Verilerimizin bir modele aktarılabilmesi için bir biçime dönüştürülmesi gerekir anlayabilir.
Öncelikle, topladığımız veri örnekleri belirli bir sırada olabilir. Google örneklerin sıralamasıyla ilgili hiçbir bilginin etkilemesini istemeyen metin ve etiketler arasındaki ilişkiyi tartışacağız. Örneğin, bir veri kümesi aynı yapıda ve daha sonra eğitim/doğrulama kümelerine ayrılır. Bu kümeler, temsili bir değerdir.
Modelin veri sırasından etkilenmemesini sağlamaya yönelik basit bir en iyi uygulama, başka bir şey yapmadan önce her zaman verileri karıştırın. Verileriniz zaten eğitim ve doğrulama kümelerine bölünüyorsa doğrulamanızı dönüştürdüğünüzden emin olun. verilerinizi eğitim verilerinizi dönüştürdüğünüz şekilde eğitebilirsiniz. Henüz bir eğitim ve doğrulama kümelerini ayırdıktan sonra, örnekleri daha sonra karıştırma; örneklemlerin% 80'ini eğitim için, %20'sini ise doğrulama.
İkinci olarak, makine öğrenimi algoritmaları sayıları giriş olarak alır. Bu, daha fazla metinleri sayısal vektörlere dönüştürmesi gerekir. İnsanları etkilerken başarılı olmanın bu işlem şu şekildedir:
Jetona dönüştürme: Metinleri kelimelere veya daha küçük alt metinlere bölün. Böylece, Bu sayede metinler ve etiketler arasındaki ilişkinin iyi bir genellemesi yapılabilir. Bu, veri kümesinin “kelimeliğini” belirler (Google Etiket Yöneticisi'nde bulunan gerekir.
Vektörleştirme: Bunları nitelendirmek için iyi bir sayısal ölçü tanımlayın metinler.
Şimdi bu iki adımın hem n-gram vektörleri hem de dizi için nasıl uygulanacağına bakalım. ve ayrıca özellik kullanılarak vektör temsillerin nasıl optimize edileceği ve normalleştirme tekniklerini anlatacağım.
N-gram vektörleri [Seçenek A]
Sonraki paragraflarda, jetonlara ayırmanın nasıl yapılacağını ve vektörleştirmeden ibaret değildir. Ayrıca, üçüncü taraf reklam gruplarında n- özellik seçimi ve normalleştirme tekniklerini kullanarak gram gösterimi.
Bir n-gram vektöründe, metin benzersiz n-gramların bir koleksiyonu olarak temsil edilir:
n bitişik simgeden oluşan grup (genellikle, kelimeler). The mouse ran
up the clock metnini düşünün. Burada:
- Ünigramlar (n = 1)
['the', 'mouse', 'ran', 'up', 'clock']. - Bigrams kelimesi (n = 2)
['the mouse', 'mouse ran', 'ran up', 'up the', 'the clock'] - Örnekler çoğaltılabilir.
Tokenizasyon
Kelime unigramlarına ve bigram'lara ayırmanın hem de daha az işlem süresi gerektirir.
Vektörleştirme
Metin örneklerimizi n-gram'lara böldükten sonra, bu n-gram'ları dönüştürmemiz gerekir makine öğrenimi modellerimizin işleyebildiği sayısal vektörlere dönüştürür. Örnek aşağıda, iki örnek için oluşturulan unigram ve bigram'lara atanan indeksler metinler.
Texts: 'The mouse ran up the clock' and 'The mouse ran down' Index assigned for every token: {'the': 7, 'mouse': 2, 'ran': 4, 'up': 10, 'clock': 0, 'the mouse': 9, 'mouse ran': 3, 'ran up': 6, 'up the': 11, 'the clock': 8, 'down': 1, 'ran down': 5}
Dizinler n-gramlara atandıktan sonra genellikle kullanabilirsiniz.
