В этом глоссарии даны определения терминов, связанных с искусственным интеллектом.
А
абляция
Метод оценки важности признака или компонента путем его временного удаления из модели . Затем модель переобучается без этого признака или компонента, и если переобученная модель показывает значительно худшие результаты, то удаленный признак или компонент, вероятно, был важен.
Например, предположим, вы обучили модель классификации на 10 признаках и достигли точности 88% на тестовом наборе . Чтобы проверить важность первого признака, вы можете переобучить модель, используя только девять других признаков. Если переобученная модель показывает значительно худшие результаты (например, точность 55%), то, вероятно, удаленный признак был важен. И наоборот, если переобученная модель показывает такие же хорошие результаты, то, вероятно, этот признак был не так уж важен.
Абляция также может помочь определить значимость следующих факторов:
- Более крупные компоненты, такие как целая подсистема более крупной системы машинного обучения.
- Процессы или методы, например, этап предварительной обработки данных.
В обоих случаях вы сможете наблюдать, как изменяется (или не изменяется) производительность системы после удаления компонента.
A/B-тестирование
Статистический способ сравнения двух (или более) методов — A и B. Как правило, A — это уже существующий метод, а B — новый. A/B-тестирование позволяет не только определить, какой метод работает лучше, но и выяснить, является ли разница статистически значимой.
A/B-тестирование обычно сравнивает один показатель по двум методам; например, как точность модели соотносится с точностью двух методов? Однако A/B-тестирование может также сравнивать любое конечное число показателей.
чип-ускоритель
Категория специализированных аппаратных компонентов, предназначенных для выполнения ключевых вычислений, необходимых для алгоритмов глубокого обучения.
Ускорительные чипы (или просто ускорители ) могут значительно повысить скорость и эффективность задач обучения и вывода по сравнению с центральным процессором общего назначения. Они идеально подходят для обучения нейронных сетей и аналогичных ресурсоемких вычислительных задач.
Примерами микросхем-ускорителей являются:
- Тензорные процессоры Google ( TPU ) со специализированным оборудованием для глубокого обучения.
- Графические процессоры NVIDIA, хотя и были изначально разработаны для обработки графики, позволяют использовать параллельную обработку, что может значительно повысить скорость обработки.
точность
Количество правильных классификационных прогнозов, деленное на общее количество прогнозов. То есть:
Например, модель, сделавшая 40 правильных и 10 неправильных прогнозов, будет иметь точность:
Бинарная классификация предоставляет конкретные названия для различных категорий правильных и неправильных прогнозов . Таким образом, формула точности для бинарной классификации выглядит следующим образом:
где:
- TP — это количество истинно положительных результатов (правильных прогнозов).
- TN — это количество истинно отрицательных результатов (правильных предсказаний).
- FP — это количество ложноположительных результатов (неверных прогнозов).
- FN — это количество ложноотрицательных результатов (неверных прогнозов).
Сравните и сопоставьте точность с прецизией и полнотой .
Дополнительную информацию см. в разделе «Классификация: точность, полнота, прецизионность и связанные с ними показатели» в кратком курсе по машинному обучению.
действие
В обучении с подкреплением механизм, посредством которого агент переходит между состояниями окружающей среды , заключается в выборе действия с использованием стратегии .
функция активации
Функция, позволяющая нейронным сетям изучать нелинейные (сложные) взаимосвязи между признаками и меткой.
К популярным функциям активации относятся:
Графики функций активации никогда не представляют собой одну прямую линию. Например, график функции активации ReLU состоит из двух прямых линий:

График сигмоидной функции активации выглядит следующим образом:

Нажмите на значок, чтобы увидеть пример.
В нейронной сети функции активации обрабатывают взвешенную сумму всех входных сигналов нейрона . Для вычисления взвешенной суммы нейрон суммирует произведения соответствующих значений и весов. Например, предположим, что соответствующие входные сигналы для нейрона состоят из следующего:
| входное значение | входной вес |
| 2 | -1.3 |
| -1 | 0,6 |
| 3 | 0,4 |
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
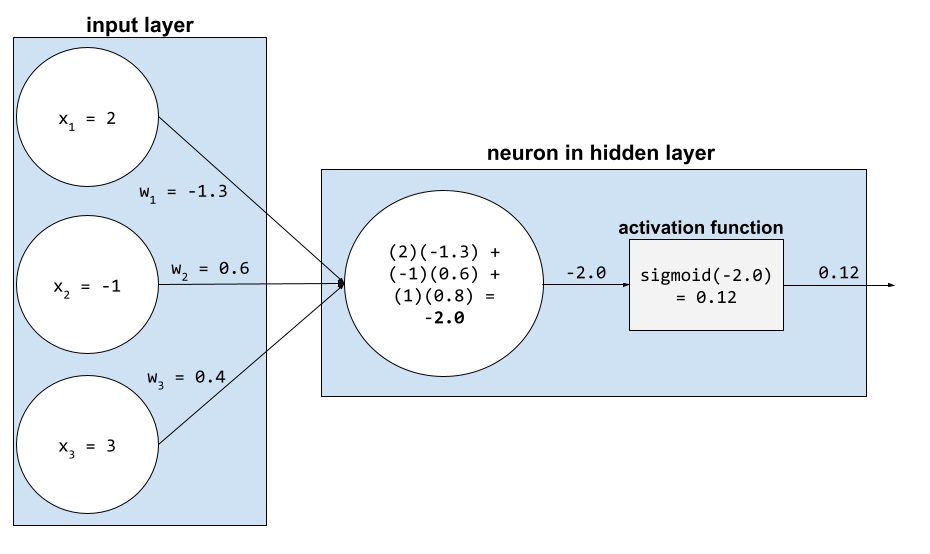
Дополнительную информацию можно найти в разделе «Нейронные сети: функции активации» в кратком курсе по машинному обучению.
активное обучение
Активное обучение — это подход к обучению , при котором алгоритм выбирает часть данных, на которых он обучается. Оно особенно ценно, когда размеченные примеры редки или их получение обходится дорого. Вместо того чтобы слепо искать разнообразный набор размеченных примеров, алгоритм активного обучения избирательно ищет именно тот набор примеров, который ему необходим для обучения.
АдаГрад
Сложный алгоритм градиентного спуска, который масштабирует градиенты каждого параметра , фактически задавая каждому параметру независимую скорость обучения . Подробное объяснение см. в разделе «Адаптивные субградиентные методы для онлайн-обучения и стохастической оптимизации» .
приспособление
Синоним к слову «настройка» или «тонкая настройка» .
агент
Программное обеспечение, способное анализировать многомодальные пользовательские данные для планирования и выполнения действий от имени пользователя.
В обучении с подкреплением агент — это сущность, которая использует стратегию для максимизации ожидаемой отдачи от перехода между состояниями окружающей среды .
агентный
Прилагательная форма слова «агент» . «Агентный» относится к качествам, которыми обладают агенты (например, автономия).
агентский рабочий процесс
Динамический процесс, в котором агент автономно планирует и выполняет действия для достижения цели. Этот процесс может включать рассуждения, использование внешних инструментов и самокоррекцию плана.
агломеративная кластеризация
См. иерархическую кластеризацию .
AI slop
Результат работы генеративной системы искусственного интеллекта , которая отдает предпочтение количеству, а не качеству. Например, веб-страница, созданная с помощью ИИ, заполнена дешевым, сгенерированным ИИ, низкокачественным контентом.
обнаружение аномалий
Процесс выявления выбросов . Например, если среднее значение для определенного параметра равно 100 со стандартным отклонением 10, то система обнаружения аномалий должна пометить значение 200 как подозрительное.
АР
Сокращение от «дополненная реальность» .
площадь под кривой PR
См. PR AUC (площадь под кривой PR) .
площадь под кривой ROC
См. AUC (площадь под ROC-кривой) .
искусственный общий интеллект
Нечеловеческий механизм, демонстрирующий широкий спектр способностей к решению проблем, креативность и адаптивность. Например, программа, демонстрирующая искусственный общий интеллект, могла бы переводить текст, сочинять симфонии и преуспевать в играх, которые еще не изобретены.
искусственный интеллект
Нечеловеческая программа или модель , способная решать сложные задачи. Например, программа или модель, переводящая текст, или программа или модель, определяющая заболевания по рентгеновским снимкам, — обе демонстрируют искусственный интеллект.
Формально машинное обучение является подразделом искусственного интеллекта. Однако в последние годы некоторые организации стали использовать термины «искусственный интеллект» и «машинное обучение» как взаимозаменяемые.
внимание
Механизм внимания, используемый в нейронной сети , который указывает на важность конкретного слова или части слова. Внимание сжимает объем информации, необходимой модели для прогнозирования следующего токена/слова. Типичный механизм внимания может представлять собой взвешенную сумму по набору входных данных, где вес для каждого входного значения вычисляется другой частью нейронной сети.
Обратите также внимание на самовнимание и многоголовочное самовнимание , которые являются строительными блоками трансформеров .
Дополнительную информацию о механизме самовнимания см. в статье «LLMs: What's a large language model?» в сборнике «Machine Learning Crash Course».
атрибут
Синоним к слову "функция" .
В контексте машинного обучения под атрибутами часто подразумеваются характеристики, относящиеся к отдельным лицам.
выборка атрибутов
Тактика обучения дерева решений, при которой каждое дерево решений рассматривает только случайное подмножество возможных признаков при изучении условия . Как правило, для каждого узла выбирается разное подмножество признаков. В отличие от этого, при обучении дерева решений без выборки атрибутов для каждого узла рассматриваются все возможные признаки.
AUC (Площадь под ROC-кривой)
Число от 0,0 до 1,0, представляющее способность модели бинарной классификации разделять положительные и отрицательные классы . Чем ближе AUC к 1,0, тем лучше модель способна разделять классы.
Например, на следующем рисунке показана модель классификации , которая идеально разделяет положительные классы (зеленые овалы) от отрицательных классов (фиолетовые прямоугольники). Эта нереалистично идеальная модель имеет показатель AUC, равный 1,0:

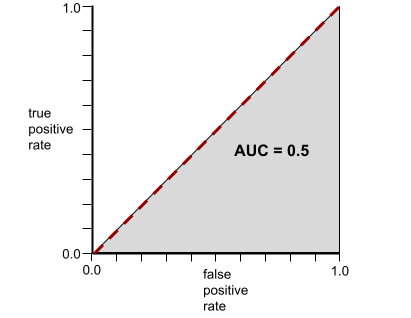
Напротив, на следующем рисунке показаны результаты для модели классификации , которая генерировала случайные результаты. Для этой модели показатель AUC равен 0,5:

Да, у предыдущей модели показатель AUC равен 0,5, а не 0,0.
Большинство моделей находятся где-то между этими двумя крайностями. Например, следующая модель несколько разделяет положительные и отрицательные значения, и поэтому имеет AUC где-то между 0,5 и 1,0:

AUC игнорирует любые значения, которые вы задаете для порога классификации . Вместо этого AUC учитывает все возможные пороги классификации.
Нажмите на значок, чтобы узнать о взаимосвязи между AUC и ROC-кривыми.
AUC представляет собой площадь под ROC-кривой . Например, ROC-кривая для модели, которая идеально разделяет положительные и отрицательные результаты, выглядит следующим образом:
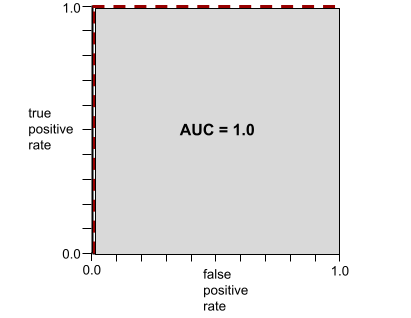
AUC — это площадь серой области на предыдущем рисунке. В этом необычном случае площадь — это просто длина серой области (1,0), умноженная на ширину серой области (1,0). Таким образом, произведение 1,0 и 1,0 дает AUC, равное ровно 1,0, что является максимально возможным значением AUC.
Напротив, ROC-кривая для модели классификации , которая вообще не может разделять классы, выглядит следующим образом. Площадь этой серой области составляет 0,5.
Типичная ROC-кривая выглядит примерно так:
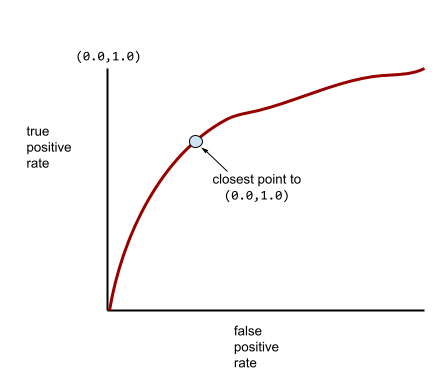
Вычисление площади под этой кривой вручную было бы трудоемким процессом, поэтому большинство значений AUC обычно рассчитываются программами.
Дополнительную информацию см. в разделе «Классификация: ROC и AUC в экспресс-курсе по машинному обучению».
дополненная реальность
Технология, которая накладывает сгенерированное компьютером изображение на реальное изображение, видимое пользователем, создавая таким образом составное изображение.
автокодировщик
Система, которая учится извлекать наиболее важную информацию из входных данных. Автокодировщики представляют собой комбинацию кодировщика и декодера . Автокодировщики используют следующий двухэтапный процесс:
- Кодировщик преобразует входные данные в (как правило) формат с потерями, имеющий промежуточную размерность.
- Декодер создает версию исходного входного сигнала с потерями, отображая формат меньшей размерности на исходный формат входного сигнала большей размерности.
Автокодировщики обучаются сквозным методом, при котором декодер пытается максимально точно восстановить исходный входной сигнал из промежуточного формата кодировщика. Поскольку промежуточный формат меньше (менее размерен), чем исходный формат, автокодировщик вынужден изучать, какая информация во входных данных является существенной, и выходные данные не будут идеально идентичны входным.
Например:
- Если входные данные представляют собой графическое изображение, то неточная копия будет похожа на исходное изображение, но несколько изменена. Возможно, неточная копия удаляет шум из исходного изображения или заполняет некоторые недостающие пиксели.
- Если входные данные представляют собой текст, автокодировщик сгенерирует новый текст, который будет имитировать (но не идентичен) исходному тексту.
См. также вариационные автокодировщики .
автоматическая оценка
Использование программного обеспечения для оценки качества результатов работы модели.
Когда выходные данные модели относительно просты, скрипт или программа могут сравнить выходные данные модели с эталонным ответом . Этот тип автоматической оценки иногда называют программной оценкой . Для программной оценки часто полезны такие метрики, как ROUGE или BLEU .
Когда результаты работы модели сложны или не имеют единственно правильного ответа , иногда автоматическую оценку выполняет отдельная программа машинного обучения, называемая авторизатором .
Сравните с человеческой оценкой .
предвзятость автоматизации
Когда человек, принимающий решения, отдает предпочтение рекомендациям автоматизированной системы принятия решений перед информацией, полученной без автоматизации, даже если автоматизированная система принятия решений допускает ошибки.
Дополнительную информацию см. в разделе «Справедливость: виды предвзятости в экспресс-курсе по машинному обучению».
AutoML
Любой автоматизированный процесс построения моделей машинного обучения . AutoML может автоматически выполнять такие задачи, как:
- Найдите наиболее подходящую модель.
- Настройте гиперпараметры .
- Подготовка данных (включая выполнение инженерии признаков ).
- Разверните полученную модель.
AutoML полезен для специалистов по обработке данных, поскольку позволяет сэкономить время и усилия при разработке конвейеров машинного обучения и повысить точность прогнозирования. Он также полезен для неспециалистов, делая сложные задачи машинного обучения более доступными для них.
Дополнительную информацию см. в разделе «Автоматизированное машинное обучение (AutoML)» в «Кратком курсе по машинному обучению».
авторская оценка
Гибридный механизм оценки качества результатов работы генеративной модели ИИ , сочетающий в себе оценку человеком и автоматическую оценку . Авторефер — это модель машинного обучения, обученная на данных, созданных в результате оценки человеком . В идеале авторефер учится имитировать действия человека-оценщика.В продаже имеются готовые автоматизированные системы оценки, но лучшие из них специально оптимизированы для решения конкретной задачи.
авторегрессионная модель
Модель , которая делает вывод на основе собственных предыдущих прогнозов. Например, авторегрессивные языковые модели прогнозируют следующий токен на основе ранее предсказанных токенов. Все большие языковые модели на основе Transformer являются авторегрессивными.
В отличие от них, модели обработки изображений на основе GAN обычно не являются авторегрессивными, поскольку они генерируют изображение за один прямой проход, а не итеративно пошагово. Однако некоторые модели генерации изображений являются авторегрессивными, поскольку они генерируют изображение пошагово.
вспомогательные потери
Функция потерь — используемая совместно с основной функцией потерь модели нейронной сети — помогает ускорить обучение на ранних итерациях, когда веса инициализируются случайным образом.
Вспомогательные функции потерь переносят эффективные градиенты на более ранние слои . Это способствует сходимости во время обучения , борясь с проблемой затухания градиента .
средняя точность при k
Метрика, суммирующая производительность модели при обработке одного запроса, генерирующего ранжированные результаты, например, нумерованный список рекомендаций книг. Средняя точность в точке k — это, собственно, среднее значение точности в точке k для каждого релевантного результата. Формула для расчета средней точности в точке k выглядит следующим образом:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
где:
- \(n\) — это количество релевантных элементов в списке.
Сравните с результатами воспроизведения на этапе k .
условие выравнивания по осям
В дереве решений условие , включающее только один признак . Например, если признаком является area , то следующее условие соответствует оси распределения:
area > 200
Сравните с косым расположением .
Б
обратное распространение
Алгоритм, реализующий градиентный спуск в нейронных сетях .
Обучение нейронной сети включает в себя множество итераций следующего двухэтапного цикла:
- В процессе прямого прохода система обрабатывает пакет примеров для получения прогнозов. Система сравнивает каждый прогноз с каждым значением метки . Разница между прогнозом и значением метки представляет собой ошибку для данного примера. Система суммирует ошибки для всех примеров, чтобы вычислить общую ошибку для текущего пакета.
- В процессе обратного распространения ошибки система уменьшает потери, корректируя веса всех нейронов во всех скрытых слоях .
Нейронные сети часто содержат множество нейронов в различных скрытых слоях. Каждый из этих нейронов вносит свой вклад в общую функцию потерь. Обратное распространение ошибки определяет, следует ли увеличивать или уменьшать веса, применяемые к конкретным нейронам.
Скорость обучения — это множитель, который регулирует степень увеличения или уменьшения каждого веса при каждом обратном проходе. Высокая скорость обучения будет увеличивать или уменьшать каждый вес сильнее, чем низкая скорость обучения.
В терминах математического анализа, обратное распространение ошибки реализует правило цепочки из математического анализа. То есть, обратное распространение ошибки вычисляет частную производную ошибки по каждому параметру.
Несколько лет назад специалистам по машинному обучению приходилось писать код для реализации обратного распространения ошибки. Современные API для машинного обучения, такие как Keras, теперь реализуют обратное распространение ошибки автоматически. Уф!
Для получения более подробной информации см. раздел «Нейронные сети в кратком курсе по машинному обучению».
упаковка
Метод обучения ансамбля , в котором каждая составляющая модель обучается на случайном подмножестве обучающих примеров, выбранных с замещением . Например, случайный лес — это набор деревьев решений, обученных с помощью метода бэггинга.
Термин bagging является сокращением от bootstrap aggregate .
Дополнительную информацию см. в разделе «Случайные леса» курса «Лесорешения».
мешок слов
Представление слов во фразе или отрывке текста независимо от порядка их следования. Например, «мешок слов» идентично представляет следующие три фразы:
- собака прыгает
- прыгает на собаку
- собака перепрыгивает
Каждое слово сопоставляется с индексом в разреженном векторе , где вектор содержит индекс для каждого слова в словаре. Например, фраза «собака прыгает» сопоставляется с вектором признаков, имеющим ненулевые значения в трех индексах, соответствующих словам «собака» , «собака» и «прыгает» . Ненулевое значение может быть любым из следующих:
- Цифра 1 обозначает наличие слова.
- Подсчет количества вхождений слова в набор. Например, если фраза "were the maroon dog is a dog with maroon fur" (бордовая собака — собака с бордовой шерстью) , то слова "maroon" и "dog" будут представлены как 2, а остальные слова — как 1.
- Какое-либо другое значение, например, логарифм количества появлений слова в мешке.
исходный уровень
Модель, используемая в качестве эталона для сравнения эффективности другой модели (как правило, более сложной). Например, модель логистической регрессии может служить хорошей базовой моделью для глубокой модели .
Для решения конкретной задачи базовый уровень помогает разработчикам моделей количественно оценить минимальную ожидаемую производительность, которую должна достичь новая модель, чтобы быть полезной.
базовая модель
Предварительно обученная модель , которая может служить отправной точкой для тонкой настройки с целью решения конкретных задач или приложений.
См. также предварительно обученную модель и базовую модель .
партия
Набор примеров, используемых в одной итерации обучения. Размер пакета определяет количество примеров в пакете.
См. раздел «Эпоха» для объяснения того, как пакет данных соотносится с эпохой.
Дополнительную информацию см. в статье «Линейная регрессия: гиперпараметры в машинном обучении» (краткий курс).
пакетный вывод
Процесс вывода прогнозов на основе множества немаркированных примеров, разделенных на более мелкие подмножества («пакеты»).
Пакетный вывод может использовать преимущества возможностей распараллеливания, предоставляемых чипами ускорителей . То есть, несколько ускорителей могут одновременно делать прогнозы на разных пакетах немаркированных примеров, что значительно увеличивает количество выводов в секунду.
Дополнительную информацию можно найти в разделе «Системы машинного обучения в производственной среде: статический и динамический вывод» в «Кратком курсе по машинному обучению».
пакетная нормализация
Нормализация входных или выходных данных функций активации в скрытом слое . Пакетная нормализация может обеспечить следующие преимущества:
- Повысьте стабильность нейронных сетей , защитив их от выбросов в весовых коэффициентах.
- Необходимо обеспечить более высокую скорость обучения , что может ускорить тренировку.
- Уменьшите переобучение .
размер партии
Количество примеров в пакете . Например, если размер пакета равен 100, то модель обрабатывает 100 примеров за итерацию .
Ниже представлены популярные стратегии определения размера партии:
- Стохастический градиентный спуск (SGD) , в котором размер пакета равен 1.
- Полный пакет (Full batch) — это стратегия, в которой размер пакета равен количеству примеров во всем обучающем наборе данных . Например, если обучающий набор содержит миллион примеров, то размер пакета будет равен миллиону примеров. Стратегия полного пакета обычно неэффективна.
- Мини-партии, размер партии которых обычно составляет от 10 до 1000 единиц. Мини-партии, как правило, являются наиболее эффективной стратегией.
Дополнительную информацию см. ниже:
- Системы машинного обучения для производственных целей: статический и динамический вывод в кратком курсе по машинному обучению.
- Руководство по настройке глубокого обучения .
Байесовская нейронная сеть
Вероятностная нейронная сеть , учитывающая неопределенность весов и выходных данных. Стандартная модель регрессии на основе нейронной сети обычно предсказывает скалярное значение; например, стандартная модель предсказывает цену дома в 853 000. В отличие от этого, байесовская нейронная сеть предсказывает распределение значений; например, байесовская модель предсказывает цену дома в 853 000 со стандартным отклонением 67 200.
Байесовская нейронная сеть использует теорему Байеса для вычисления неопределенностей в весах и прогнозах. Байесовская нейронная сеть может быть полезна, когда важно количественно оценить неопределенность, например, в моделях, связанных с фармацевтикой. Байесовские нейронные сети также могут помочь предотвратить переобучение .
Байесовская оптимизация
Метод вероятностной регрессионной модели для оптимизации ресурсоемких целевых функций путем оптимизации аппроксимирующей функции, которая количественно оценивает неопределенность с помощью байесовского обучения. Поскольку байесовская оптимизация сама по себе очень затратна, она обычно используется для оптимизации сложных задач с небольшим количеством параметров, таких как выбор гиперпараметров .
Уравнение Беллмана
В обучении с подкреплением оптимальной Q-функции удовлетворяет следующее тождество:
\[Q(s, a) = r(s, a) + \gamma \mathbb{E}_{s'|s,a} \max_{a'} Q(s', a')\]
Алгоритмы обучения с подкреплением применяют это тождество для создания Q-обучения , используя следующее правило обновления:
\[Q(s,a) \gets Q(s,a) + \alpha \left[r(s,a) + \gamma \displaystyle\max_{\substack{a_1}} Q(s',a') - Q(s,a) \right] \]
Помимо обучения с подкреплением, уравнение Беллмана находит применение в динамическом программировании. См. статью в Википедии об уравнении Беллмана .
BERT (Bidirectional Encoder Representations from Transformers)
Архитектура модели для представления текста. Обученная модель BERT может выступать в качестве части более крупной модели для классификации текста или других задач машинного обучения.
BERT обладает следующими характеристиками:
- Использует архитектуру Transformer и, следовательно, полагается на механизм самовнимания .
- Использует кодировщик, являющийся частью трансформера. Задача кодировщика — создавать качественные текстовые представления, а не выполнять какую-либо конкретную задачу, например, классификацию.
- Является двунаправленным .
- Использует маскирование для обучения без учителя .
Варианты BERT включают в себя:
Для получения общего обзора BERT см. статью «Открытый исходный код BERT: передовое предварительное обучение для обработки естественного языка» .
предвзятость (этика/справедливость)
1. Стереотипизация, предвзятость или фаворитизм по отношению к одним вещам, людям или группам по сравнению с другими. Эти предубеждения могут влиять на сбор и интерпретацию данных, проектирование системы и взаимодействие пользователей с ней. К таким формам предвзятости относятся:
- предвзятость автоматизации
- предвзятость подтверждения
- Предвзятость экспериментатора
- предвзятость групповой атрибуции
- неявная предвзятость
- предвзятость внутри группы
- смещение однородности внешней группы
2. Систематическая ошибка, возникающая в результате процедуры выборки или составления отчета. К таким формам смещения относятся:
- смещение охвата
- смещение, вызванное отсутствием ответа
- предвзятость участия
- предвзятость в репортажах
- смещение выборки
- предвзятость отбора
Не следует путать с термином «смещение» в моделях машинного обучения или смещением прогнозирования .
Дополнительную информацию см. в разделе «Справедливость: виды предвзятости в экспресс-курсе по машинному обучению».
смещение (математика) или термин, обозначающий смещение
Пересечение или смещение относительно начала координат. Смещение — это параметр в моделях машинного обучения, который обозначается одним из следующих символов:
- б
- w 0
Например, смещение обозначается буквой b в следующей формуле:
В простой двумерной прямой смещение просто означает «пересечение с осью Y». Например, смещение прямой на следующем рисунке равно 2.
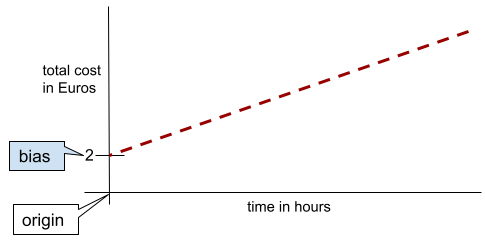
Смещение существует потому, что не все модели начинаются с начала координат (0,0). Например, предположим, что вход в парк развлечений стоит 2 евро, и дополнительно 0,5 евро за каждый час пребывания посетителя. Следовательно, модель, отображающая общую стоимость, имеет смещение, равное 2, поскольку минимальная стоимость составляет 2 евро.
Предвзятость не следует путать с предвзятостью в этике и справедливости или с предвзятостью прогнозирования .
Для получения более подробной информации см. краткий курс по линейной регрессии в машинном обучении.
двунаправленный
Термин, используемый для описания системы, которая оценивает текст, предшествующий и следующий за целевым разделом текста. В отличие от этого, однонаправленная система оценивает только текст, предшествующий целевому разделу текста.
Например, рассмотрим модель скрытого языка , которая должна определить вероятности для слова или слов, представляющих подчеркивание в следующем вопросе:
Что с тобой не так?
Однонаправленная языковая модель должна основывать свои вероятности только на контексте, предоставляемом словами «Что», «есть» и «это». В отличие от этого, двунаправленная языковая модель может также получать контекст из слов «с» и «ты», что может помочь модели генерировать более точные прогнозы.
двунаправленная языковая модель
Языковая модель , определяющая вероятность присутствия данного токена в данном месте в отрывке текста на основе предшествующего и последующего текста.
биграмма
N-грамма, в которой N=2.
бинарная классификация
Тип задачи классификации , в которой предсказывается один из двух взаимоисключающих классов:
Например, следующие две модели машинного обучения выполняют бинарную классификацию:
- Модель, определяющая, являются ли электронные письма спамом (положительный класс) или не спамом (отрицательный класс).
- Модель, которая оценивает медицинские симптомы, чтобы определить, есть ли у человека определенное заболевание (положительный класс) или нет (отрицательный класс).
В отличие от многоклассовой классификации .
См. также логистическую регрессию и порог классификации .
Дополнительную информацию см. в разделе «Краткий курс по классификации в машинном обучении».
бинарное условие
В дереве решений условие , имеющее только два возможных исхода, обычно «да» или «нет» . Например, следующее условие является бинарным:
temperature >= 100
Сравните с небинарным условием .
Дополнительную информацию см. в разделе «Типы условий» курса «Лесные модели принятия решений».
сортировка
Синоним слова «ведро» .
модель черного ящика
Модель , «рассуждения» которой невозможны или сложны для понимания человеком. То есть, хотя человек может видеть, как подсказки влияют на ответы , он не может точно определить, как модель «черного ящика» определяет ответ. Другими словами, модель «черного ящика» лишена интерпретируемости .
Большинство глубоких моделей и больших языковых моделей представляют собой «чёрные ящики».
BLEU (Двуязычный стажер по оценке)
Показатель от 0,0 до 1,0 для оценки машинного перевода , например, с испанского на японский.
Для расчета показателя BLEU обычно сравнивает перевод, выполненный моделью машинного обучения ( сгенерированный текст ), с переводом, выполненным экспертом ( эталонный текст ). Степень совпадения N-грамм в сгенерированном и эталонном тексте определяет показатель BLEU.
Оригинальная статья, посвященная этой метрике, называется BLEU: a Method for Automatic Evaluation of Machine Translation .
См. также BLEURT .
БЛЁРТ (студент-оценщик двуязычных курсов из компании Transformers)
Показатель для оценки машинного перевода с одного языка на другой, в частности, с английского на английский и с английского на английский.
При переводе с английского и на английский язык BLEURT больше соответствует оценкам людей, чем BLEU . В отличие от BLEU, BLEURT делает акцент на семантическом (смысловом) сходстве и допускает перефразирование.
BLEURT использует предварительно обученную большую языковую модель (точнее, BERT ), которая затем дорабатывается на текстах, предоставленных переводчиками-людьми.
Оригинальная статья, посвященная этой метрике, называется BLEURT: Learning Robust Metrics for Text Generation .
Логические вопросы (BoolQ)
Набор данных для оценки умения студентов магистратуры отвечать на вопросы с вариантами ответа «да» или «нет». Каждое из заданий в наборе данных состоит из трех компонентов:
- Запрос
- Отрывок, подразумевающий ответ на вопрос.
- Правильный ответ — да или нет .
Например:
- Вопрос : Есть ли в Мичигане атомные электростанции?
- Текст : ...три атомные электростанции обеспечивают штат Мичиган примерно 30% его электроэнергии.
- Правильный ответ : Да
Исследователи собрали вопросы из анонимизированных, агрегированных поисковых запросов Google, а затем использовали страницы Википедии для подтверждения полученной информации.
Для получения дополнительной информации см. BoolQ: Изучение удивительной сложности естественных вопросов типа «да/нет» .
BoolQ является компонентом ансамбля SuperGLUE .
BoolQ
Сокращение для логических вопросов .
повышение
Метод машинного обучения, который итеративно объединяет набор простых и не очень точных моделей классификации (называемых «слабыми классификаторами») в модель классификации с высокой точностью («сильный классификатор») путем повышения веса примеров, которые модель в данный момент классифицирует неправильно.
Дополнительную информацию см. в разделе «Градиентный бустинг деревьев решений?» в курсе «Леса решений».
ограничивающая рамка
На изображении координаты ( x , y ) прямоугольника, окружающего интересующую область, например, собаку на изображении ниже.

вещание
Расширение формы операнда в матричной математической операции до размеров, совместимых с этой операцией. Например, в линейной алгебре требуется, чтобы два операнда в операции сложения матриц имели одинаковые размеры. Следовательно, нельзя сложить матрицу формы (m, n) с вектором длины n. Широковещательная передача позволяет выполнить эту операцию, виртуально расширяя вектор длины n до матрицы формы (m, n) путем дублирования одних и тех же значений в каждом столбце.
Более подробное описание функции широковещательной рассылки в NumPy см. в следующем разделе.
ведро
Преобразование одного признака в несколько бинарных признаков, называемых интервалами или ячейками , обычно на основе диапазона значений. Обрезанный признак, как правило, является непрерывным признаком .
Например, вместо представления температуры в виде единого непрерывного значения с плавающей запятой, можно разделить диапазоны температур на дискретные интервалы, такие как:
- Температура <= 10 градусов Цельсия будет считаться "холодной".
- Температура от 11 до 24 градусов Цельсия соответствует "умеренному" климату.
- Температура выше или равная 25 градусам Цельсия будет считаться "теплой" температурой.
Модель будет обрабатывать каждое значение в одной и той же категории одинаково. Например, значения 13 и 22 находятся в категории умеренного климата, поэтому модель обрабатывает эти два значения одинаково.
Дополнительную информацию см. в разделе «Числовые данные: биннинг в машинном обучении» (краткий курс).
С
калибровочный слой
Постпрогнозная корректировка, как правило, для учета систематической ошибки прогнозирования . Скорректированные прогнозы и вероятности должны соответствовать распределению наблюдаемого набора меток.
генерация кандидатов
Первоначальный набор рекомендаций, выбранных рекомендательной системой . Например, рассмотрим книжный магазин, предлагающий 100 000 наименований. На этапе генерации кандидатов создается гораздо меньший список подходящих книг для конкретного пользователя, скажем, 500. Но даже 500 книг — это слишком много, чтобы рекомендовать их пользователю. Последующие, более дорогостоящие этапы рекомендательной системы (такие как оценка и переранжирование ) сокращают эти 500 до гораздо меньшего, более полезного набора рекомендаций.
Дополнительную информацию см. в разделе «Обзор генерации кандидатов» курса «Рекомендательные системы».
выборка кандидатов
Оптимизация времени обучения, которая вычисляет вероятность для всех положительных меток, используя, например, функцию softmax , но только для случайной выборки отрицательных меток. Например, для примера с метками «бигль» и «собака» метод выборки кандидатов вычисляет прогнозируемые вероятности и соответствующие члены функции потерь для:
- бигль
- собака
- случайное подмножество оставшихся отрицательных классов (например, кошка , леденец , забор ).
Идея заключается в том, что отрицательные классы могут учиться на менее частом отрицательном подкреплении, если положительные классы всегда получают надлежащее положительное подкрепление, и это действительно наблюдается эмпирически.
Метод выборочного отбора кандидатов более эффективен с точки зрения вычислительных ресурсов, чем алгоритмы обучения, которые вычисляют прогнозы для всех отрицательных классов, особенно когда количество отрицательных классов очень велико.
категориальные данные
Признаки, имеющие определенный набор возможных значений. Например, рассмотрим категориальный признак с именем traffic-light-state , который может принимать только одно из следующих трех возможных значений:
-
red -
yellow -
green
Представляя traffic-light-state как категориальный признак, модель может изучить различное влияние red , green и yellow на поведение водителя.
Категориальные признаки иногда называют дискретными признаками .
Сравните с числовыми данными .
Дополнительную информацию см. в разделе «Работа с категориальными данными» в кратком курсе по машинному обучению.
причинно-следственная языковая модель
Синоним для однонаправленной языковой модели .
См. двунаправленную языковую модель , чтобы сравнить различные направленные подходы в языковом моделировании.
КБ
Сокращенное название CommitmentBank .
центроид
Центр кластера определяется алгоритмом k-средних или k-медиан . Например, если k равно 3, то алгоритм k-средних или k-медиан находит 3 центроида.
Дополнительную информацию см. в разделе «Алгоритмы кластеризации» в курсе «Кластеризация».
кластеризация на основе центроидов
Категория алгоритмов кластеризации , которая организует данные в неиерархические кластеры. k-средних — наиболее широко используемый алгоритм кластеризации на основе центроидов.
Сравните с алгоритмами иерархической кластеризации .
Дополнительную информацию см. в разделе «Алгоритмы кластеризации» в курсе «Кластеризация».
цепочка мыслей подсказка
Метод разработки подсказок , который побуждает большую языковую модель (БЯМ) пошагово объяснять свои рассуждения. Например, рассмотрим следующую подсказку, обратив особое внимание на второе предложение:
Какую перегрузку (g) будет испытывать водитель в автомобиле, разгоняющемся от 0 до 60 миль в час за 7 секунд? В ответе покажите все необходимые расчеты.
Ответ магистра права, скорее всего, будет следующим:
- Представьте последовательность физических формул, подставив значения 0, 60 и 7 в соответствующие места.
- Объясните, почему были выбраны именно эти формулы и что означают различные переменные.
Метод подсказок, основанный на логической цепочке рассуждений, заставляет логическую модель выполнять все вычисления, что может привести к более правильному ответу. Кроме того, этот метод позволяет пользователю изучить шаги логической модели, чтобы определить, имеет ли ответ смысл.
F-мера N-граммы символа (ChrF)
Метрика для оценки моделей машинного перевода . Показатель F-меры для N-грамм символов определяет степень перекрытия N-грамм в эталонном тексте с N-граммами в тексте, сгенерированном моделью машинного перевода.
Показатель F-меры для N-грамм символов аналогичен метрикам семейств ROUGE и BLEU , за исключением того, что:
- Показатель F-score для символьных N-грамм применяется к символьным N-граммам.
- ROUGE и BLEU работают с N-граммами или токенами слов .
чат
Содержимое диалога с системой машинного обучения, как правило, с большой языковой моделью . Предыдущее взаимодействие в чате (то, что вы напечатали, и ответ большой языковой модели) становится контекстом для последующих частей чата.
Чат-бот — это приложение, использующее большую языковую модель.
контрольно-пропускной пункт
Данные, отражающие состояние параметров модели как во время обучения, так и после его завершения. Например, во время обучения можно:
- Прекратить тренировки, возможно, намеренно или, возможно, в результате допущенных ошибок.
- Захватите контрольно-пропускной пункт.
- Позже можно будет перезагрузить контрольную точку, возможно, на другом оборудовании.
- Перезапустить обучение.
Выбор правдоподобных альтернатив (COPA)
Набор данных для оценки того, насколько хорошо LLM может определить лучший из двух альтернативных ответов на предпосылку. Каждое из заданий в наборе данных состоит из трех компонентов:
- Предпосылка, которая обычно представляет собой утверждение, за которым следует вопрос.
- На поставленный в предпосылке вопрос можно ответить двумя способами, один из которых верен, а другой неверен.
- Правильный ответ
Например:
- Исходное предположение: Мужчина сломал палец на ноге. В чём причина этого?
- Возможные ответы:
- У него в носке образовалась дырка.
- Он уронил молоток себе на ногу.
- Правильный ответ: 2
COPA является компонентом ансамбля SuperGLUE .
сорт
Категория, к которой может относиться метка . Например:
- В модели бинарной классификации , предназначенной для обнаружения спама, два класса могут быть спамом , а два — не спамом .
- В многоклассовой модели классификации , определяющей породы собак, классами могут быть пудель , бигль , мопс и так далее.
Классификационная модель предсказывает класс. В отличие от неё, регрессионная модель предсказывает число, а не класс.
Дополнительную информацию см. в разделе «Краткий курс по классификации в машинном обучении».
сбалансированный по классам набор данных
Набор данных, содержащий категориальные метки , в котором количество экземпляров каждой категории приблизительно одинаково. Например, рассмотрим ботанический набор данных, бинарная метка которого может быть либо «местное растение» , либо «неместное растение» :
- Набор данных, содержащий 515 местных и 485 неместных растений, является сбалансированным по классам набором данных.
- Набор данных, содержащий 875 местных растений и 125 неместных растений, является несбалансированным по классам набором данных .
A formal dividing line between class-balanced datasets and class-imbalanced datasets doesn't exist. The distinction only becomes important when a model trained on a highly class-imbalanced dataset can't converge. See Datasets: imbalanced datasets in Machine Learning Crash Course for details.
модель классификации
A model whose prediction is a class . For example, the following are all classification models:
- A model that predicts an input sentence's language (French? Spanish? Italian?).
- A model that predicts tree species (Maple? Oak? Baobab?).
- A model that predicts the positive or negative class for a particular medical condition.
In contrast, regression models predict numbers rather than classes.
Two common types of classification models are:
classification threshold
In a binary classification , a number between 0 and 1 that converts the raw output of a logistic regression model into a prediction of either the positive class or the negative class . Note that the classification threshold is a value that a human chooses, not a value chosen by model training.
A logistic regression model outputs a raw value between 0 and 1. Then:
- If this raw value is greater than the classification threshold, then the positive class is predicted.
- If this raw value is less than the classification threshold, then the negative class is predicted.
For example, suppose the classification threshold is 0.8. If the raw value is 0.9, then the model predicts the positive class. If the raw value is 0.7, then the model predicts the negative class.
The choice of classification threshold strongly influences the number of false positives and false negatives .
Более подробную информацию см. в разделе «Пороги и матрица ошибок» в кратком курсе по машинному обучению.
классификатор
A casual term for a classification model .
class-imbalanced dataset
A dataset for a classification in which the total number of labels of each class differs significantly. For example, consider a binary classification dataset whose two labels are divided as follows:
- 1,000,000 negative labels
- 10 positive labels
The ratio of negative to positive labels is 100,000 to 1, so this is a class-imbalanced dataset.
In contrast, the following dataset is class-balanced because the ratio of negative labels to positive labels is relatively close to 1:
- 517 negative labels
- 483 positive labels
Multi-class datasets can also be class-imbalanced. For example, the following multi-class classification dataset is also class-imbalanced because one label has far more examples than the other two:
- 1,000,000 labels with class "green"
- 200 labels with class "purple"
- 350 labels with class "orange"
Training class-imbalanced datasets can present special challenges. See Imbalanced datasets in Machine Learning Crash Course for details.
See also entropy , majority class , and minority class .
обрезка
A technique for handling outliers by doing either or both of the following:
- Reducing feature values that are greater than a maximum threshold down to that maximum threshold.
- Увеличение значений характеристик, которые ниже минимального порогового значения, до этого минимального порогового значения.
Например, предположим, что менее 0,5% значений для определенного параметра выходят за пределы диапазона 40–60. В этом случае можно сделать следующее:
- Обрежьте все значения, превышающие 60 (максимальный порог), до значения ровно 60.
- Обрежьте все значения ниже 40 (минимальный порог) до значения ровно 40.
Выбросы могут навредить моделям, иногда вызывая переполнение весов во время обучения. Некоторые выбросы также могут значительно ухудшить такие показатели, как точность . Ограничение — распространенный метод для минимизации ущерба.
Ограничение градиента заставляет значения градиента находиться в заданном диапазоне во время обучения.
Дополнительную информацию см. в разделе «Числовые данные: нормализация в машинном обучении» (краткий курс).
Облачный TPU
Специализированный аппаратный ускоритель, разработанный для ускорения рабочих нагрузок машинного обучения в облаке Google.
кластеризация
Группировка связанных примеров , особенно в процессе обучения без учителя . После того, как все примеры сгруппированы, человек может по желанию придать смысл каждой группе.
Существует множество алгоритмов кластеризации. Например, алгоритм k-средних кластеризует примеры на основе их близости к центроиду , как показано на следующей диаграмме:

Затем исследователь-человек мог бы проанализировать эти кластеры и, например, обозначить кластер 1 как «карликовые деревья», а кластер 2 как «полноразмерные деревья».
В качестве еще одного примера рассмотрим алгоритм кластеризации, основанный на расстоянии примера от центральной точки, который иллюстрируется следующим образом:

Для получения более подробной информации см. курс «Кластеризация» .
коадаптация
Нежелательное поведение, при котором нейроны предсказывают закономерности в обучающих данных, полагаясь почти исключительно на выходные сигналы отдельных других нейронов, а не на поведение сети в целом. Когда закономерности, вызывающие коадаптацию, отсутствуют в данных валидации, коадаптация приводит к переобучению . Регуляризация с помощью Dropout уменьшает коадаптацию, поскольку Dropout гарантирует, что нейроны не могут полагаться исключительно на отдельные другие нейроны.
коллаборативная фильтрация
Прогнозирование интересов одного пользователя на основе интересов многих других пользователей. Коллаборативная фильтрация часто используется в рекомендательных системах .
Дополнительную информацию см. в разделе «Коллаборативная фильтрация» курса «Рекомендательные системы».
CommitmentBank (CB)
Набор данных для оценки уровня владения студентом магистратуры правом определять, верит ли автор отрывка текста целевому предложению в этом отрывке. Каждая запись в наборе данных содержит:
- Отрывок
- Целевое предложение в этом отрывке
- Логическое значение, указывающее, верит ли автор отрывка целевому предложению.
Например:
- Отрывок: Как же приятно слышать смех Артемиды. Она такая серьёзная девочка. Я и не знала, что у неё есть чувство юмора.
- Целевое условие: у неё было чувство юмора
- Логическое значение : True, что означает, что автор верит целевому предложению.
CommitmentBank является компонентом комплекса SuperGLUE .
компактная модель
Любая компактная модель, предназначенная для работы на небольших устройствах с ограниченными вычислительными ресурсами. Например, компактные модели могут работать на мобильных телефонах, планшетах или встроенных системах.
вычислить
(Существительное) Вычислительные ресурсы, используемые моделью или системой, такие как вычислительная мощность, память и хранилище.
См. микросхемы ускорителей .
дрейф концепции
Изменение взаимосвязи между характеристиками и меткой. Со временем дрейф концепции снижает качество модели.
В процессе обучения модель изучает взаимосвязь между признаками и их метками в обучающем наборе данных. Если метки в обучающем наборе данных хорошо соответствуют реальному миру, то модель должна делать хорошие прогнозы в реальном мире. Однако из-за дрейфа концепции точность прогнозов модели со временем имеет тенденцию снижаться.
Например, рассмотрим модель бинарной классификации , которая предсказывает, является ли определенная модель автомобиля «экономичной с точки зрения расхода топлива». То есть, признаками могут быть:
- вес автомобиля
- компрессия двигателя
- transmission type
при этом метка может быть любой из следующих:
- экономичный расход топлива
- неэкономичен с точки зрения расхода топлива
Однако концепция «экономичного автомобиля» постоянно меняется. Модель автомобиля, названная экономичной в 1994 году, почти наверняка будет названа неэкономичной в 2024 году. Модель, страдающая от концептуального дрейфа, со временем, как правило, дает все менее и менее полезные прогнозы.
Сравните и сопоставьте с нестационарностью .
состояние
В дереве решений любой узел выполняет проверку. Например, следующее дерево решений содержит два условия: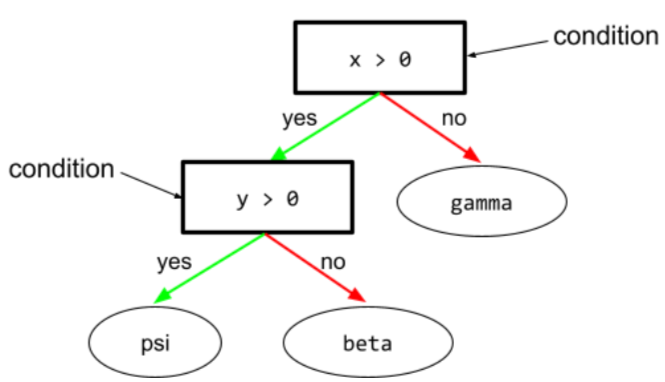
Условие также называется расщеплением или тестом.
Сравните условия с состоянием листа .
См. также:
Дополнительную информацию см. в разделе «Типы условий» курса «Лесные модели принятия решений».
конфабуляция
Синоним слова «галлюцинация» .
Конфабуляция, вероятно, является более точным с технической точки зрения термином, чем галлюцинация. Однако термин «галлюцинация» стал популярным первым.
конфигурация
Процесс присвоения начальных значений свойствам, используемым для обучения модели, включает в себя:
- составные слои модели
- местоположение данных
- гиперпараметры, такие как:
В проектах по машинному обучению настройка может осуществляться с помощью специального конфигурационного файла или библиотек конфигурации, таких как следующие:
предвзятость подтверждения
Тенденция искать, интерпретировать, отдавать предпочтение и вспоминать информацию таким образом, чтобы она подтверждала уже существующие убеждения или гипотезы. Разработчики машинного обучения могут непреднамеренно собирать или маркировать данные таким образом, что это влияет на результат, подтверждающий их существующие убеждения. Предвзятость подтверждения — это форма скрытой предвзятости .
Предвзятость экспериментатора — это форма предвзятости подтверждения, при которой экспериментатор продолжает обучение моделей до тех пор, пока не подтвердится ранее выдвинутая гипотеза.
матрица ошибок
Таблица размером NxN, в которой суммируется количество правильных и неправильных предсказаний, сделанных моделью классификации . Например, рассмотрим следующую матрицу ошибок для модели бинарной классификации :
| Опухоль (прогнозируемая) | Неопухолевый (прогнозируемый) | |
|---|---|---|
| Опухоль (эталонные данные) | 18 (ТП) | 1 (FN) |
| Нетуморальный (эталонный) | 6 (FP) | 452 (ТН) |
Представленная выше матрица ошибок показывает следующее:
- Из 19 прогнозов, в которых в качестве истинного диагноза была указана опухоль, модель правильно классифицировала 18 и неправильно классифицировала 1.
- Из 458 прогнозов, в которых истинное значение указывало на отсутствие опухоли, модель правильно классифицировала 452 случая и неправильно — 6.
The confusion matrix for a multi-class classification problem can help you identify patterns of mistakes. For example, consider the following confusion matrix for a 3-class multi-class classification model that categorizes three different iris types (Virginica, Versicolor, and Setosa). When the ground truth was Virginica, the confusion matrix shows that the model was far more likely to mistakenly predict Versicolor than Setosa:
| Setosa (predicted) | Versicolor (predicted) | Virginica (predicted) | |
|---|---|---|---|
| Setosa (ground truth) | 88 | 12 | 0 |
| Versicolor (ground truth) | 6 | 141 | 7 |
| Virginica (ground truth) | 2 | 27 | 109 |
As yet another example, a confusion matrix could reveal that a model trained to recognize handwritten digits tends to mistakenly predict 9 instead of 4, or mistakenly predict 1 instead of 7.
Confusion matrixes contain sufficient information to calculate a variety of performance metrics, including precision and recall .
анализ избирательных округов
Dividing a sentence into smaller grammatical structures ("constituents"). A later part of the ML system, such as a natural language understanding model, can parse the constituents more easily than the original sentence. For example, consider the following sentence:
My friend adopted two cats.
A constituency parser can divide this sentence into the following two constituents:
- My friend is a noun phrase.
- adopted two cats is a verb phrase.
These constituents can be further subdivided into smaller constituents. For example, the verb phrase
adopted two cats
could be further subdivided into:
- adopted is a verb.
- two cats is another noun phrase.
контекстуализированное встраивание языка
An embedding that comes close to "understanding" words and phrases in ways that fluent human speakers can. Contextualized language embeddings can understand complex syntax, semantics, and context.
For example, consider embeddings of the English word cow . Older embeddings such as word2vec can represent English words such that the distance in the embedding space from cow to bull is similar to the distance from ewe (female sheep) to ram (male sheep) or from female to male . Contextualized language embeddings can go a step further by recognizing that English speakers sometimes casually use the word cow to mean either cow or bull.
контекстное окно
The number of tokens a model can process in a given prompt . The larger the context window, the more information the model can use to provide coherent and consistent responses to the prompt.
непрерывная функция
A floating-point feature with an infinite range of possible values, such as temperature or weight.
Contrast with discrete feature .
выборочная выборка по удобству
Using a dataset not gathered scientifically in order to run quick experiments. Later on, it's essential to switch to a scientifically gathered dataset.
конвергенция
A state reached when loss values change very little or not at all with each iteration . For example, the following loss curve suggests convergence at around 700 iterations:
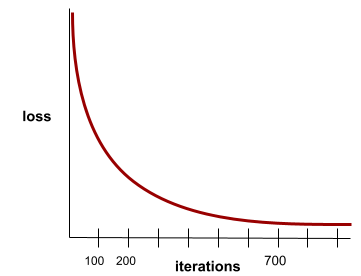
A model converges when additional training won't improve the model.
In deep learning , loss values sometimes stay constant or nearly so for many iterations before finally descending. During a long period of constant loss values, you may temporarily get a false sense of convergence.
See also early stopping .
See Model convergence and loss curves in Machine Learning Crash Course for more information.
разговорное программирование
An iterative dialog between you and a generative AI model for the purpose of creating software. You issue a prompt describing some software. Then, the model uses that description to generate code. Then, you issue a new prompt to address the flaws in the previous prompt or in the generated code, and the model generates updated code. You two keep going back and forth until the generated software is good enough.
Conversation coding is essentially the original meaning of vibe coding .
Contrast with specificational coding .
выпуклая функция
A function in which the region above the graph of the function is a convex set . The prototypical convex function is shaped something like the letter U . For example, the following are all convex functions:
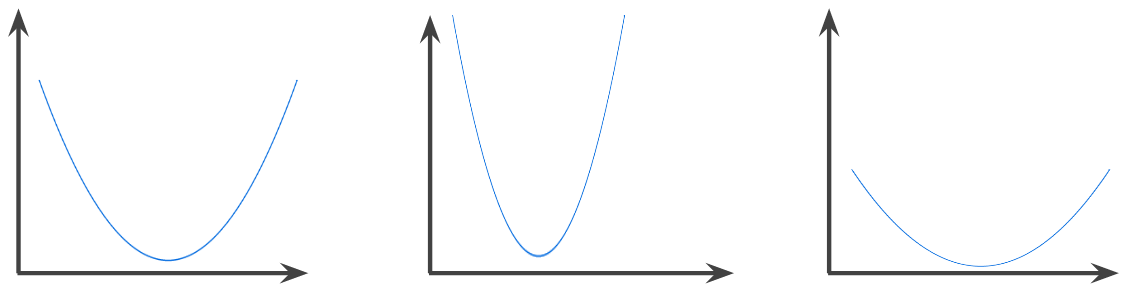
In contrast, the following function is not convex. Notice how the region above the graph is not a convex set:

A strictly convex function has exactly one local minimum point, which is also the global minimum point. The classic U-shaped functions are strictly convex functions. However, some convex functions (for example, straight lines) are not U-shaped.
See Convergence and convex functions in Machine Learning Crash Course for more information.
выпуклая оптимизация
The process of using mathematical techniques such as gradient descent to find the minimum of a convex function . A great deal of research in machine learning has focused on formulating various problems as convex optimization problems and in solving those problems more efficiently.
For complete details, see Boyd and Vandenberghe, Convex Optimization .
выпуклое множество
A subset of Euclidean space such that a line drawn between any two points in the subset remains completely within the subset. For instance, the following two shapes are convex sets:

In contrast, the following two shapes are not convex sets:

свертка
In mathematics, casually speaking, a mixture of two functions. In machine learning, a convolution mixes the convolutional filter and the input matrix in order to train weights .
The term "convolution" in machine learning is often a shorthand way of referring to either convolutional operation or convolutional layer .
Without convolutions, a machine learning algorithm would have to learn a separate weight for every cell in a large tensor . For example, a machine learning algorithm training on 2K x 2K images would be forced to find 4M separate weights. Thanks to convolutions, a machine learning algorithm only has to find weights for every cell in the convolutional filter , dramatically reducing the memory needed to train the model. When the convolutional filter is applied, it is simply replicated across cells such that each is multiplied by the filter.
сверточный фильтр
One of the two actors in a convolutional operation . (The other actor is a slice of an input matrix.) A convolutional filter is a matrix having the same rank as the input matrix, but a smaller shape. For example, given a 28x28 input matrix, the filter could be any 2D matrix smaller than 28x28.
In photographic manipulation, all the cells in a convolutional filter are typically set to a constant pattern of ones and zeroes. In machine learning, convolutional filters are typically seeded with random numbers and then the network trains the ideal values.
сверточный слой
A layer of a deep neural network in which a convolutional filter passes along an input matrix. For example, consider the following 3x3 convolutional filter :
![Матрица 3x3 со следующими значениями: [[0,1,0], [1,0,1], [0,1,0]]](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalFilter33.svg?hl=ru)
The following animation shows a convolutional layer consisting of 9 convolutional operations involving the 5x5 input matrix. Notice that each convolutional operation works on a different 3x3 slice of the input matrix. The resulting 3x3 matrix (on the right) consists of the results of the 9 convolutional operations:
![An animation showing two matrixes. The first matrix is the 5x5
matrix: [[128,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]].
The second matrix is the 3x3 matrix:
[[181,303,618], [115,338,605], [169,351,560]].
The second matrix is calculated by applying the convolutional
filter [[0, 1, 0], [1, 0, 1], [0, 1, 0]] across
different 3x3 subsets of the 5x5 matrix.](https://developers.google.com/static/machine-learning/glossary/images/AnimatedConvolution.gif?hl=ru)
сверточная нейронная сеть
A neural network in which at least one layer is a convolutional layer . A typical convolutional neural network consists of some combination of the following layers:
Convolutional neural networks have had great success in certain kinds of problems, such as image recognition.
сверточная операция
The following two-step mathematical operation:
- Element-wise multiplication of the convolutional filter and a slice of an input matrix. (The slice of the input matrix has the same rank and size as the convolutional filter.)
- Summation of all the values in the resulting product matrix.
For example, consider the following 5x5 input matrix:
![The 5x5 matrix: [[128,97,53,201,198], [35,22,25,200,195],
[37,24,28,197,182], [33,28,92,195,179], [31,40,100,192,177]].](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerInputMatrix.svg?hl=ru)
Now imagine the following 2x2 convolutional filter:
![Матрица 2x2: [[1, 0], [0, 1]]](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerFilter.svg?hl=ru)
Each convolutional operation involves a single 2x2 slice of the input matrix. For example, suppose we use the 2x2 slice at the top-left of the input matrix. So, the convolution operation on this slice looks as follows:
![Applying the convolutional filter [[1, 0], [0, 1]] to the top-left
2x2 section of the input matrix, which is [[128,97], [35,22]].
The convolutional filter leaves the 128 and 22 intact, but zeroes
out the 97 and 35. Consequently, the convolution operation yields
the value 150 (128+22).](https://developers.google.com/static/machine-learning/glossary/images/ConvolutionalLayerOperation.svg?hl=ru)
A convolutional layer consists of a series of convolutional operations, each acting on a different slice of the input matrix.
КОПА
Abbreviation for Choice of Plausible Alternatives .
расходы
Synonym for loss .
совместное обучение
A semi-supervised learning approach particularly useful when all of the following conditions are true:
- В наборе данных высокое соотношение немаркированных примеров к маркированным примерам .
- This is a classification problem ( binary or multi-class ).
- The dataset contains two different sets of predictive features that are independent of each other and complementary.
Co-training essentially amplifies independent signals into a stronger signal. For example, consider a classification model that categorizes individual used cars as either Good or Bad . One set of predictive features might focus on aggregate characteristics such as the year, make, and model of the car; another set of predictive features might focus on the previous owner's driving record and the car's maintenance history.
The seminal paper on co-training is Combining Labeled and Unlabeled Data with Co-Training by Blum and Mitchell.
контрфактуальная справедливость
A fairness metric that checks whether a classification model produces the same result for one individual as it does for another individual who is identical to the first, except with respect to one or more sensitive attributes . Evaluating a classification model for counterfactual fairness is one method for surfacing potential sources of bias in a model.
See either of the following for more information:
- Fairness: Counterfactual fairness in Machine Learning Crash Course.
- When Worlds Collide: Integrating Different Counterfactual Assumptions in Fairness
смещение охвата
See selection bias .
круша цветения
A sentence or phrase with an ambiguous meaning. Crash blossoms present a significant problem in natural language understanding . For example, the headline Red Tape Holds Up Skyscraper is a crash blossom because an NLU model could interpret the headline literally or figuratively.
критик
Synonym for Deep Q-Network .
перекрестная энтропия
A generalization of Log Loss to multi-class classification problems . Cross-entropy quantifies the difference between two probability distributions. See also perplexity .
перекрестная проверка
A mechanism for estimating how well a model would generalize to new data by testing the model against one or more non-overlapping data subsets withheld from the training set .
Функция кумулятивного распределения (ФКР)
A function that defines the frequency of samples less than or equal to a target value. For example, consider a normal distribution of continuous values. A CDF tells you that approximately 50% of samples should be less than or equal to the mean and that approximately 84% of samples should be less than or equal to one standard deviation above the mean.
Д
анализ данных
Obtaining an understanding of data by considering samples, measurement, and visualization. Data analysis can be particularly useful when a dataset is first received, before one builds the first model . It is also crucial in understanding experiments and debugging problems with the system.
data augmentation
Artificially boosting the range and number of training examples by transforming existing examples to create additional examples. For example, suppose images are one of your features , but your dataset doesn't contain enough image examples for the model to learn useful associations. Ideally, you'd add enough labeled images to your dataset to enable your model to train properly. If that's not possible, data augmentation can rotate, stretch, and reflect each image to produce many variants of the original picture, possibly yielding enough labeled data to enable excellent training.
DataFrame
A popular pandas data type for representing datasets in memory.
A DataFrame is analogous to a table or a spreadsheet. Each column of a DataFrame has a name (a header), and each row is identified by a unique number.
Each column in a DataFrame is structured like a 2D array, except that each column can be assigned its own data type.
See also the official pandas.DataFrame reference page .
data parallelism
A way of scaling training or inference that replicates an entire model onto multiple devices and then passes a subset of the input data to each device. Data parallelism can enable training and inference on very large batch sizes ; however, data parallelism requires that the model be small enough to fit on all devices.
Data parallelism typically speeds training and inference.
See also model parallelism .
Dataset API (tf.data)
A high-level TensorFlow API for reading data and transforming it into a form that a machine learning algorithm requires. A tf.data.Dataset object represents a sequence of elements, in which each element contains one or more Tensors . A tf.data.Iterator object provides access to the elements of a Dataset .
data set or dataset
A collection of raw data, commonly (but not exclusively) organized in one of the following formats:
- электронная таблица
- a file in CSV (comma-separated values) format
decision boundary
The separator between classes learned by a model in a binary class or multi-class classification problems . For example, in the following image representing a binary classification problem, the decision boundary is the frontier between the orange class and the blue class:

decision forest
A model created from multiple decision trees . A decision forest makes a prediction by aggregating the predictions of its decision trees. Popular types of decision forests include random forests and gradient boosted trees .
See the Decision Forests section in the Decision Forests course for more information.
decision threshold
Synonym for classification threshold .
дерево решений
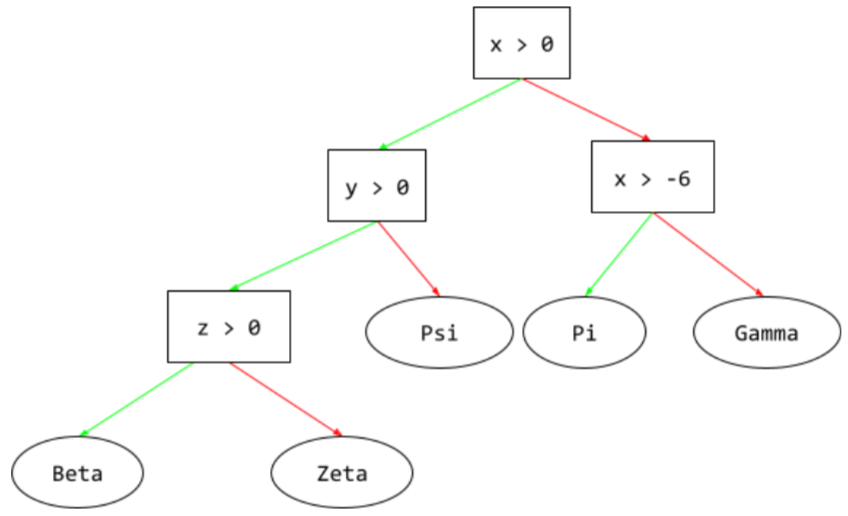
A supervised learning model composed of a set of conditions and leaves organized hierarchically. For example, the following is a decision tree:
декодер
In general, any ML system that converts from a processed, dense, or internal representation to a more raw, sparse, or external representation.
Decoders are often a component of a larger model, where they are frequently paired with an encoder .
In sequence-to-sequence tasks , a decoder starts with the internal state generated by the encoder to predict the next sequence.
Refer to Transformer for the definition of a decoder within the Transformer architecture.
See Large language models in Machine Learning Crash Course for more information.
deep model
A neural network containing more than one hidden layer .
A deep model is also called a deep neural network .
Contrast with wide model .
глубокая нейронная сеть
Synonym for deep model .
Глубокая Q-сеть (DQN)
In Q-learning , a deep neural network that predicts Q-functions .
Critic is a synonym for Deep Q-Network.
демографическое равенство
A fairness metric that is satisfied if the results of a model's classification are not dependent on a given sensitive attribute .
For example, if both Lilliputians and Brobdingnagians apply to Glubbdubdrib University, demographic parity is achieved if the percentage of Lilliputians admitted is the same as the percentage of Brobdingnagians admitted, irrespective of whether one group is on average more qualified than the other.
Contrast with equalized odds and equality of opportunity , which permit classification results in aggregate to depend on sensitive attributes, but don't permit classification results for certain specified ground truth labels to depend on sensitive attributes. See "Attacking discrimination with smarter machine learning" for a visualization exploring the tradeoffs when optimizing for demographic parity.
See Fairness: demographic parity in Machine Learning Crash Course for more information.
шумоподавление
A common approach to self-supervised learning in which:
Denoising enables learning from unlabeled examples . The original dataset serves as the target or label and the noisy data as the input.
Some masked language models use denoising as follows:
- Noise is artificially added to an unlabeled sentence by masking some of the tokens.
- The model tries to predict the original tokens.
dense feature
A feature in which most or all values are nonzero, typically a Tensor of floating-point values. For example, the following 10-element Tensor is dense because 9 of its values are nonzero:
| 8 | 3 | 7 | 5 | 2 | 4 | 0 | 4 | 9 | 6 |
Contrast with sparse feature .
плотный слой
Synonym for fully connected layer .
глубина
The sum of the following in a neural network :
- the number of hidden layers
- the number of output layers , which is typically 1
- the number of any embedding layers
For example, a neural network with five hidden layers and one output layer has a depth of 6.
Notice that the input layer doesn't influence depth.
depthwise separable convolutional neural network (sepCNN)
A convolutional neural network architecture based on Inception , but where Inception modules are replaced with depthwise separable convolutions. Also known as Xception.
A depthwise separable convolution (also abbreviated as separable convolution) factors a standard 3D convolution into two separate convolution operations that are more computationally efficient: first, a depthwise convolution, with a depth of 1 (n ✕ n ✕ 1), and then second, a pointwise convolution, with length and width of 1 (1 ✕ 1 ✕ n).
To learn more, see Xception: Deep Learning with Depthwise Separable Convolutions .
derived label
Synonym for proxy label .
устройство
An overloaded term with the following two possible definitions:
- A category of hardware that can run a TensorFlow session, including CPUs, GPUs, and TPUs .
- When training an ML model on accelerator chips (GPUs or TPUs), the part of the system that actually manipulates tensors and embeddings . The device runs on accelerator chips. In contrast, the host typically runs on a CPU.
differential privacy
In machine learning, an anonymization approach to protect any sensitive data (for example, an individual's personal information) included in a model's training set from being exposed. This approach ensures that the model doesn't learn or remember much about a specific individual. This is accomplished by sampling and adding noise during model training to obscure individual data points, mitigating the risk of exposing sensitive training data.
Differential privacy is also used outside of machine learning. For example, data scientists sometimes use differential privacy to protect individual privacy when computing product usage statistics for different demographics.
dimension reduction
Decreasing the number of dimensions used to represent a particular feature in a feature vector, typically by converting to an embedding vector .
размеры
Overloaded term having any of the following definitions:
The number of levels of coordinates in a Tensor . For example:
- A scalar has zero dimensions; for example,
["Hello"]. - A vector has one dimension; for example,
[3, 5, 7, 11]. - A matrix has two dimensions; for example,
[[2, 4, 18], [5, 7, 14]]. You can uniquely specify a particular cell in a one-dimensional vector with one coordinate; you need two coordinates to uniquely specify a particular cell in a two-dimensional matrix.
- A scalar has zero dimensions; for example,
The number of entries in a feature vector .
The number of elements in an embedding layer .
direct prompting
Synonym for zero-shot prompting .
discrete feature
A feature with a finite set of possible values. For example, a feature whose values may only be animal , vegetable , or mineral is a discrete (or categorical) feature.
Contrast with continuous feature .
дискриминативная модель
A model that predicts labels from a set of one or more features . More formally, discriminative models define the conditional probability of an output given the features and weights ; that is:
p(output | features, weights)
For example, a model that predicts whether an email is spam from features and weights is a discriminative model.
The vast majority of supervised learning models, including classification and regression models, are discriminative models.
Contrast with generative model .
дискриминатор
A system that determines whether examples are real or fake.
Alternatively, the subsystem within a generative adversarial network that determines whether the examples created by the generator are real or fake.
See The discriminator in the GAN course for more information.
неравномерное воздействие
Making decisions about people that impact different population subgroups disproportionately. This usually refers to situations where an algorithmic decision-making process harms or benefits some subgroups more than others.
For example, suppose an algorithm that determines a Lilliputian's eligibility for a miniature-home loan is more likely to classify them as "ineligible" if their mailing address contains a certain postal code. If Big-Endian Lilliputians are more likely to have mailing addresses with this postal code than Little-Endian Lilliputians, then this algorithm may result in disparate impact.
Contrast with disparate treatment , which focuses on disparities that result when subgroup characteristics are explicit inputs to an algorithmic decision-making process.
неравное обращение
Factoring subjects' sensitive attributes into an algorithmic decision-making process such that different subgroups of people are treated differently.
For example, consider an algorithm that determines Lilliputians' eligibility for a miniature-home loan based on the data they provide in their loan application. If the algorithm uses a Lilliputian's affiliation as Big-Endian or Little-Endian as an input, it is enacting disparate treatment along that dimension.
Contrast with disparate impact , which focuses on disparities in the societal impacts of algorithmic decisions on subgroups, irrespective of whether those subgroups are inputs to the model.
дистилляция
The process of reducing the size of one model (known as the teacher ) into a smaller model (known as the student ) that emulates the original model's predictions as faithfully as possible. Distillation is useful because the smaller model has two key benefits over the larger model (the teacher):
- Faster inference time
- Reduced memory and energy usage
However, the student's predictions are typically not as good as the teacher's predictions.
Distillation trains the student model to minimize a loss function based on the difference between the outputs of the predictions of the student and teacher models.
Compare and contrast distillation with the following terms:
See LLMs: Fine-tuning, distillation, and prompt engineering in Machine Learning Crash Course for more information.
распределение
The frequency and range of different values for a given feature or label . A distribution captures how likely a particular value is.
The following image shows histograms of two different distributions:
- On the left, a power law distribution of wealth versus the number of people possessing that wealth.
- On the right, a normal distribution of height versus the number of people possessing that height.
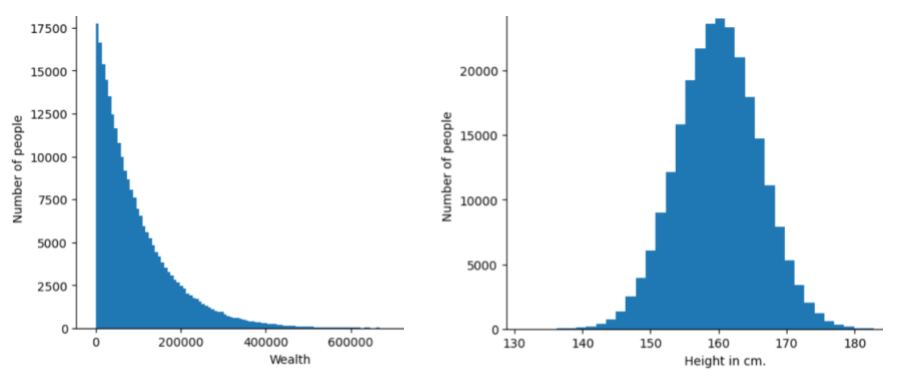
Understanding each feature and label's distribution can help you determine how to normalize values and detect outliers .
The phrase out of distribution refers to a value that doesn't appear in the dataset or is very rare. For example, an image of the planet Saturn would be considered out of distribution for a dataset consisting of cat images.
divisive clustering
See hierarchical clustering .
понижение разрешения
Overloaded term that can mean either of the following:
- Reducing the amount of information in a feature in order to train a model more efficiently. For example, before training an image recognition model, downsampling high-resolution images to a lower-resolution format.
- Training on a disproportionately low percentage of over-represented class examples in order to improve model training on under-represented classes. For example, in a class-imbalanced dataset , models tend to learn a lot about the majority class and not enough about the minority class . Downsampling helps balance the amount of training on the majority and minority classes.
Дополнительную информацию см. в разделе «Наборы данных: Несбалансированные наборы данных» в кратком курсе по машинному обучению.
ДКН
Abbreviation for Deep Q-Network .
dropout regularization
A form of regularization useful in training neural networks . Dropout regularization removes a random selection of a fixed number of the units in a network layer for a single gradient step. The more units dropped out, the stronger the regularization. This is analogous to training the network to emulate an exponentially large ensemble of smaller networks. For full details, see Dropout: A Simple Way to Prevent Neural Networks from Overfitting .
динамический
Something done frequently or continuously. The terms dynamic and online are synonyms in machine learning. The following are common uses of dynamic and online in machine learning:
- A dynamic model (or online model ) is a model that is retrained frequently or continuously.
- Dynamic training (or online training ) is the process of training frequently or continuously.
- Dynamic inference (or online inference ) is the process of generating predictions on demand.
динамическая модель
A model that is frequently (maybe even continuously) retrained. A dynamic model is a "lifelong learner" that constantly adapts to evolving data. A dynamic model is also known as an online model .
Contrast with static model .
Е
eager execution
A TensorFlow programming environment in which operations run immediately. In contrast, operations called in graph execution don't run until they are explicitly evaluated. Eager execution is an imperative interface , much like the code in most programming languages. Eager execution programs are generally far easier to debug than graph execution programs.
ранняя остановка
A method for regularization that involves ending training before training loss finishes decreasing. In early stopping, you intentionally stop training the model when the loss on a validation dataset starts to increase; that is, when generalization performance worsens.
Contrast with early exit .
earth mover's distance (EMD)
A measure of the relative similarity of two distributions . The lower the earth mover's distance, the more similar the distributions.
расстояние редактирования
A measurement of how similar two text strings are to each other. In machine learning, edit distance is useful for the following reasons:
- Edit distance is easy to compute.
- Edit distance can compare two strings known to be similar to each other.
- Edit distance can determine the degree to which different strings are similar to a given string.
Several definitions of edit distance exist, each using different string operations. See Levenshtein distance for an example.
Einsum notation
An efficient notation for describing how two tensors are to be combined. The tensors are combined by multiplying the elements of one tensor by the elements of the other tensor and then summing the products. Einsum notation uses symbols to identify the axes of each tensor, and those same symbols are rearranged to specify the shape of the new resulting tensor.
NumPy provides a common Einsum implementation.
embedding layer
A special hidden layer that trains on a high-dimensional categorical feature to gradually learn a lower dimension embedding vector. An embedding layer enables a neural network to train far more efficiently than training just on the high-dimensional categorical feature.
For example, Earth currently supports about 73,000 tree species. Suppose tree species is a feature in your model, so your model's input layer includes a one-hot vector 73,000 elements long. For example, perhaps baobab would be represented something like this:

