इससे पहले कि हमारा डेटा किसी मॉडल में फ़ीड किया जा सके, उसे फ़ॉर्मैट में बदलने की ज़रूरत है जिसे मॉडल समझ सके.
पहली बात, हमने डेटा के जो सैंपल इकट्ठा किए हैं वे किसी खास क्रम में हो सकते हैं. हम करते हैं आप सैंपल के क्रम से जुड़ी किसी भी जानकारी पर असर नहीं डालना चाहते टेक्स्ट और लेबल के बीच संबंध. उदाहरण के लिए, अगर डेटासेट को क्रम से लगाया गया है क्लास के मुताबिक इस्तेमाल किया जाता है और फिर उसे ट्रेनिंग/वैलिडेशन सेट में बांटा जाता है, तो ये सेट डेटा के पूरे डिस्ट्रिब्यूशन का प्रतिनिधित्व करता है.
यह पक्का करने का सबसे सही तरीका कि मॉडल पर डेटा के क्रम का असर न हो और कुछ भी करने से पहले डेटा को शफ़ल करना. अगर आपका डेटा पहले से इन्हें ट्रेनिंग और वैलिडेशन सेट में बांटा जा सकता है. साथ ही, अपनी पुष्टि को ट्रांसफ़ॉर्म करना ना भूलें ट्रेनिंग डेटा की तरह ही ट्रांसफ़ॉर्मेशन करते हैं. अगर आपने पहले से ऐसा नहीं किया है तो आप सैंपल को बाद में शफ़ल करना; आम तौर पर, ट्रेनिंग के लिए 80% सैंपल और पुष्टि करने के लिए.
दूसरा, मशीन लर्निंग एल्गोरिदम संख्याओं को इनपुट के रूप में लेते हैं. इसका मतलब है कि हम टेक्स्ट को अंकों वाले वेक्टर में बदलना होगा. इसके दो चरण हैं. इस प्रोसेस पर ध्यान दें:
टोकनाइज़ेशन: टेक्स्ट को शब्दों या छोटे-छोटे सब-टेक्स्ट में बांटें. इससे टेक्स्ट और लेबल के बीच संबंध को बेहतर तरीके से समझाने में मदद कर सके. यह डेटासेट की "शब्दावली" तय करता है (यूनीक टोकन का सेट डेटा).
वेक्टराइज़ेशन: इनकी विशेषता बताने के लिए, अंकों वाला एक अच्छा माप तय करें टेक्स्ट.
हम देखते हैं कि एन-ग्राम सदिशों और अनुक्रम, दोनों के लिए इन दो चरणों को कैसे करना है और साथ ही, फ़ीचर का इस्तेमाल करके वेक्टर निरूपणों को कैसे ऑप्टिमाइज़ करें चुनने और नॉर्मलाइज़ेशन की तकनीकें इस्तेमाल कर सकते हैं.
एन-ग्राम वेक्टर [विकल्प A]
बाद के पैराग्राफ़ में, हम टोकनाइज़ेशन करने का तरीका देखेंगे और एन-ग्राम मॉडल के लिए वेक्टराइज़ेशन. हम यह भी कवर करेंगे कि हम n- सुविधा चुनने और नॉर्मलाइज़ेशन तकनीकों का इस्तेमाल करके, ग्राम निरूपण करें.
किसी एन-ग्राम वेक्टर में, टेक्स्ट को यूनीक एन-ग्राम के कलेक्शन के तौर पर दिखाया जाता है:
n सन्निकट टोकन के समूह (आम तौर पर, शब्द). The mouse ran
up the clock टेक्स्ट का इस्तेमाल करें. यहां:
- यूनिग्राम (n = 1) शब्द
['the', 'mouse', 'ran', 'up', 'clock']होते हैं. - बिगम्स शब्द (n = 2)
['the mouse', 'mouse ran', 'ran up', 'up the', 'the clock']होता है - और ऐसे ही अन्य कार्य.
टोकनाइज़ेशन
हमने देखा है कि वर्ड यूनिग्राम और बाइग्राम में टोकन करने से अच्छी इसमें कम समय लगता है, क्योंकि इसमें सटीक जानकारी भी मिलती है.