Tek kullanımlık kodlama: Her örnek metin, bir sunucu tarafından temsil edilen metinde bir simgenin olup olmadığı
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1]
Sayı kodlaması: Her örnek metin
metindeki bir jetonun sayısını. Öğeye karşılık gelen öğenin
unigram "the" "the" kelimesi artık 2 olarak temsil edilmektedir
metinde iki kez görünüyor.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 2, 1, 1, 1, 1]
Tf-idf kodlaması: Sorun Yukarıdaki iki yaklaşımda da, benzer cümlelerdeki yaygın kelimelerin sıklığına dikkat edin (ör. özellikle şirket için benzersiz olmayan veri kümesindeki metin örnekleri) cezalandırılmaz. Örneğin, "a" gibi kelimeler her metinde sık geçen bir şekilde kullanılır. Dolayısıyla “the” için pek işe yaramaz.
'The mouse ran up the clock' = [0.33, 0, 0.23, 0.23, 0.23, 0, 0.33, 0.47, 0.33, 0.23, 0.33, 0.33]
(bkz. Scikit-learn TfidfTransformer)
Daha pek çok vektör temsili mevcuttur ancak önceki üçü, en yaygın kullanılan türlerden biridir.
tf-idf kodlamasının diğer ikisine göre marjinal şekilde daha iyi olduğunu (ortalama: %0,25-15 daha yüksek) olup bu yöntemi kullanmanızı öneririz. n-gram vektörü için kullanılabilir. Ancak bu komut dosyasının daha fazla bellek işgal ettiği kullanır) ve hesaplaması daha fazla zaman alır. (bazı durumlarda iki kat daha uzun sürebilir).
Özellik seçimi
Bir veri kümesindeki tüm metinleri kelime uni+bigram belirteçlerine dönüştürdüğümüzde, on binlerce jeton olabilir. Bu jetonların/özelliklerin tümü değil etiket tahminine katkıda bulunur. Örneğin, bazı jetonları bırakabiliriz. ve veri kümesinde son derece nadir görülen etkinliklerdir. Ayrıca zaman çizelgesi özellik önemi (her bir jetonun etiket tahminlerine ne kadar katkıda bulunduğu) ve yalnızca en bilgilendirici jetonları içermelidir.
Özellikler ve bunlara karşılık gelen istatistikler alan birçok istatistiksel fonksiyon vardır ve özellik önem puanının çıktısını göreceksiniz. Yaygın olarak kullanılan iki işlev f_classif ve chi2'dir. Bizim denemeler, bu işlevlerin ikisinin de eşit derecede iyi performans gösterdiğini ortaya koyuyor.
Daha da önemlisi, birçok kullanıcı için doğruluğun yaklaşık 20.000 özellikte zirveye ulaştığını gördük. (bkz. Şekil 6). Bu eşiğin üzerinde daha fazla özellik eklemek, çok az bulunur ve hatta bazen sıkıştırma ve performansı düşürür.

Şekil 6: En İyi K özellikleri ile Doğruluk. Veri kümelerinde en iyi 20.000 özellikteki doğruluk platoları.
Normalleştirme
Normalleştirme, tüm özellik/örnek değerlerini küçük ve benzer değerlere dönüştürür. Bu, öğrenme algoritmalarında gradyan azalma yakınsaklığını basitleştirir. Hangi kaynaktan Gördüğümüz kadarıyla veri ön işlemesi sırasında normalleştirme, metin sınıflandırma problemlerinde değer; bu adımı atlamanızı öneririz.
Aşağıdaki kod yukarıdaki adımların tümünü bir araya getirir:
- Metin örneklerini kelime uni+bigram olarak şifreleyerek
- tf-idf kodlamasını kullanarak vektörleştirin,
- Jeton vektöründen yalnızca ilk 20.000 özelliği seçmek için 2'den daha az gösterilen jetonlar ve özelliği hesaplamak için f_classif kullanan jetonlar önem taşır.
