Прежде чем наши данные можно будет передать в модель, их необходимо преобразовать в формат, понятный модели.
Во-первых, образцы данных, которые мы собрали, могут располагаться в определенном порядке. Мы не хотим, чтобы какая-либо информация, связанная с заказом образцов, влияла на взаимосвязь между текстами и этикетками. Например, если набор данных отсортирован по классам, а затем разделен на наборы обучения/проверки, эти наборы не будут репрезентативными для общего распределения данных.
Самый простой способ гарантировать, что порядок данных не влияет на модель, — всегда перемешивать данные, прежде чем делать что-либо еще. Если ваши данные уже разделены на наборы обучения и проверки, обязательно преобразуйте данные проверки так же, как вы преобразуете данные обучения. Если у вас еще нет отдельных наборов для обучения и проверки, вы можете разделить выборки после перетасовки; обычно 80 % образцов используется для обучения и 20 % — для проверки.
Во-вторых, алгоритмы машинного обучения принимают числа в качестве входных данных. Это означает, что нам нужно будет преобразовать тексты в числовые векторы. Этот процесс состоит из двух этапов:
Токенизация : разделите тексты на слова или более мелкие подтексты, что позволит хорошо обобщить взаимосвязь между текстами и метками. Это определяет «словарь» набора данных (набор уникальных токенов, присутствующих в данных).
Векторизация : Определите хорошую числовую меру для характеристики этих текстов.
Давайте посмотрим, как выполнить эти два шага как для векторов n-грамм, так и для векторов последовательности, а также как оптимизировать векторные представления с помощью методов выбора признаков и нормализации.
Векторы N-грамм [Вариант A]
В следующих параграфах мы увидим, как выполнять токенизацию и векторизацию для моделей n-грамм. Мы также расскажем, как можно оптимизировать представление n-грамм, используя методы выбора признаков и нормализации.
В векторе n-грамм текст представлен как набор уникальных n-грамм: группы из n соседних токенов (обычно слов). Рассмотрим текст The mouse ran up the clock . Здесь:
- Словесные униграммы (n = 1) — это
['the', 'mouse', 'ran', 'up', 'clock']. - Биграммы слов (n = 2) — это
['the mouse', 'mouse ran', 'ran up', 'up the', 'the clock'] - И так далее.
Токенизация
Мы обнаружили, что токенизация в словесные униграммы + биграммы обеспечивает хорошую точность, требуя при этом меньше времени вычислений.
Векторизация
После того, как мы разделили образцы текста на n-граммы, нам нужно превратить эти n-граммы в числовые векторы, которые смогут обрабатывать наши модели машинного обучения. В примере ниже показаны индексы, присвоенные униграммам и биграммам, сгенерированным для двух текстов.
Texts: 'The mouse ran up the clock' and 'The mouse ran down' Index assigned for every token: {'the': 7, 'mouse': 2, 'ran': 4, 'up': 10, 'clock': 0, 'the mouse': 9, 'mouse ran': 3, 'ran up': 6, 'up the': 11, 'the clock': 8, 'down': 1, 'ran down': 5}
После присвоения индексов n-граммам мы обычно векторизуем их, используя один из следующих вариантов.
Горячее кодирование : каждый образец текста представлен в виде вектора, указывающего наличие или отсутствие токена в тексте.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1]
Кодирование подсчета : каждый образец текста представлен в виде вектора, указывающего количество токенов в тексте. Обратите внимание, что элемент, соответствующий униграмме «the», теперь обозначается как 2 поскольку слово «the» встречается в тексте дважды.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 2, 1, 1, 1, 1]
Кодирование Tf-idf . Проблема двух вышеупомянутых подходов заключается в том, что общие слова, которые встречаются с одинаковой частотой во всех документах (т. е. слова, которые не являются уникальными для образцов текста в наборе данных), не наказываются. Например, такие слова, как «а», будут очень часто встречаться во всех текстах. Таким образом, большее количество токенов для «the», чем для других более значимых слов, не очень полезно.
'The mouse ran up the clock' = [0.33, 0, 0.23, 0.23, 0.23, 0, 0.33, 0.47, 0.33, 0.23, 0.33, 0.33]
(См. Scikit-learn TfidfTransformer )
Существует множество других векторных представлений, но наиболее часто используются предыдущие три.
Мы заметили, что кодирование tf-idf немного лучше двух других с точки зрения точности (в среднем: на 0,25–15 %), и рекомендуем использовать этот метод для векторизации n-грамм. Однако имейте в виду, что он занимает больше памяти (поскольку использует представление с плавающей запятой) и требует больше времени для вычислений, особенно для больших наборов данных (в некоторых случаях это может занять вдвое больше времени).
