최적화 실패를 디버그하고 완화하려면 어떻게 해야 하나요?
요약: 모델에 최적화 문제가 있는 경우 다른 작업을 시도하기 전에 문제를 해결하는 것이 중요합니다. 학습 실패를 진단하고 수정하는 것은 활발한 연구 분야입니다.
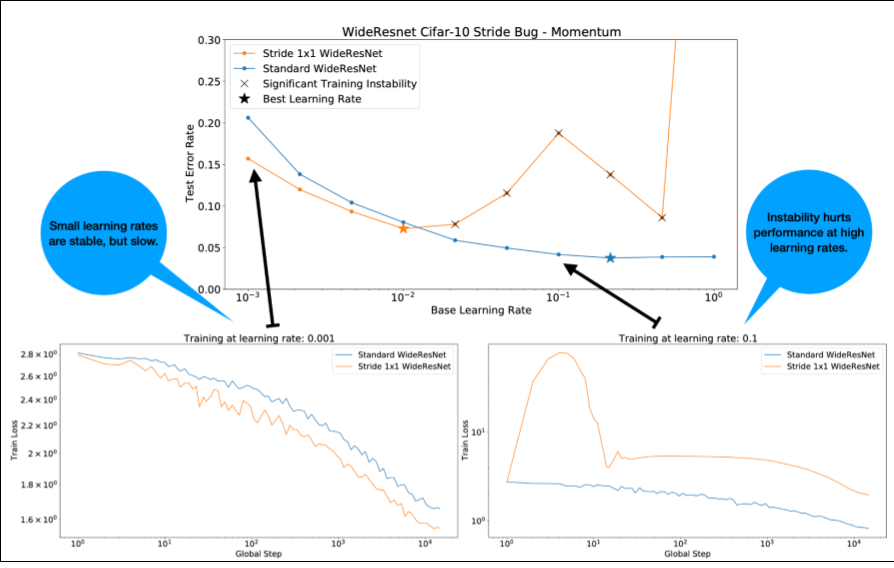
그림 4에 관해 다음 사항에 유의하세요.
- 보폭을 변경해도 낮은 학습률에서는 성능이 저하되지 않습니다.
- 불안정성으로 인해 높은 학습률이 더 이상 제대로 학습되지 않습니다.
- 학습률 워밍업을 1, 000단계 적용하면 이 특정 불안정성 인스턴스가 해결되어 최대 학습률 0.1에서 안정적인 학습이 가능합니다.
불안정한 워크로드 식별
학습률이 너무 크면 워크로드가 불안정해집니다. 불안정성은 너무 작은 학습률을 사용해야 하는 경우에만 문제가 됩니다. 구분할 만한 학습 불안정성에는 두 가지 유형이 있습니다.
- 초기화 시 또는 학습 초기에 불안정함
- 학습 도중 갑자기 불안정해짐
다음과 같이 하여 워크로드의 안정성 문제를 체계적으로 식별할 수 있습니다.
- 학습률 스위프를 실행하고 최적의 학습률 lr*을 찾습니다.
- lr* 바로 위의 학습률에 대한 학습 손실 곡선을 플롯합니다.
- 학습률이 lr* 보다 큰 경우 손실이 불안정하면 (학습 기간 동안 손실이 감소하지 않고 증가함) 일반적으로 불안정성을 수정하면 학습이 개선됩니다.
학습 중에 전체 손실 기울기의 L2 norm을 로깅합니다. 이상치 값은 학습 중간에 가짜 불안정을 일으킬 수 있기 때문입니다. 이를 통해 그라데이션이나 가중치 업데이트를 얼마나 적극적으로 클리핑할지 알 수 있습니다.
참고: 일부 모델에서는 매우 초기에 불안정성이 나타난 후 복구되어 느리지만 안정적인 학습이 진행됩니다. 일반적인 평가 일정은 충분히 자주 평가하지 않아 이러한 문제를 놓칠 수 있습니다.
이를 확인하려면 lr = 2 * current best를 사용하여 약 500단계의 단축된 실행을 학습하되 모든 단계를 평가하면 됩니다.

일반적인 불안정 패턴의 잠재적 수정사항
일반적인 불안정 패턴에 대해 다음과 같은 해결 방법을 고려해 보세요.
