Dans cette section, nous allons créer, former et évaluer
dans un modèle de ML. À l'étape 3, nous
nous avons choisi d'utiliser un modèle de n-grammes ou de séquence avec notre ratio S/W.
Il est maintenant temps d'écrire notre algorithme de classification et de l'entraîner. Nous utiliserons
TensorFlow avec
tf.keras
pour cela.
Créer des modèles de machine learning avec Keras consiste à assembler des modèles des couches, des blocs de construction pour le traitement des données, un peu comme si nous assemblerions des Lego de briques. Ces couches nous permettent de spécifier la séquence de transformations souhaitée. à effectuer sur notre entrée. Comme notre algorithme d'apprentissage accepte une seule entrée de texte et génère une classification unique, nous pouvons créer une pile linéaire de couches à l'aide du Modèle séquentiel API.
Figure 9: Pile linéaire de calques
La couche d'entrée et les couches intermédiaires seront construites différemment, selon que nous construisons un modèle de N-grammes ou de séquence. Toutefois, quel que soit le type de modèle, la dernière couche est la même pour un problème donné.
Construire la dernière couche
Lorsque nous n'avons que deux classes (classification binaire), notre modèle doit générer une
score de probabilité unique. Par exemple, générer 0.2 pour un échantillon d'entrée donné.
signifie « de confiance de 20% que cet échantillon se trouve dans la première classe (classe 1), 80% que
elle se trouve dans la deuxième classe (classe 0)." Pour obtenir un tel score de probabilité,
fonction d'activation
de la dernière couche doit être
fonction sigmoïde,
et
fonction de perte
pour entraîner le modèle doit être
entropie croisée binaire.
(voir la Figure 10, à gauche).
Lorsqu'il y a plus de deux classes (classification à classes multiples), notre modèle
doit générer un score de probabilité par classe. La somme de ces scores doit être
1. Par exemple, la sortie {0: 0.2, 1: 0.7, 2: 0.1} signifie "un taux de confiance de 20 %
Cet échantillon appartient à la classe 0, 70% à la classe 1 et 10% à la classe 1
classe 2." Pour générer ces scores, la fonction d'activation de la dernière couche
doit être softmax, et la fonction de perte utilisée pour entraîner le modèle doit être
l'entropie croisée catégorielle. (voir la Figure 10, à droite).
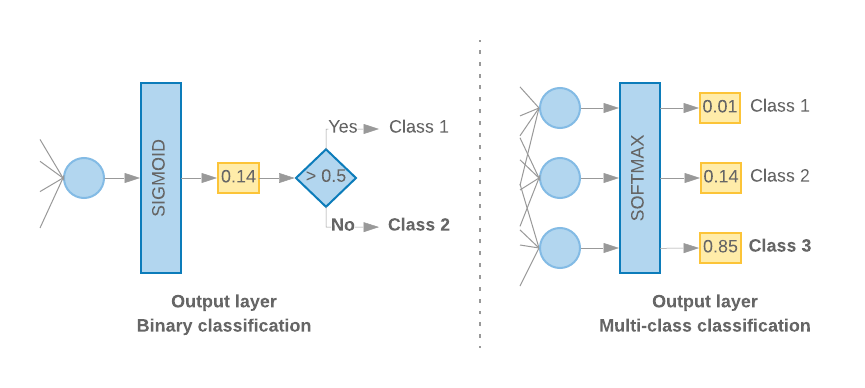
Figure 10: Dernière couche
Le code suivant définit une fonction qui accepte en entrée le nombre de classes, et génère le nombre approprié d'unités de couche (1 pour les unités binaires) la classification ; sinon 1 unité pour chaque classe) et l'activation appropriée :
def _get_last_layer_units_and_activation(num_classes):
"""Gets the # units and activation function for the last network layer.
# Arguments
num_classes: int, number of classes.
# Returns
units, activation values.
"""
if num_classes == 2:
activation = 'sigmoid'
units = 1
else:
activation = 'softmax'
units = num_classes
return units, activation
Les deux sections suivantes expliquent comment créer le modèle restant pour les modèles de n-grammes et de séquences.
Lorsque le ratio S/W est faible, nous avons constaté que les modèles de n-grammes sont plus performants
que les modèles de séquence. Les modèles de séquence sont plus efficaces lorsqu'il existe un grand nombre
de petits vecteurs denses. En effet, les relations de représentation vectorielle continue sont apprises
un espace dense, ce qui se produit
plus efficacement sur de nombreux échantillons.
