В этом разделе мы будем работать над построением, обучением и оценкой нашей модели. На шаге 3 мы решили использовать либо n-граммовую модель, либо модель последовательности, используя наше соотношение S/W . Теперь пришло время написать наш алгоритм классификации и обучить его. Для этого мы будем использовать TensorFlow с API tf.keras .
Создание моделей машинного обучения с помощью Keras — это сборка слоев, строительных блоков обработки данных, так же, как мы собираем кубики Lego. Эти слои позволяют нам указать последовательность преобразований, которые мы хотим выполнить с входными данными. Поскольку наш алгоритм обучения принимает один текстовый ввод и выводит одну классификацию, мы можем создать линейный стек слоев, используя API последовательной модели .
Рисунок 9: Линейная стопка слоев
Входной слой и промежуточные слои будут построены по-разному, в зависимости от того, строим ли мы n-грамму или модель последовательности. Но независимо от типа модели последний слой будет одинаковым для данной задачи.
Создание последнего слоя
Когда у нас есть только 2 класса (двоичная классификация), наша модель должна выдавать одну оценку вероятности. Например, вывод 0.2 для заданной входной выборки означает «20% уверенности в том, что эта выборка относится к первому классу (класс 1), 80% — что она относится ко второму классу (класс 0)». Чтобы вывести такую оценку вероятности, функция активации последнего слоя должна быть сигмовидной функцией , а функция потерь, используемая для обучения модели, должна быть двоичной кросс-энтропией . (См. рис. 10 слева).
Если существует более двух классов (многоклассовая классификация), наша модель должна выводить одну оценку вероятности для каждого класса. Сумма этих оценок должна быть равна 1. Например, вывод {0: 0.2, 1: 0.7, 2: 0.1} означает «20% уверенности в том, что этот образец относится к классу 0, 70% — что он находится в классе 1 и 10». %, что он относится к классу 2». Чтобы вывести эти оценки, функция активации последнего слоя должна быть softmax, а функция потерь, используемая для обучения модели, должна быть категориальной кросс-энтропией. (См. рис. 10 справа).
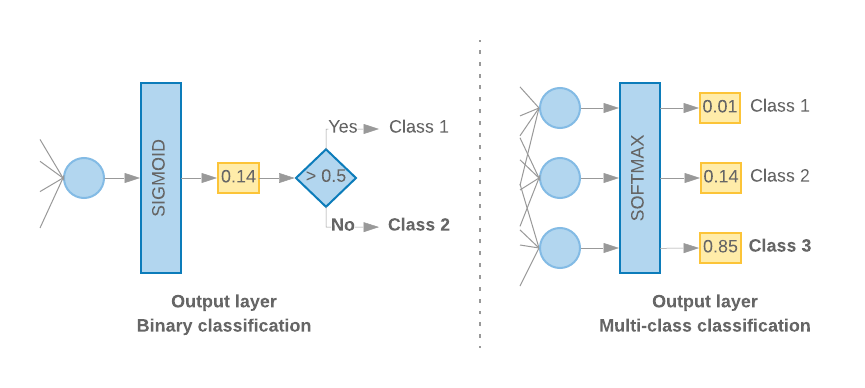
Рисунок 10: Последний слой
Следующий код определяет функцию, которая принимает на вход количество классов и выводит соответствующее количество единиц слоя (1 единица для двоичной классификации; в противном случае 1 единица для каждого класса) и соответствующую функцию активации:
def _get_last_layer_units_and_activation(num_classes):
"""Gets the # units and activation function for the last network layer.
# Arguments
num_classes: int, number of classes.
# Returns
units, activation values.
"""
if num_classes == 2:
activation = 'sigmoid'
units = 1
else:
activation = 'softmax'
units = num_classes
return units, activation
В следующих двух разделах описывается создание остальных слоев модели для моделей n-грамм и моделей последовательностей.