वेक्टराइज़ेशन
अपने टेक्स्ट के सैंपल को n-ग्राम में बांट देने के बाद, हमें इन्हें n-ग्राम में बदलना होता है जिन्हें हमारे मशीन लर्निंग मॉडल प्रोसेस कर सकते हैं. उदाहरण के लिए यहां दिए गए इंडेक्स में दो पेजों के लिए जनरेट हुए यूनिग्राम और बाइग्राम को टेक्स्ट.
Texts: 'The mouse ran up the clock' and 'The mouse ran down' Index assigned for every token: {'the': 7, 'mouse': 2, 'ran': 4, 'up': 10, 'clock': 0, 'the mouse': 9, 'mouse ran': 3, 'ran up': 6, 'up the': 11, 'the clock': 8, 'down': 1, 'ran down': 5}
इंडेक्स के n-ग्राम में असाइन हो जाने के बाद, हम आम तौर पर इनमें से किसी एक का इस्तेमाल करके वेक्टर तैयार करते हैं को यहां दिया गया है.
वन-हॉट एन्कोडिंग: हर सैंपल टेक्स्ट को एक वेक्टर के तौर पर दिखाया जाता है. इससे पता चलता है कि टेक्स्ट में टोकन का होना या न होना.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1]
काउंट एन्कोडिंग: हर सैंपल टेक्स्ट को एक वेक्टर के तौर पर दिखाया जाता है. इससे पता चलता है कि
टेक्स्ट में टोकन की संख्या. ध्यान दें कि
ऊनीग्राम 'द' अब 2 के रूप में दिखाया जाता है, क्योंकि "the"
टेक्स्ट में दो बार दिखता है.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 2, 1, 1, 1, 1]
Tf-idf एन्कोडिंग: समस्या ऊपर दिए गए दो तरीकों से यह हो सकता है कि सामान्य शब्द जो समान रूप से हों सभी दस्तावेज़ों में आवृत्तियां (यानी, वे शब्द जो विशेष रूप से डेटासेट में मौजूद टेक्स्ट के सैंपल) पर कोई कार्रवाई नहीं की जाती. उदाहरण के लिए, “a” जैसे शब्द सभी टेक्स्ट में बहुत बार आएगा. इसलिए, “The” के लिए टोकन की संख्या उपयोगी नहीं है.
'The mouse ran up the clock' = [0.33, 0, 0.23, 0.23, 0.23, 0, 0.33, 0.47, 0.33, 0.23, 0.33, 0.33]
(Scikit-learn TFifTransformer देखें)
कई अन्य सदिश निरूपण हैं, लेकिन पहले तीन सबसे ज़्यादा इस्तेमाल होते हैं.
हमने पाया है कि tf-idf एन्कोडिंग, और यह सुझाव दिया जाता है कि आप इस तरीके का इस्तेमाल करें (औसतन: 0.25-15% ज़्यादा) एन-ग्राम को वेक्टराइज़ करने के लिए. हालांकि, ध्यान रखें कि यह ज़्यादा स्टोरेज लेता है (जैसा कि यह फ़्लोटिंग-पॉइंट रिप्रज़ेंटेशन का इस्तेमाल करता है) और कंप्यूट करने में ज़्यादा समय लेता है, खास तौर पर बड़े डेटासेट के लिए (कुछ मामलों में दोगुना समय लग सकता है).
सुविधा चुनना
जब हम किसी डेटासेट के सभी टेक्स्ट को वर्ड यूनि+बिग्राम टोकन में बदलते हैं, तो हम हज़ारों टोकन मिल सकते हैं. ये सभी टोकन/सुविधाएं मौजूद नहीं हैं लेबल के सुझाव देने में मदद मिलती है. उदाहरण के लिए, हम कुछ टोकन छोड़ सकते हैं जो डेटासेट में शायद ही कभी होते हैं. हम यह भी पता लगा सकते हैं कि सुविधा की अहमियत (लेबल अनुमान लगाने में हर टोकन का कितना योगदान है), और सिर्फ़ सबसे ज़्यादा जानकारी देने वाले टोकन शामिल करें.
आंकड़ों से जुड़े ऐसे कई फ़ंक्शन हैं जो सुविधाओं और संबंधित लेबल और सुविधा के ज़रूरी स्कोर का आउटपुट देते हैं. आम तौर पर इस्तेमाल किए जाने वाले दो फ़ंक्शन हैं f_classif और chi2. हमारे प्रयोगों से पता चलता है कि ये दोनों फ़ंक्शन समान रूप से अच्छा परफ़ॉर्म करते हैं.
