Целью машинного обучения в производственной среде является не создание одной модели и её развёртывание, а создание автоматизированных конвейеров для разработки, тестирования и развёртывания моделей с течением времени. Почему? По мере изменения мира меняются и тенденции в данных, что приводит к устареванию моделей в производственной среде. Модели, как правило, требуют переобучения на актуальных данных, чтобы продолжать предоставлять высококачественные прогнозы в долгосрочной перспективе. Другими словами, вам понадобится способ замены устаревших моделей новыми.
Без конвейеров замена устаревшей модели — процесс, подверженный ошибкам. Например, как только модель начинает выдавать неверные прогнозы, кому-то потребуется вручную собрать и обработать новые данные, обучить новую модель, проверить её качество и, наконец, развернуть её. Конвейеры машинного обучения автоматизируют многие из этих повторяющихся процессов, делая управление и обслуживание моделей более эффективными и надёжными.
Строительство трубопроводов
Конвейеры машинного обучения организуют этапы создания и развертывания моделей в четко определенные задачи. Конвейеры выполняют одну из двух функций: предоставление прогнозов или обновление модели.
Предоставление прогнозов
Конвейер обслуживания предоставляет прогнозы. Он делает вашу модель доступной для пользователей. Например, когда пользователь хочет получить прогноз — какой будет погода завтра, сколько минут займёт дорога до аэропорта или список рекомендуемых видео, — конвейер обслуживания получает и обрабатывает данные пользователя, составляет прогноз и отправляет его пользователю.
Обновление модели
Модели, как правило, устаревают практически сразу после запуска в эксплуатацию. По сути, они строят прогнозы на основе устаревшей информации. Их обучающие наборы данных отражали состояние мира день назад, а в некоторых случаях и час назад. Мир неизбежно изменился: пользователь посмотрел больше видео и ему нужен новый список рекомендаций; из-за дождя движение замедлилось, и пользователям нужны актуальные оценки времени прибытия; популярная тенденция заставляет розничных продавцов запрашивать актуальные прогнозы по запасам определённых товаров.
Как правило, команды обучают новые модели задолго до того, как производственная модель устареет. В некоторых случаях команды обучают и развертывают новые модели ежедневно, в непрерывном цикле обучения и развертывания. В идеале обучение новой модели должно происходить задолго до того, как производственная модель устареет.
Для обучения новой модели совместно работают следующие конвейеры:
- Конвейер данных . Конвейер данных обрабатывает пользовательские данные для создания обучающих и тестовых наборов данных.
- Обучающий конвейер . Обучающий конвейер обучает модели, используя новые обучающие наборы данных из конвейера данных.
- Конвейер проверки . Конвейер проверки проверяет обученную модель, сравнивая её с производственной моделью, используя тестовые наборы данных, сгенерированные конвейером данных.
На рисунке 4 показаны входы и выходы каждого конвейера машинного обучения.
ML-конвейеры

Рисунок 4. Конвейеры машинного обучения автоматизируют множество процессов разработки и поддержки моделей. Каждый конвейер отображает свои входы и выходы.
На самом общем уровне вот как конвейеры поддерживают новую модель в производстве:
Сначала модель запускается в эксплуатацию, и обслуживающий конвейер начинает предоставлять прогнозы.
Конвейер данных немедленно начинает собирать данные для создания новых обучающих и тестовых наборов данных.
На основе расписания или триггера конвейеры обучения и проверки обучают и проверяют новую модель, используя наборы данных, сгенерированные конвейером данных.
Когда конвейер проверки подтверждает, что новая модель не хуже рабочей модели, новая модель внедряется.
Этот процесс повторяется непрерывно.
Устаревание модели и частота обучения
Почти все модели устаревают. Некоторые модели устаревают быстрее других. Например, модели, рекомендующие одежду, обычно быстро устаревают, поскольку потребительские предпочтения, как известно, часто меняются. С другой стороны, модели, идентифицирующие цветы, могут никогда не устареть. Идентификационные характеристики цветка остаются стабильными.
Большинство моделей начинают устаревать сразу после запуска в эксплуатацию. Необходимо установить частоту обучения, отражающую характер ваших данных. Если данные динамичны, проводите обучение часто. Если же они менее динамичны, то, возможно, вам не потребуется так часто обучаться.
Обучайте модели до того, как они устареют. Раннее обучение обеспечивает резерв для решения потенциальных проблем, например, в случае сбоя данных или процесса обучения, или низкого качества модели.