Мы обнаружили, что когда отношение S/W невелико, n-граммовые модели работают лучше, чем модели последовательностей. Модели последовательностей лучше работают, когда имеется большое количество маленьких плотных векторов. Это связано с тем, что отношения внедрения изучаются в плотном пространстве, и лучше всего это происходит на многих выборках.
Постройте n-граммную модель [Вариант A]
Модели, обрабатывающие токены независимо (не учитывая порядок слов), мы называем n-граммными моделями. Простые многослойные перцептроны (включая машины повышения градиента логистической регрессии и модели машин опорных векторов ) подпадают под эту категорию; они не могут использовать какую-либо информацию о порядке текста.
Мы сравнили производительность некоторых из упомянутых выше n-граммных моделей и заметили, что многослойные перцептроны (MLP) обычно работают лучше , чем другие варианты. MLP просты в определении и понимании, обеспечивают хорошую точность и требуют относительно небольших вычислений.
Следующий код определяет двухуровневую модель MLP в tf.keras, добавляя пару слоев Dropout для регуляризации и предотвращения переобучения обучающих выборок.
from tensorflow.python.keras import models
from tensorflow.python.keras.layers import Dense
from tensorflow.python.keras.layers import Dropout
def mlp_model(layers, units, dropout_rate, input_shape, num_classes):
"""Creates an instance of a multi-layer perceptron model.
# Arguments
layers: int, number of `Dense` layers in the model.
units: int, output dimension of the layers.
dropout_rate: float, percentage of input to drop at Dropout layers.
input_shape: tuple, shape of input to the model.
num_classes: int, number of output classes.
# Returns
An MLP model instance.
"""
op_units, op_activation = _get_last_layer_units_and_activation(num_classes)
model = models.Sequential()
model.add(Dropout(rate=dropout_rate, input_shape=input_shape))
for _ in range(layers-1):
model.add(Dense(units=units, activation='relu'))
model.add(Dropout(rate=dropout_rate))
model.add(Dense(units=op_units, activation=op_activation))
return model
Построение модели последовательности [Вариант Б]
Мы называем модели, которые могут учиться на смежности токенов, моделями последовательностей. Сюда входят классы моделей CNN и RNN. Данные предварительно обрабатываются как векторы последовательности для этих моделей.
Модели последовательностей обычно имеют большее количество параметров для изучения. Первый уровень в этих моделях — это уровень внедрения, который изучает отношения между словами в плотном векторном пространстве. Изучение отношений слов лучше всего работает на многих образцах.
Слова в данном наборе данных, скорее всего, не уникальны для этого набора данных. Таким образом, мы можем узнать взаимосвязь между словами в нашем наборе данных, используя другие наборы данных. Для этого мы можем перенести встраивание, полученное из другого набора данных, в наш уровень внедрения. Эти внедрения называются предварительно обученными внедрениями . Использование предварительно обученного внедрения дает модели преимущество в процессе обучения.
Доступны предварительно обученные внедрения, обученные с использованием больших корпусов, таких как GloVe . GloVe прошел обучение на нескольких корпусах (в основном на Википедии). Мы протестировали обучение наших моделей последовательностей с использованием версии вложений GloVe и заметили, что если мы заморозим веса предварительно обученных вложений и обучим только остальную часть сети, модели не будут работать хорошо. Возможно, это связано с тем, что контекст, в котором обучался слой внедрения, мог отличаться от контекста, в котором мы его использовали.
Встраивания GloVe, обученные на данных Википедии, могут не совпадать с языковыми шаблонами в нашем наборе данных IMDb. Выведенные отношения могут нуждаться в некотором обновлении, т. е. веса внедрения могут нуждаться в контекстной настройке. Делаем это в два этапа:
При первом запуске, заморозив веса слоев внедрения, мы позволяем остальной части сети обучаться. В конце этого прогона веса модели достигают состояния, которое намного лучше, чем их неинициализированные значения. Во втором запуске мы позволяем также обучаться слою внедрения, внося точную настройку всех весов в сети. Мы называем этот процесс использованием точно настроенного встраивания.