इससे भी अहम बात यह है कि हमने देखा कि कई डेटासेट (इमेज 6 देखें). इस थ्रेशोल्ड से ज़्यादा सुविधाएं जोड़ने से योगदान मिलता है बहुत कम होता है और कभी-कभी ओवरफ़िटिंग और परफ़ॉर्मेंस में गिरावट आती है.

छठी इमेज: टॉप K सुविधाएं बनाम ऐक्यूरसी. पूरे डेटासेट में, करीब 20 हज़ार सुविधाओं के लिए सटीक होने का स्तर तय किया गया है.
नॉर्मलाइज़ेशन
नॉर्मलाइज़ेशन की सुविधा, सभी सुविधा/सैंपल की वैल्यू को छोटे और मिलते-जुलते वैल्यू में बदल देती है. यह लर्निंग एल्गोरिदम में ग्रेडिएंट डिसेंट अभिसरण को आसान बनाता है. किस तरह से हमने देखा है कि डेटा प्री-प्रोसेसिंग के दौरान नॉर्मलाइज़ेशन के टेक्स्ट की कैटगरी तय करने से जुड़ी समस्याओं में वैल्यू; हमारी सलाह है कि आप इस चरण को छोड़ दें.
नीचे दिया गया कोड, ऊपर दिए गए सभी चरणों को एक साथ रखता है:
- टेक्स्ट के सैंपल को वर्ड यूनि+बिग्राम में टोकन करें,
- tf-idf एन्कोडिंग का उपयोग करके वेक्टर बनाएं,
- टोकन को खारिज करके, वेक्टर के वेक्टर से सिर्फ़ टॉप 20,000 सुविधाओं को चुनें ऐसे टोकन जो दो से कम बार दिखते हैं और सुविधा का हिसाब लगाने के लिए f_classif का इस्तेमाल करते हैं महत्व.
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import f_classif # Vectorization parameters # Range (inclusive) of n-gram sizes for tokenizing text. NGRAM_RANGE = (1, 2) # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Whether text should be split into word or character n-grams. # One of 'word', 'char'. TOKEN_MODE = 'word' # Minimum document/corpus frequency below which a token will be discarded. MIN_DOCUMENT_FREQUENCY = 2 def ngram_vectorize(train_texts, train_labels, val_texts): """Vectorizes texts as n-gram vectors. 1 text = 1 tf-idf vector the length of vocabulary of unigrams + bigrams. # Arguments train_texts: list, training text strings. train_labels: np.ndarray, training labels. val_texts: list, validation text strings. # Returns x_train, x_val: vectorized training and validation texts """ # Create keyword arguments to pass to the 'tf-idf' vectorizer. kwargs = { 'ngram_range': NGRAM_RANGE, # Use 1-grams + 2-grams. 'dtype': 'int32', 'strip_accents': 'unicode', 'decode_error': 'replace', 'analyzer': TOKEN_MODE, # Split text into word tokens. 'min_df': MIN_DOCUMENT_FREQUENCY, } vectorizer = TfidfVectorizer(**kwargs) # Learn vocabulary from training texts and vectorize training texts. x_train = vectorizer.fit_transform(train_texts) # Vectorize validation texts. x_val = vectorizer.transform(val_texts) # Select top 'k' of the vectorized features. selector = SelectKBest(f_classif, k=min(TOP_K, x_train.shape[1])) selector.fit(x_train, train_labels) x_train = selector.transform(x_train).astype('float32') x_val = selector.transform(x_val).astype('float32') return x_train, x_val
एन-ग्राम वेक्टर दिखाने पर, हम शब्दों के बारे में बहुत सारी जानकारी छोड़ देते हैं और व्याकरण (सबसे अच्छी तरह, हम आंशिक क्रम की जानकारी को बनाए रख सकते हैं) जब n > 1). इसे 'बैग-ऑफ़-वर्ड्स अप्रोच' कहते हैं. इस प्रतिनिधित्व का इस्तेमाल किया गया है यह ऐसे मॉडल के साथ लागू होता है जो ऑर्डर में शामिल नहीं होते, जैसे लॉजिस्टिक रिग्रेशन, कई लेयर वाली पर्सेप्ट्रॉन, ग्रेडिएंट बूस्टिंग मशीन, वेक्टर मशीनें.