Рекомендуется ежедневное обучение и развертывание новых моделей. Как и в обычных программных проектах, где сборка и выпуск выполняются ежедневно, конвейеры машинного обучения и валидации часто работают эффективнее при ежедневном запуске.
Проверьте свое понимание
Трубопровод обслуживания
Конвейер обслуживания генерирует и доставляет прогнозы двумя способами: онлайн или офлайн.
Онлайн-прогнозы . Онлайн-прогнозы выполняются в режиме реального времени, как правило, путём отправки запроса на онлайн-сервер и возврата прогноза. Например, когда пользователь хочет получить прогноз, его данные отправляются в модель, и модель возвращает прогноз.
Офлайн-прогнозы . Офлайн-прогнозы предварительно вычисляются и кэшируются. Для выполнения прогноза приложение находит кэшированный прогноз в базе данных и возвращает его. Например, сервис, работающий по подписке, может прогнозировать скорость оттока подписчиков. Модель прогнозирует вероятность оттока для каждого подписчика и кэширует её. Когда приложению требуется прогноз, например, чтобы поощрить пользователей, которые могут уйти, оно просто ищет предварительно вычисленный прогноз.
На рисунке 5 показано, как генерируются и доставляются онлайн- и офлайн-прогнозы.
Онлайн и офлайн прогнозы
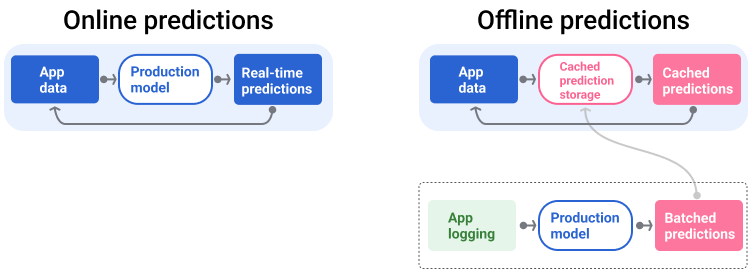
Рисунок 5. Онлайн-прогнозы предоставляются в режиме реального времени. Офлайн-прогнозы кэшируются и проверяются во время обслуживания.
Постобработка прогнозирования
Как правило, прогнозы проходят постобработку перед отправкой. Например, прогнозы могут быть подвергнуты постобработке для удаления токсичного или предвзятого контента. Результаты классификации могутпройти через процессдля изменения порядка результатов вместо отображения необработанных выходных данных модели, например, для продвижения более авторитетного контента, представления разнообразных результатов, понижения рейтинга определенных результатов (например, кликбейтных) или удаления результатов по юридическим причинам.
На рисунке 6 показан конвейер обслуживания и типичные задачи, связанные с предоставлением прогнозов.
Прогнозы постобработки
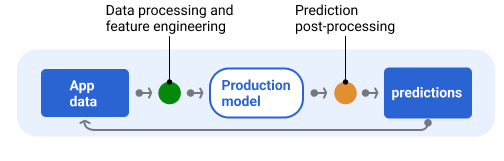
Рисунок 6. Конвейер обслуживания, иллюстрирующий типичные задачи, необходимые для предоставления прогнозов.
Обратите внимание, что этап проектирования признаков обычно реализуется внутри модели, а не в виде отдельного, автономного процесса. Код обработки данных в обслуживающем конвейере часто практически идентичен коду обработки данных, который конвейер данных использует для создания обучающих и тестовых наборов данных.
Хранилище активов и метаданных
Конвейер обслуживания должен включать в себя хранилище для регистрации прогнозов модели и, если возможно, реальных данных.
Регистрация прогнозов модели позволяет отслеживать её качество. Агрегируя прогнозы, вы можете отслеживать общее качество модели и определять, начинает ли оно теряться. Как правило, прогнозы производственной модели должны иметь такое же среднее значение, как и метки из обучающего набора данных. Подробнее см. в разделе «Смещение прогноза» .
Сбор фактов с земли
В некоторых случаях истинная информация становится доступной гораздо позже. Например, если приложение прогнозирует погоду на шесть недель вперёд, истинная информация (какая погода будет на самом деле) будет доступна только через шесть недель.