Выбор функции
Когда мы преобразуем все тексты в наборе данных в токены слов uni+bigram, мы можем получить десятки тысяч токенов. Не все эти токены/функции способствуют прогнозированию меток. Таким образом, мы можем удалить определенные токены, например те, которые встречаются в наборе данных крайне редко. Мы также можем измерить важность функции (насколько каждый токен способствует прогнозированию меток) и включать только наиболее информативные токены.
Существует множество статистических функций, которые берут функции и соответствующие метки и выводят оценку важности функции. Две часто используемые функции — это f_classif и chi2 . Наши эксперименты показывают, что обе эти функции выполняются одинаково хорошо.
Что еще более важно, мы увидели, что для многих наборов данных точность достигает около 20 000 функций (см. рис. 6 ). Добавление дополнительных функций сверх этого порога дает очень мало пользы, а иногда даже приводит к переоснащению и снижению производительности.

Рисунок 6: Основные функции в сравнении с точностью . Во всех наборах данных точность стабилизируется примерно на уровне 20 тысяч основных функций.
Нормализация
Нормализация преобразует все значения объектов/выборок в небольшие и похожие значения. Это упрощает сходимость градиентного спуска в алгоритмах обучения. Судя по тому, что мы видели, нормализация во время предварительной обработки данных, по-видимому, не добавляет особой ценности в задачах классификации текста; мы рекомендуем пропустить этот шаг.
Следующий код объединяет все вышеперечисленные шаги:
- Токенизировать образцы текста в словесные уни+биграммы,
- Векторизовать с использованием кодировки tf-idf,
- Выберите только 20 000 лучших объектов из вектора токенов, отбросив токены, которые появляются менее 2 раз, и используя f_classif для расчета важности функций.
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import f_classif # Vectorization parameters # Range (inclusive) of n-gram sizes for tokenizing text. NGRAM_RANGE = (1, 2) # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Whether text should be split into word or character n-grams. # One of 'word', 'char'. TOKEN_MODE = 'word' # Minimum document/corpus frequency below which a token will be discarded. MIN_DOCUMENT_FREQUENCY = 2 def ngram_vectorize(train_texts, train_labels, val_texts): """Vectorizes texts as n-gram vectors. 1 text = 1 tf-idf vector the length of vocabulary of unigrams + bigrams. # Arguments train_texts: list, training text strings. train_labels: np.ndarray, training labels. val_texts: list, validation text strings. # Returns x_train, x_val: vectorized training and validation texts """ # Create keyword arguments to pass to the 'tf-idf' vectorizer. kwargs = { 'ngram_range': NGRAM_RANGE, # Use 1-grams + 2-grams. 'dtype': 'int32', 'strip_accents': 'unicode', 'decode_error': 'replace', 'analyzer': TOKEN_MODE, # Split text into word tokens. 'min_df': MIN_DOCUMENT_FREQUENCY, } vectorizer = TfidfVectorizer(**kwargs) # Learn vocabulary from training texts and vectorize training texts. x_train = vectorizer.fit_transform(train_texts) # Vectorize validation texts. x_val = vectorizer.transform(val_texts) # Select top 'k' of the vectorized features. selector = SelectKBest(f_classif, k=min(TOP_K, x_train.shape[1])) selector.fit(x_train, train_labels) x_train = selector.transform(x_train).astype('float32') x_val = selector.transform(x_val).astype('float32') return x_train, x_val
При векторном представлении n-грамм мы отбрасываем много информации о порядке слов и грамматике (в лучшем случае мы можем сохранить некоторую информацию о частичном порядке, когда n > 1). Это называется подходом «мешка слов». Это представление используется в сочетании с моделями, которые не учитывают порядок, такими как логистическая регрессия, многослойные перцептроны, машины повышения градиента, машины опорных векторов.
Векторы последовательности [Вариант B]
В последующих параграфах мы увидим, как выполнять токенизацию и векторизацию для моделей последовательностей. Мы также расскажем, как можно оптимизировать представление последовательности, используя методы выбора признаков и нормализации.
Для некоторых образцов текста порядок слов имеет решающее значение для смысла текста. Например, предложения: «Раньше я ненавидел дорогу на работу. Мой новый мотоцикл полностью изменил это» можно понять, только прочитав по порядку. Такие модели, как CNN/RNN, могут определять значение по порядку слов в образце. Для этих моделей мы представляем текст как последовательность токенов, сохраняющих порядок.
