Линейная регрессия: градиентный спуск
Оптимизируйте свои подборки
Сохраняйте и классифицируйте контент в соответствии со своими настройками.
Градиентный спуск — это математический метод, который итеративно находит веса и смещения, обеспечивающие модель с наименьшей функцией потерь. Градиентный спуск находит оптимальные веса и смещения, повторяя следующий процесс в течение заданного пользователем количества итераций.
Обучение модели начинается со случайных весов и смещений, близких к нулю, а затем повторяются следующие шаги:
Рассчитайте потери при текущем весе и смещении.
Определите направление перемещения весов и смещения, чтобы уменьшить потери.
Слегка измените значения веса и смещения в направлении, которое уменьшит потери.
Вернитесь к первому шагу и повторяйте процесс до тех пор, пока модель не сможет уменьшить значение функции потерь еще больше.
На приведенной ниже диаграмме показаны итеративные шаги, которые выполняет градиентный спуск для нахождения весов и смещения, позволяющих получить модель с наименьшей функцией потерь.
Рисунок 11. Градиентный спуск — это итеративный процесс, который находит веса и смещения, обеспечивающие модель с наименьшей функцией потерь.
Нажмите на значок плюса, чтобы узнать больше о математических принципах градиентного спуска.
На конкретном уровне мы можем рассмотреть этапы градиентного спуска, используя следующий небольшой набор данных по топливной эффективности с семью примерами и среднеквадратичную ошибку (MSE) в качестве метрики потерь:
Фунты в тысячах (статья)
Расход топлива (в милях на галлон) (по данным этикетки)
3.5
18
3.69
15
3.44
18
3.43
16
4.34
15
4.42
14
2.37
24
Обучение модели начинается с установки веса и смещения равными нулю:
Нажмите на значок плюса, чтобы узнать о расчете наклона.
Чтобы получить наклон касательных к весу и смещению, мы берем производную функции потерь по весу и смещению, а затем решаем уравнения.
Уравнение для прогнозирования мы запишем следующим образом: $ f_{w,b}(x) = (w*x)+b $.
Фактическое значение мы запишем так: $y$.
Мы рассчитаем среднеквадратичную ошибку, используя: $ \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)})^2 $ где $i$ обозначает $ith$ обучающий пример, а $M$ обозначает количество примеров.
Производная веса
Производная функции потерь по весу записывается следующим образом: $ \frac{\partial }{\partial w} \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)})^2 $
и оценивается следующим образом: $ \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)}) * 2x_{(i)} $
Сначала мы суммируем каждое прогнозируемое значение за вычетом фактического значения, а затем умножаем полученную сумму на удвоенное значение признака. Затем делим сумму на количество примеров. Результатом является наклон касательной к значению веса.
Если мы решим это уравнение с нулевым весом и смещением, то получим -119,7 для наклона прямой.
Смещение производной
Производная функции потерь по смещению записывается следующим образом: $ \frac{\partial }{\partial b} \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)})^2 $
и оценивается следующим образом: $ \frac{1}{M} \sum_{i=1}^{M} (f_{w,b}(x_{(i)}) - y_{(i)}) * 2 $
Сначала мы суммируем каждое прогнозируемое значение за вычетом фактического значения, а затем умножаем полученную сумму на два. Затем делим сумму на количество примеров. Результатом является наклон касательной к значению смещения.
Если мы решим это уравнение с нулевым весом и смещением, то получим наклон прямой -34,3.
Сдвиньте ось на небольшую величину в направлении отрицательного наклона, чтобы получить следующий вес и смещение. Пока что мы условно обозначим эту «небольшую величину» как 0,01:
Используйте новые веса и смещения для расчета функции потерь и повторите процесс. Завершив процесс в течение шести итераций, мы получим следующие веса, смещения и функции потерь:
Итерация
Масса
Предвзятость
Убыток (MSE)
1
0
0
303.71
2
1.20
0,34
170.84
3
2.05
0,59
103.17
4
2.66
0,78
68.70
5
3.09
0,91
51.13
6
3.40
1.01
42.17
Вы можете видеть, что потери уменьшаются с каждым обновленным весом и смещением. В этом примере мы остановились после шести итераций. На практике модель обучается до тех пор, пока не сойдется . Когда модель сходится, дополнительные итерации не уменьшают потери еще больше, потому что градиентный спуск нашел веса и смещения, которые почти минимизируют потери.