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import f_classif # Vectorization parameters # Range (inclusive) of n-gram sizes for tokenizing text. NGRAM_RANGE = (1, 2) # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Whether text should be split into word or character n-grams. # One of 'word', 'char'. TOKEN_MODE = 'word' # Minimum document/corpus frequency below which a token will be discarded. MIN_DOCUMENT_FREQUENCY = 2 def ngram_vectorize(train_texts, train_labels, val_texts): """Vectorizes texts as n-gram vectors. 1 text = 1 tf-idf vector the length of vocabulary of unigrams + bigrams. # Arguments train_texts: list, training text strings. train_labels: np.ndarray, training labels. val_texts: list, validation text strings. # Returns x_train, x_val: vectorized training and validation texts """ # Create keyword arguments to pass to the 'tf-idf' vectorizer. kwargs = { 'ngram_range': NGRAM_RANGE, # Use 1-grams + 2-grams. 'dtype': 'int32', 'strip_accents': 'unicode', 'decode_error': 'replace', 'analyzer': TOKEN_MODE, # Split text into word tokens. 'min_df': MIN_DOCUMENT_FREQUENCY, } vectorizer = TfidfVectorizer(**kwargs) # Learn vocabulary from training texts and vectorize training texts. x_train = vectorizer.fit_transform(train_texts) # Vectorize validation texts. x_val = vectorizer.transform(val_texts) # Select top 'k' of the vectorized features. selector = SelectKBest(f_classif, k=min(TOP_K, x_train.shape[1])) selector.fit(x_train, train_labels) x_train = selector.transform(x_train).astype('float32') x_val = selector.transform(x_val).astype('float32') return x_train, x_val
n-gram vektör gösterimiyle, kelime hakkındaki birçok bilgiyi sıra ve dilbilgisi (en iyi, bazı kısmi sipariş bilgilerini koruyabiliriz n > olduğunda 1). Buna kısa kelime yaklaşımı adı verilir. Bu temsil, şurada kullanılıyor: sıralamayı hesaba katmayan modellerle bağlantılı olarak mantıksal regresyon, çok katmanlı algılayıcılar, gradyan artırma makineleri, destek vektör makinelerini kullanabilirsiniz.
Sıra Vektörleri [Seçenek B]
Sonraki paragraflarda, jetonlara ayırmanın nasıl yapılacağını ve vektörleştirmeden bahsedeceğiz. Ayrıca, kullanıcı başına maliyeti nasıl optimize edebileceğimize de özellik seçimi ve normalleştirme tekniklerini kullanarak dizi gösterimi.
Bazı metin örneklerinde kelime sırası, metnin anlamı açısından kritik öneme sahiptir. Örneğin, "İşe gidip gelme rotamdan nefret ediyordum. Yeni bisikletim bu durumu değiştirdi yalnızca sırayla okunduğunda anlaşılır. CNN'ler/RNN'ler gibi modeller bir örneklemdeki kelimelerin sırasından anlam çıkarımını yapabilir. Bu modeller için metni bir simge dizisi olarak temsil ederek sırası korur.
Tokenizasyon
Metin, bir karakter dizisi veya kelimeler. Kelime düzeyinde temsil kullanmanın, pazarlamacıların daha yüksek bir performansa sahip olması gerekir. Bu aynı zamanda proje yönetiminin ardından sektör geliyor. Karakter simgelerini kullanmak, yalnızca metinlerde çok sayıda bu da normalde böyle bir durum değildir.
Vektörleştirme
Metin örneklerimizi kelime dizilerine dönüştürdükten sonra, tekrar sayısal vektörlere dönüştürür. Aşağıdaki örnekte, önce iki metin için oluşturulan unigramlara ve ardından ilk metnin dönüştürüldüğü dizinleri ifade eder.
Texts: 'The mouse ran up the clock' and 'The mouse ran down'
Her jetona atanan dizin:
{'clock': 5, 'ran': 3, 'up': 4, 'down': 6, 'the': 1, 'mouse': 2}
NOT: "the" kelimesi sık görüldüğünden, 1'in indeks değeri atanabilir. Bazı kitaplıklar, olduğu gibi bilinmeyen jetonlar için dizin 0'ı ayırır ayrıntılı bir şekilde anlatacağım.