A 73,000-element array is very long. If you don't add an embedding layer to the model, training is going to be very time consuming due to multiplying 72,999 zeros. Perhaps you pick the embedding layer to consist of 12 dimensions. Consequently, the embedding layer will gradually learn a new embedding vector for each tree species.
In certain situations, hashing is a reasonable alternative to an embedding layer.
See Embeddings in Machine Learning Crash Course for more information.
embedding space
The d-dimensional vector space that features from a higher-dimensional vector space are mapped to. Embedding space is trained to capture structure that is meaningful for the intended application.
The dot product of two embeddings is a measure of their similarity.
вектор встраивания
Broadly speaking, an array of floating-point numbers taken from any hidden layer that describe the inputs to that hidden layer. Often, an embedding vector is the array of floating-point numbers trained in an embedding layer. For example, suppose an embedding layer must learn an embedding vector for each of the 73,000 tree species on Earth. Perhaps the following array is the embedding vector for a baobab tree:

An embedding vector is not a bunch of random numbers. An embedding layer determines these values through training, similar to the way a neural network learns other weights during training. Each element of the array is a rating along some characteristic of a tree species. Which element represents which tree species' characteristic? That's very hard for humans to determine.
The mathematically remarkable part of an embedding vector is that similar items have similar sets of floating-point numbers. For example, similar tree species have a more similar set of floating-point numbers than dissimilar tree species. Redwoods and sequoias are related tree species, so they'll have a more similar set of floating-pointing numbers than redwoods and coconut palms. The numbers in the embedding vector will change each time you retrain the model, even if you retrain the model with identical input.
empirical cumulative distribution function (eCDF or EDF)
A cumulative distribution function based on empirical measurements from a real dataset. The value of the function at any point along the x-axis is the fraction of observations in the dataset that are less than or equal to the specified value.
empirical risk minimization (ERM)
Choosing the function that minimizes loss on the training set. Contrast with structural risk minimization .
кодировщик
In general, any ML system that converts from a raw, sparse, or external representation into a more processed, denser, or more internal representation.
Encoders are often a component of a larger model, where they are frequently paired with a decoder . Some Transformers pair encoders with decoders, though other Transformers use only the encoder or only the decoder.
Some systems use the encoder's output as the input to a classification or regression network.
In sequence-to-sequence tasks , an encoder takes an input sequence and returns an internal state (a vector). Then, the decoder uses that internal state to predict the next sequence.
Refer to Transformer for the definition of an encoder in the Transformer architecture.
See LLMs: What's a large language model in Machine Learning Crash Course for more information.
конечные точки
A network-addressable location (typically a URL) where a service can be reached.
ансамбль
A collection of models trained independently whose predictions are averaged or aggregated. In many cases, an ensemble produces better predictions than a single model. For example, a random forest is an ensemble built from multiple decision trees . Note that not all decision forests are ensembles.
See Random Forest in Machine Learning Crash Course for more information.
энтропия
In information theory , a description of how unpredictable a probability distribution is. Alternatively, entropy is also defined as how much information each example contains. A distribution has the highest possible entropy when all values of a random variable are equally likely.
The entropy of a set with two possible values "0" and "1" (for example, the labels in a binary classification problem) has the following formula:
H = -p log p - q log q = -p log p - (1-p) * log (1-p)
где:
- H is the entropy.
- p is the fraction of "1" examples.
- q is the fraction of "0" examples. Note that q = (1 - p)
- log is generally log 2 . In this case, the entropy unit is a bit.
For example, suppose the following:
- 100 examples contain the value "1"
- 300 examples contain the value "0"
Therefore, the entropy value is:
- p = 0,25
- q = 0.75
- H = (-0.25)log 2 (0.25) - (0.75)log 2 (0.75) = 0.81 bits per example
A set that is perfectly balanced (for example, 200 "0"s and 200 "1"s) would have an entropy of 1.0 bit per example. As a set becomes more imbalanced , its entropy moves towards 0.0.
In decision trees , entropy helps formulate information gain to help the splitter select the conditions during the growth of a classification decision tree.
Compare entropy with:
- примесь Джини
- cross-entropy loss function
Entropy is often called Shannon's entropy .
See Exact splitter for binary classification with numerical features in the Decision Forests course for more information.
среда
In reinforcement learning, the world that contains the agent and allows the agent to observe that world's state . For example, the represented world can be a game like chess, or a physical world like a maze. When the agent applies an action to the environment, then the environment transitions between states.
эпизод
In reinforcement learning, each of the repeated attempts by the agent to learn an environment .
эпоха
A full training pass over the entire training set such that each example has been processed once.
An epoch represents N / batch size training iterations , where N is the total number of examples.
For instance, suppose the following:
- The dataset consists of 1,000 examples.
- The batch size is 50 examples.
Therefore, a single epoch requires 20 iterations:
1 epoch = (N/batch size) = (1,000 / 50) = 20 iterations
Дополнительную информацию см. в статье «Линейная регрессия: гиперпараметры в машинном обучении» (краткий курс).
эпсилон жадная политика
In reinforcement learning, a policy that either follows a random policy with epsilon probability or a greedy policy otherwise. For example, if epsilon is 0.9, then the policy follows a random policy 90% of the time and a greedy policy 10% of the time.
Over successive episodes, the algorithm reduces epsilon's value in order to shift from following a random policy to following a greedy policy. By shifting the policy, the agent first randomly explores the environment and then greedily exploits the results of random exploration.
equality of opportunity
A fairness metric to assess whether a model is predicting the desirable outcome equally well for all values of a sensitive attribute . In other words, if the desirable outcome for a model is the positive class , the goal would be to have the true positive rate be the same for all groups.
Equality of opportunity is related to equalized odds , which requires that both the true positive rates and false positive rates are the same for all groups.
Suppose Glubbdubdrib University admits both Lilliputians and Brobdingnagians to a rigorous mathematics program. Lilliputians' secondary schools offer a robust curriculum of math classes, and the vast majority of students are qualified for the university program. Brobdingnagians' secondary schools don't offer math classes at all, and as a result, far fewer of their students are qualified. Equality of opportunity is satisfied for the preferred label of "admitted" with respect to nationality (Lilliputian or Brobdingnagian) if qualified students are equally likely to be admitted irrespective of whether they're a Lilliputian or a Brobdingnagian.
For example, suppose 100 Lilliputians and 100 Brobdingnagians apply to Glubbdubdrib University, and admissions decisions are made as follows:
Table 1. Lilliputian applicants (90% are qualified)
| Квалифицированный | Неквалифицированный | |
|---|---|---|
| Допущенный | 45 | 3 |
| Отклоненный | 45 | 7 |
| Общий | 90 | 10 |
| Percentage of qualified students admitted: 45/90 = 50% Percentage of unqualified students rejected: 7/10 = 70% Total percentage of Lilliputian students admitted: (45+3)/100 = 48% | ||
Table 2. Brobdingnagian applicants (10% are qualified):
| Квалифицированный | Неквалифицированный | |
|---|---|---|
| Допущенный | 5 | 9 |
| Отклоненный | 5 | 81 |
| Общий | 10 | 90 |
| Percentage of qualified students admitted: 5/10 = 50% Percentage of unqualified students rejected: 81/90 = 90% Total percentage of Brobdingnagian students admitted: (5+9)/100 = 14% | ||
The preceding examples satisfy equality of opportunity for acceptance of qualified students because qualified Lilliputians and Brobdingnagians both have a 50% chance of being admitted.
While equality of opportunity is satisfied, the following two fairness metrics are not satisfied:
- demographic parity : Lilliputians and Brobdingnagians are admitted to the university at different rates; 48% of Lilliputians students are admitted, but only 14% of Brobdingnagian students are admitted.
- equalized odds : While qualified Lilliputian and Brobdingnagian students both have the same chance of being admitted, the additional constraint that unqualified Lilliputians and Brobdingnagians both have the same chance of being rejected is not satisfied. Unqualified Lilliputians have a 70% rejection rate, whereas unqualified Brobdingnagians have a 90% rejection rate.
See Fairness: Equality of opportunity in Machine Learning Crash Course for more information.
уравненные шансы
A fairness metric to assess whether a model is predicting outcomes equally well for all values of a sensitive attribute with respect to both the positive class and negative class —not just one class or the other exclusively. In other words, both the true positive rate and false negative rate should be the same for all groups.
Equalized odds is related to equality of opportunity , which only focuses on error rates for a single class (positive or negative).
For example, suppose Glubbdubdrib University admits both Lilliputians and Brobdingnagians to a rigorous mathematics program. Lilliputians' secondary schools offer a robust curriculum of math classes, and the vast majority of students are qualified for the university program. Brobdingnagians' secondary schools don't offer math classes at all, and as a result, far fewer of their students are qualified. Equalized odds is satisfied provided that no matter whether an applicant is a Lilliputian or a Brobdingnagian, if they are qualified, they are equally as likely to get admitted to the program, and if they are not qualified, they are equally as likely to get rejected.
Suppose 100 Lilliputians and 100 Brobdingnagians apply to Glubbdubdrib University, and admissions decisions are made as follows:
Table 3. Lilliputian applicants (90% are qualified)
| Квалифицированный | Неквалифицированный | |
|---|---|---|
| Допущенный | 45 | 2 |
| Отклоненный | 45 | 8 |
| Общий | 90 | 10 |
| Percentage of qualified students admitted: 45/90 = 50% Percentage of unqualified students rejected: 8/10 = 80% Total percentage of Lilliputian students admitted: (45+2)/100 = 47% | ||
Table 4. Brobdingnagian applicants (10% are qualified):
| Квалифицированный | Неквалифицированный | |
|---|---|---|
| Допущенный | 5 | 18 |
| Отклоненный | 5 | 72 |
| Общий | 10 | 90 |
| Percentage of qualified students admitted: 5/10 = 50% Percentage of unqualified students rejected: 72/90 = 80% Total percentage of Brobdingnagian students admitted: (5+18)/100 = 23% | ||
Уравненные шансы соблюдены, поскольку у квалифицированных студентов уровня лилипута и бробдингнага вероятность поступления составляет 50%, а у неквалифицированных студентов уровня лилипута и бробдингнага — 80%.
Equalized odds is formally defined in "Equality of Opportunity in Supervised Learning" as follows: "predictor Ŷ satisfies equalized odds with respect to protected attribute A and outcome Y if Ŷ and A are independent, conditional on Y."
Оценщик
Устаревший API TensorFlow. Используйте tf.keras вместо Estimators.
оценки
В основном используется как аббревиатура для обозначения оценок в рамках магистерской программы по праву . В более широком смысле, «оценки» — это аббревиатура для любой формы оценки .
оценка
Процесс оценки качества модели или сравнения различных моделей друг с другом.
Для оценки модели машинного обучения с учителем обычно проводят сравнение с проверочным и тестовым наборами данных . Оценка модели машинного обучения с учителем, как правило, включает в себя более широкие оценки качества и безопасности.
точное совпадение
Метрика типа «всё или ничего», при которой выходные данные модели либо точно соответствуют истинным значениям или эталонному тексту , либо нет. Например, если истинные значения — «оранжевый» , то единственным результатом работы модели, удовлетворяющим условию точного совпадения, будет «оранжевый» .
Точное совпадение также может оценивать модели, выходные данные которых представляют собой последовательность (ранжированный список элементов). В общем случае, для точного совпадения требуется, чтобы сгенерированный ранжированный список точно соответствовал истинным значениям; то есть каждый элемент в обоих списках должен быть в одном и том же порядке. Однако, если истинные значения состоят из нескольких правильных последовательностей, то для точного совпадения достаточно, чтобы выходные данные модели совпадали только с одной из правильных последовательностей.
пример
Значения одной строки признаков и, возможно, метка . Примеры в контролируемом обучении делятся на две общие категории:
- Размеченный пример состоит из одного или нескольких признаков и метки. Размеченные примеры используются во время обучения.
- Пример без меток состоит из одного или нескольких признаков, но не имеет метки. Примеры без меток используются при выводе результатов.
Например, предположим, вы обучаете модель для определения влияния погодных условий на результаты тестов учащихся. Вот три примера с обозначениями:
| Функции | Этикетка | ||
|---|---|---|---|
| Температура | Влажность | Давление | Результат теста |
| 15 | 47 | 998 | Хороший |
| 19 | 34 | 1020 | Отличный |
| 18 | 92 | 1012 | Бедный |
Вот три примера без подписей:
| Температура | Влажность | Давление | |
|---|---|---|---|
| 12 | 62 | 1014 | |
| 21 | 47 | 1017 | |
| 19 | 41 | 1021 |
Строка набора данных обычно является исходным материалом для примера. То есть пример, как правило, представляет собой подмножество столбцов набора данных. Кроме того, признаки в примере могут также включать синтетические признаки , такие как перекрестные признаки .
Более подробную информацию см. в разделе «Обучение с учителем» курса «Введение в машинное обучение».
повторный просмотр
В обучении с подкреплением используется метод DQN для уменьшения временных корреляций в обучающих данных. Агент сохраняет переходы состояний в буфере воспроизведения , а затем выбирает переходы из этого буфера для создания обучающих данных.
Предвзятость экспериментатора
См. предвзятость подтверждения .
проблема взрывающегося градиента
В глубоких нейронных сетях (особенно в рекуррентных нейронных сетях ) наблюдается тенденция к неожиданно высоким градиентам . Крутые градиенты часто приводят к очень большим обновлениям весов каждого узла в глубокой нейронной сети.
Модели, страдающие от проблемы взрыва градиента, становится сложно или невозможно обучить. Ограничение градиента может смягчить эту проблему.
Сравните с задачей об исчезающем градиенте .
Экстремальное суммирование (xsum)
Набор данных для оценки способности магистра права (LLM) обобщать содержание одного документа. Каждая запись в наборе данных состоит из:
- Документ, подготовленный Британской вещательной корпорацией (BBC).
- Краткое изложение этого документа в одном предложении.
Подробности см. в статье «Не рассказывайте мне подробности, только краткое изложение! Тематически ориентированные сверточные нейронные сети для экстремального суммирования» .
Ф
Ф 1
Сводная метрика бинарной классификации , основанная как на точности , так и на полноте . Вот формула:
фактичность
В мире машинного обучения фактичность — это свойство, описывающее модель, выходные данные которой основаны на реальности. Фактичность — это скорее концепция, чем метрика. Например, предположим, вы отправляете следующий запрос большой языковой модели :
Какова химическая формула поваренной соли?
Модель, оптимизирующая достоверность фактов, дала бы следующий ответ:
NaCl
Заманчиво предположить, что все модели должны основываться на фактах. Однако некоторые подсказки, например, следующие, должны побудить генеративную модель ИИ оптимизировать креативность, а не факты .
Расскажите мне лимерик об астронавте и гусенице.
Маловероятно, что получившийся лимерик будет основан на реальных событиях.
В отличие от устойчивости .
ограничение справедливости
Применение ограничения к алгоритму для обеспечения выполнения одного или нескольких определений справедливости. Примеры ограничений справедливости включают:- Постобработка выходных данных вашей модели.
- Изменение функции потерь с целью включения штрафа за нарушение критерия справедливости .
- Непосредственное добавление математического ограничения к задаче оптимизации.
метрика справедливости
Математическое определение «справедливости», поддающееся измерению. К числу часто используемых показателей справедливости относятся:
- уравненные шансы
- прогнозируемая паритетность
- контрфактуальная справедливость
- демографическое равенство
Многие показатели справедливости являются взаимоисключающими; см. несовместимость показателей справедливости .
ложноотрицательный результат (FN)
Пример, в котором модель ошибочно предсказывает отрицательный класс . Например, модель предсказывает, что конкретное электронное письмо не является спамом (отрицательный класс), но на самом деле это письмо является спамом .
частота ложноотрицательных результатов
Доля фактически положительных примеров, для которых модель ошибочно предсказала отрицательный класс. Следующая формула вычисляет частоту ложноотрицательных результатов:
Более подробную информацию см. в разделе «Пороги и матрица ошибок» в кратком курсе по машинному обучению.
ложноположительный результат (FP)
Пример, в котором модель ошибочно предсказывает положительный класс . Например, модель предсказывает, что конкретное электронное письмо является спамом (положительный класс), но на самом деле это электронное письмо не является спамом .
Более подробную информацию см. в разделе «Пороги и матрица ошибок» в кратком курсе по машинному обучению.
Частота ложноположительных результатов (FPR)
Доля фактически отрицательных примеров, для которых модель ошибочно предсказала положительный класс. Следующая формула вычисляет частоту ложноположительных результатов:
Показатель ложноположительных результатов отображается по оси x на ROC-кривой .
Дополнительную информацию см. в разделе «Классификация: ROC и AUC в экспресс-курсе по машинному обучению».
быстрый распад
A training technique to improve the performance of LLMs . Fast decay involves rapidly decreasing the learning rate during training. This strategy helps prevent the model from overfitting to the training data, and improves generalization .
особенность
An input variable to a machine learning model. An example consists of one or more features. For instance, suppose you are training a model to determine the influence of weather conditions on student test scores. The following table shows three examples, each of which contains three features and one label:
| Функции | Этикетка | ||
|---|---|---|---|
| Температура | Влажность | Давление | Результат теста |
| 15 | 47 | 998 | 92 |
| 19 | 34 | 1020 | 84 |
| 18 | 92 | 1012 | 87 |
Contrast with label .
Более подробную информацию см. в разделе «Обучение с учителем» курса «Введение в машинное обучение».
feature cross
A synthetic feature formed by "crossing" categorical or bucketed features.
For example, consider a "mood forecasting" model that represents temperature in one of the following four buckets:
-
freezing -
chilly -
temperate -
warm
And represents wind speed in one of the following three buckets:
-
still -
light -
windy
Without feature crosses, the linear model trains independently on each of the preceding seven various buckets. So, the model trains on, for example, freezing independently of the training on, for example, windy .
Alternatively, you could create a feature cross of temperature and wind speed. This synthetic feature would have the following 12 possible values:
-
freezing-still -
freezing-light -
freezing-windy -
chilly-still -
chilly-light -
chilly-windy -
temperate-still -
temperate-light -
temperate-windy -
warm-still -
warm-light -
warm-windy
Thanks to feature crosses, the model can learn mood differences between a freezing-windy day and a freezing-still day.
If you create a synthetic feature from two features that each have a lot of different buckets, the resulting feature cross will have a huge number of possible combinations. For example, if one feature has 1,000 buckets and the other feature has 2,000 buckets, the resulting feature cross has 2,000,000 buckets.
Formally, a cross is a Cartesian product .
Feature crosses are mostly used with linear models and are rarely used with neural networks.
See Categorical data: Feature crosses in Machine Learning Crash Course for more information.
разработка функций
A process that involves the following steps:
- Determining which features might be useful in training a model.
- Converting raw data from the dataset into efficient versions of those features.
For example, you might determine that temperature might be a useful feature. Then, you might experiment with bucketing to optimize what the model can learn from different temperature ranges.
Feature engineering is sometimes called feature extraction or featurization .
See Numerical data: How a model ingests data using feature vectors in Machine Learning Crash Course for more information.
извлечение признаков
Overloaded term having either of the following definitions:
- Retrieving intermediate feature representations calculated by an unsupervised or pre-trained model (for example, hidden layer values in a neural network ) for use in another model as input.
- Synonym for feature engineering .
feature importances
Synonym for variable importances .
набор функций
The group of features your machine learning model trains on. For example, a simple feature set for a model that predicts housing prices might consist of postal code, property size, and property condition.
feature spec
Describes the information required to extract features data from the tf.Example protocol buffer. Because the tf.Example protocol buffer is just a container for data, you must specify the following:
- The data to extract (that is, the keys for the features)
- The data type (for example, float or int)
- The length (fixed or variable)
feature vector
The array of feature values comprising an example . The feature vector is input during training and during inference . For example, the feature vector for a model with two discrete features might be:
[0.92, 0.56]
Each example supplies different values for the feature vector, so the feature vector for the next example could be something like:
[0.73, 0.49]
Feature engineering determines how to represent features in the feature vector. For example, a binary categorical feature with five possible values might be represented with one-hot encoding . In this case, the portion of the feature vector for a particular example would consist of four zeroes and a single 1.0 in the third position, as follows:
[0.0, 0.0, 1.0, 0.0, 0.0]
As another example, suppose your model consists of three features:
- a binary categorical feature with five possible values represented with one-hot encoding; for example:
[0.0, 1.0, 0.0, 0.0, 0.0] - another binary categorical feature with three possible values represented with one-hot encoding; for example:
[0.0, 0.0, 1.0] - a floating-point feature; for example:
8.3.
In this case, the feature vector for each example would be represented by nine values. Given the example values in the preceding list, the feature vector would be:
0.0 1.0 0.0 0.0 0.0 0.0 0.0 1.0 8.3
See Numerical data: How a model ingests data using feature vectors in Machine Learning Crash Course for more information.
фетеризация
The process of extracting features from an input source, such as a document or video, and mapping those features into a feature vector .
Some ML experts use featurization as a synonym for feature engineering or feature extraction .
федеративное обучение
A distributed machine learning approach that trains machine learning models using decentralized examples residing on devices such as smartphones. In federated learning, a subset of devices downloads the current model from a central coordinating server. The devices use the examples stored on the devices to make improvements to the model. The devices then upload the model improvements (but not the training examples) to the coordinating server, where they are aggregated with other updates to yield an improved global model. After the aggregation, the model updates computed by devices are no longer needed, and can be discarded.
Since the training examples are never uploaded, federated learning follows the privacy principles of focused data collection and data minimization.
See the Federated Learning comic (yes, a comic) for more details.
петля обратной связи
In machine learning, a situation in which a model's predictions influence the training data for the same model or another model. For example, a model that recommends movies will influence the movies that people see, which will then influence subsequent movie recommendation models.
See Production ML systems: Questions to ask in Machine Learning Crash Course for more information.
feedforward neural network (FFN)
A neural network without cyclic or recursive connections. For example, traditional deep neural networks are feedforward neural networks. Contrast with recurrent neural networks , which are cyclic.
обучение с малым количеством примеров
A machine learning approach, often used for object classification, designed to train effective classification models from only a small number of training examples.
See also one-shot learning and zero-shot learning .
подсказка с небольшим количеством попыток
A prompt that contains more than one (a "few") example demonstrating how the large language model should respond. For example, the following lengthy prompt contains two examples showing a large language model how to answer a query.
| Части одного задания | Примечания |
|---|---|
| Какая официальная валюта указанной страны? | Вопрос, на который вы хотите получить ответ в рамках программы LLM. |
| France: EUR | Один пример. |
| United Kingdom: GBP | Ещё один пример. |
| Индия: | Сам запрос. |
Few-shot prompting generally produces more desirable results than zero-shot prompting and one-shot prompting . However, few-shot prompting requires a lengthier prompt.
Few-shot prompting is a form of few-shot learning applied to prompt-based learning .
See Prompt engineering in Machine Learning Crash Course for more information.
Скрипка
A Python-first configuration library that sets the values of functions and classes without invasive code or infrastructure. In the case of Pax —and other ML codebases—these functions and classes represent models and training hyperparameters .
Fiddle assumes that machine learning codebases are typically divided into:
- Library code, which defines the layers and optimizers.
- Dataset "glue" code, which calls the libraries and wires everything together.
Fiddle captures the call structure of the glue code in an unevaluated and mutable form.
тонкая настройка
A second, task-specific training pass performed on a pre-trained model to refine its parameters for a specific use case. For example, the full training sequence for some large language models is as follows:
- Pre-training: Train a large language model on a vast general dataset, such as all the English language Wikipedia pages.
- Fine-tuning: Train the pre-trained model to perform a specific task, such as responding to medical queries. Fine-tuning typically involves hundreds or thousands of examples focused on the specific task.
As another example, the full training sequence for a large image model is as follows:
- Pre-training: Train a large image model on a vast general image dataset, such as all the images in Wikimedia commons.
- Fine-tuning: Train the pre-trained model to perform a specific task, such as generating images of orcas.
Fine-tuning can entail any combination of the following strategies:
- Modifying all of the pre-trained model's existing parameters . This is sometimes called full fine-tuning .
- Modifying only some of the pre-trained model's existing parameters (typically, the layers closest to the output layer ), while keeping other existing parameters unchanged (typically, the layers closest to the input layer ). See parameter-efficient tuning .
- Adding more layers, typically on top of the existing layers closest to the output layer.
Fine-tuning is a form of transfer learning . As such, fine-tuning might use a different loss function or a different model type than those used to train the pre-trained model. For example, you could fine-tune a pre-trained large image model to produce a regression model that returns the number of birds in an input image.
Compare and contrast fine-tuning with the following terms:
See Fine-tuning in Machine Learning Crash Course for more information.
Флэш-модель
A family of relatively small Gemini models optimized for speed and low latency . Flash models are designed for a wide range of applications where quick responses and high throughput are crucial.
Лен
A high-performance open-source library for deep learning built on top of JAX . Flax provides functions for training neural networks , as well as methods for evaluating their performance.
Flaxformer
An open-source Transformer library , built on Flax , designed primarily for natural language processing and multimodal research.
forget gate
The portion of a Long Short-Term Memory cell that regulates the flow of information through the cell. Forget gates maintain context by deciding which information to discard from the cell state.
фундаментальная модель
A very large pre-trained model trained on an enormous and diverse training set . A foundation model can do both of the following:
- Respond well to a wide range of requests.
- Serve as a base model for additional fine-tuning or other customization.
In other words, a foundation model is already very capable in a general sense but can be further customized to become even more useful for a specific task.
fraction of successes
A metric for evaluating an ML model's generated text . The fraction of successes is the number of "successful" generated text outputs divided by the total number of generated text outputs. For example, if a large language model generated 10 blocks of code, five of which were successful, then the fraction of successes would be 50%.
Although fraction of successes is broadly useful throughout statistics, within ML, this metric is primarily useful for measuring verifiable tasks like code generation or math problems.
full softmax
Synonym for softmax .
Contrast with candidate sampling .
Дополнительную информацию см. в разделе «Нейронные сети: многоклассовая классификация» в кратком курсе по машинному обучению.
fully connected layer
A hidden layer in which each node is connected to every node in the subsequent hidden layer.
A fully connected layer is also known as a dense layer .
function transformation
A function that takes a function as input and returns a transformed function as output. JAX uses function transformations.
Г
ГАН
Abbreviation for generative adversarial network .
Близнецы
The ecosystem comprising Google's most advanced AI. Elements of this ecosystem include:
- Various Gemini models .
- The interactive conversational interface to a Gemini model. Users type prompts and Gemini responds to those prompts.
- Various Gemini APIs.
- Various business products based on Gemini models; for example, Gemini for Google Cloud .
модели Близнецов
Google's state-of-the-art Transformer -based multimodal models . Gemini models are specifically designed to integrate with agents .
Users can interact with Gemini models in a variety of ways, including through an interactive dialog interface and through SDKs.
Джемма
A family of lightweight open models built from the same research and technology used to create the Gemini models. Several different Gemma models are available, each providing different features, such as vision, code, and instruction following. See Gemma for details.
GenAI or genAI
Abbreviation for generative AI .
обобщение
A model's ability to make correct predictions on new, previously unseen data. A model that can generalize is the opposite of a model that is overfitting .
See Generalization in Machine Learning Crash Course for more information.
generalization curve
A plot of both training loss and validation loss as a function of the number of iterations .
A generalization curve can help you detect possible overfitting . For example, the following generalization curve suggests overfitting because validation loss ultimately becomes significantly higher than training loss.
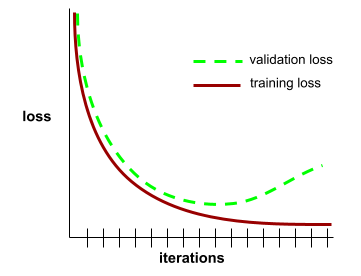
See Generalization in Machine Learning Crash Course for more information.
обобщенная линейная модель
A generalization of least squares regression models, which are based on Gaussian noise , to other types of models based on other types of noise, such as Poisson noise or categorical noise. Examples of generalized linear models include:
- логистическая регрессия
- multi-class regression
- least squares regression
The parameters of a generalized linear model can be found through convex optimization .
Generalized linear models exhibit the following properties:
- The average prediction of the optimal least squares regression model is equal to the average label on the training data.
- The average probability predicted by the optimal logistic regression model is equal to the average label on the training data.
The power of a generalized linear model is limited by its features. Unlike a deep model, a generalized linear model cannot "learn new features."
сгенерированный текст
In general, the text that an ML model outputs. When evaluating large language models, some metrics compare generated text against reference text . For example, suppose you are trying to determine how effectively an ML model translates from French to Dutch. In this case:
- The generated text is the Dutch translation that the ML model outputs.
- The reference text is the Dutch translation that a human translator (or software) creates.
Note that some evaluation strategies don't involve reference text.
generative adversarial network (GAN)
A system to create new data in which a generator creates data and a discriminator determines whether that created data is valid or invalid.
See the Generative Adversarial Networks course for more information.
генеративный ИИ
An emerging transformative field with no formal definition. That said, most experts agree that generative AI models can create ("generate") content that is all of the following:
- сложный
- согласованный
- оригинал
Examples of generative AI include:
- Large language models , which can generate sophisticated original text and answer questions.
- Image generation model, which can produce unique images.
- Audio and music generation models, which can compose original music or generate realistic speech.
- Video generation models, which can generate original videos.
Some earlier technologies, including LSTMs and RNNs , can also generate original and coherent content. Some experts view these earlier technologies as generative AI, while others feel that true generative AI requires more complex output than those earlier technologies can produce.
Contrast with predictive ML .
генеративная модель
Practically speaking, a model that does either of the following:
- Creates (generates) new examples from the training dataset. For example, a generative model could create poetry after training on a dataset of poems. The generator part of a generative adversarial network falls into this category.
- Determines the probability that a new example comes from the training set, or was created from the same mechanism that created the training set. For example, after training on a dataset consisting of English sentences, a generative model could determine the probability that new input is a valid English sentence.
A generative model can theoretically discern the distribution of examples or particular features in a dataset. That is:
p(examples)
Unsupervised learning models are generative.
Contrast with discriminative models .
генератор
The subsystem within a generative adversarial network that creates new examples .
Contrast with discriminative model .
примесь Джини
A metric similar to entropy . Splitters use values derived from either gini impurity or entropy to compose conditions for classification decision trees . Information gain is derived from entropy. No universally accepted equivalent term for the metric derived from gini impurity exists; however, this unnamed metric is just as important as information gain.
Gini impurity is also called gini index , or simply gini .
золотой набор данных
A set of manually curated data that captures ground truth . Teams can use one or more golden datasets to evaluate a model's quality.
Some golden datasets capture different subdomains of ground truth. For example, a golden dataset for image classification might capture lighting conditions and image resolution.
golden response
A response known to be good. For example, given the following prompt :
2 + 2
The golden response is hopefully:
4
Google AI Studio
A Google tool providing a user-friendly interface for experimenting with and building applications using Google's large language models . See the Google AI Studio home page for details.
GPT (Generative Pre-trained Transformer)
A family of Transformer -based large language models developed by OpenAI .
GPT variants can apply to multiple modalities , including:
- image generation (for example, ImageGPT)
- text-to-image generation (for example, DALL-E ).
градиент
The vector of partial derivatives with respect to all of the independent variables. In machine learning, the gradient is the vector of partial derivatives of the model function. The gradient points in the direction of steepest ascent.
градиентное накопление
Метод обратного распространения ошибки , который обновляет параметры только один раз за эпоху, а не один раз за итерацию. После обработки каждого мини-пакета накопление градиентов просто обновляет текущую сумму градиентов. Затем, после обработки последнего мини-пакета в эпохе, система окончательно обновляет параметры на основе суммы всех изменений градиентов.
Накопление градиента полезно, когда размер пакета данных очень велик по сравнению с объемом доступной памяти для обучения. Когда память является проблемой, естественная тенденция — уменьшить размер пакета. Однако уменьшение размера пакета в обычном алгоритме обратного распространения ошибки увеличивает количество обновлений параметров. Накопление градиента позволяет модели избежать проблем с памятью, сохраняя при этом эффективность обучения.
Градиентные бустинговые (решающие) деревья (GBT)
Тип леса решений, в котором:
- Обучение основано на градиентном бустинге .
- Слабая модель — это дерево решений .
Дополнительную информацию см. в разделе «Градиентный бустинг деревьев решений» курса «Леса решений».
градиентный бустинг
Алгоритм обучения, в котором слабые модели обучаются итеративно для улучшения качества (уменьшения функции потерь) сильной модели. Например, слабой моделью может быть линейная модель или небольшая модель дерева решений. Сильная модель становится суммой всех ранее обученных слабых моделей.
В простейшей форме градиентного бустинга на каждой итерации обучается слабая модель, которая предсказывает градиент функции потерь сильной модели. Затем выходные данные сильной модели обновляются путем вычитания предсказанного градиента, аналогично градиентному спуску .
где:
- $F_{0}$ is the starting strong model.
- $F_{i+1}$ is the next strong model.
- $F_{i}$ is the current strong model.
- $\xi$ is a value between 0.0 and 1.0 called shrinkage , which is analogous to the learning rate in gradient descent.
- $f_{i}$ is the weak model trained to predict the loss gradient of $F_{i}$.
Современные варианты градиентного бустинга также включают в свои вычисления вторую производную (гессиан) функции потерь.
Деревья решений обычно используются в качестве слабых моделей в градиентном бустинге. См. градиентный бустинг (деревья решений) .
градиентная обрезка
Распространенный механизм для смягчения проблемы взрыва градиента путем искусственного ограничения (обрезания) максимального значения градиента при использовании градиентного спуска для обучения модели.
градиентный спуск
Математический метод минимизации потерь . Градиентный спуск итеративно корректирует веса и смещения , постепенно находя наилучшую комбинацию для минимизации потерь.
Метод градиентного спуска старше — намного, намного старше — машинного обучения.
Для получения более подробной информации см. статью «Линейная регрессия: градиентный спуск» в кратком курсе по машинному обучению.
график
В TensorFlow это спецификация вычислений. Узлы в графе представляют операции. Ребра являются направленными и представляют собой передачу результата операции ( тензора ) в качестве операнда другой операции. Используйте TensorBoard для визуализации графа.
выполнение графа
Среда программирования TensorFlow, в которой программа сначала строит граф , а затем выполняет весь этот граф или его часть. Выполнение графа является режимом выполнения по умолчанию в TensorFlow 1.x.
В отличие от поспешного исполнения .
жадная политика
В обучении с подкреплением стратегия , которая всегда выбирает действие с наибольшей ожидаемой отдачей .
обоснованность
Свойство модели, выходные данные которой основаны на конкретном исходном материале (являются «привязанными к нему»). Например, предположим, вы предоставляете в качестве входных данных («контекста») для большой языковой модели целый учебник по физике. Затем вы задаете этой большой языковой модели вопрос по физике. Если ответ модели отражает информацию из этого учебника, то эта модель является «привязанной к этому учебнику».Следует отметить, что обоснованная модель не всегда является фактической . Например, в исходном учебнике по физике могут содержаться ошибки.
эталонные данные
Реальность.
То, что произошло на самом деле.
Например, рассмотрим модель бинарной классификации , которая предсказывает, закончит ли студент первого курса университета обучение в течение шести лет. Истинное значение для этой модели — это то, действительно ли студент окончил университет в течение шести лет.
предвзятость групповой атрибуции
Предполагается, что то, что верно для отдельного человека, верно и для всех членов этой группы. Влияние групповой предвзятости в атрибуции может усугубиться, если для сбора данных используется выборочная совокупность по принципу удобства . В нерепрезентативной выборке могут быть сделаны атрибуции, не отражающие реальность.
См. также предвзятость, связанную с однородностью внешней группы , и предвзятость внутри группы . Также см. раздел «Справедливость: типы предвзятости» в «Кратком курсе по машинному обучению» для получения дополнительной информации.
ЧАС
галлюцинация
Генеративная модель искусственного интеллекта выдает на первый взгляд правдоподобные, но фактически неверные утверждения, которые якобы отражают реальный мир. Например, генеративная модель ИИ, утверждающая, что Барак Обама умер в 1865 году, — это галлюцинация .
хеширование
В машинном обучении это механизм группировки категориальных данных , особенно когда количество категорий велико, но количество категорий, фактически присутствующих в наборе данных, сравнительно невелико.
Например, на Земле произрастает около 73 000 видов деревьев. Каждый из этих 73 000 видов деревьев можно представить в 73 000 отдельных категориальных группах. В качестве альтернативы, если в наборе данных фактически присутствует только 200 из этих видов деревьев, можно использовать хеширование для разделения видов деревьев, например, на 500 групп.
В одном контейнере может содержаться несколько видов деревьев. Например, хеширование может поместить баобаб и красный клен — два генетически разных вида — в один контейнер. Тем не менее, хеширование по-прежнему является хорошим способом отображения больших наборов категориальных значений в выбранное количество контейнеров. Хеширование преобразует категориальный признак, имеющий большое количество возможных значений, в гораздо меньшее количество значений путем детерминированного группирования значений.
Дополнительную информацию см. в разделе «Категориальные данные: словарь и one-hot кодирование» в «Кратком курсе по машинному обучению».
эвристический
Простое и быстро реализуемое решение проблемы. Например: «С помощью эвристического метода мы достигли точности 86%. Когда мы перешли к глубокой нейронной сети, точность выросла до 98%».
скрытый слой
Скрытый слой в нейронной сети находится между входным слоем (признаками) и выходным слоем (прогнозированием). Каждый скрытый слой состоит из одного или нескольких нейронов . Например, следующая нейронная сеть содержит два скрытых слоя: первый с тремя нейронами, а второй с двумя нейронами:
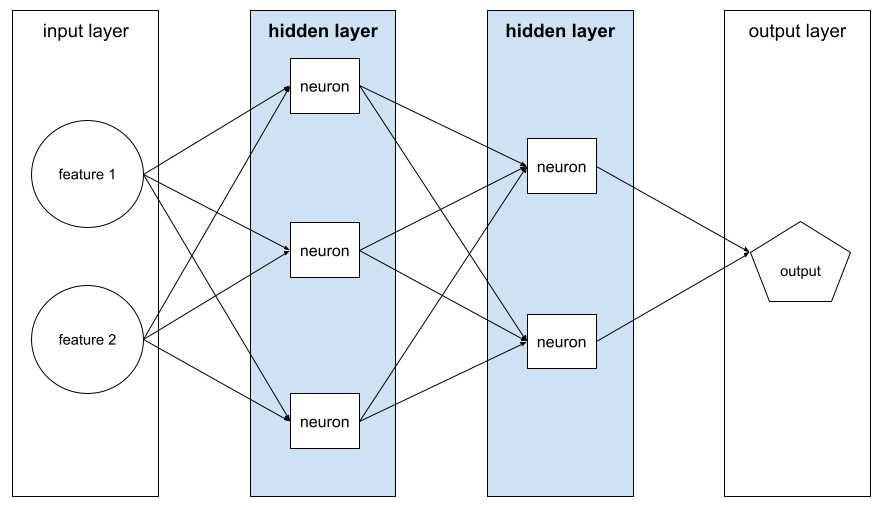
Глубокая нейронная сеть содержит более одного скрытого слоя. Например, на приведенном выше рисунке показана глубокая нейронная сеть, поскольку модель содержит два скрытых слоя.
Дополнительную информацию можно найти в разделе «Нейронные сети: узлы и скрытые слои» в кратком курсе по машинному обучению.
hierarchical clustering
Иерархическая кластеризация — это категория алгоритмов кластеризации , которые создают дерево кластеров. Она хорошо подходит для иерархических данных, таких как ботанические таксономии. Существует два типа алгоритмов иерархической кластеризации:
- Агломеративная кластеризация сначала относит каждый пример к своему собственному кластеру, а затем итеративно объединяет ближайшие кластеры для создания иерархического дерева.
- Метод кластеризации с разделением сначала объединяет все примеры в один кластер, а затем итеративно делит этот кластер на иерархическое дерево.
Сравните с кластеризацией на основе центроидов .
Дополнительную информацию см. в разделе «Алгоритмы кластеризации» в курсе «Кластеризация».
восхождение на холм
Алгоритм итеративного улучшения («подъема в гору») модели машинного обучения до тех пор, пока модель не перестанет улучшаться («достигнет вершины холма»). Общая форма алгоритма выглядит следующим образом:
- Создайте исходную модель.
- Создавайте новые модели-кандидаты, внося небольшие корректировки в процесс обучения или тонкой настройки . Это может включать работу с немного другим обучающим набором данных или другими гиперпараметрами.
- Оцените новые модели-кандидаты и предпримите одно из следующих действий:
- Если модель-кандидат превосходит исходную модель, то эта модель-кандидат становится новой исходной моделью. В этом случае повторите шаги 1, 2 и 3.
- Если ни одна модель не превосходит начальную, значит, вы достигли вершины и следует прекратить итерации.
See Deep Learning Tuning Playbook for guidance on hyperparameter tuning. See the Data modules of Machine Learning Crash Course for guidance on feature engineering.
потеря шарнира
A family of loss functions for classification designed to find the decision boundary as distant as possible from each training example, thus maximizing the margin between examples and the boundary. KSVMs use hinge loss (or a related function, such as squared hinge loss). For binary classification, the hinge loss function is defined as follows:
where y is the true label, either -1 or +1, and y' is the raw output of the classification model :
Consequently, a plot of hinge loss versus (y * y') looks as follows:

historical bias
A type of bias that already exists in the world and has made its way into a dataset. These biases have a tendency to reflect existing cultural stereotypes, demographic inequalities, and prejudices against certain social groups.
For example, consider a classification model that predicts whether or not a loan applicant will default on their loan, which was trained on historical loan-default data from the 1980s from local banks in two different communities. If past applicants from Community A were six times more likely to default on their loans than applicants from Community B, the model might learn a historical bias resulting in the model being less likely to approve loans in Community A, even if the historical conditions that resulted in that community's higher default rates were no longer relevant.
Дополнительную информацию см. в разделе «Справедливость: виды предвзятости в экспресс-курсе по машинному обучению».
holdout data
Examples intentionally not used ("held out") during training. The validation dataset and test dataset are examples of holdout data. Holdout data helps evaluate your model's ability to generalize to data other than the data it was trained on. The loss on the holdout set provides a better estimate of the loss on an unseen dataset than does the loss on the training set.
хозяин
When training an ML model on accelerator chips (GPUs or TPUs ), the part of the system that controls both of the following:
- The overall flow of the code.
- The extraction and transformation of the input pipeline.
The host typically runs on a CPU, not on an accelerator chip; the device manipulates tensors on the accelerator chips.
оценка человеком
A process in which people judge the quality of an ML model's output; for example, having bilingual people judge the quality of an ML translation model. Human evaluation is particularly useful for judging models that have no one right answer .
Contrast with automatic evaluation and autorater evaluation .
human in the loop (HITL)
A loosely-defined idiom that could mean either of the following:
- A policy of viewing generative AI output critically or skeptically.
- A strategy or system for ensuring that people help shape, evaluate, and refine a model's behavior. Keeping a human in the loop enables an AI to benefit from both machine intelligence and human intelligence. For example, a system in which an AI generates code which software engineers then review is a human-in-the-loop system.
гиперпараметр
The variables that you or a hyperparameter tuning serviceadjust during successive runs of training a model. For example, learning rate is a hyperparameter. You could set the learning rate to 0.01 before one training session. If you determine that 0.01 is too high, you could perhaps set the learning rate to 0.003 for the next training session.
In contrast, parameters are the various weights and bias that the model learns during training.
Дополнительную информацию см. в статье «Линейная регрессия: гиперпараметры в машинном обучении» (краткий курс).
гиперплоскость
A boundary that separates a space into two subspaces. For example, a line is a hyperplane in two dimensions and a plane is a hyperplane in three dimensions. More typically in machine learning, a hyperplane is the boundary separating a high-dimensional space. Kernel Support Vector Machines use hyperplanes to separate positive classes from negative classes, often in a very high-dimensional space.
я
иид
Abbreviation for independently and identically distributed .
распознавание изображений
A process that classifies object(s), pattern(s), or concept(s) in an image. Image recognition is also known as image classification .
imbalanced dataset
Synonym for class-imbalanced dataset .
неявная предвзятость
Automatically making an association or assumption based on one's mind models and memories. Implicit bias can affect the following:
- How data is collected and classified.
- How machine learning systems are designed and developed.
For example, when building a classification model to identify wedding photos, an engineer may use the presence of a white dress in a photo as a feature. However, white dresses have been customary only during certain eras and in certain cultures.
See also confirmation bias .
импутация
Short form of value imputation .
incompatibility of fairness metrics
The idea that some notions of fairness are mutually incompatible and cannot be satisfied simultaneously. As a result, there is no single universal metric for quantifying fairness that can be applied to all ML problems.
While this may seem discouraging, incompatibility of fairness metrics doesn't imply that fairness efforts are fruitless. Instead, it suggests that fairness must be defined contextually for a given ML problem, with the goal of preventing harms specific to its use cases.
See "On the (im)possibility of fairness" for a more detailed discussion of the incompatibility of fairness metrics.
обучение в контексте
Synonym for few-shot prompting .
independently and identically distributed (iid)
Data drawn from a distribution that doesn't change, and where each value drawn doesn't depend on values that have been drawn previously. An iid is the ideal gas of machine learning—a useful mathematical construct but almost never exactly found in the real world. For example, the distribution of visitors to a web page may be iid over a brief window of time; that is, the distribution doesn't change during that brief window and one person's visit is generally independent of another's visit. However, if you expand that window of time, seasonal differences in the web page's visitors may appear.
See also nonstationarity .
individual fairness
A fairness metric that checks whether similar individuals are classified similarly. For example, Brobdingnagian Academy might want to satisfy individual fairness by ensuring that two students with identical grades and standardized test scores are equally likely to gain admission.
Note that individual fairness relies entirely on how you define "similarity" (in this case, grades and test scores), and you can run the risk of introducing new fairness problems if your similarity metric misses important information (such as the rigor of a student's curriculum).
See "Fairness Through Awareness" for a more detailed discussion of individual fairness.
вывод
In traditional machine learning, the process of making predictions by applying a trained model to unlabeled examples . See Supervised Learning in the Intro to ML course to learn more.
In large language models , inference is the process of using a trained model to generate a response to an input prompt .
Inference has a somewhat different meaning in statistics. See the Wikipedia article on statistical inference for details.
inference path
In a decision tree , during inference , the route a particular example takes from the root to other conditions , terminating with a leaf . For example, in the following decision tree, the thicker arrows show the inference path for an example with the following feature values:
- x = 7
- y = 12
- z = -3
The inference path in the following illustration travels through three conditions before reaching the leaf ( Zeta ).
The three thick arrows show the inference path.
See Decision trees in the Decision Forests course for more information.
получение информации
In decision forests , the difference between a node's entropy and the weighted (by number of examples) sum of the entropy of its children nodes. A node's entropy is the entropy of the examples in that node.
For example, consider the following entropy values:
- entropy of parent node = 0.6
- entropy of one child node with 16 relevant examples = 0.2
- entropy of another child node with 24 relevant examples = 0.1
So 40% of the examples are in one child node and 60% are in the other child node. Therefore:
- weighted entropy sum of child nodes = (0.4 * 0.2) + (0.6 * 0.1) = 0.14
So, the information gain is:
- information gain = entropy of parent node - weighted entropy sum of child nodes
- information gain = 0.6 - 0.14 = 0.46
Most splitters seek to create conditions that maximize information gain.
предвзятость внутри группы
Showing partiality to one's own group or own characteristics. If testers or raters consist of the machine learning developer's friends, family, or colleagues, then in-group bias may invalidate product testing or the dataset.
In-group bias is a form of group attribution bias . See also out-group homogeneity bias .
Дополнительную информацию см. в разделе «Справедливость: виды предвзятости в экспресс-курсе по машинному обучению».
input generator
A mechanism by which data is loaded into a neural network .
An input generator can be thought of as a component responsible for processing raw data into tensors which are iterated over to generate batches for training, evaluation, and inference.
input layer
The layer of a neural network that holds the feature vector . That is, the input layer provides examples for training or inference . For example, the input layer in the following neural network consists of two features:
in-set condition
In a decision tree , a condition that tests for the presence of one item in a set of items. For example, the following is an in-set condition:
house-style in [tudor, colonial, cape]
During inference, if the value of the house-style feature is tudor or colonial or cape , then this condition evaluates to Yes. If the value of the house-style feature is something else (for example, ranch ), then this condition evaluates to No.
In-set conditions usually lead to more efficient decision trees than conditions that test one-hot encoded features.
пример
Synonym for example .
настройка инструкций
A form of fine-tuning that improves a generative AI model's ability to follow instructions. Instruction tuning involves training a model on a series of instruction prompts, typically covering a wide variety of tasks. The resulting instruction-tuned model then tends to generate useful responses to zero-shot prompts across a variety of tasks.
Compare and contrast with:
интерпретируемость
The ability to explain or to present an ML model's reasoning in understandable terms to a human.
Most linear regression models, for example, are highly interpretable. (You merely need to look at the trained weights for each feature.) Decision forests are also highly interpretable. Some models, however, require sophisticated visualization to become interpretable.
You can use the Learning Interpretability Tool (LIT) to interpret ML models.
inter-rater agreement
A measurement of how often human raters agree when doing a task. If raters disagree, the task instructions may need to be improved. Also sometimes called inter-annotator agreement or inter-rater reliability . See also Cohen's kappa , which is one of the most popular inter-rater agreement measurements.
See Categorical data: Common issues in Machine Learning Crash Course for more information.
Пересечение над объединением (IoU)
The intersection of two sets divided by their union. In machine-learning image-detection tasks, IoU is used to measure the accuracy of the model's predicted bounding box with respect to the ground-truth bounding box. In this case, the IoU for the two boxes is the ratio between the overlapping area and the total area, and its value ranges from 0 (no overlap of predicted bounding box and ground-truth bounding box) to 1 (predicted bounding box and ground-truth bounding box have the exact same coordinates).
For example, in the image below:
- The predicted bounding box (the coordinates delimiting where the model predicts the night table in the painting is located) is outlined in purple.
- Ограничивающая рамка (координаты, определяющие фактическое местоположение прикроватного столика на картине) обозначена зеленым цветом.
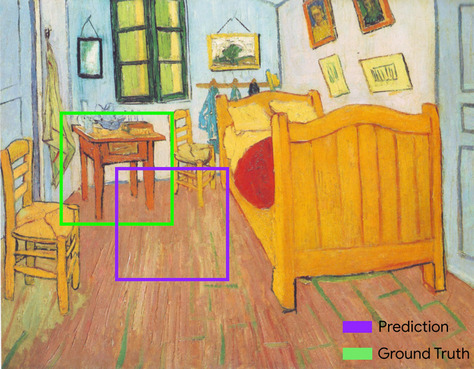
Здесь пересечение ограничивающих прямоугольников для прогноза и истинных значений (внизу слева) равно 1, а объединение ограничивающих прямоугольников для прогноза и истинных значений (внизу справа) равно 7, поэтому IoU равно \(\frac{1}{7}\).
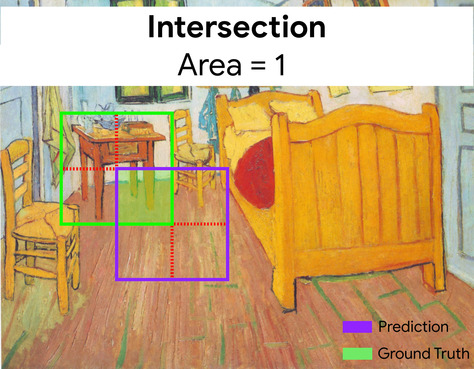
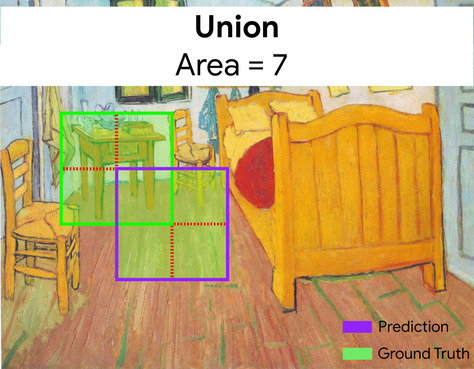
IoU
Сокращение от intersection over union (пересечение над объединением).
матрица элементов
В системах рекомендаций используется матрица векторов встраивания , сгенерированная методом матричной факторизации , которая содержит скрытые сигналы о каждом элементе . Каждая строка матрицы элементов содержит значение одной скрытой характеристики для всех элементов. Например, рассмотрим систему рекомендаций фильмов. Каждый столбец матрицы элементов представляет собой отдельный фильм. Скрытые сигналы могут представлять жанры или быть более сложными для интерпретации сигналами, включающими сложные взаимодействия между жанром, актерами, возрастом фильма или другими факторами.
Матрица элементов имеет такое же количество столбцов, как и целевая матрица, которая подвергается факторизации. Например, если система рекомендаций фильмов оценивает 10 000 названий фильмов, матрица элементов будет иметь 10 000 столбцов.
предметы
В рекомендательной системе речь идет об объектах, которые система рекомендует. Например, видеомагазин рекомендует видео, а книжный магазин — книги.
итерация
Однократное обновление параметров модели — весов и смещений — во время обучения . Размер пакета определяет, сколько примеров модель обрабатывает за одну итерацию. Например, если размер пакета равен 20, то модель обрабатывает 20 примеров, прежде чем корректировать параметры.
При обучении нейронной сети одна итерация включает в себя следующие два прохода:
- Прямой проход для оценки потерь в отдельной партии.
- Обратный проход ( backpropagation ) используется для корректировки параметров модели на основе функции потерь и скорости обучения.
Дополнительную информацию см. в разделе «Градиентный спуск» в «Кратком курсе по машинному обучению».
Дж.
ДЖАКС
Библиотека для вычислений с массивами, объединяющая XLA (ускоренную линейную алгебру) и автоматическое дифференцирование для высокопроизводительных численных вычислений. JAX предоставляет простой и мощный API для написания ускоренного численного кода с компонуемыми преобразованиями. JAX предоставляет такие возможности, как:
-
grad(automatic differentiation) -
jit(just-in-time compilation) -
vmap(automatic vectorization or batching) -
pmap(parallelization)
JAX — это язык для выражения и компоновки преобразований числового кода, аналогичный — но гораздо более масштабный — библиотеке NumPy в Python. (Фактически, библиотека .numpy в рамках JAX является функционально эквивалентной, но полностью переписанной версией библиотеки NumPy в Python.)
JAX особенно хорошо подходит для ускорения многих задач машинного обучения, преобразуя модели и данные в форму, подходящую для параллельной обработки на графических процессорах (GPU) и процессорах TPU ( Tuned Processor ).
Flax , Optax , Pax и многие другие библиотеки построены на инфраструктуре JAX.
К
Керас
Keras — популярный API для машинного обучения на Python. Он работает на нескольких фреймворках глубокого обучения, включая TensorFlow, где доступен под именем tf.keras .
Машины опорных векторов ядра (KSVM)
Алгоритм классификации, стремящийся максимизировать разницу между положительными и отрицательными классами путем отображения входных векторов данных в многомерное пространство. Например, рассмотрим задачу классификации, в которой входной набор данных содержит сто признаков. Чтобы максимизировать разницу между положительными и отрицательными классами, KSVM может внутренне отобразить эти признаки в миллионмерное пространство. KSVM использует функцию потерь, называемую функцией потерь типа «шарнир» .
ключевые моменты
Координаты отдельных элементов изображения. Например, для модели распознавания изображений , различающей виды цветов, ключевыми точками могут быть центр каждого лепестка, стебель, тычинка и так далее.
k-кратная перекрестная проверка
Алгоритм прогнозирования способности модели к обобщению на новые данные. k в k-кратной фолд-модели обозначает количество равных групп, на которые вы делите примеры набора данных; то есть, вы обучаете и тестируете свою модель k раз. Для каждого раунда обучения и тестирования другая группа становится тестовым набором, а все оставшиеся группы становятся обучающим набором. После k раундов обучения и тестирования вы вычисляете среднее значение и стандартное отклонение выбранной(ых) метрики(метрик) теста.
Например, предположим, что ваш набор данных состоит из 120 примеров. Далее предположим, что вы решили установить k равным 4. Следовательно, после перемешивания примеров вы делите набор данных на четыре равные группы по 30 примеров и проводите четыре раунда обучения и тестирования:
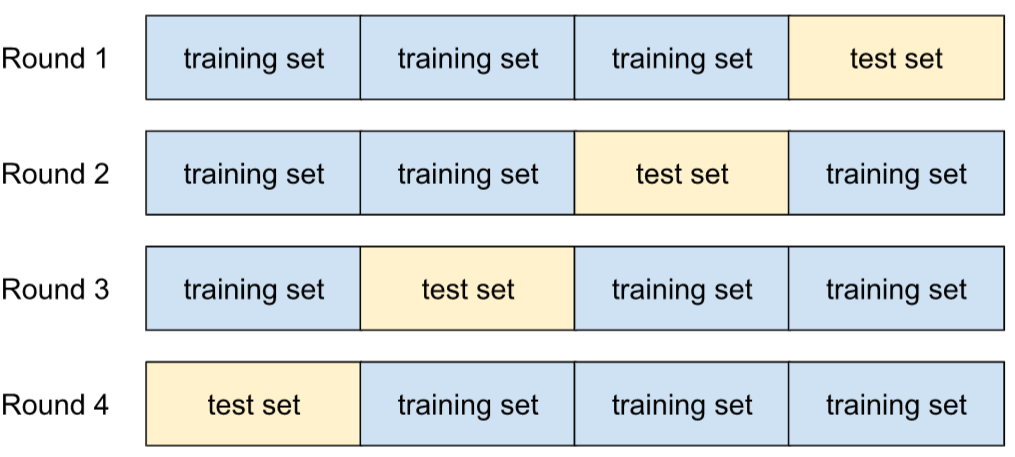
Например, среднеквадратичная ошибка (MSE) может быть наиболее значимым показателем для модели линейной регрессии. Поэтому вам нужно будет найти среднее значение и стандартное отклонение MSE по всем четырем итерациям.
k-means
Популярный алгоритм кластеризации , который группирует примеры в неконтролируемом обучении. Алгоритм k-средних, по сути, делает следующее:
- Метод итеративно определяет наилучшие k центральных точек (известных как центроиды ).
- Присваивает каждому примеру ближайший центроид. Примеры, расположенные ближе всего к одному и тому же центроиду, принадлежат к одной группе.
Алгоритм k-средних выбирает координаты центроидов таким образом, чтобы минимизировать суммарный квадрат расстояний от каждого примера до ближайшего к нему центроида.
Например, рассмотрим следующий график зависимости высоты собаки от ее ширины:

Если k=3, алгоритм k-средних определит три центроида. Каждому примеру присваивается ближайший к нему центроид, в результате чего образуются три группы:

Представьте, что производитель хочет определить идеальные размеры свитеров для собак маленьких, средних и больших размеров. Три центроида определяют среднюю высоту и среднюю ширину каждой собаки в этой группе. Следовательно, производителю, вероятно, следует основывать размеры свитеров на этих трех центроидах. Обратите внимание, что центроид группы обычно не является примером в этой группе.
На приведенных выше иллюстрациях показан алгоритм k-средних для примеров, имеющих только две характеристики (высоту и ширину). Обратите внимание, что алгоритм k-средних может группировать примеры по множеству характеристик.
Дополнительную информацию см. в разделе «Что такое кластеризация методом k-средних?» в курсе «Кластеризация».
k-медиана
Алгоритм кластеризации, тесно связанный с алгоритмом k-средних . Практическое различие между ними заключается в следующем:
- В алгоритме k-средних центроиды определяются путем минимизации суммы квадратов расстояний между потенциальным центроидом и каждым из его аналогов.
- В алгоритме k-медианы центроиды определяются путем минимизации суммы расстояний между кандидатом в центроиды и каждым из его аналогов.
Следует отметить, что определения расстояния также различаются:
- Алгоритм k-средних основан на евклидовом расстоянии от центроида до точки. (В двумерном случае евклидово расстояние означает использование теоремы Пифагора для вычисления гипотенузы.) Например, расстояние k-средних между (2,2) и (5,-2) будет следующим:
- k-медиана основана на манхэттенском расстоянии от центроида до точки. Это расстояние представляет собой сумму абсолютных значений в каждом измерении. Например, k-медианное расстояние между (2,2) и (5,-2) будет следующим:
Л
L0 регуляризация
Тип регуляризации , который наказывает за общее количество ненулевых весов в модели. Например, модель с 11 ненулевыми весами будет наказываться сильнее, чем аналогичная модель с 10 ненулевыми весами.
Регуляризация L0 иногда называется регуляризацией по норме L0 .
Потеря L 1
Функция потерь , которая вычисляет абсолютное значение разницы между фактическими значениями меток и значениями, предсказанными моделью . Например, вот расчет функции потерь L1 для группы из пяти примеров :
| Фактическая ценность примера | Прогнозируемое значение модели | Абсолютное значение дельты |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = L 1 потеря | ||
Функция потерь L1 менее чувствительна к выбросам , чем функция потерь L2 .
Средняя абсолютная ошибка — это средняя ошибка L1 на пример.
Дополнительную информацию см. в разделе «Линейная регрессия: функция потерь в машинном обучении» (краткий курс).
L1- регуляризация
L1- регуляризация — это тип регуляризации , который наказывает веса пропорционально сумме абсолютных значений весов. Регуляризация L1 помогает обнулить веса нерелевантных или едва релевантных признаков. Признак с весом 0 фактически удаляется из модели.
Сравните с L2 - регуляризацией .
Потеря L 2
Функция потерь , которая вычисляет квадрат разницы между фактическими значениями меток и значениями, предсказанными моделью . Например, вот расчет функции потерь L2 для группы из пяти примеров :
| Фактическая ценность примера | Прогнозируемое значение модели | Квадрат дельты |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = L 2 потери | ||
Вследствие возведения в квадрат, функция потерь L2 усиливает влияние выбросов . То есть, функция потерь L2 реагирует на плохие прогнозы сильнее, чем функция потерь L1 . Например, функция потерь L1 для предыдущей партии составила бы 8, а не 16. Обратите внимание, что один выброс объясняет 9 из 16.
В регрессионных моделях в качестве функции потерь обычно используется L2- функция потерь.
Среднеквадратичная ошибка — это средняя ошибка L2 -пространства на пример. Квадратичная ошибка — это другое название ошибки L2 - пространства.
Дополнительную информацию см. в разделе «Логистическая регрессия: функция потерь и регуляризация» в книге «Краткий курс по машинному обучению».
L2- регуляризация
L2- регуляризация — это тип регуляризации , который наказывает веса пропорционально сумме квадратов этих весов. Она помогает приблизить веса выбросов (с высокими положительными или низкими отрицательными значениями) к нулю, но не довести их до нуля . Признаки со значениями, очень близкими к нулю, остаются в модели, но не оказывают существенного влияния на её предсказания.
L2 - регуляризация всегда улучшает обобщающую способность в линейных моделях .
Сравните с L1 - регуляризацией .
Дополнительную информацию см. в разделе «Переобучение: L2-регуляризация» в «Кратком курсе по машинному обучению».
этикетка
В контролируемом машинном обучении «ответ» или «результат» примера .
Каждый размеченный пример состоит из одного или нескольких признаков и метки. Например, в наборе данных для обнаружения спама метка, вероятно, будет либо «спам», либо «не спам». В наборе данных об осадках меткой может быть количество осадков, выпавших за определенный период.
Дополнительную информацию см. в разделе «Обучение с учителем» в книге «Введение в машинное обучение».
пример с подписью
Пример, содержащий одну или несколько характеристик и метку . Например, в следующей таблице показаны три примера с метками из модели оценки стоимости дома, каждый из которых содержит три характеристики и одну метку:
| Количество спален | Количество ванных комнат | Возраст дома | Цена дома (на этикетке) |
|---|---|---|---|
| 3 | 2 | 15 | 345 000 долларов США |
| 2 | 1 | 72 | 179 000 долларов США |
| 4 | 2 | 34 | 392 000 долларов США |
В контролируемом машинном обучении модели обучаются на размеченных примерах и делают прогнозы на неразмеченных примерах .
Сравните примеры с подписями с примерами без подписей.
Дополнительную информацию см. в разделе «Обучение с учителем» в книге «Введение в машинное обучение».
утечка этикетки
A model design flaw in which a feature is a proxy for the label . For example, consider a binary classification model that predicts whether or not a prospective customer will purchase a particular product. Suppose that one of the features for the model is a Boolean named SpokeToCustomerAgent . Further suppose that a customer agent is only assigned after the prospective customer has actually purchased the product. During training, the model will quickly learn the association between SpokeToCustomerAgent and the label.
Дополнительную информацию см. в разделе «Мониторинг конвейеров» в «Кратком курсе по машинному обучению».
лямбда
Синоним к показателю регуляризации .
Термин «лямбда» является перегруженным. Здесь мы сосредоточимся на определении этого термина в контексте регуляризации .
LaMDA (Language Model for Dialogue Applications)
Разработанная Google языковая модель на основе Transformer , обученная на большом наборе данных диалогов, способна генерировать реалистичные ответы в разговорной речи.
LaMDA: наша революционная технология ведения диалога предоставляет общий обзор.
достопримечательности
Синоним для ключевых моментов .
языковая модель
Модель , которая оценивает вероятность появления токена или последовательности токенов в более длинной последовательности токенов.
Дополнительную информацию можно найти в разделе «Что такое языковая модель?» в кратком курсе по машинному обучению.
большая языковая модель
At a minimum, a language model having a very high number of parameters . More informally, any Transformer -based language model, such as Gemini or GPT .
See Large language models (LLMs) in Machine Learning Crash Course for more information.
задержка
The time it takes for a model to process input and generate a response. A high latency response takes takes longer to generate than a low latency response.
Factors that influence latency of large language models include:
- Input and output token lengths
- Model complexity
- The infrastructure the model runs on
Optimizing for latency is crucial for creating responsive and user-friendly applications.
скрытое пространство
Synonym for embedding space .
слой
A set of neurons in a neural network . Three common types of layers are as follows:
- The input layer , which provides values for all the features .
- One or more hidden layers , which find nonlinear relationships between the features and the label.
- The output layer , which provides the prediction.
For example, the following illustration shows a neural network with one input layer, two hidden layers, and one output layer:
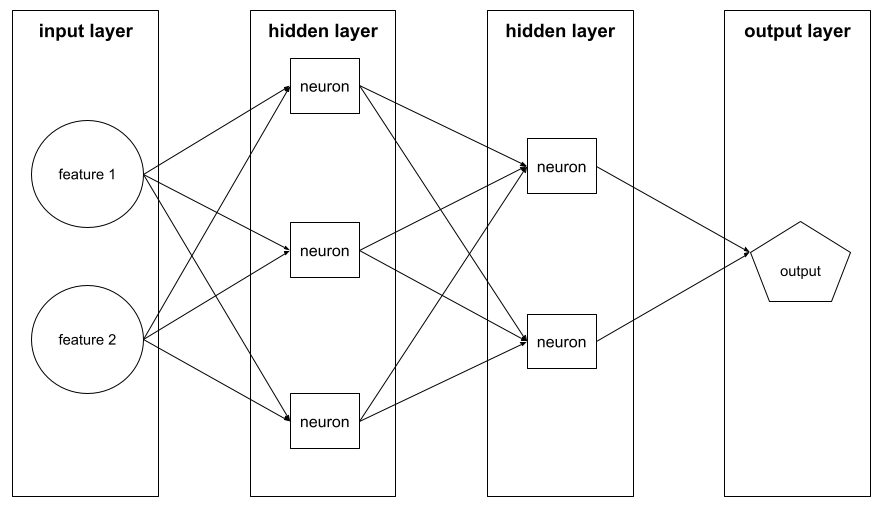
In TensorFlow , layers are also Python functions that take Tensors and configuration options as input and produce other tensors as output.
Layers API (tf.layers)
A TensorFlow API for constructing a deep neural network as a composition of layers. The Layers API lets you build different types of layers , such as:
-
tf.layers.Densefor a fully-connected layer . -
tf.layers.Conv2Dfor a convolutional layer.
The Layers API follows the Keras layers API conventions. That is, aside from a different prefix, all functions in the Layers API have the same names and signatures as their counterparts in the Keras layers API.
лист
Any endpoint in a decision tree . Unlike a condition , a leaf doesn't perform a test. Rather, a leaf is a possible prediction. A leaf is also the terminal node of an inference path .
For example, the following decision tree contains three leaves:
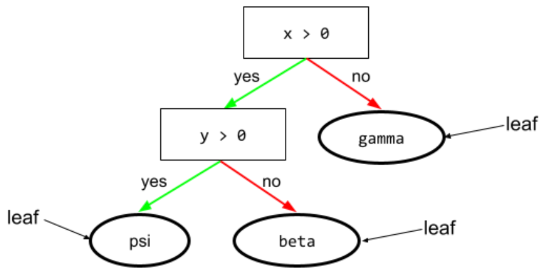
See Decision trees in the Decision Forests course for more information.
Learning Interpretability Tool (LIT)
A visual, interactive model-understanding and data visualization tool.
You can use open-source LIT to interpret models or to visualize text, image, and tabular data.
скорость обучения
A floating-point number that tells the gradient descent algorithm how strongly to adjust weights and biases on each iteration . For example, a learning rate of 0.3 would adjust weights and biases three times more powerfully than a learning rate of 0.1.
Learning rate is a key hyperparameter . If you set the learning rate too low, training will take too long. If you set the learning rate too high, gradient descent often has trouble reaching convergence .
Дополнительную информацию см. в статье «Линейная регрессия: гиперпараметры в машинном обучении» (краткий курс).
least squares regression
A linear regression model trained by minimizing L 2 Loss .
Расстояние Левенштейна
An edit distance metric that calculates the fewest delete, insert, and substitute operations required to change one word to another. For example, the Levenshtein distance between the words "heart" and "darts" is three because the following three edits are the fewest changes to turn one word into the other:
- heart → deart (substitute "h" with "d")
- deart → dart (delete "e")
- dart → darts (insert "s")
Note that the preceding sequence isn't the only path of three edits.
линейный
A relationship between two or more variables that can be represented solely through addition and multiplication.
The plot of a linear relationship is a line.
Contrast with nonlinear .
линейная модель
A model that assigns one weight per feature to make predictions . (Linear models also incorporate a bias .) In contrast, the relationship of features to predictions in deep models is generally nonlinear .
Linear models are usually easier to train and more interpretable than deep models. However, deep models can learn complex relationships between features.
Linear regression and logistic regression are two types of linear models.
линейная регрессия
A type of machine learning model in which both of the following are true:
- The model is a linear model .
- The prediction is a floating-point value. (This is the regression part of linear regression .)
Contrast linear regression with logistic regression . Also, contrast regression with classification .
Более подробную информацию можно найти в разделе «Линейная регрессия» в «Кратком курсе по машинному обучению».
ЛИТ
Abbreviation for the Learning Interpretability Tool (LIT) , which was previously known as the Language Interpretability Tool.
магистр права
Abbreviation for large language model .
LLM evaluations (evals)
A set of metrics and benchmarks for assessing the performance of large language models (LLMs). At a high level, LLM evaluations:
- Help researchers identify areas where LLMs need improvement.
- Are useful in comparing different LLMs and identifying the best LLM for a particular task.
- Help ensure that LLMs are safe and ethical to use.
See Large language models (LLMs) in Machine Learning Crash Course for more information.
логистическая регрессия
A type of regression model that predicts a probability. Logistic regression models have the following characteristics:
- The label is categorical . The term logistic regression usually refers to binary logistic regression , that is, to a model that calculates probabilities for labels with two possible values. A less common variant, multinomial logistic regression , calculates probabilities for labels with more than two possible values.
- The loss function during training is Log Loss . (Multiple Log Loss units can be placed in parallel for labels with more than two possible values.)
- The model has a linear architecture, not a deep neural network. However, the remainder of this definition also applies to deep models that predict probabilities for categorical labels.
For example, consider a logistic regression model that calculates the probability of an input email being either spam or not spam. During inference, suppose the model predicts 0.72. Therefore, the model is estimating:
- A 72% chance of the email being spam.
- A 28% chance of the email not being spam.
A logistic regression model uses the following two-step architecture:
- The model generates a raw prediction (y') by applying a linear function of input features.
- The model uses that raw prediction as input to a sigmoid function , which converts the raw prediction to a value between 0 and 1, exclusive.
Like any regression model, a logistic regression model predicts a number. However, this number typically becomes part of a binary classification model as follows:
- If the predicted number is greater than the classification threshold , the binary classification model predicts the positive class.
- If the predicted number is less than the classification threshold, the binary classification model predicts the negative class.
See Logistic regression in Machine Learning Crash Course for more information.
логиты
The vector of raw (non-normalized) predictions that a classification model generates, which is ordinarily then passed to a normalization function. If the model is solving a multi-class classification problem, logits typically become an input to the softmax function. The softmax function then generates a vector of (normalized) probabilities with one value for each possible class.
Потери логарифма
The loss function used in binary logistic regression .
Дополнительную информацию см. в разделе «Логистическая регрессия: функция потерь и регуляризация» в книге «Краткий курс по машинному обучению».
логарифм шансов
The logarithm of the odds of some event.
Долговременная кратковременная память (LSTM)
A type of cell in a recurrent neural network used to process sequences of data in applications such as handwriting recognition, machine translation , and image captioning. LSTMs address the vanishing gradient problem that occurs when training RNNs due to long data sequences by maintaining history in an internal memory state based on new input and context from previous cells in the RNN.
ЛоРА
Abbreviation for Low-Rank Adaptability .
потеря
During the training of a supervised model , a measure of how far a model's prediction is from its label .
A loss function calculates the loss.
Дополнительную информацию см. в разделе «Линейная регрессия: функция потерь в машинном обучении» (краткий курс).
loss aggregator
A type of machine learning algorithm that improves the performance of a model by combining the predictions of multiple models and using those predictions to make a single prediction. As a result, a loss aggregator can reduce the variance of the predictions and improve the accuracy of the predictions.
loss curve
A plot of loss as a function of the number of training iterations . The following plot shows a typical loss curve:
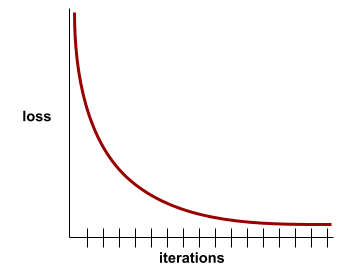
Loss curves can help you determine when your model is converging or overfitting .
Loss curves can plot all of the following types of loss:
См. также кривую обобщения .
Дополнительную информацию см. в разделе «Переобучение: интерпретация кривых потерь» в книге «Краткий курс по машинному обучению».
функция потерь
В процессе обучения или тестирования используется математическая функция, которая вычисляет потери на наборе примеров. Функция потерь возвращает меньшие значения для моделей, которые делают хорошие прогнозы, чем для моделей, которые делают плохие прогнозы.
Цель обучения, как правило, состоит в минимизации потерь, которые возвращает функция потерь.
Существует множество различных типов функций потерь. Выберите подходящую функцию потерь для типа модели, которую вы строите. Например:
- Функция потерь L2 (или среднеквадратичная ошибка ) — это функция потерь для линейной регрессии .
- Функция потерь Log Loss используется в логистической регрессии .
потеря поверхности
График зависимости веса(ов) от потерь. Метод градиентного спуска направлен на поиск веса(ов), при котором поверхность потерь находится в локальном минимуме.
эффект «потерянный посередине»
Тенденция LLM использовать информацию из начала и конца длинного контекстного окна более эффективно, чем информацию из середины. Иными словами, при наличии длинного контекста эффект «потери информации в середине» приводит к следующей точности:
- Относительно высокий уровень , когда необходимая для формирования ответа информация находится в начале или конце контекста.
- Относительно низкий уровень, когда необходимая для формирования ответа информация находится в середине контекста.
Этот термин взят из книги «Затерянные посередине: как языковые модели используют длинные контексты» .
Low-Rank Adaptability (LoRA)
Эффективный с точки зрения параметров метод тонкой настройки , который «замораживает» предварительно обученные веса модели (так что их больше нельзя изменять), а затем вставляет в модель небольшой набор обучаемых весов. Этот набор обучаемых весов (также известный как «матрицы обновления») значительно меньше базовой модели и, следовательно, обучается гораздо быстрее.
LoRA предоставляет следующие преимущества:
- Улучшает качество прогнозов модели в той области, где применяется тонкая настройка.
- Этот метод позволяет быстрее выполнять тонкую настройку параметров модели, чем методы, требующие тонкой настройки всех параметров модели.
- Снижает вычислительные затраты на вывод результатов , позволяя одновременно запускать несколько специализированных моделей, использующих одну и ту же базовую модель.
LSTM
Сокращение от Long Short-Term Memory (долговременная кратковременная память).
М
машинное обучение
Программа или система, которая обучает модель на основе входных данных. Обученная модель может делать полезные прогнозы на основе новых (ранее не встречавшихся) данных, полученных из того же распределения, что и данные, использованные для обучения модели.
Машинное обучение также относится к области исследований, занимающейся этими программами или системами.
Для получения более подробной информации см. курс «Введение в машинное обучение» .
машинный перевод
Использование программного обеспечения (как правило, модели машинного обучения) для преобразования текста с одного человеческого языка на другой человеческий язык, например, с английского на японский.
большинство класса
Наиболее распространенная метка в наборе данных с несбалансированным распределением классов . Например, если набор данных содержит 99% отрицательных меток и 1% положительных меток, то отрицательные метки составляют преобладающий класс.
В отличие от класса меньшинств .
Дополнительную информацию см. в разделе «Наборы данных: Несбалансированные наборы данных» в кратком курсе по машинному обучению.
Марковский процесс принятия решений (МПР)
Граф, представляющий модель принятия решений, в которой решения (или действия ) предпринимаются для перехода между последовательностями состояний при условии выполнения свойства Маркова . В обучении с подкреплением эти переходы между состояниями возвращают числовое вознаграждение .
Свойство Маркова
Свойство определенных сред , в которых переходы между состояниями полностью определяются информацией, неявно содержащейся в текущем состоянии и действиях агента.
модель маскированного языка
Языковая модель , которая предсказывает вероятность того, что потенциальные токены заполнят пробелы в последовательности. Например, модель с маскированием может вычислить вероятность того, что потенциальное слово (или слова) заменит подчеркнутое слово в следующем предложении:
Тот, кто был в шляпе, вернулся.
В литературе обычно используется строка "MASK" вместо подчеркивания. Например:
«МАСКА» в шляпе вернулась.
Большинство современных моделей маскированного языка являются двунаправленными .
math-pass@k
Показатель, определяющий точность решения математической задачи учащимся магистратуры в течение K попыток. Например, math-pass@2 измеряет способность учащегося решать математические задачи за две попытки. Точность 0,85 по показателю math-pass@2 означает, что учащийся смог решить математические задачи в 85% случаев за две попытки.
Показатель math-pass@k идентичен показателю pass@k , за исключением того, что термин math-pass@k используется специально для оценки математических навыков.
matplotlib
Библиотека matplotlib с открытым исходным кодом для построения 2D-графиков на Python помогает визуализировать различные аспекты машинного обучения.
матричная факторизация
В математике это механизм для нахождения матриц, скалярное произведение которых аппроксимирует целевую матрицу.
В рекомендательных системах целевая матрица часто содержит оценки пользователей по товарам . Например, целевая матрица для системы рекомендаций фильмов может выглядеть примерно так, где положительные целые числа — это оценки пользователей, а 0 означает, что пользователь не оценил фильм:
| Касабланка | Филадельфийская история | Чёрная Пантера | Чудо-женщина | Криминальное чтиво | |
|---|---|---|---|---|---|
| Пользователь 1 | 5.0 | 3.0 | 0.0 | 2.0 | 0.0 |
| Пользователь 2 | 4.0 | 0.0 | 0.0 | 1.0 | 5.0 |
| Пользователь 3 | 3.0 | 1.0 | 4.0 | 5.0 | 0.0 |
Система рекомендаций фильмов призвана прогнозировать пользовательские оценки фильмов без рейтинга. Например, понравится ли пользователю 1 фильм «Чёрная пантера» ?
Один из подходов к созданию рекомендательных систем заключается в использовании матричной факторизации для генерации следующих двух матриц:
- Матрица пользователей имеет форму числа пользователей, умноженного на число измерений встраивания.
- Матрица элементов , имеющая форму, где количество измерений встраивания умножено на количество элементов.
Например, применение матричной факторизации к нашим трем пользователям и пяти товарам может дать следующую матрицу пользователей и матрицу товаров:
User Matrix Item Matrix 1.1 2.3 0.9 0.2 1.4 2.0 1.2 0.6 2.0 1.7 1.2 1.2 -0.1 2.1 2.5 0.5
Скалярное произведение матрицы пользователей и матрицы товаров дает матрицу рекомендаций, которая содержит не только исходные оценки пользователей, но и прогнозы для фильмов, которые каждый пользователь еще не смотрел. Например, рассмотрим оценку пользователя 1 фильма «Касабланка» , которая составила 5,0. Скалярное произведение, соответствующее этой ячейке в матрице рекомендаций, должно быть около 5,0, и оно таково:
(1.1 * 0.9) + (2.3 * 1.7) = 4.9Что еще более важно, понравится ли Пользователю 1 фильм «Черная пантера» ? Скалярное произведение данных из первой строки и третьего столбца дает прогнозируемый рейтинг 4,3:
(1.1 * 1.4) + (2.3 * 1.2) = 4.3Как правило, при разложении матрицы на составляющие получаются матрица пользователей и матрица товаров, которые вместе значительно компактнее целевой матрицы.
МБПП
Сокращение от Mostly Basic Python Problems (В основном простые задачи на Python).
Средняя абсолютная ошибка (MAE)
Средний убыток на пример при использовании функции потерь L1 . Вычислите среднюю абсолютную ошибку следующим образом:
- Рассчитайте потери L1 для партии.
- Разделите значение функции потерь L1 на количество примеров в пакете.
Например, рассмотрим расчет потерь L1 на следующей группе из пяти примеров:
| Фактическая ценность примера | Прогнозируемое значение модели | Убыток (разница между фактическим и прогнозируемым значением) |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = L 1 потеря | ||
Таким образом, функция потерь L1 равна 8, а количество примеров равно 5. Следовательно, средняя абсолютная ошибка составляет:
Mean Absolute Error = L1 loss / Number of Examples Mean Absolute Error = 8/5 = 1.6
Сравните среднюю абсолютную ошибку со средней квадратичной ошибкой и среднеквадратичной ошибкой .
mean average precision at k (mAP@k)
Среднестатистическое значение всех показателей средней точности при k значениях по всему набору данных для валидации. Один из способов применения средней точности при k — оценка качества рекомендаций, генерируемых рекомендательной системой .
Хотя фраза «среднее арифметическое» звучит избыточно, название метрики вполне уместно. В конце концов, эта метрика вычисляет среднее значение точности множественных усреднений для k значений.
Среднеквадратичная ошибка (MSE)
The average loss per example when L 2 loss is used. Calculate Mean Squared Error as follows:
- Calculate the L 2 loss for a batch.
- Разделите значение функции потерь L2 на количество примеров в пакете.
Например, рассмотрим потери на следующих пяти примерах:
| Фактическая стоимость | Прогноз модели | Потеря | Квадрат убытка |
|---|---|---|---|
| 7 | 6 | 1 | 1 |
| 5 | 4 | 1 | 1 |
| 8 | 11 | 3 | 9 |
| 4 | 6 | 2 | 4 |
| 9 | 8 | 1 | 1 |
| 16 = L 2 потери | |||
Следовательно, среднеквадратичная ошибка составляет:
Mean Squared Error = L2 loss / Number of Examples Mean Squared Error = 16/5 = 3.2
Среднеквадратичная ошибка (Mean Squared Error) — популярный оптимизатор обучения, особенно для линейной регрессии .
Сравните среднеквадратичную ошибку со средней абсолютной ошибкой и среднеквадратичной ошибкой .
TensorFlow Playground использует среднеквадратичную ошибку для расчета значений функции потерь.
сетка
В параллельном программировании в машинном обучении это термин, связанный с распределением данных и модели по чипам TPU и определением того, как эти значения будут сегментированы или реплицированы.
Термин «сетка» является перегруженным и может означать любое из следующих:
- Физическая компоновка микросхем TPU.
- Абстрактная логическая конструкция для сопоставления данных и модели с микросхемами TPU.
В любом случае, сетка задается в виде формы .
meta-learning
Мета-обучение — это подмножество машинного обучения, которое занимается открытием или улучшением алгоритмов обучения. Система мета-обучения также может быть направлена на обучение модели быстрому освоению новой задачи на основе небольшого объема данных или опыта, полученного в предыдущих задачах. Алгоритмы мета-обучения, как правило, стремятся к достижению следующих целей:
- Улучшите или изучите функции, разработанные вручную (например, инициализатор или оптимизатор).
- Повышайте эффективность использования данных и вычислительных ресурсов.
- Улучшить обобщающую способность.
Метаобучение связано с обучением на небольшом количестве примеров .
метрика
Статистические данные, которые вас волнуют.
Цель — это показатель, который система машинного обучения пытается оптимизировать.
Metrics API (tf.metrics)
A TensorFlow API for evaluating models. For example, tf.metrics.accuracy determines how often a model's predictions match labels.
мини-партия
Небольшое, случайно выбранное подмножество из пакета, обрабатываемого за одну итерацию . Размер мини-пакета обычно составляет от 10 до 1000 примеров.
Например, предположим, что весь обучающий набор (полный пакет) состоит из 1000 примеров. Далее предположим, что вы установили размер каждого мини-пакета равным 20. Таким образом, на каждой итерации функция потерь определяется на случайных 20 из 1000 примеров, а затем соответствующим образом корректируются веса и смещения .
Рассчитать потери по мини-пакету данных гораздо эффективнее, чем по всем примерам в полном пакете.
Дополнительную информацию см. в статье «Линейная регрессия: гиперпараметры в машинном обучении» (краткий курс).
мини-пакетный стохастический градиентный спуск
Алгоритм градиентного спуска , использующий мини-пакеты . Другими словами, стохастический градиентный спуск с использованием мини-пакетов оценивает градиент на основе небольшого подмножества обучающих данных. Обычный стохастический градиентный спуск использует мини-пакет размером 1.
минимакс потери
Функция потерь для генеративных состязательных сетей , основанная на кросс-энтропии между распределением сгенерированных данных и реальных данных.
В первой статье для описания генеративных состязательных сетей используется функция минимаксных потерь.
Дополнительную информацию см. в разделе «Функции потерь» курса «Генеративные состязательные сети».
класс меньшинства
Менее распространенная метка в наборе данных с несбалансированным распределением классов . Например, если набор данных содержит 99% отрицательных меток и 1% положительных меток, то положительные метки составляют минорный класс.
В отличие от большинства .
Дополнительную информацию см. в разделе «Наборы данных: Несбалансированные наборы данных» в кратком курсе по машинному обучению.
смесь экспертов
Схема повышения эффективности нейронной сети путем использования только подмножества ее параметров (известного как эксперт ) для обработки заданного входного токена или примера . Сеть-управляющий направляет каждый входной токен или пример к соответствующему эксперту (экспертам).
Более подробную информацию можно найти в одной из следующих статей:
- Невероятно большие нейронные сети: слой разреженно управляемой смеси экспертов.
- Маршрутизация с использованием комбинации экспертов и выбора эксперта
ML
Сокращение от machine learning (машинное обучение) .
ММИТ
Сокращение от multimodal instruction-tuned (мультимодальная настройка инструкций) .
МНИСТ
Общедоступный набор данных, составленный ЛеКуном, Кортесом и Берджесом, содержит 60 000 изображений, каждое из которых показывает, как человек вручную написал определенную цифру от 0 до 9. Каждое изображение хранится в виде массива целых чисел размером 28x28, где каждое целое число представляет собой значение оттенков серого от 0 до 255 включительно.
MNIST — это канонический набор данных для машинного обучения, часто используемый для тестирования новых подходов к машинному обучению. Подробнее см. в разделе «База данных рукописных цифр MNIST» .
модальность
Категория данных высокого уровня. Например, числа, текст, изображения, видео и аудио — это пять различных типов данных.
модель
В общем, модель — это любая математическая конструкция, которая обрабатывает входные данные и возвращает выходные. Иными словами, модель — это набор параметров и структура, необходимые системе для прогнозирования. В контролируемом машинном обучении модель принимает пример в качестве входных данных и выводит прогноз в качестве выходных данных. В рамках контролируемого машинного обучения модели несколько различаются. Например:
- Модель линейной регрессии состоит из набора весов и смещения .
- Модель нейронной сети состоит из:
- Набор скрытых слоев , каждый из которых содержит один или несколько нейронов .
- Весовые коэффициенты и смещения, связанные с каждым нейроном.
- Модель дерева решений состоит из:
- Форма дерева, то есть схема, по которой условия и листья связаны между собой.
- Условия и отпуска.
Вы можете сохранять, восстанавливать или создавать копии модели.
В машинном обучении без учителя также создаются модели, как правило, функция, которая может сопоставить входной пример с наиболее подходящим кластером .
модельная емкость
Сложность задач, которые может изучить модель. Чем сложнее задачи, которые может изучить модель, тем выше её возможности. Возможности модели обычно увеличиваются с увеличением количества параметров модели. Формальное определение возможностей модели классификации см. в разделе «Размерность VC» .
каскадирование моделей
Система, которая выбирает идеальную модель для конкретного запроса на вывод.
Представьте себе группу моделей, от очень больших (много параметров ) до гораздо меньших (значительно меньше параметров). Очень большие модели потребляют больше вычислительных ресурсов во время вывода , чем меньшие модели. Однако очень большие модели, как правило, могут выполнять более сложные запросы, чем меньшие. Каскадирование моделей определяет сложность запроса на вывод, а затем выбирает подходящую модель для выполнения вывода. Основная цель каскадирования моделей — снижение затрат на вывод за счет, как правило, выбора меньших моделей и выбора более крупной модели только для более сложных запросов.
Imagine that a small model runs on a phone and a larger version of that model runs on a remote server. Good model cascading reduces cost and latency by enabling the smaller model to handle simple requests and only calling the remote model to handle complex requests.
См. также модель маршрутизатора .
модельный параллелизм
Способ масштабирования обучения или вывода, при котором различные части одной модели размещаются на разных устройствах . Параллельная обработка моделей позволяет создавать модели, которые слишком велики, чтобы поместиться на одном устройстве.
Для реализации параллельной обработки моделей система обычно выполняет следующие действия:
- Разделяет модель на более мелкие части.
- Распределяет обучение этих более мелких частей между несколькими процессорами. Каждый процессор обучает свою собственную часть модели.
- Объединяет результаты для создания единой модели.
Параллельная обработка моделей замедляет обучение.
См. также параллелизм данных .
модель маршрутизатора
Алгоритм, определяющий идеальную модель для вывода в каскадном построении моделей . Маршрутизатор моделей сам по себе обычно представляет собой модель машинного обучения, которая постепенно учится выбирать наилучшую модель для заданных входных данных. Однако иногда маршрутизатор моделей может быть более простым алгоритмом, не относящимся к машинному обучению.
обучение модели
Процесс определения наилучшей модели .
МОЭ
Сокращение от "смешанная группа экспертов" .
Импульс
Сложный алгоритм градиентного спуска, в котором шаг обучения зависит не только от производной на текущем шаге, но и от производных шагов, непосредственно предшествовавших ему. Импульс включает вычисление экспоненциально взвешенного скользящего среднего градиентов во времени, аналогично импульсу в физике. Импульс иногда предотвращает застревание процесса обучения в локальных минимумах.
Задачи по базовому Python (MBPP)
Набор данных для оценки уровня владения программой LLM навыками написания кода на Python. В наборе данных Mostly Basic Python Problems содержится около 1000 задач по программированию, созданных пользователями. Каждая задача в наборе данных включает в себя:
- Описание задачи
- Код решения
- Three automated test cases
МТ
Сокращение для машинного перевода .
multi-class classification
В контролируемом обучении это задача классификации , в которой набор данных содержит более двух классов меток. Например, метки в наборе данных Iris должны принадлежать к одному из следующих трех классов:
- Ирис сетоза
- Iris virginica
- Iris versicolor
Модель, обученная на наборе данных Iris и предсказывающая тип ириса на новых примерах, выполняет многоклассовую классификацию.
В отличие от этого, задачи классификации, которые различают ровно два класса, представляют собой модели бинарной классификации . Например, модель электронной почты, которая предсказывает либо спам , либо не спам, является моделью бинарной классификации.
В задачах кластеризации многоклассовая классификация подразумевает наличие более двух кластеров.
Дополнительную информацию см. в разделе «Нейронные сети: многоклассовая классификация» в кратком курсе по машинному обучению.
многоклассовая логистическая регрессия
Применение логистической регрессии в задачах многоклассовой классификации .
многоголовочное самовнимание
Расширение механизма самовнимания , которое применяет этот механизм несколько раз для каждой позиции во входной последовательности.
В фильме «Трансформеры» впервые была представлена технология самовнимания для нескольких голов.
многомодальные инструкции, настроенные
Модель , оптимизированная под конкретные инструкции , способная обрабатывать не только текстовые данные, но и изображения, видео и аудио.
мультимодальная модель
Модель, входные данные, выходные данные или и то, и другое которой включают более одной модальности . Например, рассмотрим модель, которая принимает в качестве признаков как изображение, так и текстовую подпись (две модальности) и выдает оценку, указывающую на то, насколько текстовая подпись соответствует изображению. Таким образом, входные данные этой модели являются мультимодальными, а выходные — унимодальными.
многономиальная классификация
Синоним для многоклассовой классификации .
многомерная регрессия
Синоним для многоклассовой логистической регрессии .
Multi-sentence Reading Comprehension (MultiRC)
Набор данных для оценки способности студентов магистратуры решать задачи с множественным выбором. Каждый пример в наборе данных содержит:
- Контекстный абзац
- Вопрос по поводу этого абзаца.
- На вопрос можно дать несколько ответов. Каждый ответ помечен как «Верно» или «Неверно». Несколько ответов могут быть верными.
Например:
Контекстный абзац :
Сьюзен хотела устроить вечеринку в честь своего дня рождения. Она позвонила всем своим друзьям. У неё пять подруг. Мама сказала, что Сьюзен может пригласить их всех на вечеринку. Первая подруга не смогла пойти, потому что заболела. Вторая подруга уезжала из города. Третья подруга не была уверена, разрешат ли ей родители. Четвёртая сказала, что, возможно, да. Пятая подруга точно могла пойти на вечеринку. Сьюзен немного расстроилась. В день вечеринки все пять подруг пришли. У каждой подруги был подарок для Сьюзен. Сьюзен была счастлива и на следующей неделе отправила каждой подруге благодарственную открытку.
Вопрос : Выздоровела ли больная подруга Сьюзен?
Несколько вариантов ответа :
- Да, она выздоровела. (Верно)
- Нет. (Ложно)
- Да. (Верно)
- Нет, она не выздоровела. (Неверно)
- Да, она была на вечеринке у Сьюзен. (Верно)
MultiRC является компонентом комплекса SuperGLUE .
Подробнее см. в статье «Заглядывая за поверхность: задание на развитие навыков понимания прочитанного текста, состоящего из нескольких предложений» .
многозадачность
Метод машинного обучения, при котором одна модель обучается выполнению нескольких задач .
Многозадачные модели создаются путем обучения на данных, подходящих для каждой из различных задач. Это позволяет модели научиться обмениваться информацией между задачами, что способствует более эффективному обучению.
Модель, обученная для решения нескольких задач, часто обладает улучшенными обобщающими способностями и может быть более устойчивой к обработке различных типов данных.
Н
Нано
Относительно компактная модель Gemini , предназначенная для использования непосредственно на устройстве. Подробнее см. Gemini Nano .
NaN trap
Когда одно число в вашей модели становится NaN во время обучения, это приводит к тому, что многие или все остальные числа в вашей модели в конечном итоге становятся NaN.
NaN is an abbreviation for N ot a N umber.
обработка естественного языка
Область обучения компьютеров обработке слов или текста пользователя с использованием лингвистических правил. Практически вся современная обработка естественного языка основана на машинном обучении.понимание естественного языка
Подмножество обработки естественного языка , определяющее намерения сказанного или набранного. Понимание естественного языка может выходить за рамки обработки естественного языка и учитывать сложные аспекты языка, такие как контекст, сарказм и эмоциональная составляющая.
отрицательный класс
В бинарной классификации один класс называется положительным , а другой — отрицательным . Положительный класс — это то, что модель проверяет, а отрицательный класс — это другая возможность. Например:
- В медицинском тесте отрицательный результат может означать «не опухоль».
- В модели классификации электронных писем отрицательным классом может быть «не спам».
В отличие от позитивного класса .
отрицательная выборка
Синоним для отбора кандидатов .
Поиск нейронной архитектуры (NAS)
Метод автоматического проектирования архитектуры нейронной сети . Алгоритмы NAS позволяют сократить время и ресурсы, необходимые для обучения нейронной сети.
В системах NAS обычно используются:
- Пространство поиска — это набор возможных архитектур.
- Функция пригодности — это мера того, насколько хорошо конкретная архитектура справляется с заданной задачей.
Алгоритмы NAS часто начинаются с небольшого набора возможных архитектур и постепенно расширяют пространство поиска по мере того, как алгоритм узнает больше об эффективных архитектурах. Функция пригодности обычно основана на производительности архитектуры на обучающем наборе данных, а обучение алгоритма, как правило, осуществляется с использованием метода обучения с подкреплением .
Алгоритмы NAS доказали свою эффективность в поиске высокопроизводительных архитектур для решения различных задач, включая классификацию изображений, классификацию текста и машинный перевод .
нейронная сеть
A model containing at least one hidden layer . A deep neural network is a type of neural network containing more than one hidden layer. For example, the following diagram shows a deep neural network containing two hidden layers.
Each neuron in a neural network connects to all of the nodes in the next layer. For example, in the preceding diagram, notice that each of the three neurons in the first hidden layer separately connect to both of the two neurons in the second hidden layer.
Neural networks implemented on computers are sometimes called artificial neural networks to differentiate them from neural networks found in brains and other nervous systems.
Some neural networks can mimic extremely complex nonlinear relationships between different features and the label.
See also convolutional neural network and recurrent neural network .
See Neural networks in Machine Learning Crash Course for more information.
нейрон
In machine learning, a distinct unit within a hidden layer of a neural network . Each neuron performs the following two-step action:
- Calculates the weighted sum of input values multiplied by their corresponding weights.
- Passes the weighted sum as input to an activation function .
A neuron in the first hidden layer accepts inputs from the feature values in the input layer . A neuron in any hidden layer beyond the first accepts inputs from the neurons in the preceding hidden layer. For example, a neuron in the second hidden layer accepts inputs from the neurons in the first hidden layer.
The following illustration highlights two neurons and their inputs.
A neuron in a neural network mimics the behavior of neurons in brains and other parts of nervous systems.
N-грамма
An ordered sequence of N words. For example, truly madly is a 2-gram. Because order is relevant, madly truly is a different 2-gram than truly madly .
| Н | Name(s) for this kind of N-gram | Примеры |
|---|---|---|
| 2 | bigram or 2-gram | to go, go to, eat lunch, eat dinner |
| 3 | trigram or 3-gram | ate too much, happily ever after, the bell tolls |
| 4 | 4-gram | walk in the park, dust in the wind, the boy ate lentils |
Many natural language understanding models rely on N-grams to predict the next word that the user will type or say. For example, suppose a user typed happily ever . An NLU model based on trigrams would likely predict that the user will next type the word after .
Contrast N-grams with bag of words , which are unordered sets of words.
See Large language models in Machine Learning Crash Course for more information.
НЛП
Abbreviation for natural language processing .
НЛУ
Abbreviation for natural language understanding .
node (decision tree)
In a decision tree , any condition or leaf .
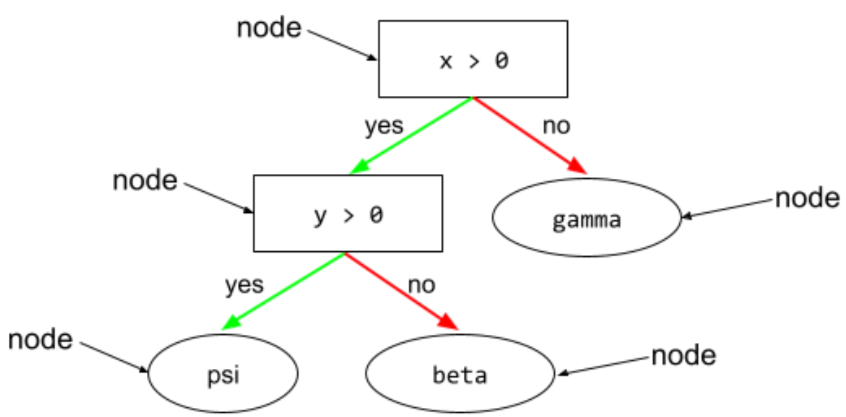
See Decision Trees in the Decision Forests course for more information.
node (neural network)
A neuron in a hidden layer .
See Neural Networks in Machine Learning Crash Course for more information.
node (TensorFlow graph)
An operation in a TensorFlow graph .
шум
Broadly speaking, anything that obscures the signal in a dataset. Noise can be introduced into data in a variety of ways. For example:
- Human raters make mistakes in labeling.
- Humans and instruments mis-record or omit feature values.
non-binary condition
A condition containing more than two possible outcomes. For example, the following non-binary condition contains three possible outcomes:
Дополнительную информацию см. в разделе «Типы условий» курса «Лесные модели принятия решений».
нелинейный
A relationship between two or more variables that can't be represented solely through addition and multiplication. A linear relationship can be represented as a line; a nonlinear relationship can't be represented as a line. For example, consider two models that each relate a single feature to a single label. The model on the left is linear and the model on the right is nonlinear:

See Neural networks: Nodes and hidden layers in Machine Learning Crash Course to experiment with different kinds of nonlinear functions.
смещение, вызванное отсутствием ответа
See selection bias .
нестационарность
A feature whose values change across one or more dimensions, usually time. For example, consider the following examples of nonstationarity:
- The number of swimsuits sold at a particular store varies with the season.
- The quantity of a particular fruit harvested in a particular region is zero for much of the year but large for a brief period.
- Due to climate change, annual mean temperatures are shifting.
Contrast with stationarity .
no one right answer (NORA)
A prompt having multiple correct responses . For example, the following prompt has no one right answer:
Tell me a funny joke about elephants.
Evaluating the responses to no one right answer prompts is usually far more subjective than evaluating prompts with one right answer . For example, evaluating an elephant joke requires a systematic way to determine how funny the joke is.
НОРА
Abbreviation for no one right answer .
нормализация
Broadly speaking, the process of converting a variable's actual range of values into a standard range of values, such as:
- от -1 до +1
- от 0 до 1
- Z-scores (roughly, -3 to +3)
For example, suppose the actual range of values of a certain feature is 800 to 2,400. As part of feature engineering , you could normalize the actual values down to a standard range, such as -1 to +1.
Normalization is a common task in feature engineering . Models usually train faster (and produce better predictions) when every numerical feature in the feature vector has roughly the same range.
See also Z-score normalization .
See Numerical Data: Normalization in Machine Learning Crash Course for more information.
Блокнот LM
A Gemini-based tool that enables users to upload documents and then use prompts to ask questions about, summarize, or organize those documents. For example, an author could upload several short stories and ask Notebook LM to find their common themes or to identify which one would make the best movie.
novelty detection
The process of determining whether a new (novel) example comes from the same distribution as the training set . In other words, after training on the training set, novelty detection determines whether a new example (during inference or during additional training) is an outlier .
Contrast with outlier detection .
числовые данные
Features represented as integers or real-valued numbers. For example, a house valuation model would probably represent the size of a house (in square feet or square meters) as numerical data. Representing a feature as numerical data indicates that the feature's values have a mathematical relationship to the label. That is, the number of square meters in a house probably has some mathematical relationship to the value of the house.
Not all integer data should be represented as numerical data. For example, postal codes in some parts of the world are integers; however, integer postal codes shouldn't be represented as numerical data in models. That's because a postal code of 20000 is not twice (or half) as potent as a postal code of 10000. Furthermore, although different postal codes do correlate to different real estate values, we can't assume that real estate values at postal code 20000 are twice as valuable as real estate values at postal code 10000. Postal codes should be represented as categorical data instead.
Numerical features are sometimes called continuous features .
Дополнительную информацию см. в разделе «Работа с числовыми данными» в кратком курсе по машинному обучению.
NumPy
An open-source math library that provides efficient array operations in Python. pandas is built on NumPy.
О
цель
A metric that your algorithm is trying to optimize.
целевая функция
The mathematical formula or metric that a model aims to optimize. For example, the objective function for linear regression is usually Mean Squared Loss . Therefore, when training a linear regression model, training aims to minimize Mean Squared Loss.
In some cases, the goal is to maximize the objective function. For example, if the objective function is accuracy, the goal is to maximize accuracy.
See also loss .
oblique condition
In a decision tree , a condition that involves more than one feature . For example, if height and width are both features, then the following is an oblique condition:
height > width
Contrast with axis-aligned condition .
Дополнительную информацию см. в разделе «Типы условий» курса «Лесные модели принятия решений».
офлайн
Synonym for static .
offline inference
The process of a model generating a batch of predictions and then caching (saving) those predictions. Apps can then access the inferred prediction from the cache rather than rerunning the model.
For example, consider a model that generates local weather forecasts (predictions) once every four hours. After each model run, the system caches all the local weather forecasts. Weather apps retrieve the forecasts from the cache.
Offline inference is also called static inference .
Contrast with online inference . See Production ML systems: Static versus dynamic inference in Machine Learning Crash Course for more information.
one-hot encoding
Representing categorical data as a vector in which:
- One element is set to 1.
- All other elements are set to 0.
One-hot encoding is commonly used to represent strings or identifiers that have a finite set of possible values. For example, suppose a certain categorical feature named Scandinavia has five possible values:
- "Дания"
- "Швеция"
- "Норвегия"
- "Финляндия"
- "Исландия"
One-hot encoding could represent each of the five values as follows:
| Страна | Вектор | ||||
|---|---|---|---|---|---|
| "Дания" | 1 | 0 | 0 | 0 | 0 |
| "Швеция" | 0 | 1 | 0 | 0 | 0 |
| "Норвегия" | 0 | 0 | 1 | 0 | 0 |
| "Финляндия" | 0 | 0 | 0 | 1 | 0 |
| "Исландия" | 0 | 0 | 0 | 0 | 1 |
Thanks to one-hot encoding, a model can learn different connections based on each of the five countries.
Representing a feature as numerical data is an alternative to one-hot encoding. Unfortunately, representing the Scandinavian countries numerically is not a good choice. For example, consider the following numeric representation:
- "Denmark" is 0
- "Sweden" is 1
- "Norway" is 2
- "Finland" is 3
- "Iceland" is 4
With numeric encoding, a model would interpret the raw numbers mathematically and would try to train on those numbers. However, Iceland isn't actually twice as much (or half as much) of something as Norway, so the model would come to some strange conclusions.
Дополнительную информацию см. в разделе «Категориальные данные: словарь и one-hot кодирование» в «Кратком курсе по машинному обучению».
one right answer (ORA)
A prompt having a single correct response . For example, consider the following prompt:
True or false: Saturn is bigger than Mars.
The only correct response is true .
Contrast with no one right answer .
one-shot learning
A machine learning approach, often used for object classification, designed to learn effective classification model from a single training example.
See also few-shot learning and zero-shot learning .
одноразовая подсказка
A prompt that contains one example demonstrating how the large language model should respond. For example, the following prompt contains one example showing a large language model how it should answer a query.
| Части одного задания | Примечания |
|---|---|
| Какая официальная валюта указанной страны? | Вопрос, на который вы хотите получить ответ в рамках программы LLM. |
| France: EUR | Один пример. |
| Индия: | Сам запрос. |
Compare and contrast one-shot prompting with the following terms:
one-vs.-all
Given a classification problem with N classes, a solution consisting of N separate binary classification model—one binary classification model for each possible outcome. For example, given a model that classifies examples as animal, vegetable, or mineral, a one-vs.-all solution would provide the following three separate binary classification models:
- animal versus not animal
- vegetable versus not vegetable
- mineral versus not mineral
онлайн
Synonym for dynamic .
online inference
Generating predictions on demand. For example, suppose an app passes input to a model and issues a request for a prediction. A system using online inference responds to the request by running the model (and returning the prediction to the app).
Contrast with offline inference .
See Production ML systems: Static versus dynamic inference in Machine Learning Crash Course for more information.
operation (op)
In TensorFlow, any procedure that creates, manipulates, or destroys a Tensor . For example, a matrix multiply is an operation that takes two Tensors as input and generates one Tensor as output.
Оптакс
A gradient processing and optimization library for JAX . Optax facilitates research by providing building blocks that can be recombined in custom ways to optimize parametric models such as deep neural networks. Other goals include:
- Providing readable, well-tested, efficient implementations of core components.
- Improving productivity by making it possible to combine low level ingredients into custom optimizers (or other gradient processing components).
- Accelerating adoption of new ideas by making it easy for anyone to contribute.
оптимизатор
A specific implementation of the gradient descent algorithm. Popular optimizers include:
- AdaGrad , which stands for ADAptive GRADient descent.
- Adam, which stands for ADAptive with Momentum.
ОРА
Abbreviation for one right answer .
смещение однородности внешней группы
The tendency to see out-group members as more alike than in-group members when comparing attitudes, values, personality traits, and other characteristics. In-group refers to people you interact with regularly; out-group refers to people you don't interact with regularly. If you create a dataset by asking people to provide attributes about out-groups, those attributes may be less nuanced and more stereotyped than attributes that participants list for people in their in-group.
For example, Lilliputians might describe the houses of other Lilliputians in great detail, citing small differences in architectural styles, windows, doors, and sizes. However, the same Lilliputians might simply declare that Brobdingnagians all live in identical houses.
Out-group homogeneity bias is a form of group attribution bias .
See also in-group bias .
outlier detection
The process of identifying outliers in a training set .
Contrast with novelty detection .
выбросы
Values distant from most other values. In machine learning, any of the following are outliers:
- Input data whose values are more than roughly 3 standard deviations from the mean.
- Weights with high absolute values.
- Predicted values relatively far away from the actual values.
For example, suppose that widget-price is a feature of a certain model. Assume that the mean widget-price is 7 Euros with a standard deviation of 1 Euro. Examples containing a widget-price of 12 Euros or 2 Euros would therefore be considered outliers because each of those prices is five standard deviations from the mean.
Выбросы часто возникают из-за опечаток или других ошибок ввода. В других случаях выбросы не являются ошибками; в конце концов, значения, отклоняющиеся от среднего на пять стандартных отклонений, встречаются редко, но отнюдь не исключены.
Выбросы часто создают проблемы при обучении модели. Отсечение — один из способов управления выбросами.
Дополнительную информацию см. в разделе «Работа с числовыми данными» в кратком курсе по машинному обучению.
Оценка результатов вне выгрузки (OOB-оценка)
Механизм оценки качества дерева решений путем проверки каждого дерева решений на примерах , не использованных во время его обучения . Например, на следующей диаграмме обратите внимание, что система обучает каждое дерево решений примерно на двух третях примеров, а затем оценивает его на оставшейся одной трети примеров.
Вневыборочная оценка (OOB-оценка) — это вычислительно эффективная и консервативная аппроксимация механизма перекрестной проверки . При перекрестной проверке для каждого раунда перекрестной проверки обучается одна модель (например, в 10-кратной перекрестной проверке обучается 10 моделей). При OOB-оценке обучается одна модель. Поскольку при обучении методом бэггинга часть данных из каждого дерева исключается, OOB-оценка может использовать эти данные для аппроксимации перекрестной проверки.
Дополнительную информацию см. в разделе «Вневыборочная оценка» курса «Лесные модели принятия решений».
выходной слой
Финальный слой нейронной сети. Выходной слой содержит предсказание.
На следующем рисунке показана небольшая глубокая нейронная сеть с входным слоем, двумя скрытыми слоями и выходным слоем:
overfitting
Создание модели , которая настолько точно соответствует обучающим данным , что не может делать правильные прогнозы на новых данных.
Регуляризация может уменьшить переобучение. Обучение на большом и разнообразном обучающем наборе данных также может уменьшить переобучение.
Для получения дополнительной информации см. «Краткий курс по переобучению в машинном обучении».
передискретизация
Повторное использование примеров миноритарного класса в наборе данных с несбалансированным распределением классов для создания более сбалансированного обучающего набора .
Например, рассмотрим задачу бинарной классификации , в которой соотношение мажоритарного класса к миноритарному составляет 5000:1. Если набор данных содержит миллион примеров, то в нем будет всего около 200 примеров миноритарного класса, чего может быть недостаточно для эффективного обучения. Чтобы преодолеть этот недостаток, можно многократно использовать эти 200 примеров, что, возможно, позволит получить достаточное количество примеров для полезного обучения.
При использовании метода передискретизации необходимо проявлять осторожность, чтобы избежать переобучения .
Сравните с недовыборкой .
П
упакованные данные
Один из подходов к более эффективному хранению данных.
В упакованных данных информация хранится либо в сжатом формате, либо иным способом, обеспечивающим более эффективный доступ к ней. Упакованные данные минимизируют объем памяти и вычислительных ресурсов, необходимых для доступа к ним, что приводит к более быстрому обучению и более эффективному выводу модели.
Упакованные данные часто используются в сочетании с другими методами, такими как аугментация данных и регуляризация , что еще больше повышает производительность моделей .
Ладонь
Сокращение от Pathways Language Model (языковая модель Pathways) .
панды
API для анализа данных, ориентированный на столбцы, построенный на основе numpy . Многие фреймворки машинного обучения, включая TensorFlow, поддерживают структуры данных pandas в качестве входных данных. Подробности см. в документации pandas .
параметр
Веса и смещения , которые модель изучает в процессе обучения . Например, в модели линейной регрессии параметры состоят из смещения ( b ) и всех весов ( w1 , w2 и так далее) в следующей формуле:
В отличие от этого, гиперпараметры — это значения, которые вы (или сервис настройки гиперпараметров) предоставляете модели. Например, скорость обучения — это гиперпараметр.
параметрически эффективная настройка
Набор методов для более эффективной тонкой настройки большой предварительно обученной языковой модели (PLM) , чем полная тонкая настройка . Параметроэффективная настройка обычно позволяет настроить гораздо меньше параметров , чем полная тонкая настройка, но, как правило, создает большую языковую модель , которая работает так же хорошо (или почти так же хорошо), как большая языковая модель, построенная на основе полной тонкой настройки.
Сравните и сопоставьте параметрически эффективную настройку с помощью:
Параметрически эффективная настройка также известна как параметрически эффективная тонкая настройка .
Сервер параметров (PS)
A job that keeps track of a model's parameters in a distributed setting.
parameter update
The operation of adjusting a model's parameters during training, typically within a single iteration of gradient descent .
частная производная
A derivative in which all but one of the variables is considered a constant. For example, the partial derivative of f(x, y) with respect to x is the derivative of f considered as a function of x alone (that is, keeping y constant). The partial derivative of f with respect to x focuses only on how x is changing and ignores all other variables in the equation.
предвзятость участия
Synonym for non-response bias. See selection bias .
partitioning strategy
The algorithm by which variables are divided across parameter servers .
pass at k (pass@k)
A metric to determine the quality of code (for example, Python) that a large language model generates. More specifically, pass at k tells you the likelihood that at least one generated block of code out of k generated blocks of code will pass all of its unit tests.
Large language models often struggle to generate good code for complex programming problems. Software engineers adapt to this problem by prompting the large language model to generate multiple ( k ) solutions for the same problem. Then, software engineers test each of the solutions against unit tests. The calculation of pass at k depends on the outcome of the unit tests:
- If one or more of those solutions pass the unit test, then the LLM Passes that code generation challenge.
- If none of the solutions pass the unit test, then the LLM Fails that code generation challenge.
The formula for pass at k is as follows:
\[\text{pass at k} = \frac{\text{total number of passes}} {\text{total number of challenges}}\]
In general, higher values of k produce higher pass at k scores; however, higher values of k require more large language model and unit testing resources.
Pathways Language Model (PaLM)
An older model and predecessor to Gemini models .
Пакс
A programming framework designed for training large-scale neural network models so large that they span multiple TPU accelerator chip slices or pods .
Pax is built on Flax , which is built on JAX .
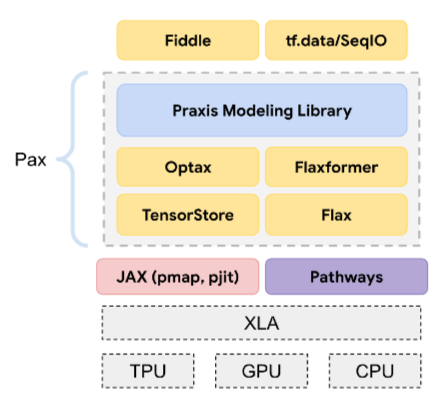
перцептрон
A system (either hardware or software) that takes in one or more input values, runs a function on the weighted sum of the inputs, and computes a single output value. In machine learning, the function is typically nonlinear, such as ReLU , sigmoid , or tanh . For example, the following perceptron relies on the sigmoid function to process three input values:
In the following illustration, the perceptron takes three inputs, each of which is itself modified by a weight before entering the perceptron:

Perceptrons are the neurons in neural networks .
производительность
Overloaded term with the following meanings:
- The standard meaning within software engineering. Namely: How fast (or efficiently) does this piece of software run?
- The meaning within machine learning. Here, performance answers the following question: How correct is this model ? That is, how good are the model's predictions?
permutation variable importances
A type of variable importance that evaluates the increase in the prediction error of a model after permuting the feature's values. Permutation variable importance is a model-independent metric.
недоумение
One measure of how well a model is accomplishing its task. For example, suppose your task is to read the first few letters of a word a user is typing on a phone keyboard, and to offer a list of possible completion words. Perplexity, P, for this task is approximately the number of guesses you need to offer in order for your list to contain the actual word the user is trying to type.
Perplexity is related to cross-entropy as follows:
конвейер
The infrastructure surrounding a machine learning algorithm. A pipeline includes gathering the data, putting the data into training data files, training one or more models, and exporting the models to production.
See ML pipelines in the Managing ML Projects course for more information.
трубопроводная
A form of model parallelism in which a model's processing is divided into consecutive stages and each stage is executed on a different device. While a stage is processing one batch, the preceding stage can work on the next batch.
See also staged training .
pjit
A JAX function that splits code to run across multiple accelerator chips . The user passes a function to pjit, which returns a function that has the equivalent semantics but is compiled into an XLA computation that runs across multiple devices (such as GPUs or TPU cores).
pjit enables users to shard computations without rewriting them by using the SPMD partitioner.
As of March 2023, pjit has been merged with jit . Refer to Distributed arrays and automatic parallelization for more details.
ПЛМ
Abbreviation for pre-trained language model .
pmap
A JAX function that executes copies of an input function on multiple underlying hardware devices (CPUs, GPUs, or TPUs ), with different input values. pmap relies on SPMD .
политика
In reinforcement learning, an agent's probabilistic mapping from states to actions .
объединение
Reducing a matrix (or matrixes) created by an earlier convolutional layer to a smaller matrix. Pooling usually involves taking either the maximum or average value across the pooled area. For example, suppose we have the following 3x3 matrix:
![Матрица 3x3 [[5,3,1], [8,2,5], [9,4,3]].](https://developers.google.com/static/machine-learning/glossary/images/PoolingStart.svg?hl=ru)
A pooling operation, just like a convolutional operation, divides that matrix into slices and then slides that convolutional operation by strides . For example, suppose the pooling operation divides the convolutional matrix into 2x2 slices with a 1x1 stride. As the following diagram illustrates, four pooling operations take place. Imagine that each pooling operation picks the maximum value of the four in that slice:
![The input matrix is 3x3 with the values: [[5,3,1], [8,2,5], [9,4,3]].
The top-left 2x2 submatrix of the input matrix is [[5,3], [8,2]], so
the top-left pooling operation yields the value 8 (which is the
maximum of 5, 3, 8, and 2). The top-right 2x2 submatrix of the input
matrix is [[3,1], [2,5]], so the top-right pooling operation yields
the value 5. The bottom-left 2x2 submatrix of the input matrix is
[[8,2], [9,4]], so the bottom-left pooling operation yields the value
9. The bottom-right 2x2 submatrix of the input matrix is
[[2,5], [4,3]], so the bottom-right pooling operation yields the value
5. In summary, the pooling operation yields the 2x2 matrix
[[8,5], [9,5]].](https://developers.google.com/static/machine-learning/glossary/images/PoolingConvolution.svg?hl=ru)
Pooling helps enforce translational invariance in the input matrix.
Pooling for vision applications is known more formally as spatial pooling . Time-series applications usually refer to pooling as temporal pooling . Less formally, pooling is often called subsampling or downsampling .
позиционное кодирование
A technique to add information about the position of a token in a sequence to the token's embedding. Transformer models use positional encoding to better understand the relationship between different parts of the sequence.
A common implementation of positional encoding uses a sinusoidal function. (Specifically, the frequency and amplitude of the sinusoidal function are determined by the position of the token in the sequence.) This technique enables a Transformer model to learn to attend to different parts of the sequence based on their position.
позитивный класс
The class you are testing for.
For example, the positive class in a cancer model might be "tumor." The positive class in an email classification model might be "spam."
Contrast with negative class .
постобработка
Adjusting the output of a model after the model has been run. Post-processing can be used to enforce fairness constraints without modifying models themselves.
For example, one might apply post-processing to a binary classification model by setting a classification threshold such that equality of opportunity is maintained for some attribute by checking that the true positive rate is the same for all values of that attribute.
post-trained model
Loosely-defined term that typically refers to a pre-trained model that has gone through some post-processing, such as one or more of the following:
PR AUC (area under the PR curve)
Площадь под интерполированной кривой точности-полноты , полученная путем построения точек (полнота, точность) для различных значений порога классификации .
Практика
Базовая высокопроизводительная библиотека машинного обучения от Pax . Praxis часто называют «библиотекой слоев».
Praxis содержит не только определения класса Layer, но и большинство его вспомогательных компонентов, включая:
- входные данные
- Библиотеки конфигурации (HParam и Fiddle )
- optimizers
Praxis предоставляет определения для класса Model.
точность
Метрика для моделей классификации , которая отвечает на следующий вопрос:
Когда модель предсказывала положительный класс , какой процент предсказаний оказался верным?
Вот формула:
где:
- Истинно положительный результат означает, что модель правильно предсказала положительный класс.
- Ложноположительный результат означает, что модель ошибочно предсказала положительный класс.
Например, предположим, что модель сделала 200 положительных прогнозов. Из этих 200 положительных прогнозов:
- 150 случаев оказались истинно положительными.
- 50 из них оказались ложноположительными результатами.
В этом случае:
Сравните с точностью и запоминанием .
Дополнительную информацию см. в разделе «Классификация: точность, полнота, прецизионность и связанные с ними показатели» в кратком курсе по машинному обучению.
точность при k (precision@k)
Показатель точности при k определяет долю первых k элементов в этом списке, которые являются «релевантными». То есть:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
Значение k должно быть меньше или равно длине возвращаемого списка. Обратите внимание, что длина возвращаемого списка не учитывается при вычислении.
Релевантность часто бывает субъективной; даже опытные эксперты-оценщики нередко расходятся во мнениях относительно того, какие элементы являются релевантными.
Сравните с:
кривая точности-полноты
Кривая зависимости точности от полноты при различных пороговых значениях классификации .
прогноз
Результат работы модели. Например:
- Модель бинарной классификации предсказывает либо положительный, либо отрицательный класс.
- Прогноз многоклассовой модели соответствует одному классу.
- Результатом прогнозирования с помощью модели линейной регрессии является число.
смещение прогноза
Значение, указывающее, насколько сильно среднее значение прогнозов отличается от среднего значения меток в наборе данных.
Не следует путать с термином «предвзятость» в моделях машинного обучения или с предвзятостью в этике и справедливости .
прогнозирование машинного обучения
Любая стандартная («классическая») система машинного обучения .
Термин «прогностическое машинное обучение» не имеет формального определения. Скорее, этот термин обозначает категорию систем машинного обучения, не основанных на генеративном искусственном интеллекте .
прогнозируемая паритетность
Показатель справедливости , проверяющий, являются ли для данной модели классификации показатели точности эквивалентными для рассматриваемых подгрупп.
Например, модель, предсказывающая поступление в колледж, будет удовлетворять условию паритета прогнозирования по национальности, если ее точность будет одинаковой для лилипутов и бробдингнагцев.
Прогностическая паритетность иногда также называется прогностической паритетностью скорости .
Более подробное обсуждение понятия прогнозируемого равенства см. в разделе «Разъяснение определений справедливости» (раздел 3.2.1).
прогнозируемое паритетное соотношение скоростей
Другое название для прогнозируемой паритеты .
предварительная обработка
Обработка данных перед их использованием для обучения модели. Предварительная обработка может быть как простой, например, удалением слов из английского текстового корпуса, которые не встречаются в английском словаре, так и сложной, например, переформулированием точек данных таким образом, чтобы исключить как можно больше атрибутов, коррелирующих с конфиденциальными атрибутами . Предварительная обработка может помочь соблюсти ограничения справедливости .предварительно обученная модель
Хотя этот термин может относиться к любой обученной модели или обученному вектору встраивания , в настоящее время под предварительно обученной моделью обычно подразумевается обученная большая языковая модель или другая форма обученной модели генеративного искусственного интеллекта .
См. также базовую модель и модель фундамента .
предварительная подготовка
Первоначальное обучение модели на большом наборе данных . Некоторые предварительно обученные модели представляют собой неуклюжие гиганты и, как правило, требуют доработки посредством дополнительного обучения. Например, эксперты по машинному обучению могут предварительно обучить большую языковую модель на огромном текстовом наборе данных, таком как все англоязычные страницы Википедии. После предварительного обучения полученная модель может быть дополнительно доработана с помощью любого из следующих методов:
- дистилляция
- тонкая настройка
- настройка инструкций
- параметрически эффективная настройка
- prompt-tuning
предварительные убеждения
То, во что вы верите относительно данных, прежде чем начать на них обучение. Например, L2- регуляризация основана на предварительном убеждении, что веса должны быть небольшими и нормально распределены вокруг нуля.
Про
Модель Gemini с меньшим количеством параметров , чем Ultra , но большим количеством параметров, чем Nano . Подробнее см. Gemini Pro .
вероятностная регрессионная модель
Модель регрессии , которая использует не только веса для каждого признака , но и неопределенность этих весов. Вероятностная регрессионная модель генерирует прогноз и неопределенность этого прогноза. Например, вероятностная регрессионная модель может дать прогноз 325 со стандартным отклонением 12. Для получения дополнительной информации о вероятностных регрессионных моделях см. этот пример в Colab на tensorflow.org .
функция плотности вероятности
A function that identifies the frequency of data samples having exactly a particular value. When a dataset's values are continuous floating-point numbers, exact matches rarely occur. However, integrating a probability density function from value x to value y yields the expected frequency of data samples between x and y .
Например, рассмотрим нормальное распределение со средним значением 200 и стандартным отклонением 30. Чтобы определить ожидаемую частоту выборок данных, попадающих в диапазон от 211,4 до 218,7, можно проинтегрировать функцию плотности вероятности для нормального распределения в диапазоне от 211,4 до 218,7.
быстрый
Любой текст, введенный в качестве входных данных для большой языковой модели с целью обучить модель определенному поведению. Подсказки могут быть как короткими, например, фразами, так и произвольно длинными (например, весь текст романа). Подсказки делятся на несколько категорий, в том числе и те, которые показаны в следующей таблице:
| Категория подсказки | Пример | Примечания |
|---|---|---|
| Вопрос | С какой скоростью может летать голубь? | |
| Инструкция | Write a funny poem about arbitrage. | Запрос, который просит большую языковую модель выполнить определенное действие. |
| Пример | Translate Markdown code to HTML. For example: Markdown: * list item HTML: <ul> <li>list item</li> </ul> | Первое предложение в этом примере задания — это инструкция. Остальная часть задания — это пример. |
| Роль | Объясните, почему градиентный спуск используется в машинном обучении для подготовки кандидатов наук по физике. | Первая часть предложения — это инструкция; фраза «получить докторскую степень по физике» — это указание на роль. |
| Частичные входные данные для завершения работы модели. | Премьер-министр Соединенного Королевства проживает по адресу: | Частично введенный запрос может либо резко обрываться (как в этом примере), либо заканчиваться подчеркиванием. |
Модель генеративного искусственного интеллекта может отвечать на запрос текстом, кодом, изображениями, встраиваниями , видео… практически чем угодно.
обучение на основе подсказок
Способность некоторых моделей адаптировать свое поведение в ответ на произвольный текстовый ввод ( подсказки ). В типичной парадигме обучения на основе подсказок большая языковая модель реагирует на подсказку, генерируя текст. Например, предположим, пользователь вводит следующую подсказку:
Кратко изложите третий закон движения Ньютона.
Модель, способная к обучению на основе подсказок, не обучается специально отвечать на предыдущую подсказку. Скорее, модель «знает» множество фактов из физики, много об общих правилах языка и много о том, что представляет собой в целом полезные ответы. Этих знаний достаточно, чтобы дать (надеемся) полезный ответ. Дополнительная обратная связь от человека («Этот ответ был слишком сложным» или «Что такое реакция?») позволяет некоторым системам обучения на основе подсказок постепенно повышать полезность своих ответов.
быстрый дизайн
Синоним к слову «оперативное проектирование» .
оперативное проектирование
Искусство создания подсказок , которые вызывают желаемые ответы от большой языковой модели . Разработка подсказок осуществляется людьми. Написание хорошо структурированных подсказок является важной частью обеспечения полезных ответов от большой языковой модели. Разработка подсказок зависит от многих факторов, включая:
- The dataset used to pre-train and possibly fine-tune the large language model.
- Температура и другие параметры декодирования, которые модель использует для генерации ответов.
Оперативное проектирование — синоним оперативного инженерного дела.
Более подробную информацию о написании полезных подсказок можно найти в разделе «Введение в разработку подсказок» .
набор подсказок
Набор подсказок для оценки большой языковой модели . Например, на следующем рисунке показан набор подсказок, состоящий из трех пунктов:
Хорошие наборы подсказок представляют собой достаточно «широкую» коллекцию вопросов, позволяющую тщательно оценить безопасность и полезность большой языковой модели.
См. также набор ответов .
быстрая настройка
Эффективный с точки зрения параметров механизм настройки , который обучается «префиксу», добавляемому системой в начало фактического запроса .
Один из вариантов настройки подсказок — иногда называемый префиксной настройкой — заключается в добавлении префикса к каждому слою . В отличие от этого, большинство методов настройки подсказок добавляют префикс только к входному слою .
прокси (конфиденциальные атрибуты)
Атрибут, используемый в качестве замены конфиденциального атрибута . Например, почтовый индекс человека может использоваться в качестве косвенного показателя его дохода, расы или этнической принадлежности.метки прокси
Данные используются для приблизительной оценки меток, которые отсутствуют непосредственно в наборе данных.
Например, предположим, вам нужно обучить модель для прогнозирования уровня стресса у сотрудников. Ваш набор данных содержит множество прогностических признаков, но не содержит метки с названием «уровень стресса». Не теряя надежды, вы выбираете «производственные травмы» в качестве косвенной метки для уровня стресса. В конце концов, сотрудники, находящиеся в состоянии сильного стресса, попадают в аварии чаще, чем спокойные сотрудники. Или нет? Возможно, количество производственных травм на самом деле увеличивается и уменьшается по нескольким причинам.
В качестве второго примера предположим, что вы хотите , чтобы «Идет ли дождь?» был логической меткой для вашего набора данных, но ваш набор данных не содержит данных о дожде. Если есть фотографии, вы можете использовать изображения людей с зонтами в качестве замещающей метки для вопроса «Идет ли дождь?». Подходит ли эта замещающая метка? Возможно, но в некоторых культурах люди могут чаще носить зонты для защиты от солнца, чем от дождя.
Замещающие метки часто бывают неточными. По возможности выбирайте настоящие метки, а не замещающие. Однако, если настоящая метка отсутствует, выбирайте замещающую метку очень тщательно, отдавая предпочтение наименее неудачному варианту.
Дополнительную информацию см. в разделе «Наборы данных: метки в машинном обучении» (краткий курс).
чистая функция
Функция, выходные данные которой зависят только от входных данных и которая не имеет побочных эффектов. В частности, чистая функция не использует и не изменяет какое-либо глобальное состояние, такое как содержимое файла или значение переменной вне функции.
Чистые функции можно использовать для создания потокобезопасного кода, что полезно при распределении кода модели между несколькими микросхемами ускорителя .
Методы преобразования функций в JAX требуют, чтобы входные функции были чистыми функциями.
В
Q-функция
В обучении с подкреплением функция, которая предсказывает ожидаемую отдачу от совершения действия в определенном состоянии и последующего следования заданной стратегии .
Q-функция также известна как функция ценности состояния и действия .
Q-обучение
В обучении с подкреплением алгоритм, позволяющий агенту изучить оптимальную Q-функцию марковского процесса принятия решений путем применения уравнения Беллмана . Марковский процесс принятия решений моделирует окружающую среду .
квантиль
Каждый сегмент в квантильном разбиении .
квантильное группировка
Распределение значений признака по группам таким образом, чтобы каждая группа содержала одинаковое (или почти одинаковое) количество примеров. Например, на следующем рисунке 44 точки разделены на 4 группы, каждая из которых содержит 11 точек. Для того чтобы каждая группа на рисунке содержала одинаковое количество точек, некоторые группы имеют разную ширину значений x.