- 학습률 워밍업을 적용합니다. 초기 학습 불안정성에 가장 적합합니다.
- 경사 제한을 적용합니다. 이는 초기 및 중간 학습 불안정성에 모두 유용하며, 워밍업으로 해결할 수 없는 일부 잘못된 초기화를 수정할 수 있습니다.
- 새 최적화 도구를 사용해 보세요. Adam은 Momentum이 처리할 수 없는 불안정성을 처리할 수 있습니다. 이는 활발한 연구 분야입니다.
- 모델 아키텍처에 권장사항과 최적의 초기화를 사용해야 합니다 (예시는 아래 참고). 모델에 아직 잔차 연결과 정규화가 포함되어 있지 않다면 추가합니다.
- 잔차 전 마지막 작업으로 정규화합니다. 예를 들면
x + Norm(f(x))입니다.Norm(x + f(x))로 인해 문제가 발생할 수 있습니다. - 잔차 브랜치를 0으로 초기화해 보세요. (ReZero is All You Need: Fast Convergence at Large Depth 참고)
- 학습률을 낮춥니다. 이는 최후의 수단입니다.
학습률 워밍업

학습률 워밍업을 적용해야 하는 경우


그림 7a는 최적의 학습률이 불안정성의 가장자리에 있으므로 최적화 불안정을 겪고 있는 모델을 나타내는 초매개변수 축 플롯을 보여줍니다.
그림 7b에서는 이 피크보다 5배 또는 10배 더 큰 학습률로 학습된 모델의 학습 손실을 검사하여 이를 다시 확인할 수 있는 방법을 보여줍니다. 이 그래프에서 꾸준히 감소한 후 갑자기 손실이 증가하는 것으로 표시되면 (예: 위의 그림에서 ~10,000단계) 모델에 최적화 불안정 문제가 있을 수 있습니다.
학습률 워밍업을 적용하는 방법

앞의 절차를 사용하여 모델이 불안정해지는 학습률을 unstable_base_learning_rate라고 합니다.
워밍업에는 학습률을 0에서 unstable_base_learning_rate보다 최소한 한 자릿수 큰 안정적인 base_learning_rate로 높이는 학습률 일정을 앞에 추가하는 작업이 포함됩니다.
기본적으로 unstable_base_learning_rate의 10배인 base_learning_rate를 시도합니다. 100x unstable_base_learning_rate와 같은 경우 이 전체 절차를 다시 실행할 수 있습니다. 구체적인 일정은 다음과 같습니다.
- warmup_steps에 걸쳐 0에서 base_learning_rate까지 증가합니다.
- post_warmup_steps 동안 일정한 비율로 학습합니다.
목표는 unstable_base_learning_rate보다 훨씬 높은 최고 학습률에 액세스할 수 있는 가장 짧은 warmup_steps를 찾는 것입니다.
따라서 각 base_learning_rate에 대해 warmup_steps 및 post_warmup_steps를 조정해야 합니다. 일반적으로 post_warmup_steps을 2*warmup_steps로 설정해도 괜찮습니다.
워밍업은 기존 감소 일정과 독립적으로 조정할 수 있습니다. warmup_steps
몇 가지 다른 크기로 스윕해야 합니다. 예를 들어 예시 연구에서는 [10, 1000, 10,000, 100,000]을 시도할 수 있습니다. 가장 큰 실행 가능한 포인트는 max_train_steps의 10% 를 초과해서는 안 됩니다.
base_learning_rate에서 학습을 중단하지 않는 warmup_steps가 설정되면 기준 모델에 적용해야 합니다.
기본적으로 이 일정을 기존 일정에 추가하고 위에서 설명한 최적의 체크포인트 선택을 사용하여 이 실험을 기준과 비교합니다. 예를 들어 원래 max_train_steps가 10,000개이고 1,000단계 동안 warmup_steps를 실행한 경우 새 학습 절차는 총 11,000단계 동안 실행해야 합니다.
안정적인 학습을 위해 긴 warmup_steps이 필요한 경우(max_train_steps의 5% 초과) 이를 고려하여 max_train_steps을 늘려야 할 수 있습니다.
전체 워크로드 범위에서 '일반적인' 값은 없습니다. 일부 모델에는 100단계만 필요하지만 다른 모델 (특히 트랜스포머)에는 40, 000단계 이상이 필요할 수 있습니다.
