاع على التعميم.
الإجابة عن أسئلة المعلومات العامة
مجموعات البيانات لتقييم قدرة نموذج اللغة الكبير على الإجابة عن أسئلة المعلومات العامة تحتوي كل مجموعة بيانات على أزواج من الأسئلة والأجوبة من تأليف محبّي المسابقات الترفيهية. تستند مجموعات البيانات المختلفة إلى مصادر مختلفة، بما في ذلك:
- بحث الويب (TriviaQA)
- Wikipedia (TriviaQA_wiki)
لمزيد من المعلومات، يُرجى الاطّلاع على TriviaQA: مجموعة بيانات كبيرة الحجم للتحدّي بإشراف عن بُعد حول فهم المقروء.
سالب صحيح (TN)
مثال يوضّح كيف يتنبأ النموذج بشكل صحيح بالفئة السلبية. على سبيل المثال، يستنتج النموذج أنّ رسالة إلكترونية معيّنة ليست غير مرغوب فيها، وأنّ هذه الرسالة الإلكترونية ليست غير مرغوب فيها بالفعل.
موجب صحيح (TP)
مثال يوضح كيف يتنبأ النموذج بشكل صحيح بالفئة الإيجابية. على سبيل المثال، يستنتج النموذج أنّ رسالة إلكترونية معيّنة هي رسالة غير مرغوب فيها، وتكون هذه الرسالة الإلكترونية في الواقع رسالة غير مرغوب فيها.
معدّل الموجب الصحيح (TPR)
مرادف لكلمة استدعاء والمقصود:
معدل الموجب الصحيح هو المحور الصادي في منحنى ROC.
Typologically Diverse Question Answering (TyDi QA)
مجموعة بيانات كبيرة لتقييم مدى إتقان نموذج لغوي كبير للإجابة عن الأسئلة تحتوي مجموعة البيانات على أزواج من الأسئلة والأجوبة بلغات عديدة.
للحصول على التفاصيل، يُرجى الاطّلاع على TyDi QA: معيار لتقييم أداء أنظمة الإجابة عن الأسئلة المتعلقة بالبحث عن المعلومات في لغات متنوعة من الناحية التصنيفية.
U
معدّل المطالبات غير الصالحة (UCR)
النسبة المئوية للمطالبات في ردّ غير مستندة إلى معلومات أساسية على سبيل المثال، إذا تضمّن ردّ النموذج اللغوي الكبير 10 ادّعاءات، وكان ادّعاء واحد فقط يستند إلى مصادر، تكون نسبة الادّعاءات المستندة إلى مصادر 90%.
يشير ارتفاع معدّل UCR إلى أنّ نموذج اللغة الكبير يهلوس بشكل متكرّر جدًا.
راجِع أيضًا دقة الاقتباس واكتمال الاقتباس.
V
فقدان التحقّق من الصحة
مقياس يمثّل الخسارة التي يتكبّدها النموذج على مجموعة التحقّق خلال تكرار معيّن من التدريب.
اطّلِع أيضًا على منحنى التعميم.
أهمية المتغيرات
مجموعة من النتائج تشير إلى الأهمية النسبية لكل سمة في النموذج.
على سبيل المثال، لنفترض أنّ لديك شجرة قرارات تقدّر أسعار المنازل. لنفترض أنّ شجرة القرار هذه تستخدم ثلاث سمات: الحجم والعمر والأسلوب. إذا تم حساب مجموعة من أهمية المتغيرات للميزات الثلاث على النحو التالي: {size=5.8, age=2.5, style=4.7}، فإنّ الحجم أكثر أهمية لشجرة القرار من العمر أو النمط.
تتوفّر مقاييس مختلفة لأهمية المتغيّرات، ويمكن أن تفيد خبراء تعلُّم الآلة بشأن جوانب مختلفة من النماذج.