Дополнительную информацию см. в разделе «Числовые данные: биннинг в машинном обучении» (краткий курс).
квантование
Перегруженный термин, который может использоваться любым из следующих способов:
- Применение квантильного сегментирования к определенному признаку .
- Преобразование данных в нули и единицы для более быстрого хранения, обучения и вывода результатов. Поскольку булевы данные более устойчивы к шуму и ошибкам, чем другие форматы, квантизация может повысить корректность модели. Методы квантизации включают округление, усечение и группировку .
Уменьшение количества бит, используемых для хранения параметров модели. Например, предположим, что параметры модели хранятся в виде 32-битных чисел с плавающей запятой. Квантование преобразует эти параметры из 32 бит в 4, 8 или 16 бит. Квантование уменьшает следующее:
- Использование вычислительных ресурсов, памяти, дискового пространства и сети.
- Время для вывода предсказания
- Потребление электроэнергии
Однако квантование иногда снижает точность прогнозов модели.
очередь
Операция TensorFlow, реализующая структуру данных "очередь". Обычно используется в операциях ввода-вывода.
Р
ТРЯПКА
Сокращение от "retrieval-augmented generation" (генерация с расширенными возможностями поиска).
случайный лес
Ансамбль деревьев решений , в котором каждое дерево решений обучается с использованием определенного случайного шума, например, методом бэггинга .
Случайные леса — это разновидность решающих лесов .
Дополнительную информацию см. в разделе «Случайный лес» курса «Лесорешения».
случайная политика
В обучении с подкреплением это стратегия , которая выбирает действие случайным образом.
ранг (порядковый номер)
Порядковый номер класса в задаче машинного обучения, которая классифицирует классы от наивысшего к наинизшему. Например, система ранжирования поведения может ранжировать вознаграждения для собаки от наивысшего (стейк) до наинизшего (увядшая капуста).
ранг (тензор)
Количество измерений в тензоре . Например, скаляр имеет ранг 0, вектор — ранг 1, а матрица — ранг 2.
Не следует путать с рангом (порядковым положением) .
рейтинг
Тип обучения с учителем, целью которого является упорядочивание списка элементов.
rater
A human who provides labels for examples . "Annotator" is another name for rater.
See Categorical data: Common issues in Machine Learning Crash Course for more information.
Reading Comprehension with Commonsense Reasoning Dataset (ReCoRD)
A dataset to evaluate an LLM's ability to perform commonsense reasoning. Each example in the dataset contains three components:
- A paragraph or two from a news article
- A query in which one of the entities explicitly or implicitly identified in the passage is masked .
- The answer (the name of the entity that belongs in the mask)
See ReCoRD for an extensive list of examples.
ReCoRD is a component of the SuperGLUE ensemble.
RealToxicityPrompts
A dataset that contains a set of sentence beginnings that might contain toxic content. Use this dataset to evaluate an LLM's ability to generate non-toxic text to complete the sentence. Typically, you use the Perspective API to determine how well the LLM performed at this task.
See RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models for details.
отзывать
Метрика для моделей классификации , которая отвечает на следующий вопрос:
When ground truth was the positive class , what percentage of predictions did the model correctly identify as the positive class?
Вот формула:
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
где:
- Истинно положительный результат означает, что модель правильно предсказала положительный класс.
- false negative means that the model mistakenly predicted the negative class .
For instance, suppose your model made 200 predictions on examples for which ground truth was the positive class. Of these 200 predictions:
- 180 were true positives.
- 20 were false negatives.
В этом случае:
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
See Classification: Accuracy, recall, precision and related metrics for more information.
recall at k (recall@k)
A metric for evaluating systems that output a ranked (ordered) list of items. Recall at k identifies the fraction of relevant items in the first k items in that list out of the total number of relevant items returned.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
Contrast with precision at k .
Recognizing Textual Entailment (RTE)
A dataset for evaluating an LLM's ability to determine whether a hypothesis can be entailed (logically drawn) from a text passage. Each example in an RTE evaluation consists of three parts:
- A passage, typically from news or Wikipedia articles
- Гипотеза
- The correct answer, which is either:
- True, meaning the hypothesis can be entailed from the passage
- False, meaning the hypothesis can't be entailed from the passage
Например:
- Passage: The Euro is the currency of the European Union.
- Hypothesis: France uses the Euro as currency.
- Entailment: True, because France is part of the European Union.
RTE is a component of the SuperGLUE ensemble.
система рекомендаций
A system that selects for each user a relatively small set of desirable items from a large corpus. For example, a video recommendation system might recommend two videos from a corpus of 100,000 videos, selecting Casablanca and The Philadelphia Story for one user, and Wonder Woman and Black Panther for another. A video recommendation system might base its recommendations on factors such as:
- Movies that similar users have rated or watched.
- Genre, directors, actors, target demographic...
See the Recommendation Systems course for more information.
Записывать
Abbreviation for Reading Comprehension with Commonsense Reasoning Dataset .
Rectified Linear Unit (ReLU)
An activation function with the following behavior:
- If input is negative or zero, then the output is 0.
- If input is positive, then the output is equal to the input.
Например:
- If the input is -3, then the output is 0.
- If the input is +3, then the output is 3.0.
Here is a plot of ReLU:
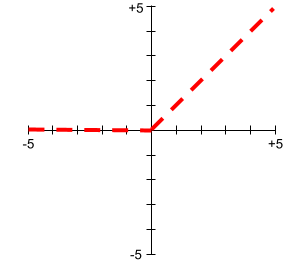
ReLU is a very popular activation function. Despite its simple behavior, ReLU still enables a neural network to learn nonlinear relationships between features and the label .
рекуррентная нейронная сеть
A neural network that is intentionally run multiple times, where parts of each run feed into the next run. Specifically, hidden layers from the previous run provide part of the input to the same hidden layer in the next run. Recurrent neural networks are particularly useful for evaluating sequences, so that the hidden layers can learn from previous runs of the neural network on earlier parts of the sequence.
For example, the following figure shows a recurrent neural network that runs four times. Notice that the values learned in the hidden layers from the first run become part of the input to the same hidden layers in the second run. Similarly, the values learned in the hidden layer on the second run become part of the input to the same hidden layer in the third run. In this way, the recurrent neural network gradually trains and predicts the meaning of the entire sequence rather than just the meaning of individual words.

справочный текст
An expert's response to a prompt . For example, given the following prompt:
Translate the question "What is your name?" from English to French.
An expert's response might be:
Comment vous appelez-vous?
Various metrics (such as ROUGE ) measure the degree to which the reference text matches an ML model's generated text .
отражение
A strategy for improving the quality of an agentic workflow by examining (reflecting on) a step's output before passing that output to the next step.
The examiner is often the same LLM that generated the response (though it could be a different LLM). How could the same LLM that generated a response be a fair judge of its own response? The "trick" is to put the LLM in a critical (reflective) mindset. This process is analogous to a writer who uses a creative mindset to write a first draft and then switches to a critical mindset to edit it.
For example, imagine an agentic workflow whose first step is to create text for coffee mugs. The prompt for this step might be:
You are a creative. Generate humorous, original text of less than 50 characters suitable for a coffee mug.
Now imagine the following reflective prompt:
You are a coffee drinker. Would you find the preceding response humorous?
The workflow might then only pass text that receives a high reflection score to the next stage.
регрессионная модель
Informally, a model that generates a numerical prediction. (In contrast, a classification model generates a class prediction.) For example, the following are all regression models:
- A model that predicts a certain house's value in Euros, such as 423,000.
- A model that predicts a certain tree's life expectancy in years, such as 23.2.
- A model that predicts the amount of rain in inches that will fall in a certain city over the next six hours, such as 0.18.
Two common types of regression models are:
- Linear regression , which finds the line that best fits label values to features.
- Logistic regression , which generates a probability between 0.0 and 1.0 that a system typically then maps to a class prediction.
Not every model that outputs numerical predictions is a regression model. In some cases, a numeric prediction is really just a classification model that happens to have numeric class names. For example, a model that predicts a numeric postal code is a classification model, not a regression model.
регуляризация
Any mechanism that reduces overfitting . Popular types of regularization include:
- L1- регуляризация
- L2- регуляризация
- dropout regularization
- early stopping (this is not a formal regularization method, but can effectively limit overfitting)
Regularization can also be defined as the penalty on a model's complexity.
See Overfitting: Model complexity in Machine Learning Crash Course for more information.
regularization rate
A number that specifies the relative importance of regularization during training. Raising the regularization rate reduces overfitting but may reduce the model's predictive power. Conversely, reducing or omitting the regularization rate increases overfitting.
Дополнительную информацию см. в разделе «Переобучение: L2-регуляризация» в «Кратком курсе по машинному обучению».
reinforcement learning (RL)
A family of algorithms that learn an optimal policy , whose goal is to maximize return when interacting with an environment . For example, the ultimate reward of most games is victory. Reinforcement learning systems can become expert at playing complex games by evaluating sequences of previous game moves that ultimately led to wins and sequences that ultimately led to losses.
Обучение с подкреплением на основе обратной связи от человека (RLHF)
Using feedback from human raters to improve the quality of a model's responses . For example, an RLHF mechanism can ask users to rate the quality of a model's response with a 👍 or 👎 emoji. The system can then adjust its future responses based on that feedback.
РеЛУ
Abbreviation for Rectified Linear Unit .
replay buffer
In DQN -like algorithms, the memory used by the agent to store state transitions for use in experience replay .
реплика
A copy (or part of) of a training set or model , typically stored on another machine. For example, a system could use the following strategy for implementing data parallelism :
- Place replicas of an existing model on multiple machines.
- Send different subsets of the training set to each replica.
- Aggregate the parameter updates.
A replica can also refer to another copy of an inference server. Increasing the number of replicas increases the number of requests that the system can serve simultaneously but also increases serving costs.
предвзятость в репортажах
The fact that the frequency with which people write about actions, outcomes, or properties is not a reflection of their real-world frequencies or the degree to which a property is characteristic of a class of individuals. Reporting bias can influence the composition of data that machine learning systems learn from.
For example, in books, the word laughed is more prevalent than breathed . A machine learning model that estimates the relative frequency of laughing and breathing from a book corpus would probably determine that laughing is more common than breathing.
Дополнительную информацию см. в разделе «Справедливость: виды предвзятости в экспресс-курсе по машинному обучению».
представление
The process of mapping data to useful features .
re-ranking
The final stage of a recommendation system , during which scored items may be re-graded according to some other (typically, non-ML) algorithm. Re-ranking evaluates the list of items generated by the scoring phase, taking actions such as:
- Eliminating items that the user has already purchased.
- Boosting the score of fresher items.
See Re-ranking in the Recommendation Systems course for more information.
ответ
The text, images, audio, or video that a generative AI model infers . In other words, a prompt is the input to a generative AI model and the response is the output .
response set
The collection of responses a large language model returns to an input prompt set .
Генерация с расширенным извлечением (RAG)
A technique for improving the quality of large language model (LLM) output by grounding it with sources of knowledge retrieved after the model was trained. RAG improves the accuracy of LLM responses by providing the trained LLM with access to information retrieved from trusted knowledge bases or documents.
Common motivations to use retrieval-augmented generation include:
- Increasing the factual accuracy of a model's generated responses.
- Giving the model access to knowledge it was not trained on.
- Changing the knowledge that the model uses.
- Enabling the model to cite sources.
For example, suppose that a chemistry app uses the PaLM API to generate summaries related to user queries. When the app's backend receives a query, the backend:
- Searches for ("retrieves") data that's relevant to the user's query.
- Appends ("augments") the relevant chemistry data to the user's query.
- Instructs the LLM to create a summary based on the appended data.
возвращаться
In reinforcement learning, given a certain policy and a certain state, the return is the sum of all rewards that the agent expects to receive when following the policy from the state to the end of the episode . The agent accounts for the delayed nature of expected rewards by discounting rewards according to the state transitions required to obtain the reward.
Therefore, if the discount factor is \(\gamma\), и \(r_0, \ldots, r_{N}\)denote the rewards until the end of the episode, then the return calculation is as follows:
награда
In reinforcement learning, the numerical result of taking an action in a state , as defined by the environment .
ridge regularization
Synonym for L 2 regularization . The term ridge regularization is more frequently used in pure statistics contexts, whereas L 2 regularization is used more often in machine learning.
RNN
Abbreviation for recurrent neural networks .
ROC (receiver operating characteristic) Curve
A graph of true positive rate versus false positive rate for different classification thresholds in binary classification.
The shape of an ROC curve suggests a binary classification model's ability to separate positive classes from negative classes. Suppose, for example, that a binary classification model perfectly separates all the negative classes from all the positive classes:
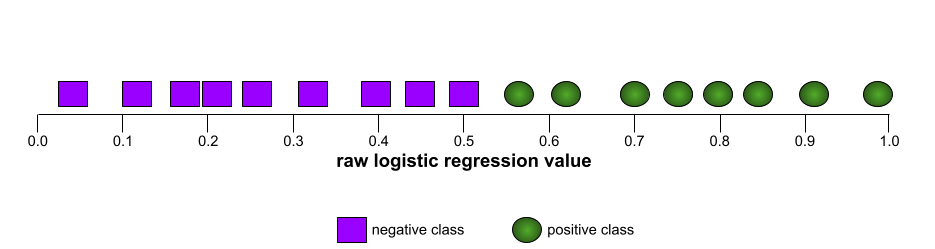
The ROC curve for the preceding model looks as follows:
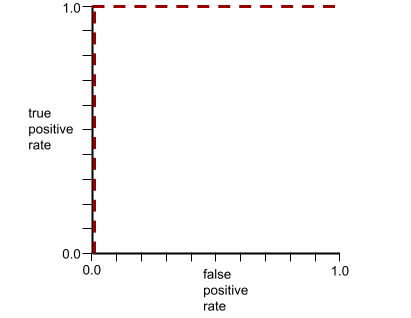
In contrast, the following illustration graphs the raw logistic regression values for a terrible model that can't separate negative classes from positive classes at all:
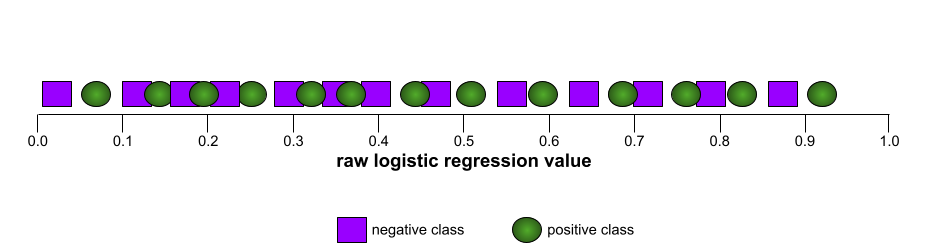
The ROC curve for this model looks as follows:
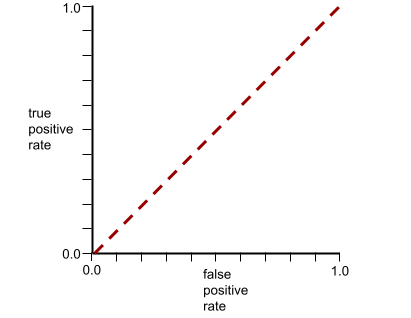
Meanwhile, back in the real world, most binary classification models separate positive and negative classes to some degree, but usually not perfectly. So, a typical ROC curve falls somewhere between the two extremes:
The point on an ROC curve closest to (0.0,1.0) theoretically identifies the ideal classification threshold. However, several other real-world issues influence the selection of the ideal classification threshold. For example, perhaps false negatives cause far more pain than false positives.
A numerical metric called AUC summarizes the ROC curve into a single floating-point value.
role prompting
A prompt , typically beginning with the pronoun you , that tells a generative AI model to pretend to be a certain person or a certain role when generating the response . Role prompting can help a generative AI model get into the right "mindset" in order to generate a more useful response. For example, any of the following role prompts might be appropriate depending on the kind of response you are seeking:
You have a PhD in computer science.
You are a software engineer who enjoys giving patient explanations about Python to new programming students.
You are an action hero with a very particular set of programming skills. Assure me that you will find a particular item in a Python list.
корень
The starting node (the first condition ) in a decision tree . By convention, diagrams put the root at the top of the decision tree. For example:
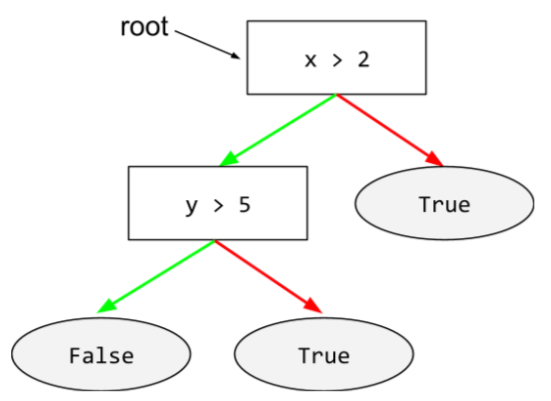
корневой каталог
The directory you specify for hosting subdirectories of the TensorFlow checkpoint and events files of multiple models.
Среднеквадратичная ошибка (RMSE)
The square root of the Mean Squared Error .
rotational invariance
In an image classification problem, an algorithm's ability to successfully classify images even when the orientation of the image changes. For example, the algorithm can still identify a tennis racket whether it is pointing up, sideways, or down. Note that rotational invariance is not always desirable; for example, an upside-down 9 shouldn't be classified as a 9.
See also translational invariance and size invariance .
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
A family of metrics that evaluate automatic summarization and machine translation models. ROUGE metrics determine the degree to which a reference text overlaps an ML model's generated text . Each member of the ROUGE family measures overlap in a different way. Higher ROUGE scores indicate more similarity between the reference text and generated text than lower ROUGE scores.
Each ROUGE family member typically generates the following metrics:
- Точность
- Отзывать
- Ф 1
For details and examples, see:
РУЖ-Л
A member of the ROUGE family focused on the length of the longest common subsequence in the reference text and generated text . The following formulas calculate recall and precision for ROUGE-L:
You can then use F 1 to roll up ROUGE-L recall and ROUGE-L precision into a single metric:
ROUGE-L ignores any newlines in the reference text and generated text, so the longest common subsequence could cross multiple sentences. When the reference text and generated text involve multiple sentences, a variation of ROUGE-L called ROUGE-Lsum is generally a better metric. ROUGE-Lsum determines the longest common subsequence for each sentence in a passage and then calculates the mean of those longest common subsequences.
ROUGE-N
A set of metrics within the ROUGE family that compares the shared N-grams of a certain size in the reference text and generated text . For example:
- ROUGE-1 measures the number of shared tokens in the reference text and generated text.
- ROUGE-2 measures the number of shared bigrams (2-grams) in the reference text and generated text.
- ROUGE-3 measures the number of shared trigrams (3-grams) in the reference text and generated text.
You can use the following formulas to calculate ROUGE-N recall and ROUGE-N precision for any member of the ROUGE-N family:
You can then use F 1 to roll up ROUGE-N recall and ROUGE-N precision into a single metric:
ROUGE-S
A forgiving form of ROUGE-N that enables skip-gram matching. That is, ROUGE-N only counts N-grams that match exactly , but ROUGE-S also counts N-grams separated by one or more words. For example, consider the following:
- reference text : White clouds
- generated text : White billowing clouds
When calculating ROUGE-N, the 2-gram, White clouds doesn't match White billowing clouds . However, when calculating ROUGE-S, White clouds does match White billowing clouds .
R-squared
A regression metric indicating how much variation in a label is due to an individual feature or to a feature set. R-squared is a value between 0 and 1, which you can interpret as follows:
- An R-squared of 0 means that none of a label's variation is due to the feature set.
- An R-squared of 1 means that all of a label's variation is due to the feature set.
- An R-squared between 0 and 1 indicates the extent to which the label's variation can be predicted from a particular feature or the feature set. For example, an R-squared of 0.10 means that 10 percent of the variance in the label is due to the feature set, an R-squared of 0.20 means that 20 percent is due to the feature set, and so on.
R-squared is the square of the Pearson correlation coefficient between the values that a model predicted and ground truth .
РТЭ
Abbreviation for Recognizing Textual Entailment .
С
смещение выборки
See selection bias .
sampling with replacement
A method of picking items from a set of candidate items in which the same item can be picked multiple times. The phrase "with replacement" means that after each selection, the selected item is returned to the pool of candidate items. The inverse method, sampling without replacement , means that a candidate item can only be picked once.
For example, consider the following fruit set:
fruit = {kiwi, apple, pear, fig, cherry, lime, mango} Suppose that the system randomly picks fig as the first item. If using sampling with replacement, then the system picks the second item from the following set:
fruit = {kiwi, apple, pear, fig, cherry, lime, mango} Yes, that's the same set as before, so the system could potentially pick fig again.
If using sampling without replacement, once picked, a sample can't be picked again. For example, if the system randomly picks fig as the first sample, then fig can't be picked again. Therefore, the system picks the second sample from the following (reduced) set:
fruit = {kiwi, apple, pear, cherry, lime, mango}Сохраненная модель
The recommended format for saving and recovering TensorFlow models. SavedModel is a language-neutral, recoverable serialization format, which enables higher-level systems and tools to produce, consume, and transform TensorFlow models.
See the Saving and Restoring section of the TensorFlow Programmer's Guide for complete details.
Экономия
A TensorFlow object responsible for saving model checkpoints.
скаляр
A single number or a single string that can be represented as a tensor of rank 0. For example, the following lines of code each create one scalar in TensorFlow:
breed = tf.Variable("poodle", tf.string)
temperature = tf.Variable(27, tf.int16)
precision = tf.Variable(0.982375101275, tf.float64)масштабирование
Any mathematical transform or technique that shifts the range of a label, a feature value, or both. Some forms of scaling are very useful for transformations like normalization .
Common forms of scaling useful in Machine Learning include:
- linear scaling, which typically uses a combination of subtraction and division to replace the original value with a number between -1 and +1 or between 0 and 1.
- logarithmic scaling, which replaces the original value with its logarithm.
- Z-score normalization , which replaces the original value with a floating-point value representing the number of standard deviations from that feature's mean.
scikit-learn
A popular open-source machine learning platform. See scikit-learn.org .
подсчет очков
The part of a recommendation system that provides a value or ranking for each item produced by the candidate generation phase.
предвзятость отбора
Errors in conclusions drawn from sampled data due to a selection process that generates systematic differences between samples observed in the data and those not observed. The following forms of selection bias exist:
- coverage bias : The population represented in the dataset doesn't match the population that the machine learning model is making predictions about.
- sampling bias : Data is not collected randomly from the target group.
- non-response bias (also called participation bias ): Users from certain groups opt-out of surveys at different rates than users from other groups.
For example, suppose you are creating a machine learning model that predicts people's enjoyment of a movie. To collect training data, you hand out a survey to everyone in the front row of a theater showing the movie. Offhand, this may sound like a reasonable way to gather a dataset; however, this form of data collection may introduce the following forms of selection bias:
- coverage bias: By sampling from a population who chose to see the movie, your model's predictions may not generalize to people who did not already express that level of interest in the movie.
- Смещение выборки: Вместо случайной выборки из целевой популяции (всех людей, присутствовавших на киносеансе), вы отобрали только людей, сидевших в первом ряду. Возможно, люди, сидевшие в первом ряду, были больше заинтересованы в фильме, чем те, кто сидел в других рядах.
- Смещение, вызванное отказом от участия в опросе: В целом, люди с твердыми убеждениями чаще отвечают на дополнительные опросы, чем люди с умеренными убеждениями. Поскольку опрос о фильмах является необязательным, ответы с большей вероятностью образуют бимодальное распределение, чем нормальное (колоколообразное) распределение.
самовнимание (также называемый слоем самовнимания)
Слой нейронной сети, который преобразует последовательность векторных представлений (например, векторных представлений токенов ) в другую последовательность векторных представлений. Каждое векторное представление в выходной последовательности строится путем интеграции информации из элементов входной последовательности с помощью механизма внимания .
Часть «самовнимание » в механизме самовнимания относится к тому, что последовательность обращает внимание на себя, а не на какой-либо другой контекст. Самовнимание является одним из основных строительных блоков для трансформеров и использует терминологию поиска в словаре, такую как «запрос», «ключ» и «значение».
Слой самовнимания начинается с последовательности входных представлений, по одному для каждого слова. Входное представление слова может представлять собой простое векторное представление (эмбеддинг). Для каждого слова во входной последовательности сеть оценивает релевантность слова каждому элементу во всей последовательности слов. Оценки релевантности определяют, насколько итоговое представление слова включает в себя представления других слов.
Например, рассмотрим следующее предложение:
Животное не перешло улицу, потому что слишком устало.
Следующая иллюстрация (из книги Transformer: A Novel Neural Network Architecture for Language Understanding ) показывает схему внимания слоя самовнимания к местоимению «it» , при этом насыщенность каждой линии указывает на вклад каждого слова в представление:
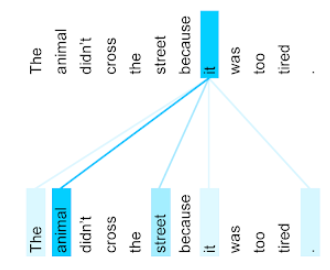
Слой самовнимания выделяет слова, имеющие отношение к «этому». В данном случае слой внимания научился выделять слова, на которые он может ссылаться, присваивая наибольший вес слову «животное ».
Для последовательности из n токенов механизм самовнимания преобразует последовательность векторных представлений n раз, по одному разу в каждой позиции последовательности.
См. также внимание и многоголовочное самовнимание .
самообучение
A family of techniques for converting an unsupervised machine learning problem into a supervised machine learning problem by creating surrogate labels from unlabeled examples .
Некоторые модели на основе Transformer , такие как BERT, используют самообучение.
Self-supervised training is a semi-supervised learning approach.
самообучение
Вариант самообучения , особенно полезный при выполнении всех следующих условий:
- В наборе данных высокое соотношение немаркированных примеров к маркированным примерам .
- Это задача классификации .
Самообучение работает путем итераций по следующим двум шагам до тех пор, пока модель не перестанет улучшаться:
- Используйте контролируемое машинное обучение для обучения модели на размеченных примерах.
- Используйте модель, созданную на шаге 1, для генерации прогнозов (меток) для немаркированных примеров, перемещая те, в которых есть высокая степень уверенности, в маркированные примеры с прогнозируемой меткой.
Обратите внимание, что на каждой итерации шага 2 добавляется больше размеченных примеров для обучения на шаге 1.
полуконтролируемое обучение
Обучение модели на данных, где некоторые обучающие примеры имеют метки, а другие — нет. Один из методов полуконтролируемого обучения заключается в том, чтобы определить метки для немаркированных примеров, а затем обучить модель на основе этих меток для создания новой модели. Полуконтролируемое обучение может быть полезно, если получение меток обходится дорого, но немаркированных примеров много.
Самостоятельное обучение — это один из методов полуконтролируемого обучения.
чувствительный атрибут
Человеческое качество, которому может быть уделено особое внимание по правовым, этическим, социальным или личным причинам.анализ настроений
Использование статистических алгоритмов или алгоритмов машинного обучения для определения общего отношения группы — положительного или отрицательного — к услуге, продукту, организации или теме. Например, используя понимание естественного языка , алгоритм мог бы провести анализ настроений в текстовых отзывах об университетском курсе, чтобы определить, насколько студентам в целом понравился или не понравился этот курс.
See the Text classification guide for more information.
модель последовательности
Модель, входные данные которой имеют последовательную зависимость. Например, прогнозирование следующего просмотренного видео на основе последовательности ранее просмотренных видео.
задача последовательности
Задача, которая преобразует входную последовательность токенов в выходную последовательность токенов. Например, два популярных типа задач преобразования последовательности в последовательность:
- Переводчики:
- Пример входной последовательности: "Я люблю тебя."
- Пример выходной последовательности: «Я люблю тебя».
- Ответы на вопросы:
- Пример входной последовательности: "Мне нужна машина в Нью-Йорке?"
- Пример выходных данных: "Нет. Оставьте машину дома."
подача
Процесс предоставления обученной модели для прогнозирования посредством онлайн- или офлайн-вывода .
форма (тензор)
Количество элементов в каждом измерении тензора. Форма представляется в виде списка целых чисел. Например, следующий двумерный тензор имеет форму [3,4]:
[[5, 7, 6, 4], [2, 9, 4, 8], [3, 6, 5, 1]]
TensorFlow uses row-major (C-style) format to represent the order of dimensions, which is why the shape in TensorFlow is [3,4] rather than [4,3] . In other words, in a two-dimensional TensorFlow Tensor, the shape is [ number of rows , number of columns ] .
Статическая форма — это форма тензора, известная на этапе компиляции.
A dynamic shape is unknown at compile time and is therefore dependent on runtime data. This tensor might be represented with a placeholder dimension in TensorFlow, as in [3, ?] .
shard
Логическое разделение обучающего набора данных или модели . Как правило, некий процесс создает фрагменты, разделяя примеры или параметры на (обычно) равные по размеру части. Затем каждый фрагмент назначается отдельной машине.
Разделение модели на сегменты называется параллелизмом модели ; разделение данных на сегменты называется параллелизмом данных .
усадка
Гиперпараметр в градиентном бустинге , контролирующий переобучение . Сжатие (shrinkage) в градиентном бустинге аналогично скорости обучения в градиентном спуске . Сжатие — это десятичное значение от 0,0 до 1,0. Меньшее значение сжатия уменьшает переобучение сильнее, чем большее.
сравнительная оценка
Сравнение качества двух моделей путем оценки их ответов на один и тот же вопрос . Например, предположим, что двум разным моделям дается следующий вопрос:
Создайте изображение милой собачки, жонглирующей тремя мячами.
При сравнении изображений эксперт выбирал бы, какое из них «лучше» (более точное? Более красивое? Более симпатичное?).
сигмоидная функция
Математическая функция, которая «сжимает» входное значение в ограниченный диапазон, обычно от 0 до 1 или от -1 до +1. То есть, вы можете передать любое число (два, миллион, минус миллиард и т. д.) в сигмоидную функцию, и выходное значение все равно будет находиться в ограниченном диапазоне. График сигмоидной функции активации выглядит следующим образом:
Сигмоидная функция находит несколько применений в машинном обучении, в том числе:
- Преобразование исходных данных модели логистической регрессии или многомерной регрессии в вероятность.
- Acting as an activation function in some neural networks.
similarity measure
In clustering algorithms, the metric used to determine how alike (how similar) any two examples are.
single program / multiple data (SPMD)
A parallelism technique where the same computation is run on different input data in parallel on different devices. The goal of SPMD is to obtain results more quickly. It is the most common style of parallel programming.
size invariance
In an image classification problem, an algorithm's ability to successfully classify images even when the size of the image changes. For example, the algorithm can still identify a cat whether it consumes 2M pixels or 200K pixels. Note that even the best image classification algorithms still have practical limits on size invariance. For example, an algorithm (or human) is unlikely to correctly classify a cat image consuming only 20 pixels.
See also translational invariance and rotational invariance .
Для получения более подробной информации см. курс «Кластеризация» .
эскизирование
In unsupervised machine learning , a category of algorithms that perform a preliminary similarity analysis on examples. Sketching algorithms use a locality-sensitive hash function to identify points that are likely to be similar, and then group them into buckets.
Sketching decreases the computation required for similarity calculations on large datasets. Instead of calculating similarity for every single pair of examples in the dataset, we calculate similarity only for each pair of points within each bucket.
skip-gram
An n-gram which may omit (or "skip") words from the original context, meaning the N words might not have been originally adjacent. More precisely, a "k-skip-n-gram" is an n-gram for which up to k words may have been skipped.
For example, "the quick brown fox" has the following possible 2-grams:
- "the quick"
- "quick brown"
- "brown fox"
A "1-skip-2-gram" is a pair of words that have at most 1 word between them. Therefore, "the quick brown fox" has the following 1-skip 2-grams:
- "the brown"
- "quick fox"
In addition, all the 2-grams are also 1-skip-2-grams, since fewer than one word may be skipped.
Skip-grams are useful for understanding more of a word's surrounding context. In the example, "fox" was directly associated with "quick" in the set of 1-skip-2-grams, but not in the set of 2-grams.
Skip-grams help train word embedding models.
софтмакс
A function that determines probabilities for each possible class in a multi-class classification model . The probabilities add up to exactly 1.0. For example, the following table shows how softmax distributes various probabilities:
| Image is a... | Вероятность |
|---|---|
| собака | .85 |
| кот | .13 |
| лошадь | .02 |
Softmax is also called full softmax .
Contrast with candidate sampling .
Дополнительную информацию см. в разделе «Нейронные сети: многоклассовая классификация» в кратком курсе по машинному обучению.
soft prompt tuning
A technique for tuning a large language model for a particular task, without resource intensive fine-tuning . Instead of retraining all the weights in the model, soft prompt tuning automatically adjusts a prompt to achieve the same goal.
Given a textual prompt, soft prompt tuning typically appends additional token embeddings to the prompt and uses backpropagation to optimize the input.
A "hard" prompt contains actual tokens instead of token embeddings.
sparse feature
A feature whose values are predominately zero or empty. For example, a feature containing a single 1 value and a million 0 values is sparse. In contrast, a dense feature has values that are predominantly not zero or empty.
In machine learning, a surprising number of features are sparse features. Categorical features are usually sparse features. For example, of the 300 possible tree species in a forest, a single example might identify just a maple tree . Or, of the millions of possible videos in a video library, a single example might identify just "Casablanca."
In a model, you typically represent sparse features with one-hot encoding . If the one-hot encoding is big, you might put an embedding layer on top of the one-hot encoding for greater efficiency.
sparse representation
Storing only the position(s) of nonzero elements in a sparse feature.
For example, suppose a categorical feature named species identifies the 36 tree species in a particular forest. Further assume that each example identifies only a single species.
You could use a one-hot vector to represent the tree species in each example. A one-hot vector would contain a single 1 (to represent the particular tree species in that example) and 35 0 s (to represent the 35 tree species not in that example). So, the one-hot representation of maple might look something like the following:

Alternatively, sparse representation would simply identify the position of the particular species. If maple is at position 24, then the sparse representation of maple would simply be:
24
Notice that the sparse representation is much more compact than the one-hot representation.
Click the icon for a slightly more complex example.
Suppose each example in your model must represent the words—but not the order of those words—in an English sentence. English consists of about 170,000 words, so English is a categorical feature with about 170,000 elements. Most English sentences use an extremely tiny fraction of those 170,000 words, so the set of words in a single example is almost certainly going to be sparse data.
Consider the following sentence:
My dog is a great dog
You could use a variant of one-hot vector to represent the words in this sentence. In this variant, multiple cells in the vector can contain a nonzero value. Furthermore, in this variant, a cell can contain an integer other than one. Although the words "my", "is", "a", and "great" appear only once in the sentence, the word "dog" appears twice. Using this variant of one-hot vectors to represent the words in this sentence yields the following 170,000-element vector:

A sparse representation of the same sentence would simply be:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
See Working with categorical data in Machine Learning Crash Course for more information.
разреженный вектор
A vector whose values are mostly zeroes. See also sparse feature and sparsity .
разреженность
The number of elements set to zero (or null) in a vector or matrix divided by the total number of entries in that vector or matrix. For example, consider a 100-element matrix in which 98 cells contain zero. The calculation of sparsity is as follows:
Feature sparsity refers to the sparsity of a feature vector; model sparsity refers to the sparsity of the model weights.
spatial pooling
См. раздел "Объединение" .
спецификация кодирования
The process of writing and maintaining a file in a human language (for example, English) that describes software. You can then tell a generative AI model or another software engineer to create the software that fulfills that description.
Automatically-generated code generally requires iteration. In specificational coding, you iterate on the description file. By contrast, in conversational coding , you iterate within the prompt box. In practice, automatic code generation sometimes involves a combination of both specificational coding and conversational coding.
расколоть
In a decision tree , another name for a condition .
разветвитель
While training a decision tree , the routine (and algorithm) responsible for finding the best condition at each node .
СПМД
Abbreviation for single program / multiple data .
Отряд
Acronym for Stanford Question Answering Dataset , introduced in the paper SQuAD: 100,000+ Questions for Machine Comprehension of Text . The questions in this dataset come from people posing questions about Wikipedia articles. Some of the questions in SQuAD have answers, but other questions intentionally don't have answers. Therefore, you can use SQuAD to evaluate an LLM's ability to do both of the following:
- Answer questions that can be answered.
- Identify questions that cannot be answered.
Exact match in combination with F 1 are the most common metrics for evaluating LLMs against SQuAD.
squared hinge loss
The square of the hinge loss . Squared hinge loss penalizes outliers more harshly than regular hinge loss.
squared loss
Synonym for L 2 loss .
staged training
A tactic of training a model in a sequence of discrete stages. The goal can be either to speed up the training process, or to achieve better model quality.
An illustration of the progressive stacking approach is shown below:
- Stage 1 contains 3 hidden layers, stage 2 contains 6 hidden layers, and stage 3 contains 12 hidden layers.
- Stage 2 begins training with the weights learned in the 3 hidden layers of Stage 1. Stage 3 begins training with the weights learned in the 6 hidden layers of Stage 2.
See also pipelining .
состояние
In reinforcement learning, the parameter values that describe the current configuration of the environment, which the agent uses to choose an action .
state-action value function
Synonym for Q-function .
статический
Something done once rather than continuously. The terms static and offline are synonyms. The following are common uses of static and offline in machine learning:
- static model (or offline model ) is a model trained once and then used for a while.
- static training (or offline training ) is the process of training a static model.
- static inference (or offline inference ) is a process in which a model generates a batch of predictions at a time.
Contrast with dynamic .
static inference
Synonym for offline inference .
stationarity
A feature whose values don't change across one or more dimensions, usually time. For example, a feature whose values look about the same in 2021 and 2023 exhibits stationarity.
В реальном мире лишь немногие характеристики демонстрируют стационарность. Даже характеристики, синонимичные стабильности (например, уровень моря), меняются со временем.
В отличие от нестационарности .
шаг
A forward pass and backward pass of one batch .
Дополнительную информацию о прямом и обратном проходах см. в разделе «Обратное распространение ошибки ».
размер шага
Синоним к слову «скорость обучения» .
стохастический градиентный спуск (SGD)
A gradient descent algorithm in which the batch size is one. In other words, SGD trains on a single example chosen uniformly at random from a training set .
Дополнительную информацию см. в статье «Линейная регрессия: гиперпараметры в машинном обучении» (краткий курс).
шаг
В операции свертки или пулинга разница в каждом измерении следующей серии входных срезов. Например, следующая анимация демонстрирует шаг (1,1) во время операции свертки. Следовательно, следующий входной срез начинается на одну позицию правее предыдущего входного среза. Когда операция достигает правого края, следующий срез находится полностью слева, но на одну позицию ниже.
Приведенный выше пример демонстрирует двумерный шаг. Если входная матрица трехмерная, то и шаг будет трехмерным.
минимизация структурных рисков (SRM)
Алгоритм, который уравновешивает две цели:
- Необходимость построения наиболее прогностической модели (например, с наименьшими потерями).
- Необходимость максимально упростить модель (например, использовать строгую регуляризацию).
Например, функция, которая минимизирует потери + регуляризацию на обучающем наборе данных, является алгоритмом минимизации структурного риска.
В отличие от эмпирической минимизации риска .
субвыборка
См. раздел "Объединение" .
токен подслова
In language models , a token that is a substring of a word, which may be the entire word.
Например, слово «itemize» можно разбить на части «item» (корень) и «ize» (суффикс), каждая из которых представлена своим собственным токеном. Разделение редких слов на такие части, называемые подсловами, позволяет языковым моделям работать с более распространенными составляющими слова, такими как префиксы и суффиксы.
И наоборот, такие распространенные слова, как "going", могут не разбиваться на части и могут быть представлены одним единственным словом.
краткое содержание
In TensorFlow, a value or set of values calculated at a particular step , usually used for tracking model metrics during training.
SuperGLUE
Набор данных для оценки общей способности магистра права понимать и создавать текст. В состав набора данных входят следующие наборы данных:
- Логические вопросы (BoolQ)
- CommitmentBank (CB)
- Choice of Plausible Alternatives (COPA)
- Multi-sentence Reading Comprehension (MultiRC)
- Reading Comprehension with Commonsense Reasoning Dataset (ReCoRD)
- Recognizing Textual Entailment (RTE)
- Words in Context (WiC)
- Вызов схемы Винограда (WSC)
For details, see SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems .
контролируемое машинное обучение
Training a model from features and their corresponding labels . Supervised machine learning is analogous to learning a subject by studying a set of questions and their corresponding answers. After mastering the mapping between questions and answers, a student can then provide answers to new (never-before-seen) questions on the same topic.
Compare with unsupervised machine learning .
See Supervised Learning in the Introduction to ML course for more information.
synthetic feature
A feature not present among the input features, but assembled from one or more of them. Methods for creating synthetic features include the following:
- Bucketing a continuous feature into range bins.
- Creating a feature cross .
- Multiplying (or dividing) one feature value by other feature value(s) or by itself. For example, if
aandbare input features, then the following are examples of synthetic features:- аб
- а 2
- Applying a transcendental function to a feature value. For example, if
cis an input feature, then the following are examples of synthetic features:- sin(c)
- ln(c)
Features created by normalizing or scaling alone are not considered synthetic features.
Т
Т5
A text-to-text transfer learning model introduced by Google AI in 2020 . T5 is an encoder - decoder model, based on the Transformer architecture, trained on an extremely large dataset. It is effective at a variety of natural language processing tasks, such as generating text, translating languages, and answering questions in a conversational manner.
T5 gets its name from the five letter Ts in "Text-to-Text Transfer Transformer."
Т5Х
An open-source, machine learning framework designed to build and train large-scale natural language processing (NLP) models. T5 is implemented on the T5X codebase (which is built on JAX and Flax ).
tabular Q-learning
In reinforcement learning , implementing Q-learning by using a table to store the Q-functions for every combination of state and action .
цель
Synonym for label .
target network
In Deep Q-learning , a neural network that is a stable approximation of the main neural network, where the main neural network implements either a Q-function or a policy . Then, you can train the main network on the Q-values predicted by the target network. Therefore, you prevent the feedback loop that occurs when the main network trains on Q-values predicted by itself. By avoiding this feedback, training stability increases.
задача
A problem that can be solved using machine learning techniques, such as:
температура
A hyperparameter that controls the degree of randomness of a model's output. Higher temperatures result in more random output, while lower temperatures result in less random output.
Choosing the best temperature depends on the specific application and or string values.
временные данные
Data recorded at different points in time. For example, winter coat sales recorded for each day of the year would be temporal data.
Тензор
The primary data structure in TensorFlow programs. Tensors are N-dimensional (where N could be very large) data structures, most commonly scalars, vectors, or matrixes. The elements of a Tensor can hold integer, floating-point, or string values.
TensorBoard
The dashboard that displays the summaries saved during the execution of one or more TensorFlow programs.
TensorFlow
A large-scale, distributed, machine learning platform. The term also refers to the base API layer in the TensorFlow stack, which supports general computation on dataflow graphs.
Although TensorFlow is primarily used for machine learning, you may also use TensorFlow for non-ML tasks that require numerical computation using dataflow graphs.
TensorFlow Playground
A program that visualizes how different hyperparameters influence model (primarily neural network) training. Go to http://playground.tensorflow.org to experiment with TensorFlow Playground.
TensorFlow Serving
A platform to deploy trained models in production.
Блок обработки тензоров (TPU)
An application-specific integrated circuit (ASIC) that optimizes the performance of machine learning workloads. These ASICs are deployed as multiple TPU chips on a TPU device .
ранг тензора
See rank (Tensor) .
Tensor shape
The number of elements a Tensor contains in various dimensions. For example, a [5, 10] Tensor has a shape of 5 in one dimension and 10 in another.
Tensor size
The total number of scalars a Tensor contains. For example, a [5, 10] Tensor has a size of 50.
TensorStore
A library for efficiently reading and writing large multi-dimensional arrays.
termination condition
In reinforcement learning , the conditions that determine when an episode ends, such as when the agent reaches a certain state or exceeds a threshold number of state transitions. For example, in tic-tac-toe (also known as noughts and crosses), an episode terminates either when a player marks three consecutive spaces or when all spaces are marked.
тест
In a decision tree , another name for a condition .
test loss
A metric representing a model's loss against the test set . When building a model , you typically try to minimize test loss. That's because a low test loss is a stronger quality signal than a low training loss or low validation loss .
A large gap between test loss and training loss or validation loss sometimes suggests that you need to increase the regularization rate .
тестовый набор
A subset of the dataset reserved for testing a trained model .
Traditionally, you divide examples in the dataset into the following three distinct subsets:
- тренировочный набор
- набор для проверки
- тестовый набор
Each example in a dataset should belong to only one of the preceding subsets. For instance, a single example shouldn't belong to both the training set and the test set.
The training set and validation set are both closely tied to training a model. Because the test set is only indirectly associated with training, test loss is a less biased, higher quality metric than training loss or validation loss .
Дополнительную информацию см. в разделе «Наборы данных: Разделение исходного набора данных» в «Кратком курсе по машинному обучению».
text span
The array index span associated with a specific subsection of a text string. For example, the word good in the Python string s="Be good now" occupies the text span from 3 to 6.
tf.Example
A standard protocol buffer for describing input data for machine learning model training or inference.
tf.keras
An implementation of Keras integrated into TensorFlow .
threshold (for decision trees)
In an axis-aligned condition , the value that a feature is being compared against. For example, 75 is the threshold value in the following condition:
grade >= 75
See Exact splitter for binary classification with numerical features in the Decision Forests course for more information.
анализ временных рядов
A subfield of machine learning and statistics that analyzes temporal data . Many types of machine learning problems require time series analysis, including classification, clustering, forecasting, and anomaly detection. For example, you could use time series analysis to forecast the future sales of winter coats by month based on historical sales data.
временной шаг
One "unrolled" cell within a recurrent neural network . For example, the following figure shows three timesteps (labeled with the subscripts t-1, t, and t+1):