경사 제한

그라데이션 클리핑은 크거나 이상치 그라데이션 문제가 발생할 때 가장 유용합니다. 그라데이션 클리핑은 다음 문제 중 하나를 해결할 수 있습니다.
- 초기 학습 불안정성 (초기에 큰 기울기 노름)
- 학습 중 불안정 (학습 중 갑작스러운 기울기 급증)
클리핑으로 해결되지 않는 불안정성은 워밍업 기간을 늘리면 해결될 수 있습니다. 자세한 내용은 학습률 워밍업을 참고하세요.
🤖 워밍업 중에 클리핑이 발생하면 어떻게 되나요?
이상적인 클립 임계값은 '일반적인' 그라데이션 표준보다 약간 높습니다.
다음은 그라데이션 클리핑을 수행하는 방법의 예입니다.
- 그라데이션의 표준 $\left | g \right |$ 이 그라데이션 클리핑 임계값 $\lambda$보다 크면 ${g}'= \lambda \times \frac{g}{\left | g \right |}$을 실행합니다. 여기서 ${g}'$ 은 새 그라데이션입니다.
학습 중에 클리핑되지 않은 그라데이션 노름을 로깅합니다. 기본적으로 다음을 생성합니다.
- 경사 노름 대 단계의 플롯
- 모든 단계에서 집계된 그라데이션 노름의 히스토그램
그라데이션 노름의 90번째 백분위수를 기반으로 그라데이션 클리핑 기준점을 선택합니다. 이 기준은 워크로드에 따라 다르지만 90% 가 좋은 시작점입니다. 90% 가 작동하지 않으면 이 기준점을 조정할 수 있습니다.
🤖 적응형 전략은 어떤가요?
그라데이션 클리핑을 시도했는데 불안정성 문제가 계속되면 더 강하게 시도해 보세요. 즉, 기준점을 더 작게 만들 수 있습니다.
매우 적극적인 경사 클리핑 (즉, 업데이트의 50% 이상이 클리핑됨)은 기본적으로 학습률을 줄이는 이상한 방법입니다. 매우 공격적인 클리핑을 사용하고 있다면 학습률을 대신 줄이는 것이 좋습니다.
학습률 및 기타 최적화 매개변수를 초매개변수라고 하는 이유는 무엇인가요? 이러한 값은 이전 분포의 매개변수가 아닙니다.
'하이퍼파라미터'라는 용어는 베이즈 머신러닝에서 정확한 의미를 가지므로 학습률과 조정 가능한 대부분의 기타 딥 러닝 파라미터를 '하이퍼파라미터'라고 하는 것은 용어의 오용이라고 할 수 있습니다. 학습률, 아키텍처 매개변수, 딥 러닝에서 조정 가능한 기타 모든 항목에는 '메타 매개변수'라는 용어를 사용하는 것이 좋습니다. 이는 메타 매개변수가 '초매개변수'라는 단어를 잘못 사용했을 때 발생할 수 있는 혼동을 방지하기 때문입니다. 이러한 혼동은 확률적 반응 표면 모델에 자체적인 실제 하이퍼파라미터가 있는 베이즈 최적화를 논의할 때 특히 발생하기 쉽습니다.
혼동스러울 수 있지만 '하이퍼파라미터'라는 용어는 딥 러닝 커뮤니티에서 매우 일반적이 되었습니다. 따라서 이 기술을 알지 못하는 많은 사람들을 포함한 광범위한 독자를 대상으로 하는 이 문서에서는 다른 혼란을 피하기 위해 이 분야의 혼란의 한 가지 원인에 기여하기로 했습니다. 하지만 연구 논문을 발표할 때는 다른 선택을 할 수도 있으며, 대부분의 맥락에서 '메타 매개변수'를 대신 사용하는 것이 좋습니다.
검증 세트 성능을 직접 개선하기 위해 배치 크기를 조정하면 안 되는 이유는 무엇인가요?
학습 파이프라인의 다른 세부정보를 변경하지 않고 배치 크기를 변경하면 검증 세트 성능에 영향을 미치는 경우가 많습니다. 하지만 각 배치 크기에 대해 학습 파이프라인을 독립적으로 최적화하면 일반적으로 두 배치 크기 간의 검증 세트 성능 차이가 사라집니다.
