Bu bölümde, eğitim ve uygulama geliştirme ve
modeli. 3. adımda,
S/W oranımızı kullanarak n-gram modeli veya sıra modeli kullanmayı tercih ettik.
Şimdi sıra, sınıflandırma algoritmamızı yazıp eğitmeye geldi. Şunu kullanacağız:
TensorFlow
tf.keras
API'de bulabilirsiniz.
Keras ile makine öğrenimi modelleri derlemek, parçaları bir araya getirmekten ibarettir katmanları, veri işleme yapı taşları, bizimki gibi Lego'yu olduğunu unutmayın. Bu katmanlar, istediğimiz dönüşüm sırasını belirlememize pek çok yolu vardır. Öğrenme algoritmamız tek bir metin girişi aldığında ve tek bir sınıflandırma çıkarsa, doğrusal bir katman yığını oluşturabiliriz. her bir arama terimi için Sıralı model API'ye gidin.
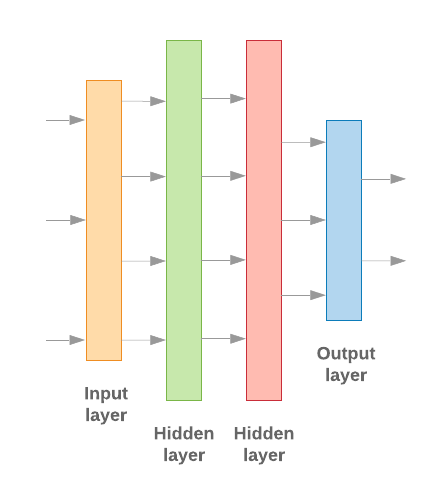
Şekil 9: Doğrusal katman yığını
Giriş katmanı ve ara katmanlar farklı şekilde oluşturulacaktır, n-gram mı yoksa dizi modeli mi yaptığımıza bağlı. Ama model türünden bağımsız olarak son katman belirli bir sorun için aynı olur.
Son Katmanı Oluşturma
Yalnızca 2 sınıfınız olduğunda (ikili sınıflandırma) modelimiz bir
tek olasılık puanıdır. Örneğin, belirli bir giriş örneği için 0.2 çıkışı
"Bu örneklemin birinci sınıfta (1. sınıf) olduğuna% 20 güven, %80
çünkü 0. sınıftayız." Böyle bir olasılık puanı oluşturmak için
etkinleştirme işlevi
son katmanın değeri bir
sigmoid işlevi,
ve
kayıp işlevi
modeli eğitmek için kullanılan
ikili çapraz entropi.
(Soldaki Şekil 10'a bakın).
2'den fazla sınıf (çok sınıflı sınıflandırma) olduğunda, modelimiz
her sınıf için bir olasılık puanı vermelidir. Bu puanların toplamı,
1. Örneğin, {0: 0.2, 1: 0.7, 2: 0.1} çıktısı, şu anlama gelir: "%20
bu örnek 0. sınıfta, %70'inde 1. sınıfta ve% 10'unda ise
2. sınıf.” Bu puanların çıktısını almak için son katmanın aktivasyon fonksiyonu
değeri softmax olmalı ve modeli eğitmek için kullanılan kayıp işlevi
kategorik çapraz entropi. (bkz. Şekil 10, sağdaki).
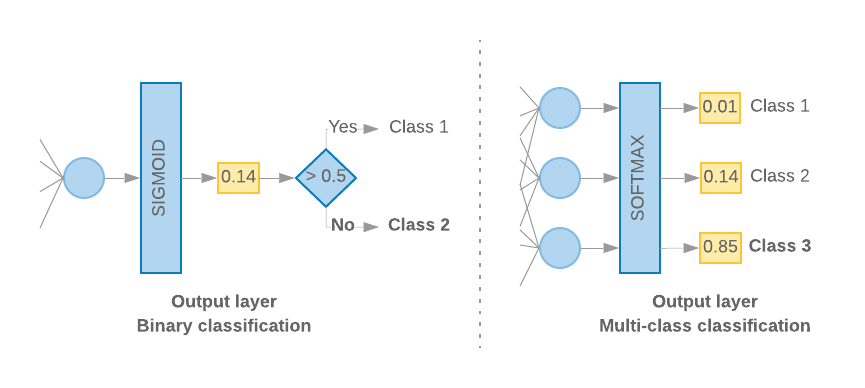
Şekil 10: Son katman
Aşağıdaki kod, sınıf sayısını giriş olarak alan bir fonksiyon tanımlar. ve uygun sayıda katman birimi çıktısını verir (ikili program için 1 birim sınıflandırma; aksi takdirde her sınıf için 1 ünite) ve uygun etkinleştirme işlev:
def _get_last_layer_units_and_activation(num_classes):
"""Gets the # units and activation function for the last network layer.