токен
In a language model , the atomic unit that the model is training on and making predictions on. A token is typically one of the following:
- a word—for example, the phrase "dogs like cats" consists of three word tokens: "dogs", "like", and "cats".
- a character—for example, the phrase "bike fish" consists of nine character tokens. (Note that the blank space counts as one of the tokens.)
- subwords—in which a single word can be a single token or multiple tokens. A subword consists of a root word, a prefix, or a suffix. For example, a language model that uses subwords as tokens might view the word "dogs" as two tokens (the root word "dog" and the plural suffix "s"). That same language model might view the single word "taller" as two subwords (the root word "tall" and the suffix "er").
In domains outside of language models, tokens can represent other kinds of atomic units. For example, in computer vision, a token might be a subset of an image.
See Large language models in Machine Learning Crash Course for more information.
tokenizer
A system or algorithm that translates a sequence of input data into tokens .
Most modern foundation models are multimodal . A tokenizer for a multimodal system must translate each input type into the appropriate format. For example, given input data consisting of both text and graphics, the tokenizer might translate input text into subwords and input images into small patches. The tokenizer must then convert all the tokens into a single unified embedding space, which enables the model to "understand" a stream of multimodal input.
top-k accuracy
The percentage of times that a "target label" appears within the first k positions of generated lists. The lists could be personalized recommendations or a list of items ordered by softmax .
Top-k accuracy is also known as accuracy at k .
башня
A component of a deep neural network that is itself a deep neural network. In some cases, each tower reads from an independent data source, and those towers stay independent until their output is combined in a final layer. In other cases, (for example, in the encoder and decoder tower of many Transformers ), towers have cross-connections to each other.
токсичность
The degree to which content is abusive, threatening, or offensive. Many machine learning models can identify, measure, and classify toxicity. Most of these models identify toxicity along multiple parameters, such as the level of abusive language and the level of threatening language.
ТПУ
Abbreviation for Tensor Processing Unit .
TPU chip
A programmable linear algebra accelerator with on-chip high bandwidth memory that is optimized for machine learning workloads. Multiple TPU chips are deployed on a TPU device .
TPU device
A printed circuit board (PCB) with multiple TPU chips , high bandwidth network interfaces, and system cooling hardware.
TPU node
A TPU resource on Google Cloud with a specific TPU type . The TPU node connects to your VPC Network from a peer VPC network . TPU nodes are a resource defined in the Cloud TPU API .
TPU Pod
A specific configuration of TPU devices in a Google data center. All of the devices in a TPU Pod are connected to one another over a dedicated high-speed network. A TPU Pod is the largest configuration of TPU devices available for a specific TPU version.
TPU resource
A TPU entity on Google Cloud that you create, manage, or consume. For example, TPU nodes and TPU types are TPU resources.
TPU slice
A TPU slice is a fractional portion of the TPU devices in a TPU Pod . All of the devices in a TPU slice are connected to one another over a dedicated high-speed network.
TPU type
A configuration of one or more TPU devices with a specific TPU hardware version. You select a TPU type when you create a TPU node on Google Cloud. For example, a v2-8 TPU type is a single TPU v2 device with 8 cores. A v3-2048 TPU type has 256 networked TPU v3 devices and a total of 2048 cores. TPU types are a resource defined in the Cloud TPU API .
TPU worker
A process that runs on a host machine and executes machine learning programs on TPU devices .
обучение
The process of determining the ideal parameters (weights and biases) comprising a model . During training, a system reads in examples and gradually adjusts parameters. Training uses each example anywhere from a few times to billions of times.
See Supervised Learning in the Introduction to ML course for more information.
training loss
A metric representing a model's loss during a particular training iteration. For example, suppose the loss function is Mean Squared Error . Perhaps the training loss (the Mean Squared Error) for the 10th iteration is 2.2, and the training loss for the 100th iteration is 1.9.
A loss curve plots training loss versus the number of iterations. A loss curve provides the following hints about training:
- A downward slope implies that the model is improving.
- An upward slope implies that the model is getting worse.
- A flat slope implies that the model has reached convergence .
For example, the following somewhat idealized loss curve shows:
- A steep downward slope during the initial iterations, which implies rapid model improvement.
- A gradually flattening (but still downward) slope until close to the end of training, which implies continued model improvement at a somewhat slower pace then during the initial iterations.
- A flat slope towards the end of training, which suggests convergence.
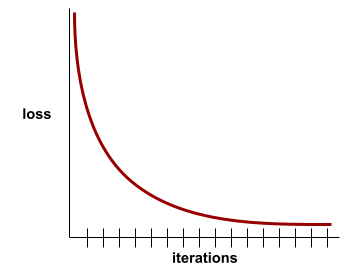
Although training loss is important, see also generalization .
training-serving skew
The difference between a model's performance during training and that same model's performance during serving .
тренировочный набор
The subset of the dataset used to train a model .
Traditionally, examples in the dataset are divided into the following three distinct subsets:
- тренировочный набор
- набор для проверки
- тестовый набор
В идеале каждый пример в наборе данных должен принадлежать только к одному из предыдущих подмножеств. Например, один и тот же пример не должен одновременно принадлежать к обучающему и валидационному наборам данных.
Дополнительную информацию см. в разделе «Наборы данных: Разделение исходного набора данных» в «Кратком курсе по машинному обучению».
траектория
In reinforcement learning , a sequence of tuples that represent a sequence of state transitions of the agent , where each tuple corresponds to the state, action , reward , and next state for a given state transition.
перенос обучения
Transferring information from one machine learning task to another. For example, in multi-task learning, a single model solves multiple tasks, such as a deep model that has different output nodes for different tasks. Transfer learning might involve transferring knowledge from the solution of a simpler task to a more complex one, or involve transferring knowledge from a task where there is more data to one where there is less data.
Most machine learning systems solve a single task. Transfer learning is a baby step towards artificial intelligence in which a single program can solve multiple tasks.
Трансформатор
A neural network architecture developed at Google that relies on self-attention mechanisms to transform a sequence of input embeddings into a sequence of output embeddings without relying on convolutions or recurrent neural networks . A Transformer can be viewed as a stack of self-attention layers.
A Transformer can include any of the following:
An encoder transforms a sequence of embeddings into a new sequence of the same length. An encoder includes N identical layers, each of which contains two sub-layers. These two sub-layers are applied at each position of the input embedding sequence, transforming each element of the sequence into a new embedding. The first encoder sub-layer aggregates information from across the input sequence. The second encoder sub-layer transforms the aggregated information into an output embedding.
A decoder transforms a sequence of input embeddings into a sequence of output embeddings, possibly with a different length. A decoder also includes N identical layers with three sub-layers, two of which are similar to the encoder sub-layers. The third decoder sub-layer takes the output of the encoder and applies the self-attention mechanism to gather information from it.
The blog post Transformer: A Novel Neural Network Architecture for Language Understanding provides a good introduction to Transformers.
See LLMs: What's a large language model? in Machine Learning Crash Course for more information.
translational invariance
In an image classification problem, an algorithm's ability to successfully classify images even when the position of objects within the image changes. For example, the algorithm can still identify a dog, whether it is in the center of the frame or at the left end of the frame.
See also size invariance and rotational invariance .
триграмма
An N-gram in which N=3.
Trivia Question Answering
Datasets to evaluate an LLM's ability to answer trivia questions. Each dataset contains question-answer pairs authored by trivia enthusiasts. Different datasets are grounded by different sources, including:
- Web search (TriviaQA)
- Wikipedia (TriviaQA_wiki)
For more information see TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension .
true negative (TN)
An example in which the model correctly predicts the negative class . For example, the model infers that a particular email message is not spam , and that email message really is not spam .
true positive (TP)
An example in which the model correctly predicts the positive class . For example, the model infers that a particular email message is spam, and that email message really is spam.
true positive rate (TPR)
Synonym for recall . That is:
True positive rate is the y-axis in an ROC curve .
ТТЛ
Abbreviation for time to live .
Typologically Diverse Question Answering (TyDi QA)
A large dataset for evaluating an LLM's proficiency in answering questions. The dataset contains question and answer pairs in many languages.
For details, see TyDi QA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages .
У
Ультра
The Gemini model with the most parameters . See Gemini Ultra for details.
unawareness (to a sensitive attribute)
A situation in which sensitive attributes are present, but not included in the training data. Because sensitive attributes are often correlated with other attributes of one's data, a model trained with unawareness about a sensitive attribute could still have disparate impact with respect to that attribute, or violate other fairness constraints .
несоответствие
Producing a model with poor predictive ability because the model hasn't fully captured the complexity of the training data. Many problems can cause underfitting, including:
- Training on the wrong set of features .
- Training for too few epochs or at too low a learning rate .
- Training with too high a regularization rate .
- Providing too few hidden layers in a deep neural network.
Для получения дополнительной информации см. «Краткий курс по переобучению в машинном обучении».
undersampling
Removing examples from the majority class in a class-imbalanced dataset in order to create a more balanced training set .
For example, consider a dataset in which the ratio of the majority class to the minority class is 20:1. To overcome this class imbalance, you could create a training set consisting of all of the minority class examples but only a tenth of the majority class examples, which would create a training-set class ratio of 2:1. Thanks to undersampling, this more balanced training set might produce a better model. Alternatively, this more balanced training set might contain insufficient examples to train an effective model.
Contrast with oversampling .
однонаправленный
A system that only evaluates the text that precedes a target section of text. In contrast, a bidirectional system evaluates both the text that precedes and follows a target section of text. See bidirectional for more details.
unidirectional language model
A language model that bases its probabilities only on the tokens appearing before , not after , the target token(s). Contrast with bidirectional language model .
unlabeled example
An example that contains features but no label . For example, the following table shows three unlabeled examples from a house valuation model, each with three features but no house value:
| Количество спален | Количество ванных комнат | Возраст дома |
|---|---|---|
| 3 | 2 | 15 |
| 2 | 1 | 72 |
| 4 | 2 | 34 |
В контролируемом машинном обучении модели обучаются на размеченных примерах и делают прогнозы на неразмеченных примерах .
In semi-supervised and unsupervised learning, unlabeled examples are used during training.
Contrast unlabeled example with labeled example .
машинное обучение без учителя
Training a model to find patterns in a dataset, typically an unlabeled dataset.
The most common use of unsupervised machine learning is to cluster data into groups of similar examples. For example, an unsupervised machine learning algorithm can cluster songs based on various properties of the music. The resulting clusters can become an input to other machine learning algorithms (for example, to a music recommendation service). Clustering can help when useful labels are scarce or absent. For example, in domains such as anti-abuse and fraud, clusters can help humans better understand the data.
Contrast with supervised machine learning .
See What is Machine Learning? in the Introduction to ML course for more information.
uplift modeling
A modeling technique, commonly used in marketing, that models the "causal effect" (also known as the "incremental impact") of a "treatment" on an "individual." Here are two examples:
- Doctors might use uplift modeling to predict the mortality decrease (causal effect) of a medical procedure (treatment) depending on the age and medical history of a patient (individual).
- Marketers might use uplift modeling to predict the increase in probability of a purchase (causal effect) due to an advertisement (treatment) on a person (individual).
Uplift modeling differs from classification or regression in that some labels (for example, half of the labels in binary treatments) are always missing in uplift modeling. For example, a patient can either receive or not receive a treatment; therefore, we can only observe whether the patient is going to heal or not heal in only one of these two situations (but never both). The main advantage of an uplift model is that it can generate predictions for the unobserved situation (the counterfactual) and use it to compute the causal effect.
upweighting
Applying a weight to the downsampled class equal to the factor by which you downsampled.
user matrix
В рекомендательных системах вектор встраивания , сгенерированный с помощью матричной факторизации , содержит скрытые сигналы о предпочтениях пользователя. Каждая строка матрицы пользователей содержит информацию об относительной силе различных скрытых сигналов для одного пользователя. Например, рассмотрим систему рекомендаций фильмов. В этой системе скрытые сигналы в матрице пользователей могут представлять интерес каждого пользователя к определенным жанрам или могут быть более сложными для интерпретации сигналами, включающими сложные взаимодействия между множеством факторов.
Матрица пользователей содержит столбец для каждой скрытой характеристики и строку для каждого пользователя. То есть, матрица пользователей имеет такое же количество строк, как и целевая матрица, которая подвергается факторизации. Например, если у нас есть система рекомендаций фильмов для 1 000 000 пользователей, матрица пользователей будет иметь 1 000 000 строк.
В
валидация
The initial evaluation of a model's quality. Validation checks the quality of a model's predictions against the validation set .
Because the validation set differs from the training set , validation helps guard against overfitting .
You might think of evaluating the model against the validation set as the first round of testing and evaluating the model against the test set as the second round of testing.
потери валидации
Метрика , отражающая потери модели на валидационном наборе данных в течение конкретной итерации обучения.
См. также кривую обобщения .
набор валидации
Подмножество набора данных , используемое для первоначальной оценки обученной модели . Как правило, обученную модель оценивают на проверочном наборе данных несколько раз, прежде чем оценивать ее на тестовом наборе .
Традиционно примеры в наборе данных делятся на три отдельных подмножества:
- тренировочный набор
- набор для проверки
- тестовый набор
В идеале каждый пример в наборе данных должен принадлежать только к одному из предыдущих подмножеств. Например, один и тот же пример не должен одновременно принадлежать к обучающему и валидационному наборам данных.
Дополнительную информацию см. в разделе «Наборы данных: Разделение исходного набора данных» в «Кратком курсе по машинному обучению».
вменение значения
Процесс замены отсутствующего значения приемлемым аналогом. Если значение отсутствует, можно либо отбросить весь пример, либо использовать метод замещения значений для его восстановления.
For example, consider a dataset containing a temperature feature that is supposed to be recorded every hour. However, the temperature reading was unavailable for a particular hour. Here is a section of the dataset:
| Отметка времени | Температура |
|---|---|
| 1680561000 | 10 |
| 1680564600 | 12 |
| 1680568200 | отсутствующий |
| 1680571800 | 20 |
| 1680575400 | 21 |
| 1680579000 | 21 |
В зависимости от алгоритма заполнения, система может либо удалить отсутствующий пример, либо заменить отсутствующую температуру значениями 12, 16, 18 или 20.
проблема исчезающего градиента
В некоторых глубоких нейронных сетях градиенты ранних скрытых слоев имеют тенденцию становиться удивительно плоскими (низкими). Все более низкие градиенты приводят к все меньшим изменениям весов узлов в глубокой нейронной сети, что ведет к незначительному или полному отсутствию обучения. Модели, страдающие от проблемы исчезающего градиента, становятся сложными или невозможными для обучения. Ячейки долговременной кратковременной памяти (LSTM) решают эту проблему.
Сравните с проблемой взрыва градиента .
важность переменных
Набор оценок, указывающих на относительную важность каждой характеристики для модели.
Например, рассмотрим дерево решений , которое оценивает цены на жилье. Предположим, это дерево решений использует три признака: размер, возраст и стиль. Если набор значений важности переменных для этих трех признаков равен {размер=5,8, возраст=2,5, стиль=4,7}, то размер для дерева решений важнее возраста или стиля.
Существуют различные метрики важности переменных, которые могут помочь экспертам в области машинного обучения оценить различные аспекты моделей.
Вариационный автокодировщик (VAE)
Вариационные автокодировщики — это тип автокодировщика , который использует несоответствие между входными и выходными данными для генерации модифицированных версий входных данных. Они полезны для генеративного искусственного интеллекта .
Вариационные автоэнтропийные модели (ВАЭ) основаны на вариационном выводе: методе оценки параметров вероятностной модели.
вектор
Очень перегруженный термин, значение которого варьируется в разных математических и научных областях. В машинном обучении вектор обладает двумя свойствами:
- Тип данных: В машинном обучении векторы обычно содержат числа с плавающей запятой.
- Количество элементов: это длина вектора или его размерность .
Например, рассмотрим вектор признаков , содержащий восемь чисел с плавающей запятой. Длина или размерность этого вектора признаков равна восьми. Следует отметить, что векторы в машинном обучении часто имеют огромное количество измерений.
В виде вектора можно представить множество различных типов информации. Например:
- Любая точка на поверхности Земли может быть представлена в виде двумерного вектора, где одно измерение — это широта, а другое — долгота.
- Текущие цены каждой из 500 акций можно представить в виде 500-мерного вектора.
- A probability distribution over a finite number of classes can be represented as a vector. For example, a multiclass classification system that predicts one of three output colors (red, green, or yellow) could output the vector
(0.3, 0.2, 0.5)to meanP[red]=0.3, P[green]=0.2, P[yellow]=0.5.
Векторы можно объединять; следовательно, различные медиафайлы могут быть представлены в виде одного вектора. Некоторые модели работают непосредственно с объединением множества one-hot кодировок .
Специализированные процессоры, такие как TPU, оптимизированы для выполнения математических операций над векторами.
Вершина
Платформа Google Cloud для искусственного интеллекта и машинного обучения. Vertex предоставляет инструменты и инфраструктуру для создания, развертывания и управления приложениями ИИ, включая доступ к моделям Gemini .кодирование вибрации
Использование генеративной модели ИИ для создания программного обеспечения. То есть, ваши подсказки описывают назначение и функции программного обеспечения, которые генеративная модель ИИ преобразует в исходный код. Сгенерированный код не всегда соответствует вашим намерениям, поэтому программирование с использованием Vibe обычно требует итераций.
Андрей Карпати ввел термин «вайб-кодирование» в этом посте на X. В посте на X Карпати описывает его как «новый вид кодирования…где вы полностью отдаетесь вайбам…». Таким образом, первоначально этот термин подразумевал намеренно небрежный подход к созданию программного обеспечения, при котором вы можете даже не проверять сгенерированный код. Однако в различных кругах этот термин быстро эволюционировал и теперь означает любую форму кодирования, сгенерированного искусственным интеллектом.
For a more detailed description of vibe coding, seeWhat is vibe coding? .
Кроме того, сравните и сопоставьте кодирование атмосферы с:
В
поражение Вассерштейна
Одна из функций потерь, часто используемых в генеративных состязательных сетях , основана на расстоянии перемещения земли между распределением сгенерированных данных и реальными данными.
масса
Значение, на которое модель умножает другое значение. Обучение — это процесс определения идеальных весов модели; вывод — это процесс использования этих полученных весов для прогнозирования.
Более подробную информацию можно найти в разделе «Линейная регрессия» в «Кратком курсе по машинному обучению».
Взвешенный метод чередующихся наименьших квадратов (WALS)
Алгоритм минимизации целевой функции в процессе разложения матрицы на составляющие в рекомендательных системах , позволяющий уменьшить вес отсутствующих примеров. WALS минимизирует взвешенную квадратичную ошибку между исходной матрицей и реконструированной матрицей, чередуя фиксированное разложение на строки и столбцы. Каждая из этих оптимизаций может быть решена методом наименьших квадратов (методом выпуклой оптимизации) . Подробности см. в курсе «Рекомендательные системы» .
взвешенная сумма
Сумма всех соответствующих входных значений, умноженная на их соответствующие веса. Например, предположим, что соответствующие входные данные состоят из следующего:
| входное значение | входной вес |
| 2 | -1.3 |
| -1 | 0,6 |
| 3 | 0,4 |
Таким образом, взвешенная сумма составляет:
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
Взвешенная сумма является входным аргументом функции активации .
WiC
Сокращение для слов в контексте .
широкая модель
Линейная модель, которая обычно имеет множество разреженных входных признаков . Мы называем её «широкой», поскольку такая модель представляет собой особый тип нейронной сети с большим количеством входных сигналов, которые напрямую соединены с выходным узлом. Широкие модели часто проще отлаживать и анализировать, чем глубокие модели . Хотя широкие модели не могут выражать нелинейности через скрытые слои , они могут использовать преобразования, такие как пересечение признаков и сегментирование, для моделирования нелинейностей различными способами.
Сравните с глубокой моделью .
ширина
Количество нейронов в определенном слое нейронной сети .
WikiLingua (wiki_lingua)
Набор данных для оценки способности магистра права (LLM) к составлению кратких обзоров статей. WikiHow , энциклопедия статей, объясняющих, как выполнять различные задачи, является источником как самих статей, так и их обзоров, созданных людьми. Каждая запись в наборе данных состоит из:
- Статья, которая создается путем добавления каждого шага прозаической (абзацной) версии нумерованного списка за вычетом первого предложения каждого шага.
- Краткое изложение этой статьи, состоящее из первого предложения каждого шага в пронумерованном списке.
Подробности см. в статье WikiLingua: Новый эталонный набор данных для кросс-лингвального абстрактного суммирования .
Вызов схемы Винограда (WSC)
Формат (или набор данных, соответствующий этому формату) для оценки способности магистра права определять именное словосочетание, к которому относится местоимение .
Каждая работа в конкурсе Winograd Schema Challenge состоит из:
- Короткий отрывок, содержащий целевое местоимение.
- Целевое местоимение
- Candidate noun phrases, followed by the correct answer (a Boolean). If the target pronoun refers to this candidate, the answer is True. If the target pronoun does not refer to this candidate, the answer is False.
Например:
- Passage : Mark told Pete many lies about himself, which Pete included in his book. He should have been more truthful.
- Target pronoun : He
- Candidate noun phrases :
- Mark: True, because the target pronoun refers to Mark
- Pete: False, because the target pronoun doesn't refer to Peter
The Winograd Schema Challenge is a component of the SuperGLUE ensemble.
мудрость толпы
The idea that averaging the opinions or estimates of a large group of people ("the crowd") often produces surprisingly good results. For example, consider a game in which people guess the number of jelly beans packed into a large jar. Although most individual guesses will be inaccurate, the average of all the guesses has been empirically shown to be surprisingly close to the actual number of jelly beans in the jar.
Ensembles are a software analog of wisdom of the crowd. Even if individual models make wildly inaccurate predictions, averaging the predictions of many models often generates surprisingly good predictions. For example, although an individual decision tree might make poor predictions, a decision forest often makes very good predictions.
WMT
Strangely, an abbreviation for Conference on Machine Translation . (The abbreviation is W MT because the original name was Workshop on Machine Translation.) The conference focuses on developments in machine translation systems.
word embedding
Representing each word in a word set within an embedding vector ; that is, representing each word as a vector of floating-point values between 0.0 and 1.0. Words with similar meanings have more-similar representations than words with different meanings. For example, carrots , celery , and cucumbers would all have relatively similar representations, which would be very different from the representations of airplane , sunglasses , and toothpaste .
Words in Context (WiC)
A dataset for evaluating how well an LLM uses context to understand words that have multiple meanings. Each entry in the dataset contains:
- Two sentences, each containing the target word
- The target word
- The correct answer (a Boolean), where:
- True means the target word has the same meaning in the two sentences
- False means the target word has a different meaning in the two sentences
Например:
- Two sentences:
- There's a lot of trash on the bed of the river.
- Когда я сплю, рядом с кроватью стоит стакан воды.
- Целевое слово: кровать
- Правильный ответ : Ложь, потому что целевое слово имеет разное значение в двух предложениях.
Подробности см. в WiC: набор данных «Слово в контексте» для оценки контекстно-зависимых представлений значения .
Words in Context — это компонент комплекса SuperGLUE .
WSC
Сокращение от Winograd Schema Challenge (Задача Винограда по схемной механике ).
X
XLA (Ускоренная линейная алгебра)
Компилятор машинного обучения с открытым исходным кодом для графических процессоров (GPU), центральных процессоров (CPU) и ускорителей машинного обучения.
The XLA compiler takes models from popular ML frameworks such as PyTorch , TensorFlow , and JAX , and optimizes them for high-performance execution across different hardware platforms including GPUs, CPUs, and ML accelerators .
XL-Sum (xlsum)
Набор данных для оценки уровня владения навыками составления кратких изложений текста у студентов магистратуры. XL-Sum содержит записи на многих языках. Каждая запись в наборе данных содержит:
- Статья, взятая с сайта Британской вещательной компании (BBC).
- Краткое содержание статьи, написанное автором статьи. Обратите внимание, что это краткое содержание может содержать слова или фразы, отсутствующие в статье.
Более подробную информацию см. в статье XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages .
xsum
Сокращение от Extreme Summarization (экстремальное обобщение).
З
обучение без примеров
Тип обучения машинного обучения, при котором модель делает вывод для задачи, для которой она не была специально обучена. Другими словами, модели не предоставляется ни одного примера для обучения, специфичного для данной задачи, но её просят сделать вывод для этой задачи.
подсказка без предварительного примера
Запрос , не содержащий примера того, как вы хотите, чтобы большая языковая модель ответила. Например:
| Части одного задания | Примечания |
|---|---|
| What is the official currency of the specified country? | Вопрос, на который вы хотите получить ответ в рамках программы LLM. |
| Индия: | Сам запрос. |
The large language model might respond with any of the following:
- Рупия
- мРНК
- ₹
- индийская рупия
- The rupee
- Индийская рупия
Все ответы верны, хотя вы можете предпочесть определенный формат.
Сравните и сопоставьте метод «нулевого предварительного запроса» со следующими терминами:
Z-нормализация
Метод масштабирования , при котором исходное значение признака заменяется значением с плавающей запятой, представляющим количество стандартных отклонений от среднего значения этого признака. Например, рассмотрим признак, среднее значение которого равно 800, а стандартное отклонение равно 100. В следующей таблице показано, как нормализация по Z-баллу преобразует исходное значение в его Z-балл:
| Сырое значение | Z-показатель |
|---|---|
| 800 | 0 |
| 950 | +1.5 |
| 575 | -2.25 |
Затем модель машинного обучения обучается на основе Z-баллов для этого признака, а не на исходных значениях.
Дополнительную информацию см. в разделе «Числовые данные: нормализация в машинном обучении» (краткий курс).
,В этом глоссарии даны определения терминов, связанных с искусственным интеллектом.
А
абляция
Метод оценки важности признака или компонента путем его временного удаления из модели . Затем модель переобучается без этого признака или компонента, и если переобученная модель показывает значительно худшие результаты, то удаленный признак или компонент, вероятно, был важен.
Например, предположим, вы обучили модель классификации на 10 признаках и достигли точности 88% на тестовом наборе . Чтобы проверить важность первого признака, вы можете переобучить модель, используя только девять других признаков. Если переобученная модель показывает значительно худшие результаты (например, точность 55%), то, вероятно, удаленный признак был важен. И наоборот, если переобученная модель показывает такие же хорошие результаты, то, вероятно, этот признак был не так уж важен.
Абляция также может помочь определить значимость следующих факторов:
- Более крупные компоненты, такие как целая подсистема более крупной системы машинного обучения.
- Процессы или методы, например, этап предварительной обработки данных.
В обоих случаях вы сможете наблюдать, как изменяется (или не изменяется) производительность системы после удаления компонента.
A/B-тестирование
Статистический способ сравнения двух (или более) методов — A и B. Как правило, A — это уже существующий метод, а B — новый. A/B-тестирование позволяет не только определить, какой метод работает лучше, но и выяснить, является ли разница статистически значимой.
A/B-тестирование обычно сравнивает один показатель по двум методам; например, как точность модели соотносится с точностью двух методов? Однако A/B-тестирование может также сравнивать любое конечное число показателей.
чип-ускоритель
Категория специализированных аппаратных компонентов, предназначенных для выполнения ключевых вычислений, необходимых для алгоритмов глубокого обучения.
Ускорительные чипы (или просто ускорители ) могут значительно повысить скорость и эффективность задач обучения и вывода по сравнению с центральным процессором общего назначения. Они идеально подходят для обучения нейронных сетей и аналогичных ресурсоемких вычислительных задач.
Примерами микросхем-ускорителей являются:
- Тензорные процессоры Google ( TPU ) со специализированным оборудованием для глубокого обучения.
- Графические процессоры NVIDIA, хотя и были изначально разработаны для обработки графики, позволяют использовать параллельную обработку, что может значительно повысить скорость обработки.
точность
Количество правильных классификационных прогнозов, деленное на общее количество прогнозов. То есть:
Например, модель, сделавшая 40 правильных и 10 неправильных прогнозов, будет иметь точность:
Бинарная классификация предоставляет конкретные названия для различных категорий правильных и неправильных прогнозов . Таким образом, формула точности для бинарной классификации выглядит следующим образом:
где:
- TP — это количество истинно положительных результатов (правильных прогнозов).
- TN — это количество истинно отрицательных результатов (правильных предсказаний).
- FP — это количество ложноположительных результатов (неверных прогнозов).
- FN — это количество ложноотрицательных результатов (неверных прогнозов).
Сравните и сопоставьте точность с прецизией и полнотой .
Дополнительную информацию см. в разделе «Классификация: точность, полнота, прецизионность и связанные с ними показатели» в кратком курсе по машинному обучению.
действие
В обучении с подкреплением механизм, посредством которого агент переходит между состояниями окружающей среды , заключается в выборе действия с использованием стратегии .
функция активации
Функция, позволяющая нейронным сетям изучать нелинейные (сложные) взаимосвязи между признаками и меткой.
К популярным функциям активации относятся:
Графики функций активации никогда не представляют собой одну прямую линию. Например, график функции активации ReLU состоит из двух прямых линий:
График сигмоидной функции активации выглядит следующим образом:
Нажмите на значок, чтобы увидеть пример.
В нейронной сети функции активации обрабатывают взвешенную сумму всех входных сигналов нейрона . Для вычисления взвешенной суммы нейрон суммирует произведения соответствующих значений и весов. Например, предположим, что соответствующие входные сигналы для нейрона состоят из следующего:
| входное значение | входной вес |
| 2 | -1.3 |
| -1 | 0,6 |
| 3 | 0,4 |
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
Дополнительную информацию можно найти в разделе «Нейронные сети: функции активации» в кратком курсе по машинному обучению.
активное обучение
Активное обучение — это подход к обучению , при котором алгоритм выбирает часть данных, на которых он обучается. Оно особенно ценно, когда размеченные примеры редки или их получение обходится дорого. Вместо того чтобы слепо искать разнообразный набор размеченных примеров, алгоритм активного обучения избирательно ищет именно тот набор примеров, который ему необходим для обучения.
АдаГрад
Сложный алгоритм градиентного спуска, который масштабирует градиенты каждого параметра , фактически задавая каждому параметру независимую скорость обучения . Подробное объяснение см. в разделе «Адаптивные субградиентные методы для онлайн-обучения и стохастической оптимизации» .
приспособление
Синоним к слову «настройка» или «тонкая настройка» .
агент
Программное обеспечение, способное анализировать многомодальные пользовательские данные для планирования и выполнения действий от имени пользователя.
В обучении с подкреплением агент — это сущность, которая использует стратегию для максимизации ожидаемой отдачи от перехода между состояниями окружающей среды .
агентный
Прилагательная форма слова «агент» . «Агентный» относится к качествам, которыми обладают агенты (например, автономия).
агентский рабочий процесс
Динамический процесс, в котором агент автономно планирует и выполняет действия для достижения цели. Этот процесс может включать рассуждения, использование внешних инструментов и самокоррекцию плана.
агломеративная кластеризация
См. иерархическую кластеризацию .
AI slop
Результат работы генеративной системы искусственного интеллекта , которая отдает предпочтение количеству, а не качеству. Например, веб-страница, созданная с помощью ИИ, заполнена дешевым, сгенерированным ИИ, низкокачественным контентом.
обнаружение аномалий
Процесс выявления выбросов . Например, если среднее значение для определенного параметра равно 100 со стандартным отклонением 10, то система обнаружения аномалий должна пометить значение 200 как подозрительное.
АР
Сокращение от «дополненная реальность» .
площадь под кривой PR
См. PR AUC (площадь под кривой PR) .
площадь под кривой ROC
См. AUC (площадь под ROC-кривой) .
искусственный общий интеллект
Нечеловеческий механизм, демонстрирующий широкий спектр способностей к решению проблем, креативность и адаптивность. Например, программа, демонстрирующая искусственный общий интеллект, могла бы переводить текст, сочинять симфонии и преуспевать в играх, которые еще не изобретены.
искусственный интеллект
Нечеловеческая программа или модель , способная решать сложные задачи. Например, программа или модель, переводящая текст, или программа или модель, определяющая заболевания по рентгеновским снимкам, — обе демонстрируют искусственный интеллект.
Формально машинное обучение является подразделом искусственного интеллекта. Однако в последние годы некоторые организации стали использовать термины «искусственный интеллект» и «машинное обучение» как взаимозаменяемые.
внимание
Механизм внимания, используемый в нейронной сети , который указывает на важность конкретного слова или части слова. Внимание сжимает объем информации, необходимой модели для прогнозирования следующего токена/слова. Типичный механизм внимания может представлять собой взвешенную сумму по набору входных данных, где вес для каждого входного значения вычисляется другой частью нейронной сети.
Обратите также внимание на самовнимание и многоголовочное самовнимание , которые являются строительными блоками трансформеров .
Дополнительную информацию о механизме самовнимания см. в статье «LLMs: What's a large language model?» в сборнике «Machine Learning Crash Course».
атрибут
Синоним к слову "функция" .
В контексте машинного обучения под атрибутами часто подразумеваются характеристики, относящиеся к отдельным лицам.
выборка атрибутов
Тактика обучения дерева решений, при которой каждое дерево решений рассматривает только случайное подмножество возможных признаков при изучении условия . Как правило, для каждого узла выбирается разное подмножество признаков. В отличие от этого, при обучении дерева решений без выборки атрибутов для каждого узла рассматриваются все возможные признаки.
AUC (Площадь под ROC-кривой)
Число от 0,0 до 1,0, представляющее способность модели бинарной классификации разделять положительные и отрицательные классы . Чем ближе AUC к 1,0, тем лучше модель способна разделять классы.
Например, на следующем рисунке показана модель классификации , которая идеально разделяет положительные классы (зеленые овалы) от отрицательных классов (фиолетовые прямоугольники). Эта нереалистично идеальная модель имеет показатель AUC, равный 1,0:
Напротив, на следующем рисунке показаны результаты для модели классификации , которая генерировала случайные результаты. Для этой модели показатель AUC равен 0,5:
Да, у предыдущей модели показатель AUC равен 0,5, а не 0,0.
Большинство моделей находятся где-то между этими двумя крайностями. Например, следующая модель несколько разделяет положительные и отрицательные значения, и поэтому имеет AUC где-то между 0,5 и 1,0:
AUC игнорирует любые значения, которые вы задаете для порога классификации . Вместо этого AUC учитывает все возможные пороги классификации.
Нажмите на значок, чтобы узнать о взаимосвязи между AUC и ROC-кривыми.
AUC представляет собой площадь под ROC-кривой . Например, ROC-кривая для модели, которая идеально разделяет положительные и отрицательные результаты, выглядит следующим образом:
AUC — это площадь серой области на предыдущем рисунке. В этом необычном случае площадь — это просто длина серой области (1,0), умноженная на ширину серой области (1,0). Таким образом, произведение 1,0 и 1,0 дает AUC, равное ровно 1,0, что является максимально возможным значением AUC.
Напротив, ROC-кривая для модели классификации , которая вообще не может разделять классы, выглядит следующим образом. Площадь этой серой области составляет 0,5.
Типичная ROC-кривая выглядит примерно так:
Вычисление площади под этой кривой вручную было бы трудоемким процессом, поэтому большинство значений AUC обычно рассчитываются программами.
Дополнительную информацию см. в разделе «Классификация: ROC и AUC в экспресс-курсе по машинному обучению».
дополненная реальность
Технология, которая накладывает сгенерированное компьютером изображение на реальное изображение, видимое пользователем, создавая таким образом составное изображение.
автокодировщик
Система, которая учится извлекать наиболее важную информацию из входных данных. Автокодировщики представляют собой комбинацию кодировщика и декодера . Автокодировщики используют следующий двухэтапный процесс:
- Кодировщик преобразует входные данные в (как правило) формат с потерями, имеющий промежуточную размерность.
- Декодер создает версию исходного входного сигнала с потерями, отображая формат меньшей размерности на исходный формат входного сигнала большей размерности.
Автокодировщики обучаются сквозным методом, при котором декодер пытается максимально точно восстановить исходный входной сигнал из промежуточного формата кодировщика. Поскольку промежуточный формат меньше (менее размерен), чем исходный формат, автокодировщик вынужден изучать, какая информация во входных данных является существенной, и выходные данные не будут идеально идентичны входным.
Например:
- Если входные данные представляют собой графическое изображение, то неточная копия будет похожа на исходное изображение, но несколько изменена. Возможно, неточная копия удаляет шум из исходного изображения или заполняет некоторые недостающие пиксели.
- Если входные данные представляют собой текст, автокодировщик сгенерирует новый текст, который будет имитировать (но не идентичен) исходному тексту.
См. также вариационные автокодировщики .
автоматическая оценка
Использование программного обеспечения для оценки качества результатов работы модели.
Когда выходные данные модели относительно просты, скрипт или программа могут сравнить выходные данные модели с эталонным ответом . Этот тип автоматической оценки иногда называют программной оценкой . Для программной оценки часто полезны такие метрики, как ROUGE или BLEU .
Когда результаты работы модели сложны или не имеют единственно правильного ответа , иногда автоматическую оценку выполняет отдельная программа машинного обучения, называемая авторизатором .
Сравните с человеческой оценкой .
предвзятость автоматизации
Когда человек, принимающий решения, отдает предпочтение рекомендациям автоматизированной системы принятия решений перед информацией, полученной без автоматизации, даже если автоматизированная система принятия решений допускает ошибки.
Дополнительную информацию см. в разделе «Справедливость: виды предвзятости в экспресс-курсе по машинному обучению».
AutoML
Любой автоматизированный процесс построения моделей машинного обучения . AutoML может автоматически выполнять такие задачи, как:
- Найдите наиболее подходящую модель.
- Настройте гиперпараметры .
- Подготовка данных (включая выполнение инженерии признаков ).
- Разверните полученную модель.
AutoML полезен для специалистов по обработке данных, поскольку позволяет сэкономить время и усилия при разработке конвейеров машинного обучения и повысить точность прогнозирования. Он также полезен для неспециалистов, делая сложные задачи машинного обучения более доступными для них.
Дополнительную информацию см. в разделе «Автоматизированное машинное обучение (AutoML)» в «Кратком курсе по машинному обучению».
авторская оценка
Гибридный механизм оценки качества результатов работы генеративной модели ИИ , сочетающий в себе оценку человеком и автоматическую оценку . Авторефер — это модель машинного обучения, обученная на данных, созданных в результате оценки человеком . В идеале авторефер учится имитировать действия человека-оценщика.В продаже имеются готовые автоматизированные системы оценки, но лучшие из них специально оптимизированы для решения конкретной задачи.
авторегрессионная модель
Модель , которая делает вывод на основе собственных предыдущих прогнозов. Например, авторегрессивные языковые модели прогнозируют следующий токен на основе ранее предсказанных токенов. Все большие языковые модели на основе Transformer являются авторегрессивными.
В отличие от них, модели обработки изображений на основе GAN обычно не являются авторегрессивными, поскольку они генерируют изображение за один прямой проход, а не итеративно пошагово. Однако некоторые модели генерации изображений являются авторегрессивными, поскольку они генерируют изображение пошагово.
вспомогательные потери
Функция потерь — используемая совместно с основной функцией потерь модели нейронной сети — помогает ускорить обучение на ранних итерациях, когда веса инициализируются случайным образом.
Вспомогательные функции потерь переносят эффективные градиенты на более ранние слои . Это способствует сходимости во время обучения , борясь с проблемой затухания градиента .
средняя точность при k
Метрика, суммирующая производительность модели при обработке одного запроса, генерирующего ранжированные результаты, например, нумерованный список рекомендаций книг. Средняя точность в точке k — это, собственно, среднее значение точности в точке k для каждого релевантного результата. Формула для расчета средней точности в точке k выглядит следующим образом:
\[{\text{average precision at k}} = \frac{1}{n} \sum_{i=1}^n {\text{precision at k for each relevant item} } \]
где:
- \(n\) — это количество релевантных элементов в списке.
Сравните с результатами воспроизведения на этапе k .
условие выравнивания по осям
В дереве решений условие , включающее только один признак . Например, если признаком является area , то следующее условие соответствует оси распределения:
area > 200
Сравните с косым расположением .
Б
обратное распространение
Алгоритм, реализующий градиентный спуск в нейронных сетях .
Обучение нейронной сети включает в себя множество итераций следующего двухэтапного цикла:
- В процессе прямого прохода система обрабатывает пакет примеров для получения прогнозов. Система сравнивает каждый прогноз с каждым значением метки . Разница между прогнозом и значением метки представляет собой ошибку для данного примера. Система суммирует ошибки для всех примеров, чтобы вычислить общую ошибку для текущего пакета.
- В процессе обратного распространения ошибки система уменьшает потери, корректируя веса всех нейронов во всех скрытых слоях .
Нейронные сети часто содержат множество нейронов в различных скрытых слоях. Каждый из этих нейронов вносит свой вклад в общую функцию потерь. Обратное распространение ошибки определяет, следует ли увеличивать или уменьшать веса, применяемые к конкретным нейронам.
Скорость обучения — это множитель, который регулирует степень увеличения или уменьшения каждого веса при каждом обратном проходе. Высокая скорость обучения будет увеличивать или уменьшать каждый вес сильнее, чем низкая скорость обучения.
В терминах математического анализа, обратное распространение ошибки реализует правило цепочки из математического анализа. То есть, обратное распространение ошибки вычисляет частную производную ошибки по каждому параметру.
Несколько лет назад специалистам по машинному обучению приходилось писать код для реализации обратного распространения ошибки. Современные API для машинного обучения, такие как Keras, теперь реализуют обратное распространение ошибки автоматически. Уф!
Для получения более подробной информации см. раздел «Нейронные сети в кратком курсе по машинному обучению».
упаковка
Метод обучения ансамбля , в котором каждая составляющая модель обучается на случайном подмножестве обучающих примеров, выбранных с замещением . Например, случайный лес — это набор деревьев решений, обученных с помощью метода бэггинга.
Термин bagging является сокращением от bootstrap aggregate .
Дополнительную информацию см. в разделе «Случайные леса» курса «Лесорешения».
мешок слов
Представление слов во фразе или отрывке текста независимо от порядка их следования. Например, «мешок слов» идентично представляет следующие три фразы:
- собака прыгает
- прыгает на собаку
- собака перепрыгивает
Каждое слово сопоставляется с индексом в разреженном векторе , где вектор содержит индекс для каждого слова в словаре. Например, фраза «собака прыгает» сопоставляется с вектором признаков, имеющим ненулевые значения в трех индексах, соответствующих словам «собака» , «собака» и «прыгает» . Ненулевое значение может быть любым из следующих:
- Цифра 1 обозначает наличие слова.
- Подсчет количества вхождений слова в набор. Например, если фраза "were the maroon dog is a dog with maroon fur" (бордовая собака — собака с бордовой шерстью) , то слова "maroon" и "dog" будут представлены как 2, а остальные слова — как 1.
- Какое-либо другое значение, например, логарифм количества появлений слова в мешке.
исходный уровень
Модель, используемая в качестве эталона для сравнения эффективности другой модели (как правило, более сложной). Например, модель логистической регрессии может служить хорошей базовой моделью для глубокой модели .
Для решения конкретной задачи базовый уровень помогает разработчикам моделей количественно оценить минимальную ожидаемую производительность, которую должна достичь новая модель, чтобы быть полезной.
базовая модель
Предварительно обученная модель , которая может служить отправной точкой для тонкой настройки с целью решения конкретных задач или приложений.
См. также предварительно обученную модель и базовую модель .
партия
Набор примеров, используемых в одной итерации обучения. Размер пакета определяет количество примеров в пакете.
См. раздел «Эпоха» для объяснения того, как пакет данных соотносится с эпохой.
Дополнительную информацию см. в статье «Линейная регрессия: гиперпараметры в машинном обучении» (краткий курс).
пакетный вывод
Процесс вывода прогнозов на основе множества немаркированных примеров, разделенных на более мелкие подмножества («пакеты»).
Пакетный вывод может использовать преимущества возможностей распараллеливания, предоставляемых чипами ускорителей . То есть, несколько ускорителей могут одновременно делать прогнозы на разных пакетах немаркированных примеров, что значительно увеличивает количество выводов в секунду.
Дополнительную информацию можно найти в разделе «Системы машинного обучения в производственной среде: статический и динамический вывод» в «Кратком курсе по машинному обучению».
пакетная нормализация
Нормализация входных или выходных данных функций активации в скрытом слое . Пакетная нормализация может обеспечить следующие преимущества:
- Повысьте стабильность нейронных сетей , защитив их от выбросов в весовых коэффициентах.
- Необходимо обеспечить более высокую скорость обучения , что может ускорить тренировку.
- Уменьшите переобучение .
размер партии
Количество примеров в пакете . Например, если размер пакета равен 100, то модель обрабатывает 100 примеров за итерацию .
Ниже представлены популярные стратегии определения размера партии:
- Стохастический градиентный спуск (SGD) , в котором размер пакета равен 1.
- Полный пакет (Full batch) — это стратегия, в которой размер пакета равен количеству примеров во всем обучающем наборе данных . Например, если обучающий набор содержит миллион примеров, то размер пакета будет равен миллиону примеров. Стратегия полного пакета обычно неэффективна.
- Мини-партии, размер партии которых обычно составляет от 10 до 1000 единиц. Мини-партии, как правило, являются наиболее эффективной стратегией.
Дополнительную информацию см. ниже:
- Системы машинного обучения для производственных целей: статический и динамический вывод в кратком курсе по машинному обучению.
- Руководство по настройке глубокого обучения .
Байесовская нейронная сеть
Вероятностная нейронная сеть , учитывающая неопределенность весов и выходных данных. Стандартная модель регрессии на основе нейронной сети обычно предсказывает скалярное значение; например, стандартная модель предсказывает цену дома в 853 000. В отличие от этого, байесовская нейронная сеть предсказывает распределение значений; например, байесовская модель предсказывает цену дома в 853 000 со стандартным отклонением 67 200.
Байесовская нейронная сеть использует теорему Байеса для вычисления неопределенностей в весах и прогнозах. Байесовская нейронная сеть может быть полезна, когда важно количественно оценить неопределенность, например, в моделях, связанных с фармацевтикой. Байесовские нейронные сети также могут помочь предотвратить переобучение .
Байесовская оптимизация
Метод вероятностной регрессионной модели для оптимизации ресурсоемких целевых функций путем оптимизации аппроксимирующей функции, которая количественно оценивает неопределенность с помощью байесовского обучения. Поскольку байесовская оптимизация сама по себе очень затратна, она обычно используется для оптимизации сложных задач с небольшим количеством параметров, таких как выбор гиперпараметров .
Уравнение Беллмана
В обучении с подкреплением оптимальной Q-функции удовлетворяет следующее тождество:
\[Q(s, a) = r(s, a) + \gamma \mathbb{E}_{s'|s,a} \max_{a'} Q(s', a')\]
Алгоритмы обучения с подкреплением применяют это тождество для создания Q-обучения , используя следующее правило обновления:
\[Q(s,a) \gets Q(s,a) + \alpha \left[r(s,a) + \gamma \displaystyle\max_{\substack{a_1}} Q(s',a') - Q(s,a) \right] \]
Помимо обучения с подкреплением, уравнение Беллмана находит применение в динамическом программировании. См. статью в Википедии об уравнении Беллмана .
BERT (Bidirectional Encoder Representations from Transformers)
Архитектура модели для представления текста. Обученная модель BERT может выступать в качестве части более крупной модели для классификации текста или других задач машинного обучения.
BERT обладает следующими характеристиками:
- Использует архитектуру Transformer и, следовательно, полагается на механизм самовнимания .
- Использует кодировщик, являющийся частью трансформера. Задача кодировщика — создавать качественные текстовые представления, а не выполнять какую-либо конкретную задачу, например, классификацию.
- Является двунаправленным .
- Использует маскирование для обучения без учителя .
Варианты BERT включают в себя:
Для получения общего обзора BERT см. статью «Открытый исходный код BERT: передовое предварительное обучение для обработки естественного языка» .
предвзятость (этика/справедливость)
1. Стереотипизация, предвзятость или фаворитизм по отношению к одним вещам, людям или группам по сравнению с другими. Эти предубеждения могут влиять на сбор и интерпретацию данных, проектирование системы и взаимодействие пользователей с ней. К таким формам предвзятости относятся:
- предвзятость автоматизации
- предвзятость подтверждения
- Предвзятость экспериментатора
- предвзятость групповой атрибуции
- неявная предвзятость
- предвзятость внутри группы
- смещение однородности внешней группы
2. Систематическая ошибка, возникающая в результате процедуры выборки или составления отчета. К таким формам смещения относятся:
- смещение охвата
- смещение, вызванное отсутствием ответа
- предвзятость участия
- предвзятость в репортажах
- смещение выборки
- предвзятость отбора
Не следует путать с термином «смещение» в моделях машинного обучения или смещением прогнозирования .
Дополнительную информацию см. в разделе «Справедливость: виды предвзятости в экспресс-курсе по машинному обучению».
смещение (математика) или термин, обозначающий смещение
Пересечение или смещение относительно начала координат. Смещение — это параметр в моделях машинного обучения, который обозначается одним из следующих символов:
- б
- w 0
Например, смещение обозначается буквой b в следующей формуле:
В простой двумерной прямой смещение просто означает «пересечение с осью Y». Например, смещение прямой на следующем рисунке равно 2.
Смещение существует потому, что не все модели начинаются с начала координат (0,0). Например, предположим, что вход в парк развлечений стоит 2 евро, и дополнительно 0,5 евро за каждый час пребывания посетителя. Следовательно, модель, отображающая общую стоимость, имеет смещение, равное 2, поскольку минимальная стоимость составляет 2 евро.
Предвзятость не следует путать с предвзятостью в этике и справедливости или с предвзятостью прогнозирования .
Для получения более подробной информации см. краткий курс по линейной регрессии в машинном обучении.
двунаправленный
Термин, используемый для описания системы, которая оценивает текст, предшествующий и следующий за целевым разделом текста. В отличие от этого, однонаправленная система оценивает только текст, предшествующий целевому разделу текста.
Например, рассмотрим модель скрытого языка , которая должна определить вероятности для слова или слов, представляющих подчеркивание в следующем вопросе:
Что с тобой не так?
Однонаправленная языковая модель должна основывать свои вероятности только на контексте, предоставляемом словами «Что», «есть» и «это». В отличие от этого, двунаправленная языковая модель может также получать контекст из слов «с» и «ты», что может помочь модели генерировать более точные прогнозы.
двунаправленная языковая модель
Языковая модель , определяющая вероятность присутствия данного токена в данном месте в отрывке текста на основе предшествующего и последующего текста.
биграмма
N-грамма, в которой N=2.
бинарная классификация
Тип задачи классификации , в которой предсказывается один из двух взаимоисключающих классов:
Например, следующие две модели машинного обучения выполняют бинарную классификацию:
- Модель, определяющая, являются ли электронные письма спамом (положительный класс) или не спамом (отрицательный класс).
- Модель, которая оценивает медицинские симптомы, чтобы определить, есть ли у человека определенное заболевание (положительный класс) или нет (отрицательный класс).
В отличие от многоклассовой классификации .
См. также логистическую регрессию и порог классификации .
Дополнительную информацию см. в разделе «Краткий курс по классификации в машинном обучении».
бинарное условие
В дереве решений условие , имеющее только два возможных исхода, обычно «да» или «нет» . Например, следующее условие является бинарным:
temperature >= 100
Сравните с небинарным условием .
Дополнительную информацию см. в разделе «Типы условий» курса «Лесные модели принятия решений».
сортировка
Синоним слова «ведро» .
модель черного ящика
Модель , «рассуждения» которой невозможны или сложны для понимания человеком. То есть, хотя человек может видеть, как подсказки влияют на ответы , он не может точно определить, как модель «черного ящика» определяет ответ. Другими словами, модель «черного ящика» лишена интерпретируемости .
Большинство глубоких моделей и больших языковых моделей представляют собой «чёрные ящики».
BLEU (Двуязычный стажер по оценке)
Показатель от 0,0 до 1,0 для оценки машинного перевода , например, с испанского на японский.
Для расчета показателя BLEU обычно сравнивает перевод, выполненный моделью машинного обучения ( сгенерированный текст ), с переводом, выполненным экспертом ( эталонный текст ). Степень совпадения N-грамм в сгенерированном и эталонном тексте определяет показатель BLEU.
Оригинальная статья, посвященная этой метрике, называется BLEU: a Method for Automatic Evaluation of Machine Translation .
См. также BLEURT .
БЛЁРТ (студент-оценщик двуязычных курсов из компании Transformers)
Показатель для оценки машинного перевода с одного языка на другой, в частности, с английского на английский и с английского на английский.
При переводе с английского и на английский язык BLEURT больше соответствует оценкам людей, чем BLEU . В отличие от BLEU, BLEURT делает акцент на семантическом (смысловом) сходстве и допускает перефразирование.
BLEURT использует предварительно обученную большую языковую модель (точнее, BERT ), которая затем дорабатывается на текстах, предоставленных переводчиками-людьми.
Оригинальная статья, посвященная этой метрике, называется BLEURT: Learning Robust Metrics for Text Generation .
Логические вопросы (BoolQ)
Набор данных для оценки умения студентов магистратуры отвечать на вопросы с вариантами ответа «да» или «нет». Каждое из заданий в наборе данных состоит из трех компонентов:
- Запрос
- Отрывок, подразумевающий ответ на вопрос.
- Правильный ответ — да или нет .
Например:
- Вопрос : Есть ли в Мичигане атомные электростанции?
- Текст : ...три атомные электростанции обеспечивают штат Мичиган примерно 30% его электроэнергии.
- Правильный ответ : Да
Исследователи собрали вопросы из анонимизированных, агрегированных поисковых запросов Google, а затем использовали страницы Википедии для подтверждения полученной информации.
Для получения дополнительной информации см. BoolQ: Изучение удивительной сложности естественных вопросов типа «да/нет» .
BoolQ является компонентом ансамбля SuperGLUE .
BoolQ
Сокращение для логических вопросов .
повышение
Метод машинного обучения, который итеративно объединяет набор простых и не очень точных моделей классификации (называемых «слабыми классификаторами») в модель классификации с высокой точностью («сильный классификатор») путем повышения веса примеров, которые модель в данный момент классифицирует неправильно.
Дополнительную информацию см. в разделе «Градиентный бустинг деревьев решений?» в курсе «Леса решений».
ограничивающая рамка
На изображении координаты ( x , y ) прямоугольника, окружающего интересующую область, например, собаку на изображении ниже.
вещание
Расширение формы операнда в матричной математической операции до размеров, совместимых с этой операцией. Например, в линейной алгебре требуется, чтобы два операнда в операции сложения матриц имели одинаковые размеры. Следовательно, нельзя сложить матрицу формы (m, n) с вектором длины n. Широковещательная передача позволяет выполнить эту операцию, виртуально расширяя вектор длины n до матрицы формы (m, n) путем дублирования одних и тех же значений в каждом столбце.
Более подробное описание функции широковещательной рассылки в NumPy см. в следующем разделе.
ведро
Преобразование одного признака в несколько бинарных признаков, называемых интервалами или ячейками , обычно на основе диапазона значений. Обрезанный признак, как правило, является непрерывным признаком .
Например, вместо представления температуры в виде единого непрерывного значения с плавающей запятой, можно разделить диапазоны температур на дискретные интервалы, такие как:
- Температура <= 10 градусов Цельсия будет считаться "холодной".
- Температура от 11 до 24 градусов Цельсия соответствует "умеренному" климату.
- Температура выше или равная 25 градусам Цельсия будет считаться "теплой" температурой.
Модель будет обрабатывать каждое значение в одной и той же категории одинаково. Например, значения 13 и 22 находятся в категории умеренного климата, поэтому модель обрабатывает эти два значения одинаково.
Дополнительную информацию см. в разделе «Числовые данные: биннинг в машинном обучении» (краткий курс).
С
калибровочный слой
Постпрогнозная корректировка, как правило, для учета систематической ошибки прогнозирования . Скорректированные прогнозы и вероятности должны соответствовать распределению наблюдаемого набора меток.
генерация кандидатов
Первоначальный набор рекомендаций, выбранных рекомендательной системой . Например, рассмотрим книжный магазин, предлагающий 100 000 наименований. На этапе генерации кандидатов создается гораздо меньший список подходящих книг для конкретного пользователя, скажем, 500. Но даже 500 книг — это слишком много, чтобы рекомендовать их пользователю. Последующие, более дорогостоящие этапы рекомендательной системы (такие как оценка и переранжирование ) сокращают эти 500 до гораздо меньшего, более полезного набора рекомендаций.
Дополнительную информацию см. в разделе «Обзор генерации кандидатов» курса «Рекомендательные системы».
выборка кандидатов
Оптимизация времени обучения, которая вычисляет вероятность для всех положительных меток, используя, например, функцию softmax , но только для случайной выборки отрицательных меток. Например, для примера с метками «бигль» и «собака» метод выборки кандидатов вычисляет прогнозируемые вероятности и соответствующие члены функции потерь для:
- бигль
- собака
- случайное подмножество оставшихся отрицательных классов (например, кошка , леденец , забор ).
Идея заключается в том, что отрицательные классы могут учиться на менее частом отрицательном подкреплении, если положительные классы всегда получают надлежащее положительное подкрепление, и это действительно наблюдается эмпирически.
Метод выборочного отбора кандидатов более эффективен с точки зрения вычислительных ресурсов, чем алгоритмы обучения, которые вычисляют прогнозы для всех отрицательных классов, особенно когда количество отрицательных классов очень велико.
категориальные данные
Признаки, имеющие определенный набор возможных значений. Например, рассмотрим категориальный признак с именем traffic-light-state , который может принимать только одно из следующих трех возможных значений:
-
red -
yellow -
green
Представляя traffic-light-state как категориальный признак, модель может изучить различное влияние red , green и yellow на поведение водителя.
Категориальные признаки иногда называют дискретными признаками .
Сравните с числовыми данными .
Дополнительную информацию см. в разделе «Работа с категориальными данными» в кратком курсе по машинному обучению.
причинно-следственная языковая модель
Синоним для однонаправленной языковой модели .
См. двунаправленную языковую модель , чтобы сравнить различные направленные подходы в языковом моделировании.
КБ
Сокращенное название CommitmentBank .
центроид
Центр кластера определяется алгоритмом k-средних или k-медиан . Например, если k равно 3, то алгоритм k-средних или k-медиан находит 3 центроида.
Дополнительную информацию см. в разделе «Алгоритмы кластеризации» в курсе «Кластеризация».
кластеризация на основе центроидов
Категория алгоритмов кластеризации , которая организует данные в неиерархические кластеры. k-средних — наиболее широко используемый алгоритм кластеризации на основе центроидов.
Сравните с алгоритмами иерархической кластеризации .
Дополнительную информацию см. в разделе «Алгоритмы кластеризации» в курсе «Кластеризация».
цепочка мыслей подсказка
Метод разработки подсказок , который побуждает большую языковую модель (БЯМ) пошагово объяснять свои рассуждения. Например, рассмотрим следующую подсказку, обратив особое внимание на второе предложение:
Какую перегрузку (g) будет испытывать водитель в автомобиле, разгоняющемся от 0 до 60 миль в час за 7 секунд? В ответе покажите все необходимые расчеты.
Ответ магистра права, скорее всего, будет следующим:
- Представьте последовательность физических формул, подставив значения 0, 60 и 7 в соответствующие места.
- Объясните, почему были выбраны именно эти формулы и что означают различные переменные.
Метод подсказок, основанный на логической цепочке рассуждений, заставляет логическую модель выполнять все вычисления, что может привести к более правильному ответу. Кроме того, этот метод позволяет пользователю изучить шаги логической модели, чтобы определить, имеет ли ответ смысл.
F-мера N-граммы символа (ChrF)
Метрика для оценки моделей машинного перевода . Показатель F-меры для N-грамм символов определяет степень перекрытия N-грамм в эталонном тексте с N-граммами в тексте, сгенерированном моделью машинного перевода.
Показатель F-меры для N-грамм символов аналогичен метрикам семейств ROUGE и BLEU , за исключением того, что:
- Показатель F-score для символьных N-грамм применяется к символьным N-граммам.
- ROUGE и BLEU работают с N-граммами или токенами слов .
чат
Содержимое диалога с системой машинного обучения, как правило, с большой языковой моделью . Предыдущее взаимодействие в чате (то, что вы напечатали, и ответ большой языковой модели) становится контекстом для последующих частей чата.
Чат-бот — это приложение, использующее большую языковую модель.
контрольно-пропускной пункт
Данные, отражающие состояние параметров модели как во время обучения, так и после его завершения. Например, во время обучения можно:
- Прекратить тренировки, возможно, намеренно или, возможно, в результате допущенных ошибок.
- Захватите контрольно-пропускной пункт.
- Позже можно будет перезагрузить контрольную точку, возможно, на другом оборудовании.
- Перезапустить обучение.
Выбор правдоподобных альтернатив (COPA)
Набор данных для оценки того, насколько хорошо LLM может определить лучший из двух альтернативных ответов на предпосылку. Каждое из заданий в наборе данных состоит из трех компонентов:
- Предпосылка, которая обычно представляет собой утверждение, за которым следует вопрос.
- На поставленный в предпосылке вопрос можно ответить двумя способами, один из которых верен, а другой неверен.
- Правильный ответ
Например:
- Исходное предположение: Мужчина сломал палец на ноге. В чём причина этого?
- Возможные ответы:
- У него в носке образовалась дырка.
- Он уронил молоток себе на ногу.
- Правильный ответ: 2
COPA является компонентом ансамбля SuperGLUE .
сорт
Категория, к которой может относиться метка . Например:
- В модели бинарной классификации , предназначенной для обнаружения спама, два класса могут быть спамом , а два — не спамом .
- В многоклассовой модели классификации , определяющей породы собак, классами могут быть пудель , бигль , мопс и так далее.
Классификационная модель предсказывает класс. В отличие от неё, регрессионная модель предсказывает число, а не класс.
Дополнительную информацию см. в разделе «Краткий курс по классификации в машинном обучении».
сбалансированный по классам набор данных
Набор данных, содержащий категориальные метки , в котором количество экземпляров каждой категории приблизительно одинаково. Например, рассмотрим ботанический набор данных, бинарная метка которого может быть либо «местное растение» , либо «неместное растение» :
- Набор данных, содержащий 515 местных и 485 неместных растений, является сбалансированным по классам набором данных.
- Набор данных, содержащий 875 местных растений и 125 неместных растений, является несбалансированным по классам набором данных .
A formal dividing line between class-balanced datasets and class-imbalanced datasets doesn't exist. The distinction only becomes important when a model trained on a highly class-imbalanced dataset can't converge. See Datasets: imbalanced datasets in Machine Learning Crash Course for details.
модель классификации
A model whose prediction is a class . For example, the following are all classification models:
- A model that predicts an input sentence's language (French? Spanish? Italian?).
- A model that predicts tree species (Maple? Oak? Baobab?).
- A model that predicts the positive or negative class for a particular medical condition.
In contrast, regression models predict numbers rather than classes.
Two common types of classification models are:
classification threshold
In a binary classification , a number between 0 and 1 that converts the raw output of a logistic regression model into a prediction of either the positive class or the negative class . Note that the classification threshold is a value that a human chooses, not a value chosen by model training.
A logistic regression model outputs a raw value between 0 and 1. Then:
- If this raw value is greater than the classification threshold, then the positive class is predicted.
- If this raw value is less than the classification threshold, then the negative class is predicted.
For example, suppose the classification threshold is 0.8. If the raw value is 0.9, then the model predicts the positive class. If the raw value is 0.7, then the model predicts the negative class.
The choice of classification threshold strongly influences the number of false positives and false negatives .
Более подробную информацию см. в разделе «Пороги и матрица ошибок» в кратком курсе по машинному обучению.
классификатор
A casual term for a classification model .
class-imbalanced dataset
A dataset for a classification in which the total number of labels of each class differs significantly. For example, consider a binary classification dataset whose two labels are divided as follows:
- 1,000,000 negative labels
- 10 positive labels
The ratio of negative to positive labels is 100,000 to 1, so this is a class-imbalanced dataset.
In contrast, the following dataset is class-balanced because the ratio of negative labels to positive labels is relatively close to 1:
- 517 negative labels
- 483 positive labels
Multi-class datasets can also be class-imbalanced. For example, the following multi-class classification dataset is also class-imbalanced because one label has far more examples than the other two:
- 1,000,000 labels with class "green"
- 200 labels with class "purple"
- 350 labels with class "orange"
Training class-imbalanced datasets can present special challenges. See Imbalanced datasets in Machine Learning Crash Course for details.
See also entropy , majority class , and minority class .
обрезка
A technique for handling outliers by doing either or both of the following:
- Reducing feature values that are greater than a maximum threshold down to that maximum threshold.
- Увеличение значений характеристик, которые ниже минимального порогового значения, до этого минимального порогового значения.
Например, предположим, что менее 0,5% значений для определенного параметра выходят за пределы диапазона 40–60. В этом случае можно сделать следующее:
- Обрежьте все значения, превышающие 60 (максимальный порог), до значения ровно 60.
- Обрежьте все значения ниже 40 (минимальный порог) до значения ровно 40.
Выбросы могут навредить моделям, иногда вызывая переполнение весов во время обучения. Некоторые выбросы также могут значительно ухудшить такие показатели, как точность . Ограничение — распространенный метод для минимизации ущерба.
Ограничение градиента заставляет значения градиента находиться в заданном диапазоне во время обучения.
Дополнительную информацию см. в разделе «Числовые данные: нормализация в машинном обучении» (краткий курс).
Облачный TPU
Специализированный аппаратный ускоритель, разработанный для ускорения рабочих нагрузок машинного обучения в облаке Google.
кластеризация
Группировка связанных примеров , особенно в процессе обучения без учителя . После того, как все примеры сгруппированы, человек может по желанию придать смысл каждой группе.
Существует множество алгоритмов кластеризации. Например, алгоритм k-средних кластеризует примеры на основе их близости к центроиду , как показано на следующей диаграмме:
Затем исследователь-человек мог бы проанализировать эти кластеры и, например, обозначить кластер 1 как «карликовые деревья», а кластер 2 как «полноразмерные деревья».
В качестве еще одного примера рассмотрим алгоритм кластеризации, основанный на расстоянии примера от центральной точки, который иллюстрируется следующим образом:
Для получения более подробной информации см. курс «Кластеризация» .
коадаптация
Нежелательное поведение, при котором нейроны предсказывают закономерности в обучающих данных, полагаясь почти исключительно на выходные сигналы отдельных других нейронов, а не на поведение сети в целом. Когда закономерности, вызывающие коадаптацию, отсутствуют в данных валидации, коадаптация приводит к переобучению . Регуляризация с помощью Dropout уменьшает коадаптацию, поскольку Dropout гарантирует, что нейроны не могут полагаться исключительно на отдельные другие нейроны.
коллаборативная фильтрация
Прогнозирование интересов одного пользователя на основе интересов многих других пользователей. Коллаборативная фильтрация часто используется в рекомендательных системах .
Дополнительную информацию см. в разделе «Коллаборативная фильтрация» курса «Рекомендательные системы».
CommitmentBank (CB)
Набор данных для оценки уровня владения студентом магистратуры правом определять, верит ли автор отрывка текста целевому предложению в этом отрывке. Каждая запись в наборе данных содержит:
- Отрывок
- Целевое предложение в этом отрывке
- Логическое значение, указывающее, верит ли автор отрывка целевому предложению.
Например:
- Отрывок: Как же приятно слышать смех Артемиды. Она такая серьёзная девочка. Я и не знала, что у неё есть чувство юмора.
- Целевое условие: у неё было чувство юмора
- Логическое значение : True, что означает, что автор верит целевому предложению.
CommitmentBank является компонентом комплекса SuperGLUE .
компактная модель
Любая компактная модель, предназначенная для работы на небольших устройствах с ограниченными вычислительными ресурсами. Например, компактные модели могут работать на мобильных телефонах, планшетах или встроенных системах.
вычислить
(Существительное) Вычислительные ресурсы, используемые моделью или системой, такие как вычислительная мощность, память и хранилище.
См. микросхемы ускорителей .
дрейф концепции
Изменение взаимосвязи между характеристиками и меткой. Со временем дрейф концепции снижает качество модели.
В процессе обучения модель изучает взаимосвязь между признаками и их метками в обучающем наборе данных. Если метки в обучающем наборе данных хорошо соответствуют реальному миру, то модель должна делать хорошие прогнозы в реальном мире. Однако из-за дрейфа концепции точность прогнозов модели со временем имеет тенденцию снижаться.
Например, рассмотрим модель бинарной классификации , которая предсказывает, является ли определенная модель автомобиля «экономичной с точки зрения расхода топлива». То есть, признаками могут быть:
- вес автомобиля
- компрессия двигателя
- transmission type
при этом метка может быть любой из следующих:
- экономичный расход топлива
- неэкономичен с точки зрения расхода топлива
Однако концепция «экономичного автомобиля» постоянно меняется. Модель автомобиля, названная экономичной в 1994 году, почти наверняка будет названа неэкономичной в 2024 году. Модель, страдающая от концептуального дрейфа, со временем, как правило, дает все менее и менее полезные прогнозы.
Сравните и сопоставьте с нестационарностью .
состояние
В дереве решений любой узел выполняет проверку. Например, следующее дерево решений содержит два условия:
Условие также называется расщеплением или тестом.
Сравните условия с состоянием листа .
См. также:
Дополнительную информацию см. в разделе «Типы условий» курса «Лесные модели принятия решений».
конфабуляция
Синоним слова «галлюцинация» .
Конфабуляция, вероятно, является более точным с технической точки зрения термином, чем галлюцинация. Однако термин «галлюцинация» стал популярным первым.
конфигурация
Процесс присвоения начальных значений свойствам, используемым для обучения модели, включает в себя:
- составные слои модели
- местоположение данных
- гиперпараметры, такие как:
В проектах по машинному обучению настройка может осуществляться с помощью специального конфигурационного файла или библиотек конфигурации, таких как следующие:
предвзятость подтверждения
Тенденция искать, интерпретировать, отдавать предпочтение и вспоминать информацию таким образом, чтобы она подтверждала уже существующие убеждения или гипотезы. Разработчики машинного обучения могут непреднамеренно собирать или маркировать данные таким образом, что это влияет на результат, подтверждающий их существующие убеждения. Предвзятость подтверждения — это форма скрытой предвзятости .
Предвзятость экспериментатора — это форма предвзятости подтверждения, при которой экспериментатор продолжает обучение моделей до тех пор, пока не подтвердится ранее выдвинутая гипотеза.
матрица ошибок
Таблица размером NxN, в которой суммируется количество правильных и неправильных предсказаний, сделанных моделью классификации . Например, рассмотрим следующую матрицу ошибок для модели бинарной классификации :
| Опухоль (прогнозируемая) | Неопухолевый (прогнозируемый) | |
|---|---|---|
| Опухоль (эталонные данные) | 18 (ТП) | 1 (FN) |
| Нетуморальный (эталонный) | 6 (FP) | 452 (ТН) |
Представленная выше матрица ошибок показывает следующее:
- Из 19 прогнозов, в которых в качестве истинного диагноза была указана опухоль, модель правильно классифицировала 18 и неправильно классифицировала 1.
- Из 458 прогнозов, в которых истинное значение указывало на отсутствие опухоли, модель правильно классифицировала 452 случая и неправильно — 6.
The confusion matrix for a multi-class classification problem can help you identify patterns of mistakes. For example, consider the following confusion matrix for a 3-class multi-class classification model that categorizes three different iris types (Virginica, Versicolor, and Setosa). When the ground truth was Virginica, the confusion matrix shows that the model was far more likely to mistakenly predict Versicolor than Setosa:
| Setosa (predicted) | Versicolor (predicted) | Virginica (predicted) | |
|---|---|---|---|
| Setosa (ground truth) | 88 | 12 | 0 |
| Versicolor (ground truth) | 6 | 141 | 7 |
| Virginica (ground truth) | 2 | 27 | 109 |
As yet another example, a confusion matrix could reveal that a model trained to recognize handwritten digits tends to mistakenly predict 9 instead of 4, or mistakenly predict 1 instead of 7.
Confusion matrixes contain sufficient information to calculate a variety of performance metrics, including precision and recall .
анализ избирательных округов
Dividing a sentence into smaller grammatical structures ("constituents"). A later part of the ML system, such as a natural language understanding model, can parse the constituents more easily than the original sentence. For example, consider the following sentence:
My friend adopted two cats.
A constituency parser can divide this sentence into the following two constituents:
- My friend is a noun phrase.
- adopted two cats is a verb phrase.
These constituents can be further subdivided into smaller constituents. For example, the verb phrase
adopted two cats
could be further subdivided into:
- adopted is a verb.
- two cats is another noun phrase.
контекстуализированное встраивание языка
An embedding that comes close to "understanding" words and phrases in ways that fluent human speakers can. Contextualized language embeddings can understand complex syntax, semantics, and context.
For example, consider embeddings of the English word cow . Older embeddings such as word2vec can represent English words such that the distance in the embedding space from cow to bull is similar to the distance from ewe (female sheep) to ram (male sheep) or from female to male . Contextualized language embeddings can go a step further by recognizing that English speakers sometimes casually use the word cow to mean either cow or bull.
контекстное окно
The number of tokens a model can process in a given prompt . The larger the context window, the more information the model can use to provide coherent and consistent responses to the prompt.
непрерывная функция
A floating-point feature with an infinite range of possible values, such as temperature or weight.
Contrast with discrete feature .
выборочная выборка по удобству
Using a dataset not gathered scientifically in order to run quick experiments. Later on, it's essential to switch to a scientifically gathered dataset.
конвергенция
A state reached when loss values change very little or not at all with each iteration . For example, the following loss curve suggests convergence at around 700 iterations:
A model converges when additional training won't improve the model.
In deep learning , loss values sometimes stay constant or nearly so for many iterations before finally descending. During a long period of constant loss values, you may temporarily get a false sense of convergence.
See also early stopping .
See Model convergence and loss curves in Machine Learning Crash Course for more information.
разговорное программирование
An iterative dialog between you and a generative AI model for the purpose of creating software. You issue a prompt describing some software. Then, the model uses that description to generate code. Then, you issue a new prompt to address the flaws in the previous prompt or in the generated code, and the model generates updated code. You two keep going back and forth until the generated software is good enough.
Conversation coding is essentially the original meaning of vibe coding .
Contrast with specificational coding .
выпуклая функция
A function in which the region above the graph of the function is a convex set . The prototypical convex function is shaped something like the letter U . For example, the following are all convex functions:
In contrast, the following function is not convex. Notice how the region above the graph is not a convex set:
A strictly convex function has exactly one local minimum point, which is also the global minimum point. The classic U-shaped functions are strictly convex functions. However, some convex functions (for example, straight lines) are not U-shaped.
See Convergence and convex functions in Machine Learning Crash Course for more information.
выпуклая оптимизация
The process of using mathematical techniques such as gradient descent to find the minimum of a convex function . A great deal of research in machine learning has focused on formulating various problems as convex optimization problems and in solving those problems more efficiently.
For complete details, see Boyd and Vandenberghe, Convex Optimization .
выпуклое множество
A subset of Euclidean space such that a line drawn between any two points in the subset remains completely within the subset. For instance, the following two shapes are convex sets:
In contrast, the following two shapes are not convex sets:
свертка
In mathematics, casually speaking, a mixture of two functions. In machine learning, a convolution mixes the convolutional filter and the input matrix in order to train weights .
The term "convolution" in machine learning is often a shorthand way of referring to either convolutional operation or convolutional layer .
Without convolutions, a machine learning algorithm would have to learn a separate weight for every cell in a large tensor . For example, a machine learning algorithm training on 2K x 2K images would be forced to find 4M separate weights. Thanks to convolutions, a machine learning algorithm only has to find weights for every cell in the convolutional filter , dramatically reducing the memory needed to train the model. When the convolutional filter is applied, it is simply replicated across cells such that each is multiplied by the filter.
сверточный фильтр
One of the two actors in a convolutional operation . (The other actor is a slice of an input matrix.) A convolutional filter is a matrix having the same rank as the input matrix, but a smaller shape. For example, given a 28x28 input matrix, the filter could be any 2D matrix smaller than 28x28.
In photographic manipulation, all the cells in a convolutional filter are typically set to a constant pattern of ones and zeroes. In machine learning, convolutional filters are typically seeded with random numbers and then the network trains the ideal values.
сверточный слой
A layer of a deep neural network in which a convolutional filter passes along an input matrix. For example, consider the following 3x3 convolutional filter :
The following animation shows a convolutional layer consisting of 9 convolutional operations involving the 5x5 input matrix. Notice that each convolutional operation works on a different 3x3 slice of the input matrix. The resulting 3x3 matrix (on the right) consists of the results of the 9 convolutional operations:
сверточная нейронная сеть
A neural network in which at least one layer is a convolutional layer . A typical convolutional neural network consists of some combination of the following layers:
Convolutional neural networks have had great success in certain kinds of problems, such as image recognition.
сверточная операция
The following two-step mathematical operation:
- Element-wise multiplication of the convolutional filter and a slice of an input matrix. (The slice of the input matrix has the same rank and size as the convolutional filter.)
- Summation of all the values in the resulting product matrix.
For example, consider the following 5x5 input matrix:
Now imagine the following 2x2 convolutional filter:
Each convolutional operation involves a single 2x2 slice of the input matrix. For example, suppose we use the 2x2 slice at the top-left of the input matrix. So, the convolution operation on this slice looks as follows:
A convolutional layer consists of a series of convolutional operations, each acting on a different slice of the input matrix.
КОПА
Abbreviation for Choice of Plausible Alternatives .
расходы
Synonym for loss .
совместное обучение
A semi-supervised learning approach particularly useful when all of the following conditions are true:
- В наборе данных высокое соотношение немаркированных примеров к маркированным примерам .
- This is a classification problem ( binary or multi-class ).
- The dataset contains two different sets of predictive features that are independent of each other and complementary.
Co-training essentially amplifies independent signals into a stronger signal. For example, consider a classification model that categorizes individual used cars as either Good or Bad . One set of predictive features might focus on aggregate characteristics such as the year, make, and model of the car; another set of predictive features might focus on the previous owner's driving record and the car's maintenance history.
The seminal paper on co-training is Combining Labeled and Unlabeled Data with Co-Training by Blum and Mitchell.
контрфактуальная справедливость
A fairness metric that checks whether a classification model produces the same result for one individual as it does for another individual who is identical to the first, except with respect to one or more sensitive attributes . Evaluating a classification model for counterfactual fairness is one method for surfacing potential sources of bias in a model.
See either of the following for more information:
- Fairness: Counterfactual fairness in Machine Learning Crash Course.
- When Worlds Collide: Integrating Different Counterfactual Assumptions in Fairness
смещение охвата
See selection bias .
круша цветения
A sentence or phrase with an ambiguous meaning. Crash blossoms present a significant problem in natural language understanding . For example, the headline Red Tape Holds Up Skyscraper is a crash blossom because an NLU model could interpret the headline literally or figuratively.
критик
Synonym for Deep Q-Network .
перекрестная энтропия
A generalization of Log Loss to multi-class classification problems . Cross-entropy quantifies the difference between two probability distributions. See also perplexity .
перекрестная проверка
A mechanism for estimating how well a model would generalize to new data by testing the model against one or more non-overlapping data subsets withheld from the training set .
Функция кумулятивного распределения (ФКР)
A function that defines the frequency of samples less than or equal to a target value. For example, consider a normal distribution of continuous values. A CDF tells you that approximately 50% of samples should be less than or equal to the mean and that approximately 84% of samples should be less than or equal to one standard deviation above the mean.
Д
анализ данных
Obtaining an understanding of data by considering samples, measurement, and visualization. Data analysis can be particularly useful when a dataset is first received, before one builds the first model . It is also crucial in understanding experiments and debugging problems with the system.
data augmentation
Artificially boosting the range and number of training examples by transforming existing examples to create additional examples. For example, suppose images are one of your features , but your dataset doesn't contain enough image examples for the model to learn useful associations. Ideally, you'd add enough labeled images to your dataset to enable your model to train properly. If that's not possible, data augmentation can rotate, stretch, and reflect each image to produce many variants of the original picture, possibly yielding enough labeled data to enable excellent training.
DataFrame
A popular pandas data type for representing datasets in memory.
A DataFrame is analogous to a table or a spreadsheet. Each column of a DataFrame has a name (a header), and each row is identified by a unique number.
Each column in a DataFrame is structured like a 2D array, except that each column can be assigned its own data type.
See also the official pandas.DataFrame reference page .
data parallelism
A way of scaling training or inference that replicates an entire model onto multiple devices and then passes a subset of the input data to each device. Data parallelism can enable training and inference on very large batch sizes ; however, data parallelism requires that the model be small enough to fit on all devices.
Data parallelism typically speeds training and inference.
See also model parallelism .
Dataset API (tf.data)
A high-level TensorFlow API for reading data and transforming it into a form that a machine learning algorithm requires. A tf.data.Dataset object represents a sequence of elements, in which each element contains one or more Tensors . A tf.data.Iterator object provides access to the elements of a Dataset .
data set or dataset
A collection of raw data, commonly (but not exclusively) organized in one of the following formats:
- электронная таблица
- a file in CSV (comma-separated values) format
decision boundary
The separator between classes learned by a model in a binary class or multi-class classification problems . For example, in the following image representing a binary classification problem, the decision boundary is the frontier between the orange class and the blue class:
decision forest
A model created from multiple decision trees . A decision forest makes a prediction by aggregating the predictions of its decision trees. Popular types of decision forests include random forests and gradient boosted trees .
See the Decision Forests section in the Decision Forests course for more information.
decision threshold
Synonym for classification threshold .
дерево решений
A supervised learning model composed of a set of conditions and leaves organized hierarchically. For example, the following is a decision tree:
декодер
In general, any ML system that converts from a processed, dense, or internal representation to a more raw, sparse, or external representation.
Decoders are often a component of a larger model, where they are frequently paired with an encoder .
In sequence-to-sequence tasks , a decoder starts with the internal state generated by the encoder to predict the next sequence.
Refer to Transformer for the definition of a decoder within the Transformer architecture.
See Large language models in Machine Learning Crash Course for more information.
deep model
A neural network containing more than one hidden layer .
A deep model is also called a deep neural network .
Contrast with wide model .
глубокая нейронная сеть
Synonym for deep model .
Глубокая Q-сеть (DQN)
In Q-learning , a deep neural network that predicts Q-functions .
Critic is a synonym for Deep Q-Network.
демографическое равенство
A fairness metric that is satisfied if the results of a model's classification are not dependent on a given sensitive attribute .
For example, if both Lilliputians and Brobdingnagians apply to Glubbdubdrib University, demographic parity is achieved if the percentage of Lilliputians admitted is the same as the percentage of Brobdingnagians admitted, irrespective of whether one group is on average more qualified than the other.
Contrast with equalized odds and equality of opportunity , which permit classification results in aggregate to depend on sensitive attributes, but don't permit classification results for certain specified ground truth labels to depend on sensitive attributes. See "Attacking discrimination with smarter machine learning" for a visualization exploring the tradeoffs when optimizing for demographic parity.
See Fairness: demographic parity in Machine Learning Crash Course for more information.
шумоподавление
A common approach to self-supervised learning in which:
Denoising enables learning from unlabeled examples . The original dataset serves as the target or label and the noisy data as the input.
Some masked language models use denoising as follows:
- Noise is artificially added to an unlabeled sentence by masking some of the tokens.
- The model tries to predict the original tokens.
dense feature
A feature in which most or all values are nonzero, typically a Tensor of floating-point values. For example, the following 10-element Tensor is dense because 9 of its values are nonzero:
| 8 | 3 | 7 | 5 | 2 | 4 | 0 | 4 | 9 | 6 |
Contrast with sparse feature .
плотный слой
Synonym for fully connected layer .
глубина
The sum of the following in a neural network :
- the number of hidden layers
- the number of output layers , which is typically 1
- the number of any embedding layers
For example, a neural network with five hidden layers and one output layer has a depth of 6.
Notice that the input layer doesn't influence depth.
depthwise separable convolutional neural network (sepCNN)
A convolutional neural network architecture based on Inception , but where Inception modules are replaced with depthwise separable convolutions. Also known as Xception.
A depthwise separable convolution (also abbreviated as separable convolution) factors a standard 3D convolution into two separate convolution operations that are more computationally efficient: first, a depthwise convolution, with a depth of 1 (n ✕ n ✕ 1), and then second, a pointwise convolution, with length and width of 1 (1 ✕ 1 ✕ n).
To learn more, see Xception: Deep Learning with Depthwise Separable Convolutions .
derived label
Synonym for proxy label .
устройство
An overloaded term with the following two possible definitions:
- A category of hardware that can run a TensorFlow session, including CPUs, GPUs, and TPUs .
- When training an ML model on accelerator chips (GPUs or TPUs), the part of the system that actually manipulates tensors and embeddings . The device runs on accelerator chips. In contrast, the host typically runs on a CPU.
differential privacy
In machine learning, an anonymization approach to protect any sensitive data (for example, an individual's personal information) included in a model's training set from being exposed. This approach ensures that the model doesn't learn or remember much about a specific individual. This is accomplished by sampling and adding noise during model training to obscure individual data points, mitigating the risk of exposing sensitive training data.
Differential privacy is also used outside of machine learning. For example, data scientists sometimes use differential privacy to protect individual privacy when computing product usage statistics for different demographics.
dimension reduction
Decreasing the number of dimensions used to represent a particular feature in a feature vector, typically by converting to an embedding vector .
размеры
Overloaded term having any of the following definitions:
The number of levels of coordinates in a Tensor . For example:
- A scalar has zero dimensions; for example,
["Hello"]. - A vector has one dimension; for example,
[3, 5, 7, 11]. - A matrix has two dimensions; for example,
[[2, 4, 18], [5, 7, 14]]. You can uniquely specify a particular cell in a one-dimensional vector with one coordinate; you need two coordinates to uniquely specify a particular cell in a two-dimensional matrix.
- A scalar has zero dimensions; for example,
The number of entries in a feature vector .
The number of elements in an embedding layer .
direct prompting
Synonym for zero-shot prompting .
discrete feature
A feature with a finite set of possible values. For example, a feature whose values may only be animal , vegetable , or mineral is a discrete (or categorical) feature.
Contrast with continuous feature .
дискриминативная модель
A model that predicts labels from a set of one or more features . More formally, discriminative models define the conditional probability of an output given the features and weights ; that is:
p(output | features, weights)
For example, a model that predicts whether an email is spam from features and weights is a discriminative model.
The vast majority of supervised learning models, including classification and regression models, are discriminative models.
Contrast with generative model .
дискриминатор
A system that determines whether examples are real or fake.
Alternatively, the subsystem within a generative adversarial network that determines whether the examples created by the generator are real or fake.
See The discriminator in the GAN course for more information.
неравномерное воздействие
Making decisions about people that impact different population subgroups disproportionately. This usually refers to situations where an algorithmic decision-making process harms or benefits some subgroups more than others.
For example, suppose an algorithm that determines a Lilliputian's eligibility for a miniature-home loan is more likely to classify them as "ineligible" if their mailing address contains a certain postal code. If Big-Endian Lilliputians are more likely to have mailing addresses with this postal code than Little-Endian Lilliputians, then this algorithm may result in disparate impact.
Contrast with disparate treatment , which focuses on disparities that result when subgroup characteristics are explicit inputs to an algorithmic decision-making process.
неравное обращение
Factoring subjects' sensitive attributes into an algorithmic decision-making process such that different subgroups of people are treated differently.
For example, consider an algorithm that determines Lilliputians' eligibility for a miniature-home loan based on the data they provide in their loan application. If the algorithm uses a Lilliputian's affiliation as Big-Endian or Little-Endian as an input, it is enacting disparate treatment along that dimension.
Contrast with disparate impact , which focuses on disparities in the societal impacts of algorithmic decisions on subgroups, irrespective of whether those subgroups are inputs to the model.
дистилляция
The process of reducing the size of one model (known as the teacher ) into a smaller model (known as the student ) that emulates the original model's predictions as faithfully as possible. Distillation is useful because the smaller model has two key benefits over the larger model (the teacher):
- Faster inference time
- Reduced memory and energy usage
However, the student's predictions are typically not as good as the teacher's predictions.
Distillation trains the student model to minimize a loss function based on the difference between the outputs of the predictions of the student and teacher models.
Compare and contrast distillation with the following terms:
See LLMs: Fine-tuning, distillation, and prompt engineering in Machine Learning Crash Course for more information.
распределение
The frequency and range of different values for a given feature or label . A distribution captures how likely a particular value is.
The following image shows histograms of two different distributions:
- On the left, a power law distribution of wealth versus the number of people possessing that wealth.
- On the right, a normal distribution of height versus the number of people possessing that height.
Understanding each feature and label's distribution can help you determine how to normalize values and detect outliers .
The phrase out of distribution refers to a value that doesn't appear in the dataset or is very rare. For example, an image of the planet Saturn would be considered out of distribution for a dataset consisting of cat images.
divisive clustering
See hierarchical clustering .
понижение разрешения
Overloaded term that can mean either of the following:
- Reducing the amount of information in a feature in order to train a model more efficiently. For example, before training an image recognition model, downsampling high-resolution images to a lower-resolution format.
- Training on a disproportionately low percentage of over-represented class examples in order to improve model training on under-represented classes. For example, in a class-imbalanced dataset , models tend to learn a lot about the majority class and not enough about the minority class . Downsampling helps balance the amount of training on the majority and minority classes.
Дополнительную информацию см. в разделе «Наборы данных: Несбалансированные наборы данных» в кратком курсе по машинному обучению.
ДКН
Abbreviation for Deep Q-Network .
dropout regularization
A form of regularization useful in training neural networks . Dropout regularization removes a random selection of a fixed number of the units in a network layer for a single gradient step. The more units dropped out, the stronger the regularization. This is analogous to training the network to emulate an exponentially large ensemble of smaller networks. For full details, see Dropout: A Simple Way to Prevent Neural Networks from Overfitting .
динамический
Something done frequently or continuously. The terms dynamic and online are synonyms in machine learning. The following are common uses of dynamic and online in machine learning:
- A dynamic model (or online model ) is a model that is retrained frequently or continuously.
- Dynamic training (or online training ) is the process of training frequently or continuously.
- Dynamic inference (or online inference ) is the process of generating predictions on demand.
динамическая модель
A model that is frequently (maybe even continuously) retrained. A dynamic model is a "lifelong learner" that constantly adapts to evolving data. A dynamic model is also known as an online model .
Contrast with static model .
Е
eager execution
A TensorFlow programming environment in which operations run immediately. In contrast, operations called in graph execution don't run until they are explicitly evaluated. Eager execution is an imperative interface , much like the code in most programming languages. Eager execution programs are generally far easier to debug than graph execution programs.
ранняя остановка
A method for regularization that involves ending training before training loss finishes decreasing. In early stopping, you intentionally stop training the model when the loss on a validation dataset starts to increase; that is, when generalization performance worsens.
Contrast with early exit .
earth mover's distance (EMD)
A measure of the relative similarity of two distributions . The lower the earth mover's distance, the more similar the distributions.
расстояние редактирования
A measurement of how similar two text strings are to each other. In machine learning, edit distance is useful for the following reasons:
- Edit distance is easy to compute.
- Edit distance can compare two strings known to be similar to each other.
- Edit distance can determine the degree to which different strings are similar to a given string.
Several definitions of edit distance exist, each using different string operations. See Levenshtein distance for an example.
Einsum notation
An efficient notation for describing how two tensors are to be combined. The tensors are combined by multiplying the elements of one tensor by the elements of the other tensor and then summing the products. Einsum notation uses symbols to identify the axes of each tensor, and those same symbols are rearranged to specify the shape of the new resulting tensor.
NumPy provides a common Einsum implementation.
embedding layer
A special hidden layer that trains on a high-dimensional categorical feature to gradually learn a lower dimension embedding vector. An embedding layer enables a neural network to train far more efficiently than training just on the high-dimensional categorical feature.
For example, Earth currently supports about 73,000 tree species. Suppose tree species is a feature in your model, so your model's input layer includes a one-hot vector 73,000 elements long. For example, perhaps baobab would be represented something like this:
A 73,000-element array is very long. If you don't add an embedding layer to the model, training is going to be very time consuming due to multiplying 72,999 zeros. Perhaps you pick the embedding layer to consist of 12 dimensions. Consequently, the embedding layer will gradually learn a new embedding vector for each tree species.
In certain situations, hashing is a reasonable alternative to an embedding layer.
See Embeddings in Machine Learning Crash Course for more information.
embedding space
The d-dimensional vector space that features from a higher-dimensional vector space are mapped to. Embedding space is trained to capture structure that is meaningful for the intended application.
The dot product of two embeddings is a measure of their similarity.
вектор встраивания
Broadly speaking, an array of floating-point numbers taken from any hidden layer that describe the inputs to that hidden layer. Often, an embedding vector is the array of floating-point numbers trained in an embedding layer. For example, suppose an embedding layer must learn an embedding vector for each of the 73,000 tree species on Earth. Perhaps the following array is the embedding vector for a baobab tree:
An embedding vector is not a bunch of random numbers. An embedding layer determines these values through training, similar to the way a neural network learns other weights during training. Each element of the array is a rating along some characteristic of a tree species. Which element represents which tree species' characteristic? That's very hard for humans to determine.
The mathematically remarkable part of an embedding vector is that similar items have similar sets of floating-point numbers. For example, similar tree species have a more similar set of floating-point numbers than dissimilar tree species. Redwoods and sequoias are related tree species, so they'll have a more similar set of floating-pointing numbers than redwoods and coconut palms. The numbers in the embedding vector will change each time you retrain the model, even if you retrain the model with identical input.
empirical cumulative distribution function (eCDF or EDF)
A cumulative distribution function based on empirical measurements from a real dataset. The value of the function at any point along the x-axis is the fraction of observations in the dataset that are less than or equal to the specified value.
empirical risk minimization (ERM)
Choosing the function that minimizes loss on the training set. Contrast with structural risk minimization .
кодировщик
In general, any ML system that converts from a raw, sparse, or external representation into a more processed, denser, or more internal representation.
Encoders are often a component of a larger model, where they are frequently paired with a decoder . Some Transformers pair encoders with decoders, though other Transformers use only the encoder or only the decoder.
Some systems use the encoder's output as the input to a classification or regression network.
In sequence-to-sequence tasks , an encoder takes an input sequence and returns an internal state (a vector). Then, the decoder uses that internal state to predict the next sequence.
Refer to Transformer for the definition of an encoder in the Transformer architecture.
See LLMs: What's a large language model in Machine Learning Crash Course for more information.
конечные точки
A network-addressable location (typically a URL) where a service can be reached.
ансамбль
A collection of models trained independently whose predictions are averaged or aggregated. In many cases, an ensemble produces better predictions than a single model. For example, a random forest is an ensemble built from multiple decision trees . Note that not all decision forests are ensembles.
See Random Forest in Machine Learning Crash Course for more information.
энтропия
In information theory , a description of how unpredictable a probability distribution is. Alternatively, entropy is also defined as how much information each example contains. A distribution has the highest possible entropy when all values of a random variable are equally likely.
The entropy of a set with two possible values "0" and "1" (for example, the labels in a binary classification problem) has the following formula:
H = -p log p - q log q = -p log p - (1-p) * log (1-p)
где:
- H is the entropy.
- p is the fraction of "1" examples.
- q is the fraction of "0" examples. Note that q = (1 - p)
- log is generally log 2 . In this case, the entropy unit is a bit.
For example, suppose the following:
- 100 examples contain the value "1"
- 300 examples contain the value "0"
Therefore, the entropy value is:
- p = 0,25
- q = 0.75
- H = (-0.25)log 2 (0.25) - (0.75)log 2 (0.75) = 0.81 bits per example
A set that is perfectly balanced (for example, 200 "0"s and 200 "1"s) would have an entropy of 1.0 bit per example. As a set becomes more imbalanced , its entropy moves towards 0.0.
In decision trees , entropy helps formulate information gain to help the splitter select the conditions during the growth of a classification decision tree.
Compare entropy with:
- примесь Джини
- cross-entropy loss function
Entropy is often called Shannon's entropy .
See Exact splitter for binary classification with numerical features in the Decision Forests course for more information.
среда
In reinforcement learning, the world that contains the agent and allows the agent to observe that world's state . For example, the represented world can be a game like chess, or a physical world like a maze. When the agent applies an action to the environment, then the environment transitions between states.
эпизод
In reinforcement learning, each of the repeated attempts by the agent to learn an environment .
эпоха
A full training pass over the entire training set such that each example has been processed once.
An epoch represents N / batch size training iterations , where N is the total number of examples.
For instance, suppose the following:
- The dataset consists of 1,000 examples.
- The batch size is 50 examples.
Therefore, a single epoch requires 20 iterations:
1 epoch = (N/batch size) = (1,000 / 50) = 20 iterations
Дополнительную информацию см. в статье «Линейная регрессия: гиперпараметры в машинном обучении» (краткий курс).
эпсилон жадная политика
In reinforcement learning, a policy that either follows a random policy with epsilon probability or a greedy policy otherwise. For example, if epsilon is 0.9, then the policy follows a random policy 90% of the time and a greedy policy 10% of the time.
Over successive episodes, the algorithm reduces epsilon's value in order to shift from following a random policy to following a greedy policy. By shifting the policy, the agent first randomly explores the environment and then greedily exploits the results of random exploration.
equality of opportunity
A fairness metric to assess whether a model is predicting the desirable outcome equally well for all values of a sensitive attribute . In other words, if the desirable outcome for a model is the positive class , the goal would be to have the true positive rate be the same for all groups.
Equality of opportunity is related to equalized odds , which requires that both the true positive rates and false positive rates are the same for all groups.
Suppose Glubbdubdrib University admits both Lilliputians and Brobdingnagians to a rigorous mathematics program. Lilliputians' secondary schools offer a robust curriculum of math classes, and the vast majority of students are qualified for the university program. Brobdingnagians' secondary schools don't offer math classes at all, and as a result, far fewer of their students are qualified. Equality of opportunity is satisfied for the preferred label of "admitted" with respect to nationality (Lilliputian or Brobdingnagian) if qualified students are equally likely to be admitted irrespective of whether they're a Lilliputian or a Brobdingnagian.
For example, suppose 100 Lilliputians and 100 Brobdingnagians apply to Glubbdubdrib University, and admissions decisions are made as follows:
Table 1. Lilliputian applicants (90% are qualified)
| Квалифицированный | Неквалифицированный | |
|---|---|---|
| Допущенный | 45 | 3 |
| Отклоненный | 45 | 7 |
| Общий | 90 | 10 |
| Percentage of qualified students admitted: 45/90 = 50% Percentage of unqualified students rejected: 7/10 = 70% Total percentage of Lilliputian students admitted: (45+3)/100 = 48% | ||
Table 2. Brobdingnagian applicants (10% are qualified):
| Квалифицированный | Неквалифицированный | |
|---|---|---|
| Допущенный | 5 | 9 |
| Отклоненный | 5 | 81 |
| Общий | 10 | 90 |
| Percentage of qualified students admitted: 5/10 = 50% Percentage of unqualified students rejected: 81/90 = 90% Total percentage of Brobdingnagian students admitted: (5+9)/100 = 14% | ||
The preceding examples satisfy equality of opportunity for acceptance of qualified students because qualified Lilliputians and Brobdingnagians both have a 50% chance of being admitted.
While equality of opportunity is satisfied, the following two fairness metrics are not satisfied:
- demographic parity : Lilliputians and Brobdingnagians are admitted to the university at different rates; 48% of Lilliputians students are admitted, but only 14% of Brobdingnagian students are admitted.
- equalized odds : While qualified Lilliputian and Brobdingnagian students both have the same chance of being admitted, the additional constraint that unqualified Lilliputians and Brobdingnagians both have the same chance of being rejected is not satisfied. Unqualified Lilliputians have a 70% rejection rate, whereas unqualified Brobdingnagians have a 90% rejection rate.
See Fairness: Equality of opportunity in Machine Learning Crash Course for more information.
уравненные шансы
A fairness metric to assess whether a model is predicting outcomes equally well for all values of a sensitive attribute with respect to both the positive class and negative class —not just one class or the other exclusively. In other words, both the true positive rate and false negative rate should be the same for all groups.
Equalized odds is related to equality of opportunity , which only focuses on error rates for a single class (positive or negative).
For example, suppose Glubbdubdrib University admits both Lilliputians and Brobdingnagians to a rigorous mathematics program. Lilliputians' secondary schools offer a robust curriculum of math classes, and the vast majority of students are qualified for the university program. Brobdingnagians' secondary schools don't offer math classes at all, and as a result, far fewer of their students are qualified. Equalized odds is satisfied provided that no matter whether an applicant is a Lilliputian or a Brobdingnagian, if they are qualified, they are equally as likely to get admitted to the program, and if they are not qualified, they are equally as likely to get rejected.
Suppose 100 Lilliputians and 100 Brobdingnagians apply to Glubbdubdrib University, and admissions decisions are made as follows:
Table 3. Lilliputian applicants (90% are qualified)
| Квалифицированный | Неквалифицированный | |
|---|---|---|
| Допущенный | 45 | 2 |
| Отклоненный | 45 | 8 |
| Общий | 90 | 10 |
| Percentage of qualified students admitted: 45/90 = 50% Percentage of unqualified students rejected: 8/10 = 80% Total percentage of Lilliputian students admitted: (45+2)/100 = 47% | ||
Table 4. Brobdingnagian applicants (10% are qualified):
| Квалифицированный | Неквалифицированный | |
|---|---|---|
| Допущенный | 5 | 18 |
| Отклоненный | 5 | 72 |
| Общий | 10 | 90 |
| Percentage of qualified students admitted: 5/10 = 50% Percentage of unqualified students rejected: 72/90 = 80% Total percentage of Brobdingnagian students admitted: (5+18)/100 = 23% | ||
Уравненные шансы соблюдены, поскольку у квалифицированных студентов уровня лилипута и бробдингнага вероятность поступления составляет 50%, а у неквалифицированных студентов уровня лилипута и бробдингнага — 80%.
Equalized odds is formally defined in "Equality of Opportunity in Supervised Learning" as follows: "predictor Ŷ satisfies equalized odds with respect to protected attribute A and outcome Y if Ŷ and A are independent, conditional on Y."
Оценщик
Устаревший API TensorFlow. Используйте tf.keras вместо Estimators.
оценки
В основном используется как аббревиатура для обозначения оценок в рамках магистерской программы по праву . В более широком смысле, «оценки» — это аббревиатура для любой формы оценки .
оценка
Процесс оценки качества модели или сравнения различных моделей друг с другом.
Для оценки модели машинного обучения с учителем обычно проводят сравнение с проверочным и тестовым наборами данных . Оценка модели машинного обучения с учителем, как правило, включает в себя более широкие оценки качества и безопасности.
точное совпадение
Метрика типа «всё или ничего», при которой выходные данные модели либо точно соответствуют истинным значениям или эталонному тексту , либо нет. Например, если истинные значения — «оранжевый» , то единственным результатом работы модели, удовлетворяющим условию точного совпадения, будет «оранжевый» .
Точное совпадение также может оценивать модели, выходные данные которых представляют собой последовательность (ранжированный список элементов). В общем случае, для точного совпадения требуется, чтобы сгенерированный ранжированный список точно соответствовал истинным значениям; то есть каждый элемент в обоих списках должен быть в одном и том же порядке. Однако, если истинные значения состоят из нескольких правильных последовательностей, то для точного совпадения достаточно, чтобы выходные данные модели совпадали только с одной из правильных последовательностей.
пример
Значения одной строки признаков и, возможно, метка . Примеры в контролируемом обучении делятся на две общие категории:
- Размеченный пример состоит из одного или нескольких признаков и метки. Размеченные примеры используются во время обучения.
- Пример без меток состоит из одного или нескольких признаков, но не имеет метки. Примеры без меток используются при выводе результатов.
Например, предположим, вы обучаете модель для определения влияния погодных условий на результаты тестов учащихся. Вот три примера с обозначениями:
| Функции | Этикетка | ||
|---|---|---|---|
| Температура | Влажность | Давление | Результат теста |
| 15 | 47 | 998 | Хороший |
| 19 | 34 | 1020 | Отличный |
| 18 | 92 | 1012 | Бедный |
Вот три примера без подписей:
| Температура | Влажность | Давление | |
|---|---|---|---|
| 12 | 62 | 1014 | |
| 21 | 47 | 1017 | |
| 19 | 41 | 1021 |
Строка набора данных обычно является исходным материалом для примера. То есть пример, как правило, представляет собой подмножество столбцов набора данных. Кроме того, признаки в примере могут также включать синтетические признаки , такие как перекрестные признаки .
Более подробную информацию см. в разделе «Обучение с учителем» курса «Введение в машинное обучение».
повторный просмотр
В обучении с подкреплением используется метод DQN для уменьшения временных корреляций в обучающих данных. Агент сохраняет переходы состояний в буфере воспроизведения , а затем выбирает переходы из этого буфера для создания обучающих данных.
Предвзятость экспериментатора
См. предвзятость подтверждения .
проблема взрывающегося градиента
В глубоких нейронных сетях (особенно в рекуррентных нейронных сетях ) наблюдается тенденция к неожиданно высоким градиентам . Крутые градиенты часто приводят к очень большим обновлениям весов каждого узла в глубокой нейронной сети.
Модели, страдающие от проблемы взрыва градиента, становится сложно или невозможно обучить. Ограничение градиента может смягчить эту проблему.
Сравните с задачей об исчезающем градиенте .
Экстремальное суммирование (xsum)
Набор данных для оценки способности магистра права (LLM) обобщать содержание одного документа. Каждая запись в наборе данных состоит из:
- Документ, подготовленный Британской вещательной корпорацией (BBC).
- Краткое изложение этого документа в одном предложении.
Подробности см. в статье «Не рассказывайте мне подробности, только краткое изложение! Тематически ориентированные сверточные нейронные сети для экстремального суммирования» .
Ф
Ф 1
Сводная метрика бинарной классификации , основанная как на точности , так и на полноте . Вот формула:
фактичность
В мире машинного обучения фактичность — это свойство, описывающее модель, выходные данные которой основаны на реальности. Фактичность — это скорее концепция, чем метрика. Например, предположим, вы отправляете следующий запрос большой языковой модели :
Какова химическая формула поваренной соли?
Модель, оптимизирующая достоверность фактов, дала бы следующий ответ:
NaCl
Заманчиво предположить, что все модели должны основываться на фактах. Однако некоторые подсказки, например, следующие, должны побудить генеративную модель ИИ оптимизировать креативность, а не факты .
Расскажите мне лимерик об астронавте и гусенице.
Маловероятно, что получившийся лимерик будет основан на реальных событиях.
В отличие от устойчивости .
ограничение справедливости
Применение ограничения к алгоритму для обеспечения выполнения одного или нескольких определений справедливости. Примеры ограничений справедливости включают:- Постобработка выходных данных вашей модели.
- Изменение функции потерь с целью включения штрафа за нарушение критерия справедливости .
- Непосредственное добавление математического ограничения к задаче оптимизации.
метрика справедливости
Математическое определение «справедливости», поддающееся измерению. К числу часто используемых показателей справедливости относятся:
- уравненные шансы
- прогнозируемая паритетность
- контрфактуальная справедливость
- демографическое равенство
Многие показатели справедливости являются взаимоисключающими; см. несовместимость показателей справедливости .
ложноотрицательный результат (FN)
Пример, в котором модель ошибочно предсказывает отрицательный класс . Например, модель предсказывает, что конкретное электронное письмо не является спамом (отрицательный класс), но на самом деле это письмо является спамом .
частота ложноотрицательных результатов
Доля фактически положительных примеров, для которых модель ошибочно предсказала отрицательный класс. Следующая формула вычисляет частоту ложноотрицательных результатов:
Более подробную информацию см. в разделе «Пороги и матрица ошибок» в кратком курсе по машинному обучению.
ложноположительный результат (FP)
Пример, в котором модель ошибочно предсказывает положительный класс . Например, модель предсказывает, что конкретное электронное письмо является спамом (положительный класс), но на самом деле это электронное письмо не является спамом .
Более подробную информацию см. в разделе «Пороги и матрица ошибок» в кратком курсе по машинному обучению.
Частота ложноположительных результатов (FPR)
Доля фактически отрицательных примеров, для которых модель ошибочно предсказала положительный класс. Следующая формула вычисляет частоту ложноположительных результатов:
Показатель ложноположительных результатов отображается по оси x на ROC-кривой .
Дополнительную информацию см. в разделе «Классификация: ROC и AUC в экспресс-курсе по машинному обучению».
быстрый распад
A training technique to improve the performance of LLMs . Fast decay involves rapidly decreasing the learning rate during training. This strategy helps prevent the model from overfitting to the training data, and improves generalization .
особенность
An input variable to a machine learning model. An example consists of one or more features. For instance, suppose you are training a model to determine the influence of weather conditions on student test scores. The following table shows three examples, each of which contains three features and one label:
| Функции | Этикетка | ||
|---|---|---|---|
| Температура | Влажность | Давление | Результат теста |
| 15 | 47 | 998 | 92 |
| 19 | 34 | 1020 | 84 |
| 18 | 92 | 1012 | 87 |
Contrast with label .
Более подробную информацию см. в разделе «Обучение с учителем» курса «Введение в машинное обучение».
feature cross
A synthetic feature formed by "crossing" categorical or bucketed features.
For example, consider a "mood forecasting" model that represents temperature in one of the following four buckets:
-
freezing -
chilly -
temperate -
warm
And represents wind speed in one of the following three buckets:
-
still -
light -
windy
Without feature crosses, the linear model trains independently on each of the preceding seven various buckets. So, the model trains on, for example, freezing independently of the training on, for example, windy .
Alternatively, you could create a feature cross of temperature and wind speed. This synthetic feature would have the following 12 possible values:
-
freezing-still -
freezing-light -
freezing-windy -
chilly-still -
chilly-light -
chilly-windy -
temperate-still -
temperate-light -
temperate-windy -
warm-still -
warm-light -
warm-windy
Thanks to feature crosses, the model can learn mood differences between a freezing-windy day and a freezing-still day.
If you create a synthetic feature from two features that each have a lot of different buckets, the resulting feature cross will have a huge number of possible combinations. For example, if one feature has 1,000 buckets and the other feature has 2,000 buckets, the resulting feature cross has 2,000,000 buckets.
Formally, a cross is a Cartesian product .
Feature crosses are mostly used with linear models and are rarely used with neural networks.
See Categorical data: Feature crosses in Machine Learning Crash Course for more information.
разработка функций
A process that involves the following steps:
- Determining which features might be useful in training a model.
- Converting raw data from the dataset into efficient versions of those features.
For example, you might determine that temperature might be a useful feature. Then, you might experiment with bucketing to optimize what the model can learn from different temperature ranges.
Feature engineering is sometimes called feature extraction or featurization .
See Numerical data: How a model ingests data using feature vectors in Machine Learning Crash Course for more information.
извлечение признаков
Overloaded term having either of the following definitions:
- Retrieving intermediate feature representations calculated by an unsupervised or pre-trained model (for example, hidden layer values in a neural network ) for use in another model as input.
- Synonym for feature engineering .
feature importances
Synonym for variable importances .
набор функций
The group of features your machine learning model trains on. For example, a simple feature set for a model that predicts housing prices might consist of postal code, property size, and property condition.
feature spec
Describes the information required to extract features data from the tf.Example protocol buffer. Because the tf.Example protocol buffer is just a container for data, you must specify the following:
- The data to extract (that is, the keys for the features)
- The data type (for example, float or int)
- The length (fixed or variable)
feature vector
The array of feature values comprising an example . The feature vector is input during training and during inference . For example, the feature vector for a model with two discrete features might be:
[0.92, 0.56]
Each example supplies different values for the feature vector, so the feature vector for the next example could be something like:
[0.73, 0.49]
Feature engineering determines how to represent features in the feature vector. For example, a binary categorical feature with five possible values might be represented with one-hot encoding . In this case, the portion of the feature vector for a particular example would consist of four zeroes and a single 1.0 in the third position, as follows:
[0.0, 0.0, 1.0, 0.0, 0.0]
As another example, suppose your model consists of three features:
- a binary categorical feature with five possible values represented with one-hot encoding; for example:
[0.0, 1.0, 0.0, 0.0, 0.0] - another binary categorical feature with three possible values represented with one-hot encoding; for example:
[0.0, 0.0, 1.0] - a floating-point feature; for example:
8.3.
In this case, the feature vector for each example would be represented by nine values. Given the example values in the preceding list, the feature vector would be:
0.0 1.0 0.0 0.0 0.0 0.0 0.0 1.0 8.3
See Numerical data: How a model ingests data using feature vectors in Machine Learning Crash Course for more information.
фетеризация
The process of extracting features from an input source, such as a document or video, and mapping those features into a feature vector .
Some ML experts use featurization as a synonym for feature engineering or feature extraction .
федеративное обучение
A distributed machine learning approach that trains machine learning models using decentralized examples residing on devices such as smartphones. In federated learning, a subset of devices downloads the current model from a central coordinating server. The devices use the examples stored on the devices to make improvements to the model. The devices then upload the model improvements (but not the training examples) to the coordinating server, where they are aggregated with other updates to yield an improved global model. After the aggregation, the model updates computed by devices are no longer needed, and can be discarded.
Since the training examples are never uploaded, federated learning follows the privacy principles of focused data collection and data minimization.
See the Federated Learning comic (yes, a comic) for more details.
петля обратной связи
In machine learning, a situation in which a model's predictions influence the training data for the same model or another model. For example, a model that recommends movies will influence the movies that people see, which will then influence subsequent movie recommendation models.
See Production ML systems: Questions to ask in Machine Learning Crash Course for more information.
feedforward neural network (FFN)
A neural network without cyclic or recursive connections. For example, traditional deep neural networks are feedforward neural networks. Contrast with recurrent neural networks , which are cyclic.
обучение с малым количеством примеров
A machine learning approach, often used for object classification, designed to train effective classification models from only a small number of training examples.
See also one-shot learning and zero-shot learning .
подсказка с небольшим количеством попыток
A prompt that contains more than one (a "few") example demonstrating how the large language model should respond. For example, the following lengthy prompt contains two examples showing a large language model how to answer a query.
| Части одного задания | Примечания |
|---|---|
| Какая официальная валюта указанной страны? | Вопрос, на который вы хотите получить ответ в рамках программы LLM. |
| France: EUR | Один пример. |
| United Kingdom: GBP | Ещё один пример. |
| Индия: | Сам запрос. |
Few-shot prompting generally produces more desirable results than zero-shot prompting and one-shot prompting . However, few-shot prompting requires a lengthier prompt.
Few-shot prompting is a form of few-shot learning applied to prompt-based learning .
See Prompt engineering in Machine Learning Crash Course for more information.
Скрипка
A Python-first configuration library that sets the values of functions and classes without invasive code or infrastructure. In the case of Pax —and other ML codebases—these functions and classes represent models and training hyperparameters .
Fiddle assumes that machine learning codebases are typically divided into:
- Library code, which defines the layers and optimizers.
- Dataset "glue" code, which calls the libraries and wires everything together.
Fiddle captures the call structure of the glue code in an unevaluated and mutable form.
тонкая настройка
A second, task-specific training pass performed on a pre-trained model to refine its parameters for a specific use case. For example, the full training sequence for some large language models is as follows:
- Pre-training: Train a large language model on a vast general dataset, such as all the English language Wikipedia pages.
- Fine-tuning: Train the pre-trained model to perform a specific task, such as responding to medical queries. Fine-tuning typically involves hundreds or thousands of examples focused on the specific task.
As another example, the full training sequence for a large image model is as follows:
- Pre-training: Train a large image model on a vast general image dataset, such as all the images in Wikimedia commons.
- Fine-tuning: Train the pre-trained model to perform a specific task, such as generating images of orcas.
Fine-tuning can entail any combination of the following strategies:
- Modifying all of the pre-trained model's existing parameters . This is sometimes called full fine-tuning .
- Modifying only some of the pre-trained model's existing parameters (typically, the layers closest to the output layer ), while keeping other existing parameters unchanged (typically, the layers closest to the input layer ). See parameter-efficient tuning .
- Adding more layers, typically on top of the existing layers closest to the output layer.
Fine-tuning is a form of transfer learning . As such, fine-tuning might use a different loss function or a different model type than those used to train the pre-trained model. For example, you could fine-tune a pre-trained large image model to produce a regression model that returns the number of birds in an input image.
Compare and contrast fine-tuning with the following terms:
See Fine-tuning in Machine Learning Crash Course for more information.
Флэш-модель
A family of relatively small Gemini models optimized for speed and low latency . Flash models are designed for a wide range of applications where quick responses and high throughput are crucial.
Лен
A high-performance open-source library for deep learning built on top of JAX . Flax provides functions for training neural networks , as well as methods for evaluating their performance.
Flaxformer
An open-source Transformer library , built on Flax , designed primarily for natural language processing and multimodal research.
forget gate
The portion of a Long Short-Term Memory cell that regulates the flow of information through the cell. Forget gates maintain context by deciding which information to discard from the cell state.
фундаментальная модель
A very large pre-trained model trained on an enormous and diverse training set . A foundation model can do both of the following:
- Respond well to a wide range of requests.
- Serve as a base model for additional fine-tuning or other customization.
In other words, a foundation model is already very capable in a general sense but can be further customized to become even more useful for a specific task.
fraction of successes
A metric for evaluating an ML model's generated text . The fraction of successes is the number of "successful" generated text outputs divided by the total number of generated text outputs. For example, if a large language model generated 10 blocks of code, five of which were successful, then the fraction of successes would be 50%.
Although fraction of successes is broadly useful throughout statistics, within ML, this metric is primarily useful for measuring verifiable tasks like code generation or math problems.
full softmax
Synonym for softmax .
Contrast with candidate sampling .
Дополнительную информацию см. в разделе «Нейронные сети: многоклассовая классификация» в кратком курсе по машинному обучению.
fully connected layer
A hidden layer in which each node is connected to every node in the subsequent hidden layer.
A fully connected layer is also known as a dense layer .
function transformation
A function that takes a function as input and returns a transformed function as output. JAX uses function transformations.
Г
ГАН
Abbreviation for generative adversarial network .
Близнецы
The ecosystem comprising Google's most advanced AI. Elements of this ecosystem include:
- Various Gemini models .
- The interactive conversational interface to a Gemini model. Users type prompts and Gemini responds to those prompts.
- Various Gemini APIs.
- Various business products based on Gemini models; for example, Gemini for Google Cloud .
модели Близнецов
Google's state-of-the-art Transformer -based multimodal models . Gemini models are specifically designed to integrate with agents .
Users can interact with Gemini models in a variety of ways, including through an interactive dialog interface and through SDKs.
Джемма
A family of lightweight open models built from the same research and technology used to create the Gemini models. Several different Gemma models are available, each providing different features, such as vision, code, and instruction following. See Gemma for details.
GenAI or genAI
Abbreviation for generative AI .
обобщение
A model's ability to make correct predictions on new, previously unseen data. A model that can generalize is the opposite of a model that is overfitting .
See Generalization in Machine Learning Crash Course for more information.
generalization curve
A plot of both training loss and validation loss as a function of the number of iterations .
A generalization curve can help you detect possible overfitting . For example, the following generalization curve suggests overfitting because validation loss ultimately becomes significantly higher than training loss.
See Generalization in Machine Learning Crash Course for more information.
обобщенная линейная модель
A generalization of least squares regression models, which are based on Gaussian noise , to other types of models based on other types of noise, such as Poisson noise or categorical noise. Examples of generalized linear models include:
- логистическая регрессия
- multi-class regression
- least squares regression
The parameters of a generalized linear model can be found through convex optimization .
Generalized linear models exhibit the following properties:
- The average prediction of the optimal least squares regression model is equal to the average label on the training data.
- The average probability predicted by the optimal logistic regression model is equal to the average label on the training data.
The power of a generalized linear model is limited by its features. Unlike a deep model, a generalized linear model cannot "learn new features."
сгенерированный текст
In general, the text that an ML model outputs. When evaluating large language models, some metrics compare generated text against reference text . For example, suppose you are trying to determine how effectively an ML model translates from French to Dutch. In this case:
- The generated text is the Dutch translation that the ML model outputs.
- The reference text is the Dutch translation that a human translator (or software) creates.
Note that some evaluation strategies don't involve reference text.
generative adversarial network (GAN)
A system to create new data in which a generator creates data and a discriminator determines whether that created data is valid or invalid.
See the Generative Adversarial Networks course for more information.
генеративный ИИ
An emerging transformative field with no formal definition. That said, most experts agree that generative AI models can create ("generate") content that is all of the following:
- сложный
- согласованный
- оригинал
Examples of generative AI include:
- Large language models , which can generate sophisticated original text and answer questions.
- Image generation model, which can produce unique images.
- Audio and music generation models, which can compose original music or generate realistic speech.
- Video generation models, which can generate original videos.
Some earlier technologies, including LSTMs and RNNs , can also generate original and coherent content. Some experts view these earlier technologies as generative AI, while others feel that true generative AI requires more complex output than those earlier technologies can produce.
Contrast with predictive ML .
генеративная модель
Practically speaking, a model that does either of the following:
- Creates (generates) new examples from the training dataset. For example, a generative model could create poetry after training on a dataset of poems. The generator part of a generative adversarial network falls into this category.
- Determines the probability that a new example comes from the training set, or was created from the same mechanism that created the training set. For example, after training on a dataset consisting of English sentences, a generative model could determine the probability that new input is a valid English sentence.
A generative model can theoretically discern the distribution of examples or particular features in a dataset. That is:
p(examples)
Unsupervised learning models are generative.
Contrast with discriminative models .
генератор
The subsystem within a generative adversarial network that creates new examples .
Contrast with discriminative model .
примесь Джини
A metric similar to entropy . Splitters use values derived from either gini impurity or entropy to compose conditions for classification decision trees . Information gain is derived from entropy. No universally accepted equivalent term for the metric derived from gini impurity exists; however, this unnamed metric is just as important as information gain.
Gini impurity is also called gini index , or simply gini .
золотой набор данных
A set of manually curated data that captures ground truth . Teams can use one or more golden datasets to evaluate a model's quality.
Some golden datasets capture different subdomains of ground truth. For example, a golden dataset for image classification might capture lighting conditions and image resolution.
golden response
A response known to be good. For example, given the following prompt :
2 + 2
The golden response is hopefully:
4
Google AI Studio
A Google tool providing a user-friendly interface for experimenting with and building applications using Google's large language models . See the Google AI Studio home page for details.
GPT (Generative Pre-trained Transformer)
A family of Transformer -based large language models developed by OpenAI .
GPT variants can apply to multiple modalities , including:
- image generation (for example, ImageGPT)
- text-to-image generation (for example, DALL-E ).
градиент
The vector of partial derivatives with respect to all of the independent variables. In machine learning, the gradient is the vector of partial derivatives of the model function. The gradient points in the direction of steepest ascent.
градиентное накопление
Метод обратного распространения ошибки , который обновляет параметры только один раз за эпоху, а не один раз за итерацию. После обработки каждого мини-пакета накопление градиентов просто обновляет текущую сумму градиентов. Затем, после обработки последнего мини-пакета в эпохе, система окончательно обновляет параметры на основе суммы всех изменений градиентов.
Накопление градиента полезно, когда размер пакета данных очень велик по сравнению с объемом доступной памяти для обучения. Когда память является проблемой, естественная тенденция — уменьшить размер пакета. Однако уменьшение размера пакета в обычном алгоритме обратного распространения ошибки увеличивает количество обновлений параметров. Накопление градиента позволяет модели избежать проблем с памятью, сохраняя при этом эффективность обучения.
Градиентные бустинговые (решающие) деревья (GBT)
Тип леса решений, в котором:
- Обучение основано на градиентном бустинге .
- Слабая модель — это дерево решений .
Дополнительную информацию см. в разделе «Градиентный бустинг деревьев решений» курса «Леса решений».
градиентный бустинг
Алгоритм обучения, в котором слабые модели обучаются итеративно для улучшения качества (уменьшения функции потерь) сильной модели. Например, слабой моделью может быть линейная модель или небольшая модель дерева решений. Сильная модель становится суммой всех ранее обученных слабых моделей.
В простейшей форме градиентного бустинга на каждой итерации обучается слабая модель, которая предсказывает градиент функции потерь сильной модели. Затем выходные данные сильной модели обновляются путем вычитания предсказанного градиента, аналогично градиентному спуску .
где:
- $F_{0}$ is the starting strong model.
- $F_{i+1}$ is the next strong model.
- $F_{i}$ is the current strong model.
- $\xi$ is a value between 0.0 and 1.0 called shrinkage , which is analogous to the learning rate in gradient descent.
- $f_{i}$ is the weak model trained to predict the loss gradient of $F_{i}$.
Современные варианты градиентного бустинга также включают в свои вычисления вторую производную (гессиан) функции потерь.
Деревья решений обычно используются в качестве слабых моделей в градиентном бустинге. См. градиентный бустинг (деревья решений) .
градиентная обрезка
Распространенный механизм для смягчения проблемы взрыва градиента путем искусственного ограничения (обрезания) максимального значения градиента при использовании градиентного спуска для обучения модели.
градиентный спуск
Математический метод минимизации потерь . Градиентный спуск итеративно корректирует веса и смещения , постепенно находя наилучшую комбинацию для минимизации потерь.
Метод градиентного спуска старше — намного, намного старше — машинного обучения.
Для получения более подробной информации см. статью «Линейная регрессия: градиентный спуск» в кратком курсе по машинному обучению.
график
В TensorFlow это спецификация вычислений. Узлы в графе представляют операции. Ребра являются направленными и представляют собой передачу результата операции ( тензора ) в качестве операнда другой операции. Используйте TensorBoard для визуализации графа.
выполнение графа
Среда программирования TensorFlow, в которой программа сначала строит граф , а затем выполняет весь этот граф или его часть. Выполнение графа является режимом выполнения по умолчанию в TensorFlow 1.x.
В отличие от поспешного исполнения .
жадная политика
В обучении с подкреплением стратегия , которая всегда выбирает действие с наибольшей ожидаемой отдачей .
обоснованность
Свойство модели, выходные данные которой основаны на конкретном исходном материале (являются «привязанными к нему»). Например, предположим, вы предоставляете в качестве входных данных («контекста») для большой языковой модели целый учебник по физике. Затем вы задаете этой большой языковой модели вопрос по физике. Если ответ модели отражает информацию из этого учебника, то эта модель является «привязанной к этому учебнику».Следует отметить, что обоснованная модель не всегда является фактической . Например, в исходном учебнике по физике могут содержаться ошибки.
эталонные данные
Реальность.
То, что произошло на самом деле.
Например, рассмотрим модель бинарной классификации , которая предсказывает, закончит ли студент первого курса университета обучение в течение шести лет. Истинное значение для этой модели — это то, действительно ли студент окончил университет в течение шести лет.
предвзятость групповой атрибуции
Предполагается, что то, что верно для отдельного человека, верно и для всех членов этой группы. Влияние групповой предвзятости в атрибуции может усугубиться, если для сбора данных используется выборочная совокупность по принципу удобства . В нерепрезентативной выборке могут быть сделаны атрибуции, не отражающие реальность.
См. также предвзятость, связанную с однородностью внешней группы , и предвзятость внутри группы . Также см. раздел «Справедливость: типы предвзятости» в «Кратком курсе по машинному обучению» для получения дополнительной информации.
ЧАС
галлюцинация
Генеративная модель искусственного интеллекта выдает на первый взгляд правдоподобные, но фактически неверные утверждения, которые якобы отражают реальный мир. Например, генеративная модель ИИ, утверждающая, что Барак Обама умер в 1865 году, — это галлюцинация .
хеширование
В машинном обучении это механизм группировки категориальных данных , особенно когда количество категорий велико, но количество категорий, фактически присутствующих в наборе данных, сравнительно невелико.
Например, на Земле произрастает около 73 000 видов деревьев. Каждый из этих 73 000 видов деревьев можно представить в 73 000 отдельных категориальных группах. В качестве альтернативы, если в наборе данных фактически присутствует только 200 из этих видов деревьев, можно использовать хеширование для разделения видов деревьев, например, на 500 групп.
В одном контейнере может содержаться несколько видов деревьев. Например, хеширование может поместить баобаб и красный клен — два генетически разных вида — в один контейнер. Тем не менее, хеширование по-прежнему является хорошим способом отображения больших наборов категориальных значений в выбранное количество контейнеров. Хеширование преобразует категориальный признак, имеющий большое количество возможных значений, в гораздо меньшее количество значений путем детерминированного группирования значений.
Дополнительную информацию см. в разделе «Категориальные данные: словарь и one-hot кодирование» в «Кратком курсе по машинному обучению».
эвристический
Простое и быстро реализуемое решение проблемы. Например: «С помощью эвристического метода мы достигли точности 86%. Когда мы перешли к глубокой нейронной сети, точность выросла до 98%».
скрытый слой
Скрытый слой в нейронной сети находится между входным слоем (признаками) и выходным слоем (прогнозированием). Каждый скрытый слой состоит из одного или нескольких нейронов . Например, следующая нейронная сеть содержит два скрытых слоя: первый с тремя нейронами, а второй с двумя нейронами:
Глубокая нейронная сеть содержит более одного скрытого слоя. Например, на приведенном выше рисунке показана глубокая нейронная сеть, поскольку модель содержит два скрытых слоя.
Дополнительную информацию можно найти в разделе «Нейронные сети: узлы и скрытые слои» в кратком курсе по машинному обучению.
hierarchical clustering
Иерархическая кластеризация — это категория алгоритмов кластеризации , которые создают дерево кластеров. Она хорошо подходит для иерархических данных, таких как ботанические таксономии. Существует два типа алгоритмов иерархической кластеризации:
- Агломеративная кластеризация сначала относит каждый пример к своему собственному кластеру, а затем итеративно объединяет ближайшие кластеры для создания иерархического дерева.
- Метод кластеризации с разделением сначала объединяет все примеры в один кластер, а затем итеративно делит этот кластер на иерархическое дерево.
Сравните с кластеризацией на основе центроидов .
Дополнительную информацию см. в разделе «Алгоритмы кластеризации» в курсе «Кластеризация».
восхождение на холм
Алгоритм итеративного улучшения («подъема в гору») модели машинного обучения до тех пор, пока модель не перестанет улучшаться («достигнет вершины холма»). Общая форма алгоритма выглядит следующим образом:
- Создайте исходную модель.
- Создавайте новые модели-кандидаты, внося небольшие корректировки в процесс обучения или тонкой настройки . Это может включать работу с немного другим обучающим набором данных или другими гиперпараметрами.
- Оцените новые модели-кандидаты и предпримите одно из следующих действий:
- Если модель-кандидат превосходит исходную модель, то эта модель-кандидат становится новой исходной моделью. В этом случае повторите шаги 1, 2 и 3.
- Если ни одна модель не превосходит начальную, значит, вы достигли вершины и следует прекратить итерации.
See Deep Learning Tuning Playbook for guidance on hyperparameter tuning. See the Data modules of Machine Learning Crash Course for guidance on feature engineering.
потеря шарнира
A family of loss functions for classification designed to find the decision boundary as distant as possible from each training example, thus maximizing the margin between examples and the boundary. KSVMs use hinge loss (or a related function, such as squared hinge loss). For binary classification, the hinge loss function is defined as follows:
where y is the true label, either -1 or +1, and y' is the raw output of the classification model :
Consequently, a plot of hinge loss versus (y * y') looks as follows:
historical bias
A type of bias that already exists in the world and has made its way into a dataset. These biases have a tendency to reflect existing cultural stereotypes, demographic inequalities, and prejudices against certain social groups.
For example, consider a classification model that predicts whether or not a loan applicant will default on their loan, which was trained on historical loan-default data from the 1980s from local banks in two different communities. If past applicants from Community A were six times more likely to default on their loans than applicants from Community B, the model might learn a historical bias resulting in the model being less likely to approve loans in Community A, even if the historical conditions that resulted in that community's higher default rates were no longer relevant.
Дополнительную информацию см. в разделе «Справедливость: виды предвзятости в экспресс-курсе по машинному обучению».
holdout data
Examples intentionally not used ("held out") during training. The validation dataset and test dataset are examples of holdout data. Holdout data helps evaluate your model's ability to generalize to data other than the data it was trained on. The loss on the holdout set provides a better estimate of the loss on an unseen dataset than does the loss on the training set.
хозяин
When training an ML model on accelerator chips (GPUs or TPUs ), the part of the system that controls both of the following:
- The overall flow of the code.
- The extraction and transformation of the input pipeline.
The host typically runs on a CPU, not on an accelerator chip; the device manipulates tensors on the accelerator chips.
оценка человеком
A process in which people judge the quality of an ML model's output; for example, having bilingual people judge the quality of an ML translation model. Human evaluation is particularly useful for judging models that have no one right answer .
Contrast with automatic evaluation and autorater evaluation .
human in the loop (HITL)
A loosely-defined idiom that could mean either of the following:
- A policy of viewing generative AI output critically or skeptically.
- A strategy or system for ensuring that people help shape, evaluate, and refine a model's behavior. Keeping a human in the loop enables an AI to benefit from both machine intelligence and human intelligence. For example, a system in which an AI generates code which software engineers then review is a human-in-the-loop system.
гиперпараметр
The variables that you or a hyperparameter tuning serviceadjust during successive runs of training a model. For example, learning rate is a hyperparameter. You could set the learning rate to 0.01 before one training session. If you determine that 0.01 is too high, you could perhaps set the learning rate to 0.003 for the next training session.
In contrast, parameters are the various weights and bias that the model learns during training.
Дополнительную информацию см. в статье «Линейная регрессия: гиперпараметры в машинном обучении» (краткий курс).
гиперплоскость
A boundary that separates a space into two subspaces. For example, a line is a hyperplane in two dimensions and a plane is a hyperplane in three dimensions. More typically in machine learning, a hyperplane is the boundary separating a high-dimensional space. Kernel Support Vector Machines use hyperplanes to separate positive classes from negative classes, often in a very high-dimensional space.
я
иид
Abbreviation for independently and identically distributed .
распознавание изображений
A process that classifies object(s), pattern(s), or concept(s) in an image. Image recognition is also known as image classification .
imbalanced dataset
Synonym for class-imbalanced dataset .
неявная предвзятость
Automatically making an association or assumption based on one's mind models and memories. Implicit bias can affect the following:
- How data is collected and classified.
- How machine learning systems are designed and developed.
For example, when building a classification model to identify wedding photos, an engineer may use the presence of a white dress in a photo as a feature. However, white dresses have been customary only during certain eras and in certain cultures.
See also confirmation bias .
импутация
Short form of value imputation .
incompatibility of fairness metrics
The idea that some notions of fairness are mutually incompatible and cannot be satisfied simultaneously. As a result, there is no single universal metric for quantifying fairness that can be applied to all ML problems.
While this may seem discouraging, incompatibility of fairness metrics doesn't imply that fairness efforts are fruitless. Instead, it suggests that fairness must be defined contextually for a given ML problem, with the goal of preventing harms specific to its use cases.
See "On the (im)possibility of fairness" for a more detailed discussion of the incompatibility of fairness metrics.
обучение в контексте
Synonym for few-shot prompting .
independently and identically distributed (iid)
Data drawn from a distribution that doesn't change, and where each value drawn doesn't depend on values that have been drawn previously. An iid is the ideal gas of machine learning—a useful mathematical construct but almost never exactly found in the real world. For example, the distribution of visitors to a web page may be iid over a brief window of time; that is, the distribution doesn't change during that brief window and one person's visit is generally independent of another's visit. However, if you expand that window of time, seasonal differences in the web page's visitors may appear.
See also nonstationarity .
individual fairness
A fairness metric that checks whether similar individuals are classified similarly. For example, Brobdingnagian Academy might want to satisfy individual fairness by ensuring that two students with identical grades and standardized test scores are equally likely to gain admission.
Note that individual fairness relies entirely on how you define "similarity" (in this case, grades and test scores), and you can run the risk of introducing new fairness problems if your similarity metric misses important information (such as the rigor of a student's curriculum).
See "Fairness Through Awareness" for a more detailed discussion of individual fairness.
вывод
In traditional machine learning, the process of making predictions by applying a trained model to unlabeled examples . See Supervised Learning in the Intro to ML course to learn more.
In large language models , inference is the process of using a trained model to generate a response to an input prompt .
Inference has a somewhat different meaning in statistics. See the Wikipedia article on statistical inference for details.
inference path
In a decision tree , during inference , the route a particular example takes from the root to other conditions , terminating with a leaf . For example, in the following decision tree, the thicker arrows show the inference path for an example with the following feature values:
- x = 7
- y = 12
- z = -3
The inference path in the following illustration travels through three conditions before reaching the leaf ( Zeta ).
The three thick arrows show the inference path.
See Decision trees in the Decision Forests course for more information.
получение информации
In decision forests , the difference between a node's entropy and the weighted (by number of examples) sum of the entropy of its children nodes. A node's entropy is the entropy of the examples in that node.
For example, consider the following entropy values:
- entropy of parent node = 0.6
- entropy of one child node with 16 relevant examples = 0.2
- entropy of another child node with 24 relevant examples = 0.1
So 40% of the examples are in one child node and 60% are in the other child node. Therefore:
- weighted entropy sum of child nodes = (0.4 * 0.2) + (0.6 * 0.1) = 0.14
So, the information gain is:
- information gain = entropy of parent node - weighted entropy sum of child nodes
- information gain = 0.6 - 0.14 = 0.46
Most splitters seek to create conditions that maximize information gain.
предвзятость внутри группы
Showing partiality to one's own group or own characteristics. If testers or raters consist of the machine learning developer's friends, family, or colleagues, then in-group bias may invalidate product testing or the dataset.
In-group bias is a form of group attribution bias . See also out-group homogeneity bias .
Дополнительную информацию см. в разделе «Справедливость: виды предвзятости в экспресс-курсе по машинному обучению».
input generator
A mechanism by which data is loaded into a neural network .
An input generator can be thought of as a component responsible for processing raw data into tensors which are iterated over to generate batches for training, evaluation, and inference.
input layer
The layer of a neural network that holds the feature vector . That is, the input layer provides examples for training or inference . For example, the input layer in the following neural network consists of two features:
in-set condition
In a decision tree , a condition that tests for the presence of one item in a set of items. For example, the following is an in-set condition:
house-style in [tudor, colonial, cape]
During inference, if the value of the house-style feature is tudor or colonial or cape , then this condition evaluates to Yes. If the value of the house-style feature is something else (for example, ranch ), then this condition evaluates to No.
In-set conditions usually lead to more efficient decision trees than conditions that test one-hot encoded features.
пример
Synonym for example .
настройка инструкций
A form of fine-tuning that improves a generative AI model's ability to follow instructions. Instruction tuning involves training a model on a series of instruction prompts, typically covering a wide variety of tasks. The resulting instruction-tuned model then tends to generate useful responses to zero-shot prompts across a variety of tasks.
Compare and contrast with:
интерпретируемость
The ability to explain or to present an ML model's reasoning in understandable terms to a human.
Most linear regression models, for example, are highly interpretable. (You merely need to look at the trained weights for each feature.) Decision forests are also highly interpretable. Some models, however, require sophisticated visualization to become interpretable.
You can use the Learning Interpretability Tool (LIT) to interpret ML models.
inter-rater agreement
A measurement of how often human raters agree when doing a task. If raters disagree, the task instructions may need to be improved. Also sometimes called inter-annotator agreement or inter-rater reliability . See also Cohen's kappa , which is one of the most popular inter-rater agreement measurements.
See Categorical data: Common issues in Machine Learning Crash Course for more information.
Пересечение над объединением (IoU)
The intersection of two sets divided by their union. In machine-learning image-detection tasks, IoU is used to measure the accuracy of the model's predicted bounding box with respect to the ground-truth bounding box. In this case, the IoU for the two boxes is the ratio between the overlapping area and the total area, and its value ranges from 0 (no overlap of predicted bounding box and ground-truth bounding box) to 1 (predicted bounding box and ground-truth bounding box have the exact same coordinates).
For example, in the image below:
- The predicted bounding box (the coordinates delimiting where the model predicts the night table in the painting is located) is outlined in purple.
- Ограничивающая рамка (координаты, определяющие фактическое местоположение прикроватного столика на картине) обозначена зеленым цветом.
Здесь пересечение ограничивающих прямоугольников для прогноза и истинных значений (внизу слева) равно 1, а объединение ограничивающих прямоугольников для прогноза и истинных значений (внизу справа) равно 7, поэтому IoU равно \(\frac{1}{7}\).
IoU
Сокращение от intersection over union (пересечение над объединением).
матрица элементов
В системах рекомендаций используется матрица векторов встраивания , сгенерированная методом матричной факторизации , которая содержит скрытые сигналы о каждом элементе . Каждая строка матрицы элементов содержит значение одной скрытой характеристики для всех элементов. Например, рассмотрим систему рекомендаций фильмов. Каждый столбец матрицы элементов представляет собой отдельный фильм. Скрытые сигналы могут представлять жанры или быть более сложными для интерпретации сигналами, включающими сложные взаимодействия между жанром, актерами, возрастом фильма или другими факторами.
Матрица элементов имеет такое же количество столбцов, как и целевая матрица, которая подвергается факторизации. Например, если система рекомендаций фильмов оценивает 10 000 названий фильмов, матрица элементов будет иметь 10 000 столбцов.
предметы
В рекомендательной системе речь идет об объектах, которые система рекомендует. Например, видеомагазин рекомендует видео, а книжный магазин — книги.
итерация