सीक्वेंस वेक्टर [विकल्प B]
बाद के पैराग्राफ़ में, हम टोकनाइज़ेशन करने का तरीका देखेंगे और सीक्वेंस मॉडल का वेक्टराइज़ेशन. हम यह भी बताएंगे कि हम सुविधा को चुनने और नॉर्मलाइज़ेशन की तकनीकों का इस्तेमाल करके, सीक्वेंस प्रज़ेंटेशन बनाएं.
टेक्स्ट के कुछ सैंपल में, टेक्स्ट के मतलब के लिए शब्दों का क्रम अहम होता है. इसके लिए उदाहरण के लिए, वाक्य “मुझे अपनी यात्रा से नफ़रत थी. मेरी नई बाइक ने उसे बदल दिया पूरी तरह से” को सिर्फ़ तब समझा जा सकता है, जब उसे क्रम से पढ़ा जाए. CNNs/RNNs जैसे मॉडल किसी सैंपल में मौजूद शब्दों के क्रम से उसका मतलब निकाल सकते हैं. इन मॉडल के लिए, हम टेक्स्ट को टोकन के क्रम के तौर पर दिखाते हैं, जिससे ऑर्डर बरकरार रहता है.
टोकनाइज़ेशन
टेक्स्ट को वर्णों के क्रम या क्रम के तौर पर दिखाया जा सकता है शब्द. हमने पाया है कि शब्द-स्तरीय निरूपण का उपयोग करने से बेहतर नहीं करना चाहिए. यह एक सामान्य मानदंड भी है इंडस्ट्री का लेवल है. वर्ण टोकन का इस्तेमाल सिर्फ़ तब सही होता है, जब टेक्स्ट में बहुत टाइपिंग की गलतियां होती हैं, जो आम तौर पर नहीं होती हैं.
वेक्टराइज़ेशन
हमारे टेक्स्ट सैंपल को शब्दों के क्रम में बदलने के बाद, हमें इन क्रमों को संख्यात्मक वेक्टर में बदल दिया जाता है. नीचे दिए गए उदाहरण में इंडेक्स दिखाए गए हैं असाइन किए गए यूनिग्राम को दो टेक्स्ट के लिए जनरेट किया जाता है और फिर टोकन का क्रम वे इंडेक्स जिनमें पहला टेक्स्ट बदला जाता है.
Texts: 'The mouse ran up the clock' and 'The mouse ran down'
हर टोकन के लिए इंडेक्स असाइन किया गया:
{'clock': 5, 'ran': 3, 'up': 4, 'down': 6, 'the': 1, 'mouse': 2}
ध्यान दें: शब्द "the" सबसे ज़्यादा बार होता है, इसलिए 1 का इंडेक्स मान है असाइन कर दिया है. कुछ लाइब्रेरी, अज्ञात टोकन के लिए इंडेक्स 0 को रिज़र्व करती हैं, जैसा कि मामला यहां देखें.
टोकन इंडेक्स का क्रम:
'The mouse ran up the clock' = [1, 2, 3, 4, 1, 5]
टोकन सीक्वेंस को वेक्टराइज़ करने के लिए दो विकल्प उपलब्ध हैं:
वन-हॉट एन्कोडिंग: क्रमों को n- वर्ड वेक्टर का इस्तेमाल करके दिखाया जाता है डाइमेंशन स्पेस, जहां n = शब्दावली का साइज़ होना चाहिए. यह कॉन्टेंट बेहतरीन तरीके से काम करता है जब हम वर्णों के रूप में टोकन बनाते हैं, और इसलिए उसका शब्द भंडार बहुत छोटा होता है. जब हम शब्दों को टोकन करते हैं, तो शब्दकोश में आम तौर पर दस हज़ारों टोकन हैं, जिसकी वजह से वन-हॉट वेक्टर बहुत कम और कम कारगर होता है. उदाहरण:
'The mouse ran up the clock' = [
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0]
]
शब्दों को एम्बेड करना: शब्दों के मतलब, उनसे जुड़े होते हैं. इस वजह से, हम सघन सदिश स्थान (~कुछ सौ वास्तविक संख्याएं) में शब्द टोकन दिखाई दे सकते हैं, जहां शब्दों के बीच की जगह और दूरी से पता चलता है कि वे कितने मिलते-जुलते हैं अर्थ के हिसाब से (इमेज 7 देखें). इस प्रतिनिधित्व को कहा जाता है शब्दों को एम्बेड करना.