Точная настройка встраивания обеспечивает более высокую точность. Однако это происходит за счет увеличения вычислительной мощности, необходимой для обучения сети. Имея достаточное количество образцов, мы могли бы с таким же успехом изучить встраивание с нуля. Мы заметили, что для
S/W > 15Kзапуск с нуля эффективно дает примерно ту же точность, что и использование точно настроенного встраивания .
Мы сравнили различные модели последовательностей, такие как CNN, sepCNN , RNN (LSTM и GRU), CNN-RNN и сложенную RNN, варьируя архитектуру модели. Мы обнаружили, что sepCNN, вариант сверточной сети, который часто более эффективен в отношении данных и вычислений, работает лучше, чем другие модели.
Следующий код создает четырехуровневую модель sepCNN:
from tensorflow.python.keras import models from tensorflow.python.keras import initializers from tensorflow.python.keras import regularizers from tensorflow.python.keras.layers import Dense from tensorflow.python.keras.layers import Dropout from tensorflow.python.keras.layers import Embedding from tensorflow.python.keras.layers import SeparableConv1D from tensorflow.python.keras.layers import MaxPooling1D from tensorflow.python.keras.layers import GlobalAveragePooling1D def sepcnn_model(blocks, filters, kernel_size, embedding_dim, dropout_rate, pool_size, input_shape, num_classes, num_features, use_pretrained_embedding=False, is_embedding_trainable=False, embedding_matrix=None): """Creates an instance of a separable CNN model. # Arguments blocks: int, number of pairs of sepCNN and pooling blocks in the model. filters: int, output dimension of the layers. kernel_size: int, length of the convolution window. embedding_dim: int, dimension of the embedding vectors. dropout_rate: float, percentage of input to drop at Dropout layers. pool_size: int, factor by which to downscale input at MaxPooling layer. input_shape: tuple, shape of input to the model. num_classes: int, number of output classes. num_features: int, number of words (embedding input dimension). use_pretrained_embedding: bool, true if pre-trained embedding is on. is_embedding_trainable: bool, true if embedding layer is trainable. embedding_matrix: dict, dictionary with embedding coefficients. # Returns A sepCNN model instance. """ op_units, op_activation = _get_last_layer_units_and_activation(num_classes) model = models.Sequential() # Add embedding layer. If pre-trained embedding is used add weights to the # embeddings layer and set trainable to input is_embedding_trainable flag. if use_pretrained_embedding: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0], weights=[embedding_matrix], trainable=is_embedding_trainable)) else: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0])) for _ in range(blocks-1): model.add(Dropout(rate=dropout_rate)) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(MaxPooling1D(pool_size=pool_size)) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(GlobalAveragePooling1D()) model.add(Dropout(rate=dropout_rate)) model.add(Dense(op_units, activation=op_activation)) return model
Тренируйте свою модель
Теперь, когда мы построили архитектуру модели, нам нужно ее обучить. Обучение включает в себя составление прогноза на основе текущего состояния модели, вычисление того, насколько неверным является прогноз, и обновление весов или параметров сети, чтобы минимизировать эту ошибку и улучшить прогнозирование модели. Мы повторяем этот процесс до тех пор, пока наша модель не сойдётся и больше не сможет обучаться. Для этого процесса необходимо выбрать три ключевых параметра (см. Таблицу 2 ).
- Метрика : Как измерить производительность нашей модели с помощью метрики . В наших экспериментах мы использовали точность в качестве показателя.
- Функция потерь : функция, которая используется для расчета значения потерь, которое затем в процессе обучения пытается минимизировать путем настройки весов сети. Для задач классификации хорошо работает перекрестная энтропийная потеря.
- Оптимизатор : функция, которая решает, как будут обновляться веса сети на основе выходных данных функции потерь. В наших экспериментах мы использовали популярный оптимизатор Adam .