# Arguments
num_classes: int, number of classes.
# Returns
units, activation values.
"""
if num_classes == 2:
activation = 'sigmoid'
units = 1
else:
activation = 'softmax'
units = num_classes
return units, activation
Aşağıdaki iki bölümde kalan model oluşturma adımları açıklanmaktadır. ve sıra modelleri için farklı katmanlarda mevcuttur.
S/W oranı düşük olduğunda n-gram modellerinin daha iyi performans gösterdiğini tespit ettik
daha fazla avantaj sunar. Sıra modelleri, çok sayıda öğe olduğunda daha iyidir
küçük ve yoğun vektörleri vardır. Bunun nedeni, yerleştirme ilişkilerinin
bir örneğidir. Bu durum en iyi, birçok örnekte gözlemlenebilir.
n-gram modeli oluşturma [Seçenek A]
Jetonları bağımsız olarak işleyen ( hesap kelime sırası) n-gram modelleri olarak kullanılır. Basit çok katmanlı algılayıcılar (ör. mantıksal regresyon gradyan artırma makineleri ve vektör makinelerini destekleme modellerini destekler) Bunların tümü bu kategoride yer alır; ilgili hiçbir bilgiyi metin sıralaması.
Yukarıda bahsedilen n-gram modellerinden bazılarının performansını karşılaştırdık ve çok katmanlı algıların (MLP) genellikle diğer seçeneklere dokunun. MLP'lerin tanımlanması ve anlaşılması kolay, doğruluk oranı yüksek, ve nispeten daha az hesaplama gerektirir.
Aşağıdaki kod, tf.keras'ta iki katmanlı bir MLP modelini tanımlar ve Normalleştirme için katmanları bırakma önlemek için fazla uyum örneklere bakalım.
from tensorflow.python.keras import models
from tensorflow.python.keras.layers import Dense
from tensorflow.python.keras.layers import Dropout
def mlp_model(layers, units, dropout_rate, input_shape, num_classes):
"""Creates an instance of a multi-layer perceptron model.
# Arguments
layers: int, number of `Dense` layers in the model.
units: int, output dimension of the layers.
dropout_rate: float, percentage of input to drop at Dropout layers.
input_shape: tuple, shape of input to the model.
num_classes: int, number of output classes.
# Returns
An MLP model instance.
"""
op_units, op_activation = _get_last_layer_units_and_activation(num_classes)
model = models.Sequential()
model.add(Dropout(rate=dropout_rate, input_shape=input_shape))
for _ in range(layers-1):
model.add(Dense(units=units, activation='relu'))
model.add(Dropout(rate=dropout_rate))
model.add(Dense(units=op_units, activation=op_activation))
return model
Sıra modeli oluşturma [Option B]
Jetonların bitişiğinden bilgi edinebilen modellere, dizi olarak modeller. Buna, CNN ve RNN model sınıfları dahildir. Veriler, önceden şu şekilde işlenir: dizi vektörlerini de oluşturur.
Dizi modelleri genellikle öğrenilecek daha fazla sayıda parametreye sahiptir. İlk katman, bu modeller arasındaki ilişkiyi öğrenen bir yerleştirme katmanıdır. arasındaki farkları düşünün. Kelime ilişkilerinin öğrenilmesi işe yarar birçok örnekte en iyisi.
Belirli bir veri kümesindeki kelimeler büyük olasılıkla söz konusu veri kümesine özgü değildir. Böylece, veri kümesimizdeki kelimeler arasındaki ilişkiyi başka veri kümeleri kullanarak öğrenme. Bunu yapmak için, başka bir veri kümesinden öğrenilen bir yerleştirmeyi yerleştirme katmanıdır. Bu yerleştirmelere önceden eğitilmiş yerleştirmeler. Önceden eğitilmiş bir yerleştirme tekniğinin kullanılması, öğrenme sürecidir.
Büyük boyutlar ve öğeler kullanılarak eğitilmiş, önceden eğitilmiş GloVe gibi bir dizin. GloVe birden fazla derleme üzerinde (öncelikle Vikipedi) eğitilmiş olmalıdır. Eğitim planlarımızı bir sürümünü kullanan dizi modellerinin sayısını artırdı ve 2004'e kadar gömmelerin ağırlıklarını dondurdular ve yalnızca geri kalan modeller iyi performans göstermedi. Bu durum belgedeki bağlamın Gömme katmanının eğitildiği içerik, bağlamdan farklı olabilirdi bir fikir edinmiş olduk.