Токенизация
Текст может быть представлен как последовательностью символов, так и последовательностью слов. Мы обнаружили, что использование представления на уровне слов обеспечивает лучшую производительность, чем символьные токены. Это также общая норма, которой следует промышленность. Использование токенов символов имеет смысл только в том случае, если в текстах много опечаток, что обычно не происходит.
Векторизация
После того как мы преобразовали образцы текста в последовательности слов, нам нужно превратить эти последовательности в числовые векторы. В примере ниже показаны индексы, присвоенные униграммам, сгенерированным для двух текстов, а затем последовательность индексов токенов, в которые преобразуется первый текст.
Texts: 'The mouse ran up the clock' and 'The mouse ran down'
Индекс, назначенный для каждого токена:
{'clock': 5, 'ran': 3, 'up': 4, 'down': 6, 'the': 1, 'mouse': 2}
ПРИМЕЧАНИЕ. Слово «the» встречается чаще всего, поэтому ему присваивается значение индекса 1. Некоторые библиотеки резервируют индекс 0 для неизвестных токенов, как в данном случае.
Последовательность индексов токенов:
'The mouse ran up the clock' = [1, 2, 3, 4, 1, 5]
Существует два варианта векторизации последовательностей токенов:
Горячее кодирование : последовательности представляются с помощью векторов слов в n-мерном пространстве, где n = размер словаря. Это представление отлично работает, когда мы маркируем символы, и поэтому словарный запас невелик. Когда мы используем токенизацию как слова, словарь обычно содержит десятки тысяч токенов, что делает вектора one-hot очень разреженными и неэффективными. Пример:
'The mouse ran up the clock' = [
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0]
]
Вложения слов : слова имеют связанные с ними значения. В результате мы можем представлять токены слов в плотном векторном пространстве (~несколько сотен действительных чисел), где расположение и расстояние между словами указывают, насколько они похожи семантически (см. рисунок 7 ). Это представление называется встраиванием слов .
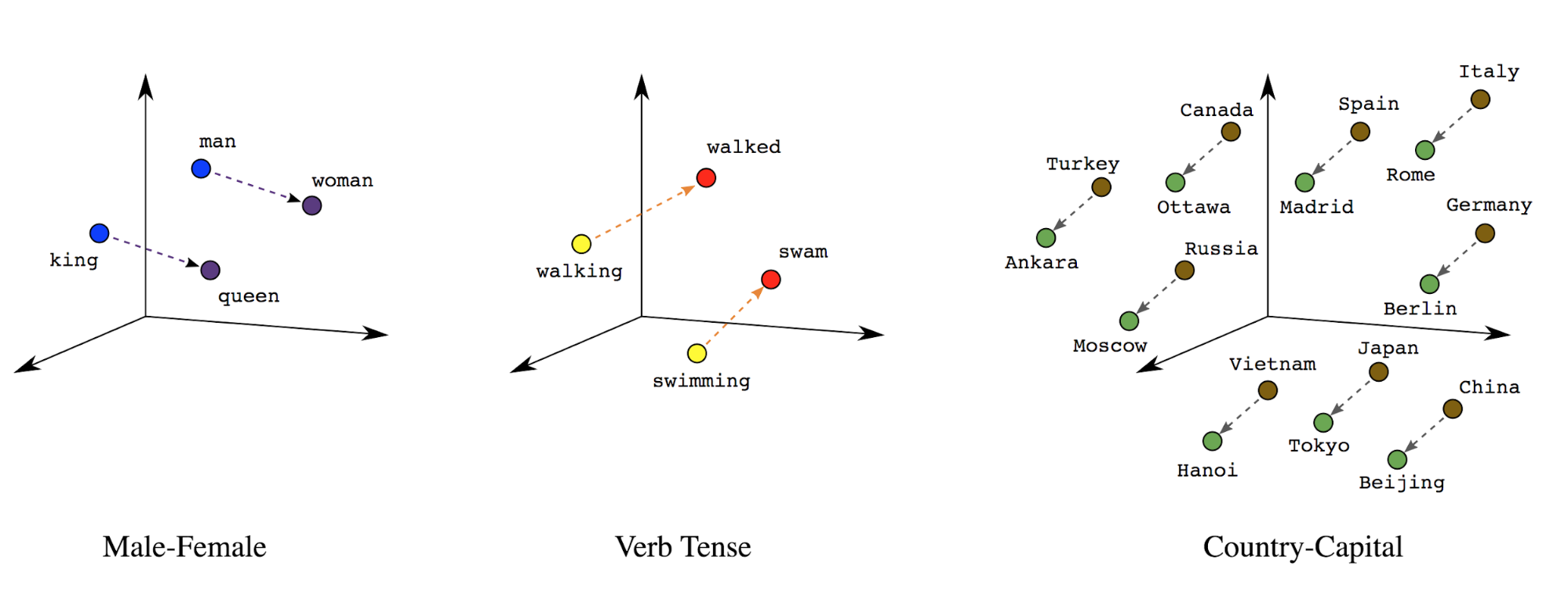
Рисунок 7: Встраивание слов
Модели последовательностей часто имеют такой слой внедрения в качестве первого слоя. Этот уровень учится превращать последовательности индексов слов в векторы встраивания слов во время процесса обучения, так что каждый индекс слова сопоставляется с плотным вектором реальных значений, представляющих местоположение этого слова в семантическом пространстве (см. Рисунок 8 ).