Если модель продолжает обучение после сходимости, функция потерь начинает незначительно колебаться, поскольку модель постоянно обновляет параметры вокруг их минимальных значений. Это может затруднить проверку того, действительно ли модель сошлась. Чтобы подтвердить сходимость модели, необходимо продолжать обучение до тех пор, пока функция потерь не стабилизируется.
Кривые сходимости модели и потери
При обучении модели часто используют кривую потерь , чтобы определить, сошлась ли модель. Кривая потерь показывает, как изменяется значение потерь в процессе обучения модели. Ниже показана типичная кривая потерь. По оси Y отложены потери, а по оси X — итерации:
Рисунок 12. Кривая потерь, показывающая сходимость модели к отметке в 1000 итераций.
Как видно, функция потерь резко уменьшается в течение первых нескольких итераций, затем постепенно снижается, прежде чем стабилизироваться примерно на отметке в 1000 итераций. После 1000 итераций мы можем быть в основном уверены, что модель сошлась.
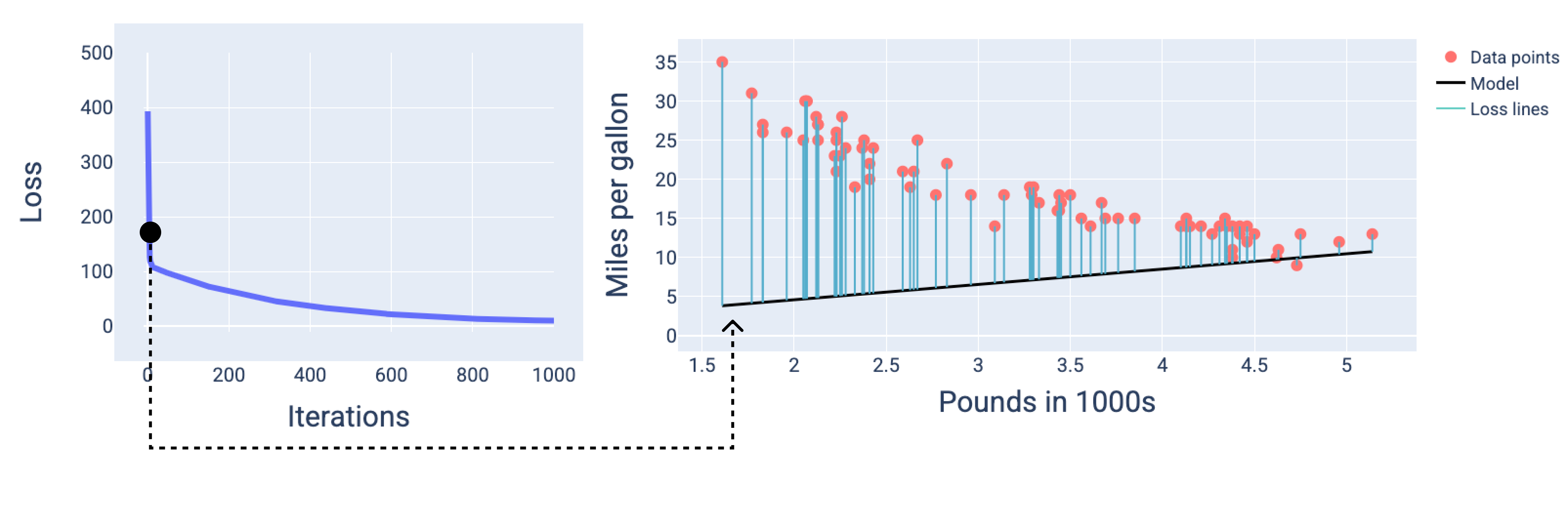
На следующих рисунках мы отображаем модель в трех точках процесса обучения: в начале, в середине и в конце. Визуализация состояния модели в отдельные моменты времени в процессе обучения подтверждает связь между обновлением весов и смещения, уменьшением функции потерь и сходимостью модели.