По возможности побуждайте пользователей сообщать истинную информацию, добавляя в приложение механизмы обратной связи. Почтовое приложение может неявно собирать отзывы пользователей, когда они перемещают письма из папки «Входящие» в папку «Спам». Однако это работает только в том случае, если пользователи правильно классифицируют свои письма. Когда пользователи оставляют спам в папке «Входящие» (потому что знают, что это спам, и никогда его не открывают), данные для обучения становятся неточными. Это конкретное письмо будет помечено как «не спам», хотя должно быть именно «спамом». Другими словами, всегда старайтесь находить способы собирать и регистрировать истинную информацию , но помните о недостатках, которые могут быть присущи механизмам обратной связи.
На рисунке 7 показаны прогнозы, доставляемые пользователю и регистрируемые в репозитории.
Прогнозы регистрации
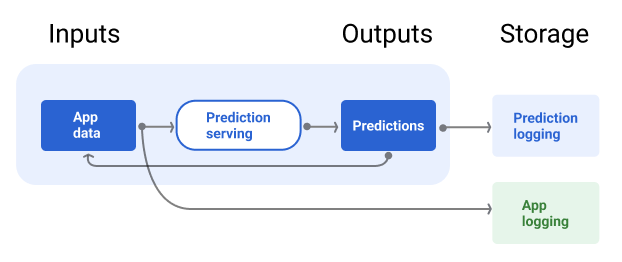
Рисунок 7. Журнал прогнозов для контроля качества модели.
Конвейеры данных
Конвейеры данных генерируют обучающие и тестовые наборы данных из данных приложения. Конвейеры обучения и проверки затем используют эти наборы данных для обучения и проверки новых моделей.
Конвейер данных создаёт обучающие и тестовые наборы данных с теми же характеристиками и метками, которые изначально использовались для обучения модели, но с более новой информацией. Например, приложение «Карты» может генерировать обучающие и тестовые наборы данных на основе недавнего времени в пути между точками для миллионов пользователей, а также другие релевантные данные, например, о погоде.
Приложение для рекомендации видео будет генерировать обучающие и тестовые наборы данных, включающие видеоролики, на которые пользователь нажал из списка рекомендуемых (а также те, на которые не нажал), а также другие релевантные данные, например, историю просмотров.
На рисунке 8 показан конвейер данных, использующий данные приложения для создания обучающих и тестовых наборов данных.
Конвейер данных

Рисунок 8. Конвейер данных обрабатывает данные приложения для создания наборов данных для конвейеров обучения и проверки.
Сбор и обработка данных
Задачи по сбору и обработке данных в конвейерах данных, вероятно, будут отличаться от этапа экспериментирования (когда вы определили, что ваше решение осуществимо):
Сбор данных . В ходе экспериментов сбор данных обычно требует доступа к сохранённым данным. Для конвейеров данных сбор данных может потребовать обнаружения и получения разрешения на доступ к данным журналов потоковой передачи.
Если вам нужны данные, маркированные человеком (например, медицинские изображения), вам также понадобится процесс их сбора и обновления.
Обработка данных . В ходе экспериментов нужные признаки были получены путём извлечения, объединения и выборки экспериментальных наборов данных. Для конвейеров данных генерация тех же признаков может потребовать совершенно иных процессов. Однако обязательно продублируйте преобразования данных, выполненные на этапе экспериментов, применив те же математические операции к признакам и меткам.
Хранилище активов и метаданных
Вам потребуется процесс хранения, управления версиями и управления обучающими и тестовыми наборами данных. Репозитории с контролем версий обеспечивают следующие преимущества:
Воспроизводимость . Воссоздайте и стандартизируйте среды обучения моделей и сравните качество прогнозов между различными моделями.
Соблюдение нормативных требований. Соблюдайте нормативные требования к проверяемости и прозрачности.
Хранение . Установите значения срока хранения данных.
Управление доступом . Управляйте доступом к вашим данным с помощью детальной настройки разрешений.
Целостность данных . Отслеживайте и анализируйте изменения в наборах данных с течением времени, что упрощает диагностику проблем с данными или моделью.
Обнаруживаемость . Сделайте так, чтобы другие могли легко найти ваши наборы данных и функции. Другие команды смогут определить, будут ли они полезны для их целей.
Документирование ваших данных
Хорошая документация помогает другим понять ключевую информацию о ваших данных, такую как их тип, источник, размер и другие важные метаданные. В большинстве случаев документирование данных в проектной документации Достаточно. Если вы планируете поделиться или опубликовать свои данные, используйтекарты данныхструктурировать информацию. Карточки данных облегчают другим поиск и понимание ваших наборов данных.
Конвейеры обучения и проверки
Процессы обучения и валидации создают новые модели, которые заменяют производственные модели, прежде чем они устареют. Постоянное обучение и валидация новых моделей гарантируют, что в производстве всегда будет наилучшая модель.