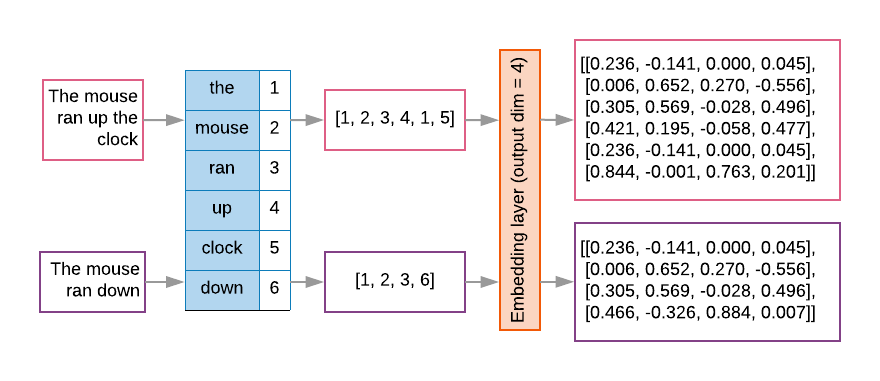
Рисунок 8: Слой внедрения
Выбор функции
Не все слова в наших данных способствуют предсказаниям на этикетках. Мы можем оптимизировать процесс обучения, исключив из своего словаря редкие или ненужные слова. Фактически мы видим, что использования наиболее частых 20 000 функций обычно достаточно. Это справедливо и для моделей n-грамм (см. рисунок 6 ).
Давайте объединим все вышеперечисленные шаги в векторизации последовательности. Следующий код выполняет эти задачи:
- Токенизирует тексты в слова
- Создает словарь, используя 20 000 лучших токенов.
- Преобразует токены в векторы последовательности.
- Дополняет последовательности до фиксированной длины последовательности
from tensorflow.python.keras.preprocessing import sequence from tensorflow.python.keras.preprocessing import text # Vectorization parameters # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Limit on the length of text sequences. Sequences longer than this # will be truncated. MAX_SEQUENCE_LENGTH = 500 def sequence_vectorize(train_texts, val_texts): """Vectorizes texts as sequence vectors. 1 text = 1 sequence vector with fixed length. # Arguments train_texts: list, training text strings. val_texts: list, validation text strings. # Returns x_train, x_val, word_index: vectorized training and validation texts and word index dictionary. """ # Create vocabulary with training texts. tokenizer = text.Tokenizer(num_words=TOP_K) tokenizer.fit_on_texts(train_texts) # Vectorize training and validation texts. x_train = tokenizer.texts_to_sequences(train_texts) x_val = tokenizer.texts_to_sequences(val_texts) # Get max sequence length. max_length = len(max(x_train, key=len)) if max_length > MAX_SEQUENCE_LENGTH: max_length = MAX_SEQUENCE_LENGTH # Fix sequence length to max value. Sequences shorter than the length are # padded in the beginning and sequences longer are truncated # at the beginning. x_train = sequence.pad_sequences(x_train, maxlen=max_length) x_val = sequence.pad_sequences(x_val, maxlen=max_length) return x_train, x_val, tokenizer.word_index
Векторизация меток
Мы увидели, как преобразовать образцы текстовых данных в числовые векторы. Аналогичный процесс необходимо применить и к этикеткам. Мы можем просто преобразовать метки в значения в диапазоне [0, num_classes - 1] . Например, если есть 3 класса, мы можем просто использовать значения 0, 1 и 2 для их представления. Внутри сеть будет использовать горячие векторы для представления этих значений (чтобы избежать неправильной связи между метками). Это представление зависит от функции потерь и функции активации последнего слоя, которую мы используем в нашей нейронной сети. Мы узнаем больше об этом в следующем разделе.