Jeton dizinlerinin sırası:
'The mouse ran up the clock' = [1, 2, 3, 4, 1, 5]
Jeton sıralarını vektörleştirmek için kullanılabilecek iki seçenek vardır:
Tek kullanımlık kodlama: Sıralar, n-cinsiyetinde kelime vektörleri kullanılarak gösterilir. kelime dağarcığının n = boyutu olduğu boyutsal alan. Bu temsilin performansı çok iyi yani kelime haznesi kısıtlıdır. Kelimeler olarak nitelendirdiğimizde, sözlükte genellikle onlarca kelime bulunur. bu da en iyi vektörlerin çok az ve verimsiz olmasına neden oluyor. Örnek:
'The mouse ran up the clock' = [
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0]
]
Kelime yerleştirme: Kelimelerle ilişkili anlamlar vardır. Sonuç olarak, kelime simgelerini yoğun bir vektör alanında (yaklaşık birkaç yüz reel sayı) temsil edebilir. kelimelerin arasındaki konum ve mesafe, kelimelerin ne kadar benzer olduğunu gösterir (bkz. Şekil 7). Bu temsil kelime yerleştirme.
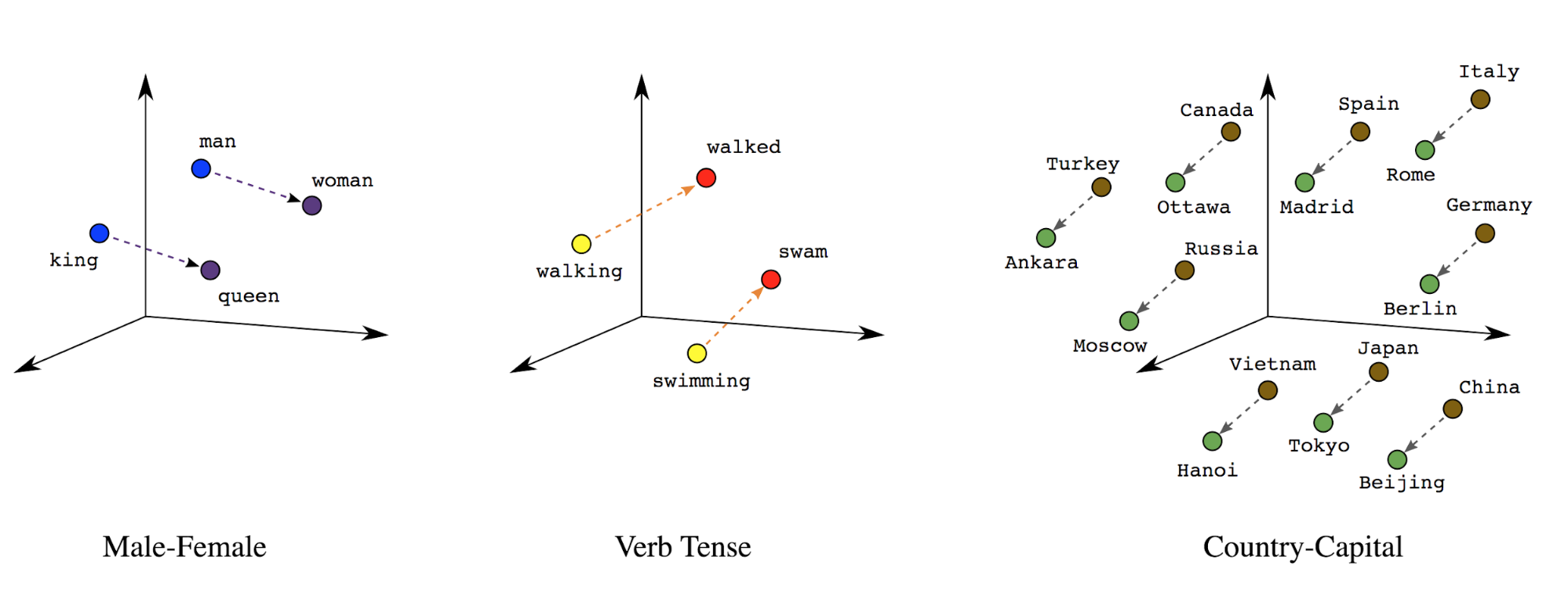
Şekil 7: Kelime yerleştirme
Dizi modellerinin ilk katmanları genellikle böyle bir yerleştirme katmanına sahiptir. Bu katmanının çalışması sırasında kelime dizini dizilerini kelime yerleştirme vektörlerine her kelime dizininin yoğun bir vektörel eşlenir ve kelimenin anlamsal boşluktaki konumunu temsil eden gerçek değerler (bkz. Şekil 8).