Однократное обновление параметров модели — весов и смещений — во время обучения . Размер пакета определяет, сколько примеров модель обрабатывает за одну итерацию. Например, если размер пакета равен 20, то модель обрабатывает 20 примеров, прежде чем корректировать параметры.
При обучении нейронной сети одна итерация включает в себя следующие два прохода:
- Прямой проход для оценки потерь в отдельной партии.
- Обратный проход ( backpropagation ) используется для корректировки параметров модели на основе функции потерь и скорости обучения.
Дополнительную информацию см. в разделе «Градиентный спуск» в «Кратком курсе по машинному обучению».
Дж.
ДЖАКС
Библиотека для вычислений с массивами, объединяющая XLA (ускоренную линейную алгебру) и автоматическое дифференцирование для высокопроизводительных численных вычислений. JAX предоставляет простой и мощный API для написания ускоренного численного кода с компонуемыми преобразованиями. JAX предоставляет такие возможности, как:
-
grad(automatic differentiation) -
jit(just-in-time compilation) -
vmap(automatic vectorization or batching) -
pmap(parallelization)
JAX — это язык для выражения и компоновки преобразований числового кода, аналогичный — но гораздо более масштабный — библиотеке NumPy в Python. (Фактически, библиотека .numpy в рамках JAX является функционально эквивалентной, но полностью переписанной версией библиотеки NumPy в Python.)
JAX особенно хорошо подходит для ускорения многих задач машинного обучения, преобразуя модели и данные в форму, подходящую для параллельной обработки на графических процессорах (GPU) и процессорах TPU ( Tuned Processor ).
Flax , Optax , Pax и многие другие библиотеки построены на инфраструктуре JAX.
К
Керас
Keras — популярный API для машинного обучения на Python. Он работает на нескольких фреймворках глубокого обучения, включая TensorFlow, где доступен под именем tf.keras .
Машины опорных векторов ядра (KSVM)
Алгоритм классификации, стремящийся максимизировать разницу между положительными и отрицательными классами путем отображения входных векторов данных в многомерное пространство. Например, рассмотрим задачу классификации, в которой входной набор данных содержит сто признаков. Чтобы максимизировать разницу между положительными и отрицательными классами, KSVM может внутренне отобразить эти признаки в миллионмерное пространство. KSVM использует функцию потерь, называемую функцией потерь типа «шарнир» .
ключевые моменты
Координаты отдельных элементов изображения. Например, для модели распознавания изображений , различающей виды цветов, ключевыми точками могут быть центр каждого лепестка, стебель, тычинка и так далее.
k-кратная перекрестная проверка
Алгоритм прогнозирования способности модели к обобщению на новые данные. k в k-кратной фолд-модели обозначает количество равных групп, на которые вы делите примеры набора данных; то есть, вы обучаете и тестируете свою модель k раз. Для каждого раунда обучения и тестирования другая группа становится тестовым набором, а все оставшиеся группы становятся обучающим набором. После k раундов обучения и тестирования вы вычисляете среднее значение и стандартное отклонение выбранной(ых) метрики(метрик) теста.
Например, предположим, что ваш набор данных состоит из 120 примеров. Далее предположим, что вы решили установить k равным 4. Следовательно, после перемешивания примеров вы делите набор данных на четыре равные группы по 30 примеров и проводите четыре раунда обучения и тестирования:
Например, среднеквадратичная ошибка (MSE) может быть наиболее значимым показателем для модели линейной регрессии. Поэтому вам нужно будет найти среднее значение и стандартное отклонение MSE по всем четырем итерациям.
k-means
Популярный алгоритм кластеризации , который группирует примеры в неконтролируемом обучении. Алгоритм k-средних, по сути, делает следующее:
- Метод итеративно определяет наилучшие k центральных точек (известных как центроиды ).
- Присваивает каждому примеру ближайший центроид. Примеры, расположенные ближе всего к одному и тому же центроиду, принадлежат к одной группе.
Алгоритм k-средних выбирает координаты центроидов таким образом, чтобы минимизировать суммарный квадрат расстояний от каждого примера до ближайшего к нему центроида.
Например, рассмотрим следующий график зависимости высоты собаки от ее ширины:
Если k=3, алгоритм k-средних определит три центроида. Каждому примеру присваивается ближайший к нему центроид, в результате чего образуются три группы:
Представьте, что производитель хочет определить идеальные размеры свитеров для собак маленьких, средних и больших размеров. Три центроида определяют среднюю высоту и среднюю ширину каждой собаки в этой группе. Следовательно, производителю, вероятно, следует основывать размеры свитеров на этих трех центроидах. Обратите внимание, что центроид группы обычно не является примером в этой группе.
На приведенных выше иллюстрациях показан алгоритм k-средних для примеров, имеющих только две характеристики (высоту и ширину). Обратите внимание, что алгоритм k-средних может группировать примеры по множеству характеристик.
Дополнительную информацию см. в разделе «Что такое кластеризация методом k-средних?» в курсе «Кластеризация».
k-медиана
Алгоритм кластеризации, тесно связанный с алгоритмом k-средних . Практическое различие между ними заключается в следующем:
- В алгоритме k-средних центроиды определяются путем минимизации суммы квадратов расстояний между потенциальным центроидом и каждым из его аналогов.
- В алгоритме k-медианы центроиды определяются путем минимизации суммы расстояний между кандидатом в центроиды и каждым из его аналогов.
Следует отметить, что определения расстояния также различаются:
- Алгоритм k-средних основан на евклидовом расстоянии от центроида до точки. (В двумерном случае евклидово расстояние означает использование теоремы Пифагора для вычисления гипотенузы.) Например, расстояние k-средних между (2,2) и (5,-2) будет следующим:
- k-медиана основана на манхэттенском расстоянии от центроида до точки. Это расстояние представляет собой сумму абсолютных значений в каждом измерении. Например, k-медианное расстояние между (2,2) и (5,-2) будет следующим:
Л
L0 регуляризация
Тип регуляризации , который наказывает за общее количество ненулевых весов в модели. Например, модель с 11 ненулевыми весами будет наказываться сильнее, чем аналогичная модель с 10 ненулевыми весами.
Регуляризация L0 иногда называется регуляризацией по норме L0 .
Потеря L 1
Функция потерь , которая вычисляет абсолютное значение разницы между фактическими значениями меток и значениями, предсказанными моделью . Например, вот расчет функции потерь L1 для группы из пяти примеров :
| Фактическая ценность примера | Прогнозируемое значение модели | Абсолютное значение дельты |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = L 1 потеря | ||
Функция потерь L1 менее чувствительна к выбросам , чем функция потерь L2 .
Средняя абсолютная ошибка — это средняя ошибка L1 на пример.
Дополнительную информацию см. в разделе «Линейная регрессия: функция потерь в машинном обучении» (краткий курс).
L1- регуляризация
L1- регуляризация — это тип регуляризации , который наказывает веса пропорционально сумме абсолютных значений весов. Регуляризация L1 помогает обнулить веса нерелевантных или едва релевантных признаков. Признак с весом 0 фактически удаляется из модели.
Сравните с L2 - регуляризацией .
Потеря L 2
Функция потерь , которая вычисляет квадрат разницы между фактическими значениями меток и значениями, предсказанными моделью . Например, вот расчет функции потерь L2 для группы из пяти примеров :
| Фактическая ценность примера | Прогнозируемое значение модели | Квадрат дельты |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 9 |
| 4 | 6 | 4 |
| 9 | 8 | 1 |
| 16 = L 2 потери | ||
Вследствие возведения в квадрат, функция потерь L2 усиливает влияние выбросов . То есть, функция потерь L2 реагирует на плохие прогнозы сильнее, чем функция потерь L1 . Например, функция потерь L1 для предыдущей партии составила бы 8, а не 16. Обратите внимание, что один выброс объясняет 9 из 16.
В регрессионных моделях в качестве функции потерь обычно используется L2- функция потерь.
Среднеквадратичная ошибка — это средняя ошибка L2 -пространства на пример. Квадратичная ошибка — это другое название ошибки L2 - пространства.
Дополнительную информацию см. в разделе «Логистическая регрессия: функция потерь и регуляризация» в книге «Краткий курс по машинному обучению».
L2- регуляризация
L2- регуляризация — это тип регуляризации , который наказывает веса пропорционально сумме квадратов этих весов. Она помогает приблизить веса выбросов (с высокими положительными или низкими отрицательными значениями) к нулю, но не довести их до нуля . Признаки со значениями, очень близкими к нулю, остаются в модели, но не оказывают существенного влияния на её предсказания.
L2 - регуляризация всегда улучшает обобщающую способность в линейных моделях .
Сравните с L1 - регуляризацией .
Дополнительную информацию см. в разделе «Переобучение: L2-регуляризация» в «Кратком курсе по машинному обучению».
этикетка
В контролируемом машинном обучении «ответ» или «результат» примера .
Каждый размеченный пример состоит из одного или нескольких признаков и метки. Например, в наборе данных для обнаружения спама метка, вероятно, будет либо «спам», либо «не спам». В наборе данных об осадках меткой может быть количество осадков, выпавших за определенный период.
Дополнительную информацию см. в разделе «Обучение с учителем» в книге «Введение в машинное обучение».
пример с подписью
Пример, содержащий одну или несколько характеристик и метку . Например, в следующей таблице показаны три примера с метками из модели оценки стоимости дома, каждый из которых содержит три характеристики и одну метку:
| Количество спален | Количество ванных комнат | Возраст дома | Цена дома (на этикетке) |
|---|---|---|---|
| 3 | 2 | 15 | 345 000 долларов США |
| 2 | 1 | 72 | 179 000 долларов США |
| 4 | 2 | 34 | 392 000 долларов США |
В контролируемом машинном обучении модели обучаются на размеченных примерах и делают прогнозы на неразмеченных примерах .
Сравните примеры с подписями с примерами без подписей.
Дополнительную информацию см. в разделе «Обучение с учителем» в книге «Введение в машинное обучение».
утечка этикетки
A model design flaw in which a feature is a proxy for the label . For example, consider a binary classification model that predicts whether or not a prospective customer will purchase a particular product. Suppose that one of the features for the model is a Boolean named SpokeToCustomerAgent . Further suppose that a customer agent is only assigned after the prospective customer has actually purchased the product. During training, the model will quickly learn the association between SpokeToCustomerAgent and the label.
Дополнительную информацию см. в разделе «Мониторинг конвейеров» в «Кратком курсе по машинному обучению».
лямбда
Синоним к показателю регуляризации .
Термин «лямбда» является перегруженным. Здесь мы сосредоточимся на определении этого термина в контексте регуляризации .
LaMDA (Language Model for Dialogue Applications)
Разработанная Google языковая модель на основе Transformer , обученная на большом наборе данных диалогов, способна генерировать реалистичные ответы в разговорной речи.
LaMDA: наша революционная технология ведения диалога предоставляет общий обзор.
достопримечательности
Синоним для ключевых моментов .
языковая модель
Модель , которая оценивает вероятность появления токена или последовательности токенов в более длинной последовательности токенов.
Дополнительную информацию можно найти в разделе «Что такое языковая модель?» в кратком курсе по машинному обучению.
большая языковая модель
At a minimum, a language model having a very high number of parameters . More informally, any Transformer -based language model, such as Gemini or GPT .
See Large language models (LLMs) in Machine Learning Crash Course for more information.
задержка
The time it takes for a model to process input and generate a response. A high latency response takes takes longer to generate than a low latency response.
Factors that influence latency of large language models include:
- Input and output token lengths
- Model complexity
- The infrastructure the model runs on
Optimizing for latency is crucial for creating responsive and user-friendly applications.
скрытое пространство
Synonym for embedding space .
слой
A set of neurons in a neural network . Three common types of layers are as follows:
- The input layer , which provides values for all the features .
- One or more hidden layers , which find nonlinear relationships between the features and the label.
- The output layer , which provides the prediction.
For example, the following illustration shows a neural network with one input layer, two hidden layers, and one output layer:
In TensorFlow , layers are also Python functions that take Tensors and configuration options as input and produce other tensors as output.
Layers API (tf.layers)
A TensorFlow API for constructing a deep neural network as a composition of layers. The Layers API lets you build different types of layers , such as:
-
tf.layers.Densefor a fully-connected layer . -
tf.layers.Conv2Dfor a convolutional layer.
The Layers API follows the Keras layers API conventions. That is, aside from a different prefix, all functions in the Layers API have the same names and signatures as their counterparts in the Keras layers API.
лист
Any endpoint in a decision tree . Unlike a condition , a leaf doesn't perform a test. Rather, a leaf is a possible prediction. A leaf is also the terminal node of an inference path .
For example, the following decision tree contains three leaves:
See Decision trees in the Decision Forests course for more information.
Learning Interpretability Tool (LIT)
A visual, interactive model-understanding and data visualization tool.
You can use open-source LIT to interpret models or to visualize text, image, and tabular data.
скорость обучения
A floating-point number that tells the gradient descent algorithm how strongly to adjust weights and biases on each iteration . For example, a learning rate of 0.3 would adjust weights and biases three times more powerfully than a learning rate of 0.1.
Learning rate is a key hyperparameter . If you set the learning rate too low, training will take too long. If you set the learning rate too high, gradient descent often has trouble reaching convergence .
Дополнительную информацию см. в статье «Линейная регрессия: гиперпараметры в машинном обучении» (краткий курс).
least squares regression
A linear regression model trained by minimizing L 2 Loss .
Расстояние Левенштейна
An edit distance metric that calculates the fewest delete, insert, and substitute operations required to change one word to another. For example, the Levenshtein distance between the words "heart" and "darts" is three because the following three edits are the fewest changes to turn one word into the other:
- heart → deart (substitute "h" with "d")
- deart → dart (delete "e")
- dart → darts (insert "s")
Note that the preceding sequence isn't the only path of three edits.
линейный
A relationship between two or more variables that can be represented solely through addition and multiplication.
The plot of a linear relationship is a line.
Contrast with nonlinear .
линейная модель
A model that assigns one weight per feature to make predictions . (Linear models also incorporate a bias .) In contrast, the relationship of features to predictions in deep models is generally nonlinear .
Linear models are usually easier to train and more interpretable than deep models. However, deep models can learn complex relationships between features.
Linear regression and logistic regression are two types of linear models.
линейная регрессия
A type of machine learning model in which both of the following are true:
- The model is a linear model .
- The prediction is a floating-point value. (This is the regression part of linear regression .)
Contrast linear regression with logistic regression . Also, contrast regression with classification .
Более подробную информацию можно найти в разделе «Линейная регрессия» в «Кратком курсе по машинному обучению».
ЛИТ
Abbreviation for the Learning Interpretability Tool (LIT) , which was previously known as the Language Interpretability Tool.
магистр права
Abbreviation for large language model .
LLM evaluations (evals)
A set of metrics and benchmarks for assessing the performance of large language models (LLMs). At a high level, LLM evaluations:
- Help researchers identify areas where LLMs need improvement.
- Are useful in comparing different LLMs and identifying the best LLM for a particular task.
- Help ensure that LLMs are safe and ethical to use.
See Large language models (LLMs) in Machine Learning Crash Course for more information.
логистическая регрессия
A type of regression model that predicts a probability. Logistic regression models have the following characteristics:
- The label is categorical . The term logistic regression usually refers to binary logistic regression , that is, to a model that calculates probabilities for labels with two possible values. A less common variant, multinomial logistic regression , calculates probabilities for labels with more than two possible values.
- The loss function during training is Log Loss . (Multiple Log Loss units can be placed in parallel for labels with more than two possible values.)
- The model has a linear architecture, not a deep neural network. However, the remainder of this definition also applies to deep models that predict probabilities for categorical labels.
For example, consider a logistic regression model that calculates the probability of an input email being either spam or not spam. During inference, suppose the model predicts 0.72. Therefore, the model is estimating:
- A 72% chance of the email being spam.
- A 28% chance of the email not being spam.
A logistic regression model uses the following two-step architecture:
- The model generates a raw prediction (y') by applying a linear function of input features.
- The model uses that raw prediction as input to a sigmoid function , which converts the raw prediction to a value between 0 and 1, exclusive.
Like any regression model, a logistic regression model predicts a number. However, this number typically becomes part of a binary classification model as follows:
- If the predicted number is greater than the classification threshold , the binary classification model predicts the positive class.
- If the predicted number is less than the classification threshold, the binary classification model predicts the negative class.
See Logistic regression in Machine Learning Crash Course for more information.
логиты
The vector of raw (non-normalized) predictions that a classification model generates, which is ordinarily then passed to a normalization function. If the model is solving a multi-class classification problem, logits typically become an input to the softmax function. The softmax function then generates a vector of (normalized) probabilities with one value for each possible class.
Потери логарифма
The loss function used in binary logistic regression .
Дополнительную информацию см. в разделе «Логистическая регрессия: функция потерь и регуляризация» в книге «Краткий курс по машинному обучению».
логарифм шансов
The logarithm of the odds of some event.
Долговременная кратковременная память (LSTM)
A type of cell in a recurrent neural network used to process sequences of data in applications such as handwriting recognition, machine translation , and image captioning. LSTMs address the vanishing gradient problem that occurs when training RNNs due to long data sequences by maintaining history in an internal memory state based on new input and context from previous cells in the RNN.
ЛоРА
Abbreviation for Low-Rank Adaptability .
потеря
During the training of a supervised model , a measure of how far a model's prediction is from its label .
A loss function calculates the loss.
Дополнительную информацию см. в разделе «Линейная регрессия: функция потерь в машинном обучении» (краткий курс).
loss aggregator
A type of machine learning algorithm that improves the performance of a model by combining the predictions of multiple models and using those predictions to make a single prediction. As a result, a loss aggregator can reduce the variance of the predictions and improve the accuracy of the predictions.
loss curve
A plot of loss as a function of the number of training iterations . The following plot shows a typical loss curve:
Loss curves can help you determine when your model is converging or overfitting .
Loss curves can plot all of the following types of loss:
См. также кривую обобщения .
Дополнительную информацию см. в разделе «Переобучение: интерпретация кривых потерь» в книге «Краткий курс по машинному обучению».
функция потерь
В процессе обучения или тестирования используется математическая функция, которая вычисляет потери на наборе примеров. Функция потерь возвращает меньшие значения для моделей, которые делают хорошие прогнозы, чем для моделей, которые делают плохие прогнозы.
Цель обучения, как правило, состоит в минимизации потерь, которые возвращает функция потерь.
Существует множество различных типов функций потерь. Выберите подходящую функцию потерь для типа модели, которую вы строите. Например:
- Функция потерь L2 (или среднеквадратичная ошибка ) — это функция потерь для линейной регрессии .
- Функция потерь Log Loss используется в логистической регрессии .
потеря поверхности
График зависимости веса(ов) от потерь. Метод градиентного спуска направлен на поиск веса(ов), при котором поверхность потерь находится в локальном минимуме.
эффект «потерянный посередине»
Тенденция LLM использовать информацию из начала и конца длинного контекстного окна более эффективно, чем информацию из середины. Иными словами, при наличии длинного контекста эффект «потери информации в середине» приводит к следующей точности:
- Относительно высокий уровень , когда необходимая для формирования ответа информация находится в начале или конце контекста.
- Относительно низкий уровень, когда необходимая для формирования ответа информация находится в середине контекста.
Этот термин взят из книги «Затерянные посередине: как языковые модели используют длинные контексты» .
Low-Rank Adaptability (LoRA)
Эффективный с точки зрения параметров метод тонкой настройки , который «замораживает» предварительно обученные веса модели (так что их больше нельзя изменять), а затем вставляет в модель небольшой набор обучаемых весов. Этот набор обучаемых весов (также известный как «матрицы обновления») значительно меньше базовой модели и, следовательно, обучается гораздо быстрее.
LoRA предоставляет следующие преимущества:
- Улучшает качество прогнозов модели в той области, где применяется тонкая настройка.
- Этот метод позволяет быстрее выполнять тонкую настройку параметров модели, чем методы, требующие тонкой настройки всех параметров модели.
- Снижает вычислительные затраты на вывод результатов , позволяя одновременно запускать несколько специализированных моделей, использующих одну и ту же базовую модель.
LSTM
Сокращение от Long Short-Term Memory (долговременная кратковременная память).
М
машинное обучение
Программа или система, которая обучает модель на основе входных данных. Обученная модель может делать полезные прогнозы на основе новых (ранее не встречавшихся) данных, полученных из того же распределения, что и данные, использованные для обучения модели.
Машинное обучение также относится к области исследований, занимающейся этими программами или системами.
Для получения более подробной информации см. курс «Введение в машинное обучение» .
машинный перевод
Использование программного обеспечения (как правило, модели машинного обучения) для преобразования текста с одного человеческого языка на другой человеческий язык, например, с английского на японский.
большинство класса
Наиболее распространенная метка в наборе данных с несбалансированным распределением классов . Например, если набор данных содержит 99% отрицательных меток и 1% положительных меток, то отрицательные метки составляют преобладающий класс.
В отличие от класса меньшинств .
Дополнительную информацию см. в разделе «Наборы данных: Несбалансированные наборы данных» в кратком курсе по машинному обучению.
Марковский процесс принятия решений (МПР)
Граф, представляющий модель принятия решений, в которой решения (или действия ) предпринимаются для перехода между последовательностями состояний при условии выполнения свойства Маркова . В обучении с подкреплением эти переходы между состояниями возвращают числовое вознаграждение .
Свойство Маркова
Свойство определенных сред , в которых переходы между состояниями полностью определяются информацией, неявно содержащейся в текущем состоянии и действиях агента.
модель маскированного языка
Языковая модель , которая предсказывает вероятность того, что потенциальные токены заполнят пробелы в последовательности. Например, модель с маскированием может вычислить вероятность того, что потенциальное слово (или слова) заменит подчеркнутое слово в следующем предложении:
Тот, кто был в шляпе, вернулся.
В литературе обычно используется строка "MASK" вместо подчеркивания. Например:
«МАСКА» в шляпе вернулась.
Большинство современных моделей маскированного языка являются двунаправленными .
math-pass@k
Показатель, определяющий точность решения математической задачи учащимся магистратуры в течение K попыток. Например, math-pass@2 измеряет способность учащегося решать математические задачи за две попытки. Точность 0,85 по показателю math-pass@2 означает, что учащийся смог решить математические задачи в 85% случаев за две попытки.
Показатель math-pass@k идентичен показателю pass@k , за исключением того, что термин math-pass@k используется специально для оценки математических навыков.
matplotlib
Библиотека matplotlib с открытым исходным кодом для построения 2D-графиков на Python помогает визуализировать различные аспекты машинного обучения.
матричная факторизация
В математике это механизм для нахождения матриц, скалярное произведение которых аппроксимирует целевую матрицу.
В рекомендательных системах целевая матрица часто содержит оценки пользователей по товарам . Например, целевая матрица для системы рекомендаций фильмов может выглядеть примерно так, где положительные целые числа — это оценки пользователей, а 0 означает, что пользователь не оценил фильм:
| Касабланка | Филадельфийская история | Чёрная Пантера | Чудо-женщина | Криминальное чтиво | |
|---|---|---|---|---|---|
| Пользователь 1 | 5.0 | 3.0 | 0.0 | 2.0 | 0.0 |
| Пользователь 2 | 4.0 | 0.0 | 0.0 | 1.0 | 5.0 |
| Пользователь 3 | 3.0 | 1.0 | 4.0 | 5.0 | 0.0 |
Система рекомендаций фильмов призвана прогнозировать пользовательские оценки фильмов без рейтинга. Например, понравится ли пользователю 1 фильм «Чёрная пантера» ?
Один из подходов к созданию рекомендательных систем заключается в использовании матричной факторизации для генерации следующих двух матриц:
- Матрица пользователей имеет форму числа пользователей, умноженного на число измерений встраивания.
- Матрица элементов , имеющая форму, где количество измерений встраивания умножено на количество элементов.
Например, применение матричной факторизации к нашим трем пользователям и пяти товарам может дать следующую матрицу пользователей и матрицу товаров:
User Matrix Item Matrix 1.1 2.3 0.9 0.2 1.4 2.0 1.2 0.6 2.0 1.7 1.2 1.2 -0.1 2.1 2.5 0.5
Скалярное произведение матрицы пользователей и матрицы товаров дает матрицу рекомендаций, которая содержит не только исходные оценки пользователей, но и прогнозы для фильмов, которые каждый пользователь еще не смотрел. Например, рассмотрим оценку пользователя 1 фильма «Касабланка» , которая составила 5,0. Скалярное произведение, соответствующее этой ячейке в матрице рекомендаций, должно быть около 5,0, и оно таково:
(1.1 * 0.9) + (2.3 * 1.7) = 4.9Что еще более важно, понравится ли Пользователю 1 фильм «Черная пантера» ? Скалярное произведение данных из первой строки и третьего столбца дает прогнозируемый рейтинг 4,3:
(1.1 * 1.4) + (2.3 * 1.2) = 4.3Как правило, при разложении матрицы на составляющие получаются матрица пользователей и матрица товаров, которые вместе значительно компактнее целевой матрицы.
МБПП
Сокращение от Mostly Basic Python Problems (В основном простые задачи на Python).
Средняя абсолютная ошибка (MAE)
Средний убыток на пример при использовании функции потерь L1 . Вычислите среднюю абсолютную ошибку следующим образом:
- Рассчитайте потери L1 для партии.
- Разделите значение функции потерь L1 на количество примеров в пакете.
Например, рассмотрим расчет потерь L1 на следующей группе из пяти примеров:
| Фактическая ценность примера | Прогнозируемое значение модели | Убыток (разница между фактическим и прогнозируемым значением) |
|---|---|---|
| 7 | 6 | 1 |
| 5 | 4 | 1 |
| 8 | 11 | 3 |
| 4 | 6 | 2 |
| 9 | 8 | 1 |
| 8 = L 1 потеря | ||
Таким образом, функция потерь L1 равна 8, а количество примеров равно 5. Следовательно, средняя абсолютная ошибка составляет:
Mean Absolute Error = L1 loss / Number of Examples Mean Absolute Error = 8/5 = 1.6
Сравните среднюю абсолютную ошибку со средней квадратичной ошибкой и среднеквадратичной ошибкой .
mean average precision at k (mAP@k)
Среднестатистическое значение всех показателей средней точности при k значениях по всему набору данных для валидации. Один из способов применения средней точности при k — оценка качества рекомендаций, генерируемых рекомендательной системой .
Хотя фраза «среднее арифметическое» звучит избыточно, название метрики вполне уместно. В конце концов, эта метрика вычисляет среднее значение точности множественных усреднений для k значений.
Среднеквадратичная ошибка (MSE)
The average loss per example when L 2 loss is used. Calculate Mean Squared Error as follows:
- Calculate the L 2 loss for a batch.
- Разделите значение функции потерь L2 на количество примеров в пакете.
Например, рассмотрим потери на следующих пяти примерах:
| Фактическая стоимость | Прогноз модели | Потеря | Квадрат убытка |
|---|---|---|---|
| 7 | 6 | 1 | 1 |
| 5 | 4 | 1 | 1 |
| 8 | 11 | 3 | 9 |
| 4 | 6 | 2 | 4 |
| 9 | 8 | 1 | 1 |
| 16 = L 2 потери | |||
Следовательно, среднеквадратичная ошибка составляет:
Mean Squared Error = L2 loss / Number of Examples Mean Squared Error = 16/5 = 3.2
Среднеквадратичная ошибка (Mean Squared Error) — популярный оптимизатор обучения, особенно для линейной регрессии .
Сравните среднеквадратичную ошибку со средней абсолютной ошибкой и среднеквадратичной ошибкой .
TensorFlow Playground использует среднеквадратичную ошибку для расчета значений функции потерь.
сетка
В параллельном программировании в машинном обучении это термин, связанный с распределением данных и модели по чипам TPU и определением того, как эти значения будут сегментированы или реплицированы.
Термин «сетка» является перегруженным и может означать любое из следующих:
- Физическая компоновка микросхем TPU.
- Абстрактная логическая конструкция для сопоставления данных и модели с микросхемами TPU.
В любом случае, сетка задается в виде формы .
meta-learning
Мета-обучение — это подмножество машинного обучения, которое занимается открытием или улучшением алгоритмов обучения. Система мета-обучения также может быть направлена на обучение модели быстрому освоению новой задачи на основе небольшого объема данных или опыта, полученного в предыдущих задачах. Алгоритмы мета-обучения, как правило, стремятся к достижению следующих целей:
- Улучшите или изучите функции, разработанные вручную (например, инициализатор или оптимизатор).
- Повышайте эффективность использования данных и вычислительных ресурсов.
- Улучшить обобщающую способность.
Метаобучение связано с обучением на небольшом количестве примеров .
метрика
Статистические данные, которые вас волнуют.
Цель — это показатель, который система машинного обучения пытается оптимизировать.
Metrics API (tf.metrics)
A TensorFlow API for evaluating models. For example, tf.metrics.accuracy determines how often a model's predictions match labels.
мини-партия
Небольшое, случайно выбранное подмножество из пакета, обрабатываемого за одну итерацию . Размер мини-пакета обычно составляет от 10 до 1000 примеров.
Например, предположим, что весь обучающий набор (полный пакет) состоит из 1000 примеров. Далее предположим, что вы установили размер каждого мини-пакета равным 20. Таким образом, на каждой итерации функция потерь определяется на случайных 20 из 1000 примеров, а затем соответствующим образом корректируются веса и смещения .
Рассчитать потери по мини-пакету данных гораздо эффективнее, чем по всем примерам в полном пакете.
Дополнительную информацию см. в статье «Линейная регрессия: гиперпараметры в машинном обучении» (краткий курс).
мини-пакетный стохастический градиентный спуск
Алгоритм градиентного спуска , использующий мини-пакеты . Другими словами, стохастический градиентный спуск с использованием мини-пакетов оценивает градиент на основе небольшого подмножества обучающих данных. Обычный стохастический градиентный спуск использует мини-пакет размером 1.
минимакс потери
Функция потерь для генеративных состязательных сетей , основанная на кросс-энтропии между распределением сгенерированных данных и реальных данных.
В первой статье для описания генеративных состязательных сетей используется функция минимаксных потерь.
Дополнительную информацию см. в разделе «Функции потерь» курса «Генеративные состязательные сети».
класс меньшинства
Менее распространенная метка в наборе данных с несбалансированным распределением классов . Например, если набор данных содержит 99% отрицательных меток и 1% положительных меток, то положительные метки составляют минорный класс.
В отличие от большинства .
Дополнительную информацию см. в разделе «Наборы данных: Несбалансированные наборы данных» в кратком курсе по машинному обучению.
смесь экспертов
Схема повышения эффективности нейронной сети путем использования только подмножества ее параметров (известного как эксперт ) для обработки заданного входного токена или примера . Сеть-управляющий направляет каждый входной токен или пример к соответствующему эксперту (экспертам).
Более подробную информацию можно найти в одной из следующих статей:
- Невероятно большие нейронные сети: слой разреженно управляемой смеси экспертов.
- Маршрутизация с использованием комбинации экспертов и выбора эксперта
ML
Сокращение от machine learning (машинное обучение) .
ММИТ
Сокращение от multimodal instruction-tuned (мультимодальная настройка инструкций) .
МНИСТ
Общедоступный набор данных, составленный ЛеКуном, Кортесом и Берджесом, содержит 60 000 изображений, каждое из которых показывает, как человек вручную написал определенную цифру от 0 до 9. Каждое изображение хранится в виде массива целых чисел размером 28x28, где каждое целое число представляет собой значение оттенков серого от 0 до 255 включительно.
MNIST — это канонический набор данных для машинного обучения, часто используемый для тестирования новых подходов к машинному обучению. Подробнее см. в разделе «База данных рукописных цифр MNIST» .
модальность
Категория данных высокого уровня. Например, числа, текст, изображения, видео и аудио — это пять различных типов данных.
модель
В общем, модель — это любая математическая конструкция, которая обрабатывает входные данные и возвращает выходные. Иными словами, модель — это набор параметров и структура, необходимые системе для прогнозирования. В контролируемом машинном обучении модель принимает пример в качестве входных данных и выводит прогноз в качестве выходных данных. В рамках контролируемого машинного обучения модели несколько различаются. Например:
- Модель линейной регрессии состоит из набора весов и смещения .
- Модель нейронной сети состоит из:
- Набор скрытых слоев , каждый из которых содержит один или несколько нейронов .
- Весовые коэффициенты и смещения, связанные с каждым нейроном.
- Модель дерева решений состоит из:
- Форма дерева, то есть схема, по которой условия и листья связаны между собой.
- Условия и отпуска.
Вы можете сохранять, восстанавливать или создавать копии модели.
В машинном обучении без учителя также создаются модели, как правило, функция, которая может сопоставить входной пример с наиболее подходящим кластером .
модельная емкость
Сложность задач, которые может изучить модель. Чем сложнее задачи, которые может изучить модель, тем выше её возможности. Возможности модели обычно увеличиваются с увеличением количества параметров модели. Формальное определение возможностей модели классификации см. в разделе «Размерность VC» .
каскадирование моделей
Система, которая выбирает идеальную модель для конкретного запроса на вывод.
Представьте себе группу моделей, от очень больших (много параметров ) до гораздо меньших (значительно меньше параметров). Очень большие модели потребляют больше вычислительных ресурсов во время вывода , чем меньшие модели. Однако очень большие модели, как правило, могут выполнять более сложные запросы, чем меньшие. Каскадирование моделей определяет сложность запроса на вывод, а затем выбирает подходящую модель для выполнения вывода. Основная цель каскадирования моделей — снижение затрат на вывод за счет, как правило, выбора меньших моделей и выбора более крупной модели только для более сложных запросов.
Imagine that a small model runs on a phone and a larger version of that model runs on a remote server. Good model cascading reduces cost and latency by enabling the smaller model to handle simple requests and only calling the remote model to handle complex requests.
См. также модель маршрутизатора .
модельный параллелизм
Способ масштабирования обучения или вывода, при котором различные части одной модели размещаются на разных устройствах . Параллельная обработка моделей позволяет создавать модели, которые слишком велики, чтобы поместиться на одном устройстве.
Для реализации параллельной обработки моделей система обычно выполняет следующие действия:
- Разделяет модель на более мелкие части.
- Распределяет обучение этих более мелких частей между несколькими процессорами. Каждый процессор обучает свою собственную часть модели.
- Объединяет результаты для создания единой модели.
Параллельная обработка моделей замедляет обучение.
См. также параллелизм данных .
модель маршрутизатора
Алгоритм, определяющий идеальную модель для вывода в каскадном построении моделей . Маршрутизатор моделей сам по себе обычно представляет собой модель машинного обучения, которая постепенно учится выбирать наилучшую модель для заданных входных данных. Однако иногда маршрутизатор моделей может быть более простым алгоритмом, не относящимся к машинному обучению.
обучение модели
Процесс определения наилучшей модели .
МОЭ
Сокращение от "смешанная группа экспертов" .
Импульс
Сложный алгоритм градиентного спуска, в котором шаг обучения зависит не только от производной на текущем шаге, но и от производных шагов, непосредственно предшествовавших ему. Импульс включает вычисление экспоненциально взвешенного скользящего среднего градиентов во времени, аналогично импульсу в физике. Импульс иногда предотвращает застревание процесса обучения в локальных минимумах.
Задачи по базовому Python (MBPP)
Набор данных для оценки уровня владения программой LLM навыками написания кода на Python. В наборе данных Mostly Basic Python Problems содержится около 1000 задач по программированию, созданных пользователями. Каждая задача в наборе данных включает в себя:
- Описание задачи
- Код решения
- Three automated test cases
МТ
Сокращение для машинного перевода .
multi-class classification
В контролируемом обучении это задача классификации , в которой набор данных содержит более двух классов меток. Например, метки в наборе данных Iris должны принадлежать к одному из следующих трех классов:
- Ирис сетоза
- Iris virginica
- Iris versicolor
Модель, обученная на наборе данных Iris и предсказывающая тип ириса на новых примерах, выполняет многоклассовую классификацию.
В отличие от этого, задачи классификации, которые различают ровно два класса, представляют собой модели бинарной классификации . Например, модель электронной почты, которая предсказывает либо спам , либо не спам, является моделью бинарной классификации.
В задачах кластеризации многоклассовая классификация подразумевает наличие более двух кластеров.
Дополнительную информацию см. в разделе «Нейронные сети: многоклассовая классификация» в кратком курсе по машинному обучению.
многоклассовая логистическая регрессия
Применение логистической регрессии в задачах многоклассовой классификации .
многоголовочное самовнимание
Расширение механизма самовнимания , которое применяет этот механизм несколько раз для каждой позиции во входной последовательности.
В фильме «Трансформеры» впервые была представлена технология самовнимания для нескольких голов.
многомодальные инструкции, настроенные
Модель , оптимизированная под конкретные инструкции , способная обрабатывать не только текстовые данные, но и изображения, видео и аудио.
мультимодальная модель
Модель, входные данные, выходные данные или и то, и другое которой включают более одной модальности . Например, рассмотрим модель, которая принимает в качестве признаков как изображение, так и текстовую подпись (две модальности) и выдает оценку, указывающую на то, насколько текстовая подпись соответствует изображению. Таким образом, входные данные этой модели являются мультимодальными, а выходные — унимодальными.
многономиальная классификация
Синоним для многоклассовой классификации .
многомерная регрессия
Синоним для многоклассовой логистической регрессии .
Multi-sentence Reading Comprehension (MultiRC)
Набор данных для оценки способности студентов магистратуры решать задачи с множественным выбором. Каждый пример в наборе данных содержит:
- Контекстный абзац
- Вопрос по поводу этого абзаца.
- На вопрос можно дать несколько ответов. Каждый ответ помечен как «Верно» или «Неверно». Несколько ответов могут быть верными.
Например:
Контекстный абзац :
Сьюзен хотела устроить вечеринку в честь своего дня рождения. Она позвонила всем своим друзьям. У неё пять подруг. Мама сказала, что Сьюзен может пригласить их всех на вечеринку. Первая подруга не смогла пойти, потому что заболела. Вторая подруга уезжала из города. Третья подруга не была уверена, разрешат ли ей родители. Четвёртая сказала, что, возможно, да. Пятая подруга точно могла пойти на вечеринку. Сьюзен немного расстроилась. В день вечеринки все пять подруг пришли. У каждой подруги был подарок для Сьюзен. Сьюзен была счастлива и на следующей неделе отправила каждой подруге благодарственную открытку.
Вопрос : Выздоровела ли больная подруга Сьюзен?
Несколько вариантов ответа :
- Да, она выздоровела. (Верно)
- Нет. (Ложно)
- Да. (Верно)
- Нет, она не выздоровела. (Неверно)
- Да, она была на вечеринке у Сьюзен. (Верно)
MultiRC является компонентом комплекса SuperGLUE .
Подробнее см. в статье «Заглядывая за поверхность: задание на развитие навыков понимания прочитанного текста, состоящего из нескольких предложений» .
многозадачность
Метод машинного обучения, при котором одна модель обучается выполнению нескольких задач .
Многозадачные модели создаются путем обучения на данных, подходящих для каждой из различных задач. Это позволяет модели научиться обмениваться информацией между задачами, что способствует более эффективному обучению.
Модель, обученная для решения нескольких задач, часто обладает улучшенными обобщающими способностями и может быть более устойчивой к обработке различных типов данных.
Н
Нано
Относительно компактная модель Gemini , предназначенная для использования непосредственно на устройстве. Подробнее см. Gemini Nano .
NaN trap
Когда одно число в вашей модели становится NaN во время обучения, это приводит к тому, что многие или все остальные числа в вашей модели в конечном итоге становятся NaN.
NaN is an abbreviation for N ot a N umber.
обработка естественного языка
Область обучения компьютеров обработке слов или текста пользователя с использованием лингвистических правил. Практически вся современная обработка естественного языка основана на машинном обучении.понимание естественного языка
Подмножество обработки естественного языка , определяющее намерения сказанного или набранного. Понимание естественного языка может выходить за рамки обработки естественного языка и учитывать сложные аспекты языка, такие как контекст, сарказм и эмоциональная составляющая.
отрицательный класс
В бинарной классификации один класс называется положительным , а другой — отрицательным . Положительный класс — это то, что модель проверяет, а отрицательный класс — это другая возможность. Например:
- В медицинском тесте отрицательный результат может означать «не опухоль».
- В модели классификации электронных писем отрицательным классом может быть «не спам».
В отличие от позитивного класса .
отрицательная выборка
Синоним для отбора кандидатов .
Поиск нейронной архитектуры (NAS)
Метод автоматического проектирования архитектуры нейронной сети . Алгоритмы NAS позволяют сократить время и ресурсы, необходимые для обучения нейронной сети.
В системах NAS обычно используются:
- Пространство поиска — это набор возможных архитектур.
- Функция пригодности — это мера того, насколько хорошо конкретная архитектура справляется с заданной задачей.
Алгоритмы NAS часто начинаются с небольшого набора возможных архитектур и постепенно расширяют пространство поиска по мере того, как алгоритм узнает больше об эффективных архитектурах. Функция пригодности обычно основана на производительности архитектуры на обучающем наборе данных, а обучение алгоритма, как правило, осуществляется с использованием метода обучения с подкреплением .
Алгоритмы NAS доказали свою эффективность в поиске высокопроизводительных архитектур для решения различных задач, включая классификацию изображений, классификацию текста и машинный перевод .
нейронная сеть
A model containing at least one hidden layer . A deep neural network is a type of neural network containing more than one hidden layer. For example, the following diagram shows a deep neural network containing two hidden layers.
Each neuron in a neural network connects to all of the nodes in the next layer. For example, in the preceding diagram, notice that each of the three neurons in the first hidden layer separately connect to both of the two neurons in the second hidden layer.
Neural networks implemented on computers are sometimes called artificial neural networks to differentiate them from neural networks found in brains and other nervous systems.
Some neural networks can mimic extremely complex nonlinear relationships between different features and the label.
See also convolutional neural network and recurrent neural network .
See Neural networks in Machine Learning Crash Course for more information.
нейрон
In machine learning, a distinct unit within a hidden layer of a neural network . Each neuron performs the following two-step action:
- Calculates the weighted sum of input values multiplied by their corresponding weights.
- Passes the weighted sum as input to an activation function .
A neuron in the first hidden layer accepts inputs from the feature values in the input layer . A neuron in any hidden layer beyond the first accepts inputs from the neurons in the preceding hidden layer. For example, a neuron in the second hidden layer accepts inputs from the neurons in the first hidden layer.
The following illustration highlights two neurons and their inputs.
A neuron in a neural network mimics the behavior of neurons in brains and other parts of nervous systems.
N-грамма
An ordered sequence of N words. For example, truly madly is a 2-gram. Because order is relevant, madly truly is a different 2-gram than truly madly .
| Н | Name(s) for this kind of N-gram | Примеры |
|---|---|---|
| 2 | bigram or 2-gram | to go, go to, eat lunch, eat dinner |
| 3 | trigram or 3-gram | ate too much, happily ever after, the bell tolls |
| 4 | 4-gram | walk in the park, dust in the wind, the boy ate lentils |
Many natural language understanding models rely on N-grams to predict the next word that the user will type or say. For example, suppose a user typed happily ever . An NLU model based on trigrams would likely predict that the user will next type the word after .
Contrast N-grams with bag of words , which are unordered sets of words.
See Large language models in Machine Learning Crash Course for more information.
НЛП
Abbreviation for natural language processing .
НЛУ
Abbreviation for natural language understanding .
node (decision tree)
In a decision tree , any condition or leaf .
See Decision Trees in the Decision Forests course for more information.
node (neural network)
A neuron in a hidden layer .
See Neural Networks in Machine Learning Crash Course for more information.
node (TensorFlow graph)
An operation in a TensorFlow graph .
шум
Broadly speaking, anything that obscures the signal in a dataset. Noise can be introduced into data in a variety of ways. For example:
- Human raters make mistakes in labeling.
- Humans and instruments mis-record or omit feature values.
non-binary condition
A condition containing more than two possible outcomes. For example, the following non-binary condition contains three possible outcomes:
Дополнительную информацию см. в разделе «Типы условий» курса «Лесные модели принятия решений».
нелинейный
A relationship between two or more variables that can't be represented solely through addition and multiplication. A linear relationship can be represented as a line; a nonlinear relationship can't be represented as a line. For example, consider two models that each relate a single feature to a single label. The model on the left is linear and the model on the right is nonlinear:
See Neural networks: Nodes and hidden layers in Machine Learning Crash Course to experiment with different kinds of nonlinear functions.
смещение, вызванное отсутствием ответа
See selection bias .
нестационарность
A feature whose values change across one or more dimensions, usually time. For example, consider the following examples of nonstationarity:
- The number of swimsuits sold at a particular store varies with the season.
- The quantity of a particular fruit harvested in a particular region is zero for much of the year but large for a brief period.
- Due to climate change, annual mean temperatures are shifting.
Contrast with stationarity .
no one right answer (NORA)
A prompt having multiple correct responses . For example, the following prompt has no one right answer:
Tell me a funny joke about elephants.
Evaluating the responses to no one right answer prompts is usually far more subjective than evaluating prompts with one right answer . For example, evaluating an elephant joke requires a systematic way to determine how funny the joke is.
НОРА
Abbreviation for no one right answer .
нормализация
Broadly speaking, the process of converting a variable's actual range of values into a standard range of values, such as:
- от -1 до +1
- от 0 до 1
- Z-scores (roughly, -3 to +3)
For example, suppose the actual range of values of a certain feature is 800 to 2,400. As part of feature engineering , you could normalize the actual values down to a standard range, such as -1 to +1.
Normalization is a common task in feature engineering . Models usually train faster (and produce better predictions) when every numerical feature in the feature vector has roughly the same range.
See also Z-score normalization .
See Numerical Data: Normalization in Machine Learning Crash Course for more information.
Блокнот LM
A Gemini-based tool that enables users to upload documents and then use prompts to ask questions about, summarize, or organize those documents. For example, an author could upload several short stories and ask Notebook LM to find their common themes or to identify which one would make the best movie.
novelty detection
The process of determining whether a new (novel) example comes from the same distribution as the training set . In other words, after training on the training set, novelty detection determines whether a new example (during inference or during additional training) is an outlier .
Contrast with outlier detection .
числовые данные
Features represented as integers or real-valued numbers. For example, a house valuation model would probably represent the size of a house (in square feet or square meters) as numerical data. Representing a feature as numerical data indicates that the feature's values have a mathematical relationship to the label. That is, the number of square meters in a house probably has some mathematical relationship to the value of the house.
Not all integer data should be represented as numerical data. For example, postal codes in some parts of the world are integers; however, integer postal codes shouldn't be represented as numerical data in models. That's because a postal code of 20000 is not twice (or half) as potent as a postal code of 10000. Furthermore, although different postal codes do correlate to different real estate values, we can't assume that real estate values at postal code 20000 are twice as valuable as real estate values at postal code 10000. Postal codes should be represented as categorical data instead.
Numerical features are sometimes called continuous features .
Дополнительную информацию см. в разделе «Работа с числовыми данными» в кратком курсе по машинному обучению.
NumPy
An open-source math library that provides efficient array operations in Python. pandas is built on NumPy.
О
цель
A metric that your algorithm is trying to optimize.
целевая функция
The mathematical formula or metric that a model aims to optimize. For example, the objective function for linear regression is usually Mean Squared Loss . Therefore, when training a linear regression model, training aims to minimize Mean Squared Loss.
In some cases, the goal is to maximize the objective function. For example, if the objective function is accuracy, the goal is to maximize accuracy.
See also loss .
oblique condition
In a decision tree , a condition that involves more than one feature . For example, if height and width are both features, then the following is an oblique condition:
height > width
Contrast with axis-aligned condition .
Дополнительную информацию см. в разделе «Типы условий» курса «Лесные модели принятия решений».
офлайн
Synonym for static .
offline inference
The process of a model generating a batch of predictions and then caching (saving) those predictions. Apps can then access the inferred prediction from the cache rather than rerunning the model.
For example, consider a model that generates local weather forecasts (predictions) once every four hours. After each model run, the system caches all the local weather forecasts. Weather apps retrieve the forecasts from the cache.
Offline inference is also called static inference .
Contrast with online inference . See Production ML systems: Static versus dynamic inference in Machine Learning Crash Course for more information.
one-hot encoding
Representing categorical data as a vector in which:
- One element is set to 1.
- All other elements are set to 0.
One-hot encoding is commonly used to represent strings or identifiers that have a finite set of possible values. For example, suppose a certain categorical feature named Scandinavia has five possible values:
- "Дания"
- "Швеция"
- "Норвегия"
- "Финляндия"
- "Исландия"
One-hot encoding could represent each of the five values as follows:
| Страна | Вектор | ||||
|---|---|---|---|---|---|
| "Дания" | 1 | 0 | 0 | 0 | 0 |
| "Швеция" | 0 | 1 | 0 | 0 | 0 |
| "Норвегия" | 0 | 0 | 1 | 0 | 0 |
| "Финляндия" | 0 | 0 | 0 | 1 | 0 |
| "Исландия" | 0 | 0 | 0 | 0 | 1 |
Thanks to one-hot encoding, a model can learn different connections based on each of the five countries.
Representing a feature as numerical data is an alternative to one-hot encoding. Unfortunately, representing the Scandinavian countries numerically is not a good choice. For example, consider the following numeric representation:
- "Denmark" is 0
- "Sweden" is 1
- "Norway" is 2
- "Finland" is 3
- "Iceland" is 4
With numeric encoding, a model would interpret the raw numbers mathematically and would try to train on those numbers. However, Iceland isn't actually twice as much (or half as much) of something as Norway, so the model would come to some strange conclusions.
Дополнительную информацию см. в разделе «Категориальные данные: словарь и one-hot кодирование» в «Кратком курсе по машинному обучению».
one right answer (ORA)
A prompt having a single correct response . For example, consider the following prompt:
True or false: Saturn is bigger than Mars.
The only correct response is true .
Contrast with no one right answer .
one-shot learning
A machine learning approach, often used for object classification, designed to learn effective classification model from a single training example.
See also few-shot learning and zero-shot learning .
одноразовая подсказка
A prompt that contains one example demonstrating how the large language model should respond. For example, the following prompt contains one example showing a large language model how it should answer a query.
| Части одного задания | Примечания |
|---|---|
| Какая официальная валюта указанной страны? | Вопрос, на который вы хотите получить ответ в рамках программы LLM. |
| France: EUR | Один пример. |
| Индия: | Сам запрос. |
Compare and contrast one-shot prompting with the following terms:
one-vs.-all
Given a classification problem with N classes, a solution consisting of N separate binary classification model—one binary classification model for each possible outcome. For example, given a model that classifies examples as animal, vegetable, or mineral, a one-vs.-all solution would provide the following three separate binary classification models:
- animal versus not animal
- vegetable versus not vegetable
- mineral versus not mineral
онлайн
Synonym for dynamic .
online inference
Generating predictions on demand. For example, suppose an app passes input to a model and issues a request for a prediction. A system using online inference responds to the request by running the model (and returning the prediction to the app).
Contrast with offline inference .
See Production ML systems: Static versus dynamic inference in Machine Learning Crash Course for more information.
operation (op)
In TensorFlow, any procedure that creates, manipulates, or destroys a Tensor . For example, a matrix multiply is an operation that takes two Tensors as input and generates one Tensor as output.
Оптакс
A gradient processing and optimization library for JAX . Optax facilitates research by providing building blocks that can be recombined in custom ways to optimize parametric models such as deep neural networks. Other goals include:
- Providing readable, well-tested, efficient implementations of core components.
- Improving productivity by making it possible to combine low level ingredients into custom optimizers (or other gradient processing components).
- Accelerating adoption of new ideas by making it easy for anyone to contribute.
оптимизатор
A specific implementation of the gradient descent algorithm. Popular optimizers include:
- AdaGrad , which stands for ADAptive GRADient descent.
- Adam, which stands for ADAptive with Momentum.
ОРА
Abbreviation for one right answer .
смещение однородности внешней группы
The tendency to see out-group members as more alike than in-group members when comparing attitudes, values, personality traits, and other characteristics. In-group refers to people you interact with regularly; out-group refers to people you don't interact with regularly. If you create a dataset by asking people to provide attributes about out-groups, those attributes may be less nuanced and more stereotyped than attributes that participants list for people in their in-group.
For example, Lilliputians might describe the houses of other Lilliputians in great detail, citing small differences in architectural styles, windows, doors, and sizes. However, the same Lilliputians might simply declare that Brobdingnagians all live in identical houses.
Out-group homogeneity bias is a form of group attribution bias .
See also in-group bias .
outlier detection
The process of identifying outliers in a training set .
Contrast with novelty detection .
выбросы
Values distant from most other values. In machine learning, any of the following are outliers:
- Input data whose values are more than roughly 3 standard deviations from the mean.
- Weights with high absolute values.
- Predicted values relatively far away from the actual values.
For example, suppose that widget-price is a feature of a certain model. Assume that the mean widget-price is 7 Euros with a standard deviation of 1 Euro. Examples containing a widget-price of 12 Euros or 2 Euros would therefore be considered outliers because each of those prices is five standard deviations from the mean.
Выбросы часто возникают из-за опечаток или других ошибок ввода. В других случаях выбросы не являются ошибками; в конце концов, значения, отклоняющиеся от среднего на пять стандартных отклонений, встречаются редко, но отнюдь не исключены.
Выбросы часто создают проблемы при обучении модели. Отсечение — один из способов управления выбросами.
Дополнительную информацию см. в разделе «Работа с числовыми данными» в кратком курсе по машинному обучению.
Оценка результатов вне выгрузки (OOB-оценка)
Механизм оценки качества дерева решений путем проверки каждого дерева решений на примерах , не использованных во время его обучения . Например, на следующей диаграмме обратите внимание, что система обучает каждое дерево решений примерно на двух третях примеров, а затем оценивает его на оставшейся одной трети примеров.
Вневыборочная оценка (OOB-оценка) — это вычислительно эффективная и консервативная аппроксимация механизма перекрестной проверки . При перекрестной проверке для каждого раунда перекрестной проверки обучается одна модель (например, в 10-кратной перекрестной проверке обучается 10 моделей). При OOB-оценке обучается одна модель. Поскольку при обучении методом бэггинга часть данных из каждого дерева исключается, OOB-оценка может использовать эти данные для аппроксимации перекрестной проверки.
Дополнительную информацию см. в разделе «Вневыборочная оценка» курса «Лесные модели принятия решений».
выходной слой
Финальный слой нейронной сети. Выходной слой содержит предсказание.
На следующем рисунке показана небольшая глубокая нейронная сеть с входным слоем, двумя скрытыми слоями и выходным слоем:
overfitting
Создание модели , которая настолько точно соответствует обучающим данным , что не может делать правильные прогнозы на новых данных.
Регуляризация может уменьшить переобучение. Обучение на большом и разнообразном обучающем наборе данных также может уменьшить переобучение.
Для получения дополнительной информации см. «Краткий курс по переобучению в машинном обучении».
передискретизация
Повторное использование примеров миноритарного класса в наборе данных с несбалансированным распределением классов для создания более сбалансированного обучающего набора .
Например, рассмотрим задачу бинарной классификации , в которой соотношение мажоритарного класса к миноритарному составляет 5000:1. Если набор данных содержит миллион примеров, то в нем будет всего около 200 примеров миноритарного класса, чего может быть недостаточно для эффективного обучения. Чтобы преодолеть этот недостаток, можно многократно использовать эти 200 примеров, что, возможно, позволит получить достаточное количество примеров для полезного обучения.
При использовании метода передискретизации необходимо проявлять осторожность, чтобы избежать переобучения .
Сравните с недовыборкой .
П
упакованные данные
Один из подходов к более эффективному хранению данных.
В упакованных данных информация хранится либо в сжатом формате, либо иным способом, обеспечивающим более эффективный доступ к ней. Упакованные данные минимизируют объем памяти и вычислительных ресурсов, необходимых для доступа к ним, что приводит к более быстрому обучению и более эффективному выводу модели.
Упакованные данные часто используются в сочетании с другими методами, такими как аугментация данных и регуляризация , что еще больше повышает производительность моделей .
Ладонь
Сокращение от Pathways Language Model (языковая модель Pathways) .
панды
API для анализа данных, ориентированный на столбцы, построенный на основе numpy . Многие фреймворки машинного обучения, включая TensorFlow, поддерживают структуры данных pandas в качестве входных данных. Подробности см. в документации pandas .
параметр
Веса и смещения , которые модель изучает в процессе обучения . Например, в модели линейной регрессии параметры состоят из смещения ( b ) и всех весов ( w1 , w2 и так далее) в следующей формуле:
В отличие от этого, гиперпараметры — это значения, которые вы (или сервис настройки гиперпараметров) предоставляете модели. Например, скорость обучения — это гиперпараметр.
параметрически эффективная настройка
Набор методов для более эффективной тонкой настройки большой предварительно обученной языковой модели (PLM) , чем полная тонкая настройка . Параметроэффективная настройка обычно позволяет настроить гораздо меньше параметров , чем полная тонкая настройка, но, как правило, создает большую языковую модель , которая работает так же хорошо (или почти так же хорошо), как большая языковая модель, построенная на основе полной тонкой настройки.
Сравните и сопоставьте параметрически эффективную настройку с помощью:
Параметрически эффективная настройка также известна как параметрически эффективная тонкая настройка .
Сервер параметров (PS)
A job that keeps track of a model's parameters in a distributed setting.
parameter update
The operation of adjusting a model's parameters during training, typically within a single iteration of gradient descent .
частная производная
A derivative in which all but one of the variables is considered a constant. For example, the partial derivative of f(x, y) with respect to x is the derivative of f considered as a function of x alone (that is, keeping y constant). The partial derivative of f with respect to x focuses only on how x is changing and ignores all other variables in the equation.
предвзятость участия
Synonym for non-response bias. See selection bias .
partitioning strategy
The algorithm by which variables are divided across parameter servers .
pass at k (pass@k)
A metric to determine the quality of code (for example, Python) that a large language model generates. More specifically, pass at k tells you the likelihood that at least one generated block of code out of k generated blocks of code will pass all of its unit tests.
Large language models often struggle to generate good code for complex programming problems. Software engineers adapt to this problem by prompting the large language model to generate multiple ( k ) solutions for the same problem. Then, software engineers test each of the solutions against unit tests. The calculation of pass at k depends on the outcome of the unit tests:
- If one or more of those solutions pass the unit test, then the LLM Passes that code generation challenge.
- If none of the solutions pass the unit test, then the LLM Fails that code generation challenge.
The formula for pass at k is as follows:
\[\text{pass at k} = \frac{\text{total number of passes}} {\text{total number of challenges}}\]
In general, higher values of k produce higher pass at k scores; however, higher values of k require more large language model and unit testing resources.
Pathways Language Model (PaLM)
An older model and predecessor to Gemini models .
Пакс
A programming framework designed for training large-scale neural network models so large that they span multiple TPU accelerator chip slices or pods .
Pax is built on Flax , which is built on JAX .
перцептрон
A system (either hardware or software) that takes in one or more input values, runs a function on the weighted sum of the inputs, and computes a single output value. In machine learning, the function is typically nonlinear, such as ReLU , sigmoid , or tanh . For example, the following perceptron relies on the sigmoid function to process three input values:
In the following illustration, the perceptron takes three inputs, each of which is itself modified by a weight before entering the perceptron:
Perceptrons are the neurons in neural networks .
производительность
Overloaded term with the following meanings:
- The standard meaning within software engineering. Namely: How fast (or efficiently) does this piece of software run?
- The meaning within machine learning. Here, performance answers the following question: How correct is this model ? That is, how good are the model's predictions?
permutation variable importances
A type of variable importance that evaluates the increase in the prediction error of a model after permuting the feature's values. Permutation variable importance is a model-independent metric.
недоумение
One measure of how well a model is accomplishing its task. For example, suppose your task is to read the first few letters of a word a user is typing on a phone keyboard, and to offer a list of possible completion words. Perplexity, P, for this task is approximately the number of guesses you need to offer in order for your list to contain the actual word the user is trying to type.
Perplexity is related to cross-entropy as follows:
конвейер
The infrastructure surrounding a machine learning algorithm. A pipeline includes gathering the data, putting the data into training data files, training one or more models, and exporting the models to production.
See ML pipelines in the Managing ML Projects course for more information.
трубопроводная
A form of model parallelism in which a model's processing is divided into consecutive stages and each stage is executed on a different device. While a stage is processing one batch, the preceding stage can work on the next batch.
See also staged training .
pjit
A JAX function that splits code to run across multiple accelerator chips . The user passes a function to pjit, which returns a function that has the equivalent semantics but is compiled into an XLA computation that runs across multiple devices (such as GPUs or TPU cores).
pjit enables users to shard computations without rewriting them by using the SPMD partitioner.
As of March 2023, pjit has been merged with jit . Refer to Distributed arrays and automatic parallelization for more details.
ПЛМ
Abbreviation for pre-trained language model .
pmap
A JAX function that executes copies of an input function on multiple underlying hardware devices (CPUs, GPUs, or TPUs ), with different input values. pmap relies on SPMD .
политика
In reinforcement learning, an agent's probabilistic mapping from states to actions .
объединение
Reducing a matrix (or matrixes) created by an earlier convolutional layer to a smaller matrix. Pooling usually involves taking either the maximum or average value across the pooled area. For example, suppose we have the following 3x3 matrix:
A pooling operation, just like a convolutional operation, divides that matrix into slices and then slides that convolutional operation by strides . For example, suppose the pooling operation divides the convolutional matrix into 2x2 slices with a 1x1 stride. As the following diagram illustrates, four pooling operations take place. Imagine that each pooling operation picks the maximum value of the four in that slice:
Pooling helps enforce translational invariance in the input matrix.
Pooling for vision applications is known more formally as spatial pooling . Time-series applications usually refer to pooling as temporal pooling . Less formally, pooling is often called subsampling or downsampling .
позиционное кодирование
A technique to add information about the position of a token in a sequence to the token's embedding. Transformer models use positional encoding to better understand the relationship between different parts of the sequence.
A common implementation of positional encoding uses a sinusoidal function. (Specifically, the frequency and amplitude of the sinusoidal function are determined by the position of the token in the sequence.) This technique enables a Transformer model to learn to attend to different parts of the sequence based on their position.
позитивный класс
The class you are testing for.
For example, the positive class in a cancer model might be "tumor." The positive class in an email classification model might be "spam."
Contrast with negative class .
постобработка
Adjusting the output of a model after the model has been run. Post-processing can be used to enforce fairness constraints without modifying models themselves.
For example, one might apply post-processing to a binary classification model by setting a classification threshold such that equality of opportunity is maintained for some attribute by checking that the true positive rate is the same for all values of that attribute.
post-trained model
Loosely-defined term that typically refers to a pre-trained model that has gone through some post-processing, such as one or more of the following:
PR AUC (area under the PR curve)
Площадь под интерполированной кривой точности-полноты , полученная путем построения точек (полнота, точность) для различных значений порога классификации .
Практика
Базовая высокопроизводительная библиотека машинного обучения от Pax . Praxis часто называют «библиотекой слоев».
Praxis содержит не только определения класса Layer, но и большинство его вспомогательных компонентов, включая:
- входные данные
- Библиотеки конфигурации (HParam и Fiddle )
- optimizers
Praxis предоставляет определения для класса Model.
точность
Метрика для моделей классификации , которая отвечает на следующий вопрос:
Когда модель предсказывала положительный класс , какой процент предсказаний оказался верным?
Вот формула:
где:
- Истинно положительный результат означает, что модель правильно предсказала положительный класс.
- Ложноположительный результат означает, что модель ошибочно предсказала положительный класс.
Например, предположим, что модель сделала 200 положительных прогнозов. Из этих 200 положительных прогнозов:
- 150 случаев оказались истинно положительными.
- 50 из них оказались ложноположительными результатами.
В этом случае:
Сравните с точностью и запоминанием .
Дополнительную информацию см. в разделе «Классификация: точность, полнота, прецизионность и связанные с ними показатели» в кратком курсе по машинному обучению.
точность при k (precision@k)
Показатель точности при k определяет долю первых k элементов в этом списке, которые являются «релевантными». То есть:
\[\text{precision at k} = \frac{\text{relevant items in first k items of the list}} {\text{k}}\]
Значение k должно быть меньше или равно длине возвращаемого списка. Обратите внимание, что длина возвращаемого списка не учитывается при вычислении.
Релевантность часто бывает субъективной; даже опытные эксперты-оценщики нередко расходятся во мнениях относительно того, какие элементы являются релевантными.
Сравните с:
кривая точности-полноты
Кривая зависимости точности от полноты при различных пороговых значениях классификации .
прогноз
Результат работы модели. Например:
- Модель бинарной классификации предсказывает либо положительный, либо отрицательный класс.
- Прогноз многоклассовой модели соответствует одному классу.
- Результатом прогнозирования с помощью модели линейной регрессии является число.
смещение прогноза
Значение, указывающее, насколько сильно среднее значение прогнозов отличается от среднего значения меток в наборе данных.
Не следует путать с термином «предвзятость» в моделях машинного обучения или с предвзятостью в этике и справедливости .
прогнозирование машинного обучения
Любая стандартная («классическая») система машинного обучения .
Термин «прогностическое машинное обучение» не имеет формального определения. Скорее, этот термин обозначает категорию систем машинного обучения, не основанных на генеративном искусственном интеллекте .
прогнозируемая паритетность
Показатель справедливости , проверяющий, являются ли для данной модели классификации показатели точности эквивалентными для рассматриваемых подгрупп.
Например, модель, предсказывающая поступление в колледж, будет удовлетворять условию паритета прогнозирования по национальности, если ее точность будет одинаковой для лилипутов и бробдингнагцев.
Прогностическая паритетность иногда также называется прогностической паритетностью скорости .
Более подробное обсуждение понятия прогнозируемого равенства см. в разделе «Разъяснение определений справедливости» (раздел 3.2.1).
прогнозируемое паритетное соотношение скоростей
Другое название для прогнозируемой паритеты .
предварительная обработка
Обработка данных перед их использованием для обучения модели. Предварительная обработка может быть как простой, например, удалением слов из английского текстового корпуса, которые не встречаются в английском словаре, так и сложной, например, переформулированием точек данных таким образом, чтобы исключить как можно больше атрибутов, коррелирующих с конфиденциальными атрибутами . Предварительная обработка может помочь соблюсти ограничения справедливости .предварительно обученная модель
Хотя этот термин может относиться к любой обученной модели или обученному вектору встраивания , в настоящее время под предварительно обученной моделью обычно подразумевается обученная большая языковая модель или другая форма обученной модели генеративного искусственного интеллекта .
См. также базовую модель и модель фундамента .
предварительная подготовка
Первоначальное обучение модели на большом наборе данных . Некоторые предварительно обученные модели представляют собой неуклюжие гиганты и, как правило, требуют доработки посредством дополнительного обучения. Например, эксперты по машинному обучению могут предварительно обучить большую языковую модель на огромном текстовом наборе данных, таком как все англоязычные страницы Википедии. После предварительного обучения полученная модель может быть дополнительно доработана с помощью любого из следующих методов:
- дистилляция
- тонкая настройка
- настройка инструкций
- параметрически эффективная настройка
- prompt-tuning
предварительные убеждения
То, во что вы верите относительно данных, прежде чем начать на них обучение. Например, L2- регуляризация основана на предварительном убеждении, что веса должны быть небольшими и нормально распределены вокруг нуля.
Про
Модель Gemini с меньшим количеством параметров , чем Ultra , но большим количеством параметров, чем Nano . Подробнее см. Gemini Pro .
вероятностная регрессионная модель
Модель регрессии , которая использует не только веса для каждого признака , но и неопределенность этих весов. Вероятностная регрессионная модель генерирует прогноз и неопределенность этого прогноза. Например, вероятностная регрессионная модель может дать прогноз 325 со стандартным отклонением 12. Для получения дополнительной информации о вероятностных регрессионных моделях см. этот пример в Colab на tensorflow.org .
функция плотности вероятности
A function that identifies the frequency of data samples having exactly a particular value. When a dataset's values are continuous floating-point numbers, exact matches rarely occur. However, integrating a probability density function from value x to value y yields the expected frequency of data samples between x and y .
Например, рассмотрим нормальное распределение со средним значением 200 и стандартным отклонением 30. Чтобы определить ожидаемую частоту выборок данных, попадающих в диапазон от 211,4 до 218,7, можно проинтегрировать функцию плотности вероятности для нормального распределения в диапазоне от 211,4 до 218,7.
быстрый
Любой текст, введенный в качестве входных данных для большой языковой модели с целью обучить модель определенному поведению. Подсказки могут быть как короткими, например, фразами, так и произвольно длинными (например, весь текст романа). Подсказки делятся на несколько категорий, в том числе и те, которые показаны в следующей таблице:
| Категория подсказки | Пример | Примечания |
|---|---|---|
| Вопрос | С какой скоростью может летать голубь? | |
| Инструкция | Write a funny poem about arbitrage. | Запрос, который просит большую языковую модель выполнить определенное действие. |
| Пример | Translate Markdown code to HTML. For example: Markdown: * list item HTML: <ul> <li>list item</li> </ul> | Первое предложение в этом примере задания — это инструкция. Остальная часть задания — это пример. |
| Роль | Объясните, почему градиентный спуск используется в машинном обучении для подготовки кандидатов наук по физике. | Первая часть предложения — это инструкция; фраза «получить докторскую степень по физике» — это указание на роль. |
| Частичные входные данные для завершения работы модели. | Премьер-министр Соединенного Королевства проживает по адресу: | Частично введенный запрос может либо резко обрываться (как в этом примере), либо заканчиваться подчеркиванием. |
Модель генеративного искусственного интеллекта может отвечать на запрос текстом, кодом, изображениями, встраиваниями , видео… практически чем угодно.
обучение на основе подсказок
Способность некоторых моделей адаптировать свое поведение в ответ на произвольный текстовый ввод ( подсказки ). В типичной парадигме обучения на основе подсказок большая языковая модель реагирует на подсказку, генерируя текст. Например, предположим, пользователь вводит следующую подсказку:
Кратко изложите третий закон движения Ньютона.
Модель, способная к обучению на основе подсказок, не обучается специально отвечать на предыдущую подсказку. Скорее, модель «знает» множество фактов из физики, много об общих правилах языка и много о том, что представляет собой в целом полезные ответы. Этих знаний достаточно, чтобы дать (надеемся) полезный ответ. Дополнительная обратная связь от человека («Этот ответ был слишком сложным» или «Что такое реакция?») позволяет некоторым системам обучения на основе подсказок постепенно повышать полезность своих ответов.
быстрый дизайн
Синоним к слову «оперативное проектирование» .
оперативное проектирование
Искусство создания подсказок , которые вызывают желаемые ответы от большой языковой модели . Разработка подсказок осуществляется людьми. Написание хорошо структурированных подсказок является важной частью обеспечения полезных ответов от большой языковой модели. Разработка подсказок зависит от многих факторов, включая:
- The dataset used to pre-train and possibly fine-tune the large language model.
- Температура и другие параметры декодирования, которые модель использует для генерации ответов.
Оперативное проектирование — синоним оперативного инженерного дела.
Более подробную информацию о написании полезных подсказок можно найти в разделе «Введение в разработку подсказок» .
набор подсказок
Набор подсказок для оценки большой языковой модели . Например, на следующем рисунке показан набор подсказок, состоящий из трех пунктов:
Хорошие наборы подсказок представляют собой достаточно «широкую» коллекцию вопросов, позволяющую тщательно оценить безопасность и полезность большой языковой модели.
См. также набор ответов .
быстрая настройка
Эффективный с точки зрения параметров механизм настройки , который обучается «префиксу», добавляемому системой в начало фактического запроса .
Один из вариантов настройки подсказок — иногда называемый префиксной настройкой — заключается в добавлении префикса к каждому слою . В отличие от этого, большинство методов настройки подсказок добавляют префикс только к входному слою .
прокси (конфиденциальные атрибуты)
Атрибут, используемый в качестве замены конфиденциального атрибута . Например, почтовый индекс человека может использоваться в качестве косвенного показателя его дохода, расы или этнической принадлежности.метки прокси
Данные используются для приблизительной оценки меток, которые отсутствуют непосредственно в наборе данных.
Например, предположим, вам нужно обучить модель для прогнозирования уровня стресса у сотрудников. Ваш набор данных содержит множество прогностических признаков, но не содержит метки с названием «уровень стресса». Не теряя надежды, вы выбираете «производственные травмы» в качестве косвенной метки для уровня стресса. В конце концов, сотрудники, находящиеся в состоянии сильного стресса, попадают в аварии чаще, чем спокойные сотрудники. Или нет? Возможно, количество производственных травм на самом деле увеличивается и уменьшается по нескольким причинам.
В качестве второго примера предположим, что вы хотите , чтобы «Идет ли дождь?» был логической меткой для вашего набора данных, но ваш набор данных не содержит данных о дожде. Если есть фотографии, вы можете использовать изображения людей с зонтами в качестве замещающей метки для вопроса «Идет ли дождь?». Подходит ли эта замещающая метка? Возможно, но в некоторых культурах люди могут чаще носить зонты для защиты от солнца, чем от дождя.
Замещающие метки часто бывают неточными. По возможности выбирайте настоящие метки, а не замещающие. Однако, если настоящая метка отсутствует, выбирайте замещающую метку очень тщательно, отдавая предпочтение наименее неудачному варианту.
Дополнительную информацию см. в разделе «Наборы данных: метки в машинном обучении» (краткий курс).
чистая функция
Функция, выходные данные которой зависят только от входных данных и которая не имеет побочных эффектов. В частности, чистая функция не использует и не изменяет какое-либо глобальное состояние, такое как содержимое файла или значение переменной вне функции.