배치 크기와 가장 강력하게 상호작용하므로 각 배치 크기에 대해 별도로 조정하는 것이 가장 중요한 초매개변수는 옵티마이저 초매개변수 (예: 학습률, 모멘텀)와 정규화 초매개변수입니다. 배치 크기가 작을수록 샘플 분산으로 인해 학습 알고리즘에 노이즈가 더 많이 발생합니다. 이 노이즈는 정규화 효과를 가질 수 있습니다. 따라서 배치 크기가 클수록 과적합이 발생하기 쉬우며 더 강력한 정규화 또는 추가 정규화 기법이 필요할 수 있습니다. 또한 배치 크기를 변경할 때 학습 단계 수를 조정해야 할 수도 있습니다.
이러한 모든 효과를 고려하면 배치 크기가 달성 가능한 최대 검증 성능에 영향을 미친다는 설득력 있는 증거는 없습니다. 자세한 내용은 Shallue et al. 2018을 참고하세요.
인기 있는 모든 최적화 알고리즘의 업데이트 규칙은 무엇인가요?
이 섹션에서는 몇 가지 인기 있는 최적화 알고리즘의 업데이트 규칙을 제공합니다.
확률적 경사하강법 (SGD)
\[\theta_{t+1} = \theta_{t} - \eta_t \nabla \mathcal{l}(\theta_t)\]
여기서 $\eta_t$ 는 $t$ 단계의 학습률입니다.
모멘텀
\[v_0 = 0\]
\[v_{t+1} = \gamma v_{t} + \nabla \mathcal{l}(\theta_t)\]
\[\theta_{t+1} = \theta_{t} - \eta_t v_{t+1}\]
여기서 $\eta_t$ 는 $t$ 단계의 학습률이고 $\gamma$ 는 모멘텀 계수입니다.
Nesterov
\[v_0 = 0\]
\[v_{t+1} = \gamma v_{t} + \nabla \mathcal{l}(\theta_t)\]
\[\theta_{t+1} = \theta_{t} - \eta_t ( \gamma v_{t+1} + \nabla \mathcal{l}(\theta_{t}) )\]
여기서 $\eta_t$ 는 $t$ 단계의 학습률이고 $\gamma$ 는 모멘텀 계수입니다.
RMSProp
\[v_0 = 1 \text{, } m_0 = 0\]
\[v_{t+1} = \rho v_{t} + (1 - \rho) \nabla \mathcal{l}(\theta_t)^2\]
\[m_{t+1} = \gamma m_{t} + \frac{\eta_t}{\sqrt{v_{t+1} + \epsilon}}\nabla \mathcal{l}(\theta_t)\]
\[\theta_{t+1} = \theta_{t} - m_{t+1}\]
ADAM
\[m_0 = 0 \text{, } v_0 = 0\]
\[m_{t+1} = \beta_1 m_{t} + (1 - \beta_1) \nabla \mathcal{l} (\theta_t)\]
\[v_{t+1} = \beta_2 v_{t} + (1 - \beta_2) \nabla \mathcal{l}(\theta_t)^2\]
\[b_{t+1} = \frac{\sqrt{1 - \beta_2^{t+1}}}{1 - \beta_1^{t+1}}\]
\[\theta_{t+1} = \theta_{t} - \alpha_t \frac{m_{t+1}}{\sqrt{v_{t+1}} + \epsilon} b_{t+1}\]
NADAM
\[m_0 = 0 \text{, } v_0 = 0\]
\[m_{t+1} = \beta_1 m_{t} + (1 - \beta_1) \nabla \mathcal{l} (\theta_t)\]
\[v_{t+1} = \beta_2 v_{t} + (1 - \beta_2) \nabla \mathcal{l} (\theta_t)^2\]
\[b_{t+1} = \frac{\sqrt{1 - \beta_2^{t+1}}}{1 - \beta_1^{t+1}}\]
\[\theta_{t+1} = \theta_{t} - \alpha_t \frac{\beta_1 m_{t+1} + (1 - \beta_1) \nabla \mathcal{l} (\theta_t)}{\sqrt{v_{t+1}} + \epsilon} b_{t+1}\]