واط
فقدان Wasserstein
إحدى دوال الخسارة الشائعة الاستخدام في الشبكات التوليدية الخصومية، استنادًا إلى مسافة نقل التربة بين توزيع البيانات التي تم إنشاؤها والبيانات الحقيقية
WiC
اختصار الكلمات في السياق
WikiLingua (wiki_lingua)
مجموعة بيانات لتقييم قدرة نموذج لغوي كبير على تلخيص المقالات القصيرة WikiHow هي موسوعة تضم مقالات تشرح كيفية تنفيذ مهام مختلفة، وهي مصدر المحتوى الذي كتبه الإنسان لكل من المقالات والملخّصات. يتألف كل إدخال في مجموعة البيانات مما يلي:
- مقال، يتم إنشاؤه من خلال إضافة كل خطوة من النسخة النثرية (فقرة) من القائمة المرقمة، باستثناء الجملة الافتتاحية لكل خطوة.
- ملخّص لتلك المقالة يتألف من الجملة الافتتاحية لكل خطوة في القائمة المرقمة
لمزيد من التفاصيل، يُرجى الاطّلاع على WikiLingua: مجموعة بيانات جديدة لقياس أداء التلخيص الاستخلاصي المتعدد اللغات.
تحدّي مخطط وينوغراد (WSC)
تنسيق (أو مجموعة بيانات متوافقة مع هذا التنسيق) لتقييم قدرة نموذج لغوي كبير على تحديد العبارة الاسمية التي يشير إليها الضمير.
يتألف كل إدخال في تحدي Winograd Schema مما يلي:
- مقطع قصير يحتوي على ضمير مستهدف
- ضمير الهدف
- عبارات اسمية مرشّحة، متبوعة بالإجابة الصحيحة (قيمة منطقية). إذا كان الضمير المستهدَف يشير إلى هذا المرشّح، تكون الإجابة "صحيح". إذا لم يشِر الضمير المستهدَف إلى هذا المرشّح، تكون الإجابة False.
على سبيل المثال:
- مقتطف: أخبر "مارك" "بيت" العديد من الأكاذيب عن نفسه، وقد أدرجها "بيت" في كتابه. كان عليه أن يكون أكثر صدقًا.
- الضمير المستهدَف: هو
- عبارات اسمية مرشّحة:
- الإجابة: صحيحة، لأنّ الضمير المستهدَف يشير إلى "مارك"
- بيتر: خطأ، لأنّ الضمير المستهدف لا يشير إلى بيتر
يشكّل تحدّي Winograd Schema جزءًا من مجموعة SuperGLUE.
الكلمات في السياق (WiC)
مجموعة بيانات لتقييم مدى جودة استخدام نموذج لغوي كبير للسياق من أجل فهم الكلمات التي لها معانٍ متعددة. يحتوي كل إدخال في مجموعة البيانات على ما يلي:
- جملتان تحتوي كل منهما على الكلمة المستهدَفة
- الكلمة المستهدَفة
- الإجابة الصحيحة (قيمة منطقية)، حيث:
- تعني القيمة "صحيح" أنّ الكلمة المستهدَفة تحمل المعنى نفسه في الجملتَين
- تعني القيمة False أنّ الكلمة المستهدَفة لها معنى مختلف في الجملتين
على سبيل المثال:
- جملتان:
- هناك الكثير من القمامة في قاع النهر.
- أضع كوبًا من الماء بجانب سريري عندما أنام.
- الكلمة المستهدَفة: سرير
- الإجابة الصحيحة: خطأ، لأنّ الكلمة المستهدَفة لها معنى مختلف في الجملتين.
لمزيد من التفاصيل، يُرجى الاطّلاع على WiC: مجموعة بيانات Word-in-Context لتقييم تمثيلات المعاني الحساسة للسياق.
Words in Context هي أحد مكوّنات مجموعة SuperGLUE.
WSC
اختصار تحدّي مخطط وينوغراد
X
XL-Sum (xlsum)
مجموعة بيانات لتقييم كفاءة نموذج لغوي كبير في تلخيص النصوص تقدّم XL-Sum إدخالات بلغات عديدة. يحتوي كل إدخال في مجموعة البيانات على ما يلي:
- مقالة مأخوذة من هيئة الإذاعة البريطانية (BBC)
- تمثّل هذه السمة ملخّصًا للمقالة كتبه مؤلفها. يُرجى العِلم أنّ هذا الملخّص يمكن أن يحتوي على كلمات أو عبارات غير واردة في المقالة.
لمزيد من التفاصيل، يُرجى الاطّلاع على XL-Sum: تلخيص تجريدي متعدد اللغات على نطاق واسع لـ 44 لغة.