Créer un modèle de n-grammes [Option A]
Il s'agit de modèles qui traitent les jetons de manière indépendante (sans tenir compte l'ordre des mots du compte) en tant que modèles de n-grammes. Perceptrons à plusieurs couches simples (y compris Régression logistique machines d'optimisation de gradient, et prennent en charge les modèles de machines vectorielles) relèvent toutes de cette catégorie ; il ne peut utiliser aucune information sur l’ordre des textes.
Nous avons comparé les performances de certains des modèles de N-grammes mentionnés ci-dessus et observé que les perceptrons multicouches (MLP) sont généralement plus performants que d'autres options. Les MLP sont simples à définir et à comprendre, offrent une bonne justesse, et nécessitent relativement peu de calculs.
Le code suivant définit un modèle MLP à deux couches dans tf.keras, en ajoutant quelques Couches d'abandon pour la régularisation pour éviter surapprentissage aux échantillons d'entraînement.
from tensorflow.python.keras import models
from tensorflow.python.keras.layers import Dense
from tensorflow.python.keras.layers import Dropout
def mlp_model(layers, units, dropout_rate, input_shape, num_classes):
"""Creates an instance of a multi-layer perceptron model.
# Arguments
layers: int, number of `Dense` layers in the model.
units: int, output dimension of the layers.
dropout_rate: float, percentage of input to drop at Dropout layers.
input_shape: tuple, shape of input to the model.
num_classes: int, number of output classes.
# Returns
An MLP model instance.
"""
op_units, op_activation = _get_last_layer_units_and_activation(num_classes)
model = models.Sequential()
model.add(Dropout(rate=dropout_rate, input_shape=input_shape))
for _ in range(layers-1):
model.add(Dense(units=units, activation='relu'))
model.add(Dropout(rate=dropout_rate))
model.add(Dense(units=op_units, activation=op_activation))
return model
Créer un modèle de séquence [Option B]
Nous faisons référence à des modèles qui peuvent apprendre de la contiguïté des jetons en tant que séquence des modèles de ML. Cela inclut les classes de modèles CNN et RNN. Les données sont prétraitées des vecteurs de séquence pour ces modèles.
Les modèles de séquence ont généralement un plus grand nombre de paramètres à apprendre. Le premier de ces modèles est une couche de représentation vectorielle continue, qui apprend la relation entre les mots dans un espace vectoriel dense. Apprendre des relations entre mots sur de nombreux échantillons.
Les mots d'un jeu de données ne sont probablement pas uniques à ce jeu de données. Nous pouvons ainsi apprendre la relation entre les mots de notre ensemble de données en utilisant un ou plusieurs autres ensembles de données. Pour ce faire, nous pouvons transférer une représentation vectorielle continue apprise d'un autre ensemble de données dans notre la couche de représentation vectorielle continue. Ces représentations vectorielles continues sont appelées pré-entraînés représentations vectorielles continues. L'utilisation d'une représentation vectorielle continue pré-entraînée permet au modèle de prendre une longueur d'avance dans la de machine learning.
Il existe des représentations vectorielles continues pré-entraînées qui ont été entraînées à l'aide de grandes corpus, tel que GloVe. GloVe propose ont été entraînés sur plusieurs corpus (principalement Wikipédia). Nous avons testé l'entraînement des modèles séquentiels à l'aide d'une version de représentations vectorielles continues GloVe et nous avons observé a figé les pondérations des représentations vectorielles continues pré-entraînées et n'a entraîné que le reste des les modèles n'ont pas été performants. Cela peut être dû au fait que le contexte pour laquelle la couche de représentation vectorielle continue a été entraînée peut être différent du contexte dans lequel nous l'utilisions.
Il est possible que les représentations vectorielles continues GloVe entraînées à partir de données Wikipédia ne correspondent pas à la langue. des modèles dans notre jeu de données IMDb. Les relations déduites peuvent nécessiter la mise à jour, c'est-à-dire que les pondérations des représentations vectorielles continues peuvent nécessiter un réglage contextuel. Nous le faisons dans en deux étapes:
Lors de la première exécution, avec les pondérations de la couche de représentation vectorielle continue figées, nous autorisons le reste du réseau à apprendre. À la fin de cette exécution, les pondérations du modèle atteignent un état bien mieux que leurs valeurs non initialisées. Pour la deuxième exécution, permettent également à la couche de représentation vectorielle continue d'apprendre, ce qui permet d'ajuster précisément toutes les pondérations du réseau. Nous appelons ce processus l'utilisation d'une représentation vectorielle continue affinée.