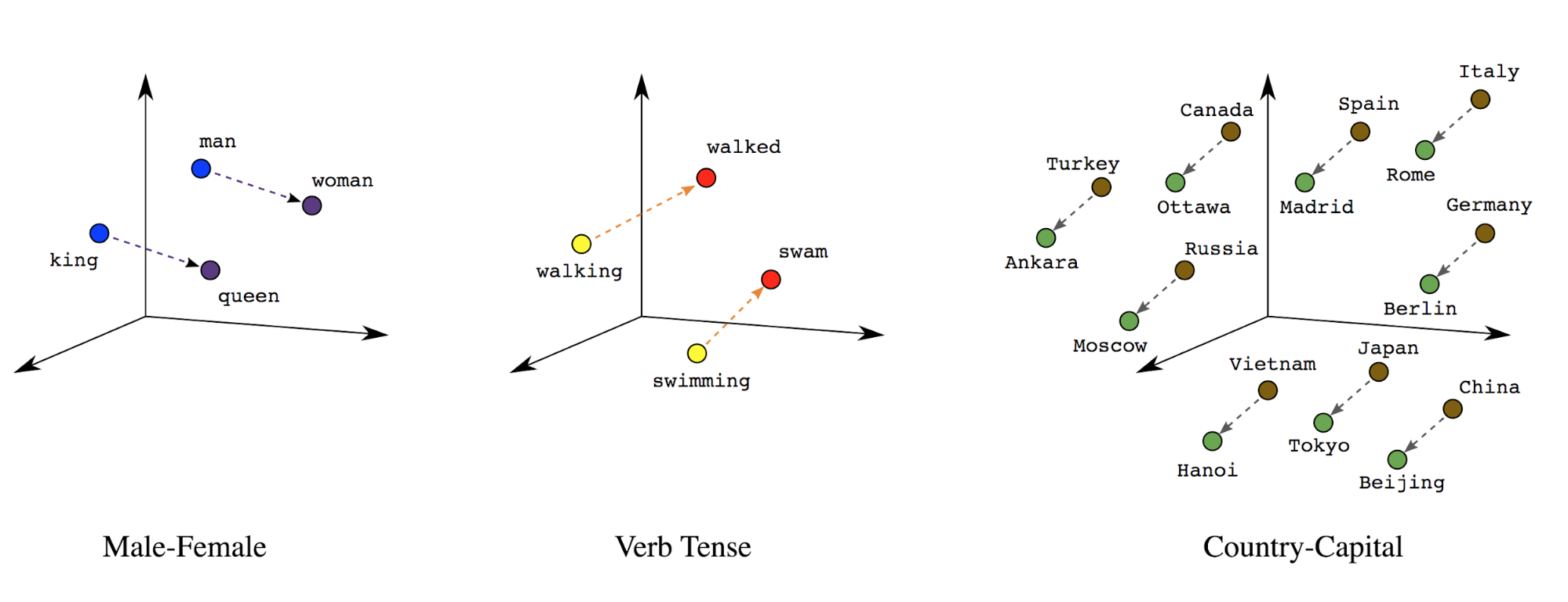
सातवीं इमेज: शब्द एम्बेड करना
सीक्वेंस मॉडल की पहली लेयर में अक्सर ऐसी एम्बेडिंग लेयर होती है. यह लेयर वर्ड इंडेक्स क्रम को शब्द एम्बेड करने वाले वेक्टर में बदलना सीखती है. ट्रेनिंग प्रक्रिया का पालन करती है, जिससे हर वर्ड इंडेक्स को सिमैंटिक स्पेस में उस शब्द की जगह दिखाने वाली असली वैल्यू (इमेज 8 देखें).