Чистые функции можно использовать для создания потокобезопасного кода, что полезно при распределении кода модели между несколькими микросхемами ускорителя .
Методы преобразования функций в JAX требуют, чтобы входные функции были чистыми функциями.
В
Q-функция
В обучении с подкреплением функция, которая предсказывает ожидаемую отдачу от совершения действия в определенном состоянии и последующего следования заданной стратегии .
Q-функция также известна как функция ценности состояния и действия .
Q-обучение
В обучении с подкреплением алгоритм, позволяющий агенту изучить оптимальную Q-функцию марковского процесса принятия решений путем применения уравнения Беллмана . Марковский процесс принятия решений моделирует окружающую среду .
квантиль
Каждый сегмент в квантильном разбиении .
квантильное группировка
Распределение значений признака по группам таким образом, чтобы каждая группа содержала одинаковое (или почти одинаковое) количество примеров. Например, на следующем рисунке 44 точки разделены на 4 группы, каждая из которых содержит 11 точек. Для того чтобы каждая группа на рисунке содержала одинаковое количество точек, некоторые группы имеют разную ширину значений x.
Дополнительную информацию см. в разделе «Числовые данные: биннинг в машинном обучении» (краткий курс).
квантование
Перегруженный термин, который может использоваться любым из следующих способов:
- Применение квантильного сегментирования к определенному признаку .
- Преобразование данных в нули и единицы для более быстрого хранения, обучения и вывода результатов. Поскольку булевы данные более устойчивы к шуму и ошибкам, чем другие форматы, квантизация может повысить корректность модели. Методы квантизации включают округление, усечение и группировку .
Уменьшение количества бит, используемых для хранения параметров модели. Например, предположим, что параметры модели хранятся в виде 32-битных чисел с плавающей запятой. Квантование преобразует эти параметры из 32 бит в 4, 8 или 16 бит. Квантование уменьшает следующее:
- Использование вычислительных ресурсов, памяти, дискового пространства и сети.
- Время для вывода предсказания
- Потребление электроэнергии
Однако квантование иногда снижает точность прогнозов модели.
очередь
Операция TensorFlow, реализующая структуру данных "очередь". Обычно используется в операциях ввода-вывода.
Р
ТРЯПКА
Сокращение от "retrieval-augmented generation" (генерация с расширенными возможностями поиска).
случайный лес
Ансамбль деревьев решений , в котором каждое дерево решений обучается с использованием определенного случайного шума, например, методом бэггинга .
Случайные леса — это разновидность решающих лесов .
Дополнительную информацию см. в разделе «Случайный лес» курса «Лесорешения».
случайная политика
В обучении с подкреплением это стратегия , которая выбирает действие случайным образом.
ранг (порядковый номер)
Порядковый номер класса в задаче машинного обучения, которая классифицирует классы от наивысшего к наинизшему. Например, система ранжирования поведения может ранжировать вознаграждения для собаки от наивысшего (стейк) до наинизшего (увядшая капуста).
ранг (тензор)
Количество измерений в тензоре . Например, скаляр имеет ранг 0, вектор — ранг 1, а матрица — ранг 2.
Не следует путать с рангом (порядковым положением) .
рейтинг
Тип обучения с учителем, целью которого является упорядочивание списка элементов.
rater
A human who provides labels for examples . "Annotator" is another name for rater.
See Categorical data: Common issues in Machine Learning Crash Course for more information.
Reading Comprehension with Commonsense Reasoning Dataset (ReCoRD)
A dataset to evaluate an LLM's ability to perform commonsense reasoning. Each example in the dataset contains three components:
- A paragraph or two from a news article
- A query in which one of the entities explicitly or implicitly identified in the passage is masked .
- The answer (the name of the entity that belongs in the mask)
See ReCoRD for an extensive list of examples.
ReCoRD is a component of the SuperGLUE ensemble.
RealToxicityPrompts
A dataset that contains a set of sentence beginnings that might contain toxic content. Use this dataset to evaluate an LLM's ability to generate non-toxic text to complete the sentence. Typically, you use the Perspective API to determine how well the LLM performed at this task.
See RealToxicityPrompts: Evaluating Neural Toxic Degeneration in Language Models for details.
отзывать
Метрика для моделей классификации , которая отвечает на следующий вопрос:
When ground truth was the positive class , what percentage of predictions did the model correctly identify as the positive class?
Вот формула:
\[\text{Recall} = \frac{\text{true positives}} {\text{true positives} + \text{false negatives}} \]
где:
- Истинно положительный результат означает, что модель правильно предсказала положительный класс.
- false negative means that the model mistakenly predicted the negative class .
For instance, suppose your model made 200 predictions on examples for which ground truth was the positive class. Of these 200 predictions:
- 180 were true positives.
- 20 were false negatives.
В этом случае:
\[\text{Recall} = \frac{\text{180}} {\text{180} + \text{20}} = 0.9 \]
See Classification: Accuracy, recall, precision and related metrics for more information.
recall at k (recall@k)
A metric for evaluating systems that output a ranked (ordered) list of items. Recall at k identifies the fraction of relevant items in the first k items in that list out of the total number of relevant items returned.
\[\text{recall at k} = \frac{\text{relevant items in first k items of the list}} {\text{total number of relevant items in the list}}\]
Contrast with precision at k .
Recognizing Textual Entailment (RTE)
A dataset for evaluating an LLM's ability to determine whether a hypothesis can be entailed (logically drawn) from a text passage. Each example in an RTE evaluation consists of three parts:
- A passage, typically from news or Wikipedia articles
- Гипотеза
- The correct answer, which is either:
- True, meaning the hypothesis can be entailed from the passage
- False, meaning the hypothesis can't be entailed from the passage
Например:
- Passage: The Euro is the currency of the European Union.
- Hypothesis: France uses the Euro as currency.
- Entailment: True, because France is part of the European Union.
RTE is a component of the SuperGLUE ensemble.
система рекомендаций
A system that selects for each user a relatively small set of desirable items from a large corpus. For example, a video recommendation system might recommend two videos from a corpus of 100,000 videos, selecting Casablanca and The Philadelphia Story for one user, and Wonder Woman and Black Panther for another. A video recommendation system might base its recommendations on factors such as:
- Movies that similar users have rated or watched.
- Genre, directors, actors, target demographic...
See the Recommendation Systems course for more information.
Записывать
Abbreviation for Reading Comprehension with Commonsense Reasoning Dataset .
Rectified Linear Unit (ReLU)
An activation function with the following behavior:
- If input is negative or zero, then the output is 0.
- If input is positive, then the output is equal to the input.
Например:
- If the input is -3, then the output is 0.
- If the input is +3, then the output is 3.0.
Here is a plot of ReLU:
ReLU is a very popular activation function. Despite its simple behavior, ReLU still enables a neural network to learn nonlinear relationships between features and the label .
рекуррентная нейронная сеть
A neural network that is intentionally run multiple times, where parts of each run feed into the next run. Specifically, hidden layers from the previous run provide part of the input to the same hidden layer in the next run. Recurrent neural networks are particularly useful for evaluating sequences, so that the hidden layers can learn from previous runs of the neural network on earlier parts of the sequence.
For example, the following figure shows a recurrent neural network that runs four times. Notice that the values learned in the hidden layers from the first run become part of the input to the same hidden layers in the second run. Similarly, the values learned in the hidden layer on the second run become part of the input to the same hidden layer in the third run. In this way, the recurrent neural network gradually trains and predicts the meaning of the entire sequence rather than just the meaning of individual words.
справочный текст
An expert's response to a prompt . For example, given the following prompt:
Translate the question "What is your name?" from English to French.
An expert's response might be:
Comment vous appelez-vous?
Various metrics (such as ROUGE ) measure the degree to which the reference text matches an ML model's generated text .
отражение
A strategy for improving the quality of an agentic workflow by examining (reflecting on) a step's output before passing that output to the next step.
The examiner is often the same LLM that generated the response (though it could be a different LLM). How could the same LLM that generated a response be a fair judge of its own response? The "trick" is to put the LLM in a critical (reflective) mindset. This process is analogous to a writer who uses a creative mindset to write a first draft and then switches to a critical mindset to edit it.
For example, imagine an agentic workflow whose first step is to create text for coffee mugs. The prompt for this step might be:
You are a creative. Generate humorous, original text of less than 50 characters suitable for a coffee mug.
Now imagine the following reflective prompt:
You are a coffee drinker. Would you find the preceding response humorous?
The workflow might then only pass text that receives a high reflection score to the next stage.
регрессионная модель
Informally, a model that generates a numerical prediction. (In contrast, a classification model generates a class prediction.) For example, the following are all regression models:
- A model that predicts a certain house's value in Euros, such as 423,000.
- A model that predicts a certain tree's life expectancy in years, such as 23.2.
- A model that predicts the amount of rain in inches that will fall in a certain city over the next six hours, such as 0.18.
Two common types of regression models are:
- Linear regression , which finds the line that best fits label values to features.
- Logistic regression , which generates a probability between 0.0 and 1.0 that a system typically then maps to a class prediction.
Not every model that outputs numerical predictions is a regression model. In some cases, a numeric prediction is really just a classification model that happens to have numeric class names. For example, a model that predicts a numeric postal code is a classification model, not a regression model.
регуляризация
Any mechanism that reduces overfitting . Popular types of regularization include:
- L1- регуляризация
- L2- регуляризация
- dropout regularization
- early stopping (this is not a formal regularization method, but can effectively limit overfitting)
Regularization can also be defined as the penalty on a model's complexity.
See Overfitting: Model complexity in Machine Learning Crash Course for more information.
regularization rate
A number that specifies the relative importance of regularization during training. Raising the regularization rate reduces overfitting but may reduce the model's predictive power. Conversely, reducing or omitting the regularization rate increases overfitting.
Дополнительную информацию см. в разделе «Переобучение: L2-регуляризация» в «Кратком курсе по машинному обучению».
reinforcement learning (RL)
A family of algorithms that learn an optimal policy , whose goal is to maximize return when interacting with an environment . For example, the ultimate reward of most games is victory. Reinforcement learning systems can become expert at playing complex games by evaluating sequences of previous game moves that ultimately led to wins and sequences that ultimately led to losses.
Обучение с подкреплением на основе обратной связи от человека (RLHF)
Using feedback from human raters to improve the quality of a model's responses . For example, an RLHF mechanism can ask users to rate the quality of a model's response with a 👍 or 👎 emoji. The system can then adjust its future responses based on that feedback.
РеЛУ
Abbreviation for Rectified Linear Unit .
replay buffer
In DQN -like algorithms, the memory used by the agent to store state transitions for use in experience replay .
реплика
A copy (or part of) of a training set or model , typically stored on another machine. For example, a system could use the following strategy for implementing data parallelism :
- Place replicas of an existing model on multiple machines.
- Send different subsets of the training set to each replica.
- Aggregate the parameter updates.
A replica can also refer to another copy of an inference server. Increasing the number of replicas increases the number of requests that the system can serve simultaneously but also increases serving costs.
предвзятость в репортажах
The fact that the frequency with which people write about actions, outcomes, or properties is not a reflection of their real-world frequencies or the degree to which a property is characteristic of a class of individuals. Reporting bias can influence the composition of data that machine learning systems learn from.
For example, in books, the word laughed is more prevalent than breathed . A machine learning model that estimates the relative frequency of laughing and breathing from a book corpus would probably determine that laughing is more common than breathing.
Дополнительную информацию см. в разделе «Справедливость: виды предвзятости в экспресс-курсе по машинному обучению».
представление
The process of mapping data to useful features .
re-ranking
The final stage of a recommendation system , during which scored items may be re-graded according to some other (typically, non-ML) algorithm. Re-ranking evaluates the list of items generated by the scoring phase, taking actions such as:
- Eliminating items that the user has already purchased.
- Boosting the score of fresher items.
See Re-ranking in the Recommendation Systems course for more information.
ответ
The text, images, audio, or video that a generative AI model infers . In other words, a prompt is the input to a generative AI model and the response is the output .
response set
The collection of responses a large language model returns to an input prompt set .
Генерация с расширенным извлечением (RAG)
A technique for improving the quality of large language model (LLM) output by grounding it with sources of knowledge retrieved after the model was trained. RAG improves the accuracy of LLM responses by providing the trained LLM with access to information retrieved from trusted knowledge bases or documents.
Common motivations to use retrieval-augmented generation include:
- Increasing the factual accuracy of a model's generated responses.
- Giving the model access to knowledge it was not trained on.
- Changing the knowledge that the model uses.
- Enabling the model to cite sources.
For example, suppose that a chemistry app uses the PaLM API to generate summaries related to user queries. When the app's backend receives a query, the backend:
- Searches for ("retrieves") data that's relevant to the user's query.
- Appends ("augments") the relevant chemistry data to the user's query.
- Instructs the LLM to create a summary based on the appended data.
возвращаться
In reinforcement learning, given a certain policy and a certain state, the return is the sum of all rewards that the agent expects to receive when following the policy from the state to the end of the episode . The agent accounts for the delayed nature of expected rewards by discounting rewards according to the state transitions required to obtain the reward.
Therefore, if the discount factor is \(\gamma\), и \(r_0, \ldots, r_{N}\)denote the rewards until the end of the episode, then the return calculation is as follows:
награда
In reinforcement learning, the numerical result of taking an action in a state , as defined by the environment .
ridge regularization
Synonym for L 2 regularization . The term ridge regularization is more frequently used in pure statistics contexts, whereas L 2 regularization is used more often in machine learning.
RNN
Abbreviation for recurrent neural networks .
ROC (receiver operating characteristic) Curve
A graph of true positive rate versus false positive rate for different classification thresholds in binary classification.
The shape of an ROC curve suggests a binary classification model's ability to separate positive classes from negative classes. Suppose, for example, that a binary classification model perfectly separates all the negative classes from all the positive classes:
The ROC curve for the preceding model looks as follows:
In contrast, the following illustration graphs the raw logistic regression values for a terrible model that can't separate negative classes from positive classes at all:
The ROC curve for this model looks as follows:
Meanwhile, back in the real world, most binary classification models separate positive and negative classes to some degree, but usually not perfectly. So, a typical ROC curve falls somewhere between the two extremes:
The point on an ROC curve closest to (0.0,1.0) theoretically identifies the ideal classification threshold. However, several other real-world issues influence the selection of the ideal classification threshold. For example, perhaps false negatives cause far more pain than false positives.
A numerical metric called AUC summarizes the ROC curve into a single floating-point value.
role prompting
A prompt , typically beginning with the pronoun you , that tells a generative AI model to pretend to be a certain person or a certain role when generating the response . Role prompting can help a generative AI model get into the right "mindset" in order to generate a more useful response. For example, any of the following role prompts might be appropriate depending on the kind of response you are seeking:
You have a PhD in computer science.
You are a software engineer who enjoys giving patient explanations about Python to new programming students.
You are an action hero with a very particular set of programming skills. Assure me that you will find a particular item in a Python list.
корень
The starting node (the first condition ) in a decision tree . By convention, diagrams put the root at the top of the decision tree. For example:
корневой каталог
The directory you specify for hosting subdirectories of the TensorFlow checkpoint and events files of multiple models.
Среднеквадратичная ошибка (RMSE)
The square root of the Mean Squared Error .
rotational invariance
In an image classification problem, an algorithm's ability to successfully classify images even when the orientation of the image changes. For example, the algorithm can still identify a tennis racket whether it is pointing up, sideways, or down. Note that rotational invariance is not always desirable; for example, an upside-down 9 shouldn't be classified as a 9.
See also translational invariance and size invariance .
ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
A family of metrics that evaluate automatic summarization and machine translation models. ROUGE metrics determine the degree to which a reference text overlaps an ML model's generated text . Each member of the ROUGE family measures overlap in a different way. Higher ROUGE scores indicate more similarity between the reference text and generated text than lower ROUGE scores.
Each ROUGE family member typically generates the following metrics:
- Точность
- Отзывать
- Ф 1
For details and examples, see:
РУЖ-Л
A member of the ROUGE family focused on the length of the longest common subsequence in the reference text and generated text . The following formulas calculate recall and precision for ROUGE-L:
You can then use F 1 to roll up ROUGE-L recall and ROUGE-L precision into a single metric:
ROUGE-L ignores any newlines in the reference text and generated text, so the longest common subsequence could cross multiple sentences. When the reference text and generated text involve multiple sentences, a variation of ROUGE-L called ROUGE-Lsum is generally a better metric. ROUGE-Lsum determines the longest common subsequence for each sentence in a passage and then calculates the mean of those longest common subsequences.
ROUGE-N
A set of metrics within the ROUGE family that compares the shared N-grams of a certain size in the reference text and generated text . For example:
- ROUGE-1 measures the number of shared tokens in the reference text and generated text.
- ROUGE-2 measures the number of shared bigrams (2-grams) in the reference text and generated text.
- ROUGE-3 measures the number of shared trigrams (3-grams) in the reference text and generated text.
You can use the following formulas to calculate ROUGE-N recall and ROUGE-N precision for any member of the ROUGE-N family:
You can then use F 1 to roll up ROUGE-N recall and ROUGE-N precision into a single metric:
ROUGE-S
A forgiving form of ROUGE-N that enables skip-gram matching. That is, ROUGE-N only counts N-grams that match exactly , but ROUGE-S also counts N-grams separated by one or more words. For example, consider the following:
- reference text : White clouds
- generated text : White billowing clouds
When calculating ROUGE-N, the 2-gram, White clouds doesn't match White billowing clouds . However, when calculating ROUGE-S, White clouds does match White billowing clouds .
R-squared
A regression metric indicating how much variation in a label is due to an individual feature or to a feature set. R-squared is a value between 0 and 1, which you can interpret as follows:
- An R-squared of 0 means that none of a label's variation is due to the feature set.
- An R-squared of 1 means that all of a label's variation is due to the feature set.
- An R-squared between 0 and 1 indicates the extent to which the label's variation can be predicted from a particular feature or the feature set. For example, an R-squared of 0.10 means that 10 percent of the variance in the label is due to the feature set, an R-squared of 0.20 means that 20 percent is due to the feature set, and so on.
R-squared is the square of the Pearson correlation coefficient between the values that a model predicted and ground truth .
РТЭ
Abbreviation for Recognizing Textual Entailment .
С
смещение выборки
See selection bias .
sampling with replacement
A method of picking items from a set of candidate items in which the same item can be picked multiple times. The phrase "with replacement" means that after each selection, the selected item is returned to the pool of candidate items. The inverse method, sampling without replacement , means that a candidate item can only be picked once.
For example, consider the following fruit set:
fruit = {kiwi, apple, pear, fig, cherry, lime, mango} Suppose that the system randomly picks fig as the first item. If using sampling with replacement, then the system picks the second item from the following set:
fruit = {kiwi, apple, pear, fig, cherry, lime, mango} Yes, that's the same set as before, so the system could potentially pick fig again.
If using sampling without replacement, once picked, a sample can't be picked again. For example, if the system randomly picks fig as the first sample, then fig can't be picked again. Therefore, the system picks the second sample from the following (reduced) set:
fruit = {kiwi, apple, pear, cherry, lime, mango}Сохраненная модель
The recommended format for saving and recovering TensorFlow models. SavedModel is a language-neutral, recoverable serialization format, which enables higher-level systems and tools to produce, consume, and transform TensorFlow models.
See the Saving and Restoring section of the TensorFlow Programmer's Guide for complete details.
Экономия
A TensorFlow object responsible for saving model checkpoints.
скаляр
A single number or a single string that can be represented as a tensor of rank 0. For example, the following lines of code each create one scalar in TensorFlow:
breed = tf.Variable("poodle", tf.string)
temperature = tf.Variable(27, tf.int16)
precision = tf.Variable(0.982375101275, tf.float64)масштабирование
Any mathematical transform or technique that shifts the range of a label, a feature value, or both. Some forms of scaling are very useful for transformations like normalization .
Common forms of scaling useful in Machine Learning include:
- linear scaling, which typically uses a combination of subtraction and division to replace the original value with a number between -1 and +1 or between 0 and 1.
- logarithmic scaling, which replaces the original value with its logarithm.
- Z-score normalization , which replaces the original value with a floating-point value representing the number of standard deviations from that feature's mean.
scikit-learn
A popular open-source machine learning platform. See scikit-learn.org .
подсчет очков
The part of a recommendation system that provides a value or ranking for each item produced by the candidate generation phase.
предвзятость отбора
Errors in conclusions drawn from sampled data due to a selection process that generates systematic differences between samples observed in the data and those not observed. The following forms of selection bias exist:
- coverage bias : The population represented in the dataset doesn't match the population that the machine learning model is making predictions about.
- sampling bias : Data is not collected randomly from the target group.
- non-response bias (also called participation bias ): Users from certain groups opt-out of surveys at different rates than users from other groups.
For example, suppose you are creating a machine learning model that predicts people's enjoyment of a movie. To collect training data, you hand out a survey to everyone in the front row of a theater showing the movie. Offhand, this may sound like a reasonable way to gather a dataset; however, this form of data collection may introduce the following forms of selection bias:
- coverage bias: By sampling from a population who chose to see the movie, your model's predictions may not generalize to people who did not already express that level of interest in the movie.
- Смещение выборки: Вместо случайной выборки из целевой популяции (всех людей, присутствовавших на киносеансе), вы отобрали только людей, сидевших в первом ряду. Возможно, люди, сидевшие в первом ряду, были больше заинтересованы в фильме, чем те, кто сидел в других рядах.
- Смещение, вызванное отказом от участия в опросе: В целом, люди с твердыми убеждениями чаще отвечают на дополнительные опросы, чем люди с умеренными убеждениями. Поскольку опрос о фильмах является необязательным, ответы с большей вероятностью образуют бимодальное распределение, чем нормальное (колоколообразное) распределение.
самовнимание (также называемый слоем самовнимания)
Слой нейронной сети, который преобразует последовательность векторных представлений (например, векторных представлений токенов ) в другую последовательность векторных представлений. Каждое векторное представление в выходной последовательности строится путем интеграции информации из элементов входной последовательности с помощью механизма внимания .
Часть «самовнимание » в механизме самовнимания относится к тому, что последовательность обращает внимание на себя, а не на какой-либо другой контекст. Самовнимание является одним из основных строительных блоков для трансформеров и использует терминологию поиска в словаре, такую как «запрос», «ключ» и «значение».
Слой самовнимания начинается с последовательности входных представлений, по одному для каждого слова. Входное представление слова может представлять собой простое векторное представление (эмбеддинг). Для каждого слова во входной последовательности сеть оценивает релевантность слова каждому элементу во всей последовательности слов. Оценки релевантности определяют, насколько итоговое представление слова включает в себя представления других слов.
Например, рассмотрим следующее предложение:
Животное не перешло улицу, потому что слишком устало.
Следующая иллюстрация (из книги Transformer: A Novel Neural Network Architecture for Language Understanding ) показывает схему внимания слоя самовнимания к местоимению «it» , при этом насыщенность каждой линии указывает на вклад каждого слова в представление:
Слой самовнимания выделяет слова, имеющие отношение к «этому». В данном случае слой внимания научился выделять слова, на которые он может ссылаться, присваивая наибольший вес слову «животное ».
Для последовательности из n токенов механизм самовнимания преобразует последовательность векторных представлений n раз, по одному разу в каждой позиции последовательности.
См. также внимание и многоголовочное самовнимание .
самообучение
A family of techniques for converting an unsupervised machine learning problem into a supervised machine learning problem by creating surrogate labels from unlabeled examples .
Некоторые модели на основе Transformer , такие как BERT, используют самообучение.
Self-supervised training is a semi-supervised learning approach.
самообучение
Вариант самообучения , особенно полезный при выполнении всех следующих условий:
- В наборе данных высокое соотношение немаркированных примеров к маркированным примерам .
- Это задача классификации .
Самообучение работает путем итераций по следующим двум шагам до тех пор, пока модель не перестанет улучшаться:
- Используйте контролируемое машинное обучение для обучения модели на размеченных примерах.
- Используйте модель, созданную на шаге 1, для генерации прогнозов (меток) для немаркированных примеров, перемещая те, в которых есть высокая степень уверенности, в маркированные примеры с прогнозируемой меткой.
Обратите внимание, что на каждой итерации шага 2 добавляется больше размеченных примеров для обучения на шаге 1.
полуконтролируемое обучение
Обучение модели на данных, где некоторые обучающие примеры имеют метки, а другие — нет. Один из методов полуконтролируемого обучения заключается в том, чтобы определить метки для немаркированных примеров, а затем обучить модель на основе этих меток для создания новой модели. Полуконтролируемое обучение может быть полезно, если получение меток обходится дорого, но немаркированных примеров много.
Самостоятельное обучение — это один из методов полуконтролируемого обучения.
чувствительный атрибут
Человеческое качество, которому может быть уделено особое внимание по правовым, этическим, социальным или личным причинам.анализ настроений
Использование статистических алгоритмов или алгоритмов машинного обучения для определения общего отношения группы — положительного или отрицательного — к услуге, продукту, организации или теме. Например, используя понимание естественного языка , алгоритм мог бы провести анализ настроений в текстовых отзывах об университетском курсе, чтобы определить, насколько студентам в целом понравился или не понравился этот курс.
See the Text classification guide for more information.
модель последовательности
Модель, входные данные которой имеют последовательную зависимость. Например, прогнозирование следующего просмотренного видео на основе последовательности ранее просмотренных видео.
задача последовательности
Задача, которая преобразует входную последовательность токенов в выходную последовательность токенов. Например, два популярных типа задач преобразования последовательности в последовательность:
- Переводчики:
- Пример входной последовательности: "Я люблю тебя."
- Пример выходной последовательности: «Я люблю тебя».
- Ответы на вопросы:
- Пример входной последовательности: "Мне нужна машина в Нью-Йорке?"
- Пример выходных данных: "Нет. Оставьте машину дома."
подача
Процесс предоставления обученной модели для прогнозирования посредством онлайн- или офлайн-вывода .
форма (тензор)
Количество элементов в каждом измерении тензора. Форма представляется в виде списка целых чисел. Например, следующий двумерный тензор имеет форму [3,4]:
[[5, 7, 6, 4], [2, 9, 4, 8], [3, 6, 5, 1]]
TensorFlow uses row-major (C-style) format to represent the order of dimensions, which is why the shape in TensorFlow is [3,4] rather than [4,3] . In other words, in a two-dimensional TensorFlow Tensor, the shape is [ number of rows , number of columns ] .
Статическая форма — это форма тензора, известная на этапе компиляции.
A dynamic shape is unknown at compile time and is therefore dependent on runtime data. This tensor might be represented with a placeholder dimension in TensorFlow, as in [3, ?] .
shard
Логическое разделение обучающего набора данных или модели . Как правило, некий процесс создает фрагменты, разделяя примеры или параметры на (обычно) равные по размеру части. Затем каждый фрагмент назначается отдельной машине.
Разделение модели на сегменты называется параллелизмом модели ; разделение данных на сегменты называется параллелизмом данных .
усадка
Гиперпараметр в градиентном бустинге , контролирующий переобучение . Сжатие (shrinkage) в градиентном бустинге аналогично скорости обучения в градиентном спуске . Сжатие — это десятичное значение от 0,0 до 1,0. Меньшее значение сжатия уменьшает переобучение сильнее, чем большее.
сравнительная оценка
Сравнение качества двух моделей путем оценки их ответов на один и тот же вопрос . Например, предположим, что двум разным моделям дается следующий вопрос:
Создайте изображение милой собачки, жонглирующей тремя мячами.
При сравнении изображений эксперт выбирал бы, какое из них «лучше» (более точное? Более красивое? Более симпатичное?).
сигмоидная функция
Математическая функция, которая «сжимает» входное значение в ограниченный диапазон, обычно от 0 до 1 или от -1 до +1. То есть, вы можете передать любое число (два, миллион, минус миллиард и т. д.) в сигмоидную функцию, и выходное значение все равно будет находиться в ограниченном диапазоне. График сигмоидной функции активации выглядит следующим образом:
Сигмоидная функция находит несколько применений в машинном обучении, в том числе:
- Преобразование исходных данных модели логистической регрессии или многомерной регрессии в вероятность.
- Acting as an activation function in some neural networks.
similarity measure
In clustering algorithms, the metric used to determine how alike (how similar) any two examples are.
single program / multiple data (SPMD)
A parallelism technique where the same computation is run on different input data in parallel on different devices. The goal of SPMD is to obtain results more quickly. It is the most common style of parallel programming.
size invariance
In an image classification problem, an algorithm's ability to successfully classify images even when the size of the image changes. For example, the algorithm can still identify a cat whether it consumes 2M pixels or 200K pixels. Note that even the best image classification algorithms still have practical limits on size invariance. For example, an algorithm (or human) is unlikely to correctly classify a cat image consuming only 20 pixels.
See also translational invariance and rotational invariance .
Для получения более подробной информации см. курс «Кластеризация» .
эскизирование
In unsupervised machine learning , a category of algorithms that perform a preliminary similarity analysis on examples. Sketching algorithms use a locality-sensitive hash function to identify points that are likely to be similar, and then group them into buckets.
Sketching decreases the computation required for similarity calculations on large datasets. Instead of calculating similarity for every single pair of examples in the dataset, we calculate similarity only for each pair of points within each bucket.
skip-gram
An n-gram which may omit (or "skip") words from the original context, meaning the N words might not have been originally adjacent. More precisely, a "k-skip-n-gram" is an n-gram for which up to k words may have been skipped.
For example, "the quick brown fox" has the following possible 2-grams:
- "the quick"
- "quick brown"
- "brown fox"
A "1-skip-2-gram" is a pair of words that have at most 1 word between them. Therefore, "the quick brown fox" has the following 1-skip 2-grams:
- "the brown"
- "quick fox"
In addition, all the 2-grams are also 1-skip-2-grams, since fewer than one word may be skipped.
Skip-grams are useful for understanding more of a word's surrounding context. In the example, "fox" was directly associated with "quick" in the set of 1-skip-2-grams, but not in the set of 2-grams.
Skip-grams help train word embedding models.
софтмакс
A function that determines probabilities for each possible class in a multi-class classification model . The probabilities add up to exactly 1.0. For example, the following table shows how softmax distributes various probabilities:
| Image is a... | Вероятность |
|---|---|
| собака | .85 |
| кот | .13 |
| лошадь | .02 |
Softmax is also called full softmax .
Contrast with candidate sampling .
Дополнительную информацию см. в разделе «Нейронные сети: многоклассовая классификация» в кратком курсе по машинному обучению.
soft prompt tuning
A technique for tuning a large language model for a particular task, without resource intensive fine-tuning . Instead of retraining all the weights in the model, soft prompt tuning automatically adjusts a prompt to achieve the same goal.
Given a textual prompt, soft prompt tuning typically appends additional token embeddings to the prompt and uses backpropagation to optimize the input.
A "hard" prompt contains actual tokens instead of token embeddings.
sparse feature
A feature whose values are predominately zero or empty. For example, a feature containing a single 1 value and a million 0 values is sparse. In contrast, a dense feature has values that are predominantly not zero or empty.
In machine learning, a surprising number of features are sparse features. Categorical features are usually sparse features. For example, of the 300 possible tree species in a forest, a single example might identify just a maple tree . Or, of the millions of possible videos in a video library, a single example might identify just "Casablanca."
In a model, you typically represent sparse features with one-hot encoding . If the one-hot encoding is big, you might put an embedding layer on top of the one-hot encoding for greater efficiency.
sparse representation
Storing only the position(s) of nonzero elements in a sparse feature.
For example, suppose a categorical feature named species identifies the 36 tree species in a particular forest. Further assume that each example identifies only a single species.
You could use a one-hot vector to represent the tree species in each example. A one-hot vector would contain a single 1 (to represent the particular tree species in that example) and 35 0 s (to represent the 35 tree species not in that example). So, the one-hot representation of maple might look something like the following:
Alternatively, sparse representation would simply identify the position of the particular species. If maple is at position 24, then the sparse representation of maple would simply be:
24
Notice that the sparse representation is much more compact than the one-hot representation.
Click the icon for a slightly more complex example.
Suppose each example in your model must represent the words—but not the order of those words—in an English sentence. English consists of about 170,000 words, so English is a categorical feature with about 170,000 elements. Most English sentences use an extremely tiny fraction of those 170,000 words, so the set of words in a single example is almost certainly going to be sparse data.
Consider the following sentence:
My dog is a great dog
You could use a variant of one-hot vector to represent the words in this sentence. In this variant, multiple cells in the vector can contain a nonzero value. Furthermore, in this variant, a cell can contain an integer other than one. Although the words "my", "is", "a", and "great" appear only once in the sentence, the word "dog" appears twice. Using this variant of one-hot vectors to represent the words in this sentence yields the following 170,000-element vector:
A sparse representation of the same sentence would simply be:
0: 1 26100: 2 45770: 1 58906: 1 91520: 1
See Working with categorical data in Machine Learning Crash Course for more information.
разреженный вектор
A vector whose values are mostly zeroes. See also sparse feature and sparsity .
разреженность
The number of elements set to zero (or null) in a vector or matrix divided by the total number of entries in that vector or matrix. For example, consider a 100-element matrix in which 98 cells contain zero. The calculation of sparsity is as follows:
Feature sparsity refers to the sparsity of a feature vector; model sparsity refers to the sparsity of the model weights.
spatial pooling
См. раздел "Объединение" .
спецификация кодирования
The process of writing and maintaining a file in a human language (for example, English) that describes software. You can then tell a generative AI model or another software engineer to create the software that fulfills that description.
Automatically-generated code generally requires iteration. In specificational coding, you iterate on the description file. By contrast, in conversational coding , you iterate within the prompt box. In practice, automatic code generation sometimes involves a combination of both specificational coding and conversational coding.
расколоть
In a decision tree , another name for a condition .
разветвитель
While training a decision tree , the routine (and algorithm) responsible for finding the best condition at each node .
СПМД
Abbreviation for single program / multiple data .
Отряд
Acronym for Stanford Question Answering Dataset , introduced in the paper SQuAD: 100,000+ Questions for Machine Comprehension of Text . The questions in this dataset come from people posing questions about Wikipedia articles. Some of the questions in SQuAD have answers, but other questions intentionally don't have answers. Therefore, you can use SQuAD to evaluate an LLM's ability to do both of the following:
- Answer questions that can be answered.
- Identify questions that cannot be answered.
Exact match in combination with F 1 are the most common metrics for evaluating LLMs against SQuAD.
squared hinge loss
The square of the hinge loss . Squared hinge loss penalizes outliers more harshly than regular hinge loss.
squared loss
Synonym for L 2 loss .
staged training
A tactic of training a model in a sequence of discrete stages. The goal can be either to speed up the training process, or to achieve better model quality.
An illustration of the progressive stacking approach is shown below:
- Stage 1 contains 3 hidden layers, stage 2 contains 6 hidden layers, and stage 3 contains 12 hidden layers.
- Stage 2 begins training with the weights learned in the 3 hidden layers of Stage 1. Stage 3 begins training with the weights learned in the 6 hidden layers of Stage 2.
See also pipelining .
состояние
In reinforcement learning, the parameter values that describe the current configuration of the environment, which the agent uses to choose an action .
state-action value function
Synonym for Q-function .
статический
Something done once rather than continuously. The terms static and offline are synonyms. The following are common uses of static and offline in machine learning:
- static model (or offline model ) is a model trained once and then used for a while.
- static training (or offline training ) is the process of training a static model.
- static inference (or offline inference ) is a process in which a model generates a batch of predictions at a time.
Contrast with dynamic .
static inference
Synonym for offline inference .
stationarity
A feature whose values don't change across one or more dimensions, usually time. For example, a feature whose values look about the same in 2021 and 2023 exhibits stationarity.
В реальном мире лишь немногие характеристики демонстрируют стационарность. Даже характеристики, синонимичные стабильности (например, уровень моря), меняются со временем.
В отличие от нестационарности .
шаг
A forward pass and backward pass of one batch .
Дополнительную информацию о прямом и обратном проходах см. в разделе «Обратное распространение ошибки ».
размер шага
Синоним к слову «скорость обучения» .
стохастический градиентный спуск (SGD)
A gradient descent algorithm in which the batch size is one. In other words, SGD trains on a single example chosen uniformly at random from a training set .
Дополнительную информацию см. в статье «Линейная регрессия: гиперпараметры в машинном обучении» (краткий курс).
шаг
В операции свертки или пулинга разница в каждом измерении следующей серии входных срезов. Например, следующая анимация демонстрирует шаг (1,1) во время операции свертки. Следовательно, следующий входной срез начинается на одну позицию правее предыдущего входного среза. Когда операция достигает правого края, следующий срез находится полностью слева, но на одну позицию ниже.
Приведенный выше пример демонстрирует двумерный шаг. Если входная матрица трехмерная, то и шаг будет трехмерным.
минимизация структурных рисков (SRM)
Алгоритм, который уравновешивает две цели:
- Необходимость построения наиболее прогностической модели (например, с наименьшими потерями).
- Необходимость максимально упростить модель (например, использовать строгую регуляризацию).
Например, функция, которая минимизирует потери + регуляризацию на обучающем наборе данных, является алгоритмом минимизации структурного риска.
В отличие от эмпирической минимизации риска .
субвыборка
См. раздел "Объединение" .
токен подслова
In language models , a token that is a substring of a word, which may be the entire word.
Например, слово «itemize» можно разбить на части «item» (корень) и «ize» (суффикс), каждая из которых представлена своим собственным токеном. Разделение редких слов на такие части, называемые подсловами, позволяет языковым моделям работать с более распространенными составляющими слова, такими как префиксы и суффиксы.
И наоборот, такие распространенные слова, как "going", могут не разбиваться на части и могут быть представлены одним единственным словом.
краткое содержание
In TensorFlow, a value or set of values calculated at a particular step , usually used for tracking model metrics during training.
SuperGLUE
Набор данных для оценки общей способности магистра права понимать и создавать текст. В состав набора данных входят следующие наборы данных:
- Логические вопросы (BoolQ)
- CommitmentBank (CB)
- Choice of Plausible Alternatives (COPA)
- Multi-sentence Reading Comprehension (MultiRC)
- Reading Comprehension with Commonsense Reasoning Dataset (ReCoRD)
- Recognizing Textual Entailment (RTE)
- Words in Context (WiC)
- Вызов схемы Винограда (WSC)
For details, see SuperGLUE: A Stickier Benchmark for General-Purpose Language Understanding Systems .
контролируемое машинное обучение
Training a model from features and their corresponding labels . Supervised machine learning is analogous to learning a subject by studying a set of questions and their corresponding answers. After mastering the mapping between questions and answers, a student can then provide answers to new (never-before-seen) questions on the same topic.
Compare with unsupervised machine learning .
See Supervised Learning in the Introduction to ML course for more information.
synthetic feature
A feature not present among the input features, but assembled from one or more of them. Methods for creating synthetic features include the following:
- Bucketing a continuous feature into range bins.
- Creating a feature cross .
- Multiplying (or dividing) one feature value by other feature value(s) or by itself. For example, if
aandbare input features, then the following are examples of synthetic features:- аб
- а 2
- Applying a transcendental function to a feature value. For example, if
cis an input feature, then the following are examples of synthetic features:- sin(c)
- ln(c)
Features created by normalizing or scaling alone are not considered synthetic features.
Т
Т5
A text-to-text transfer learning model introduced by Google AI in 2020 . T5 is an encoder - decoder model, based on the Transformer architecture, trained on an extremely large dataset. It is effective at a variety of natural language processing tasks, such as generating text, translating languages, and answering questions in a conversational manner.
T5 gets its name from the five letter Ts in "Text-to-Text Transfer Transformer."
Т5Х
An open-source, machine learning framework designed to build and train large-scale natural language processing (NLP) models. T5 is implemented on the T5X codebase (which is built on JAX and Flax ).
tabular Q-learning
In reinforcement learning , implementing Q-learning by using a table to store the Q-functions for every combination of state and action .
цель
Synonym for label .
target network
In Deep Q-learning , a neural network that is a stable approximation of the main neural network, where the main neural network implements either a Q-function or a policy . Then, you can train the main network on the Q-values predicted by the target network. Therefore, you prevent the feedback loop that occurs when the main network trains on Q-values predicted by itself. By avoiding this feedback, training stability increases.
задача
A problem that can be solved using machine learning techniques, such as:
температура
A hyperparameter that controls the degree of randomness of a model's output. Higher temperatures result in more random output, while lower temperatures result in less random output.
Choosing the best temperature depends on the specific application and or string values.
временные данные
Data recorded at different points in time. For example, winter coat sales recorded for each day of the year would be temporal data.
Тензор
The primary data structure in TensorFlow programs. Tensors are N-dimensional (where N could be very large) data structures, most commonly scalars, vectors, or matrixes. The elements of a Tensor can hold integer, floating-point, or string values.
TensorBoard
The dashboard that displays the summaries saved during the execution of one or more TensorFlow programs.
TensorFlow
A large-scale, distributed, machine learning platform. The term also refers to the base API layer in the TensorFlow stack, which supports general computation on dataflow graphs.
Although TensorFlow is primarily used for machine learning, you may also use TensorFlow for non-ML tasks that require numerical computation using dataflow graphs.
TensorFlow Playground
A program that visualizes how different hyperparameters influence model (primarily neural network) training. Go to http://playground.tensorflow.org to experiment with TensorFlow Playground.
TensorFlow Serving
A platform to deploy trained models in production.
Блок обработки тензоров (TPU)
An application-specific integrated circuit (ASIC) that optimizes the performance of machine learning workloads. These ASICs are deployed as multiple TPU chips on a TPU device .
ранг тензора
See rank (Tensor) .
Tensor shape
The number of elements a Tensor contains in various dimensions. For example, a [5, 10] Tensor has a shape of 5 in one dimension and 10 in another.
Tensor size
The total number of scalars a Tensor contains. For example, a [5, 10] Tensor has a size of 50.
TensorStore
A library for efficiently reading and writing large multi-dimensional arrays.
termination condition
In reinforcement learning , the conditions that determine when an episode ends, such as when the agent reaches a certain state or exceeds a threshold number of state transitions. For example, in tic-tac-toe (also known as noughts and crosses), an episode terminates either when a player marks three consecutive spaces or when all spaces are marked.
тест
In a decision tree , another name for a condition .
test loss
A metric representing a model's loss against the test set . When building a model , you typically try to minimize test loss. That's because a low test loss is a stronger quality signal than a low training loss or low validation loss .
A large gap between test loss and training loss or validation loss sometimes suggests that you need to increase the regularization rate .
тестовый набор
A subset of the dataset reserved for testing a trained model .
Traditionally, you divide examples in the dataset into the following three distinct subsets:
- тренировочный набор
- набор для проверки
- тестовый набор
Each example in a dataset should belong to only one of the preceding subsets. For instance, a single example shouldn't belong to both the training set and the test set.
The training set and validation set are both closely tied to training a model. Because the test set is only indirectly associated with training, test loss is a less biased, higher quality metric than training loss or validation loss .
Дополнительную информацию см. в разделе «Наборы данных: Разделение исходного набора данных» в «Кратком курсе по машинному обучению».
text span
The array index span associated with a specific subsection of a text string. For example, the word good in the Python string s="Be good now" occupies the text span from 3 to 6.
tf.Example
A standard protocol buffer for describing input data for machine learning model training or inference.
tf.keras
An implementation of Keras integrated into TensorFlow .
threshold (for decision trees)
In an axis-aligned condition , the value that a feature is being compared against. For example, 75 is the threshold value in the following condition:
grade >= 75
See Exact splitter for binary classification with numerical features in the Decision Forests course for more information.
анализ временных рядов
A subfield of machine learning and statistics that analyzes temporal data . Many types of machine learning problems require time series analysis, including classification, clustering, forecasting, and anomaly detection. For example, you could use time series analysis to forecast the future sales of winter coats by month based on historical sales data.
временной шаг
One "unrolled" cell within a recurrent neural network . For example, the following figure shows three timesteps (labeled with the subscripts t-1, t, and t+1):
токен
In a language model , the atomic unit that the model is training on and making predictions on. A token is typically one of the following:
- a word—for example, the phrase "dogs like cats" consists of three word tokens: "dogs", "like", and "cats".
- a character—for example, the phrase "bike fish" consists of nine character tokens. (Note that the blank space counts as one of the tokens.)
- subwords—in which a single word can be a single token or multiple tokens. A subword consists of a root word, a prefix, or a suffix. For example, a language model that uses subwords as tokens might view the word "dogs" as two tokens (the root word "dog" and the plural suffix "s"). That same language model might view the single word "taller" as two subwords (the root word "tall" and the suffix "er").
In domains outside of language models, tokens can represent other kinds of atomic units. For example, in computer vision, a token might be a subset of an image.
See Large language models in Machine Learning Crash Course for more information.
tokenizer
A system or algorithm that translates a sequence of input data into tokens .
Most modern foundation models are multimodal . A tokenizer for a multimodal system must translate each input type into the appropriate format. For example, given input data consisting of both text and graphics, the tokenizer might translate input text into subwords and input images into small patches. The tokenizer must then convert all the tokens into a single unified embedding space, which enables the model to "understand" a stream of multimodal input.
top-k accuracy
The percentage of times that a "target label" appears within the first k positions of generated lists. The lists could be personalized recommendations or a list of items ordered by softmax .
Top-k accuracy is also known as accuracy at k .
башня
A component of a deep neural network that is itself a deep neural network. In some cases, each tower reads from an independent data source, and those towers stay independent until their output is combined in a final layer. In other cases, (for example, in the encoder and decoder tower of many Transformers ), towers have cross-connections to each other.
токсичность
The degree to which content is abusive, threatening, or offensive. Many machine learning models can identify, measure, and classify toxicity. Most of these models identify toxicity along multiple parameters, such as the level of abusive language and the level of threatening language.
ТПУ
Abbreviation for Tensor Processing Unit .
TPU chip
A programmable linear algebra accelerator with on-chip high bandwidth memory that is optimized for machine learning workloads. Multiple TPU chips are deployed on a TPU device .
TPU device
A printed circuit board (PCB) with multiple TPU chips , high bandwidth network interfaces, and system cooling hardware.
TPU node
A TPU resource on Google Cloud with a specific TPU type . The TPU node connects to your VPC Network from a peer VPC network . TPU nodes are a resource defined in the Cloud TPU API .
TPU Pod
A specific configuration of TPU devices in a Google data center. All of the devices in a TPU Pod are connected to one another over a dedicated high-speed network. A TPU Pod is the largest configuration of TPU devices available for a specific TPU version.
TPU resource
A TPU entity on Google Cloud that you create, manage, or consume. For example, TPU nodes and TPU types are TPU resources.
TPU slice
A TPU slice is a fractional portion of the TPU devices in a TPU Pod . All of the devices in a TPU slice are connected to one another over a dedicated high-speed network.
TPU type
A configuration of one or more TPU devices with a specific TPU hardware version. You select a TPU type when you create a TPU node on Google Cloud. For example, a v2-8 TPU type is a single TPU v2 device with 8 cores. A v3-2048 TPU type has 256 networked TPU v3 devices and a total of 2048 cores. TPU types are a resource defined in the Cloud TPU API .
TPU worker
A process that runs on a host machine and executes machine learning programs on TPU devices .
обучение
The process of determining the ideal parameters (weights and biases) comprising a model . During training, a system reads in examples and gradually adjusts parameters. Training uses each example anywhere from a few times to billions of times.
See Supervised Learning in the Introduction to ML course for more information.
training loss
A metric representing a model's loss during a particular training iteration. For example, suppose the loss function is Mean Squared Error . Perhaps the training loss (the Mean Squared Error) for the 10th iteration is 2.2, and the training loss for the 100th iteration is 1.9.
A loss curve plots training loss versus the number of iterations. A loss curve provides the following hints about training:
- A downward slope implies that the model is improving.
- An upward slope implies that the model is getting worse.
- A flat slope implies that the model has reached convergence .
For example, the following somewhat idealized loss curve shows:
- A steep downward slope during the initial iterations, which implies rapid model improvement.
- A gradually flattening (but still downward) slope until close to the end of training, which implies continued model improvement at a somewhat slower pace then during the initial iterations.
- A flat slope towards the end of training, which suggests convergence.
Although training loss is important, see also generalization .
training-serving skew
The difference between a model's performance during training and that same model's performance during serving .
тренировочный набор
The subset of the dataset used to train a model .
Traditionally, examples in the dataset are divided into the following three distinct subsets:
- тренировочный набор
- набор для проверки
- тестовый набор
В идеале каждый пример в наборе данных должен принадлежать только к одному из предыдущих подмножеств. Например, один и тот же пример не должен одновременно принадлежать к обучающему и валидационному наборам данных.
Дополнительную информацию см. в разделе «Наборы данных: Разделение исходного набора данных» в «Кратком курсе по машинному обучению».
траектория
In reinforcement learning , a sequence of tuples that represent a sequence of state transitions of the agent , where each tuple corresponds to the state, action , reward , and next state for a given state transition.
перенос обучения
Transferring information from one machine learning task to another. For example, in multi-task learning, a single model solves multiple tasks, such as a deep model that has different output nodes for different tasks. Transfer learning might involve transferring knowledge from the solution of a simpler task to a more complex one, or involve transferring knowledge from a task where there is more data to one where there is less data.
Most machine learning systems solve a single task. Transfer learning is a baby step towards artificial intelligence in which a single program can solve multiple tasks.
Трансформатор
A neural network architecture developed at Google that relies on self-attention mechanisms to transform a sequence of input embeddings into a sequence of output embeddings without relying on convolutions or recurrent neural networks . A Transformer can be viewed as a stack of self-attention layers.
A Transformer can include any of the following:
An encoder transforms a sequence of embeddings into a new sequence of the same length. An encoder includes N identical layers, each of which contains two sub-layers. These two sub-layers are applied at each position of the input embedding sequence, transforming each element of the sequence into a new embedding. The first encoder sub-layer aggregates information from across the input sequence. The second encoder sub-layer transforms the aggregated information into an output embedding.
A decoder transforms a sequence of input embeddings into a sequence of output embeddings, possibly with a different length. A decoder also includes N identical layers with three sub-layers, two of which are similar to the encoder sub-layers. The third decoder sub-layer takes the output of the encoder and applies the self-attention mechanism to gather information from it.
The blog post Transformer: A Novel Neural Network Architecture for Language Understanding provides a good introduction to Transformers.
See LLMs: What's a large language model? in Machine Learning Crash Course for more information.
translational invariance
In an image classification problem, an algorithm's ability to successfully classify images even when the position of objects within the image changes. For example, the algorithm can still identify a dog, whether it is in the center of the frame or at the left end of the frame.
See also size invariance and rotational invariance .
триграмма
An N-gram in which N=3.
Trivia Question Answering
Datasets to evaluate an LLM's ability to answer trivia questions. Each dataset contains question-answer pairs authored by trivia enthusiasts. Different datasets are grounded by different sources, including:
- Web search (TriviaQA)
- Wikipedia (TriviaQA_wiki)
For more information see TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension .
true negative (TN)
An example in which the model correctly predicts the negative class . For example, the model infers that a particular email message is not spam , and that email message really is not spam .
true positive (TP)
An example in which the model correctly predicts the positive class . For example, the model infers that a particular email message is spam, and that email message really is spam.
true positive rate (TPR)
Synonym for recall . That is:
True positive rate is the y-axis in an ROC curve .
ТТЛ
Abbreviation for time to live .
Typologically Diverse Question Answering (TyDi QA)
A large dataset for evaluating an LLM's proficiency in answering questions. The dataset contains question and answer pairs in many languages.
For details, see TyDi QA: A Benchmark for Information-Seeking Question Answering in Typologically Diverse Languages .
У
Ультра
The Gemini model with the most parameters . See Gemini Ultra for details.
unawareness (to a sensitive attribute)
A situation in which sensitive attributes are present, but not included in the training data. Because sensitive attributes are often correlated with other attributes of one's data, a model trained with unawareness about a sensitive attribute could still have disparate impact with respect to that attribute, or violate other fairness constraints .
несоответствие
Producing a model with poor predictive ability because the model hasn't fully captured the complexity of the training data. Many problems can cause underfitting, including:
- Training on the wrong set of features .
- Training for too few epochs or at too low a learning rate .
- Training with too high a regularization rate .
- Providing too few hidden layers in a deep neural network.
Для получения дополнительной информации см. «Краткий курс по переобучению в машинном обучении».
undersampling
Removing examples from the majority class in a class-imbalanced dataset in order to create a more balanced training set .
For example, consider a dataset in which the ratio of the majority class to the minority class is 20:1. To overcome this class imbalance, you could create a training set consisting of all of the minority class examples but only a tenth of the majority class examples, which would create a training-set class ratio of 2:1. Thanks to undersampling, this more balanced training set might produce a better model. Alternatively, this more balanced training set might contain insufficient examples to train an effective model.
Contrast with oversampling .
однонаправленный
A system that only evaluates the text that precedes a target section of text. In contrast, a bidirectional system evaluates both the text that precedes and follows a target section of text. See bidirectional for more details.
unidirectional language model
A language model that bases its probabilities only on the tokens appearing before , not after , the target token(s). Contrast with bidirectional language model .
unlabeled example
An example that contains features but no label . For example, the following table shows three unlabeled examples from a house valuation model, each with three features but no house value:
| Количество спален | Количество ванных комнат | Возраст дома |
|---|---|---|
| 3 | 2 | 15 |
| 2 | 1 | 72 |
| 4 | 2 | 34 |
В контролируемом машинном обучении модели обучаются на размеченных примерах и делают прогнозы на неразмеченных примерах .
In semi-supervised and unsupervised learning, unlabeled examples are used during training.
Contrast unlabeled example with labeled example .
машинное обучение без учителя
Training a model to find patterns in a dataset, typically an unlabeled dataset.
The most common use of unsupervised machine learning is to cluster data into groups of similar examples. For example, an unsupervised machine learning algorithm can cluster songs based on various properties of the music. The resulting clusters can become an input to other machine learning algorithms (for example, to a music recommendation service). Clustering can help when useful labels are scarce or absent. For example, in domains such as anti-abuse and fraud, clusters can help humans better understand the data.
Contrast with supervised machine learning .
See What is Machine Learning? in the Introduction to ML course for more information.
uplift modeling
A modeling technique, commonly used in marketing, that models the "causal effect" (also known as the "incremental impact") of a "treatment" on an "individual." Here are two examples:
- Doctors might use uplift modeling to predict the mortality decrease (causal effect) of a medical procedure (treatment) depending on the age and medical history of a patient (individual).
- Marketers might use uplift modeling to predict the increase in probability of a purchase (causal effect) due to an advertisement (treatment) on a person (individual).
Uplift modeling differs from classification or regression in that some labels (for example, half of the labels in binary treatments) are always missing in uplift modeling. For example, a patient can either receive or not receive a treatment; therefore, we can only observe whether the patient is going to heal or not heal in only one of these two situations (but never both). The main advantage of an uplift model is that it can generate predictions for the unobserved situation (the counterfactual) and use it to compute the causal effect.
upweighting
Applying a weight to the downsampled class equal to the factor by which you downsampled.
user matrix
В рекомендательных системах вектор встраивания , сгенерированный с помощью матричной факторизации , содержит скрытые сигналы о предпочтениях пользователя. Каждая строка матрицы пользователей содержит информацию об относительной силе различных скрытых сигналов для одного пользователя. Например, рассмотрим систему рекомендаций фильмов. В этой системе скрытые сигналы в матрице пользователей могут представлять интерес каждого пользователя к определенным жанрам или могут быть более сложными для интерпретации сигналами, включающими сложные взаимодействия между множеством факторов.
Матрица пользователей содержит столбец для каждой скрытой характеристики и строку для каждого пользователя. То есть, матрица пользователей имеет такое же количество строк, как и целевая матрица, которая подвергается факторизации. Например, если у нас есть система рекомендаций фильмов для 1 000 000 пользователей, матрица пользователей будет иметь 1 000 000 строк.
В
валидация
The initial evaluation of a model's quality. Validation checks the quality of a model's predictions against the validation set .
Because the validation set differs from the training set , validation helps guard against overfitting .
You might think of evaluating the model against the validation set as the first round of testing and evaluating the model against the test set as the second round of testing.
потери валидации
Метрика , отражающая потери модели на валидационном наборе данных в течение конкретной итерации обучения.
См. также кривую обобщения .
набор валидации
Подмножество набора данных , используемое для первоначальной оценки обученной модели . Как правило, обученную модель оценивают на проверочном наборе данных несколько раз, прежде чем оценивать ее на тестовом наборе .
Традиционно примеры в наборе данных делятся на три отдельных подмножества:
- тренировочный набор
- набор для проверки
- тестовый набор
В идеале каждый пример в наборе данных должен принадлежать только к одному из предыдущих подмножеств. Например, один и тот же пример не должен одновременно принадлежать к обучающему и валидационному наборам данных.
Дополнительную информацию см. в разделе «Наборы данных: Разделение исходного набора данных» в «Кратком курсе по машинному обучению».
вменение значения
Процесс замены отсутствующего значения приемлемым аналогом. Если значение отсутствует, можно либо отбросить весь пример, либо использовать метод замещения значений для его восстановления.
For example, consider a dataset containing a temperature feature that is supposed to be recorded every hour. However, the temperature reading was unavailable for a particular hour. Here is a section of the dataset:
| Отметка времени | Температура |
|---|---|
| 1680561000 | 10 |
| 1680564600 | 12 |
| 1680568200 | отсутствующий |
| 1680571800 | 20 |
| 1680575400 | 21 |
| 1680579000 | 21 |
В зависимости от алгоритма заполнения, система может либо удалить отсутствующий пример, либо заменить отсутствующую температуру значениями 12, 16, 18 или 20.
проблема исчезающего градиента
В некоторых глубоких нейронных сетях градиенты ранних скрытых слоев имеют тенденцию становиться удивительно плоскими (низкими). Все более низкие градиенты приводят к все меньшим изменениям весов узлов в глубокой нейронной сети, что ведет к незначительному или полному отсутствию обучения. Модели, страдающие от проблемы исчезающего градиента, становятся сложными или невозможными для обучения. Ячейки долговременной кратковременной памяти (LSTM) решают эту проблему.
Сравните с проблемой взрыва градиента .
важность переменных
Набор оценок, указывающих на относительную важность каждой характеристики для модели.
Например, рассмотрим дерево решений , которое оценивает цены на жилье. Предположим, это дерево решений использует три признака: размер, возраст и стиль. Если набор значений важности переменных для этих трех признаков равен {размер=5,8, возраст=2,5, стиль=4,7}, то размер для дерева решений важнее возраста или стиля.
Существуют различные метрики важности переменных, которые могут помочь экспертам в области машинного обучения оценить различные аспекты моделей.
Вариационный автокодировщик (VAE)
Вариационные автокодировщики — это тип автокодировщика , который использует несоответствие между входными и выходными данными для генерации модифицированных версий входных данных. Они полезны для генеративного искусственного интеллекта .
Вариационные автоэнтропийные модели (ВАЭ) основаны на вариационном выводе: методе оценки параметров вероятностной модели.
вектор
Очень перегруженный термин, значение которого варьируется в разных математических и научных областях. В машинном обучении вектор обладает двумя свойствами:
- Тип данных: В машинном обучении векторы обычно содержат числа с плавающей запятой.
- Количество элементов: это длина вектора или его размерность .
Например, рассмотрим вектор признаков , содержащий восемь чисел с плавающей запятой. Длина или размерность этого вектора признаков равна восьми. Следует отметить, что векторы в машинном обучении часто имеют огромное количество измерений.
В виде вектора можно представить множество различных типов информации. Например:
- Любая точка на поверхности Земли может быть представлена в виде двумерного вектора, где одно измерение — это широта, а другое — долгота.
- Текущие цены каждой из 500 акций можно представить в виде 500-мерного вектора.
- A probability distribution over a finite number of classes can be represented as a vector. For example, a multiclass classification system that predicts one of three output colors (red, green, or yellow) could output the vector
(0.3, 0.2, 0.5)to meanP[red]=0.3, P[green]=0.2, P[yellow]=0.5.
Векторы можно объединять; следовательно, различные медиафайлы могут быть представлены в виде одного вектора. Некоторые модели работают непосредственно с объединением множества one-hot кодировок .
Специализированные процессоры, такие как TPU, оптимизированы для выполнения математических операций над векторами.
Вершина
Платформа Google Cloud для искусственного интеллекта и машинного обучения. Vertex предоставляет инструменты и инфраструктуру для создания, развертывания и управления приложениями ИИ, включая доступ к моделям Gemini .кодирование вибрации
Использование генеративной модели ИИ для создания программного обеспечения. То есть, ваши подсказки описывают назначение и функции программного обеспечения, которые генеративная модель ИИ преобразует в исходный код. Сгенерированный код не всегда соответствует вашим намерениям, поэтому программирование с использованием Vibe обычно требует итераций.
Андрей Карпати ввел термин «вайб-кодирование» в этом посте на X. В посте на X Карпати описывает его как «новый вид кодирования…где вы полностью отдаетесь вайбам…». Таким образом, первоначально этот термин подразумевал намеренно небрежный подход к созданию программного обеспечения, при котором вы можете даже не проверять сгенерированный код. Однако в различных кругах этот термин быстро эволюционировал и теперь означает любую форму кодирования, сгенерированного искусственным интеллектом.
For a more detailed description of vibe coding, seeWhat is vibe coding? .
Кроме того, сравните и сопоставьте кодирование атмосферы с:
В
поражение Вассерштейна
Одна из функций потерь, часто используемых в генеративных состязательных сетях , основана на расстоянии перемещения земли между распределением сгенерированных данных и реальными данными.
масса
Значение, на которое модель умножает другое значение. Обучение — это процесс определения идеальных весов модели; вывод — это процесс использования этих полученных весов для прогнозирования.
Более подробную информацию можно найти в разделе «Линейная регрессия» в «Кратком курсе по машинному обучению».
Взвешенный метод чередующихся наименьших квадратов (WALS)
Алгоритм минимизации целевой функции в процессе разложения матрицы на составляющие в рекомендательных системах , позволяющий уменьшить вес отсутствующих примеров. WALS минимизирует взвешенную квадратичную ошибку между исходной матрицей и реконструированной матрицей, чередуя фиксированное разложение на строки и столбцы. Каждая из этих оптимизаций может быть решена методом наименьших квадратов (методом выпуклой оптимизации) . Подробности см. в курсе «Рекомендательные системы» .
взвешенная сумма
Сумма всех соответствующих входных значений, умноженная на их соответствующие веса. Например, предположим, что соответствующие входные данные состоят из следующего:
| входное значение | входной вес |
| 2 | -1.3 |
| -1 | 0,6 |
| 3 | 0,4 |
Таким образом, взвешенная сумма составляет:
weighted sum = (2)(-1.3) + (-1)(0.6) + (3)(0.4) = -2.0
Взвешенная сумма является входным аргументом функции активации .
WiC
Сокращение для слов в контексте .
широкая модель
Линейная модель, которая обычно имеет множество разреженных входных признаков . Мы называем её «широкой», поскольку такая модель представляет собой особый тип нейронной сети с большим количеством входных сигналов, которые напрямую соединены с выходным узлом. Широкие модели часто проще отлаживать и анализировать, чем глубокие модели . Хотя широкие модели не могут выражать нелинейности через скрытые слои , они могут использовать преобразования, такие как пересечение признаков и сегментирование, для моделирования нелинейностей различными способами.
Сравните с глубокой моделью .
ширина
Количество нейронов в определенном слое нейронной сети .
WikiLingua (wiki_lingua)
Набор данных для оценки способности магистра права (LLM) к составлению кратких обзоров статей. WikiHow , энциклопедия статей, объясняющих, как выполнять различные задачи, является источником как самих статей, так и их обзоров, созданных людьми. Каждая запись в наборе данных состоит из:
- Статья, которая создается путем добавления каждого шага прозаической (абзацной) версии нумерованного списка за вычетом первого предложения каждого шага.
- Краткое изложение этой статьи, состоящее из первого предложения каждого шага в пронумерованном списке.
Подробности см. в статье WikiLingua: Новый эталонный набор данных для кросс-лингвального абстрактного суммирования .
Вызов схемы Винограда (WSC)
Формат (или набор данных, соответствующий этому формату) для оценки способности магистра права определять именное словосочетание, к которому относится местоимение .
Каждая работа в конкурсе Winograd Schema Challenge состоит из:
- Короткий отрывок, содержащий целевое местоимение.
- Целевое местоимение
- Candidate noun phrases, followed by the correct answer (a Boolean). If the target pronoun refers to this candidate, the answer is True. If the target pronoun does not refer to this candidate, the answer is False.
Например:
- Passage : Mark told Pete many lies about himself, which Pete included in his book. He should have been more truthful.
- Target pronoun : He
- Candidate noun phrases :
- Mark: True, because the target pronoun refers to Mark
- Pete: False, because the target pronoun doesn't refer to Peter
The Winograd Schema Challenge is a component of the SuperGLUE ensemble.
мудрость толпы
The idea that averaging the opinions or estimates of a large group of people ("the crowd") often produces surprisingly good results. For example, consider a game in which people guess the number of jelly beans packed into a large jar. Although most individual guesses will be inaccurate, the average of all the guesses has been empirically shown to be surprisingly close to the actual number of jelly beans in the jar.
Ensembles are a software analog of wisdom of the crowd. Even if individual models make wildly inaccurate predictions, averaging the predictions of many models often generates surprisingly good predictions. For example, although an individual decision tree might make poor predictions, a decision forest often makes very good predictions.
WMT
Strangely, an abbreviation for Conference on Machine Translation . (The abbreviation is W MT because the original name was Workshop on Machine Translation.) The conference focuses on developments in machine translation systems.
word embedding
Representing each word in a word set within an embedding vector ; that is, representing each word as a vector of floating-point values between 0.0 and 1.0. Words with similar meanings have more-similar representations than words with different meanings. For example, carrots , celery , and cucumbers would all have relatively similar representations, which would be very different from the representations of airplane , sunglasses , and toothpaste .
Words in Context (WiC)
A dataset for evaluating how well an LLM uses context to understand words that have multiple meanings. Each entry in the dataset contains:
- Two sentences, each containing the target word
- The target word
- The correct answer (a Boolean), where:
- True means the target word has the same meaning in the two sentences
- False means the target word has a different meaning in the two sentences
Например:
- Two sentences:
- There's a lot of trash on the bed of the river.
- Когда я сплю, рядом с кроватью стоит стакан воды.
- Целевое слово: кровать
- Правильный ответ : Ложь, потому что целевое слово имеет разное значение в двух предложениях.
Подробности см. в WiC: набор данных «Слово в контексте» для оценки контекстно-зависимых представлений значения .
Words in Context — это компонент комплекса SuperGLUE .
WSC
Сокращение от Winograd Schema Challenge (Задача Винограда по схемной механике ).
X
XLA (Ускоренная линейная алгебра)
Компилятор машинного обучения с открытым исходным кодом для графических процессоров (GPU), центральных процессоров (CPU) и ускорителей машинного обучения.
The XLA compiler takes models from popular ML frameworks such as PyTorch , TensorFlow , and JAX , and optimizes them for high-performance execution across different hardware platforms including GPUs, CPUs, and ML accelerators .
XL-Sum (xlsum)
Набор данных для оценки уровня владения навыками составления кратких изложений текста у студентов магистратуры. XL-Sum содержит записи на многих языках. Каждая запись в наборе данных содержит:
- Статья, взятая с сайта Британской вещательной компании (BBC).
- Краткое содержание статьи, написанное автором статьи. Обратите внимание, что это краткое содержание может содержать слова или фразы, отсутствующие в статье.
Более подробную информацию см. в статье XL-Sum: Large-Scale Multilingual Abstractive Summarization for 44 Languages .
xsum
Сокращение от Extreme Summarization (экстремальное обобщение).
З
обучение без примеров
Тип обучения машинного обучения, при котором модель делает вывод для задачи, для которой она не была специально обучена. Другими словами, модели не предоставляется ни одного примера для обучения, специфичного для данной задачи, но её просят сделать вывод для этой задачи.
подсказка без предварительного примера
Запрос , не содержащий примера того, как вы хотите, чтобы большая языковая модель ответила. Например:
| Части одного задания | Примечания |
|---|---|
| What is the official currency of the specified country? | Вопрос, на который вы хотите получить ответ в рамках программы LLM. |
| Индия: | Сам запрос. |
The large language model might respond with any of the following:
- Рупия
- мРНК
- ₹
- индийская рупия
- The rupee
- Индийская рупия
Все ответы верны, хотя вы можете предпочесть определенный формат.
Сравните и сопоставьте метод «нулевого предварительного запроса» со следующими терминами:
Z-нормализация
Метод масштабирования , при котором исходное значение признака заменяется значением с плавающей запятой, представляющим количество стандартных отклонений от среднего значения этого признака. Например, рассмотрим признак, среднее значение которого равно 800, а стандартное отклонение равно 100. В следующей таблице показано, как нормализация по Z-баллу преобразует исходное значение в его Z-балл:
| Сырое значение | Z-показатель |
|---|---|
| 800 | 0 |
| 950 | +1.5 |
| 575 | -2.25 |
Затем модель машинного обучения обучается на основе Z-баллов для этого признака, а не на исходных значениях.
Дополнительную информацию см. в разделе «Числовые данные: нормализация в машинном обучении» (краткий курс).