Les représentations vectorielles continues affinées offrent une meilleure précision. Cependant, cela arrive au l'augmentation de la puissance de calcul nécessaire à l'entraînement du réseau. Avec un un nombre suffisant d'échantillons, nous pourrions tout aussi bien apprendre une représentation vectorielle continue en partant de zéro. Nous avons observé que, pour
S/W > 15K, partir de zéro efficacement offre la même précision qu'avec une intégration affinée.
Nous avons comparé différents modèles de séquence tels que CNN, sepCNN, RNN (LSTM et GRU), CNN-RNN et RNN empilé, en variant les valeurs d'architectures de modèles. Nous avons constaté que sepCNN, une variante de réseau convolutif qui est souvent plus économe en données et en calcul, est plus efficace que avec d'autres modèles.
<ph type="x-smartling-placeholder">Le code suivant construit un modèle sepCNN à quatre couches:
from tensorflow.python.keras import models from tensorflow.python.keras import initializers from tensorflow.python.keras import regularizers from tensorflow.python.keras.layers import Dense from tensorflow.python.keras.layers import Dropout from tensorflow.python.keras.layers import Embedding from tensorflow.python.keras.layers import SeparableConv1D from tensorflow.python.keras.layers import MaxPooling1D from tensorflow.python.keras.layers import GlobalAveragePooling1D def sepcnn_model(blocks, filters, kernel_size, embedding_dim, dropout_rate, pool_size, input_shape, num_classes, num_features, use_pretrained_embedding=False, is_embedding_trainable=False, embedding_matrix=None): """Creates an instance of a separable CNN model. # Arguments blocks: int, number of pairs of sepCNN and pooling blocks in the model. filters: int, output dimension of the layers. kernel_size: int, length of the convolution window. embedding_dim: int, dimension of the embedding vectors. dropout_rate: float, percentage of input to drop at Dropout layers. pool_size: int, factor by which to downscale input at MaxPooling layer. input_shape: tuple, shape of input to the model. num_classes: int, number of output classes. num_features: int, number of words (embedding input dimension). use_pretrained_embedding: bool, true if pre-trained embedding is on. is_embedding_trainable: bool, true if embedding layer is trainable. embedding_matrix: dict, dictionary with embedding coefficients. # Returns A sepCNN model instance. """ op_units, op_activation = _get_last_layer_units_and_activation(num_classes) model = models.Sequential() # Add embedding layer. If pre-trained embedding is used add weights to the # embeddings layer and set trainable to input is_embedding_trainable flag. if use_pretrained_embedding: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0], weights=[embedding_matrix], trainable=is_embedding_trainable)) else: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0])) for _ in range(blocks-1): model.add(Dropout(rate=dropout_rate)) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(MaxPooling1D(pool_size=pool_size)) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(GlobalAveragePooling1D()) model.add(Dropout(rate=dropout_rate)) model.add(Dense(op_units, activation=op_activation)) return model
Entraîner le modèle
Maintenant que nous avons construit l'architecture du modèle, nous devons l'entraîner. L'entraînement implique d'effectuer une prédiction basée sur l'état actuel du modèle, calculer le degré d'erreur de la prédiction et mettre à jour les pondérations du réseau pour minimiser l'erreur et permettre au modèle de prédire mieux encore. Nous répétons ce processus jusqu'à ce que le modèle converge et ne puisse plus apprendre. Vous devez choisir trois paramètres clés pour ce processus (voir Tableau 2).
- Métrique: comment mesurer les performances du modèle à l'aide d'un metric. Nous avons utilisé la précision dans nos tests.
- Fonction de perte: fonction utilisée pour calculer une valeur de perte que le processus d'entraînement tente ensuite de minimiser en ajustant les pondérations de réseau. Pour les problèmes de classification, la perte d'entropie croisée fonctionne bien.
- Optimizer: fonction qui détermine la façon dont les pondérations du réseau seront mis à jour en fonction de la sortie de la fonction de perte. Nous avons utilisé les technologies Adam dans nos tests.