В Keras мы можем передать эти параметры обучения в модель с помощью метода компиляции .
Таблица 2: Параметры обучения
| Параметр обучения | Ценить |
|---|---|
| Метрика | точность |
| Функция потерь – двоичная классификация | binary_crossentropy |
| Функция потерь - многоклассовая классификация | разреженная_категориальная_кроссэнтропия |
| Оптимизатор | Адам |
Фактическое обучение происходит с использованием метода подгонки . В зависимости от размера вашего набора данных на этот метод будет потрачено большинство вычислительных циклов. На каждой итерации обучения для расчета потерь используется количество образцов batch_size из ваших обучающих данных, а веса обновляются один раз на основе этого значения. Процесс обучения epoch после того, как модель просмотрит весь набор обучающих данных. В конце каждой эпохи мы используем набор проверочных данных, чтобы оценить, насколько хорошо модель обучается. Мы повторяем обучение с использованием набора данных в течение заранее определенного количества эпох. Мы можем оптимизировать это, остановившись раньше, когда точность проверки стабилизируется между последовательными эпохами, показывая, что модель больше не обучается.
| Гиперпараметр обучения | Ценить |
|---|---|
| Скорость обучения | 1е-3 |
| Эпохи | 1000 |
| Размер партии | 512 |
| Ранняя остановка | параметр: val_loss, терпение: 1 |
Таблица 3: Гиперпараметры обучения
Следующий код Keras реализует процесс обучения с использованием параметров, выбранных в таблицах 2 и 3 выше:
def train_ngram_model(data, learning_rate=1e-3, epochs=1000, batch_size=128, layers=2, units=64, dropout_rate=0.2): """Trains n-gram model on the given dataset. # Arguments data: tuples of training and test texts and labels. learning_rate: float, learning rate for training model. epochs: int, number of epochs. batch_size: int, number of samples per batch. layers: int, number of `Dense` layers in the model. units: int, output dimension of Dense layers in the model. dropout_rate: float: percentage of input to drop at Dropout layers. # Raises ValueError: If validation data has label values which were not seen in the training data. """ # Get the data. (train_texts, train_labels), (val_texts, val_labels) = data # Verify that validation labels are in the same range as training labels. num_classes = explore_data.get_num_classes(train_labels) unexpected_labels = [v for v in val_labels if v not in range(num_classes)] if len(unexpected_labels): raise ValueError('Unexpected label values found in the validation set:' ' {unexpected_labels}. Please make sure that the ' 'labels in the validation set are in the same range ' 'as training labels.'.format( unexpected_labels=unexpected_labels)) # Vectorize texts. x_train, x_val = vectorize_data.ngram_vectorize( train_texts, train_labels, val_texts) # Create model instance. model = build_model.mlp_model(layers=layers, units=units, dropout_rate=dropout_rate, input_shape=x_train.shape[1:], num_classes=num_classes) # Compile model with learning parameters. if num_classes == 2: loss = 'binary_crossentropy' else: loss = 'sparse_categorical_crossentropy' optimizer = tf.keras.optimizers.Adam(lr=learning_rate) model.compile(optimizer=optimizer, loss=loss, metrics=['acc']) # Create callback for early stopping on validation loss. If the loss does # not decrease in two consecutive tries, stop training. callbacks = [tf.keras.callbacks.EarlyStopping( monitor='val_loss', patience=2)] # Train and validate model. history = model.fit( x_train, train_labels, epochs=epochs, callbacks=callbacks, validation_data=(x_val, val_labels), verbose=2, # Logs once per epoch. batch_size=batch_size) # Print results. history = history.history print('Validation accuracy: {acc}, loss: {loss}'.format( acc=history['val_acc'][-1], loss=history['val_loss'][-1])) # Save model. model.save('IMDb_mlp_model.h5') return history['val_acc'][-1], history['val_loss'][-1]
Примеры кода для обучения модели последовательности вы найдете здесь .