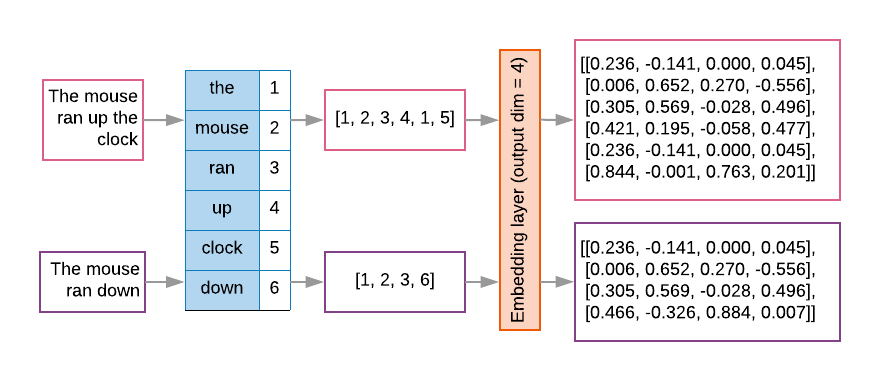
Şekil 8: Katman yerleştirme
Özellik seçimi
Verilerimizdeki tüm kelimeler etiket tahminlerine katkıda bulunmaz. Reklamlarımızın az bulunan veya alakasız kelimeleri kelime dağarcığımızdan çıkararak öğrenme sürecini teşvik edebilir. İçinde aslında en sık görülen 20.000 özelliğin kullanımının genellikle yeterli olacaktır. Bu, n-gram modelleri için de geçerlidir (bkz. Şekil 6).
Yukarıdaki tüm adımları dizi vektörlendirmede bir araya getirelim. İlgili içeriği oluşturmak için kullanılan aşağıdaki kod bu görevleri yerine getirir:
- Metinleri kelimelere dönüştürerek
- En iyi 20.000 jetonu kullanarak sözlük oluşturur
- Jetonları dizi vektörlerine dönüştürür
- Dizileri sabit bir dizi uzunluğuna doldurur
from tensorflow.python.keras.preprocessing import sequence from tensorflow.python.keras.preprocessing import text # Vectorization parameters # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Limit on the length of text sequences. Sequences longer than this # will be truncated. MAX_SEQUENCE_LENGTH = 500 def sequence_vectorize(train_texts, val_texts): """Vectorizes texts as sequence vectors. 1 text = 1 sequence vector with fixed length. # Arguments train_texts: list, training text strings. val_texts: list, validation text strings. # Returns x_train, x_val, word_index: vectorized training and validation texts and word index dictionary. """ # Create vocabulary with training texts. tokenizer = text.Tokenizer(num_words=TOP_K) tokenizer.fit_on_texts(train_texts) # Vectorize training and validation texts. x_train = tokenizer.texts_to_sequences(train_texts) x_val = tokenizer.texts_to_sequences(val_texts) # Get max sequence length. max_length = len(max(x_train, key=len)) if max_length > MAX_SEQUENCE_LENGTH: max_length = MAX_SEQUENCE_LENGTH # Fix sequence length to max value. Sequences shorter than the length are # padded in the beginning and sequences longer are truncated # at the beginning. x_train = sequence.pad_sequences(x_train, maxlen=max_length) x_val = sequence.pad_sequences(x_val, maxlen=max_length) return x_train, x_val, tokenizer.word_index
Etiket vektörleştirme
Örnek metin verilerini sayısal vektörlere nasıl dönüştüreceğimizi gördük. Benzer bir süreç
etiketlere uygulanması gerekir. Basitçe etiketleri aralıktaki değerlere dönüştürebiliriz
[0, num_classes - 1] Örneğin, yalnızca kullanabileceğimiz 3 sınıf varsa
0, 1 ve 2 değerlerini temsil eder. Dahili olarak ağ, tek seferlik
bu değerleri temsil edecek vektörleri ayarlayın (yanlış bir ilişki çıkarmayı önlemek için)
arasında). Bu gösterim, kayıp fonksiyonuna ve
katman aktivasyon fonksiyonunu kullanıyoruz. Bu kursta,
ele alacağız.