Wikipedia verileri kullanılarak eğitilen GloVe yerleştirmeleri dille uyumlu olmayabilir örüntüleri olduğunu tespit ettik. Çıkarım yapılan ilişkilerde Örneğin, yerleştirme ağırlıkları için bağlamsal ayarlama gerekebilir. Bunu bir iki aşamadan oluşur:
İlk çalıştırmada, yerleştirme katmanı ağırlıkları dondurulduktan sonra, mola vermektir. Bu çalıştırmanın sonunda model ağırlıkları belirli bir duruma ulaşır. henüz başlatılmamış değerlerinden çok daha iyidir. İkinci çalıştırmada yerleştirme katmanının da öğrenmesini ve tüm ağırlıklarda ince ayarlar yapmasını sağlar. var. Bu işleme ince ayar yapılmış bir yerleştirme işlemi diyoruz.
İnce ayarlanmış yerleştirmeler daha iyi doğruluk sağlar. Ancak bu, özellikle (ağı eğitmek için gereken işlem gücünün artması) Örneğin, örnek sayısını artırırsak 300'den fazla giriş yapmayı öğrenerek sıfırdan başlıyorum.
S/W > 15Kiçin, sıfırdan başlayarak etkili bir şekilde ayrıntılı yerleştirme kullanımıyla neredeyse aynı doğruluktadır.
CNN, sepCNN ve diğer kanal dizileri gibi farklı dizi modellerini karşılaştırdık. RNN (LSTM ve GRU), CNN-RNN ve yığılmış RNN. model mimariler. Evrişimli bir ağ varyantı olan sepCNN'lerin genelde veri açısından daha verimli ve işlem açısından verimlidir. birlikte çalışır.
Aşağıdaki kod dört katmanlı bir sepCNN modeli oluşturur:
from tensorflow.python.keras import models from tensorflow.python.keras import initializers from tensorflow.python.keras import regularizers from tensorflow.python.keras.layers import Dense from tensorflow.python.keras.layers import Dropout from tensorflow.python.keras.layers import Embedding from tensorflow.python.keras.layers import SeparableConv1D from tensorflow.python.keras.layers import MaxPooling1D from tensorflow.python.keras.layers import GlobalAveragePooling1D def sepcnn_model(blocks, filters, kernel_size, embedding_dim, dropout_rate, pool_size, input_shape, num_classes, num_features, use_pretrained_embedding=False, is_embedding_trainable=False, embedding_matrix=None): """Creates an instance of a separable CNN model. # Arguments blocks: int, number of pairs of sepCNN and pooling blocks in the model. filters: int, output dimension of the layers. kernel_size: int, length of the convolution window. embedding_dim: int, dimension of the embedding vectors. dropout_rate: float, percentage of input to drop at Dropout layers. pool_size: int, factor by which to downscale input at MaxPooling layer. input_shape: tuple, shape of input to the model. num_classes: int, number of output classes. num_features: int, number of words (embedding input dimension). use_pretrained_embedding: bool, true if pre-trained embedding is on. is_embedding_trainable: bool, true if embedding layer is trainable. embedding_matrix: dict, dictionary with embedding coefficients. # Returns A sepCNN model instance. """ op_units, op_activation = _get_last_layer_units_and_activation(num_classes) model = models.Sequential() # Add embedding layer. If pre-trained embedding is used add weights to the # embeddings layer and set trainable to input is_embedding_trainable flag. if use_pretrained_embedding: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0], weights=[embedding_matrix], trainable=is_embedding_trainable)) else: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0])) for _ in range(blocks-1): model.add(Dropout(rate=dropout_rate)) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(MaxPooling1D(pool_size=pool_size)) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(GlobalAveragePooling1D()) model.add(Dropout(rate=dropout_rate)) model.add(Dense(op_units, activation=op_activation)) return model
Modelinizi Eğitin
Artık model mimarisini oluşturduğumuza göre modeli eğitmemiz gerekiyor. Eğitim, modelin mevcut durumuna göre bir tahminde bulunulmasını içerir. tahminin ne kadar yanlış olduğunu hesaplayarak ve ağırlıkları ya da en aza indirmek ve modelin tahminde bulunmasını sağlamak için daha iyi hale getirir. Bu işlemi, modelimiz yakınlaşıncaya ve artık yerleşene kadar tekrar ederiz. öğrenmek. Bu işlem için seçilecek üç temel parametre vardır (Tablodaki 2.)
- Metrik: Bir dönüşüm hunisi kullanarak modelimizin performansını metrik. Doğruluk metriği kullanılmıştır metrik olarak kullanılmıştır.