На рисунках для представления модели используются полученные веса и смещения на конкретной итерации. На графике с точками данных и снимком модели синие линии потерь, идущие от модели к точкам данных, показывают величину потерь. Чем длиннее линии, тем больше потери.
На следующем рисунке видно, что примерно на второй итерации модель перестаёт хорошо делать прогнозы из-за большого значения функции потерь.
Рисунок 13. Кривая потерь и снимок модели в начале процесса обучения.
Примерно на 400-й итерации мы видим, что градиентный спуск определил весовые коэффициенты и смещения, которые позволяют получить более качественную модель.
Рисунок 14. Кривая потерь и снимок модели примерно в середине обучения.
Примерно на 1000-й итерации мы видим, что модель сошлась, создав модель с наименьшей возможной функцией потерь.
Рисунок 15. Кривая потерь и снимок модели ближе к концу процесса обучения.
Упражнение: Проверьте свои знания
Какова роль градиентного спуска в линейной регрессии?
Градиентный спуск — это итеративный процесс, в ходе которого находятся оптимальные веса и смещения, минимизирующие потери.
Градиентный спуск помогает определить, какой тип функции потерь использовать при обучении модели, например, L1 или L2 .
Метод градиентного спуска не используется при выборе функции потерь для обучения модели.
Метод градиентного спуска удаляет выбросы из набора данных, что помогает модели делать более точные прогнозы.
Градиентный спуск не изменяет набор данных.
Функции сходимости и выпуклости
Функции потерь для линейных моделей всегда образуют выпуклую поверхность. Вследствие этого свойства, когда модель линейной регрессии сходится, мы знаем, что модель нашла веса и смещение, которые обеспечивают наименьшие потери.
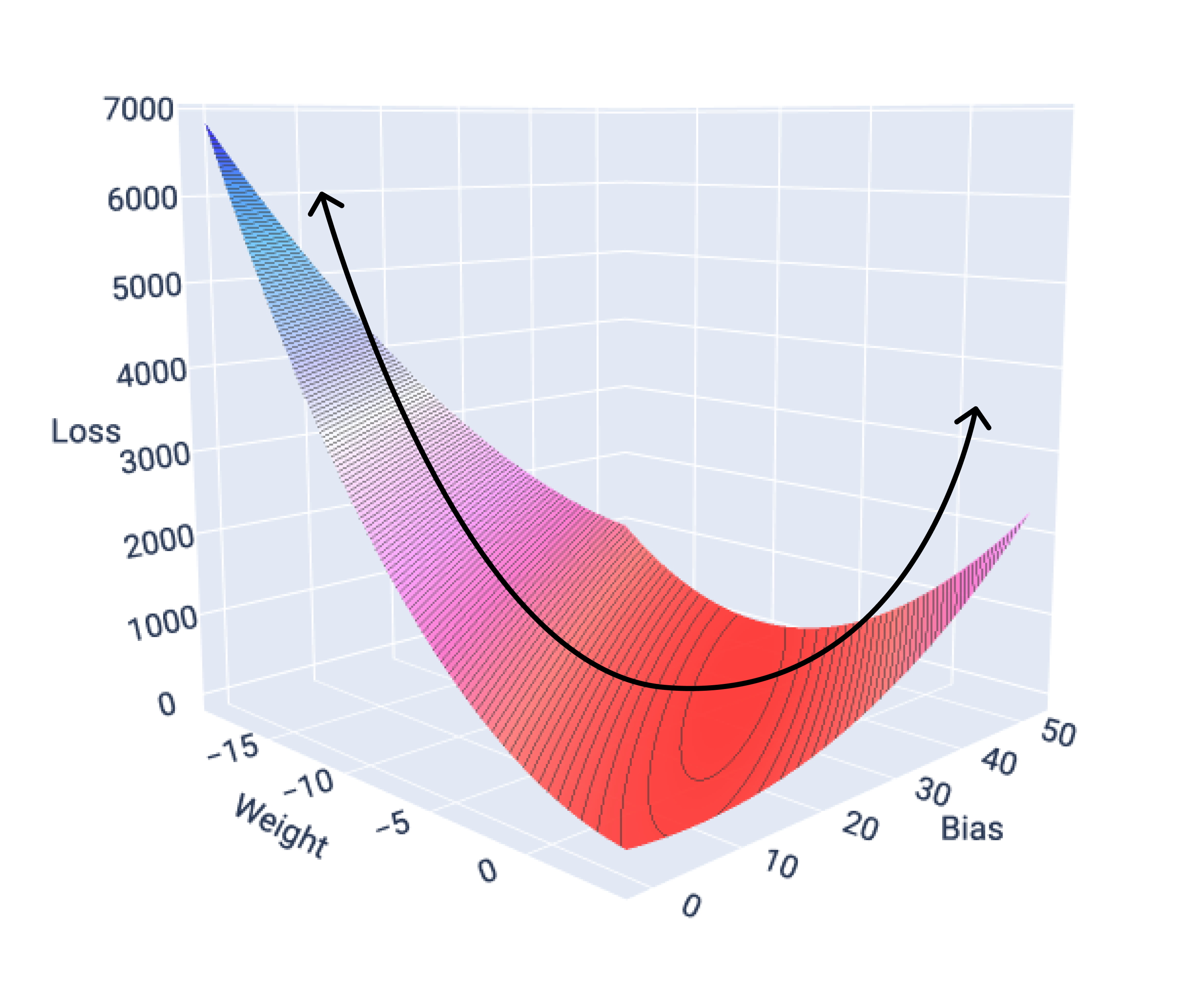
Если мы построим график поверхности потерь для модели с одним признаком, мы увидим её выпуклую форму. Ниже представлена поверхность потерь для гипотетического набора данных о расходе топлива в милях на галлон. По оси x отложен вес, по оси y — смещение, а по оси z — потери:
Рисунок 16. Поверхность потерь, демонстрирующая свою выпуклую форму.
В этом примере вес -5,44 и смещение 35,94 дают наименьший убыток в 5,54:
Рисунок 17. Поверхность потерь, показывающая значения веса и смещения, которые приводят к наименьшим потерям.
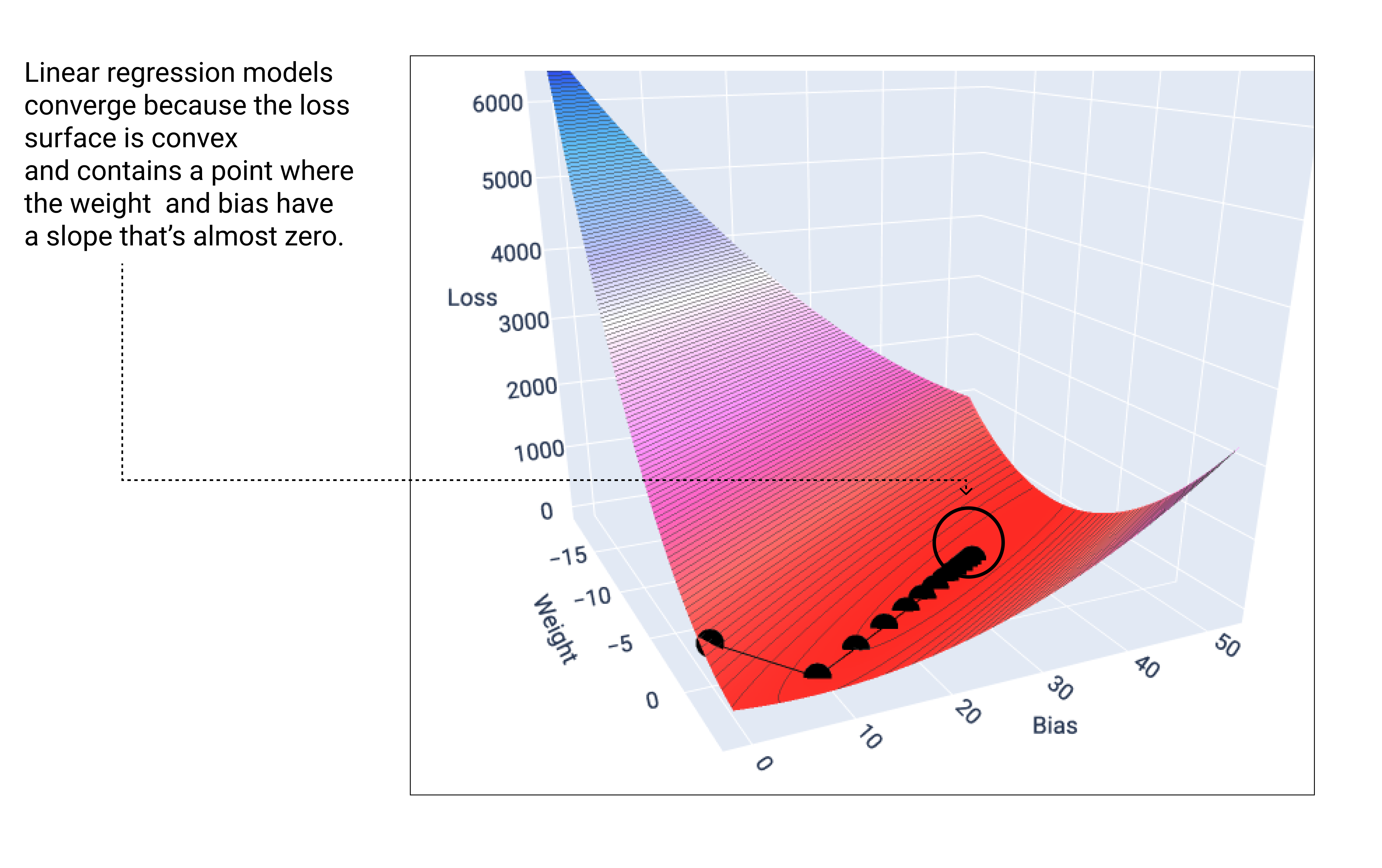
Линейная модель сходится, когда найдена минимальная функция потерь. Если построить графики весов и смещений в процессе градиентного спуска, точки будут выглядеть как шар, катящийся с горы и, наконец, останавливающийся в точке, где больше нет нисходящего склона.