Конвейер обучения генерирует новую модель из обучающих наборов данных, а конвейер проверки сравнивает качество новой модели с моделью, находящейся в производстве, с использованием тестовых наборов данных.
На рисунке 9 показан процесс обучения с использованием обучающего набора данных для обучения новой модели.
Учебный конвейер

Рисунок 9. Обучающий конвейер обучает новые модели, используя самый последний обучающий набор данных.
После обучения модели конвейер проверки использует тестовые наборы данных для сравнения качества производственной модели с обученной моделью.
Как правило, если обученная модель ненамного хуже рабочей модели, она переходит в эксплуатацию. Если же качество обученной модели хуже, инфраструктура мониторинга должна выдать оповещение. Обученные модели с худшим качеством прогнозирования могут указывать на потенциальные проблемы с данными или процессами валидации. Такой подход гарантирует, что лучшая модель, обученная на самых актуальных данных, всегда будет находиться в эксплуатации.
Хранилище активов и метаданных
Модели и их метаданные следует хранить в репозиториях с контролем версий для организации и отслеживания их развертывания. Репозитории моделей обеспечивают следующие преимущества:
Отслеживание и оценка . Отслеживайте модели в процессе производства и анализируйте показатели качества их оценки и прогнозирования.
Процесс выпуска модели . Легко проверяйте, утверждайте, выпускайте или откатывайте модели.
Воспроизводимость и отладка . Воспроизводите результаты модели и более эффективно устраняйте неполадки, отслеживая наборы данных модели и зависимости между развёртываниями.
Обнаруживаемость . Сделайте так, чтобы другие могли легко найти вашу модель. Тогда другие команды смогут определить, подходит ли ваша модель (или её части) для их целей.
На рисунке 10 показана проверенная модель, хранящаяся в репозитории моделей.
Хранение моделей

Рисунок 10. Проверенные модели хранятся в репозитории моделей для отслеживания и обнаружения.
Использоватьмодельные картыдокументировать и обмениваться ключевой информацией о вашей модели, например, ее назначением, архитектурой, требованиями к оборудованию, показателями оценки и т. д.
Проверьте свое понимание
Проблемы строительства трубопроводов
При строительстве трубопроводов вы можете столкнуться со следующими проблемами:
Получение доступа к необходимым данным . Для получения доступа к данным может потребоваться обоснование необходимости. Например, вам может потребоваться объяснить, как будут использоваться данные, и как будут решаться проблемы, связанные с персональными данными (PII). Будьте готовы продемонстрировать, как ваша модель улучшает прогнозы при доступе к определённым типам данных.
Получение нужных функций . В некоторых случаях функции, используемые на этапе экспериментов, могут быть недоступны в данных реального времени. Поэтому при экспериментировании старайтесь убедиться, что вы сможете получить те же функции в рабочей среде.
Понимание того, как собираются и представляются данные . Изучение того, как были собраны данные, кто их собирал и как это было сделано (а также решение других вопросов) может потребовать времени и усилий. Важно досконально понимать данные. Не используйте данные, в которых вы не уверены, для обучения модели, которая может быть запущена в эксплуатацию.
Понимание компромиссов между усилиями, стоимостью и качеством модели . Включение нового признака в конвейер данных может потребовать значительных усилий. Однако дополнительный признак может лишь незначительно улучшить качество модели. В других случаях добавление нового признака может быть простым. Однако ресурсы для получения и хранения этого признака могут оказаться чрезмерно дорогими.
Получение вычислительных мощностей . Если вам нужны TPU для переобучения, может быть сложно получить необходимую квоту. Кроме того, управление TPU может быть сложным. Например, некоторые части вашей модели или данных могут потребовать специальной разработки для TPU, разделив их между несколькими чипами TPU.
Поиск подходящего «золотого» набора данных . Если данные часто меняются, получение «золотых» наборов данных с единообразными и точными метками может быть сложной задачей.
Выявление подобных проблем во время экспериментов экономит время. Например, вы не хотите разрабатывать лучшие функции и модели, а потом обнаружить, что они нежизнеспособны в рабочей среде. Поэтому постарайтесь как можно раньше убедиться, что ваше решение будет работать в условиях ограничений производственной среды. Лучше потратить время на проверку работоспособности решения, чем возвращаться к этапу экспериментов из-за того, что на этапе конвейера были выявлены непреодолимые проблемы.