- Kayıp işlevi: Kayıp değerini hesaplamak için kullanılan bir işlev gerekli düzeltmeleri yaparak eğitim sürecinin en aza ağ ağırlıklarını temel alır. Sınıflandırma problemlerinde çapraz entropi kaybı iyi sonuç verir.
- Optimize edici: Ağ ağırlıklarının ne şekilde olacağını belirleyen işlev kayıp işlevinin çıkışına göre güncellenir. En çok kullanılan Denemelerimizdeki Adam optimize edici.
Keras'ta, bu öğrenme parametrelerini derleme yöntemidir.
Tablo 2: Öğrenme parametreleri
| Öğrenme parametresi | Değer |
|---|---|
| Metrik | doğruluk |
| Kayıp fonksiyonu - ikili sınıflandırma | binary_crossentropy |
| Kayıp fonksiyonu - çok sınıflı sınıflandırma | sparse_categorical_crossentropy |
| Optimizasyon Meraklısı | barış |
Asıl eğitim,
fit yöntemini kullanın.
Cihazınızın boyutuna bağlı olarak
veri kümesinden çoğu işlem döngüsünün harcanacağı yöntem budur. Her birinde
eğitim iterasyonu, eğitim verilerinizden batch_size örnek
kaybı hesaplamak için kullanılır ve ağırlıklar bu değere göre bir kez güncellenir.
Model tüm ayrıntıları gördüğünde eğitim süreci epoch
eğitim veri kümesiyle aynıdır. Her dönemin sonunda, doğrulama veri kümesini şu amaçlarla kullanırız:
ve modelin ne kadar iyi öğrendiğini değerlendirebilirsiniz. Veri kümesini kullanarak eğitimi tekrar
zaman aralığını dikkate alır. Erken durdurularak bu durumu optimize edebiliriz.
doğrulama doğruluğu art arda dönemler arasında dengelendiğinde
model artık eğitilmiyor.
| Eğitim hiperparametresi | Değer |
|---|---|
| Öğrenme oranı | 1e-3 |
| Dönemler | 1000 |
| Grup boyutu | 512 |
| Erken durdurma | parametre: val_loss, sabır: 1 |
Tablo 3: Eğitim hiperparametreleri
Aşağıdaki Keras kodu, parametreleri kullanarak eğitim sürecini uygular ve Tablo 2 ve 3 yukarıda:
def train_ngram_model(data, learning_rate=1e-3, epochs=1000, batch_size=128, layers=2, units=64, dropout_rate=0.2): """Trains n-gram model on the given dataset. # Arguments data: tuples of training and test texts and labels. learning_rate: float, learning rate for training model. epochs: int, number of epochs. batch_size: int, number of samples per batch. layers: int, number of `Dense` layers in the model. units: int, output dimension of Dense layers in the model. dropout_rate: float: percentage of input to drop at Dropout layers. # Raises ValueError: If validation data has label values which were not seen in the training data. """ # Get the data. (train_texts, train_labels), (val_texts, val_labels) = data # Verify that validation labels are in the same range as training labels. num_classes = explore_data.get_num_classes(train_labels) unexpected_labels = [v for v in val_labels if v not in range(num_classes)] if len(unexpected_labels): raise ValueError('Unexpected label values found in the validation set:' ' {unexpected_labels}. Please make sure that the ' 'labels in the validation set are in the same range ' 'as training labels.'.format( unexpected_labels=unexpected_labels)) # Vectorize texts. x_train, x_val = vectorize_data.ngram_vectorize( train_texts, train_labels, val_texts) # Create model instance. model = build_model.mlp_model(layers=layers, units=units, dropout_rate=dropout_rate, input_shape=x_train.shape[1:], num_classes=num_classes) # Compile model with learning parameters. if num_classes == 2: loss = 'binary_crossentropy' else: loss = 'sparse_categorical_crossentropy' optimizer = tf.keras.optimizers.Adam(lr=learning_rate) model.compile(optimizer=optimizer, loss=loss, metrics=['acc']) # Create callback for early stopping on validation loss. If the loss does # not decrease in two consecutive tries, stop training. callbacks = [tf.keras.callbacks.EarlyStopping( monitor='val_loss', patience=2)] # Train and validate model. history = model.fit( x_train, train_labels, epochs=epochs, callbacks=callbacks, validation_data=(x_val, val_labels), verbose=2, # Logs once per epoch. batch_size=batch_size) # Print results. history = history.history print('Validation accuracy: {acc}, loss: {loss}'.format( acc=history['val_acc'][-1], loss=history['val_loss'][-1])) # Save model. model.save('IMDb_mlp_model.h5') return history['val_acc'][-1], history['val_loss'][-1]
Sıra modelini eğitmeye yönelik kod örneklerini burada bulabilirsiniz.