Dans Keras, nous pouvons transmettre ces paramètres d'apprentissage à un modèle en utilisant compiler .
Tableau 2: Paramètres d'apprentissage
| Paramètre d'apprentissage | Valeur |
|---|---|
| Métrique | accuracy |
| Fonction de perte : classification binaire | binary_crossentropy |
| Fonction de perte – classification à classes multiples | sparse_categorical_crossentropy |
| Optimiseur | Adam |
L'entraînement est effectué à l'aide
fit.
Selon la taille de votre
il s'agit de la méthode utilisée pour la plupart des cycles de calcul. Dans chaque
itération d'entraînement, batch_size d'échantillons de vos données d'entraînement sont
utilisées pour calculer la perte, et les pondérations sont mises à jour une seule fois, en fonction de cette valeur.
Le processus d'entraînement termine une epoch une fois que le modèle a vu l'intégralité
un ensemble de données d'entraînement. À la fin de chaque époque, nous utilisons l'ensemble de données de validation
et d'évaluer la qualité de son apprentissage. Nous répétons l'entraînement avec l'ensemble de données.
pendant un nombre d'époques prédéterminé. Nous pouvons optimiser cela
en arrêtant prématurément,
lorsque la justesse de la validation se stabilise entre deux époques consécutives, ce qui montre
le modèle ne s'entraîne plus.
| Hyperparamètre d'entraînement | Valeur |
|---|---|
| Taux d'apprentissage | 1e à 3 |
| Époques | 1000 |
| Taille de lot | 512 |
| Arrêt prématuré | paramètre: val_loss, patience: 1 |
Tableau 3: Hyperparamètres d'entraînement
Le code Keras suivant met en œuvre le processus d'entraînement à l'aide des paramètres choisies dans les tableaux 2 et 3 ci-dessus:
def train_ngram_model(data, learning_rate=1e-3, epochs=1000, batch_size=128, layers=2, units=64, dropout_rate=0.2): """Trains n-gram model on the given dataset. # Arguments data: tuples of training and test texts and labels. learning_rate: float, learning rate for training model. epochs: int, number of epochs. batch_size: int, number of samples per batch. layers: int, number of `Dense` layers in the model. units: int, output dimension of Dense layers in the model. dropout_rate: float: percentage of input to drop at Dropout layers. # Raises ValueError: If validation data has label values which were not seen in the training data. """ # Get the data. (train_texts, train_labels), (val_texts, val_labels) = data # Verify that validation labels are in the same range as training labels. num_classes = explore_data.get_num_classes(train_labels) unexpected_labels = [v for v in val_labels if v not in range(num_classes)] if len(unexpected_labels): raise ValueError('Unexpected label values found in the validation set:' ' {unexpected_labels}. Please make sure that the ' 'labels in the validation set are in the same range ' 'as training labels.'.format( unexpected_labels=unexpected_labels)) # Vectorize texts. x_train, x_val = vectorize_data.ngram_vectorize( train_texts, train_labels, val_texts) # Create model instance. model = build_model.mlp_model(layers=layers, units=units, dropout_rate=dropout_rate, input_shape=x_train.shape[1:], num_classes=num_classes) # Compile model with learning parameters. if num_classes == 2: loss = 'binary_crossentropy' else: loss = 'sparse_categorical_crossentropy' optimizer = tf.keras.optimizers.Adam(lr=learning_rate) model.compile(optimizer=optimizer, loss=loss, metrics=['acc']) # Create callback for early stopping on validation loss. If the loss does # not decrease in two consecutive tries, stop training. callbacks = [tf.keras.callbacks.EarlyStopping( monitor='val_loss', patience=2)] # Train and validate model. history = model.fit( x_train, train_labels, epochs=epochs, callbacks=callbacks, validation_data=(x_val, val_labels), verbose=2, # Logs once per epoch. batch_size=batch_size) # Print results. history = history.history print('Validation accuracy: {acc}, loss: {loss}'.format( acc=history['val_acc'][-1], loss=history['val_loss'][-1])) # Save model. model.save('IMDb_mlp_model.h5') return history['val_acc'][-1], history['val_loss'][-1]
Pour trouver des exemples de code pour l'entraînement du modèle de séquence, cliquez ici.