Рисунок 18. График функции потерь, показывающий точки градиентного спуска, останавливающиеся в самой нижней точке графика.
Обратите внимание, что черные точки потерь точно повторяют форму кривой потерь: резкое падение, за которым следует постепенный спуск до достижения самой низкой точки на поверхности потерь.
Используя значения веса и смещения, которые дают наименьшую потерю — в данном случае вес -5,44 и смещение 35,94 — мы можем построить график модели, чтобы увидеть, насколько хорошо она соответствует данным:
Рисунок 19. Модель, построенная с использованием значений веса и смещения, обеспечивающих наименьшие потери.
Это была бы наилучшая модель для данного набора данных, поскольку никакие другие значения веса и смещения не позволяют получить модель с меньшими потерями.
[[["Прост для понимания","easyToUnderstand","thumb-up"],["Помог мне решить мою проблему","solvedMyProblem","thumb-up"],["Другое","otherUp","thumb-up"]],[["Отсутствует нужная мне информация","missingTheInformationINeed","thumb-down"],["Слишком сложен/слишком много шагов","tooComplicatedTooManySteps","thumb-down"],["Устарел","outOfDate","thumb-down"],["Проблема с переводом текста","translationIssue","thumb-down"],["Проблемы образцов/кода","samplesCodeIssue","thumb-down"],["Другое","otherDown","thumb-down"]],["Последнее обновление: 2026-02-03 UTC."],[],[]]