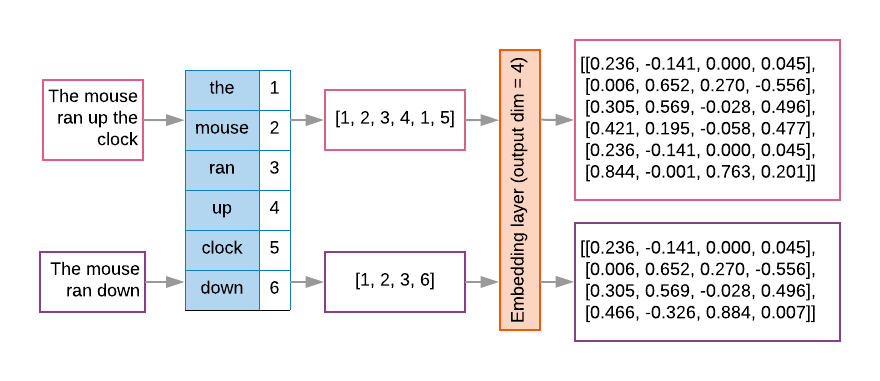
इमेज 8: एम्बेडिंग लेयर
सुविधा चुनना
हमारे डेटा के सभी शब्द, लेबल के सुझावों के लिए काम नहीं करते. हम अपने हमारी शब्दावली में से दुर्लभ या बिना काम के शब्दों को खारिज करके, सीखने की प्रक्रिया को पूरा किया जा सकता है. तय सीमा में हमने देखा है कि सामान्य 20,000 सुविधाओं का इस्तेमाल करना आम तौर पर काफ़ी हैं. यह एन-ग्राम मॉडल पर भी लागू होती है (इमेज 6 देखें).
आइए, ऊपर दिए गए सभी चरणों को सीक्वेंस वेक्टराइज़ेशन के एक साथ रखते हैं. कॉन्टेंट बनाने ये कोड ये काम करते हैं:
- टेक्स्ट को शब्दों में टोकन करता है
- टॉप 20,000 टोकन का इस्तेमाल करके शब्दावली बनाता है
- टोकन को क्रम वेक्टर में बदलता है
- अनुक्रमों को निश्चित अनुक्रम लंबाई पर पैड करता है
from tensorflow.python.keras.preprocessing import sequence from tensorflow.python.keras.preprocessing import text # Vectorization parameters # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Limit on the length of text sequences. Sequences longer than this # will be truncated. MAX_SEQUENCE_LENGTH = 500 def sequence_vectorize(train_texts, val_texts): """Vectorizes texts as sequence vectors. 1 text = 1 sequence vector with fixed length. # Arguments train_texts: list, training text strings. val_texts: list, validation text strings. # Returns x_train, x_val, word_index: vectorized training and validation texts and word index dictionary. """ # Create vocabulary with training texts. tokenizer = text.Tokenizer(num_words=TOP_K) tokenizer.fit_on_texts(train_texts) # Vectorize training and validation texts. x_train = tokenizer.texts_to_sequences(train_texts) x_val = tokenizer.texts_to_sequences(val_texts) # Get max sequence length. max_length = len(max(x_train, key=len)) if max_length > MAX_SEQUENCE_LENGTH: max_length = MAX_SEQUENCE_LENGTH # Fix sequence length to max value. Sequences shorter than the length are # padded in the beginning and sequences longer are truncated # at the beginning. x_train = sequence.pad_sequences(x_train, maxlen=max_length) x_val = sequence.pad_sequences(x_val, maxlen=max_length) return x_train, x_val, tokenizer.word_index
लेबल वेक्टराइज़ेशन
हमने देखा कि सैंपल टेक्स्ट डेटा को न्यूमेरिक वेक्टर में कैसे बदला जाता है. एक मिलती-जुलती प्रोसेस
लेबल पर लागू किया जाना चाहिए. हम लेबल को रेंज में मौजूद वैल्यू में बदल सकते हैं
[0, num_classes - 1]. उदाहरण के लिए, अगर ऐसी तीन क्लास हैं जिनका इस्तेमाल हम
वैल्यू 0, 1, 2 हैं, ताकि उन्हें दिखाया जा सके. अंदरूनी तौर पर, नेटवर्क वन-हॉट का इस्तेमाल करेगा
इन वैल्यू को दिखाने के लिए वेक्टर (गलत संबंध का पता लगाने से बचने के लिए)
के बीच में). यह वैल्यू, लॉस फ़ंक्शन और आखिरी वैल्यू पर निर्भर करती है-
हमारे न्यूरल नेटवर्क में इस्तेमाल किया जाता है. हम इसके बारे में ज़्यादा जानेंगे
इन्हें अगले सेक्शन में देखें.